
Infrared Small and Moving Target Detection on Account of the Minimization of Non-Convex Spatial-Temporal Tensor Low-Rank Approximation under the Complex Background

Abstract
:Featured Application
Abstract
1. Introduction
- (1)
- A non-convex spatial-temporal tensor low-rank approximation minimization method for the detection of infrared points and moving targets in the sequence scenarios was proposed. We introduced 3D-TV regularization into the NRAM model. The 3D-TV constraint on the background is helpful for keeping the image details and removing the noise, so it can achieve better detection performance under complex backgrounds.
- (2)
- The norm is introduced into the detection of IR points and moving targets to better describe the target components. By combining structured sparsity terms, non-target components, especially those with strong edges, can be eliminated.
- (3)
- The ADMM is used to efficiently reduce the computational complexity and solve the low-rank component recovery problem.
2. Related Work
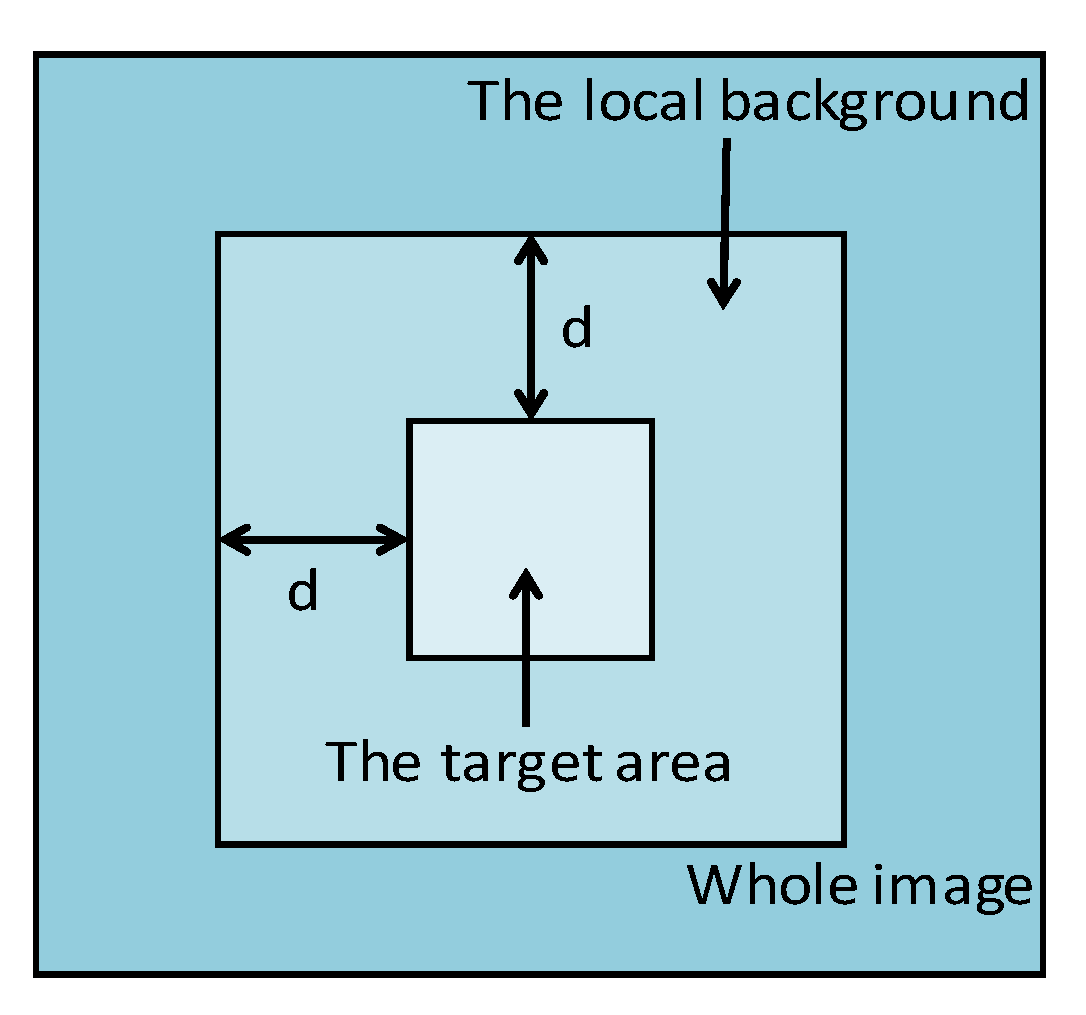
2.1. Spatial-Temporal Patch Tensor Model
2.2. Foreground Modeling on Account of 3D-TV Regularization
2.3. Background Modeling on Account of the Tensor Nuclear Norm
3. Methods
3.1. Low Rank and Sparse Frame Model
3.2. Solution Finding of MNSTLA Model
3.3. The Processing of the MNSTLA
| Algorithm 1: The Minimization of Non-Convex Spatial-Temporal Tensor Low-Rank Approximation Algorithm(MNSTLA) |
| Input:, , L and |
| Initialize:, |
| ADMM for solving the Equation (17) |
| while |
| (1) |
| (2) |
| (3) |
| (4) |
| (5) |
| (6) Update k = k + 1. |
| Output |
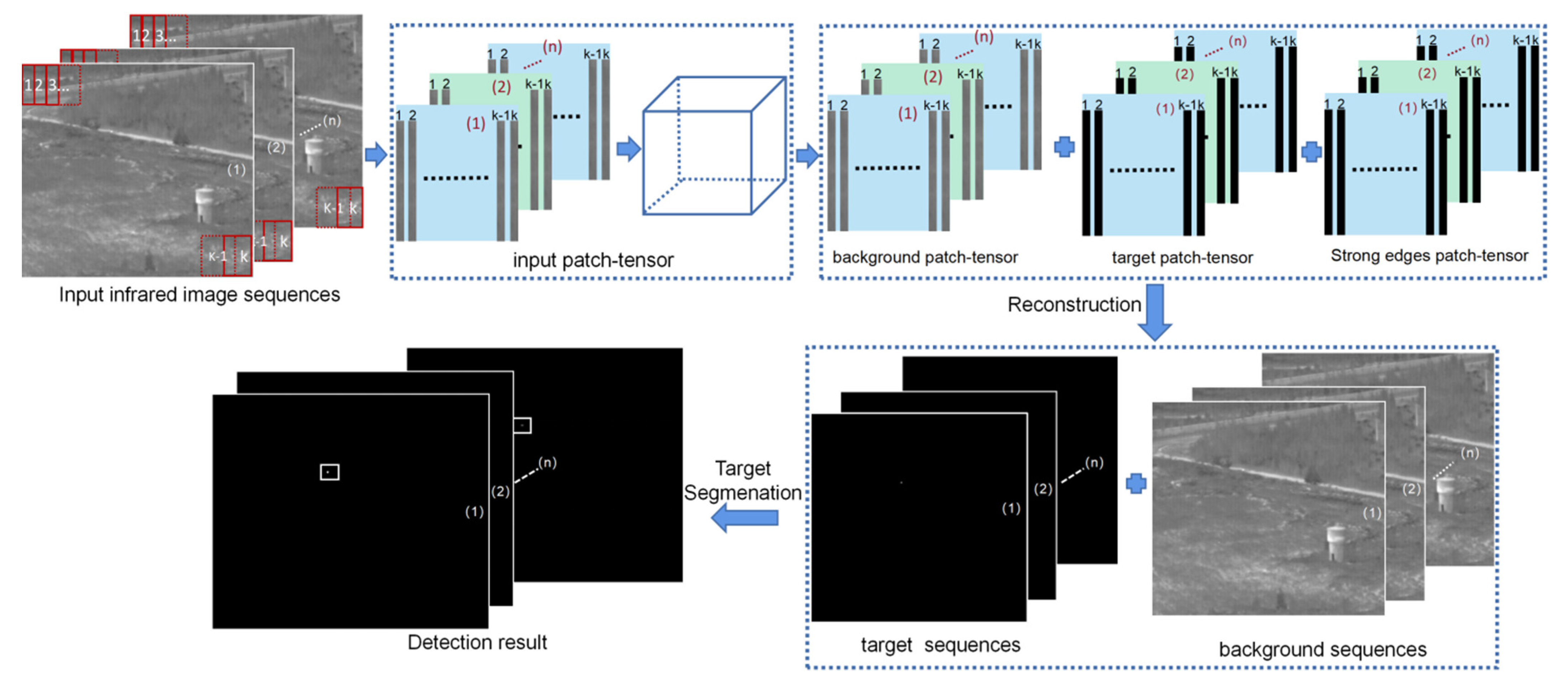
- (1)
- The original infrared image sequences are sequentially arranged by adjacent frames and are converted into several patch-tensor tensors .
- (2)
