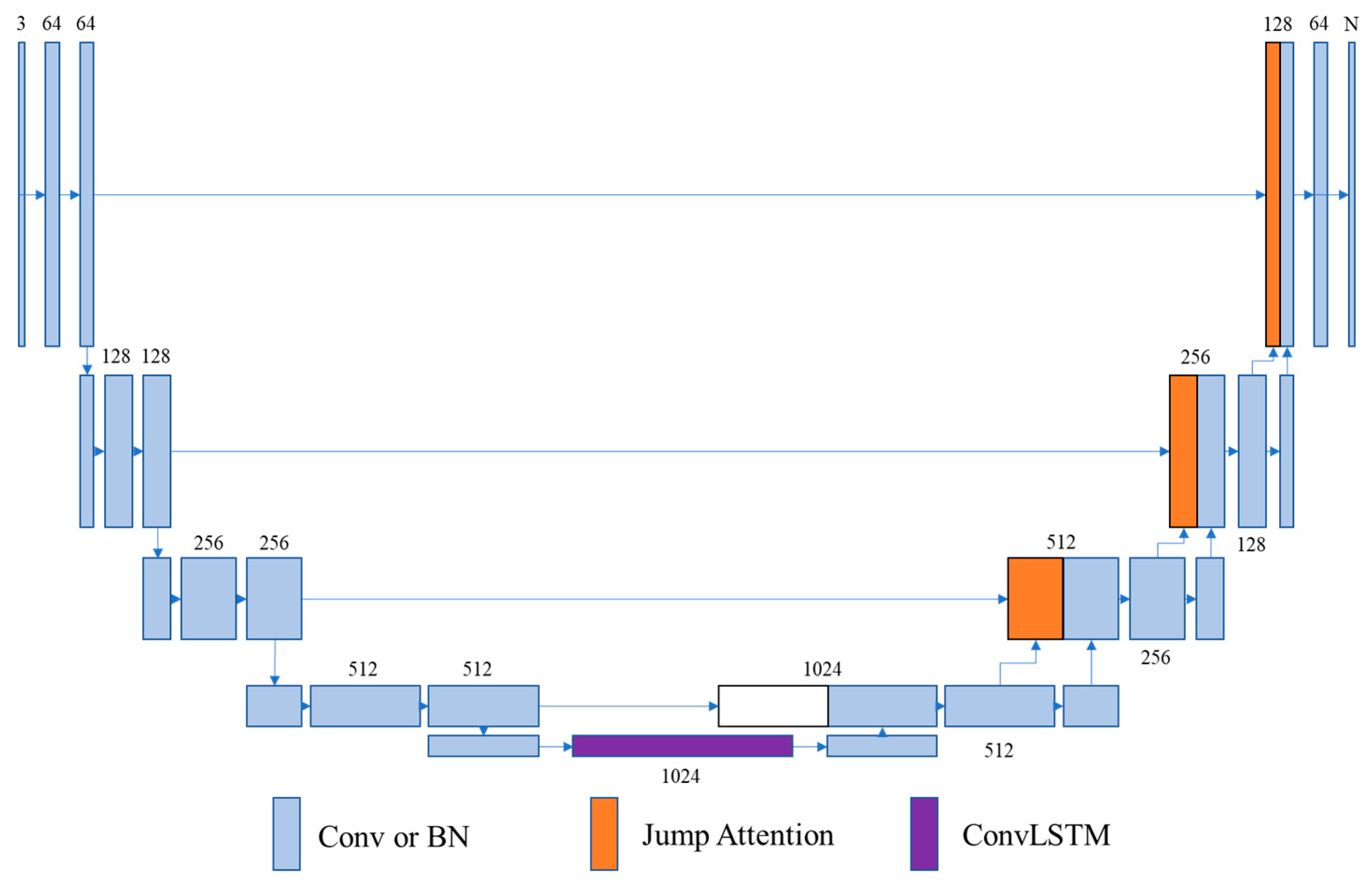
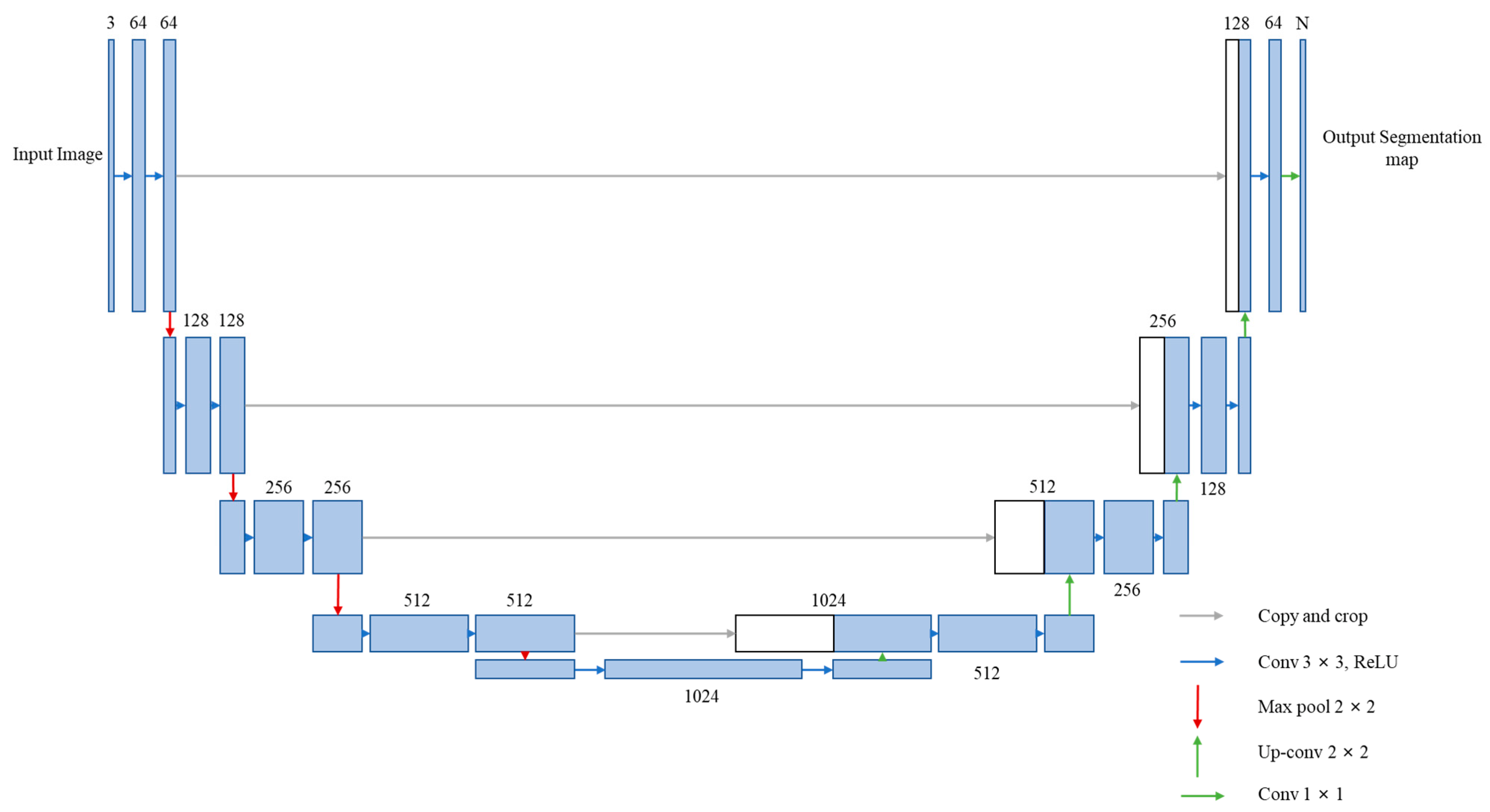
In this section, the actual segmentation performance of the trained networks on the two datasets will be presented. The segmentation images generated by each network will be presented for evaluating the visual segmentation effect, and the objective