
Semantic-Aligned Cross-Modal Visual Grounding Network with Transformers

Abstract
:1. Introduction
- 1.
- We propose a novel semantic-aligned cross-modal visual grounding network with transformers (SAC-VGNet) to integrate both visual and textual features for fine-grained visual grounding. Correspondingly, we manually annotated the text information of two fine-grained visual grounding datasets, providing valuable resources for future research in this area.
- 2.
- We designed a multi-scale cross-modal fusion module to effectively fuse visual and textual inputs. The module could effectively explore the correlations between them, and highlight the important areas in the feature map to capture the tiny differences between similar objects.
- 3.
- We adopted text-driven contrastive learning to achieve accurate feature alignment, which could effectively project the original multi-modal feature into a new feature space and, thus, the refined feature offers a stronger discrimination ability for fine-grained visual grounding.
2. Related Works
3. Method
3.1. Background
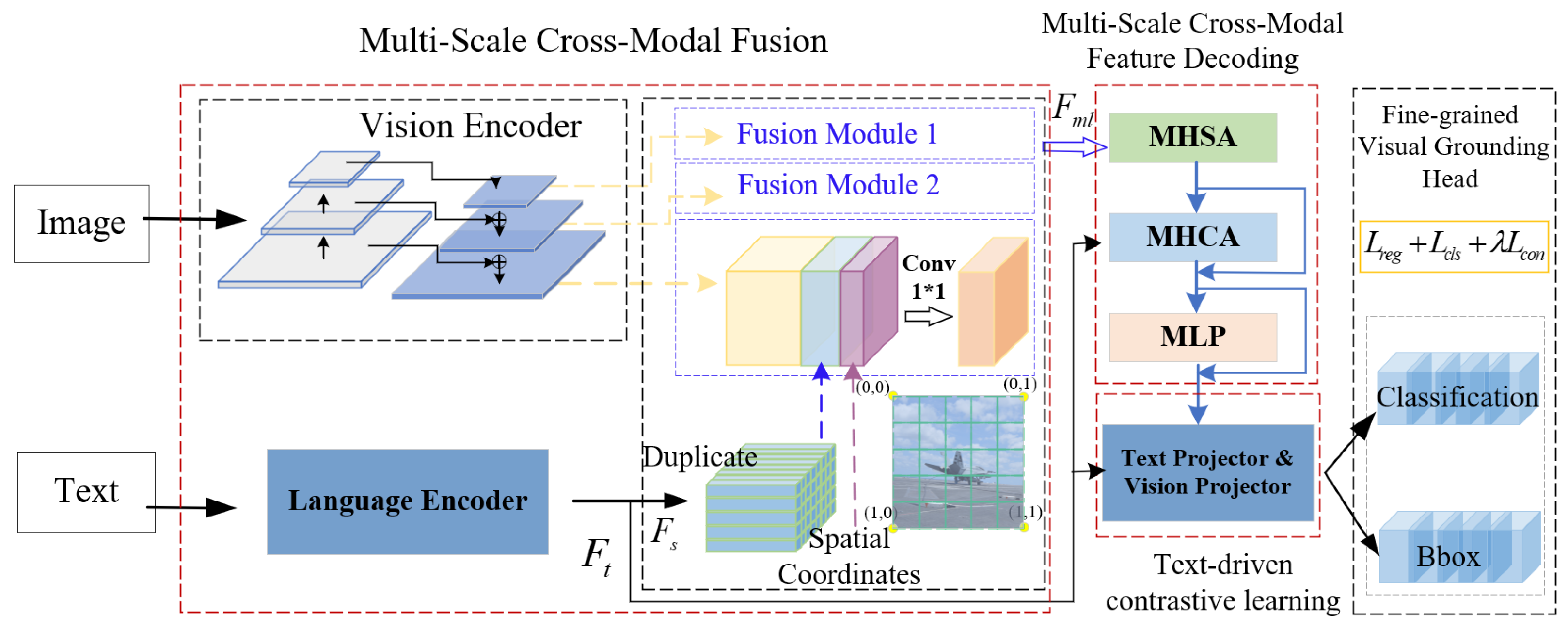
3.2. Multi-Scale Cross-Modal Fusion
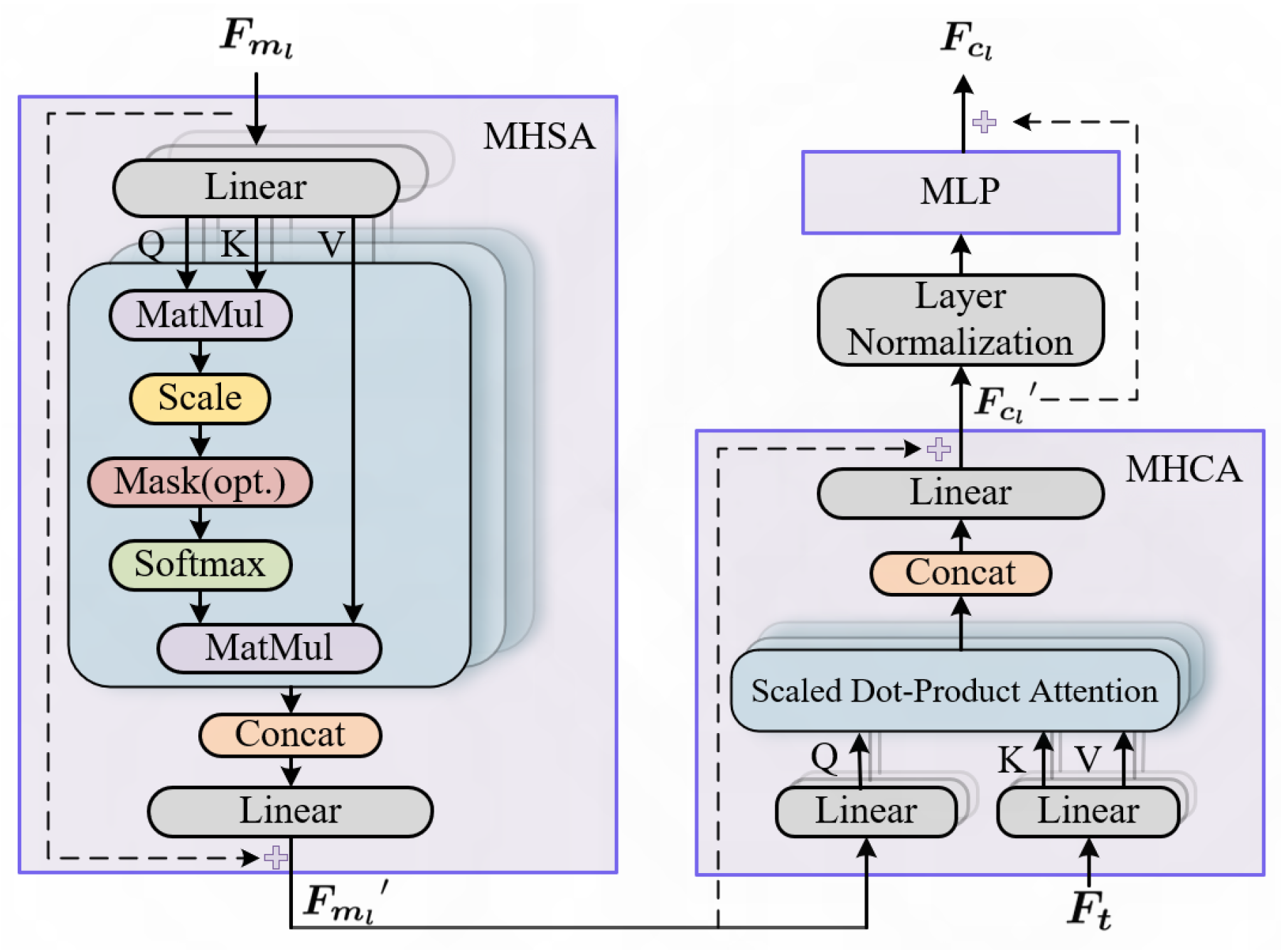
3.3. Multi-Scale Cross-Modal Feature Decoding
3.4. Text-Driven Contrastive Learning
3.5. Training
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Experimental Results
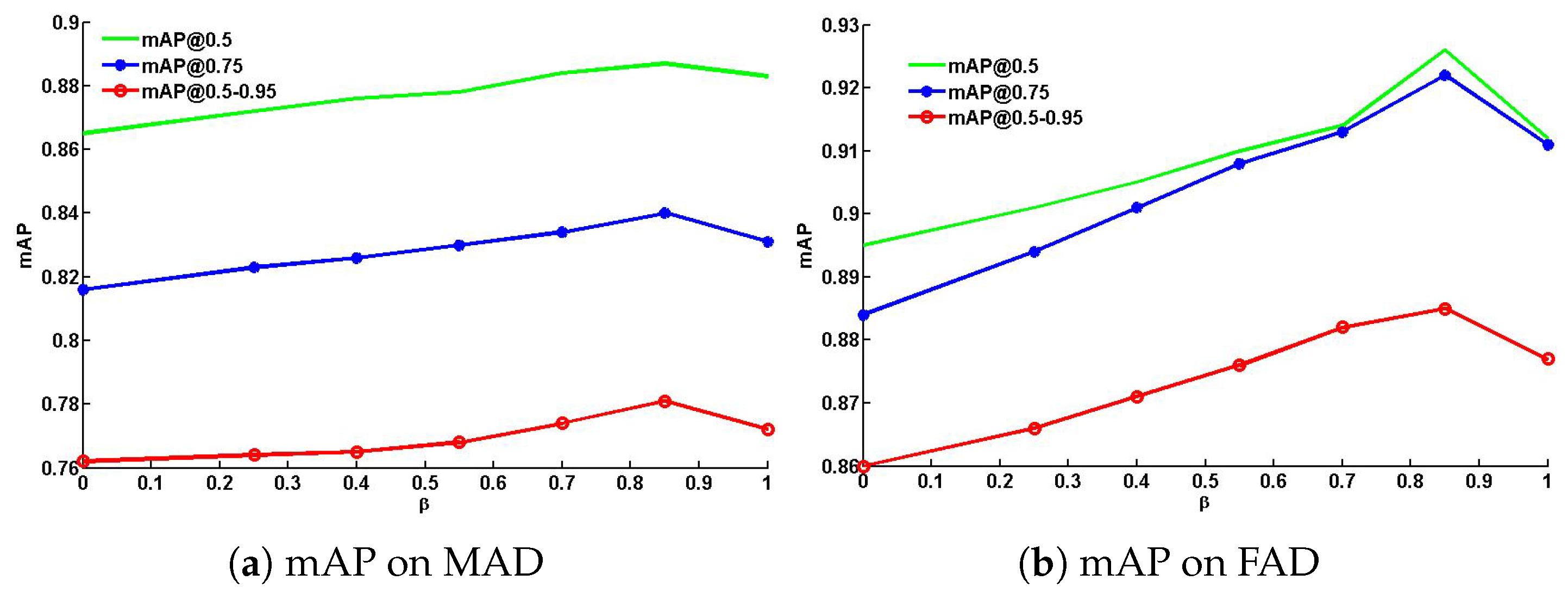
4.3.1. Parameter Analysis
4.3.2. Ablation Study
- 1.
- The introduction of multi-scale cross-modal feature decoding significantly improves the performance, increasing the mAP from to on MAD, and from to on FAD. As aforementioned, the cross-modal attention in MCFD could nicely explore the correlations between the text feature and the multi-modal feature and, thus, the highlighted multi-modal feature could nicely capture the tiny differences between similar objects.
- 2.
- The text-driven contrastive learning boosts the performance by about 1 percent in both datasets. This improvement stems from the effective feature alignment by contrastive learning, which could help the model learn discriminative features to distinguish tiny differences between similar objects.
- 3.
- Our SAC-VGNet (incorporating both components) achieves the best performance, with an mAP of on MAD, and on FAD. These remarkable results indicate the effectiveness of SAC-VGNet in fine-grained visual grounding because it could effectively fuse textual and visual features.
