
FocalMatch: Mitigating Class Imbalance of Pseudo Labels in Semi-Supervised Learning

Abstract
:1. Introduction
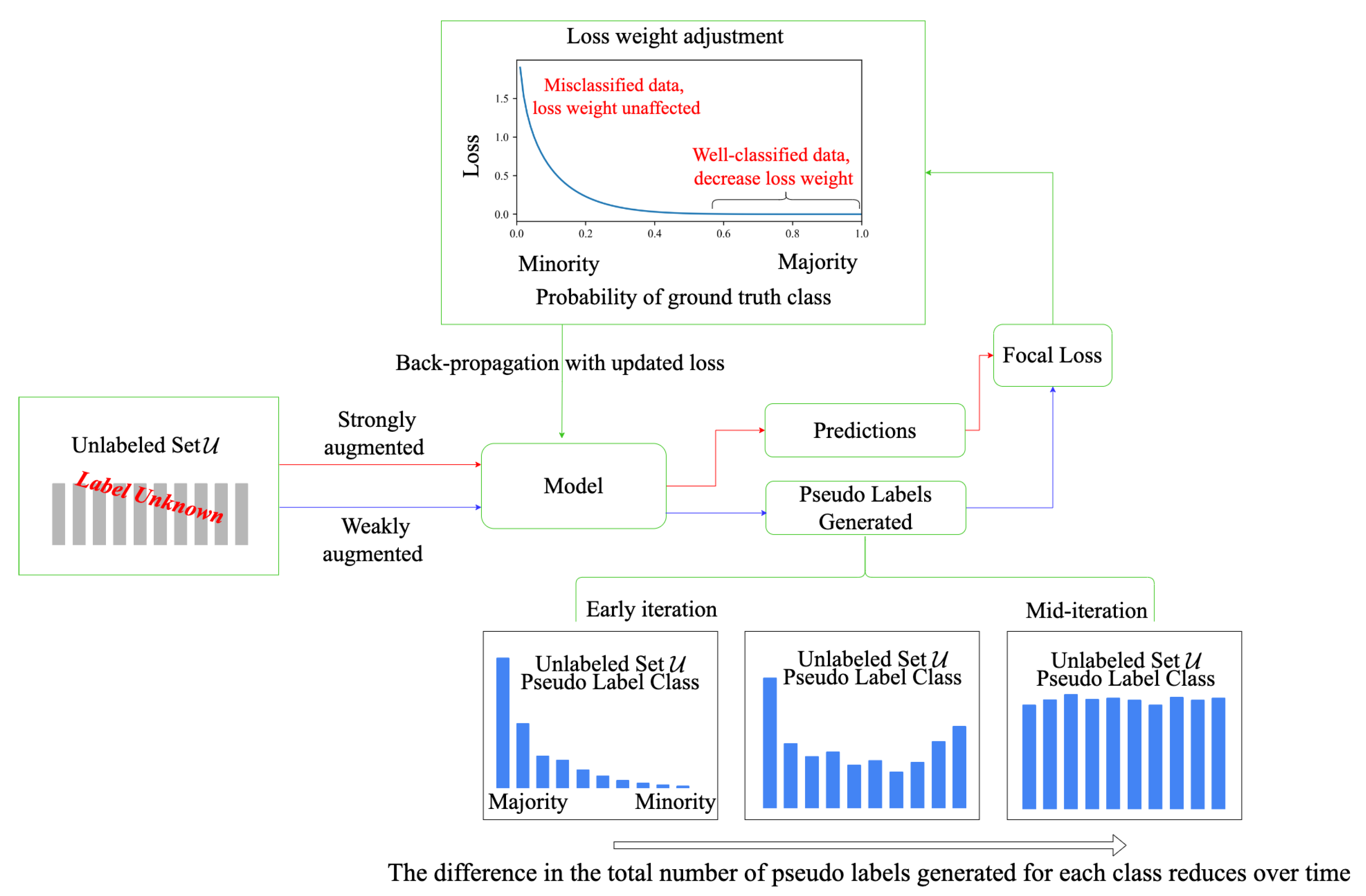
- We propose FocalMatch, a novel but simple semi-supervised learning method that combines FixMatch and focal loss, which effectively mitigates the performance degradation caused by class imbalance and gradually reduces class imbalance that occurs in the unsupervised learning part when generating pseudo labels.
