
Hybrid Sampling and Dynamic Weighting-Based Classification Method for Multi-Class Imbalanced Data Stream
Abstract
:1. Introduction
- (1)
- A novel hybrid sampling method is proposed to solve the problem of imbalance and variable class ratio in the data streams. In the hybrid sampling process, each class is clustered by adaptive spectral clustering and then sampled based on the clusters from each class. Meanwhile, a sample storage pool is designed to store samples with a high safety factor in the data chunk to solve the problems caused by extremely imbalanced and variable class ratio data streams. Finally, the safety factor of each sample is calculated for each cluster obtained from each class, and each cluster of the class is oversampled or under-sampled according to the safety factor and the number of samples, so that a balanced data chunk is obtained and the original data distribution is maintained well.
- (2)
- A dynamic weighting method based on G-mean is investigated and proposed. The G-mean value of each classifier on the current chunk is used as the weight of each base classifier in the ensemble. As the data chunk arrives, if the weight of the base classifier is not lower than the threshold set by the user, it will be added to the ensemble directly; otherwise, the base classifier will be removed. The classifiers in the ensemble are constantly in a dynamic updating process as a way to adapt to concept drift.
- (3)
- The HSDW-MI algorithm proposed in this paper deals with imbalance and concept drift in data streams by hybrid sampling phase and dynamic weighting phase and is capable of handling data streams with extreme imbalance and variable class ratio. In addition, detailed experiments are conducted to demonstrate the effectiveness and feasibility of the algorithm, including parameter sensitivity experiments, ablation experiments, and algorithm comparison experiments, and the experimental results are comprehensively analyzed.
2. Related Work
2.1. Multi-Class Imbalance Data Classification Method
2.2. Concept Drift Data Streams Learning Method
3. The Proposed HSDW-MI Algorithm
3.1. Training Process of HSDW-MI Algorithm
- (a)
- Hybrid sampling phase.
- (1)
- To begin with, the algorithm enters the hybrid sampling phase, which is responsible for dealing with the imbalances that exist in the incoming data chunk.
- (2)
- In the hybrid sampling phase, the number of samples needed to sample each class in the current data chunk is determined by calculating the class ratio of the current chunk.
- (3)
- Then, the samples of each class in the data chunk are clustered by adaptive spectral clustering, and a number of samples for each cluster in each class is determined based on the number of samples to be sampled for each class obtained in step (2).
- (4)
- After that, the safety factors of all samples in each class are calculated and ranked in descending order.
- (5)
- Based on the safety factor of the samples, the samples with a high safety factor in each class are stored in the sample storage pool. If the storage pool is full, the old samples are deleted and new samples are added.
- (6)
- Judge whether the current class is a minority class. If not, the samples with low safety factor in each cluster are removed based on the clusters divided into the current class and the number of samples to be sampled in each cluster in step (3).
- (7)
- If the current class is minority class, then the number of samples of the current class is further judged whether it is lower than the number of samples to be sampled obtained in step (2). If not, go directly to the oversampling phrase and oversample the samples with high safety factor of the current class based on the clusters divided into the current class and the number of samples to be sampled for each cluster in step (3).
- (b)
- Dynamic weighting phase.
- (1)
- Dynamic weighting phases are responsible for dynamically updating the classifiers in the ensemble to accommodate concept drift. In the dynamic weighting phase, the algorithm trains a classifier Cnew on the balanced data chunk to add to the ensemble.
- (2)
- For the classifiers in ensemble E, the algorithm calculates the G-mean value of the classifier on the current data chunk as the weight of each classifier.
- (3)
- By setting the update threshold θ to remove the classifiers whose weights are lower than θ in the ensemble during training process, so as to ensure the dynamic update of the ensemble classifiers.
- (4)
- Finally, the updated ensemble is used to predict the samples in the current data chunk and obtain the final classification results.
