
Design of an Intelligent Vehicle Behavior Decision Algorithm Based on DGAIL
Abstract
:1. Introduction
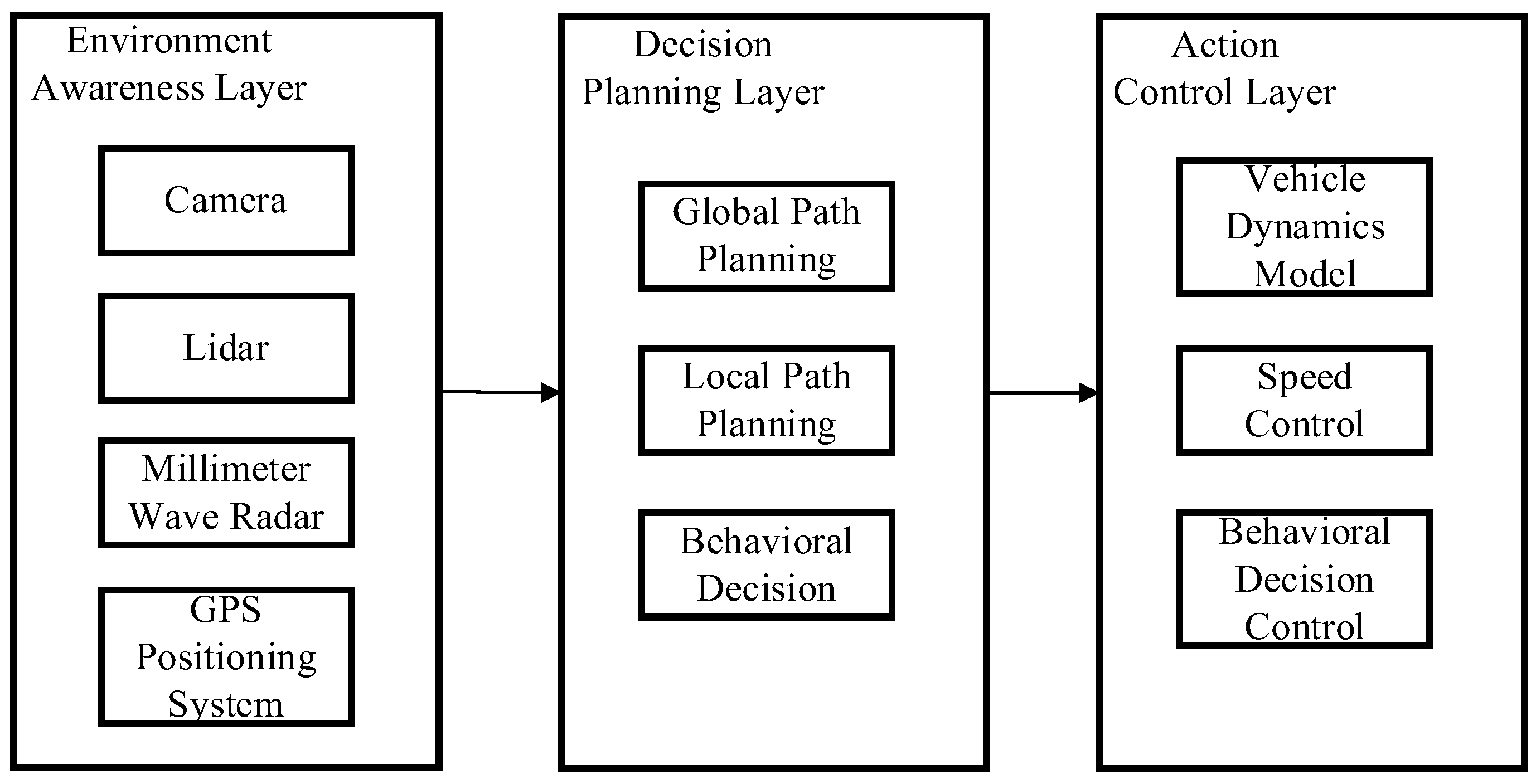
2. Methods
2.1. Improvement of the DGAIL Algorithm
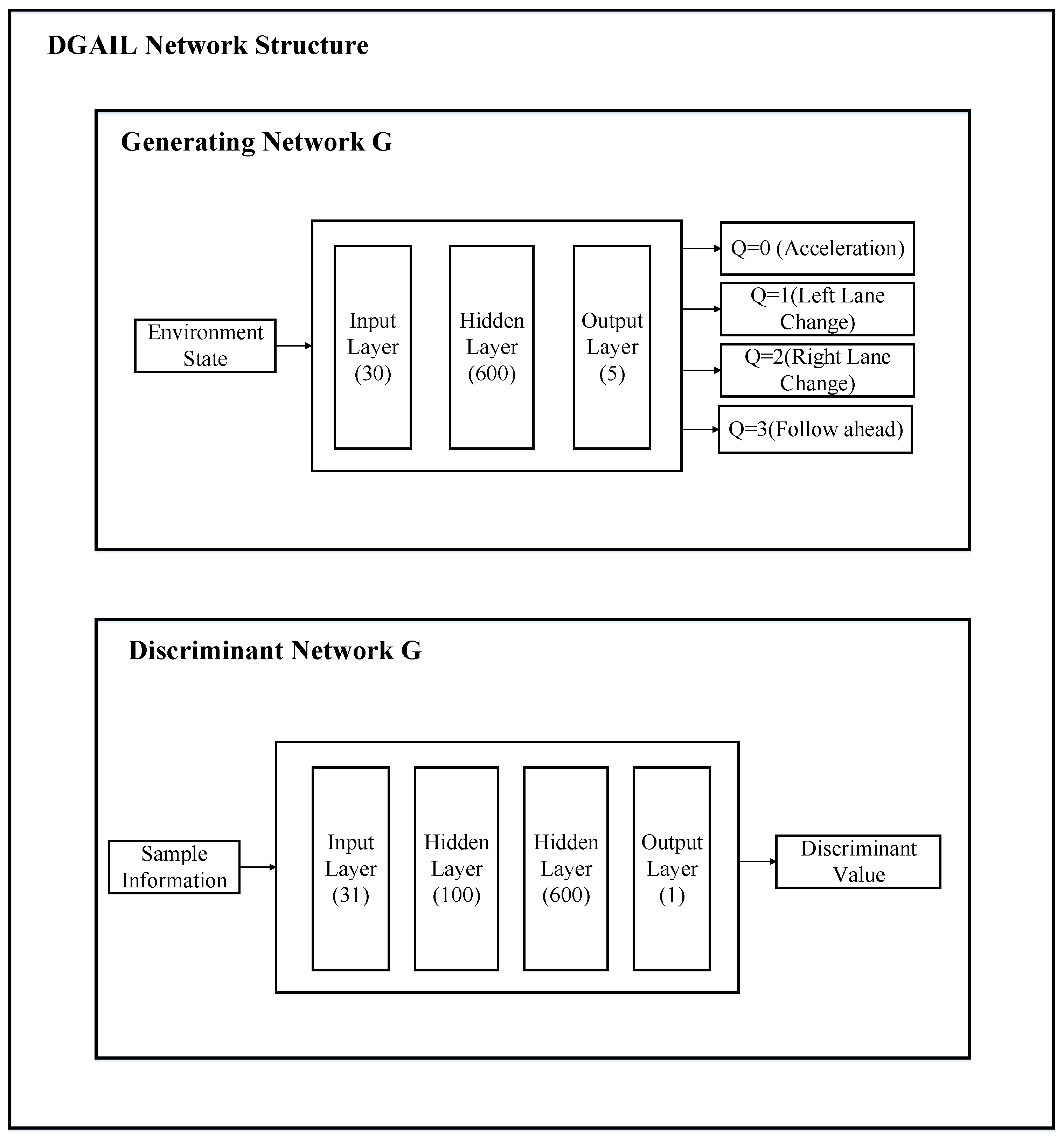
2.1.1. Generator G Is DQN
2.1.2. Activation Function of the Discriminator D
