1. Introduction
With the continuous increase in the number of motor vehicles, road traffic problems are becoming increasingly serious. In many road accidents, a significant proportion is caused by driver-related factors. To reduce the occurrence rate of road accidents and improve driving safety, many domestic and international universities and companies have conducted extensive research on ADAS [
1,
2,
3,
4]. Machine vision-based lane line type recognition technology is part of the ADAS perception module. It collects environmental information on lane lines using visual sensors and performs classification, playing an important role in providing guidance for the decision-making, control, and execution modules of the subsequent ADAS. Quickly achieving accurate recognition of lane line type is particularly important for the driver to make correct judgements about the vehicle. It enables motor vehicles to perform operations such as overtaking, lane changing, and U-turns without violating traffic line rules, thus providing a certain guarantee for driving safety.
For lane line type recognition technology, it can be divided into traditional image processing methods and deep learning methods. Traditional image processing methods, generally based on information such as colour and texture direction, separate lane lines from the background region by filtering. For example, Ma et al. [
5] proposed a lane marking region detection method based on Lab colour feature clustering. The RGB channel of the original image is converted into a Lab channel so that it can bring in more lane line information. Eventually, the lane lines are identified using K-mean clustering. Rui et al. [
6] used grayscale space to identify white lane lines and HSV space to identify yellow lane lines. The two lane line methods are merged, and the edges of the lane lines are extracted using edge detection. Then, the image is converted to bird’s-eye view using inverse perspective transform, and finally the lane lines are extracted through fitting. However, this type of method is more demanding for the process of lane line painting. If the lane lines are broken or defective, or there is complicated weather such as foggy or rainy days, then this method will most likely fail.