4.3.3. Comparison with the State-of-the-Art Approaches
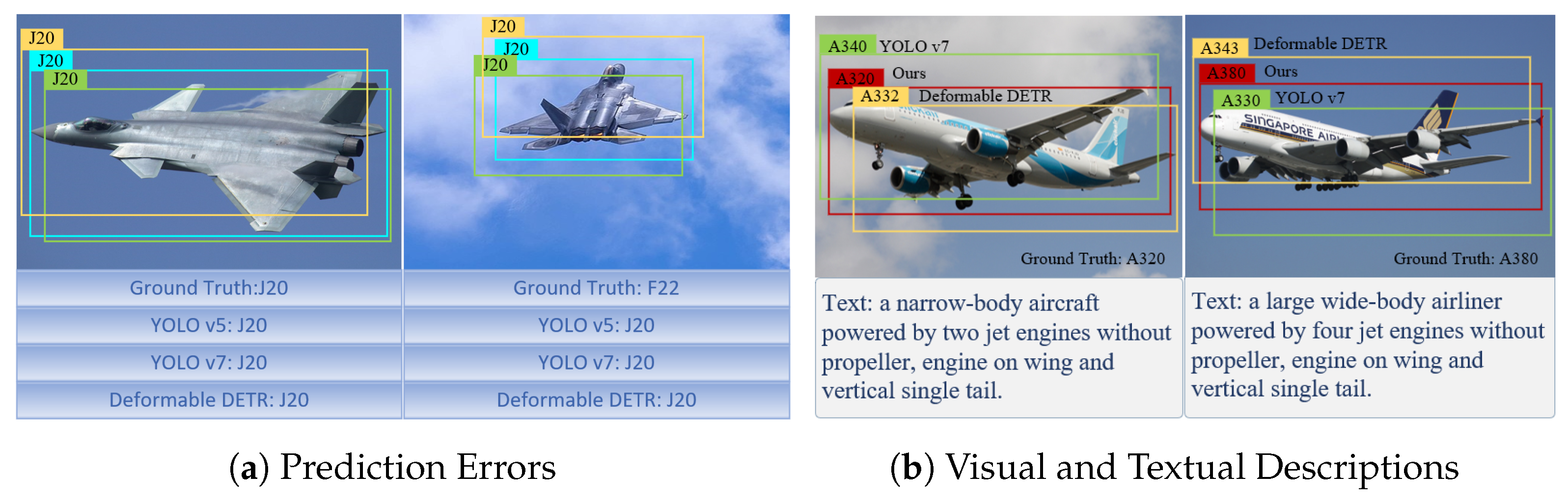
5. Limitations
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, Z.; Gong, B.; Wang, L.; Huang, W.; Yu, D.; Luo, J. A fast and accurate one-stage approach to visual grounding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4683–4693. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An evolved version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Fang, Y.; Liao, B.; Wang, X.; Fang, J.; Qi, J.; Wu, R.; Niu, J.; Liu, W. You only look at one sequence: Rethinking transformer in vision through object detection. Adv. Neural Inf. Process. Syst. 2021, 34, 26183–26197. [Google Scholar]
- Li, Y.; Wang, H.; Dang, L.M.; Nguyen, T.N.; Han, D.; Lee, A.; Jang, I.; Moon, H. A deep learning-based hybrid framework for object detection and recognition in autonomous driving. IEEE Access 2020, 8, 194228–194239. [Google Scholar] [CrossRef]
- Reddy, S.; Levine, S.; Dragan, A.D. First Contact: Unsupervised Human-Machine Co-Adaptation via Mutual Information Maximization. arXiv 2022, arXiv:2205.12381. [Google Scholar]
- Wang, Z.; Xia, M.; Lu, M.; Pan, L.; Liu, J. Parameter Identification in Power Transmission Systems Based on Graph Convolution Network. IEEE Trans. Power Deliv. 2022, 37, 3155–3163. [Google Scholar] [CrossRef]
- Shuai Zhang, L.W. STPGTN–A Multi-Branch Parameters Identification Method Considering Spatial Constraints and Transient Measurement Data. Comput. Model. Eng. Sci. 2023, 136, 2635–2654. [Google Scholar] [CrossRef]
- Chen, B.; Xia, M.; Qian, M.; Huang, J. MANet: A multi-level aggregation network for semantic segmentation of high-resolution remote sensing images. Int. J. Remote Sens. 2022, 43, 5874–5894. [Google Scholar] [CrossRef]
- Ma, Z.; Xia, M.; Weng, L.; Lin, H. Local Feature Search Network for Building and Water Segmentation of Remote Sensing Image. Sustainability 2023, 15, 3034. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Lin, H. Multi-scale strip pooling feature aggregation network for cloud and cloud shadow segmentation. Neural Comput. Appl. 2022, 34, 6149–6162. [Google Scholar] [CrossRef]
- Chen, J.; Xia, M.; Wang, D.; Lin, H. Double Branch Parallel Network for Segmentation of Buildings and Waters in Remote Sensing Images. Remote Sens. 2023, 15, 1536. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ma, Z.; Xia, M.; Lin, H.; Qian, M.; Zhang, Y. FENet: Feature enhancement network for land cover classification. Int. J. Remote Sens. 2023, 44, 1702–1725. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 13039–13048. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss v2: Learning reliable localization quality estimation for dense object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 11632–11641. [Google Scholar]
- Zhang, C.; Weng, L.; Ding, L.; Xia, M.; Lin, H. CRSNet: Cloud and Cloud Shadow Refinement Segmentation Networks for Remote Sensing Imagery. Remote Sens. 2023, 15, 1664. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Visionm, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Kamath, A.; Singh, M.; LeCun, Y.; Synnaeve, G.; Misra, I.; Carion, N. MDETR-modulated detection for end-to-end multi-modal understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1780–1790. [Google Scholar]