- The original patch-tensor is decomposed into the target patch-tensor T, background patch-tensor B, and structural noise (strong edge) patch-tensor E by using the method 1.
- (3)
- The target image and the background image are reconstructed by inverse operation.
- (4)
- In the last step, we segment the target using the adaptive threshold [8]:where is the mean value of the reconstructed confidence map, is the standard deviation, and λ is a constant.
4. Experiment and Analysis of Experimental Results
4.1. Data Set and Evaluation Indicators
4.1.1. Test Data Set
4.1.2. Evaluation Indicators
- (1)
- Background suppression factor (BSF) [9]:
- (2)
- Local contrast gain (LCG)
- (3)
- Receiver operating characteristic curve (ROC)
4.2. Parameter Setting
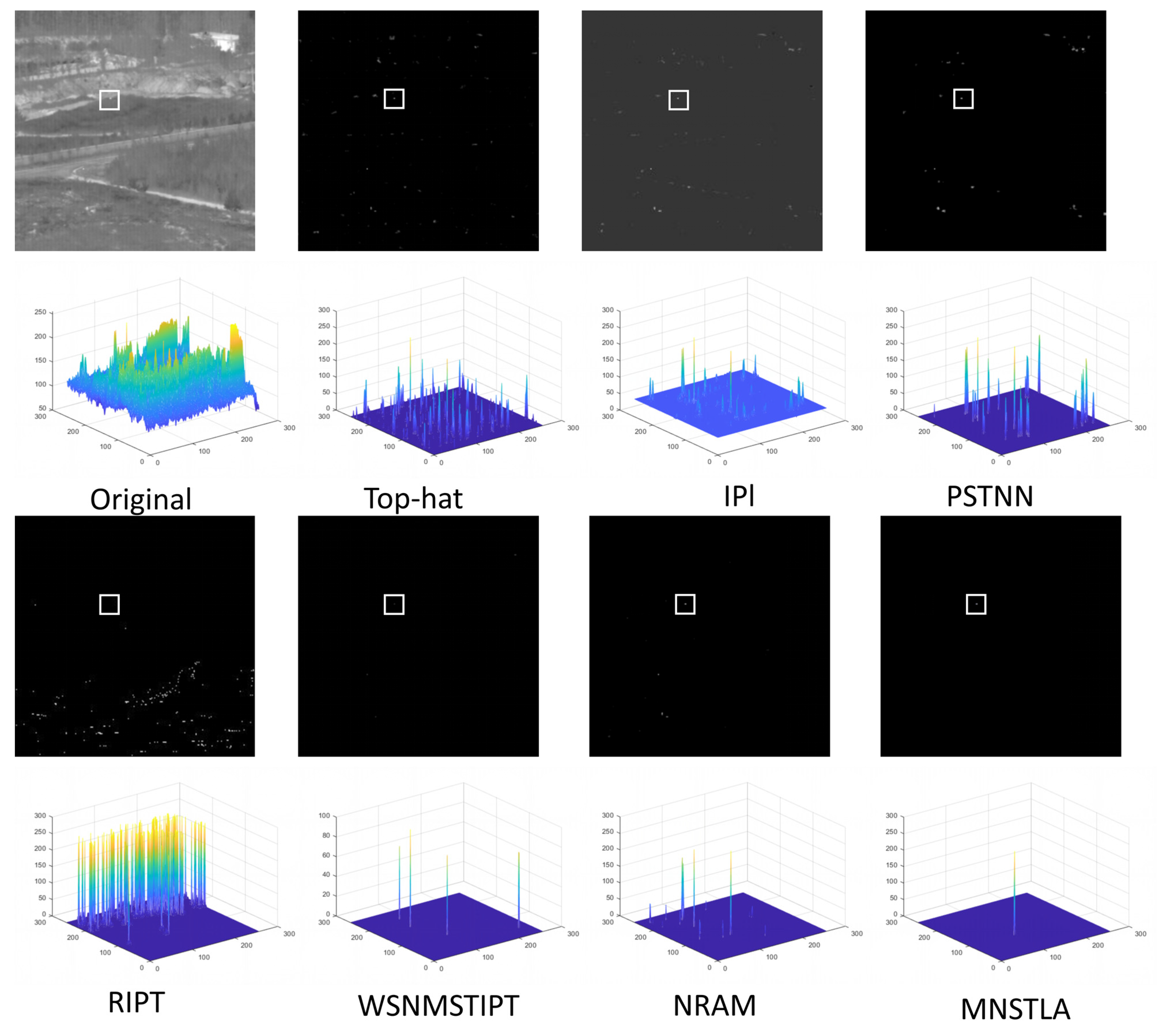
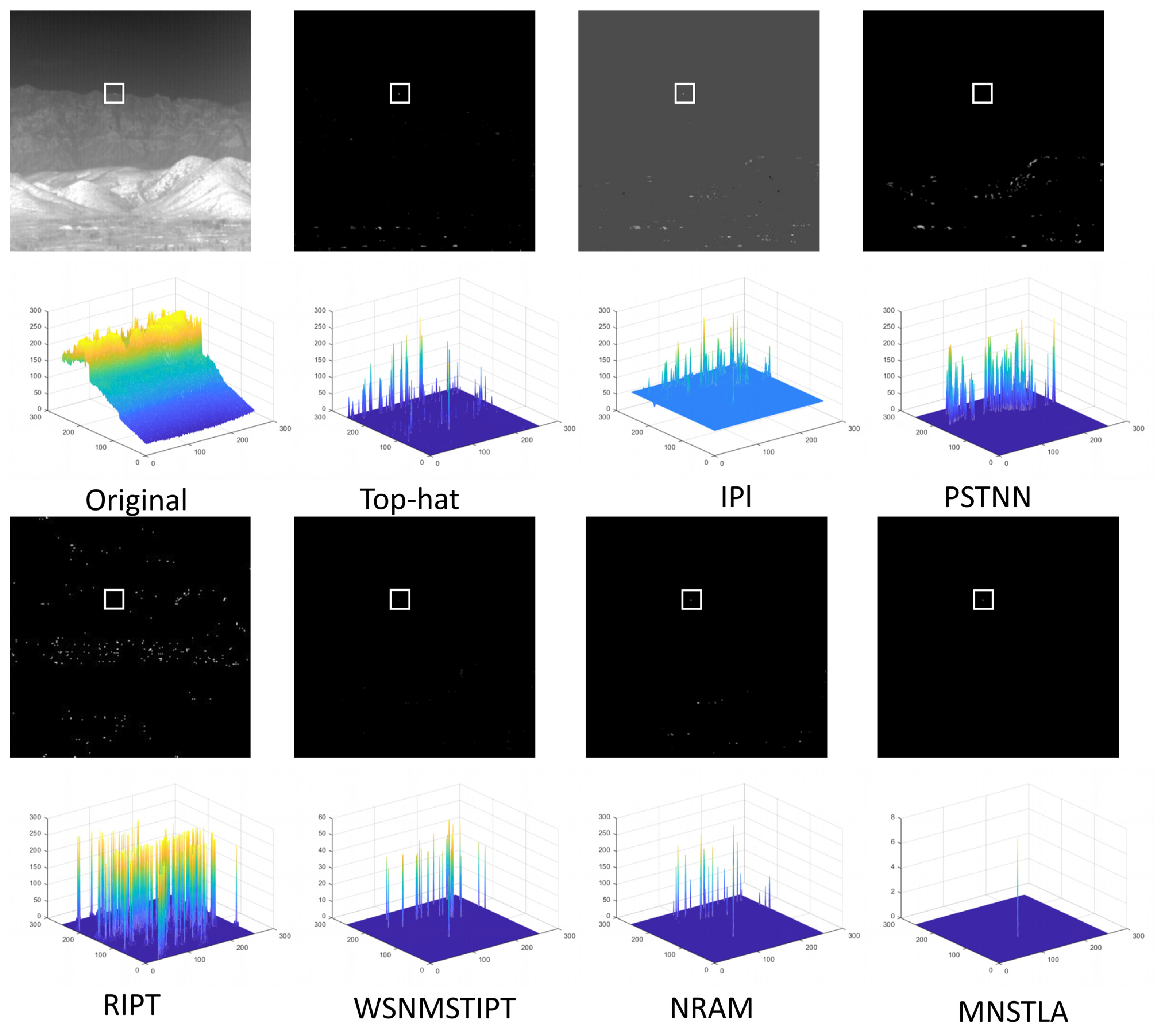
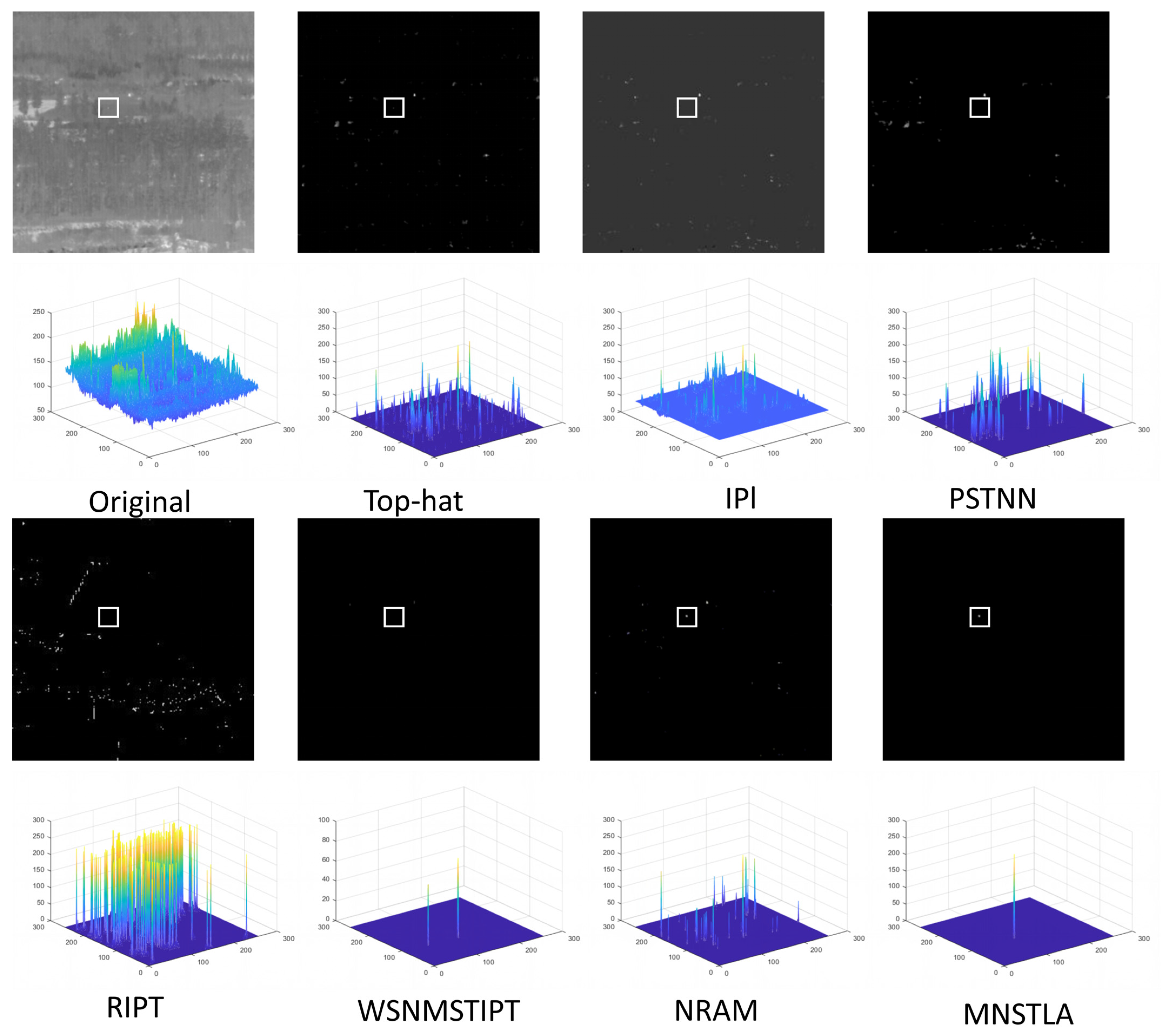
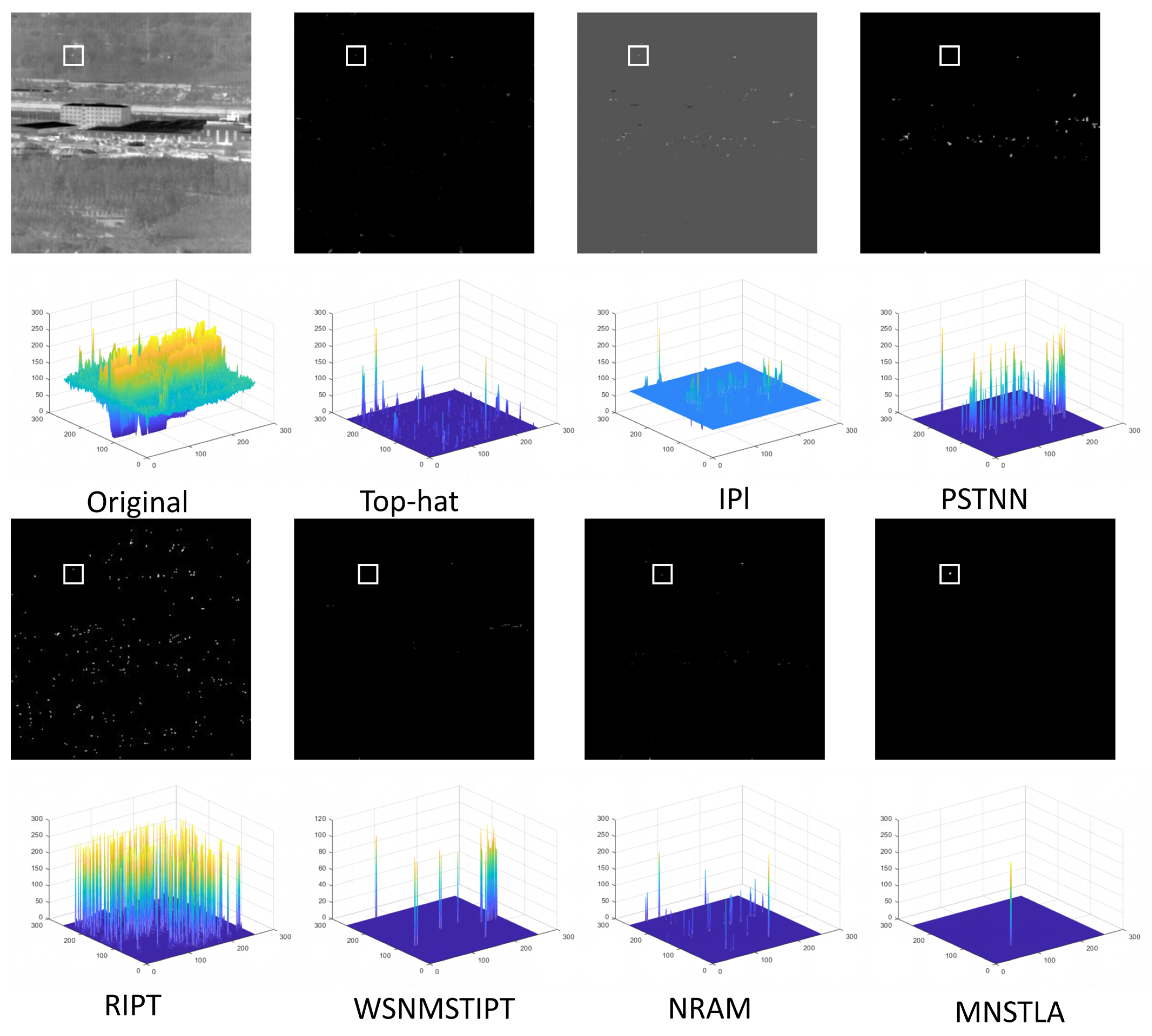
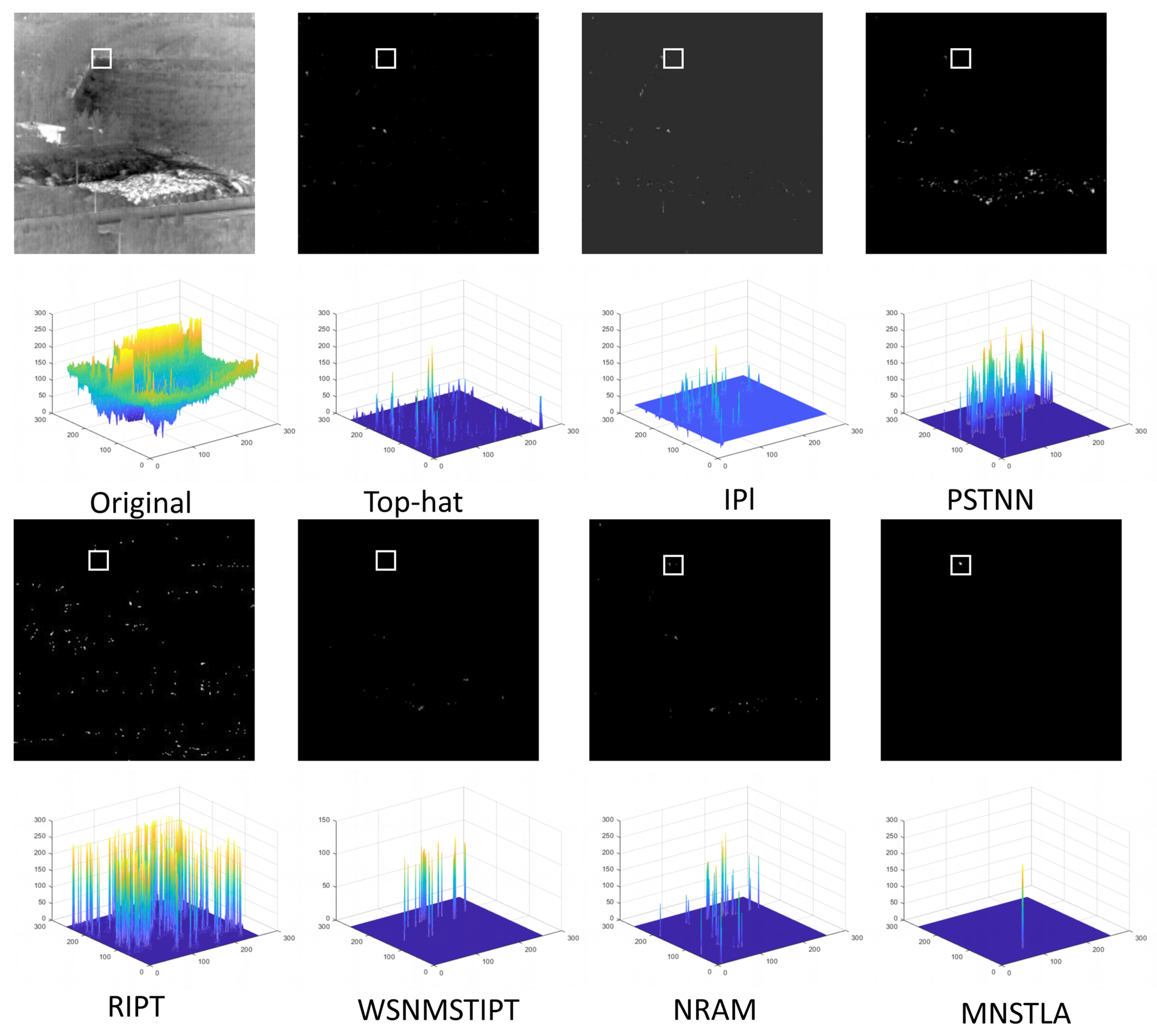
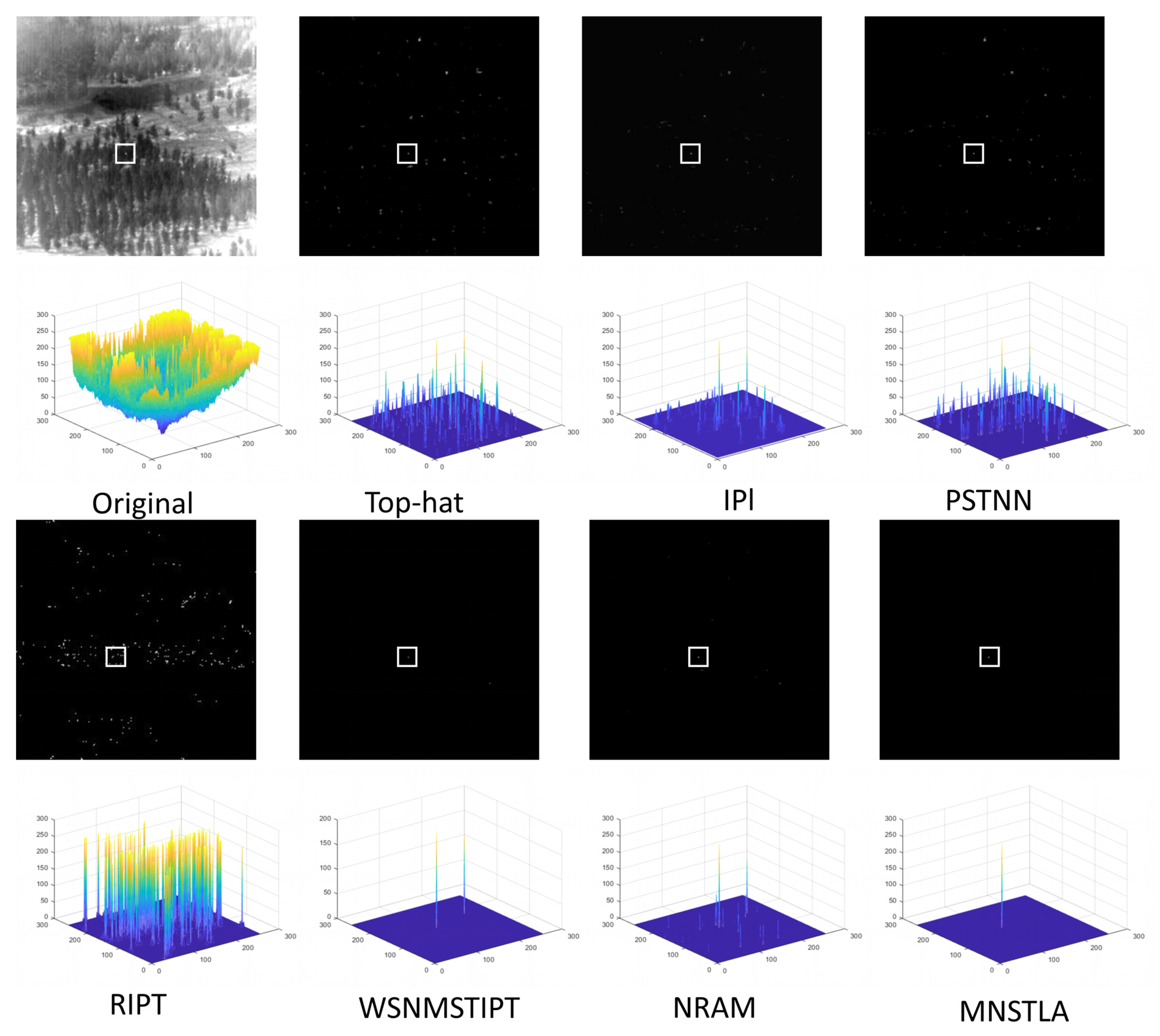
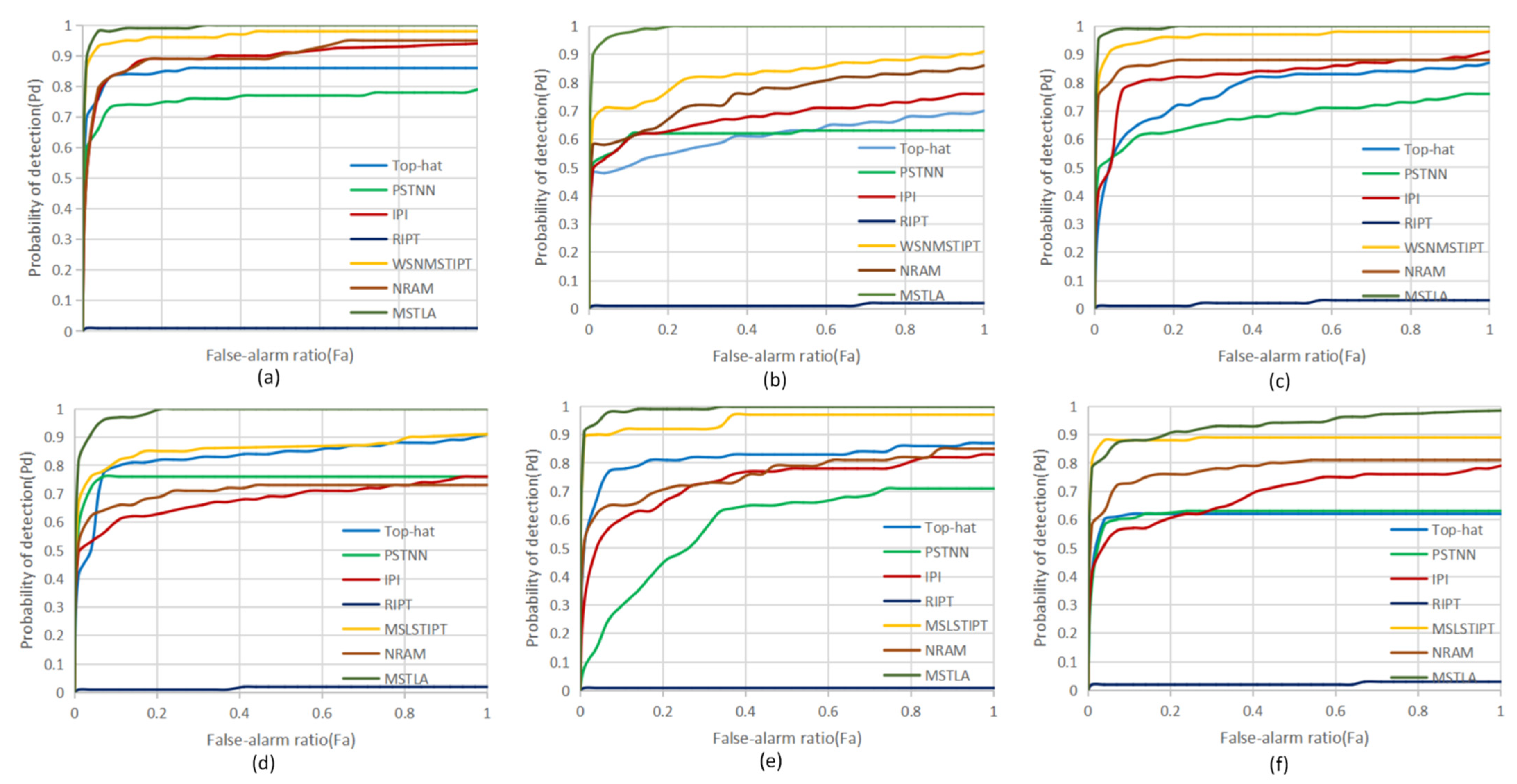
4.3. Subjective Evaluation in Different Scenes
4.4. Objective Evaluation for Different Scenes
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huan, K.W.; Pang, B.; Shi, X.G.; Zhao, Q.Y.; Shi, N.N. Research on Performance Testing and Evaluation of Infrared Imaging System. Infrared Laser Eng. 2008, 6, 482–486. [Google Scholar]
- Wang, G.H.; Mao, S.Z.; He, Y. A Survey of Radar and Infrared Data Fusion. Fire Control. Command. Control. 2002, 27, 4. [Google Scholar]
- Yang, L.; Sun, Q.; Wang, J.; Guo, B.; Li, C. Design of long-wave infrared continuous zoom optical system. Infrared Laser Eng. 2012, 41, 99–100. [Google Scholar]
- Zhou, X.; Yang, C.; Yu, W. Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 597–610. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhi, G.; Cheong, L.-F.; Wang, Y.-X. Block-Sparse RPCA for Salient Motion Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1975–1987. [Google Scholar]
