
A Deep Fusion Matching Network Semantic Reasoning Model



Abstract
:1. Introduction
2. Materials
2.1. SNLI Dataset
2.2. Multi-NLI Dataset
3. Methods
3.1. Reasoning Information Extraction Method
3.1.1. Matching Model Based on AF-DMN
3.1.2. Syntactic Structure Extraction Based on Tree Convolution Network
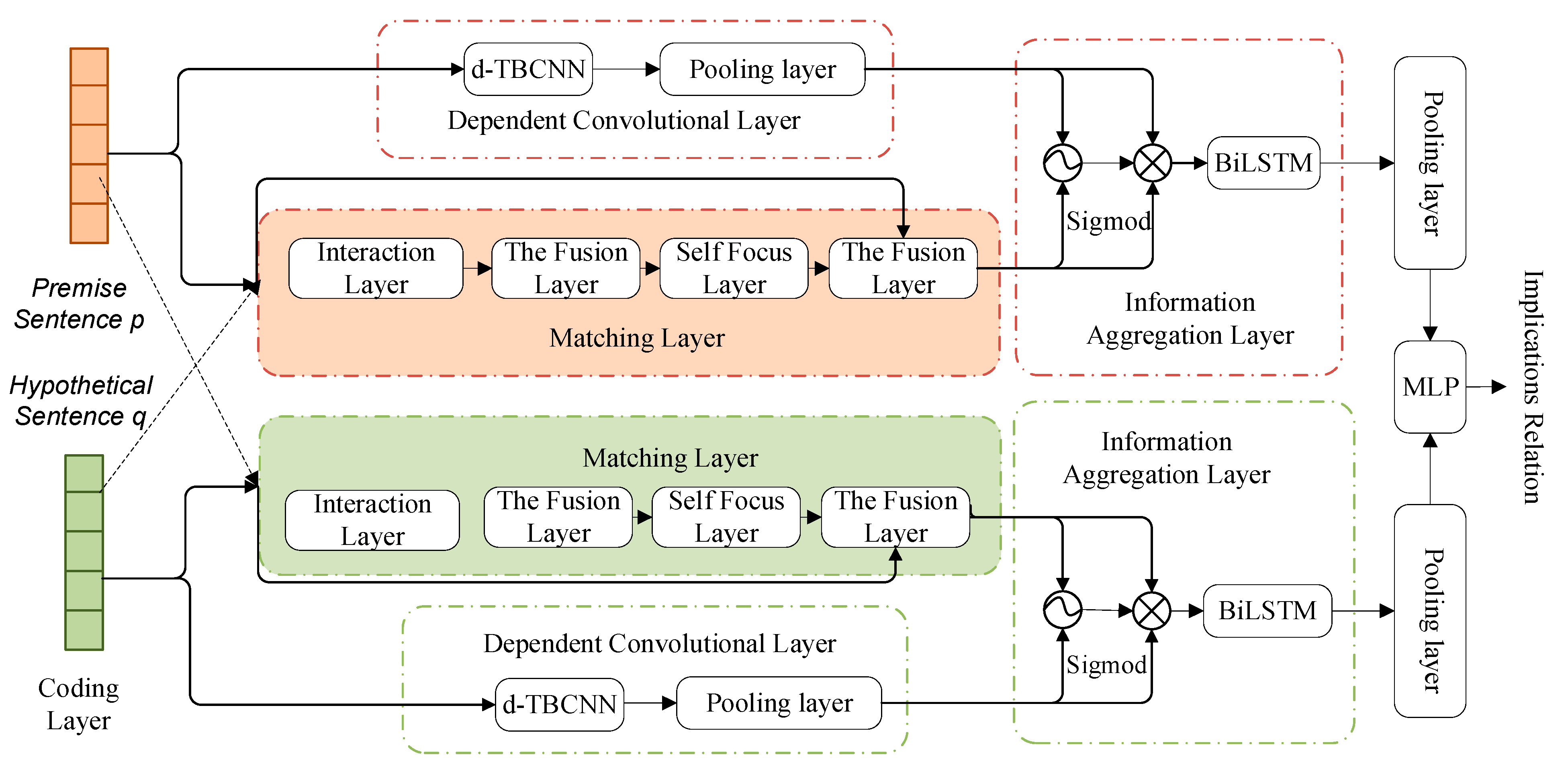
3.2. Design of Reasoning Model Based on Deep Fusion Matching Network
- (1)
- Coding layer: it mainly completes the transformation from natural language representation to sentence embedding representation, including sentence preprocessing, vectorization, semantic information coding, and embedded representation generation.