evaluation metrics calculated for comparing the segmentation effect of each network will also be presented.
3.5.2. CamVid Dataset Results
We tested some networks to compare with JAUNet, and
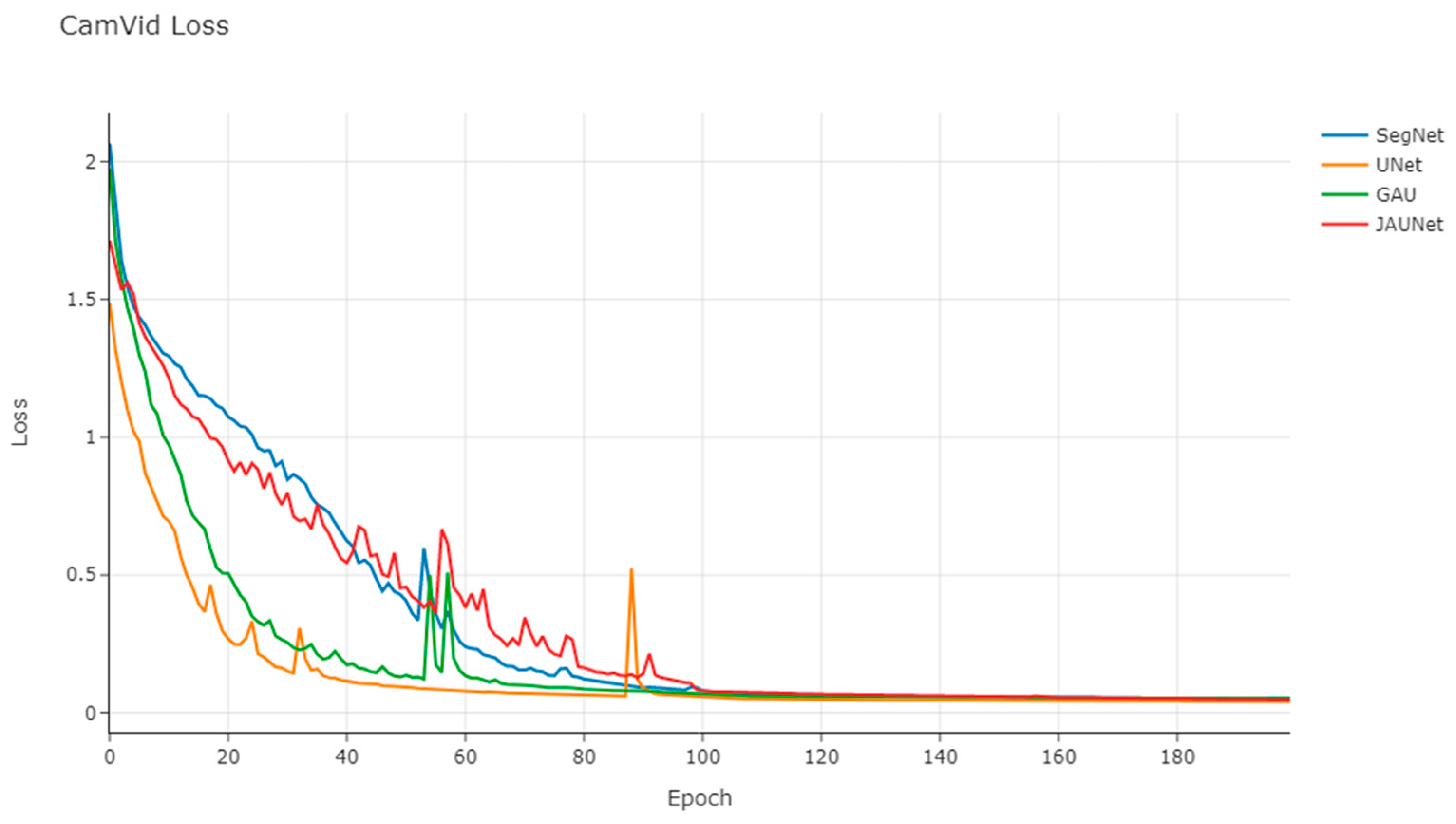
Figure 8 gives the change process of the loss function during the training of some networks.
