

Improved Detector Based on Yolov5 for Typical Targets on the Sea Surfaces
Abstract
:1. Introduction
2. Data and Methodology
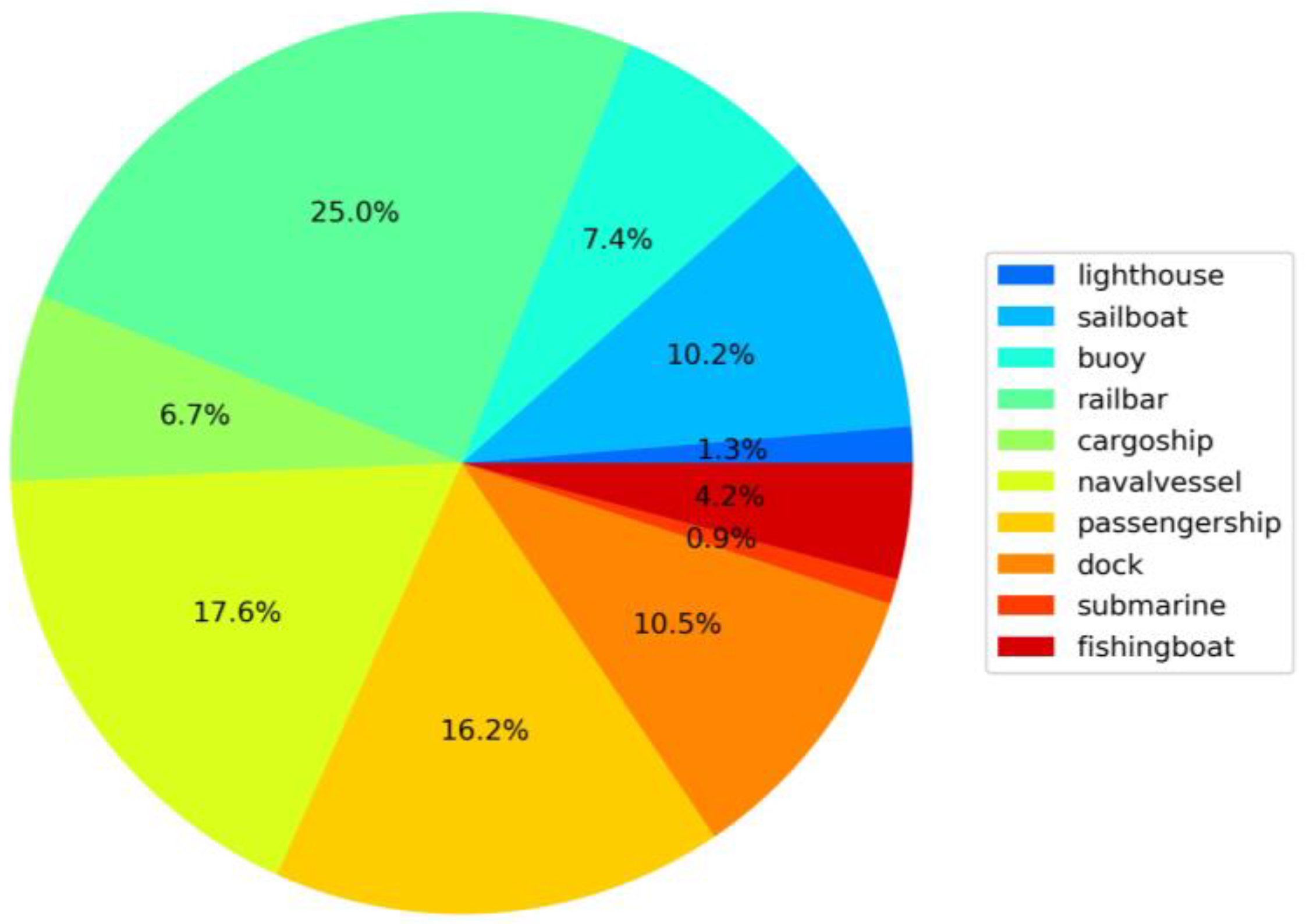
2.1. Description of the Maritime Target Dataset
2.2. Selected Model and Improvements
2.3. Tricks of Data Augmentation
2.4. Improvement in Loss Function
3. Results and Discussions
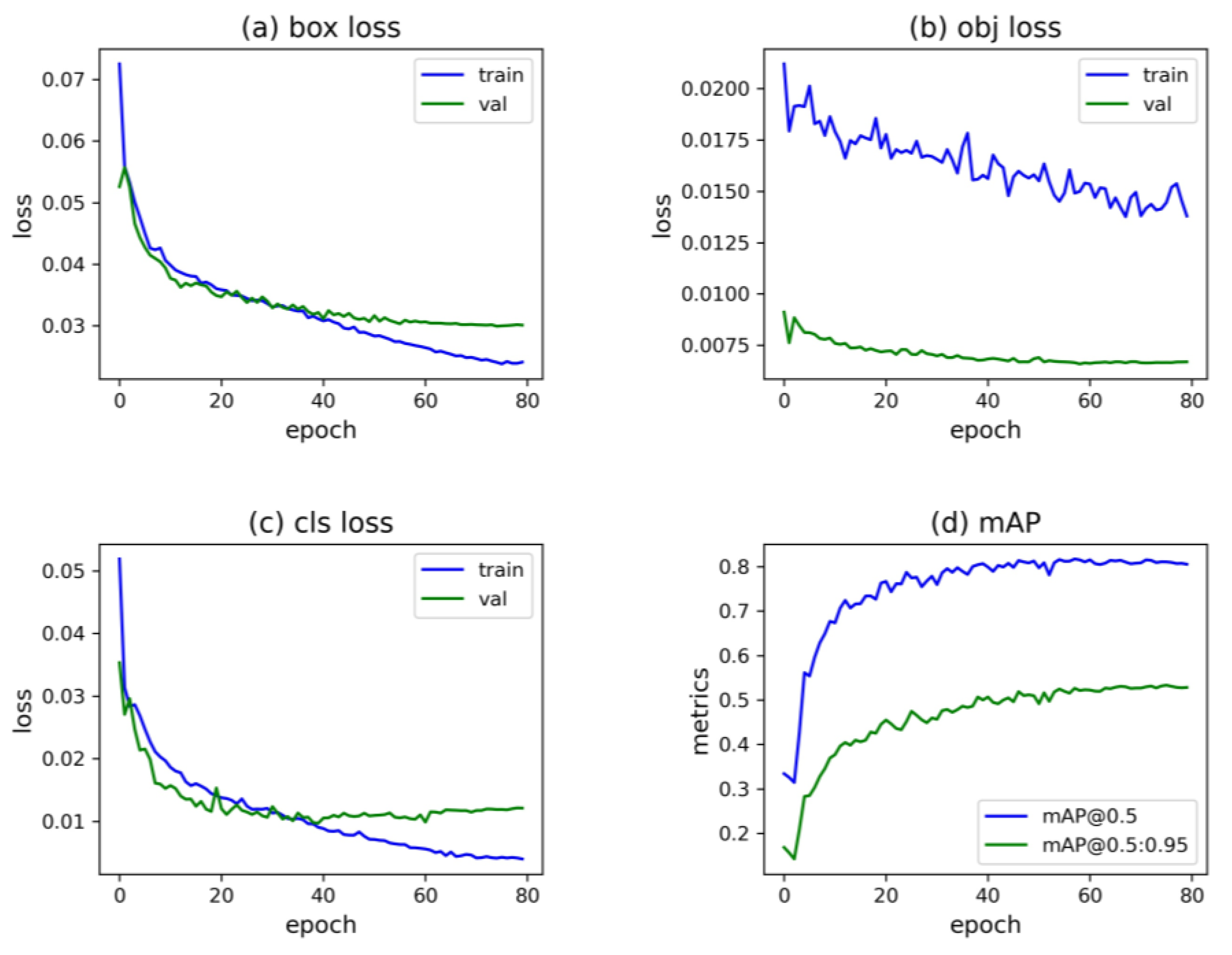
3.1. Setup of Experiments and Evaluation Metrics
3.2. Results of the Baseline Models
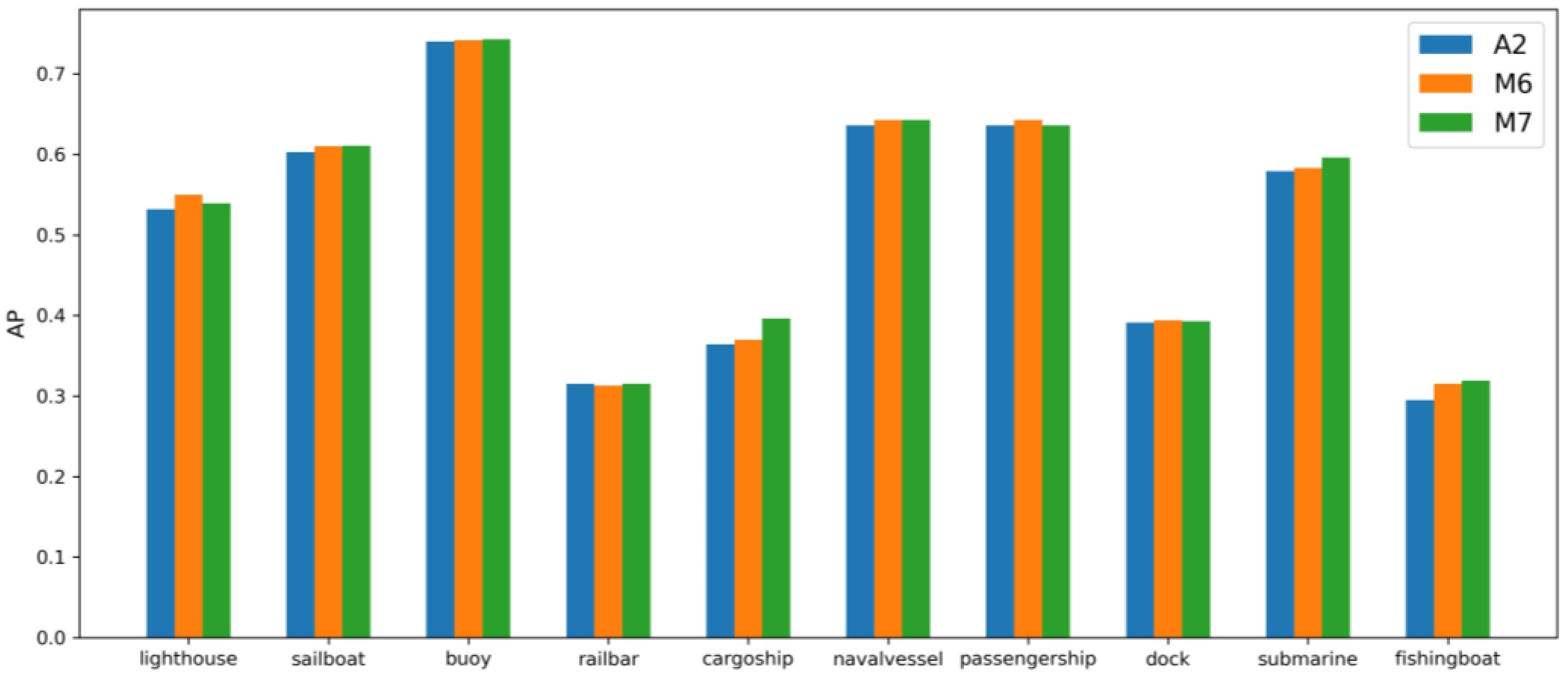
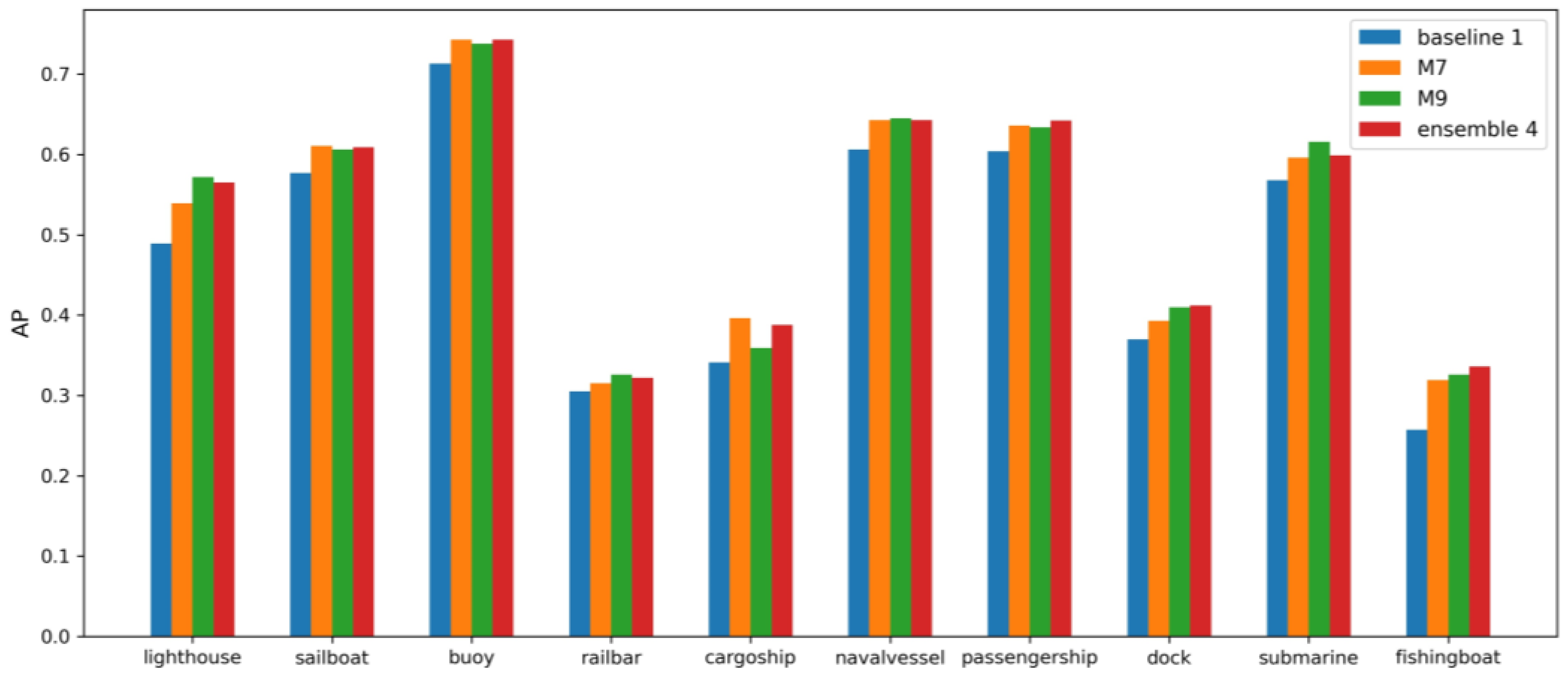
3.3. Ablation Tests with Data Augmentation
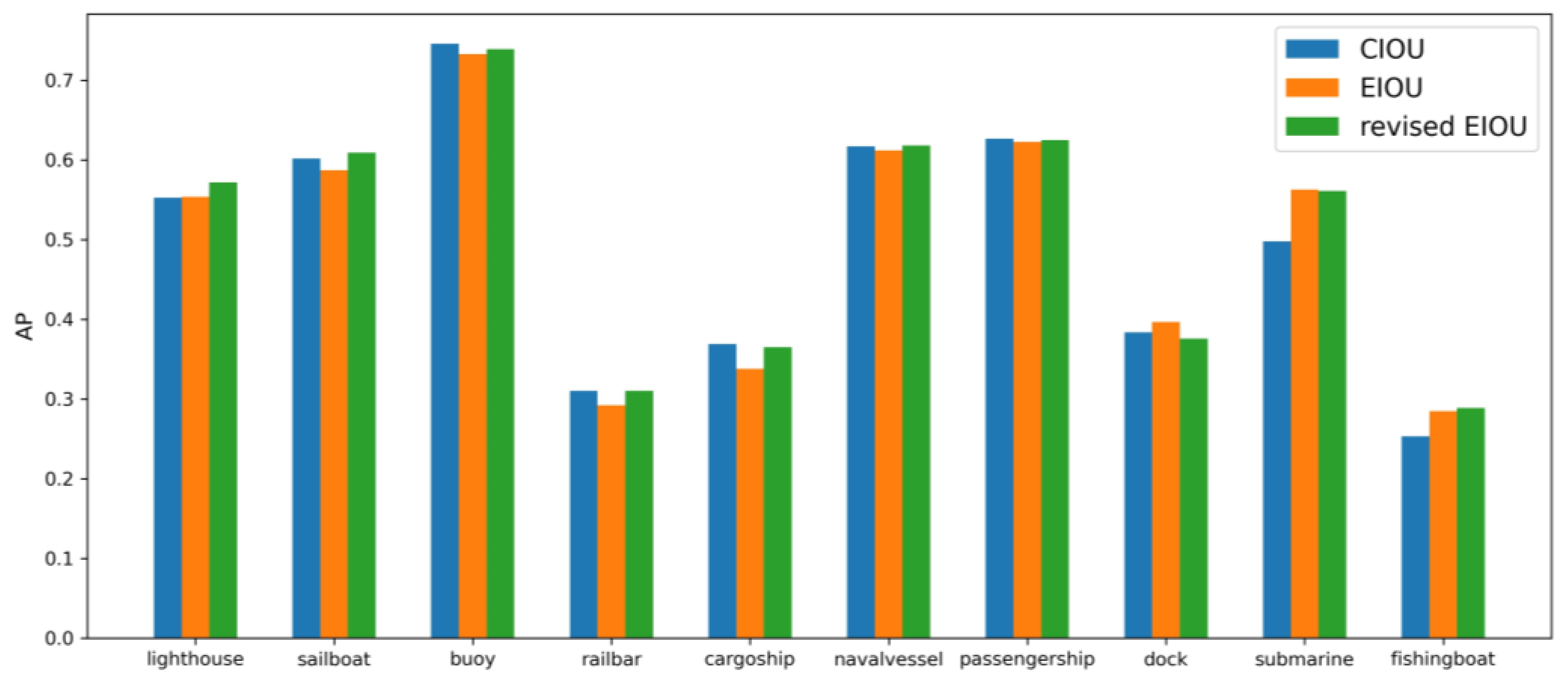
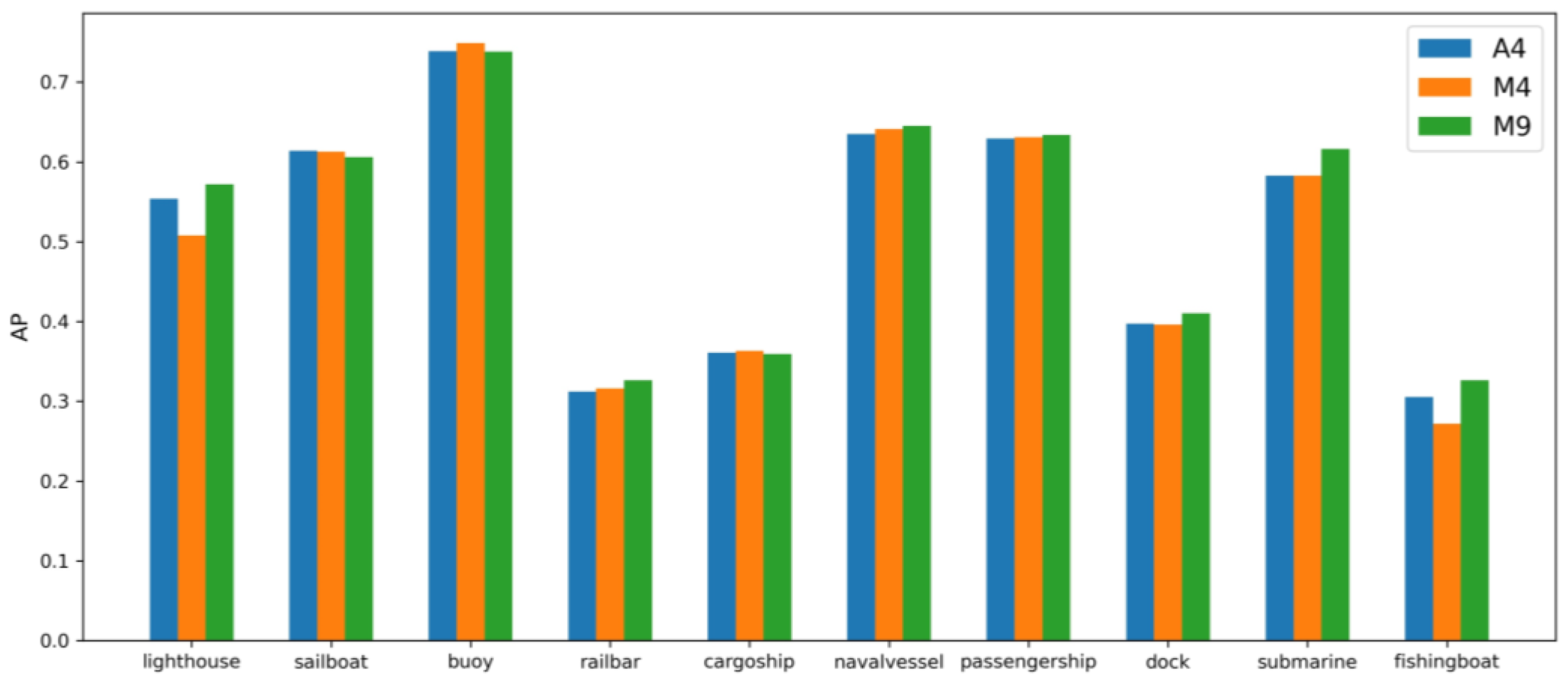
3.4. Ablation Tests with the Adapted Loss Function
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Er, M.J.; Zhang, Y.; Chen, J.; Gao, W. Ship detection with deep learning: A survey. Artif. Intell. Rev. 2023, 2023, 1–41. [Google Scholar] [CrossRef]
