


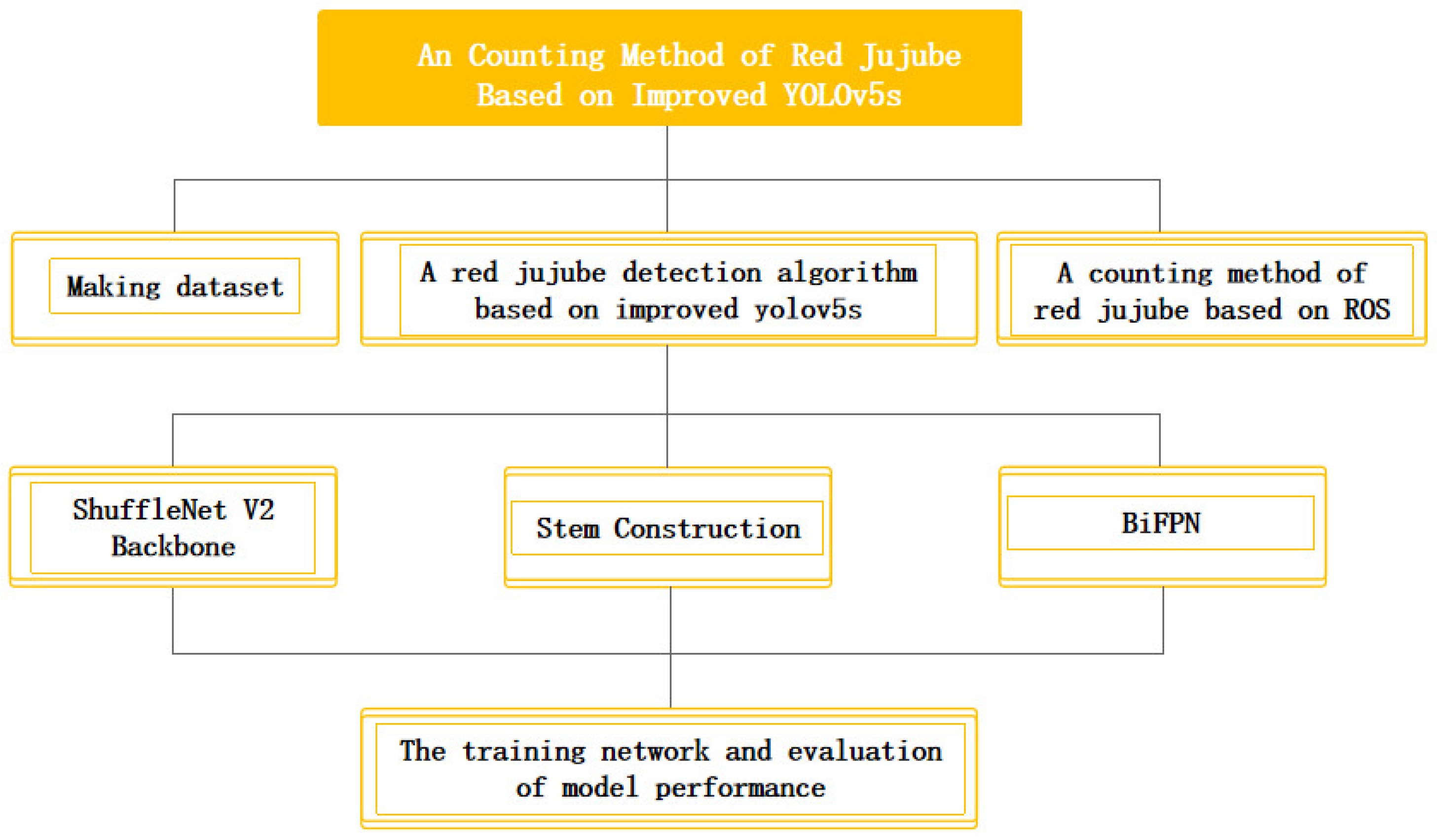
A Counting Method of Red Jujube Based on Improved YOLOv5s
 ,
,
Abstract
:1. Introduction
- (1)
- ShuffleNet V2 was used as the backbone of the network to extract the feature map and make the model lightweight.
- (2)
- The Stem, a novel data loading module, was proposed to reduce data information loss and improve model detection accuracy.
- (3)
- The original PANet (Path Aggregation Network) structure was improved to BiFPN (Bidirectional Feature Pyramid Network) for multi-scale feature fusion to enhance the model feature fusion capability and improve the model accuracy.
- (4)
- The improved YOLOv5s detection model was used to count red jujubes.
