
Distributed Online Multi-Label Learning with Privacy Protection in Internet of Things


Abstract
:1. Introduction
2. Related Work
2.1. Multi-Label Classification
2.2. Online Learning
2.3. Distributed Least-Squares Iterative Methods
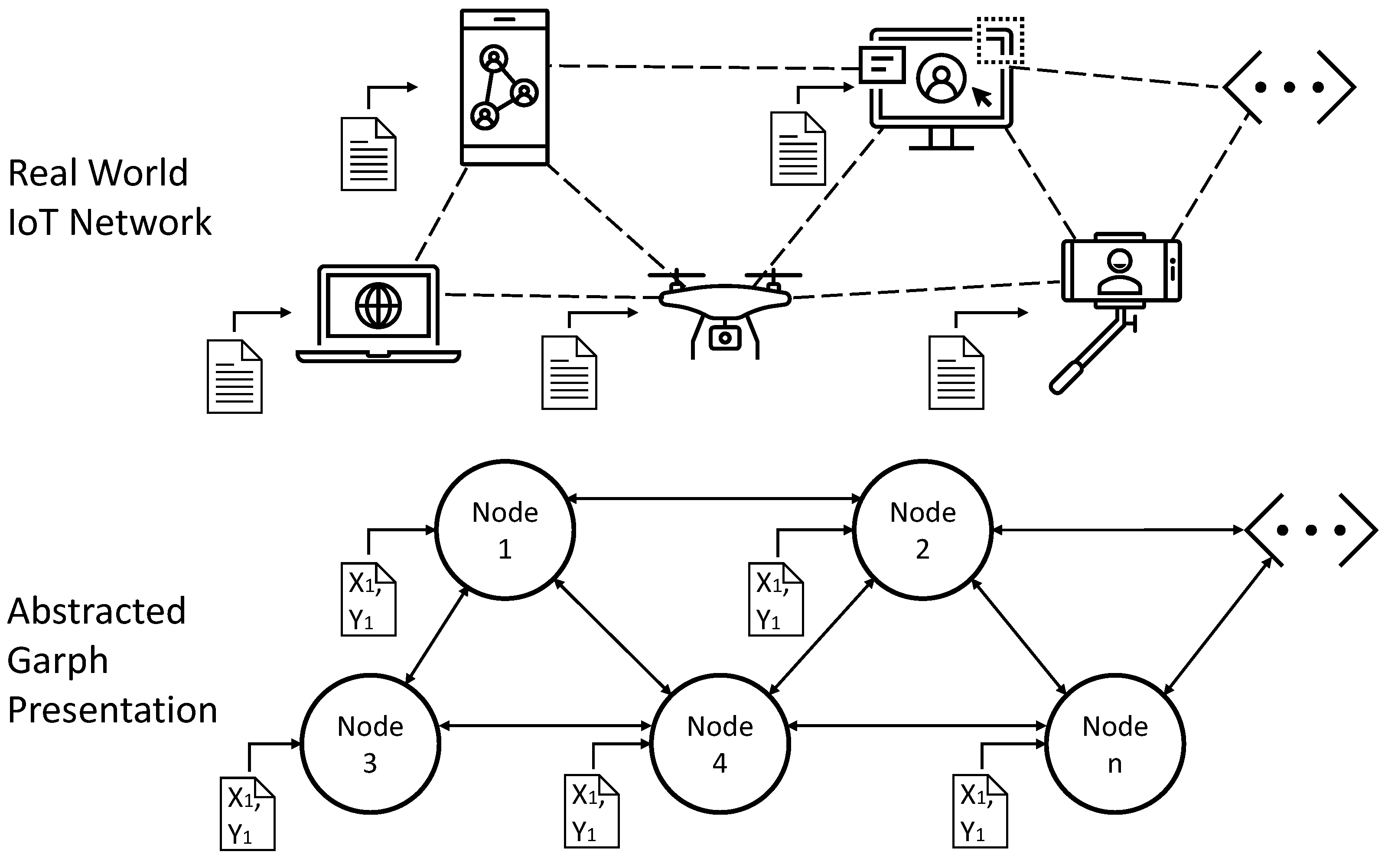
3. Problem Definition
4. Distributed OMLC Algorithm
4.1. Abstracted Problem Formulation
4.2. Distributed Discrete-Time Update
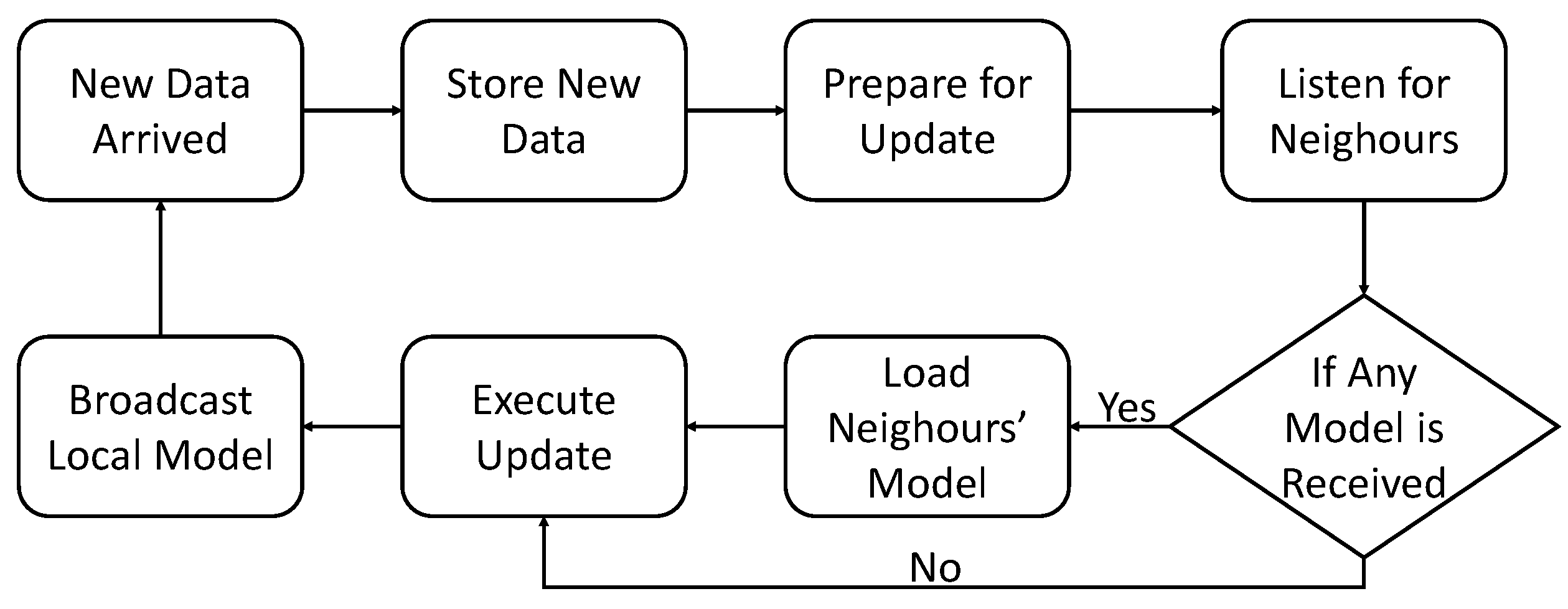
5. Our Proposed Algorithm
| Algorithm 1 Single node update of the distributed OMLC algorithm |
|
6. Experiment Setup
6.1. Evaluation Metrics
6.1.1. Hamming Loss
6.1.2. F1 Scores
6.1.3. Datasets and Baseline Methods
7. Results
7.1. Performance Comparison with Centralized Methods
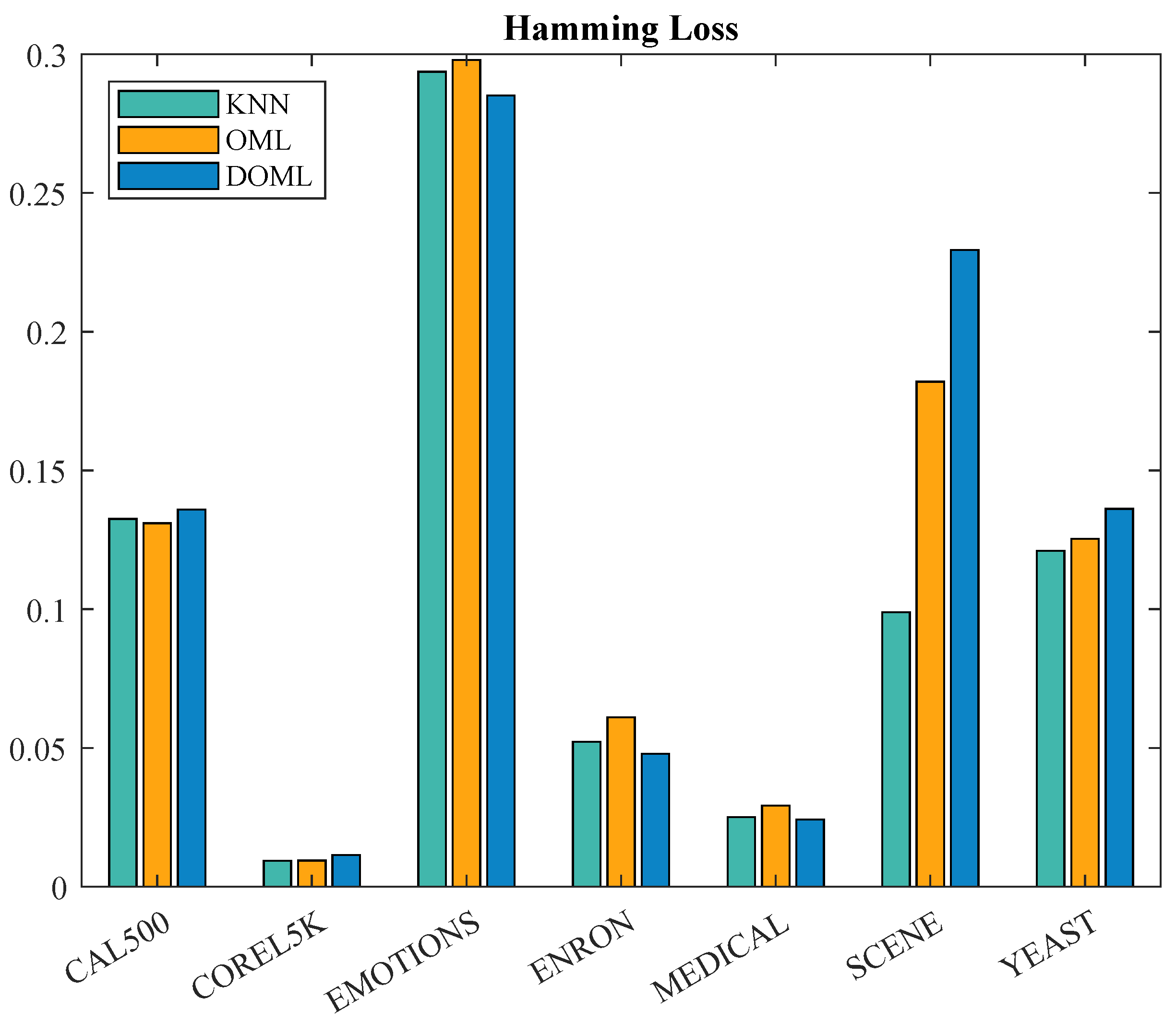
7.1.1. Hamming Loss Evaluation
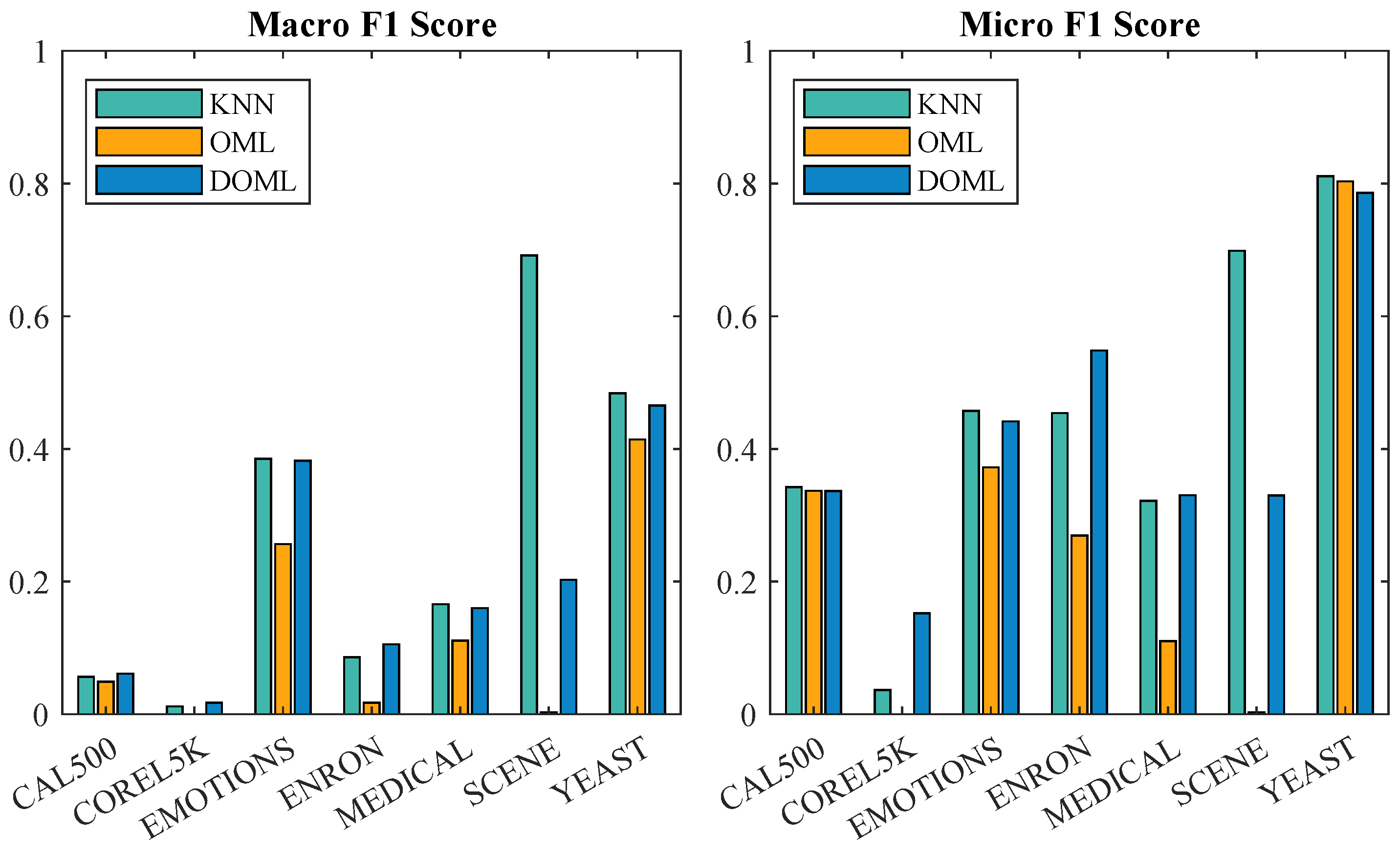
7.1.2. F1 Score Evaluation
7.2. Performance Analysis in a Large-Scale Distributed Environment