3.2. Two Phases of the HSDW-MI Algorithm
3.2.1. Hybrid Sampling Phase of HSDW-MI Algorithm
| Algorithm 1. The Hybrid Sampling Phase of HSDW-MI |
| Input: Data stream S = {D1, …, Dt−1, Dt}, Data chunk Dt = <xi, yi>, Data chunk Dt size d, Sample storage pool SP, The number of neighbors k = 7; |
| Output: Banlanced Balanced data chunks |
| 1 Initialize sample storage pool |
| 2 for Dt in S |
| 3 According to Dt to obtain the number of classes m, the ratio of classes and the number of samples of each class; |
| 4 Calculate the size of the sample storage pool SP according to Equation (7) dsp; |
| 5 for i←1 to m do |
| 6 Calculate , which is the number of classes to be sampled, according to Equation (1); |
| 7 Initialize smax and pbest; |
| 8 for p←2 to 10 do |
| 9 Calculate the Calinski-Harbasz index s for class at cluster p according to Equation (2); |
| 10 if |
| 11 ; |
| 12 ; |
| 13 End if |
| 14 End for |
| 15 Dividing class into clusters by adaptive spectral clustering; |
| 16 for p←2 to do |
| 17 Calculate the number of to be sampled for each cluster in class according to Equation (3); |
| 18 for each sample xj in cluster p |
| 19 Find the k samples which are near to sample xj by using k-NN; |
| 20 Calculate the safety factor of sample xj according to Equations (5) and (6); |
| 21 End for |
| 22 Sort each sample in cluster p in descending order based on the safety factor; |
| 23 if is full |
| 24 Remove old samples from ; |
| 25 End if |
| 26 for xj in cluster p |
| 27 ; |
| 28 End for |
| 29 if |
| 30 Remove the last samples from the cluster p; |
| 31 else |
| 32 if |
| 33 Extract the top samples from and add them to the cluster p; |
| 34 End if |
| 35 Copy the top samples from cluster p and add them to cluster p; |
| 36 End for |
| 37 End for |
| 38 End for |
3.2.2. Dynamic Weighting Phase of HSDW-MI Algorithm
| Algorithm 2. The Dynamic Weighting Phase of HSDW-MI |
| Input: Data stream S = {D1, …, Dt−1, Dt}, Data chunk Dt = <xi, yi>, Ensemble E = {C1, C2, …, Cn} Ensemble size L, Update threshold θ. |
| Output: Ensemble E = {C1, C2, …, Cn}, Predicted label . |
| 1 Train a base classifier C on Dt, E←{C}; |
| 2 Initialize the weights of the current classifier; |
| 3 for Dt in S |
| 4 According to the hybrid sampling phase to get the balanced data chunk ; |
| 5 for j←1 to L do |
| 6 Calculate the G-mean value of the classifier trained by the current data chunk using Equation (8): ; |
| 7 Update the weights of classifier using Equation (9): ; |
| 8 if |
| 9 Remove classifiers that are below the threshold θ in the ensemble: ; |
| 10 Create a new base classifier Cnew on the data chunk and add Cnew to E; |
| 11 Initialize the weights of Cnew, ; |
| 12 end if |
| 13 end for |
| 14 end for |
| 15 Output ensemble E and predicted label . |
3.3. Complexity Analysis of the Algorithm
- (1)
- Time complexity: Let N samples in the data stream be divided into D data chunks, then the number of samples in each data chunk is N/D. The time required for adaptive spectral clustering to cluster the classes in the data chunk is Tsp. The time to calculate the safety factor of the samples is Tsf. The time to create a new classifier is Tnew and the time to predict the classifier in the ensemble E containing m classifiers is O(N × mlogN). Therefore, the time required to process the data stream containing N samples is O((Tsp + (Tsf × N/D) + Tnew) × D + O(N × mlogN).
- (2)
- Space complexity: The sample storage pool of the HSDW-MI algorithm is determined based on the chunk size and the number of classes, so the space consumed is a constant, and its space complexity is O (1).
