
Multi-View Gait Recognition Based on a Siamese Vision Transformer


Abstract
:1. Introduction
- (1)
- It designs a reasonable and novel gait-view conversion method, which can deal with the problem of multi-view gait;
- (2)
- It constructs the SMViT model, and uses the view characteristic relation module to calculate the association between multi-view gait characteristics;
- (3)
- We develop a gradually moving view-training strategy that can raise the model’s robustness while raising the recognition rate for less precise gait-view data.
2. Related Work
3. SMViT and the Gradually Moving-View Training Method
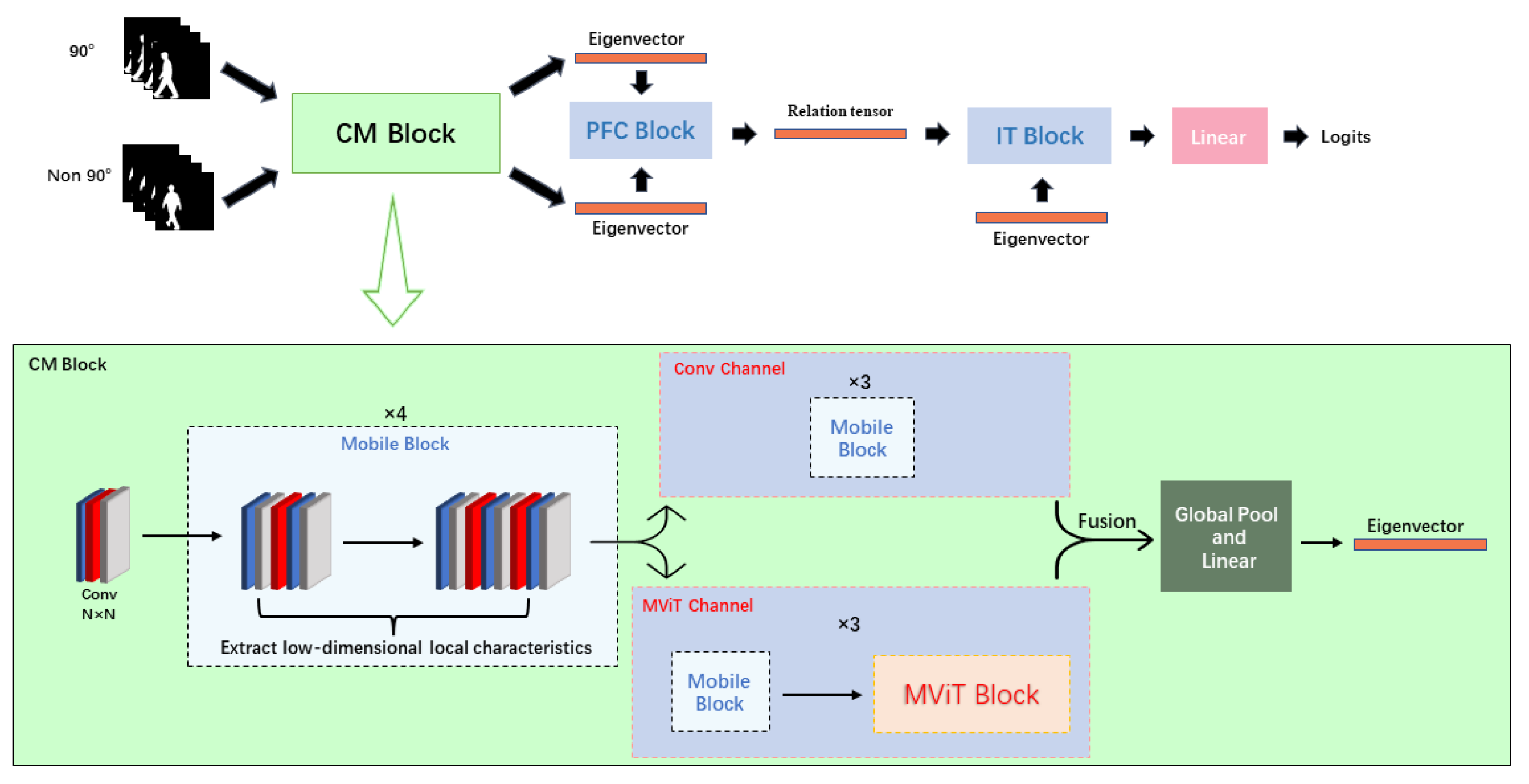
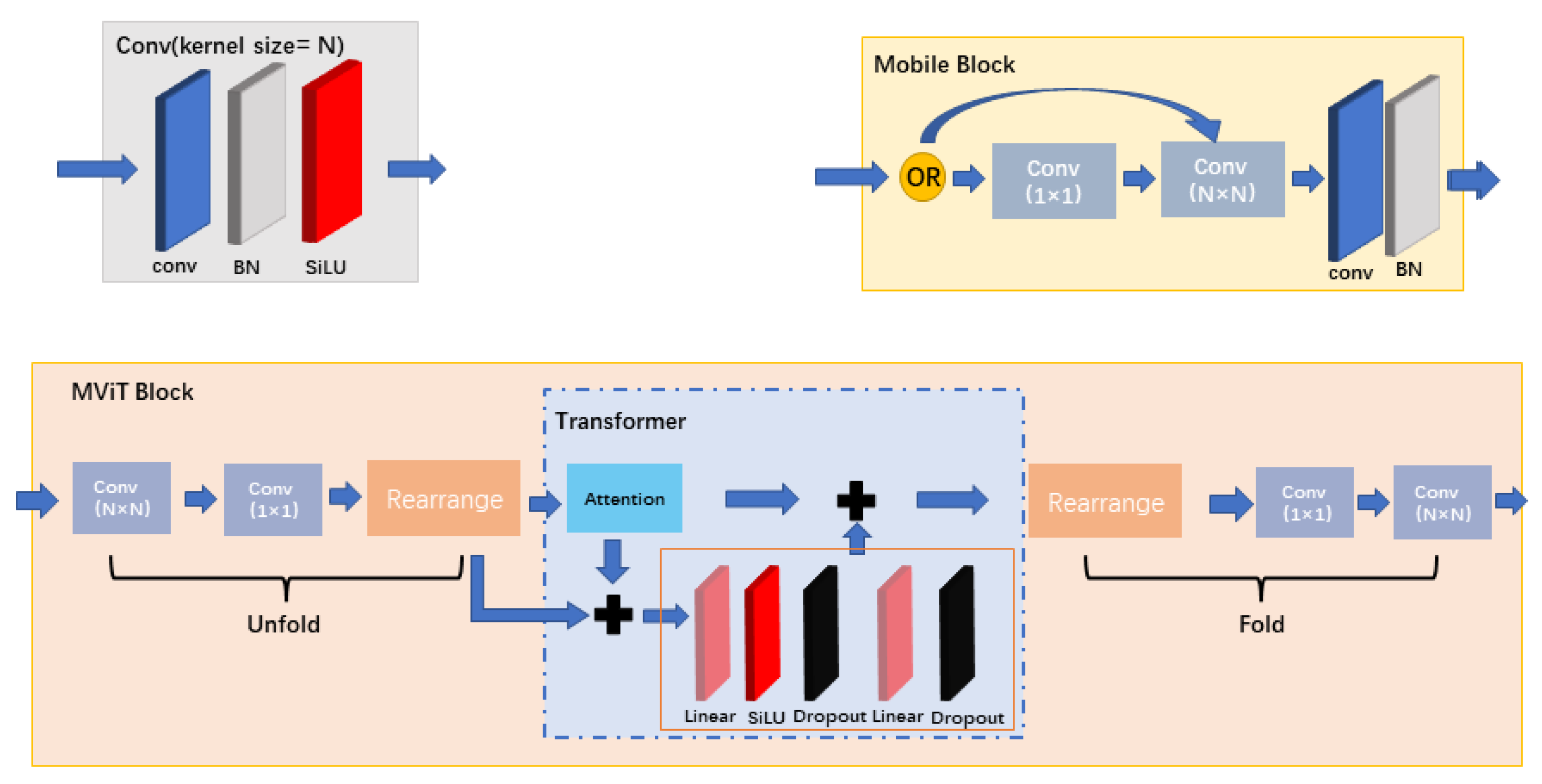
3.1. Model Structure
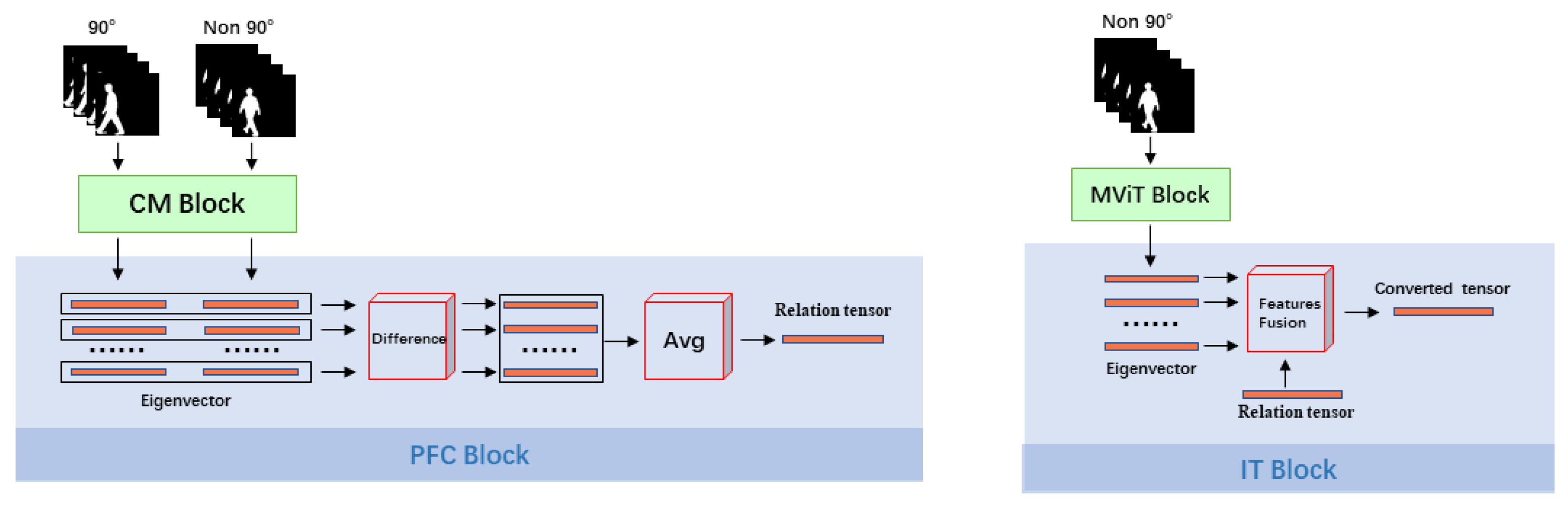
3.2. Perspective Feature Conversion Block and Inverse Transformation Block
3.3. Gradually Moving-View Training Method
| Algorithm 1: Process of training the characteristic view relationship calculation module. |
| Input: CASIA B and CASIA C gait datasets. Step 1: First, supplement the dual-channel view feature relationship calculation module as a complete classification model and conduct pre-training in the CASIA C dataset. Step 2: Freeze the pre-training parameters to remove the weight of the final classification layer. Step 3: Load the parameters from step 2 to the dual-channel perspective characteristic relationship calculation module. Step 4: Use the module obtained in step 3 