2.2. GAN Network
2.3. DGAIL Algorithm
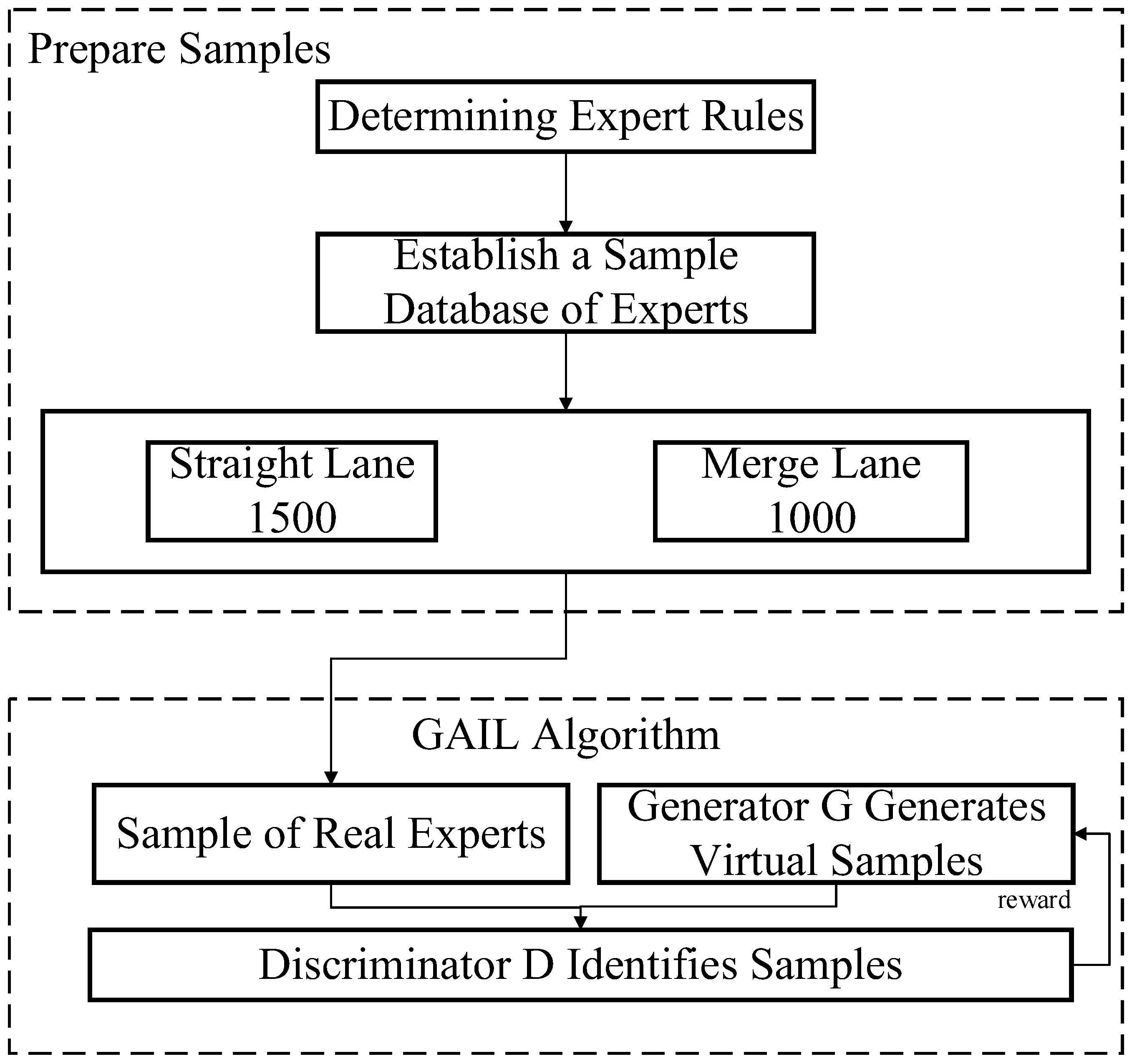
2.4. Building Expert Samples
2.4.1. Minimum Safe Distance for Vehicles
2.4.2. Determination of Dangerous Vehicles
2.4.3. Standardization of Impact Factors
2.4.4. Using the ID3 Decision Tree to Build Expert Samples
2.4.5. Sample Build Process
