
Improving Semi-Supervised Image Classification by Assigning Different Weights to Correctly and Incorrectly Classified Samples
 , ,
, ,
Abstract
:1. Introduction
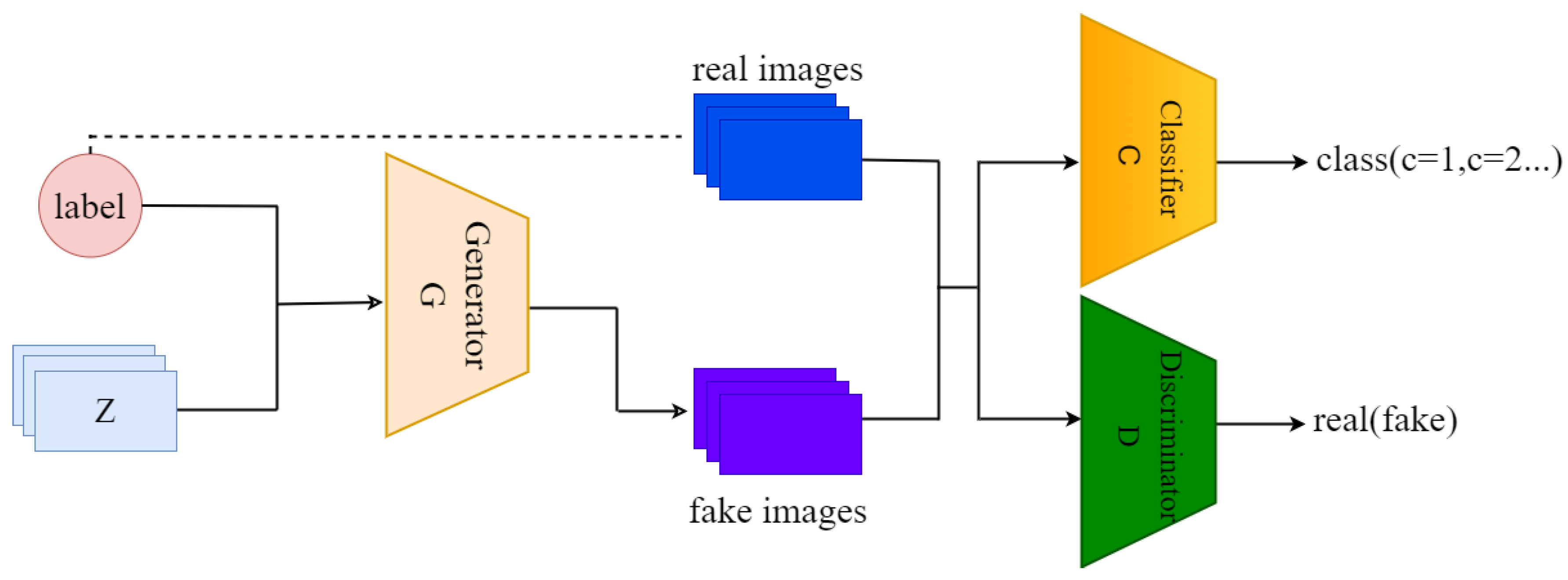
- A new image generation model is proposed to generate artificial samples designed to complement the limited number of labeled samples in the supervised modules.
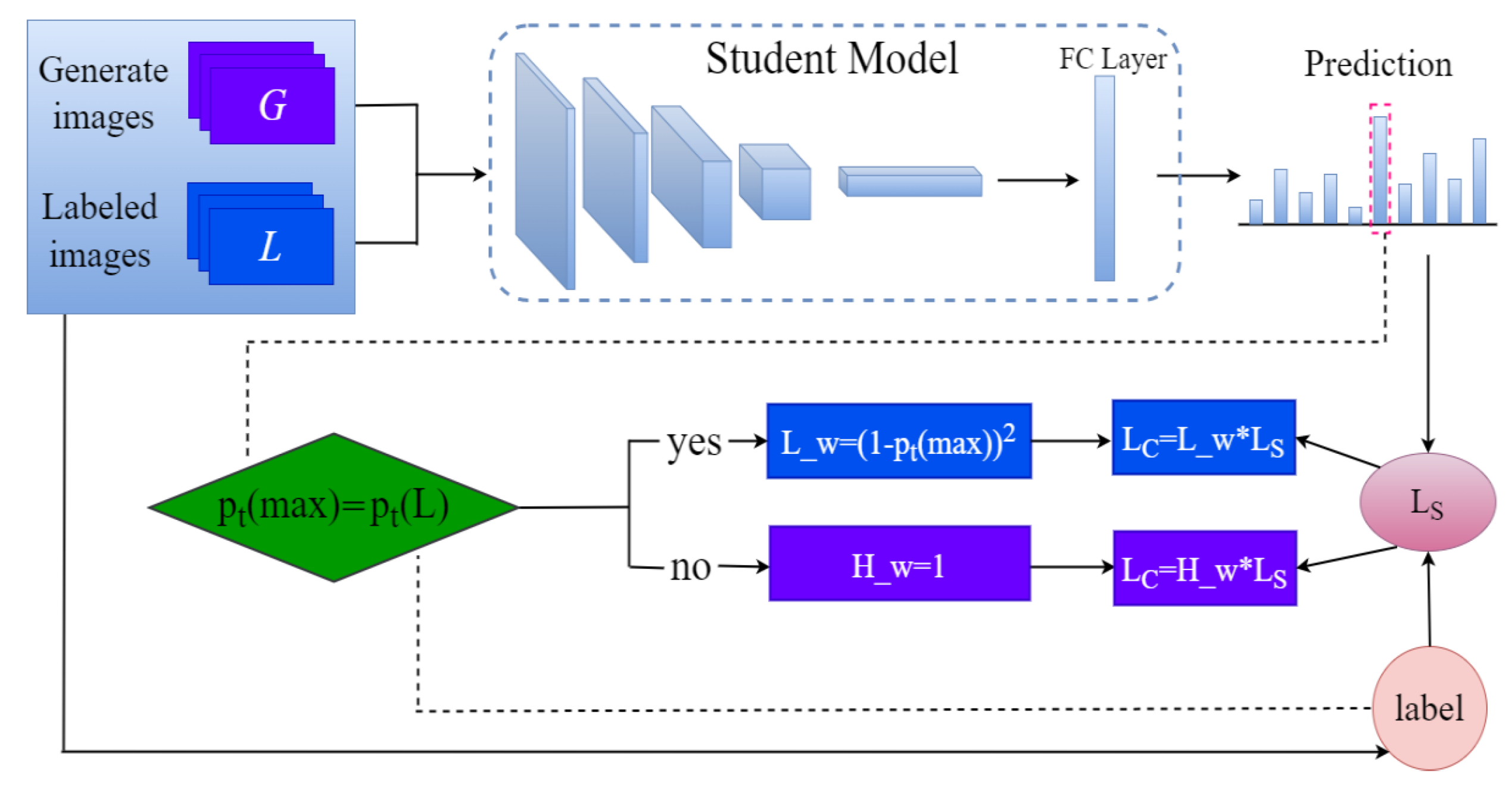