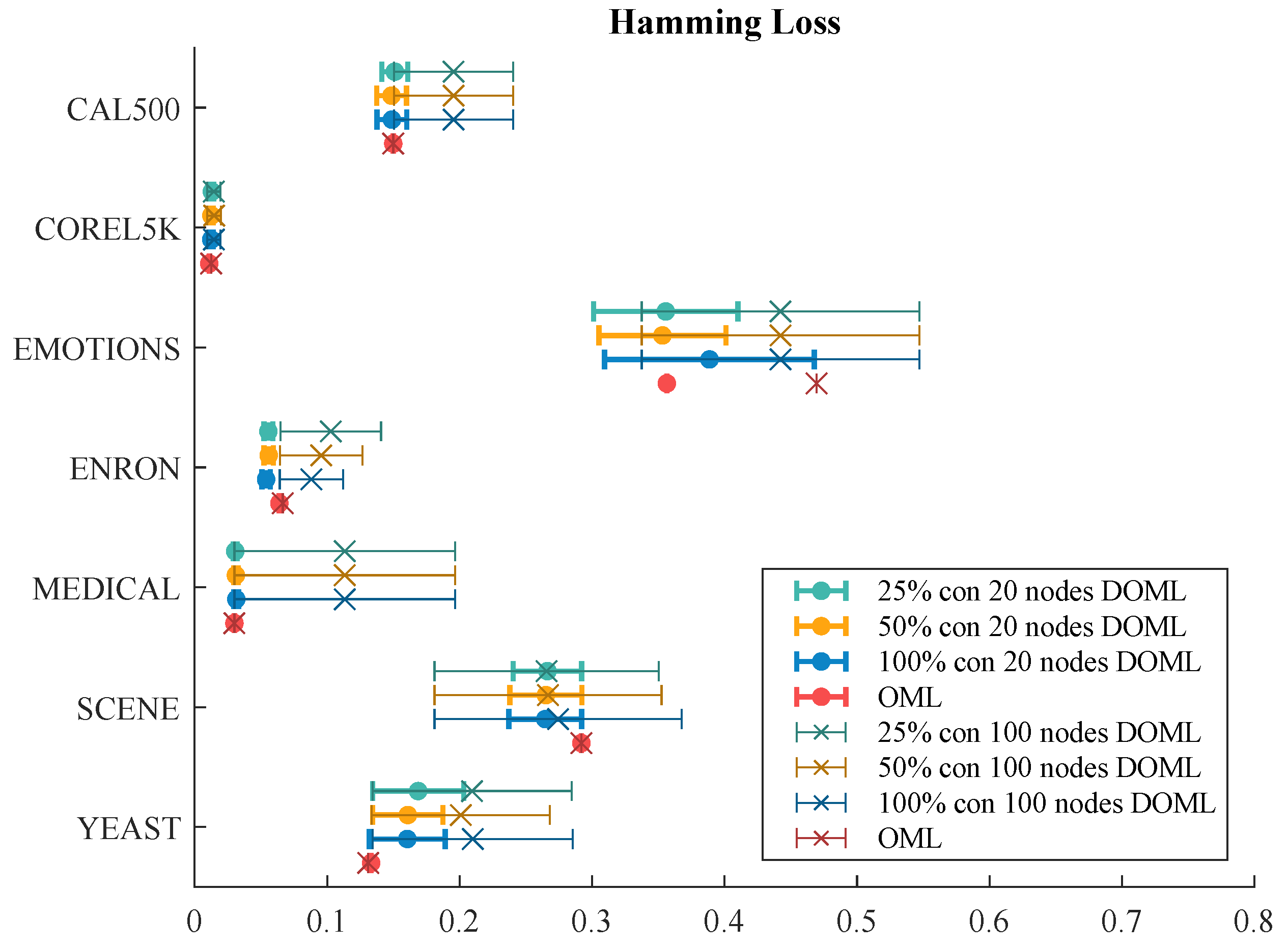
7.2.1. Hamming Loss Evaluation
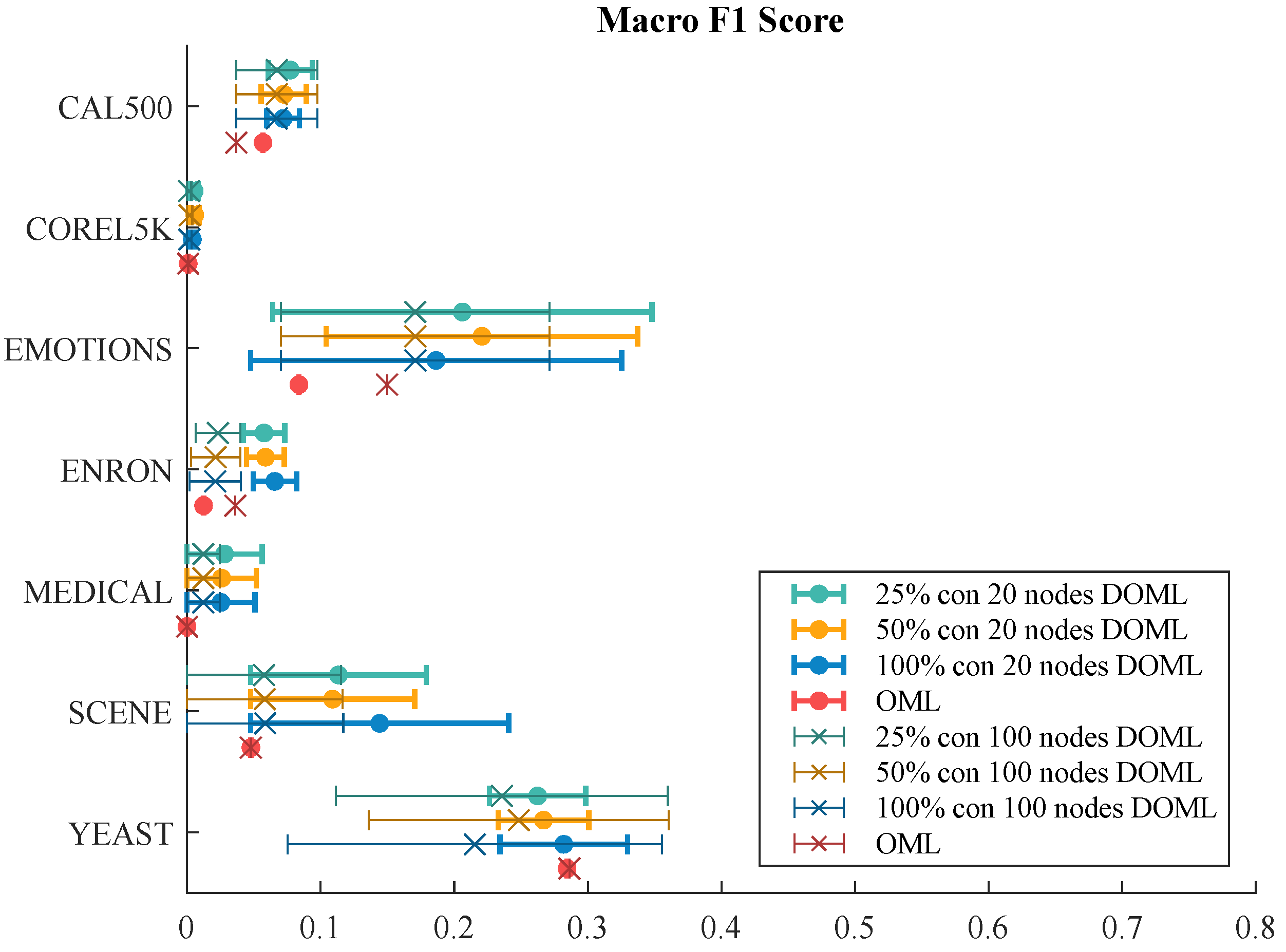
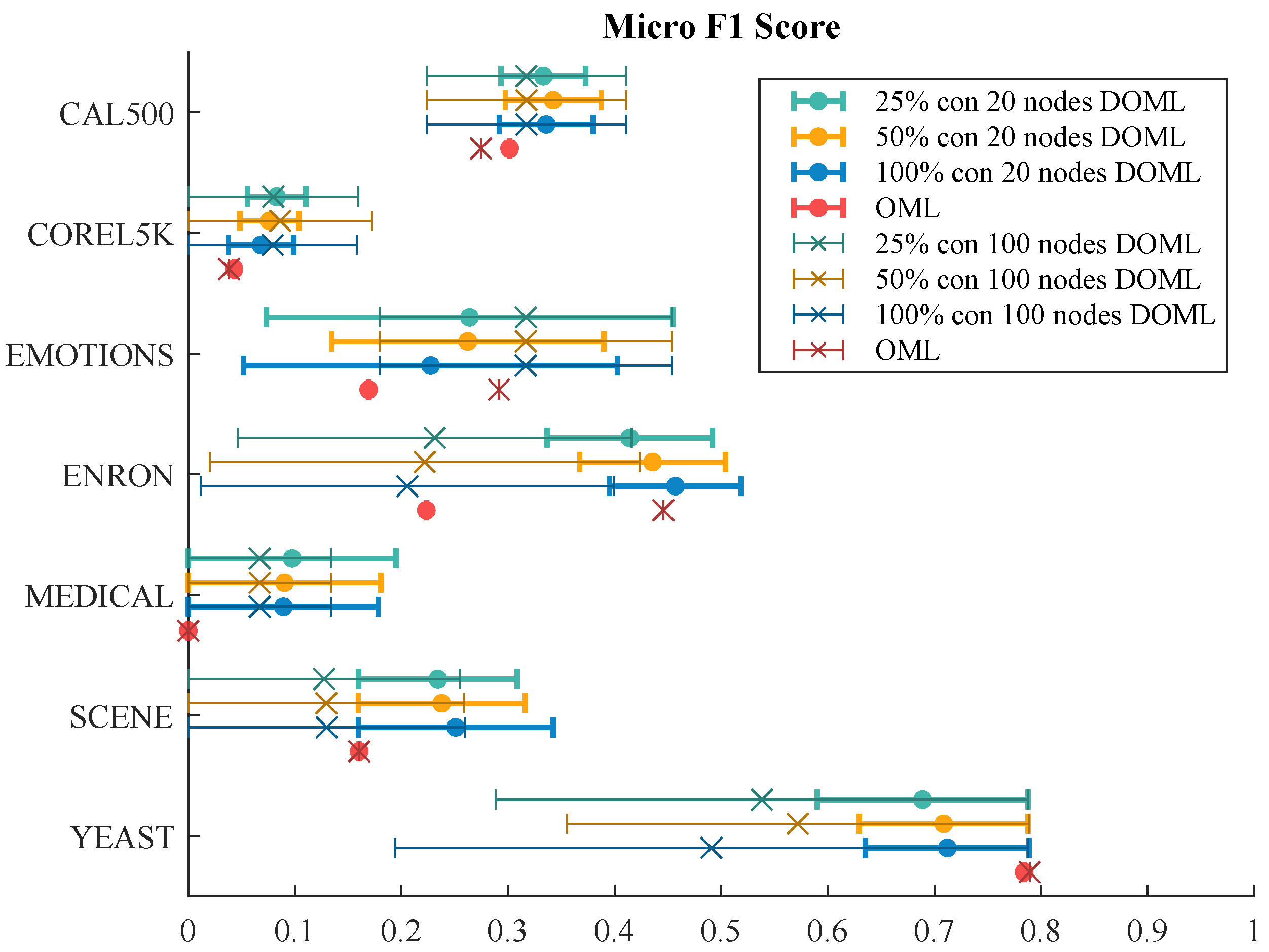
7.2.2. F1 Score Evaluation
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Graepel, T.; Herbrich, R. Bayesian online learning for multi-label and multi-variate performance measures. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 956–963. [Google Scholar]
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, L.; Zorzi, M. Internet of things for smart cities. IEEE Internet Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]
- Spyromitros-Xioufis, E.; Spiliopoulou, M.; Tsoumakas, G.; Vlahavas, I. Dealing with concept drift and class imbalance in multi-label stream classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Büyükçakir, A.; Bonab, H.; Can, F. A novel online stacked ensemble for multi-label stream classification. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 1063–1072. [Google Scholar]