2.5. The Pseudo-Code of Algorithm
3. Simulation Test and Results
3.1. Simulation Parameter Settings
3.1.1. Straight Road Scene
3.1.2. Merging Road Scene
3.1.3. Action Space Settings
3.1.4. Neural Network Parameter Settings
3.2. DGAIL Algorithm Simulation Results Analysis
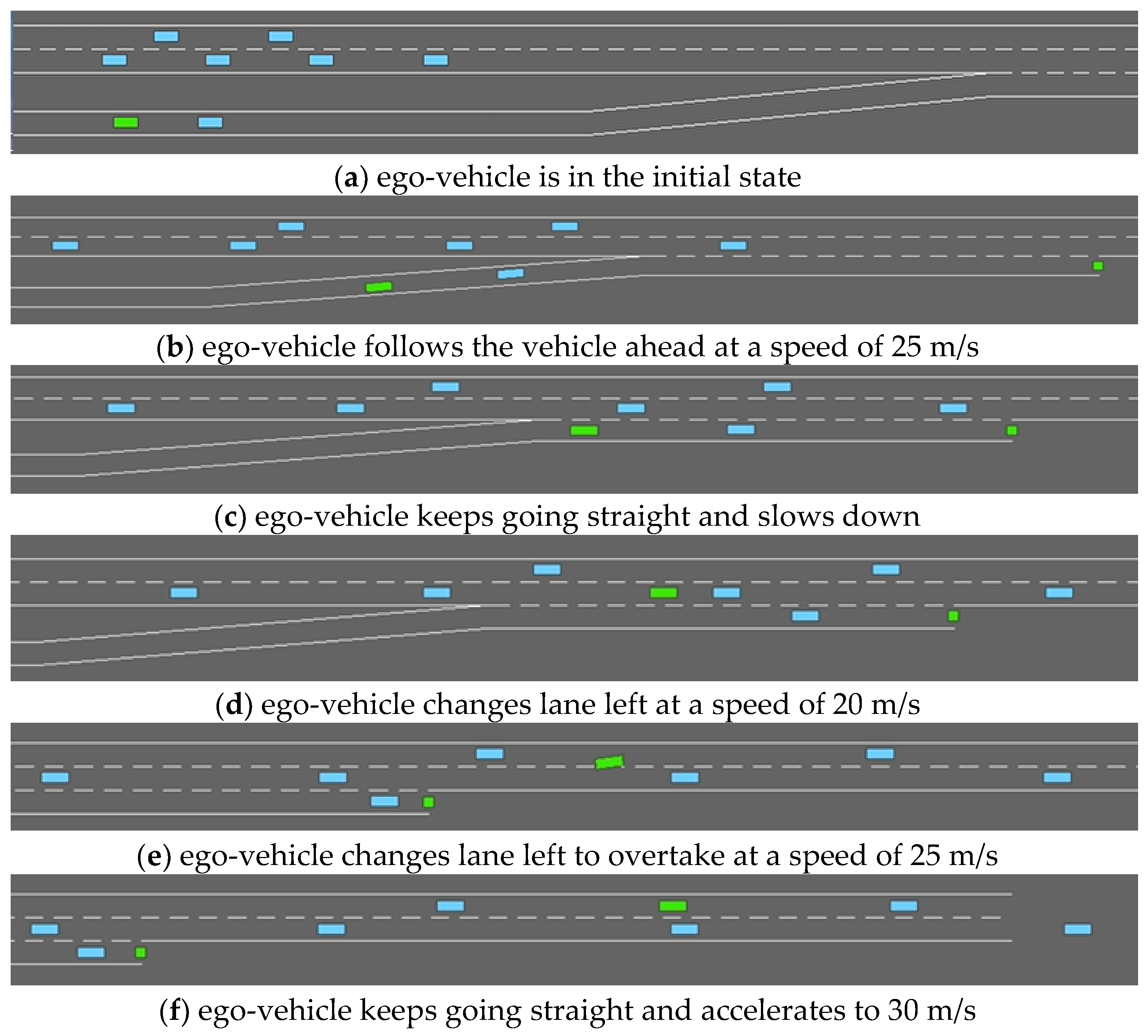
