1. Introduction
Maize is the most widely cultivated food crop, not only in China, but also the world [
1]. The latest data show maize planting areas and yields have reached 36% and 40% of the total sown area of crops in China, respectively. However, drought and nutrient deficiencies can severely affect maize growth, resulting in lower yields [
2,
3]. The LAI is one of the most important crop traits reflecting crop growth and indicating potential gain yield [
4]. Therefore, monitoring the LAI is beneficial to understand the degree of water and fertilizer stress on crop growth and to evaluate precise management of water and fertilizer [
5,
6,
7].
LAI measurement by using the traditional manual method is time-consuming and laborious, and it is difficult to achieve the accurate estimation of LAI over large areas because of crop heterogeneity. In comparison, remote sensing technology is now regarded as the suitable means for monitoring crop growth at large scales, with the improvements in spatial and spectral resolution [
8,
9]. However, satellite remote sensing remains limited by cloud cover, coarse resolution and satellite revisit time. As one of the most important emerging remote sensing platforms, unmanned aerial vehicles (UAVs) are more flexible than satellites, which can provide remote sensing data with higher temporal, spatial and spectral resolution. UAV remote sensing is becoming a promising phenotyping tool for frequent observations of crops and has been gradually employed in precise agriculture [
10].
Recently, UAV-based phenotyping data of spectral indices has been used in different statistical models to predict LAI. For example, height index and canopy cover information calculated from RGB images have been used to predict forest LAI with prediction accuracy up to R
2 = 0.83 [
11]. Furthermore, Cheng et al. [
12] studied the ability of different algorithms and built high accuracy models to predict LAI using remote sensing data. Recently, the XGBoost modeling method combined with competitive adaptive reweighted sampling and the successive projections algorithm has achieved better prediction LAI results than partial least squares regression (PLSR) and support vector regression (SVR) [
13]. Apart from the statistical model, the physical model is also used to predict the LAI. Li et al. [
14] applied the PROSAIL model combined with agronomic knowledge to crop growth monitoring, which also significantly improved the prediction accuracy of the LAI. The recent need concerning UAV-based remote sensing is to improve the ability of UAV-based estimations of LAI with the help of multi-source spectral (RGB image, multispectral, hyperspectral, thermal infrared, lidar, etc.) fusion method. Gong et al. [
15] reported that a model based on the combination of the multispectral vegetation index and the canopy height extracted from RGB images could reduce the impact of phenology specificity; whereas, LAI prediction results using the fusion of RGB, multispectral and thermal infrared data were better than a single or dual data source for the maize crop [
16]. Although rich datasets come first, the selection of features has a great impact on the simulation accuracy of the machine learning model [
17]. The selection of feature vectors cannot only improve the accuracy and stability of the model, but also reduce the difficulty and time cost of collecting features [
18].
Machine learning mainly solves problems through semi-automatic or automatic modelling, with the aim of reducing human interventions. Machine learning methods are increasingly being used for estimations of crop traits [
