1. Introduction
Transmission lines are at the heart of the power patrol and inspection tasks as their regular operation is linked to people’s productivity and lives [
1,
2]. A clamp is a critical transmission line component that connects the transmission line and high-voltage tower components [
3]. Due to prolonged exposure, the hardware is susceptible to erosion and fall-off, causing power fluctuations and possibly large-scale power outages, resulting in significant economic losses. The most typical fault of concern is clamp rust, which poses a severe risk. Accidents involving power outages caused by rust and transmission line clamps sliding off are typical [
4]. Considering the wide range of such accidents, the identification of clamp problems is critical for ensuring the stable and long-term operation of a power system. The current clamp dataset was uniformly photographed by an unmanned aerial vehicle (UAV) following the regulations of the State Grid [
5]; please read
Section 4 for further information. Since no study on rust-related efforts is available in the literature, we must create a model based on this dataset to obtain better outcomes.
Vision-based deep learning models have made remarkable progress in recent years in areas including object detection [
6,
7,
8], semantic segmentation [
9,
10], and image classification [
11,
12,
13]. However, long-tailed recognition (LTR), as a classification branch, has long puzzled scholars [
14]. As classification problems in the real world tend to exhibit long-tailed imbalanced distributions, most labels are associated with only a few samples [
15,
16]. Models trained on these datasets accrue more gradients and slant the outcomes toward dominant labels, resulting in poor results belonging to fewer sample categories.
Compared with the high cost of creating a more balanced dataset (e.g., MSCOCO [
17] or ImageNet [
18]) with manual annotation, it is more cost-effective to improve the model being utilized. After much effort, this problem has been alleviated through techniques such as resampling the training data [
19,
20,
21,
22,
23,
24,
25,
26], reweighting gradients [
27,
28,
29], loss function replacement [
30,
31,
32], transfer learning [
33,
34], and data augmentation [
35,
36,
37,
38,
39,
40,
41,
42]. Thus, weight normalization relies on the use of more minor weight norms for rare classes, which are also sensitive to the chosen optimizer. However, resampling forcibly destroys the original data’s distribution to induce a more precise fit, resulting in suboptimal solutions in real-world settings. Decoupled training is the most common and successful method at present [
43,
44]. In the first stage, researchers often conduct pretraining and extract features from the original dataset, and then train the chosen classifier using the above strategies in the second stage. This method is not elegant and requires considerable computational power for two consecutive training steps. The effect of this method still falls short in LTR. Significant research has determined that the current model-based methods primarily focus on the visual module and ignore the inherent relationship between text and visuals. Providing a text information supervision signal for an inadequate dataset could be beneficial. As a result, this research focuses on efficiently combining linguistic modules and visual features to obtain the best effect at one stage.
Recently, excellent work has been carried out alongside the rise in contrastive visual language learning, especially CLIP [
45]. Multimodule visual models frequently learn the low-level properties of targets (e.g., their color, structure, and texture). In contrast, text models frequently display high-level semantic information and concepts, enabling them to serve as highly effective supplemental solutions for unbalanced data. However, this type of model is less effective in real-world scenarios due to the gap between visual and text representations and the lack of robustness to noisy text. CLIP compares 400 million image–text pairs collected from the web to produce consistent visual text representations, revitalizing the vision community. These robust visual-language representations derived from pretraining boost zero-shot classification performance in open-vocabulary settings without further annotations. We propose a simple visual language template for LTR, termed the text-to-image network (TIN), which is an end-to-end model that can combine the benefits of text and visual modules in visual tasks.
