1. Introduction
With the advancement of the Internet, social platforms, such as WeChat, Weibo, and Twitter, have become an essential part of people’s daily lives. More and more users like to express their opinions and present their hobbies on these platforms, and the interactions between users result in a wide range of consumption behaviors. Moreover, social homogeneity [
1] and social influence theory [
2] demonstrate that connected users in social networks have similar interest preferences and continue to influence one another as information spreads. Based on these findings, social relations are frequently integrated into recommender systems as a powerful supplement to user–item interaction information to address the problem of data sparsity [
3], and numerous social recommendation methods have been developed. Social recommendation algorithms based on graph neural networks have demonstrated improved performance recently and helped advance recommendation technology; however, these models still have certain drawbacks.
1. Interaction data are sparse and noisy. Most recommendation models utilize supervised learning techniques [
4,
5], which substantially rely on user–item interaction data and are unable to develop high-quality user–item representations when data are sparse. As a result, cold-start problems usually occur. In addition, GNN-based recommendation algorithms must aggregate and propagate node embeddings and their neighbors during training, which amplifies the impact of interaction noise (i.e., user mis-click behavior), resulting in confusion with regard to user preferences.
2. The effect of the long-tail phenomenon. Due to the skewed distribution of interactive data [
4], the recommendation algorithm only emphasizes a portion of some users’ mainstream interests, resulting in underfitting of the sample tail distribution and trapping of the user’s interest in the “filter bubble” [
6], which is known as the long-tail phenomenon.
3. Noise in social relationships. Existing recommendation models are generally based on the assumption that users in social networks have similar item preferences. However, the formation of social relationships is a complicated process that can be based on interests or pure social relationships. Users may have completely different preferences for certain items, but this is not always the case. The model becomes noisier as a result of this assumption, which makes it difficult to effectively incorporate user characteristics and recommendation targets in social networks.
Present work. In view of the above limitations and challenges, this paper proposes an improved social recommendation model—graph-augmentation-free self-supervised learning for social recommendation (GAFSRec). Here, we applied self-supervised contrastive learning to recommendation with the goal of increasing the mutual information for the same user/item view, thereby reducing the reliance on labels and resolving the first and second issues mentioned above. Most contrastive learning techniques currently in use (such as random edge/node loss) improve the consistency of nodes across views through structural perturbations [
4,
7,
8,
9]. However, the most recent research demonstrates [
10] that data augmentation can still be accomplished without structural perturbation by adding the proper amount of random uniform noise to the original image. As a result, we employed the method of adding sufficiently small and uniform noise to the graph convolution layer of the recommendation task to achieve cross-layer comparative learning. This technique can operate in the embedding space, making it more effective and simpler to use, and it can subtly attenuate the long-tail phenomenon. The third problem was solved by using both explicit and implicit social relationships, employing hypergraph convolutional networks to mine users’ high-order social relationships, and adding the role of key opinion leaders to prevent extra social noise from affecting user preferences.
To improve efficiency, we employed a multi-task training technique with recommendation as the primary task and self-supervised contrastive learning as an auxiliary task. We first created four views using a social network graph and a user–item interaction graph: user–item interaction graph, explicit friend social graph, implicit friend social graph, and user–item sharing graph with explicit friends. Graph encoders (a graph convolutional network and hypergraph convolutional network) were then built for each view to learn the users’ high-order relational representation. To avoid the difficulties caused by data sparsity in modeling, we incorporated cross-layer contrastive learning without graph augmentation into GAFSRec, amplified the variance via a graph convolutional neural network, and regularized the representation of recommendations with contrast-augmented views. Finally, we combined the recommendation task and the self-supervised task within the framework of master-assisted learning. The performance of the recommendation task was significantly improved after jointly optimizing these two tasks and utilizing the interactions between all components.
The main contributions of this paper can be summarized as follows:
We designed a high-order heterogeneous graph based on motifs, integrated social relations and item ratings, comprehensively modeled relational information in the network, and undertook modeling through graph convolution to capture high-order relations between users;
We incorporated the cross-layer self-supervised contrastive learning task without graph augmentation into network training, enabling it to run more efficiently while ensuring the reliability of recommendations;
We conducted extensive experiments with multiple real datasets, and the comparative results showed that the proposed model was superior and that the model was effective in ablation experiments.
The rest of this paper is organized as follows.
Section 2 presents related work.
Section 3 describes the framework for the multi-graph contrastive social recommendation model.
Section 4 presents the experimental results and analysis. Finally,
Section 5 brings the paper to a close.
3. Proposed Model
3.1. Preliminaries
Let represent the collection of users and represent the collection of items. Since we are focused on item recommendation, we define to represent the user–item interaction binary matrix. For each pair , indicates that user has interacted with item and, conversely, indicates that user has not interacted with item or that user is not interested in item . We represent social relations using directed social networks, where represents an asymmetric relation matrix. Additionally, and denote the embeddings of the size d-dimensional users and items learned in each layer, respectively. This article uses bold uppercase letters for matrices and bold lowercase letters for vectors.
Definition 1. Hypergraph.
Let represent a hypergraph, V a vertex set containing N vertices in the hypergraph, and E an edge set containing M hyperedges. Each hyperedge contains two or more vertices and is assigned a positive weight . All weights form a diagonal matrix . A hypergraph is represented by an incidence matrix , which is defined as follows: If the hyperedge contains a vertex, then ; otherwise, . The degrees of the vertices and edges of a hypergraph are represented as follows: ; .