to extract the dual-channel features of 90° and non-90° CASIA B gait data. Step 5: Calculate the relationship tensor between the two perspectives obtained in step 4 with the PFC block. Step 6: Store the characteristic relationship between the two views obtained in step 5, and hand it over to the classification module. Output: The characteristic relationship tensor between the two views. |
| Algorithm 2: Classification Module Training Process |
| Input: CASIA B gait dataset. Step 1: First, the 90° gait data are transformed and recognized (at this time, there is no change in the characteristics of the perspective), and the parameter weight is saved. Step 2: The weight parameters obtained in step 1 are loaded to the classification module, the gait dataset (such as 72° and 108°) of the adjacent perspective is trained, and the parameter weight is saved. Step 3: The characteristic relationship tensor between the two perspectives is matched and the parameter weights obtained in the previous step are loaded into the model. Step 4: The trained perspective weight is loaded to the model, the gait dataset of adjacent non-90° perspectives is trained, and the weight parameters are saved. Step 5: The classification layer and the regression layer are used to identify and classify the characteristic tensor of the view. Step 6: Push in two directions (90°→0° and 90°→180°), and repeat steps 3, 4, and 5. Output: The gait recognition model SMViT. |
4. Experiment and Analysis
4.1. Experimental Data
4.2. Experimental Design
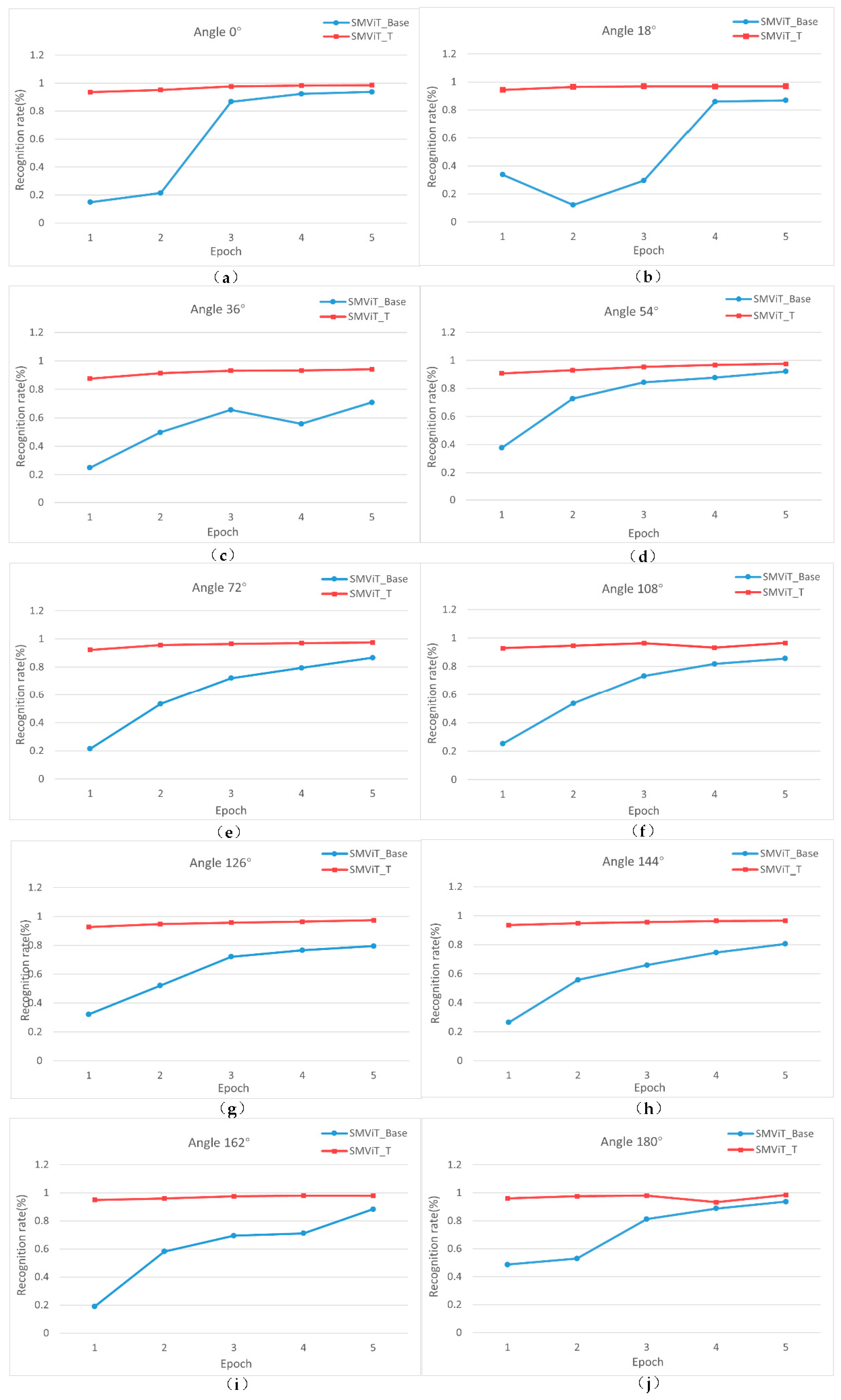
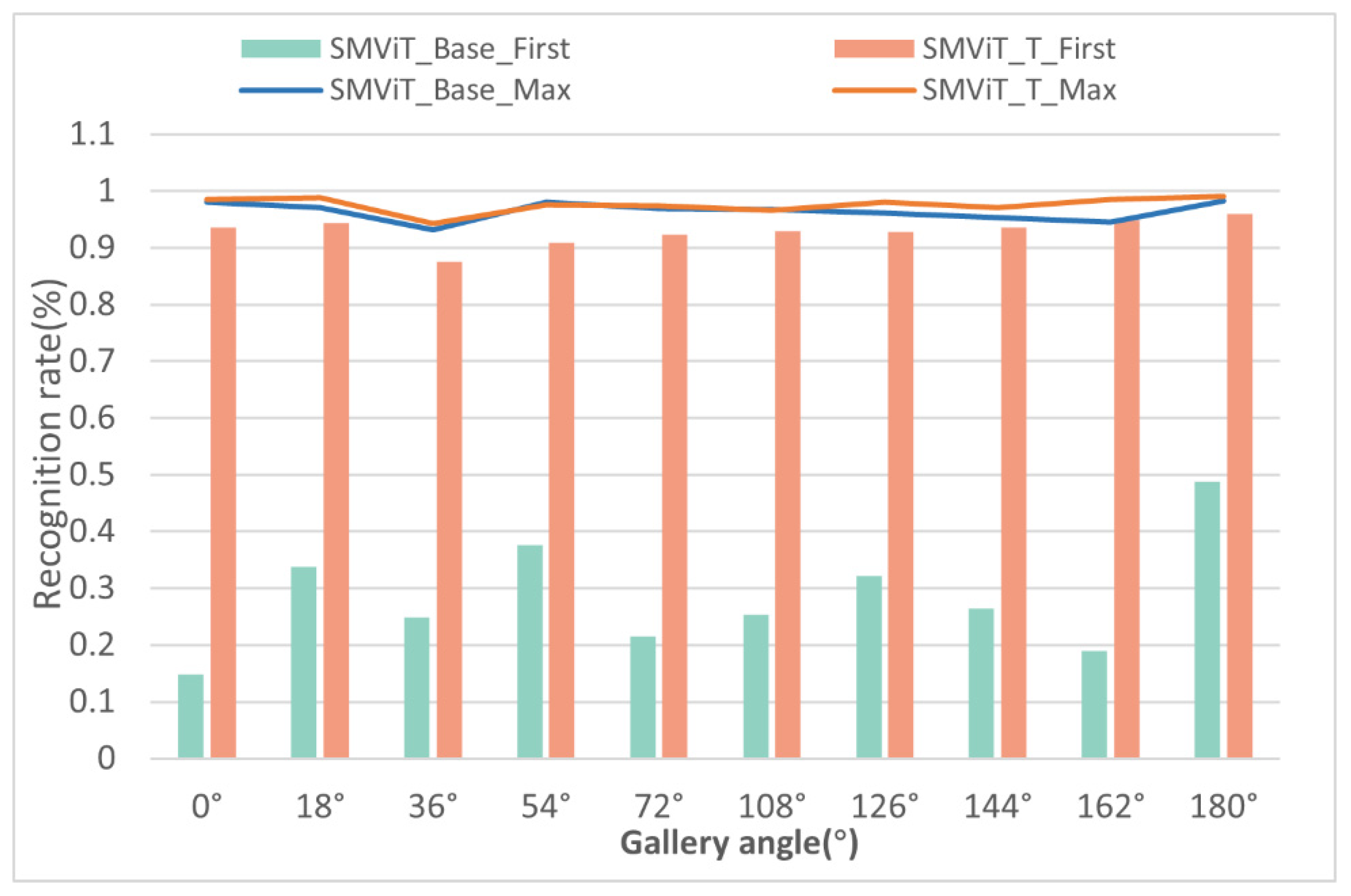
4.3. Experimental Results for the CASIA B Dataset
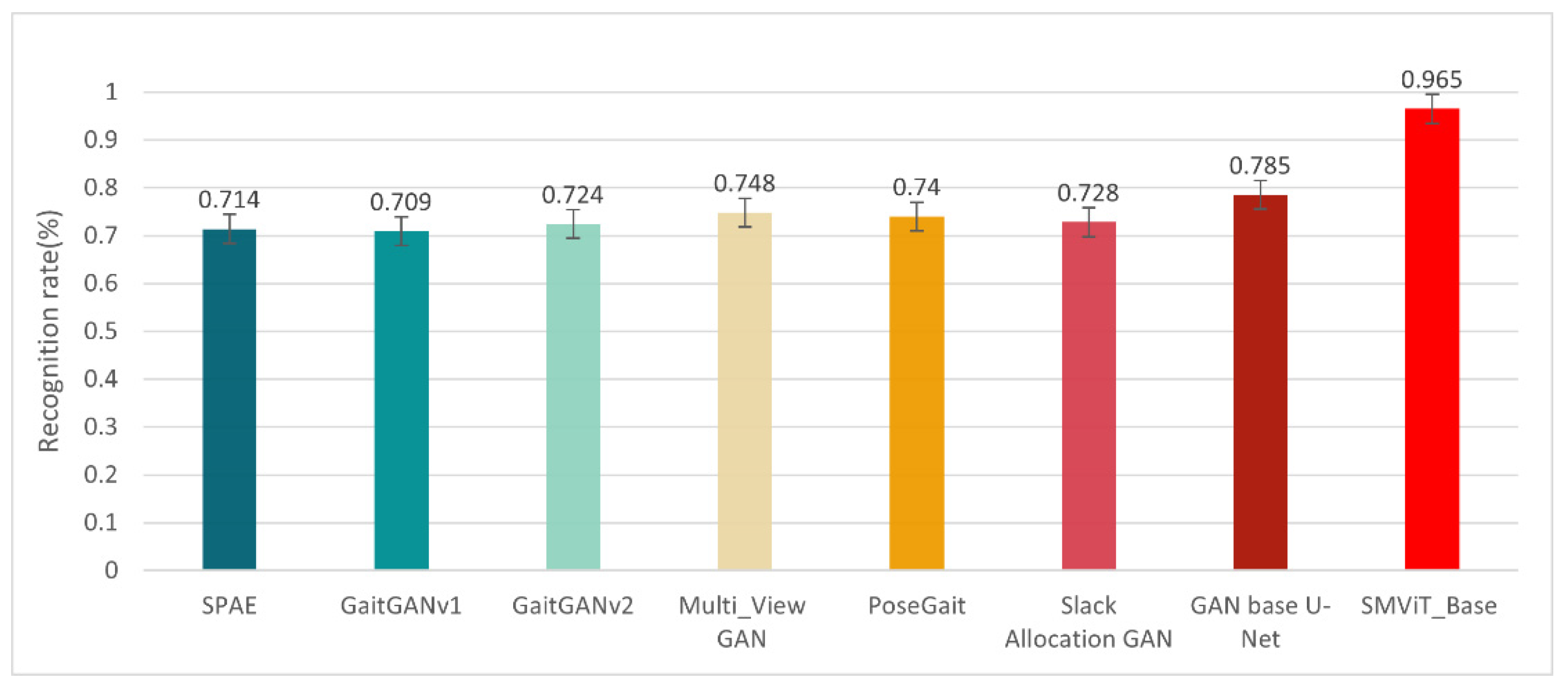
4.4. Comparison with the Latest Technology
4.4.1. Ablation Experiment
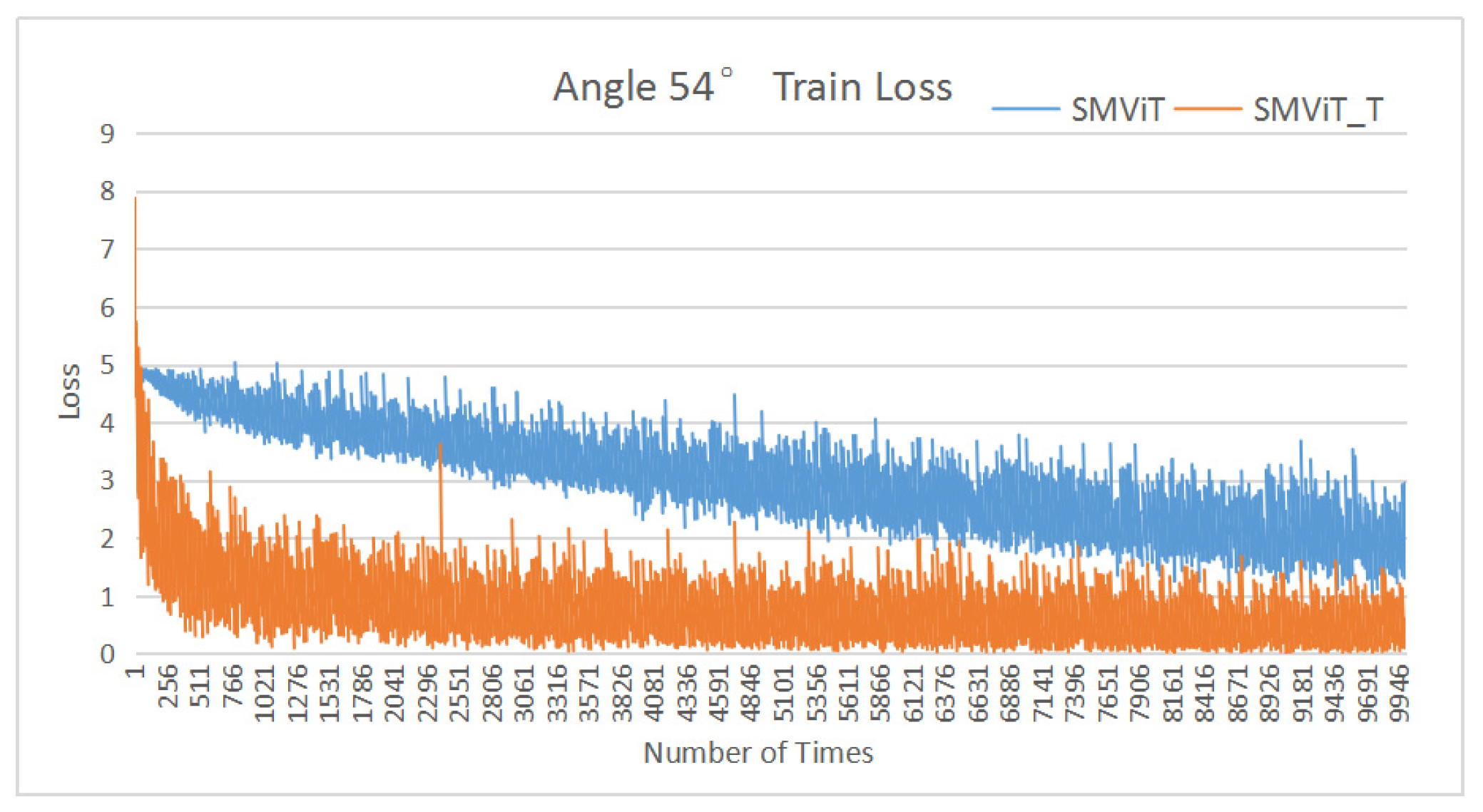
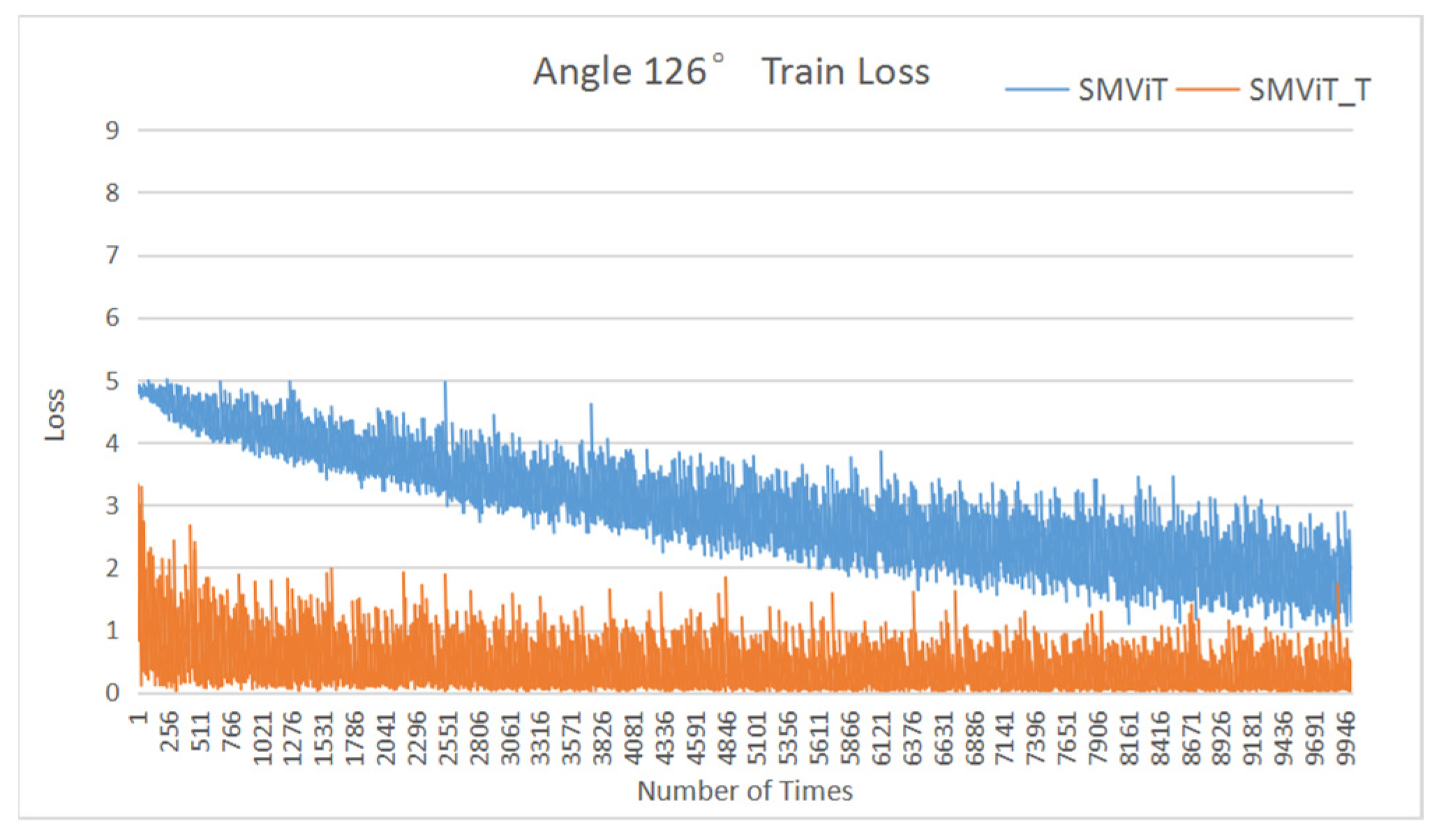
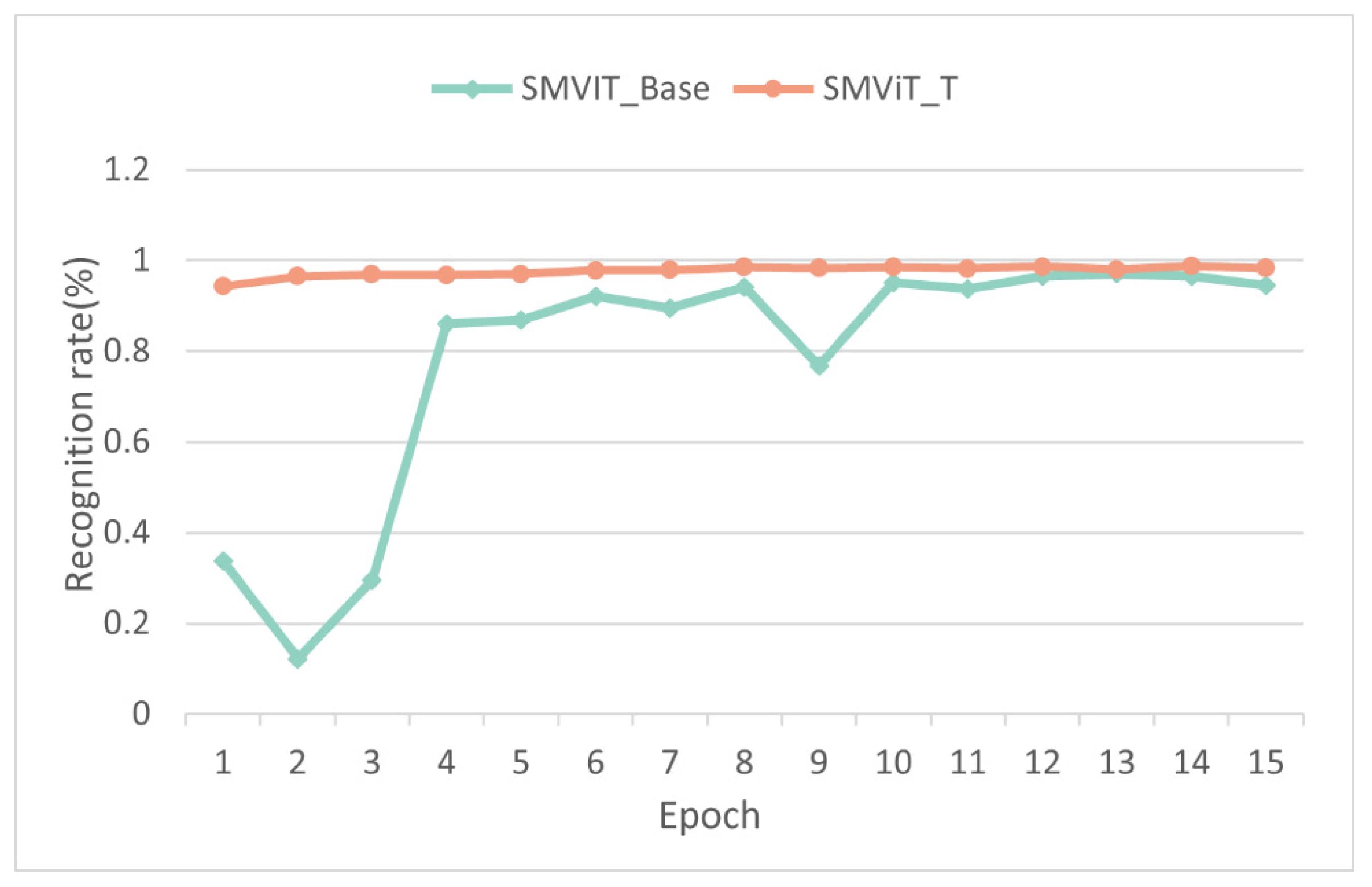
4.4.2. Validation of the Gradually Moving-View Training Strategy
5. Conclusions and Future Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, J.P.; Jain, S.; Arora, S.; Singh, U.P. Vision-based gait recognition: A survey. IEEE Access 2018, 6, 70497–70527. [Google Scholar] [CrossRef]
- A survey on gait recognition. ACM Comput. Surv. (CSUR) 2018, 51, 1–35.
- Sepas-Moghaddam, A.; Etemad, A. Deep gait recognition: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 264–284. [Google Scholar] [CrossRef] [PubMed]
- Fan, C.; Peng, Y.; Cao, C.; Liu, X.; Hou, S.; Chi, J.; Huang, Y.; Li, Q.; He, Z. Gaitpart: Temporal part-based model for gait recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14225–14233. [Google Scholar]
- Zhu, Z.; Guo, X.; Yang, T.; Huang, J.; Deng, J.; Huang, G.; Du, D.; Lu, J.; Zhou, J. Gait recognition in the wild: A benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 11–17 October 2021; pp. 14789–14799. [Google Scholar]
