Novel Hand Gesture Alert System


Abstract
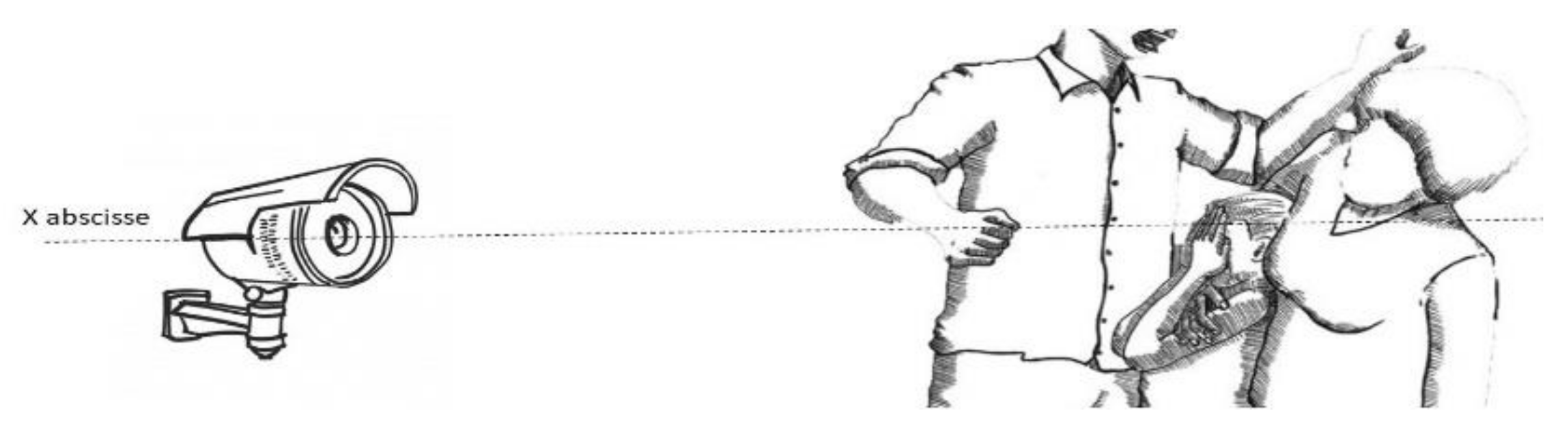
:1. Introduction
2. Related Work
2.1. Human Detection
2.2. Hand Gesture Recognition (Detection and Classification)
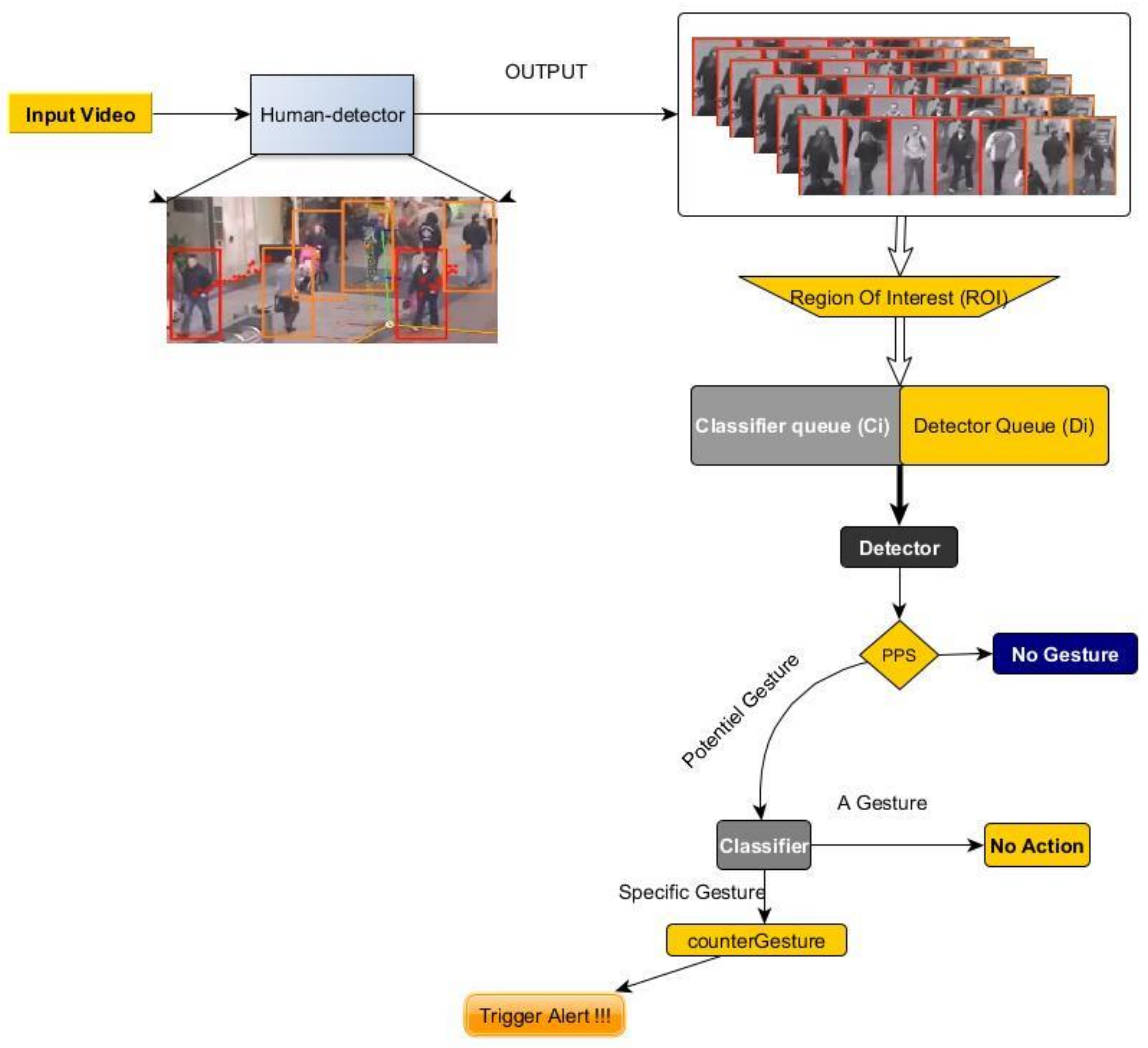
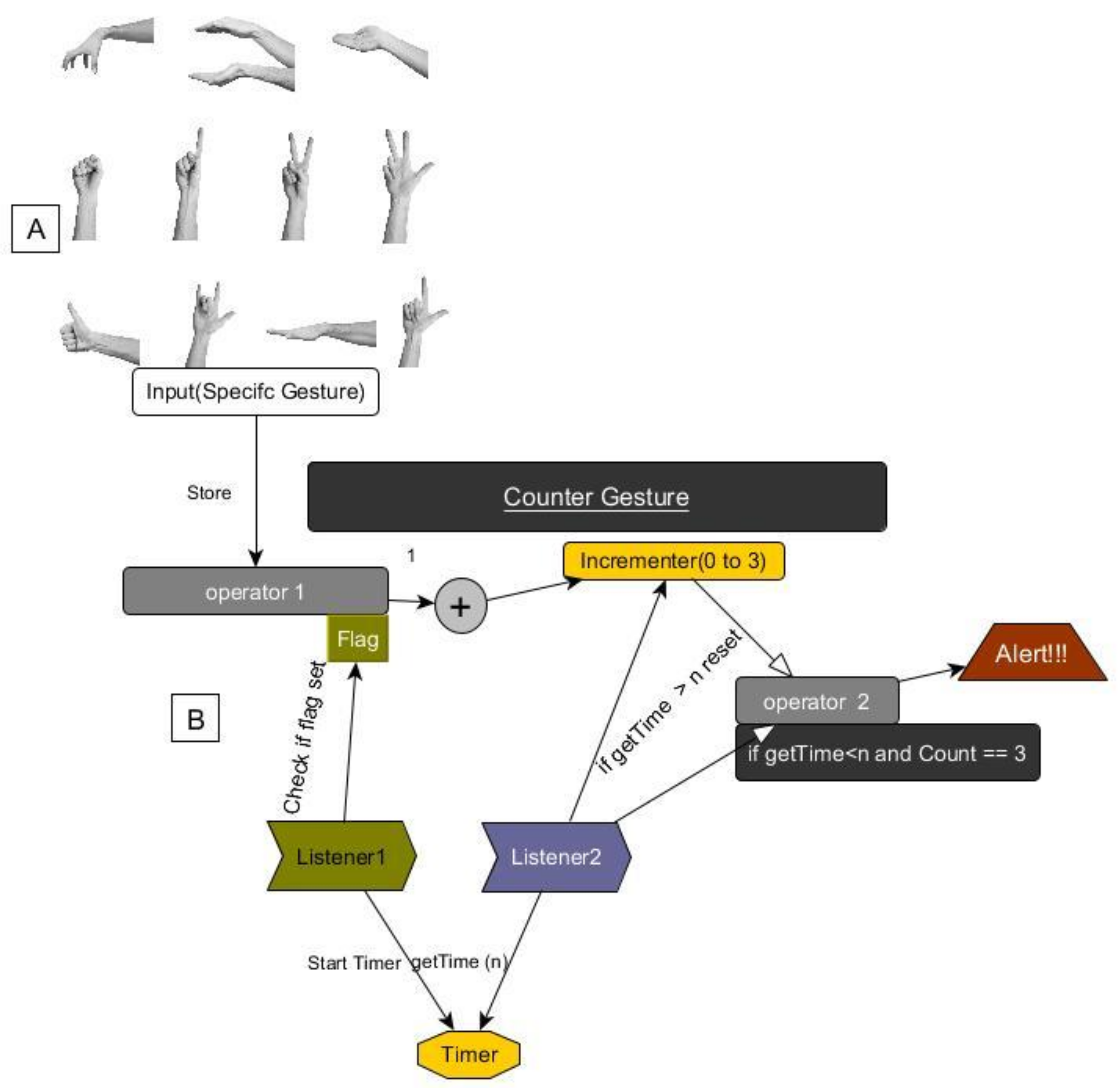
3. Proposed Model
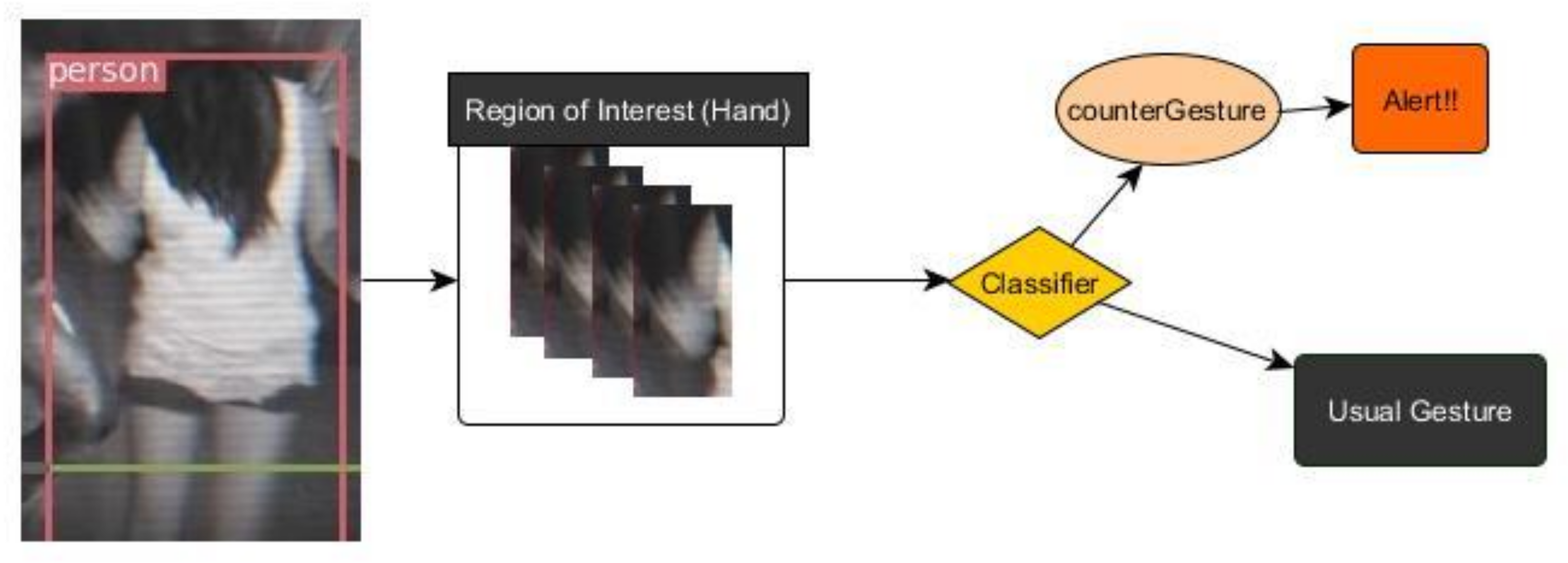
3.1. Human Detector and Regions of Interest (ROIs)
| Algorithm 1: Human detector. | |
| Input: max age (Indices | |
| Output: match | |
| 1 | Cost Co = [ ] |
| 2 | Gate |
| 3 | |
| 4 | |
| 5 | For z = 1 to , do |
| 6 | |
| 7 | (Co, I, |
| 8 | |
| 9 | |
| 10 | End |
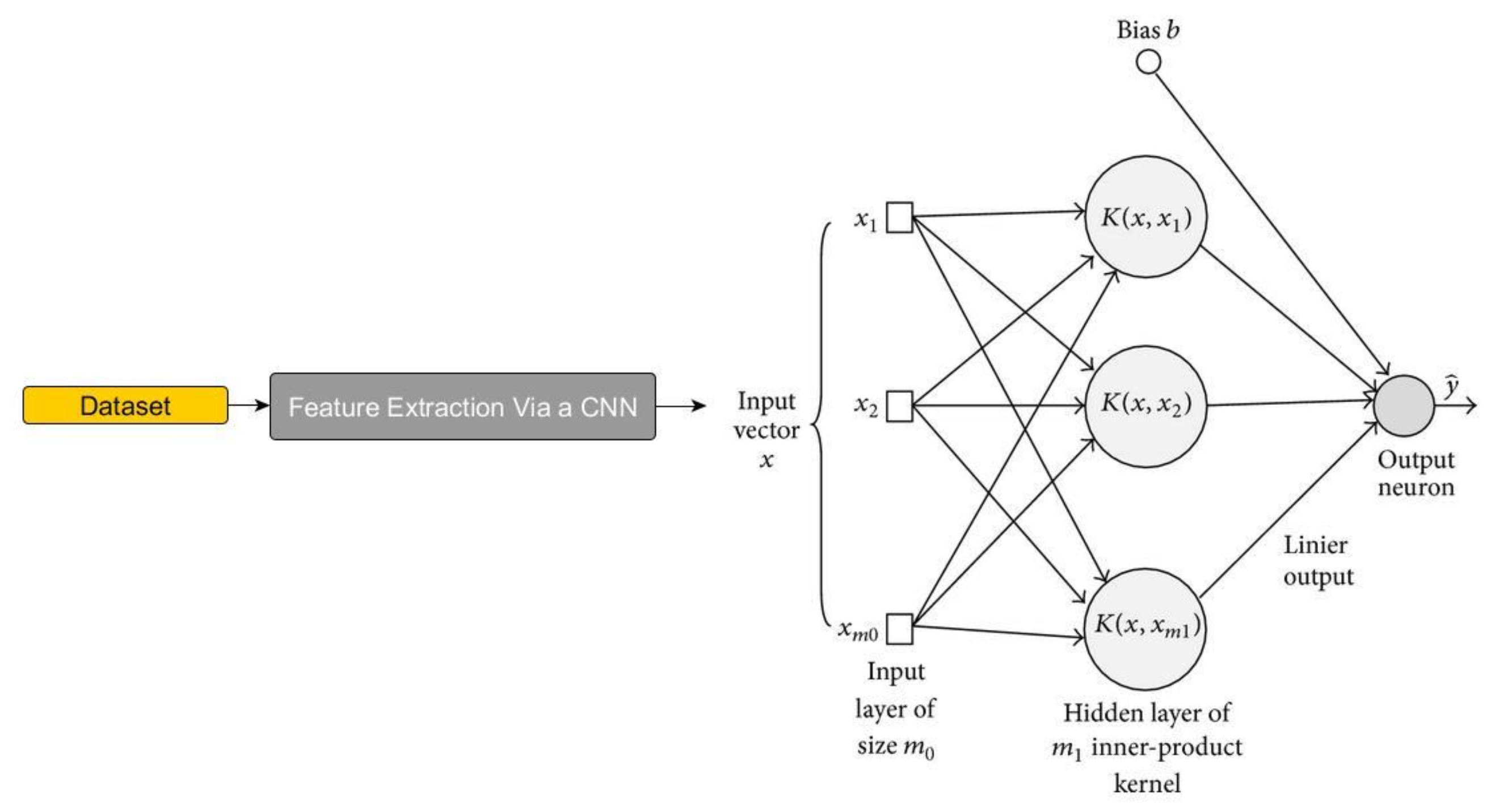
3.2. Detector and Classifier
| Algorithm 2: Gesture Recognition | |
| Input: | |
| Output: Specific Gesture | |
| 1 | For j = 1 to m, do |
| 2 | For each “frame window” do |
| 3 | Process a batch of hand images |
| 4 | classifierIsActivated |
| 5 | alpha |
| 6 | meanProbaility = |
| 7 | ) = |
| 8 | If ) then |
| 9 | isEarlyDetect |
| 10 | Return gesture ( |
| 11 | i |
| 12 | |
4. Experiments
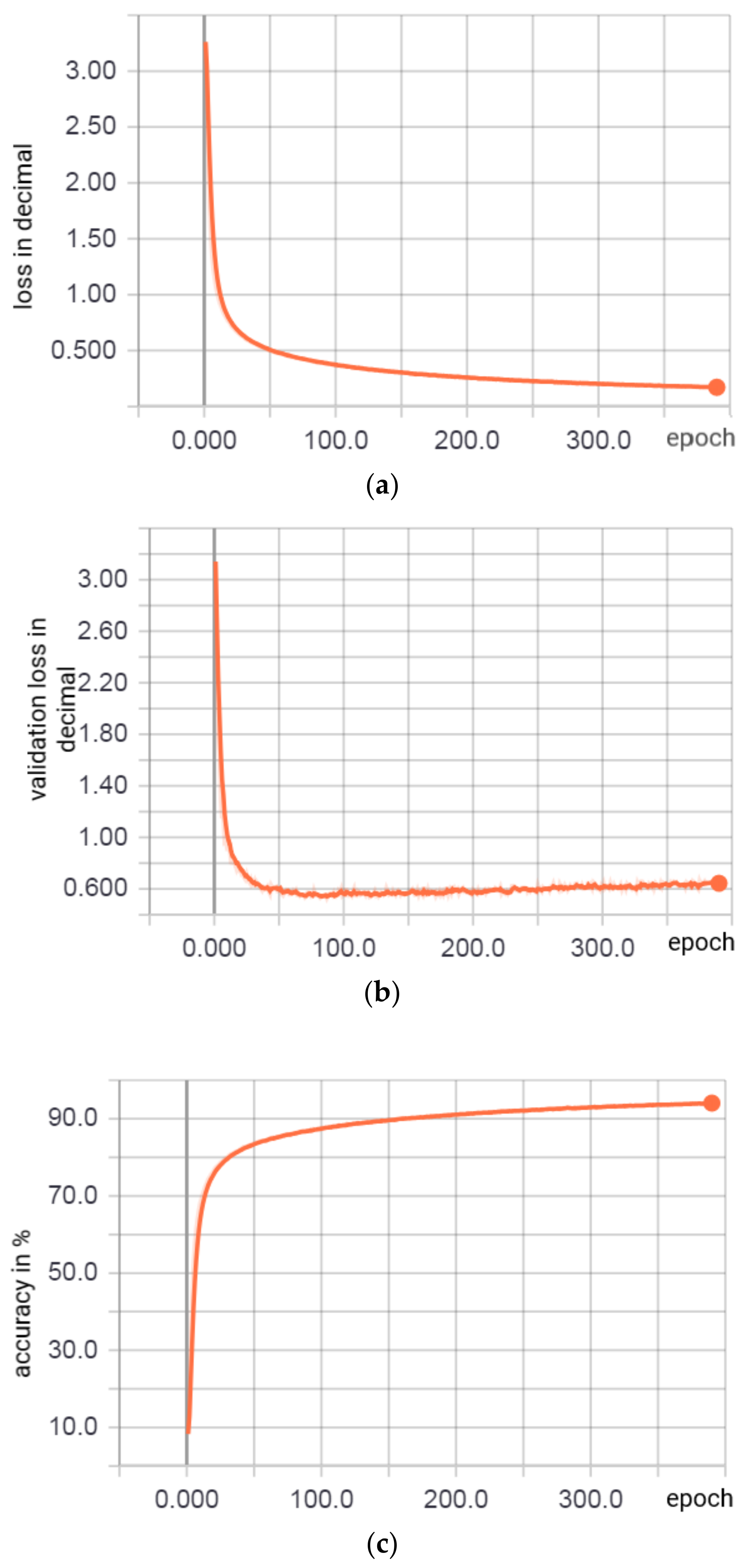