Therefore, this paper proposes a deep learning-based method for detecting the categories of lane lines. Deep learning techniques have powerful learning capabilities and thus have become the dominant approach in machine vision. Girshick proposed a region-based convolutional neural network (R-CNN) [
7], a fast region-based convolutional neural network (Fast R-CNN) [
8], and a faster region-based convolutional neural network (Faster R-CNN) [
9], which were initially applied to object detection tasks. However, these algorithms suffered from slow detection speeds and struggled to meet real-time requirements. Despite their improvement in many works in the literature [
10,
11,
12], the results are still unsatisfactory. The YOLO [
13,
14,
15,
16,
17,
18] series made significant improvements in detection speed. Among them, the YOLOv5 algorithm has been widely used in various object recognition scenarios, with many engineering projects incorporating and improving it.
Musha et al. [
19] proposed a lightweight model called CEMLB-YOLO to detect maize leaf blight in complex field environments. The method uses CIPAM attention mechanism to retain key information. After that, feature re-structuring and fusion module is introduced to extract semantic information, and finally MobileBit is added to the feature extraction network. The method achieves an accuracy of 87.5% on the NLB dataset. Abolghasemi et al. [
20], based on the improved YOLO model, applied it to the detection of skin cancer. The method adds convolutional layers and residual blocks to the YOLO model and also introduces feature splicing of different layers to achieve multi-scale fusion. Tsoulos et al. [
21] used bird image datasets captured in the field to train the YOLOv4 model. Through experiments, it is demonstrated that YOLOv4 can be used for bird detection in the field and has achieved good detection results. Pérez-Patricio et al. [
22] detected the behaviour of lambs based on predictive modelling and deep learning. In this regard, a model, an object-tracking algorithm, and a decision tree-based behavioural classifier based on YOLOv4 applied to top-view videos are proposed. Experimentally, the method achieved 99.85% accuracy in detecting lamb activity. He et al. [
