
SliceSamp: A Promising Downsampling Alternative for Retaining Information in a Neural Network

Abstract
:Featured Application
Abstract
1. Introduction
- (1)
- A novel downsampling method based on feature slicing and depthwise separable convolution, SliceSamp, is proposed which is designed to retain all feature information while optimizing computational efficiency.
- (2)
- An upsampling component, SliceUpsamp, is constructed by reconstructing the feature maps from the channel dimension to the spatial dimension, enabling the inverse operation of downsampling.
- (3)
- An ablation study is introduced to evaluate the effectiveness of the key design elements. The proposed method can achieve a better balance between algorithmic complexity and model performance.
- (4)
- Extensive experiments are conducted via various computer vision tasks, including image classification, object detection, and semantic segmentation, based on several benchmark datasets. Our method exhibits significant advantages over classical downsampling methods by replacing the original downsampling layers in different network architectures.
2. Related Works
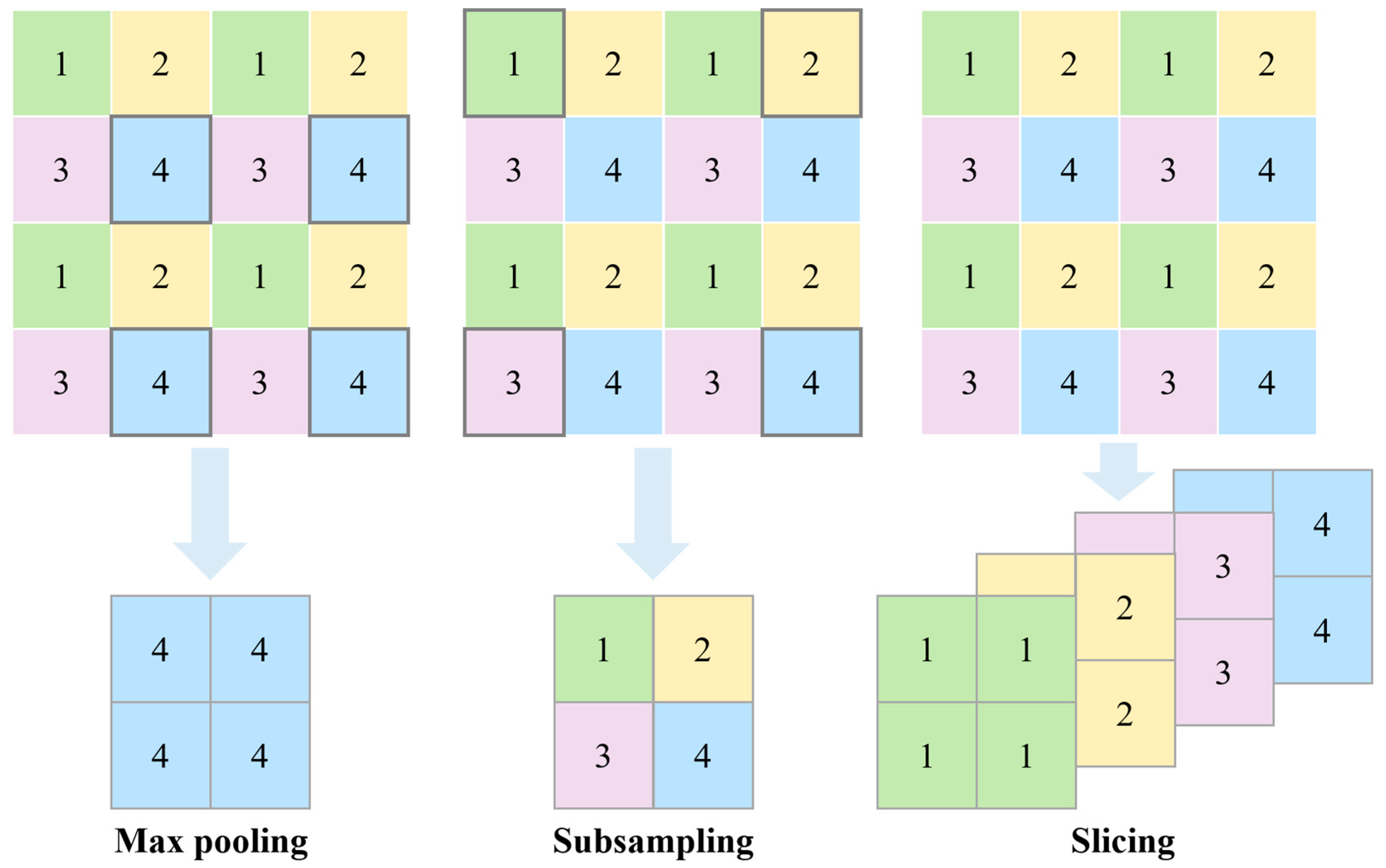
2.1. Downsampling in Neural Networks
2.2. Depthwise Separable Convolution
3. Methods
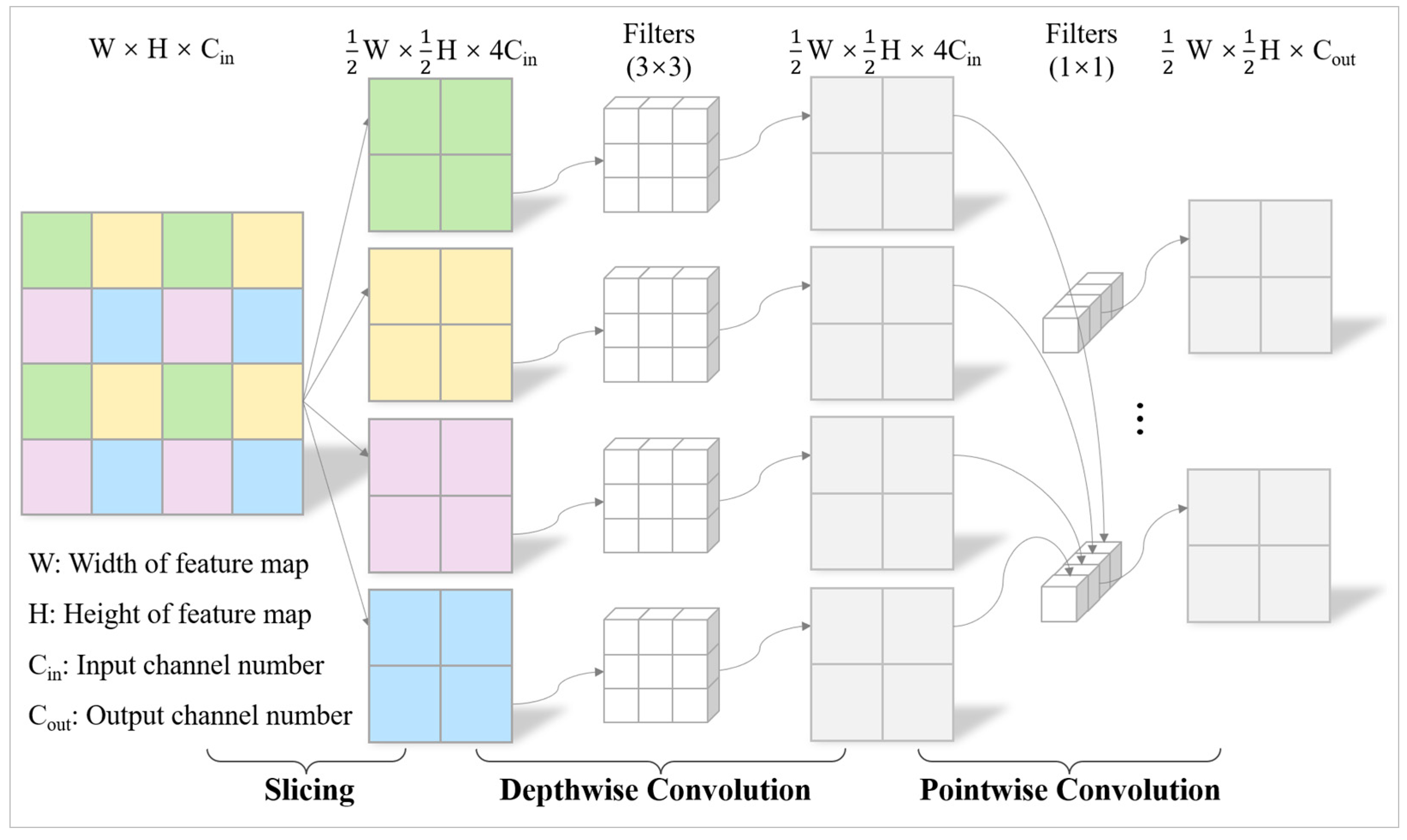
3.1. SliceSamp: The Downsampling Component
| Algorithm 1: output ← SliceSamp (X) |
/* Performs downsampling on input features using the SliceSamp algorithm. */
X [..., ::2, ::2], // Upper-left corner X [..., 1::2, ::2], // Upper-right corner X [..., ::2, 1::2], // Lower-left corner X [..., 1::2, 1::2] // Lower-right corner ] 2. X_concat ← concatenate (x_slice, axis=1) // Merge slices in channel dimension 3. Depthwise_conv ← Wdepthwise * X_ concat + bdepthwise // Depthwise Separable Convolution 4. Depthwise_bn ← BatchNormal (Depthwise_conv) 5. Depthwise_act ← GELU (Depthwise_bn) 6. Pointwise_conv ← Wpointwise * Depthwise_act + bpointwise 7. Pointwise_bn ← BatchNormal (Pointwise_conv) 8. output ← GELU (Pointwise_bn) 9. return output |
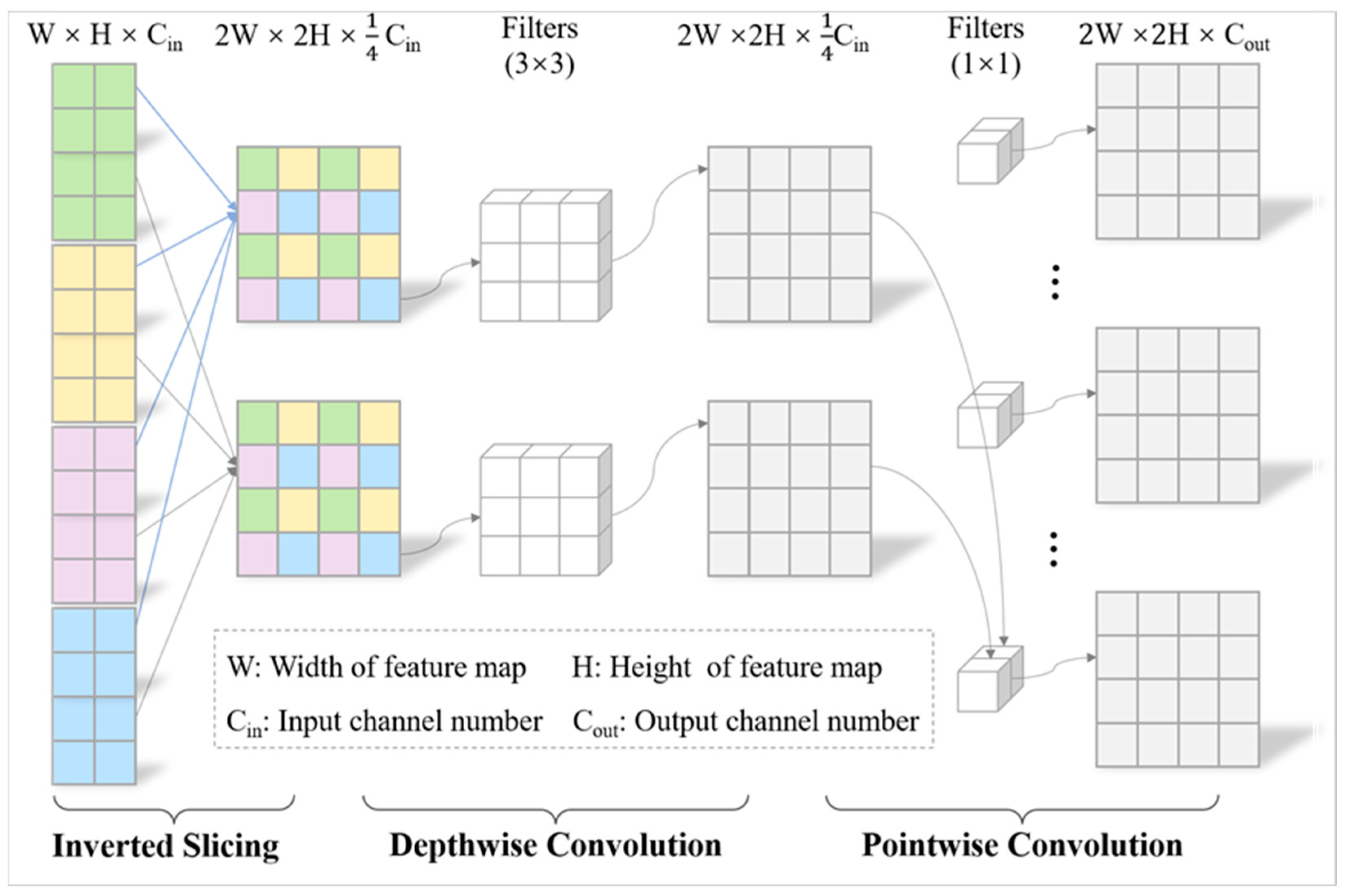
3.2. SliceUpsamp: The Upsampling Component
4. Experiments
4.1. Image Classification on ImageNet-1K
4.1.1. Image Classification Datasets
4.1.2. Experiment Setup
4.1.3. Results and Discussion
4.2. Object Detection on COCO and VOC
4.2.1. Object Detection Datasets
4.2.2. Experiment Setup
4.2.3. Results and Discussion
4.3. Semantic Segmentation on ADE20K
4.3.1. Semantic Segmentation Datasets
4.3.2. Experiment Setup
