
Multi-Channel Expression Recognition Network Based on Channel Weighting
Abstract
:1. Introduction
- Issues such as illumination, occlusion, and large face poses cause certain uncertainty in expression labels under uncontrolled conditions, which affects the accuracy of expression recognition;
- The database of reliable facial expression recognition is small in scale and poor in quality, which affects the recognition performance;
- Deep learning involves many hyperparameters, building an expression recognition model takes a long time to train, and the model is large.
- Design a multi-channel feature extraction network MFE, and construct an expression recognition network in terms of scale, information integrity and fusion methods;
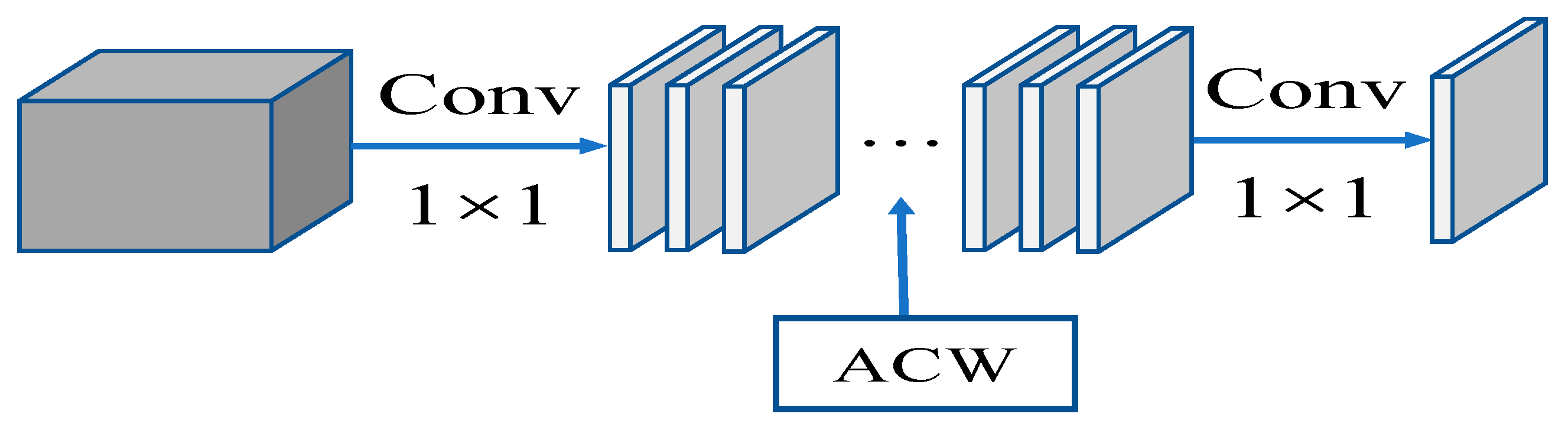
- Design and use a channel-weighted module ACW, and in the auxiliary branch of MFE, assigns weights to small features from small convolutions to help improve recognition accuracy;
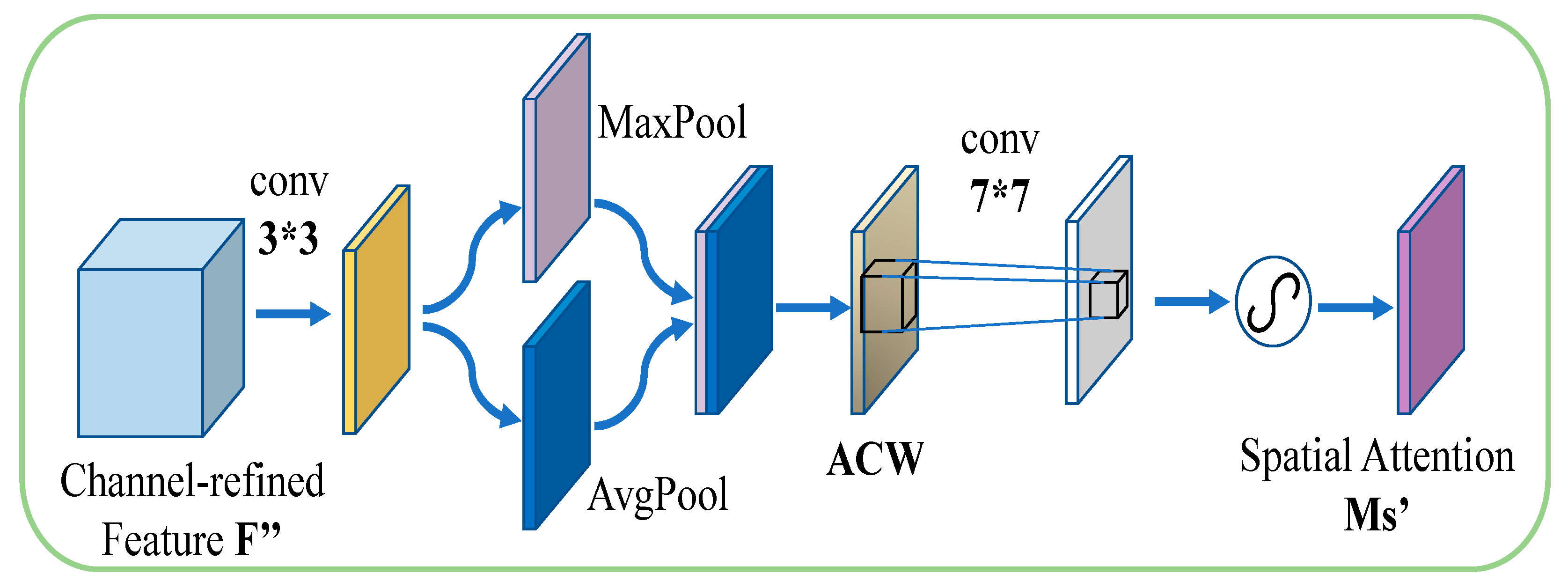
- Design and modify the spatial attention module and integrate the ACW mechanism to obtain an adaptive spatial attention module ASA, which assists in optimizing the overall network structure to improve the final expression recognition accuracy.
