
Assessing Machine Learning-Based Prediction under Different Agricultural Practices for Digital Mapping of Soil Organic Carbon and Available Phosphorus

 ,
,  ,
,  ,
,  ,
, 
Abstract
:1. Introduction
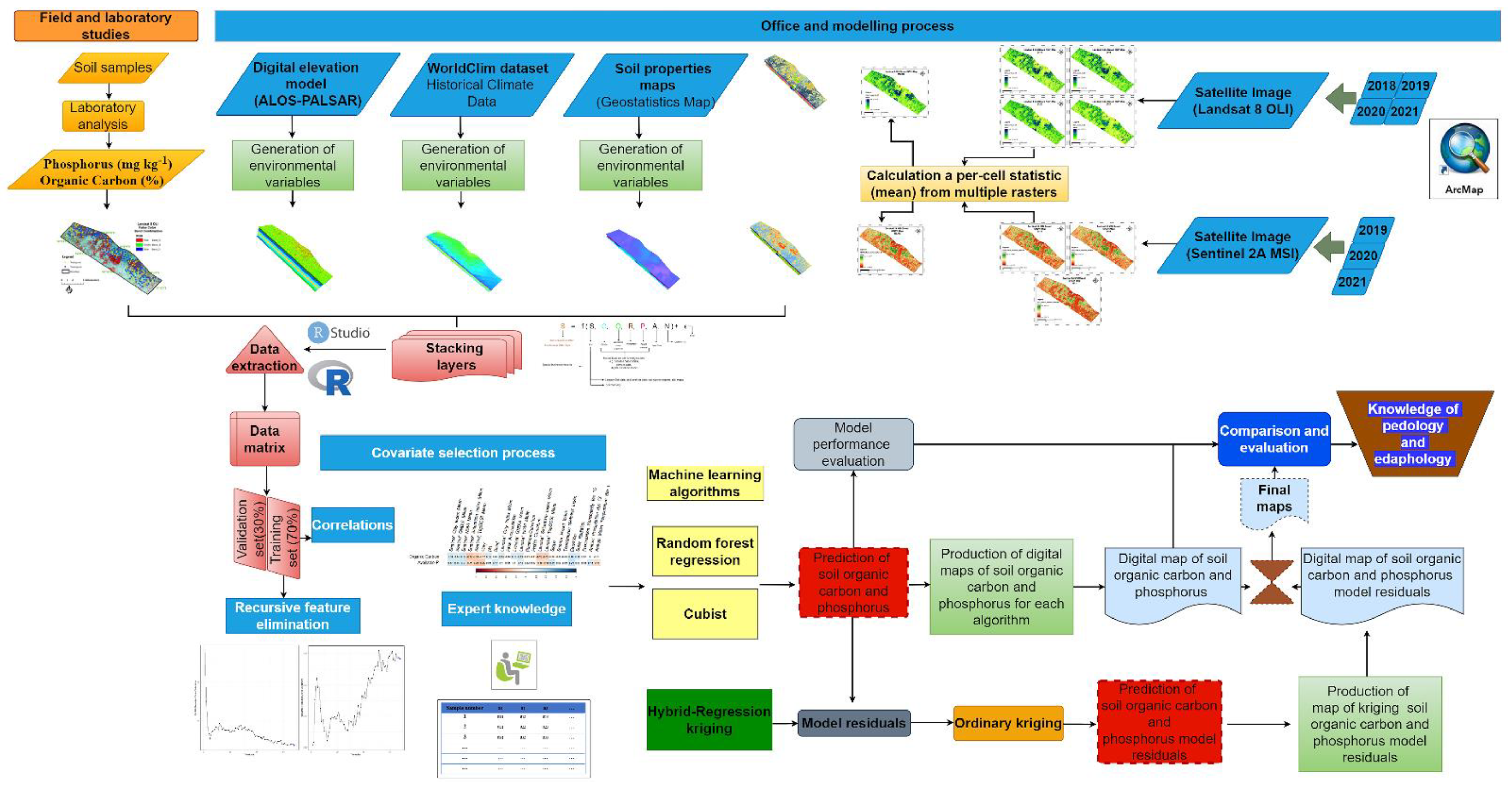
2. Materials and Methods
2.1. Study Area
2.2. Soil Sampling and Analysis
2.3. Covariates Used for DSM
2.3.1. Remote Sensing-Based Indices
2.3.2. Topographic Derivatives
2.3.3. Climate Based Covariates
2.3.4. Soil-Based Covariates

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Auxiliary Variables | Environmental Covariates |
|---|---|
| Digital Elevation Model (DEM) | Elevation (m) |
| Slope (%) | |
| Profile curvature | |
| Planform curvature | |
| Topographic wetness index (TWI) | |
| Flow Accumulation | |
| Stream Power Index (SPI) | |
| Remote Sensing Data (Both Landsat 8 OLI and Sentinel 2A MSI) (RS) | Topsoil grain size index [68] |
| Saturation index [69] | |
| Normalized clay index [12] | |
| Normalized difference vegetation index (NDVI) [70] | |
| Green Normalized Difference Vegetation Index [GNDVI) [71] | |
| Climatic Variables (CL) | BIO-1-Mean Annual Temperature (MAT) (°C) |
| BIO-12-Annual Precipitation (mm) | |
| BIO-15-Precipitation Seasonality (CV) | |
| Total Solar Radiation (kJ m−2 year−1) | |
| Soil Attributes (S) | Clay map produced with Ordinary Kriging (%) |
| Sand map produced with Ordinary Kriging (%) | |
| pH map produced with Ordinary Kriging |
2.3.5. Selection of Environmental Covariates
2.4. Modeling Process
2.5. Spatial Prediction of Soil Organic Carbon and Available Phosphorus Using Machine Learning Algorithms
2.5.1. Cubist Algorithm
2.5.2. Random Forest Algorithm
2.5.3. Spatial Prediction of Soil Organic Carbon and Available Phosphorus with Hybrid Methods
2.6. Model Accuracy of Regression-Based Algorithms
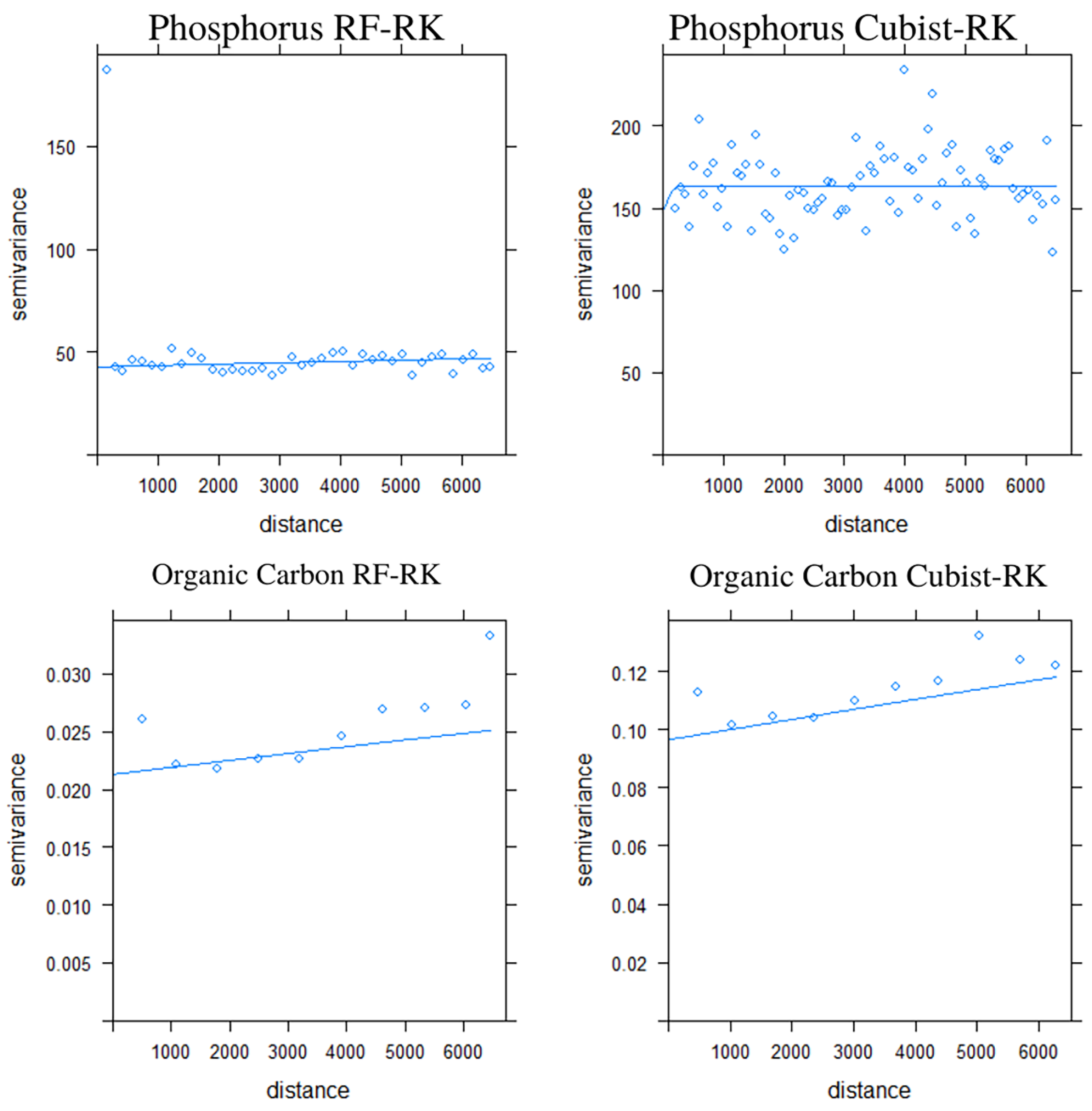
2.7. Analysis of Spatial Autocorrelation of Model Residuals
