
Real Image Deblurring Based on Implicit Degradation Representations and Reblur Estimation


Abstract
:1. Introduction
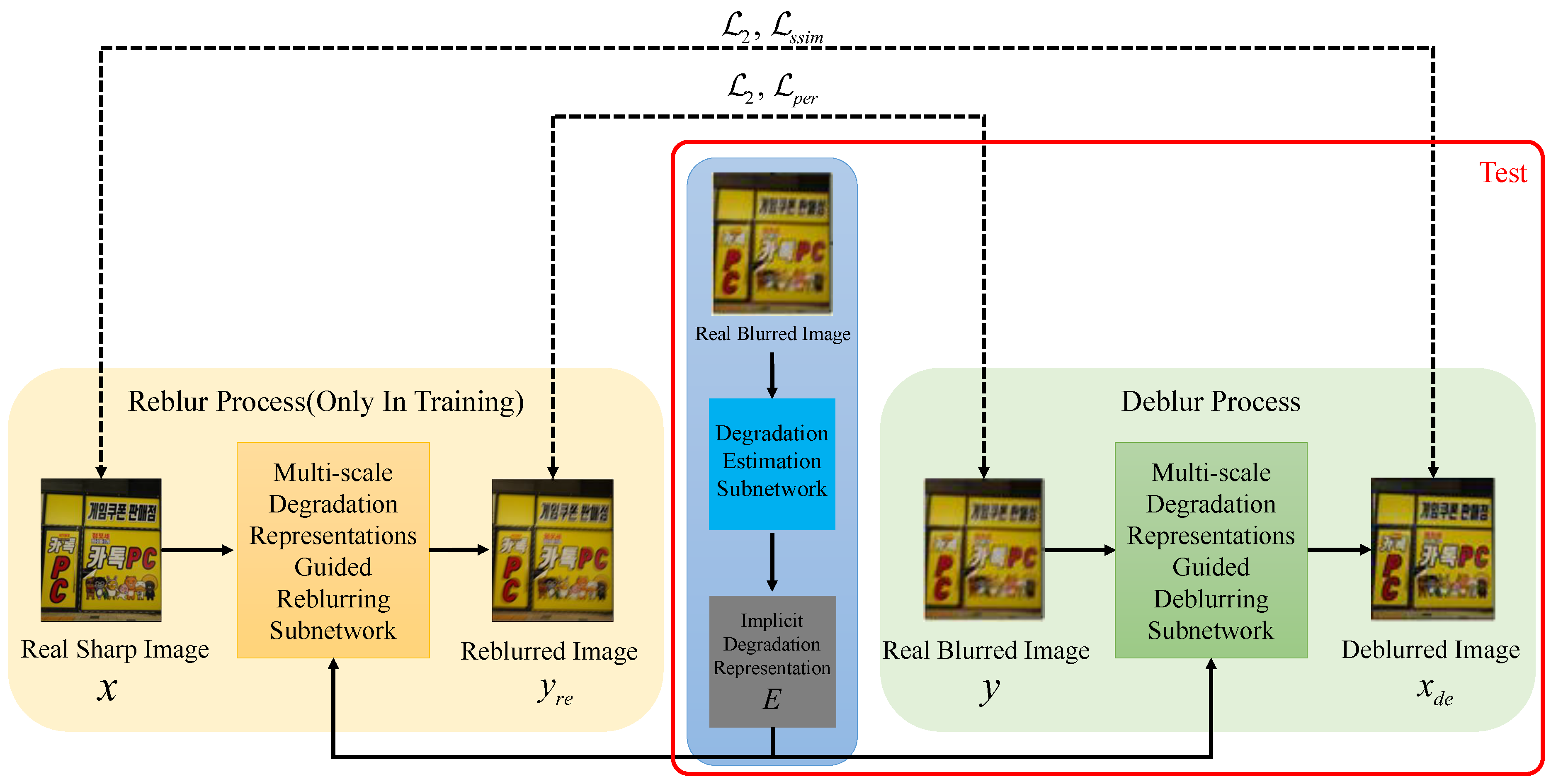
- We propose an implicit degradation representation and reblur estimation network called . The network learns and estimates implicit degradation representations in real images by reblurring sharp images (generating a reblurred image from a real sharp image that resembles a real blurred image). The degradation representations are then used to guide the deblurring process for better reconstruction. Estimating and using the degradation representations in this way has two advantages: (1) there is no need to model the complex degradation process in the real blurred image; and (2) the degradation representations estimated in a learning way can be adapted to the blurring in different images.