As shown in the figure, the losses of each network gradually converge after 100 rounds of training, and finally they all stabilize at about 0.04. Among them, UNet converges faster, while SegNet and JAUNet converge slightly slower.
The objective evaluation metrics of the four models on the CamVid dataset are shown in
Table 5.
As shown in
Table 5, compared with other types of network structures, JAUNet has advantages over most other network structures with a fixed input size of 360 × 480. Compared with the basic semantic segmentation network structure of FCN, JAUNet also achieves excellent segmentation results owing to the encoder–decoder network structure. Compared with SegNet and UNet, which are also encoder–decoder networks, the segmentation accuracy of JAUNet is significantly improved, and its edge segmentation results for small targets are even better due to the cross-channel feature fusion mechanism of JAM. Compared with small networks such as ENet and ESPNet, JAUNet has significantly better segmentation accuracy, although it is inferior to such networks in terms of inference speed and model complexity. Compared with DeepLab, which uses the same basic network structure, JAUNet also has an obvious advantage in segmentation accuracy. Compared with ICNet and DFANet, which are newer networks, JAUNet is more balanced in terms of accuracy and speed. For a large network structure such as PSPNet, JAUNet not only has an advantage in segmentation accuracy but also has a certain advantage in inference speed. Meanwhile, compared with BiSeNetV1 with an input size of 720 × 960, JAUNet is slightly inferior to its segmentation results based on ResNet18 due to its inference speed and segmentation accuracy after using Xception39 or ResNet18 as the backbone network and pre-training on ImageNet, but because it needs to perform pre-training, JAUNet is slightly inferior to its segmentation results based on ResNet18. However, since JAUNet needs to perform pre-training, the computational cost is higher, and its model parametric number is also larger (up to 49 M) compared to other network models. JAUNet can achieve better segmentation accuracy with smaller input images than BiSeNet.
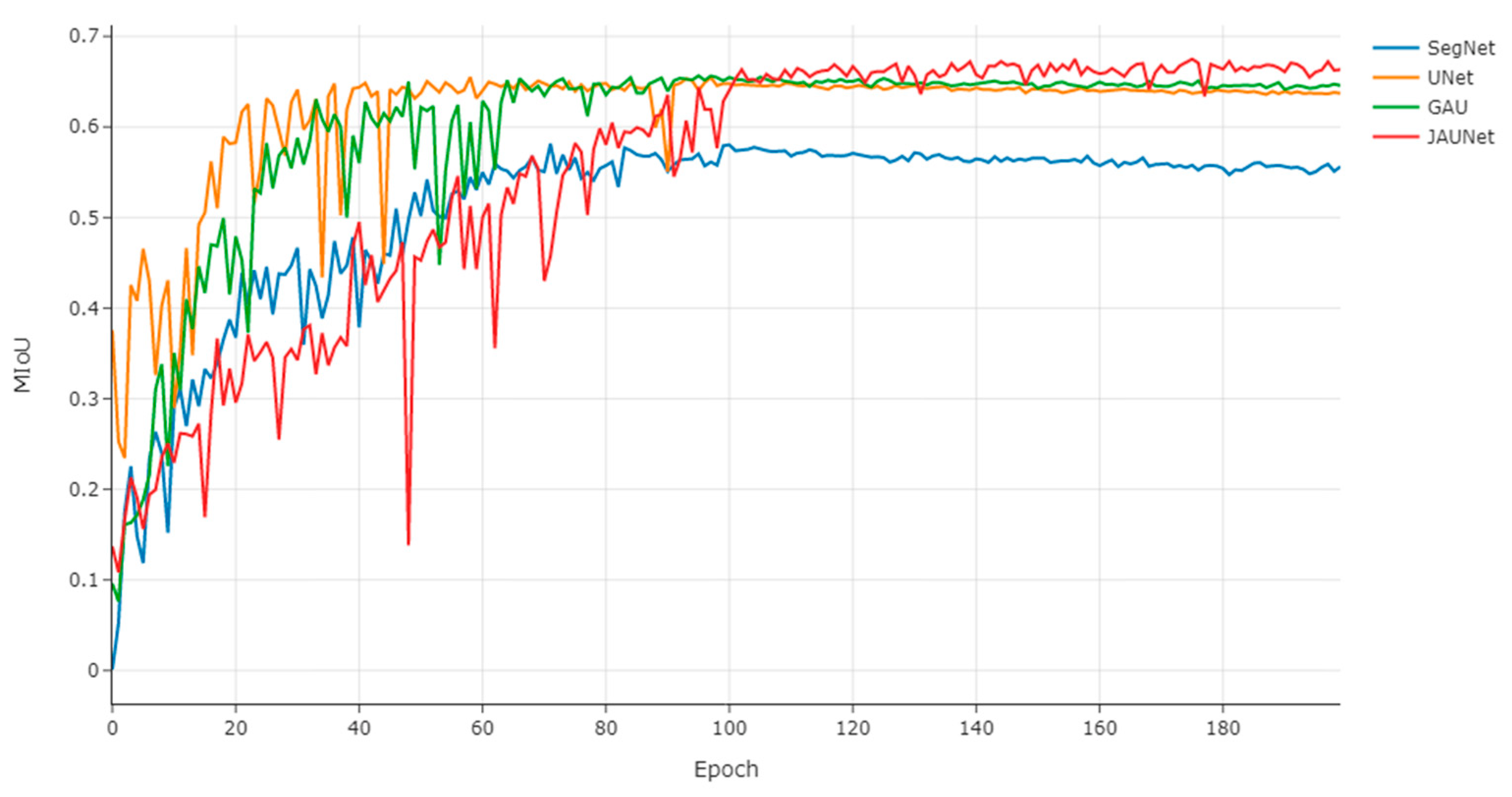
Figure 9 also shows the variation of the test machine accuracy with the number of training rounds during training.
