
A Federated Incremental Learning Algorithm Based on Dual Attention Mechanism

 , , , , , , and
, , , , , , and
Abstract
:1. Introduction
2. Background
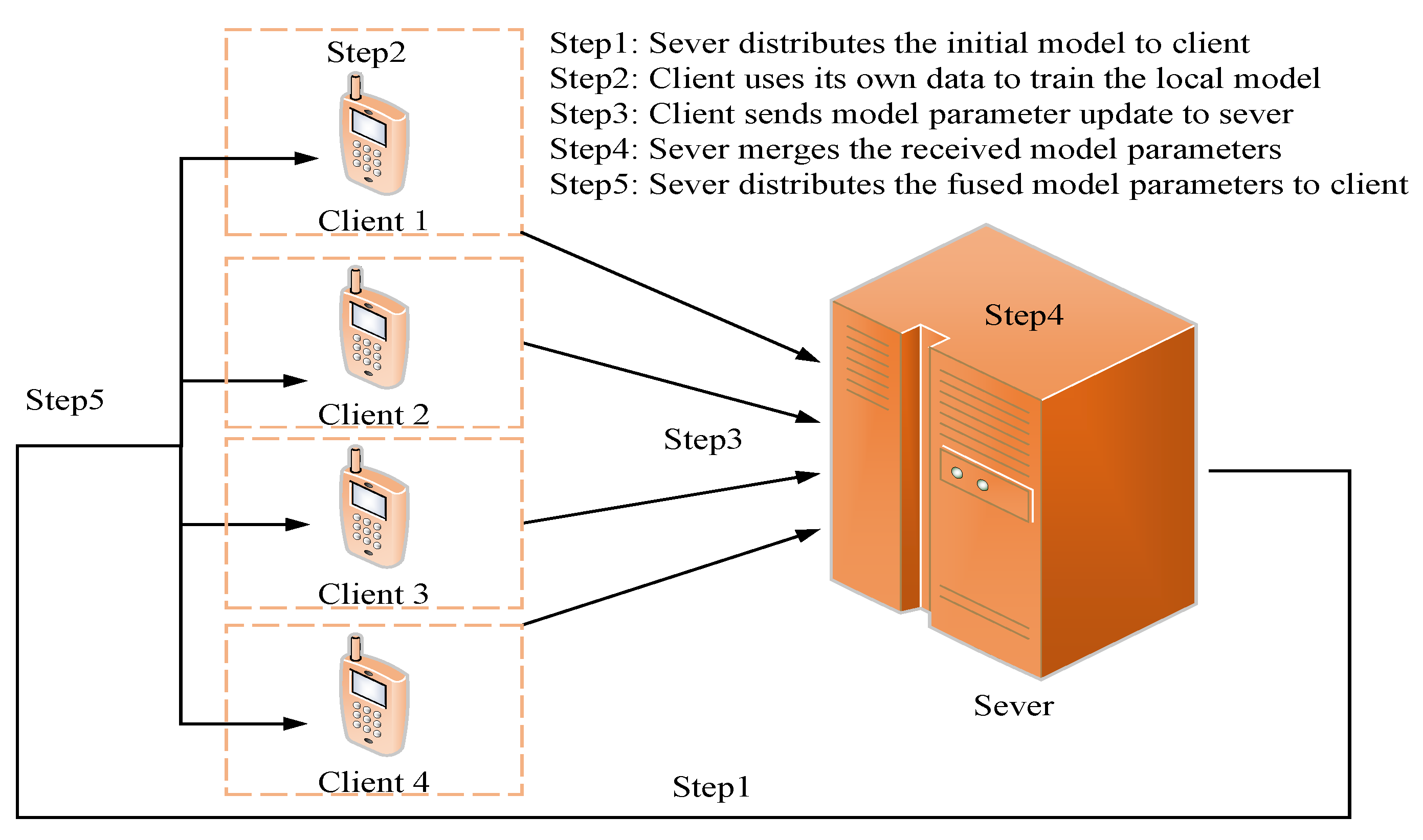
2.1. Federated Averaging Algorithm
2.2. The Basic Structure of Federated Learning
2.3. Class Incremental Learning
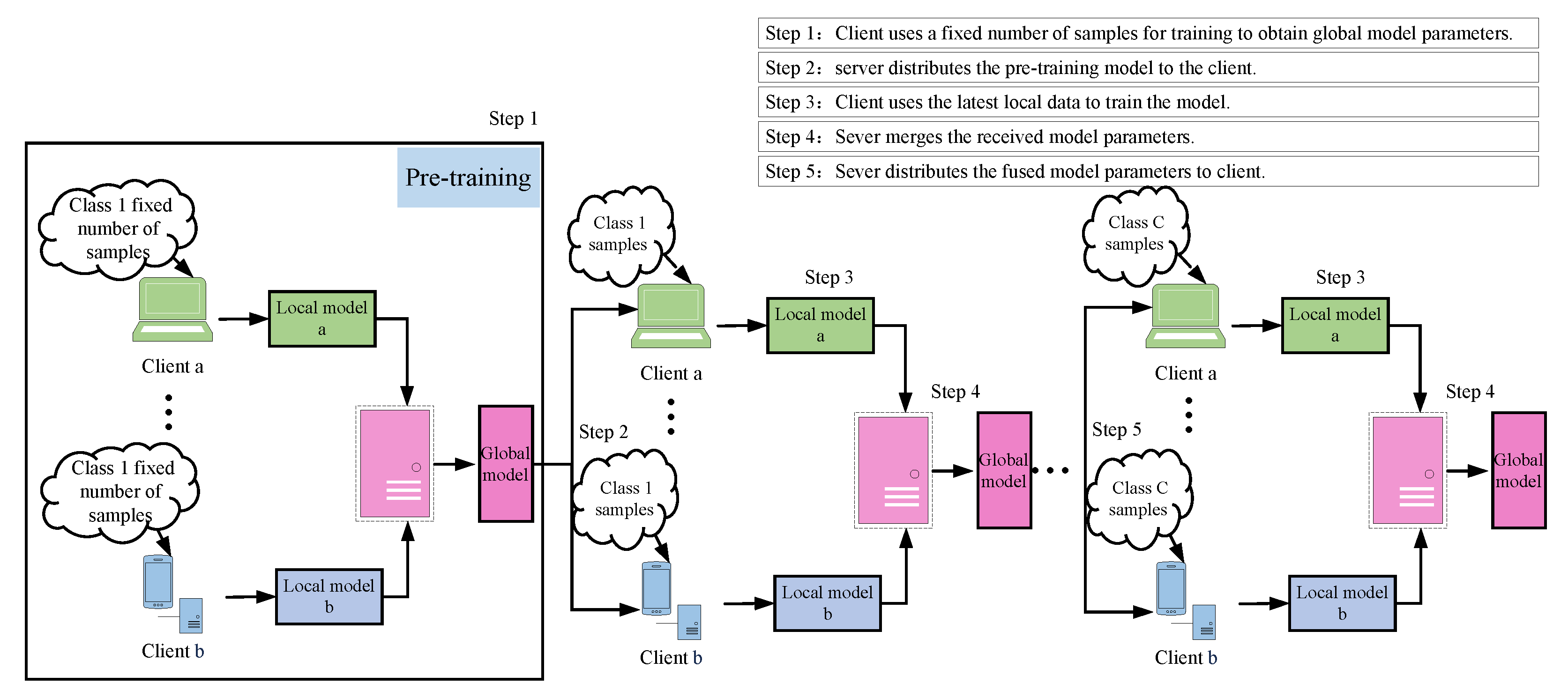
3. Federated Incremental Learning Algorithm
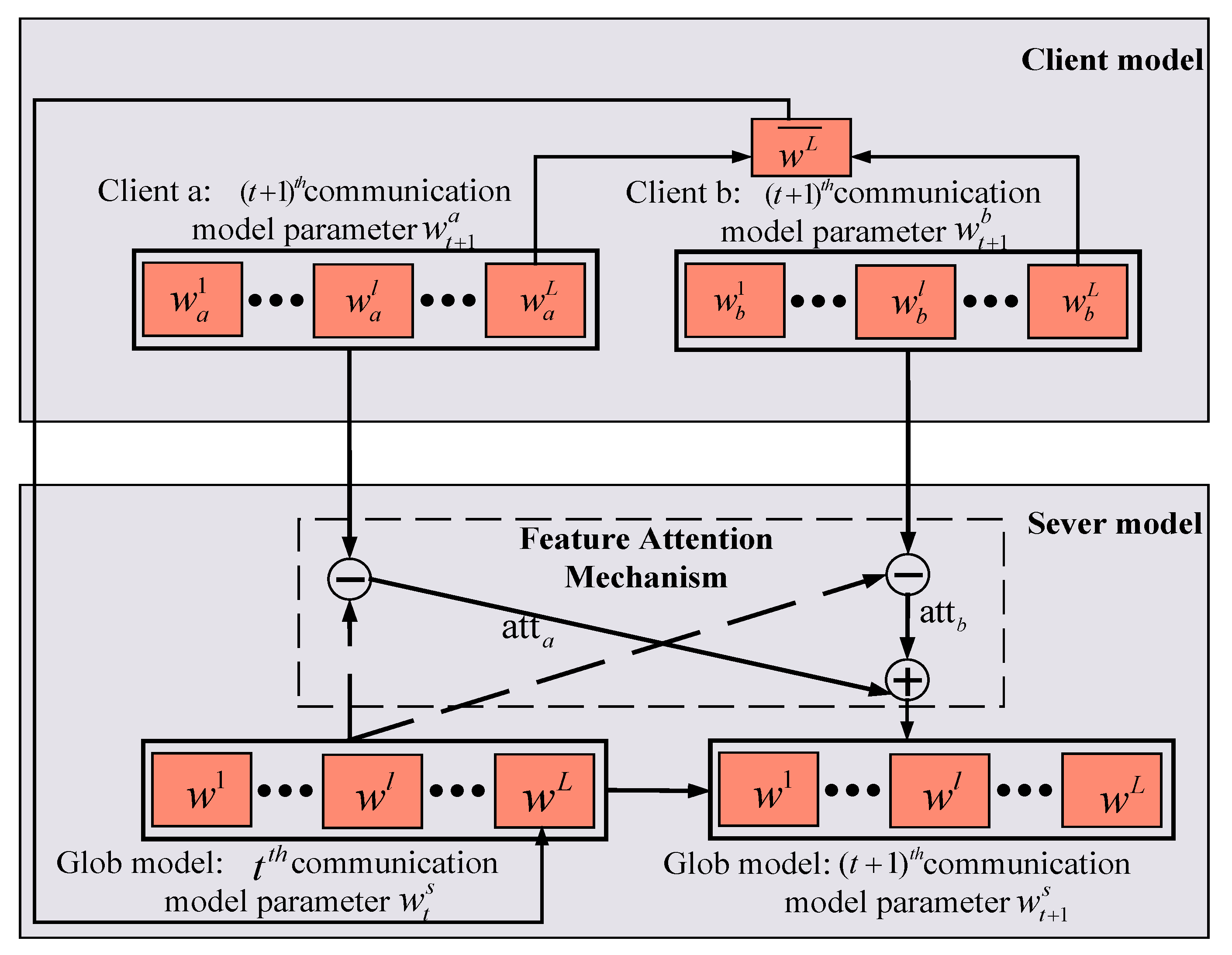
3.1. Federated Incremental Learning Framework
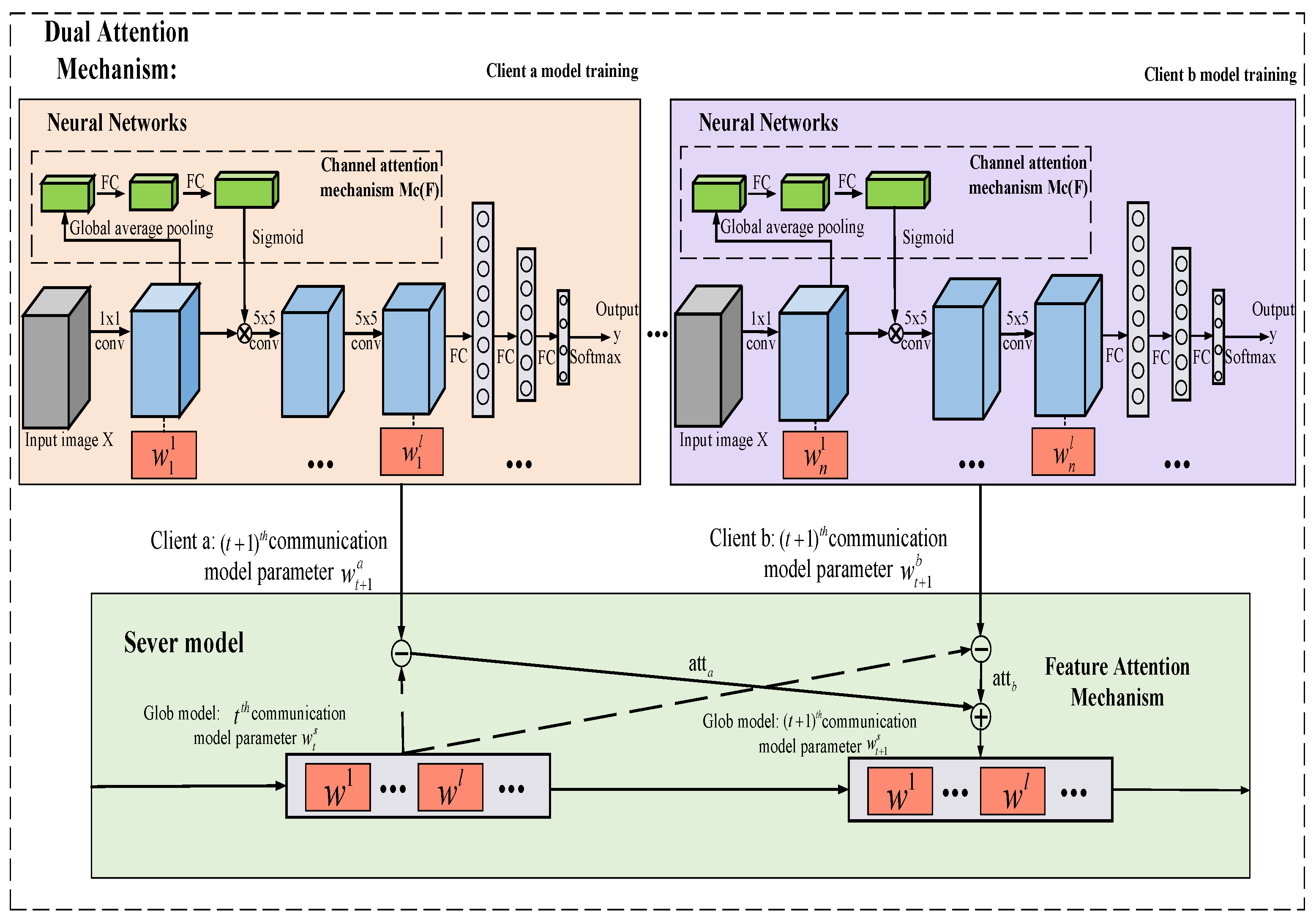
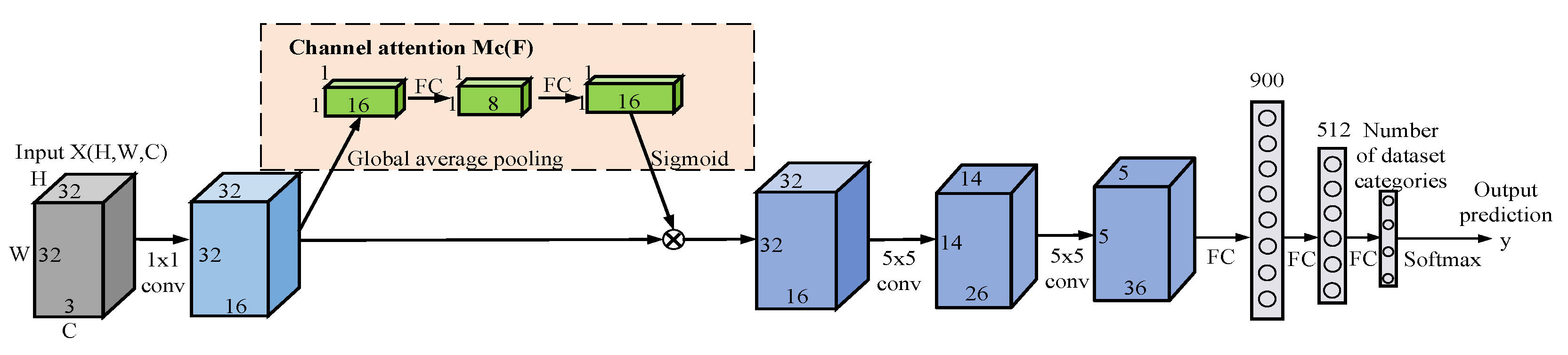
3.2. Dual Attention Mechanism Module
4. Experimental Analysis
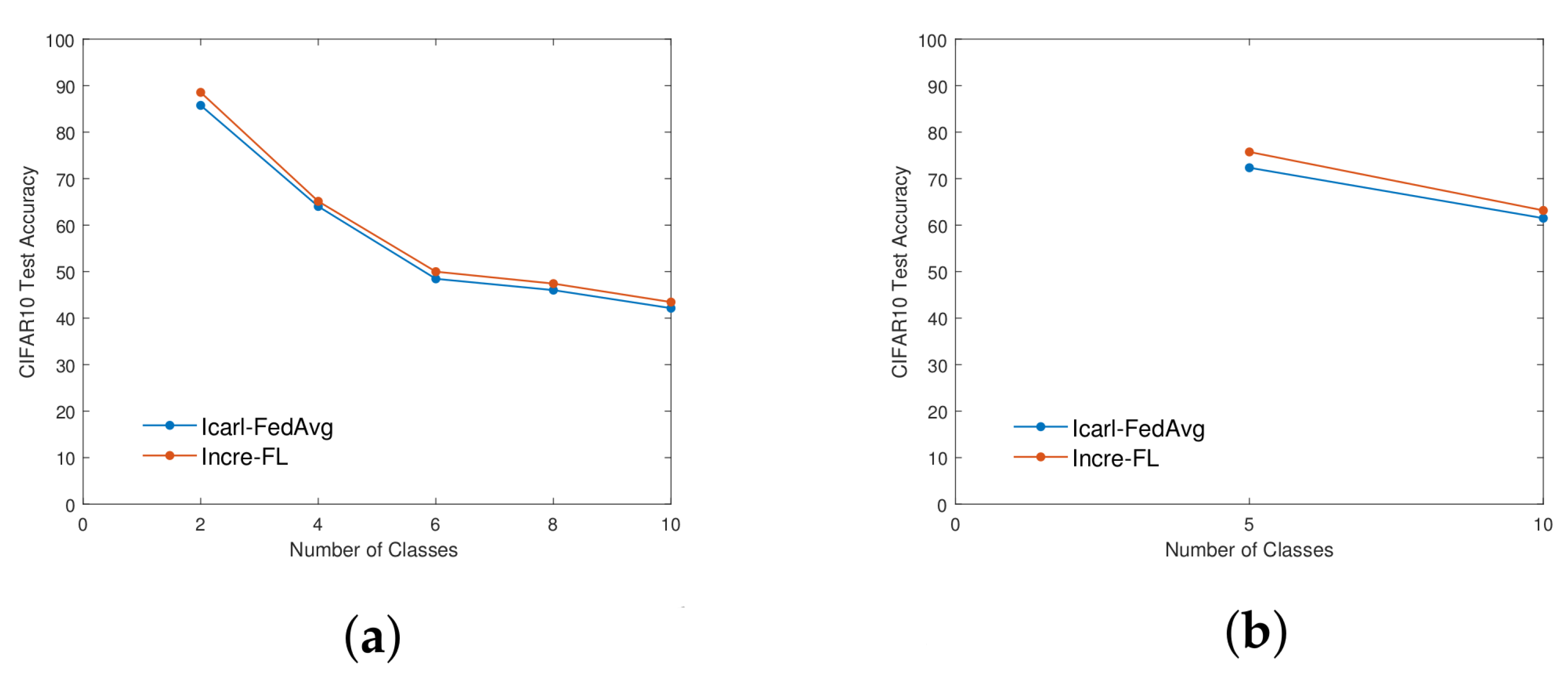
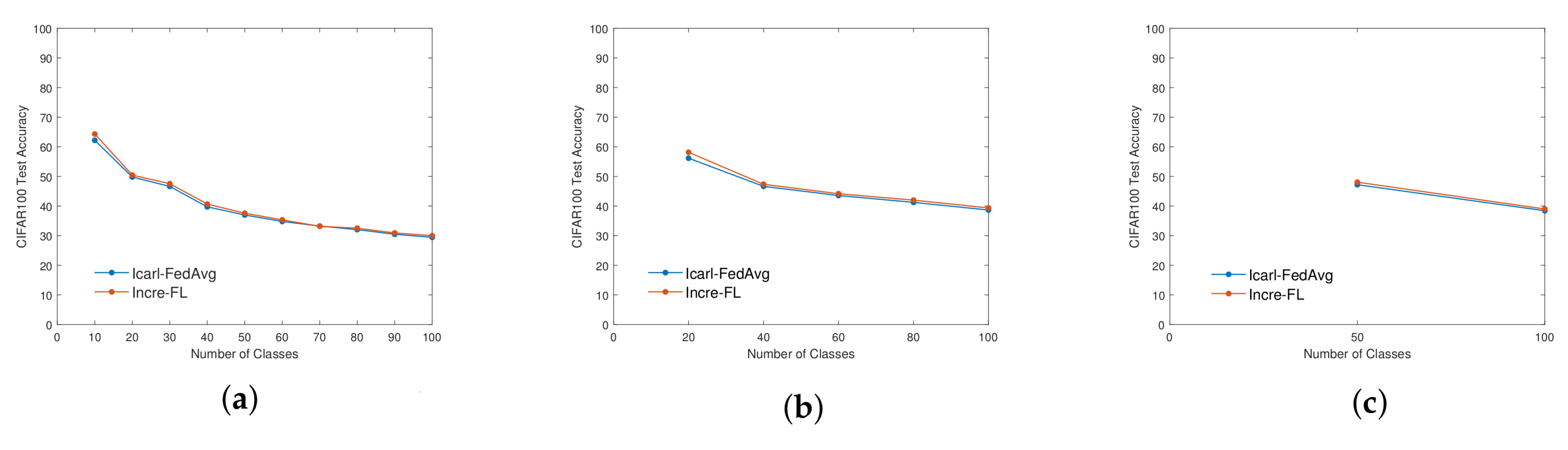
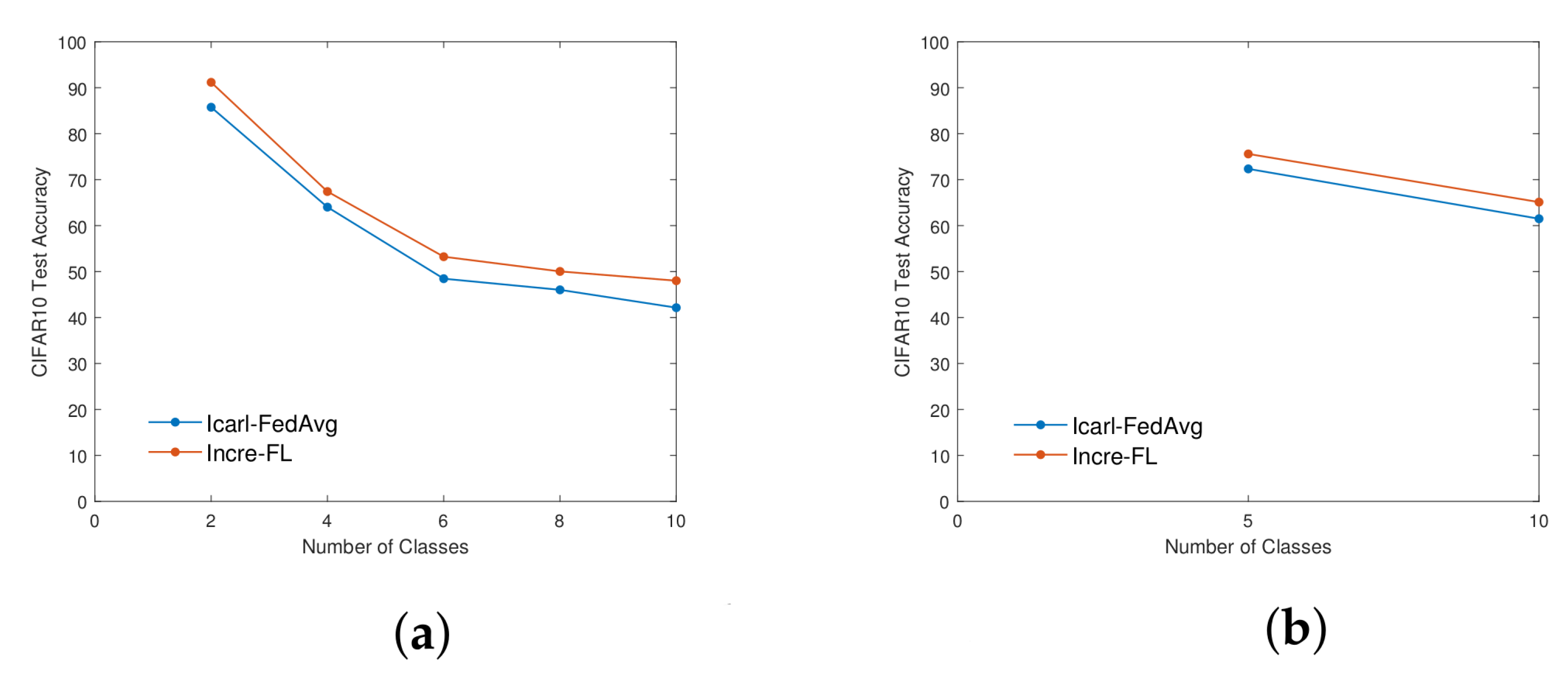
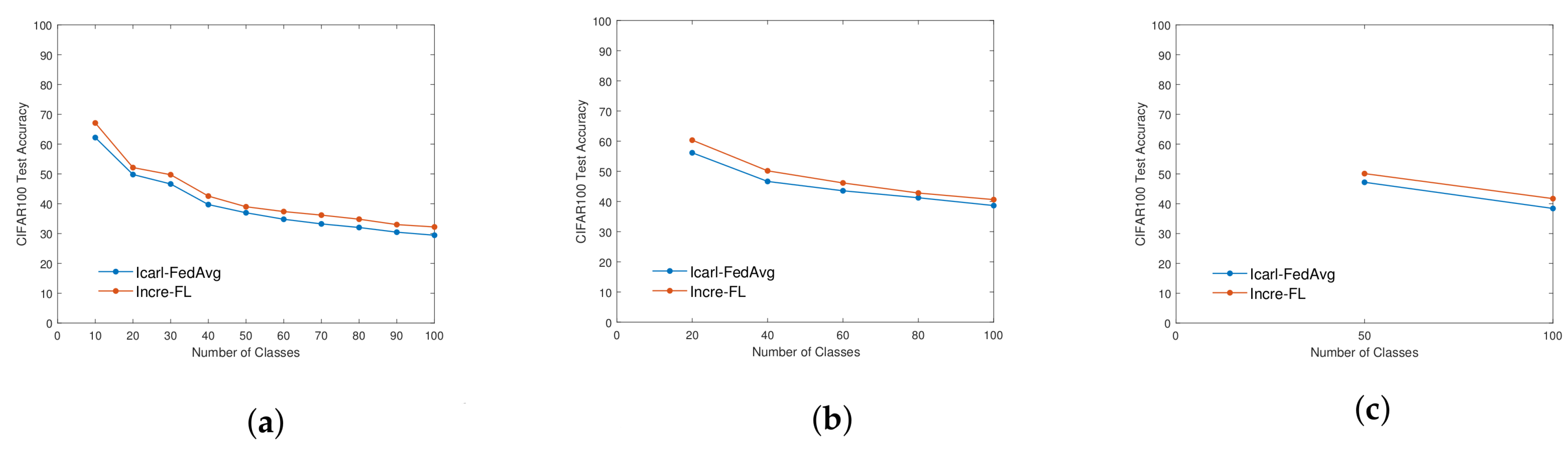
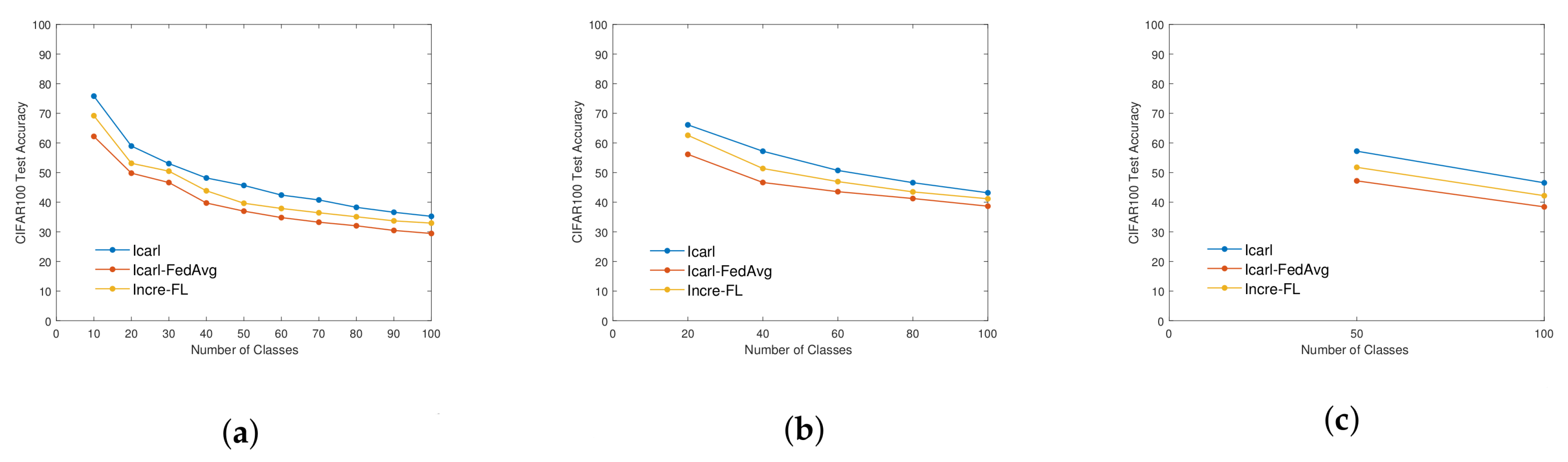
4.1. Ablation Experiment—Rationality Analysis of Pre-Training Module
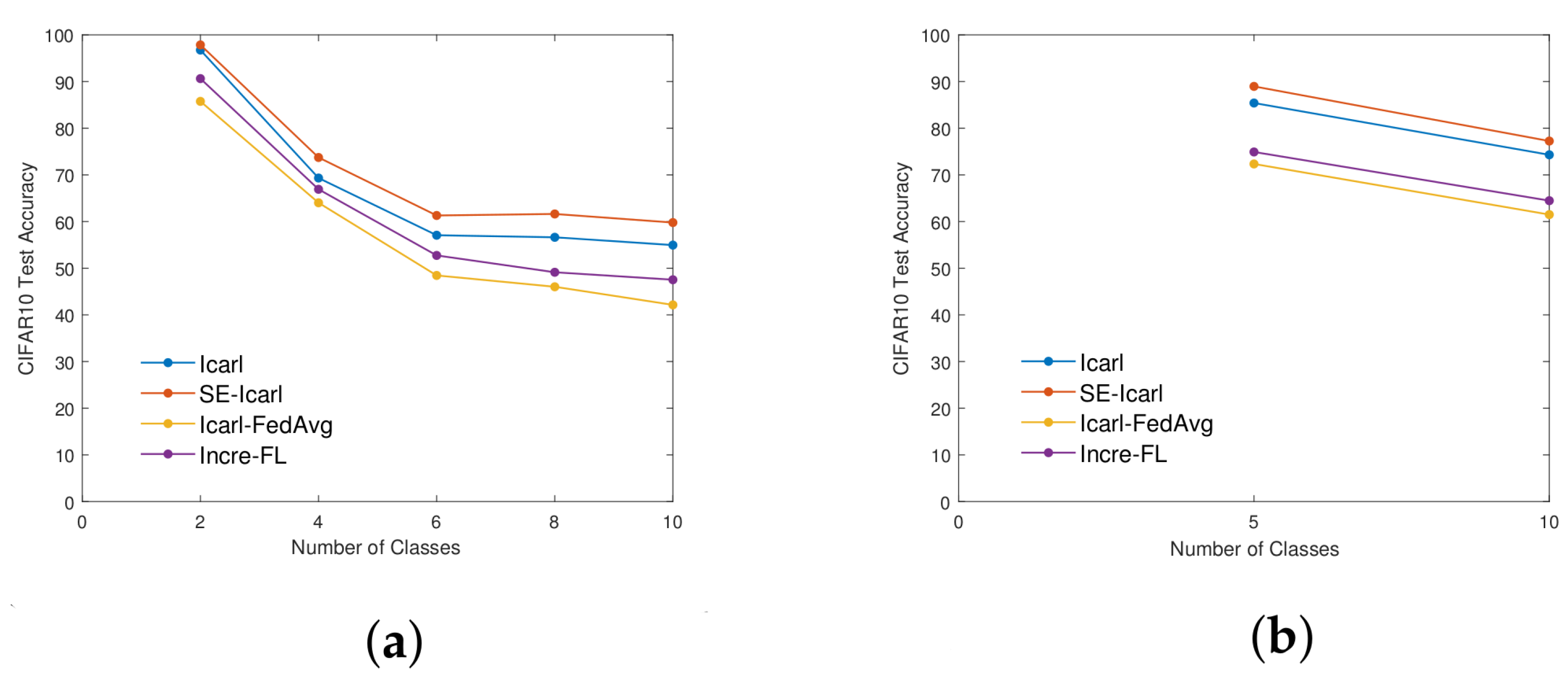
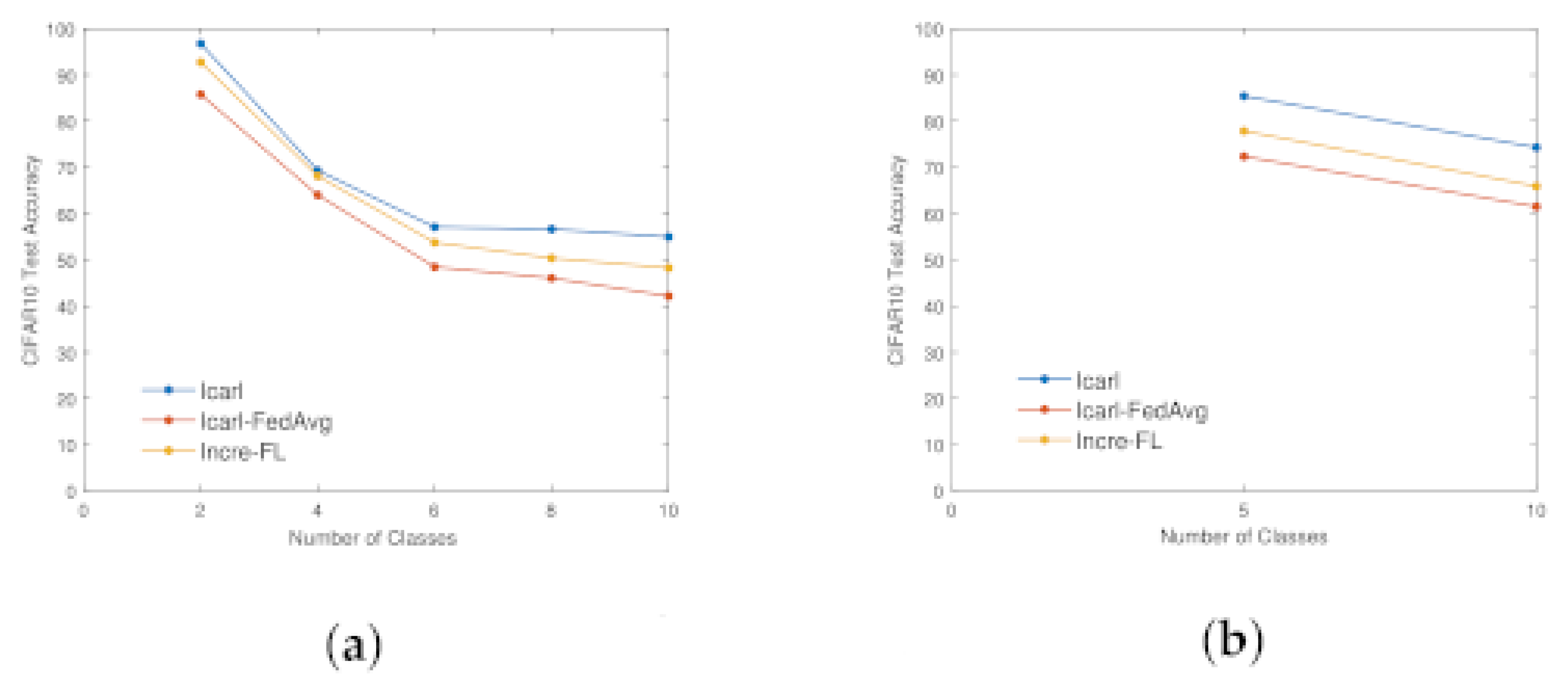
4.2. Ablation Experiment—Rationality Analysis of Dual Attention Mechanism Module
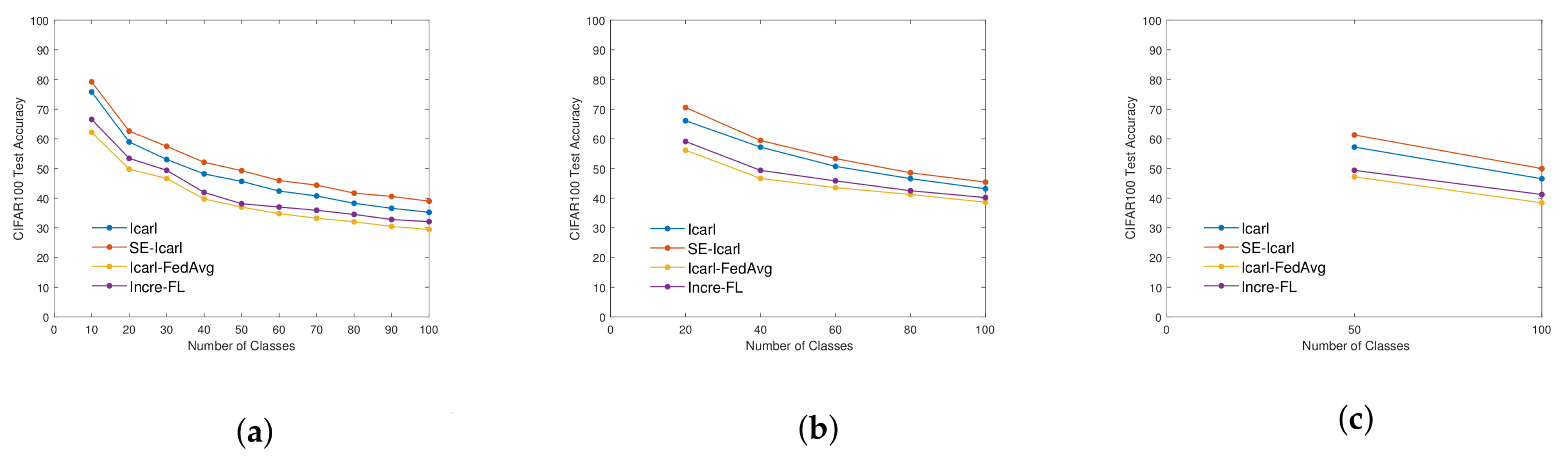
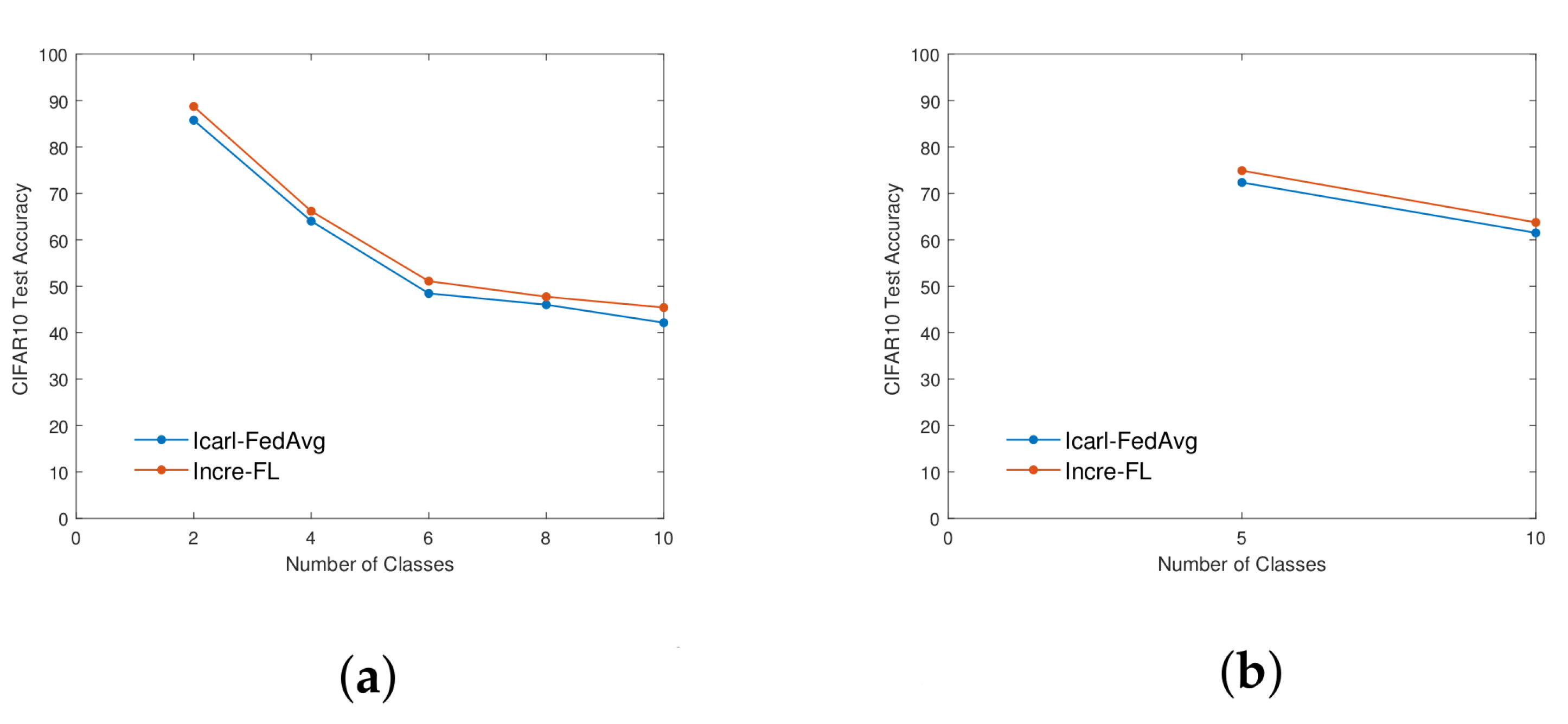
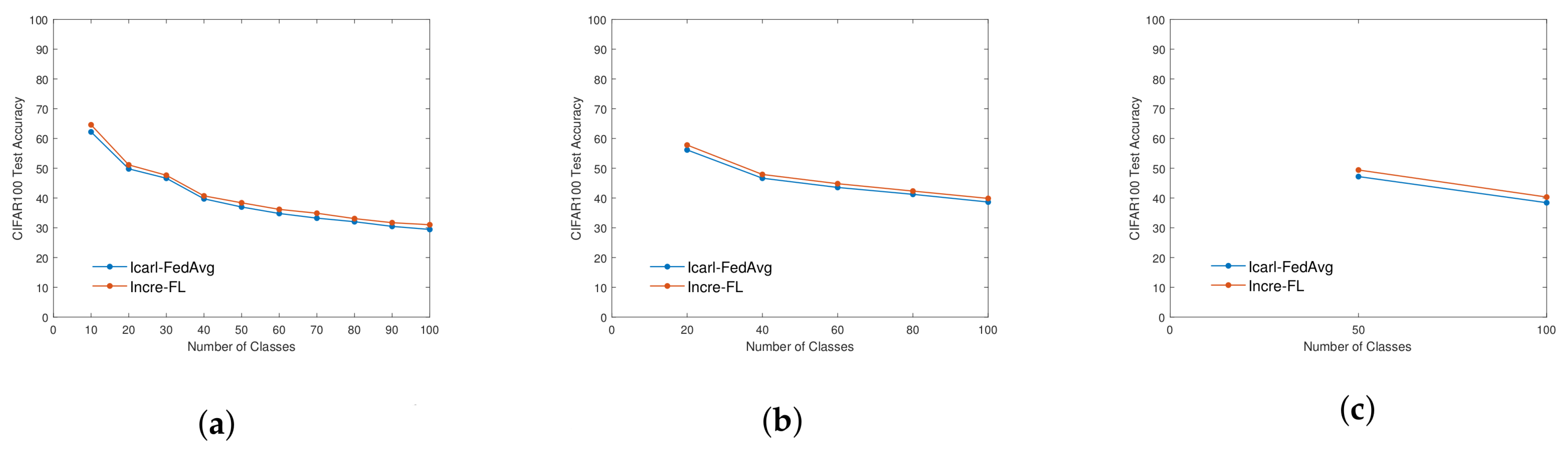
4.3. Comparative Experiment—Overall Accuracy Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. arXiv 2017, arXiv:1602.05629. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; y Arcas, B.A. Federated Learning of Deep Networks using Model Averaging. Electr. Power Syst. Res. 2017, arXiv:1602.05629v3. [Google Scholar]