2. Materials and Methods
2.1. Image Data Acquisition
2.2. Data Preprocessing and Augmentation
2.3. Images Annotation and Dataset Division
2.4. Methodologies
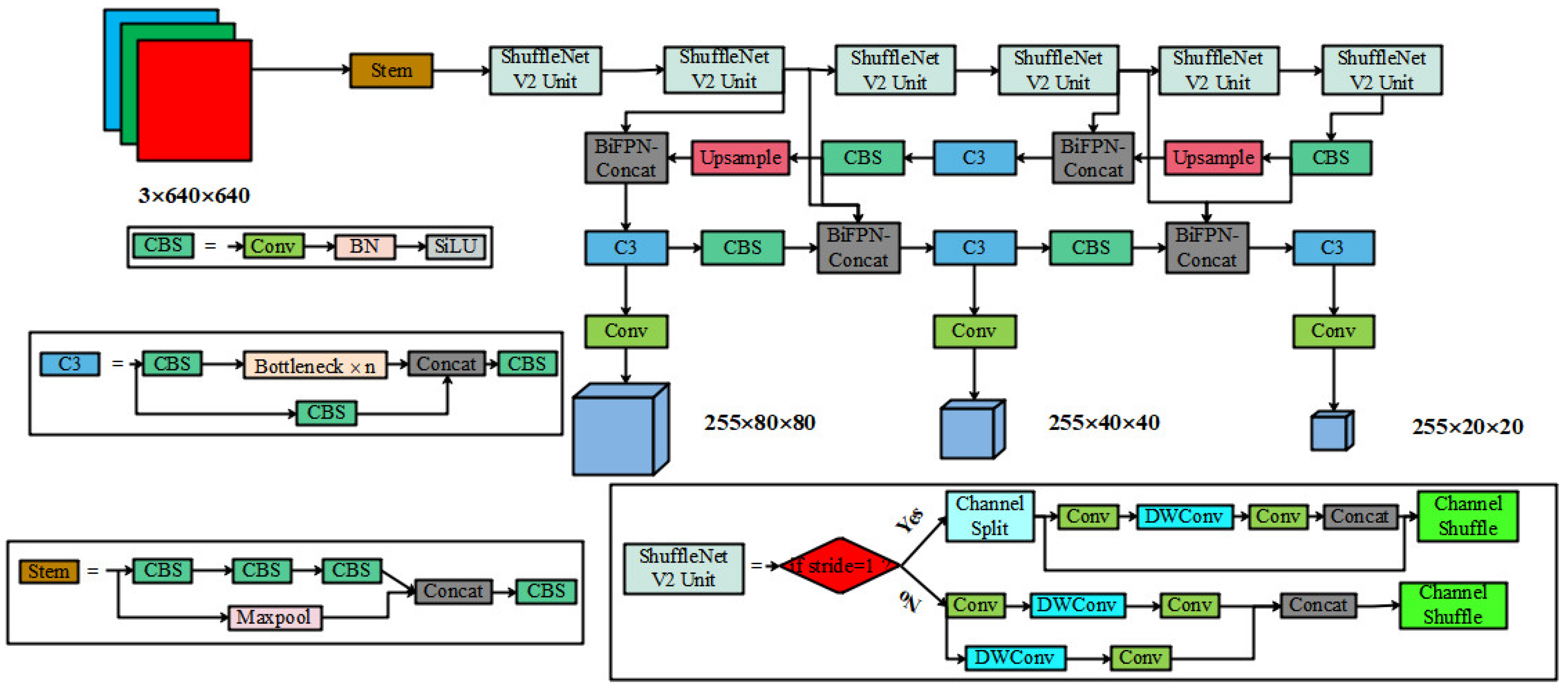
2.4.1. Yolov5s Network