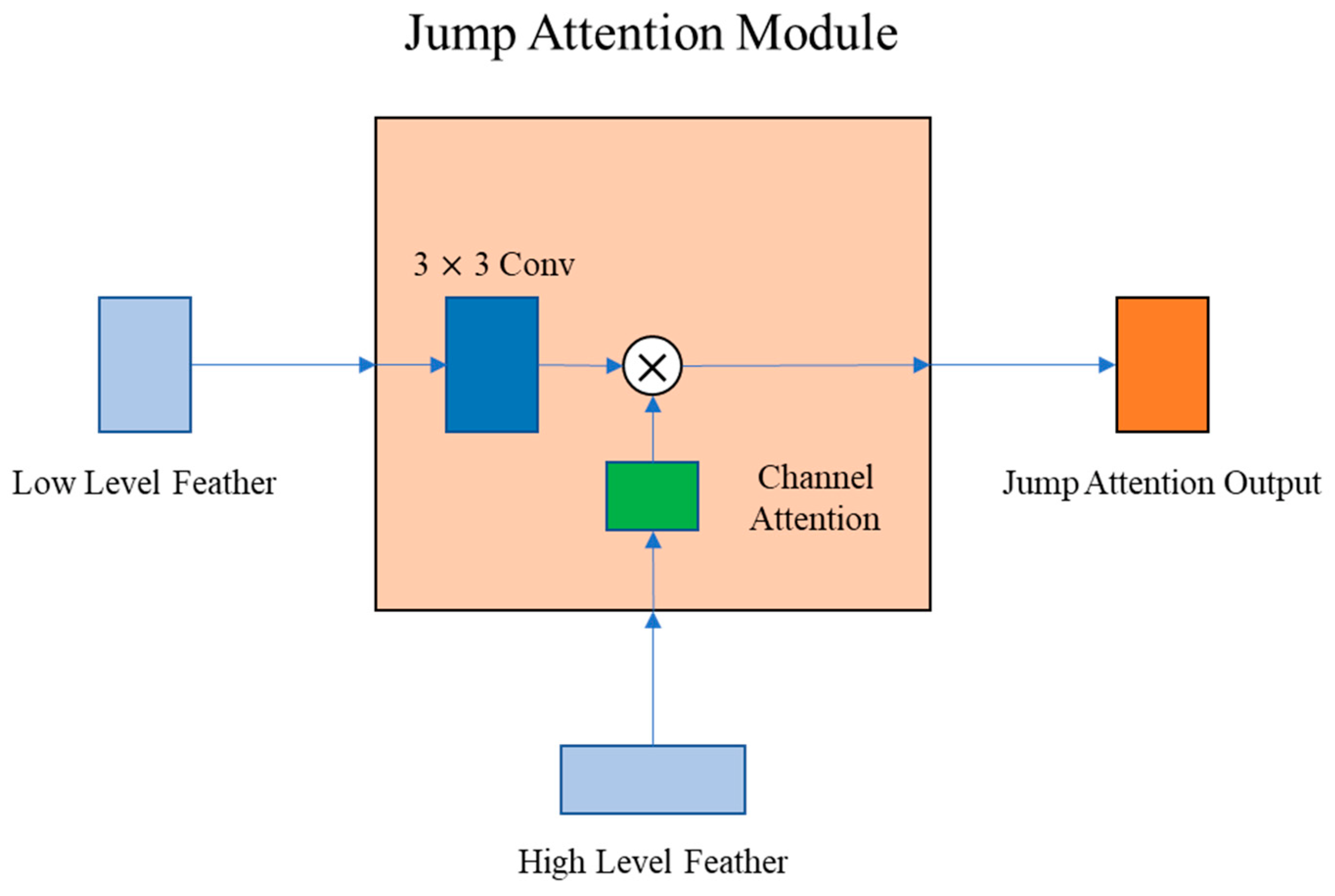
Similar to the change of loss function during the training process, the mIoU of JAUNet on the test set rises slowly with the number of training rounds and stabilizes after 100 epochs. According to the change curve of mIoU, it can be found that JAUNet has a significant accuracy advantage on the test set compared to other U-shaped networks by virtue of the JAM attention module, which demonstrates the effectiveness of the JAM module.
