

Detection of Famous Tea Buds Based on Improved YOLOv7 Network

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Acquisition
2.2. Data Enhancement
- (1)
- First, we adjusted the brightness of the image. To be specific, we raised the brightness of the image to 1.3 times and decreased it to 0.7 times compared with the original image, respectively. During our shooting time, the way of dealing with brightness could reflect the change from brightest to darkest during mechanical picking. Through this operation method, our model will be more suitable for the complex tea garden environment with changeable light;
- (2)
- Then, we adjusted the contrast of the image. To be specific, the contrast of the images was increased by 1.2 times and weakened by 0.8 times, so that the sharpness, gray level and texture details of the famous and excellent tea images could be better expressed [20];
- (3)
- Finally, we rotated the image taken. We thought rotation of 30 degrees can better reflect the detection of famous and excellent tea when the machine picks. This operation can enhance the adaptability of the detection model to shoot from different angles.
2.3. Data Annotation
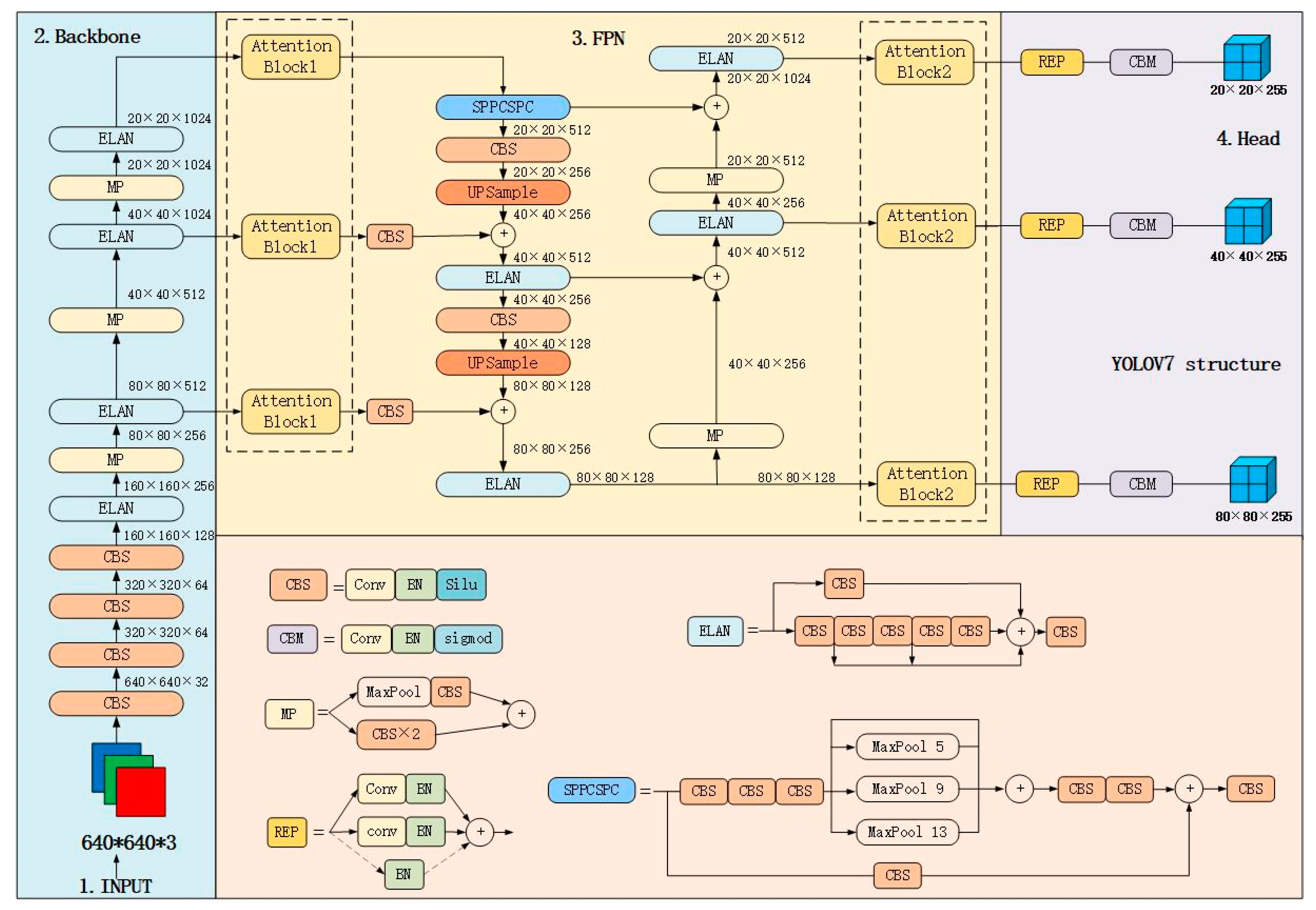
2.4. Excellent Tea Detection Algorithm
2.4.1. Yolov7 Algorithm
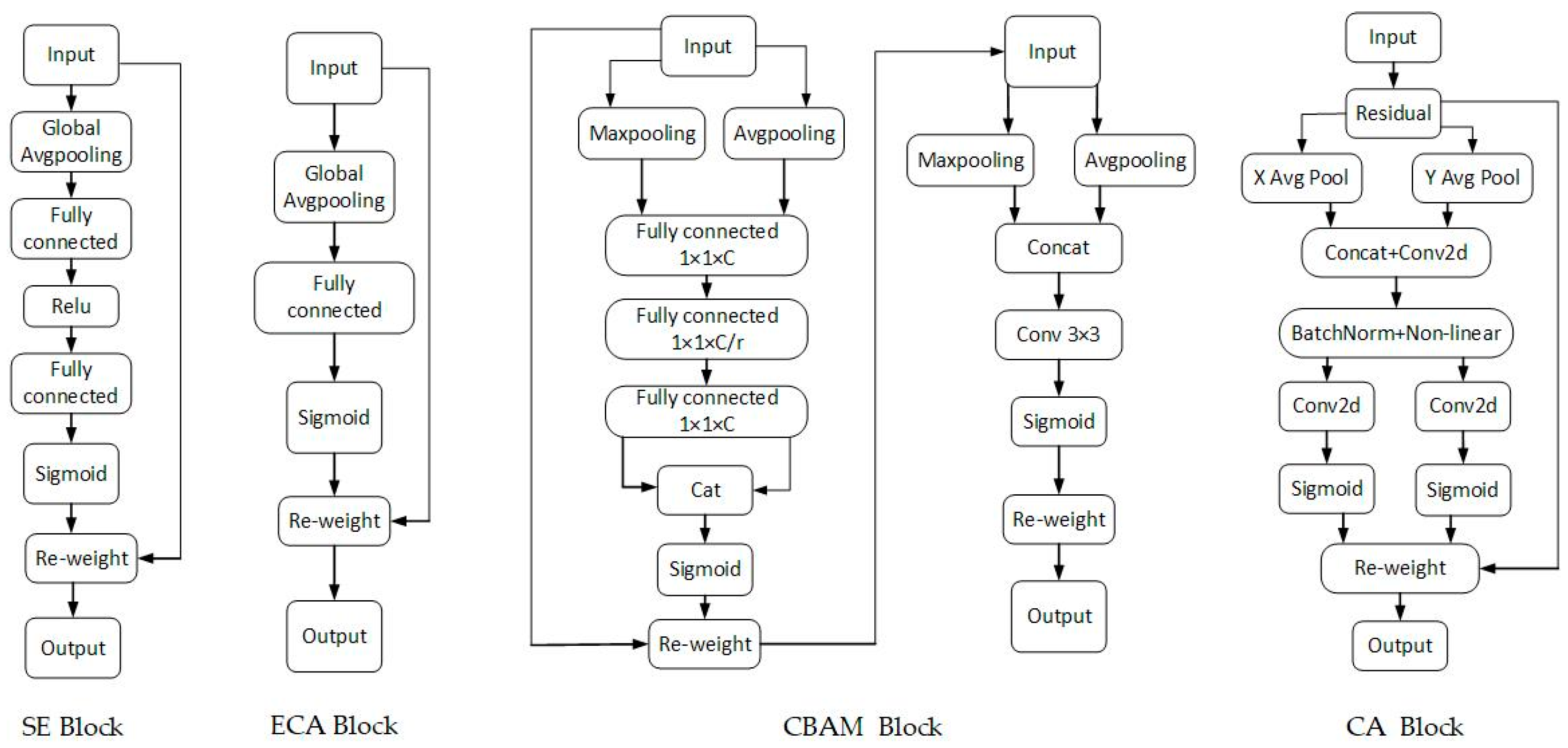
