To improve the detection rate of the algorithm, we carried out an adaptive self-order color scale enhancement on the collected low-contrast images to improve the images’ clarity and highlight the contour features of the target. The relevant enhancement principles are as follows.
2.2. Adaptive Piecewise Self-Order Enhancement Algorithm
In the image gray level enhancement algorithm of the traditional self-ranking algorithm, the image pixel enhancement is mainly based on the maximum interclass difference of the image gray level. In the study of Formula (1) above, it is found that the simple algorithm for the gray level enhancement that adjusts the relevant fixed parameters through prior knowledge uniformly uses a simple normalization to enhance the pixels between the minimum gray level and the maximum gray level. The utilization rate of the interclass gray level information of the image is not high, resulting in a poor image enhancement effect, and the distinction between dark and bright gray levels in the image is polarized. Therefore, in view of the shortcomings of the image enhancement produced by the simple processing in the above formula, this paper constructed a self-order matrix reorganization analysis model to perform an interclass enhancement on the gray levels of the intermediate stage. The image can be enhanced according to different gray intensities, and the gray difference information between each gray level can be fully used to improve the quality of the image after the enhancement. The specific model is as follows:
In the formula,
refers to the pixel stored between the minimum pixel and the maximum pixel. Other definitions are as shown in Formula (1). In this operation, all pixels smaller than the minimum and larger than the maximum are defined as 0 and 255 gray levels. For pixels larger than the minimum and smaller than the maximum, the defined reorganization model is as follows:
In the formula,
represents the pixel matrix after the matrix reorganization of the image gray levels,
represents the element reorganization function,
represents the result in Formula (2),
represents the pixel matrix with a size of the element reorganization of
. In order to effectively use the gray level between the minimum value and the maximum value of a pixel to reflect the interclass difference between the gray levels of each pixel and finally realize the gray level enhancement of the pixel, firstly, the histogram analysis of the reconstructed gray pixel is as follows:
In the formula,
represents the histogram after image normalization, and the other parameters are defined as above. The interclass coefficient of the gray level
in the histogram can be determined by defining the gray level
of the pixel according to the image as follows:
In the formula,
refers to the gray level coefficient in the range from the minimum gray level to the maximum gray level. The initial value is defined as 0, which means the defined gray level is from 1 to 256. In order to achieve the adaptive gray level enhancement, the difference between pixel classes must be adjusted by determining various gray level enhancement parameters
adaptively according to the defined gray level
. The model for determining each parameter is as follows:
In the formula, and represent the difference between adaptive gray levels according to the image information, represents the adaptive gray level value, represents the result of the operation in Formula (4), and represent the cyclic operation parameters of the gray level , where , .
Finally, the interclass variance of the output image of Formulas (5)–(7) is used as the judgment condition for the enhancement, and its mathematical model is as follows:
represents the gray scale coefficient calculated in Formula (5) from the minimum gray scale to the maximum gray scale. Other definitions are as follows.
In order to make effective use of the information of the interclass gray level of the image for the enhancement, this paper proposes an adaptive light–dark perception model to build the model based on the parameters of the adjustment of the interclass difference, the variance of the interclass difference, and the original light–dark difference of the image. The specific model is as follows:
In the formula,
is the maximum gray value of each gray category calculated in Formula (8) in the original image. Because this paper focused on the gray enhancement of dark night scenes with a low contrast and foggy weather scenes with a high brightness, it makes sense to choose different
parameters for the operation of grayscale enhancement according to the brightness of different scenes. At the same time, this paper used the brightness difference of each gray level in the original image to reflect the shadow characteristics between each gray level and obtained the brightness difference of the overall image through the difference between the highest brightness level of the image and the overall shadow coefficient of the image. The overall brightness difference of the image and the brightness difference between the image’s gray classes were combined and normalized to increase the information utilization rate of the image. The perception model of shadow parameters in this paper was as follows:
In the formula,
it is the upward rounding function, and
represents the interclass variance value of all gray levels of the image. In addition, in order to effectively improve the information utilization rate and image enhancement effect, this paper also set the corresponding fine-tuning parameters to adapt the fine-tuning image enhancement effect based on different brightness levels and different scenes. The specific model was as follows:
In the formula, represents the overall brightness of the image. When it is a foggy scene, the gray levels of the pixels are similar, so the fine adjustment coefficient should be far less than 1. In a dark scene, there is a large difference between the gray level of the target pixel and the overall background, so it is necessary to improve the fine adjustment coefficient to enhance the color scale recovery effect. This paper defined its value as 1.