- In the supervisory loss section, the sample labels are compared with the sample predictions one by one, weighting the original loss and introducing additional losses to supplement the supervisory loss.
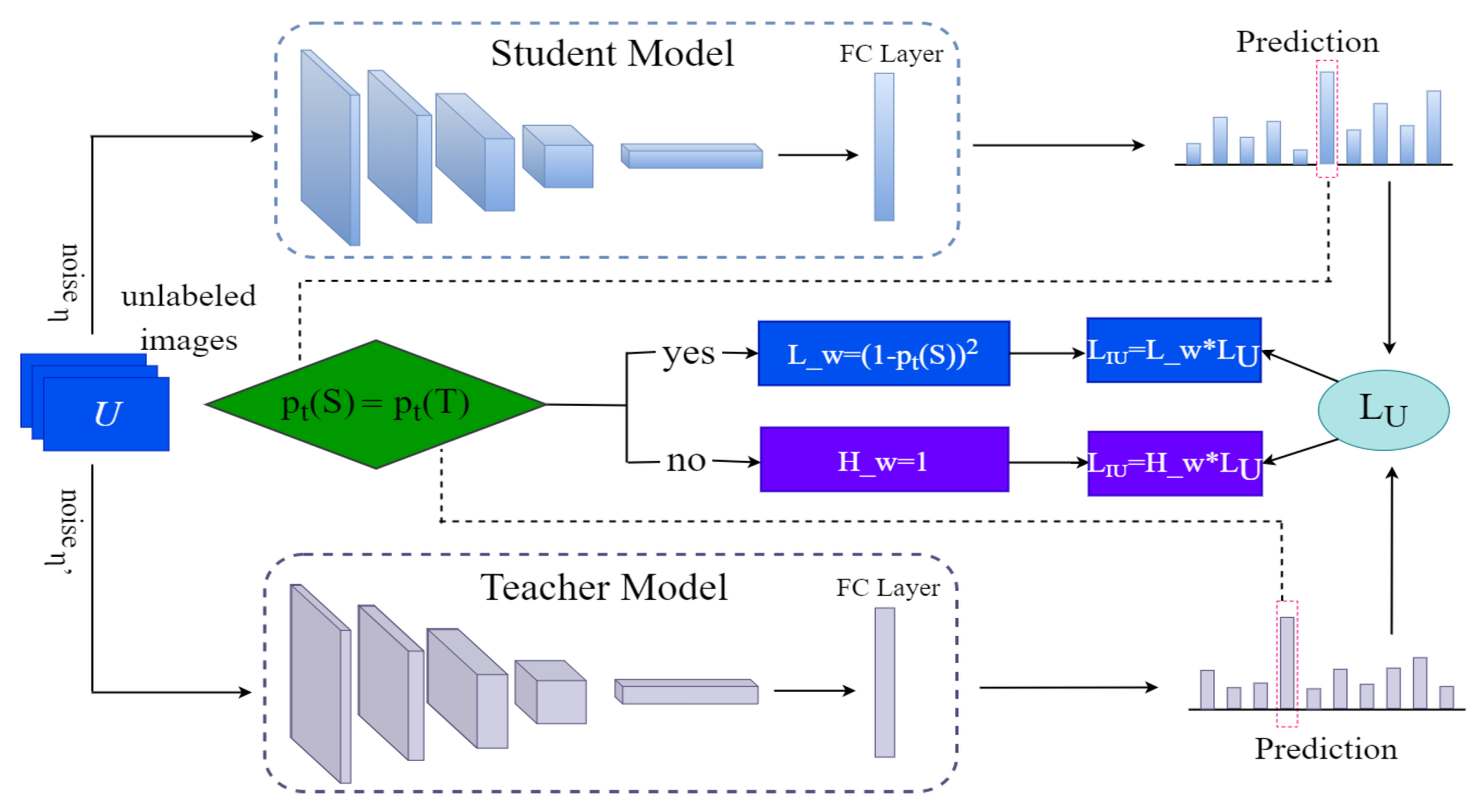
- In the unsupervised loss section, judgment conditions are added so that the correctly classified sample features dominate the network parameters.