- Chen, C.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sen. 2013, 52, 574–581. [Google Scholar] [CrossRef]
- He, Y.J.; Li, M.; Zhang, J.L.; An, Q. Small infrared target detection on account based on flow-rank and sparse representation. Infrared Phys. Technol. 2015, 68, 98–109. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared Patch-Image Model for point target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Song, Y. Infrared point target and background separation via column-wise weighted robust principal component analysis. Infrared Phys. Technol. 2016, 77, 421–430. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y. Reweighted Infrared Patch-Tensor Model With Both Nonlocal and Local Priors for Single-Frame point target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef] [Green Version]
- Dai, Y.; Wu, Y.; Song, Y.; Guo, J. Non-negative infrared patch-image model: Robust target-background separation via partial sum minimization of singular values. Infrared Phys. Technol. 2017, 81, 182–194. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, J.; Long, Y.; Shang, Z.; An, W. Infrared patch tensor model with weighted tensor nuclear norm for point target detection in a single frame. IEEE Access 2018, 6, 76140–76152. [Google Scholar] [CrossRef]
- Bin, X.; Xinhan, H.; Min, W. Infrared dim point target detection on account of adaptive target image recovery. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2017, 45, 25–30. [Google Scholar]
- Wang, X.Y.; Peng, Z.; Kong, D.; Zhang, P.; He, Y. Infrared dim target detection on account of total variation regularization and principal component pursuit. Image Vis. Comput. 2017, 63, 1–9. [Google Scholar] [CrossRef]