2. Materials and Methods
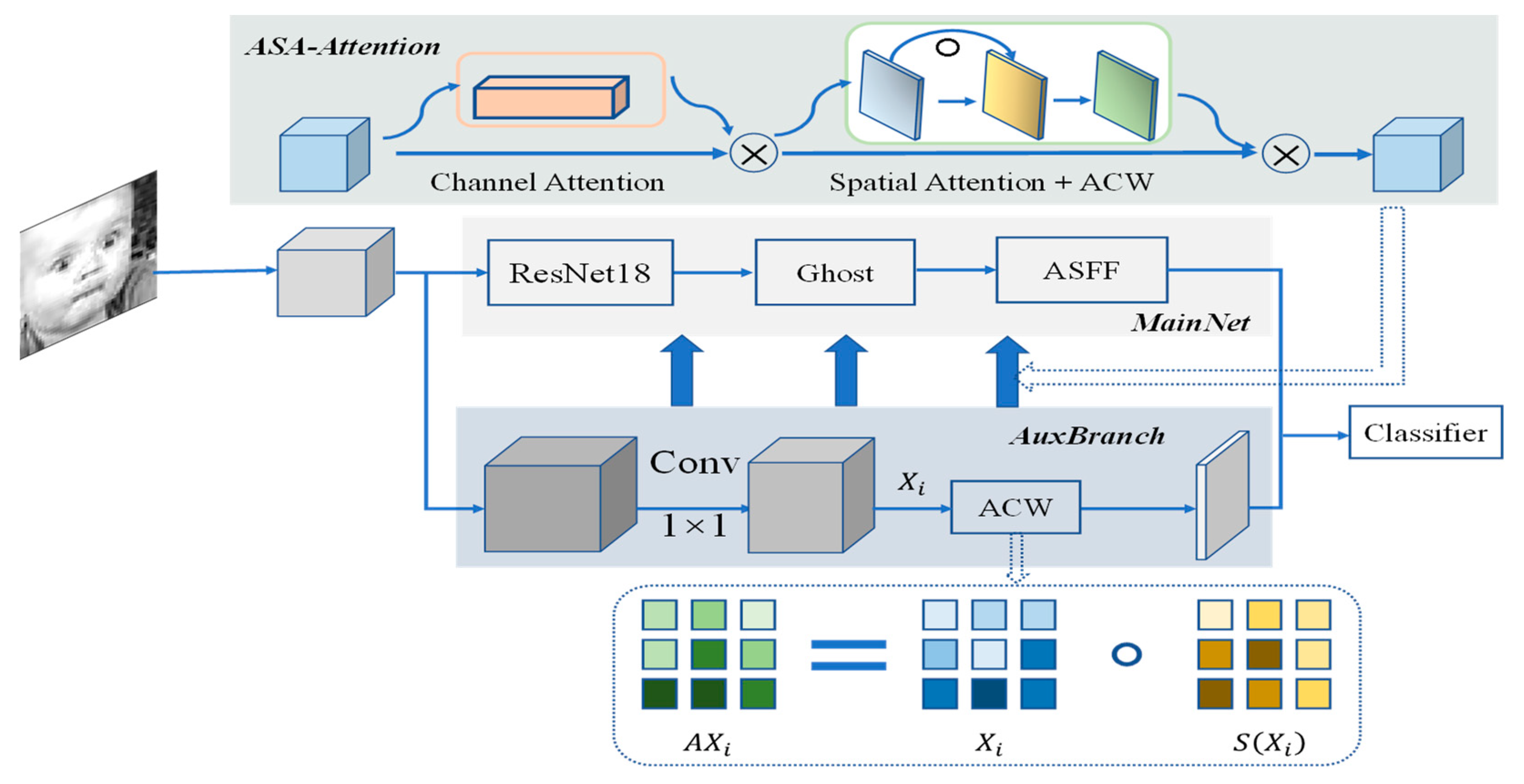
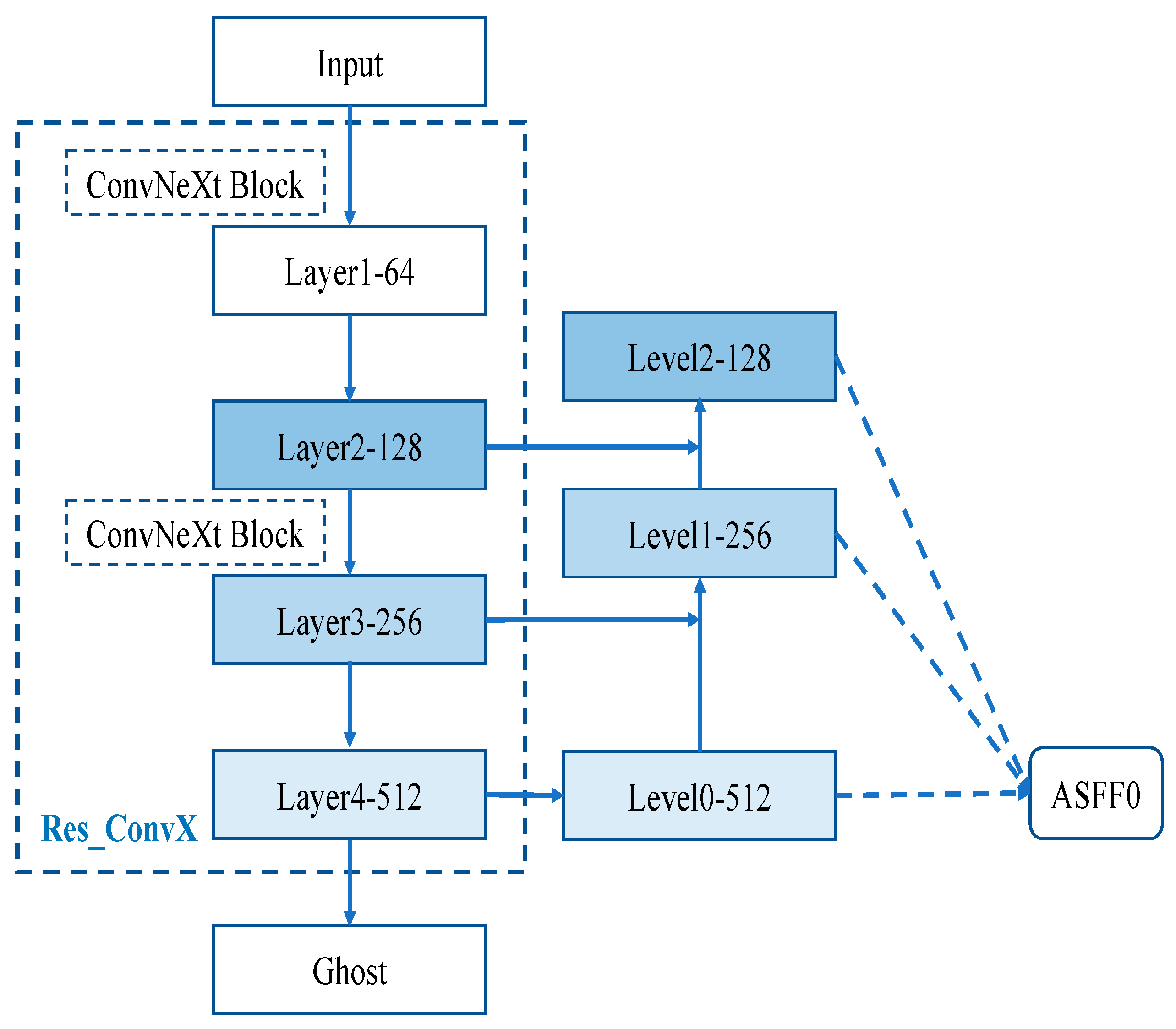
2.1. Multi-Channel Expression Recognition Network
2.1.1. MainNet
2.1.2. AuxBranch
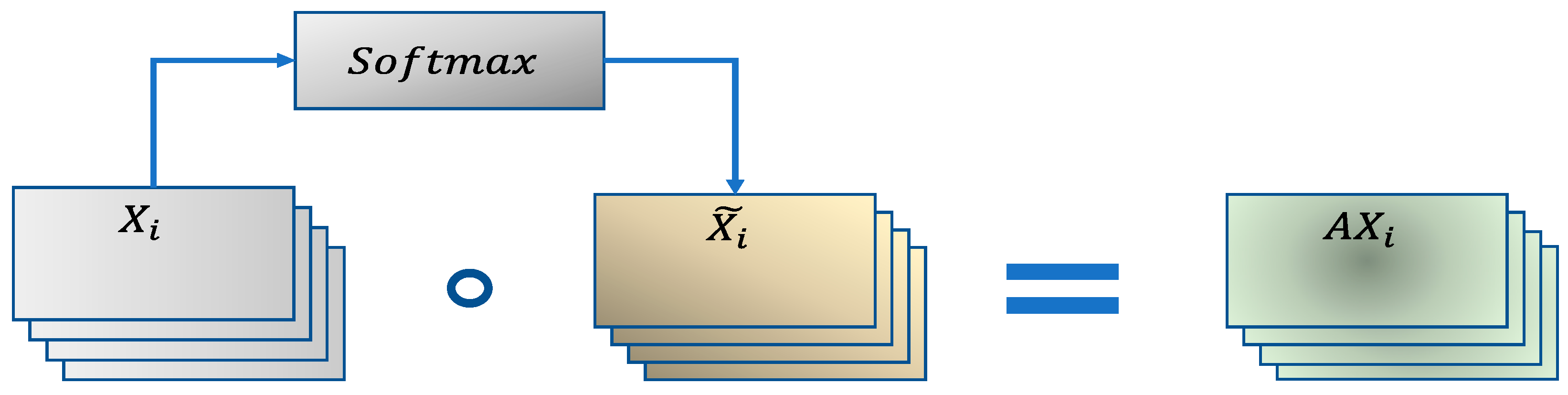
2.2. Adaptive Channel Weighting—ACW
2.3. Attention Module—ASA
3. Experimental Results and Analysis
3.1. Experimental Data
3.2. Experimental Procedure
3.3. Ablation Experiment
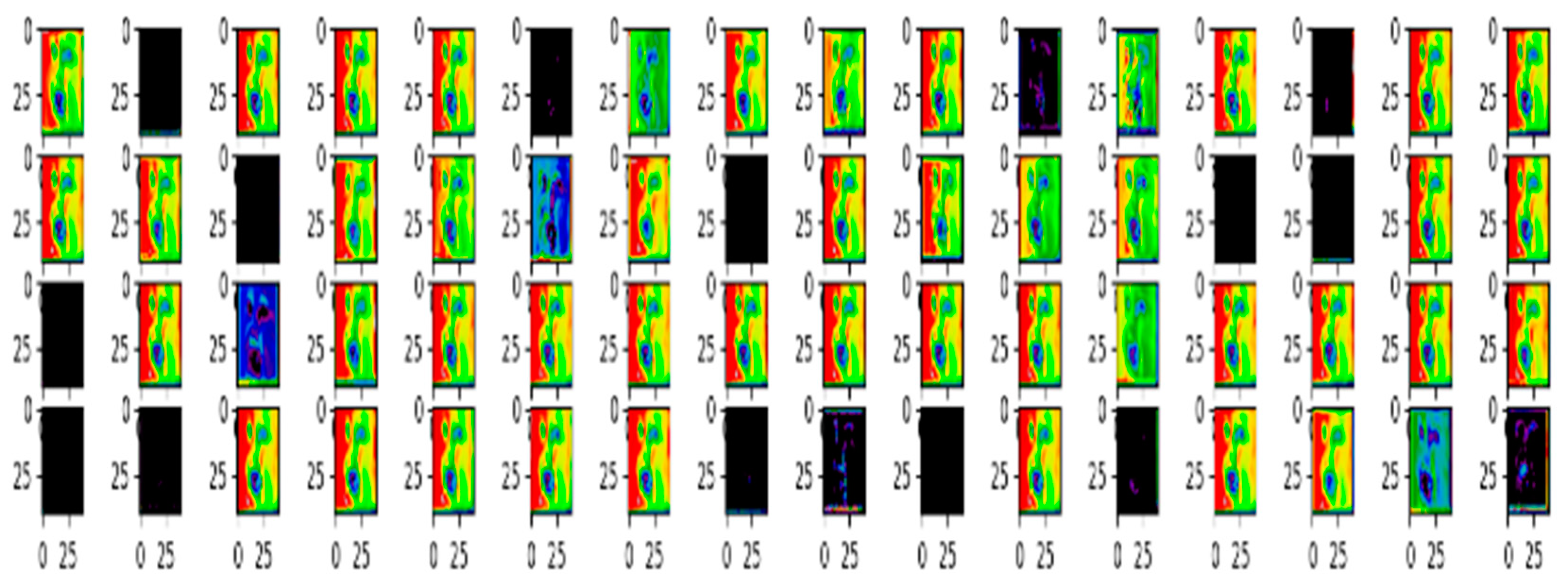
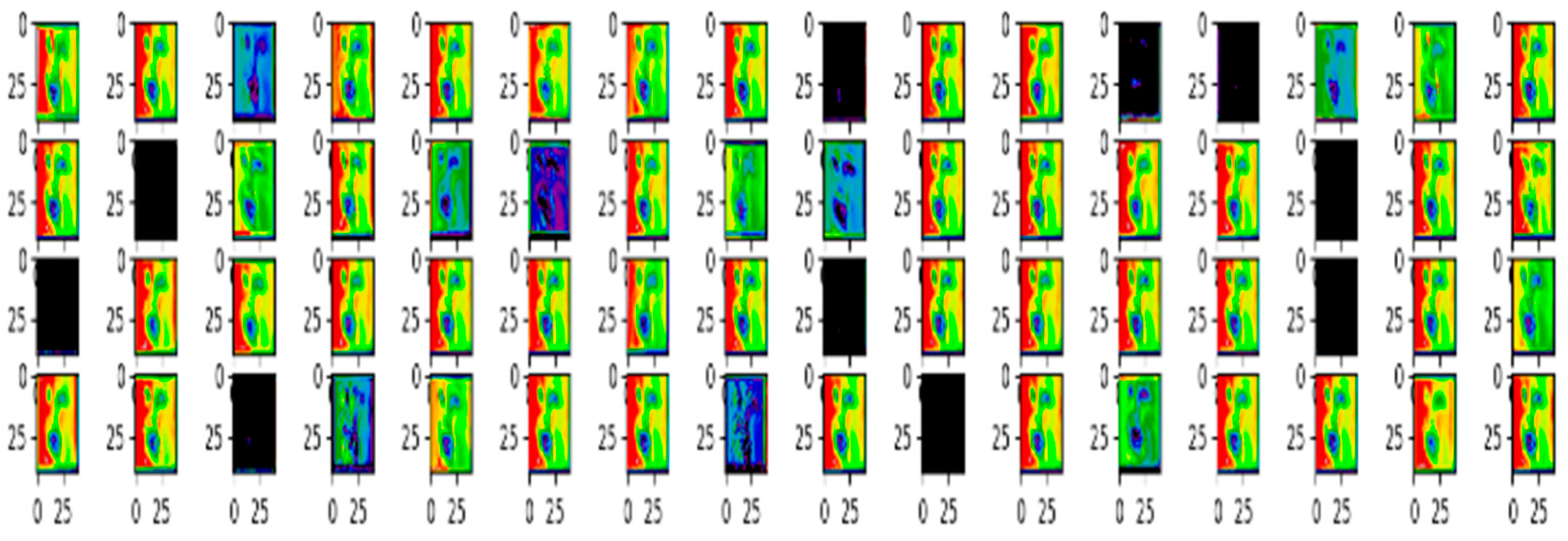
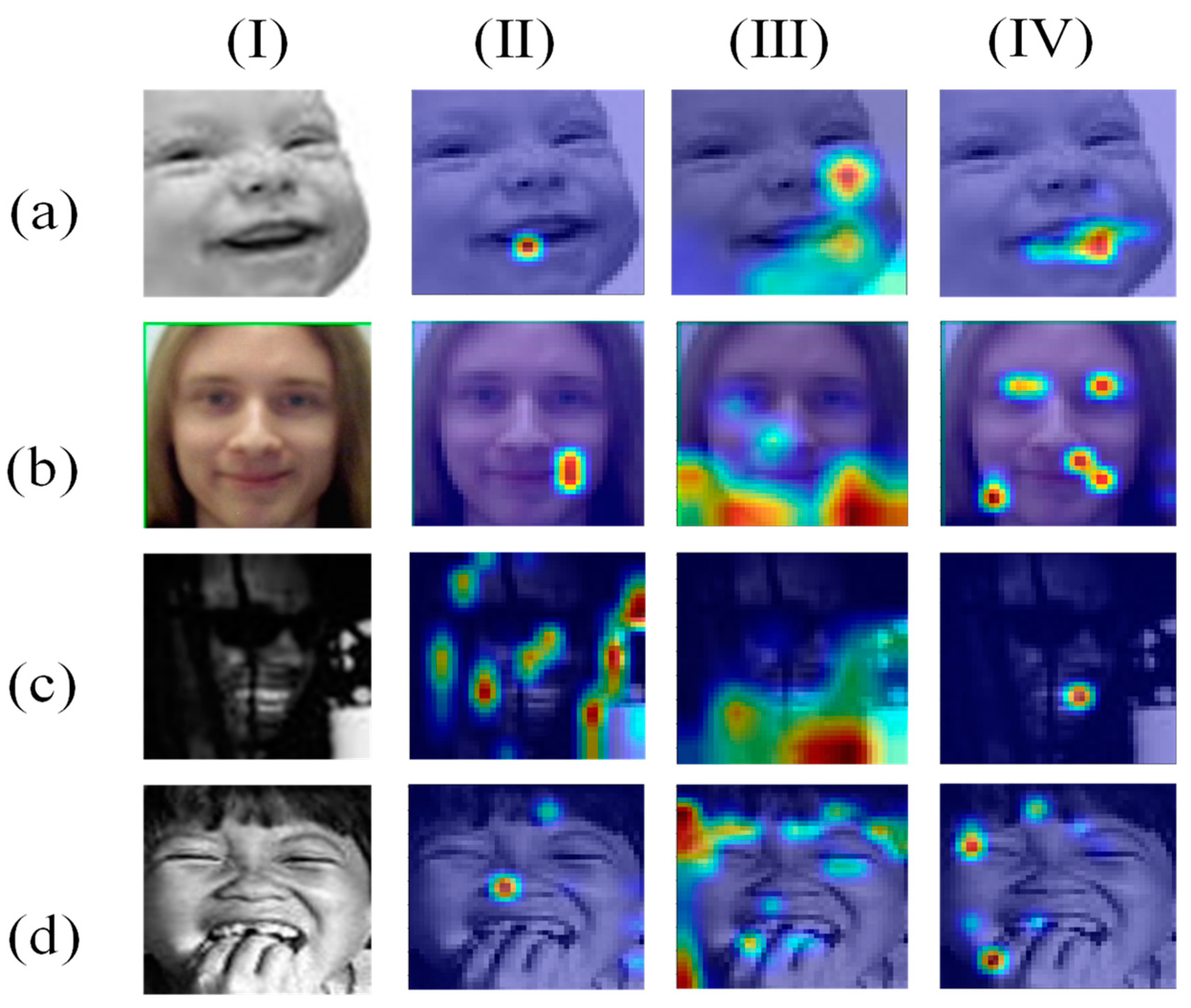
3.4. Visualization
4. Discussion
4.1. Overall Model Evaluation
4.2. Model Lightweight Experiment
4.3. Comparative Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, A.; An, L.; Che, Z. A Facial Expression Recognition Model Based on Texture and Shape Features. Trait. Du Signal 2020, 37, 627–632. [Google Scholar] [CrossRef]
- Gonzalez, J.F.E. Increasing motivation for in-class reading comprehension in a business English course at the University of Costa Rica (UCR). Res. Pedagog. 2019, 9, 254–265. [Google Scholar] [CrossRef]