4.3.3. Results and Discussion
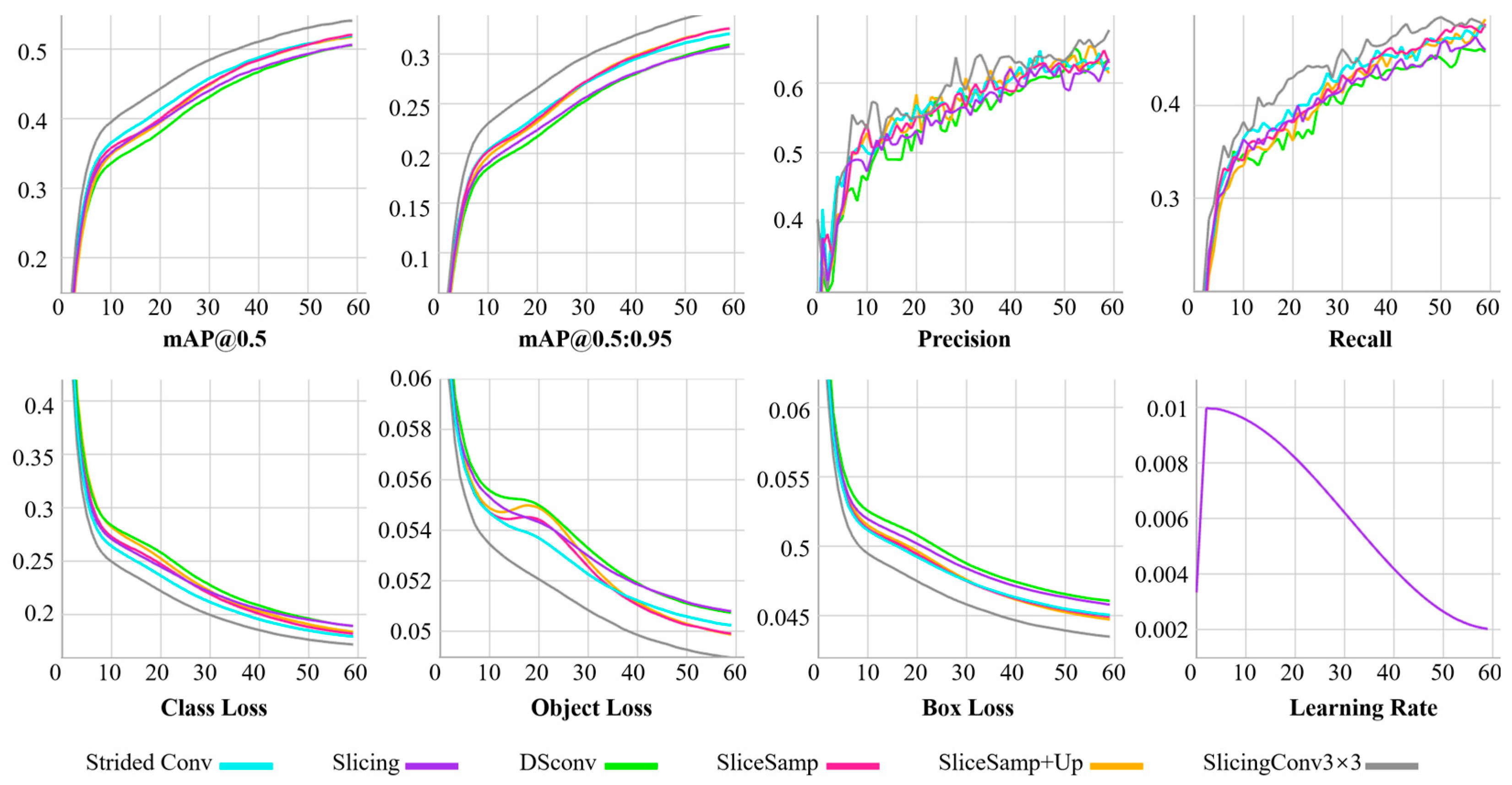
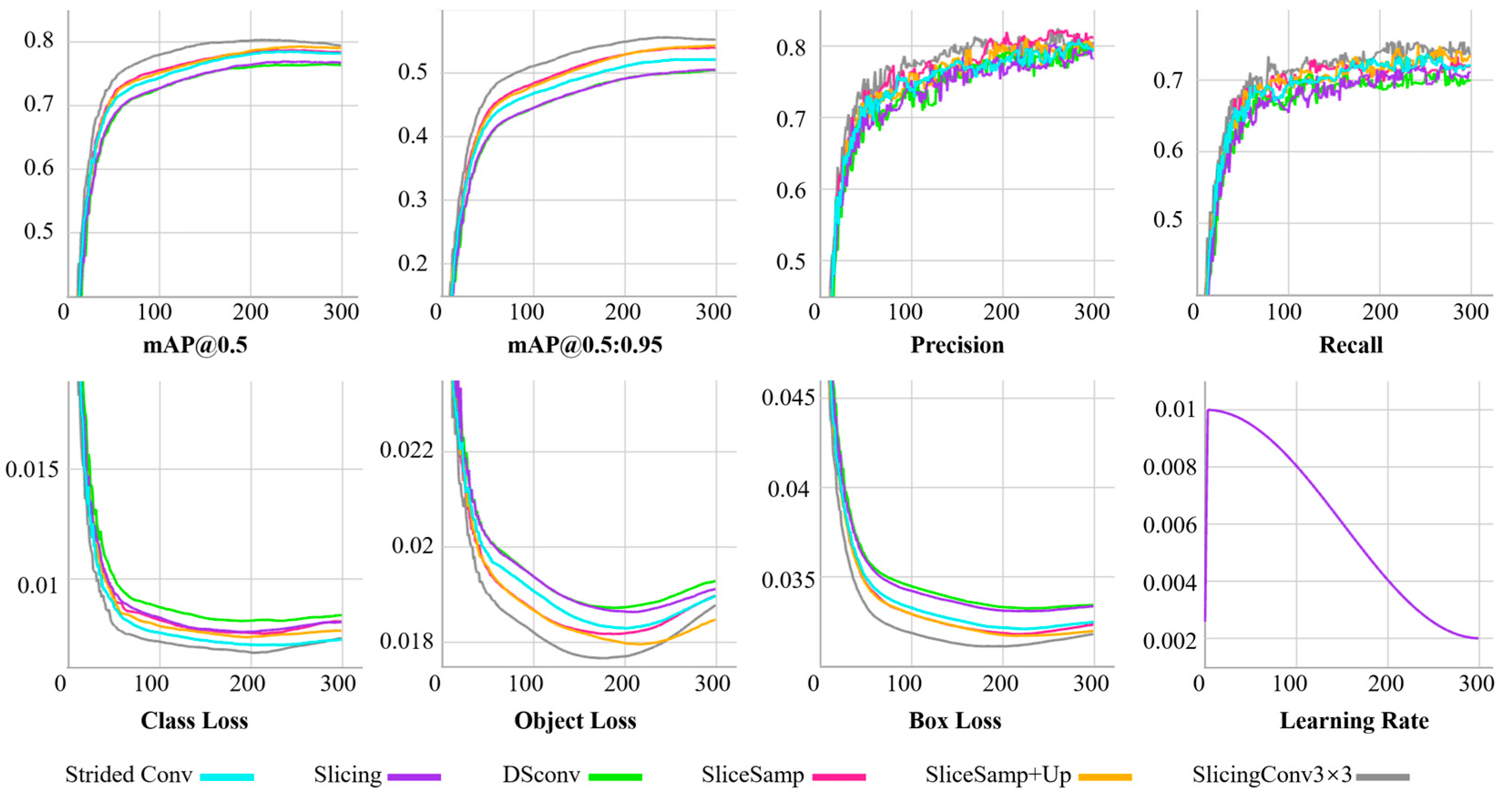
4.4. Ablation Studies
4.4.1. Experiment Setup
4.4.2. Results and Discussion
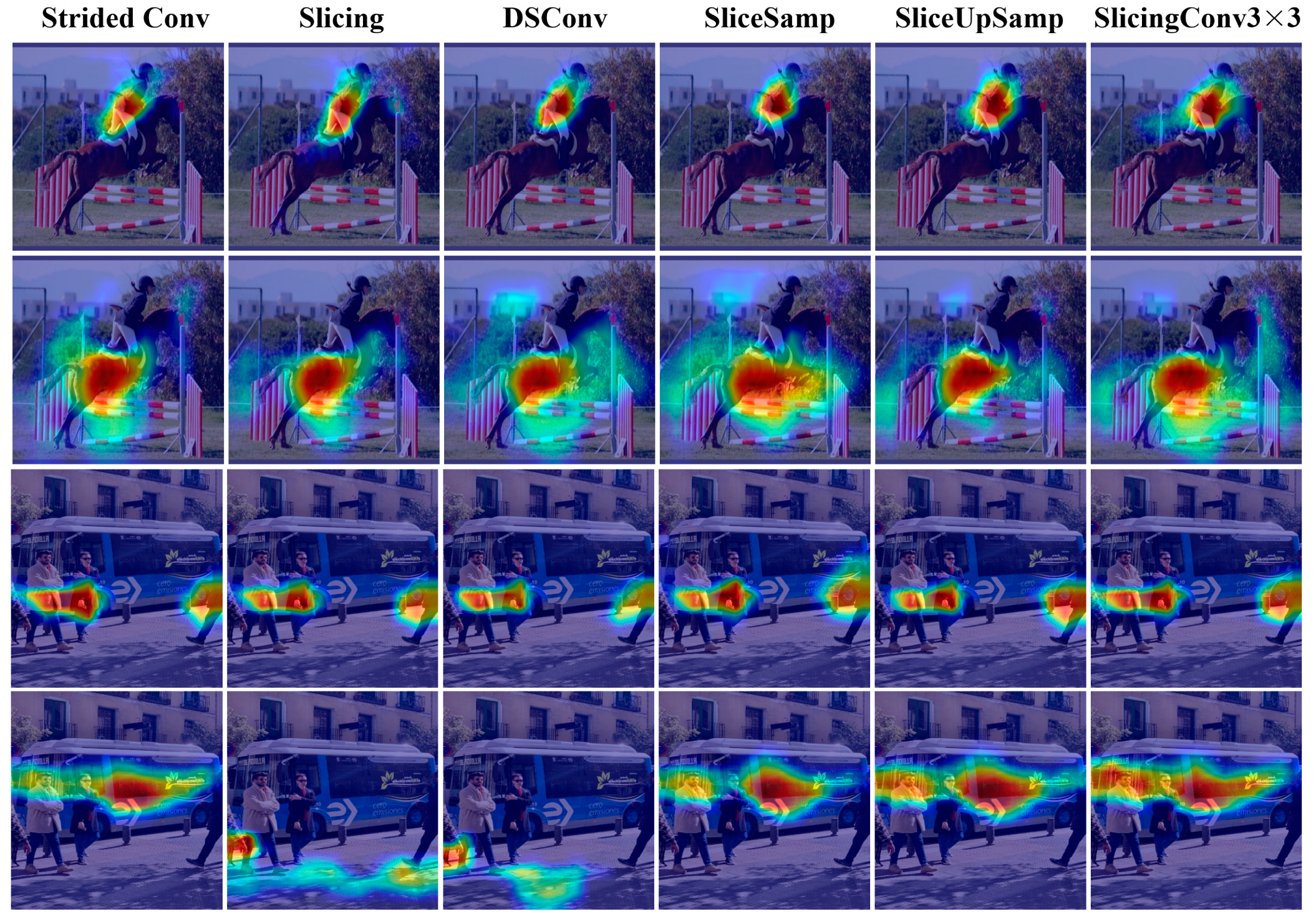
4.4.3. Visual Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. Available online: https://openaccess.thecvf.com/content_iccv_2017/html/He_Mask_R-CNN_ICCV_2017_paper.html (accessed on 20 October 2023).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Sinha, R.K.; Pandey, R.; Pattnaik, R. Deep Learning for Computer Vision Tasks: A review. arXiv 2018, arXiv:1804.03928. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Shen, S.; Li, R.; Zhao, Z.; Liu, Q.; Liang, J.; Zhang, H. Efficient Deep Structure Learning for Resource-Limited IoT Devices. In Proceedings of the GLOBECOM 2020–2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Xie, Y.; Guo, Y.; Mi, Z.; Yang, Y.; Obaidat, M.S. Edge-Assisted Real-Time Instance Segmentation for Resource-Limited IoT Devices. IEEE Internet Things J. 2023, 10, 473–485. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, e7068349. [Google Scholar] [CrossRef] [PubMed]
- Stergiou, A.; Poppe, R. AdaPool: Exponential Adaptive Pooling for Information-Retaining Downsampling. IEEE Trans. Image Process. 2023, 32, 251–266. [Google Scholar] [CrossRef] [PubMed]
- Stergiou, A.; Poppe, R.; Kalliatakis, G. Refining Activation Downsampling with SoftPool. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10357–10366. Available online: https://openaccess.thecvf.com/content/ICCV2021/html/Stergiou_Refining_Activation_Downsampling_With_SoftPool_ICCV_2021_paper.html (accessed on 20 October 2023).