19]. Recently, in UAV-based crop phenotyping studies, several machine learning algorithms, including SVR, RF, GPR, Lasso, k-nearest neighbor (KNN), gradient boosting decision tree (GBDT), etc., have been successfully used to increase the prediction accuracy of important crop traits [
20,
21,
22]. In recent years, with the development of computer technology and machine learning theory, ensemble learning algorithms have been increasingly applied in various fields, especially in agricultural research [
23,
24,
25,
26]. Ensemble learning mainly is used to combine multiple learners in order to obtain a better and more comprehensive and strongly supervised model. The underlying idea of ensemble learning is that even if one base learner gets a less accurate prediction, other base learners can correct the error. The commonly used ensemble learning algorithms include bosting, bagging and stacking algorithms. Some studies have been conducted on the use of ensemble learning for different machine learning models to predict the LAI and improve prediction accuracy [
27,
28]. It is worth mentioning that boosting and bagging mainly consider homogeneous weak learners, such as decision tree, while stacking can consider heterogeneous learners. The heterogeneity of stacking enables it to integrate not only weak learners but also strong learners, such as SVR, RF, GPR, etc. The use of the ensemble learning model trained with UAV-based multi-source data can help increase the prediction accuracy of the LAI for better and timely understanding of water and fertilizer stress as well as improve field management strategies for maize crops. Therefore, in the present study, irrigation and fertilization management based on drip irrigation were evaluated using UAV-based phenotyping and the stacking ensemble learning method.
The main objects of this study were (1) to estimate LAI using UAV-based data and stacking ensemble learning algorithms and (2) to evaluate the water and fertilizer management of drip irrigation on the estimation of LAI at multiple growth stages of summer maize.
2. Materials and Methods
2.1. Overview of the Experimental Site
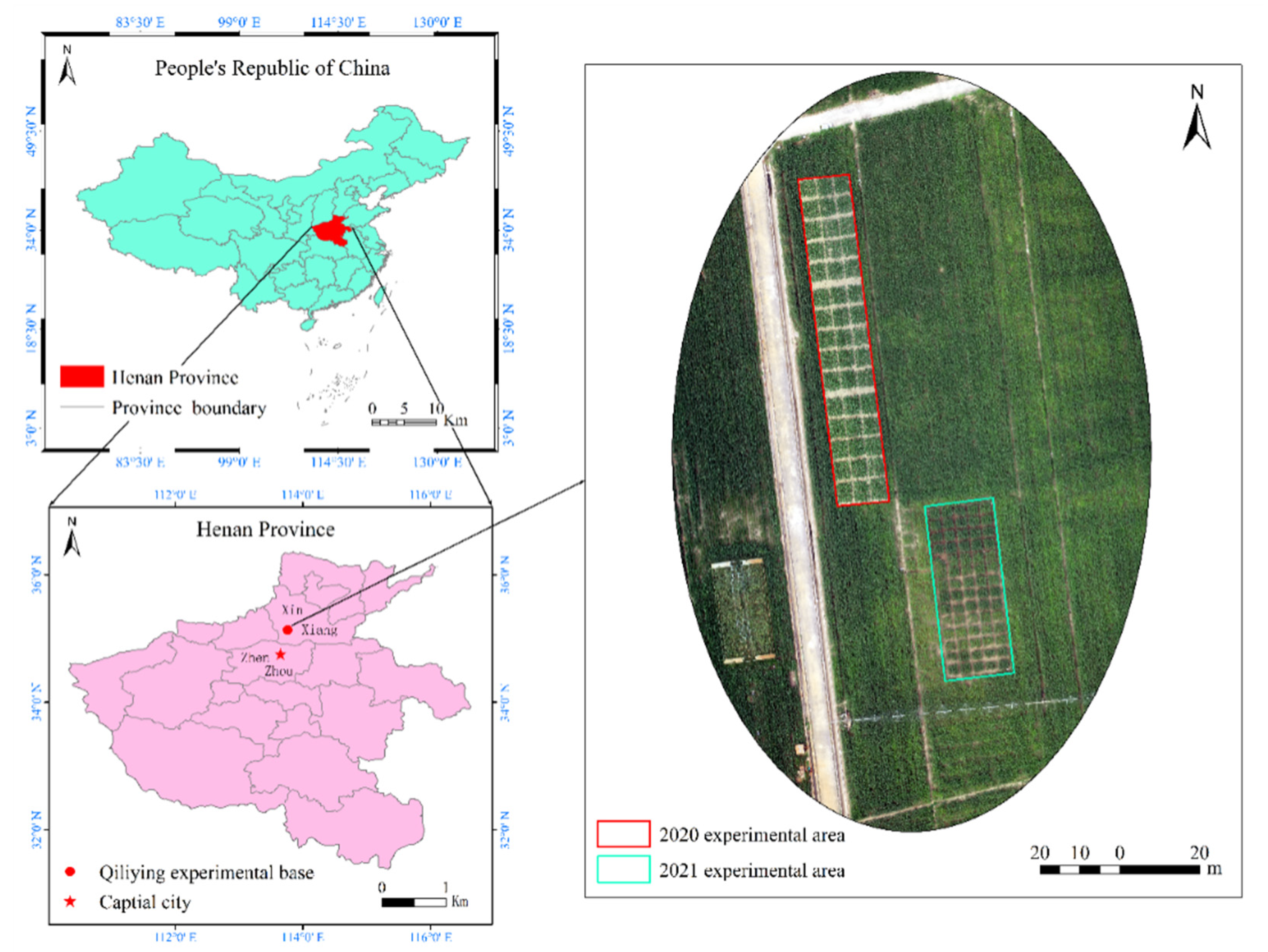
The study was conducted at Qiliying comprehensive experimental station (QCES) of the Chinese academy of agricultural sciences, Xinxiang city in Henan province of China (
Figure 1). The station lies at 35°13′ North and 113°76′ East with an average altitude of 78 m above mean sea level. The average annual temperature of the experimental site is 14.1 °C and the mean relative humidity is approximately 68%. A minimum average temperature of 0.7 °C is recorded in January while a maximum average temperature of 27.1 °C is recorded in July. The site is characterized by a unimodal rainfall regime with an average annual rainfall of 548.3 mm. Normally, rains occur between July and September. The annual evaporation recorded is 1748.4 mm. Most of the agricultural activities are rainfed, with wheat and maize being the major food crops throughout the year. The major source of irrigation water is the groundwater. The study site is light loam soil. The surface soil’s bulk density within the study sites measured is 1.4 g/cm
3. Adjacent plots were selected for the two-year experiment in order to ensure the consistency of soil nutrients when sowing in the same planting year.
2.2. Experimental Design
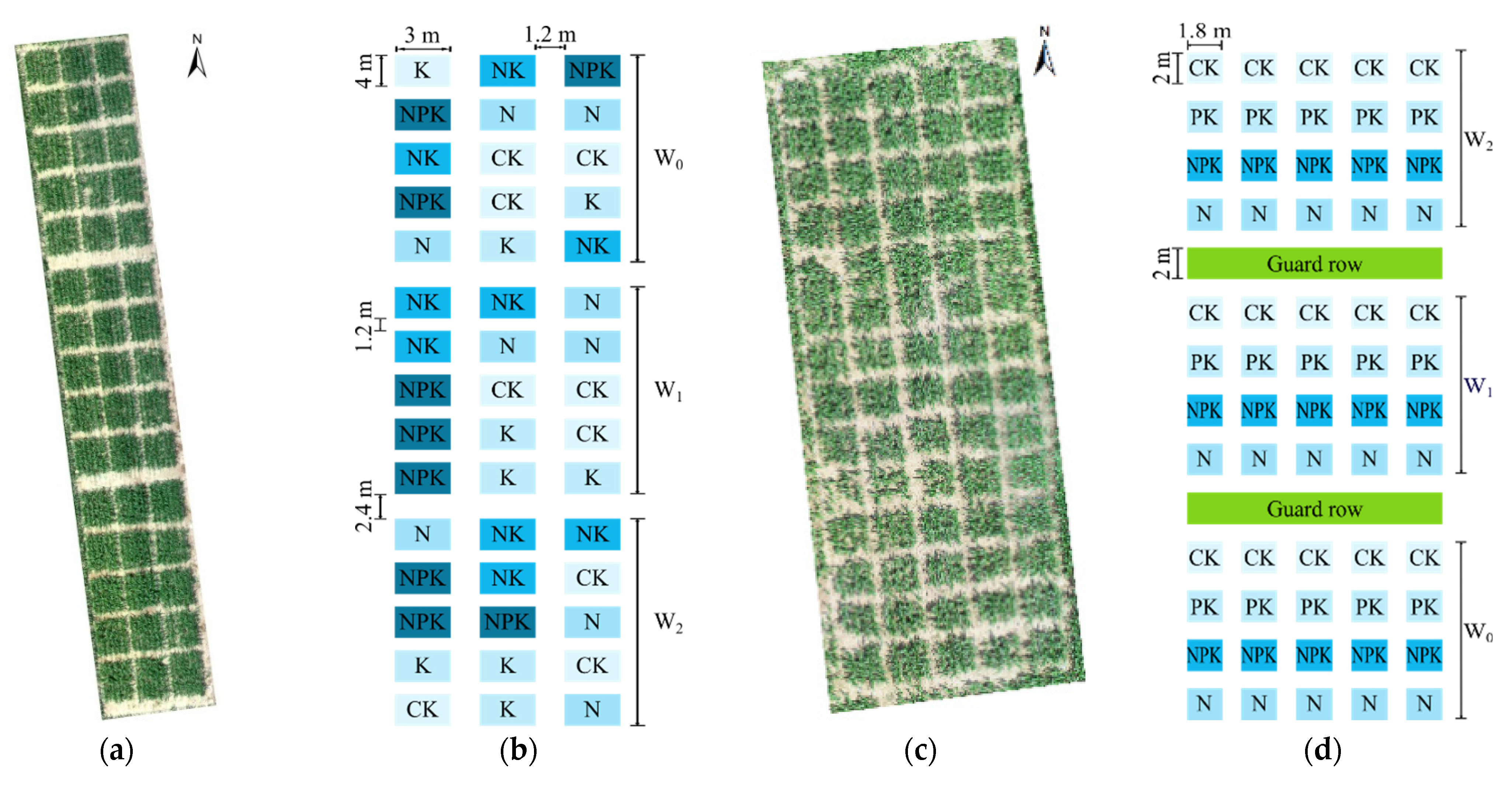
Experimental fields were evaluated across two growing seasons, 2020 and 2021, for irrigation and fertilizer treatments (
Figure 2). For this, two Maize cultivars “Taiyu 339” and “Nongda 108” were planted for two years on 20 June 2020 and 10 June 2021 with 0.6 m row spacing and 0.25 m plant spacing, and the row direction was North–South. The maize was headed on approximately 10 August and harvested on 27 September with a 96-day lifespan in 2020 and a 106-day lifespan in 2021.