- Sariyanidi, E.; Gunes, H.; Cavallaro, A. Automatic analysis of facial affect: A survey of registration, representation, and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1113–1133. [Google Scholar] [CrossRef]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A Survey of Affect Recognition Methods: Audio, Visual, and Spontaneous Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 39–58. [Google Scholar] [CrossRef]
- Li, J.; Li, H.; Wang, H.; Umer, W.; Fu, H.; Xing, X. Evaluating the impact of mental fatigue on construction equipment operators’ ability to detect hazards using wearable eye-tracking technology. Autom. Constr. 2019, 105, 102835. [Google Scholar] [CrossRef]
- Deng, W.; Wu, R. Real-Time Driver-Drowsiness Detection System Using Facial Features. IEEE Access 2019, 7, 118727–118738. [Google Scholar] [CrossRef]
- Zhan, Z. Intelligent Agent-based Emotional and Cognitive Recognition Model for Distance Learners—Coupling Supported by Eye Tracking and Expression Recognition Technology. Mod. Distance Educ. Res. 2013, 100–105. [Google Scholar] [CrossRef]
- Zhang, J.; Li, X.; Chen, K. Analysis of the impact of the animation industry on the development of AR/VR. Art Sci. Technol. 2018, 31, 104. [Google Scholar]
- Li, J.; Wang, Y.; Fang, G.; Zeng, Z. Real-time detection tracking and recognition algorithm based on multi-target faces. Multimed. Tools Appl. 2021, 80, 17223–17238. [Google Scholar] [CrossRef]