4. Experimental Design
4.1. Datasets and Evaluation Metrics
4.2. Parameter Sensitivity Experiments
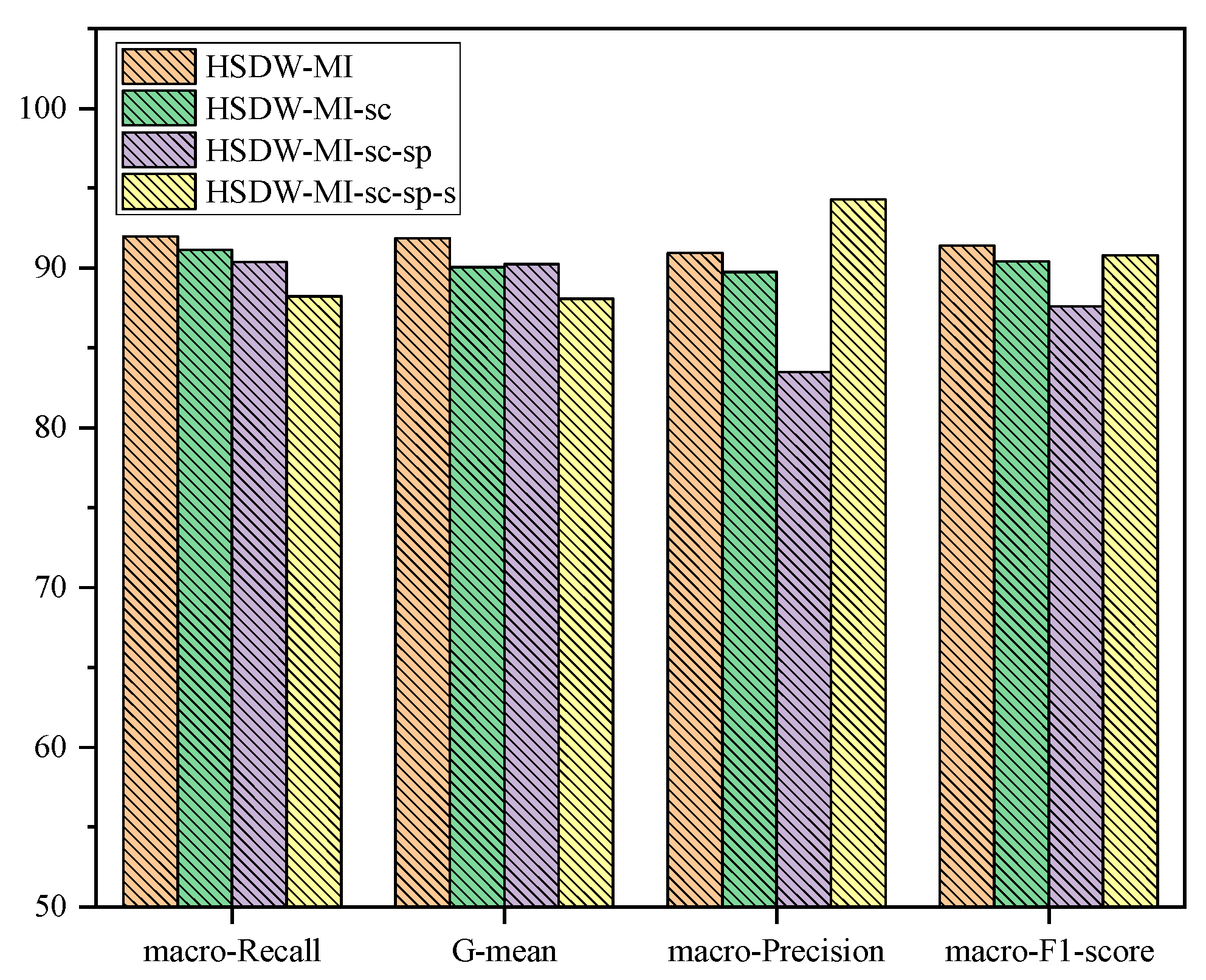
4.3. Ablation Experiments
4.4. Algorithm Comparison Experiments
5. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ancy, S.; Paulraj, D. Handling imbalanced data with concept drift by applying dynamic sampling and ensemble classification model. Comput. Commun. 2020, 153, 553–560. [Google Scholar] [CrossRef]
- Wang, S.; Minku, L.L.; Yao, X. Dealing with Multiple Classes in Online Class Imbalance Learning. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2118–2124. [Google Scholar]
- Kaddoura, S.; Arid, A.E.; Moukhtar, M. Evaluation of Supervised Machine Learning Algorithms for Multi-Class Intrusion Detection Systems. In Proceedings of the Future Technologies Conference (FTC) 2021; Springer: Berlin/Heidelberg, Germany, 2022; Volume 3, pp. 1–16. [Google Scholar]
- Bin Sulaiman, R.; Schetinin, V.; Sant, P. Review of Machine Learning Approach on Credit Card Fraud Detection. Hum. Cent. Intell. Syst. 2022, 2, 55–68. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Luna, S.A.; Siddique, Z. Machine-learning-based disease diagnosis: A comprehensive review. Healthcare 2022, 10, 541. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under concept drift: A review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef]
- Zhang, X.; Han, M.; Wu, H.; Li, M.; Chen, Z. An overview of complex data stream ensemble classification. J. Intell. Fuzzy Syst. 2021, 41, 3667–3695. [Google Scholar] [CrossRef]
- Mirza, B.; Lin, Z. Meta-cognitive online sequential extreme learning machine for imbalanced and concept-drifting data classification. Neural Netw. 2016, 80, 79–94. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, L.E.B.; Gomes, H.M.; Bifet, A.; Oliveira, L.S. Adaptive random forests with resampling for imbalanced data streams. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–6. [Google Scholar]
- Abdi, L.; Hashemi, S. To combat multi-class imbalanced problems by means of over-sampling techniques. IEEE Trans. Knowl. Data Eng. 2015, 28, 238–251. [Google Scholar] [CrossRef]
- Zhu, T.; Lin, Y.; Liu, Y. Synthetic minority oversampling technique for multiclass imbalance problems. Pattern Recognit. J. Pattern Recognit. Soc. 2017, 72, 327–340. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Hoque, S.; Farid, D.M. Cluster-based under-sampling with random forest for multi-class imbalanced classification. In Proceedings of the 11th International Conference on Software, Knowledge, Information Management and Applications (SKIMA), Malabe, Sri Lanka, 6–8 December 2017; pp. 1–6. [Google Scholar]
- Díez-Pastor, J.F.; Rodríguez, J.J.; Garcia-Osorio, C.; Kuncheva, L.I. Random balance: Ensembles of variable priors classifiers for imbalanced data. Knowl.-Based Syst. 2015, 85, 96–111. [Google Scholar] [CrossRef]
