
Detection of Water Content in Lettuce Canopies Based on Hyperspectral Imaging Technology under Outdoor Conditions
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Sample
2.2. Outdoor Hyperspectral Data Acquisition
2.3. Canopy Water Content Determination
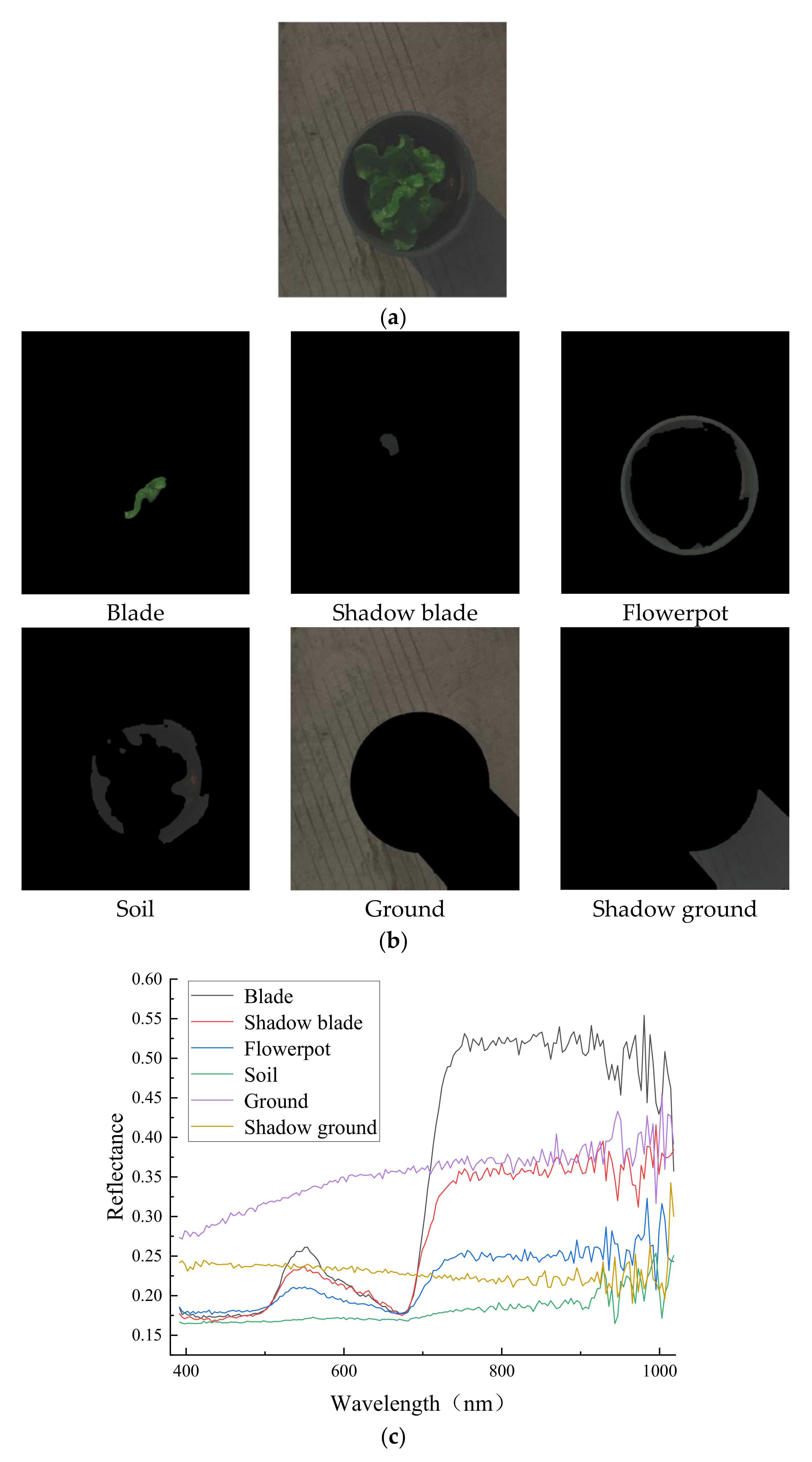
2.4. Lettuce Canopy Image Extraction
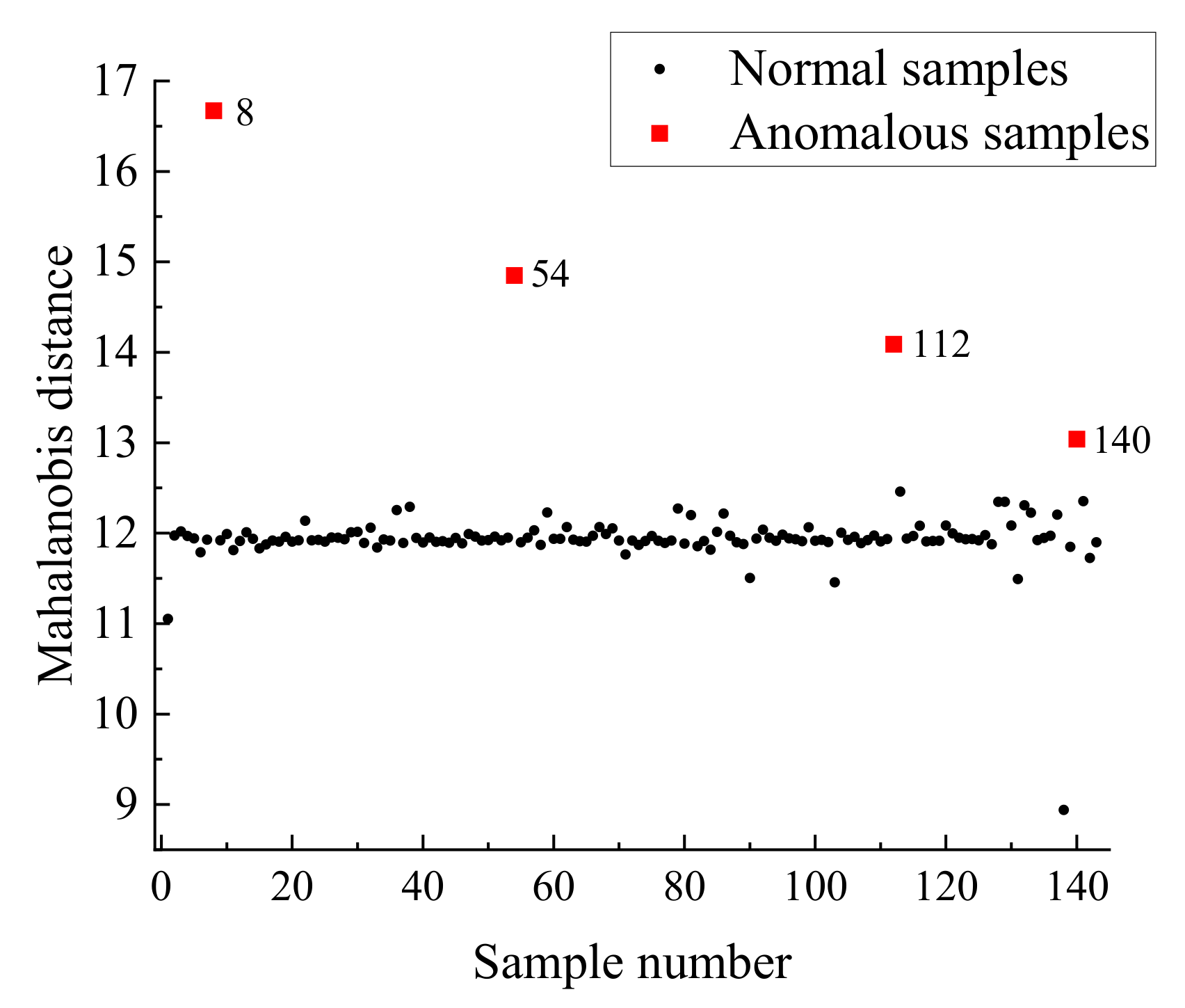
2.5. Abnormal Sample Rejection
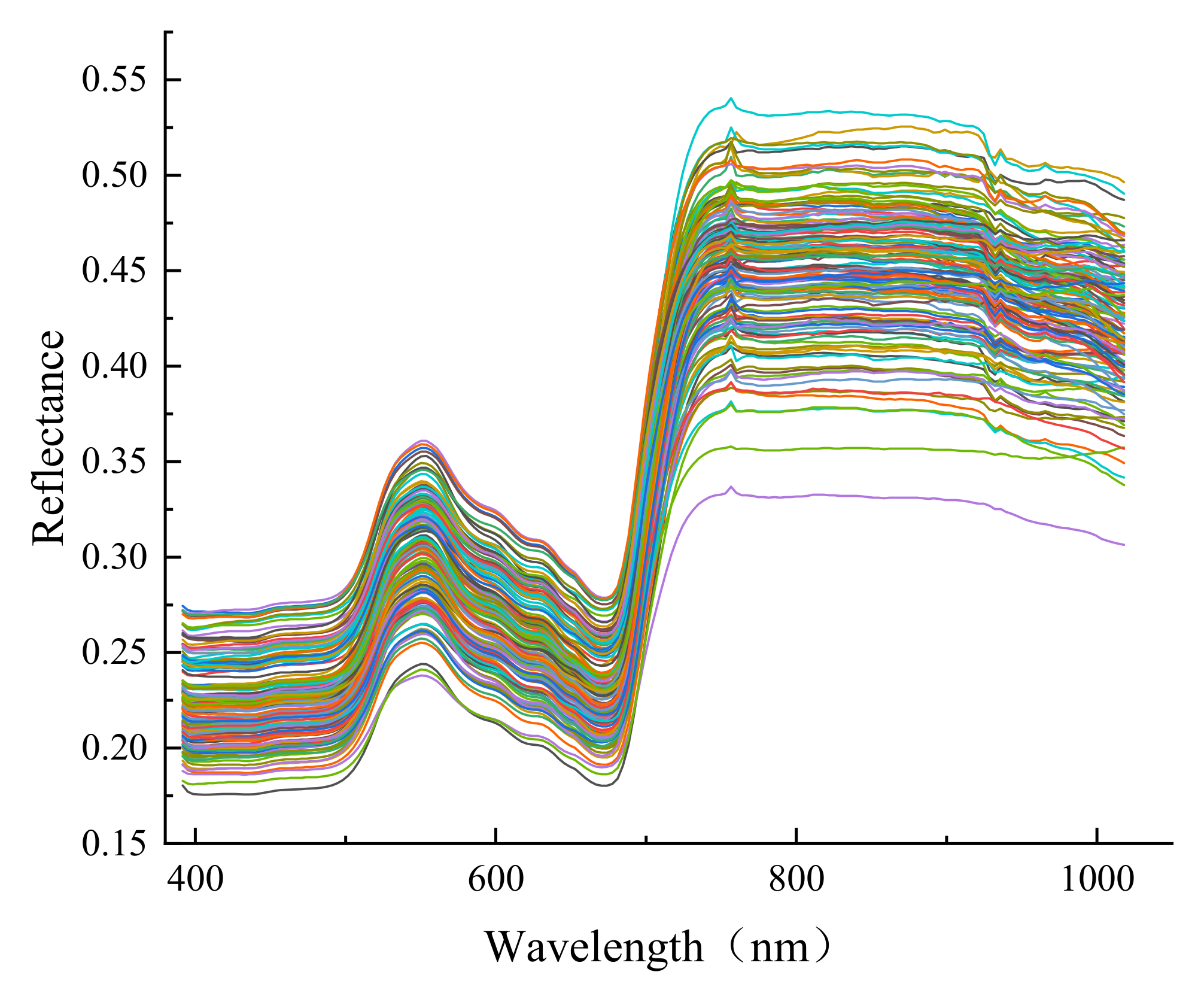
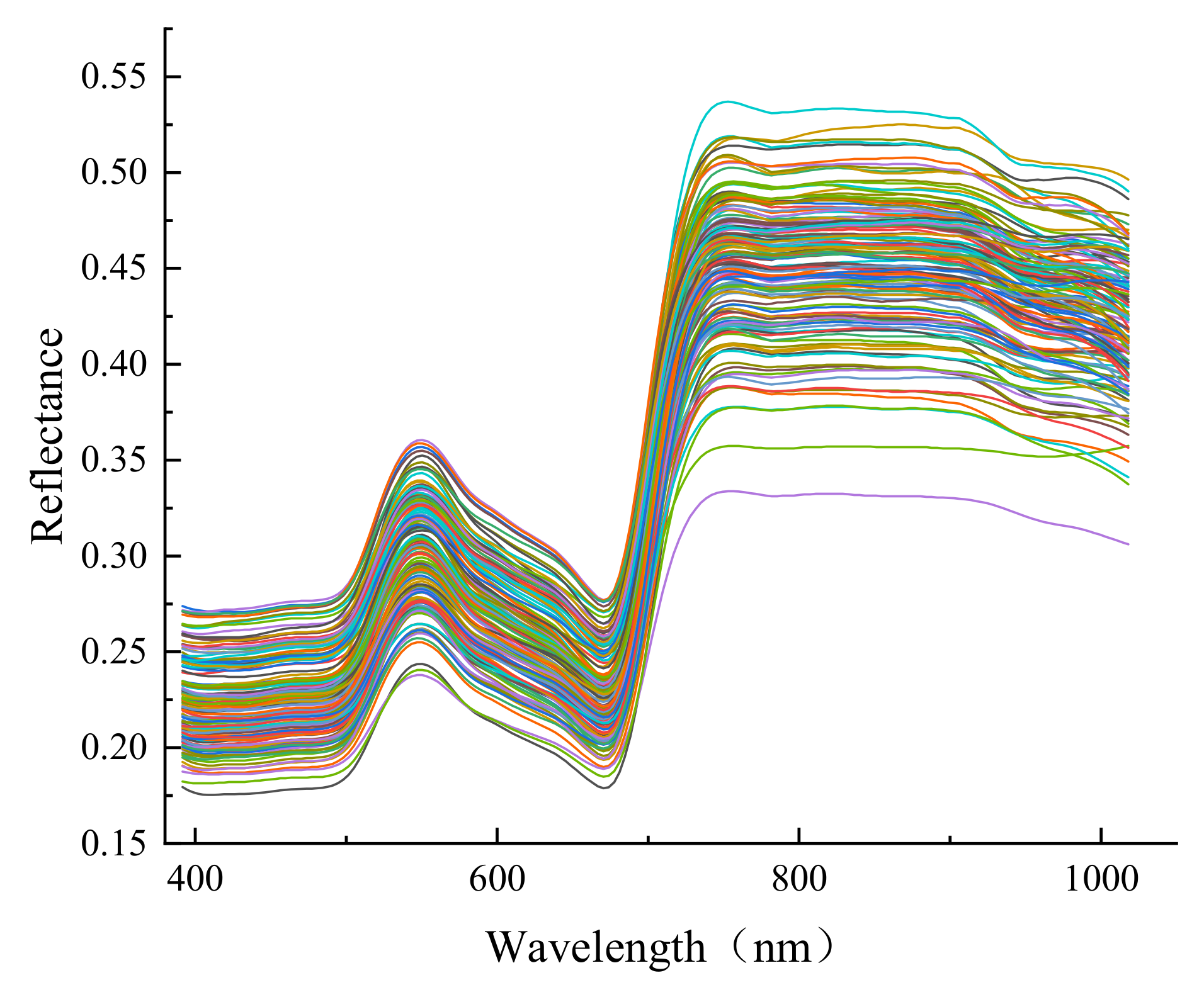
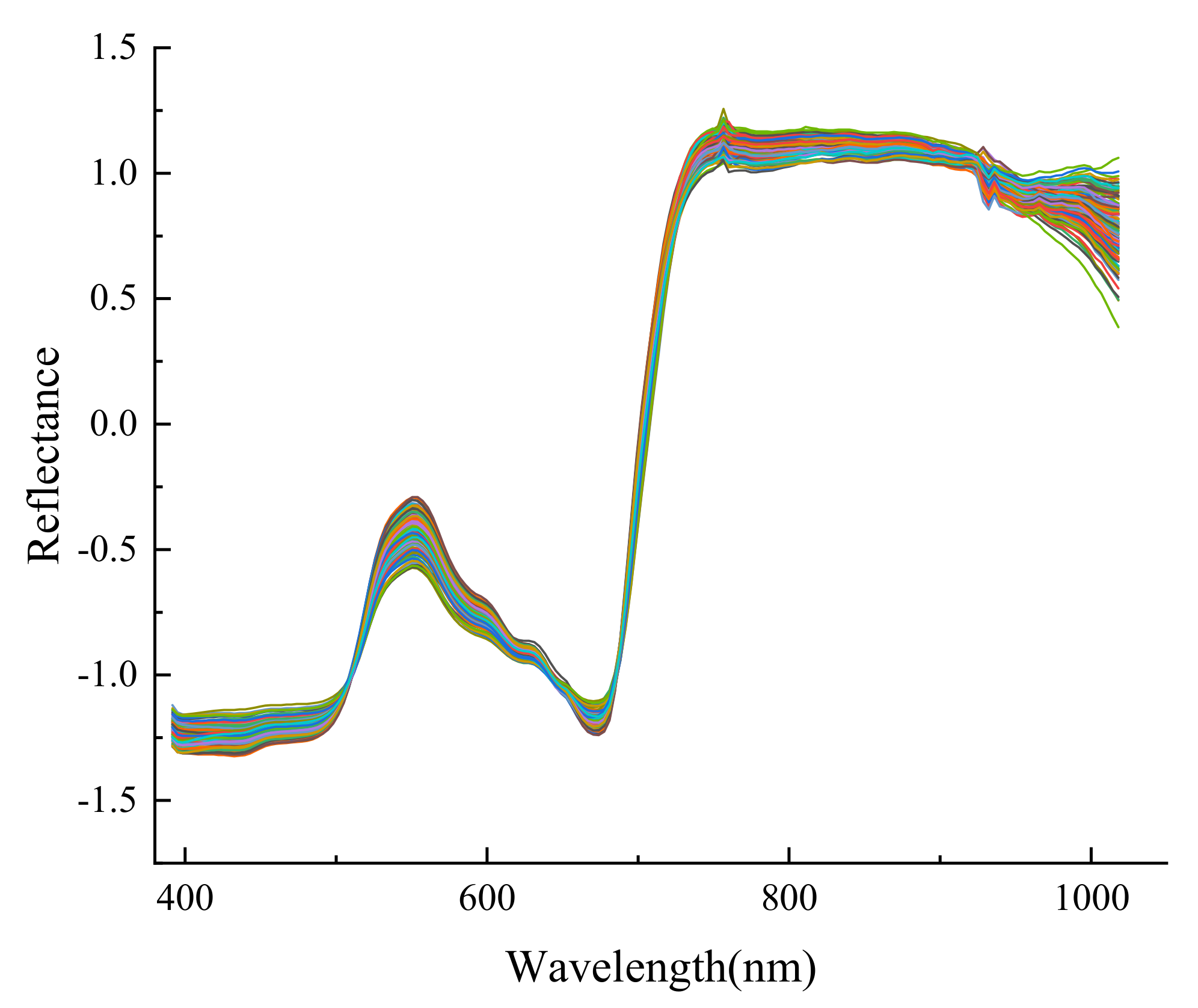
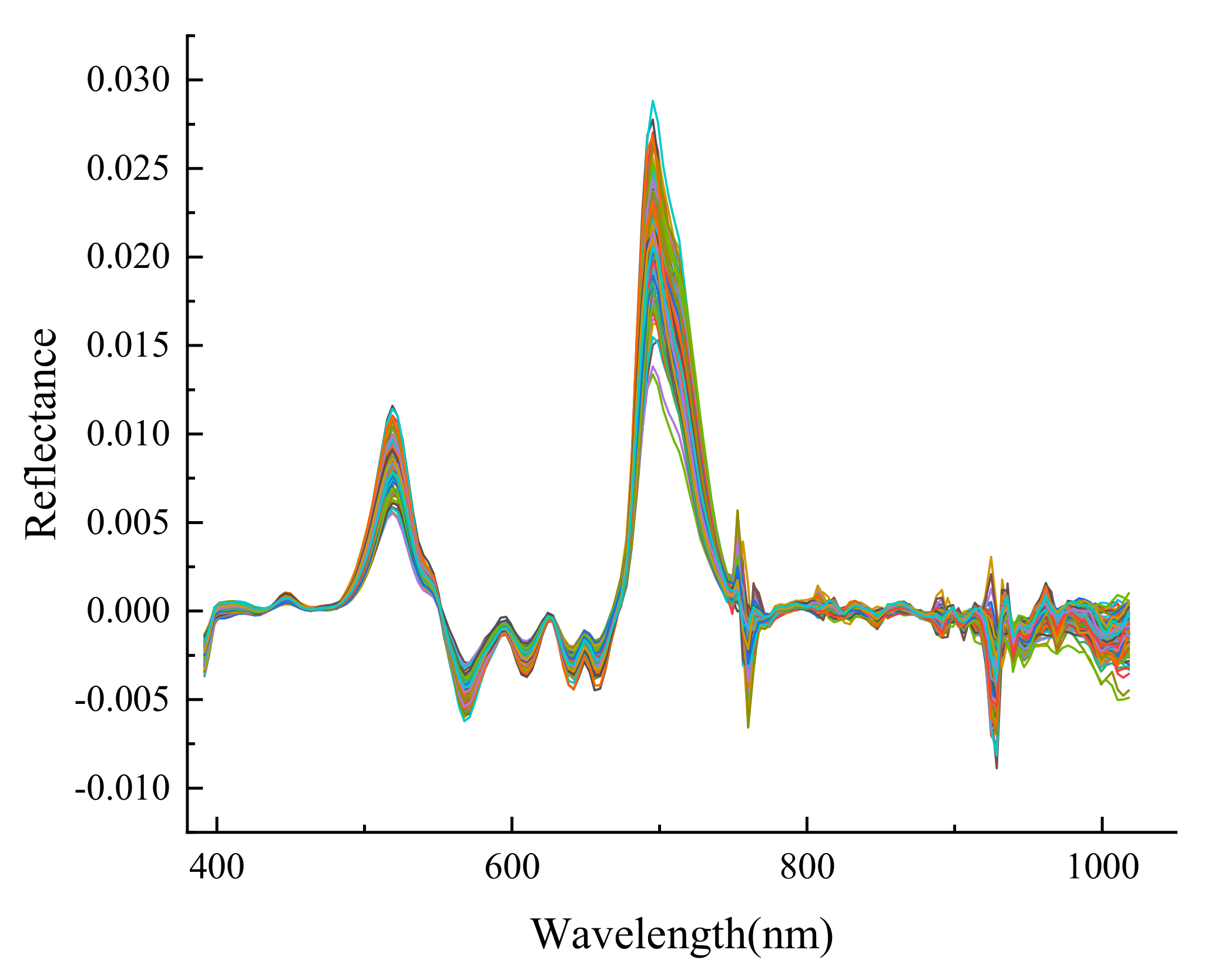
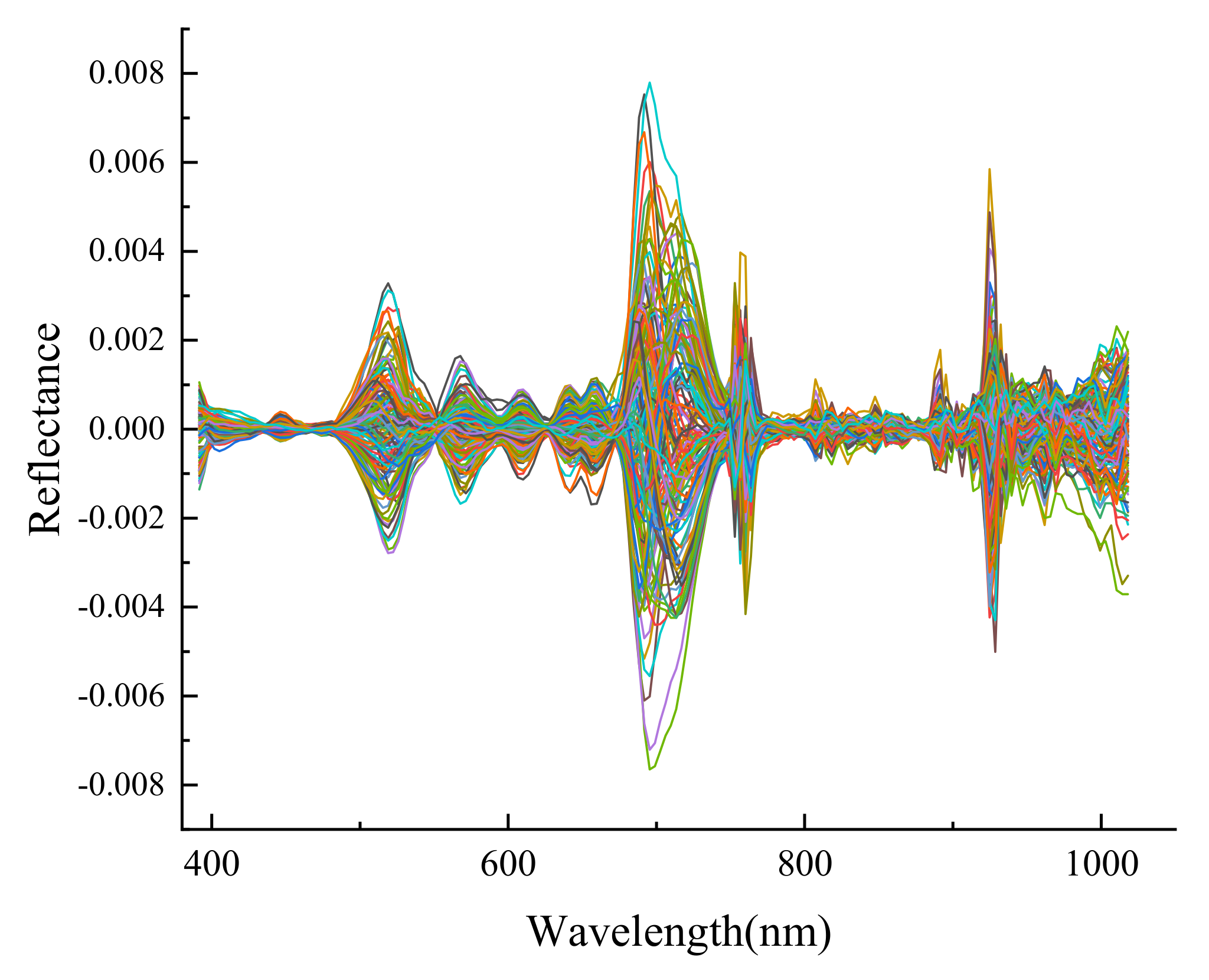
2.6. Spectral Preprocessing
2.7. Characteristic Wavelength Screening
2.7.1. Monte Carlo Uninformative Variable Elimination
2.7.2. Competitive Adaptive Reweighting Sampling
2.7.3. Successive Projections Algorithm
3. Results and Analysis
3.1. Lettuce Canopy Dry Base Water Content Statistics
3.2. Lettuce Canopy Image Extraction Accuracy
3.2.1. Segmentation Accuracy
3.2.2. Analysis of Segmentation Results
3.3. Light Intensity Correction
3.4. Performance Comparison of Different Pretreatment Methods
3.5. Dimensionality Reduction of Canopy Hyperspectral Data
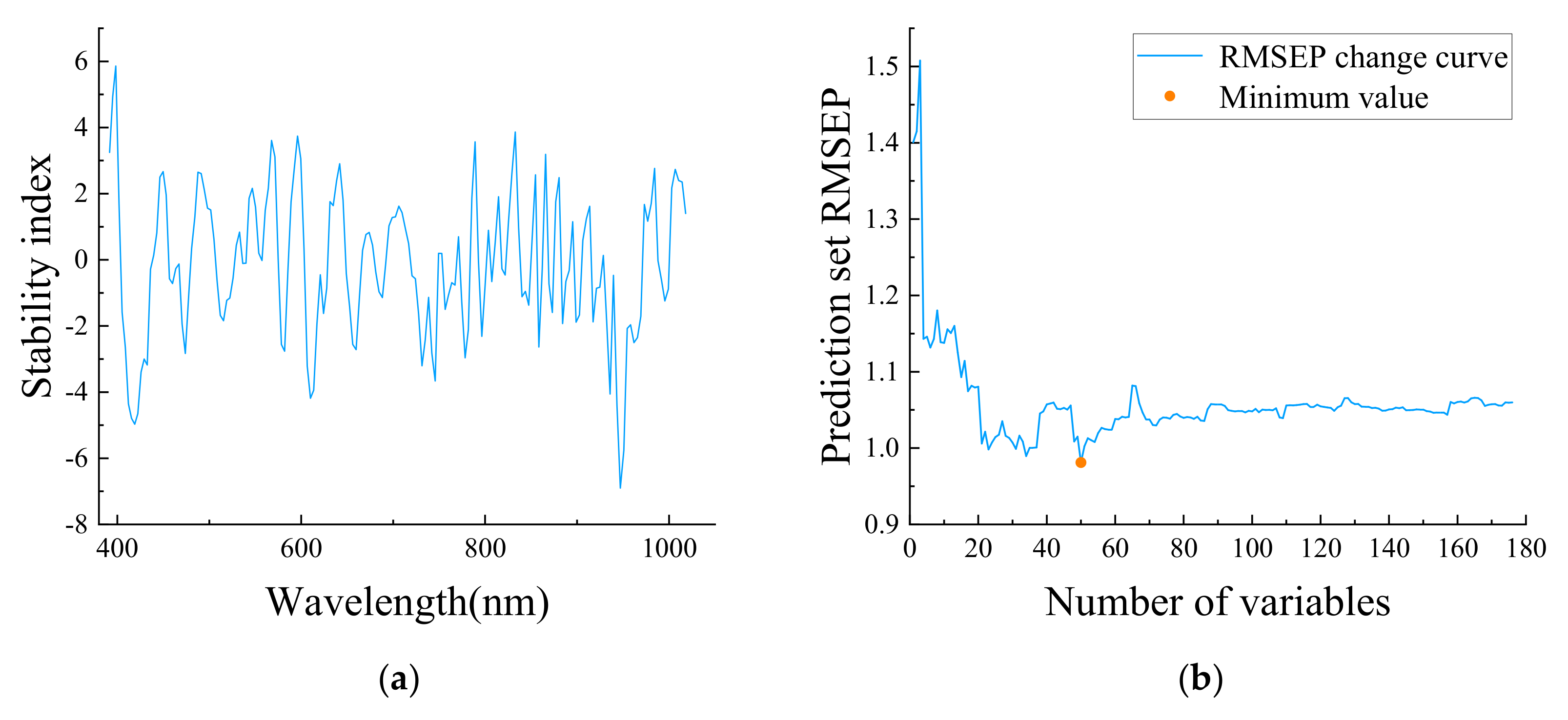
3.5.1. Eliminating Irrelevant Variables Based on MCUVE
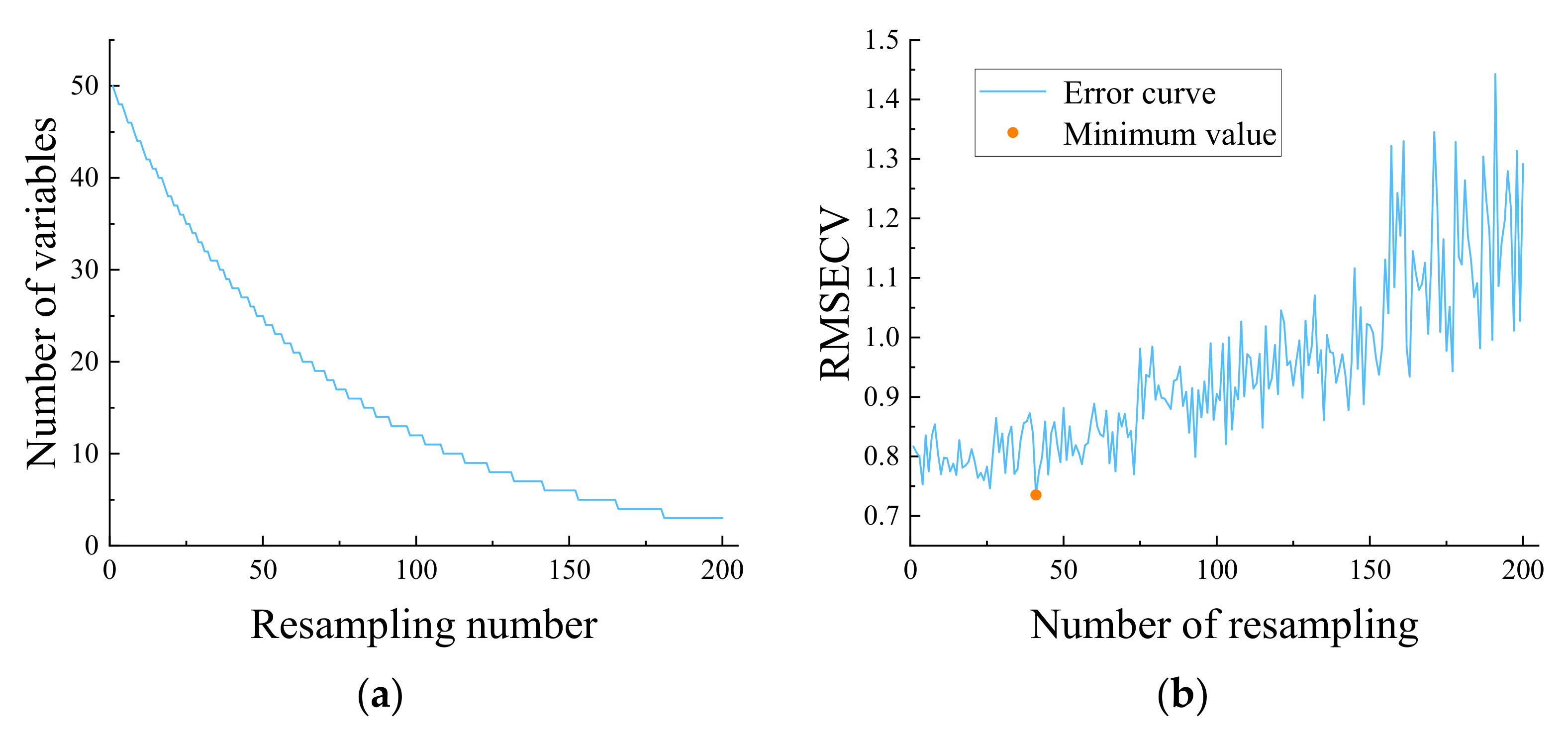
3.5.2. Feature Wavelength Extraction Based on MCUVE–CARS
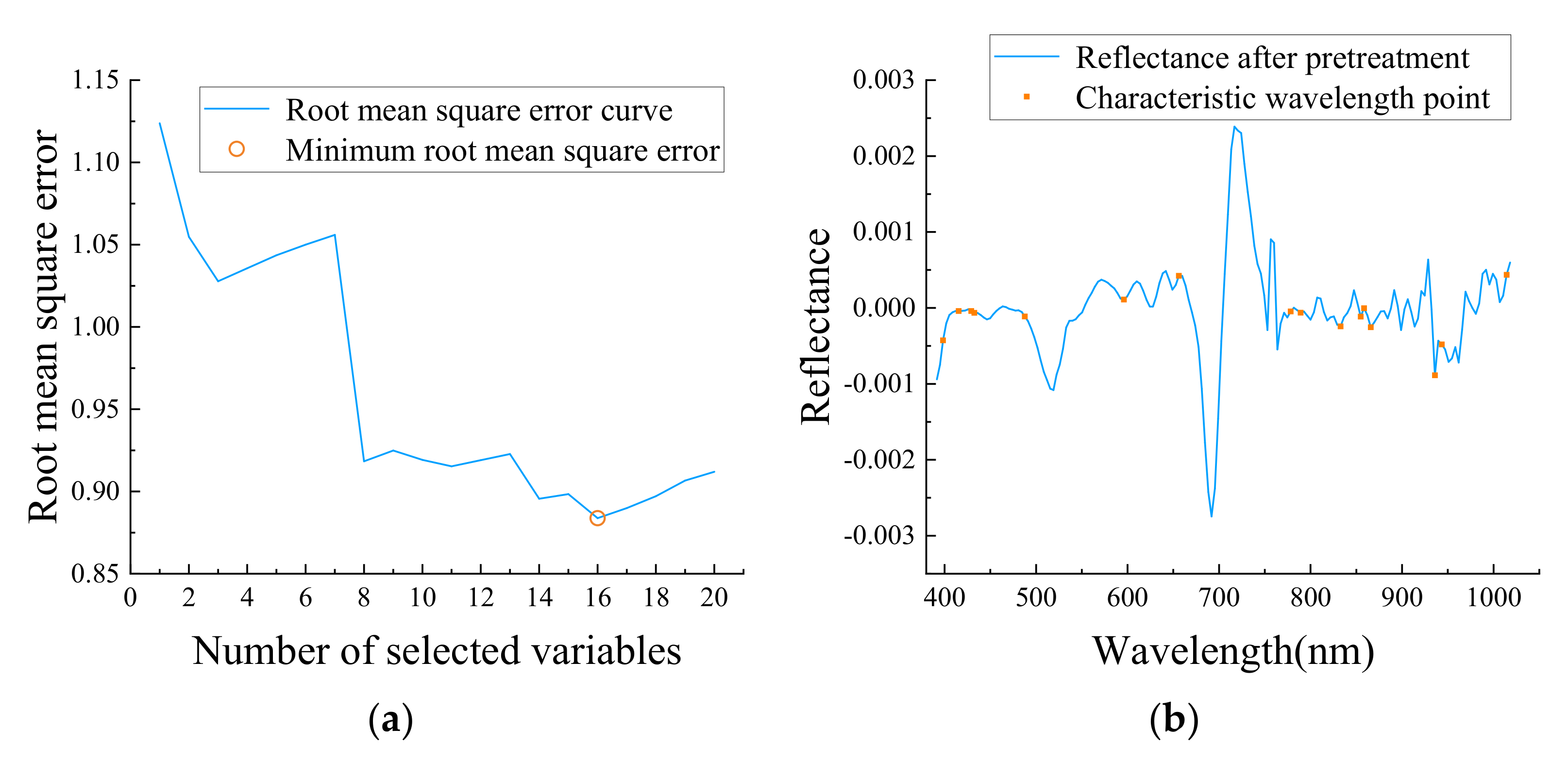
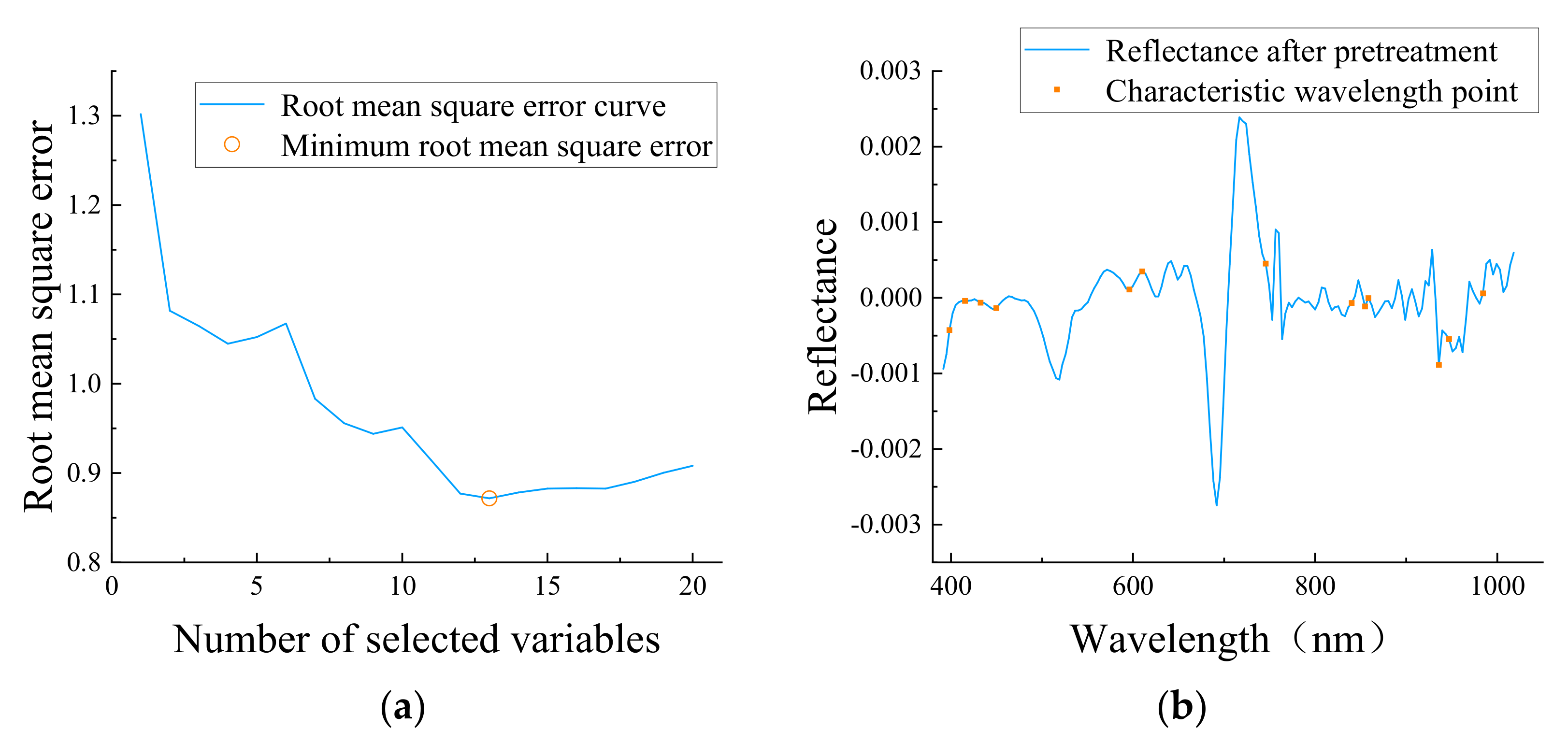
3.5.3. Feature Wavelength Extraction Based on MCUVE–SPA and MCUVE–CARS–SPA
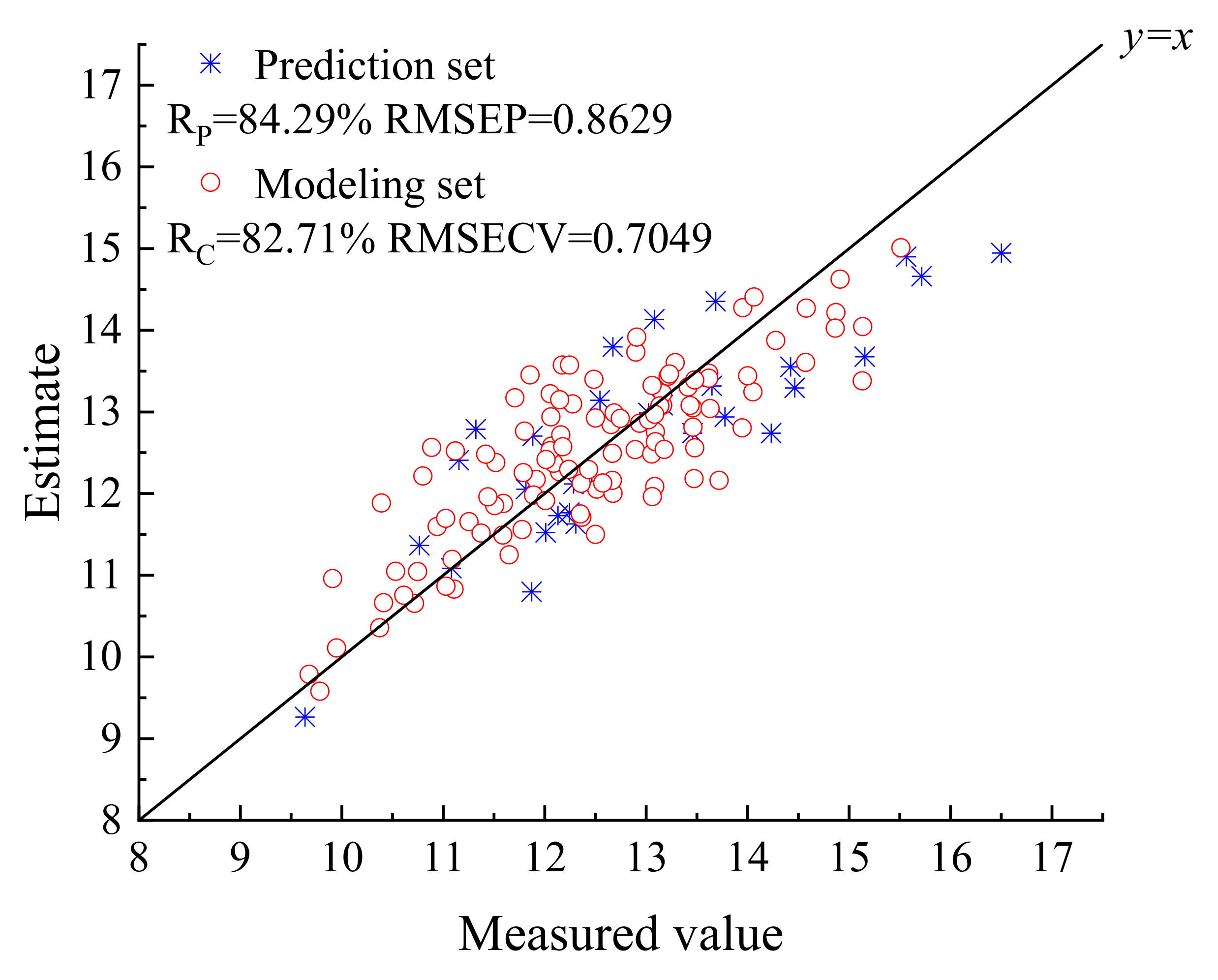
3.6. Modeling Results and Analysis
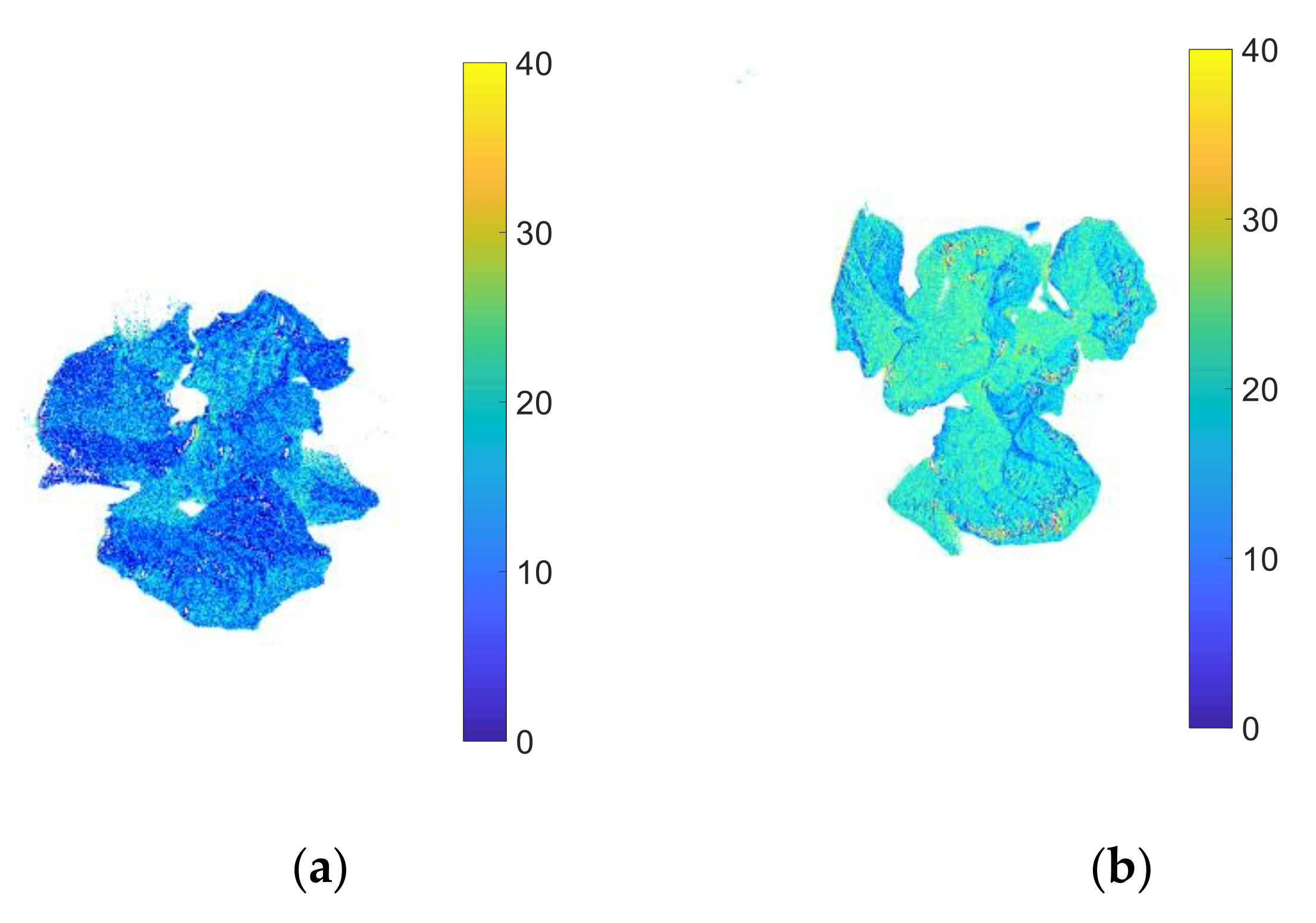
3.7. Visualization of Water Content Distribution of Lettuce Canopy Dry Base
4. Discussion
4.1. Comparison of Predicted Effects