2. Related Work
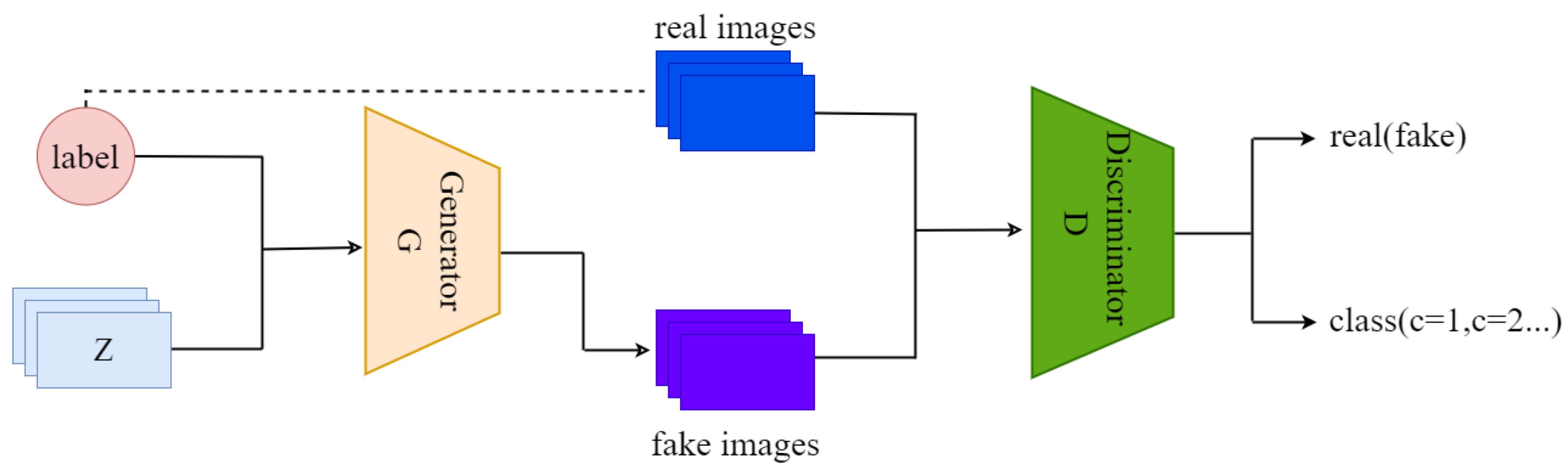
2.1. Conditional Image Synthesis with Auxiliary Classifier GANS
2.2. Semi-Supervised Image Classification Models
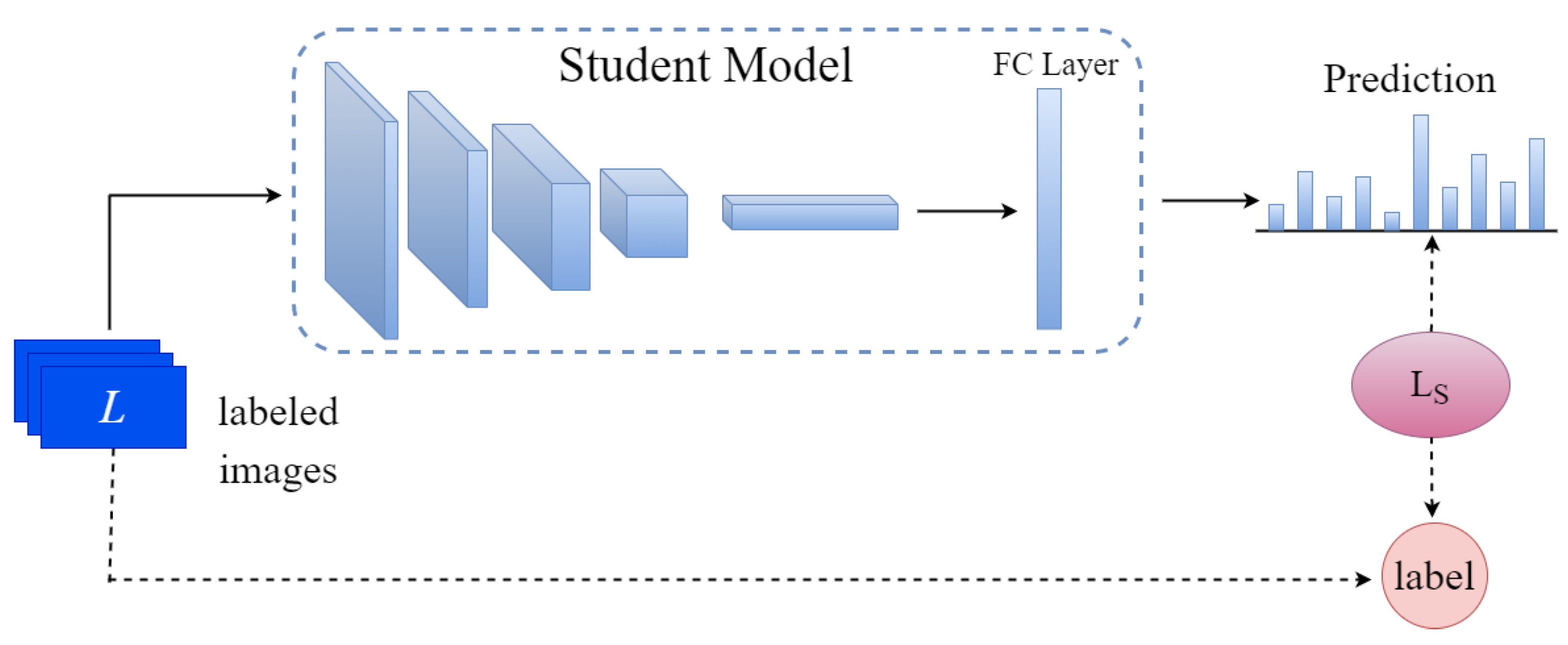
2.2.1. Full Supervised Modules
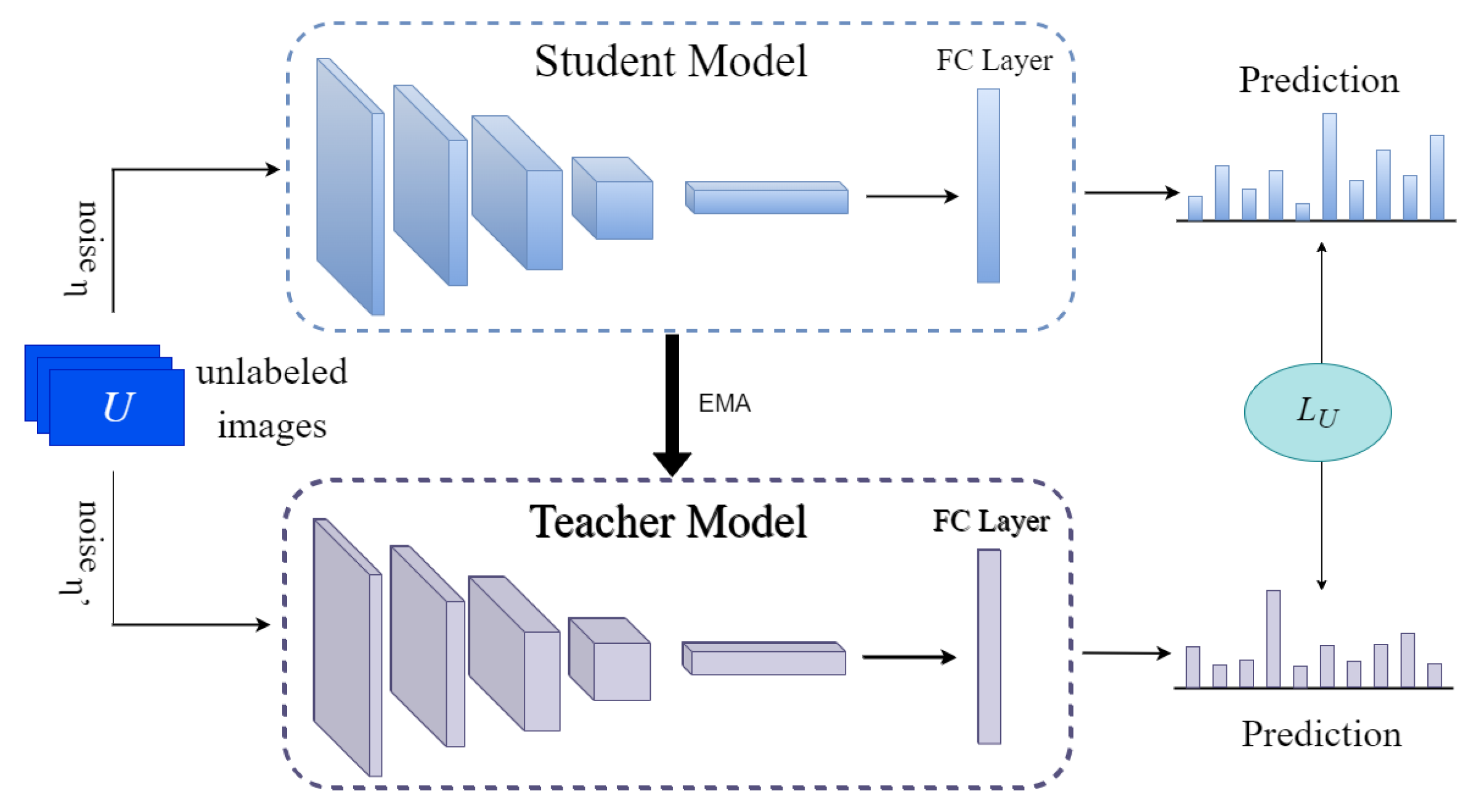
2.2.2. Unsupervised Modules
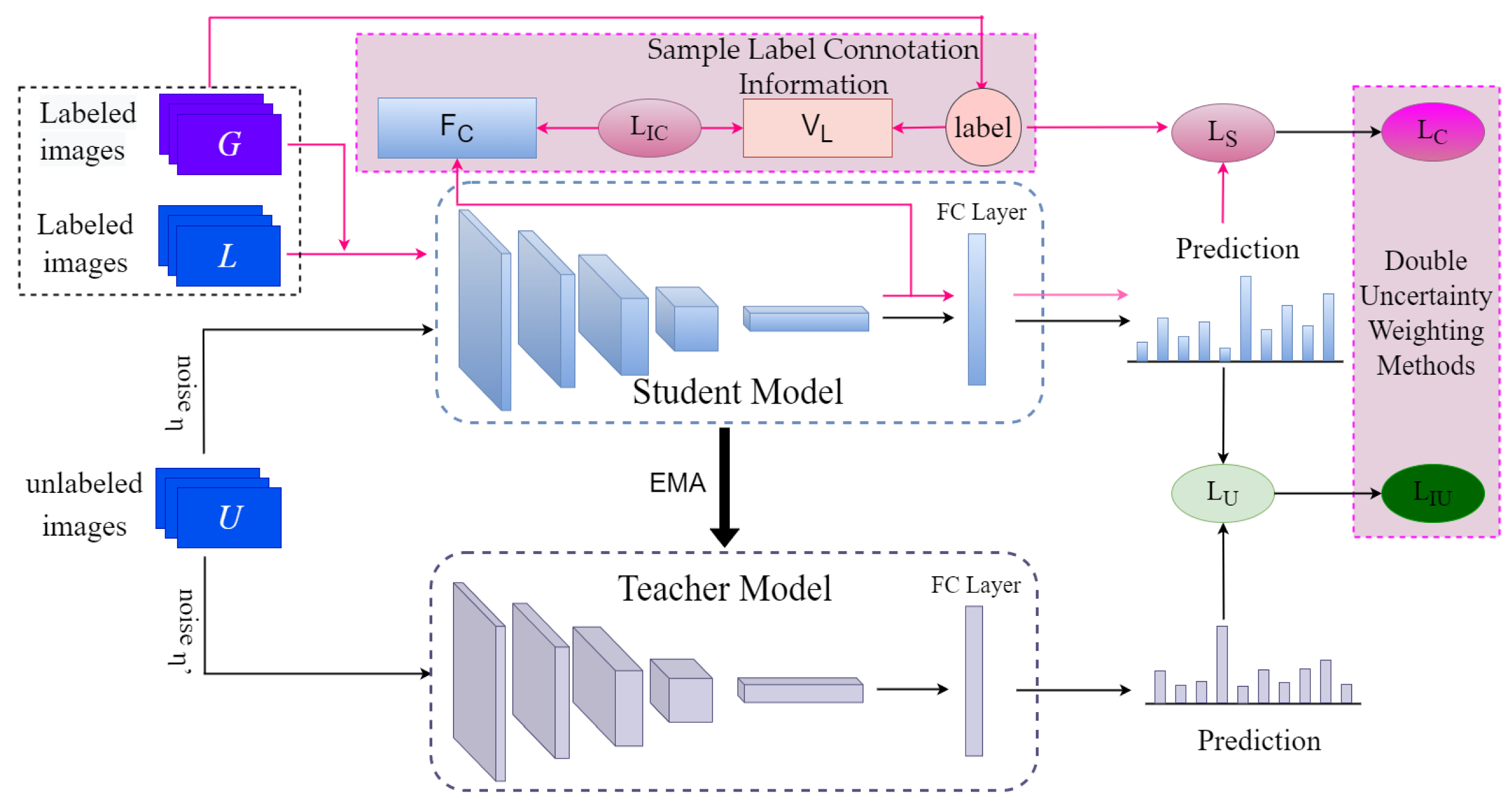
3. Proposed Methods
3.1. Image Generation Model
3.2. Supervisory Losses
3.3. Unsupervised Losses
3.4. Total Model Training Loss
4. Experiments
4.1. Experimental Parameter Settings
4.2. CIFAR-10 Dataset
4.3. SVHN Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, B.Y.; Huang, D.S. Texture classification based on support vector machine and wavelet transform. In Proceedings of the Fifth World Congress on Intelligent Control and Automation (IEEE Cat. No.04EX788), Hangzhou, China, 15–19 June 2004; pp. 1862–1864. [Google Scholar]
- Vailaya, A.; Figueiredo, M.A.; Jain, A.K.; Zhang, H.J. Image classification for content-based indexing. IEEE Trans. Image Process. 2001, 10, 117–130. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Tripathi, M. Analysis of convolutional neural network based image classification techniques. J. Innov. Image Process. JIIP 2021, 3, 100–117. [Google Scholar] [CrossRef]
