
TIG-DETR: Enhancing Texture Preservation and Information Interaction for Target Detection

Abstract
:1. Introduction
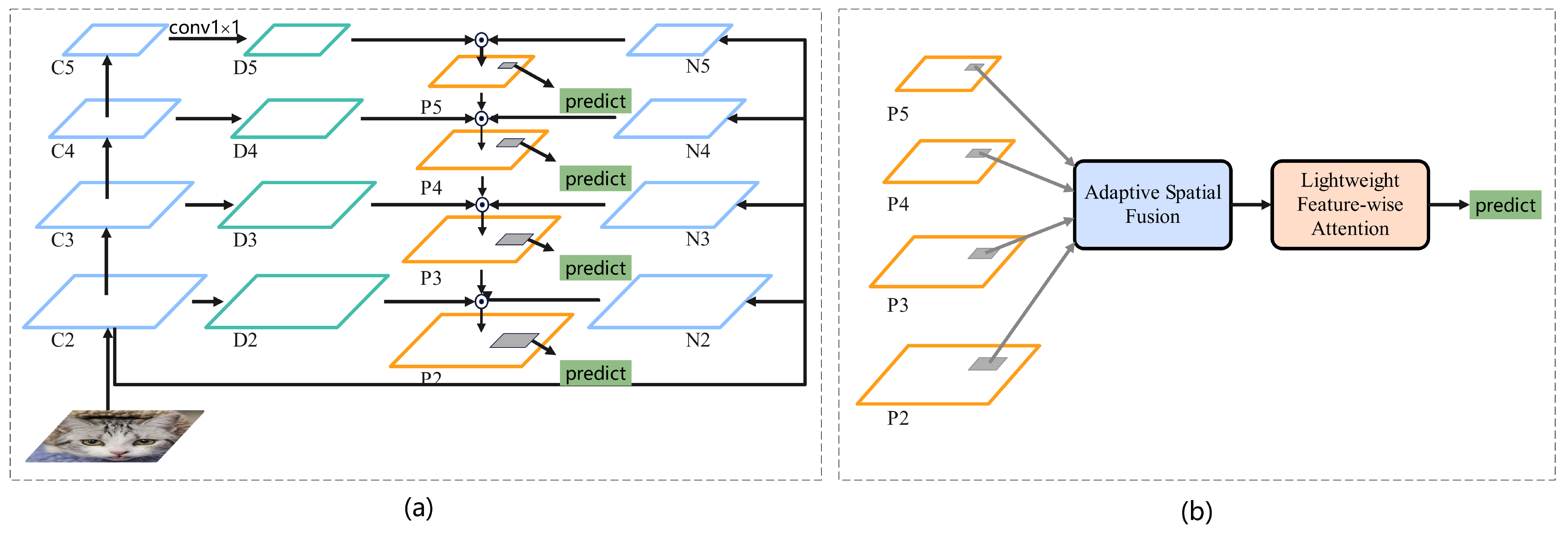
- We introduced a novel approach to address the issue of missing texture information in FPN by constructing a new bottom-up path that utilizes the low-level feature map in the backbone. Unlike the traditional downsampling process in the backbone network, our method aims to preserve textural information as much as possible by constructing a new bottom-up path. By fusing this texture-rich feature map with the features at the same level as the top-down path in FPN, we obtained a new feature map that contains both rich semantic and texture information. Although previous studies [12,17,18] have utilized bottom-up paths, their convolution-based downsampling still results in significant texture information loss. In contrast, our method effectively retains the texture information in the feature map.