- FocalMatch adjusts the loss weights of different unlabeled data based on the proximity of their predictions to their pseudo labels. Hence, the loss will not be overwhelmed by easy samples. Thus, the model can effectively learn valuable information from all classes.
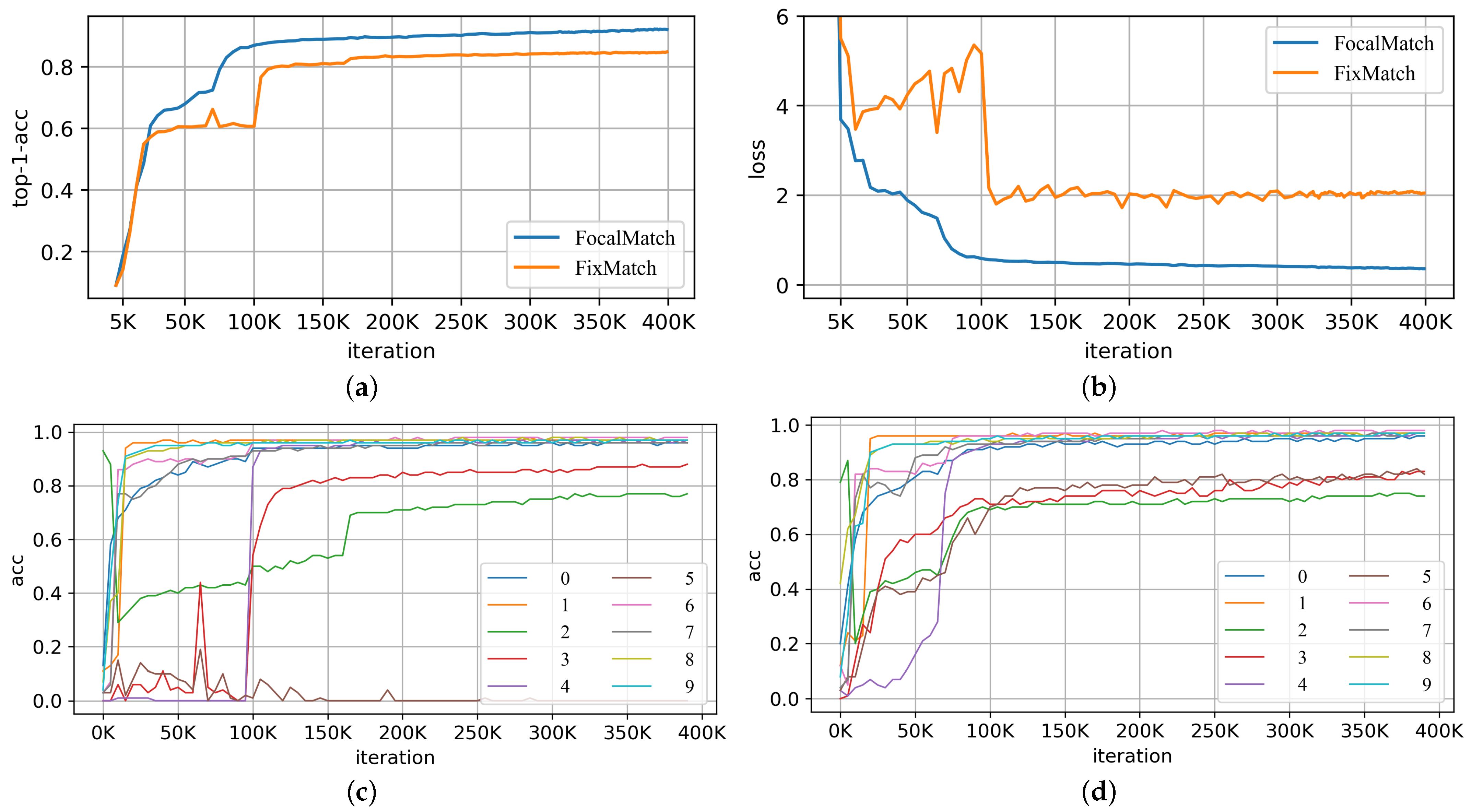
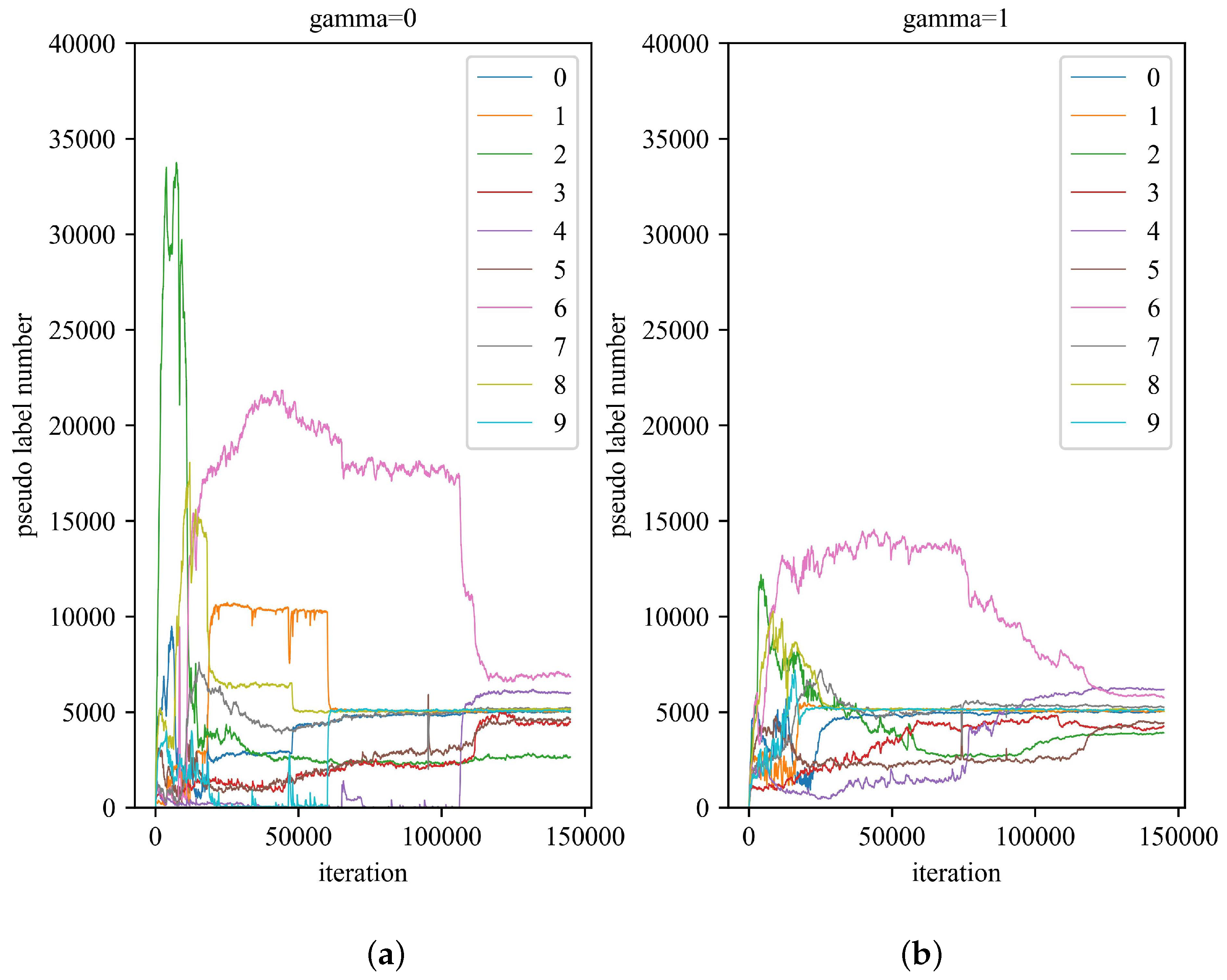
- FocalMatch outperforms most state-of-the-art semi-supervised learning methods on several benchmarks, especially when the quantity of labeled data is severely limited. Experiments show that FocalMatch significantly reduces the difference between the number of pseudo labels generated for each class. FocalMatch also has a smoother training curve and converges faster compared to FixMatch.