- Chao, H.; He, Y.; Zhang, J.; Feng, J. Gaitset: Regarding gait as a set for cross-view gait recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 22 February–1 March 2019; Volume 33, pp. 8126–8133. [Google Scholar]
- Asif, M.; Tiwana, M.I.; Khan, U.S.; Ahmad, M.W.; Qureshi, W.S.; Iqbal, J. Human gait recognition subject to different covariate factors in a multi-view environment. Results Eng. 2022, 15, 100556. [Google Scholar] [CrossRef]
- Yu, S.; Tan, D.; Tan, T. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 4, pp. 441–444. [Google Scholar]
- Bodor, R.; Drenner, A.; Fehr, D.; Masoud, O.; Papanikolopoulos, N. View-independent human motion classification using image-based reconstruction. Image Vis. Comput. 2009, 27, 1194–1206. [Google Scholar] [CrossRef]
- Ariyanto, G.; Nixon, M.S. Model-based 3D gait biometrics. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–7. [Google Scholar]
- Tome, D.; Russell, C.; Agapito, L. Lifting from the deep: Convolutional 3d pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2017; pp. 2500–2509. [Google Scholar]
- Weng, J.; Liu, M.; Jiang, X.; Yuan, G. Deformable pose traversal convolution for 3D action and gesture recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 136–152. [Google Scholar]
- Makihara, Y.; Sagawa, R.; Mukaigawa, Y.; Echigo, T.; Yagi, Y. Gait recognition using a view transformation model in the frequency domain. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 151–163. [Google Scholar]