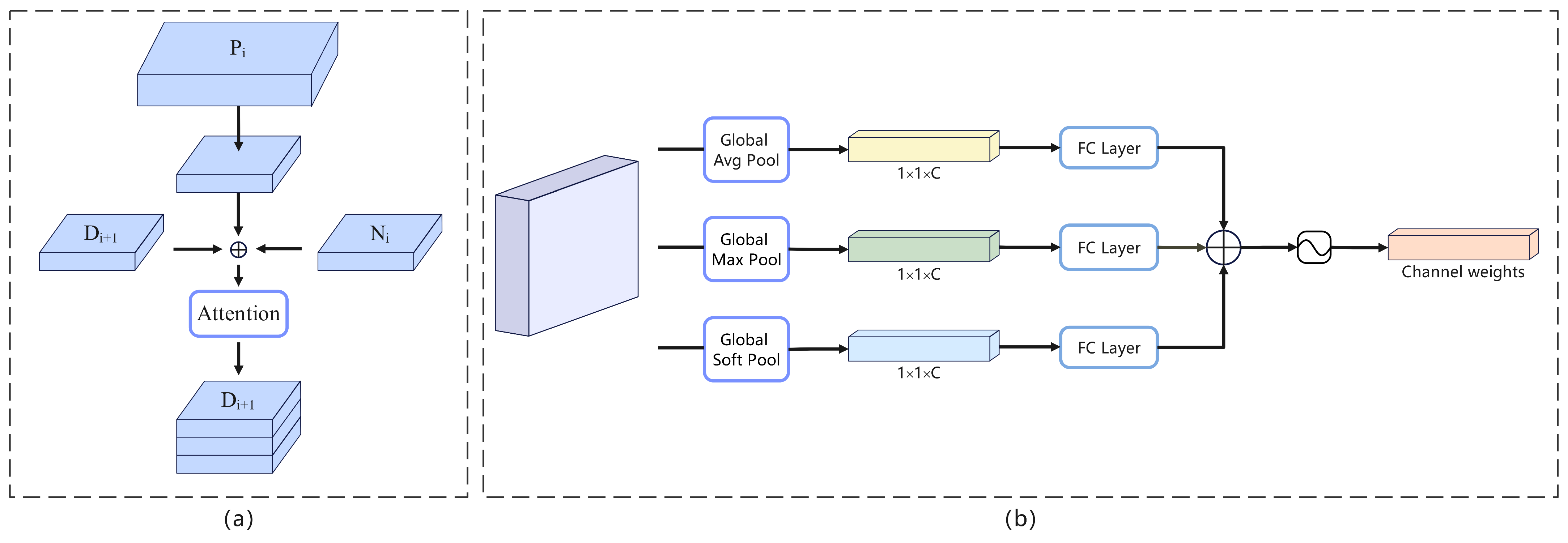
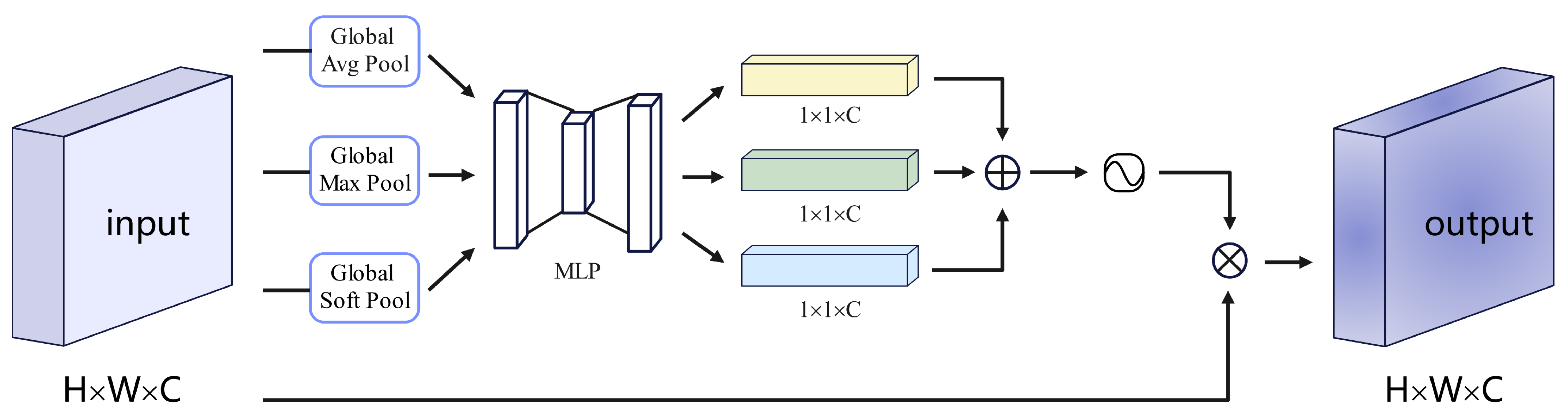
- We proposed a new attention module called ’Feature-wise Attention’ to mitigate the confounding effects caused by cross-level feature fusion in FPN. This attention module was designed to be lightweight and was applied to augment the final features of the TE-FPN output. By incorporating this attention mechanism, we enhanced the discriminative power of the features.
