
Relative Pose Estimation between Image Object and ShapeNet CAD Model for Automatic 4-DoF Annotation

Abstract
:1. Introduction
- (1)
- The 4-DoF pose estimation pipeline from a single RGB image is proposed.
- (2)
- The 4-DoF pose annotation database can be generated to align the CAD model of a real object in the image plane.
- (3)
- Three image similarity criteria are proposed to match deep features between rendered CAD and real object images.
2. Literature Review
2.1. Retrieval of CAD Models
2.2. Retrieval of CAD Models and Pose Estimation
2.3. Industrial Applications of Object Pose Estimation
2.4. RGB Image-Based Pose Estimation
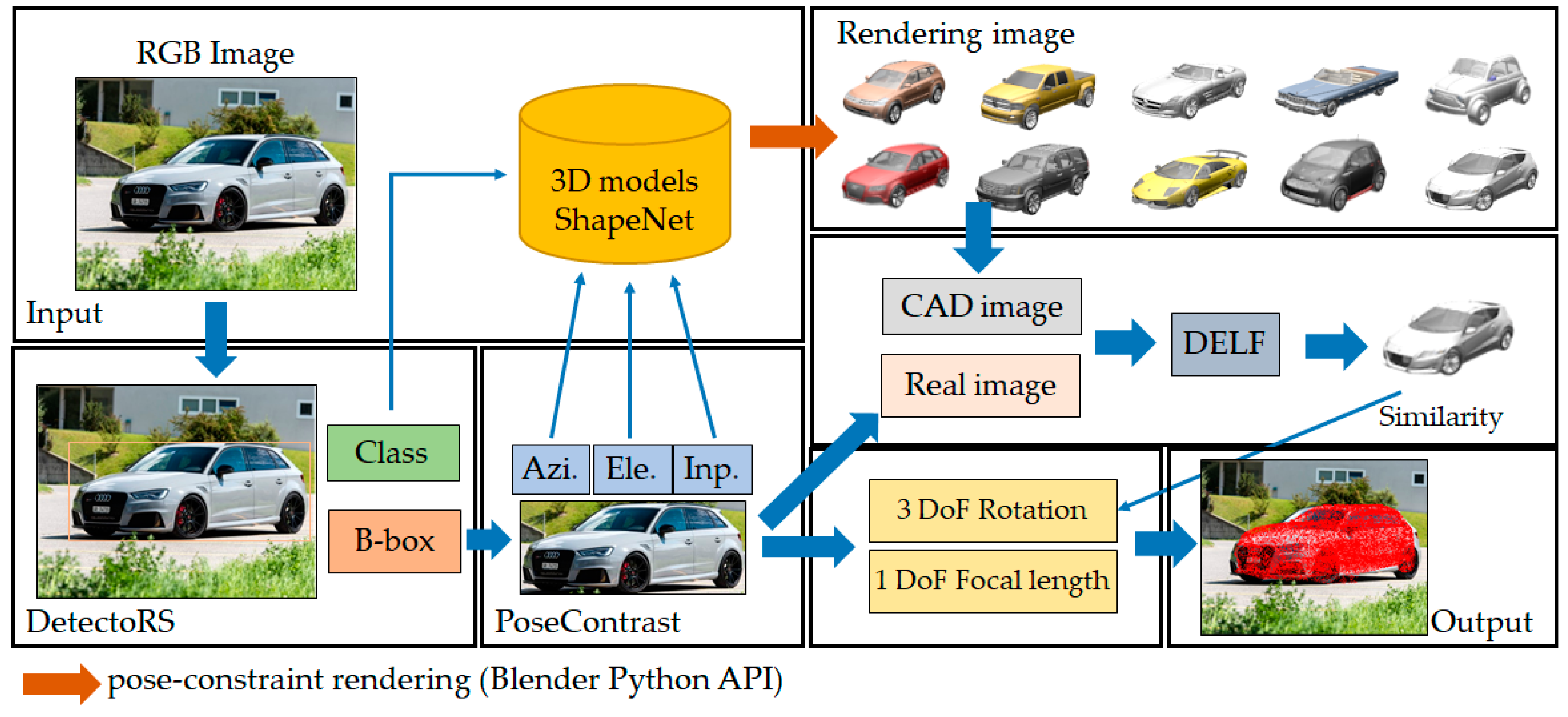
3. Proposed Pose Estimation Pipeline
3.1. Object Detection in RGB Images
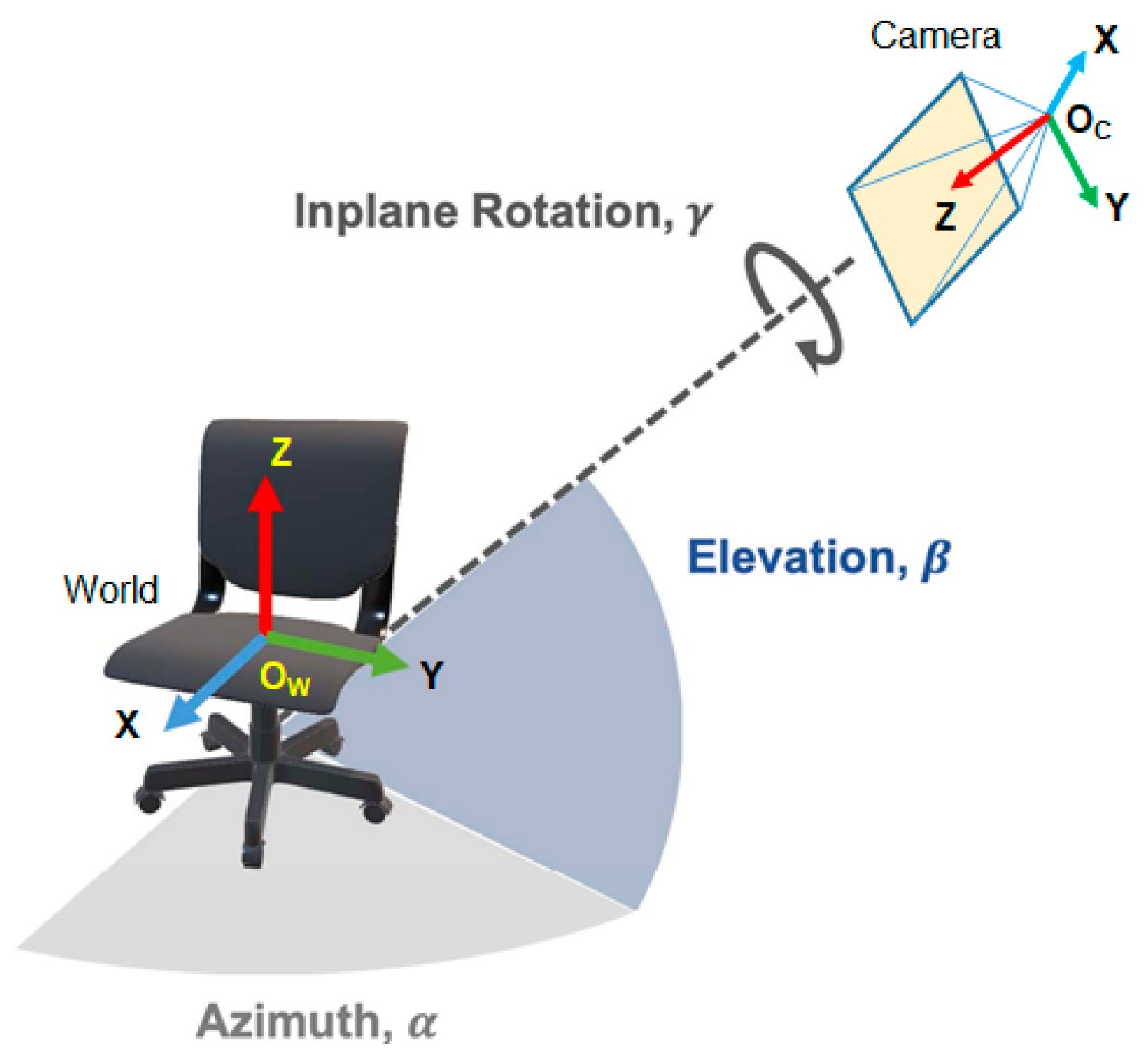
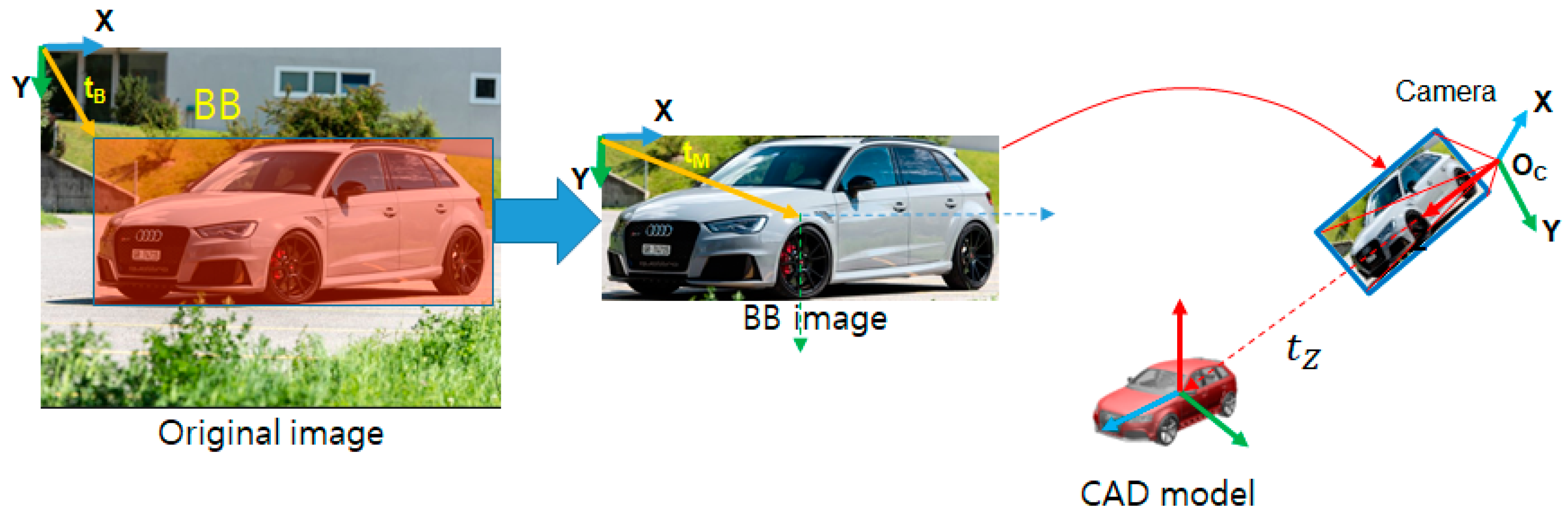
3.2. 4-DoF Pose Estimation
3.3. Estimation of Rotation and Focal Length
3.4. Retrieval of a CAD Model and Similarity Measurement
- Similarity measure 1 (SM1):
- Similarity measure 2 (SM2):
- Similarity measure 3 (SM3):
4. Experiments
4.1. Object Detection and Segmentation
4.2. Pose Estimation and Similarity Measurement
4.3. Performance Analysis of Similarity Measurement
4.4. Comparison with a Triplet Loss Learning Method
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, Z.; Feng, W.; Zhao, X.; Lv, Y. 6D Pose Estimation of Objects: Recent Technologies and Challenges. Appl. Sci. 2020, 11, 228. [Google Scholar] [CrossRef]
- Gorschlüter, F.; Rojtberg, P.; Pöllabauer, T. A Survey of 6D Object Detection Based on 3D Models for Industrial Applications. J. Imaging 2022, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, C.; Long, P.; Gu, Y.; Li, W. Recent Advances in 3D Object Detection Based on RGB-D: A Survey. Displays 2021, 70, 102077. [Google Scholar] [CrossRef]