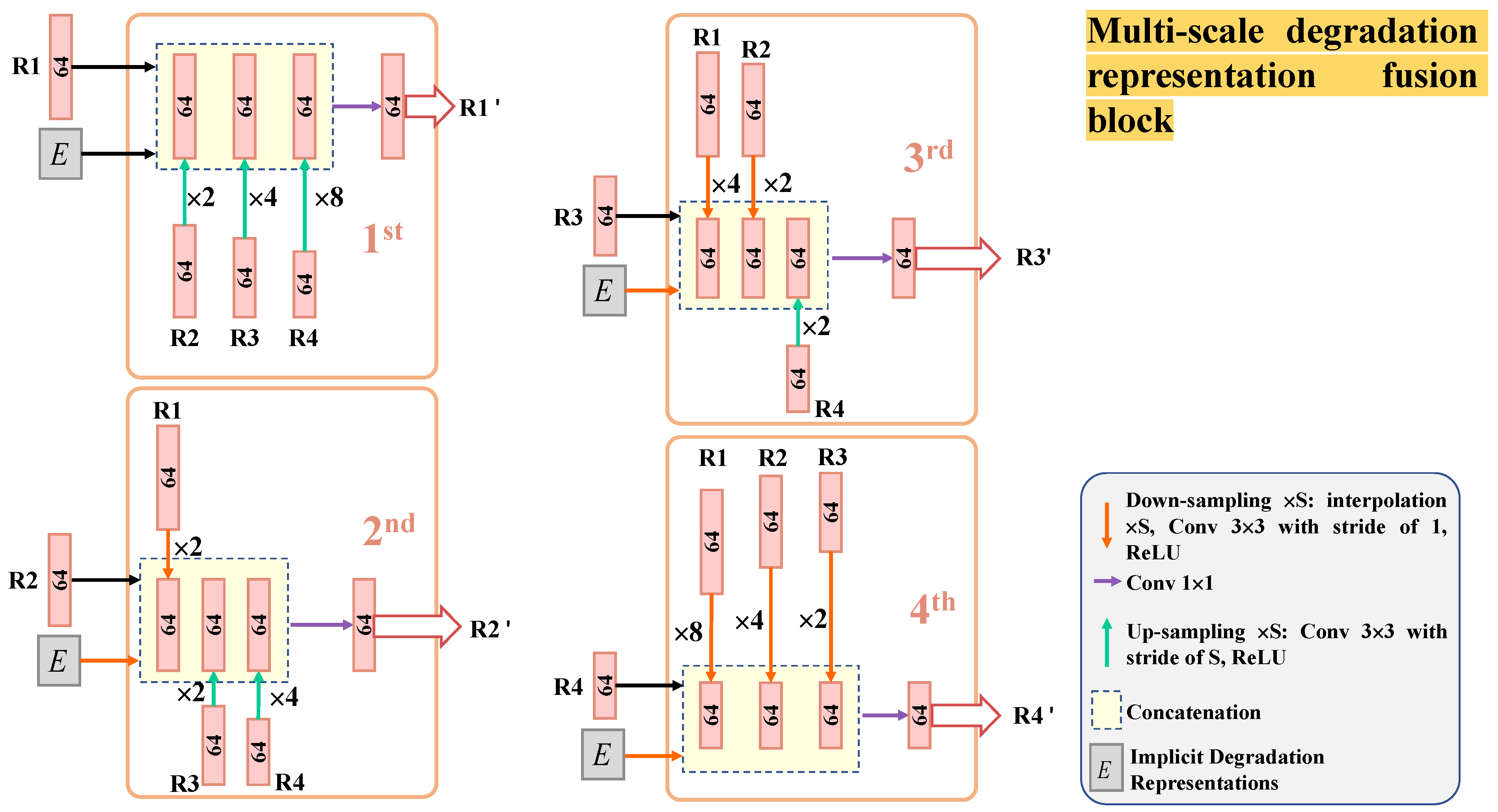
- In terms of network structure, in order to fully utilize the degradation representations, we designed a multi-scale degradation representation fusion module, which is integrated into the reblurring subnetwork and deblurring subnetwork, and is used both for training and testing. We also conduct an ablation study to demonstrate the effectiveness of implicit representation estimation. Our results show that our network achieves stable and efficient outcomes on multiple datasets.