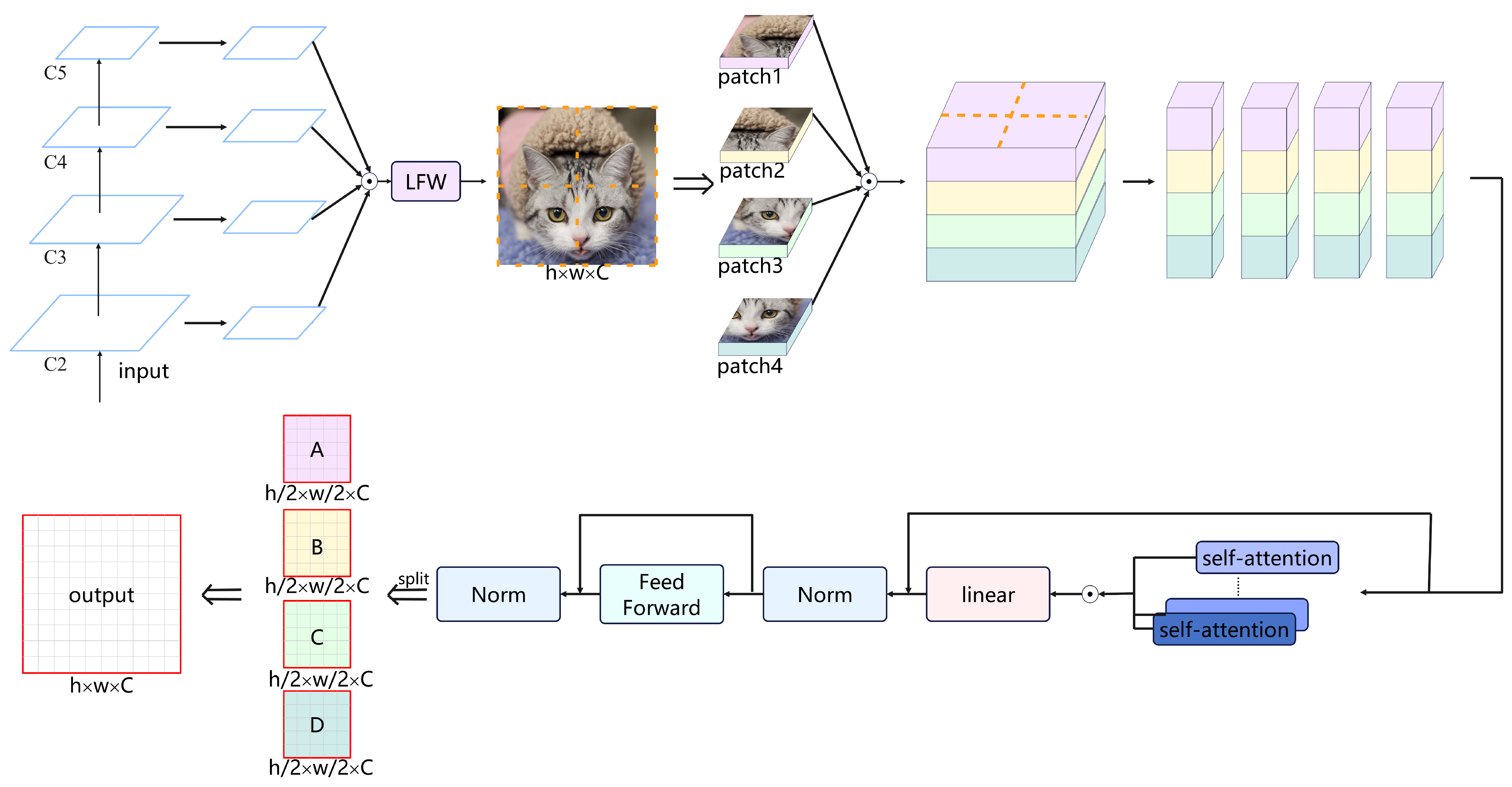
- We introduced the Instance-Based Advanced Guidance Module to overcome the limitations of interactions between windows in Shifted Window-based Self-Attention [16]. This module enhances the model’s perception of large object instances by allowing the model to perceive the instances in the image before finer self-attention and enabling information interaction between each window prior to window attention movement. This approach significantly improves the model’s ability to capture and understand large object instances.