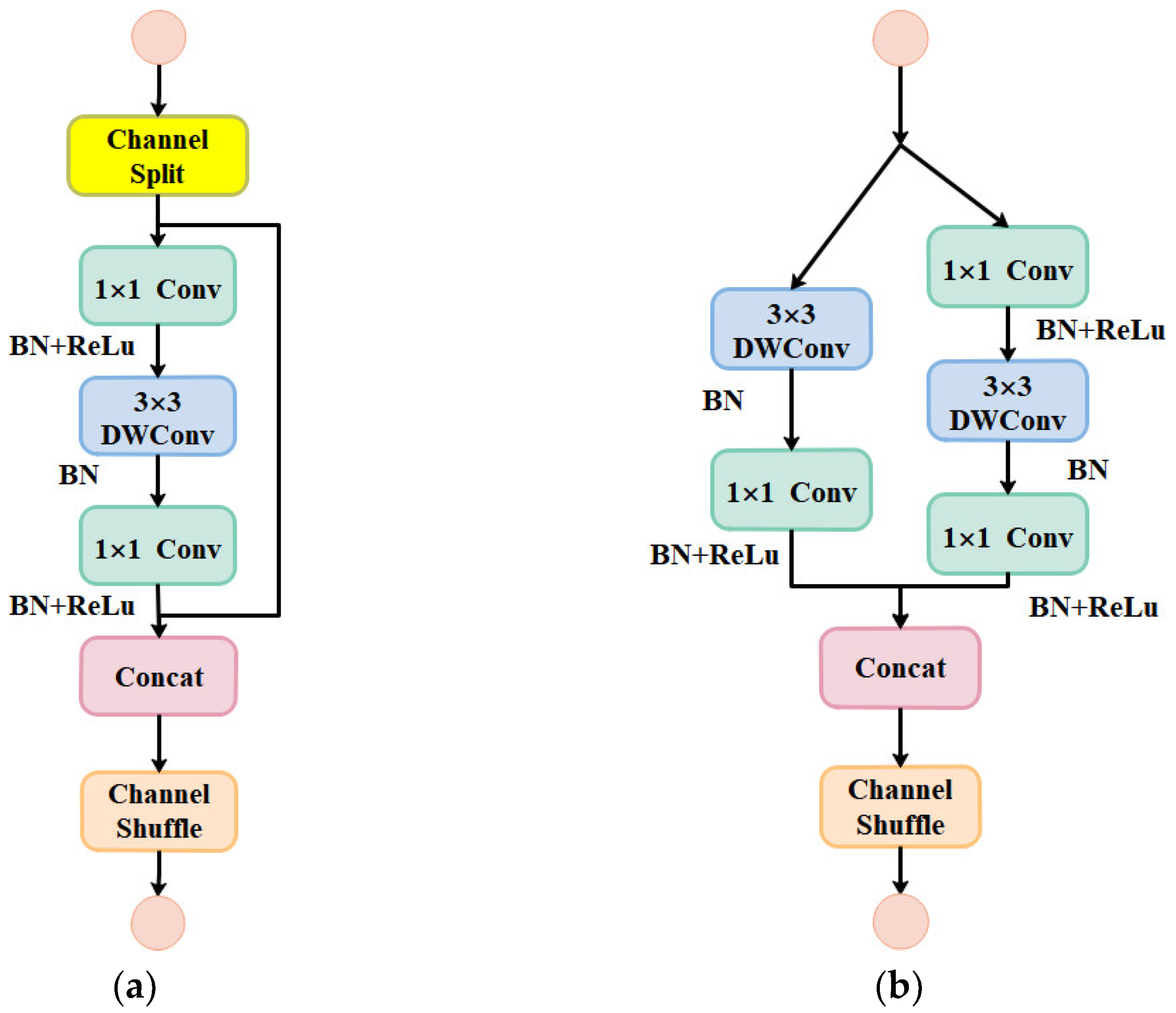
2.4.2. ShuffleNet V2 Backbone
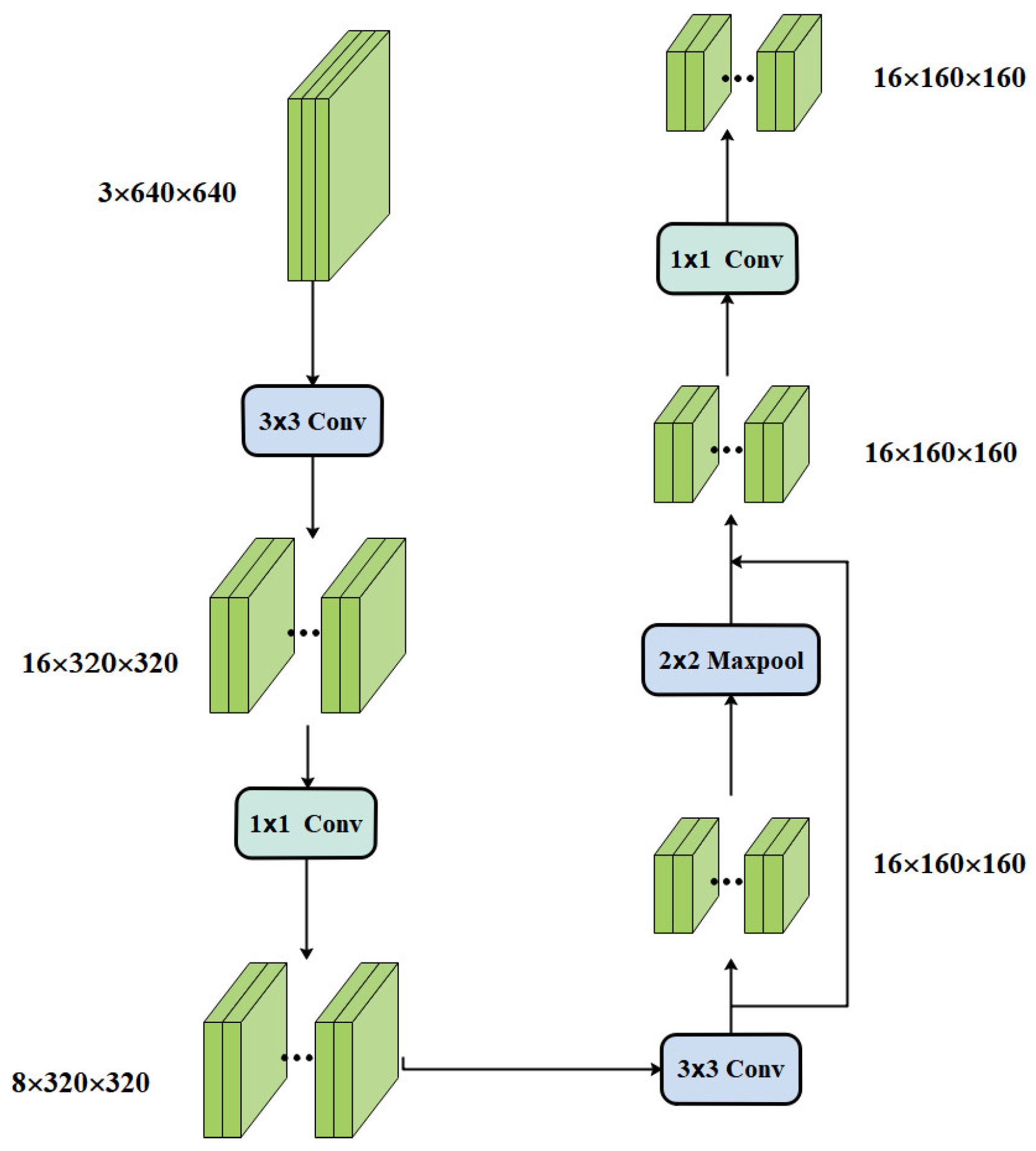
2.4.3. Stem Construction
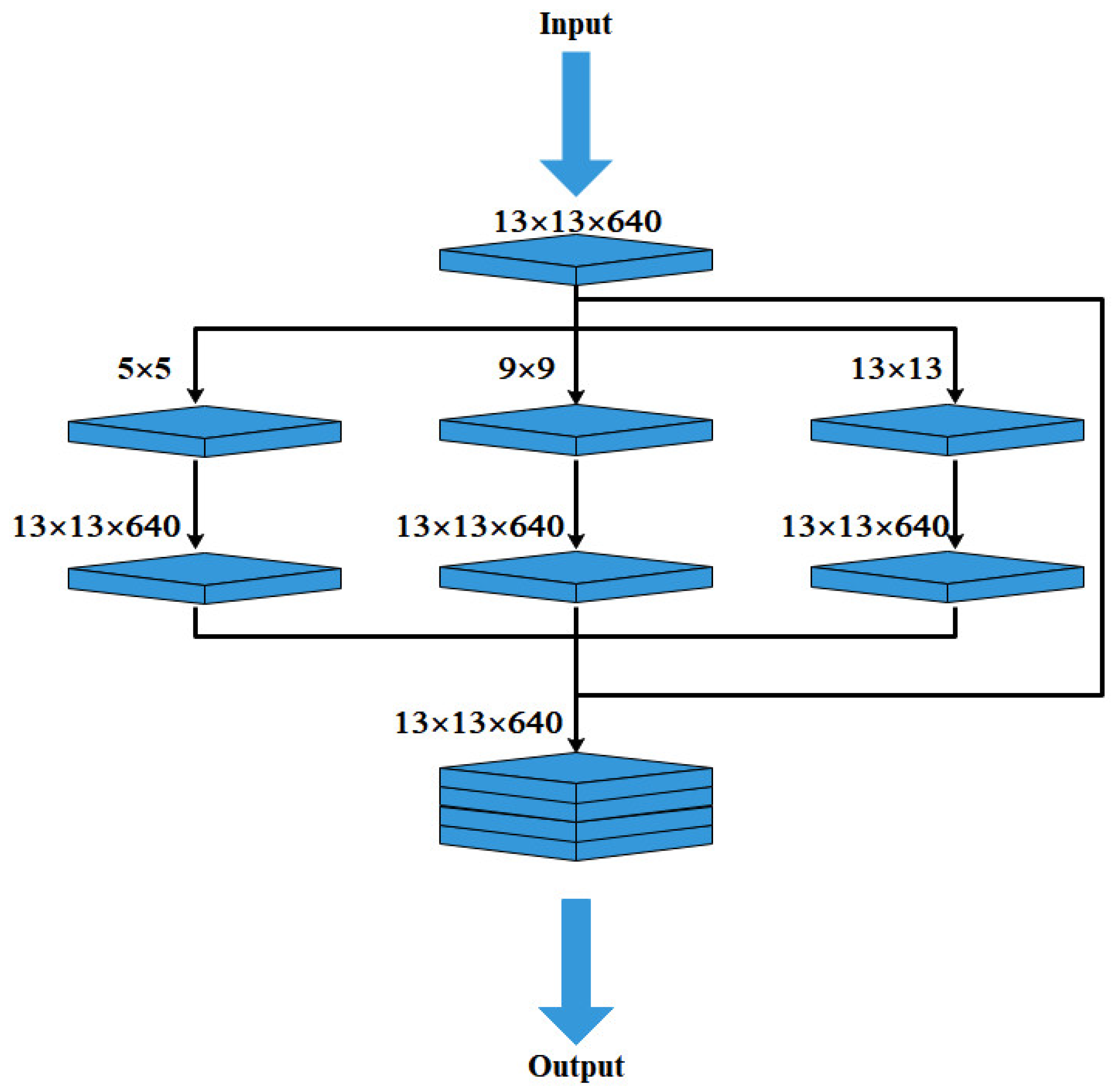
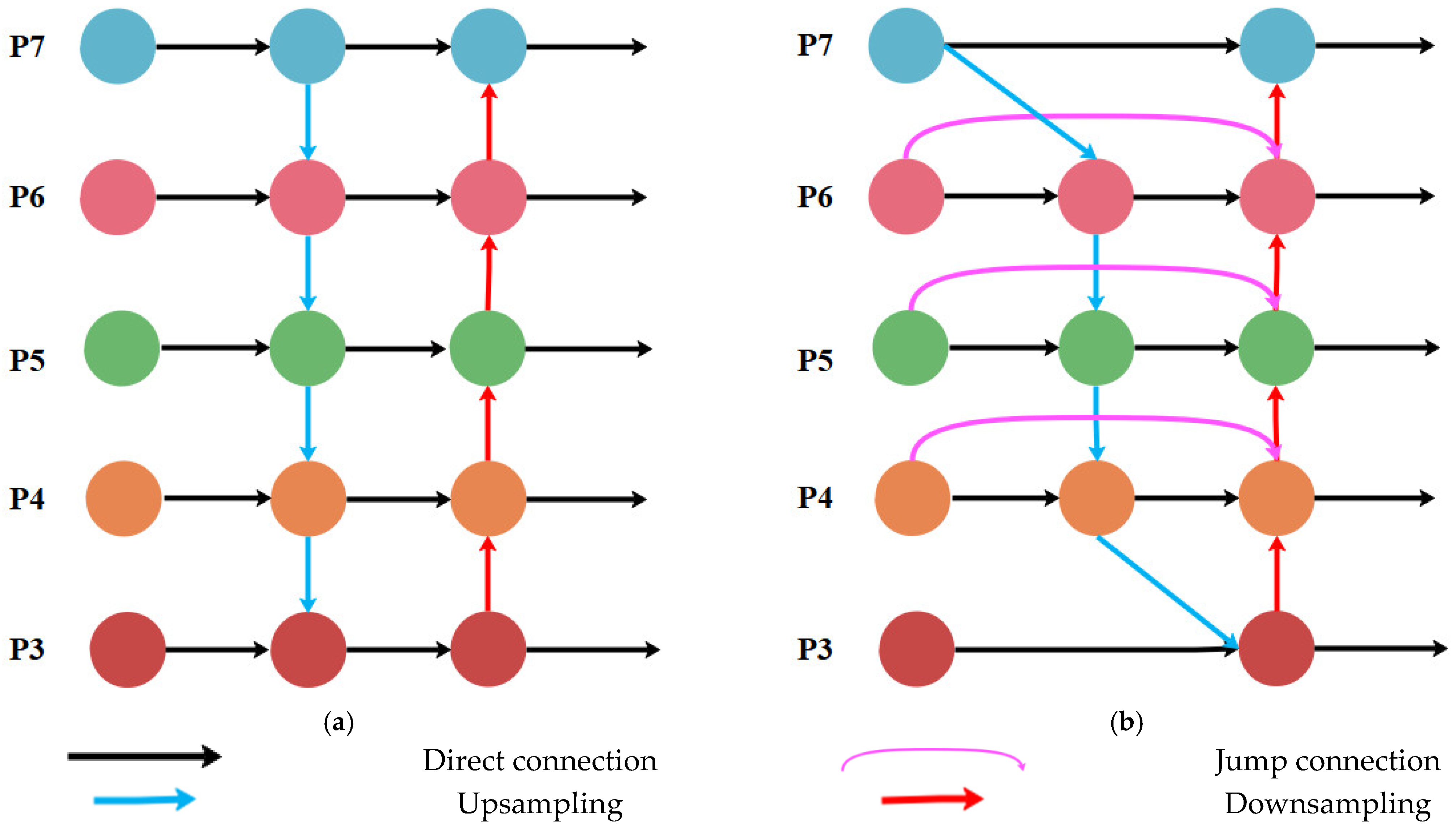
2.4.4. BiFPN