- Hua, B.S.; Truong, Q.T.; Tran, M.K.; Pham, Q.H.; Kanezaki, A.; Lee, T.; Chiang, H.Y.; Hsu, W.; Li, B.; Lu, Y.; et al. SHREC’17: RgB-D to CAD Retrieval with ObjectNN Dataset. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, EG 3DOR, Lyon, France, 23–24 April 2017; Volume 2017. [Google Scholar]
- Hua, B.S.; Pham, Q.H.; Nguyen, D.T.; Tran, M.K.; Yu, L.F.; Yeung, S.K. SceneNN: A Scene Meshes Dataset with ANNotations. In Proceedings of the 2016 4th International Conference on 3D Vision, 3DV 2016, Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Chang, A.X.; Funkhouser, T.A.; Guibas, L.J.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:abs/1512.03012. [Google Scholar]
- Gümeli, C.; Dai, A.; Nießner, M. ROCA: Robust CAD Model Retrieval and Alignment from a Single Image. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 4012–4021. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Volume 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June-1 July 2016; Volume 2016. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2844175. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Ozay, M.; Zhang, Y.; Okatani, T. Revisiting Single Image Depth Estimation: Toward Higher Resolution Maps with Accurate Object Boundaries. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision, WACV 2019, Waikoloa Village, HI, USA, 7–11 January 2019. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Volume 2017. [Google Scholar]
- Avetisyan, A.; Dahnert, M.; Dai, A.; Savva, M.; Chang, A.X.; Niebner, M. SCAN2CAD: Learning Cad Model Alignment in Rgb-d Scans. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Volume 2019. [Google Scholar]