In both years’ irrigation experiments, irrigation was carried out using the drip irrigation method with a total of three irrigation gradients. Irrigating quotas on each application were 0 mm (W0), 30 mm (W1) and 70 mm (W2), respectively. The irrigation volume was controlled by the water meter on the branch pipe. During the sowing period, the experimental field was irrigated with flood irrigation once, in order to ensure the emergence rate of maize. Afterwards, controlled irrigation treatments were carried out at the jointing stage, big trumpet stage and silking stage of summer maize.
In 2020, fertilizer treatments were conducted under each abovementioned irrigation treatment, using a completely randomized block design. Each irrigation treatment contained fifteen experiment plots of 4 × 3 m dimensions with 1.2 m spacing, with five fertilization treatments: CK, N, K, NK, NPK; where N, P, K are nitrogen (N, 250 kg hm
−1), phosphate fertilizer (P
2O
5 30 kg hm
−1) and potassium fertilizer (K
2O 120 kg hm
−1); CK is a non-nutritive fertilizer. Compound fertilizer (600 Kg hm
−1) was basally applied to all plots, which accounted for 50% of the total application amount. Carbamide CO(NH
2)
2, superphosphate Ca(H
2PO
4)
2·H
2O, potassium chloride KCL were used as topdressing fertilizers. The topdressing time was at the big trumpet stage and silking stage; each application amount accounted for 25%. Five fertilizer treatments were repeated three times, as shown in
Figure 2.
In 2021, the randomized block design was also used in the fertilization treatment experiment. However, each irrigation treatment contained twenty experiment plots (2 × 1.8 m) with 1.2 m spacing, with four fertilization treatments: CK, N, PK and NPK. Each fertilizer treatment was repeated five times. Fertilization application was divided into three times throughout the entire growth period, at the sowing stage, big trumpet stage and silking stage, while each application accounted for 33.3% of the total amount.
2.3. UAV Multispectral Images Acquisition and Process
UAV-based images were acquired using a RedEdge-MX (MicaSense, Inc., Seattle, WA, USA) sensor mounted on the DJI M210 (SZ DJI Technology Co., Shenzhen, China). The fields were georeferenced using UAV-mounted GPS. Then, the points were recorded to produce a flight route. The RedEdge-MX sensor had five multispectral bands (blue, green, red, red edge and near-infrared). The center wavelengths for the respective spectral band were 475 nm, 560 nm, 668 nm, 717 nm and 840 nm.
UAV flight missions were conducted under clear sky and low wind speed (<5 m s−1) conditions between 11:00 and 13:00 solar time, ensuring few shadows of features were collected. UAV acquired images of the field at a speed of 3 m s−1 and an altitude of 30 m above ground level. The 85% forward and 80% sideward overlap was set between images. A standard reluctance panel was used to calibrate the multispectral images.
Summer maize has a rapid growth from the jointing stage to silking stage and reached maximum LAI at the silking stage with no growth thereafter. Therefore, data collection was generally conducted from the jointing to silking stage as shown in
Table 1.
UAV images were processed using the Pix4Dmaper 3.1.22 (Pix4D, S.A., Lausanne, Switzerland) to calibrate and stitch the acquired images. The software output included the experiment map, dense point cloud extraction and digital surface model (DSM). The point clouds were accurately georeferenced to the Earth reference system, World Geodetic System 84. The shape files were produced to clip each plot from the experimental map, then the average reflectivity of the plot in each band was respectively extracted to represent the actual reflectance of the plot. This part of the work was implemented in ArcGIS 10.5 (ESRI, RedLands, CA, USA). In the next step, ENVI 5.5 (Exelis Visual Information Solutions, Boulder, CO, USA) and IDL language were used to calculate the vegetation indices. The vegetation index can simply and effectively measure the growth of crops. It is widely used to estimate LAI [
10]. In order to reduce the influence of external environmental factors, such as soil and atmosphere, 12 vegetation indices that perform well in this condition were selected according to previous studies [
29]. The calculation formula of the 12 VIs is respectively shown in
Table 2.
2.4. Ground Data Acquisition
The weather data was measured with 30 min intervals by the agricultural meteorological station installed on the flux tower near the experimental site. The parameters recorded include air temperature, relative humidity, wind speed, soil temperature and rainfall, etc. The ground truth LAI was measured by the SunScan (Delta-T Devices Ltd., Cambridge, UK) device. Each experiment plot was measured at one-third equal intervals along the planting direction, and the measurement direction was perpendicular to the planting direction; therefore, each experiment plot was completely measured three times, and the averaged LAI value of the plot was considered as the true LAI representative of the plot. The LAI measurement was performed after UAV image acquisition to ensure data synchronization.
2.5. Ensemble Learning Model Construction and Evaluation
The core idea of stacking in this study was to train the base model of the first layer, and then use the output of the first layer model as input to train the next-level model, to finally obtain the simulated value. In this study, only two layers of learners were set. At the same time, since each base model must be used as the input variable of the secondary learner, the selection of the primary model should follow some principles [
39]. Firstly, the ensemble method combines the estimated values of a single model, and the performance of each primary model can affect the final ensemble result, so each primary model should have good estimation ability [
40]. Secondly, there should be differences among the models.