- Rodríguez, J.J.; Diez-Pastor, J.F.; Arnaiz-Gonzalez, A.; Kuncheva, L.I. Random balance ensembles for multiclass imbalance learning. Knowl.-Based Syst. 2020, 193, 105434. [Google Scholar] [CrossRef]
- Hartono, H.; Risyani, Y.; Ongko, E.; Abdullah, D. HAR-MI method for multi-class imbalanced datasets. Telecommun. Comput. Electron. Control 2020, 18, 822–829. [Google Scholar] [CrossRef]
- Jadwal, P.K.; Jain, S.; Pathak, S.; Agarwal, B. Improved resampling algorithm through a modified oversampling approach based on spectral clustering and SMOTE. Microsyst. Technol. 2022, 28, 2669–2677. [Google Scholar] [CrossRef]
- Sainin, M.S.; Alfred, R.; Adnan, F.; Ahmad, F. Combining sampling and ensemble classifier for multiclass imbalance data learning. In Proceedings of the International Conference on Computational Science and Technology, Labuan, Malaysia, 28–29 August 2021; Springer: Singapore, 2017; pp. 262–272. [Google Scholar]
- Vafaie, P.; Viktor, H.; Michalowski, W. Multi-class imbalanced semi-supervised learning from streams through online ensembles. In Proceedings of the International Conference on Data Mining Workshops, Sorrento, Italy, 17–20 November 2020; pp. 867–874. [Google Scholar]
- Czarnowski, I. Weighted Ensemble with one-class Classification and Over-sampling and Instance selection (WECOI): An approach for learning from imbalanced data streams. J. Comput. Sci. 2022, 61, 101614. [Google Scholar] [CrossRef]
- Han, M.; Zhang, X.; Chen, Z.; Wu, H.; Li, M. Dynamic ensemble selection classification algorithm based on window over imbalanced drift data stream. Knowl. Inf. Syst. 2022, 65, 1105–1128. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Pfahringer, B. Leveraging bagging for evolving data streams. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2010, Barcelona, Spain, 20–24 September 2010, Proceedings, Part I 21; Springer: Berlin/Heidelberg, Germany, 2010; pp. 135–150. [Google Scholar]
- Bifet, A.; Gavalda, R. Learning from time-changing data with adaptive windowing. In Proceedings of the 7th SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; pp. 443–448. [Google Scholar]
- Gomes, H.M.; Bifet, A.; Read, J.; Barddal, J.P.; Enembreck, F.; Pfharinger, B.; Holmes, G.; Abdessalem, T. Adaptive random forests for evolving data stream classification. Mach. Learn. 2017, 106, 1469–1495. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, H.; Ding, Z.; Liu, Q.; Zhu, C. A comprehensive active learning method for multiclass imbalanced data streams with concept drift. Knowl.-Based Syst. 2021, 215, 106778. [Google Scholar] [CrossRef]
- De Barros, R.S.M.; de Carvalho Santos, S.G.T.; Júnior, P.M.G. A boosting-like online learning ensemble. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1871–1878. [Google Scholar]
- Iwashita, A.S.; Papa, J.P. An overview on concept drift learning. IEEE Access 2018, 7, 1532–1547. [Google Scholar] [CrossRef]