- Kuo, W.; Angelova, A.; Lin, T.Y.; Dai, A. Mask2CAD: 3D Shape Prediction by Learning to Segment and Retrieve. In Proceedings of the Lecture Notes in Computer Science; Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12348. [Google Scholar]
- Sun, X.; Wu, J.; Zhang, X.; Zhang, Z.; Zhang, C.; Xue, T.; Tenenbaum, J.B.; Freeman, W.T. Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Lecture Notes in Computer Science; Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8693. [Google Scholar]
- Lim, J.J.; Pirsiavash, H.; Torralba, A. Parsing IKEA Objects: Fine Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Zhang, X.; Jiang, Z.; Zhang, H.; Wei, Q. Vision-Based Pose Estimation for Textureless Space Objects by Contour Points Matching. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 2815879. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rad, M.; Lepetit, V. BB8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects without Using Depth. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Volume 2017. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. In Proceedings of the Robotics: Science and Systems, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Wang, C.; Xu, D.; Zhu, Y.; Martin-Martin, R.; Lu, C.; Fei-Fei, L.; Savarese, S. DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Volume 2019. [Google Scholar]
- He, Y.; Sun, W.; Huang, H.; Liu, J.; Fan, H.; Sun, J. PVN3D: A Deep Point-Wise 3D Keypoints Voting Network for 6DoF Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Virtual Event, 14–19 June 2020. [Google Scholar]
- He, Y.; Huang, H.; Fan, H.; Chen, Q.; Sun, J. FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Kai, L. Li Fei-Fei ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 2017. [Google Scholar]