- Qi, M. Light GBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Chen, X.; Huang, L.; Xie, D.; Zhao, Q. EGBMMDA: Extreme Gradient Boosting Machine for MiRNA-Disease Association prediction. Cell Death Dis. 2018, 9, 3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saunders, C.; Stitson, M.O.; Weston, J.; Holloway, R.; Bottou, L.; Scholkopf, B.; Smola, A. Support Vector Machine. Comput. Sci. 2002, 1, 1–28. [Google Scholar]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 3rd ed.; Macmillan: New York, NY, USA, 1998. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks; Curran Associates Inc.: New York, NY, USA, 2012. [Google Scholar]
- Liu, Y.; Chen, T.; Yang, Q. Secure Federated Transfer Learning. arXiv 2018, arXiv:1812.03337. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and applications. arXiv 2019, arXiv:1902.04885. [Google Scholar] [CrossRef]
- Zhuo, H.H.; Feng, W.; Lin, Y.; Xu, Q.; Yang, Q. Federated deep Reinforcement Learning. arXiv 2020, arXiv:1901.08277. [Google Scholar]
- Peng, Y.; He, M.; Wang, Y. A federated semi-supervised learning approach for network traffic classification. arXiv 2021, arXiv:2107.03933. [Google Scholar]
- Li, Z.; Hoiem, D. Learning without Forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.; Herranz, L.; Liu, X.; van de Weijer, J.; Raducanu, B. Memory Replay GANs: Learning to generate images from new categories without forgetting. In Proceedings of the The 