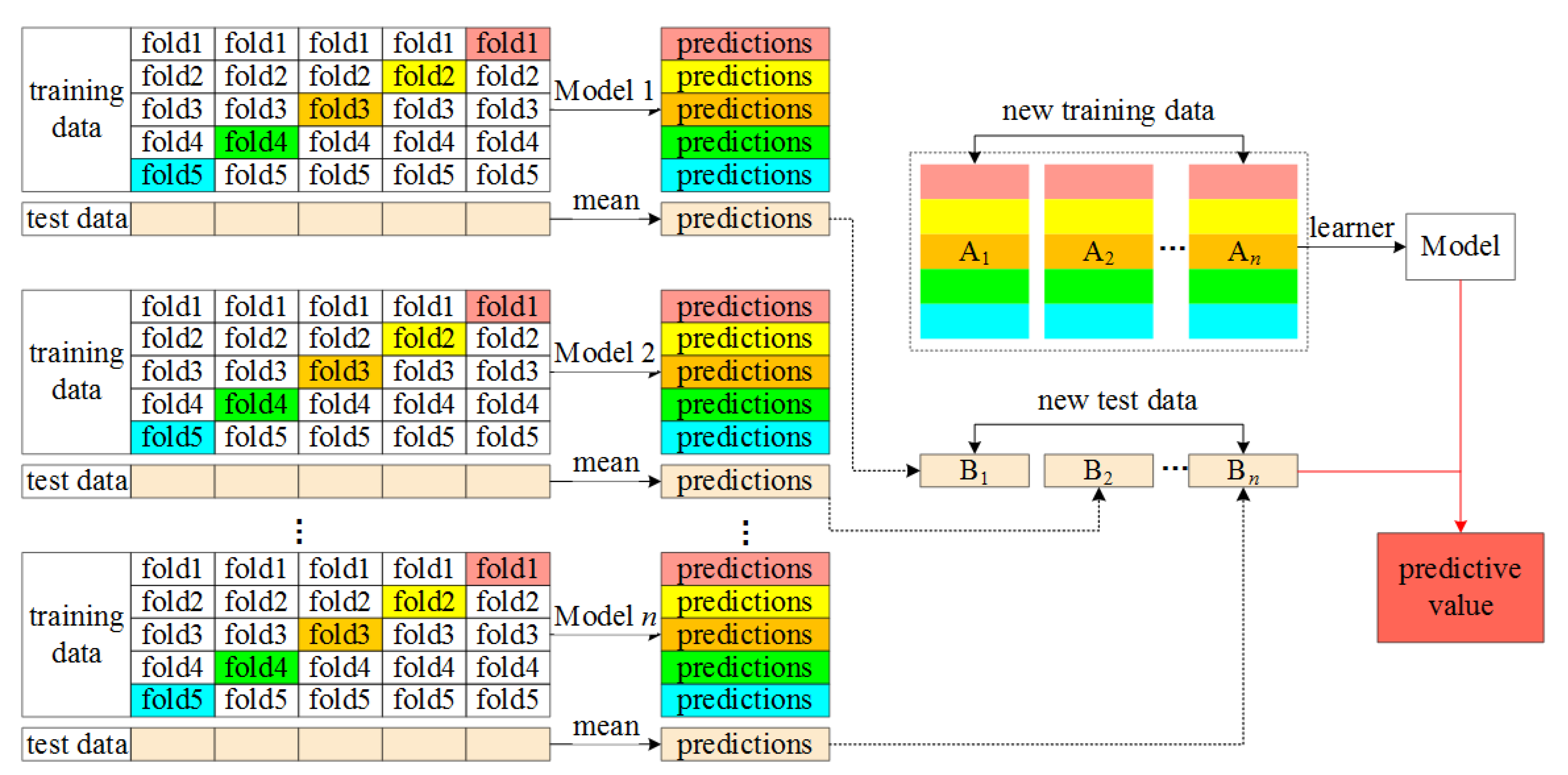
The basic principle of this algorithm is shown in
Figure 3. Firstly, the data was divided into training set and test set, while the training set was divided into five parts: fold1, fold2, fold3, fold4 and fold5. Secondly, the primary learners (basic model) were selected, and the five-fold cross validation method was used for model training, and the trained basic model was used to predict the test set. Then, the predicted values of the training set were regarded as eigenvectors “A
1, A
2,…, A
n” to form a new training set; whereas, the predicted values of the test set were regarded as eigenvectors “B
1, B
2,…, B
n” to form a new test set. Finally, a predictive model was built using the secondary learner. In this study, primary learning models included Gaussian process regression (GPR), support vector regression (SVR), random forest (RF), least absolute shrinkage, selection operator (Lasso) and Cubist regression, while secondary learning models included RF and multiple linear regression (MLR). Model construction was performed using R 4.0.3. For more information, please refer to the literature [
41,
42].
2.5.1. Stepwise Regression
In order to obtain the high-performance model, the characteristic variables need to be screened prior. Stepwise regression is used to screen all parameters. Stepwise regression combines forward stepwise regression and backward stepwise regression. Only one variable is added each time, but in each step, the variable will be re-evaluated, and the variable with no or insignificant contribution to the current model can be removed. Independent variables can be added or removed again until an optimal model is obtained. Akaike information criterion (AIC) is used as the basis to judge whether the variable can survive [
43]. The AIC formula is shown in Equation (1). Increasing the number of independent variables in the model can improve the goodness of fitting, but it may lead to over-fitting of the model. AIC encourages the goodness of data fitting and tries to avoid over-fitting. Therefore, the preferred model should be the one with the lowest AIC value. Using AIC to deal with statistical problems can be roughly divided into the following three steps: (1) constructing the statistical model; (2) the parameters are estimated by the maximum likelihood estimation method; (3) the model is selected by the minimization of AIC. The difference in AIC first depends on the likelihood function L. When there is no significant difference in L, the model with few parameters is considered to be a good model. Therefore, the model with better goodness of fit and few independent variables can be developed according to AIC.
where
k is the number of parameters; L is the likelihood function, which can be expressed as Equation (2):
where
n is the sample size; SSE is the sum of squares error. It can be seen that L mainly depends on the sum of squares error. Therefore, AIC can also be expressed as Equation (3):
2.5.2. Gaussian Process Regression
Gaussian process regression (GPR) is a machine learning algorithm based on the Gaussian process (GP) for regression prediction of observed samples. The probability density function of the GP is shown in equation 4. It can be seen from the formula that the Gaussian distribution is determined by the mean vector and the covariance matrix. The process of GPR prediction can be roughly summarized into five steps: (1) determine the observed data points as the sampling points of the GP; (2) determine the mean function and covariance function; (3) obtain the function of the observed data according to the posterior probability expression; (4) use maximum likelihood estimation to solve hyperparameters; (5) get predicted values. The specific process can be followed in Rasmussen’s research [
44].
2.5.3. Support Vector Regression
The support vector machine (SVM) is a classifier, but it can also be used for regression analysis. The application model of SVM regression is called support vector regression (SVR) [
45]. The advantage of SVR is to determine the final decision function with a few support vectors. The complexity of its calculations depends on the support vector rather than the whole sample space, which can avoid the “disaster of dimension”. Similarly, the final result is determined by a few support vectors, which is not only convenient to pay attention to key samples, but also ensures that the SVM has good “robustness”. For nonlinear problems, the main idea of SVR is to transform the original problem into a linear problem in a high-dimensional space and perform a linear solution in the high-dimensional space. Then, the solution of the problem becomes maximizing the following objective function (Equation (5)) under the constraint condition (Equation (6)).
where
is Lagrange factor; W is objective function; ε and
C are both positive constants;
is kernel function. Finally, using the optimization algorithm to calculate equation 5 can be obtained by the nonlinear regression function (Equation (7)). In this formula, only a small part of
, and their corresponding samples are called support vectors. The optimization algorithm can be expressed as Equation (8).
where
,
,
,
,
. The constraint conditions of Equation (8) are
β*(1, ∙∙∙, 1, −1, ∙∙∙, −1) = 0, and
and
i = 1, ∙∙∙,
n;
n is sample size.
2.5.4. Cubist Regression
The Cubist model is an extension of the M5 model tree developed by Quinlan [
46]. Cubist is a modeling analysis method based on specific rules, which is usually used in continuous value prediction problems. Firstly, the model tree is created through recursive processing and then simplified into a series of rules. These rules partition samples according to their spectra and a unique linear model is then applied to predict the target variable. The Cubist method can use the nearest neighbors in the sample to modify the model prediction results. The first step is to build a model tree. If there is a sample to be predicted, this method can find the closest one in the sample and finally get the predicted value. The independent variables in this method cannot only be used for modeling, but can also determine node branching. Using this algorithm in R, it is possible to automatically identify independent variables that can be used for branching and modeling. More details on Cubist and its implementation can be found in Viscarra Rossel and Webster and Minasny and McBratney [
47,
48].