- Li, P.; Wang, H.; Böhm, C.; Shao, J. Online semi-supervised multi-label classification with label compression and local smooth regression. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 1359–1365. [Google Scholar]
- Granato, G.; Martino, A.; Baiocchi, A.; Rizzi, A. Graph-Based Multi-Label Classification for WiFi Network Traffic Analysis. Appl. Sci. 2022, 12, 11303. [Google Scholar] [CrossRef]
- Appenzeller, A.; Leitner, M.; Philipp, P.; Krempel, E.; Beyerer, J. Privacy and Utility of Private Synthetic Data for Medical Data Analyses. Appl. Sci. 2022, 12, 12320. [Google Scholar] [CrossRef]
- Zheng, X.; Li, P.; Chu, Z.; Hu, X. A survey on multi-label data stream classification. IEEE Access 2019, 8, 1249–1275. [Google Scholar] [CrossRef]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Machine Learning: ECML-98; Nédellec, C., Rouveirol, C., Eds.; Springer: Berlin, Germany, 1998; pp. 137–142. [Google Scholar]
- Gonçalves, T.; Quaresma, P. A preliminary approach to the multilabel classification problem of Portuguese juridical documents. In Progress in Artificial Intelligence; Pires, F.M., Abreu, S., Eds.; Springer: Berlin, Germany, 2003; pp. 435–444. [Google Scholar]
- Luo, X.; Zincir-Heywood, A.N. Evaluation of two systems on multi-class multi-label document classification. In Foundations of Intelligent Systems; ISMIS 2005; Lecture Notes in Computer Science; Hacid, M.S., Murray, N.V., Raś, Z.W., Tsumoto, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3488, pp. 161–169. [Google Scholar] [CrossRef]
- Yu, K.; Yu, S.; Tresp, V. Multi-label informed latent semantic indexing. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Salvador, Brazil, 15–19 August 2005; pp. 258–265. [Google Scholar]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Mining multi-label data. In Data Mining and Knowledge Discovery handbook; Springer: Berlin, Germany, 2009; pp. 667–685. [Google Scholar]
- Elisseeff, A.; Weston, J. A kernel method for multi-labelled classification. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2001; Volume 14. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. A k-nearest neighbour based algorithm for multi-label classification. In Proceedings of the IEEE International Conference on Granular Computing, Beijing, China, 25–27 July 2005; Volume 2, pp. 718–721. [Google Scholar]
- Karalic, A.; Pirnat, V. Significance level based multiple tree classification. Informatica 1991, 15, 12. [Google Scholar]
- Boutell, M.; Shen, X.; Luo, J.; Brown, C. Multi-label Semantic Scene Classfication. 2003. Available online: https://urresearch.rochester.edu/fileDownloadForInstitutionalItem.action?itemId=186&itemFileId=269 (accessed on 12 February 2023).