3.2. High-Order Social Information Exploitation
In this study, we used two graphs as data sources: a user–item interaction graph and a user social network graph.
We aligned the two networks into a heterogeneous network and divided it into three sets of views—an explicit friend social graph, an implicit friend social graph, and items shared by users with explicit friends’ graphs—in order to establish high-order associations between users in the network. The project-sharing graph of users and explicit friends describes a user’s interest in sharing items with friends, which can also serve as relationship-strengthening. The social graph of explicit friends describes a user’s interest in expanding their social circle. The social graph of implicit friends describes the similar interests a user shares with similar but unfamiliar users and can alleviate the negative impact of unreliable social relations.
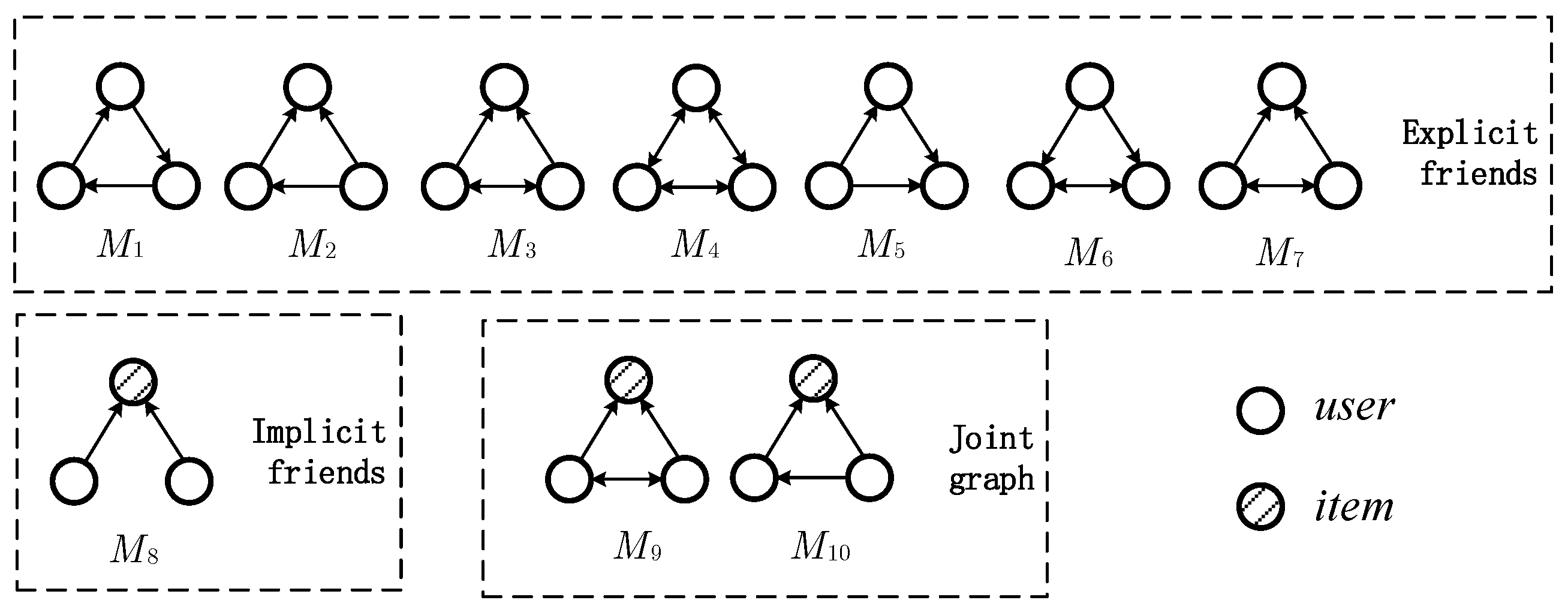
Taking into account the fact that there are some significant social network structures that have impacts on the authority and reputation of nodes in the representation of higher-order relationships as network motifs, we used the motif-based PageRank [
18] framework. PageRank is a general algorithm for ranking users in social networks [
19]. It can be utilized as a measurement standard for opinion-leader mining, impact, and credibility analyses by assessing the authority of network nodes. However, only edge-based relations are exploited, with higher-order structures in complex networks being neglected. This aspect is improved by the motif-based PageRank algorithm. As shown by
Figure 1, which covers the fundamental and significant user social types, the user–item interaction graph splits the explicit friend social graph into seven motifs. M8, also defined as the user’s implicit friend social network, represents strangers who share the user’s interests. The relationship M9–M10, generally described as users’ and explicit friends’ item-sharing graph, is, at the same time, extended in accordance with friends’ shared buying behaviors.
When given any motif set
, we can calculate the adjacency matrix of the motif using
Table 1.
In
Table 1,
and
are the adjacency matrices of two-way and one-way social networks respectively. Without considering self-connections,
,
, and
, where, in
, we only keep values greater than 5 for the reliability of the implicit friend pair experiment. Furthermore, the adjacency matrix for the user–items graph is
.