2. Related Work
2.1. Semi-Supervised Learning
2.2. Class Imbalance
3. Materials and Methods
3.1. Consistency Regularization and Pseudo-Labeling
3.2. FixMatch
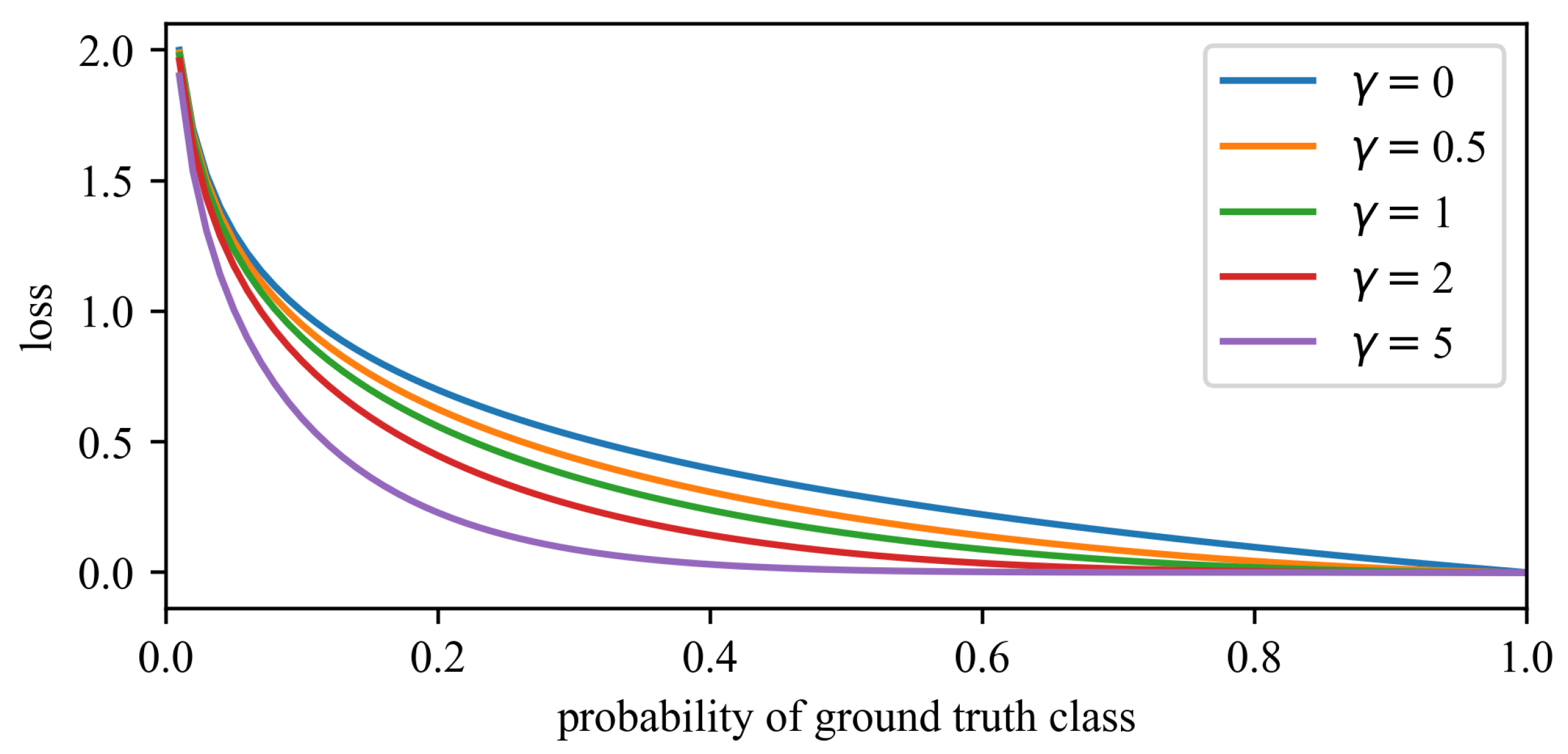
3.3. FocalMatch
| Algorithm 1 FocalMatch Algorithm |
|
4. Experimental Section
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Baselines
4.1.3. Setup
5. Results
6. Discussion and Ablation Study
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Experimental Details
Appendix A.1. Baseline Methods
Appendix A.2. Hyperparameter Settings
- : unlabeled data to labeled data ratio. 1 for model, Mean Teacher, MixMatch and ReMixMatch; 7 for UDA, FixMatch and FocalMatch.
- : weight of unsupervised loss. 10 for model, 50 for Mean Teacher, 100 for MixMatch, 1 for ReMixMatch, UDA, FixMatch and FocalMatch.
- T: temperature for sharpening soft labels. 0.5 for MixMatch and ReMixMatch, 0.4 for UDA.
- : threshold of generating pseudo label. 0.8 for UDA, 0.95 for FixMatch and FocalMatch.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Appendix A.3. Training Details
References
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NU, USA, 1997; Volume 1, p. 2. [Google Scholar]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural language processing: An introduction. J. Am. Med. Inf. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Awoyemi, J.O.; Adetunmbi, A.O.; Oluwadare, S.A. Credit card fraud detection using machine learning techniques: A comparative analysis. In Proceedings of the 2017 international conference on computing networking and informatics (ICCNI), Ota, Nigeria, 29–31 October 2017; pp. 1–9. [Google Scholar]
- Nageswaran, S.; Arunkumar, G.; Bisht, A.K.; Mewada, S.; Kumar, J.; Jawarneh, M.; Asenso, E. Lung Cancer Classification and Prediction Using Machine Learning and Image Processing. BioMed Res. Int. 2022, 2022, 1755460. [Google Scholar] [CrossRef] [PubMed]
- Sajja, G.S.; Mustafa, M.; Phasinam, K.; Kaliyaperumal, K.; Ventayen, R.J.M.; Kassanuk, T. Towards Application of Machine Learning in Classification and Prediction of Heart Disease. In Proceedings of the 2021 Second International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 4–6 August 2021; pp. 1664–1669. [Google Scholar] [CrossRef]
- Bhola, J.; Jeet, R.; Jawarneh, M.M.M.; Pattekari, S.A. Machine learning techniques for analysing and identifying autism spectrum disorder. In Artificial Intelligence for Accurate Analysis and Detection of Autism Spectrum Disorder; IGI Global: Hershey, PA, USA, 2021; pp. 69–81. [Google Scholar]