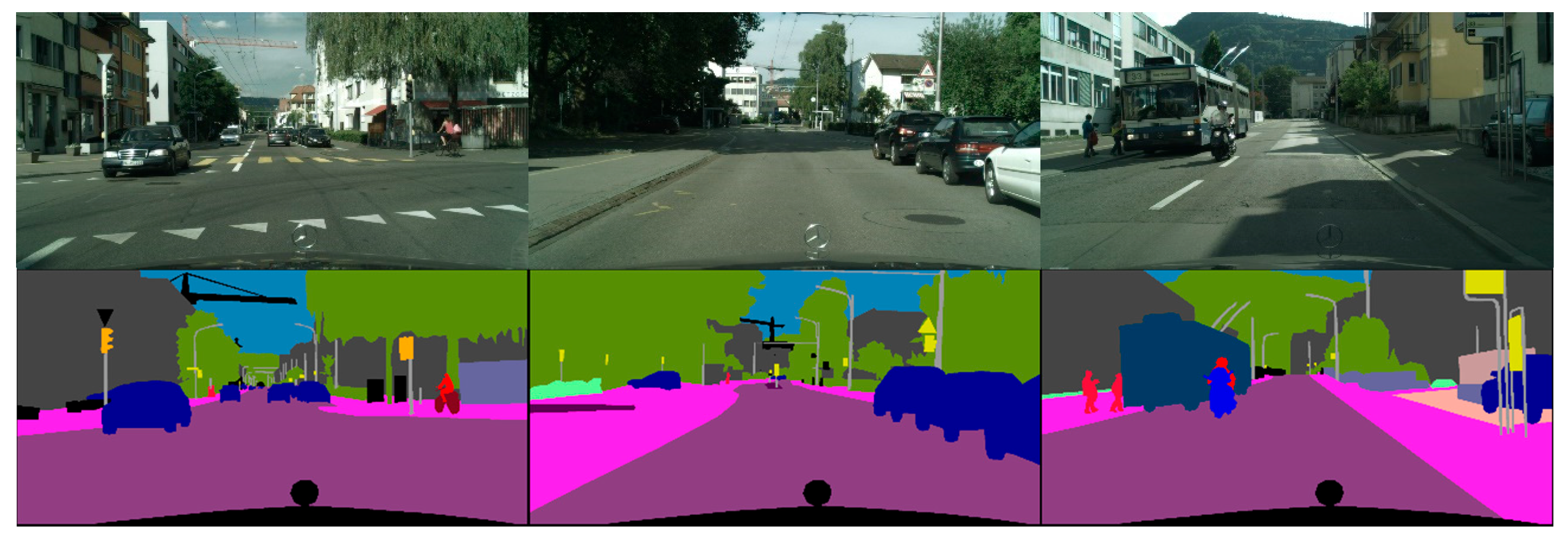
A comparison of the semantic segmentation results of the four networks on the CamVid dataset with the original and labeled images is shown in
Figure 10. In the figure, images from left to right are the input images, and labeled images and segmentation results of each network are presented in order.
As shown in
Figure 10, where the first group of images has one vehicle target and several pedestrian targets, FCN can recognize pedestrians and vehicles, but the edge segmentation and that of the road are blurred. The UNet-GAU can recognize the pedestrian target on the left side, but mis-segmentation occurs in the building part on the right side. The second image shows multi-vehicle and multi-pedestrian targets, and each network can recognize the vehicle targets, but the pedestrian targets are not well recognized. UNet and UNet-GAU are not effective in the overlapping part of pedestrians and buildings on the left side, while the best segmentation for overlapping targets is JAUNet network and the worst segmentation is FCN.
The third set of images are some continuous vehicle targets and a small pedestrian target, from which we can see that JAUNet can roughly identify the location of the traveler, while ordinary UNet is not able to accomplish it, with the appearance of a lot of noise. The fourth group of images is a bright scene of a bend and there are several vehicle targets in the distance. It can be seen that the networks can basically segment the bend contours well and the distant vehicle targets can be effectively identified. The edges of the vehicle contours are shown in detail. The fifth group of pictures is an intersection scene. There is an intentional pedestrian target in the intersection and a pet in the hand of the pedestrian obscures the road. It can be seen that JAUNet has the best segmentation effect on pedestrians and roads among the four networks. The last picture is a straight road scene and there is a line of people on the left side obscuring part of the vehicle. Among the four networks, FCN and JAUNet can identify the vehicle and pedestrian targets. FCN can recognize the situation that the traveler obscures the vehicle, but the segmentation of the contour is not good, and some mis-segmentation of the pedestrian’s leg occurs in the segmentation result of JAUNet, and the segmentation results are good for other targets. The other networks are all inferior to JAUNet for overlapping targets, and UNet-GAU appears to mis-segment the pedestrian as a bicycle. Combining the above images, JAUNet has better results in edge segmentation and small targets in the CamVid dataset compared to other semantic segmentation networks.
Details of the segmentation results for the CamVid dataset are shown in
Figure 11. As can be seen, the differences in the segmentation results of the four networks are outlined in yellow areas in the figure.