23] proposed a target recognition algorithm named TF-YOLO based on the improvement of YOLOv3. The method firstly clusters the dataset using K-means++, after which the base model is optimised using the idea of FPN. Through the experimental surface, TF-YOLO can improve the detection accuracy of small targets and achieve the light weight of the network.
While deep learning techniques have been used in a number of fields, fine-grained methods for recognising lane line type are not yet available. Some deep learning-based lane line detection methods can only singularly go about identifying the shape or colour of a lane line [
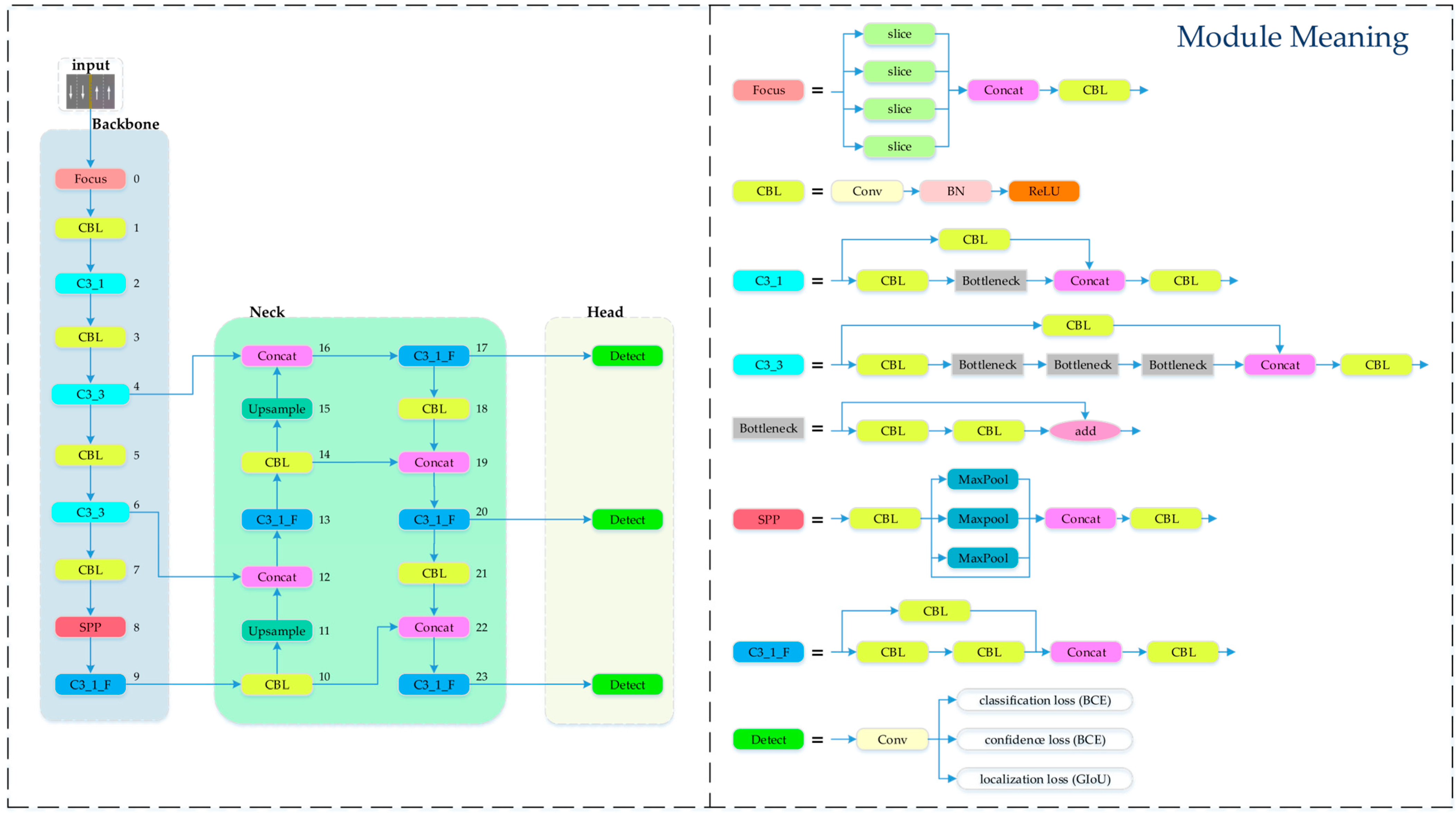
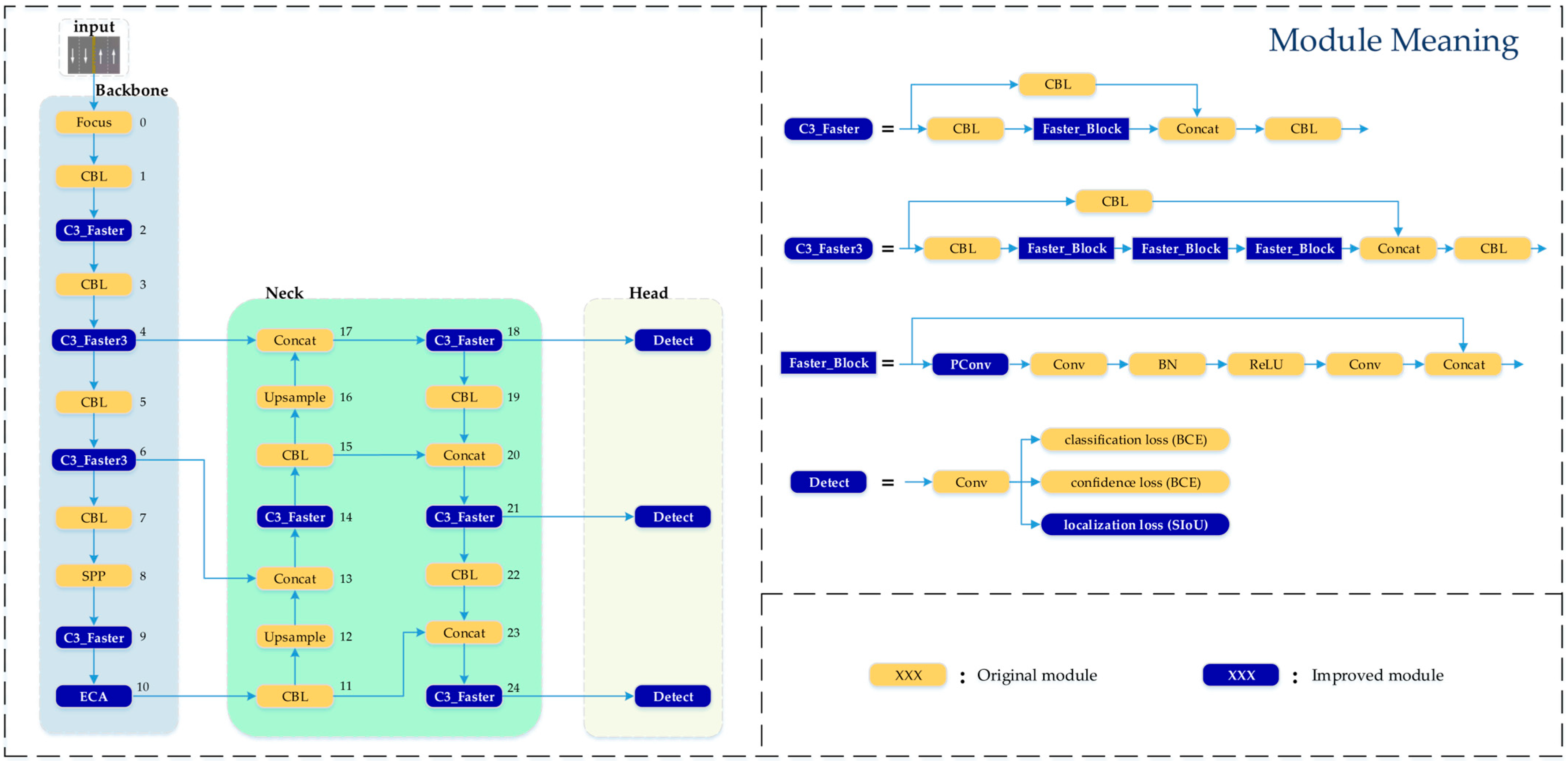
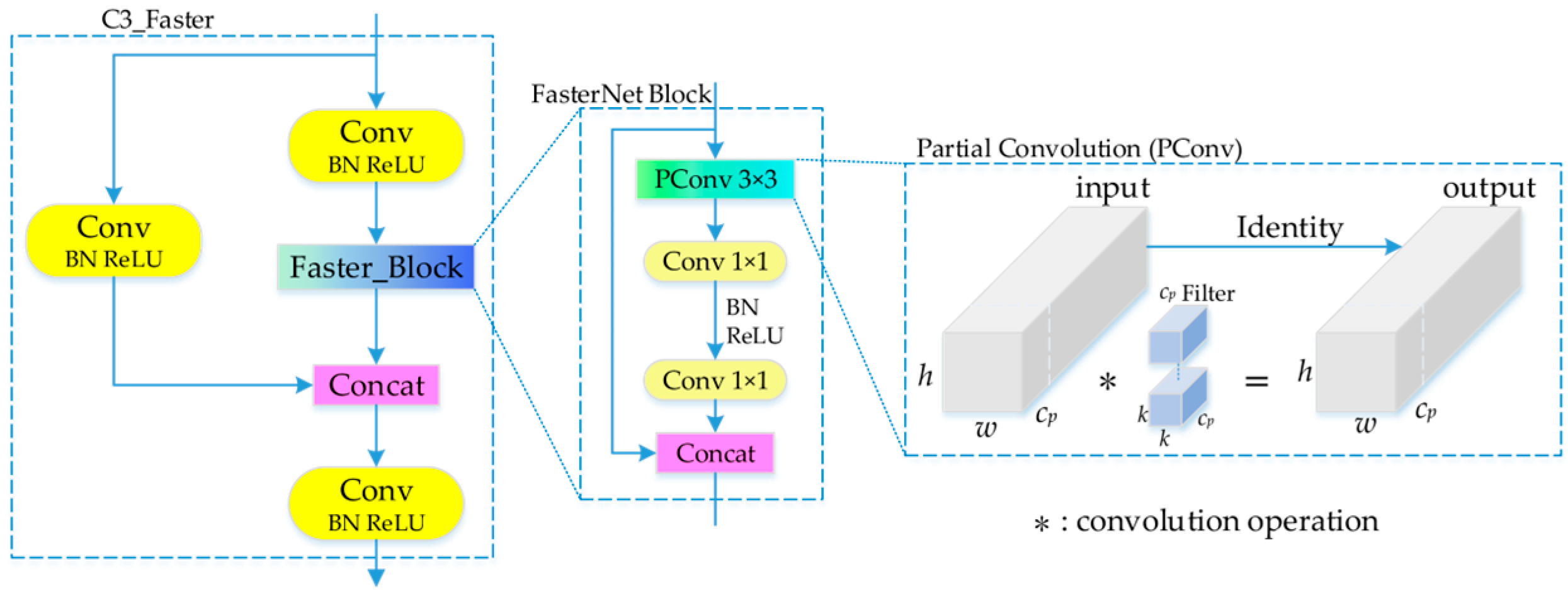
24]. This is difficult for meeting the requirements of ADAS. In summary, this paper proposes a lane line classification method based on improved YOLOv5. The main contributions include incorporating the FasterNet [
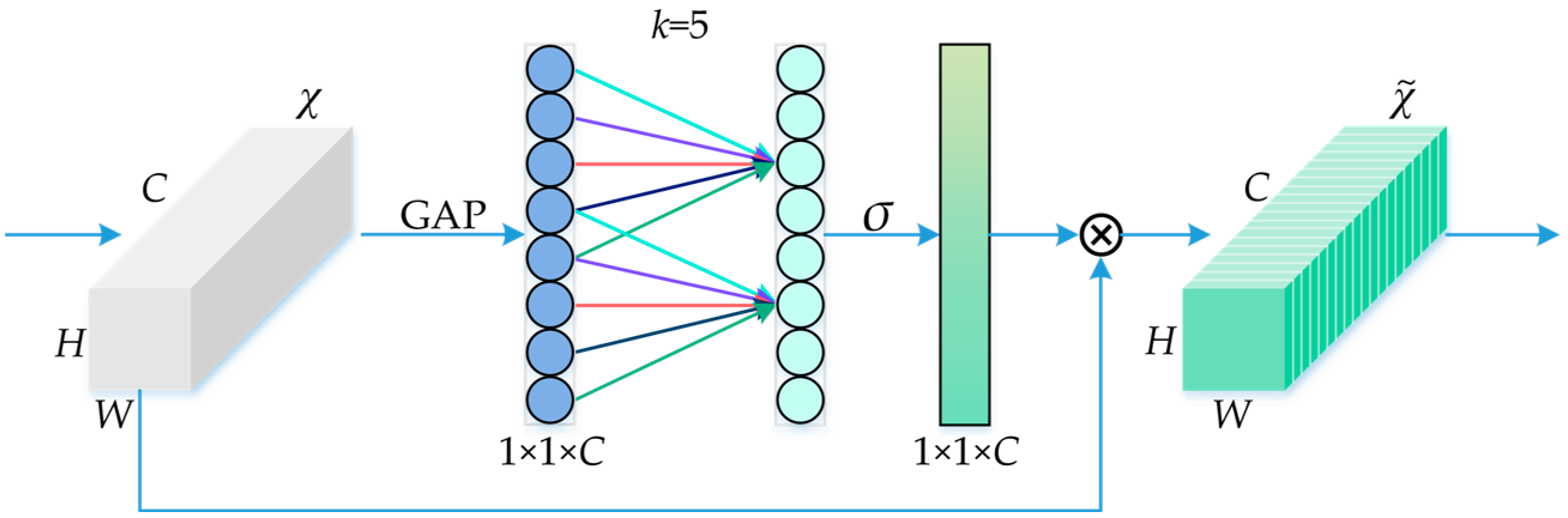
25] lightweight network into the C3 module of the overall network to achieve parameter reduction and speed improvement. The ECA [
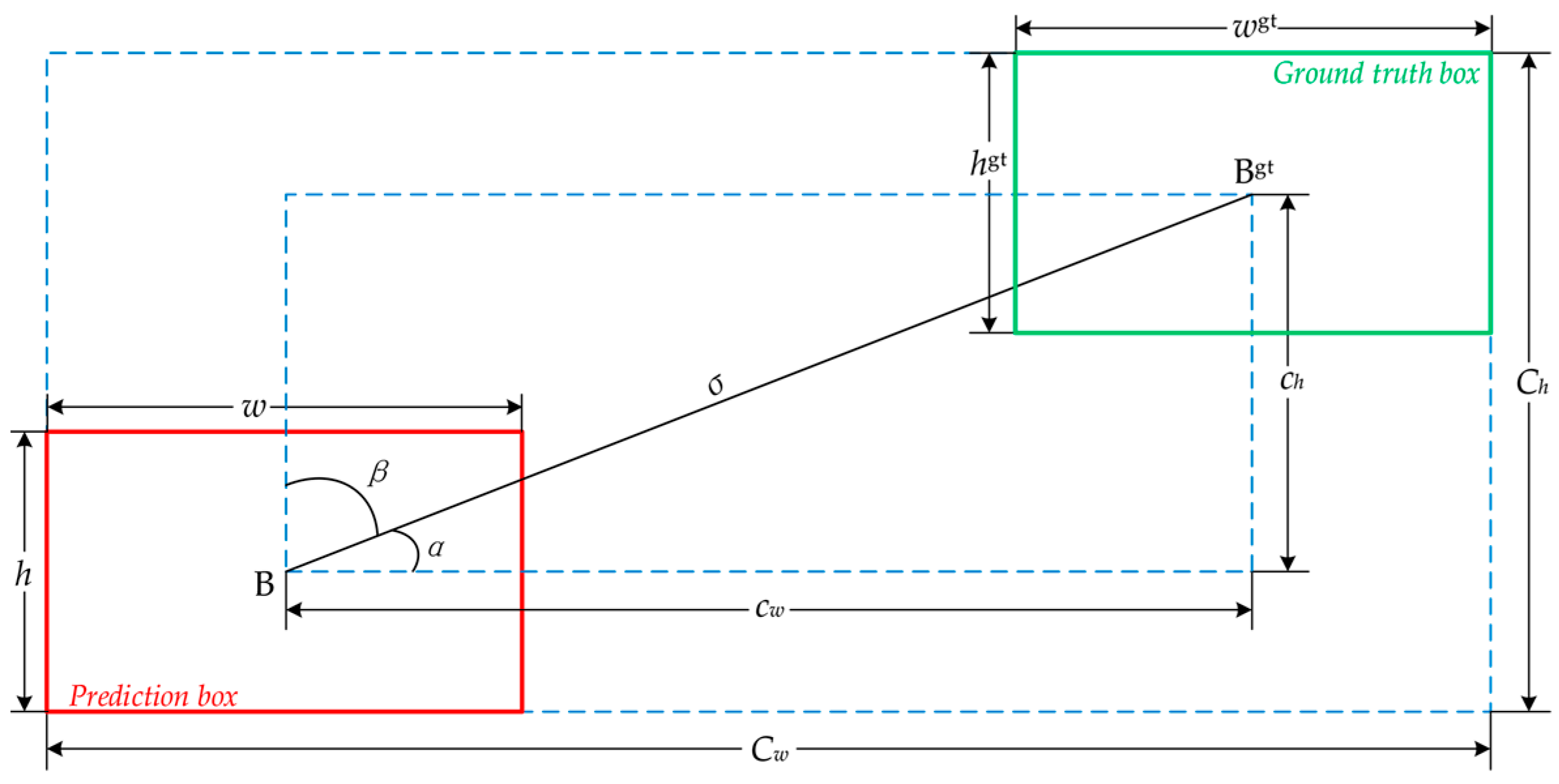
26] mechanism is introduced to enhance the model’s feature extraction capability. The SIoU [
27] loss function is used instead of the original GIoU [
28] loss function to further improve the model’s inference speed and accuracy. Through experiments, it is found that the method in this paper has high accuracy and very fast detection speed. The type of lane lines can be identified even under adverse conditions. This can fully meet the needs of ADAS. It also plays a role in promoting the development of ADAS.
The structure of the rest of this article is as follows.
Section 2 outlines the underlying network used in this paper and the strategy for improving the network.
Section 3 outlines the experimental setting, the dataset, and the evaluation metrics of the model for this paper.
Section 4 analyses the experimental results of the network improved in this paper. Finally,
Section 5 summarises the article.
3. Experimental Section
3.1. Experimental Environment and Hyperparameters
The software and hardware environment configurations used for algorithm training in this paper are shown in
Table 2.
The hyperparameter settings for the algorithm are presented in
Table 3.
3.2. Experimental Dataset