- Zhu, B.; Poon, C.K. Efficient approximation algorithms for multi-label map labeling. In Algorithms and Computation; ISAAC 1999; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1741, pp. 143–152. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Katakis, I. Multi-label classification: An overview. Int. J. Data Warehous. Min. (IJDWM) 2007, 3, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.L.; Zhou, Z.H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef] [Green Version]
- Brinker, K.; Hüllermeier, E. Case-Based Multilabel Ranking. In Proceedings of the IJCAI, Hyderabad, India, 6–12 January 2007; pp. 702–707. [Google Scholar]
- Lin, X.; Chen, X.w. Mr. KNN: Soft relevance for multi-label classification. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 349–358. [Google Scholar]
- Veloso, A.; Meira, W.; Gonçalves, M.; Zaki, M. Multi-label lazy associative classification. In Knowledge Discovery in Databases: PKDD 2007; Lecture Notes in Computer Science; Kok, J.N., Koronacki, J., Lopez de Mantaras, R., Matwin, S., Mladenič, D., Skowron, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4702, pp. 605–612. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Li, G.; Wang, S.; Huang, Q. Categorizing social multimedia by neighbourhood decision using local pairwise label correlation. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 913–920. [Google Scholar]
- Liu, H.; Wu, X.; Zhang, S. Neighbour selection for multilabel classification. Neurocomputing 2016, 182, 187–196. [Google Scholar] [CrossRef]
- Clare, A.; King, R.D. Knowledge discovery in multi-label phenotype data. In Principles of Data Mining and Knowledge Discovery; PKDD, 2001; Lecture Notes in Computer Science; De Raedt, L., Siebes, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2168, pp. 42–53. [Google Scholar]
- Blockeel, H.; De Raedt, L.; Ramon, J. Top-down induction of clustering trees. arXiv 2000, arXiv:cs/0011032. [Google Scholar]
- Petrovskiy, M. Paired comparisons method for solving multi-label learning problem. In Proceedings of the 2006 Sixth International Conference on Hybrid Intelligent Systems (HIS’06), Auckland, New Zealand, 13–15 December 2006; p. 42. [Google Scholar]
- Li, J.; Xu, J. A fast multi-label classification algorithm based on double label support vector machine. In Proceedings of the IEEE International Conference on Computational Intelligence and Security, Beijing, China, 11–14 December 2009; Volume 2, pp. 30–35. [Google Scholar]
- Crammer, K.; Singer, Y. A family of additive online algorithms for category ranking. J. Mach. Learn. Res. 2003, 3, 1025–1058. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. Multilabel neural networks with applications to functional genomics and text categorization. IEEE Trans. Knowl. Data Eng. 2006, 18, 1338–1351. [Google Scholar] [CrossRef] [Green Version]
- Gibaja, E.; Ventura, S. Multi-label learning: A review of the state of the art and ongoing research. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2014, 4, 411–444. [Google Scholar] [CrossRef]
- Moyano, J.M.; Gibaja, E.L.; Cios, K.J.; Ventura, S. Review of ensembles of multi-label classifiers: Models, experimental study and prospects. Inf. Fusion 2018, 44, 33–45. [Google Scholar] [CrossRef]
- Venkatesan, R.; Er, M.J.; Wu, S.; Pratama, M. A novel online real-time classifier for multi-label data streams. In Proceedings of the IEEE 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1833–1840. [Google Scholar]
- Zhang, Y.; Liu, W.; Ren, X.; Ren, Y. Dual weighted extreme learning machine for imbalanced data stream classification. J. Intell. Fuzzy Syst. 2017, 33, 1143–1154. [Google Scholar] [CrossRef]
- Arabmakki, E.; Kantardzic, M.; Sethi, T.S. A partial labeling framework for multi-class imbalanced streaming data. In Proceedings of the IEEE 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1018–1025. [Google Scholar]
- ALattas, A.M. Adaptive model over a multi-label streaming data. In Proceedings of the 2018 IEEE 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; pp. 1–5. [Google Scholar]