After looking closely at the yellow boxed part of the picture, we can see that the first set of images shows the noise that appears in the building and plant parts of UNet, SegNet, and JAUNet, and JAUNet performs the best. All three U-shape network structures can identify the travelers. However, some local missegmentation also occurs in all of them. JAUNet’s mis-segmentation part is smaller, and the edges are more complete, while FCN fails to identify the traveler target at all and is not effective. The second group of images focuses on the segmentation details of the top of the vehicle. All three networks except FCN can segment the vehicle outline well while JAUNet has some small noise. The third group of images focuses on the segmentation details of the continuous vehicles on the left side. Both UNet and UNet-GAU have mis-segmentation of the background part. However, JAUNet has better noise suppression and edge processing in this group of images. For the pedestrian target at the intersection in the fifth group of images, FCN identifies the pedestrian, but the edge segmentation is poor. UNet and UNet-GAU hardly identify the pedestrian, and mis-segmentation occurs. JAUNet can recognize pedestrian targets in the middle of the road and does not divide the pets of pedestrians into roads by mistake. The last set of images shows the details of the pedestrian obscuring the vehicle target. The FCN mis-segments the legs of pedestrians as vehicles, while the UNet and UNet-GAU mis-segment a portion of pedestrians as background. The JAUNet network can recognize the traveler and the vehicle. Although the part of the leg is mis-segmented into the vehicle, it is better than the other networks.
To sum up, during the classification segmentation of CamVid dataset 11, FCN could not segment the object edges well, both UNet and SegNet show much noise in the background, and JAUNet segmentation results are relatively cleaner and had clear edges. In terms of visual effect, the JAUNet network outperforms other networks.
3.5.3. Cityscape Dataset Results
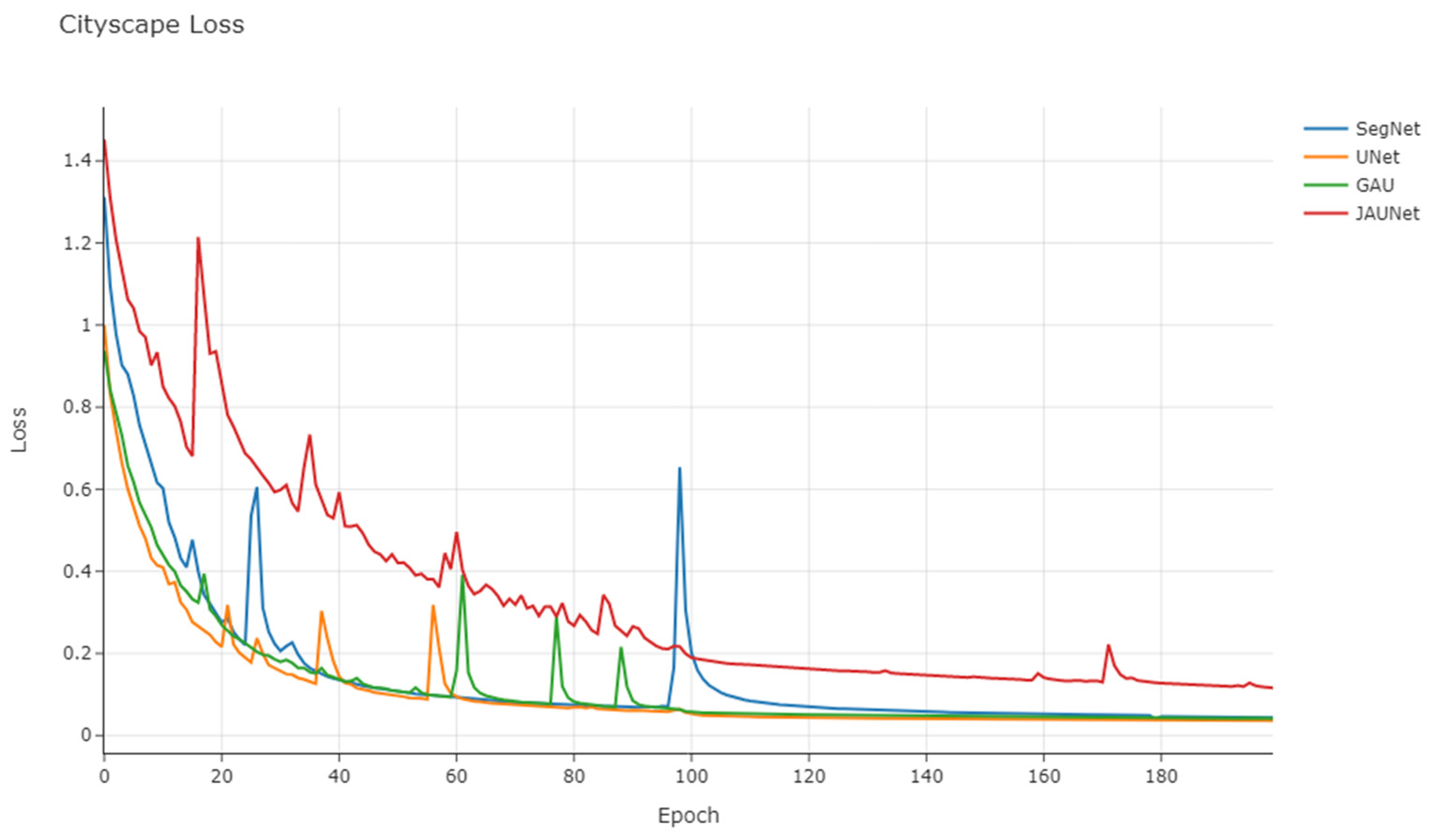
The variation of loss function for the training process of Cityscape dataset is shown in
Figure 12.
In the Cityscape dataset, the loss function of JAUNet is slightly higher than the other networks, which may be due to the higher complexity of the network making the convergence slower after the learning rate decreases. Similar to the training of the CamVid dataset, there were some fluctuations in the loss function during the training process, but they all basically leveled off after 100 epochs in the end.
The objective evaluation metrics of the four models on the Cityscape dataset are shown in
Table 6.