- Straight Road Scene

- Merging Road Scene
4. Discussion
4.1. Straight Road Scene
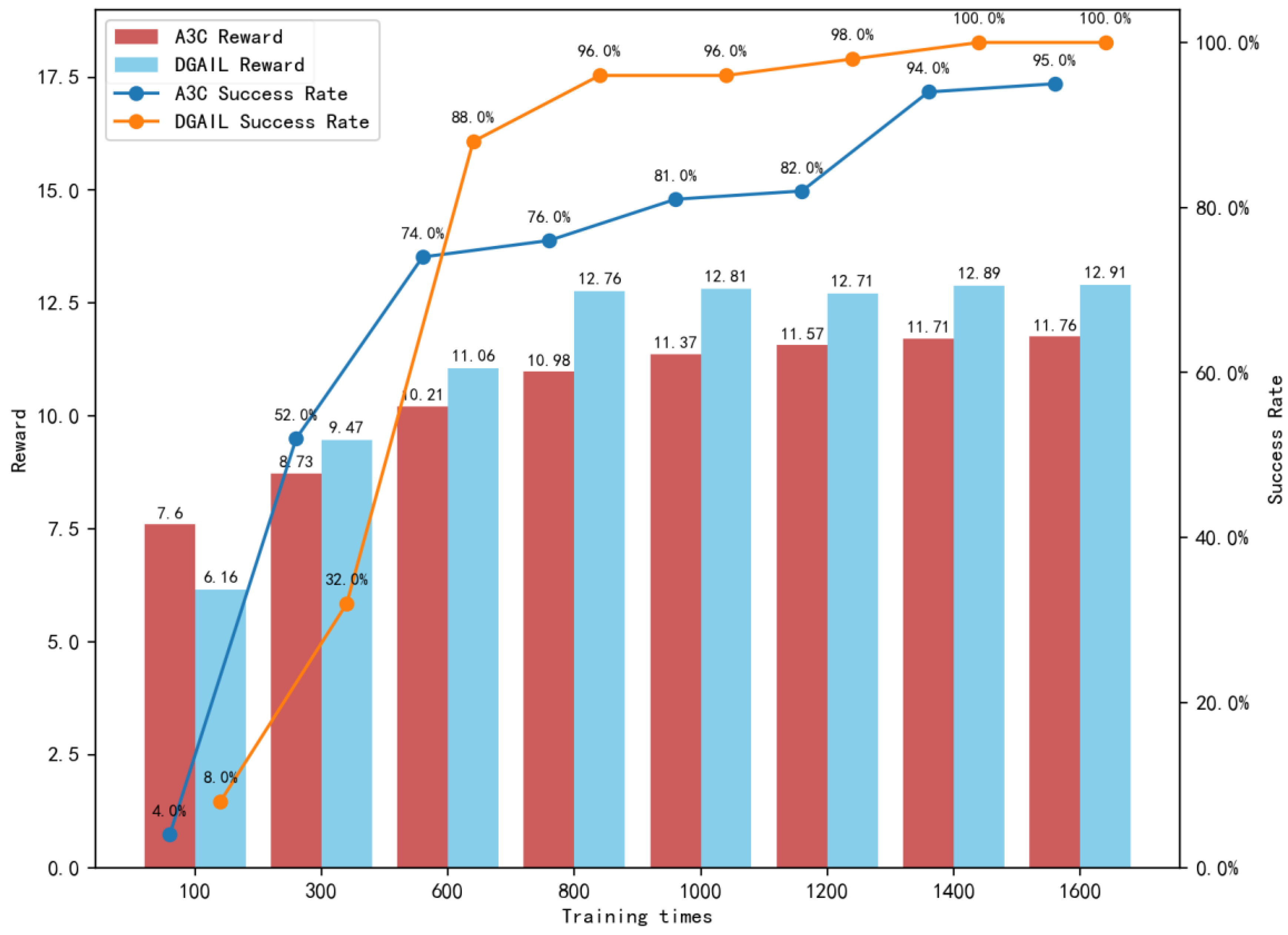
4.1.1. Training Convergence
4.1.2. Training Time Cost
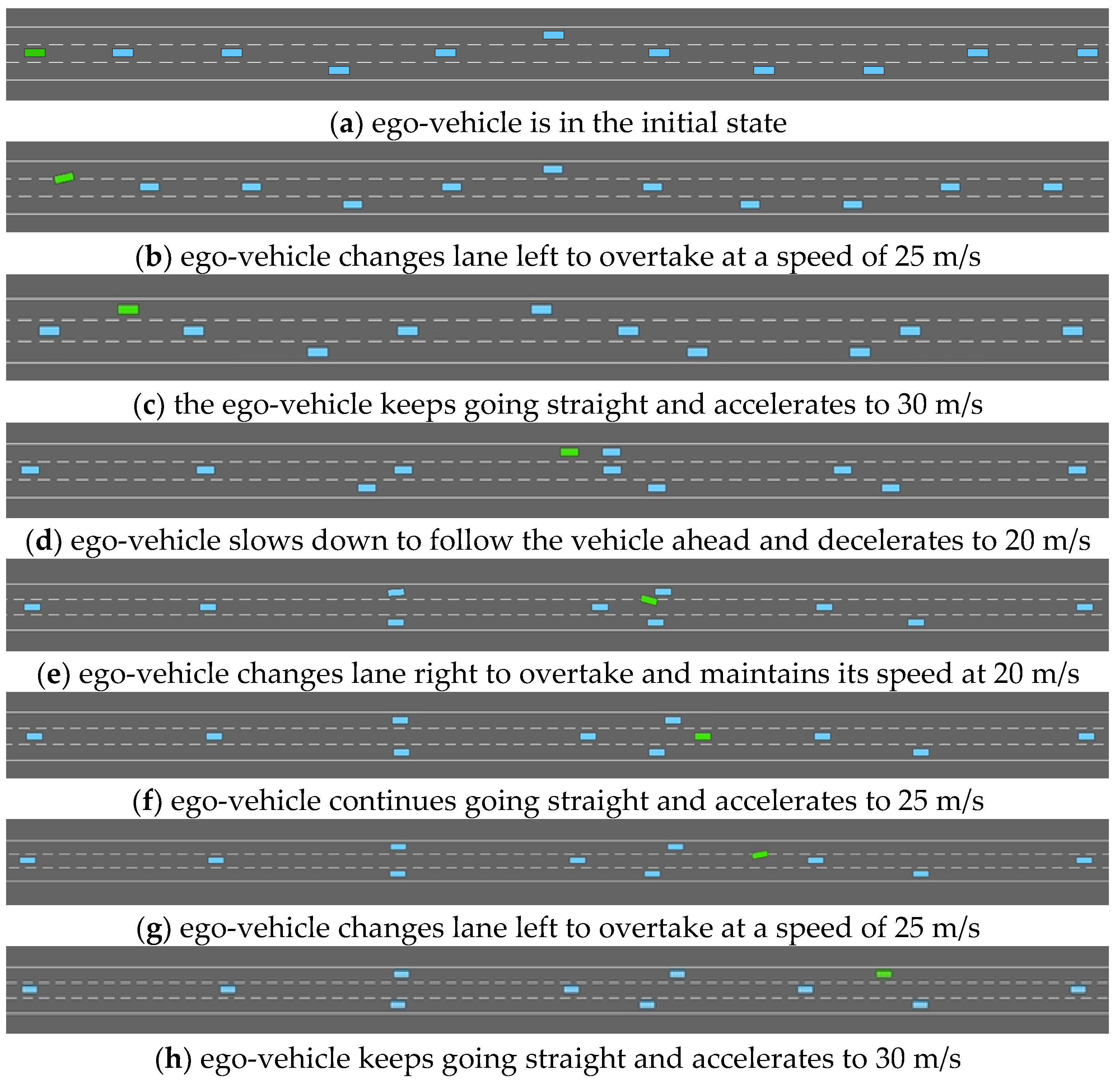
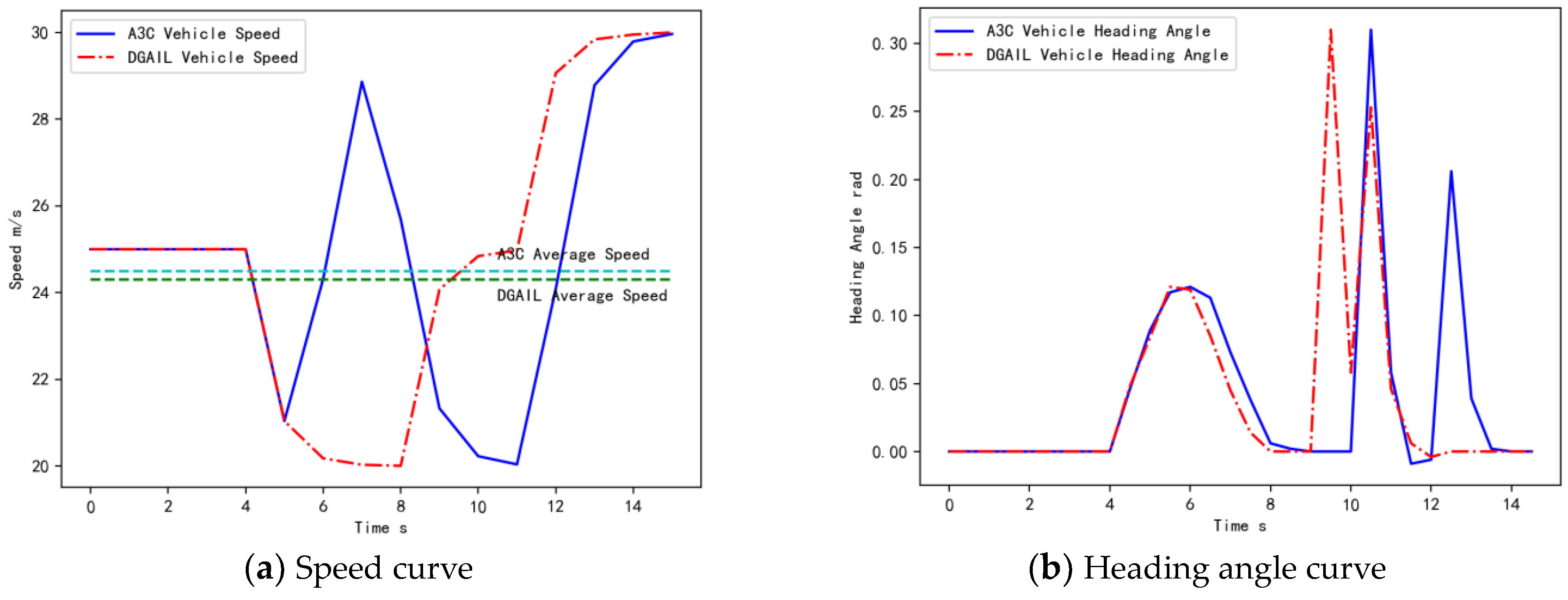
4.1.3. Effectiveness of Driving Strategies
4.2. Merging Road Scene
4.2.1. Training Convergence
4.2.2. Training Time Cost
4.2.3. Effectiveness of Driving Strategies
5. Conclusions
- A DGAIL-based intelligent vehicle driving behavior decision-making method, which can realize real-time, reliable, and stable decision-making in traffic scenarios based on structured roads, is proposed. Compared with the deep reinforcement learning DQN method, the tedious design of the reward value function is omitted. Compared with the traditional GAIL method, the DGAIL method is more suitable for scenes where the action space is discrete, the training convergence is faster, and the stability is higher.