- Wang, X.Y.; Peng, Z.; Kong, D.; He, Y. Infrared dim and small target detection on account of stable multisubspace learning in heterogeneous scene. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5481–5493. [Google Scholar] [CrossRef]
- Zhang, L.D.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared small target detection via non-convex rank approximation minimization joint l2,1 norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Lin, Z.; Zha, H. Essential tensor learning for multi-view spectral clustering. IEEE Trans. Image Process. 2019, 28, 5910–5922. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Li, X.; Jing, P.; Liu, J.; Su, Y. Low-rank regularized heterogeneous tensor decomposition for subspace clustering. IEEE Signal Process. Lett. 2018, 25, 333–337. [Google Scholar] [CrossRef]
- Jing, P.; Guan, W.; Bai, X.; Guo, H.; Su, Y. Single image super-resolution via low-rank tensor representation and hierarchical dictionary learning. Multimed. Tools Appl. 2020, 79, 11767–11785. [Google Scholar] [CrossRef]
- Zhou, P.; Lu, C.; Feng, J.; Lin, Z.; Yan, S. Tensor low-rank representation for data recovery and clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1718–1732. [Google Scholar] [CrossRef]
- Gao, C.; Wang, L.; Xiao, Y.; Zhao, Q.; Meng, D. Infrared small-dim target detection on account of Markov random field guided noise modeling. Pattern Recognit. 2018, 76, 463–475. [Google Scholar] [CrossRef]
- Chen, L.X.; Liu, J.L.; Wang, X.W. Foreground detection with weighted Schatten-p norm and 3D total variation. J. Comput. Appl. 2019, 39, 1170–1175. [Google Scholar]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor robust principal component analysis with a new tensor nuclear norm. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 925–938. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, Y.; Yang, J.; Li, M.; An, W. Infrared point target detection via spatial–temporal infrared patch-tensor model and weighted schatten p-norm minimization. Infrared Phys. Technol. 