3.3. Graph Collaborative Filtering BackBone
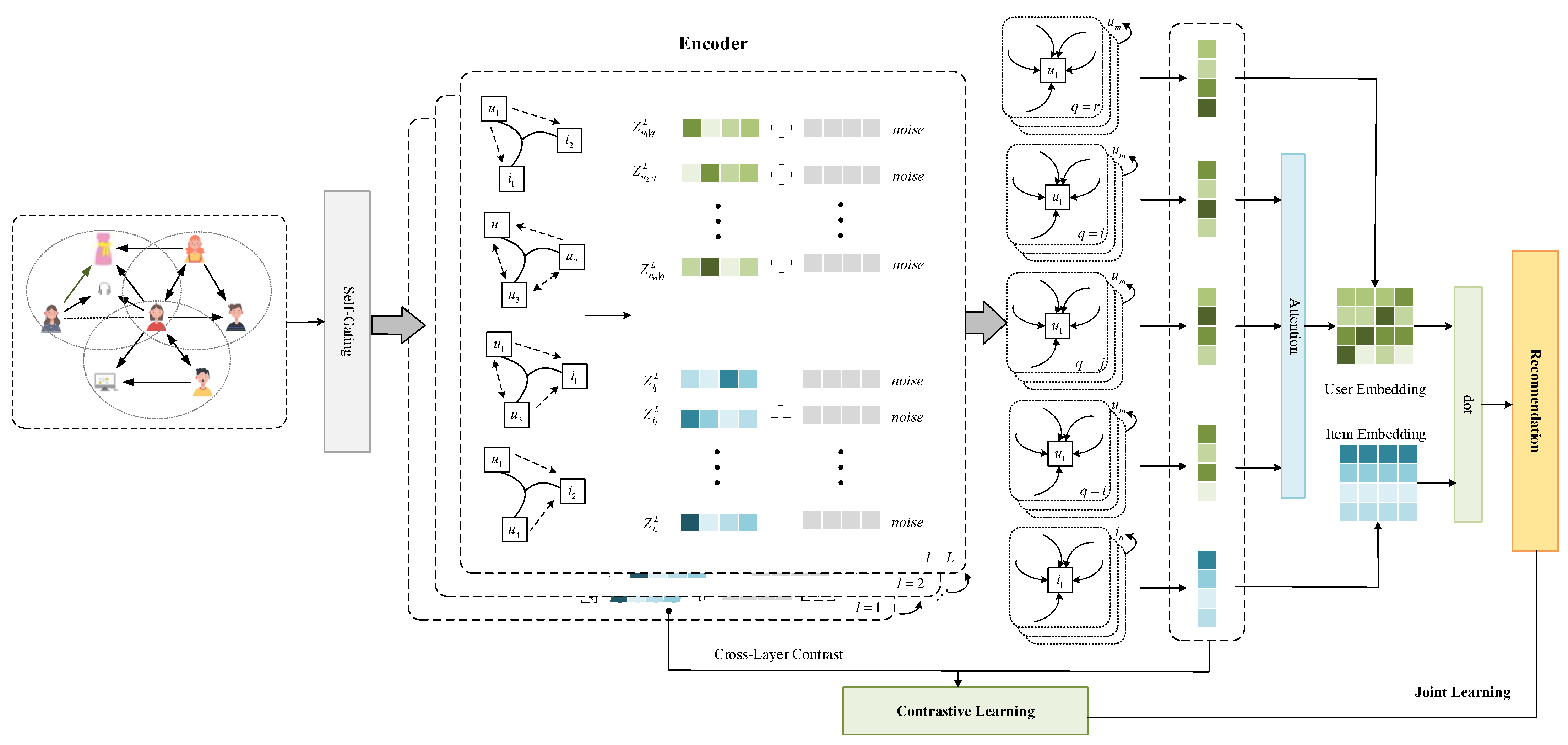
In this section, we present our model GAFSRec. In
Figure 2, the schematic overview of our model is illustrated.
Due to its strong ability to capture node dependencies, we adopted LightGCN [
20] to aggregate neighborhood information. Formally, a general GCN is constructed using the following hierarchical propagation:
where
is the
l-th layer embedding of the node, and
are the four views, with
A being the adjacency matrix and
D the degree diagonal matrix of
A. We encoded the original node vectors into the embedding vectors required by each view through gating functions.
where
,
, and
are the activation function, weight matrix, and bias vector.
represents four views.
denotes the initial embedding vector and
represents the dot product.
We used the generalization ability of hypergraph modeling to capture more effective high-level user information. Therefore, in the encoder, a hypergraph convolutional neural network [
21] was used.
where
is the Laplacian matrix of the hypergraph convolutional network; H is the incidence matrix of each hypergraph;
and
are the degree matrix of the nodes and the degree matrix of the hyperedges; and
,
, and
are activation functions, learnable filter matrices, and the parameters of the diagonal matrix.
Considering node influence and credibility, we adopted motifs [
18] to construct a hypergraph. Given the complexity of the actual construction of the Laplacian matrix for hypergraph convolution (which includes a large number of graph-induced hyperedges), matrix multiplication can be considered for simplification.
Finally, the hypergraph convolutional neural network can be expressed as: , where is the degree matrix of . It can be seen from this that the graph convolutional neural network is a special case of the hypergraph neural network.