The dataset used for the experiments includes the CULane [
33] dataset and custom dataset with inverse perspective transformation. As shown in
Figure 6, the road image is transformed using inverse perspective transform to create a bird’s-eye-view road image that reflects the real world. This image shows lane line features more clearly and facilitates feature extraction for the network.
In the inverse perspective transformation, the relationship between the original image and the transformed image can be represented by a 3 × 3 transformation matrix. This matrix is computed based on four corresponding points in the data image, as shown in this equation:
where
map_matrix represents the computed 3 × 3 inverse perspective transformation matrix, and (
xi,
yi) and (
,
) represent the coordinates of the input point and the output point, respectively. The value of
i ranges from 0 to 3, indicating the corresponding four points. This method allows us to obtain a bird’s-eye view of the road without requiring extensive computational resources. It is a simple operation that only requires processing the region of interest (ROI) containing the lane lines, thereby removing significant amounts of irrelevant information.
According to GB 5768.3-2009 National Standard of China [
34], the classification of road traffic markings includes categories such as white dashed lines, white solid lines, yellow dashed lines, yellow solid lines, double white dashed lines, double white solid lines, white dash-solid lines, double yellow solid lines, double yellow dashed lines, yellow dash-solid lines, orange dashed lines, orange solid lines, blue dashed lines, and blue solid lines. Among these, the type of lane markings used to separate traffic flows or restrict vehicle crossings include white dashed lines, white solid lines, yellow dashed lines, yellow solid lines, white dash-solid lines, double yellow solid lines, double yellow dashed lines, and yellow dash-solid lines. The white dash-solid lines and yellow dash-solid lines can be further classified as left-dashed right-solid and left-solid right-dashed based on their position in the driving lane. These lane line types are the targets we need to identify in this paper. The dataset categories are annotated, and the label names are shown in
Table 4.