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Luo, C.; Chen, X.; Ma, C.; Wang, J. An online federated incremental learning algorithm for blockchain. J. Comput. Appl. 2021, 41, 363. [Google Scholar]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. iCaRL: Incremental Classifier and Representation Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Yu, H.; Yang, S.; Zhu, S. Parallel Restarted SGD with Faster Convergence and Less Communication: Demystifying Why Model Averaging Works for Deep Learning. AAAI Tech. Track Mach. Learn. 2018, 33, AAAI-19. [Google Scholar] [CrossRef] [Green Version]
- Hu, K.; Wu, J.; Li, Y.; Lu, M.; Weng, L.; Xia, M. FedGCN: Federated Learning-Based Graph Convolutional Networks for Non-Euclidean Spatial Data. Mathematics 2022, 10, 1000. [Google Scholar] [CrossRef]
- Hu, K.; Wu, J.; Weng, L.; Zhang, Y.; Zheng, F.; Pang, Z.; Xia, M. A novel federated learning approach based on the confidence of federated Kalman filters. Int. J. Mach. Learn. Cybern. 2021, 12, 3607–3627. [Google Scholar] [CrossRef]
- Lin, Z.; Feng, M.; Santos, C.N.D.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A Structured Self-attentive Sentence Embedding. arXiv 2017, arXiv:1703.03130. [Google Scholar]
- Zhao, H.; Jian, J.; Koltun, V. Exploring Self-attention for Image Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Liu, Y.; Yang, Q.; Chen, T. Tutorial on Federated Learning and Transfer Learning for Privacy, Security and Confidentiality. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Douillard, A.; Cord, M.; Ollion, C.; Robert, T.; Valle, E. PODNet: Pooled Outputs Distillation for Small-Tasks Incremental Learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhang, D.; Chen, X.; Xu, S.; Xu, B. Knowledge Aware Emotion Recognition in Textual Conversations via Multi-Task Incremental Transformer. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020. [Google Scholar]
- Ahn, H.; Kwak, J.; Lim, S.; Bang, H.; Kim, H.; Moon, T. SS-IL: Separated Softmax for Incremental Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Kim, J.Y.; Choi, D.W. Split-and-Bridge: Adaptable Class Incremental Learning within a Single Neural Network. arXiv 2021, arXiv:2107.01349. [Google Scholar] [CrossRef]
- Shmelkov, K.; Schmid, C.; Alahari, K. Incremental Learning of Object Detectors without Catastrophic Forgetting. In Proceedings of the IEEE international Conference on Computer vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Shoham, N.; Avidor, T.; Keren, A.; Israel, N.; Benditkis, D.; Mor-Yosef, L.; Zeitak, I. Overcoming Forgetting in Federated Learning on Non-IID Data. arXiv 2019, arXiv:1910.07796. [Google Scholar]
- Hu, G.; Zhang, W.; Ding, H.; Zhu, W. Gradient Episodic Memory with a Soft Constraint for Continual Learning. arXiv 2020, arXiv:2011.07801. [Google Scholar]
- Masana, M.; Liu, X.; Twardowski, B.; Menta, M.; Weijer, J.V.D. Class-incremental learning: Survey and performance evaluation. arXiv 2020, arXiv:2010.15277. [Google Scholar]