- Zheng, G.; Xu, Y. Efficient face detection and tracking in video sequences based on deep learning. Inf. Sci. 2021, 568, 265–285. [Google Scholar] [CrossRef]
- Seng, K.P.; Ang, L.M.; Ooi, C.S. A combined rule-based & machine learning audio-visual emotion recognition approach. IEEE Trans. Affect. Comput. 2016, 9, 3–13. [Google Scholar]
- Bălan, O.; Moise, G.; Petrescu, L.; Moldoveanu, A.; Leordeanu, M.; Moldoveanu, F. Emotion classification based on biophysical signals and machine learning techniques. Symmetry 2019, 12, 21. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Joo, J. Understanding and Mitigating Annotation Bias in Facial Expression Recognition. In Proceedings of the 2021 IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Paleari, M.; Huet, B. Toward Emotion Indexing of Multimedia Excerpts. In Proceedings of the 2008 International Workshop on Content-Based Multimedia Indexing, London, UK, 18–20 June 2008; IEEE: Piscataway, NJ, USA; pp. 425–432. [Google Scholar]
- Cheng, Y.; Jiang, B.; Jia, K. A Deep Structure for Facial Expression Recognition under Partial Occlusion. In Proceedings of the Tenth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Kitakyushu, Japan, 27–29 August 2014. [Google Scholar]