- (2)
- Matching layer and dependency convolution layer: they mainly complete the extraction of local inference information between sentences and syntactic structure inference information. Moreover, by extracting the interactive information between sentences, implicit logic is introduced into the reasoning process to improve the interpretability of the reasoning process.
- (3)
- Information aggregation layer: it mainly completes the integration of representation information, interactive reasoning information, and syntactic structure reasoning information. All information is integrated into fixed-length semantic information using cyclic neural networks and pooling in deep learning.
- (4)
- Reasoning and prediction layer: it mainly completes the output of prediction results of specific reasoning tasks. In general, linear function and multi-layer fully connected network are used to infer the global reasoning information after fusion to predict the implication relationship of a given sentence pair. The detailed structure and function of the sub-networks are given below.
3.2.1. Sentence Coding
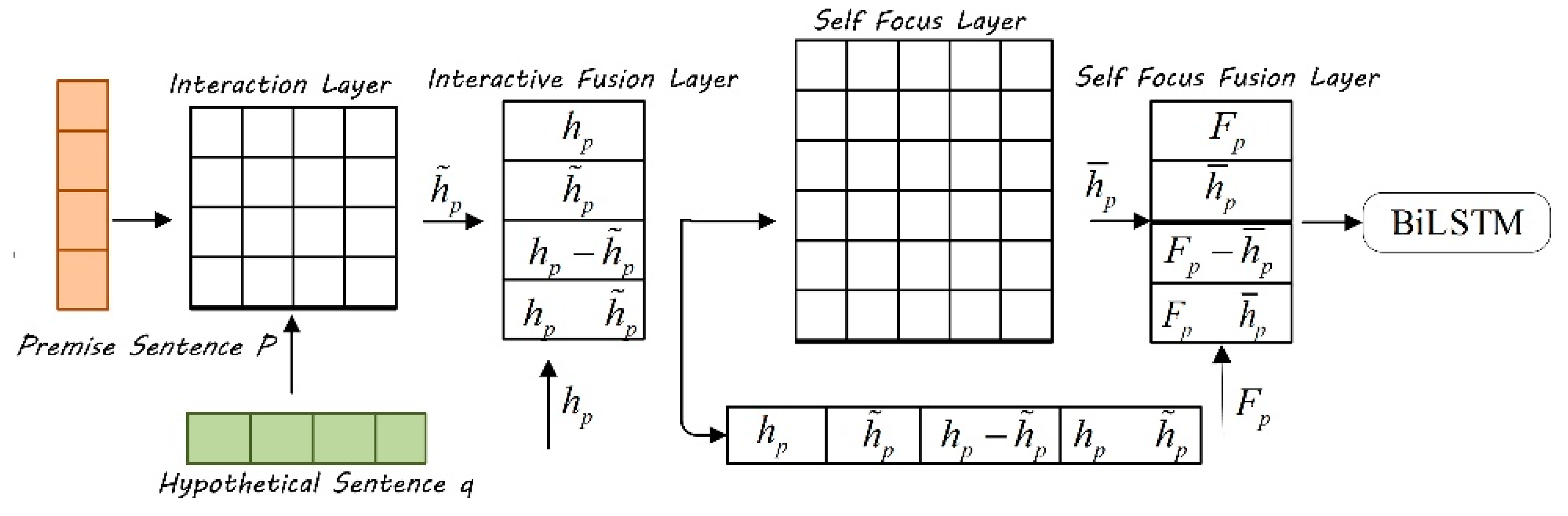
3.2.2. Local Reasoning Based on Improved AF-DMN
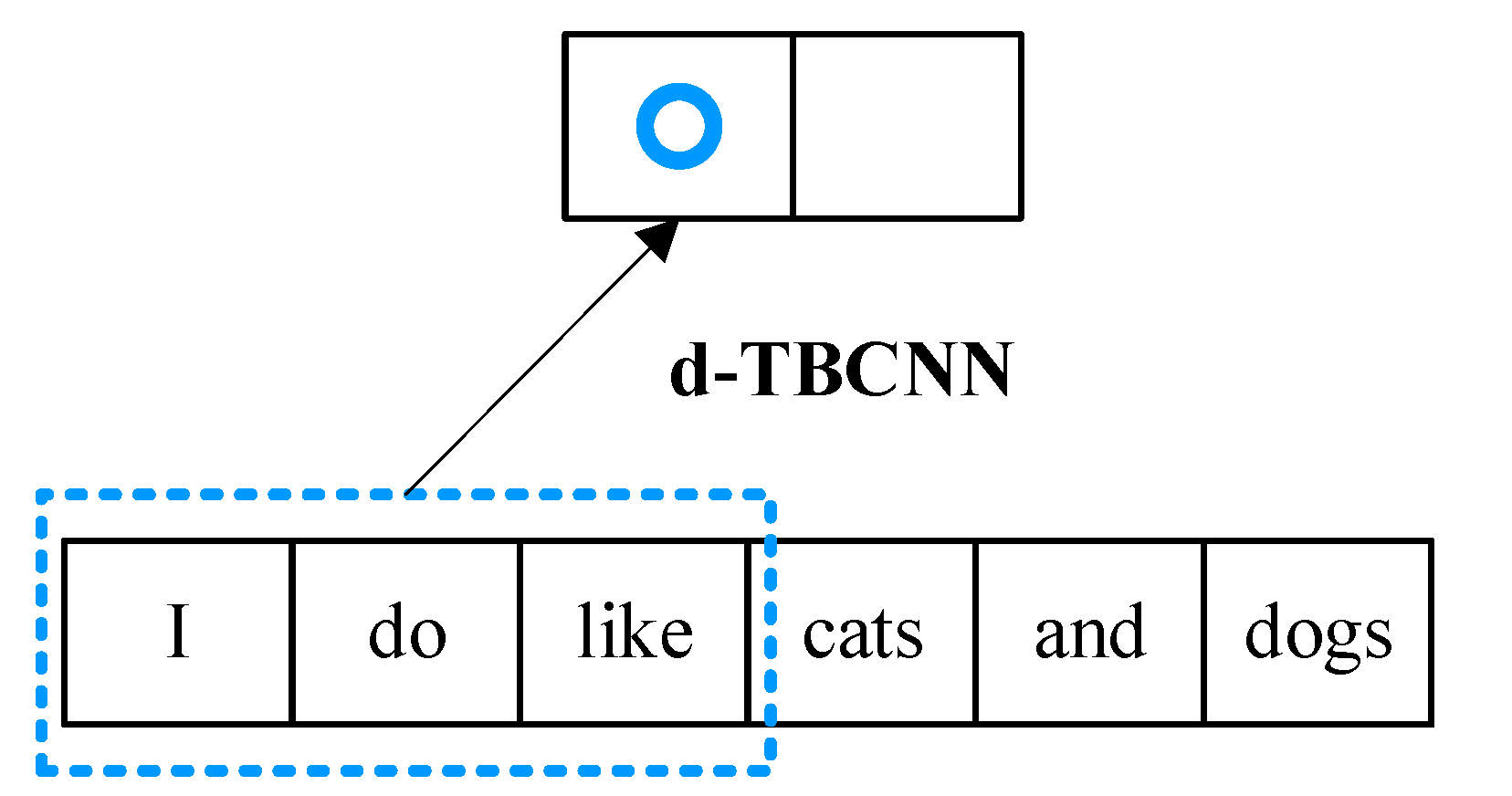
3.2.3. Syntactic Structure Modeling Based on d-TBCNN
- (1).