2. Related Work
2.1. Blind Image Deblurring
2.2. Reblur to Deblur and Degradation Estimation
3. Proposed Method
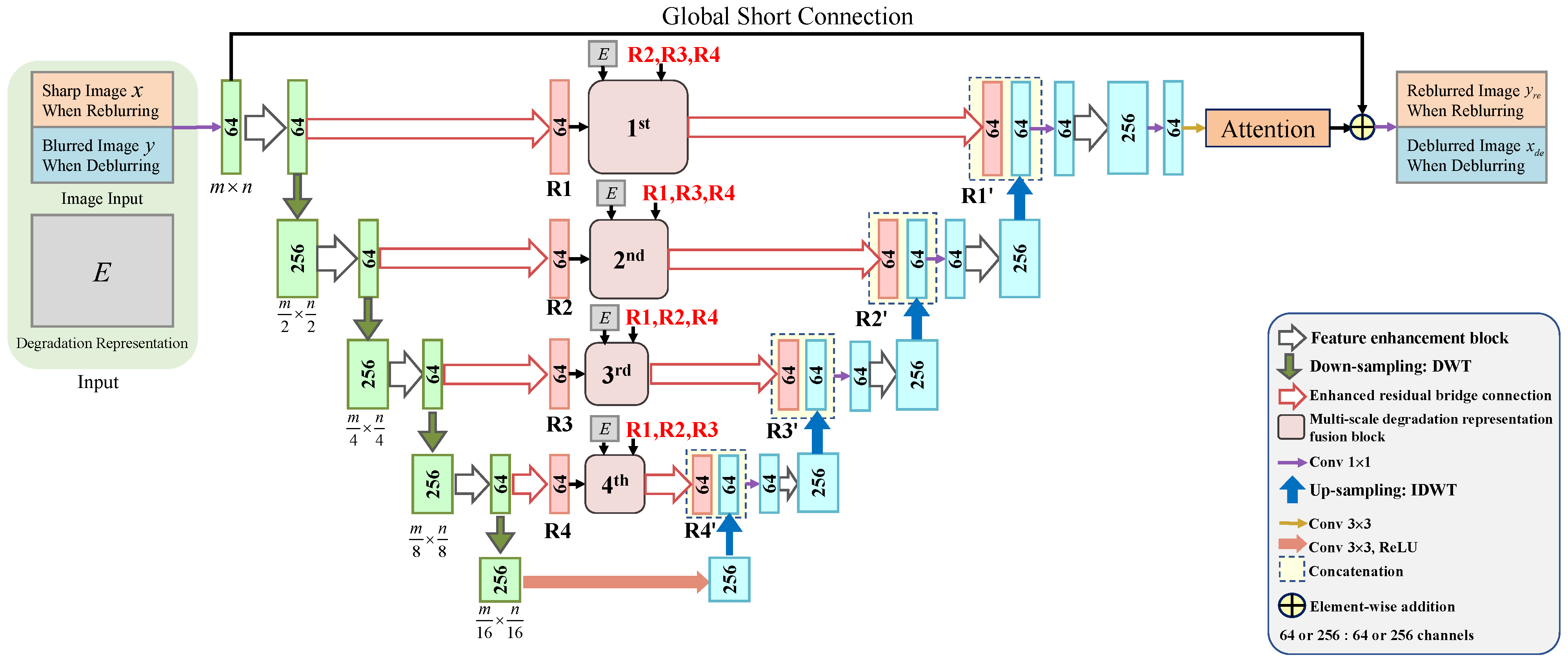
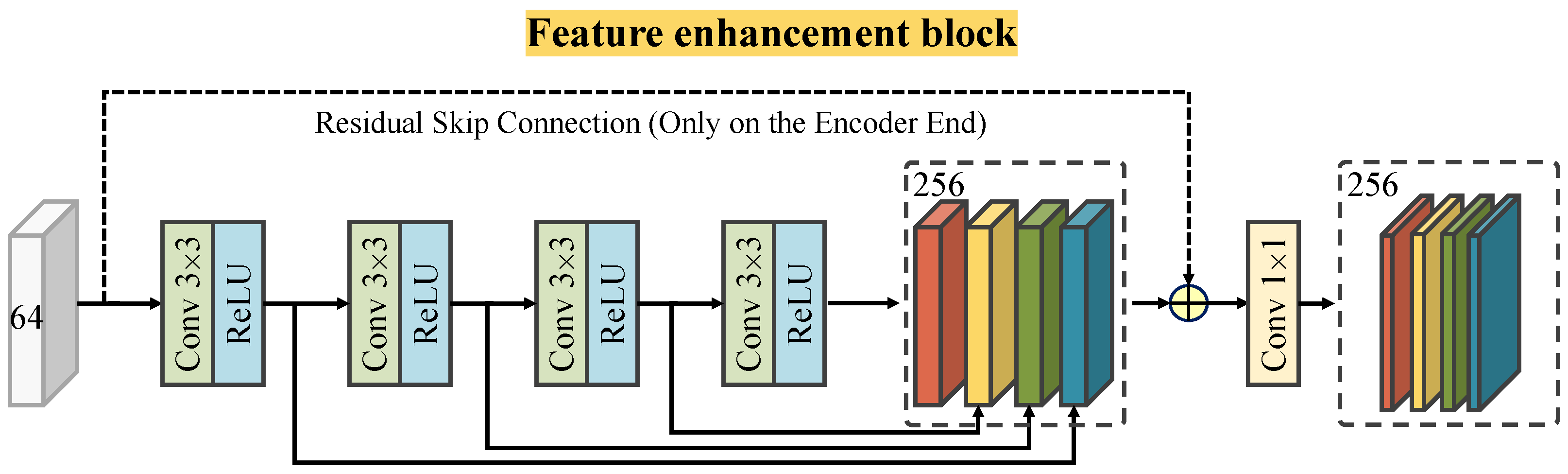
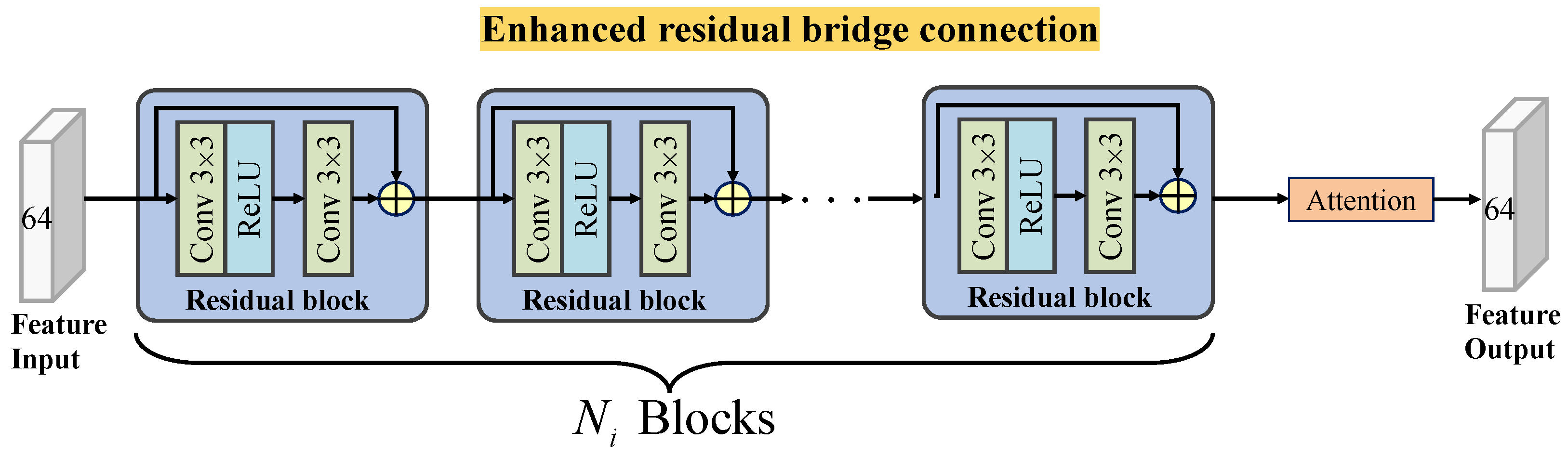
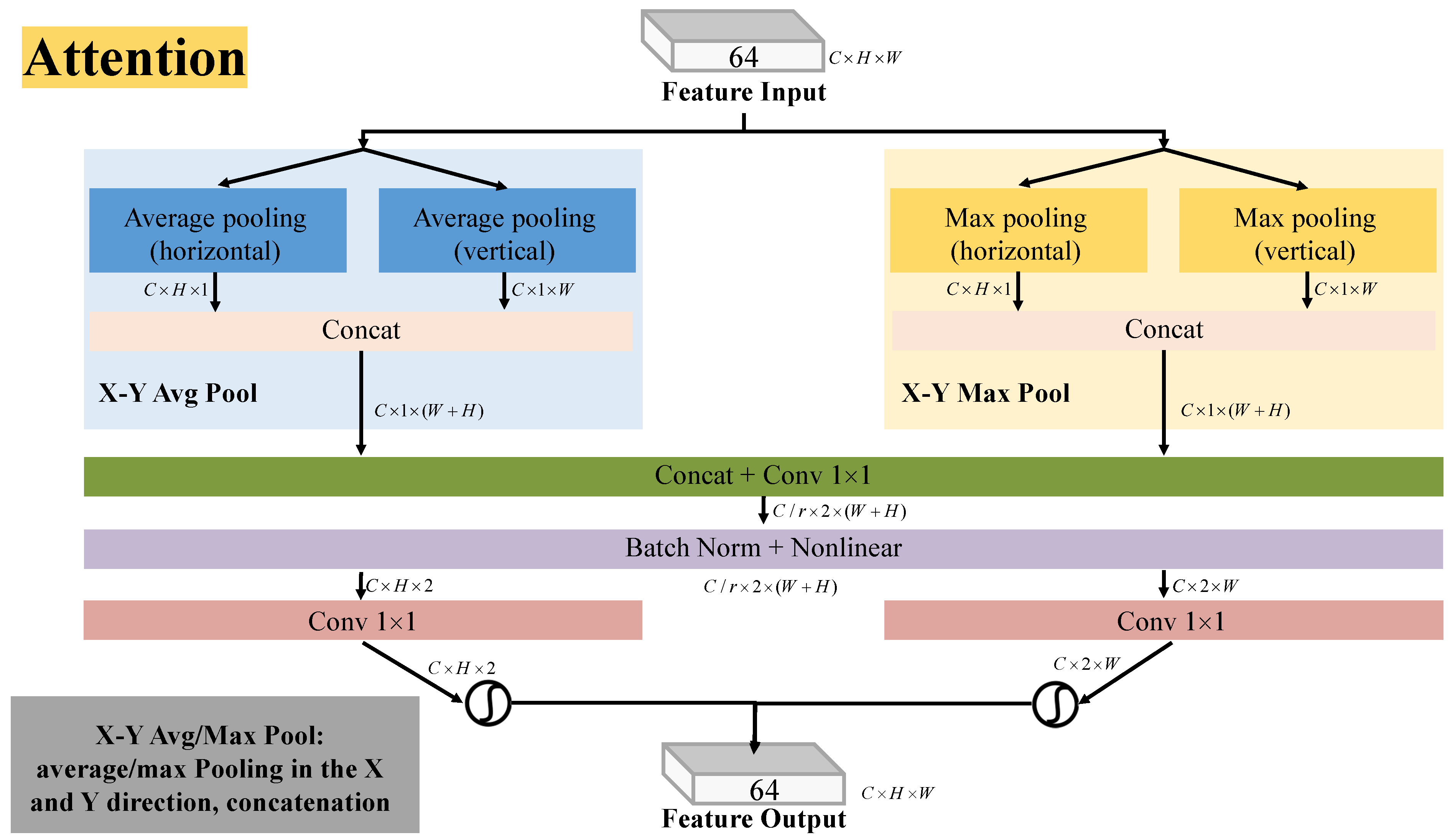
3.1. Network Structure
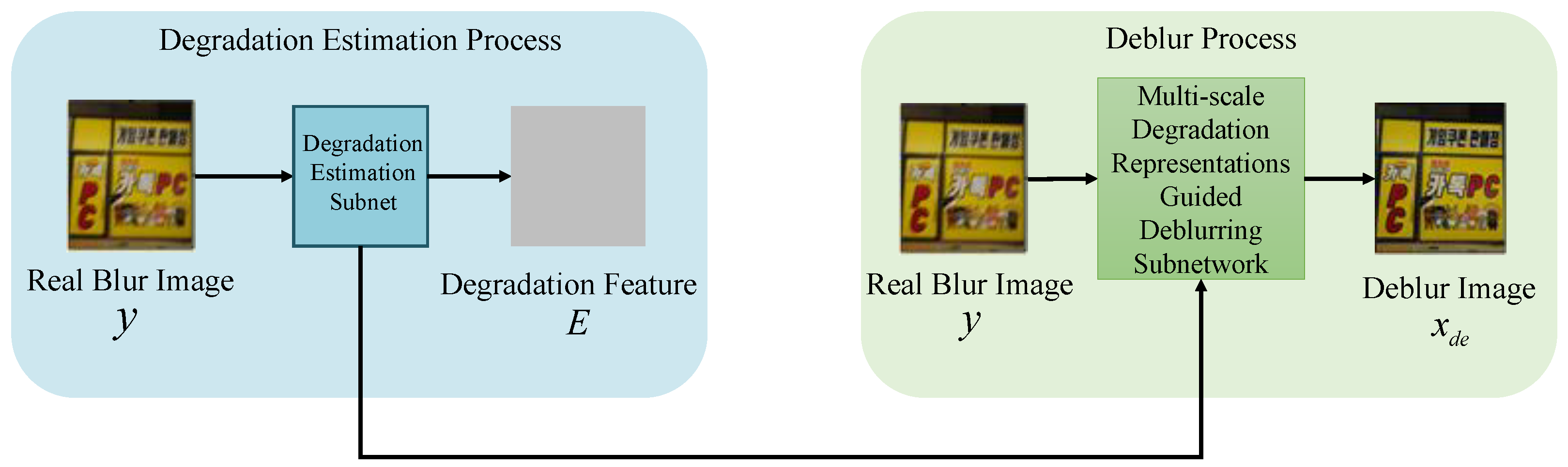
3.2. Degradation Estimation Subnetwork
3.3. Multi-Scale Degradation-Representation-Guided Deblurring (Reblurring) Subnetwork
| Algorithm 1: The Overall Process of | |||
| Data: Real Blurred Image y and the corresponding Real Sharp Image x | |||
| Result: Reblurred image and deblurred image | |||
| 1 | Initialization: Set learning rate, batch size and hyperparameters of the Adam | ||
| solver; Cropping images from datasets; | |||
| 2 | while Training do | ||
| 3 | Expand and Crop the real blurred image y and corresponding sharp image x | ||
| from the training dataset——Gopro; | |||
| 4 | Obtain the implicit degradation representations E using the degradation | ||
| estimation network in Figure 2; | |||
| 5 | Input x and E into multi-scale reblurring subnetwork in Figure 7 to obtain | ||
| reblurred image ; | |||
| 6 | Calculate using Equation (7); | ||
| 7 | Input y and E into multi-scale deblurring subnetwork in Figure 7 to obtain | ||
| deblurred image ; | |||
| 8 | Calculate using Equation (9); | ||
| 9 | Evaluate total loss using Equation (11); | ||
| 10 | Back propagation and update the network parameters; | ||
| 11 | end | ||
| 12 | Obtain the reblurred image and deblurred image ; | ||
| 13 | Obtain the test image pairs from the test dataset——RWBI or RealBlur; | ||
| 14 | while Testing do | ||
| 15 | Extract the real blurred image y from the testing dataset; | ||
| 16 | Obtain the implicit degradation representations E using the degradation | ||
| estimation network in Figure 2; | |||
| 17 | Input y and E into multi-scale deblurring subnetwork in Figure 7 to obtain | ||