2.4.2. Introduction of Attention Mechanism
2.5. Training Environment and Parameter Configuration
2.5.1. Experimental Platform and Environment Configuration
2.5.2. Training Parameter Settings
2.6. Evaluation Index
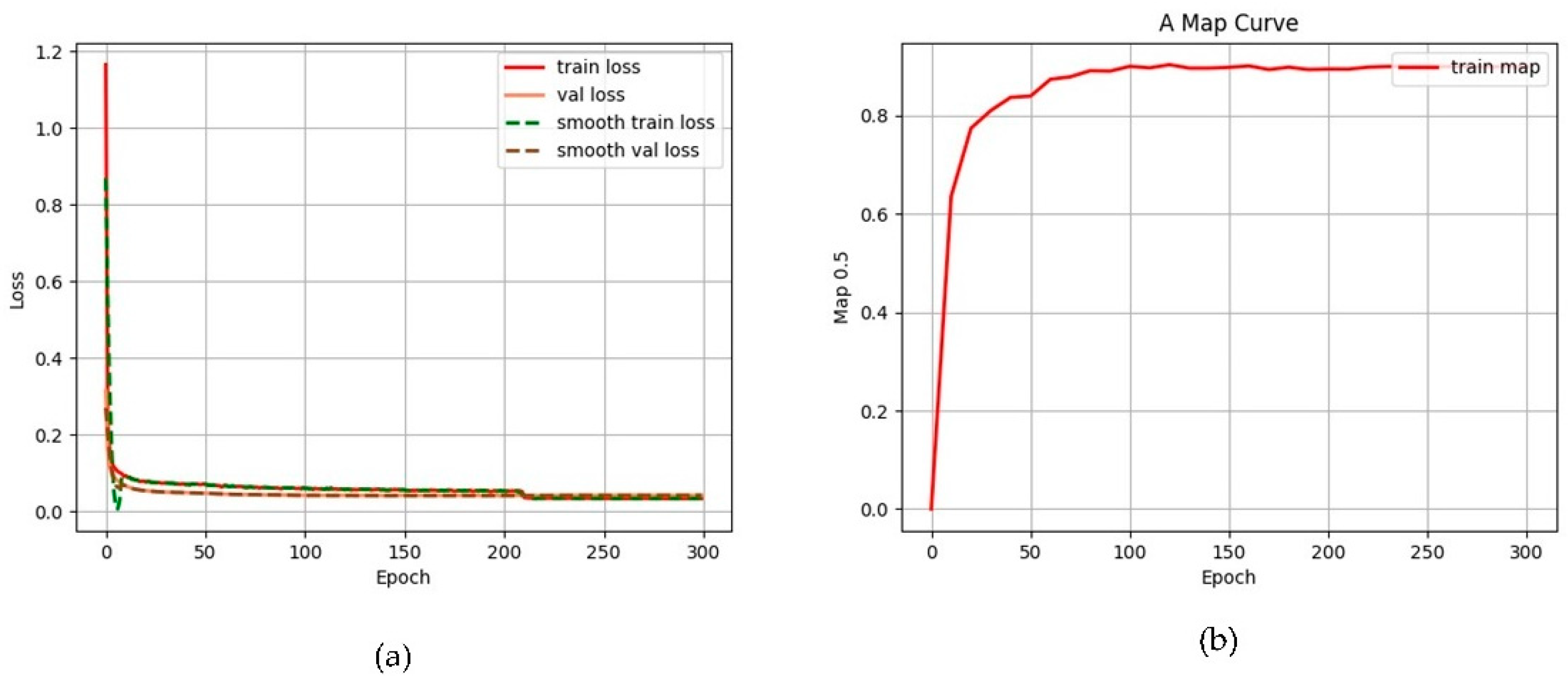
2.7. Results and Analysis
2.8. Visual Recognition of Heatmap
3. Conclusions
- (1)
- This study compared the attention mechanisms’ effects of the SE, ECA, CBAM and CA blocks on the bud detection of famous and excellent green tea in different positions of YOLOv7 network. It was found that the YOLOv7+CBAM network model had the best recognition effect with the recognition accuracy of 93.71%, recall rate of 89.23% and F1 score of 0.91.