- Presently, most research on intelligent vehicle driving behavior decision-making is mainly aimed at straight roads and intersections. In this paper, by constructing merging and roundabout scenarios in the simulation environment, the research scenarios of intelligent vehicles are enriched, and the decision-making of intelligent vehicle driving behavior can be more comprehensively verified. The applicability of the method accelerates the research process of a deep reinforcement learning algorithm in driving behavior decision-making.
- By proposing the DGAIL method, the effectiveness of generative adversarial imitation learning in structured scenarios is evaluated and then trained and validated in traffic simulation scenarios. However, there are still some deficiencies in this paper in some aspects. Further research and exploration can be carried out from the following aspects:
- The complexity of the scene: Although the scene in this paper included straight road and merging scenes, there were still certain constraints on the environmental vehicles in it, and the complexity was relatively simple. The driving behavior of smart cars in more free scenes can be explored in future studies.
- Optimization of the DGAIL algorithm: Although the DGAIL algorithm omits the design process of the reward value function, its training results have no obvious advantages over the traditional DQN algorithm. In follow-up research, the structure of the DGAIL algorithm can be optimized to improve the effectiveness and stability of the algorithm.
- Real vehicle test: The research in this paper was completely based on simulation and is still far from real practical use. In future studies, the algorithm in the simulation can be extended to real scenes through transfer learning, and the effectiveness of the method can be further demonstrated from an actual environment.
Author Contributions
Funding
Conflicts of Interest
References
- State Council of the PRC. Made in China 2025. Available online: http://www.gov.cn/zhengce/zhengceku/2015-05/19/content_9784.htm (accessed on 12 September 2022).
- Li, F. Research and Evaluation on Comprehensive Obstacle-Avoiding Behavior for Unmanned Vehicles; Beijing Institute of Technology: Beijing, China, 2015. [Google Scholar]
- Chae, H.; Kang, C.M.; Kim, B.D.; Kim, J.; Chung, C.C.; Choi, J.W. Autonomous braking system via deep reinforcement learning. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Jaritz, M.; De Charette, R.; Toromanoff, M.; Perot, E.; Nashashibi, F. End-to-end race driving with deep reinforcement learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2070–2075. [Google Scholar]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.M.; Lam, V.D.; Bewley, A.; Shah, A. Learning to drive in a day. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8248–8254. [Google Scholar]
- Fang, C. Research of the Lane Following Decision-making of Autonomous Vehicle Based on Deep Reinforcement Learning. Master Thesis, Nanjing University, Nanjing, China, 2019. [Google Scholar]
- Alizadeh, A.; Moghadam, M.; Bicer, Y.; Ure, N.K.; Yavas, U.; Kurtulus, C. Automated lane change decision making using deep reinforcement learning in dynamic and uncertain highway environment. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1399–1404. [Google Scholar]
- Luo, P.; Huang, Z.; Qing, Y.; Chen, Z. A method of vehicle driving behavior decision based on DQN algorithm. J. Transp. Inf. Saf. 2020, 38, 67–77, 112. [Google Scholar]
- Kober, J.; Peters, J. Imitation and reinforcement learning. IEEE Robot. Autom. Mag. 2010, 17, 55–62. [Google Scholar] [CrossRef]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. arXiv 2016, arXiv:1606.03476. [Google Scholar]
- Hausman, K.; Chebotar, Y.; Schaal, S.; Sukhatme, G.; Lim, J.J. Multi-modal imitation learning from unstructured demonstrations using generative adversarial nets. arXiv 2017, arXiv:1705.10479. [Google Scholar]
- Merel, J.; Tassa, Y.; Dhruva, T.B.; Srinivasan, S.; Lemmon, J.; Wang, Z.; Wayne, G.; Heess, N. Learning human behaviors from motion capture by adversarial imitation. arXiv 2017, arXiv:1707.02201. [Google Scholar]
- Li, Y.; Song, J.; Ermon, S. Infogail: Interpretable imitation learning from visual demonstrations. arXiv 2017, arXiv:1703.08840. [Google Scholar]