3. Results and Discussion
3.1. Results of Descriptive Statistics
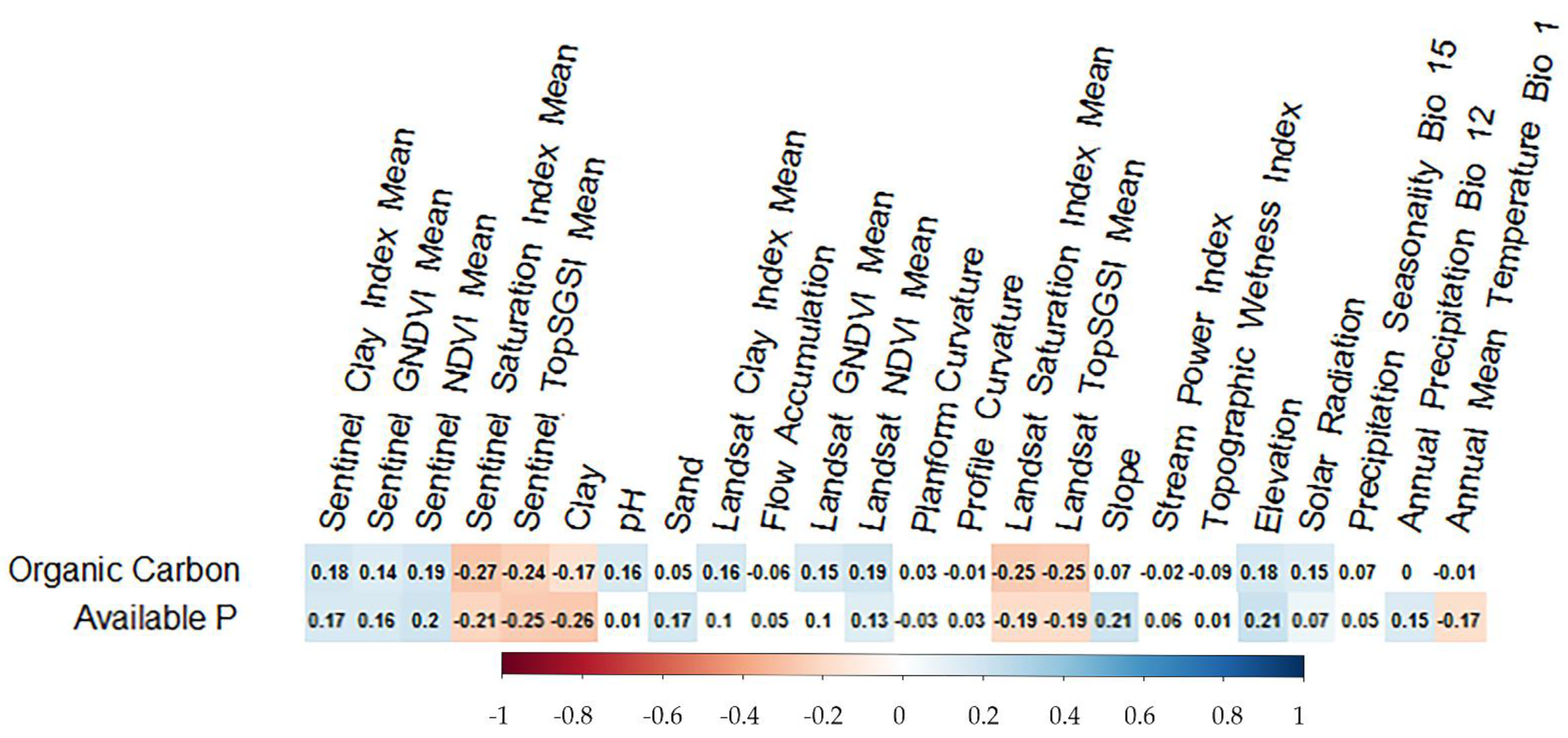
3.2. Selection of Covariates and Correlation Results
3.3. Performance of Regression Based Algorithms
3.4. Spatial Prediction of Soil Organic Carbon and Available Phosphorus
3.4.1. Model Residuals of Soil Organic Carbon and Available Phosphorus
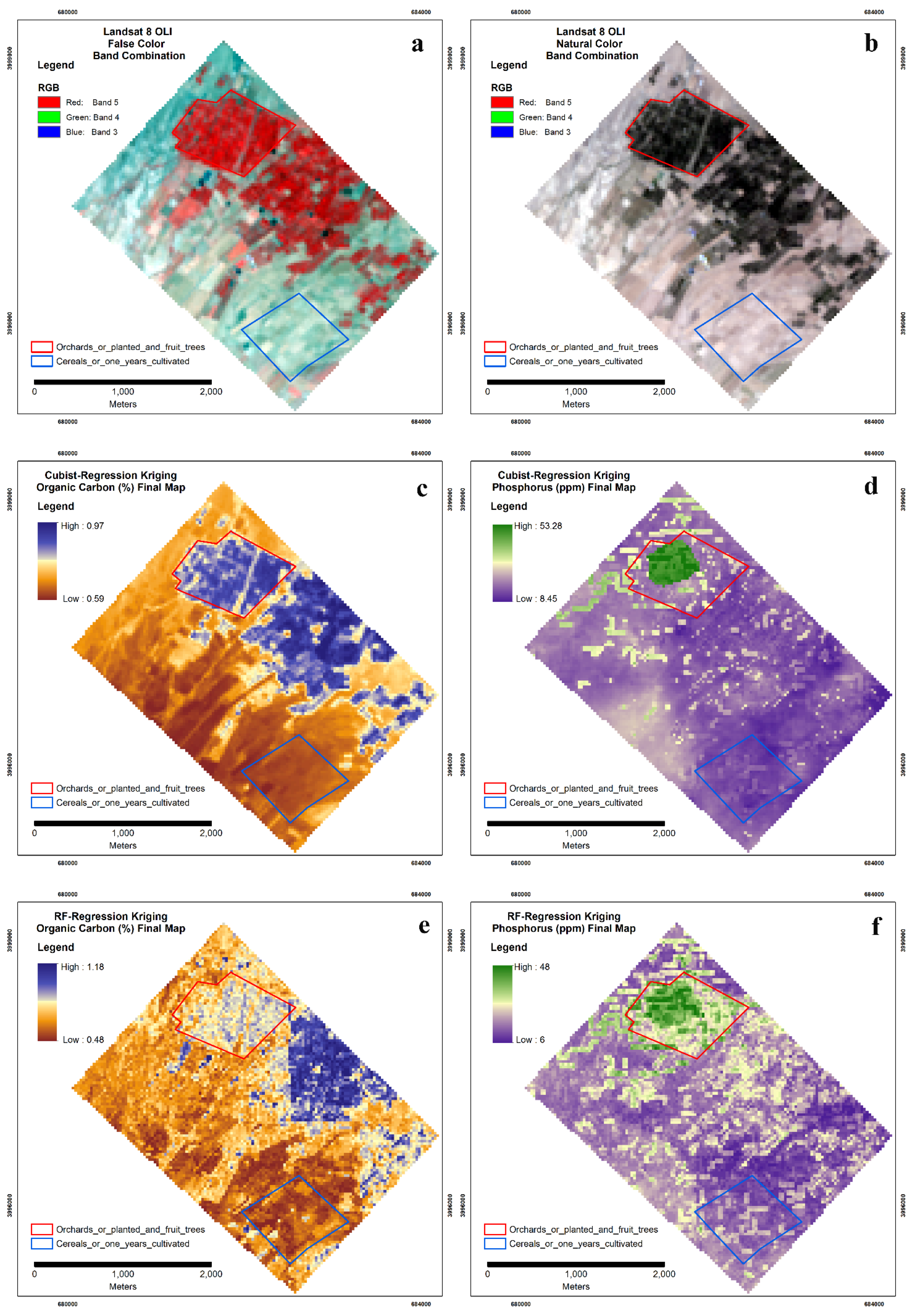
3.4.2. Spatial Prediction and Mapping

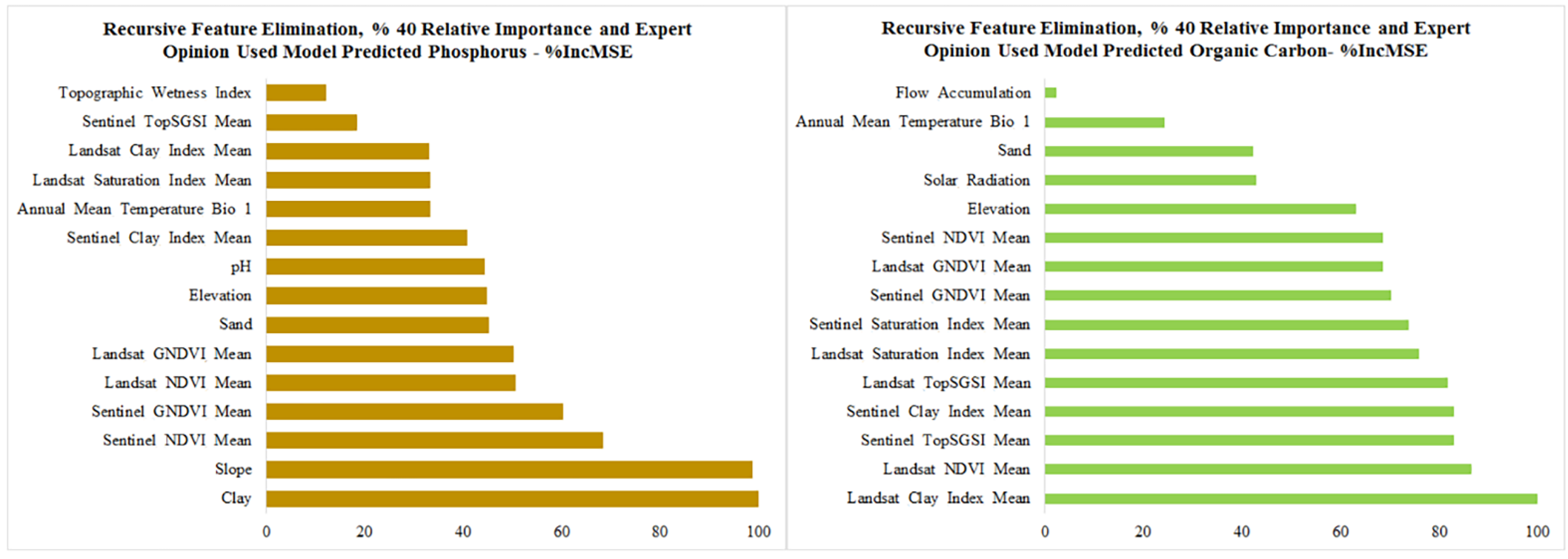
3.4.3. Importance of Environmental Covariates for Cubist and Random Forest
3.5. Remarks Related to Land Management and Soil Properties
3.6. Limitations of the Case Study and Future Perspectives
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ma, Y.; Minasny, B.; Wu, C. Mapping key soil properties to support agricultural production in Eastern China. Geoderma Reg. 2017, 10, 144–153. [Google Scholar] [CrossRef]
- Naimi, S.; Ayoubi, S.; Demattê, J.A.M.; Zeraatpisheh, M.; Amorim, M.T.A.; Mello, F.A.O. Spatial prediction of soil surface properties in an arid region using synthetic soil image and machine learning. Geocarto Int. 2021; ahead-of-print. [Google Scholar] [CrossRef]
- Žížala, D.; Minařík, R.; Zádorová, T. Soil Organic Carbon Mapping Using Multispectral Remote Sensing Data: Prediction Ability of Data with Different Spatial and Spectral Resolutions. Remote Sens. 2019, 11, 2947. [Google Scholar] [CrossRef]
- Žížala, D.; Minařík, R.; Beitlerová, H.; Juřicová, A.; Skála, J.; Rojas, J.R.; Penížek, V.; Zádorová, T. High-resolution agriculture soil property maps from digital soil mapping methods, Czech Republic. Catena 2021, 212, 106024. [Google Scholar] [CrossRef]
- Jenny, H. Factors of Soil Formation, a System of Quantitative Pedology; Dover Publications: New York, NY, USA, 1941. [Google Scholar]