| deblurred image ; | |||
| 18 | end | ||
3.4. Loss Function
4. Experiments
4.1. Datasets
4.2. Training Settings
5. Results and Analysis
5.1. Real Image Deblurring
5.2. Network Complexity Analysis
5.3. Ablation Study
5.3.1. Validation of the Effectiveness of Implicit Degradation Representations-Guided Reconstruction
5.3.2. Validation of Reblurring Process
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, K.; Ren, W.; Luo, W.; Lai, W.S.; Stenger, B.; Yang, M.H.; Li, H. Deep image deblurring: A survey. Int. J. Comput. Vis. 2022, 130, 2103–2130. [Google Scholar] [CrossRef]
- Michaeli, T.; Irani, M. Blind deblurring using internal patch recurrence. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part III 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 783–798. [Google Scholar]
- Krishnan, D.; Fergus, R. Fast image deconvolution using hyper-Laplacian priors. In Proceedings of the 22nd International Conference on Neural Information Processing Systems (NIPS’ 09), Vancouver, BC, Canada, 7–10 December 2009; Curran Associates Inc.: Red Hook, NY, USA, 2009; pp. 1033–1041. [Google Scholar]
- Fergus, R.; Singh, B.; Hertzmann, A.; Roweis, S.T.; Freeman, W.T. Removing camera shake from a single photograph. In Acm Siggraph 2006 Papers; ACM: New York, NY, USA, 2006; pp. 787–794. [Google Scholar]
- Chan, T.F.; Wong, C.K. Total variation blind deconvolution. IEEE Trans. Image Process. 1998, 7, 370–375. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, L.; Zheng, S.; Jia, J. Unnatural l0 sparse representation for natural image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1107–1114. [Google Scholar]
- Cho, S.; Lee, S. Fast Motion Deblurring. ACM Trans. Graph. 2009, 28, 145:1–145:8. [Google Scholar] [CrossRef]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8174–8182. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Schuler, C.J.; Hirsch, M.; Harmeling, S.; Schölkopf, B. Learning to Deblur. arXiv 2014, arXiv:1406.7444. [Google Scholar] [CrossRef] [PubMed]