- Han, J.; Bhanu, B. Individual recognition using gait energy image. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 28, 316–322. [Google Scholar] [CrossRef] [PubMed]
- Kusakunniran, W.; Wu, Q.; Li, H.; Zhang, J. Multiple views gait recognition using view transformation model based on optimized gait energy image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1058–1064. [Google Scholar]
- Kusakunniran, W.; Wu, Q.; Zhang, J.; Li, H.; Wang, L. Recognizing gaits across views through correlated motion co-clustering. IEEE Trans. Image Process. 2013, 23, 696–709. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Wang, Y.; Zhang, Z.; Little, J.J.; Huang, D. View-invariant discriminative projection for multi-view gait-based human identification. IEEE Trans. Inf. Forensics Secur. 2013, 8, 2034–2045. [Google Scholar] [CrossRef]
- Zhang, P.; Wu, Q.; Xu, J. VT-GAN, View transformation GAN for gait recognition across views. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Yu, S.; Chen, H.; Garcia Reyes, E.B.; Poh, N. Gaitgan: Invariant gait feature extraction using generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 30–37. [Google Scholar]
- Shiqi, Y.; Chen, H.; Liao, R.; An, W.; García, E.B.; Huang, Y.; Poh, N. GaitGANv2: Invariant gait feature extraction using generative adversarial networks. Pattern Recognit 2019, 87, 179–189. [Google Scholar]