- Pallathadka, H.; Jawarneh, M.; Sammy, F.; Garchar, V.; Sanchez, D.T.; Naved, M. A Review of Using Artificial Intelligence and Machine Learning in Food and Agriculture Industry. In Proceedings of the 2022 2nd International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 28–29 April 2022; pp. 2215–2218. [Google Scholar] [CrossRef]
- Arumugam, K.; Swathi, Y.; Sanchez, D.T.; Mustafa, M.; Phoemchalard, C.; Phasinam, K.; Okoronkwo, E. Towards applicability of machine learning techniques in agriculture and energy sector. Mater. Today Proc. 2022, 51, 2260–2263. [Google Scholar] [CrossRef]
- Akhenia, P.; Bhavsar, K.; Panchal, J.; Vakharia, V. Fault severity classification of ball bearing using SinGAN and deep convolutional neural network. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2022, 236, 3864–3877. [Google Scholar] [CrossRef]
- Sajja, G.S.; Mustafa, M.; Ponnusamy, R.; Abdufattokhov, S. Machine learning algorithms in intrusion detection and classification. Ann. Rom. Soc. Cell Biol. 2021, 25, 12211–12219. [Google Scholar]
- Arai, H.; Sakuma, J. Privacy preserving semi-supervised learning for labeled graphs. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Athens, Greece, 5–9 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 124–139. [Google Scholar]
- Lee, D.H. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks; Workshop on challenges in representation learning, ICML. Citeseer. 2013, Volume 3, p. 896. Available online: https://scholar.google.com.au/scholar?q=The+Simple+and+Efficient+Semi-Supervised+Learning+Method+for+Deep+Neural+Networks&hl=en&as_sdt=0&as_vis=1&oi=scholart (accessed on 18 October 2022).
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Grandvalet, Y.; Bengio, Y. Semi-supervised learning by entropy minimization. Adv. Neural Inf. Process. Syst. 2004, 17, 529–536. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.J. Semi-Supervised Learning Literature Survey; Technical Report 1530, Computer Sciences; University of Wisconsin-Madison: Madison, WI, USA, 2005. [Google Scholar]
- Cheplygina, V.; de Bruijne, M.; Pluim, J.P. Not-so-supervised: A survey of semi-supervised, multi-instance, and transfer learning in medical image analysis. Med. Image Anal. 2019, 54, 280–296. [Google Scholar] [CrossRef]
- Liang, P. Semi-Supervised Learning for Natural Language. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2005. [Google Scholar]
- Ouali, Y.; Hudelot, C.; Tami, M. An overview of deep semi-supervised learning. arXiv 2020, arXiv:2006.05278. [Google Scholar]