2. Related Work
3. Materials and Methods
3.1. TE-FPN
3.2. Instance Based Advanced Guidance Module
4. Results
4.1. COCO and Evaluation Metrics
4.2. Implementation Details
4.3. Main Results
4.4. Ablation Study
4.4.1. TIG-DETR
4.4.2. TE-FPN
4.5. Cityscapes
4.6. Discusses
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| TE-FPN | Texture-Enhanced FPN |
| TIG-DETR | Texturized Instance Guidance DETR |
| FPN | Three Feature pyramid network |
| SRS | Soft RoI Selection |
| ETA | Enhancing texture information with a bottom-up architecture |
| LFA | Lightweight Feature-wise Attention |
| FWA | Feature-wise Attention |
| IAM | Instance Based Advanced Guidance Module |
| S-IAM | Instance Based Advanced Guidance Module after removal of multiscale fusion |
| W-MSA | Window based Self-Attention |
| SW-MSA | Shift Window based Self-Attention |
| FFN | Feed Forward Networks |
| MLP | Multilayer Perceptron |
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient transformers: A survey. ACM Comput. Surv. 2022, 55, 1–28. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part I; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Chen, T.; Saxena, S.; Li, L.; Fleet, D.J.; Hinton, G. Pix2seq: A language modeling framework for object detection. arXiv 2021, arXiv:2109.10852. [Google Scholar]
- Wang, Z.; Huang, Z.; Fu, J.; Wang, N.; Liu, S. Object as Query: Equipping Any 2D Object Detector with 3D Detection Ability. arXiv 2023, arXiv:2301.02364. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Long, Y.; Wen, Y.; Han, J.; Xu, H.; Ren, P.; Zhang, W.; Zhao, S.; Liang, X. CapDet: Unifying dense captioning and open-world detection pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 15233–15243. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12595–12604. [Google Scholar]
- Luo, Y.; Cao, X.; Zhang, J.; Guo, J.; Shen, H.; Wang, T.; Feng, Q. CE-FPN: Enhancing channel information for object detection. Multimed. Tools Appl. 2022, 81, 30685–30704. [Google Scholar] [CrossRef]
- Jin, Z.; Yu, D.; Song, L.; Yuan, Z.; Yu, L. You Should Look at All Objects. In Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022, Proceedings, Part IX; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 332–349. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part I; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS’15), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS’14), Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Dai, Z.; Lai, G.; Yang, Y.; Le, Q. Funnel-transformer: Filtering out sequential redundancy for efficient language processing. Adv. Neural Inf. Process. Syst. 2020, 33, 4271–4282. [Google Scholar]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS’14), Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS’15), Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global second-order pooling convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3024–3033. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I. CBAM: Convolutional block attention module. In Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018, Proceedings, Part VII; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Stergiou, A.; Poppe, R.; Kalliatakis, G. Refining activation downsampling with SoftPool. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10357–10366. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part V; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Schedule | AP | |||||
|---|---|---|---|---|---|---|---|---|
| Faster R-CNN ∗ | ResNet-50-FPN | ×1 | 36.4 | 58.1 | 39.1 | 21.3 | 40.5 | 44.6 |
| Faster R-CNN ∗ | ResNet-101-FPN | ×1 | 38.6 | 60 | 42.1 | 22.2 | 42.5 | 47.1 |
| Faster R-CNN ∗ | ResNet-101-FPN | ×2 | 39.4 | 61.1 | 43.2 | 22.6 | 42.7 | 50.1 |
| Faster R-CNN ∗ | ResNext-101-32x4d-FPN | ×1 | 40.3 | 62.6 | 43.6 | 24.5 | 42.9 | 49.9 |
| Faster R-CNN ∗ | ResNext-101-64x4d-FPN | ×1 | 41.7 | 64.9 | 44.4 | 24.7 | 45.8 | 51.3 |
| Mask R-CNN ∗ | ResNet-50-FPN | ×1 | 37.1 | 58.9 | 40.3 | 22.3 | 40.5 | 45.5 |
| Mask R-CNN ∗ | ResNet-101-FPN | ×1 | 39.1 | 61.2 | 42.2 | 22.8 | 42.3 | 49.2 |
| Mask R-CNN ∗ | ResNet-101-FPN | ×2 | 40 | 61.8 | 43.7 | 22.7 | 43.4 | 52.1 |
| RetinaNet ∗ | ResNet-50-FPN | ×1 | 35.8 | 55.7 | 38.7 | 19.4 | 39.7 | 44.9 |
| RetinaNet ∗ | MobileNet-v2-FPN | ×1 | 32.9 | 52.1 | 34.9 | 17.9 | 34.8 | 42.6 |
| DETR | ResNet-50 | ×1 | 42 | 62.4 | 44.2 | 20.5 | 45.8 | 61.1 |
| Deformable DETR | ResNet-50 | ×1 | 43.8 | 62.6 | 47.7 | 26.4 | 47.1 | 58 |
| Deformable DETR+IAM | ResNet-50 | ×1 | 44.3 | 62.9 | 48.3 | 26.3 | 47.6 | 60.3 |
| Faster R-CNN * (ours) | ResNet-50-TE-FPN | ×1 | 38.4 | 61 | 41.9 | 23.1 | 41.7 | 47.5 |
| Faster R-CNN (ours) | ResNet-101-TE-FPN | ×1 | 40.2 | 62.6 | 43.6 | 23.5 | 43.5 | 50.9 |
| Faster R-CNN (ours) | ResNet-101-TE-FPN | ×2 | 41.1 | 63.4 | 44.3 | 23.6 | 44.1 | 52.7 |
| Faster R-CNN (ours) | ResNext-101-32x4d-TE-FPN | ×1 | 41.5 | 63.8 | 45.1 | 24.8 | 45.1 | 52.3 |
| Faster R-CNN (ours) | ResNext-101-64x4d-TE-FPN | ×1 | 42.7 | 65.4 | 46 | 25.9 | 45.9 | 53.5 |
| Mask R-CNN (ours) | ResNet-50-TE-FPN | ×1 | 38.9 | 61.1 | 42.4 | 23.2 | 42.2 | 49 |
| Mask R-CNN (ours) | ResNet-101-TE-FPN | ×1 | 40.4 | 63 | 44.2 | 23.7 | 43.3 | 51.4 |