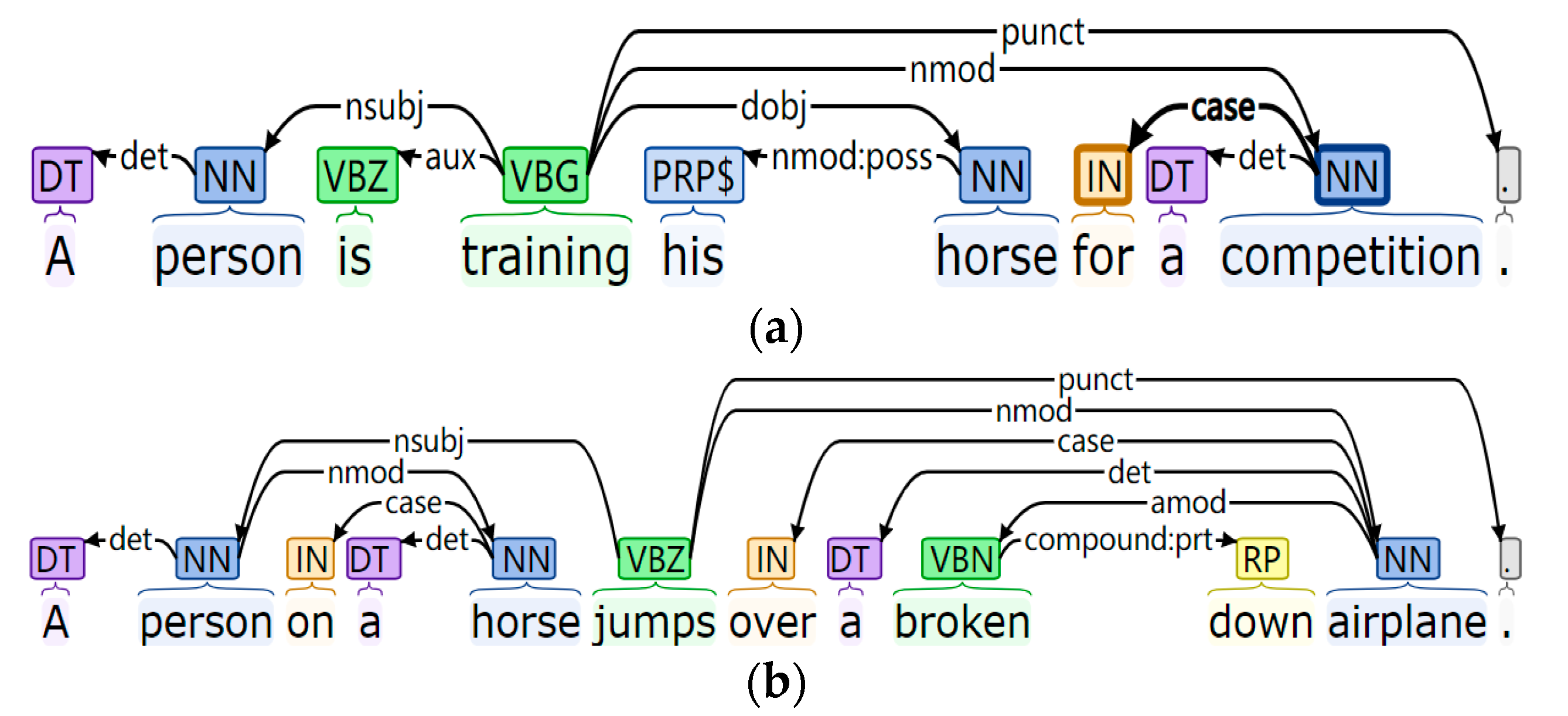
- Firstly, the natural language parser [24] proposed by Stanford University is used to transform sentences into a dependency syntax tree. Taking the premise sentence as an example, each node in the syntax tree corresponds to a word in the sentence. The arc between nodes indicates that the node (child node) and node (parent node) have a dependency relationship, and the arc is marked with the syntax relationship between the two nodes [25]. Because there are too many dependencies between words, some are meaningless for inferring sentence structure information. Therefore, referring to the work of Mou [26], the dependency convolution layer only retains 34 grammatical relationships that are frequently used and are more important. Some of the dependencies are shown in Table 3.
- (2).
- (Then, the syntactic structure features corresponding to the subtree are extracted along with the dependency subtree. The feature extractor adopts a double-layer convolution layer [27]. Suppose that the child nodes connected to the parent node are , in which represents the total number of child nodes. For each subtree , the extracted local sentence structure features are as follows:
- (3).
- By pooling the structural features of each subtree in the sentence , the syntactic structure features of the sentence are shown in Formula (20), and the syntactic structure features of the sentence are shown in Formula (21).
3.2.4. Global Reasoning Information
3.2.5. Result Reasoning and Prediction
4. Results
- The maximum length of the sentence is set to 100. The model uses word2vec technology [28] to obtain the word embedding vector, where the dimension of the word embedding vector is 300, and GloVe-840B-300D is used to initialize the pretraining word vector. For words not included in the dictionary, the value of [−0.1, 0.1] is used for random initialization, and the word vector is kept updated with the training process.
- The dimensions of all LSTM networks in the model are 300, the activation function adopts the Relu function, and the weight parameters in the network are initialized randomly [29].
- The model optimization uses the Adam optimization algorithm [30], the default parameters 1α and 2α are set to 0.9 and 0.99, respectively, and the initial learning rate of the network is set to 0.0002.
- In order to prevent data overfitting, we use the Dropout strategy during training [31]. The input and output layers of each layer of the network are added to the Dropout layer and the dropout is set to 0.8.
- For the SNLI dataset, the training process, the number of training batches, and the number of verification matches are set to 32; for the Multi-NLI dataset, the number of training batches and the number of verification matches in the training process is set to 8.