- Zhai, S.; Wu, H.; Kumar, A.; Cheng, Y.; Lu, Y.; Zhang, Z.; Feris, R. S3Pool: Pooling with Stochastic Spatial Sampling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4970–4978. Available online: https://openaccess.thecvf.com/content_cvpr_2017/html/Zhai_S3Pool_Pooling_With_CVPR_2017_paper.html (accessed on 20 October 2023).
- Akhtar, N.; Ragavendran, U. Interpretation of intelligence in CNN-pooling processes: A methodological survey. Neural Comput. Appl. 2020, 32, 879–898. [Google Scholar] [CrossRef]
- Ajani, T.S.; Imoize, A.L.; Atayero, A.A. An Overview of Machine Learning within Embedded and Mobile Devices–Optimizations and Applications. Sensors 2021, 21, 4412. [Google Scholar] [CrossRef]
- Ayachi, R.; Afif, M.; Said, Y.; Atri, M. Strided Convolution Instead of Max Pooling for Memory Efficiency of Convolutional Neural Networks. In Proceedings of the 8th International Conference on Sciences of Electronics, Technologies of Information and Telecommunications (SETIT’18), Genoa, Italy, 18–20 December 2018; Bouhlel, M., Rovetta, S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 1, pp. 234–243. [Google Scholar] [CrossRef]
- Devi, N.; Borah, B. Cascaded pooling for Convolutional Neural Networks. In Proceedings of the 2018 Fourteenth International Conference on Information Processing (ICINPRO), Bangalore, India, 21–23 December 2018; pp. 1–5. [Google Scholar]
- Kuen, J.; Kong, X.; Lin, Z.; Wang, G.; Yin, J.; See, S.; Tan, Y.-P. Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7929–7938. Available online: https://openaccess.thecvf.com/content_cvpr_2018/html/Kuen_Stochastic_Downsampling_for_CVPR_2018_paper.html (accessed on 20 October 2023).
- Saeedan, F.; Weber, N.; Goesele, M.; Roth, S. Detail-Preserving Pooling in Deep Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9108–9116. Available online: https://openaccess.thecvf.com/content_cvpr_2018/html/Saeedan_Detail-Preserving_Pooling_in_CVPR_2018_paper.html (accessed on 20 October 2023).
- Yan, Y.; Liu, C.; Chen, C.; Sun, X.; Jin, L.; Peng, X.; Zhou, X. Fine-Grained Attention and Feature-Sharing Generative Adversarial Networks for Single Image Super-Resolution. IEEE Trans. Multimed. 2022, 24, 1473–1487. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Cozzolino, D.; Marra, F.; Poggi, G.; Verdoliva, L. Are GAN Generated Images Easy to Detect? A Critical Analysis of the State-Of-The-Art. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Li, Y.; Cai, W.; Gao, Y.; Li, C.; Hu, X. More than Encoder: Introducing Transformer Decoder to Upsample. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; pp. 1597–1602. [Google Scholar] [CrossRef]
- Fadnavis, S. Image Interpolation Techniques in Digital Image Processing: An Overview. Int. J. Eng. Res. Appl. 2014, 4, 2248–962270. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the 2011 IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2018–2025. [Google Scholar] [CrossRef]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. Available online: https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Shi_Real-Time_Single_Image_CVPR_2016_paper.html (accessed on 20 October 2023).
- Olivier, R.; Hanqiang, C. Nearest Neighbor Value Interpolation. Int. J. Adv. Comput. Sci. Appl. 2012, 3, 25–30. [Google Scholar] [CrossRef]
- Hwang, J.W.; Lee, H.S. Adaptive Image Interpolation Based on Local Gradient Features. IEEE Signal Process. Lett. 2004, 11, 359–362. [Google Scholar] [CrossRef]
- Zhong, F.; Li, M.; Zhang, K.; Hu, J.; Liu, L. DSPNet: A low computational-cost network for human pose estimation. Neurocomputing 2021, 423, 327–335. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Stochastic Pooling for Regularization of Deep Convolutional Neural Networks. arXiv 2013, arXiv:1301.3557. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. Available online: http://arxiv.org/abs/2010.11929 (accessed on 20 October 2023).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. Available online: https://openaccess.thecvf.com/content/ICCV2021/html/Liu_Swin_Transformer_Hierarchical_Vision_Transformer_Using_Shifted_Windows_ICCV_2021_paper.html (accessed on 20 October 2023).
- Gao, Z.; Wang, L.; Wu, G. LIP: Local Importance-Based Pooling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3355–3364. Available online: https://openaccess.thecvf.com/content_ICCV_2019/html/Gao_LIP_Local_Importance-Based_Pooling_ICCV_2019_paper.html (accessed on 20 October 2023).