- Wen, J.; Shen, Y.; Yang, J. Multi-view gait recognition based on generative adversarial network. Neural Process. Lett. 2022, 54, 1855–1877. [Google Scholar] [CrossRef]
- Chen, X.; Luo, X.; Weng, J.; Luo, W.; Li, H.; Tian, Q. Multi-view gait image generation for cross-view gait recognition. IEEE Trans. Image Process. 2021, 30, 3041–3055. [Google Scholar] [CrossRef] [PubMed]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 10–11 July 2015; Volume 2. [Google Scholar]
- Chen, X.; Yan, X.; Zheng, F.; Jiang, Y.; Xia, S.-T.; Zhao, Y.; Ji, R. One-shot adversarial attacks on visual tracking with dual attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10176–10185. [Google Scholar]
- Chen CF, R.; Fan, Q.; Panda, R. CrossViT: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 357–366. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Li, Q. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Chai, T.; Li, A.; Zhang, S.; Li, Z.; Wang, Y. Lagrange Motion Analysis and View Embeddings for Improved Gait Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20249–20258. [Google Scholar]
- Yu, S.; Chen, H.; Wang, Q.; Shen, L.; Huang, Y. Invariant feature extraction for gait recognition using only one uniform model. Neurocomputing 2017, 239, 81–93. [Google Scholar] [CrossRef]
- Gao, J.; Zhang, S.; Guan, X.; Meng, X. Multiview Gait Recognition Based on Slack Allocation Generation Adversarial Network. Wirel. Commun. Mob. Comput. 2022, 2022, 1648138. [Google Scholar] [CrossRef]