- Song, J.; Ren, H.; Sadigh, D.; Ermon, S. Multi-agent generative adversarial imitation learning. arXiv 2018, arXiv:1807.09936. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial | Driving Behavior Decision Expert Rule Base |
|---|---|
| 1 | If (C = 0) and (W0 = 0) and (W1 = 0) Then A = 0 |
| 2 | If (C = 0) and (W0 = 0) and (W1 = 1) Then A = 0 |
| 3 | If (C = 1) and (W1 = 0) Then A = 0 |
| 4 | If (C = 2) and (W1 = 0) and (W2 = 0) Then A = 0 |
| 5 | If (C = 2) and (W0 = 0) and (W1 = 1) and (W2 = 0) Then A = 0 |
| 6 | If (C = 2) and (W0 = 1) and (W1 = 1) and (W2 = 0) Then A = 0 |
| 7 | If (C = 1) and (W0 = 0) and (W1 = 1) Then A = 1 |
| 8 | If (C = 2) and (W1 = 0) and (W2 = 1) Then A = 1 |
| 9 | If (C = 0) and (W0 = 1) and (W1 = 0) Then A = 2 |
| 10 | If (C = 1) and (W0 = 1) and (W1 = 1) and (W2 = 0) Then A = 2 |
| 11 | If (W1 = 1) and (W0 = 1) and (W2 = 1) Then A = 3 |
| 12 | If (C = 0) and (W0 = 1) and (W1 = 1) and (W2 = 0) Then A = 3 |
| 13 | If (C = 2) and (W0 = 0) and (W1 = 1) and (W2 = 1) Then A = 3 |
| Serial | DGAIL Algorithm Pseudo-Code |
|---|---|
| 1: | Initialize replay memory D to capacity N; |
| 2: | Initialize the network weight η of discriminator D; |
| 3: | For i = 1, N do(i is the total number of training rounds): |
| 4: | For j = 1, M do(j is the number of iterations for each training round): |
| 5: | The input state is st at time t, Action at is selected by the ε-greedy strategy; |
| 6: | The agent performs action a and obtains state st+1 at time t + 1; |
| 7: | END For |
| 8: | The false sample set (st, at) of the agent is obtained; |
| 9: | Discretize the expert sample χ to obtain the expert sample set (expert_st, expert_at); |
| 10: | Input the fake sample set (st, at) and expert sample set (expert_st, expert_at) into the discriminator D; |
| 11: | Discriminator D receives expert sample data and fake sample data; |
| 12: | REPEAT (5 times): |
| 13: | Discriminator D uses the gradient descent method to train the loss function, updates the weight η of the neural network, judges the authenticity of the sample, and outputs the reward value function rt; |
| 14: | Recombine (st, at, rt, and st+1) and store it in the experience pool D of generator G; |
| 15: | Update the weights θ of the generator G estimation network and target network to complete one round of training; |
| 16: | END For |
| Parameter | Description | Value |
|---|---|---|
| Lane_length | Road length/m | 1200 |
| Lane_width | Single lane width/m | 3.6 |
| Lane_number | Number of lanes | 3 |
| Length | Vehicle length/m | 5 |
| Width | Vehicle width/m | 2 |
| Acc | Max acceleration/(m/s2) | 6 |
| Dec | Max deceleration/(m/s2) | 5 |
| V_max | Maximum lane speed limit/(m/s) | 30 |
| V_min | Minimum lane speed limit/(m/s) | 20 |
| Vehice_number | Number of vehicles | 10 |
| Frequency | Environment refresh cycle/s | 0.1 |
| Parameter | Description | Value |
|---|---|---|
| Lane_length | Road length/m | 500 |
| Lane_width | Single lane width/m | 3.6 |
| Lane_number | Number of lanes | 3 |
| Length | Vehicle length/m | 5 |
| Width | Vehicle width/m | 2 |
| Acc | Max acceleration/(m/s2) | 6 |
| Dec | Max deceleration/(m/s2) | 5 |
| V_max | Maximum lane speed limit/(m/s) | 30 |
| V_min | Minimum lane speed limit/(m/s) | 20 |
| Vehice_number | Number of vehicles | 7 |
| Frequency | Environment refresh cycle/s | 0.1 |
| Algorithm | Reward Value | Round Duration | Training Times |
|---|---|---|---|
| DQN | 30.8 | 24 | 2231 |
| GAIL | 5.2 | 24 | 3000 |
| A3C | 32.3 | 40 | 1853 |
| DGAIL | 35.5 | 40 | 1651 |
| Algorithm | Reward Value | Round Duration | Training Times |
|---|---|---|---|
| DQN | 9.5 | 11 | 1782 |
| GAIL | 4.8 | 11 | 2000 |
| A3C | 11.76 | 15 | 1189 |
| DGAIL | 12.9 | 15 | 855 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, J.; Rui, Y.; Ran, B.; Luo, P. Design of an Intelligent Vehicle Behavior Decision Algorithm Based on DGAIL. Appl. Sci. 2023, 13, 5648. https://doi.org/10.3390/app13095648
Jiang J, Rui Y, Ran B, Luo P. Design of an Intelligent Vehicle Behavior Decision Algorithm Based on DGAIL. Applied Sciences. 2023; 13(9):5648. https://doi.org/10.3390/app13095648
Chicago/Turabian StyleJiang, Junfeng, Yikang Rui, Bin Ran, and Peng Luo. 2023. "Design of an Intelligent Vehicle Behavior Decision Algorithm Based on DGAIL" Applied Sciences 13, no. 9: 5648. https://doi.org/10.3390/app13095648