- Fallah, M.K.; Fazlali, M.; Daneshtalab, M. A symbiosis between population based incremental learning and LP-relaxation based parallel genetic algorithm for solving integer linear programming models. Computing 2021, 1–19. [Google Scholar] [CrossRef]
- Bielak, P.; Tagowski, K.; Falkiewicz, M.; Kajdanowicz, T.; Chawla, N.V. FILDNE: A Framework for Incremental Learning of Dynamic Networks Embeddings. Knowl.-Based Syst. 2021, 4, 107453. [Google Scholar] [CrossRef]
- Hu, K.; Jin, J.; Zheng, F.; Weng, L.; Ding, Y. Overview of behavior recognition based on deep learning. Artif. Intell. Rev. 2022, 1–33. [Google Scholar] [CrossRef]
- Cho, K.; Merrienboer, B.V.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Handb. Syst. Autoimmune Dis. 2009, 1. [Google Scholar]
- Chen, B.Y.; Xia, M.; Huang, J.Q. MFANet: A Multi-Level Feature Aggregation Network for Semantic Segmentation of Land Cover. Remote Sens. 2021, 13, 731. [Google Scholar] [CrossRef]
- Xia, M.; Wang, T.; Zhang, Y.H.; Liu, J.; Xu, Y.Q. Cloud/shadow Segmentation based on Global Attention Feature Fusion Residual Network for Remote Sensing Imagery. Int. J. Remote Sens. 2021, 42, 2022–2045. [Google Scholar] [CrossRef]
- Xia, M.; Cui, Y.C.; Zhang, Y.H.; Xu, Y.M.; Liu, J.; Xu, Y.Q. DAU-Net: A Novel Water Areas Segmentation Structure for Remote Sensing Image. Int. J. Remote Sens. 2021, 42, 2594–2621. [Google Scholar] [CrossRef]