- Hradiš, M.; Kotera, J.; Zemčík, P.; Šroubek, F. Convolutional Neural Networks for Direct Text Deblurring. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; Xie, X., Jones, M.W., Tam, G.K.L., Eds.; BMVA Press: Durham, UK, 2015; pp. 6.1–6.13. [Google Scholar] [CrossRef] [Green Version]
- Ren, D.; Zhang, K.; Wang, Q.; Hu, Q.; Zuo, W. Neural Blind Deconvolution Using Deep Priors. arXiv 2020, arXiv:1908.02197. [Google Scholar]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a Convolutional Neural Network for Non-uniform Motion Blur Removal. arXiv 2015, arXiv:1503.00593. [Google Scholar]
- Chakrabarti, A. A Neural Approach to Blind Motion Deblurring. arXiv 2016, arXiv:1603.04771. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Nimisha, T.M.; Kumar Singh, A.; Rajagopalan, A.N. Blur-invariant deep learning for blind-deblurring. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4752–4760. [Google Scholar]
- Lu, B.; Chen, J.C.; Chellappa, R. Unsupervised Domain-Specific Deblurring via Disentangled Representations. arXiv 2019, arXiv:1903.01594. [Google Scholar]
- Gao, H.; Tao, X.; Shen, X.; Jia, J. Dynamic scene deblurring with parameter selective sharing and nested skip connections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3848–3856. [Google Scholar]
- Shen, Z.; Lai, W.S.; Xu, T.; Kautz, J.; Yang, M.H. Deep semantic face deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8260–8269. [Google Scholar]
- Hu, Z.; Cho, S.; Wang, J.; Yang, M.H. Deblurring low-light images with light streaks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3382–3389. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Dong, W.; Wang, P.; Yin, W.; Shi, G.; Wu, F.; Lu, X. Denoising prior driven deep neural network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2305–2318. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhai, S.; Ren, C.; Wang, Z.; He, X.; Qing, L. An effective deep network using target vector update modules for image restoration. Pattern Recognit. 2022, 122, 108333. [Google Scholar] [CrossRef]