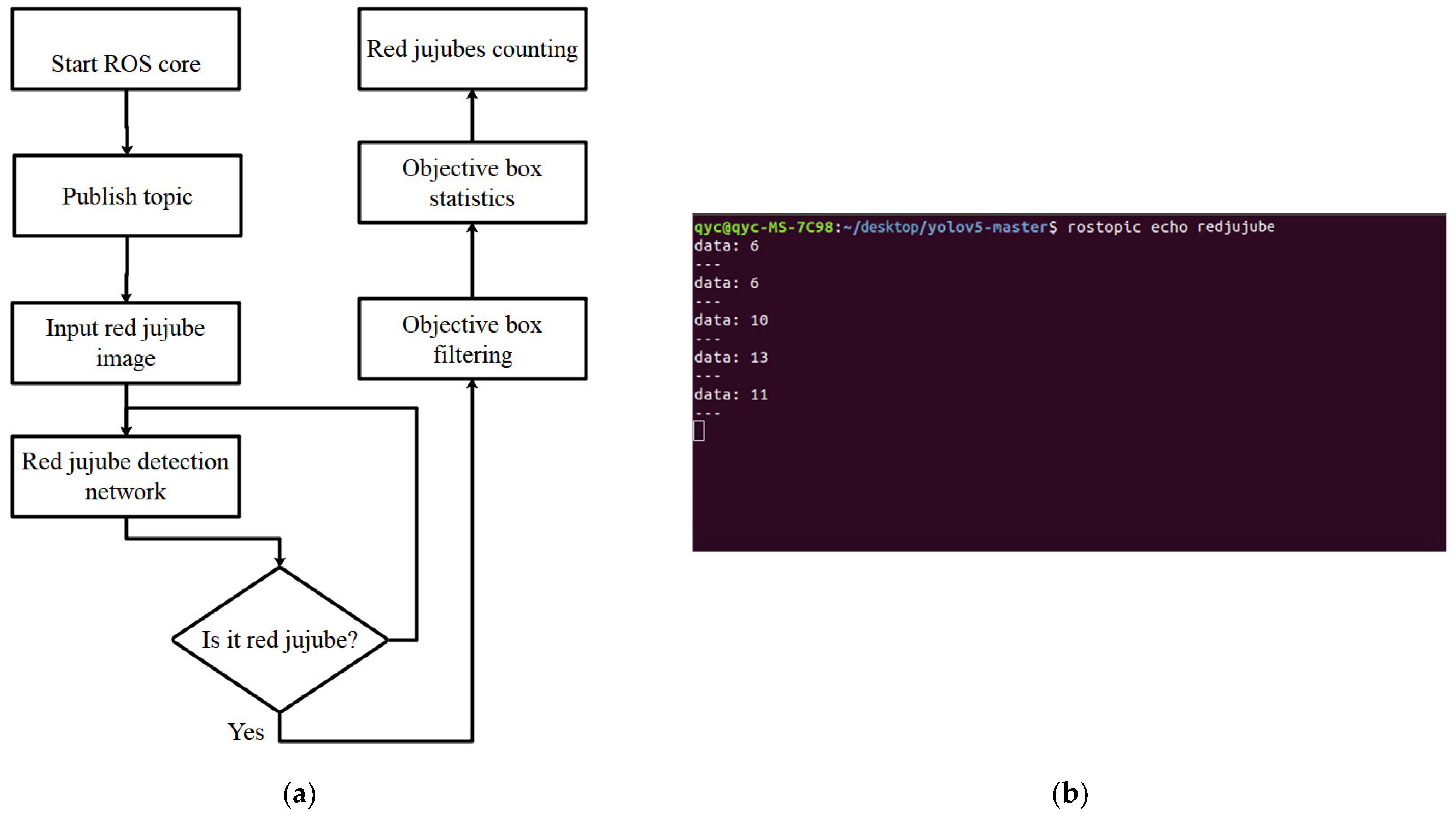
2.4.5. Counting Method of Red Jujube
2.5. Test Platform
2.6. Evaluation of Model Performance
3. Results and Discussion
3.1. Performance Comparison Using the Different Improve Method