- Yu, D.; Wang, H.; Chen, P.; Wei, Z. Mixed Pooling for Convolutional Neural Networks. In Rough Sets and Knowledge Technology; Miao, D., Pedrycz, W., Ślȩzak, D., Peters, G., Hu, Q., Wang, R., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 364–375. [Google Scholar] [CrossRef]
- Wu, Y.-H.; Liu, Y.; Zhan, X.; Cheng, M.-M. P2T: Pyramid Pooling Transformer for Scene Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 12760–12771. [Google Scholar] [CrossRef]
- Graham, B. Fractional Max-Pooling. arXiv 2015. [Google Scholar] [CrossRef]
- Sun, M.; Song, Z.; Jiang, X.; Pan, J.; Pang, Y. Learning Pooling for Convolutional Neural Network. Neurocomputing 2017, 224, 96–104. [Google Scholar] [CrossRef]
- Montavon, G.; Lapuschkin, S.; Binder, A.; Samek, W.; Müller, K.-R. Explaining nonlinear classification decisions with deep Taylor decomposition. Pattern Recognit. 2017, 65, 211–222. [Google Scholar] [CrossRef]
- Liu, Y.; Gross, L.; Li, Z.; Li, X.; Fan, X.; Qi, W. Automatic Building Extraction on High-Resolution Remote Sensing Imagery Using Deep Convolutional Encoder-Decoder with Spatial Pyramid Pooling. IEEE Access 2019, 7, 128774–128786. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. Available online: http://arxiv.org/abs/1612.08242 (accessed on 20 October 2023).
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Z.; Wang, H.; Song, L. A Down-sampling Method Based on The Discrete Wavelet Transform for CNN Classification. In Proceedings of the 2023 2nd International Conference on Big Data, Information and Computer Network (BDICN), Xishuangbanna, China, 6–8 January 2023; pp. 126–129. [Google Scholar]
- Lu, W.; Chen, S.-B.; Tang, J.; Ding, C.H.Q.; Luo, B. A Robust Feature Downsampling Module for Remote-Sensing Visual Tasks. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Ma, J.; Gu, X. Scene image retrieval with siamese spatial attention pooling. Neurocomputing 2020, 412, 252–261. [Google Scholar] [CrossRef]
- Hesse, R.; Schaub-Meyer, S.; Roth, S. Content-Adaptive Downsampling in Convolutional Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 4544–4553. [Google Scholar]
- Zhao, J.; Snoek, C.G.M. LiftPool: Bidirectional ConvNet Pooling. arXiv 2021, arXiv:2104.00996. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. Available online: https://openaccess.thecvf.com/content_cvpr_2017/html/Chollet_Xception_Deep_Learning_CVPR_2017_paper.html (accessed on 20 October 2023).
- Kaiser, L.; Gomez, A.N.; Chollet, F. Depthwise Separable Convolutions for Neural Machine Translation. arXiv 2017, arXiv:1706.03059. [Google Scholar] [CrossRef]
- Liu, B.; Zou, D.; Feng, L.; Feng, S.; Fu, P.; Li, J. An FPGA-Based CNN Accelerator Integrating Depthwise Separable Convolution. Electronics 2019, 8, 281. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Drossos, K.; Mimilakis, S.I.; Gharib, S.; Li, Y.; Virtanen, T. Sound Event Detection with Depthwise Separable and Dilated Convolutions. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. Available online: https://openaccess.thecvf.com/content_cvpr_2018/html/Zhang_ShuffleNet_An_Extremely_CVPR_2018_paper.html (accessed on 20 October 2023).
- Liu, F.; Xu, H.; Qi, M.; Liu, D.; Wang, J.; Kong, J. Depth-Wise Separable Convolution Attention Module for Garbage Image Classification. Sustainability 2022, 14, 3099. [Google Scholar] [CrossRef]
- Pilipovic, R.; Bulic, P.; Risojevic, V. Compression of convolutional neural networks: A short survey. In Proceedings of the 2018 17th International Symposium INFOTEH-JAHORINA (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 21–23 March 2018; pp. 1–6. [Google Scholar]
- Winoto, A.S.; Kristianus, M.; Premachandra, C. Small and Slim Deep Convolutional Neural Network for Mobile Device. IEEE Access 2020, 8, 125210–125222. [Google Scholar] [CrossRef]
- Elordi, U.; Unzueta, L.; Arganda-Carreras, I.; Otaegui, O. How Can Deep Neural Networks Be Generated Efficiently for Devices with Limited Resources? In Articulated Motion and Deformable Objects; Perales, F., Kittler, J., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 24–33. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote. Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- ultralytics/yolov5: v5.0—YOLOv5-P6 1280 Models, AWS, Supervise.ly and YouTube Integrations. Available online: https://zenodo.org/record/4679653 (accessed on 11 April 2021).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2014, 111, 98–136. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic Understanding of Scenes Through the ADE20K Dataset. Int. J. Comput. Vis. 2018, 127, 302–321. [Google Scholar] [CrossRef]