4.2. Improvement Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Concepcion, R.; Dadios, E.; Cuello, J.; Duarte, B. Thermo-Gas Dynamics Affect the Leaf Canopy Shape and Moisture Content of Aquaponic Lettuce in a Modified Partially Diffused Microclimatic Chamber. Sci. Hortic. 2022, 292, 110649. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Lu, B.; Hang, Y.; Chen, Q. Hyperspectral Technique Combined with Deep Learning Algorithm for Detection of Compound Heavy Metals in Lettuce. Food Chem. 2020, 321, 126503. [Google Scholar] [CrossRef] [PubMed]
- Moriya, É.A.S.; Imai, N.N.; Tommaselli, A.M.G.; Berveglieri, A.; Santos, G.H.; Soares, M.A.; Marino, M.; Reis, T.T. Detection and Mapping of Trees Infected with Citrus Gummosis Using UAV Hyperspectral Data. Comput. Electron. Agric. 2021, 188, 106298. [Google Scholar] [CrossRef]
- Gao, J.; Zhao, L.; Li, J.; Deng, L.; Ni, J.; Han, Z. Aflatoxin Rapid Detection Based on Hyperspectral with 1D-Convolution Neural Network in the Pixel Level. Food Chem. 2021, 360, 129968. [Google Scholar] [CrossRef]
- Appeltans, S.; Pieters, J.G.; Mouazen, A.M. Detection of Leek White Tip Disease under Field Conditions Using Hyperspectral Proximal Sensing and Supervised Machine Learning. Comput. Electron. Agric. 2021, 190, 106453. [Google Scholar] [CrossRef]
- Shao, Y.; Shi, Y.; Qin, Y.; Xuan, G.; Li, J.; Li, Q.; Yang, F.; Hu, Z. A New Quantitative Index for the Assessment of Tomato Quality Using Vis-NIR Hyperspectral Imaging. Food Chem. 2022, 386, 132864. [Google Scholar] [CrossRef]
- Benelli, A.; Cevoli, C.; Ragni, L.; Fabbri, A. In-Field and Non-Destructive Monitoring of Grapes Maturity by Hyperspectral Imaging. Biosyst. Eng. 2021, 207, 59–67. [Google Scholar] [CrossRef]