In combination with the parameters established by the above corresponding models, the enhancement model proposed in this paper is as follows:
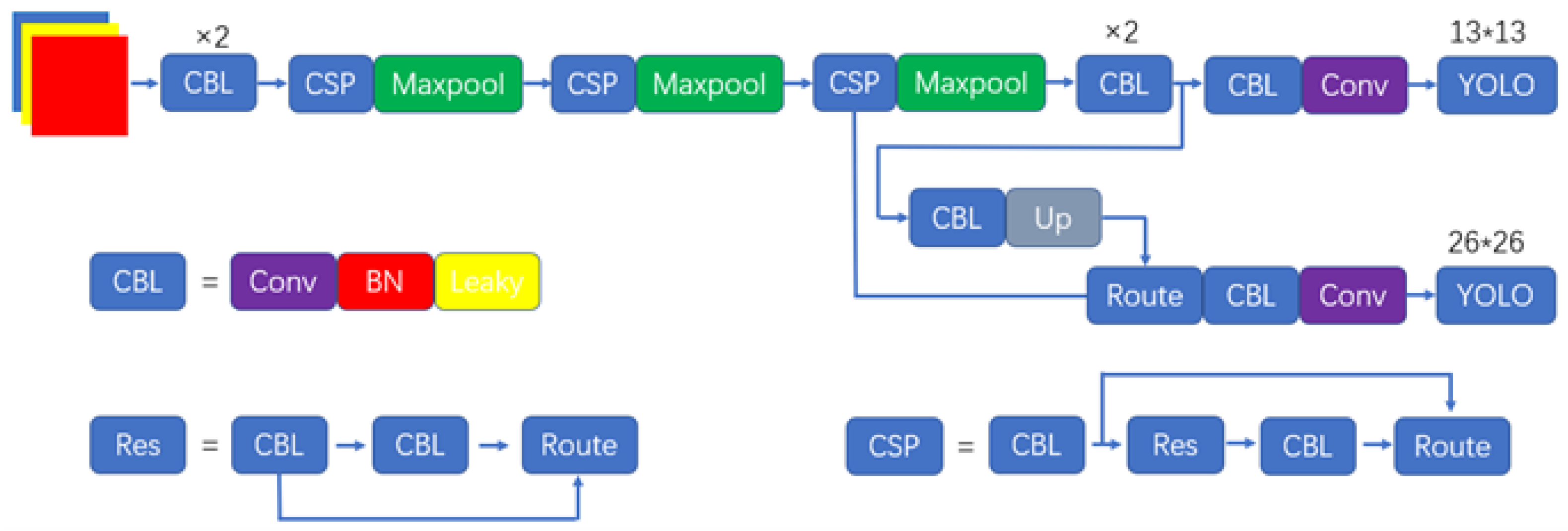
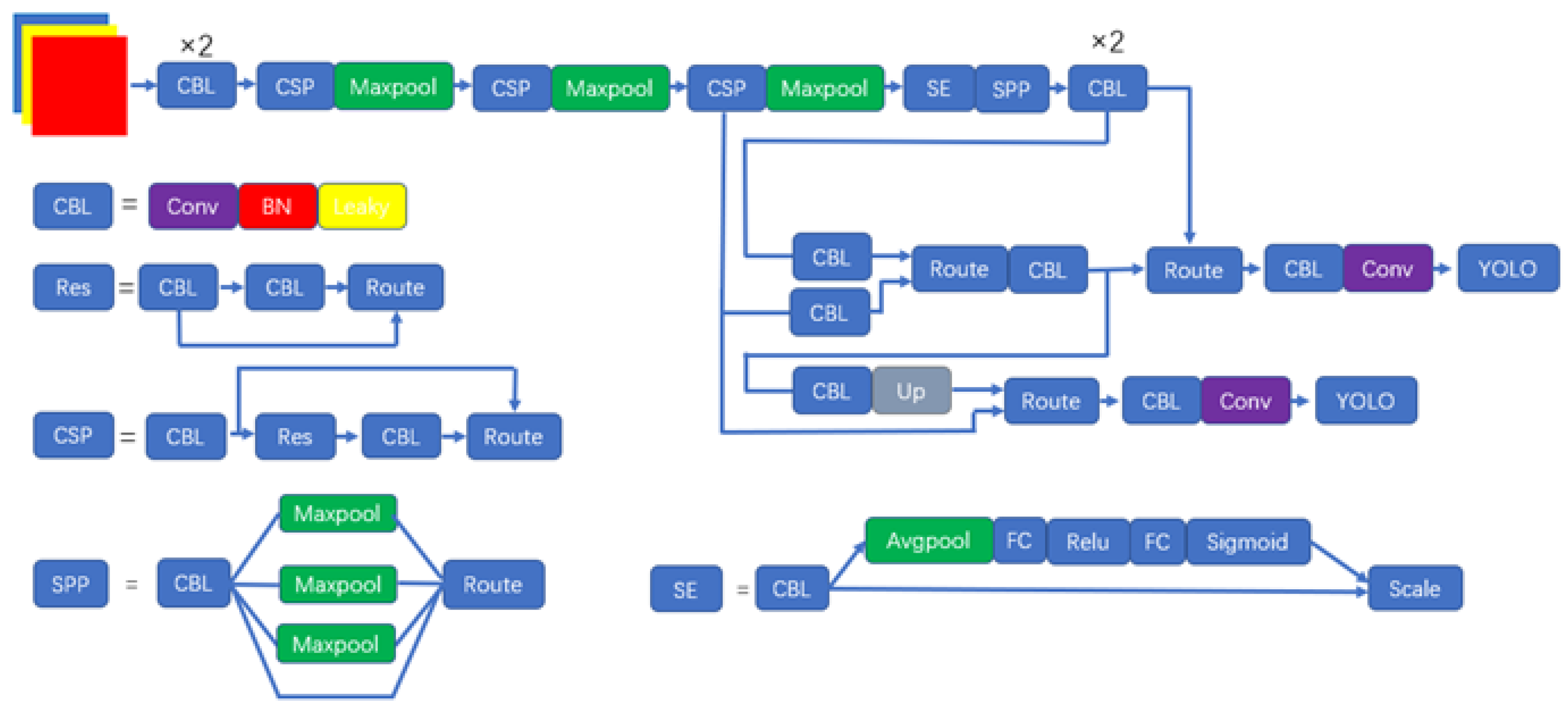
In the formula, means that the grayscale value of the