2.5.5. Lasso Regression
Lasso regression is not only a model with good generalization and estimation ability, but also acts as a stable variable filter [
49,
50]. When the autocorrelation of variables is high, this kind of method can avoid excessive interpretation of the current sample and explore the law applicable to the whole population. This shift from explanation to prediction is helpful to enhance the theoretical significance and application value of research. The loss function of Lasso regression can be expressed as Equation (9). The first part of the formula is the loss function of ordinary least square (OLS), and the second part is the penalty function.
λ (≥0) represents the tuning parameter, which is used to control the regression coefficient. The larger the value, the stronger the punishment. When
λ = 0, it means that the regression model is not penalized, and the formula becomes the OLS loss function.
where
X is the matrix of predictive variables;
Y is a vector of outcome variables;
β is the regression coefficient vector;
W is the vector with a value of ±1 (plus or minus sign corresponds to the corresponding value in the
β vector).
2.5.6. Random Forest Regression
The random forest regression model consists of multiple decision trees, and there is no relationship between each decision tree in the forest. The final output of the model is jointly determined by each decision tree in the forest [
51]. The randomness of random forest is reflected in two aspects: (1) A certain number of samples are randomly selected from the training set as the root node samples of each regression tree; (2) when establishing each regression tree, a certain number of candidate features are randomly selected, and the most suitable feature is selected as the split node.
2.5.7. Model Accuracy Evaluation
In this study, the coefficient of determination (R
2), root mean square error (
RMSE), residual prediction deviation (
RPD) and the ratio of performance to interquartile distance (
RPIQ) were used as the accuracy evaluation indexes. Among them, R
2 can characterize the stability of the model (positive relationship) and
RMSE is often used to characterize model accuracy (reverse relationship), while
RPD is the ratio of sample standard deviation (
SD) to
RMSE (Equation (10)).
When 1.5 < RPD < 2.0, it is considered that the model can only roughly estimate the LAI; when 2.0 ≤ RPD < 3.0, the model has good prediction ability and is relatively reliable; when RPD ≥ 3.0, the model has excellent prediction ability and is reliable.
RPIQ considers both the prediction error and the change in observation data. It is a more objective and easier index to compare in model verification. The larger the
RPIQ, the stronger the prediction ability of the model. Different from the residual prediction deviation,
RPIQ has no assumption on the distribution of observed values [
52]. Its formula is as shown in Equation (11):
where
IQ is the difference between the third and first quartiles.
4. Discussion
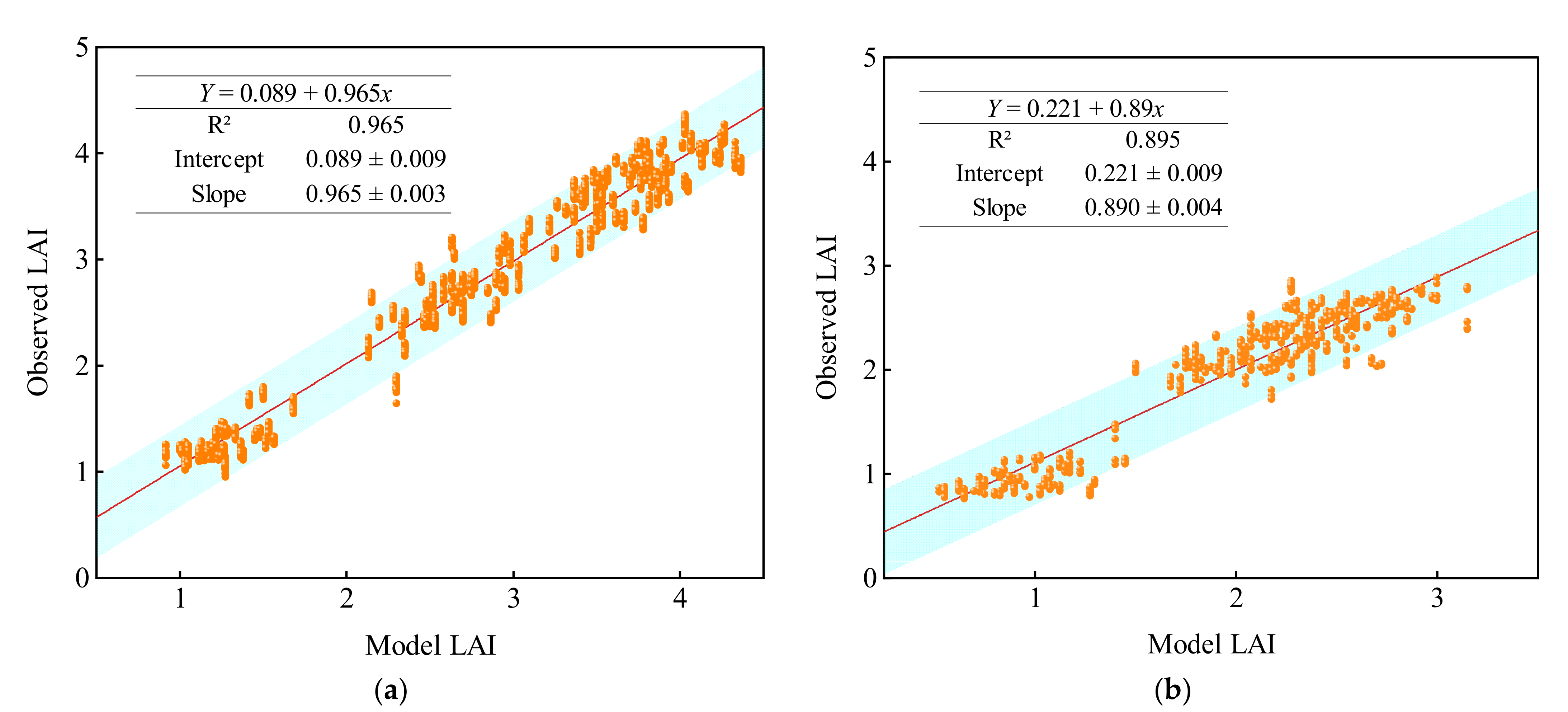
The development of crop cultivation and management strategies for efficient use of resources to enhance crop stability and yield is very important. Therefore, continuous assessments of important traits such as LAI under different water and fertilizer conditions can help to understand their effect on crop growth and to develop different crop management strategies. In this study, we successfully evaluated the UAV-based multispectral phenotyping and stacking ensemble learning approach to estimate the LAI as an indicator for the assessment of water and fertilizer stress in summer maize. Previously, several studies have reported spectral information as a good predictor of phycological characteristics of the crops.
The relation between VIs and LAI is complex. In this study, the regression model with the lowest AIC value was selected by the stepwise regression method. Then the VI was selected according to the relative importance. Finally, five vegetation indexes with the best performance were selected to use as input for predictions. There is no doubt that more VIs with high correlation or with low correlation need to be compared before being used for LAI model generation. Meanwhile, other feature selection methods can be introduced to screen VIs more accurately, such as mRMR [
53] and least angle regression (LARS) [
54].