- Cheng, J.; Sun, J.; Yao, K.; Xu, M.; Wang, S.; Fu, L. Development of Multi-Disturbance Bagging Extreme Learning Machine Method for Cadmium Content Prediction of Rape Leaf Using Hyperspectral Imaging Technology. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 279, 121479. [Google Scholar] [CrossRef]
- Tung, K.-C.; Tsai, C.-Y.; Hsu, H.-C.; Chang, Y.-H.; Chang, C.-H.; Chen, S. Evaluation of Water Potentials of Leafy Vegetables Using Hyperspectral Imaging. IFAC-Pap. 2018, 51, 5–9. [Google Scholar] [CrossRef]
- Sun, H.; Liu, N.; Wu, L.; Chen, L.; Yang, L.; Li, M.; Zhang, Q. Water Content Detection of Potato Leaves Based on Hyperspectral Image. IFAC-Pap. 2018, 51, 443–448. [Google Scholar] [CrossRef]
- Zhang, X.; Mao, H.; Zhou, Y.; Zuo, Z.; Gao, H. Study on Detection of Moisture Content in Lettuce Leaves based on Hyperspectral Imaging Technology. J. Anhui Agric. Sci. 2011, 39, 20329–20331 + 20714. [Google Scholar]
- Sun, J.; Wu, X.; Zhang, X.; Gao, H. Research on Lettuce Leaves’ Moisture Prediction Based on Hyperspectral Images. Spectrosc. Spectr. Anal. 2013, 33, 522–526. [Google Scholar]
- Li, H.; Zhang, K.; Chen, C.; Zhang, Z.; Liu, Z. Detection of Moisture Content in Lettuce Canopy Based on Hyperspectral Imaging Technique. Trans. Chin. Soc. Agric. Mach. 2021, 52, 211–217+274. [Google Scholar]
- Ma, D.; Maki, H.; Neeno, S.; Zhang, L.; Wang, L.; Jin, J. Application of Non-Linear Partial Least Squares Analysis on Prediction of Biomass of Maize Plants Using Hyperspectral Images. Biosyst. Eng. 2020, 200, 40–54. [Google Scholar] [CrossRef]
- Elvanidi, A.; Katsoulas, N.; Ferentinos, K.P.; Bartzanas, T.; Kittas, C. Hyperspectral Machine Vision as a Tool for Water Stress Severity Assessment in Soilless Tomato Crop. Biosyst. Eng. 2018, 165, 25–35. [Google Scholar] [CrossRef]