- For the SNLI dataset, the number of matching modules in the matching layer is set to 3; for the Multi-NLI matching module, the number T is set to 2 [20].
- The models are tested on two datasets to see if they could produce the correct answer or not. The accuracy of their performances is then calculated as the main evaluation index.
4.1. Experimental Results on SNLI Dataset
4.2. Results on Multi-NLI Datasets
5. Discussion
5.1. Analysis of Prediction Accuracy
5.2. Analysis of Semantic Relevance
5.3. Ablation Analysis
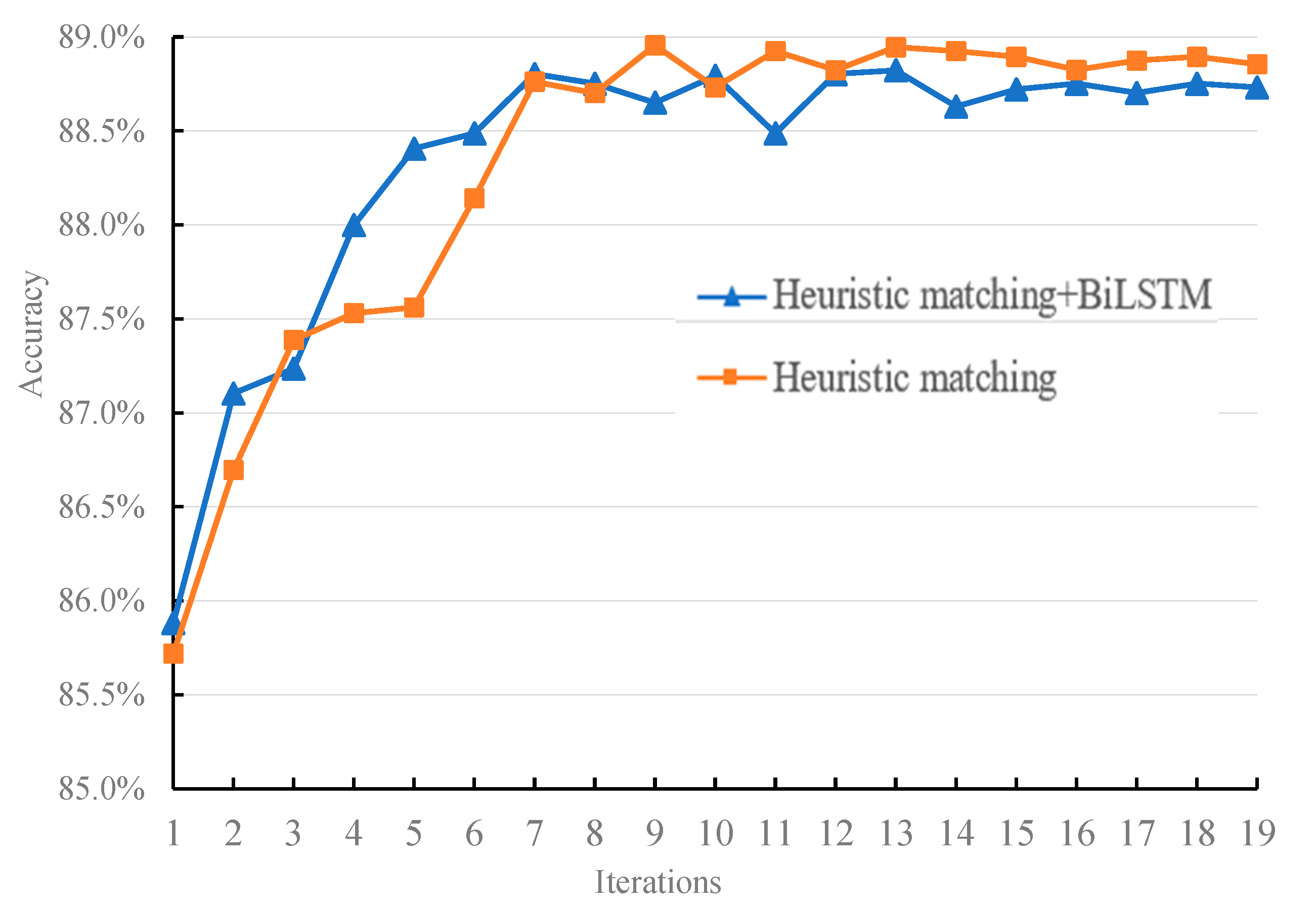
5.3.1. The Influence of Interactive Fusion Mode
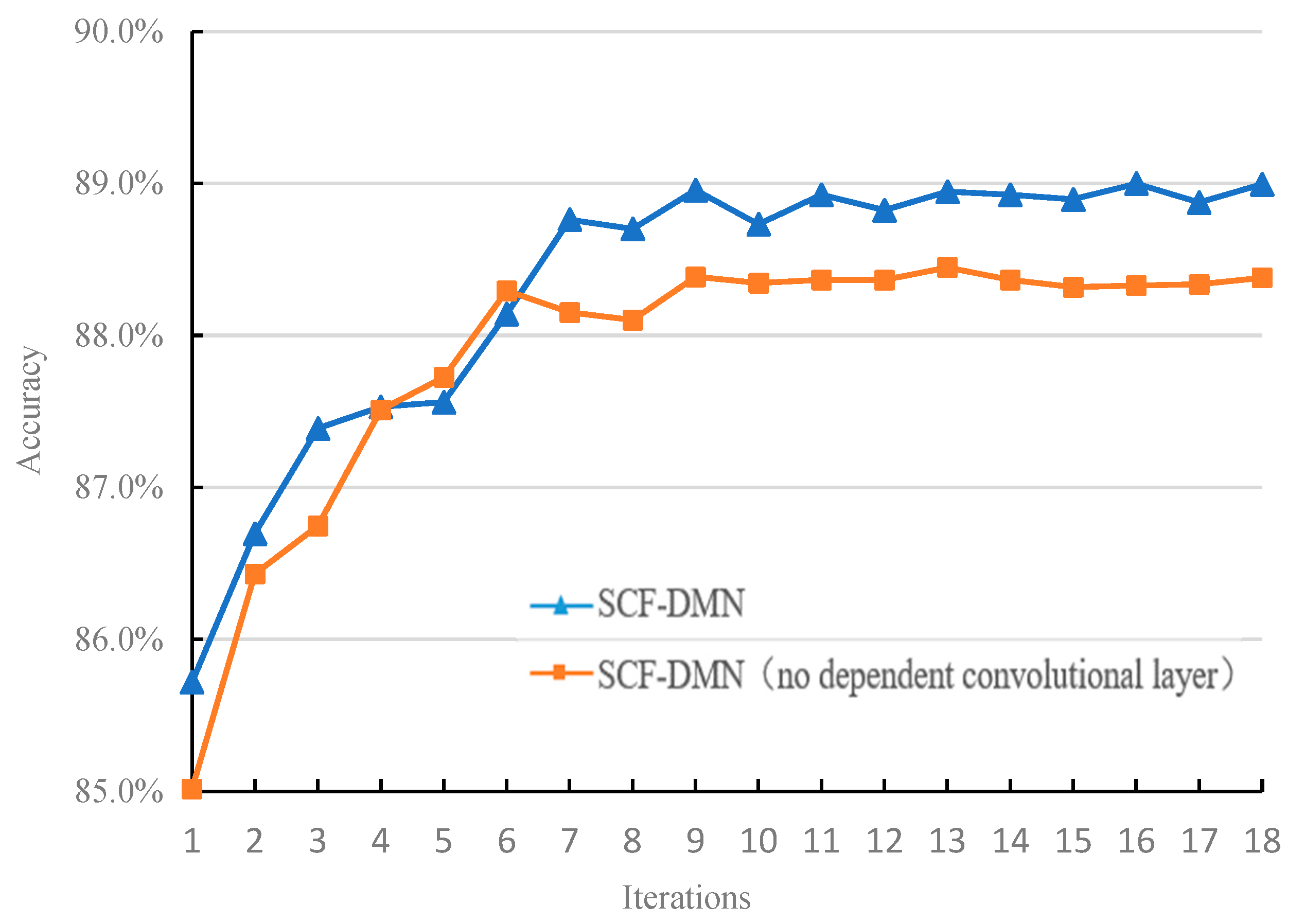
5.3.2. The Influence of Syntactic Structure Information
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hu, B.; Lu, Z.; Li, H.; Chen, Q. Convolutional neural network architectures for matching natural language sentences. Adv. Neural Inf. Process. Syst. 2014, 2, 2042––2050. [Google Scholar]
- Tan, Z.; Chen, J.; Kang, Q.; Zhou, M.; Abusorrah, A.; Sedraoui, K. Dynamic embedding projection-gated convolutional neural networks for text classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 973–982. [Google Scholar] [CrossRef] [PubMed]
- Leng, X.-L.; Miao, X.-A.; Liu, T. Using recurrent neural network structure with Enhanced Multi-Head Self-Attention for sentiment analysis. Multimed. Tools Appl. 2021, 80, 12581–12600. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- MacCartney, B. Natural Language Inference; Stanford University: Stanford, CA, USA, 2009. [Google Scholar]
- Liu, Y.; Guan, W.; Lu, D.; Zou, X. A label-oriented loss function for learning sentence representations. Comput. Speech Lang. 2021, 66, 101165. [Google Scholar] [CrossRef]
- Moldovan, D.; Clark, C.; Harabagiu, S.; Maiorano, S. Cogex: A logic prover for question answering. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology, Stroudsburg, PA, USA, 27 May–1 June 2003; Volume 1, pp. 87–93. [Google Scholar]
- Raina, R.; Ng, A.Y.; Manning, C.D. Robust textual inference via learning and abductive reasoning. In Proceedings of the Twentieth National Conference on Artificial Intelligence (AAAI-05), Pittsburgh, PA, USA, 9–13 July 2005; pp. 1099–1105. [Google Scholar]