3.2. Performance Comparison Using the Different Lightweight Backbone Networks
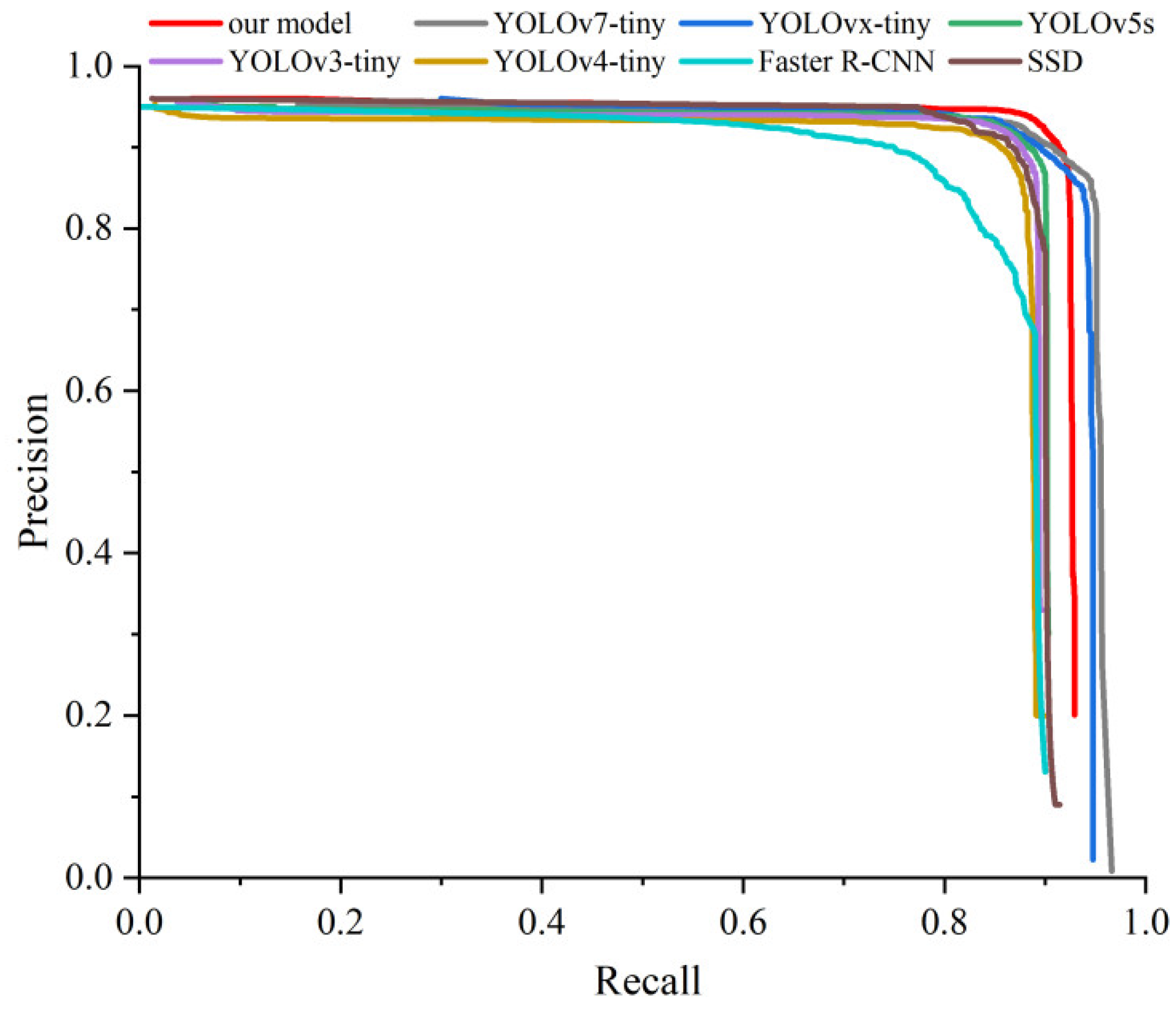
3.3. Performance Comparison in Counting Jujubes Using the Different Algorithms
4. Conclusions
- (1)
- Expand the types of data sets and increase the robustness of the model. There are only two kinds of jujube in the data set used in this research, so it is necessary to add more kinds of jujube fruit data to enhance the robustness of the model.