- Alvarez IR, T.; Sahonero-Alvarez, G. Cross-view gait recognition based on u-net. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Liao, R.; Yu, S.; An, W.; Huang, Y. A model-based gait recognition method with body pose and human prior knowledge. Pattern Recognit. 2020, 98, 107069. [Google Scholar] [CrossRef]
- Zhao, X.; He, Z.; Zhang, S.; Liang, D. Robust pedestrian detection in thermal infrared imagery using a shape distribution histogram feature and modified sparse representation classification. Pattern Recognit. 2015, 48, 1947–1960. [Google Scholar] [CrossRef]
- Li, L.; Xue, F.; Liang, D.; Chen, X. A Hard Example Mining Approach for Concealed Multi-Object Detection of Active Terahertz Image. Appl. Sci. 2021, 11, 11241. [Google Scholar] [CrossRef]
- Kang, B.; Liang, D.; Ding, W.; Zhou, H.; Zhu, W.-P. Grayscale-thermal tracking via inverse sparse representation-based collaborative encoding. IEEE Trans. Image Process. 2019, 29, 3401–3415. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Parameter/Version |
|---|---|
| CPU | I7-10700K |
| GPU | NVIDIA RTX 3060 |
| CUDA | 11.0 |
| Pytorch | 1.8 |
| Operating System | Win10 |
| Comparison of Model Accuracy for Each View When Not Crossing Views | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0° | 18° | 36° | 54° | 72° | 90° | 108° | 126° | 144° | 162° | 180° | |
| SPAE [31] | 0.7419 | 0.7661 | 0.7150 | 0.6989 | 0.7311 | 0.6801 | 0.6854 | 0.7258 | 0.7016 | 0.6881 | 0.7231 |