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hust, S.J.T.; Rodgers, K.B.; Ebreo, S.; Stefani, W. Rape myth acceptance, efficacy, and heterosexual scripts in men’s magazines: Factors associated with intentions to sexually coerce or intervene. J. Interpers. Violence 2019, 34, 1703–1733. [Google Scholar] [CrossRef] [PubMed]
- Smith, S.G.; Chen, J.; Basile, K.C.; Gilbert, L.K.; Merrick, M.T.; Patel, N.; Walling, M.; Jain, A. The National Intimate Partner and Sexual Violence Survey (NISVS): 2010-2012 State Report; National Center for Injury Prevention and Control, Centers for Disease Control and Prevention: Atlanta, GA, USA, 2017. [Google Scholar]
- Calafat, A.; Hughes, K.; Blay, N.; Bellis, M.A.; Mendes, F.; Juan, M.; Lazarov, P.; Cibin, B.; Duch, M.A. Sexual Harassment among Young Tourists Visiting Mediterranean Resorts. Arch. Sex. Behav. 2013, 42, 603–613. [Google Scholar] [CrossRef] [PubMed]
- Haering, N.; Venetianer, P.L.; Lipton, A. The evolution of video surveillance: An overview. Mach. Vis. Appl. 2008, 19, 279–290. [Google Scholar] [CrossRef]