- Ning, X.; Tian, W.; Yu, Z.; Li, W.; Bai, X.; Wang, Y. HCFNN: High-order coverage function neural network for image classification. Pattern Recognit. 2022, 131, 108873. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep learning techniques for medical image segmentation: Achievements and challenges. J. Digit. Imaging 2019, 32, 582–596. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.Q.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Wu, J.; Sheng, V.S.; Zhang, J.; Li, H.; Dadakova, T.; Swisher, C.L.; Zhao, P. Multi-label active learning algorithms for image classification: Overview and future promise. ACM Comput. Surv. CSUR 2020, 53, 1–35. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. Adv. Neural Inf. Process. Syst. 2016, 29, 3498. [Google Scholar]
- Imran, A.-A.-Z.; Terzopoulos, D. Multi-adversarial Variational Autoencoder Networks. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 777–782. [Google Scholar]
- Wang, L.; Sun, Y.; Wang, Z. CCS-GAN: A semi-supervised generative adversarial network for image classification. Vis. Comput. 2022, 38, 2009–2021. [Google Scholar] [CrossRef]
- Aviles-Rivero, A.I.; Papadakis, N.; Li, R.; Sellars, P.; Fan, Q.; Tan, R.T.; Schönlieb, C.B. GraphXNET—Chest X-Ray Classification under Extreme Minimal Supervision. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Cham, Switzerland, 2019; pp. 504–512. [Google Scholar]