| GaitGANv1 [19] | 0.6828 | 0.7123 | 0.7285 | 0.7339 | 0.6962 | 0.7043 | 0.7150 | 0.7285 | 0.7204 | 0.7042 | 0.6828 |
| GaitGANv2 [20] | 0.7258 | 0.7554 | 0.7150 | 0.7332 | 0.7527 | 0.707 | 0.6962 | 0.7392 | 0.7150 | 0.7311 | 0.6989 |
| Multi_View GAN [21] | 0.7213 | 0.7869 | 0.7814 | 0.7589 | 0.7568 | 0.7131 | 0.7322 | 0.7431 | 0.7431 | 0.7480 | 0.7513 |
| Slack Allocation GAN [32] | 0.7473 | 0.7258 | 0.7258 | 0.7141 | 0.7560 | 0.7336 | 0.6967 | 0.7365 | 0.7277 | 0.7243 | 0.7221 |
| GAN based on U-Net [33] | 0.7365 | 0.7715 | 0.7956 | 0.7957 | 0.8521 | 0.7822 | 0.8172 | 0.7956 | 0.7984 | 0.7419 | 0.7580 |
| PoseGait [34] | 0.7231 | 0.7365 | 0.7688 | 0.7822 | 0.7446 | 0.7473 | 0.7607 | 0.7284 | 0.7553 | 0.7365 | 0.6586 |
| SMViT_Base | 0.9802 | 0.9704 | 0.9318 | 0.9805 | 0.9689 | 0.9744 | 0.9668 | 0.9617 | 0.9529 | 0.9451 | 0.9831 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Yun, L.; Li, R.; Cheng, F.; Wang, K. Multi-View Gait Recognition Based on a Siamese Vision Transformer. Appl. Sci. 2023, 13, 2273. https://doi.org/10.3390/app13042273
Yang Y, Yun L, Li R, Cheng F, Wang K. Multi-View Gait Recognition Based on a Siamese Vision Transformer. Applied Sciences. 2023; 13(4):2273. https://doi.org/10.3390/app13042273
Chicago/Turabian StyleYang, Yanchen, Lijun Yun, Ruoyu Li, Feiyan Cheng, and Kun Wang. 2023. "Multi-View Gait Recognition Based on a Siamese Vision Transformer" Applied Sciences 13, no. 4: 2273. https://doi.org/10.3390/app13042273