- Reed, S.; Akata, Z.; Lee, H.; Schiele, B. Learning deep representations of fine-grained visual descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 49–58. [Google Scholar]
- He, X.; Peng, Y. Fine-grained image classification via combining vision and language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5994–6002. [Google Scholar]
- Guan, X.; Wang, G.; Xu, X.; Bin, Y. Learning Hierarchal Channel Attention for Fine-grained Visual Classification. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 5011–5019. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Deng, J.; Yang, Z.; Chen, T.; Zhou, W.; Li, H. Transvg: End-to-end visual grounding with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 1769–1779. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XI 16. Springer: Cham, Switzerland, 2020; pp. 776–794. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Wang, Z.; Lu, Y.; Li, Q.; Tao, X.; Guo, Y.; Gong, M.; Liu, T. Cris: Clip-driven referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11686–11695. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2016, arXiv:1512.02325. [Google Scholar]
- Xiang, L.; Miao, H.; Haibo, L.; Huiyuan, Y.; Jiajie, X. TSAA: A Two-Stage Anchor Assignment Method towards Anchor Drift in Crowded Object Detection. arXiv 2022, arXiv:2211.00826. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-end Object Detection. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14449–14458. [Google Scholar] [CrossRef]
- Zhang, H.; Chang, H.; Ma, B.; Wang, N.; Chen, X. Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training. arXiv 2020, arXiv:2004.06002. [Google Scholar]
- Liu, J.; Liu, S.; Xu, S.; Zhou, C. Two-Stage Underwater Object Detection Network Using Swin Transformer. IEEE Access 2022, 10, 117235–117247. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.R.; Stoken, A.; Borovec, J.; NanoCode012; ChristopherSTAN; Liu, C.; Laughing; Hogan, A.; lorenzomammana; tkianai; et al. ultralytics/yolov5: v3.0. 2020. Available online: https://zenodo.org/record/3983579#.ZEx_0YgzaHs (accessed on 27 April 2023).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Jintasuttisak, T.; Edirisinghe, E.A.; El-Battay, A. Deep neural network based date palm tree detection in drone imagery. Comput. Electron. Agric. 2022, 192, 106560. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.X.; Lu, K.; Cao, L.; Liu, Y. A Forest Fire Detection System Based on Ensemble Learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Deng, C.; Wu, Q.; Wu, Q.; Hu, F.; Lyu, F.; Tan, M. Visual grounding via accumulated attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7746–7755. [Google Scholar]
- Yang, L.; Xu, Y.; Yuan, C.; Liu, W.; Li, B.; Hu, W. Improving visual grounding with visual-linguistic verification and iterative reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9499–9508. [Google Scholar]