- Lv, Y.; Feng, Z.; Xu, C. Facial Expression Recognition via Deep Learning. In Proceedings of the 2014 International Conference on Smart Computing (SMARTCOMP), Hong Kong, 3–5 November 2014. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR05), San Diego, CA, USA, 20–25 June 2005; Volume 1, p. 886C893. [Google Scholar]
- Huang, K.C.; Lin, H.Y.; Chan, J.C.; Kuo, Y.H. Learning Collaborative Decision-Making Parameters for Multimodal Emotion Recognition. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Yibo, H.; Lingbo, Q.; Lu, W.; Rulong, J. Facial Expression Recognition Based on Adaptive Keyframe Selection. Inf. Technol. 2020, 44, 19–22. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing Uncertainties for Large-Scale Facial Expression Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6897–6906. [Google Scholar]
- Guo, X.; Ma, N.; Liu, W.; Sun, F.; Zhang, J.; Chen, Y.; Zhang, G. Expression Recognition and Interaction of Pharyngeal Swab Collection Robot. Comput. Eng. Appl. 2022, 58, 125–135. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A Convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tang, Y. Deep learning using linear support vector machines. arXiv 2013, arXiv:1306.0239. [Google Scholar]
- Shi, J.; Zhu, S.; Liang, Z. Learning to Amend Facial Expression Representation via De-albino and Affinity. arXiv 2021, arXiv:2103.10189. [Google Scholar]
- Pramerdorfer, C.; Kampel, M. Facial expression recognition using convolutional neural networks: State of the art. arXiv 2016, arXiv:1612.02903. [Google Scholar]
- Yousif, K.; Chen, Z. Facial Emotion Recognition: State of the Art Performance on FER2013. arXiv 2021, arXiv:2105.03588. [Google Scholar]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-emotion: Facial expression recognition using attentional convolutional network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef]
- Jung, H.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2983–2991. [Google Scholar] [CrossRef]
- Ding, H.; Zhou, S.; Chellappa, R. FaceNet2ExpNet: Regularizing a Deep Face Recognition Net for Expression Recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 118–126. [Google Scholar] [CrossRef]
- Zhao, X.; Liang, X.; Liu, L.; Li, T.; Han, Y.; Vasconcelos, N.; Yan, S. Peak-Piloted Deep Network for Facial Expression Recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland; pp. 425–442. [Google Scholar]