2019, 102, 103050. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, J.; Zhao, Q.; Leung, Y.; Zhao, X.; Meng, D. Hyperspectral image restoration via total variation regularized low-rank tensor decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 1227–1243. [Google Scholar] [CrossRef] [Green Version]
- Gu, S.H.; Zhang, L.; Zuo, W.M.; Feng, X.C. Weighted Nuclear Norm Minimization with Application to Image Denoising. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Kang, Z.; Peng, C.; Cheng, Q. Robust PCA via Nonconvex Rank Approximation. In Proceedings of the 2015 IEEE International Conference on Data Mining (ICDM), Atlantic City, NJ, USA, 14–17 November 2015; pp. 211–220. [Google Scholar]
- Fazel, M.; Hindi, H.; Boyd, S.P. Log-det heuristic for matrix rank minimization with applications to Hankel and Euclidean distance matrices. In Proceedings of the 2003 American Control Conference, Denver, CO, USA, 4–6 June 2003; pp. 2156–2162. [Google Scholar]
- Guo, J.; Wu, Y.Q.; Dai, Y.M. Point target detection on account of reweighted infrared patch-image model. IEEE Image Process. 2018, 12, 70–79. [Google Scholar] [CrossRef]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 2080–2088. [Google Scholar]
- Peng, Y.; Suo, J.; Dai, Q.; Xu, W. Reweighted low-rank matrix recovery and its application in image restoration. IEEE Trans. Cybern. 2014, 44, 2418–2430. [Google Scholar] [CrossRef]
- Liu, Z.S.; Li, J.C.; Li, G.; Bai, J.C.; Liu, X.N. A New Model for Sparse and Low-Rank Matrix Decomposition. J. Appl. Anal. Comput. 2017, 7, 600–616. [Google Scholar]
- Zhao, Y.; Pan, H.; Du, C.; Peng, Y.; Zheng, Y. Bilateral two-dimensional least mean square filter for infrared point target detection. Infrared Phys. Technol. 2014, 65, 17–23. [Google Scholar] [CrossRef]