- Han, M.; Chen, Z.; Li, M.; Wu, H.; Zhang, X. A survey of active and passive concept drift handling methods. Comput. Intell. 2022, 38, 1492–1535. [Google Scholar] [CrossRef]
- Brzezinski, D.; Stefanowski, J. Combining chunk-based and online methods in learning ensembles from concept drifting data streams. Inf. Sci. 2014, 265, 50–67. [Google Scholar] [CrossRef]
- Ertunç, E.; Karkınlı, A.E.; Bozdağ, A. A clustering-based approach to land valuation in land consolidation projects. Land Use Policy 2021, 111, 105739. [Google Scholar] [CrossRef]
- Janicka, M.; Lango, M.; Stefanowski, J. Using information on class interrelations to improve classification of multiclass imbalanced data: A new resampling algorithm. Int. J. Appl. Math. Comput. Sci. 2019, 29, 769–781. [Google Scholar] [CrossRef]
- Lango, M.; Stefanowski, J. Multi-class and feature selection extensions of roughly balanced bagging for imbalanced data. J. Intell. Inf. Syst. 2018, 50, 97–127. [Google Scholar] [CrossRef]
- Mahadevan, A.; Arock, M. A class imbalance-aware review rating prediction using hybrid sampling and ensemble learning. Multimed. Tools Appl. 2021, 80, 6911–6938. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Pfahringer, B.; Kranen, P.; Kremer, H.; Jansen, T.; Seidl, T. Moa: Massive online analysis, a framework for stream classification and clustering. In Proceedings of the First Workshop on Applications of Pattern Analysis, Windsor, UK, 1–3 September 2010; pp. 44–50. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Definitions |
|---|---|
| S | Data stream |
| D | Data chunk |
| D′ | Balanced data chunk |
| E | Ensemble of classifiers |
| Cnew | New created classifier |
| θ | Update threshold of classifiers |
| Data Stream | Instance | Attribute | Class | Class Distribution | Class Ratio | Drift |
|---|---|---|---|---|---|---|
| ImbSta_Stream | 200,000 | 20 | 5 | 5/4/3/2/1 | (0.33; 0.26; 0.2; 0.13; 0.08) | - |
| ImbSta_Extreme_Stream | 200,000 | 20 | 5 | 20/4/3/2/1 | (0.67; 0.14; 0.1; 0.06; 0.03) | - |
| ImbSta_SG | 200,000 | 20 | 5 | 5/4/3/2/1 | (0.33; 0.26; 0.2; 0.13; 0.08) | 2 |
| ImbSta_Extreme_SG | 200,000 | 20 | 5 | 15/4/3/2/1 | (0.6; 0.16; 0.12; 0.08; 0.04) | 2 |
| ImbSta_Extreme_SIG | 200,000 | 20 | 5 | 15/5/2/2/1 | (0.6; 0.2; 0.08; 0.08; 0.04) | 3 |
| ImbVar_Stream | 200,000 | 20 | 5 | 5/4/3/2/1 → 1/3/2/5/4 | (0.33; 0.26; 0.2; 0.13; 0.08) → (0.08; 0.2; 0.13; 0.33; 0.26) | - |
| ImbVar_Extreme_Stream | 200,000 | 20 | 5 | 20/4/3/2/1 → 1/1/2/6/20 | (0.67; 0.14; 0.1; 0.06; 0.03) → (0.03; 0.03; 0.06; 0.21; 0.67) | - |
| ImbVar_SG | 200,000 | 20 | 5 | 5/4/3/2/1 → 1/2/3/4/5 | (0.33; 0.26; 0.2; 0.13; 0.08) → (0.08; 0.13; 0.2; 0.26; 0.33) | 2 |
| ImbVar_Extreme_SG | 200,000 | 20 | 5 | 15/4/3/2/1 → 2/1/15/4/3 | (0.6; 0.16; 0.12; 0.08; 0.04) → (0.08; 0.04; 0.12; 0.16; 0.6) | 2 |