- MMSegmentation Contributors. OpenMMLab Semantic Segmentation Toolbox and Benchmark. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 11 April 2023).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Model | Epoch | Batch Size | Image Size | Params | MACs | Top-1 | Top-5 |
|---|---|---|---|---|---|---|---|---|
| MaxPool (baseline) | ResNet-18 | 60 | 256 | 224 | 11.69 M | 1.82 G | 59.73 | 82.87 |
| SoftPool | ResNet-18 | 60 | 256 | 224 | 11.69 M | 1.82 G | 59.77 | 82.86 |
| AdaPool | ResNet-18 | 60 | 256 | 224 | 11.69 M | 1.82G | 59.38 | 82.56 |
| Patch Merging | ResNet-18 | 60 | 256 | 224 | 11.71 M | 1.87 G | 41.36 | 66.95 |
| SliceSamp (Ours) | ResNet-18 | 60 | 256 | 224 | 11.71 M | 1.88 G | 61.03 | 83.74 |
| Method | Model | Params | FLOPs | COCO | VOC | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | ||||
| Strided Conv (baseline) | YOLOv5s-5.0 | 7.28 M | 17.2 G | 62.18 | 48.60 | 51.91 | 32.05 | 79.71 | 71.16 | 78.50 | 51.75 |
| Maxpool | YOLOv5s-5.0 | 5.23 M | 12.9 G | 58.52 | 44.98 | 47.14 | 27.97 | 76.16 | 70.54 | 74.98 | 47.74 |
| Softpool | YOLOv5s-5.0 | 5.23 M | 12.9 G | 6.92 | 1.11 | 0.57 | 0.32 | 15.17 | 11.75 | 4.95 | 1.98 |
| Adapool | YOLOv5s-5.0 | 5.23 M | 12.9 G | 0.64 | 4.02 | 0.36 | 0.09 | 10.80 | 14.11 | 4.41 | 1.68 |
| Patch Merging | YOLOv5s-5.0 | 6.00 M | 14.6 G | 0.06 | 0.003 | 0.002 | 0.002 | 0.64 | 8.05 | 0.26 | 0.05 |
| SliceSamp (ours) | YOLOv5s-5.0 | 6.03 M | 14.7 G | 62.89 | 48.79 | 52.08 | 32.59 | 80.88 | 71.90 | 78.71 | 53.85 |
| SliceUpsamp (ours) | YOLOv5s-5.0 | 6.06 M | 14.8 G | 65.43 | 46.85 | 51.72 | 32.45 | 79.7 | 72.99 | 79.29 | 53.95 |
| Method | Model | Iteration | Batch Size | Image Size | Params | FLOPs | mIoU | mAcc |
|---|---|---|---|---|---|---|---|---|
| Patch Merging (baseline) | Swin Transformer | 160,000 | 8 | 224 | 59.94 M | 236.1 G | 21.99 | 30.75 |
| Maxpool | Swin Transformer | 160,000 | 8 | 224 | 58.78 M | 235.4 G | 23.08 | 32.50 |
| Softpool | Swin Transformer | 160,000 | 8 | 224 | 58.78 M | 235.4 G | 22.08 | 30.87 |
| Adapool | Swin Transformer | 160,000 | 8 | 224 | 58.78 M | 235.4 G | 20.95 | 29.13 |
| SliceSamp (ours) | Swin Transformer | 160,000 | 8 | 224 | 59.97 M | 236.1 G | 24.57 | 34.39 |
| Method | Slicing | DSConv | +Up | Params | FLOPs | COCO | VOC | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | ||||||
| Strided Conv (baseline) | - | - | - | 7.28 M | 17.2 G | 62.18 (+0.00) | 48.60 (+0.00) | 51.91 (+0.00) | 32.05 (+0.00) | 79.71 (+0.00) | 71.16 (+0.00) | 78.50 (+0.00) | 51.75 (+0.00) |
| Slicing | √ | - | - | 6.00 M | 14.5 G | 63.48 (+1.30) | 45.99 (−2.61) | 50.65 (−1.26) | 30.76 (−1.29) | 76.93 (−2.78) | 71.69 (+0.53) | 76.95 (−1.55) | 49.92 (−1.83) |
| DSConv | - | √ | - | 5.24 M | 13.0 G | 63.49 (+1.31) | 45.78 (−2.82) | 50.54 (−1.37) | 30.96 (−1.09) | 78.85 (−0.86) | 70.15 (−1.01) | 76.54 (−1.96) | 50.22 (−1.53) |
| SliceSamp (ours) | √ | √ | - | 6.03 M | 14.7 G | 62.89 (+0.71) | 48.79 (+0.19) | 52.08 (+0.17) | 32.59 (+0.54) | 80.88 (+1.17) | 71.90 (+0.74) | 78.71 (+0.21) | 53.85 (+2.10) |
| SliceUpSamp (ours) | √ | √ | √ | 6.06 M | 14.8 G | 65.43 (+3.25) | 46.85 (−1.75) | 51.72 (−0.19) | 32.45 (+0.40) | 79.70 (−0.01) | 72.99 (+1.83) | 79.29 (+0.79) | 53.95 (+2.20) |
| SlicingConv3×3 | √ | - | - | 15.50 M | 33.0 G | 67.64 (+5.46) | 48.37 (−0.23) | 54.08 (+2.17) | 34.60 (+2.01) | 78.49 (−1.22) | 75.02 (+3.86) | 80.32 (+1.82) | 55.17 (+3.42) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, L.; Wang, M. SliceSamp: A Promising Downsampling Alternative for Retaining Information in a Neural Network. Appl. Sci. 2023, 13, 11657. https://doi.org/10.3390/app132111657
He L, Wang M. SliceSamp: A Promising Downsampling Alternative for Retaining Information in a Neural Network. Applied Sciences. 2023; 13(21):11657. https://doi.org/10.3390/app132111657
Chicago/Turabian StyleHe, Lianlian, and Ming Wang. 2023. "SliceSamp: A Promising Downsampling Alternative for Retaining Information in a Neural Network" Applied Sciences 13, no. 21: 11657. https://doi.org/10.3390/app132111657