- Jiang, B.; Zhang, Z.; Lin, D.; Tang, J.; Luo, B. Semi-supervised learning with graph learning-convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11313–11320. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, GA, USA, 16–21 June 2013; p. 896. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1780. [Google Scholar]
- Miyato, T.; Maeda, S.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Tan, R.T. Certainty driven consistency loss on multi-teacher networks for semi-supervised learning. Pattern Recognit. 2021, 120, 108140. [Google Scholar] [CrossRef]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C. Mixmatch: A holistic approach to semi-supervised learning. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, M.; Le, Q.V. Unsupervised data augmentation for consistency training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring. arXiv 2019, arXiv:1911.09785. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Li, C.L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 596–608. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, C.J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning (PMLR 2017), Sydney, Australia, 15–17 November 2017; pp. 2642–2651. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Sergievskiy, N.; Ponamarev, A. Reduced focal loss: 1st place solution to xview object detection in satellite imagery. arXiv 2019, arXiv:1903.01347. [Google Scholar]
- Liu, Q.; Yu, L.; Luo, L.; Dou, Q.; Heng, P.A. Semi-supervised medical image classification with relation-driven self-ensembling model. IEEE Trans. Med. Imaging 2020, 39, 3429–3440. [Google Scholar] [CrossRef]
- Zhou, Z.; Lu, C.; Wang, W.; Dang, W.; Gong, K. Semi-Supervised Medical Image Classification Based on Attention and Intrinsic Features of Samples. Appl. Sci. 2022, 12, 6726. [Google Scholar] [CrossRef]
- Haque, A. EC-GAN: Low-Sample Classification using Semi-Supervised Algorithms and GANs (Student Abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 22–24 March 2021; Volume 35, pp. 15797–15798. [Google Scholar]
- Li, C.; Xu, K.; Zhu, J.; Liu, J.; Zhang, B. Triple Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Proc. Icml. 2013, 30, 3. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (PMLR 2015), Hong Kong, China, 20–22 November 2015; pp. 448–456. [Google Scholar]
- Krizhevsky, A.; Nair, V.; Hinton, G. The CIFAR-10 Dataset. 2014, Volume 55. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 25 September 2022).