- Read, J.; Bifet, A.; Holmes, G.; Pfahringer, B. Scalable and efficient multi-label classification for evolving data streams. Mach. Learn. 2012, 88, 243–272. [Google Scholar] [CrossRef]
- Osojnik, A.; Panov, P.; Džeroski, S. Multi-label classification via multi-target regression on data streams. Mach. Learn. 2017, 106, 745–770. [Google Scholar] [CrossRef] [Green Version]
- Gong, X.; Yuan, D.; Bao, W. Online metric learning for multi-label classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4012–4019. [Google Scholar]
- Shi, L.; Zhao, L.; Song, W.Z.; Kamath, G.; Wu, Y.; Liu, X. Distributed least-squares iterative methods in networks: A survey. arXiv 2017, arXiv:1706.07098. [Google Scholar]
- Frommer, A.; Renaut, R.A. A unified approach to parallel space decomposition methods. J. Comput. Appl. Math. 1999, 110, 205–223. [Google Scholar] [CrossRef]
- Renaut, R.A. A parallel multisplitting solution of the least squares problem. Numer. Linear Algebra Appl. 1998, 5, 11–31. [Google Scholar] [CrossRef]
- Yang, L.T.; Brent, R.P. Parallel MCGLS and ICGLS methods for least squares problems on distributed memory architectures. J. Supercomput. 2004, 29, 145–156. [Google Scholar] [CrossRef]
- Sayed, A.H.; Lopes, C.G. Distributed recursive least-squares strategies over adaptive networks. In Proceedings of the 2006 IEEE Fortieth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 29 October–1 November 2006; pp. 233–237. [Google Scholar]
- Chung, F.R.K. Spectral Graph Theory; CBMS Regional Conference Series, Conference Board of the Mathematical Sciences; American Mathematical Society: Providence, RI, USA, 1997. [Google Scholar]
- Wang, X.; Zhou, J.; Mou, S.; Corless, M.J. A distributed algorithm for least squares solutions. IEEE Trans. Autom. Control. 2019, 64, 4217–4222. [Google Scholar] [CrossRef]
- Turnbull, D.; Barrington, L.; Torres, D.; Lanckriet, G. Semantic annotation and retrieval of music and sound effects. IEEE Trans. Audio, Speech, Lang. Process. 2008, 16, 467–476. [Google Scholar] [CrossRef] [Green Version]
- Duygulu, P.; Barnard, K.; de Freitas, J.F.; Forsyth, D.A. Object recognition as machine translation: Learning a lexicon for a fixed image vocabulary. In Computer Vision—ECCV 2002; Lecture Notes in Computer Science; Heyden, A., Sparr, G., Nielsen, M., Johansen, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2353, pp. 97–112. [Google Scholar]
- Trohidis, K.; Tsoumakas, G.; Kalliris, G.; Vlahavas, I.P. Multi-label classification of music into emotions. In Proceedings of the ISMIR, Philadelphia, PA, USA, 14–18 September 2008; Volume 8, pp. 325–330. [Google Scholar]
- Pestian, J.; Brew, C.; Matykiewicz, P.; Hovermale, D.J.; Johnson, N.; Cohen, K.B.; Duch, W. A shared task involving multi-label classification of clinical free text. In Proceedings of the Biological, Translational, and Clinical Language Processing, Prague, Czech Republic, 29 June 2007; pp. 97–104. [Google Scholar]
- Dietterich, T.G.; Becker, S.; Ghahramani, Z. Advances in Neural Information Processing Systems 14: Proceedings of the 2001 Conference; MIT Press: Cambridge, MA, USA, 2002; Volume 2. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Type of Methods | Description |
|---|---|---|
| OSML-ELM [37] | PT | OSM-ELM for online learning |
| dw-ELM [38] | PT | dw-ELM for OMLC |
| RLS-Multi [39] | PT | For imbalanced online data |
| AMLCM [40] | PT | AMRule problem for OMLC |
| HTPS [41] | AA | Multi-label data stream |
| iSOUP-Tree [42] | AA | Regression for classification |
| OML [43] | EMLCs | Enhance label dependencies |
| Datasets | Number of Instances | Number of Features | Number of Labels | Domain |
|---|---|---|---|---|
| CAL500 | 502 | 68 | 174 | music |
| Corel5k | 5000 | 499 | 374 | images |
| Emotions | 593 | 72 | 6 | music |
| Enron | 1702 | 1001 | 53 | text |
| Medical | 978 | 1449 | 45 | text |
| scene | 2407 | 294 | 6 | image |
| yeast | 2417 | 103 | 14 | biology |
| KNN | OML | DOML | |
|---|---|---|---|
| CAL500 | 0.1325 | 0.1310 | 0.1359 ± 0.0007 |
| Corel5k | 0.0093 | 0.0094 | 0.0114 ± 0.0003 |
| Emotions | 0.2937 | 0.2979 | 0.2851 ± 0.0161 |
| Enron | 0.0522 | 0.0610 | 0.0479 ± 0.0006 |
| Medical | 0.0251 | 0.0292 | 0.0242 ± 0.0050 |