- Bae, T.W.; Zhang, F.; Kweon, I.S. Edge directional 2D LMS filter for infrared point target detection. Infrared Phys. Technol. 2012, 55, 137–145. [Google Scholar]
- Bae, T.W.; Kim, Y.C.; Ahn, S.H.; Sohng, K.I. A novel Two-Dimensional LMS (TDLMS) using sub-sampling mask and step-size index for point target detection. IEICE Electron. Express 2010, 7, 112–117. [Google Scholar] [CrossRef] [Green Version]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. Stat. Methodol. Ser. B 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Hui, B.; Song, Z.; Fan, H.; Zhing, P.; Hu, W.; Zhang, X.; Ling, J.; Su, H.; Jin, W.; Jang, Y.; et al. A dataset for infrared detection and tracking of dim-small aircraft targets underground/air background. China Sci. Data 2020, 5, 286–297. [Google Scholar] [CrossRef]
- Gao, C.; Zhang, T.; Li, Q. Small infrared target detection using sparse ring representation. IEEE Aerosp. Electron. Syst. Mag. 2012, 27, 21–30. [Google Scholar]
- Sun, Y.; Yang, J.; Long, Y.; An, W. Infrared point target Detection Via Spatial-Temporal Total Variation Regularization and Weighted Tensor Nuclear Norm. IEEE Access 2019, 7, 56667–56682. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, J.; An, W. Infrared Dim and point target Detection via Multiple Subspace Learning and Spatial-Temporal Patch-Tensor Model. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3737–3752. [Google Scholar] [CrossRef]
- Rivest, J.-F.; Fortin, R. Detection of dim targets in digital infrared imagery by morphological image processing. Opt. Eng. 1996, 35, 1886–1893. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | No. Frame | Scenario Description |
|---|---|---|
| data1 | 399 | Close range, single target, sky background |
| data2 | 599 | Close range, two targets, sky background, cross flight |