- Moghadam, S.A.N.; Sadeghi-Namaghi, H.; Moodi, S. Plant-Mediated Effects of Water-Deficit Stress on the Performance of the Jujube Lace Bug, Monosteira Alticarinata Ghauri (Hemiptera: Tingidae) on Jujube Tree. J. Asia-Pac. Entomol. 2022, 25, 101917. [Google Scholar] [CrossRef]
- Pacheco, J.; Plazas, M.; Pettinari, I.; Landa-Faz, A.; González-Orenga, S.; Boscaiu, M.; Soler, S.; Prohens, J.; Vicente, O.; Gramazio, P. Moderate and Severe Water Stress Effects on Morphological and Biochemical Traits in a Set of Pepino (Solanum Muricatum) Cultivars. Sci. Hortic. 2021, 284, 110143. [Google Scholar] [CrossRef]
- Xiong, S.; Ding, S.; Guo, J.; Zhang, Z.; Xu, S.; Fan, Z.; Mu, Y.; Ma, X. Estimation of glutamine synthetase activity in wheat grain based on hyperspectral remote sensing. J. Henan Agric. Univ. 2021, 55, 821–829. [Google Scholar] [CrossRef]
- Huang, M.; Wang, Q.; Zhang, M.; Zhu, Q. Prediction of Color and Moisture Content for Vegetable Soybean during Drying Using Hyperspectral Imaging Technology. J. Food Eng. 2014, 128, 24–30. [Google Scholar] [CrossRef]
- Li, L.; Ming, B.; Xue, J.; Gao, S.; Wang, K.; Xie, R.; Hou, P.; Li, S. Difference in Corn Kernel Moisture Content between Pre- and Post-Harvest. J. Integr. Agric. 2021, 20, 1775–1782. [Google Scholar] [CrossRef]
- Li, C.; Zhao, C.; Ren, Y.; He, X.; Yu, X.; Song, Q. Microwave Traveling-Standing Wave Method for Density-Independent Detection of Grain Moisture Content. Measurement 2022, 198, 111373. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, D.; Ji, M.; Xie, F. Image segmentation using PSO and PCM with Mahalanobis distance. Expert Syst. Appl. 2011, 38, 9036–9040. [Google Scholar] [CrossRef]