- Le, N.Q.K.; Yapp, E.K.Y.; Nagasundaram, N.; Yeh, H.-Y. Classifying promoters by interpreting the hidden information of DNA sequences via deep learning and combination of continuous FastText N-grams. Front. Bioeng. Biotechnol. 2019, 305. [Google Scholar] [CrossRef] [Green Version]
- Le, N.Q.K.; Ho, Q.-T.; Nguyen, T.-T.-D.; Ou, Y.-Y. A transformer architecture based on BERT and 2D convolutional neural network to identify DNA enhancers from sequence information. Brief. Bioinform. 2021, 22, bbab005. [Google Scholar] [CrossRef] [PubMed]
- Ni, X.; Yin, L.; Chen, X.; Liu, S.; Yang, B.; Zheng, W. Semantic representation for visual reasoning. In MATEC Web of Conferences; EDP Sciences: Les Ulis, France, 2019; p. 02006. [Google Scholar]
- Zhu, Y.; Ko, T.; Snyder, D.; Mak, B.; Povey, D. Self-attentive speaker embeddings for text-independent speaker verification. In Proceedings of the Interspeech 2018, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 3573–3577. [Google Scholar]
- Williams, A.; Nangia, N.; Bowman, S.R. A broad-coverage challenge corpus for sentence understanding through inference. arXiv 2017, arXiv:1704.05426. [Google Scholar]
- Liu, Y.; Wan, Y.; He, L.; Peng, H.; Yu, P.S. KG-BART: Knowledge graph-augmented BART for generative commonsense reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, online. 2–9 February 2021; pp. 6418–6425. [Google Scholar]
- Quamer, W.; Jain, P.K.; Rai, A.; Saravanan, V.; Pamula, R.; Kumar, C. SACNN: Self-attentive convolutional neural network model for natural language inference. Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–16. [Google Scholar] [CrossRef]
- Cheng, Z.; Dai, X.; Huang, S.; Chen, J. Variational Explanation Generator: Generating Explanation for Natural Language Inference using Variational Auto-Encoder. Int. J. Comput. Inf. Eng. 2021, 15, 119–125. [Google Scholar]
- Wu, H.; Huang, J. Relative Position Representation over Interaction Space for Natural Language Inference. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Peng, H.; Li, J.; Wang, S.; Wang, L.; Gong, Q.; Yang, R.; Li, B.; Philip, S.Y.; He, L. Hierarchical taxonomy-aware and attentional graph capsule RCNNs for large-scale multi-label text classification. IEEE Trans. Knowl. Data Eng. 2019, 33, 2505–2519. [Google Scholar] [CrossRef] [Green Version]