- Bachman, P.; Alsharif, O.; Precup, D. Learning with pseudo-ensembles. arXiv 2014, arXiv:1412.4864. [Google Scholar] [CrossRef]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring. arXiv 2019, arXiv:1911.09785. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Japkowicz, N. The class imbalance problem: Significance and strategies. In Proceedings of the MICAI 2000: Advances in Artificial Intelligence: Mexican International Conference on Artificial Intelligence, Acapulco, Mexico, 11–14 April 2000; pp. 111–117. [Google Scholar]
- Olszewski, D. A probabilistic approach to fraud detection in telecommunications. Knowl.-Based Syst. 2012, 26, 246–258. [Google Scholar] [CrossRef]
- Thabtah, F.; Hammoud, S.; Kamalov, F.; Gonsalves, A. Data imbalance in classification: Experimental evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]
- Wang, S.; Yao, X. Using class imbalance learning for software defect prediction. IEEE Trans. Reliab. 2013, 62, 434–443. [Google Scholar] [CrossRef] [Green Version]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 1–54. [Google Scholar] [CrossRef] [Green Version]
- Yap, B.W.; Rani, K.A.; Rahman, H.A.A.; Fong, S.; Khairudin, Z.; Abdullah, N.N. An application of oversampling, undersampling, bagging and boosting in handling imbalanced datasets. In Proceedings of the First International Conference on Advanced Data and Information Engineering (DaEng-2013), Kuala Lumpur, MA, USA, 16–18 December 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 13–22. [Google Scholar]
- Ling, C.X.; Li, C. Data mining for direct marketing: Problems and solutions. Kdd 1998, 98, 73–79. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Collell, G.; Prelec, D.; Patil, K.R. A simple plug-in bagging ensemble based on threshold-moving for classifying binary and multiclass imbalanced data. Neurocomputing 2018, 275, 330–340. [Google Scholar] [CrossRef] [PubMed]
- Zhu, B.; Pan, X.; vanden Broucke, S.; Xiao, J. A GAN-based hybrid sampling method for imbalanced customer classification. Inf. Sci. 2022, 609, 1397–1411. [Google Scholar] [CrossRef]
- Rasmus, A.; Berglund, M.; Honkala, M.; Valpola, H.; Raiko, T. Semi-supervised learning with ladder networks. arXiv 2015, arXiv:1507.02672. [Google Scholar] [CrossRef]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2017, arXiv:1703.01780. [Google Scholar] [CrossRef]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. arXiv 2019, arXiv:1905.02249. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Retrieved 17 August 2022. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 18 October 2022).