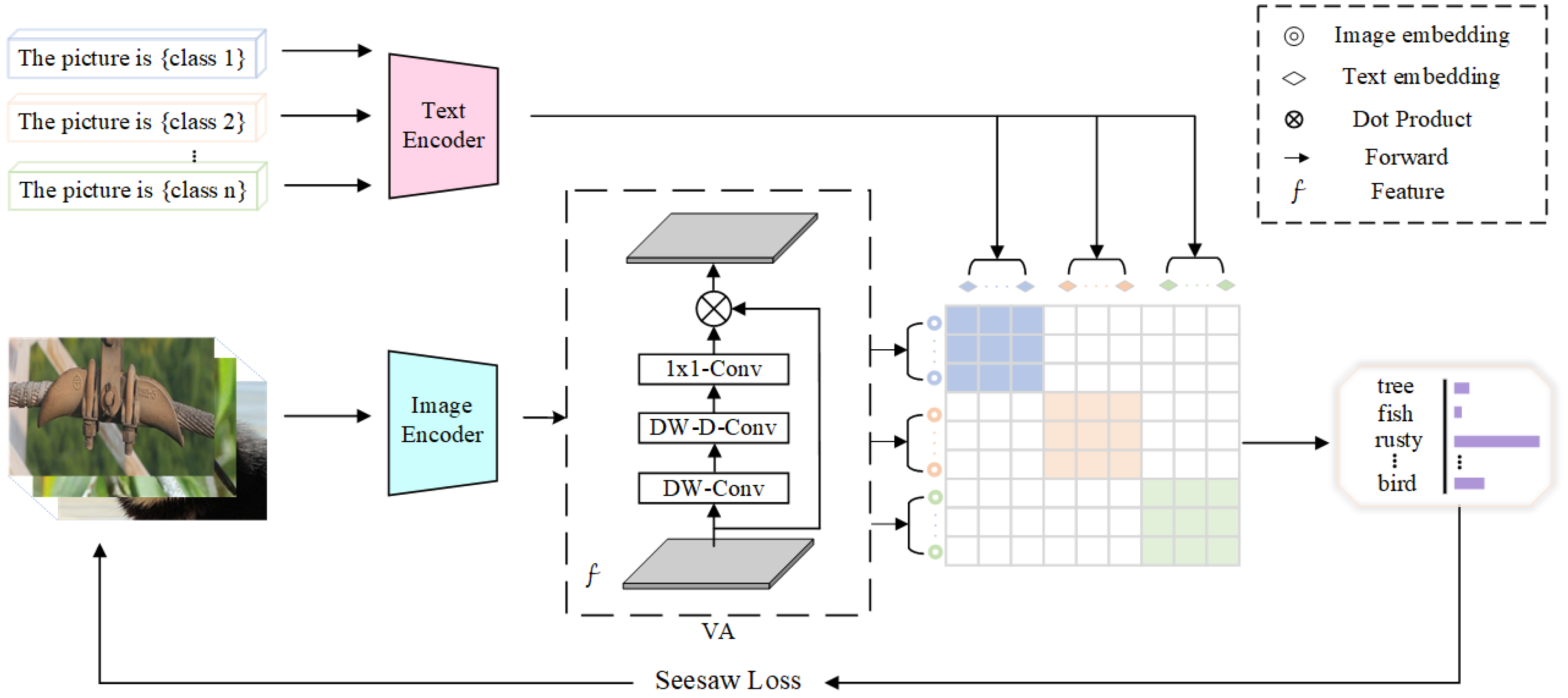
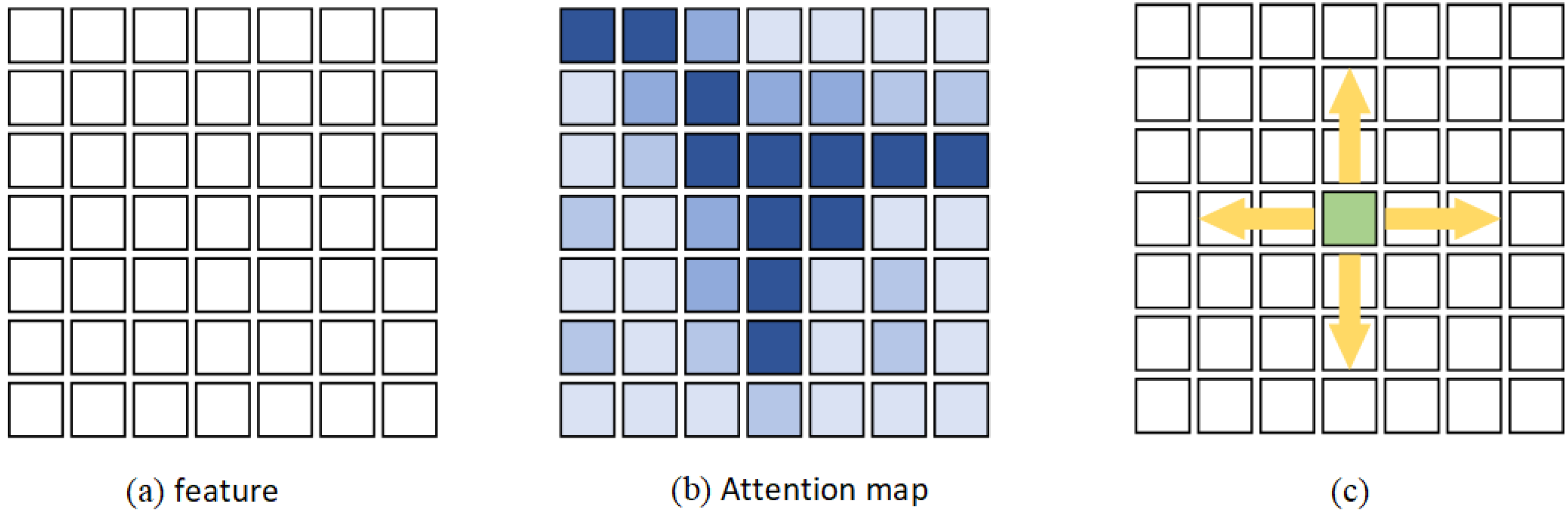
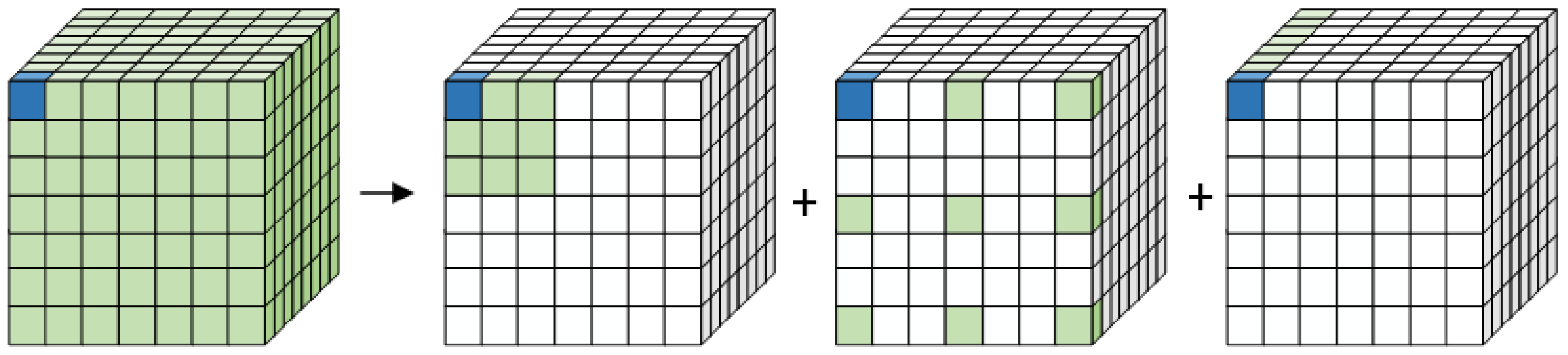
Our model has only one stage, saving a significant amount of processing time relative to two-stage models, and works well with imbalanced data. The primary process is as follows. We pretrained the model on the original unbalanced dataset and obtained language and visual expressions through comparative learning. Then, the large convolution kernel was split into three parts to generate an attention map and weigh the original image; this approach can better recognize the importance levels of different channels and ignore irrelevant parts [
46]. This operation can save computational resources and estimate each channel’s importance when obtaining long-distance dependence, which is equivalent to combining the advantages of self-attention and squeeze-and-excitation (SE) attention [