- Blanco, M.; Castillo, M.; Peinado, A.; Beneyto, R. Determination of Low Analyte Concentrations by Near-Infrared Spectroscopy: Effect of Spectral Pretreatments and Estimation of Multivariate Detection Limits. Anal. Chim. Acta 2007, 581, 318–323. [Google Scholar] [CrossRef]
- Chen, H.; Pan, T.; Chen, J.; Lu, Q. Waveband Selection for NIR Spectroscopy Analysis of Soil Organic Matter Based on SG Smoothing and MWPLS Methods. Chemom. Intell. Lab. Syst. 2011, 107, 139–146. [Google Scholar] [CrossRef]
- Zhao, N.; Wu, Z.; Cheng, Y.; Shi, X.; Qiao, Y. MDL and RMSEP Assessment of Spectral Pretreatments by Adding Different Noises in Calibration/Validation Datasets. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2016, 163, 20–27. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Lai, J.; Tan, K.; Wang, X.; Chen, Y.; Ding, J. Development of a Soil Heavy Metal Estimation Method Based on a Spectral Index: Combining Fractional-Order Derivative Pretreatment and the Absorption Mechanism. Sci. Total Environ. 2022, 813, 151882. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Chen, X.; Wang, S.; Liang, S.; Chen, C. Simultaneous Measurement of Contents of Liquirtin and Glycyrrhizic Acid in Liquorice Based on near Infrared Spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2018, 196, 209–214. [Google Scholar] [CrossRef]
- Hong, G.; El-Hamid, H.T.A. Hyperspectral Imaging Using Multivariate Analysis for Simulation and Prediction of Agricultural Crops in Ningxia, China. Comput. Electron. Agric. 2020, 172, 105355. [Google Scholar] [CrossRef]
- Li, J.; Zhang, H.; Zhan, B.; Zhang, Y.; Li, R.; Li, J. Nondestructive Firmness Measurement of the Multiple Cultivars of Pears by Vis-NIR Spectroscopy Coupled with Multivariate Calibration Analysis and MC-UVE-SPA Method. Infrared Phys. Technol. 2020, 104, 103154. [Google Scholar] [CrossRef]
