2.2. Marriage in Honey Bees Optimization Algorithm
Since honey bees are the most well-known social insects, they exhibit many features that make them seem like models for intelligent behavior [
32]. Therefore, the reproductive behavior of honey bees was used to propose an optimization algorithm in 2001 [
32,
33,
34,
35]. The algorithm is called the marriage in honey bees optimization (MBO) algorithm and it has been successfully applied for many optimization issues [
33,
34,
35]. Generally, a typical honey bee colony consists of the queen, drones, workers, and brood. The queen is the leading reproductive individual among the honey bees. Drones propagate one of their mother’s gametes and function to enable the female to act genetically as a male. Workers are specialized in brood care and in laying eggs. Broods arise either from fertilized or unfertilized eggs [
32]. The queen takes off on a mating flight and then the drones follow her. Moreover, the speed and energy of the queen affect the mating flight. The queen’s speed affects the probability of success in mating with a large drone swarm, and the queen’s energy affects the end of fertilization [
35]. After fertilization, the queen returns to the nest. Then, broods are generated and improved by the workers’ crossovers and mutations [
34].
During the mating flight, the probability of a drone mating with the queen can be represented by Equation (1):
where
P (
Q,
D) denotes the probability of adding the sperm of drone
D to the spermatheca of queen
Q (i.e., the probability of successful mating);
difference denotes the absolute difference between the fitness of drone
D and queen
Q; and
speed denotes the speed of queen
Q. Moreover, the mating flight is also affected by the flying time of the queen and the energy of the queen, as shown by the following equations:
In Equation (2),
α is a factor between 0 and 1. Generally,
α is set to be 0.9. The
step in Equation (3) denotes the degree of energy reduction after each transition. The detailed procedure for the MBO algorithm can be found in the literature [
32,
33,
34,
35].
2.4. The MBO/SVR Model
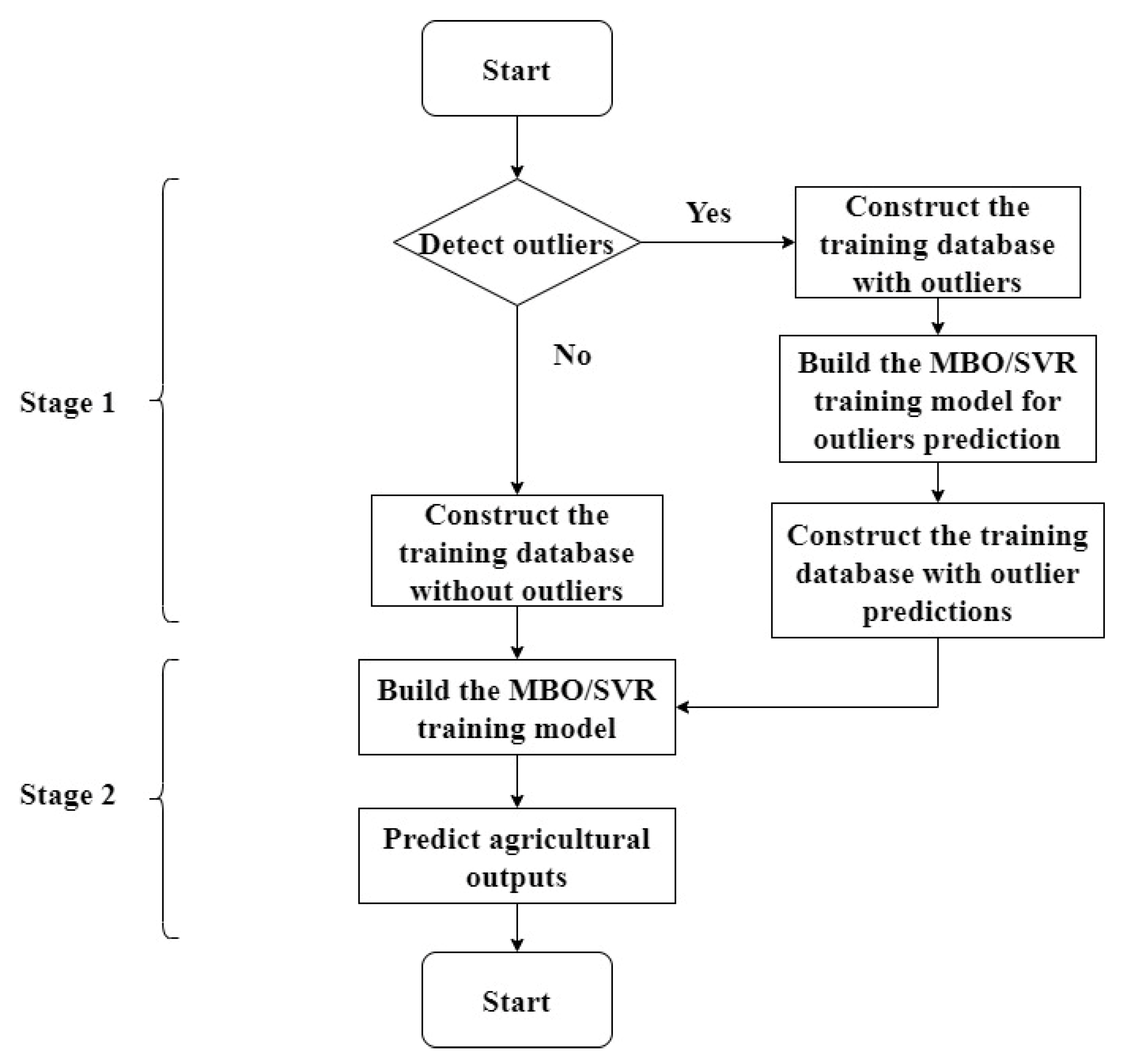
The MBO/SVR model comprises two main stages. Stage 1 is the data pre-processing stage for the training model, and Stage 2 is the prediction stage for agricultural output data prediction.