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In Proceedings of the Deep Learning and Unsupervised Feature Learning Workshop (NIPS 2011), Granada, Spain, 12–17 November 2011. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | CIFAR-10 | ||
|---|---|---|---|
| Labeled | 40 | 250 | 1000 |
| Pseudo-Label [25] | - | 50.220.43 | 83.910.28 |
| П-Model [26] | - | 45.743.87 | 85.990.38 |
| Mean-Teacher [27] | - | 67.682.30 | 90.810.19 |
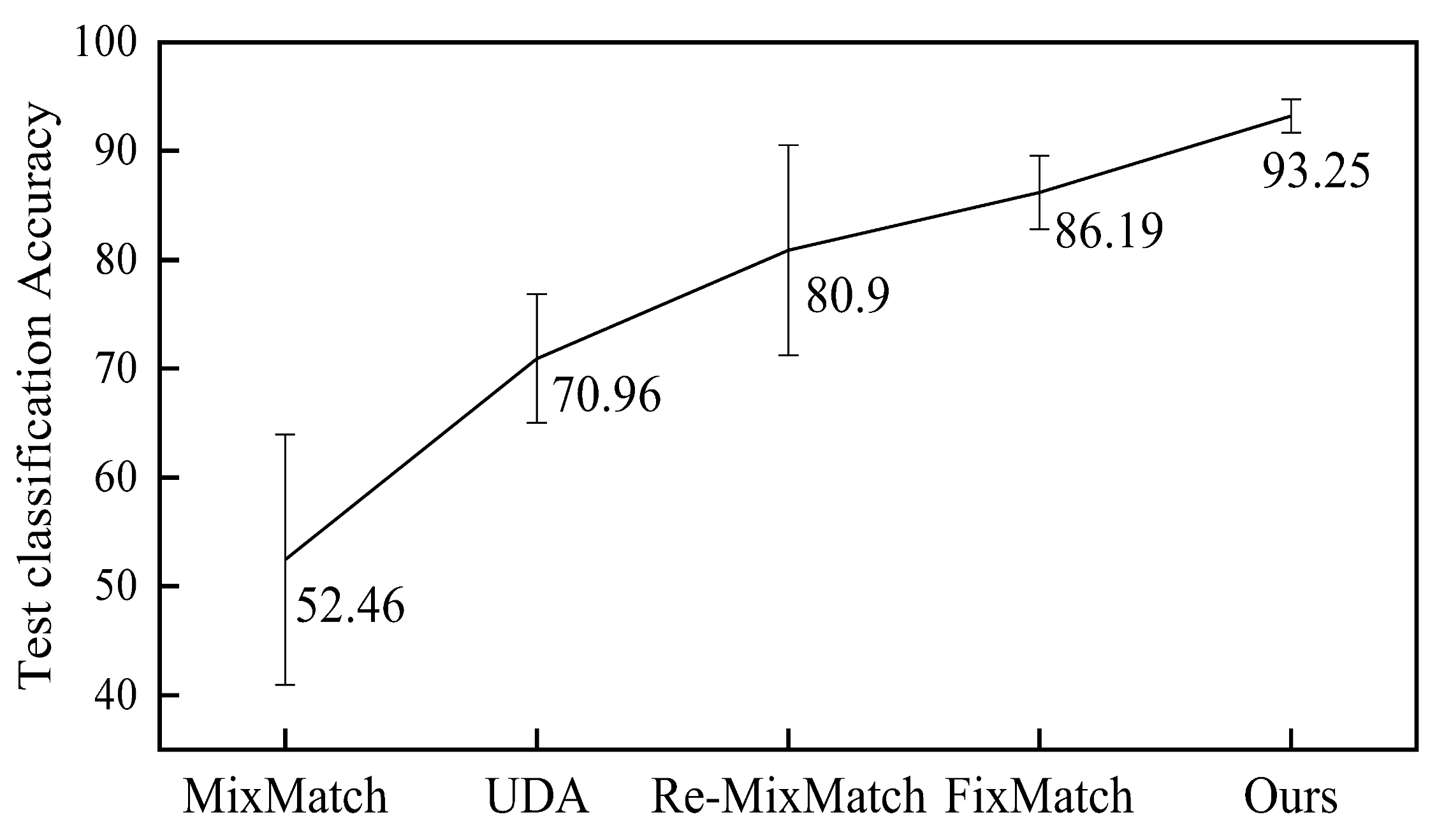
| MixMatch [30] | 52.4611.50 | 88.950.86 | 93.58 ± 0.10 |
| UDA [31] | 70.955.93 | 91.18 1.08 | 95.120.18 |
| Re-MixMatch [32] | 80.909.64 | 94.560.05 | 95.280.13 |
| FixMatch [33] | 86.193.37 | 94.930.65 | 95.740.05 |
| Ours | 93.251.53 | 95.380.84 | 95.960.21 |
| Dataset | SVHN | ||
|---|---|---|---|
| Labeled | 40 | 250 | 1000 |
| Pseudo-Label [25] | - | 79.791.09 | 90.060.61 |
| П-Model [26] | - | 81.04 1.92 | 92.460.36 |
| Mean-Teacher [27] | - | 96.430.11 | 96.580.07 |
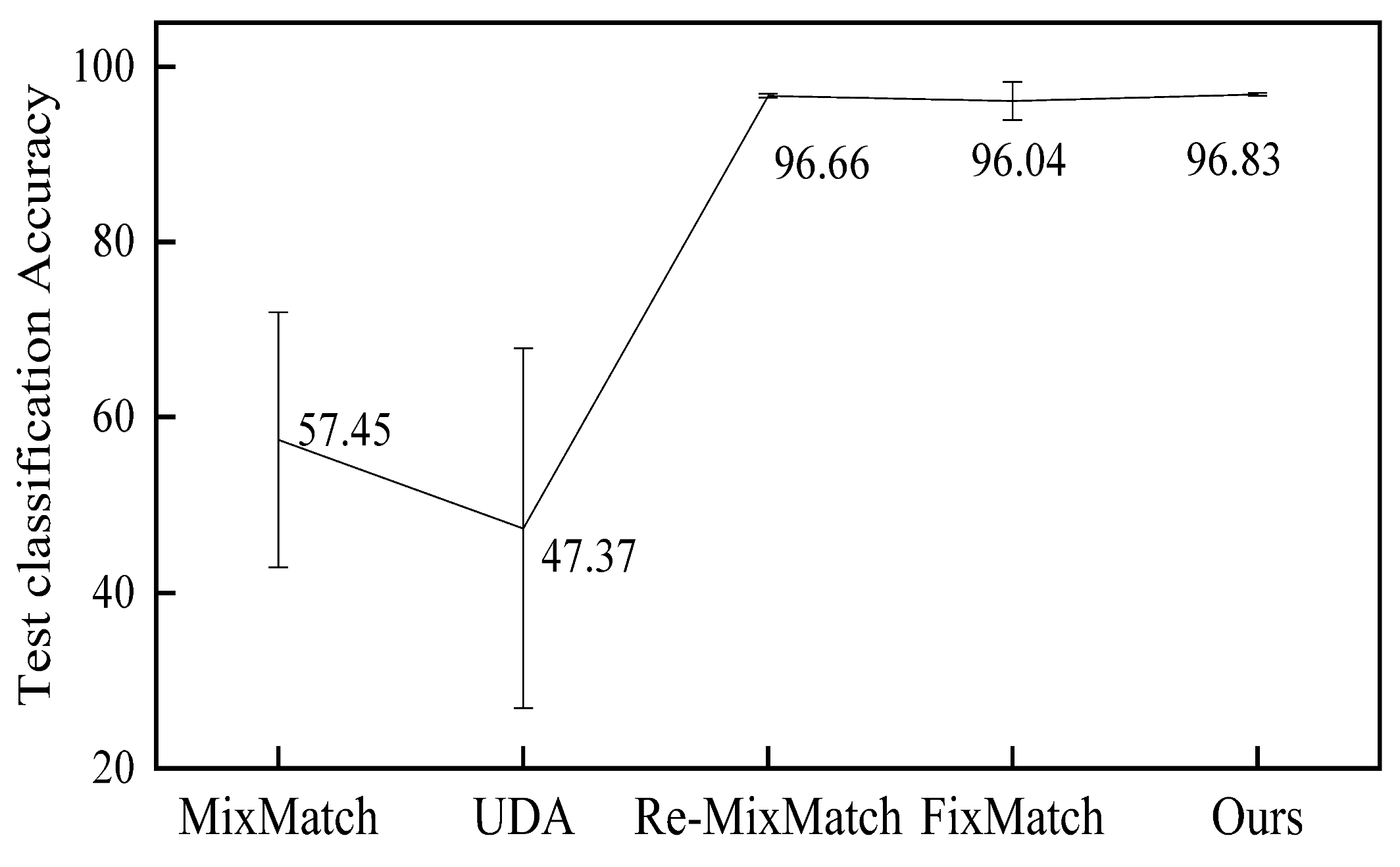
| MixMatch [30] | 57.45 14.53 | 96.020.23 | 96.500.28 |