| scene | 0.0989 | 0.1820 | 0.2294 ± 0.0375 |
| yeast | 0.1210 | 0.1254 | 0.1362 ± 0.0008 |
| Macro F1 Score | Micro F1 Score | |||||
|---|---|---|---|---|---|---|
| KNN | OML | DOML | KNN | OML | DOML | |
| CAL500 | 0.0563 | 0.0490 | 0.0614 ± 0.0035 | 0.3425 | 0.3370 | 0.3364 ± 0.0157 |
| Corel5k | 0.0118 | 0.0000 | 0.0174 ± 0.0066 | 0.0365 | 0.0000 | 0.1524 ± 0.0246 |
| Emotions | 0.3853 | 0.2566 | 0.3823 ± 0.0646 | 0.4573 | 0.3722 | 0.4415 ± 0.0661 |
| Enron | 0.0858 | 0.0173 | 0.1054 ± 0.0082 | 0.4540 | 0.2693 | 0.5483 ± 0.0161 |
| Medical | 0.1659 | 0.1111 | 0.1599 ± 0.1037 | 0.3217 | 0.1102 | 0.3304 ± 0.2344 |
| scene | 0.6916 | 0.0029 | 0.2028 ± 0.0857 | 0.6986 | 0.0031 | 0.3297 ± 0.0973 |
| yeast | 0.4840 | 0.4144 | 0.4656 ± 0.0177 | 0.8109 | 0.8034 | 0.7861 ± 0.0050 |
| DOML | OML | |||
|---|---|---|---|---|
| 25% | 50% | 100% | - | |
| CAL500 | 0.1511 ± 0.0098 | 0.1486 ± 0.0112 | 0.1489 ± 0.0112 | 0.1499 |
| Corel5k | 0.0130 ± 0.0015 | 0.0126 ± 0.0015 | 0.0125 ± 0.0015 | 0.0110 |
| Emotions | 0.3556 ± 0.0545 | 0.3531 ± 0.0479 | 0.3886 ± 0.0792 | 0.3564 |
| Enron | 0.0556 ± 0.0034 | 0.0559 ± 0.0035 | 0.0539 ± 0.0032 | 0.0639 |
| Medical | 0.0306 ± 0.0014 | 0.0311 ± 0.0017 | 0.0314 ± 0.0019 | 0.0300 |
| scene | 0.2663 ± 0.0259 | 0.2651 ± 0.0272 | 0.2647 ± 0.0275 | 0.2919 |
| yeast | 0.1687 ± 0.0344 | 0.1609 ± 0.0265 | 0.1605 ± 0.0287 | 0.1332 |
| DOML | OML | |||
|---|---|---|---|---|
| 25% | 50% | 100% | - | |
| CAL500 | 0.1954 ± 0.0450 | 0.1954 ± 0.0450 | 0.1954 ± 0.0450 | 0.1499 |
| Corel5k | 0.0145 ± 0.0051 | 0.0147 ± 0.0051 | 0.0145 ± 0.0049 | 0.0124 |
| Emotions | 0.4422 ± 0.1048 | 0.4422 ± 0.1048 | 0.4422 ± 0.1048 | 0.4695 |
| Enron | 0.1027 ± 0.0380 | 0.0955 ± 0.0311 | 0.0881 ± 0.0239 | 0.0665 |
| Medical | 0.1133 ± 0.0833 | 0.1133 ± 0.0833 | 0.1133 ± 0.0833 | 0.0300 |
| scene | 0.2656 ± 0.0846 | 0.2667 ± 0.0857 | 0.2743 ± 0.0933 | 0.2919 |
| yeast | 0.2094 ± 0.0751 | 0.2009 ± 0.0673 | 0.2099 ± 0.0756 | 0.1310 |
| Macro F1 Score | Micro F1 Score | |||||||
|---|---|---|---|---|---|---|---|---|
| DOML | OML | DOML | OML | |||||
| 25% | 50% | 100% | - | 25% | 50% | 100% | - | |
| CAL500 | 0.0773 | 0.0725 | 0.0720 | 0.0569 | 0.3331 | 0.3423 | 0.3358 | 0.3014 |
| Corel5k | 0.0054 | 0.0058 | 0.0040 | 0.0009 | 0.0829 | 0.0761 | 0.0681 | 0.0430 |
| Emotions | 0.2061 | 0.2207 | 0.1864 | 0.0838 | 0.2638 | 0.2622 | 0.2273 | 0.1692 |
| Enron | 0.0577 | 0.0587 | 0.0657 | 0.0124 | 0.4141 | 0.4356 | 0.4570 | 0.2233 |
| Medical | 0.0281 | 0.0259 | 0.0254 | 0.0000 | 0.0974 | 0.0903 | 0.0892 | 0.0000 |
| scene | 0.1133 | 0.1090 | 0.1442 | 0.0478 | 0.2341 | 0.2377 | 0.2509 | 0.1603 |
| yeast | 0.2624 | 0.2668 | 0.2820 | 0.2845 | 0.6889 | 0.7086 | 0.7120 | 0.7841 |
| Macro F1 Score | Micro F1 Score | |||||||
|---|---|---|---|---|---|---|---|---|
| DOML | OML | DOML | OML | |||||
| 25% | 50% | 100% | - | 25% | 50% | 100% | - | |
| CAL500 | 0.0672 | 0.0672 | 0.0672 | 0.0369 | 0.3173 | 0.3173 | 0.3173 | 0.2746 |
| Corel5k | 0.0016 | 0.0020 | 0.0017 | 0.0009 | 0.0798 | 0.0862 | 0.0791 | 0.0382 |
| Emotions | 0.1708 | 0.1708 | 0.1708 | 0.1497 | 0.3167 | 0.3167 | 0.3167 | 0.2914 |
| Enron | 0.0232 | 0.0214 | 0.0211 | 0.0362 | 0.2312 | 0.2217 | 0.2055 | 0.4457 |
| Medical | 0.0122 | 0.0122 | 0.0122 | 0.0000 | 0.0670 | 0.0670 | 0.0670 | 0.0000 |
| scene | 0.0577 | 0.0582 | 0.0585 | 0.0478 | 0.1275 | 0.1295 | 0.1299 | 0.1603 |
| yeast | 0.2357 | 0.2483 | 0.2154 | 0.2862 | 0.5381 | 0.5718 | 0.4908 | 0.7894 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang , F.; Yang, N.; Chen , H.; Bao, W.; Yuan, D. Distributed Online Multi-Label Learning with Privacy Protection in Internet of Things. Appl. Sci. 2023, 13, 2713. https://doi.org/10.3390/app13042713
Huang F, Yang N, Chen H, Bao W, Yuan D. Distributed Online Multi-Label Learning with Privacy Protection in Internet of Things. Applied Sciences. 2023; 13(4):2713. https://doi.org/10.3390/app13042713
Chicago/Turabian StyleHuang , Fan, Nan Yang, Huaming Chen , Wei Bao, and Dong Yuan. 2023. "Distributed Online Multi-Label Learning with Privacy Protection in Internet of Things" Applied Sciences 13, no. 4: 2713. https://doi.org/10.3390/app13042713