- (2)
- The improved YOLOv7 networks basing CBAM, ECA attention mechanism were compared with the YOLOv7 network for the bud images with occluding, small targets and dense distribution, and it was found that the YOLOv7+CBAM network had better recognition effect on various tender leaves.
- (3)
- Multi-leaf, occluding and densely distributed images containing young tea leaves were drawn by Grad-CAM, respectively. It could be seen that the YOLOv7+CBAM network model could accurately focus on different types of images and was little affected by background factors, which further proved that the network proposed in this study had a better effect on improving the recognition effect of famous and excellent green tea.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liang, Y.; Shin, Y.H.; Zhang, L.-J.; Wang, K.-R. Advances in tea Plant Breeding in China. Agric. Food 2019, 7, 1–10. [Google Scholar]
- Hicks, A. Review of global tea production and the impact on industry of the Asian economic situation. AU J. Technol. 2001, 5, 227–231. [Google Scholar]
- Yang, H.; Chen, L.; Ma, Z.; Chen, M.; Zhong, Y.; Deng, F.; Li, M. Computer vision-based high-quality tea automatic plucking robot using Delta parallel manipulator. Comput. Electron. Agric. 2021, 181, 105946. [Google Scholar] [CrossRef]
- Lu, Y.J. Debiao, Significance and realization of mechanized picking of famous green tea in China. Chin. Tea 2018, 40, 1–4. [Google Scholar]
- Fan, W.Y.H.; Xin, Y.-Y.; Fei, L.; Ting, Z.; Li, C.-H. Chinese tea mechanization picking technology research status and development trend. Jiangsu Agric. Sci. 2019, 47, 48–51. [Google Scholar]
- Fuzeng, Y.L.Y.; Yana, T.; Qing, Y. Tea bud recognition method based on color and shape characteristics. Trans. Chin. Soc. Agric. Mach. 2009, 40, 119–123. [Google Scholar]
- Jian, W. Research on tea image segmentation Algorithm Combining color and region growth Wang Jian. Tea Sci. 2011, 31, 72–77. [Google Scholar]
- Miaoting, C. Recognition and Localization of Famous Tea bud Based on Computer Vision. Master’s Thesis, Qingdao University of Science and Technology, Qingdao, China, 2019. [Google Scholar]
- Wu, X.; Zhang, F.; Lv, J. Research on tea leaf recognition method based on image color information. Tea Sci. 2013, 33, 584–589. [Google Scholar]
- Tang, Y.; Han, W.; Hu, A.; Wang, W. Design and Experiment of Intelligentized Tea-plucking Machine for Human Riding Based on Machine Vision. Nongye Jixie Xuebao/Trans. Chin. Soc. Agric. Mach. 2016, 47, 15–20. [Google Scholar] [CrossRef]
- Bao, W.; Fan, T.; Hu, G.; Liang, D.; Li, H. Detection and identification of tea leaf diseases based on AX-RetinaNet. Sci. Rep. 2022, 12, 2183. [Google Scholar] [CrossRef]
- Yang, H.; Chen, L.; Chen, M.; Ma, Z.; Deng, F.; Li, M.; Li, X. Tender tea shoots recognition and positioning for picking robot using improved YOLO-V3 model. IEEE Access 2019, 7, 180998–181011. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, K.; Zhang, W.; Wang, R.; Wan, S.; Rao, Y.; Jiang, Z.; Gu, L. Tea picking point detection and location based on Mask-RCNN. Inf. Process. Agric. 2023, 10, 267–275. [Google Scholar] [CrossRef]