- Wu, J.; Wang, Y.; Zhang, X.; Zhang, Q. Study on Algorithms of Selection of Representative Samples for Calibration in Near Infrared Spectroscopy Analysis. Trans. Chin. Soc. Agric. Mach. 2006, 37, 80–82+101. [Google Scholar]
- Ortiz, A.; Oliver, G. On the Use of the Overlapping Area Matrix for Image Segmentation Evaluation: A Survey and New Performance Measures. Pattern Recognit. Lett. 2006, 27, 1916–1926. [Google Scholar] [CrossRef]
- Moudrý, V.; Klápště, P.; Fogl, M.; Gdulová, K.; Barták, V.; Urban, R. Assessment of LiDAR Ground Filtering Algorithms for Determining Ground Surface of Non-Natural Terrain Overgrown with Forest and Steppe Vegetation. Measurement 2020, 150, 107047. [Google Scholar] [CrossRef]
- Guo, Z.; Zhao, C.; Huang, W.; Peng, Y.; Li, J.; Wang, Q. Intensity Correction of Visualized Prediction for Sugar Content in Apple Using Hyperspectral Imaging. Trans. Chin. Soc. Agric. Mach. 2015, 7, 227–232. [Google Scholar]
- Yang, F.-F.; Liu, T.; Wang, Q.-Y.; DU, M.-Z.; Yang, T.-L.; Liu, D.-Z.; Li, S.-J.; Liu, S.-P. Rapid determination of leaf water content for monitoring waterlogging in winter wheat based on hyperspectral parameters. J. Integr. Agric. 2021, 20, 2613–2626. [Google Scholar] [CrossRef]
- Meiyan, S.; Qizhou, D.; ShuaiPeng, F.; Xiaohong, Y.; Jinyu, Z.; Lei, M.; Baoguo, L.; Yuntao, M. Improved estimation of canopy water status in maize using UAV-based digital and hyperspectral images. Comput. Electron. Agric. 2022, 197, 106982. [Google Scholar] [CrossRef]
- Hao, Y.; Hua, Y.; Li, X.; Gao, X.; Chen, J. Electrical Properties Predict Wheat Leaf Moisture. Trans. ASABE 2021, 64, 929–936. [Google Scholar] [CrossRef]