Figure 3 shows the flowchart of the MOB/SVR model. The detailed algorithm of the MBO/SVR model can be introduced as follows.
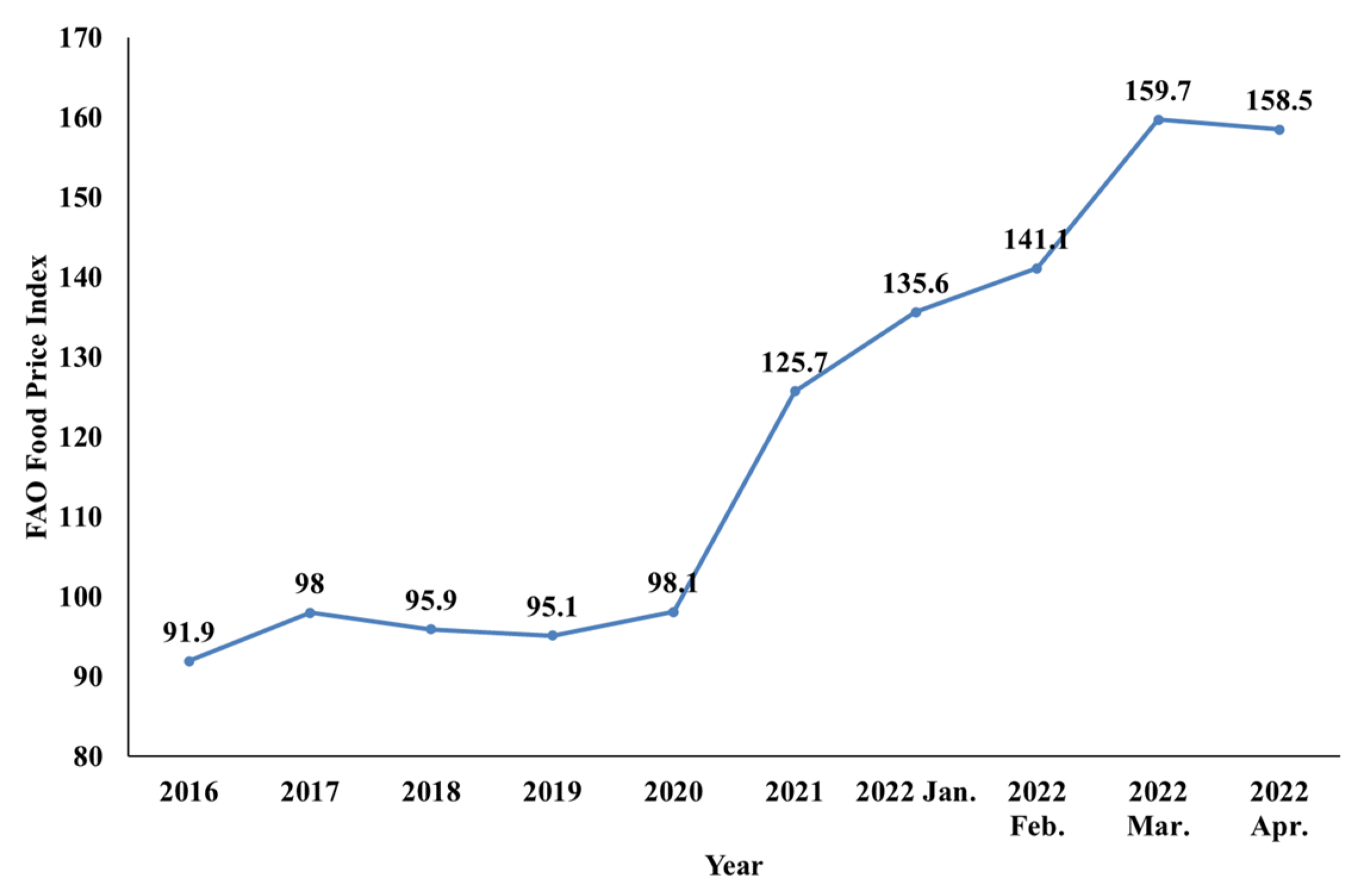
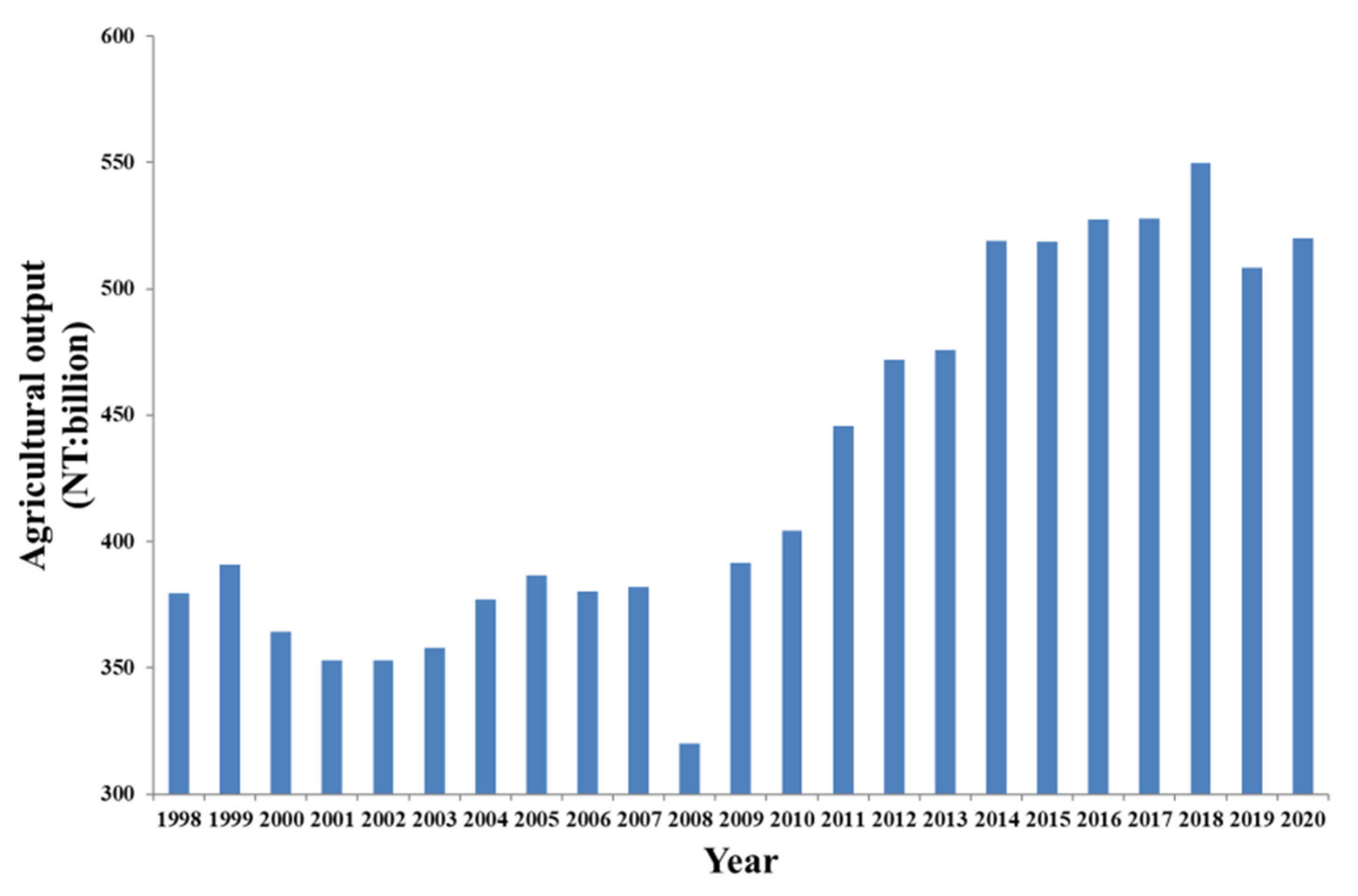
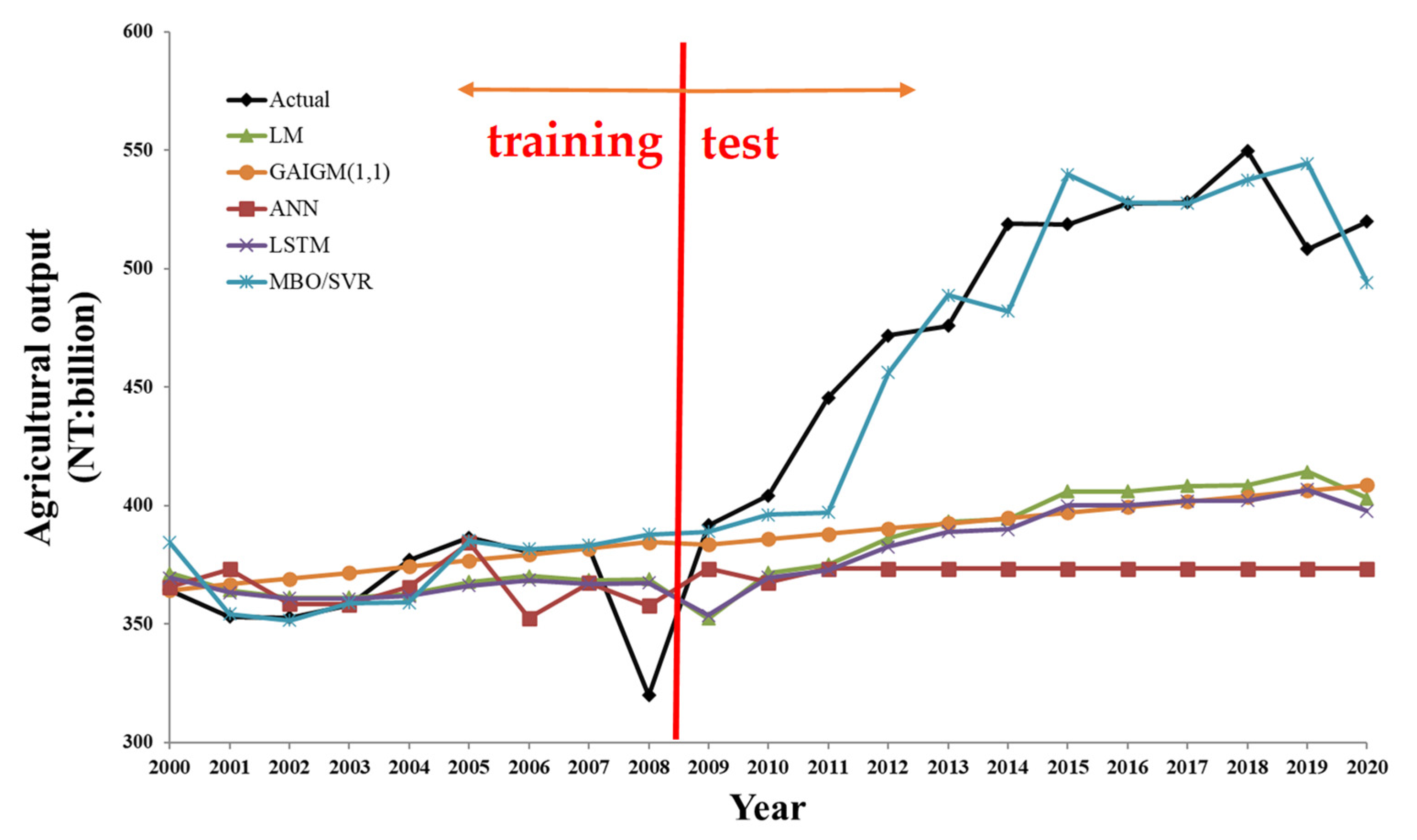
As described in
Section 2.1, the annual total agricultural output data have been highly volatile in recent years. Therefore, predictions must detect and smooth outlier data [
42]. Accordingly, the main goal of Stage 1 is detecting outlier data and reducing their effects when building the prediction model. There are two major steps in Stage 1.
Step 1: Detect outliers
First, we standardize the data based on Equation (6), where
xi denotes the
ith datum;
and
SD denote the mean and the standard deviation of the dataset, respectively; and
zi denotes the
z-score of the
ith datum of the training dataset. This study used a critical value for the outlier of ±2; i.e., when the
ith z-score is greater than 2 or less than −2, the
ith datum is an outlier. Subsequently, when there are no outliers in the training dataset, go to Step 2 to construct the training database without outliers; otherwise, go to Step 2.1 to construct the training database with outliers.
Step 2: Construct the training database without outliers