47]. A seesaw loss replaced the cross-entropy loss to better balance the two modules and long-tailed data [
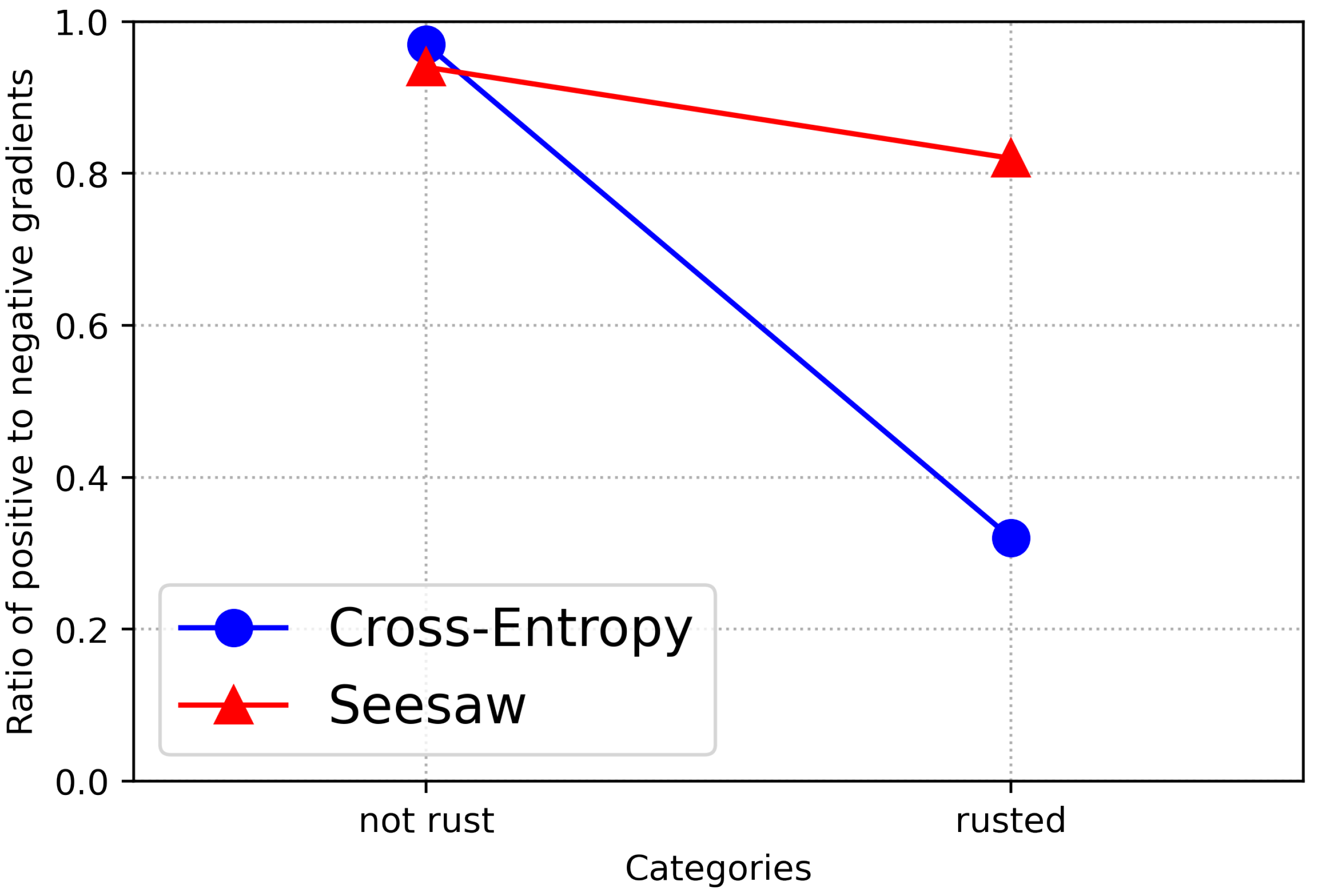
32]. Finally, classification results were obtained by matching the output text expression and image features using cosine similarity.
We performed extensive experiments on the clamp and ImageNet-LT datasets, and, in a fair comparison, our model outperformed the one-stage model by a considerable margin. In summary, our contributions are three-fold:
- (1)
We pioneer the introduction of text-supervised signals from natural language processing in a computer-vision long-tailed dataset, and propose an end-to-end single-stage model, TIN, after combining visual supervision and textual information.
- (2)
This innovative and simple template, TIN, consists of three main parts: two encoders, one for extracting text templates and the other for extracting picture features, and one visual attention method that can flexibly connect spatial location information and channel dimension importance. Ultimately, the seesaw loss function can suppress the negative gradient of the rare class and significantly improve the tail category, while only slightly sacrificing the accuracy of the head class. Unlike the previous individual visual information, we can combine visual features and text-supervised signals to conclude that the language and visual modules are complementary, especially in the case of sparse categories, effectively complementing the available information.