- Mayershofer, C.; Ge, T.; Fottner, J. Towards Fully-Synthetic Training for Industrial Applications. In LISS 2020; Springer: Singapore, 2021. [Google Scholar]
- Georgakis, G.; Karanam, S.; Wu, Z.; Kosecka, J. Matching RGB Images to CAD Models for Object Pose Estimation. arXiv 2018, arXiv:abs/1811.07249. [Google Scholar]
- Georgakis, G.; Karanam, S.; Wu, Z.; Kosecka, J. Learning Local RGB-to-CAD Correspondences for Object Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Volume 2019. [Google Scholar]
- Langer, F.; Budvytis, I.; Cipolla, R. Leveraging Geometry for Shape Estimation from a Single RGB Image. In Proceedings of the BMVC, Virtual Event, 22–25 November 2021. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Gkioxari, G.; Johnson, J.; Malik, J. Mesh R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Volume 2019. [Google Scholar]
- Janik, M.; Gard, N.; Hilsmann, A.; Eisert, P. Zero in on shape: A generic 2D–3D instance similarity metric learned from synthetic data. In Proceedings of the International Conference on Image Processing, ICIP, Anchorage, AK, USA, 19–22 September 2021; Volume 2021. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E.G. Multi-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Liu, A.; Xiang, S.; Li, W.; Nie, W.; Su, Y. Cross-Domain 3D Model Retrieval via Visual Domain Adaptation. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; Volume 2018. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021. [Google Scholar]
- CloudCompare. Available online: https://www.danielgm.net/cc/ (accessed on 29 December 2022).
- Blender Python API. Available online: https://docs.blender.org/api/current/index.html (accessed on 29 December 2022).