| UDA [31] | 47.3720.51 | 94.31 2.76 | 97.540.24 |
| Re-MixMatch [32] | 96.660.20 | 97.080.48 | 97.350.08 |
| FixMatch [33] | 96.042.17 | 97.520.38 | 97.720.11 |
| Ours | 96.830.15 | 97.540.21 | 97.630.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zhang, H.; Zhang, X.; Zhang, X.; Zhen, C.; Yuan, T.; Wu, J. Improving Semi-Supervised Image Classification by Assigning Different Weights to Correctly and Incorrectly Classified Samples. Appl. Sci. 2022, 12, 11915. https://doi.org/10.3390/app122311915
Zhang X, Zhang H, Zhang X, Zhang X, Zhen C, Yuan T, Wu J. Improving Semi-Supervised Image Classification by Assigning Different Weights to Correctly and Incorrectly Classified Samples. Applied Sciences. 2022; 12(23):11915. https://doi.org/10.3390/app122311915
Chicago/Turabian StyleZhang, Xu, Huan Zhang, Xinyue Zhang, Xinyue Zhang, Cheng Zhen, Tianguo Yuan, and Jiande Wu. 2022. "Improving Semi-Supervised Image Classification by Assigning Different Weights to Correctly and Incorrectly Classified Samples" Applied Sciences 12, no. 23: 11915. https://doi.org/10.3390/app122311915