- Jenny, H.; Salem, A.E.; Wallis, J.R. Interplay of soil organic matter and soil fertility with state factors and soil properties. In “Study Week on Organic Matter and Soil Fertility”, Pontificiae Academiae Scientiarvm Scripta Varia; John Wiley & Sons: New York, NY, USA, 1968; Volume 32, pp. 5–36. [Google Scholar]
- Yigini, Y.; Panagos, P. Assessment of soil organic carbon stocks under future climate and land cover changes in Europe. Sci. Total Environ. 2016, 557, 838–850. [Google Scholar] [CrossRef] [PubMed]
- Rodrigo-Comino, J.; Senciales, J.M.; Cerdà, A.; Brevik, E.C. The multidisciplinary origin of soil geography: A review. Earth Sci. Rev. 2018, 177, 114–123. [Google Scholar] [CrossRef] [Green Version]
- Mponela, P.; Snapp, S.; Villamor, G.; Tamene, L.; Le, Q.B.; Borgemeister, C. Digital soil mapping of nitrogen, phosphorus, potassium, organic carbon and their crop response thresholds in smallholder managed escarpments of Malawi. Appl. Geogr. 2020, 124, 102299. [Google Scholar] [CrossRef]
- Ließ, M.; Gebauer, A.; Don, A. Machine Learning with GA Optimization to Model the Agricultural Soil-Landscape of Germany: An Approach Involving Soil Functional Types with Their Multivariate Parameter Distributions along the Depth Profile. Front. Environ. Sci. 2021, 9, 692959. [Google Scholar] [CrossRef]
- Ma, Y.; Minasny, B.; Malone, B.P.; Mcbratney, A.B. Pedology and digital soil mapping (DSM). Eur. J. Soil Sci. 2019, 70, 216–235. [Google Scholar] [CrossRef]
- Brown, K.S.; Libohova, Z.; Boettinger, J. Digital Soil Mapping. In Soil Survey Manual, USDA Handbook 18; Ditzler, C., Scheffe, K., Monger, H.C., Eds.; Government Printing Office: Washington, DC, USA, 2017; pp. 295–354. [Google Scholar]
- FAO; ITPS. Soil Organic Carbon and Nitrogen: Reviewing the Challenges for Climate Change Mitigation and Adaptation in Agri-Food Systems. Rome, 2021, p. 3. Available online: https://www.fao.org/3/cb3965en/cb3965en.pdf (accessed on 15 January 2022).