After l-layer propagation, we used the weighting functions and the readout function to output the representations of all layers, obtaining the following representations:
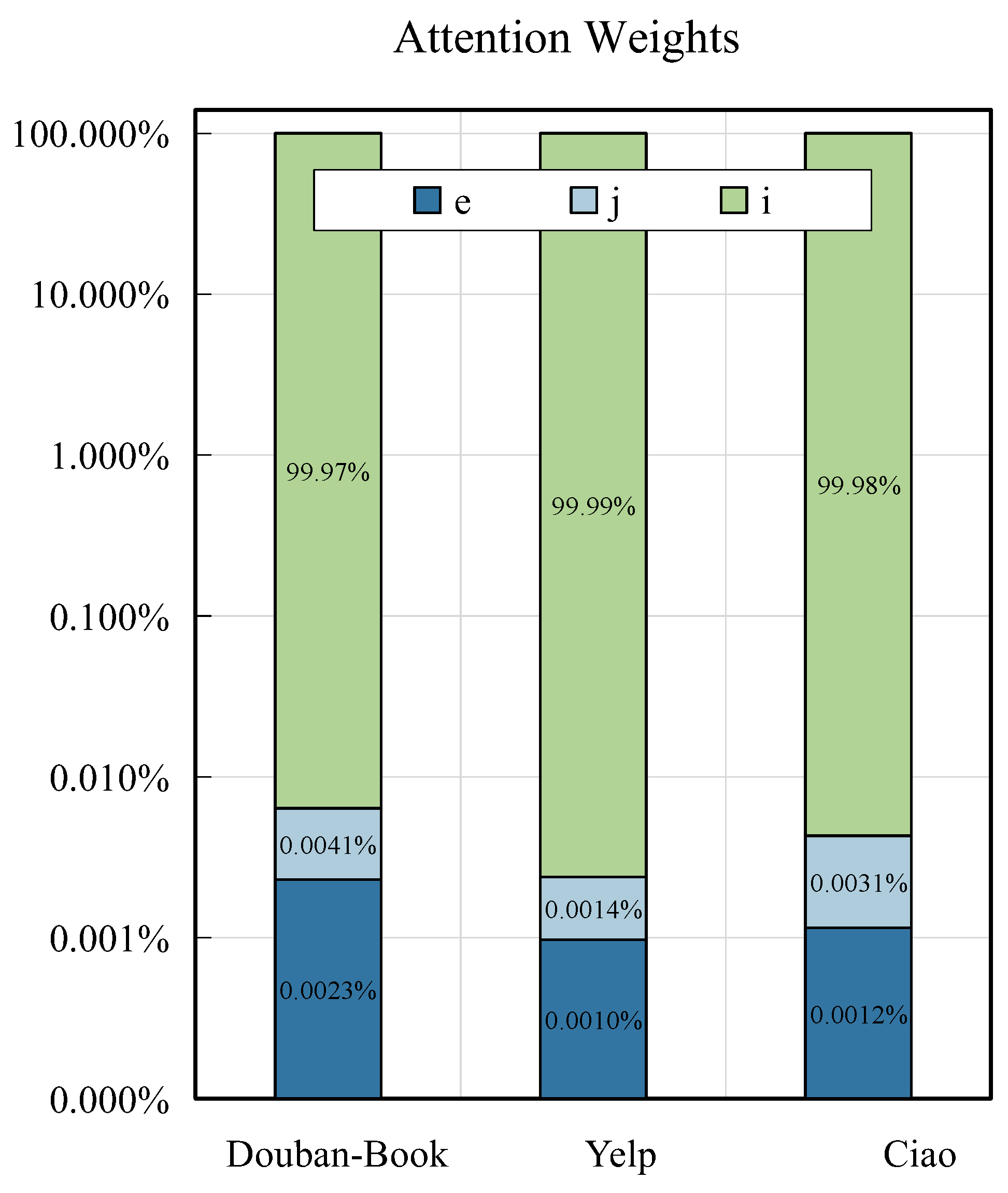
We applied an attention approach [
22] to learn the weights α and aggregate the user embedding vectors for augmented views.
where
and
are trainable parameters. The final user embedding
and item embedding
look like this:
The ranking score generated by this model recommendation is defined as the inner product with user and item embeddings:
To optimize the parameters in the model, we adopted the Bayesian loss function [
23]. The main reason was that the Bayesian loss function considers the comparison of pairwise preferences between observed interactions and unobserved interactions. The loss function of this model is:
where
is a trainable parameter and
is a regularization coefficient that controls the strength of L2 regularization, prevents overfitting, and is a sigmoid function. Each input datum is a triplet sample <
u,
i,
j >; this triplet includes the current user
u, the positive item
i purchased by
u, and the randomly drawn negative item
j. The negative item
j is the user
u’s unliked or unknown items.