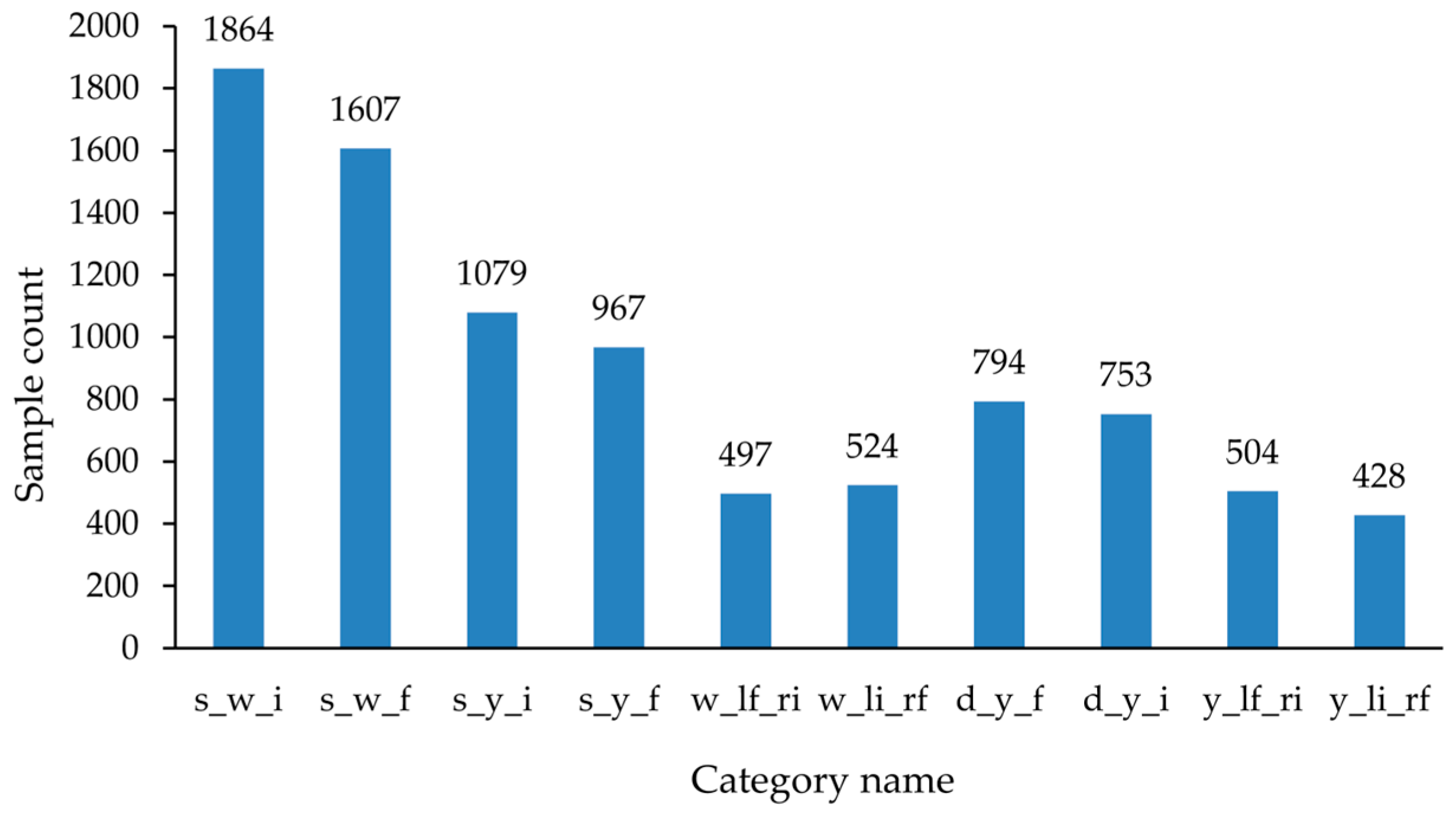
The data images were filtered to exclude road images that do not contain lane lines. Data images with different weather conditions and brightness levels were collected to enhance the model’s generalisation capability. After the filtering process, a total of 5480 images containing lane lines were selected. The dataset was then divided into training, validation, and testing sets in an 8:1:1 ratio.
The sample distribution of training dataset for each type of lane line is shown in
Figure 7.
3.3. Evaluation Metrics
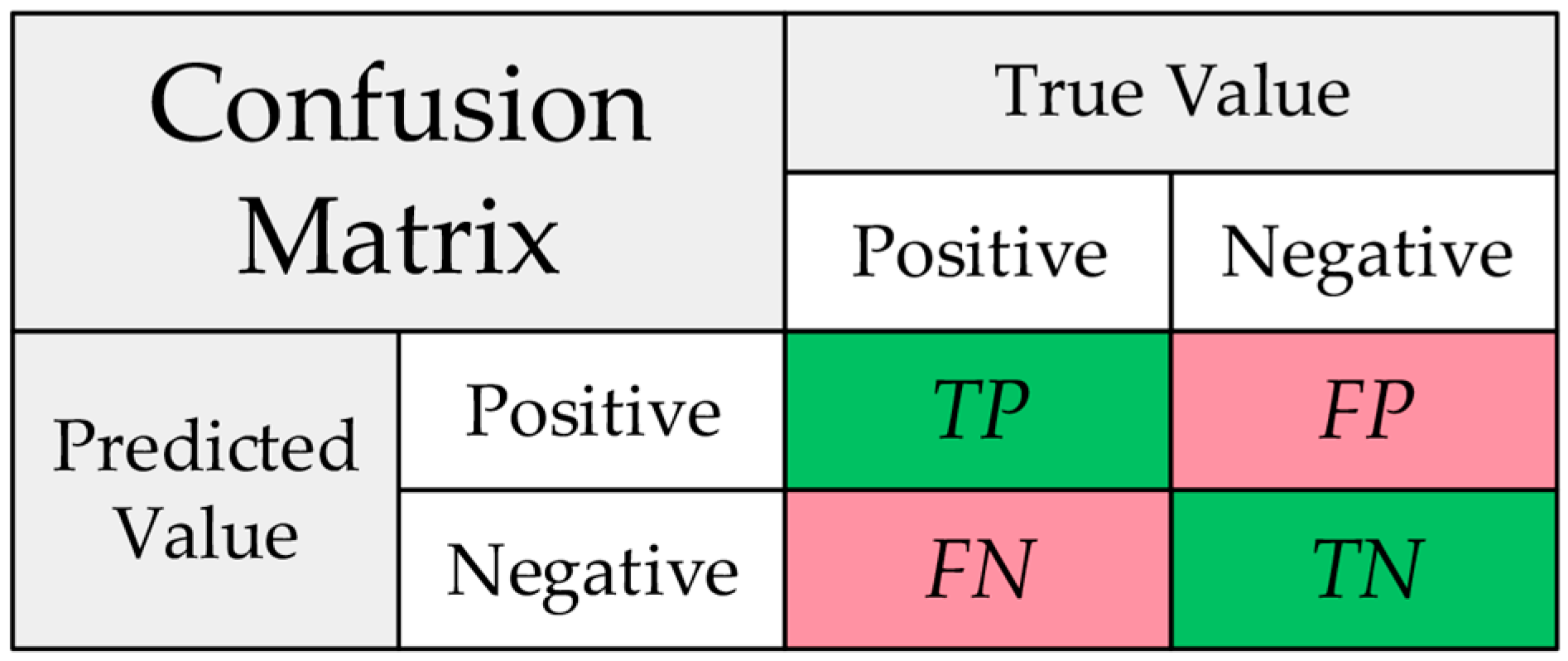
To evaluate the results of lane line category recognition and measure the performance of the trained model, evaluation metrics are used. There are many types of evaluation metrics, but they all rely on a confusion matrix, as shown in
Figure 8.
The four values in the confusion matrix are primary indicators: TP (true positive) represents actual positive samples correctly predicted as positive; FN (false negative) represents actual positive samples incorrectly predicted as negative; FP (false positive) represents actual negative samples incorrectly predicted as positive; TN (true negative) represents actual negative samples correctly predicted as negative.
To limit the values of the metrics between 0 and 1, secondary indicators are used to calculate precision and recall. Precision is calculated using the following formula:
Recall is calculated using the following formula:
Precision and recall are conflicting measures. When a higher precision is desired, the recall decreases and vice versa. Therefore, this paper uses mAP@0.5 as the evaluation metric for the model.