- (3)
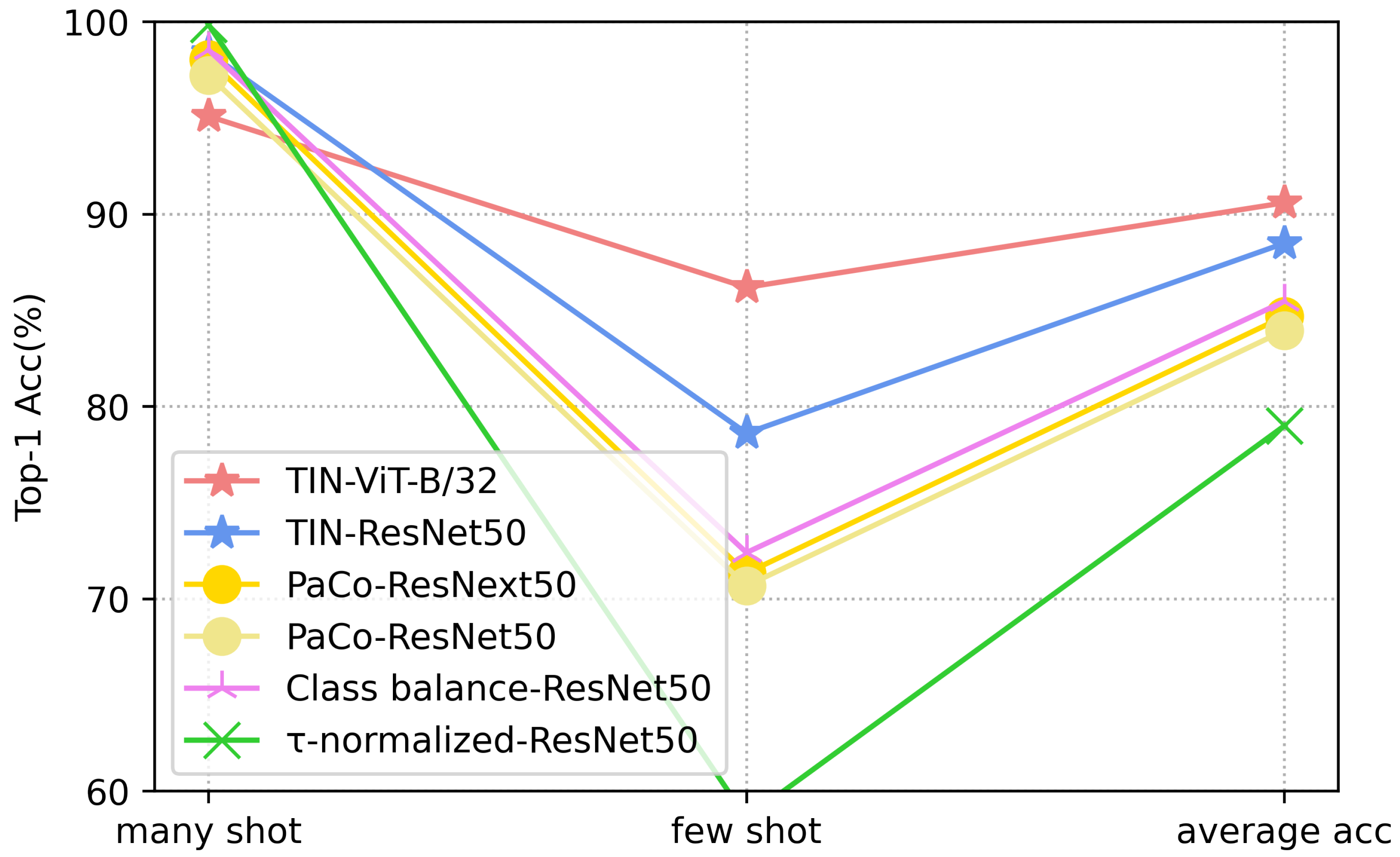
Using the clamp dataset, we conducted a comprehensive evaluation to demonstrate the effectiveness of the TIN, which substantially outperformed prior methods. Notably, we also conducted generalization experiments on the largest long-tailed dataset, ImageNet-LT, and TIN outperformed all single-stage advanced classifiers in recent years and achieved a state-of-the-art performance without bells and whistles.
2. Related Works
2.1. LTR
The distribution of training data in classic classification and identification tasks is typically artificially balanced, with no substantial variance in the sample numbers in different categories. A balanced dataset simplifies the algorithm’s robustness requirements, and somewhat ensures the reliability of the obtained model. However, as the number of categories expands, the cost of maintaining a balance exponentially increases.
We can obtain all the data naturally if we ignore the artificial equilibrium, i.e., the long-tailed dataset. Directly training for classification and detection tasks on these datasets will result in head data overfitting and tail data underfitting.