- Elhamod, M.; Levine, M.D. Automated Real-Time Detection of Potentially Suspicious Behavior in Public Transport Areas. IEEE Trans. Intell. Transp. Syst. 2013, 14, 688–699. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Jung, S.W.; Won, C.S. Order-Preserving Condensation of Moving Objects in Surveillance Videos. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2408–2418. [Google Scholar] [CrossRef]
- Hanson, G.C.; Perrin, N.; Moss, H.; Laharnar, N.; Glass, N. Workplace violence against homecare workers and its relationship with workers health outcomes: A cross-sectional study. BMC Public Heal. 2015, 15, 441. [Google Scholar]
- Lätsch, D.C.; Nett, J.C.; Hümbelin, O. Poly-victimization and its relationship with emotional and social adjustment in adolescence: Evidence from a national survey in Switzerland. Psychol. Violence 2017, 7, 1–11. [Google Scholar] [CrossRef]
- Yang, C.; Han, D.K.; Ko, H. Continuous hand gesture recognition based on trajectory shape information. Pattern Recognit. Lett. 2017, 99, 39–47. [Google Scholar] [CrossRef]
- Traore, B.B.; Kamsu-Foguem, B.; Tangara, F. Deep convolution neural network for image recognition. Ecol. Inform. 2018, 48, 257–268. [Google Scholar] [CrossRef] [Green Version]
- Pourbabaee, B.; Roshtkhari, M.J.; Khorasani, K. Deep Convolutional Neural Networks and Learning ECG Features for Screening Paroxysmal Atrial Fibrillation Patients. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 2095–2104. [Google Scholar] [CrossRef]
- Maron, H.; Galun, M.; Aigerman, N.; Trope, M.; Dym, N.; Yumer, E.; Kim, V.G.; Lipman, Y. Convolutional neural networks on surfaces via seamless toric covers. ACM Trans. Graph. 2017, 36, 1–10. [Google Scholar] [CrossRef]
- Mambou, S.J.; Maresova, P.; Krejcar, O.; Selamat, A.; Kuca, K. Breast Cancer Detection Using Infrared Thermal Imaging and a Deep Learning Model. Sensors 2018, 18, 2799. [Google Scholar] [CrossRef] [PubMed]
- Mambou, S.; Maresova, P.; Krejcar, O.; Selamat, A.; Kuca, K. Breast Cancer Detection Using Modern Visual IT Techniques. In Modern Approaches for Intelligent Information and Database Systems; Sieminski, A., Kozierkiewicz, A., Nunez, M., Ha, Q.T., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 397–407. ISBN 978-3-319-76081-0. [Google Scholar]