- (2)
- Construct the model of jujube fruit size and quality. Further, the counting method of red jujubes was used to accurately estimate the yield of red jujubes.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dicianu, D.E.; Butcaru, A.C.; Constantin, C.G.; Dobrin, A.; Stanica, F. Evaluation of some nutritional properties of Chinese jujube (Zizyphus jujuba Mill.) fruit organicaly produced in bucharest area. Sci. Pap. Ser. B Hortic. 2020, 64, 79–84. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Muruganantham, P.; Wibowo, S.; Grandhi, S.; Samrat, N.H.; Islam, N. A Systematic Literature Review on Crop Yield Prediction with Deep Learning and Remote Sensing. Remote Sens. 2022, 14, 1990. [Google Scholar] [CrossRef]
- Dorj, U.-O.; Malrey, L.; Sang-seok, Y. An yield estimation in citrus orchards via fruit detection and counting using image processing. Comput. Electron. Agric. 2017, 140, 103–112. [Google Scholar] [CrossRef]
- Wang, Z.; Kerry, W.; Anand, K. Mango fruit load estimation using a video based MangoYOLO—Kalman filter—Hungarian algorithm method. Sensors 2019, 19, 2742. [Google Scholar] [CrossRef] [Green Version]
- Lyu, S.; Li, R.; Zhao, Y.; Li, Z.; Fan, R.; Liu, S. Green Citrus Detection and Counting in Orchards Based on YOLOv5-CS and AI Edge System. Sensors 2022, 22, 576. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, W.; Yu, J.; He, L.; Chen, J.; He, Y. Complete and accurate holly fruits counting using YOLOX object detection. Comput. Electron. Agric. 2022, 198, 107062. [Google Scholar] [CrossRef]
- Li, X.; Du, Y.; Yao, L.; Wu, J.; Liu, L. Design and Experiment of a Broken Corn Kernel Detection Device Based on the YOLOv4-Tiny Algorithm. Agriculture 2021, 11, 1238. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, S.; Yan, Y.; Tang, S.; Zhao, S. Identification and Analysis of Emergency Behavior of Cage-Reared Laying Ducks Based on YOLOv5. Agriculture 2022, 12, 485. [Google Scholar] [CrossRef]
- Zheng, Z.; Yang, H.; Zhou, L.; Yu, B.; Zhang, Y. HLU 2-Net: A Residual U-Structure Embedded U-Net With Hybrid Loss for Tire Defect Inspection. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.-G.; Chen, Y.; Xue, X. Dsod: Learning deeply supervised object detectors from scratch. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 1919–1927. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and localization methods for vision-based fruit picking robots: A review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef] [PubMed]
- You, L.; Jiang, H.; Hu, J.; Chang, C.; Chen, L.; Cui, X.; Zhao, M. GPU-accelerated Faster Mean Shift with euclidean distance metrics. arXiv 2021, arXiv:2112.13891. [Google Scholar]
- Zhao, M.; Jha, A.; Liu, Q.; Millis, B.A.; Mahadevan-Jansen, A.; Lu, L.; Landman, B.A.; Tyskac, M.J.; Huo, Y. Faster mean-shift: Gpu-accelerated embedding-clustering for cell segmentation and tracking. arXiv 2020, arXiv:2007.14283. [Google Scholar] [CrossRef]
- Zhao, M.; Liu, Q.; Jha, A.; Deng, R.; Yao, T.; Mahadevan-Jansen, A.; Tyska, M.J.; Millis, B.A.; Huo, Y. VoxelEmbed: 3D instance segmentation and tracking with voxel embedding based deep learning. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Strasbourg, France, 27 September 2021; pp. 437–446. [Google Scholar]
- Lu, Y.; Young, S. A survey of public datasets for computer vision tasks in precision agriculture. Comput. Electron. Agric. 2020, 178, 105760. [Google Scholar] [CrossRef]
- Mulyono, I.; Lukita, T.; Sari, C.; Setiadi, D.; Rachmawanto, E.; Susanto, A.; Putra, M.; Santoso, D. Parijoto Fruits Classification using K-Nearest Neighbor Based on Gray Level Co-Occurrence Matrix Texture Extraction. J. Phys. Conf. Ser. 2020, 1051, 012017. [Google Scholar] [CrossRef]
- Fauliah, S.P. Implementation of learning vector quantization (lvq) algorithm for durian fruit classification using gray level co-occurrence matrix (glcm) parameters. J. Phys. Conf. Ser. 2019, 1196, 012040. [Google Scholar]
- Zhao, C.; Lee, W.S.; He, D. Immature green citrus detection based on colour feature and sum of absolute transformed difference (SATD) using colour images in the citrus grove. Comput. Electron. Agric. 2016, 124, 243–253. [Google Scholar] [CrossRef]
- Peng, H.; Shao, Y.; Chen, K.; Deng, Y.; Xue, C. Research on multi-class fruits recognition based on machine vision and SVM. IFAC-PapersOnLine 2018, 51, 817–821. [Google Scholar] [CrossRef]
- Wajid, A.; Singh, N.K.; Junjun, P.; Mughal, M.A. Recognition of ripe, unripe and scaled condition of orange citrus based on decision tree classification. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (iCoMET) 2018, Sukkur, Pakistan, 3–4 March 2018; pp. 1–4. [Google Scholar]
- Hussin, R.; Juhari, M.R.; Kang, N.W.; Ismail, R.; Kamarudin, A. Digital image processing techniques for object detection from complex background image. Procedia Eng. 2012, 41, 340–344. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Chen, Z.; Bao, R.; Zhang, C.; Wang, Z. Recognition of dense cherry tomatoes based on improved YOLOv4-LITE lightweight neural network. Trans. Chin. Soc. Agric. Eng. 2021, 37, 270–278. [Google Scholar]