- Johnson, M.; Schuster, M.; Le, Q.V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viégas, F.; Wattenberg, M.; Corrado, G. Google’s multilingual neural machine translation system: Enabling zero-shot translation. Trans. Assoc. Comput. Linguist. 2017, 5, 339–351. [Google Scholar] [CrossRef] [Green Version]
- Duan, C.; Cui, L.; Chen, X.; Wei, F.; Zhu, C.; Zhao, T. Attention-Fused Deep Matching Network for Natural Language Inference. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 4033–4040. [Google Scholar]
- Mou, L.; Peng, H.; Li, G.; Xu, Y.; Zhang, L.; Jin, Z. Discriminative neural sentence modeling by tree-based convolution. arXiv 2015, arXiv:1504.01106. [Google Scholar]
- Parikh, A.P.; Täckström, O.; Das, D.; Uszkoreit, J. A decomposable attention model for natural language inference. arXiv 2016, arXiv:1606.01933. [Google Scholar]
- Chen, Q.; Zhu, X.; Ling, Z.; Wei, S.; Jiang, H.; Inkpen, D. Enhanced LSTM for natural language inference. arXiv 2016, arXiv:1609.06038. [Google Scholar]
- Chen, D.; Manning, C.D. A fast and accurate dependency parser using neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 740–750. [Google Scholar]
- De Marneffe, M.-C.; MacCartney, B.; Manning, C.D. Generating typed dependency parses from phrase structure parses. In Proceedings of the Fifth International Conference on Language Resources and Evaluation, LREC 2006, Genoa, Italy, 22–28 May 2006; pp. 449–454. [Google Scholar]
- Mou, L.; Men, R.; Li, G.; Xu, Y.; Zhang, L.; Yan, R.; Jin, Z. Natural language inference by tree-based convolution and heuristic matching. arXiv 2015, arXiv:1512.08422. [Google Scholar]
- Graves, A.; Jaitly, N.; Mohamed, A.-r. Hybrid speech recognition with deep bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. arXiv 2015, arXiv:1508.05326. [Google Scholar]
- Munkhdalai, T.; Yu, H. Neural tree indexers for text understanding. In Proceedings of the Conference. Association for Computational Linguistics. Meeting, Vancouver, BC, Canada, 30 July–4 August 2017; p. 11. [Google Scholar]
- Graves, A.; Wayne, G.; Reynolds, M.; Harley, T.; Danihelka, I.; Grabska-Barwińska, A.; Colmenarejo, S.G.; Grefenstette, E.; Ramalho, T.; Agapiou, J. Hybrid computing using a neural network with dynamic external memory. Nature 2016, 538, 471–476. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Jiang, J. Learning natural language inference with LSTM. arXiv 2015, arXiv:1512.08849. [Google Scholar]