- Mambou, S.; Krejcar, O.; Maresova, P.; Selamat, A.; Kuca, K. Novel Four Stages Classification of Breast Cancer Using Infrared Thermal Imaging and a Deep Learning Model. In Bioinformatics and Biomedical Engineering; Rojas, I., Valenzuela, O., Rojas, F., Ortuño, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 397–407. ISBN 978-3-319-76081-0. [Google Scholar]
- Mambou, S.; Krejcar, O.; Selamat, A. Approximate Outputs of Accelerated Turing Machines Closest to Their Halting Point. In Intelligent Information and Database Systems; Nguyen, N.T., Gaol, F.L., Hong, T.P., Trawiński, B., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 702–713. [Google Scholar]
- Mambou, S.; Krejcar, O.; Kuca, K.; Selamat, A. Novel Cross-View Human Action Model Recognition Based on the Powerful View-Invariant Features Technique. Future Internet 2018, 10, 89. [Google Scholar] [CrossRef]
- Mambou, S.; Krejcar, O.; Kuca, K.; Selamat, A. Novel Human Action Recognition in RGB-D Videos Based on Powerful View Invariant Features Technique. In Modern Approaches for Intelligent Information and Database Systems; Sieminski, A., Kozierkiewicz, A., Nunez, M., Ha, Q.T., Eds.; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2018; pp. 343–353. ISBN 978-3-319-76081-0. [Google Scholar]
- Ma, Y.; Deng, L.; Chen, X.; Guo, N. Integrating Orientation Cue With EOH-OLBP-Based Multilevel Features for Human Detection. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1755–1766. [Google Scholar] [CrossRef]
- Tong, R.; Xie, D.; Tang, M. Upper Body Human Detection and Segmentation in Low Contrast Video. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1502–1509. [Google Scholar] [CrossRef]
- Jun, B.; Choi, I.; Kim, D. Local Transform Features and Hybridization for Accurate Face and Human Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1423–1436. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA; 2005; Volume 1, pp. 886–893. [Google Scholar]
- Hedged Deep Tracking. Available online: https://www.computer.org/csdl/proceedings-article/cvpr/2016/07780835/12OmNrHjqOQ (accessed on 26 May 2019).