- Lal, R. Soil Organic Matter and Feeding the Future: Environmental and Agronomic Impacts, 1st ed.; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar] [CrossRef]
- Nguyen, T.T. Predicting agricultural soil carbon using machine learning. Nat. Rev. Earth Environ. 2021, 2, 825. [Google Scholar] [CrossRef]
- Kopittke, P.M.; Berhe, A.A.; Carrillo, Y.; Cavagnaro, T.R.; Chen, D.; Chen, Q.L.; Minasny, B. Ensuring planetary survival: The centrality of organic carbon in balancing the multifunctional nature of soils. Crit. Rev. Environ. Sci. Technol. 2022; ahead-of-print. [Google Scholar] [CrossRef]
- Blume, H.P.; Brümmer, G.W.; Fleige, H.; Horn, R.; Kandeler, E.; Kögel-Knabner, I.; Wilke, B.M. Soil Organic Matter. In Scheffer/Schachtschabel Soil Science; Blume, H.P., Brümmer, G.W., Fleige, H., Horn, R., Kandeler, E., Kögel-Knabner, I., Wilke, B.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Winowiecki, L.A.; Bargués-Tobella, A.; Mukuralinda, A.; Mujawamariya, P.; Ntawuhiganayo, E.B.; Mugayi, A.B.; Vågen, T.-G. Assessing soil and land health across two landscapes in eastern Rwanda to inform restoration activities. Soil 2021, 7, 767–783. [Google Scholar] [CrossRef]
- Wadoux, A.M.C.; Román-Dobarco, M.; McBratney, A.B. Perspectives on data-driven soil research. Eur. J. Soil Sci. 2021, 72, 1675–1689. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B.; Malone, B.P.; Wheeler, I. Digital Mapping of Soil Carbon. Adv. Agron. 2013, 118, 1–47. [Google Scholar] [CrossRef]
- Guo, P.T.; Li, M.F.; Luo, W.; Tang, Q.F.; Liu, Z.W.; Lin, Z.M. Digital mapping of soil organic matter for rubber plantation at regional scale: An application of random forest plus residuals kriging approach. Geoderma 2015, 237, 49–59. [Google Scholar] [CrossRef]
- Keshavarzi, A.; Sarmadian, F.; Omran, E.S.E.; Iqbal, M. A neural network model for estimating soil phosphorus using terrain analysis. Egypt. J. Remote Sens. Space Sci. 2015, 18, 127–135. [Google Scholar] [CrossRef] [Green Version]
- Jeong, G.; Oeverdieck, H.; Park, S.J.; Huwe, B.; Ließ, M. Spatial soil nutrients prediction using three supervised learning methods for assessment of land potentials in complex terrain. Catena 2017, 154, 73–84. [Google Scholar] [CrossRef]
- Pouladi, N.; Møller, A.B.; Tabatabai, S.; Greve, M.H. Mapping soil organic matter contents at field level with Cubist, Random Forest and kriging. Geoderma 2019, 342, 85–92. [Google Scholar] [CrossRef]
- Wang, X.; Han, J.; Wang, X.; Yao, H.; Zhang, L. Estimating Soil Organic Matter Content Using Sentinel-2 Imagery by Machine Learning in Shanghai. IEEE Access 2021, 9, 78215–78225. [Google Scholar] [CrossRef]
- Sakhaee, A.; Gebauer, A.; Ließ, M.; Don, A. Performance of three machine learning algorithms for predicting soil organic carbon in German agricultural soil. Soil Discuss. 2021; in review. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Garosi, Y.; Owliaie, H.R.; Ayoubi, S.; Taghizadeh-Mehrjardi, R.; Scholten, T.; Xu, M. Improving the spatial prediction of soil organic carbon using environmental covariates selection: A comparison of a group of environmental covariates. Catena 2022, 208, 105723. [Google Scholar] [CrossRef]
- Sun, X.-L.; Lai, Y.-Q.; Ding, X.; Wu, Y.-J.; Wang, H.-L.; Wu, C. Variability of soil mapping accuracy with sample sizes, modelling methods and landform types in a regional case study. Catena 2022, 213, 106217. [Google Scholar] [CrossRef]
- Matos-Moreira, M.; Lemercier, B.; Dupas, R.; Michot, D.; Viaud, V.; Akkal-Corfini, N.; Louis, B.; Gascuel-Odoux, C. High-resolution mapping of soil phosphorus concentration in agricultural landscapes with readily available or detailed survey data. Eur. J. Soil Sci. 2017, 68, 281–294. [Google Scholar] [CrossRef] [Green Version]
- Adhikari, K.; Owens, P.R.; Ashworth, A.J.; Sauer, T.J.; Libohova, Z.; Richter, J.L.; Miller, D.M. Topographic controls on soil nutrient variations in a silvopasture system. Agrosyst. Geosci. Environ. 2018, 1, 180008. [Google Scholar] [CrossRef]
- Shahbazi, F.; Hughes, P.; McBratney, A.B.; Minasny, B.; Malone, B.P. Evaluating the spatial and vertical distribution of agriculturally important nutrients—Nitrogen, phosphorous and boron—In North West Iran. Catena 2019, 173, 71–82. [Google Scholar] [CrossRef]
- Zhou, T.; Geng, Y.; Ji, C.; Xu, X.; Wang, H.; Pan, J.; Lausch, A. Prediction of soil organic carbon and the C: N ratio on a national scale using machine learning and satellite data: A comparison between Sentinel-2, Sentinel-3 and Landsat-8 images. Sci. Total Environ. 2021, 755, 142661. [Google Scholar] [CrossRef]
- Tziachris, P.; Aschonitis, V.; Chatzistathis, T.; Papadopoulou, M. Assessment of spatial hybrid methods for predicting soil organic matter using DEM derivatives and soil parameters. Catena 2019, 174, 206–216. [Google Scholar] [CrossRef]
- Tziachris, P.; Aschonitis, V.; Chatzistathis, T.; Papadopoulou, M.; Doukas, I.J.D. Comparing Machine Learning Models and Hybrid Geostatistical Methods Using Environmental and Soil Covariates for Soil pH Prediction. ISPRS Int. J. Geo Inf. 2020, 9, 276. [Google Scholar] [CrossRef] [Green Version]
- Fathololoumi, S.; Vaezi, A.R.; Alavipanah, S.K.; Ghorbani, A.; Saurette, D.; Biswas, A. Improved digital soil mapping with multitemporal remotely sensed satellite data fusion: A case study in Iran. Sci. Total Environ. 2020, 721, 137703. [Google Scholar] [CrossRef]
- Burke, M.; Driscoll, A.; Lobell, D.B.; Ermon, S. Using satellite imagery to understand and promote sustainable development. Science 2021, 371, eabe8628. [Google Scholar] [CrossRef]
- ESA. European Space Agency. Sentinel-2 User Handbook Rev 2. 2015. Available online: https://sentinels.copernicus.eu/documents/247904/685211/Sentinel7732_User_Handbook.pdf/8869acdf-fd84-43ec-ae8c-3e80a436a16c?t=1438278087000 (accessed on 15 November 2021).