AP represents the accuracy based on the IoU threshold of positive and negative samples, determining the correctness of sample classification based on confidence levels. The
AP value is calculated by measuring the area under the precision–recall curve (
P-
R curve), effectively balancing the conflicting nature of the two indicators. The calculation formula for
AP is
mAP represents the average
AP value across all classes and is calculated using the following formula:
In this paper, mAP@0.5 is used as the evaluation metric to represent the average AP values when the IoU threshold is set to 0.5.
The complexity of a model can be evaluated by the number of parameters it has, which is mainly related to the overall structure of the model. Parameters represent the total number of trainable parameters in the network model. The larger the number of parameters, the more complex the model structure.
Real-time performance is an important metric for lane line category recognition in ADAS. Frames per second (FPS) is used to evaluate the real-time capability of the model. A higher FPS indicates faster detection speed and better real-time performance, while a lower FPS indicates poorer real-time performance.
4. Result
In order to verify the effectiveness of the improved algorithm, this paper carries out three sets of experiments based on the YOLOv5 network: the comparison experiment of attention mechanisms, the comparison experiment of loss function, and the ablation experiment of the improved algorithm. After that, comparison experiments with other mainstream target recognition algorithms and YOLO series are also set up. Finally, different environments are simulated using grayscale values and peak signal-to-noise ratios to analyse the applicability of the algorithm in real road conditions.
4.1. Comparative Experiment of Attentional Mechanisms
To verify the effectiveness of the ECA mechanism, a comparison was made with other attention mechanisms, including the convolutional block attention module (CBAM) [
35] and the squeeze-and-excitation module (SE) [
36]. The experimental results are shown in
Table 5.
From the table, it can be observed that all three attention mechanisms can improve the mAP@0.5 of the model. However, by comparison, it is found that introducing the ECA mechanism has a higher improvement in mAP@0.5 compared to the SE and CBAM mechanisms. It improved 2.2% over the original model.
4.2. Comparison Experiment of Loss Function
Based on the good performance of the ECA module in previous experiments. In this section, the effectiveness of the SIoU loss function is evaluated on this basis. And the training results are compared with the training results of the three loss functions, GIoU, complete intersection over union (CIoU) [
37], and efficient intersection over union (EIoU) [
38]. The experimental results are shown in
Table 6.
From the table, it can be observed that using the SIoU loss function outperforms the other three loss functions, effectively improving the model’s mAP@0.5. Compared with the GIoU loss function in the original model, it was increased by 1.1%, and FPS also improved slightly.
4.3. Ablation Experiment
To validate the overall effectiveness of the improved algorithm, a set of ablation experiments were conducted. The experiment included six models with different configurations: ① Original YOLOv5s; ② YOLOv5s + C3_Faster; ③ YOLOv5s + ECA; ④ YOLOv5s + SIoU; ⑤ YOLOv5s + ECA + SIoU; ⑥ YOLOv5s + C3_Faster + ECA + SIoU. The experimental results are shown in
Table 7.
From the table, it can be observed that compared to the original model, introducing the FasterNet lightweight network in the C3 module alone speeds up the model’s processing speed and reduces the number of parameters. The introduction of the ECA mechanism and SIoU loss function both improve the model’s mAP@0.5. When the three improvements are introduced simultaneously, the accuracy of the model increases by 3.0%, the FPS increases by 3.9 frame·s−1, the number of parameters decrease by 1.1 M, and the volume decreases by 2.1 MB. In conclusion, the method proposed in this paper has higher robustness and real-time performance in lane line type recognition compared to other methods. Meanwhile, the parameters and volume of the model are effectively reduced.
4.4. Comparative Experiment of Different Algorithms
To demonstrate the good performance of the YOLO algorithm on the task of lane line species recognition, this section cites one two-stage algorithm, Faster R-CNN, and two one-stage algorithms, SSD [
39] and RetinaNet [
40], as comparison networks. These are the current mainstream target recognition algorithms. These algorithms have been applied by many researchers in various task scenarios. The above algorithms are applied to the lane line pattern recognition dataset for training and testing. And the results of YOLOv5 algorithm are compared with the results of the above algorithms. The results are shown in
Table 8.
As can be seen from the table, the detection speed of Faster R-CNN is too slow and bulky. This is not suitable for application and deployment in ADAS. Compared with Faster R-CNN, the SSD and RetinaNet algorithms improve the detection speed, but the average accuracy is lower, which is still difficult for meeting the needs of ADAS. The YOLOv5 algorithm is superior to the above three algorithms in terms of average accuracy and detection speed. On this basis, the improved YOLOv5 algorithm proposed in this paper has further improved in each performance. This algorithm is fully applicable to the working requirements of ADAS.
4.5. Comparative Experiment of YOLO Series Algorithms
In order to further verify the effectiveness of the improved algorithm, this paper sets up a comparison experiment between different YOLO algorithms. It mainly includes YOLOv3, YOLOv4, and YOLOv5. The experimental results are shown in
Table 9.
From the table, it can be seen that although YOLOv3 and YOLOv4 have improved their recognition accuracy compared to the other algorithms listed in the previous section, their detection speeds are still far from adequate. YOLOv3-tiny and YOLOv4-tiny used CSPdarknet53_tiny as the backbone network and improved on the basis of the original network. Although the detection speed has been greatly improved, the detection accuracy has dropped off a cliff. After the improved algorithm in this paper, compared with the original YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x, the four different models have different degrees of improvement in detection accuracy and speed. The improved algorithm reduces the parameters and volume of the model. In practical applications, the appropriate detection model can be selected according to the embedded deployment of ADAS.