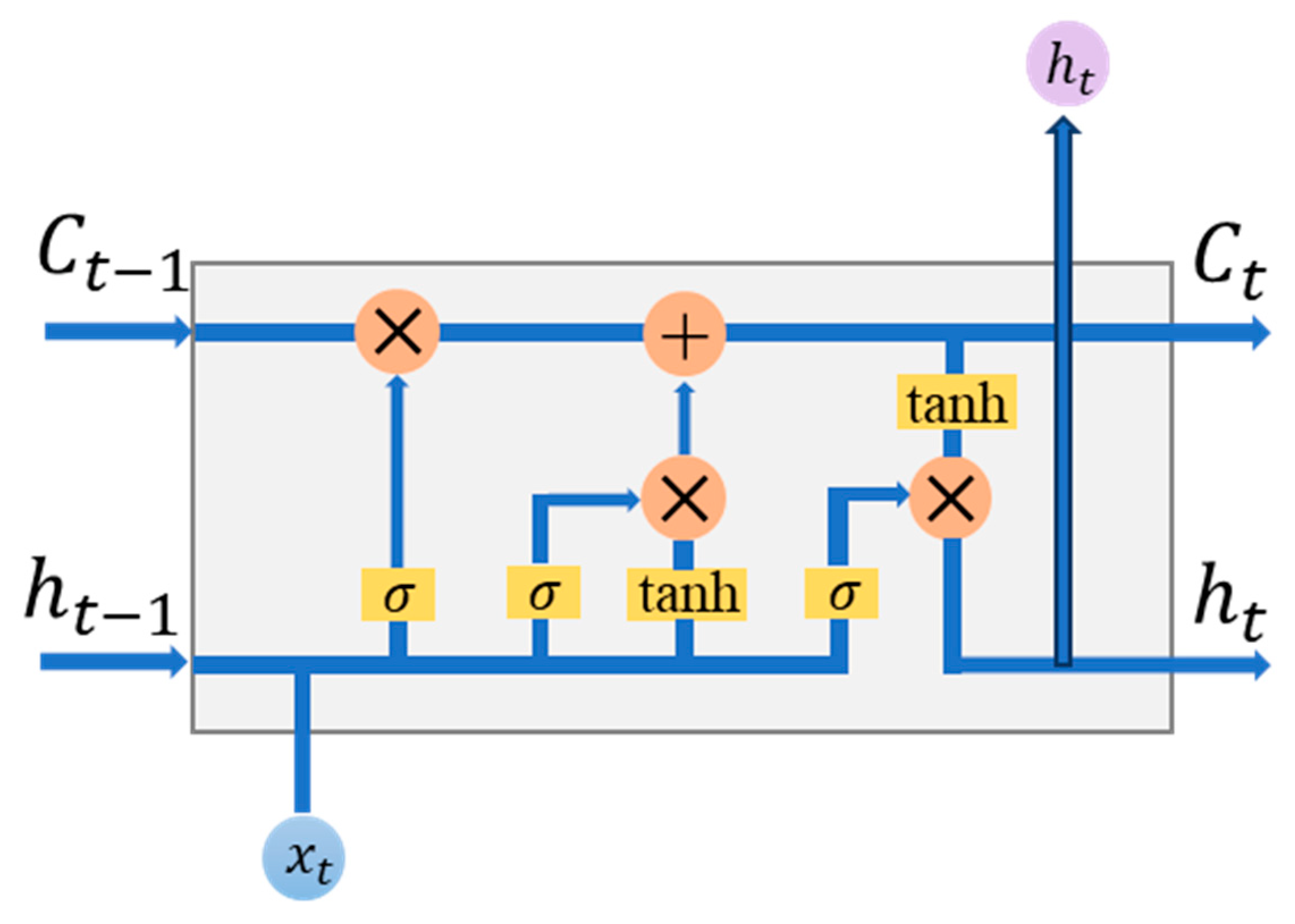
The JAUNet proposed in this paper achieves 69.1% mIoU with 33.91 M parameters on the Cityscapes test set. Owing to more training images and higher resolution input images, better segmentation results could be achieved than on the CamVid dataset but accompanied by a decrease in inference speed. Compared to other neural networks, JAUNet can obtain better segmentation accuracy. Like the test results on the CamVid dataset, JAUNet’s segmentation accuracy is higher than that of lightweight networks such as ENet and ContextNet, although the inference speed is slower. Compared with other encoder–decoder network structures, some inference speed is lost, but higher segmentation accuracy is obtained. The segmentation performance of JAUNet is still better than that of GAU, which also adds an attention mechanism, which means that the JAM module is better at extracting channel attention. The segmentation accuracy of JAUNet is similar to that of the Xception39-based network but inferior to that of the ResNet18-based network when compared to the BiSeNetV1 network pre-trained on ImageNet, which is already very good without pre-training on a large dataset. We also give results on the Cityscape dataset using ConvLSTM and UNet alone. Similar to CamVid, using the ConvLSTM module alone does not show much improvement for UNet, and we speculate that the slow convergence may be caused by too many parameters. The simultaneous use of the ConvLSTM and JAM modules also has a better performance on the Cityscape dataset.
Figure 13 shows the variation of the validation set mIoU with the number of training rounds on the Cityscape dataset. On this dataset, SegNet’s mIoU differs more from other UNet-based networks due to its use of only pooled index-assisted upsampling. JAUNet, on the other hand, has a higher segmentation accuracy than the UNet network after training 110 epochs, although its upsampling speed is slower. This is the same as the results obtained from testing on the CamVid dataset, which further illustrates the effectiveness of the JAM attention module.