- Qin, M.; Ren, C.; Yang, H.; He, X.; Wang, Z. Blind Image Denoising via Deep Unfolding Network with Degradation Information Guidance. IEEE Trans. Circuits Syst. II Express Briefs 2023. [Google Scholar] [CrossRef]
- Li, D.; Zhang, Y.; Cheung, K.C.; Wang, X.; Qin, H.; Li, H. Learning Degradation Representations for Image Deblurring. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XVIII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 736–753. [Google Scholar]
- Cannon, M. Blind deconvolution of spatially invariant image blurs with phase. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 58–63. [Google Scholar] [CrossRef]
- Kundur, D.; Hatzinakos, D. Blind image deconvolution. IEEE Signal Process. Mag. 1996, 13, 43–64. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Jia, J. Two-phase kernel estimation for robust motion deblurring. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Proceedings, Part I 11. Springer: Berlin/Heidelberg, Germany, 2010; pp. 157–170. [Google Scholar]
- Bahat, Y.; Efrat, N.; Irani, M. Non-uniform blind deblurring by reblurring. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3286–3294. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Stenger, B.; Liu, W.; Li, H. Deblurring by realistic blurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2737–2746. [Google Scholar]
- Chen, H.; Gu, J.; Gallo, O.; Liu, M.Y.; Veeraraghavan, A.; Kautz, J. Reblur2deblur: Deblurring videos via self-supervised learning. In Proceedings of the 2018 IEEE International Conference on Computational Photography (ICCP), Pittsburgh, PA, USA, 4–6 May 2018; pp. 1–9. [Google Scholar]