3.4. Graph-Augmentation-Free Self-Supervised Learning
Data augmentation is the premise of self-supervised contrastive learning models, and they can obtain a more uniform representation by perturbing the structure and optimizing the contrastive loss. With regard to the learning of graph representations, a study on SimGCL [
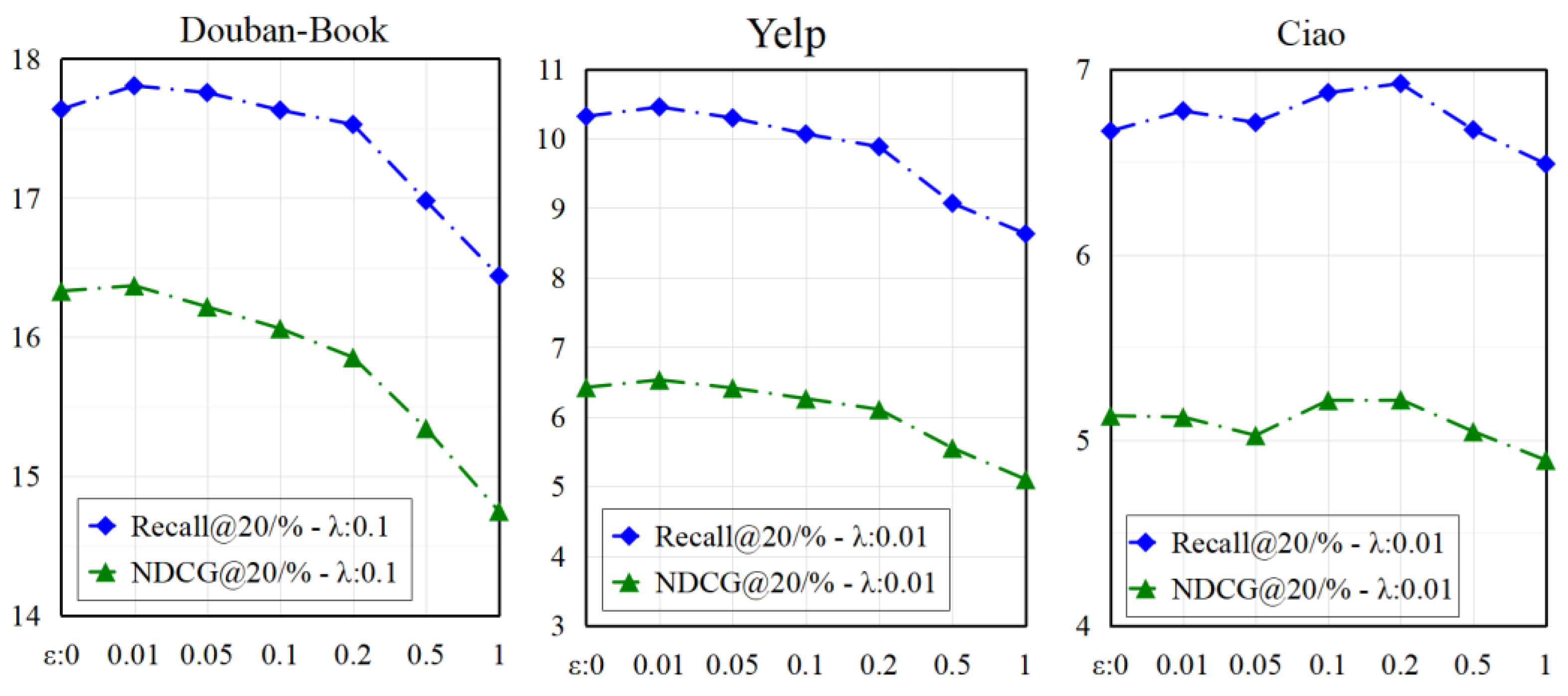
10] showed that it is the uniformity of distribution rather than dropout-based graph augmentation that has the greatest impact on the performance of self-supervised graph learning. Therefore, we considered adding random noise to the embedding to create a self-supervised signal that could enhance the performance of the contrastive learning.
where
ε is the added random uniform noise vector, and the noise direction is in the same direction as the embedding vector,
,
. The embedding representation added with perturbation retains most of the information of the original representation, as well as some invariance.
By applying different scales of embedding vectors to the current node embedding, the perturbed embedding vectors can then be fed into the encoder. The embedding vector of the final perturbed node is expressed as:
We regarded augmented views from the same node as positive examples and augmented views from different nodes as negative examples. Positive auxiliary supervision promotes the consistency of predictions among different views of the same node, while negative supervision strengthens the divergence between different nodes. Formally, we adopted the contrastive loss InfoNCE [
24] to maximize the consistency of positive examples and minimize the consistency of negative examples:
where
represents the
k-th layer L2-regularized embedding vector compared with the final layer embedding,
represents the dot-product cosine similarity between normalized embeddings, and
b.