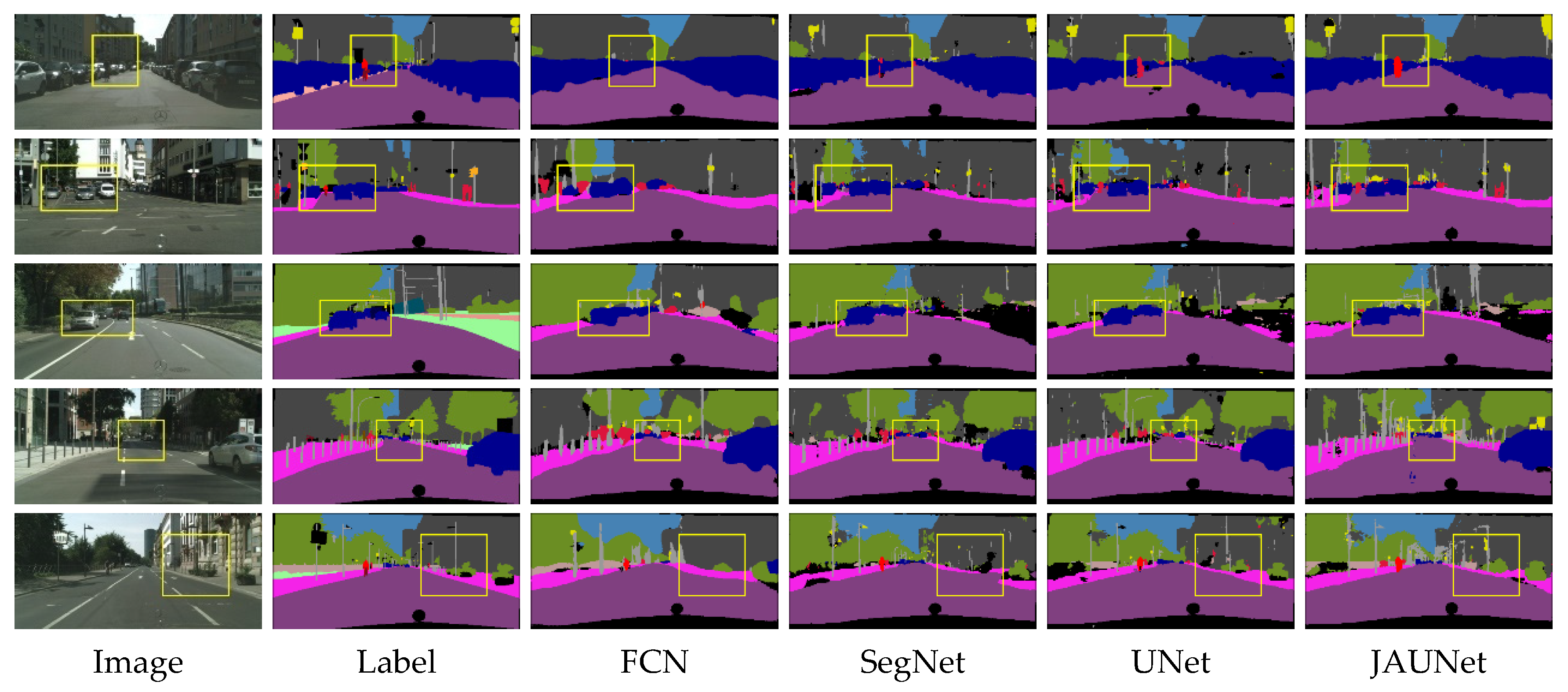
The second set of images is an intersection scene, where there are some side-by-side vehicles in opposite directions, and the segmentation effect of each network on vehicle targets is good. Compared with other networks, JAUNet has a complete segmentation effect on rod-shaped objects and an advantageous effect on small targets such as pedestrians. The third and fourth groups of images are road scenes and several opposite vehicle targets, and we can pay attention to the processing of vehicle edges and rod-shaped objects. JAUNet has the best results.
In the
Figure 14, it can also be seen that JAUNet has mis-segmented some of the road markings as car targets, probably because JAUNet is more sensitive to small targets and the markings are not labelled. At the same time, JAUNet classifies the signage target shown as background in the label on the right as a wayfinding sign as well, while the rest of the network would classify the target as a building. This shows that JAUNet classification results seem to be closer to human perception in the classification of targets without labels. The fifth group of images is mainly roads. The segmentation of road edges by FCN is completely blurred. SegNet can recognize part of the edges but mistakenly segmented part of the sidewalks as roads. UNet and JAUNet can segment road edges better, but UNet has poor recognition of the right-side streetlights, and JAUNet with added attention mechanism can be well recognized.
The segmentation details of the Cityscapes dataset are shown in
Figure 15. The yellow boxes in the figure mark the parts of the segmentation results that are significantly different. In the detailed diagram, it is obvious to see the mis-segmentation of vehicles on the right side of the first set of images, and JAUNet has the best overall performance. At the same time, other networks classified part of the person target on the left into a car, while UNet can recognize person’s outlines, and JAUNet tends to highlight small target person more. From the second row in the figure, it can be seen that, compared with the network shown, JAUNet can successfully segment the detailed information in the fine objects; in other words, the light pole of the streetlight is successfully recovered, mainly due to the multi-scale fusion of deep and shallow features by the JAM module in the network. Moreover, the results from the first, third, and fourth rows in the figure show that JAUNet is able to perform more accurately, such as the classification of large areas of foliage and ground, as well as the classification of walls and pavements, further demonstrating the enhanced effect of the JAM module for multi-scale information fusion. Compared with other models, JAUNet is able to segment not only objects with fine edges but also larger objects more accurately with significant segmentation effects, indicating that JAUNet has some enhancement in real-time semantic segmentation for different scales of objects.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}