- Wang, L.; Wang, Y.; Dong, X.; Xu, Q.; Yang, J.; An, W.; Guo, Y. Unsupervised degradation representation learning for blind super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10581–10590. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the IEEE Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Rim, J.; Lee, H.; Won, J.; Cho, S. Real-world blur dataset for learning and benchmarking deblurring algorithms. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 184–201. [Google Scholar]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Blind image deblurring using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1628–1636. [Google Scholar]
- Zhang, J.; Pan, J.; Ren, J.; Song, Y.; Bao, L.; Lau, R.W.; Yang, M.H. Dynamic scene deblurring using spatially variant recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2521–2529. [Google Scholar]
- Zhang, H.; Dai, Y.; Li, H.; Koniusz, P. Deep stacked hierarchical multi-patch network for image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5978–5986. [Google Scholar]
- Cho, S.J.; Ji, S.W.; Hong, J.P.; Jung, S.W.; Ko, S.J. Rethinking coarse-to-fine approach in single image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 4641–4650. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Liu, M.; Yu, Y.; Li, Y.; Ji, Z.; Chen, W.; Peng, Y. Lightweight MIMO-WNet for single image deblurring. Neurocomputing 2023, 516, 106–114. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Method | RealBlur-J | RealBlur-R | ||
|---|---|---|---|---|---|
| PSNR (dB) | SSIM | PSNR (dB) | SSIM | ||
| Traditional | Xu et al. [6] | 27.14 | 0.830 | 34.46 | 0.937 |
| Hu et al. [21] | 26.41 | 0.803 | 33.67 | 0.916 | |
| Pan et al. [38] | 27.22 | 0.790 | 34.01 | 0.917 | |
| Deep-Learning-Based | SRN [9] | 28.56 | 0.867 | 35.66 | 0.947 |
| SVRNN [39] | 27.80 | 0.847 | 35.48 | 0.945 | |
| DeepDeblur [8] | 27.87 | 0.827 | 32.51 | 0.841 | |