| ImbVar_Extreme_SIG | 200,000 | 20 | 5 | 15/5/2/2/1 → 1/2/2/5/20 | (0.6; 0.2; 0.08; 0.08; 0.04) → (0.03; 0.07; 0.07; 0.16; 0.67) | 3 |
| PokerHand | 830,000 | 10 | 10 | - | - | - |
| Kddcup 99_10% | 494,000 | 42 | 23 | - | - | - |
| Statlog(shuttle) | 58,000 | 9 | 7 | - | - | - |
| Size of Chunk D | Number of Base Classifiers N | Updating Threshold of Ensemble θ | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 500 | 1000 | 1500 | 2000 | 2500 | 3000 | 5 | 10 | 15 | 20 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | |
| mR | 89.90 | 92.74 | 93.94 | 94.15 | 93.98 | 93.96 | 91.98 | 94.09 | 93.93 | 94.15 | 92.87 | 93.62 | 93.74 | 94.15 | 93.90 |
| Gm | 89.74 | 92.66 | 93.89 | 94.05 | 93.89 | 93.93 | 91.93 | 93.04 | 93.67 | 94.05 | 92.81 | 93.56 | 93.71 | 94.05 | 93.83 |
| mP | 86.21 | 89.26 | 90.24 | 91.02 | 90.42 | 90.43 | 89.60 | 90.26 | 90.78 | 91.02 | 90.29 | 90.82 | 90.96 | 91.02 | 90.87 |
| mF1 | 87.65 | 90.75 | 91.97 | 92.27 | 92.14 | 92.03 | 90.08 | 90.10 | 91.94 | 92.27 | 91.01 | 91.63 | 91.91 | 92.27 | 92.08 |
| Size of Chunk D | Number of Base Classifiers N | Updating Threshold of Ensemble θ | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 500 | 1000 | 1500 | 2000 | 2500 | 3000 | 5 | 10 | 15 | 20 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | |
| mR | 90.09 | 91.24 | 92.06 | 92.33 | 92.26 | 92.20 | 90.83 | 91.77 | 92.07 | 92.33 | 91.45 | 91.79 | 92.08 | 92.33 | 92.17 |
| Gm | 89.88 | 90.97 | 91.69 | 91.81 | 91.78 | 91.62 | 90.19 | 90.90 | 91.48 | 91.81 | 91.00 | 91.22 | 91.60 | 91.81 | 91.78 |
| mP | 87.05 | 88.50 | 89.15 | 89.70 | 89.38 | 89.15 | 87.84 | 88.91 | 89.42 | 89.70 | 88.58 | 88.94 | 89.24 | 89.70 | 89.21 |
| mF1 | 87.88 | 89.21 | 90.33 | 90.38 | 90.30 | 90.21 | 88.91 | 89.87 | 90.31 | 90.38 | 89.46 | 89.71 | 90.27 | 90.38 | 90.27 |
| Data Stream | Algorithm | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| LB | OAUE | ARF | BOLE | MUOB | MOOB | CALMID | HSDW-MI | ||
| Stationary data stream | ImbSta_Stream | 96.44(3) | 94.45(6) | 96.70(2) | 94.96(5) | 82.52(8) | 94.22(7) | 96.06(4) | 97.21(1) |
| ImbSta_Extreme_Stream | 93.61(5) | 92.14(6) | 95.36(2) | 91.17(7) | 71.74(8) | 94.40(4) | 94.85(3) | 97.13(1) | |
| ImbSta_SG | 90.40(4) | 89.07(5) | 90.75(3) | 86.08(6) | 78.13(8) | 85.64(7) | 91.09(2) | 91.99(1) | |
| ImbSta_Extreme_SG | 88.19(3) | 83.25(6) | 88.13(4) | 79.18(7) | 66.05(8) | 83.67(5) | 90.85(2) | 92.25(1) | |
| ImbSta_Extreme_SIG | 84.97(4) | 80.75(6) | 88.54(3) | 77.45(7) | 63.63(8) | 81.82(5) | 88.76(2) | 92.18(1) | |
| Variable data stream | ImbVar_Stream | 76.00(8) | 91.75(4) | 91.50(5) | 92.02(3) | 87.57(6) | 92.11(2) | 86.50(7) | 92.64(1) |
| ImbVar_Extreme_Stream | 90.61(4) | 90.84(3) | 90.47(5) | 90.17(7) | 71.06(8) | 90.40(6) | 91.97(2) | 92.59(1) | |
| ImbVar_SG | 91.45(4) | 89.26(5) | 91.82(3) | 87.17(7) | 78.01(8) | 85.66(6) | 92.08(1) | 91.91(2) | |
| ImbVar_Extreme_SG | 89.44(4) | 85.23(6) | 89.52(3) | 82.88(7) | 70.89(8) | 88.90(5) | 91.82(2) | 92.51(1) | |