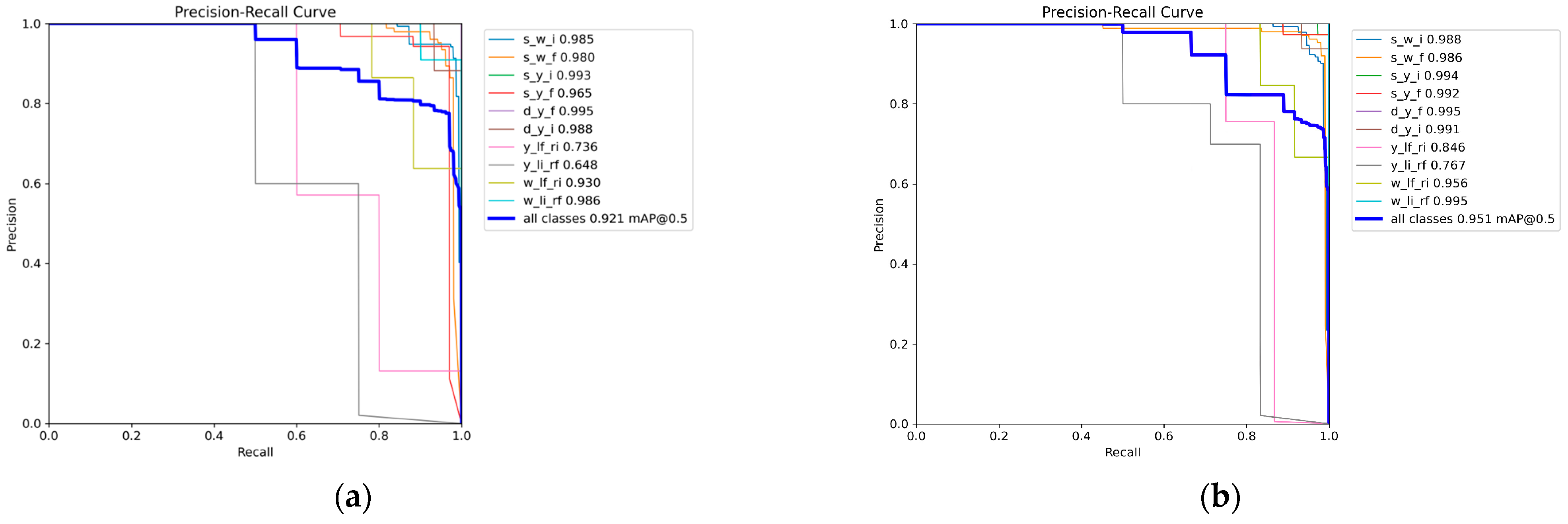
From
Figure 9, the improved algorithm has a higher confidence in the recognition of various types of lane lines. Especially in various complex situations, it can effectively avoid leakage or misdetection. This suggests that the improved YOLOv5 algorithm has a wider range of applications and is more suitable for ADAS applications and deployments.
As can be seen in
Figure 10, the improved algorithm improves the detection accuracy for all categories of targets to different degrees, especially for the lane line category with more complex features. When using YOLOv5s, the detection of the yellow dash-solid line is poor. However, under our improved algorithm, the detection results of the two types of short yellow dash-solid lines are improved by 11% and 11.9%, respectively, which indicates that our improved strategy has some effect.
4.6. Analysis of Influence of Light Intensity
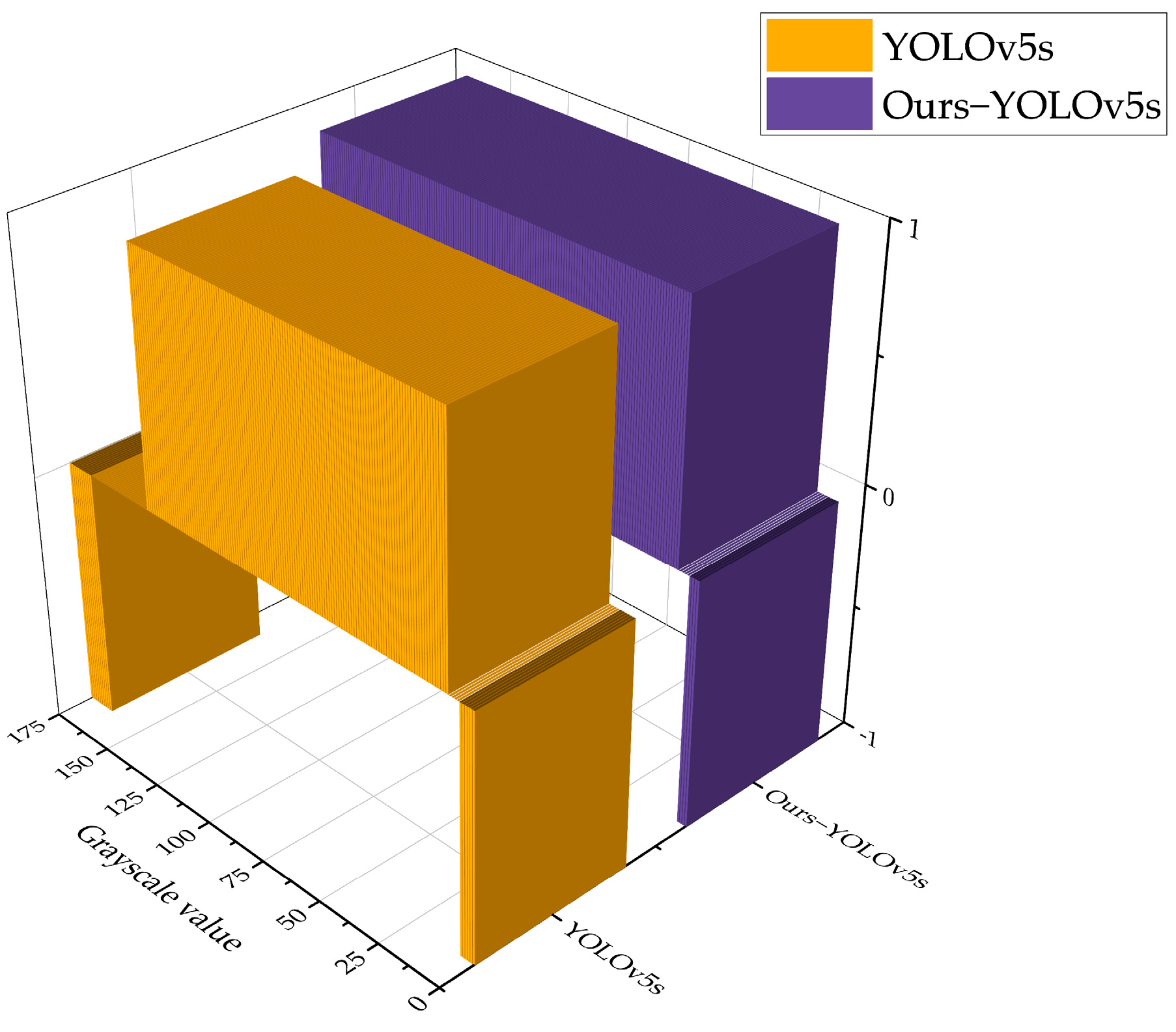
In this paper, in order to analyse the applicability of the improved algorithm in different light intensities, different light intensities outdoors are simulated using different levels of contrast and brightness. In order to simulate a real scene, the range of grayscale values is set between 0–175, and the pixels of the pictures in the test set are modified.