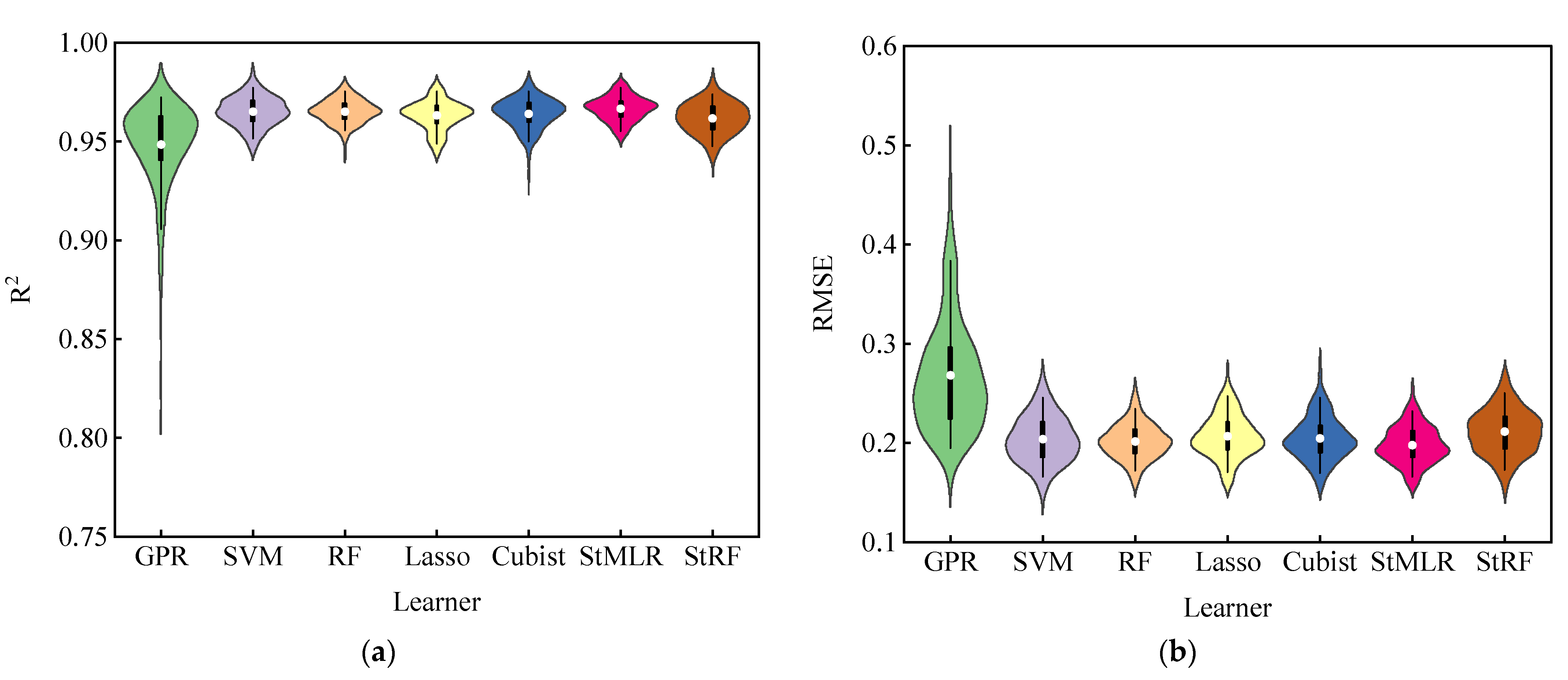
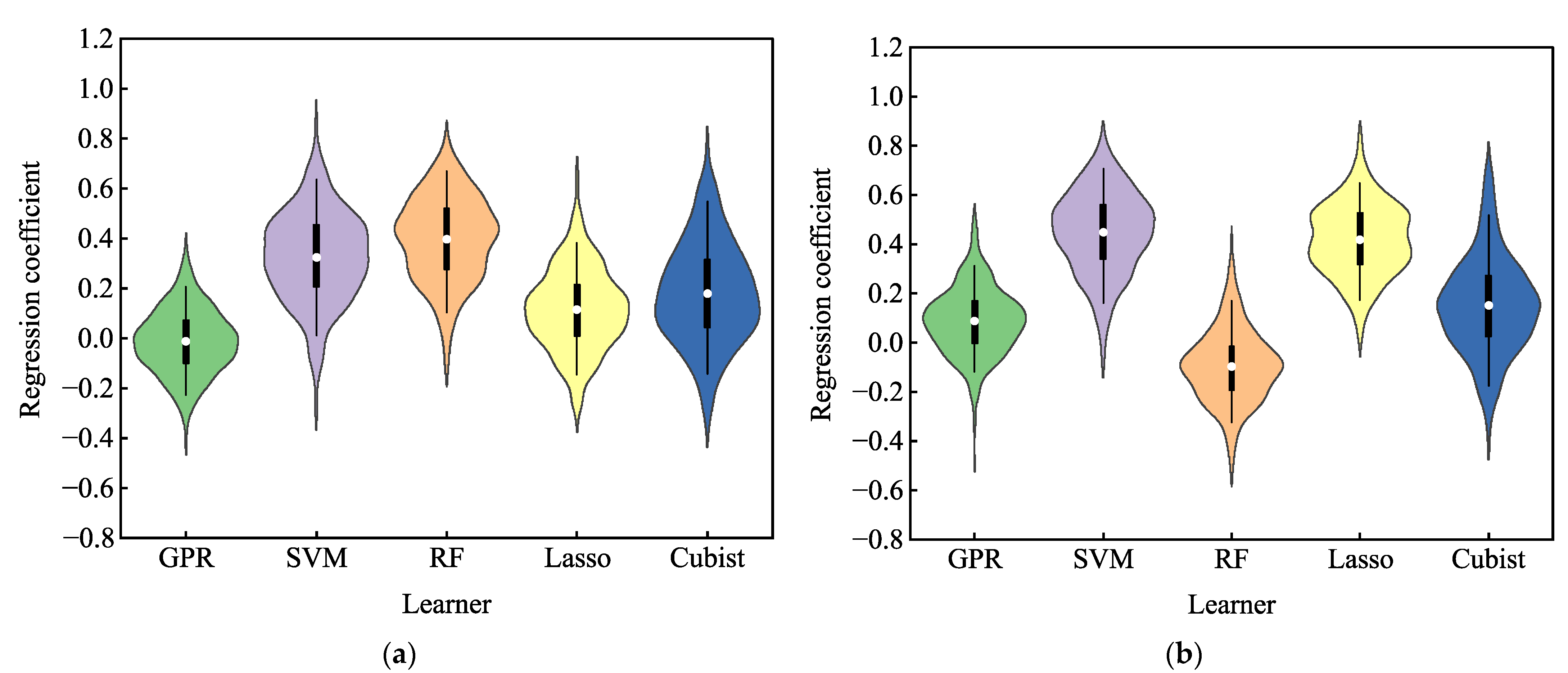
In this paper, five machine algorithms including GPR, SVM, RF, Lasso and Cubist were used as basic learners to build ensemble learning models using two years of data of maize LAI. The estimation ability of the five basic models was evaluated through four evaluation indicators. The results showed that among the models constructed by these five classical machine learning algorithms, the coefficient of determination (R
2) between the output value and the real LAI was high, but the RPD of GPR and RF models were less than 3.0 when predicting maize LAI in 2021. These results indicated that the model constructed by using a single machine learning algorithm was unstable and there was a risk of error estimation [
40]. Previously, Yuan et al. [
55] found that the RF model was the most suitable for LAI estimation during the whole growth period. However, the RF as a basic model performed poorly in our results for the 2021 cropping season. The reasons for the inconsistent results from previous reports may be due to the use of different datasets and crops [
56]. The RF basic model achieved better estimation results in the case of the 2020 dataset, which proves the correctness of the above analysis.