| data3 | 100 | Close range, single target, air-ground interface background, the target enters the field of view again after leaving the field of view. |
| data4 | 399 | Close range, two targets, sky background, cross flight |
| data5 | 3000 | Long range, single target, ground background, long time |
| data6 | 399 | From near to far, single target, ground background |
| data7 | 399 | From near to far, single target, ground background |
| data8 | 399 | From far to near, single target, ground background |
| data9 | 399 | From near to far, single target, ground background |
| data10 | 401 | Target from near to far, single target, ground-air interface background |
| data11 | 745 | Target from far to near, single target, ground background |
| data12 | 1500 | Target from far to near, single target, target mid-course maneuver, ground background |
| data13 | 763 | Target from near to far, single target, dim target, ground background |
| data14 | 1462 | Target from near to far, single target, ground background, target interfered by ground vehicles |
| data15 | 751 | Single target, target maneuver, ground background |
| data16 | 499 | Target from far to near, single target, extended target, target maneuver, ground background |
| data17 | 500 | Target from near to far, single target, dim target, ground background |
| data18 | 500 | Target from far to near, single target, ground background |
| data19 | 1599 | Single target, target maneuver, ground background |
| data20 | 400 | Single target, target maneuver, air-ground background |
| data21 | 500 | Long range, single target, ground background |
| data22 | 500 | Target from far to near, single target, ground background |
| Methods | Parameter Setting |
|---|---|
| Top-Hat | Structure size: 3 × 3, structure shape: square |
| PSTNN | , patch size: 40 × 40, ε = 1 × 10−7 |
| IPI | , ε = 10−7 |
| RIPT | , sliding step: 10, L = 0.7, h = 1, ε = 10−7 |