- He, Y.; Zhu, C.; Wang, J.; Savvides, M.; Zhang, X. Bounding Box Regression With Uncertainty for Accurate Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2883–2892. [Google Scholar]
- Benjumea, A.; Teeti, I.; Cuzzolin, F.; Bradley, A. YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles. arXiv 2021, arXiv:2112.11798. [Google Scholar]
- Zhang, H.; Chang, H.; Ma, B.; Wang, N.; Chen, X. Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training. arXiv 2020, arXiv:2004.06002. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 580–587. [Google Scholar]
- Girshick, R.B. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6154–6162. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 779–788. [Google Scholar]
- Jocher, G. Yolov5. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 September 2022).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.M.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Bashir, S.M.A.; Khan, M.; Ullah, Q.; Wang, R.; Song, Y.; Guo, Z.; Niu, Y. Remote Sensing Image Super-resolution and Object Detection: Benchmark and State of the Art. Expert. Syst. Appl. 2021, 197, 116793. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 936–944. [Google Scholar]
- Sun, X.M.; Zhang, Y.J.; Wang, H.H.; Du, Y. Research on ship detection of optical remote sensing image based on Yolo V5. J. Phys. Conf. Ser. 2022, 2215, 012027. [Google Scholar] [CrossRef]
- Zhang, X.; Yan, M.; Zhu, D.; Guan, Y. Marine ship detection and classification based on YOLOv5 model. J. Phys. Conf. Ser. 2022, 2181, 012025. [Google Scholar] [CrossRef]