| DeblurGAN [10] | 27.97 | 0.834 | 33.79 | 0.903 | |
| DMPHN [40] | 28.42 | 0.860 | 35.70 | 0.948 | |
| DeblurGAN-V2 [16] | 28.70 | 0.867 | 35.26 | 0.944 | |
| DBGAN [31] | 24.93 | 0.745 | 33.78 | 0.909 | |
| MIMO-Unet [41] | 27.76 | 0.836 | 35.47 | 0.946 | |
| MIMO-Unet+ [41] | 27.63 | 0.837 | 35.54 | 0.947 | |
| MPRNet [42] | 28.70 | 0.873 | 35.99 | 0.952 | |
| Lightweight MIMO-WNet [43] | 28.52 | 0.865 | 35.76 | 0.950 | |
| (Ours) | 28.81 | 0.876 | 35.96 | 0.952 | |
| Methods | Parameters | FLOPs | Time | RealBlur-J | |
|---|---|---|---|---|---|
| PSNR (dB) | SSIM | ||||
| DMPHN [40] | 21.7 M | 678.56 G | 0.034 s | 28.42 | 0.86 |
| DeblurGAN-v2 [16] | 60.9 M | 411.34 G | 0.082 s | 28.7 | 0.867 |
| DBGAN [31] | 11.6 M | 660.20 G | 0.084 s | 24.93 | 0.745 |
| MIMO-Unet+ [41] | 16.1 M | 154.24 G | 0.032 s | 27.63 | 0.837 |
| MPRNet [42] | 20.1 M | 760.11 G | 0.077 s | 28.7 | 0.876 |
| Lightweight MIMO-WNet [43] | 14.1 M | 138.81 G | 0.028 s | 28.52 | 0.865 |
| (Ours) Training | 13.4 M | 317.91 G | - | - | - |
| (Ours) Testing | 7.5 M | 169.78 G | 0.012 s | 28.81 | 0.876 |
| Network Framework | RealBlur-J | |
|---|---|---|
| PSNR (dB) | SSIM | |
| -Q | 28.4 | 0.863 |
| -R | 28.64 | 0.87 |
| 28.81 | 0.875 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Z.; Qin, M.; Gou, H.; Wang, Z.; Ren, C. Real Image Deblurring Based on Implicit Degradation Representations and Reblur Estimation. Appl. Sci. 2023, 13, 7738. https://doi.org/10.3390/app13137738
Zhao Z, Qin M, Gou H, Wang Z, Ren C. Real Image Deblurring Based on Implicit Degradation Representations and Reblur Estimation. Applied Sciences. 2023; 13(13):7738. https://doi.org/10.3390/app13137738
Chicago/Turabian StyleZhao, Zihe, Man Qin, Haosong Gou, Zhengyong Wang, and Chao Ren. 2023. "Real Image Deblurring Based on Implicit Degradation Representations and Reblur Estimation" Applied Sciences 13, no. 13: 7738. https://doi.org/10.3390/app13137738