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Visual Tracking with Fully Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3119–3127. [Google Scholar]
- Fu, Z.; Angelini, F.; Naqvi, S.M.; Chambers, J.A. GM-PHD Filter Based Online Multiple Human Tracking Using Deep Discriminative Correlation Matching. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4299–4303. [Google Scholar]
- He, F.; Wu, Y.; Yi, S.; Wang, X.; Wang, H.; Liu, W.; Feng, B. Depth-Projection-Map-Based Bag of Contour Fragments for Robust Hand Gesture Recognition. IEEE Trans. Hum. Mach. Syst. 2017, 47, 511–523. [Google Scholar]
- Mo, Z.; Neumann, U. Real-time hand pose recognition using low-resolution depth images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1499–1505. [Google Scholar]
- Ren, Z.; Yuan, J.; Zhang, Z. Robust Hand Gesture Recognition Based on Finger-earth Mover’s Distance with a Commodity Depth Camera. In Proceedings of the 19th ACM International Conference on Multimedia, New York, NY, USA, 28 November–1 December 2011; pp. 1093–1096. [Google Scholar]
- Liu, K.; Gong, D.; Meng, F.; Chen, H.; Wang, G.G. Gesture segmentation based on a two-phase estimation of distribution algorithm. Inf. Sci. 2017, 394–395, 88–105. [Google Scholar] [CrossRef]
- Erol, A.; Bebis, G.; Nicolescu, M.; Boyle, R.D.; Twombly, X. Vision-based Hand Pose Estimation: A Review. Comput. Vis. Image Underst. 2007, 108, 52–73. [Google Scholar] [CrossRef]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A. Efficient model-based 3D tracking of hand articulations using Kinect. In British Machine Vision Conference 2011; British Machine Vision Association: Dundee, UK, 2011; pp. 101.1–101.11. [Google Scholar]
- Tang, M. Recognizing Hand Gestures with Microsoft’s Kinect; Stanford University: Stanford, CA, USA, 2011. [Google Scholar]
- Bai, X.; Bai, S.; Zhu, Z.; Latecki, L.J. 3D Shape Matching via Two Layer Coding. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1. [Google Scholar] [CrossRef]
- Bai, X.; Latecki, L. Path Similarity Skeleton Graph Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1282–1292. [Google Scholar]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.-P. Heterogeneous hand gesture recognition using 3D dynamic skeletal data. Comput. Vis. Image Underst. 2019, 181, 60–72. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Li, S.; Gao, Z.; Wang, Z.; Liu, W. Real-Time Recognition Method for 0.8 cm Darning Needles and KR22 Bearings Based on Convolution Neural Networks and Data Increase. Appl. Sci. 2018, 8, 1857. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 8 June 2016; pp. 779–788. [Google Scholar]
- Al-masni, M.A.; Al-antari, M.A.; Park, J.M.; Gi, G.; Kim, T.Y.; Rivera, P.; Valarezo, E.; Choi, M.T.; Han, S.M.; Kim, T.S. Simultaneous detection and classification of breast masses in digital mammograms via a deep learning YOLO-based CAD system. Comput. Methods Programs Biomed. 2018, 157, 85–94. [Google Scholar] [CrossRef]
- Tang, C.; Ling, Y.; Yang, X.; Jin, W.; Zheng, C. Multi-View Object Detection Based on Deep Learning. Appl. Sci. 2018, 8, 1423. [Google Scholar] [CrossRef]
- Yang, G.; Yang, J.; Sheng, W.; Junior, F.E.F.; Li, S. Convolutional Neural Network-Based Embarrassing Situation Detection under Camera for Social Robot in Smart Homes. Sensors 2018, 18, 1530. [Google Scholar] [CrossRef]
- Jiang, M.; Hai, T.; Pan, Z.; Wang, H.; Jia, Y.; Deng, C.; Yu, Y.; Shan, J. Multi-Agent Deep Reinforcement Learning for Multi-Object Tracker. IEEE Access 2019, 7, 32400–32407. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE international Conference on Computer Vision, Washington, DC, USA, 7–13 December 2014. [Google Scholar]
- He, L.; Xu, L.; Ming, X.; Liu, Q. A Web Service System Supporting Three-dimensional Post-processing of Medical Images Based on WADO Protocol. J. Med Syst. 2015, 39, 39. [Google Scholar] [CrossRef]
- The 20BN-JESTER Dataset—Twenty Billion Neurons. Available online: https://20bn.com/datasets/jester/v1#download (accessed on 26 May 2019).
- Mumbai Girl Molesting CCTV footage—YouTube. Available online: https://www.youtube.com/watch?v=D8z1DAIo_Lg (accessed on 26 May 2019).