- Wulder, M.A.; Loveland, T.R.; Roy, D.P.; Crawford, C.J.; Masek, J.G.; Woodcock, C.E.; Zhu, Z. Current status of Landsat program, science, and applications. Remote Sens. Environ. 2019, 225, 127–147. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Pham, T.D.; Nguyen, C.T.; Delfos, J.; Archibald, R.; Dang, K.B.; Ngo, H.H. A novel intelligence approach based active and ensemble learning for agricultural soil organic carbon prediction using multispectral and SAR data fusion. Sci. Total Environ. 2022, 804, 150187. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Minaei, F.; Talebi-khiyavi, H.; Xu, T.; Homaee, M. Synergetic use of multi-temporal Sentinel-1, Sentinel-2, NDVI, and topographic factors for estimating soil organic carbon. Catena 2022, 212, 106077. [Google Scholar] [CrossRef]
- Yuzugullu, O.; Lorenz, F.; Fröhlich, P.; Liebisch, F. Understanding Fields by Remote Sensing: Soil Zoning and Property Mapping. Remote Sens. 2020, 12, 1116. [Google Scholar] [CrossRef] [Green Version]
- Hengl, T.; Miller, M.A.; Križan, J.; Shepherd, K.D.; Sila, A.; Kilibarda, M.; Crouch, J. African soil properties and nutrients mapped at 30 m spatial resolution using two-scale ensemble machine learning. Sci. Rep. 2021, 11, 6130. [Google Scholar] [CrossRef]
- Silvero, N.E.Q.; Demattê, J.A.M.; Amorim, M.T.A.; dos Santos, N.V.; Rizzo, R.; Safanelli, J.L.; Bonfatti, B.R. Soil variability and quantification based on Sentinel-2 and Landsat-8 bare soil images: A comparison. Remote Sens. Environ. 2021, 252, 112117. [Google Scholar] [CrossRef]
- Rosero-Vlasova, O.A.; Vlassova, L.; Pérez-Cabello, F.; Montorio, R.; Nadal-Romero, E. Modeling soil organic matter and texture from satellite data in areas affected by wildfires and cropland abandonment in Aragón, Northern Spain. J. Appl. Remote Sens. 2018, 12, 042803. [Google Scholar] [CrossRef]
- Castaldi, F.; Hueni, A.; Chabrillat, S.; Ward, K.; Buttafuoco, G.; Bomans, B.; van Wesemael, B. Evaluating the capability of the Sentinel 2 data for soil organic carbon prediction in croplands. ISPRS J. Photogramm. Remote Sens. 2019, 147, 267–282. [Google Scholar] [CrossRef]
- Kaya, F.; Başayiğit, L. Digital Mapping of Soil Organic Matter Using Open Source Accessible Products of ESA® in Arable Plain. ESA-ECMWF WORKSHOP Machine Learning for Earth System Observation and Prediction, ESA-ESRIN, 15 November 2021, Frascati. Available online: https://events.ecmwf.int/event/291/attachments/1518/2742/17._Kaya.pdf (accessed on 15 January 2022).
- Hengl, T.; Nussbaum, M.; Wright, M.N.; Heuvelink, G.B.; Gräler, B. Random Forest as a generic framework for predictive modeling of spatial and spatio-temporal variables. PeerJ 2018, 6, e5518. [Google Scholar] [CrossRef] [Green Version]
- Keskin, H.; Grunwald, S. Regression kriging as a workhorse in the digital soil mapper’s toolbox. Geoderma 2018, 326, 22–41. [Google Scholar] [CrossRef]
- Song, Y.Q.; Yang, L.A.; Li, B.; Hu, Y.M.; Wang, A.L.; Zhou, W.; Liu, Y.L. Spatial prediction of soil organic matter using a hybrid geostatistical model of an extreme learning machine and ordinary kriging. Sustainability 2017, 9, 754. [Google Scholar] [CrossRef] [Green Version]
- Fu, W.J.; Jiang, P.K.; Zhou, G.M.; Zhao, K.L. Using Moran’s I and GIS to study the spatial pattern of forest litter carbon density in a subtropical region of southeastern China. Biogeosciences 2014, 11, 2401–2409. [Google Scholar] [CrossRef] [Green Version]
- Wadoux, A.M.J.-C.; McBratney, A.B. Hypotheses, machine learning and soil mapping. Geoderma 2021, 383, 114725. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Jafari, A.; Bagheri, B.M.; Ayoubi, S.; Taghizadeh-Mehrjardi, R.; Toomanian, N.; Xu, M. Conventional and digital soil mapping in Iran: Past, present, and future. Catena 2020, 188, 104424. [Google Scholar] [CrossRef]
- Soil Survey Staff. Keys to Soil Taxonomy, 12th ed.; USDA-Natural Resources Conservation Service: Washington, DC, USA, 2014.
- Bagherzadeh, A.; Ghadiri, E.; Darban, A.R.S.; Gholizadeh, A. Land suitability modeling by parametric-based neural networks and fuzzy methods for soybean production in a semi-arid region. Model. Earth Syst. Environ. 2016, 2, 104. [Google Scholar] [CrossRef] [Green Version]
- Walkley, A.; Black, I.A. An examination of the Degtjareff method for determining soil organic matter, and a proposed modification of the chromic acid titration method. Soil Sci. 1934, 37, 29–38. [Google Scholar] [CrossRef]
- Olsen, S.R.; Cole, C.V.; Watanabe, F.S.; Dean, L.A. Estimation of Available Phosphorus in Soils by Extraction with Sodium Bicarbonate; U.S. Govt. Print. Office: Washington, DC, USA, 1954.
- Mulder, V.L.; De Bruin, S.; Schaepman, M.E.; Mayr, T.R. The use of remote sensing in soil and terrain mapping—A review. Geoderma 2011, 162, 1–19. [Google Scholar] [CrossRef]
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- McBratney, A.B.; Santos, M.M.; Minasny, B. On digital soil mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- ESRI. ArcGIS User’s Guide. 2021. Available online: http://www.esri.com (accessed on 15 September 2021).
- Sayler, K.; Zanter, K. Landsat 8 Collection 2 (C2) Level 2 Science Product (L2SP) Guide LSDS-1619 Version 2.0; EROS Sioux Falls: South Dakota, SD, USA, 2021. [Google Scholar]
- Guo, Z.; Adhikari, K.; Chellasamy, M.; Greve, M.B.; Owens, P.R.; Greve, M.H. Selection of terrain attributes and its scale dependency on soil organic carbon prediction. Geoderma 2019, 340, 303–312. [Google Scholar] [CrossRef]
- Adhikari, K.; Hartemink, A.E. Digital mapping of topsoil carbon content and changes in the driftless area of Wisconsin, USA. Soil Sci. Soc. Am. J. 2015, 79, 155–164. [Google Scholar] [CrossRef] [Green Version]
- Adhikari, K.; Braden, I.S.; Owens, P.R.; Ashworth, A.J.; West, C. Relating topography and soil phosphorus distribution in litter-amended pastures in Arkansas. Agrosyst. Geosci. Environ. 2021, 4, e20207. [Google Scholar] [CrossRef]
- ALOS PALSAR. Dataset: © JAXA/METI ALOS PALSAR L1.0 2007. ASF DAAC. Available online: https://asf.alaska.edu/ (accessed on 5 September 2021).
- Hengl, T.; Reuter, H.I. Geomorphometry: Concepts, Software, Applications; Elsevier: Amsterdam, The Netherlands, 2008; Volume 33. [Google Scholar]
- Wiesmeier, M.; Urbanski, L.; Hobley, E.; Lang, B.; von Lützow, M.; Marin-Spiotta, E.; Kögel-Knabner, I. Soil organic carbon storage as a key function of soils-A review of drivers and indicators at various scales. Geoderma 2019, 333, 149–162. [Google Scholar] [CrossRef]
- Xiao, J.; Shen, Y.; Tateishi, R.; Bayaer, W. Development of topsoil grain size index for monitoring desertification in arid land using remote sensing. Int. J. Remote Sens. 2006, 27, 2411–2422. [Google Scholar] [CrossRef]
- Hounkpatin, K.O.; Schmidt, K.; Stumpf, F.; Forkuor, G.; Behrens, T.; Scholten, T.; Amelung, W.; Welp, G. Predicting reference soil groups using legacy data: A data pruning and Random Forest approach for tropical environment (Dano catchment, Burkina Faso). Sci. Rep. 2018, 8, 9959. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef] [Green Version]
- Gitelson, A.A.; Kaufman, Y.J.; Merzlyak, M.N. Use of a green channel in remote sensing of global vegetation from EOS-MODIS. Remote Sens. Environ. 1996, 58, 289–298. [Google Scholar] [CrossRef]
- Hijmans, R.J. Raster: Geographic Data Analysis and Modeling. R Package Version 3.4-5. 2020. Available online: https://CRAN.R-project.org/package=raster (accessed on 15 November 2021).
- Kuhn, M. Caret: Classification and Regression Training. R Package Version 6.0-86. 2020. Available online: https://CRAN.R-project.org/package=caret (accessed on 15 November 2021).