| ImbVar_Extreme_SIG | 89.23(4) | 68.48(7) | 90.23(3) | 85.11(6) | 61.99(8) | 87.97(5) | 90.97(2) | 92.01(1) | |
| Real Stream | PokerHand | 30.81(4) | 30.23(5) | 27.26(7) | 32.32(3) | 7.82(8) | 33.78(2) | 29.50(6) | 38.13(1) |
| Kddcup 99_10% | 35.19(6) | 28.29(7) | 40.02(3) | 44.80(1) | 3.12(8) | 37.81(5) | 40.00(4) | 41.09(2) | |
| Statlog(shuttle) | 44.13(7) | 45.81(5) | 50.12(4) | 44.45(6) | 17.61(8) | 52.41(3) | 56.73(2) | 78.41(1) | |
| Data Stream | Algorithm | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| LB | OAUE | ARF | BOLE | MUOB | MOOB | CALMID | HSDW-MI | ||
| Stationary data stream | ImbSta_Stream | 96.37(3) | 94.34(6) | 96.63(2) | 94.72(5) | 82.19(8) | 94.14(7) | 95.96(4) | 97.19(1) |
| ImbSta_Extreme_Stream | 93.23(5) | 91.05(6) | 95.07(2) | 90.12(7) | 70.98(8) | 94.14(4) | 94.35(3) | 97.09(1) | |
| ImbSta_SG | 90.13(4) | 88.51(5) | 90.36(3) | 85.38(6) | 75.89(8) | 83.55(7) | 90.76(2) | 91.58(1) | |
| ImbSta_Extreme_SG | 86.94(3) | 81.39(6) | 86.63(4) | 76.73(7) | 61.40(8) | 81.46(5) | 87.86(2) | 92.21(1) | |
| ImbSta_Extreme_SIG | 83.40(4) | 78.72(5) | 87.26(3) | 74.70(7) | 60.91(8) | 78.14(6) | 89.14(2) | 92.17(1) | |
| Variable data stream | ImbVar_Stream | 56.86(8) | 91.13(5) | 91.39(4) | 91.72(2) | 87.11(6) | 91.55(3) | 81.57(7) | 92.12(1) |
| ImbVar_Extreme_Stream | 90.23(3) | 90.05(7) | 90.17(4) | 90.12(6) | 70.98(8) | 90.14(5) | 91.58(2) | 92.04(1) | |
| ImbVar_SG | 91.19(3) | 88.71(5) | 91.62(2) | 86.51(6) | 75.91(8) | 84.05(7) | 91.96(1) | 91.05(4) | |
| ImbVar_Extreme_SG | 88.56(4) | 83.76(6) | 88.65(3) | 80.73(7) | 68.26(8) | 87.41(5) | 91.01(2) | 91.95(1) | |
| ImbVar_Extreme_SIG | 87.85(3) | 62.15(7) | 87.55(4) | 82.23(6) | 57.97(8) | 85.92(5) | 90.12(2) | 91.87(1) | |
| Real Stream | PokerHand | - | - | - | - | - | - | - | 15.16(1) |
| Kddcup 99_10% | - | - | - | - | - | - | - | 5.47(1) | |
| Statlog(shuttle) | - | - | - | - | - | - | - | 38.80(1) | |
| Data Stream | Algorithm | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| LB | OAUE | ARF | BOLE | MUOB | MOOB | CALMID | HSDW-MI | ||
| Stationary data stream | ImbSta_Stream | 92.85(3) | 88.25(6) | 96.21(2) | 91.52(5) | 70.76(8) | 85.82(7) | 91.91(4) | 96.24(1) |
| ImbSta_Extreme_Stream | 92.23(4) | 88.11(6) | 93.45(3) | 90.79(5) | 58.45(8) | 80.14(7) | 93.96(2) | 94.07(1) | |
| ImbSta_SG | 83.07(5) | 84.27(4) | 92.69(1) | 81.05(6) | 65.41(8) | 79.19(7) | 90.02(3) | 92.57(2) | |
| ImbSta_Extreme_SG | 84.62(4) | 84.27(5) | 86.43(2) | 81.84(6) | 57.42(8) | 76.90(7) | 86.89(1) | 86.24(3) | |
| ImbSta_Extreme_SIG | 82.30(5) | 81.72(6) | 84.63(3) | 82.75(4) | 54.59(8) | 74.54(7) | 89.77(1) | 85.96(2) | |
| Variable data stream | ImbVar_Stream | 89.65(4) | 89.75(2) | 89.67(3) | 88.29(6) | 80.32(8) | 90.45(1) | 88.56(5) | 88.26(7) |
| ImbVar_Extreme_Stream | 89.23(4) | 88.11(6) | 90.47(2) | 90.79(1) | 58.45(8) | 80.14(7) | 90.33(3) | 88.29(5) | |