- Pang, L.; Li, B.; Zhang, F.; Meng, X.; Zhang, L. A Lightweight YOLOv5-MNE Algorithm for SAR Ship Detection. Sensors 2022, 22, 7088. [Google Scholar] [CrossRef] [PubMed]
- Lei, F.; Tang, F.; Li, S. Underwater Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2022, 10, 310. [Google Scholar] [CrossRef]
- Liu, Z.; Zhuang, Y.; Jia, P.; Wu, C.; Xu, H.; Liu, Z. A Novel Underwater Image Enhancement Algorithm and an Improved Underwater Biological Detection Pipeline. J. Mar. Sci. Eng. 2022, 10, 1204. [Google Scholar] [CrossRef]
- Rezatofighi, S.H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.D.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2021, 506, 146–157. [Google Scholar] [CrossRef]
- Peng, C.; Xiao, T.; Li, Z.; Jiang, Y.; Zhang, X.; Jia, K.; Yu, G.; Sun, J. MegDet: A Large Mini-Batch Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6181–6189. [Google Scholar]
- Zhang, Z.; He, T.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Freebies for Training Object Detection Neural Networks. arXiv 2019, arXiv:1902.04103. [Google Scholar]
- Buslaev, A.V.; Parinov, A.; Khvedchenya, E.; Iglovikov, V.I.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. arXiv 2018, arXiv:1809.06839. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tests | Pr | Re | F1 | mAP (%) |
|---|---|---|---|---|
| Baseline 1 | 0.835 | 0.766 | 0.799 | 48.3 |
| Baseline 1 + TTA | 0.849 | 0.76 | 0.802 | 49 |
| Baseline 2 | 0.844 | 0.771 | 0.806 | 49.6 |
| Test | Augmentation Groups | Setting | Pr | Re | mAP (%) |
|---|---|---|---|---|---|
| A1 | A, B, C | Ⅰ | 0.825 | 0.786 | 50.4 |
| A2 | A, B, C | Ⅱ | 0.835 | 0.787 | 50.9 |
| A3 | D, E | Ⅰ | 0.815 | 0.777 | 50.8 |