- Xia, M.; Liu, W.A.; Wang, K.; Song, W.Z.; Chen, C.L.; Li, Y.P. Non-intrusive Load Disaggregation based on Composite Deep Long Short-term Memory Network. Expert Syst. Appl. 2020, 160, 113669. [Google Scholar] [CrossRef]
- Xia, M.; Zhang, X.; Liu, W.A.; Weng, L.G.; Xu, Y.Q. Multi-stage Feature Constraints Learning for Age Estimation. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2417–2428. [Google Scholar] [CrossRef]
- Hu, K.; Ding, Y.; Jin, J.; Weng, L.; Xia, M. Skeleton Motion Recognition Based on Multi-Scale Deep Spatio-Temporal Features. Appl. Sci. 2022, 12, 1028. [Google Scholar] [CrossRef]
- Hu, K.; Weng, C.; Zhang, Y.; Jin, J.; Xia, Q. An Overview of Underwater Vision Enhancement: From Traditional Methods to Recent Deep Learning. J. Mar. Sci. Eng. 2022, 10, 241. [Google Scholar] [CrossRef]
- Hu, K.; Chen, X.; Xia, Q. A Control Algorithm for Sea–Air Cooperative Observation Tasks Based on a Data-Driven Algorithm. J. Mar. Sci. Eng. 2021, 9, 1189. [Google Scholar] [CrossRef]
- Lu, E.; Hu, X. Image super-resolution via channel attention and spatial attention. Appl. Intell. 2021, 10, 2260–2268. [Google Scholar] [CrossRef]
- Chen, J.; Yang, L.; Tan, L.; Xu, R. Orthogonal channel attention-based multi-task learning for multi-view facial expression recognition. Pattern Recognit. 2022, 129, 108753. [Google Scholar] [CrossRef]
- Yao, L.; Ding, W.; He, T.; Liu, S.; Nie, L. A multiobjective prediction model with incremental learning ability by developing a multi-source filter neural network for the electrolytic aluminium process. Appl. Intell. 2022, 1, 1–23. [Google Scholar] [CrossRef]