- Liaw, A.; Wiener, M. Classification and regression by random Forest. R News 2002, 2, 18–22. [Google Scholar]
- Kuhn, M.; Quinlan, R. Cubist: Rule- and Instance-Based Regression Modeling. R Package Version 0.2.3. 2020. Available online: https://CRAN.R-project.org/package=Cubist (accessed on 15 November 2021).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Tasmania, 16–18 November 1992. [Google Scholar]
- Quinlan, J.R. Combining instance-based and model-based learning. In Proceedings of the Tenth International Conference on Machine Learning, Amherst, MA, USA, 27–29 July 1993. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for machine learning. Mach. Learn. 1994, 16, 235–240. [Google Scholar] [CrossRef] [Green Version]
- Lacoste, M.; Minasny, B.; McBratney, A.; Michot, D.; Viaud, V.; Walter, C. High resolution 3D mapping of soil organic carbon in a heterogeneous agricultural landscape. Geoderma 2014, 213, 296–311. [Google Scholar] [CrossRef]
- Rudiyanto Minasny, B.; Setiawan, B.I.; Saptomo, S.K.; McBratney, A.B. Open digital mapping as a cost-effective method for mapping peat thickness and assessing the carbon stock of tropical peatlands. Geoderma 2018, 313, 25–40. [Google Scholar] [CrossRef]
- Chen, S.; Mulder, V.L.; Heuvelink, G.B.; Poggio, L.; Caubet, M.; Dobarco, M.R.; Arrouays, D. Model averaging for mapping topsoil organic carbon in France. Geoderma 2020, 366, 114237. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B. Regression rules as a tool for predicting soil properties from infrared reflectance spectroscopy. Chemom. Intell. Lab. Syst. 2008, 94, 72–79. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Khaledian, Y.; Miller, B.A. Selecting appropriate machine learning methods for digital soil mapping. Appl. Math. Model. 2020, 81, 401–418. [Google Scholar] [CrossRef]
- Biau, G.; Scornet, E. A random forest-guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Sahragard, P.H.; Pahlavan-Rad, M.R. Prediction of Soil Properties Using Random Forest with Sparse Data in a Semi-Active Volcanic Mountain. Eurasian Soil Sci. 2020, 53, 1222–1233. [Google Scholar] [CrossRef]
- Stum, A.K.; Boettinger, J.L.; White, M.A.; Ramsey, R.D. Random forests applied as a soil spatial predictive model in arid Utah. In Digital Soil Mapping; Springer: Dordrecht, The Netherlands, 2010. [Google Scholar] [CrossRef] [Green Version]
- Pahlavan-Rad, M.R.; Dahmardeh, K.; Hadizadeh, M.; Keykha, G.; Mohammadnia, N.; Gangali, M.; Brungard, C. Prediction of soil water infiltration using multiple linear regression and random forest in a dry flood plain, eastern Iran. Catena 2020, 194, 104715. [Google Scholar] [CrossRef]
- Hengl, T.; Heuvelink, G.B.; Rossiter, D.G. About regression-kriging: From equations to case studies. Comput. Geosci. 2007, 33, 1301–1315. [Google Scholar] [CrossRef]
- Zambrano-Bigiarini, M. hydroGOF: Goodness-of-Fit Functions for Comparison of Simulated and Observed Hydrological Time Series R Package Version 0.4-0. 2020. Available online: https://github.com/hzambran/hydroGOF (accessed on 15 November 2021).
- Mashalaba, L.; Galleguillos, M.; Seguel, O.; Poblete-Olivares, J. Predicting spatial variability of selected soil properties using digital soil mapping in a rainfed vineyard of central Chile. Geoderma Reg. 2020, 22, e00289. [Google Scholar] [CrossRef]
- Gopp, N.V.; Savenkov, O.A. Relationships between the NDVI, yield of spring wheat, and properties of the plow horizon of eluviated clay-illuvial chernozems and dark gray soils. Eurasian Soil Sci. 2019, 52, 339–347. [Google Scholar] [CrossRef]
- Lin, L.I.K. A concordance correlation coefficient to evaluate reproducibility. Biometrics 1989, 45, 255–268. [Google Scholar] [CrossRef]
- Keshavarzi, A.; Tuffour, H.O.; Brevik, E.C.; Ertunç, G. Spatial variability of soil mineral fractions and bulk density in Northern Ireland: Assessing the influence of topography using different interpolation methods and fractal analysis. Catena 2021, 207, 105646. [Google Scholar] [CrossRef]
- Pebesma, E.J. Multivariable geostatistics in S: The gstat package. Comput. Geosci. 2004, 30, 683–691. [Google Scholar] [CrossRef]
- Gräler, B.; Pebesma, E.J.; Heuvelink, G.B. Spatio-temporal interpolation using gstat. R J. 2016, 8, 204. [Google Scholar] [CrossRef]
- Moran, P.A. Notes on continuous stochastic phenomena. Biometrika 1950, 37, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Adhikari, P.; Shukla, M.K.; Mexal, J.G. Spatial variability of electrical conductivity of desert soil irrigated with treated wastewater: Implications for irrigation management. Appl. Environ. Soil Sci. 2011, 2011, 504249. [Google Scholar] [CrossRef] [Green Version]
- Wilding, L. Spatial variability: Its documentation, accommodation and implication to soil surveys. In Soil Spatial Variability; Workshop: Wageningen, The Netherlands, 1985. [Google Scholar]
- Moura-Bueno, J.M.; Dalmolin, R.S.D.; Horst-Heinen, T.Z.; Cancian, L.C.; Schenato, R.B.; Dotto, A.C.; Flores, C.A. Prediction of soil classes in a complex landscape in Southern Brazil. Pesqui. Agropecuária Bras. 2019, 54, e00420. [Google Scholar] [CrossRef]
- Zhi, J.; Zhang, G.; Yang, F.; Yang, R.; Liu, F.; Song, X.; Li, D. Predicting mattic epipedons in the northeastern Qinghai-Tibetan Plateau using Random Forest. Geoderma Reg. 2017, 10, 1–10. [Google Scholar] [CrossRef]
- Maleki, S.; Zeraatpisheh, M.; Karimi, A.; Sareban, G.; Wang, L. Assessing Variation of Soil Quality in Agroecosystem in an Arid Environment Using Digital Soil Mapping. Agronomy 2022, 12, 578. [Google Scholar] [CrossRef]
- Xu, X.; Shi, Z.; Li, D.; Rey, A.; Ruan, H.; Craine, J.M.; Liang, J.; Zhou, J.; Luo, Y. Soil properties control decomposition of soil organic carbon: Results from data-assimilation analysis. Geoderma 2016, 262, 235–242. [Google Scholar] [CrossRef] [Green Version]
- Sahabiev, I.; Smirnova, E.; Giniyatullin, K. Spatial Prediction of Agrochemical Properties on the Scale of a Single Field Using Machine Learning Methods Based on Remote Sensing Data. Agronomy 2021, 11, 2266. [Google Scholar] [CrossRef]
- Maleki, S.; Khormali, F.; Chen, S.; Pourghasemi, H.R.; Hosseinalizadeh, M. Digital soil mapping of organic carbon at two depths in loess hilly region of Northern Iran. In Computers in Earth and Environmental Sciences; Elsevier: Amsterdam, The Netherlands, 2022; pp. 467–475. [Google Scholar] [CrossRef]
- Sönmez, B.; Özbahçe, A.; Keçeci, M.; Akgül, S.; Aksoy, E.; Madenoğlu, S.; Vargas, R. Turkey’s national geospatial soil organic carbon information system. In Proceedings of the Global Symposium on Soil Organic Carbon, Rome, Italy, 21–23 March 2017. [Google Scholar]