τ is the temperature parameter. The total loss function for self-supervised learning includes the contrastive loss for each view user and the item contrastive loss, as shown in the following equation:
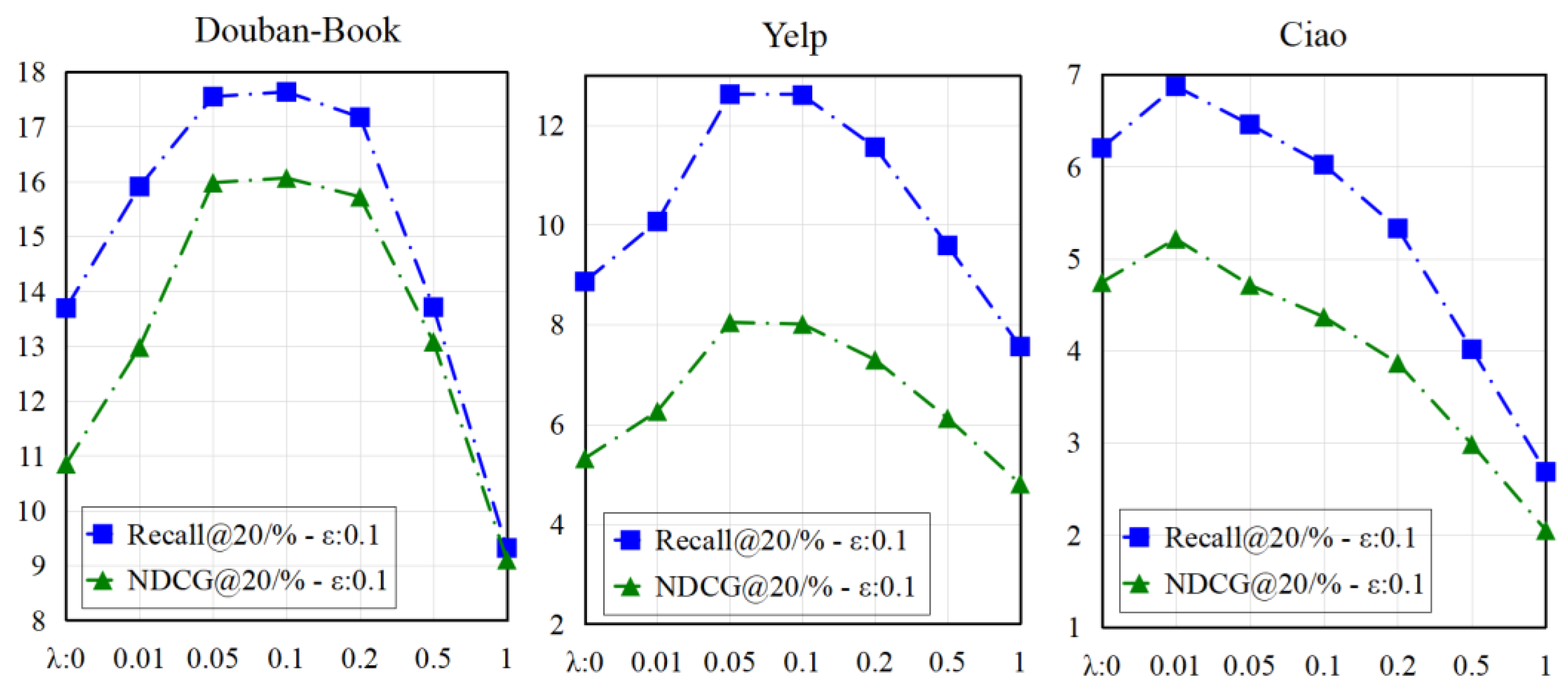
To improve recommendation through contrastive learning, we utilized a multi-task training strategy to jointly optimize the recommendation task and the self-supervised learning task, as shown in the following equation:
where
λ is the hyperparameter used to control the auxiliary task.
3.5. Complexity Analysis
In this section, we analyze the theoretical complexity of GAFSRec. Since the time complexity of LightGCN-based convolutional graph encoding is
, the total encoder complexity of this architecture is less than
because the adjacency matrix of the auxiliary encoder is sparser than that of the user–item interaction graph. The time costs of the gate function and the aggregation layer are both