- Song, L.; Xia, M.; Weng, L.; Lin, H.; Qian, M.; Chen, B. Axial Cross Attention Meets CNN: Bibranch Fusion Network for Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 32–43. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Miao, S.; Xia, M.; Qian, M.; Zhang, Y.; Liu, J.; Lin, H. Cloud/shadow segmentation based on multi-level feature enhanced network for remote sensing imagery. Int. J. Remote Sens. 2022, 43, 5940–5960. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. MCANet: A Multi-Branch Network for Cloud/Snow Segmentation in High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Mafla, A.; Dey, S.; Biten, A.F.; Gomez, L.; Karatzas, D. Multi-Modal Reasoning Graph for Scene-Text Based Fine-Grained Image Classification and Retrieval. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; pp. 4022–4032. [Google Scholar]
- Yuan, Z.; Zhang, W.; Fu, K.; Li, X.; Deng, C.; Wang, H.; Sun, X. Exploring a Fine-Grained Multiscale Method for Cross-Modal Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–19. [Google Scholar] [CrossRef]
- Gao, J.; Weng, L.; Xia, M.; Lin, H. MLNet: Multichannel feature fusion lozenge network for land segmentation. J. Appl. Remote Sens. 2022, 16, 1–19. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 13733–13742. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Chen, Y.; Yang, J.; Wang, J.; Zhou, X.; Zou, J.; Li, Y. An Improved YOLOv5 Real-time Detection Method for Aircraft Target Detection. In Proceedings of the International Conference on Automation and Computing (ICAC), Bristol, UK, 1–3 September 2022; pp. 1–6. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-grained visual classification of aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MCFD | TCL | mAP@0.5 | mAP@0.75 | mAP@0.5:0.95 |
|---|---|---|---|---|
| - | - | |||
| ✔ | - | |||
| - | ✔ | |||
| ✔ | ✔ |
| MCFD | TCL | mAP@0.5 | mAP@0.75 | mAP@0.5:0.95 |
|---|---|---|---|---|
| - | - | |||
| ✔ | - | |||
| - | ✔ | |||
| ✔ | ✔ |
| Method | Resolution | mAP@0.5 | mAP@0.75 | mAP |
|---|---|---|---|---|
| DETR [19] | ||||
| YOLOv5 [41] | ||||
| Deformable DETR [35] | 640 × | |||
| Sparse R-CNN [36] | 640 | |||
| YOLOv7 [24] | ||||
| SAC-VGNet | ||||
| DETR [19] | ||||
| YOLOv5 [41] | ||||
| Deformable DETR [35] | 1280 × | |||
| Sparse R-CNN [36] | 1280 | |||
| YOLOv7 [24] | ||||
| SAC-VGNet |
| Method | Resolution | mAP@0.5 | mAP@0.75 | mAP |
|---|---|---|---|---|
| DETR [19] | ||||
| YOLOv5 [41] | ||||
| Deformable DETR [35] | 640 × | |||
| Sparse R-CNN [36] | 640 | |||
| YOLOv7 [24] | ||||
| SAC-VGNet | ||||
| DETR [19] | ||||
| YOLOv5 [41] | ||||
| Deformable DETR [35] | 1280 × | |||
| Sparse R-CNN [36] | 1280 | |||
| YOLOv7 [24] | ||||
| SAC-VGNet |
| Category | YOLOv7 | SAC-VGNet | ||||
|---|---|---|---|---|---|---|
| mAP@0.5 | mAP@0.75 | mAP | mAP@0.5 | mAP@0.75 | mAP | |
| All | 0.856 | 0.815 | 0.762 | 0.887 | 0.840 | 0.782 |
| A10 | 0.939 | 0.888 | 0.822 | 0.931 | 0.89 | 0.829 |