- Shahriari, M.; Delbari, M.; Afrasiab, P.; Pahlavan-Rad, M.R. Predicting regional spatial distribution of soil texture in floodplains using remote sensing data: A case of southeastern Iran. Catena 2019, 182, 104149. [Google Scholar] [CrossRef]
- Szatmári, G.; Pásztor, L. Comparison of various uncertainty modelling approaches based on geostatistics and machine learning algorithms. Geoderma 2019, 337, 1329–1340. [Google Scholar] [CrossRef]
- Vaysse, K.; Lagacherie, P. Using quantile regression forest to estimate uncertainty of digital soil mapping products. Geoderma 2017, 291, 55–64. [Google Scholar] [CrossRef]
- Mayes, M.; Marin-Spiotta, E.; Szymanski, L.; Erdoğan, M.A.; Ozdoğan, M.; Clayton, M. Soil type mediates effects of land use on soil carbon and nitrogen in the Konya Basin, Turkey. Geoderma 2014, 232, 517–527. [Google Scholar] [CrossRef]
- Maleki, S.; Karimi, A.; Zeraatpisheh, M.; Poozeshi, R.; Feizi, H. Long-term cultivation effects on soil properties variations in different landforms in an arid region of eastern Iran. Catena 2021, 206, 105465. [Google Scholar] [CrossRef]
- Anderson, K.R.; Moore, P.A.; Pilon, C.; Martin, J.W.; Pote, D.H.; Owens, P.R.; Ashworth, A.J.; Miller, D.M.; Delaune, P.B. Long-term effects of grazing management and buffer strips on phosphorus runoff from pastures fertilized with poultry litter. J. Environ. Qual. 2020, 49, 85–96. [Google Scholar] [CrossRef]
- Xu, G.; Li, Z.; Li, P.; Zhang, T.; Cheng, S. Spatial variability of soil available phosphorus in a typical watershed in the source area of the middle Dan River, China. Environ. Earth Sci. 2014, 71, 3953–3962. [Google Scholar] [CrossRef]
- Dupas, R.; Delmas, M.; Dorioz, J.M.; Garnier, J.; Moatar, F.; Gascuel-Odoux, C. Assessing the impact of agricultural pres-sures on N and P loads and eutrophication risk. Ecol. Indic. 2015, 48, 396–407. [Google Scholar] [CrossRef]
- Cheng, Y.; Li, P.; Xu, G.; Li, Z.; Cheng, S.; Gao, H. Spatial distribution of soil total phosphorus in Yingwugou watershed of the Dan River, China. Catena 2016, 136, 175–181. [Google Scholar] [CrossRef]
- Shen, Q.; Wang, Y.; Wang, X.; Liu, X.; Zhang, X.; Zhang, S. Comparing interpolation methods to predict soil total phosphorus in the Mollisol area of Northeast China. Catena 2019, 174, 59–72. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B. Digital soil mapping: A brief history and some lessons. Geoderma 2016, 264, 301–311. [Google Scholar] [CrossRef]
- Gautam, S.; Mishra, U.; Scown, C.D.; Wills, S.A.; Adhikari, K.; Drewniak, B.A. Continental United States may lose 1.8 petagrams of soil organic carbon under climate change by 2100. Glob. Ecol. Biogeogr. 2022, 31, 1147–1160. [Google Scholar] [CrossRef]
- Blume, H.P.; Brümmer, G.W.; Fleige, H.; Horn, R.; Kandeler, E.; Kögel-Knabner, I.; Wilke, B.M. (Eds.) Chemical Properties and Processes. In Scheffer/Schachtschabel Soil Science; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Castro Padilha, M.C.; Vicente, L.E.; Demattê, J.A.; Loebmann, D.G.D.S.W.; Vicente, A.K.; Salazar, D.F.; Guimarãe, C.C.B. Using Landsat and soil clay content to map soil organic carbon of oxisols and Ultisols near São Paulo, Brazil. Geoderma Reg. 2020, 21, e00253. [Google Scholar] [CrossRef]
- Akbari, M.; Goudarzi, I.; Tahmoures, M.; Elveny, M.; Bakhshayeshi, I. Predicting soil organic carbon by integrating Landsat 8 OLI, GIS and data mining techniques in semi-arid region. Earth Sci. Inform. 2021, 14, 2113–2122. [Google Scholar] [CrossRef]
- Luo, C.; Zhang, X.; Meng, X.; Zhu, H.; Ni, C.; Chen, M.; Liu, H. Regional mapping of soil organic matter content using multitemporal synthetic Landsat 8 images in Google Earth Engine. Catena 2022, 209, 105842. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Nabiollahi, K.; Kerry, R. Digital mapping of soil organic carbon at multiple depths using different data mining techniques in Baneh region, Iran. Geoderma 2016, 266, 98–110. [Google Scholar] [CrossRef]
- Kunkel, V.R.; Wells, T.; Hancock, G. Modelling soil organic carbon using vegetation indices across large catchments in eastern Australia. Sci. Total Environ. 2021, 817, 152690. [Google Scholar] [CrossRef]
- Mosleh, Z.; Salehi, M.H.; Jafari, A.; Borujeni, I.E.; Mehnatkesh, A. The effectiveness of digital soil mapping to predict soil properties over low-relief areas. Environ. Monit. Assess. 2016, 188, 195. [Google Scholar] [CrossRef]
- Emadi, M.; Taghizadeh-Mehrjardi, R.; Cherati, A.; Danesh, M.; Mosavi, A.; Scholten, T. Predicting and mapping of soil organic carbon using machine learning algorithms in Northern Iran. Remote Sens. 2020, 12, 2234. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, S.; Adhikari, K.; Wang, Q.; Sui, Y.; Xin, G. Effect of cultivation history on soil organic carbon status of arable land in northeastern China. Geoderma 2019, 342, 55–64. [Google Scholar] [CrossRef]
- Lamichhane, S.; Adhikari, K.; Kumar, L. Use of Multi-Seasonal Satellite Images to Predict SOC from Cultivated Lands in a Montane Ecosystem. Remote Sens. 2021, 13, 4772. [Google Scholar] [CrossRef]
- Lamichhane, S.; Kumar, L.; Adhikari, K. Digital mapping of topsoil organic carbon content in an alluvial plain area of the Terai region of Nepal. Catena 2021, 202, 105299. [Google Scholar] [CrossRef]
- Poggio, L.; De Sousa, L.; Genova, G.; D’Angelo, P.; Schwind, P.; Heiden, U. Soil Organic Carbon Modelling with Digital Soil Mapping and Remote Sensing for Permanently Vegetated Areas. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, M.; Adhikari, K.; Zhuang, Q.; Bian, Z.; Wang, Y.; Jin, X. Anthropogenic controls over soil organic carbon distribution from the cultivated lands in Northeast China. Catena 2022, 210, 105897. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, H.; Xu, E. Enhancing the digital mapping accuracy of farmland soil organic carbon in arid areas using agricultural land use history. J. Clean. Prod. 2022, 334, 130232. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, Y.; Wu, Z.; Wang, B.; Wang, S. Geographical detector-based stratified regression kriging strategy for mapping soil organic carbon with high spatial heterogeneity. Catena 2021, 196, 104953. [Google Scholar] [CrossRef]
- Wu, Z.; Liu, Y.; Han, Y.; Zhou, J.; Liu, J.; Wu, J. Mapping farmland soil organic carbon density in plains with combined cropping system extracted from NDVI time-series data. Sci. Total Environ. 2021, 754, 142120. [Google Scholar] [CrossRef]