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning 2011. 2011. Available online: http://www.iapr-tc11.org/dataset/SVHN/nips2011_housenumbers.pdf (accessed on 18 October 2022).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, Y.; Hou, W.; Wu, H.; Wang, J.; Okumura, M.; Shinozaki, T. Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling. Adv. Neural Inf. Process. Syst. 2021, 34, 18408–18419. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 17–19 June 2013; pp. 1139–1147. [Google Scholar]
- Polyak, B.T. Some methods of speeding up the convergence of iteration methods. Ussr Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]




| CIFAR-10 | CIFAR-100 | SVHN | ||||
|---|---|---|---|---|---|---|
| 40 Labels | 100 Labels | 400 Labels | 1000 Labels | 40 Labels | 100 Labels | |
| -Model | 22.92 ± 1.26 | 34.98 ± 1.53 | 12.34 ± 1.37 | 26.17 ± 2.31 | 31.33 ± 0.75 | 78.88± 0.32 |
| Mean Teacher | 27.13 ± 1.31 | 44.41 ± 2.42 | 14.31 ± 1.53 | 29.50 ± 3.67 | 64.04 ± 3.18 | 79.83 ± 4.41 |
| MixMatch | 61.64 ± 3.47 | 79.24 ± 2.63 | 22.96 ± 2.16 | 44.62 ± 2.47 | 71.4 2± 6.37 | 96.09 ± 0.29 |
| ReMixMatch | 90.26 ± 1.41 | 91.96 ± 0.75 | 44.03 ± 1.33 | 57.49 ± 0.95 | 76.27 ± 9.54 | 94.18 ± 0.48 |
| UDA | 85.31 ± 4.37 | 92.33 ± 0.23 | 43.17 ± 1.41 | 57.85 ± 0.71 | 95.36 ± 3.47 | 97.92 ± 0.04 |
| FixMatch | 89.94 ± 0.34 | 92.87 ± 0.17 | 43.38 ± 1.09 | 57.99 ± 0.69 | 96.79 ± 1.42 | 97.71 ± 0.15 |
| FocalMatch | 92.29 ± 0.27 | 93.09 ± 0.15 | 46.02 ± 0.86 | 58.70 ± 0.31 | 97.37 ± 1.25 | 97.53 ± 0.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Y.; Zhang, C.; Yang, N.; Chen, H. FocalMatch: Mitigating Class Imbalance of Pseudo Labels in Semi-Supervised Learning. Appl. Sci. 2022, 12, 10623. https://doi.org/10.3390/app122010623
Deng Y, Zhang C, Yang N, Chen H. FocalMatch: Mitigating Class Imbalance of Pseudo Labels in Semi-Supervised Learning. Applied Sciences. 2022; 12(20):10623. https://doi.org/10.3390/app122010623
Chicago/Turabian StyleDeng, Yongkun, Chenghao Zhang, Nan Yang, and Huaming Chen. 2022. "FocalMatch: Mitigating Class Imbalance of Pseudo Labels in Semi-Supervised Learning" Applied Sciences 12, no. 20: 10623. https://doi.org/10.3390/app122010623