- Fu, L.; Feng, Y.; Majeed, Y.; Zhang, X.; Zhang, J.; Karkee, M.; Zhang, Q. Kiwifruit detection in field images using Faster R-CNN with ZFNet. IFAC-PapersOnLine 2018, 51, 45–50. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, J.; Fu, L.; Majeed, Y.; Feng, Y.; Li, R.; Cui, Y. Improved kiwifruit detection using pre-trained VGG16 with RGB and NIR information fusion. IEEE Access 2019, 8, 2327–2336. [Google Scholar] [CrossRef]
- Wang, Y.; Xue, J. Lightweight object detection method for Lingwu long jujube images based on improved SSD. Trans. Chin. Soc. Agric. Eng. 2021, 37, 173–182. [Google Scholar]
- Li, X.; Pan, J.; Xie, F.; Zeng, J.; Li, Q.; Huang, X.; Liu, D.; Wang, X. Fast and accurate green pepper detection in complex backgrounds via an improved YOLOv4-tiny model. Comput. Electron. Agric. 2021, 191, 106503. [Google Scholar] [CrossRef]
- Novtahaning, D.; Shah, H.A.; Kang, J.-M. Deep Learning Ensemble-Based Automated and High-Performing Recognition of Coffee Leaf Disease. Agriculture 2022, 12, 1909. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Wu, S.; Yang, J.; Wang, X.; Li, X. Iou-balanced loss functions for single-stage object detection. Pattern Recognit. Lett. 2022, 156, 96–103. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence 2020, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Grey Jujube | Jun Jujube | Total Number |
|---|---|---|---|
| illumination change images | 136 | 190 | 326 |
| leaf shading images | 132 | 225 | 357 |
| fruit overlap images | 139 | 204 | 343 |
| Total Number | 407 | 619 | 1026 |
| Configuration | Parameter |
|---|---|
| CPU | Intel(R) Core(TM) i7-10700K |
| GPU | NVIDIA GeForce RTX 3070 |
| Accelerated environment | CUDA11.1 CUDNN8.2.1 |
| Development environment | Pycharm2021.3.2 |
| Operating system | Windows 10 |
| Model | Precision (%) | Recall (%) | F1-Score (%) | AP (%) | Parameters | Model Size (KB) | Fps |
|---|---|---|---|---|---|---|---|
| YOLOv5s | 89.10 | 90.30 | 89.70 | 95.60 | 7,063,542 | 14,052 | 35.10 |
| YOLOv5s + Stem | 87.60 | 93.90 | 90.60 | 96.00 | 7,281,341 | 14,026 | 38.40 |
| YOLOv5s + BiFPN | 88.60 | 90.90 | 89.70 | 95.30 | 7,063,542 | 14,052 | 39.40 |
| YOLOv5s + ShuffleNet V2 | 83.80 | 91.60 | 87.50 | 94.00 | 490,205 | 1322 | 35.50 |
| YOLOv5s + Stem + BiFPN | 89.70 | 94.50 | 92.00 | 96.20 | 7,281,341 | 14,026 | 39.40 |
| YOLOv5s + Stem + ShuffleNet V2 | 93.70 | 89.20 | 91.40 | 95.90 | 441,606 | 1149 | 36.30 |
| YOLOv5s + BiFPN + ShuffleNet V2 | 83.40 | 92.10 | 87.50 | 94.10 | 490,205 | 1322 | 35.50 |
| Our model | 93.40 | 92.30 | 92.80 | 96.20 | 441,606 | 1149 | 36.50 |
| Model | Precision (%) | Recall (%) | AP (%) | Parameters | Model Size (KB) | Fps |
|---|---|---|---|---|---|---|
| YOLOv5s | 89.1 | 90.3 | 95.6 | 7,063,542 | 14,052 | 35.1 |
| MoblieNet V2-YOLOv5s | 81.2 | 90.3 | 93.6 | 2,917,046 | 5423 | 23.4 |
| MoblieNet V3-YOLOv5s | 94.2 | 85.8 | 95.6 | 3,538,532 | 7189 | 22.2 |
| Ghost-YOLOv5s | 85.4 | 92.3 | 93.4 | 3,897,605 | 8492 | 23.2 |
| ShuffleNet V2-YOLOv5s | 83.8 | 91.6 | 94.0 | 490,205 | 1149 | 35.5 |
| Model | The Number of Actual Jujube | The Number of Predicted Jujube | Precision (%) | Recall (%) | AP (%) | RMSE | MAPE (%) | Model Size (KB) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 1 | 2 | 3 | 4 | 5 | 6 | |||||||
| YOLOv5s | 10 | 15 | 15 | 9 | 10 | 6 | 9 | 16 | 14 | 8 | 8 | 6 | 89.10 | 90.30 | 95.60 | 1.15 | 9.07 | 14,052 |
| YOLOv4-tiny | 10 | 15 | 11 | 9 | 8 | 6 | 91.60 | 89.40 | 95.90 | 1.83 | 7.78 | 103,012 | ||||||
| YOLOv3-tiny | 10 | 14 | 11 | 7 | 8 | 6 | 92.30 | 88.70 | 95.50 | 2.04 | 12.59 | 481,391 | ||||||
| YOLOvx-tiny | 8 | 10 | 11 | 7 | 7 | 6 | 86.60 | 91.30 | 95.70 | 3.11 | 22.04 | 19,901 | ||||||
| YOLOv7-tiny | 10 | 11 | 12 | 7 | 8 | 6 | 89.20 | 90.50 | 95.10 | 2.35 | 14.81 | 23,674 | ||||||
| SSD | 8 | 11 | 14 | 7 | 8 | 6 | 88.30 | 87.10 | 90.50 | 2.19 | 15.93 | 92,782 | ||||||
| Faster R-CNN | 9 | 12 | 13 | 7 | 7 | 6 | 64.00 | 89.30 | 87.90 | 2.12 | 15.93 | 110,773 | ||||||
| Our Model | 10 | 15 | 13 | 9 | 9 | 6 | 93.40 | 92.30 | 96.20 | 0.91 | 3.89 | 1149 | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, Y.; Hu, Y.; Zheng, Z.; Yang, H.; Zhang, K.; Hou, J.; Guo, J. A Counting Method of Red Jujube Based on Improved YOLOv5s. Agriculture 2022, 12, 2071. https://doi.org/10.3390/agriculture12122071
Qiao Y, Hu Y, Zheng Z, Yang H, Zhang K, Hou J, Guo J. A Counting Method of Red Jujube Based on Improved YOLOv5s. Agriculture. 2022; 12(12):2071. https://doi.org/10.3390/agriculture12122071
Chicago/Turabian StyleQiao, Yichen, Yaohua Hu, Zhouzhou Zheng, Huanbo Yang, Kaili Zhang, Juncai Hou, and Jiapan Guo. 2022. "A Counting Method of Red Jujube Based on Improved YOLOv5s" Agriculture 12, no. 12: 2071. https://doi.org/10.3390/agriculture12122071