Through experiments, the original YOLOv5s algorithm is able to correctly identify lane line type with grayscale values ranging from 10–137, with detection failures in ranges smaller than 6 and larger than 164. The rest of the ranges are false-positive cases, mainly in that yellow lane lines are incorrectly identified as white lane lines. While the improved YOLOv5s algorithm can correctly identify the type of lane line grayscale values ranging between 8–155, less than 4 and greater than 171 are the range of detection failure. The rest of the range are cases of false positives. As shown in
Figure 11, where the
Z-axis indicates the detection results, 1 indicates accurate recognition, 0 indicates false positive, and −1 indicates recognition failure.
In summary, the method proposed in this paper has a wider detection range for different light intensities compared to the original algorithm.
4.7. Analysis of the Influence of Noise
In this paper, in order to analyse the applicability of the improved algorithm in the case of noise interference in different weather, different levels of Gaussian noise are added to the images to simulate rain, snow, or foggy weather. The peak signal-to-noise ratio (PSNR) is utilised to evaluate the quality of the image after adding noise. PSNR is defined based on mean square error (MSE). The definition of MSE is
where
m ×
n represents the size of the image, and
I(
i,
j) and
K(
i,
j) represent the pixels of the original image and the pixels of the noisy image, respectively.
Then, PSNR can be defined as
where
MAXI is the maximum pixel value of the image.
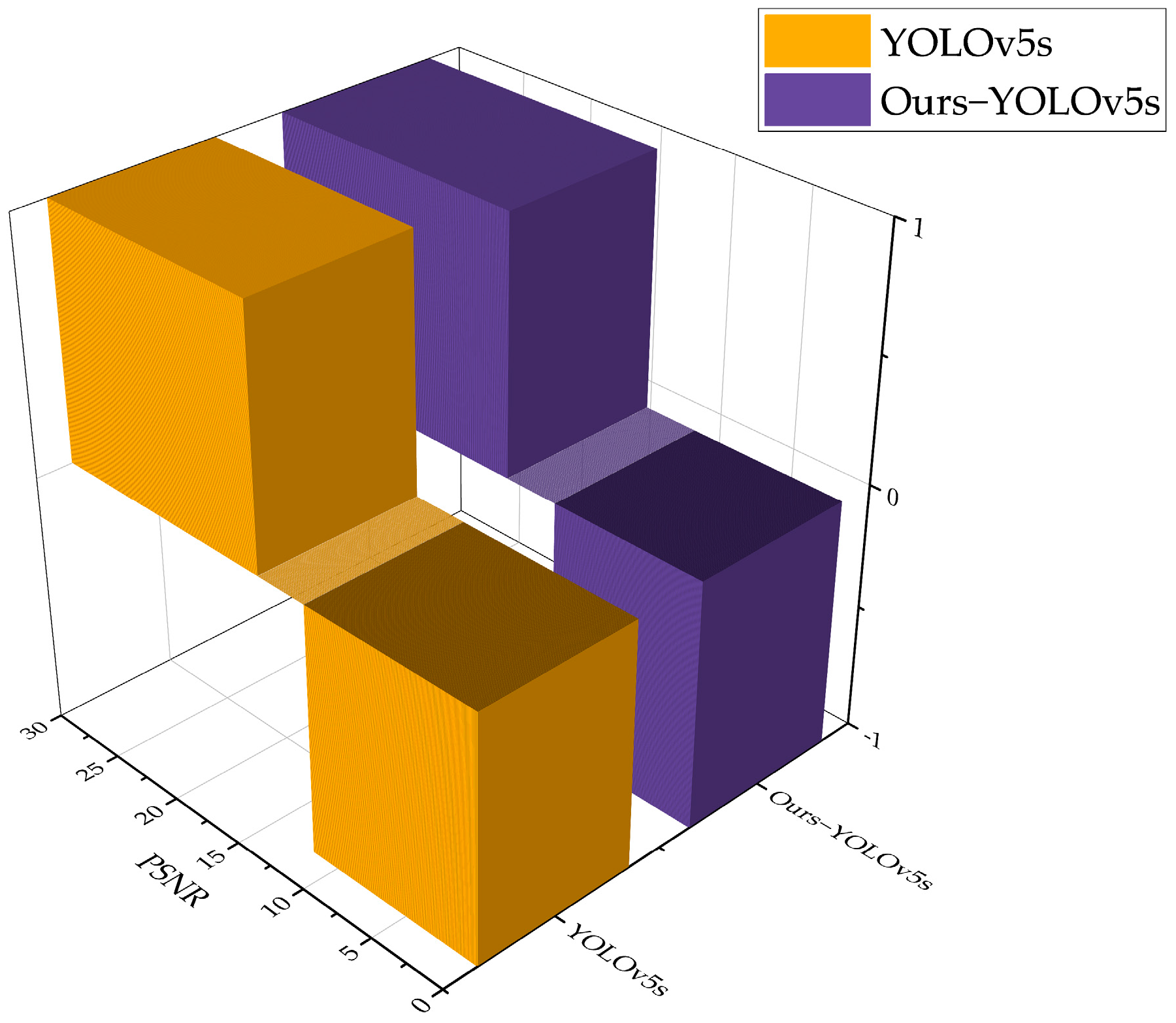
Through experiments, under the influence of noise, the original YOLOv5s algorithm correctly recognises lane line type in the range greater than 15.2 dB, while the range of recognition failure is less than 11.8 dB. The rest of the ranges are false positives or false negatives. While the improved algorithm correctly recognises the lane line type in the range greater than 13.3 dB, the range of recognition failure is less than 9.8 dB. The rest of the ranges are false positives or false negatives. As shown in
Figure 12, where the
Z-axis indicates the detection results, 1 indicates accurate recognition, 0 indicates false positive or false negative, and −1 indicates recognition failure.
In summary, compared to the original algorithm, the method proposed in this paper is able to accurately recognise lane line type in more severe weather.
5. Conclusions
To ensure the accuracy and real-time performance of lane line category recognition, this paper proposes an improved YOLOv5 algorithm. Through experiments, the following conclusions have been drawn:
Introducing FasterNet into the C3 module of the backbone and necking networks can speed up the inference speed of the model and reduce the calculation parameters.
Introducing the ECA mechanism into the backbone network can significantly improve the recognition accuracy of the model.
The use of SIoU loss function can further improve the accuracy of the model and speed up the inference speed to some extent.
According to the experimental results on the dataset, the improved YOLOv5 model achieves the mAP@0.5 of 95.1% and the FPS of 95.2 frames·s−1 in the test. This meets the requirements for accuracy and real-time performance in lane line type recognition. Moreover, the parameters and the volume of the model are only 6.0 M and 11.7 MB, respectively. It also has a wider detection range than the original YOLOv5 algorithm in different environments. Therefore, the proposed method can be effectively applied to lane line category recognition and has practical significance for application in ADAS.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