| WSNMSTIPT | |
| NRAM | /2.5, ε = 10−7 |
| MNSTLA | where c = 3, L = 3. C = 2.5, ε = 1 × 10−7 |
| Methods | a | b | c | d | e | f | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BSF | LCG | BSF | LCG | BSF | LCG | BSF | LCG | BSF | LCG | BSF | LCG | |
| Top-Hat | 7.73 | 5.94 | 3.28 | 6.76 | 7.86 | 1.67 | 9.66 | 7.53 | 10.25 | 3.64 | 7.34 | 3.45 |
| PSTNN | 3.85 | 1.23 | 3.86 | 8.20 | 4.16 | 1.18 | 3.67 | 2.43 | 4.14 | 3.16 | 3.14 | 2.99 |
| IPI | 3.35 | 1.70 | 2.30 | 5.65 | 3.45 | 1.06 | 3.19 | 3.18 | 5.61 | 2.37 | 2.02 | 1.94 |
| RIPT | 0.92 | 3.11 | 0.72 | 3.16 | 1.76 | 1.29 | 1.62 | 2.01 | 1.26 | 1.29 | 0.56 | 1.93 |
| WSNMSTIPT | 5.16 | 6.22 | 2.08 | 22.35 | 4.26 | 2.36 | 5.08 | 2.86 | 3.46 | 4.16 | 3.29 | 3.38 |
| NRAM | 26.45 | 1.235 | 23.74 | 6.39 | 7.08 | 1.68 | 18.16 | 16.18 | 9.31 | 2.17 | 10.67 | 4.86 |
| MNSTLA | 61.25 | 8.353 | 36.29 | 26.58 | 63.42 | 6.98 | 39.61 | 7.69 | 54.36 | 5.93 | 53.17 | 5.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, K.; Jiang, D.; Yun, L.; Liu, X. Infrared Small and Moving Target Detection on Account of the Minimization of Non-Convex Spatial-Temporal Tensor Low-Rank Approximation under the Complex Background. Appl. Sci. 2023, 13, 1196. https://doi.org/10.3390/app13021196
Wang K, Jiang D, Yun L, Liu X. Infrared Small and Moving Target Detection on Account of the Minimization of Non-Convex Spatial-Temporal Tensor Low-Rank Approximation under the Complex Background. Applied Sciences. 2023; 13(2):1196. https://doi.org/10.3390/app13021196
Chicago/Turabian StyleWang, Kun, Defu Jiang, Lijun Yun, and Xiaoyang Liu. 2023. "Infrared Small and Moving Target Detection on Account of the Minimization of Non-Convex Spatial-Temporal Tensor Low-Rank Approximation under the Complex Background" Applied Sciences 13, no. 2: 1196. https://doi.org/10.3390/app13021196