. This architecture adopts BPR loss; each batch contains B interactions, and the time cost is
. Since the contrasting between positive/negative samples in contrastive learning increases the time cost, cross-layer self-supervised contrastive learning contributes a time complexity of
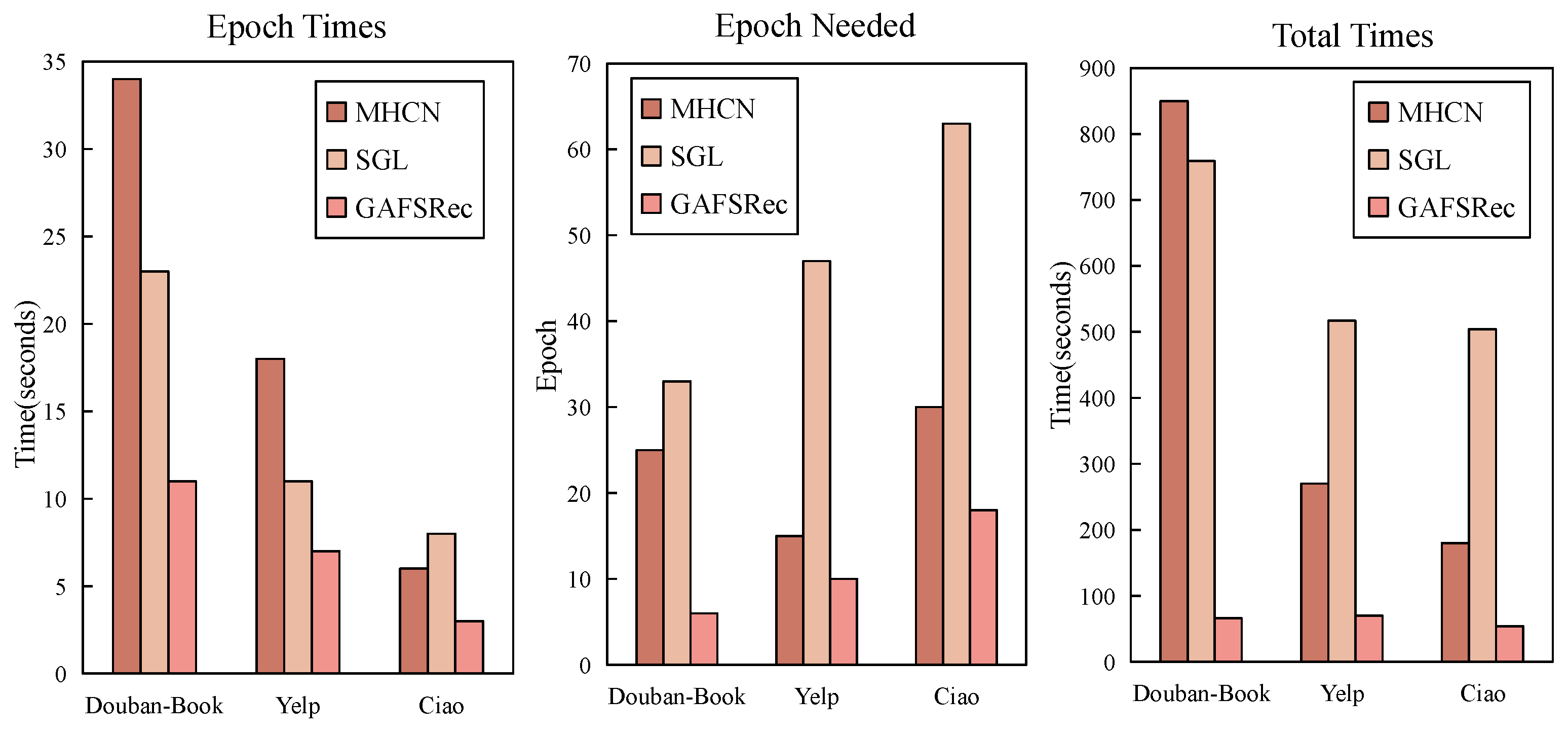
, where M represents the number of nodes in a batch. Since this model does not involve graph augmentation, the complexity of GAFSRec is much lower than that of graph-augmented social recommendation models. In our experiments, with the same embedding size and using the Douban-Book dataset, MHCN took 34 s per epoch and GAFSRec only took 11 s. Detailed information on the experiments can be found in
Section 4.2.1.
5. Conclusions
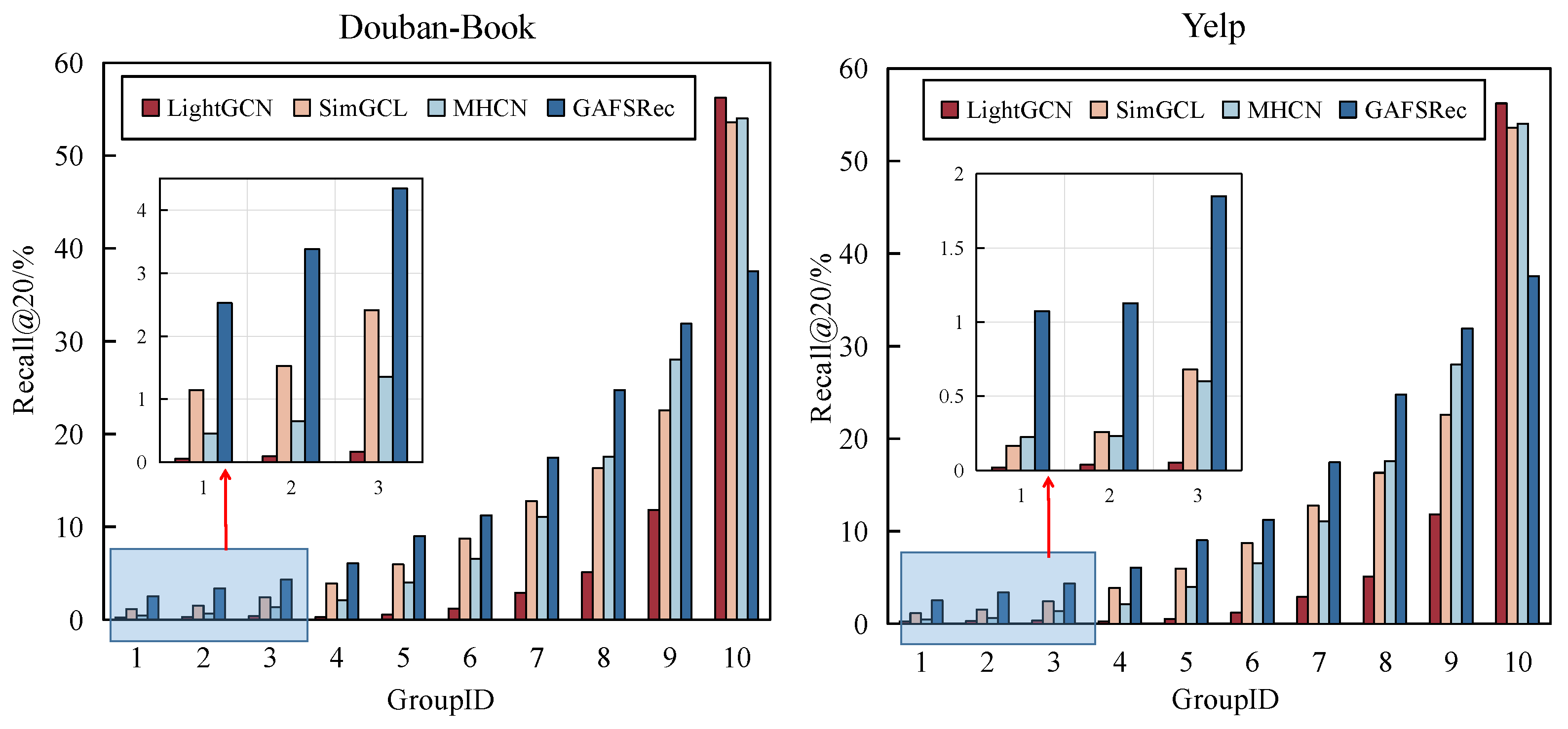
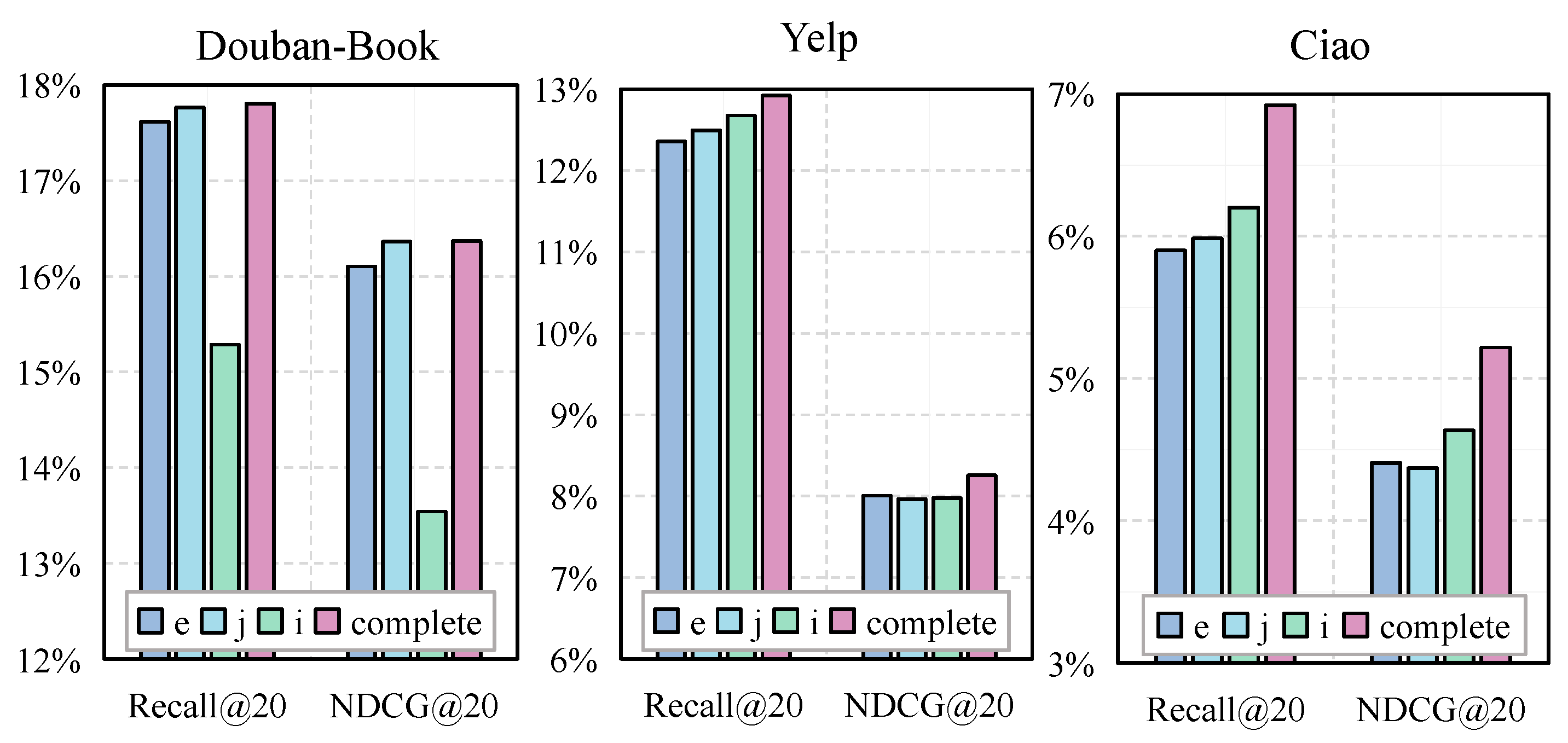
In this paper, we proposed a graph-contrastive social recommendation model (GAFSRec) for ranking predictions. To fully mine high-order user relationships, the social graph was divided into multiple views, which were modeled using a hypergraph encoder to improve social recommendations. In particular, we presented a method of cross-layer comparative learning to help maintain the consistency of user preferences. Our experiments showed that implicit users outperformed datasets with sparse explicit social relations, and GAFSRec outperformed state-of-the-art baselines using three real datasets. Here, we only considered incorporating the trust relationships between friends in a social network into the recommendations. In the real world, however, a social graph with attributes could better reflect the relationships between users and products. Therefore, exploring social recommendations with attributes will be our next research direction.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}