- Arroyo-Mora, J.P.; Kalacska, M.; Løke, T.; Schläpfer, D.; Coops, N.C.; Lucanus, O.; Leblanc, G. Assessing the impact of illumination on UAV pushbroom hyperspectral imagery collected under various cloud cover conditions. Remote Sens. Environ. 2021, 258, 112396. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, Y.; Nunes, M.H.; Stoddart, J.; Khoury, S.; Chan, A.H.; Coomes, D.A. Predicting leaf traits of temperate broadleaf deciduous trees from hyperspectral reflectance: Can a general model be applied across a growing season. Remote Sens. Environ. 2022, 269, 112767. [Google Scholar] [CrossRef]
- Yang, R. Study on Tree Species Identification based on Leaf Hyperspectral Images. Ph.D. Thesis, Beijing Forestry University, Beijing, China, 2020. [Google Scholar]
- Wei, Y. Moisture Content Detection of Tea Leaves Based on Spectral and Spectral Imaging Technologies. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2019. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sample Size | Maximum Value | Minimum Value | Average Value | Standard Deviation |
|---|---|---|---|---|---|
| Total Sample | 139 | 16.5000 | 9.6353 | 12.5583 | 1.3386 |
| Modeling set | 109 | 15.5106 | 9.6774 | 12.4624 | 1.2551 |
| Prediction set | 30 | 16.5000 | 9.6353 | 12.9348 | 1.5778 |
| Sample | Area Overlap Measure (AOM) | Misclassified Error (ME) | ||
|---|---|---|---|---|
| Reflectance Threshold | Correlation Difference | Reflectance Threshold | Correlation Difference | |
| 1 | 0.6726 | 0.9571 | 0.2036 | 0.0109 |
| 2 | 0.7095 | 0.9457 | 0.1021 | 0.0308 |
| 3 | 0.5326 | 0.9047 | 0.2453 | 0.0189 |
| 4 | 0.4192 | 0.8911 | 0.3328 | 0.0441 |
| 5 | 0.4859 | 0.9274 | 0.2791 | 0.0414 |
| Average | 0.5640 | 0.9252 | 0.2326 | 0.0292 |
| Variance | 0.1235 | 0.0275 | 0.0869 | 0.0143 |
| Preprocessing Methods | Master Score | Modeling Set | Prediction Set | ||
|---|---|---|---|---|---|
| RMSECV | RMSEP | ||||
| Raw data | 11 | 76.28% | 0.8012 | 79.34% | 0.9677 |