- Wu, Z.; Liu, Y.; Li, G.; Han, Y.; Li, X.; Chen, Y. Influences of Environmental Variables and Their Interactions on Chinese Farmland Soil Organic Carbon Density and Its Dynamics. Land 2022, 11, 208. [Google Scholar] [CrossRef]
- Dai, L.; Ge, J.; Wang, L.; Zhang, Q.; Liang, T.; Bolan, N.; Rinklebe, J. Influence of soil properties, topography, and land cover on soil organic carbon and total nitrogen concentration: A case study in Qinghai-Tibet plateau based on random forest regression and structural equation modeling. Sci. Total Environ. 2022, 821, 153440. [Google Scholar] [CrossRef] [PubMed]
- Feeney, C.J.; Cosby, B.J.; Robinson, D.A.; Thomas, A.; Emmett, B.A.; Henrys, P. Multiple soil map comparison highlights challenges for predicting topsoil organic carbon concentration at national scale. Sci. Rep. 2022, 12, 1379. [Google Scholar] [CrossRef]
- Wadoux, A.M.C.; Heuvelink, G.B.; Lark, R.M.; Lagacherie, P.; Bouma, J.; Mulder, V.L.; Libohova, Z.; Yang, L.; McBratney, A.B. Ten challenges for the future of pedometrics. Geoderma 2021, 401, 115155. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.; Mathis, M.; Brumby, S. Global land use/land cover with Sentinel-2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021. [Google Scholar] [CrossRef]
- Heuvelink, G.B.; Angelini, M.E.; Poggio, L.; Bai, Z.; Batjes, N.H.; van den Bosch, R.; Bossio, D.; Estella Lehmann, J.; Olmedo, G.F.; Sanderman, J. Machine learning in space and time for modelling soil organic carbon change. Eur. J. Soil Sci. 2021, 72, 1607–1623. [Google Scholar] [CrossRef]
- Chen, S.; Arrouays, D.; Mulder, V.L.; Poggio, L.; Minasny, B.; Roudier, P.; Libohova, Z.; Lagacherie, P.; Shi, Z.; Hannam, J.; et al. Digital mapping of GlobalSoilMap soil properties at a broad scale: A review. Geoderma 2022, 409, 115567. [Google Scholar] [CrossRef]
- Piikki, K.; Wetterlind, J.; Söderström, M.; Stenberg, B. Perspectives on validation in digital soil mapping of continuous attributes—A review. Soil Use Manag. 2021, 37, 7–21. [Google Scholar] [CrossRef]
- de Sousa, L.; van den Berg, F.; Heuvelink, G.B.M. A Soil Organic Matter Map for Arable Land in the EU; Report/Wageningen Environmental Research; No. 3126; Wageningen Environmental Research: Wageningen, The Netherlands, 2022. [Google Scholar] [CrossRef]
- Zhou, Y.; Chartin, C.; Van Oost, K.; van Wesemael, B. High-resolution soil organic carbon mapping at the field scale in Southern Belgium (Wallonia). Geoderma 2022, 422, 115929. [Google Scholar] [CrossRef]








| Landsat-8 OLI | Sentinel-2A | ||||
|---|---|---|---|---|---|
| Bands | Pixel Size (m) | Wavelength (µm) | Bands | Pixel Size (m) | Wavelength (nm) |
| B1-Coastal | 30 | 0.435–0.451 | B1-Coastal | 60 | 443.9 |
| B2-Blue | 30 | 0.452–0.512 | B2-Blue | 10 | 496.6 |
| B3-Green | 30 | 0.533–0.590 | B3-Green | 10 | 560.0 |
| B4-Red | 30 | 0.636–0.673 | B4-Red | 10 | 664.5 |
| B5-NIR * | 30 | 0.851–0.879 | B5-Vegetation Red Edge | 20 | 703.9 |
| B6-SWIR * 1 | 30 | 1.566–1.651 | B6-Vegetation Red Edge | 20 | 740.2 |
| B7-SWIR * 2 | 30 | 2.107–2.294 | B7-Vegetation Red Edge | 20 | 782.5 |
| B8-Pan | 15 | 0.500–0.680 | B8-NIR * | 10 | 835.1 |
| B8A-Narrow NIR * | 20 | 864.8 | |||
| B9-Cirrus | 30 | 1.36–1.38 | B9-Water Vapor | 60 | 945.0 |
| B10-TIRS * 1 | 100 | 10.60–11.19 | B10-SWIR *-Cirrus | 60 | 1360.0 |
| B11-TIRS * 2 | 100 | 11.50–12.51 | B11-SWIR* | 20 | 1613.7 |
| B12-SWIR* | 20 | 2202.4 | |||
| Dataset | Count | Mean | SD * | CV * | Minimum | Median | Maximum | Skewness | Kurtosis | |
|---|---|---|---|---|---|---|---|---|---|---|
| Available Phosphorus (mg kg−1)—Ava-P | Training | 201 | 19.33 | 16.58 | 85.74 | 2.40 | 11.60 | 70.40 | 1.28 | 0.68 |
| Validation | 87 | 17.36 | 15.36 | 88.47 | 2.40 | 10.40 | 70.40 | 1.60 | 2.08 | |
| Soil Organic Carbon (%)—SOC | Training | 201 | 0.73 | 0.33 | 45.83 | 0.17 | 0.67 | 2.23 | 1.95 | 5.06 |
| Validation | 87 | 0.73 | 0.31 | 42.96 | 0.25 | 0.67 | 1.83 | 1.38 | 2.14 |
| Variable | Model | Training | Validation | Hybrid Model-Validation | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LCCC | RMSE | NRMSE | MAPE | LCCC | RMSE | NRMSE | MAPE | LCCC | RMSE | NRMSE | MAPE | ||
| Ava-P | Cubist | 0.52 | 13.02 | 78.6 | 69.6 | 0.13 | 15.94 | 103.9 | 105.5 | 0.13 | 15.95 | 103.9 | 124.1 |
| RF | 0.88 | 6.63 | 40.0 | 46.8 | 0.26 | 14.86 | 96.8 | 126.3 | 0.27 | 14.81 | 96.5 | 123.8 | |
| SOC | Cubist | 0.06 | 0.33 | 99.4 | 30.8 | 0.16 | 0.30 | 94.2 | 30.4 | 0.21 | 0.28 | 91.5 | 32.01 |
| RF | 0.84 | 0.15 | 45.2 | 15.4 | 0.19 | 0.30 | 94.5 | 33.6 | 0.20 | 0.30 | 94.8 | 33.68 | |
| Variable | Model | Model | Nugget | Sill | Nugget/Sill Ratio | Effective Range (m) | Class of Spatial Structure | Moran’s Index |
|---|---|---|---|---|---|---|---|---|
| Residual Ava—P | Cubist-RK | Spherical | 130.44 | 168.61 | 77.36 | 694 | Weak | 0.0380 |
| RF-RK | Exponential | 40.75 | 46.34 | 87.93 | 1826 | Weak | 0.0325 | |
| Residual SOC | Cubist-RK | Spherical. | 0.097 | 0.12 | 80.83 | 6208 | Weak | 0.043 |
| RF-RK | Spherical. | 0.021 | 0.03 | 66.66 | 6589 | Moderate | −0.022 |
| Cereals (Annually Cultivated) | Orchards or Planted and Fruit Trees | |||
|---|---|---|---|---|
| Count | 6 | 7 | ||
| Properties | Ava-P * | SOC * | Ava-P | SOC |
| Mean | 7.93 | 0.53 | 35.94 | 0.86 |
| SD * | 1.67 | 0.08 | 20.25 | 0.48 |
| CV * (%) | 21.01 | 15.13 | 56.35 | 55.73 |
| Minimum | 5.6 | 0.46 | 15.6 | 0.25 |
| Q1 | 6.5 | 0.46 | 16.8 | 0.46 |
| Median | 8 | 0.50 | 30.4 | 0.68 |
| Q3 | 9.2 | 0.61 | 55.6 | 1.46 |
| Maximum | 10.4 | 0.64 | 70.4 | 1.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaya, F.; Keshavarzi, A.; Francaviglia, R.; Kaplan, G.; Başayiğit, L.; Dedeoğlu, M. Assessing Machine Learning-Based Prediction under Different Agricultural Practices for Digital Mapping of Soil Organic Carbon and Available Phosphorus. Agriculture 2022, 12, 1062. https://doi.org/10.3390/agriculture12071062
Kaya F, Keshavarzi A, Francaviglia R, Kaplan G, Başayiğit L, Dedeoğlu M. Assessing Machine Learning-Based Prediction under Different Agricultural Practices for Digital Mapping of Soil Organic Carbon and Available Phosphorus. Agriculture. 2022; 12(7):1062. https://doi.org/10.3390/agriculture12071062
Chicago/Turabian StyleKaya, Fuat, Ali Keshavarzi, Rosa Francaviglia, Gordana Kaplan, Levent Başayiğit, and Mert Dedeoğlu. 2022. "Assessing Machine Learning-Based Prediction under Different Agricultural Practices for Digital Mapping of Soil Organic Carbon and Available Phosphorus" Agriculture 12, no. 7: 1062. https://doi.org/10.3390/agriculture12071062