| ImbVar_SG | 89.06(4) | 84.50(5) | 93.15(1) | 83.23(6) | 65.19(8) | 79.26(7) | 89.33(3) | 92.71(2) | |
| ImbVar_Extreme_SG | 90.10(2) | 85.56(6) | 90.32(1) | 87.68(5) | 58.89(8) | 81.76(7) | 89.82(3) | 88.32(4) | |
| ImbVar_Extreme_SIG | 91.30(3) | 79.25(7) | 91.36(1) | 90.71(5) | 58.80(8) | 86.10(6) | 91.35(2) | 90.94(4) | |
| Real Stream | PokerHand | 44.28(1) | 39.87(3) | - | 41.69(2) | - | 34.73(5) | - | 35.03(4) |
| Kddcup 99_10% | - | - | - | - | - | - | - | 56.91(1) | |
| Statlog(shuttle) | - | - | 13.48(3) | 5.93(4) | - | 40.44(2) | 6.86(5) | 75.05(1) | |
| Data Stream | Algorithm | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| LB | OAUE | ARF | BOLE | MUOB | MOOB | CALMID | HSDW-MI | ||
| Stationary data stream | ImbSta_Stream | 94.61(3) | 91.24(6) | 96.45(2) | 93.21(5) | 76.19(8) | 89.82(7) | 93.94(4) | 96.72(1) |
| ImbSta_Extreme_Stream | 92.91(4) | 90.08(6) | 94.40(2) | 90.98(5) | 64.42(8) | 86.69(7) | 94.40(2) | 95.58(1) | |
| ImbSta_SG | 86.58(5) | 86.60(4) | 91.71(2) | 83.49(6) | 71.21(8) | 82.29(7) | 90.55(3) | 92.28(1) | |
| ImbSta_Extreme_SG | 86.37(4) | 83.76(5) | 87.27(3) | 80.49(6) | 61.43(8) | 80.14(7) | 88.83(2) | 89.14(1) | |
| ImbSta_Extreme_SIG | 83.61(4) | 81.23(5) | 86.54(3) | 80.01(6) | 58.76(8) | 78.01(7) | 89.26(1) | 88.96(2) | |
| Variable data stream | ImbVar_Stream | 82.26(8) | 90.74(2) | 90.58(3) | 90.12(5) | 83.79(7) | 91.27(1) | 87.52(6) | 90.40(4) |
| ImbVar_Extreme_Stream | 89.91(5) | 89.45(6) | 90.47(3) | 90.48(2) | 64.14(8) | 84.96(7) | 91.14(1) | 90.39(4) | |
| ImbVar_SG | 90.24(4) | 86.81(5) | 92.48(1) | 85.15(6) | 71.03(8) | 82.34(7) | 90.68(3) | 92.31(2) | |
| ImbVar_Extreme_SG | 89.77(4) | 85.39(5) | 89.92(3) | 85.21(6) | 64.34(8) | 85.18(7) | 90.81(1) | 90.37(2) | |
| ImbVar_Extreme_SIG | 90.25(4) | 73.47(7) | 90.79(3) | 87.82(5) | 60.35(8) | 87.02(6) | 91.16(2) | 91.47(1) | |
| Real Stream | PokerHand | 36.34(3) | 34.39(4) | - | 36.41(2) | - | 34.25(5) | - | 36.51(1) |
| Kddcup 99_10% | - | - | - | - | - | - | - | 47.72(1) | |
| Statlog(shuttle) | - | - | 21.25(3) | 10.46(5) | - | 45.65(2) | 12.24(4) | 76.69(1) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, M.; Li, A.; Gao, Z.; Mu, D.; Liu, S. Hybrid Sampling and Dynamic Weighting-Based Classification Method for Multi-Class Imbalanced Data Stream. Appl. Sci. 2023, 13, 5924. https://doi.org/10.3390/app13105924
Han M, Li A, Gao Z, Mu D, Liu S. Hybrid Sampling and Dynamic Weighting-Based Classification Method for Multi-Class Imbalanced Data Stream. Applied Sciences. 2023; 13(10):5924. https://doi.org/10.3390/app13105924
Chicago/Turabian StyleHan, Meng, Ang Li, Zhihui Gao, Dongliang Mu, and Shujuan Liu. 2023. "Hybrid Sampling and Dynamic Weighting-Based Classification Method for Multi-Class Imbalanced Data Stream" Applied Sciences 13, no. 10: 5924. https://doi.org/10.3390/app13105924