- Chen, Y.-T.; Chen, S.-F. Localizing plucking points of tea leaves using deep convolutional neural networks. Comput. Electron. Agric. 2020, 171, 105298. [Google Scholar] [CrossRef]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Cardellicchio, F.S.A.; Dimauro, G.; Petrozza, A.; Summerer, S.; Cellini, F.; Renò, V. Detection of tomato plant phenotyping traits using YOLOv5-based single stage detectors. Comput. Electron. Agric. 2023, 207, 1077757. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Liu, T.; Teng, G.; Yuan, Y.; Liu, B.; Liu, Z. Winter jujube fruit recognition method in natural scene based on improved YOLO v3. Trans. Chin. Soc. Agric. Mach. 2021, 52, 17–25. [Google Scholar]
- Yang, B.; Gao, Z.; Gao, Y.; Zhu, Y. Rapid Detection and Counting of Wheat Ears in the Field Using YOLOv4 with Attention Module. Agronomy 2021, 11, 1202. [Google Scholar] [CrossRef]
- Liu, Y.; Cao, X.; Guo, B.; Chen, H.; Dai, Z.; Gong, C. Research on Attitude detection Algorithm of meat goose in complex scene based on improved YOLO v5. J. Nanjing Agric. Univ. 2022, 1–12. [Google Scholar]
- Fang, M.; Lü, J.; Ruan, J.; Bian, L.; Wu, C.; Qing, Y. Tea bud detection model based on improved YOLOv4-tiny. Tea Sci. 2022, 42, 549–560. [Google Scholar]
- Fu, X.; Li, A.; Meng, Z.; Yin, X.; Zhang, C.; Zhang, W.; Qi, L. A Dynamic Detection Method for Phenotyping Pods in a Soybean Population Based on an Improved YOLO-v5 Network. Agronomy 2022, 12, 3209. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Supplementary material for ‘ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13–19. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Lang, C.; Chao, J. X-ray image rotating object detection based on improved YOLOv7. J. Graph. 2023, 44, 324–334. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference On Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P/% | Recall/% | F1 Score/% | Detection Speed/FPS |
|---|---|---|---|---|
| AB1=SE | 85.75 | 77.32 | 0.82 | 54.92 |
| AB2=SE | 86.97 | 81.56 | 0.83 | 49.74 |
| AB1=ECA | 89.04 | 84.43 | 0.84 | 58.37 |
| AB2=ECA | 86.48 | 81.97 | 0.84 | 55.09 |
| AB1=CBAM | 89.06 | 84.70 | 0.87 | 60.03 |
| AB2=CBAM | 87.11 | 81.97 | 0.84 | 58.79 |
| AB1=CA | 87.16 | 82.38 | 0.85 | 56.26 |
| AB2=CA | 85.36 | 81.23 | 0.83 | 54.23 |
| No additions | 87.33 | 83.12 | 0.84 | 57.37 |
| Model | P/% | Recall/% | F1 Score/% | Detection Speed/FPS |
|---|---|---|---|---|
| YOLOv7 | 89.23 | 85.34 | 0.87 | 58.21 |
| YOLOv7+ECA | 91.83 | 87.16 | 0.89 | 59.64 |
| YOLOv7+CBAM | 93.71 | 89.23 | 0.91 | 61.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Xiao, M.; Wang, S.; Jiang, Q.; Wang, X.; Zhang, Y. Detection of Famous Tea Buds Based on Improved YOLOv7 Network. Agriculture 2023, 13, 1190. https://doi.org/10.3390/agriculture13061190
Wang Y, Xiao M, Wang S, Jiang Q, Wang X, Zhang Y. Detection of Famous Tea Buds Based on Improved YOLOv7 Network. Agriculture. 2023; 13(6):1190. https://doi.org/10.3390/agriculture13061190
Chicago/Turabian StyleWang, Yongwei, Maohua Xiao, Shu Wang, Qing Jiang, Xiaochan Wang, and Yongnian Zhang. 2023. "Detection of Famous Tea Buds Based on Improved YOLOv7 Network" Agriculture 13, no. 6: 1190. https://doi.org/10.3390/agriculture13061190