- Wang, S.M.; Shuai, H.; Liu, Q.S. Facial expression recognition based on deep facial landmark features. J. Image Graph. 2020, 25, 0813–0823. [Google Scholar]
- Li, S.; Deng, W. Reliable crowdsourcing and deep locality-preserving learining for unconstrained facial expression recognition. IEEE Trans. Image Process. 2019, 28, 356–370. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
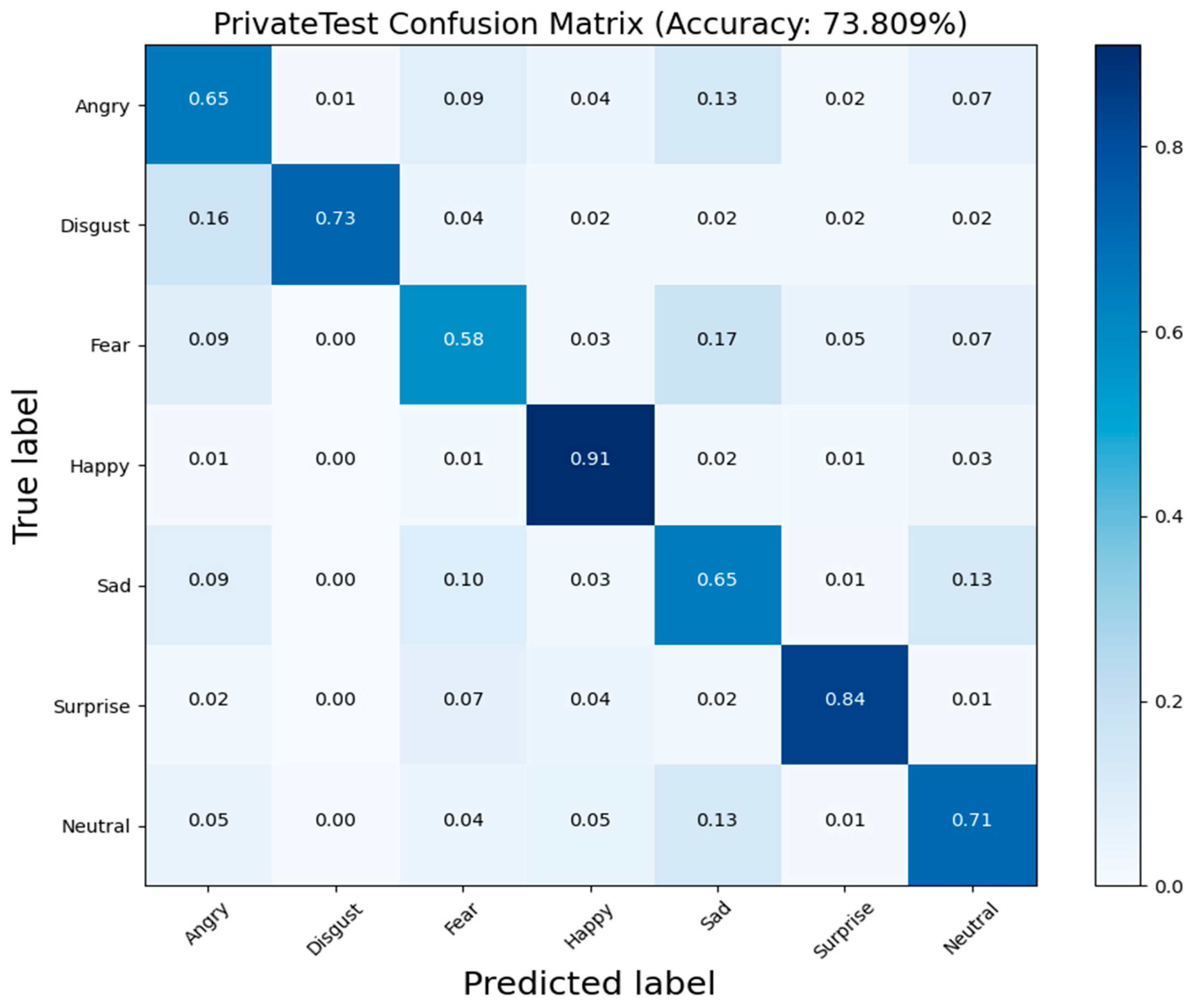{kind=link}
| Method | Base(ResNet) | Xception | MFE | ACW | ASA | Acc |
|---|---|---|---|---|---|---|
| ① | √ | -- | -- | -- | -- | 72.88% |
| ② | -- | √ | -- | -- | -- | 71.69% |
| ③ | -- | √ | -- | -- | √ | 71.78% |
| ④ | -- | √ | √ | -- | -- | 72.11% |
| ⑤ | -- | √ | -- | √ | -- | 72.25% |
| ⑥ | √ | -- | -- | √ | -- | 73.34% |
| ⑦ | √ | -- | √ | -- | -- | 73.50% |
| ⑧ | √ | -- | -- | -- | √ | 73.53% |
| ⑨ | √ | -- | √ | √ | √ | 73.81% |
| Experiment | Method | Parameter Quantity(M) | Accuracy |
|---|---|---|---|
| ① | Base | 11.17 | 72.88% |
| ② | Xception-MF | 10.48 | 72.11% |
| ③ | MF | 15.50 | 73.36% |
| ④ | MF_Sep | 11.05 | 73.34% |
| ⑤ | MFE(This paper) | 10.92 | 73.50% |
| ⑥ | MAWNet(This paper) | 11.60 | 73.81% |
| FER2013 | |
|---|---|
| Method | Accuracy |
| Attentional ConvNet [33] | 70.02% |