When there are no outliers in the dataset, the training database can be constructed without outliers the MBO/SVR training model can be built in Step 3. Data volatility affects the training model’s performance regardless of whether outliers are detected. Accordingly, the actual data must be transformed based on Equation (7) before constructing the training database. In Equation (7),
Tt denotes the
tth transformed datum, and
At and
At−1 are the actual
tth and (
t − 1)th data, respectively.
We can provide a simple example to describe the process of constructing the training database. Suppose a dataset includes ten years’ annual total agricultural output data;
Table 1 shows the actual and transformed data according to Equation (7). The training database can be constructed as shown in
Table 2. In
Table 2, each training ID denotes a sample, and the input variable (X) and output variable (Y) are fed into the MBO/SVR model to build the training model. When constructing the training database, go to Step 3 to build the MBO/SVR training model.
Step 2.1: Construct the training database with outliers
As described in Step 2, the actual annual total agricultural output data must be transformed using Equation (7) to reduce the effect of data volatility whether outliers are detected or not. Therefore, when outliers are detected,
Table 1 must still be constructed. As the agricultural output data are presented in a time-series dataset, prediction of future values should be based on previously observed values [
40,
41,
43,
44]. Accordingly, parts of the data should be removed to construct the training database for the training model. For example, suppose the Year
3 data in
Table 1 is detected as outlier data. Then,
T3 and
T4 will be removed because they were caused by Year
3 data. Therefore, the data with training IDs 1 to 3 in
Table 2 are also released.
Table 3 shows the constructed training database with outliers.
Step 2.2: Build the MBO/SVR training model for outlier prediction
Step 2.2 involves building the MBO/SVR training model for outlier prediction using the training database with outliers. As the central concept of the MBO/SVR model is searching for the best and most suitable parameter setting in the SVR model by using the MBO algorithm to enhance the performance, the procedures of the MBO/SVR model for outlier prediction include two steps, as described in Step 2.2.1 and Step 2.2.2.