- Yuan, K.; Xu, W.; Li, W. An incremental learning mechanism for object classification based on progressive fuzzy three-way concept. Inform. Sci. 2022, 584, 127–147. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Increments/Test Classes | Model | Accuracy (%) |
|---|---|---|---|
| CIFAR10 | 2/10 | Icarl-FedAvg | 42.14 |
| Incre-FL | 43.45 | ||
| 5/10 | Icarl-FedAvg | 61.49 | |
| Incre-FL | 63.16 | ||
| CIFAR100 | 10/100 | Icarl-FedAvg | 29.44 |
| Incre-FL | 30.03 | ||
| 20/100 | Icarl-FedAvg | 38.65 | |
| Incre-FL | 39.35 | ||
| 50/100 | Icarl-FedAvg | 38.42 | |
| Incre-FL | 39.00 |
| Dataset | Increments/Test Classes | Model | Accuracy (%) |
|---|---|---|---|
| CIFAR10 | 2/10 | Icarl-FedAvg | 42.14 |
| Incre-FL | 48.01 | ||
| 5/10 | Icarl-FedAvg | 61.49 | |
| Incre-FL | 65.11 | ||
| CIFAR100 | 10/100 | Icarl-FedAvg | 29.44 |
| Incre-FL | 32.22 | ||
| 20/100 | Icarl-FedAvg | 38.65 | |
| Incre-FL | 40.62 | ||
| 50/100 | Icarl-FedAvg | 38.42 | |
| Incre-FL | 41.72 |
| Dataset | Increments/Test Classes | Model | Accuracy (%) |
|---|---|---|---|
| CIFAR10 | 2/10 | Icarl-FedAvg | 42.14 |
| Incre-FL | 47.53 | ||
| 5/10 | Icarl-FedAvg | 61.49 | |
| Incre-FL | 64.47 | ||
| CIFAR100 | 10/100 | Icarl-FedAvg | 29.44 |
| Incre-FL | 32.09 | ||
| 20/100 | Icarl-FedAvg | 38.65 | |
| Incre-FL | 40.20 | ||
| 50/100 | Icarl-FedAvg | 38.42 | |
| Incre-FL | 41.23 |
| Dataset | Increments/Test Classes | Model | Accuracy (%) |