| CNN+SVM [29] | 71.20% |
| ARM(ResNet18) [30] | 71.38% |
| Inception [31] | 71.60% |
| ResNet [31] | 72.40% |
| VGG [31] | 72.70% |
| FER(2021) [32] | 73.28% |
| MFE (This paper) | 73.50% |
| MAWNet (This paper) | 73.81% |
| Oulu | |
|---|---|
| Method | Accuracy |
| DTAGN [34] | 81.46% |
| VGG finetune [35] | 83.26% |
| PPDN [36] | 84.59% |
| FaceNet2ExpNet [37] | 87.71% |
| MFE (This paper) | 88.34% |
| MAWNet (This paper) | 89.65% |
| RAF-DB | |
|---|---|
| Method | Accuracy |
| DLP-CNN [38] | 84.13% |
| Base | 84.29% |
| MFE (This paper) | 84.52% |
| MAWNet (This paper) | 85.24% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, X.; Zhang, H.; Zhang, Q.; Han, X. Multi-Channel Expression Recognition Network Based on Channel Weighting. Appl. Sci. 2023, 13, 1968. https://doi.org/10.3390/app13031968
Lu X, Zhang H, Zhang Q, Han X. Multi-Channel Expression Recognition Network Based on Channel Weighting. Applied Sciences. 2023; 13(3):1968. https://doi.org/10.3390/app13031968
Chicago/Turabian StyleLu, Xiuwen, Hongying Zhang, Qi Zhang, and Xue Han. 2023. "Multi-Channel Expression Recognition Network Based on Channel Weighting" Applied Sciences 13, no. 3: 1968. https://doi.org/10.3390/app13031968