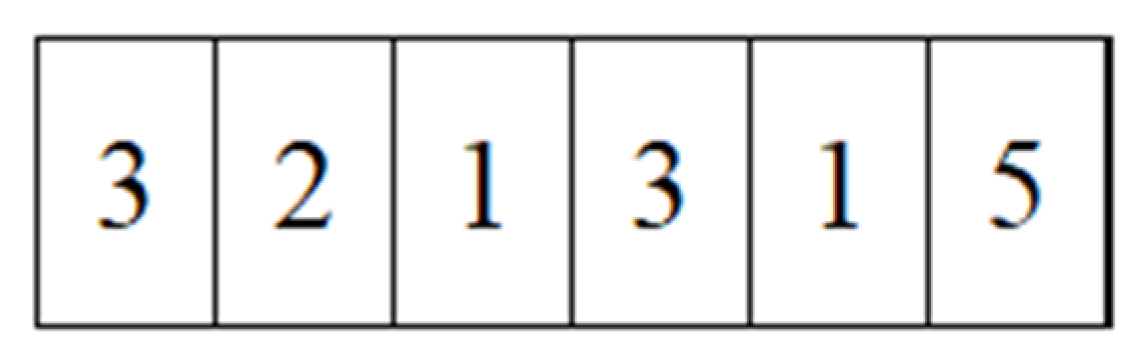
Step 2.2.1: Set the initial queen of the MBO
The queen of the MBO refers to a candidate parameter setting in the MBO/SVR model. A queen is coded as an integer sequence with six spermathecae. The first three spermathecae indicate a candidate solution for the
Cost parameter of the SVR model; the remainders are candidate solutions for the
Gamma parameter of the SVR model.
Figure 4 shows an example of a queen. As the
Cost parameter is set between 0 and 10, the first three spermathecae (321) in
Figure 4 indicate that the
Cost parameter is set to 3.21. Similarly, because the
Gamma parameter is set between 0 and 1, the remaining spermatheca (315) in
Figure 4 indicate that the
Gamma parameter is set to 0.315. Subsequently, the parameter settings build the training MBO/SVR model. The fitness function of the MBO/SVR model is defined by Equations (8) and (9). In Equations (8) and (9),
and
denote the
tth predicted transformed agricultural output datum and the
tth predicted agricultural output datum, respectively;
At denotes the
tth actual agricultural output data; and
n denotes the number of predictions.
Step 2.2.2: Complete the mating flight of the MBO
To search for the optimization solution, the MBO algorithm generates the next generation of broods through a mating flight. After completing the mating flight of the MBO algorithm, many broods will have been generated. We then calculate the fitness values of the broods. When a brood’s fitness value is better than the queen’s fitness value, the queen will be replaced with the brood.
There are two termination conditions in the MBO/SVR model: (a) when the last 50 generations’ fitness values are the same, the best queen is selected as the best parameter setting in the MBO/SVR model; (b) when the number of generations is greater than 500, the best queen is selected as the best parameter setting in the MBO/SVR model.
Step 2.3: Build the MBO/SVR training model for outlier prediction
When terminating the algorithm, the best queen is selected as the best parameter setting in the MBO/SVR model. Subsequently, the input variables (X) and output variables (Y) in the training database with outliers are fed into the MBO/SVR model to build the training model for outlier prediction. As the example in Step 2.1 shows, the Year
3 in
Table 1 is detected as outlier data.
T2 is fed into the training MBO/SVR model to predict the output value
and to replace
T3 with
. Subsequently,
and
can be calculated by
according to Equations (7) and (8).
Step 2.4: Construct the training database with outlier predictions
After Step 2.3, we use the outlier predictions to construct the training database with outlier predictions according to the same approach as in Step 2.
Table 4 shows the results for the training database with outlier predictions according to the example in Step 2.1.
Step 3: Build the MBO/SVR training model
After constructing the training database, we then use it to build the MBO/SVR training model. The procedure for building the MBO/SVR training model is the same as in Step 2.2. The MBO/SVR training model also needs to search for the best and most suitable parameter setting in the SVR model with the MBO algorithm.
Step 4: Predict agricultural outputs
Once the MBO/SVR training model has been built, we predict the agricultural outputs by feeding the test data into the MBO/SVR model. The procedure for prediction is the same as in Step 2.3.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}