- Wang, M.; Deng, W. Deep Visual Domain Adaptation: A Survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Noh, H.; Araujo, A.; Sim, J.; Weyand, T.; Han, B. Large-Scale Image Retrieval with Attentive Deep Local Features. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Volume 2017. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | 1-st Rank | 2-nd Rank | 3-rd Rank | Top-3 |
|---|---|---|---|---|
| Bag (19) | 7 | 2 | 0 | 9 |
| Bed (24) | 4 | 7 | 3 | 14 |
| Bench (63) | 38 | 10 | 1 | 49 |
| Bottle (77) | 47 | 14 | 8 | 69 |
| Car (80) | 33 | 11 | 8 | 52 |
| Chair (80) | 45 | 21 | 3 | 69 |
| Clock (59) | 27 | 12 | 4 | 43 |
| Motorbike (76) | 37 | 8 | 8 | 53 |
| Oven (79) | 34 | 10 | 10 | 54 |
| Table (39) | 18 | 2 | 2 | 22 |
| Total (596) | 290 | 97 | 47 | 434 |
| Success rate (%) | 48.65 | 16.27 | 7.88 | 72.81 |
| Category | 1-st Rank | 2-nd Rank | 3-Rd Rank | Top-3 |
|---|---|---|---|---|
| Bag (19) | 7 | 3 | 3 | 13 |
| Bed (24) | 6 | 7 | 3 | 16 |
| Bench (63) | 39 | 16 | 2 | 57 |
| Bottle (77) | 41 | 15 | 14 | 70 |
| Car (80) | 33 | 16 | 6 | 55 |
| Chair (80) | 45 | 20 | 2 | 67 |
| Clock (59) | 26 | 13 | 4 | 43 |
| Motorbike (76) | 39 | 8 | 6 | 53 |
| Oven (79) | 33 | 9 | 12 | 54 |
| Table (39) | 20 | 4 | 1 | 25 |
| Total (596) | 289 | 111 | 53 | 453 |
| Success rate (%) | 48.48 | 18.62 | 8.89 | 76.00 |
| Category | 1-St Rank | 2-Nd Rank | 3-rd Rank | Top-3 |
|---|---|---|---|---|
| Bag (19) | 6 | 1 | 4 | 11 |
| Bed (24) | 6 | 5 | 5 | 16 |
| Bench (63) | 39 | 15 | 1 | 55 |
| Bottle (77) | 41 | 14 | 15 | 70 |
| Car (80) | 32 | 14 | 6 | 52 |
| Chair (80) | 43 | 20 | 3 | 66 |
| Clock (59) | 25 | 14 | 5 | 44 |
| Motorbike (76) | 38 | 7 | 7 | 52 |
| Oven (79) | 33 | 9 | 12 | 54 |
| Table (39) | 16 | 6 | 3 | 25 |
| Total (596) | 279 | 105 | 61 | 445 |
| Success rate (%) | 46.81 | 17.61 | 10.23 | 74.66 |
| Methods | 1-st Rank | 2-nd Rank | 3-rd Rank | Top-3 |
|---|---|---|---|---|
| Triplet loss learning [30] (w/o negative mining) | 31 | 18 | 19 | 68 |
| Triplet loss learning [30] (w/negative mining) | 29 | 25 | 17 | 71 |
| Proposed (SM1) | 56 | 13 | 4 | 73 |
| Proposed (SM2) | 56 | 16 | 6 | 78 |
| Proposed (SM3) | 51 | 15 | 12 | 78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.-Y.; Son, C.-M.; Jeong, W.-J.; Park, S. Relative Pose Estimation between Image Object and ShapeNet CAD Model for Automatic 4-DoF Annotation. Appl. Sci. 2023, 13, 693. https://doi.org/10.3390/app13020693
Park S-Y, Son C-M, Jeong W-J, Park S. Relative Pose Estimation between Image Object and ShapeNet CAD Model for Automatic 4-DoF Annotation. Applied Sciences. 2023; 13(2):693. https://doi.org/10.3390/app13020693
Chicago/Turabian StylePark, Soon-Yong, Chang-Min Son, Won-Jae Jeong, and Sieun Park. 2023. "Relative Pose Estimation between Image Object and ShapeNet CAD Model for Automatic 4-DoF Annotation" Applied Sciences 13, no. 2: 693. https://doi.org/10.3390/app13020693