The performance of a single algorithm can be varied for different datasets, so it is difficult to optimize a single model-based estimation of traits under different modeling conditions. The ensemble learning algorithm can avoid the above phenomenon by stacking different base models. The stacking approach used in this study is an ensemble learning method, which has strong adaptability for different datasets. The anti-noise performance and fitting ability of the stacking algorithm has superiority over a single algorithm. The hypothesis space considered by different types of algorithms will also be different. If the real assumptions of some algorithms for the LAI of summer maize are not within the hypothesis space calculated by the currently selected model, then it is meaningless to use this algorithm for modeling. After integrating multiple regression algorithms through the stacking method, the corresponding hypothesis space will be expanded to a certain extent, thereby improving the universality of the model. In this study, the results state that the performance of the ensemble learning model was optimal in both years of data. Previously, some studies also demonstrated that the stacking method can improve the performance of the model in plant phenotype evaluation [
57,
58].
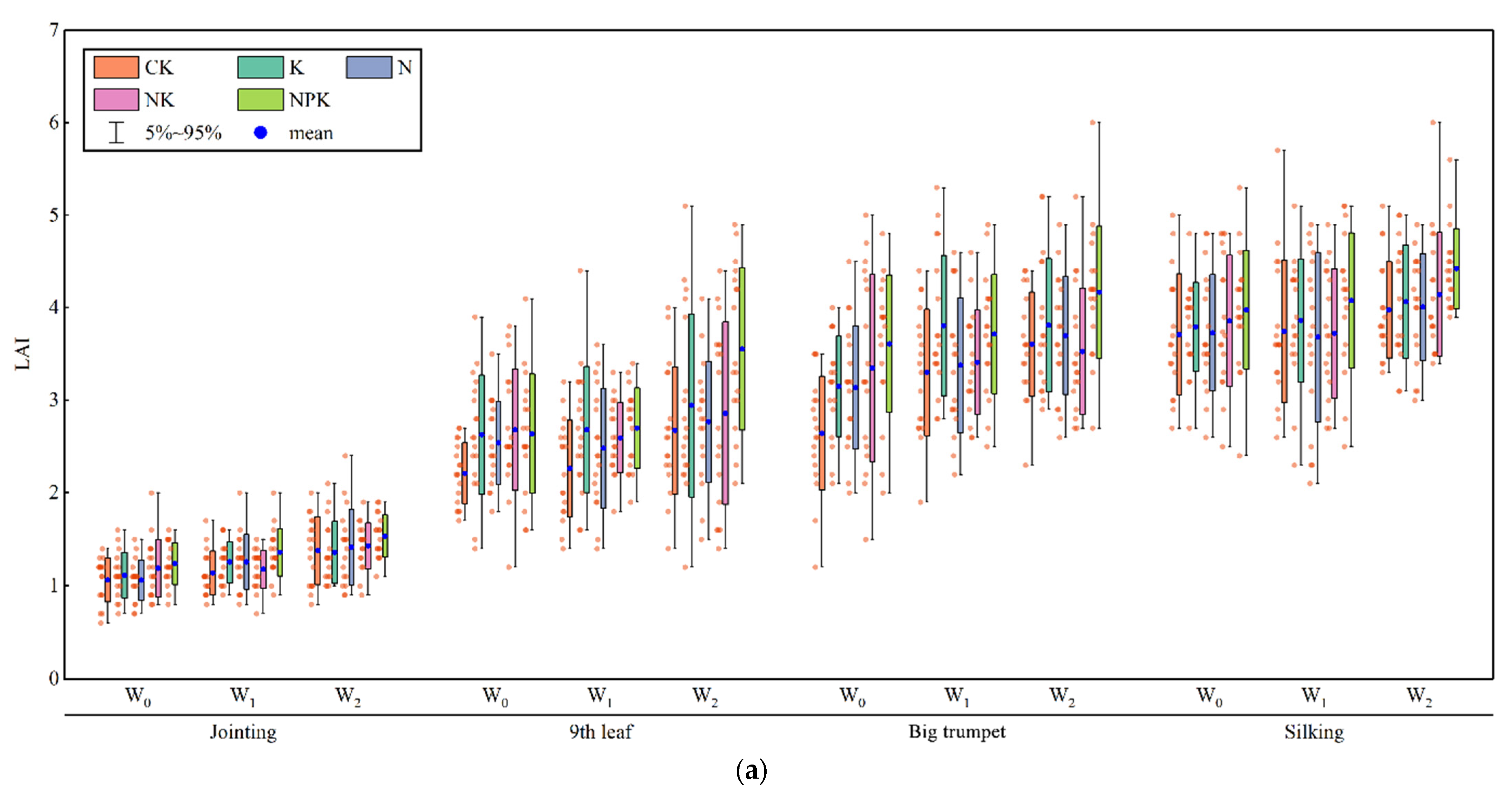
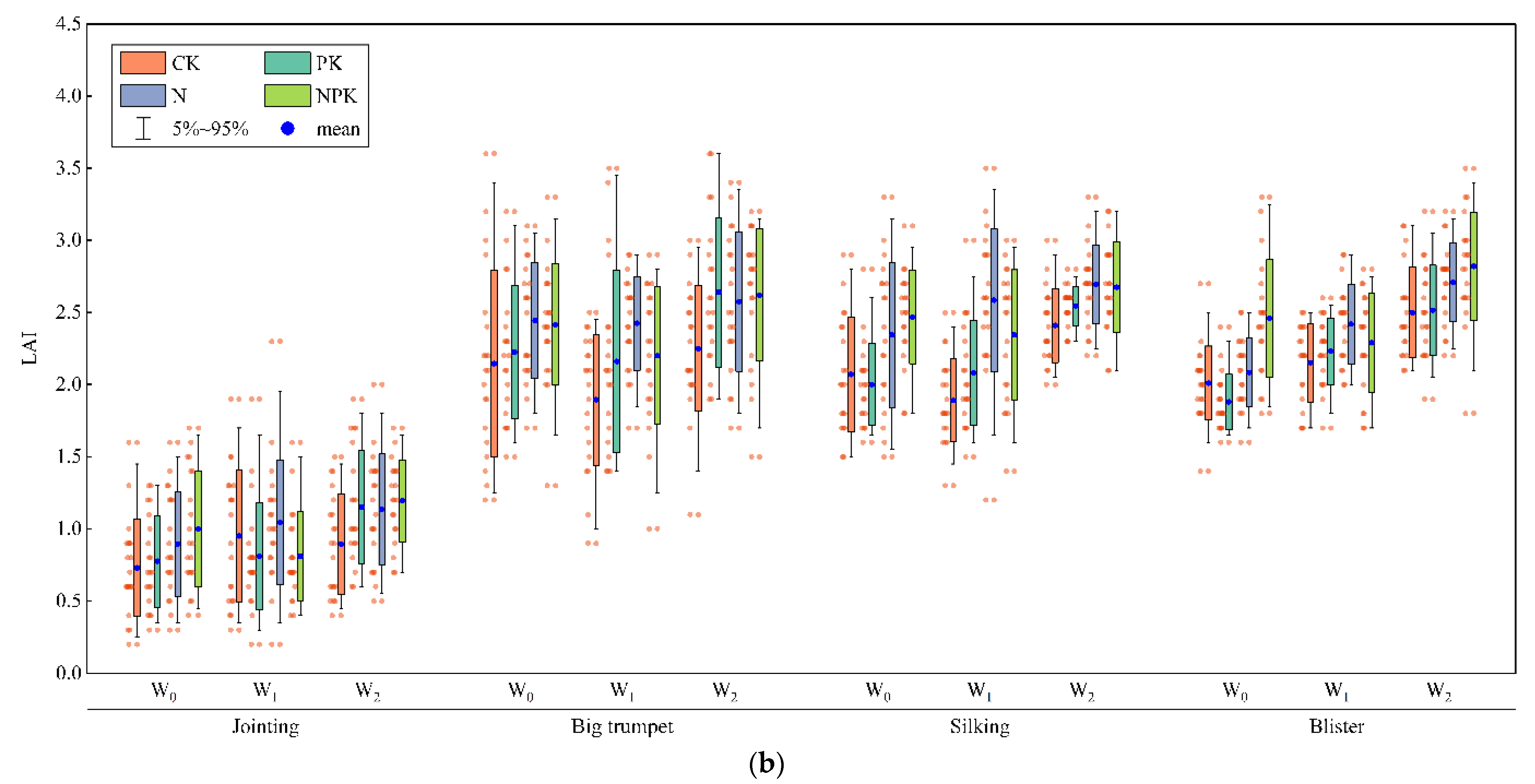
In this study, the irrigation method used for summer maize was drip irrigation and the amount of water per irrigation did not reach the field capacity. Therefore, there were different degrees of water stress under the three irrigation treatments W0 > W1 > W2. It was close to no deficit under W2 irrigation treatment conditions, which had little effect on the normal growth and development of summer maize. The water deficit was the most serious under the W0 irrigation treatment, which had a significant effect on the LAI over the whole growth period. At the same time, the LAI of the experimental plot with the most complete fertilizer ratio was better than that of the other fertilized plots, indicating that the LAI of summer maize can reflect the degree of fertilizer deficiency. More experiments with additional irrigation and fertilizer amount gradients should be set up to accurately diagnose the degree of irrigation and nutrient deficiency in each growth period of maize and realize intelligent and precise irrigation with integrated water and fertilizer.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
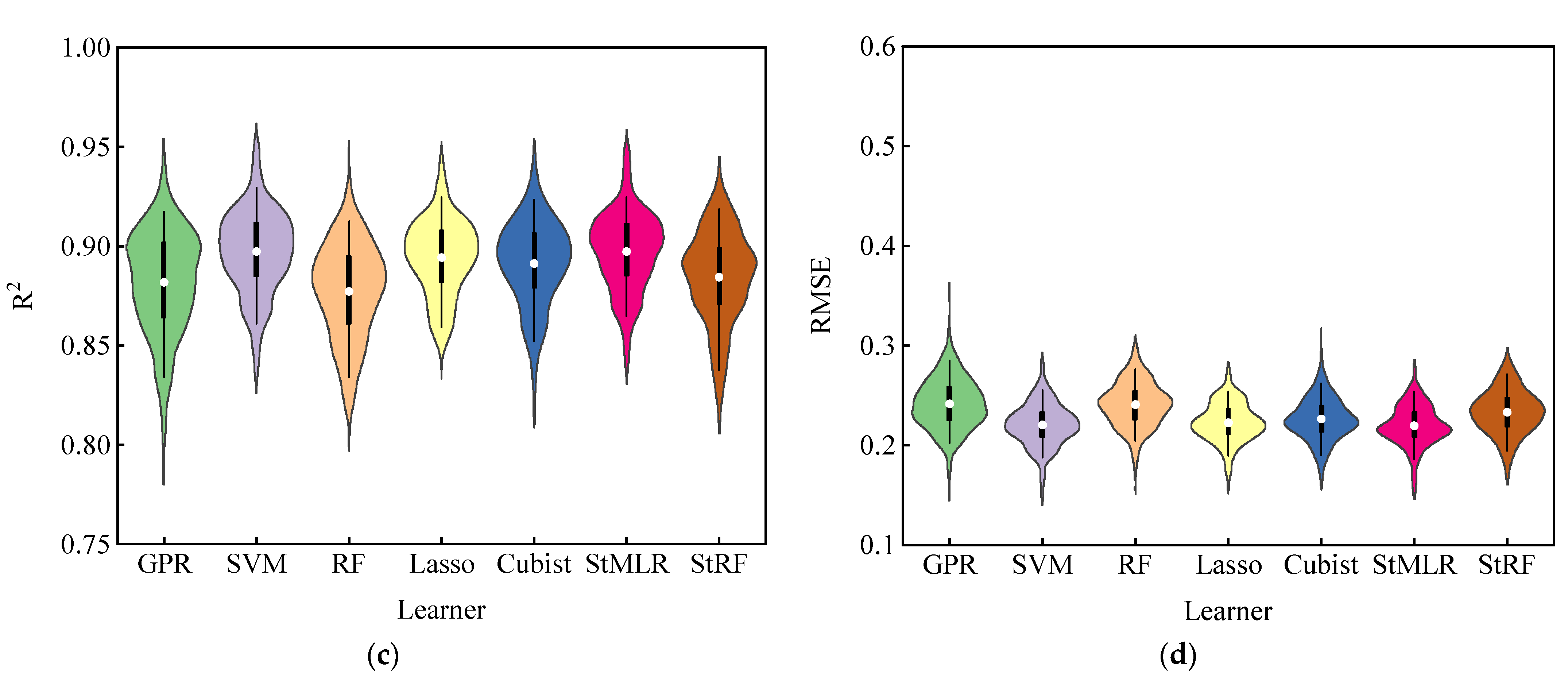{kind=link}
{kind=link}
{kind=link}