| S-G | 17 | 81.14% | 0.7327 | 77.38% | 1.0101 |
| 1st derivative | 11 | 82.21% | 0.7213 | 81.25% | 0.9103 |
| SNV | 12 | 80.14% | 0.7484 | 75.41% | 1.0262 |
| Models | Number of Variables | Modeling Set | Prediction Set | ||
|---|---|---|---|---|---|
| RC | RMSECV | RP | RMSEP | ||
| PLS | 176 | 82.32% | 0.7109 | 82.38% | 0.8911 |
| MCUVE–PLS | 50 | 82.21% | 0.7142 | 82.68% | 0.9153 |
| MCUVE–CARS–PLS | 28 | 82.71% | 0.7049 | 84.29% | 0.8629 |
| MCUVE–SPA–PLS | 16 | 79.91% | 0.7530 | 83.52% | 0.8900 |
| MCUVE–CARS–SPA–PLS | 13 | 78.86% | 0.7700 | 84.67% | 0.8487 |
| Sample | Average Water Content | Predicted Mean Value | Prediction Root Mean Square Error |
|---|---|---|---|
| 1 | 12.5119 | 11.8726 | 0.7248 |
| 2 | 13.0226 | 13.5659 | |
| 3 | 13.4793 | 14.1203 | |
| 4 | 10.7640 | 11.5225 | |
| 5 | 11.5929 | 10.7398 | |
| 6 | 10.4118 | 11.0234 | |
| 7 | 15.5106 | 14.8997 | |
| 8 | 14.4628 | 15.2131 | |
| 9 | 12.1731 | 11.2341 | |
| 10 | 12.0544 | 12.8563 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Li, H.; Chen, C.; Pang, Y.; Zhu, X. Detection of Water Content in Lettuce Canopies Based on Hyperspectral Imaging Technology under Outdoor Conditions. Agriculture 2022, 12, 1796. https://doi.org/10.3390/agriculture12111796
Zhao J, Li H, Chen C, Pang Y, Zhu X. Detection of Water Content in Lettuce Canopies Based on Hyperspectral Imaging Technology under Outdoor Conditions. Agriculture. 2022; 12(11):1796. https://doi.org/10.3390/agriculture12111796
Chicago/Turabian StyleZhao, Jing, Hong Li, Chao Chen, Yiyuan Pang, and Xiaoqing Zhu. 2022. "Detection of Water Content in Lettuce Canopies Based on Hyperspectral Imaging Technology under Outdoor Conditions" Agriculture 12, no. 11: 1796. https://doi.org/10.3390/agriculture12111796