|---|---|---|---|
| CIFAR10 | 2/10 | Icarl-FedAvg | 42.14 |
| Incre-FL | 45.40 | ||
| 5/10 | Icarl-FedAvg | 61.49 | |
| Incre-FL | 63.73 | ||
| CIFAR100 | 10/100 | Icarl-FedAvg | 29.44 |
| Incre-FL | 31.02 | ||
| 20/100 | Icarl-FedAvg | 38.65 | |
| Incre-FL | 39.86 | ||
| 50/100 | Icarl-FedAvg | 38.42 | |
| Incre-FL | 40.32 |
| Dataset | Increments/Test Classes | Model | Accuracy (%) |
|---|---|---|---|
| CIFAR10 | 2/10 | Icarl-FedAvg | 42.14 |
| Incre-FL | 48.24 | ||
| 5/10 | Icarl-FedAvg | 61.49 | |
| Incre-FL | 65.90 | ||
| CIFAR100 | 10/100 | Icarl-FedAvg | 29.44 |
| Incre-FL | 32.94 | ||
| 20/100 | Icarl-FedAvg | 38.65 | |
| Incre-FL | 41.15 | ||
| 50/100 | Icarl-FedAvg | 38.42 | |
| Incre-FL | 42.19 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, K.; Lu, M.; Li, Y.; Gong, S.; Wu, J.; Zhou, F.; Jiang, S.; Yang, Y. A Federated Incremental Learning Algorithm Based on Dual Attention Mechanism. Appl. Sci. 2022, 12, 10025. https://doi.org/10.3390/app121910025
Hu K, Lu M, Li Y, Gong S, Wu J, Zhou F, Jiang S, Yang Y. A Federated Incremental Learning Algorithm Based on Dual Attention Mechanism. Applied Sciences. 2022; 12(19):10025. https://doi.org/10.3390/app121910025
Chicago/Turabian StyleHu, Kai, Meixia Lu, Yaogen Li, Sheng Gong, Jiasheng Wu, Fenghua Zhou, Shanshan Jiang, and Yi Yang. 2022. "A Federated Incremental Learning Algorithm Based on Dual Attention Mechanism" Applied Sciences 12, no. 19: 10025. https://doi.org/10.3390/app121910025