image between the maximum and minimum grayscale, , means the minimum and maximum gray levels of the image, respectively. represents the brightness of the image, represents the shadow parameter of the image, represents the brightness difference of a certain gray level in the whole image, denotes the operation result of Formula (8), represents the average gray level difference of the gray level, denotes the coordinates of the image element, and is the final enhancement result of the gray level. The overall process and pseudocode of the algorithm are as follows:
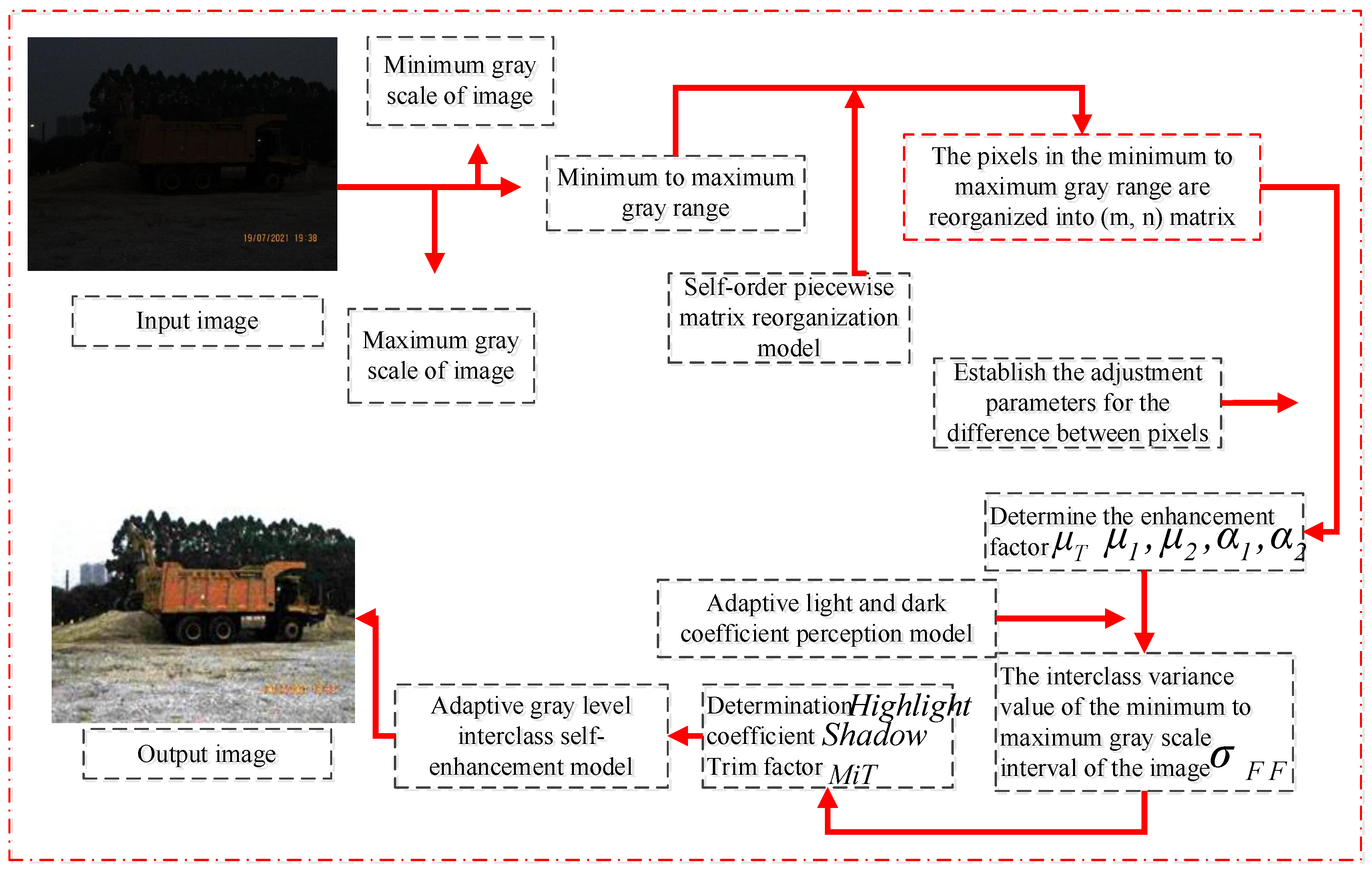
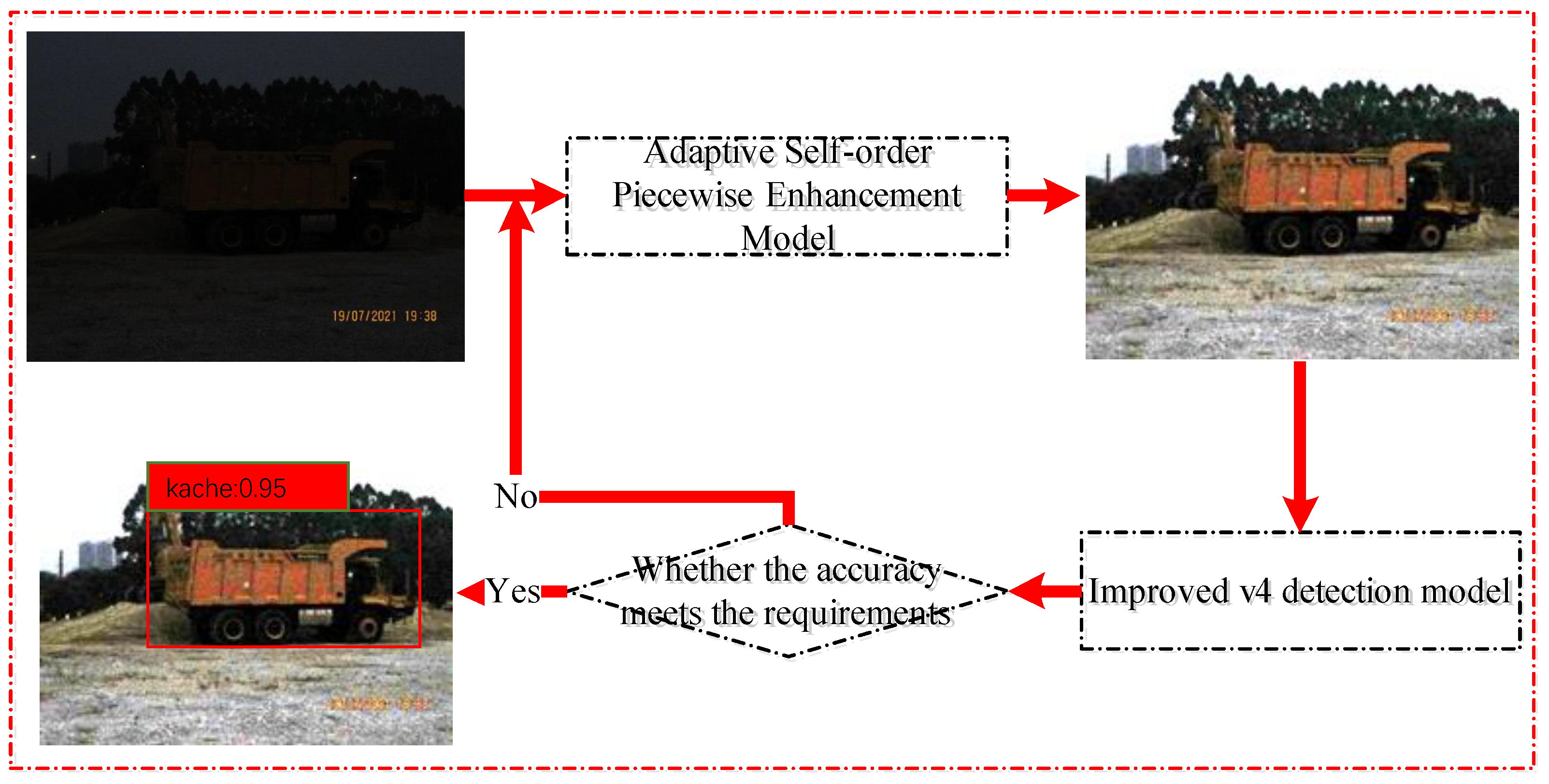
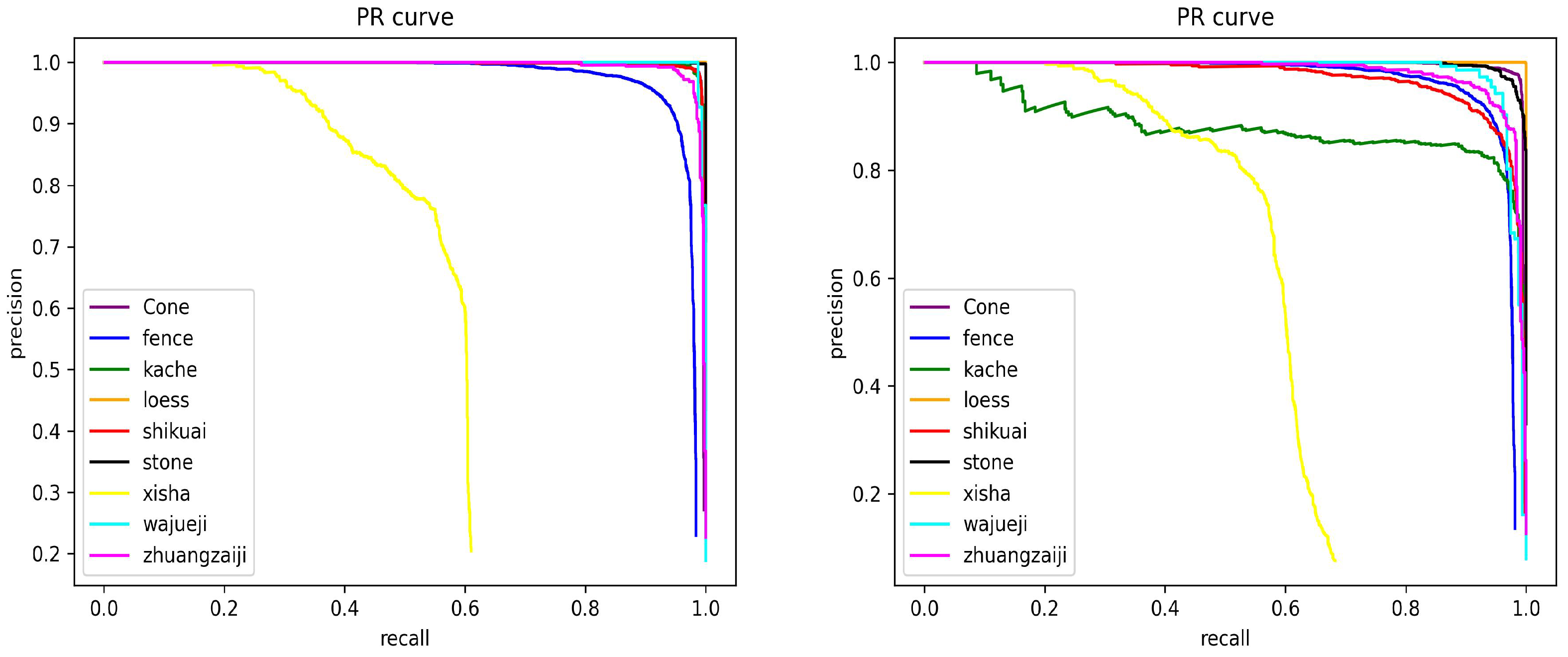
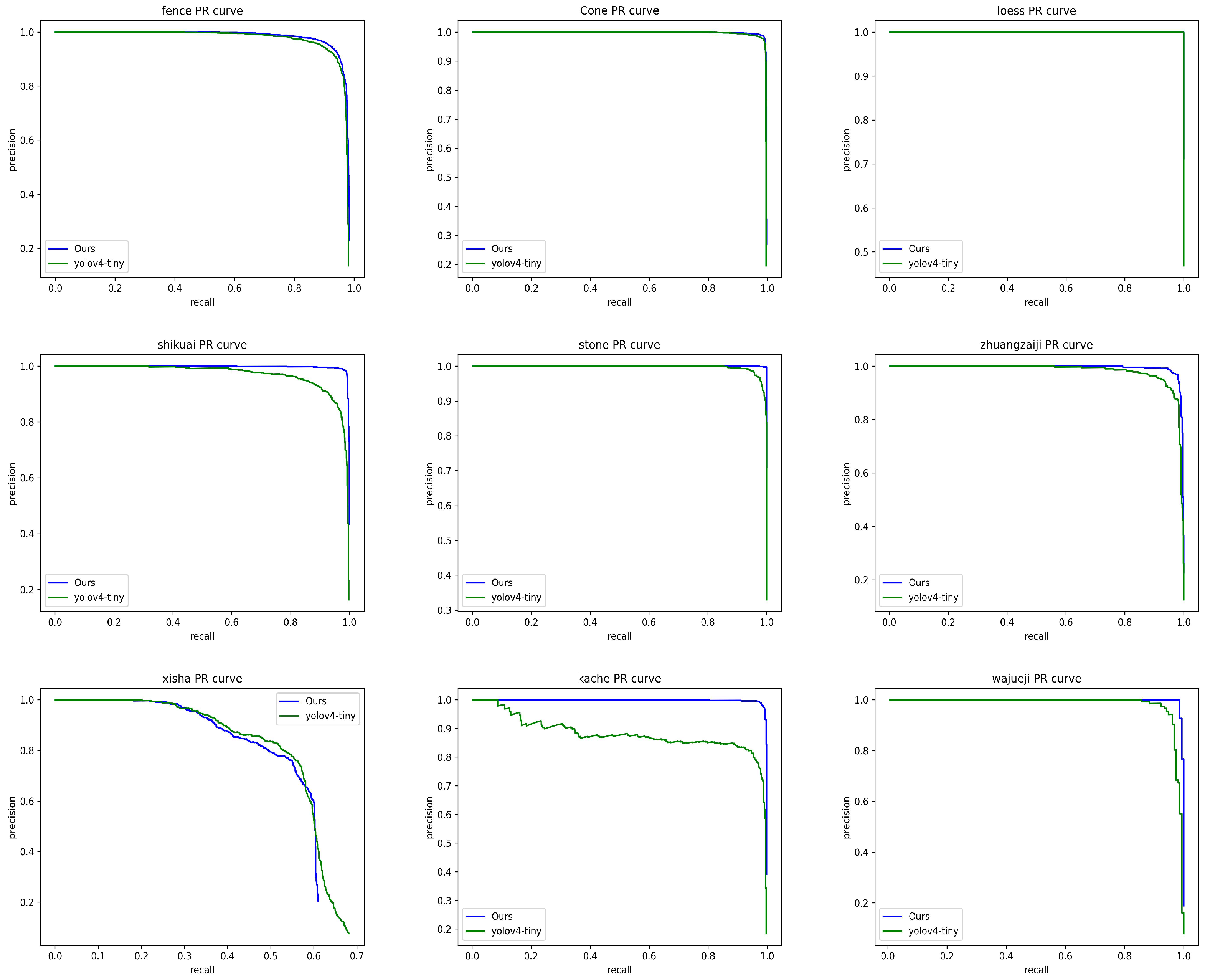
As shown in
Figure 1 below, the image enhancement effect of the algorithm proposed in this paper is obtained after preliminary verification. It can be seen from the figure that the image enhancement effect of the algorithm proposed in this paper is obvious. The pseudocode of the overall algorithm is shown in
Table 1:













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}