Resampling and reweighting are the two most basic long-tailed distribution solutions [
19,
25,
26,
27,
28,
29]. These strategies destroy the existing data distribution to fit an equilibrium function, i.e., by reverse weighting, strengthening the tail category learning process, and offsetting the long-tailed impact, thus reducing the effect of the head class to some extent. Moreover, some researchers have discovered that the image feature and category distributions are irrelevant. When learning to perform backbone feature extraction, we should avoid resampling with the category distribution and instead use the original data distribution [
44]. Better outcomes can be achieved when extracting features in the first stage and retraining the employed classifiers in the second stage. Additionally, some academics believe that the head and tail classes have certain commonalities in transfer learning [
48]. The visual information knowledge contained in head labels can be transferred to tail labels via a set of dynamic meta embeddings [
49]. Some works have also created virtual samples to surround the tail samples to build a feature region, instead of the original feature points, e.g., a feature cloud, to relieve the problem of sample scarcity. For further information, see
Table 1 for details.
2.2. Vision-Language Models
Visionl-Language models are mainly divided into single-stream models and two-stream models. A single-stream model combines picture and text embeddings and feeds the result into a transformer model. On the other hand, a two-stream model allows the visual and text sides of the input data to be encoded separately using two independent transformers, where attention is inserted in the intermediate layer between the two encoders to merge the multimodule information.
The visual encoder method primarily extracts features from images and feeds them into a multimodule model. This primarily consists of three aspects: object detection (OD)-based region features, convolutional neural network (CNN)-based grid features, and vision transformer (ViT)-based patch features. OD-based region features identify the target region in the given image using a pretarget detection model and extract the representation of each region as the image side input. CNN-based grid features use CNN models such as ResNet to extract information from the original image [
11], tile the final CNN input features into a sequence, and feed them into the multimodule model. ViT-based patch features extract picture information using the patch embedding approach as a reference [
50].
VisualBERT splices text and image embedding sequences and feeds them into a transformer network using a single-stream model structure [
51]. The network needs to clarify whether each embedding comes from a text measurement, an image measurement, or a position embedding. Then, the OD-based region feature extraction strategy is used to identify the target area on the image side and identify the results as the inputs for the next step. The text token is masked in one stage, and then the masked text is forecasted using additional text and image information in the next stage. Finally, the approach evaluates whether the image and text are consistent. Unicode-VL describes location data more thoroughly, creating a five-dimensional vector for each region [
52]. The first four dimensions show the region’s position with respect to the complete image, and the fifth dimension represents the region’s size in proportion to that of the original image. VL-BERT adds a visual feature embedding module to the input, using the original image to improve the text encoding [
53]. ImageBERT collects images and text from a website and ranks the positive sample pairings to incorporate more weakly supervised data and boost the learning effect [
54]. Uniter calculates the corresponding relationship between the image and text embeddings via optimal transport [
55]. In mask tasks, a sample only masks one module at a time during mask operations to avoid blocking critical information.
Lxmert [
56], an OD-based two-stream model, employs two encoders to encode pictures and words and an interactive transformer to fuse the two data streams. Instead of using the OD technique, Pixel-BERT employs a CNN to extract the characteristics of the original picture and then splices the image and text embeddings into the model, drastically reducing the model’s complexity [
57]. CLIP uses comparison learning to calculate the similarities between pictures and labels by gathering 400 million image–text pairs from the Internet as pretraining data; this approach has spawned a slew of CLIP-based models [
45].
In this research, we demonstrate the effectiveness of CLIP in long-tailed data and the benefits of comparative learning compared to standard classifiers. As a result, we offer a CLIP-based single-stage network, which improves the essential information between channels using visual attention, adjusts the weight balance via the seesaw loss, and achieves a more balanced performance across all categories.