| Mask R-CNN (ours) | ResNet-101-TE-FPN | ×2 | 41.5 | 63.6 | 45.7 | 24.1 | 44.2 | 53.2 |
| RetinaNet (ours) | ResNet-50-TE-FPN | ×1 | 36.9 | 57.9 | 39.6 | 20.8 | 40.1 | 46.4 |
| RetinaNet (ours) | MobileNet-v2-TE-FPN | ×1 | 33.9 | 53.7 | 35.8 | 18.5 | 35.7 | 43.9 |
| TIG-DETR | ResNet-50 | ×1 | 43.1 | 62.1 | 46.2 | 24.7 | 46.8 | 60.5 |
| TIG-DETR | ResNet-50-TE-FPN | ×1 | 44.1 | 62.8 | 48.4 | 25.6 | 47.9 | 62.4 |
| IAM | S-IAM | TE-FPN | AP | |||||
|---|---|---|---|---|---|---|---|---|
| 40.3 | 60.5 | 42.9 | 22.2 | 44.5 | 57.4 | |||
| √ | 43.1 | 62.1 | 46.2 | 24.7 | 46.8 | 60.5 | ||
| √ | 40.7 | 60.6 | 44.1 | 22.1 | 44.4 | 59.1 | ||
| √ | 43.7 | 62.4 | 47.6 | 26.7 | 47.6 | 60.7 | ||
| √ | √ | 44.1 | 62.8 | 48.4 | 26.6 | 47.9 | 62.4 |
| SRS | ETA | LFA | SRS+FWA | AP | |||||
|---|---|---|---|---|---|---|---|---|---|
| 36.2 | 56.1 | 38.6 | 20.0 | 39.6 | 47.5 | ||||
| √ | 36.8 | 59.1 | 39.8 | 20.7 | 40.2 | 48.3 | |||
| √ | 37.0 | 56.7 | 39.9 | 20.8 | 40.3 | 48.1 | |||
| √ | 36.8 | 56.5 | 39.3 | 20.6 | 40.2 | 48.0 | |||
| √ | 37.5 | 57.4 | 40.1 | 21.5 | 40.7 | 49.0 | |||
| √ | √ | 37.5 | 57.5 | 40.2 | 21.4 | 41.0 | 49.4 | ||
| √ | √ | 37.6 | 58.0 | 40.1 | 21.5 | 41.3 | 49.6 | ||
| √ | √ | 37.8 | 57.9 | 40.4 | 21.6 | 41.2 | 49.8 | ||
| √ | √ | √ | 38.2 | 58.8 | 40.9 | 21.9 | 42.3 | 50.4 |
| Method | AP [val] | AP | Person | Rider | Car | Truck | Bus | Train | Motorcycle | Bicycle | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask R-CNN [fine-only] | 31.5 | 26.2 | 49.9 | 30.5 | 23.7 | 46.9 | 22.8 | 32.2 | 18.6 | 19.1 | 16.0 |
| Mask R-CNN [COCO] | 36.4 | 32.0 | 58.1 | 34.8 | 27.0 | 49.1 | 30.1 | 40.9 | 30.9 | 24.1 | 18.7 |
| TE-FPN [fine-only] | 34.2 | 29.5 | 54.8 | 34.0 | 27.8 | 52.7 | 25.6 | 35.2 | 23.0 | 21.1 | 19.1 |
| TE-FPN [COCO] | 39.6 | 34.9 | 61.2 | 39.1 | 31.1 | 54.3 | 31.5 | 43.9 | 31.1 | 26.2 | 22.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Wang, K.; Li, C.; Wang, Y.; Luo, G. TIG-DETR: Enhancing Texture Preservation and Information Interaction for Target Detection. Appl. Sci. 2023, 13, 8037. https://doi.org/10.3390/app13148037
Liu Z, Wang K, Li C, Wang Y, Luo G. TIG-DETR: Enhancing Texture Preservation and Information Interaction for Target Detection. Applied Sciences. 2023; 13(14):8037. https://doi.org/10.3390/app13148037
Chicago/Turabian StyleLiu, Zhiyong, Kehan Wang, Changming Li, Yixuan Wang, and Guoqian Luo. 2023. "TIG-DETR: Enhancing Texture Preservation and Information Interaction for Target Detection" Applied Sciences 13, no. 14: 8037. https://doi.org/10.3390/app13148037