| A4 | D, E | Ⅱ | 0.826 | 0.797 | 51.3 |
| A5 | C(H), D, E | Ⅰ | 0.813 | 0.784 | 51 |
| A6 | C(H), D, E | Ⅱ | 0.824 | 0.786 | 51.3 |
| A7 | A, B, C, D, E | Ⅰ | 0.843 | 0.767 | 51 |
| A8 | A, B, C, D, E | Ⅱ | 0.823 | 0.796 | 51.6 |
| 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | |
| mAP (%) | 50.5 | 51.0 | 50.9 | 51.0 | 50.2 |
| Test | Loss Function | Augmentation Groups | Additional Techniques | mAP (%) |
|---|---|---|---|---|
| M1 | Setting Ⅰ | 49.8 | ||
| M2 | 50.1 | |||
| M3 | 50.9 | |||
| M4 | D, E | 50.7 | ||
| M5 | A, B, C, D, E | 51.6 | ||
| M6 | A, B, C | 51.6 | ||
| M7 | A, B, C | mixup, label smoothing | 51.9 | |
| M8 | A, B, C, D, E | mixup, label smoothing | 51.4 | |
| M9 | D, E | mixup, label smoothing | 52.3 |
| Test | Ensemble Models | mAP (%) |
|---|---|---|
| Ensemble 1 | (A8, M3) | 51.8 |
| Ensemble 2 | (M4, M6) | 51.5 |
| Ensemble 3 | (M5, M7) | 52.2 |
| Ensemble 4 (proposed method) | (M7, M9) | 52.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, A.; Ding, J.; Liu, J.; Zhou, H.; Zhang, J.; Zhang, P.; Dong, J.; Sun, Z. Improved Detector Based on Yolov5 for Typical Targets on the Sea Surfaces. Appl. Sci. 2023, 13, 7695. https://doi.org/10.3390/app13137695
Sun A, Ding J, Liu J, Zhou H, Zhang J, Zhang P, Dong J, Sun Z. Improved Detector Based on Yolov5 for Typical Targets on the Sea Surfaces. Applied Sciences. 2023; 13(13):7695. https://doi.org/10.3390/app13137695
Chicago/Turabian StyleSun, Anzhu, Jun Ding, Jiarui Liu, Heng Zhou, Jiale Zhang, Peng Zhang, Junwei Dong, and Ze Sun. 2023. "Improved Detector Based on Yolov5 for Typical Targets on the Sea Surfaces" Applied Sciences 13, no. 13: 7695. https://doi.org/10.3390/app13137695