6. Conclusions
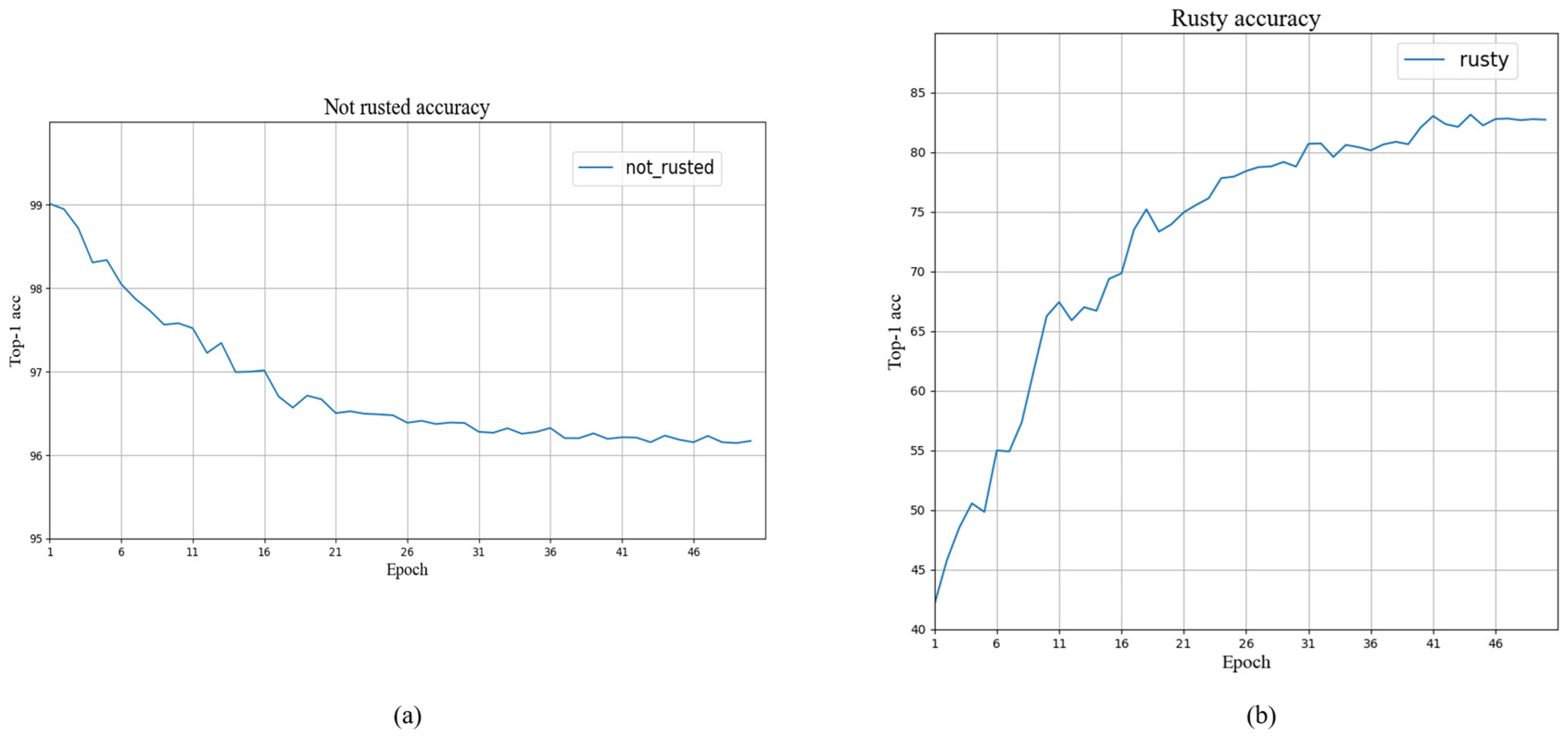
The work in this paper mainly proposes an end-to-end model called the TIN to solve the LTR problem in engineering. First, a text module was introduced as a supplementary part of the visual feature mechanism with CLIP, which provides the model with an inherent multimodule advantage. Then, visual attention further improved the feature extraction process by strengthening the correlations between pixels in different channels. Finally, a seesaw loss was used to balance the weights between different categories. TIN achieved a state-of-the-art performance without bells and whistles on both datasets, outperforming the advanced classifiers developed in recent years. This demonstrates that text-supervised signals are important in the field of vision, especially in LTR, and can be an effective means of complementing the existing information. This work focuses on long-tailed image classification tasks, but the proposed approach is generalizable and may benefit other applications. For example, TIN can be applied to an image segmentation task. We can design a set of keywords that correspond to different detection categories in the image segmentation task. Since the final output feature map of the segmentation task is the same size as the input and has a high level of fine-grained information, we can match the similarities between each layer of the segmented feature map with the keywords to achieve better classification results. Although the proposed TIN achieved a good performance on multiple long-tailed recognition benchmarks, it still has some flaws. First, due to the limited text corpus, our method heavily relies on the use of pre-trained weights to learn high-quality language representation. Second, these results are trained on two Nvidia 3090, which are demanding graphics cards that are not easy to deploy. To allow for a better use in industrial equipment, the latter could be used in an attempt to simplify the model in terms of model quantization and pruning.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}