- Zhang, Y.; Cao, C.; Cheng, J.; Lu, H. EgoGesture: A New Dataset and Benchmark for Egocentric Hand Gesture Recognition. IEEE Trans. Multimedia 2018, 20, 1038–1050. [Google Scholar] [CrossRef]
- Balagopal, A.; Kazemifar, S.; Nguyen, D.; Lin, M.-H.; Hannan, R.; Owrangi, A.M.; Jiang, S.B. Fully automated organ segmentation in male pelvic CT images. Phys. Med. Boil. 2018, 63, 245015. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wang, Z. A survey of recent work on fine-grained image classification techniques. J. Vis. Commun. Image Represent. 2019, 59, 210–214. [Google Scholar] [CrossRef]
- Le, T.H.; Huang, S.C.; Jaw, D.W. Cross-Resolution Feature Fusion for Fast Hand Detection in Intelligent Homecare Systems. IEEE Sens. J. 2019, 19, 4696–4704. [Google Scholar] [CrossRef]
- Zhaodi, W.; Menghan, H.; Guangtao, Z. Application of Deep Learning Architectures for Accurate and Rapid Detection of Internal Mechanical Damage of Blueberry Using Hyperspectral Transmittance Data. Sensors 2018, 18, 1126. [Google Scholar] [CrossRef]
- Chen, Y.P.; Li, Y.; Wang, G.; Xu, Q. A Multi–Strategy Region Proposal Network. Expert Syst. Appl. 2018, 113, 1–17. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection. IEEE Trans. Image Process. 2019, 28, 265–278. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Filters | Stride | Output |
|---|---|---|---|
| Conv | 32 | ||
| Maxpool | |||
| Conv | 64 | ||
| Maxpool | |||
| Conv | 128 | ||
| Conv | 64 | ||
| Conv | 128 | ||
| Maxpool | |||
| Conv | 256 | ||
| Conv | 128 | ||
| Conv | 256 | ||
| Maxpool | |||
| Conv | 512 | ||
| Conv | 256 | ||
| Conv | 512 | ||
| Conv | 256 | ||
| Conv | 512 | ||
| Maxpool | |||
| Conv | 1024 | ||
| Conv | 512 | ||
| Conv | 1024 | ||
| Conv | 512 | ||
| Conv | 1024 | ||
| Conv | 1000 | ||
| AveragPool | Global | 1000 | |
| Softmax | |||
| Layers | Filters | Stride | Output |
|---|---|---|---|
| Conv 3D | 84 | ||
| Maxpool 3D | |||
| Conv 3D | 64 | ||
| Maxpool 3D | |||
| Conv 3D | 128 | ||
| Maxpool 3D | |||
| Conv 3D | 128 | ||
| Maxpool 3D | |||
| FC | |||
| FC | |||
| Station Characteristics | |
| CPU | Intel(R) Core ™ i7-3.20 GHz |
| RAM | |
| Device 0: “GeForce GTX 1070” | |
| Components | Specifications |
| CUDA Driver Version/ Runtime Version | 10.1/10.1 |
| CUDA Capability Major/Minor Version Number | 6.1 |
| Total Amount of Global Memory | 8118 MB |
| (15) Multiprocessors (MP), (128) CUDA Cores/MP | 1920 CUDA Cores |
| GPU Max Clock Rate: | 1721 MHz |
| Memory Bus Width | 256 bits |
| Model | Number of Input Frames | % Accuracy on RGB | % Accuracy on Depth |
|---|---|---|---|
| VGG-16 [47] | 16 | 62.5 | 62.30 |
| VGG-16 + LSTM [47] | 16 | 74.60 | 77.69 |
| Custom 3D CNN | 16 | 85.1 | 87.9 |
| Custom 3D CNN | 24 | 90.3 | 90.6 |
| Custom 3D CNN | 32 | 91 | 91.3 |
| Frames | Algorithm 1 | Algorithm 2 | CounterGesture | Alarm |
|---|---|---|---|---|
 | Human detected | Specific gesture detected | +1 | Alarm triggered as CounterGesture= 3 |
 | Human detected | Specific gesture detected | +1 | |
 | Human detected | NA | 0 | |
 | Human detected | Specific gesture detected | +1 | |
 | Human detected | Normal gesture detected | 0 | NA |
 | Human detected | NA | 0 | NA |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mambou, S.; Krejcar, O.; Maresova, P.; Selamat, A.; Kuca, K. Novel Hand Gesture Alert System. Appl. Sci. 2019, 9, 3419. https://doi.org/10.3390/app9163419
Mambou S, Krejcar O, Maresova P, Selamat A, Kuca K. Novel Hand Gesture Alert System. Applied Sciences. 2019; 9(16):3419. https://doi.org/10.3390/app9163419
Chicago/Turabian StyleMambou, Sebastien, Ondrej Krejcar, Petra Maresova, Ali Selamat, and Kamil Kuca. 2019. "Novel Hand Gesture Alert System" Applied Sciences 9, no. 16: 3419. https://doi.org/10.3390/app9163419