| A400M | 0.957 | 0.918 | 0.844 | 0.952 | 0.911 | 0.86 |
| AG600 | 0.929 | 0.929 | 0.873 | 0.967 | 0.967 | 0.892 |
| AV8B | 0.944 | 0.939 | 0.88 | 0.938 | 0.935 | 0.882 |
| B1 | 0.889 | 0.862 | 0.802 | 0.88 | 0.842 | 0.79 |
| B2 | 0.881 | 0.831 | 0.749 | 0.908 | 0.847 | 0.774 |
| B52 | 0.943 | 0.943 | 0.867 | 0.951 | 0.951 | 0.87 |
| Be200 | 0.989 | 0.989 | 0.929 | 0.987 | 0.987 | 0.926 |
| C130 | 0.826 | 0.72 | 0.674 | 0.83 | 0.728 | 0.682 |
| C17 | 0.86 | 0.791 | 0.73 | 0.905 | 0.825 | 0.747 |
| C5 | 0.913 | 0.913 | 0.836 | 0.955 | 0.936 | 0.877 |
| E2 | 0.902 | 0.879 | 0.815 | 0.906 | 0.906 | 0.844 |
| EF2000 | 0.786 | 0.764 | 0.738 | 0.843 | 0.843 | 0.798 |
| F117 | 0.711 | 0.597 | 0.552 | 0.794 | 0.663 | 0.613 |
| F14 | 0.842 | 0.842 | 0.808 | 0.902 | 0.874 | 0.808 |
| F15 | 0.869 | 0.828 | 0.775 | 0.878 | 0.84 | 0.776 |
| F16 | 0.725 | 0.645 | 0.603 | 0.745 | 0.698 | 0.632 |
| F18 | 0.837 | 0.791 | 0.713 | 0.855 | 0.833 | 0.741 |
| F22 | 0.798 | 0.798 | 0.74 | 0.822 | 0.822 | 0.757 |
| F35 | 0.857 | 0.775 | 0.729 | 0.894 | 0.814 | 0.765 |
| F4 | 0.78 | 0.704 | 0.7 | 0.847 | 0.756 | 0.744 |
| JAS39 | 0.726 | 0.689 | 0.661 | 0.769 | 0.718 | 0.672 |
| MQ9 | 0.84 | 0.84 | 0.775 | 0.901 | 0.881 | 0.784 |
| Mig31 | 0.914 | 0.914 | 0.835 | 0.935 | 0.904 | 0.852 |
| Mirage2000 | 0.958 | 0.912 | 0.839 | 0.975 | 0.952 | 0.882 |
| RQ4 | 0.82 | 0.603 | 0.597 | 0.836 | 0.625 | 0.608 |
| Rafale | 0.888 | 0.862 | 0.817 | 0.873 | 0.847 | 0.803 |
| SR71 | 0.861 | 0.67 | 0.681 | 0.927 | 0.737 | 0.716 |
| Su34 | 0.818 | 0.792 | 0.752 | 0.904 | 0.867 | 0.827 |
| Su57 | 0.754 | 0.747 | 0.714 | 0.81 | 0.793 | 0.749 |
| Tu160 | 0.904 | 0.884 | 0.847 | 0.956 | 0.888 | 0.862 |
| Tu95 | 0.859 | 0.833 | 0.815 | 0.888 | 0.888 | 0.823 |
| Tornado | 0.675 | 0.623 | 0.62 | 0.762 | 0.687 | 0.675 |
| U2 | 0.861 | 0.787 | 0.774 | 0.932 | 0.827 | 0.824 |
| US2 | 0.935 | 0.916 | 0.866 | 0.953 | 0.931 | 0.884 |
| V22 | 0.918 | 0.857 | 0.766 | 0.921 | 0.871 | 0.768 |
| XB70 | 0.887 | 0.878 | 0.733 | 0.908 | 0.893 | 0.742 |
| YF23 | 0.977 | 0.977 | 0.909 | 0.991 | 0.991 | 0.915 |
| Vulcan | 0.709 | 0.649 | 0.637 | 0.798 | 0.711 | 0.672 |
| J20 | 0.754 | 0.723 | 0.681 | 0.752 | 0.737 | 0.69 |
| Model | #Param. | FLOPs | Size | FPS |
|---|---|---|---|---|
| Sparse R-CNN | 77.8 M | 23.3 G | 1333 | 23 |
| YOLOv5 | 86.7 M | 205.7 G | 1280 | 15 |
| YOLOv7 | 36.9 M | 104.7 G | 1280 | 26 |
| DETR | 41 M | 187 G | 1333 | 12 |
| Deformable DETR | 40 M | 173 G | 1333 | 19 |
| SAC-VGNet | 45 M | 113 G | 1280 | 21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Yuan, J. Semantic-Aligned Cross-Modal Visual Grounding Network with Transformers. Appl. Sci. 2023, 13, 5649. https://doi.org/10.3390/app13095649
Zhang Q, Yuan J. Semantic-Aligned Cross-Modal Visual Grounding Network with Transformers. Applied Sciences. 2023; 13(9):5649. https://doi.org/10.3390/app13095649
Chicago/Turabian StyleZhang, Qianjun, and Jin Yuan. 2023. "Semantic-Aligned Cross-Modal Visual Grounding Network with Transformers" Applied Sciences 13, no. 9: 5649. https://doi.org/10.3390/app13095649