- Sha, L.; Chang, B.; Sui, Z.; Li, S. Reading and thinking: Re-read lstm unit for textual entailment recognition. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 2870–2879. [Google Scholar]
- Liu, P.; Qiu, X.; Chen, J.; Huang, X.-J. Deep fusion lstms for text semantic matching. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 1034–1043. [Google Scholar]
- Liu, Y.; Zhao, T.; Chai, Y.; Jiang, Y. A Word Elimination Strategy for Learning Document Representation. IOP Conf. Ser. Mater. Sci. Eng. 2018, 466, 012091. [Google Scholar] [CrossRef]
- Bhowmik, P.; Pantho, J.H.; Mbongue, J.M.; Bobda, C. ESCA: Event-based split-CNN architecture with data-level parallelism on ultrascale+ FPGA. In Proceedings of the 2021 IEEE 29th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Orlando, FL, USA, 9–12 May 2021; pp. 176–180. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Premise Sentence | The Label | Hypothetical Sentence |
|---|---|---|
| Two women are embracing while holding to-go packages. | Entailment E E E E E | Two woman are holding packages. |
| A man selling donuts to a customer during a world exhibition event held in the city of Los Angeles. | Contradiction C C C C C | A woman drinks her coffee in a small café. |
| A man in a blue shirt standing in front of a garage-like structure painted with geometric designs. | Neutral N E N N N | A man is repainting a garage. |
| Type | Premise Sentence | The Label | Hypothetical Sentence |
|---|---|---|---|
| Novel | The Old One always comforted Ca’daan, except today. | neutral | Ca’daan knew the Old One very well. |
| Message | Your gift is appreciated by each and every student who will benefit from your generosity. | neutral | Hundreds of students will benefit from your generosity. |
| Cell | yes now you know if everybody like in August when everybody’s on vacation or something we can dress a little more casual or | contradiction | August is a black out month for vacations in the company. |
| Sign | Relationship Type |
|---|---|
| SBV | Subject–verb |
| VOB | Verb–object |
| IOB | Indirect–object |
| FOB | Fronting–object |
| Model | Training (%) | Test Set (%) |
|---|---|---|
| 300D Tree-CNN (Mou et al., 2015) | 83.3 | 82.1 |
| 300D NSE (Munkhdalai et al., 2016) | 86.2 | 84.6 |
| 100D LSTMs with attention (Rocktäschel et al., 2015) | 85.3 | 83.5 |
| 100D Deep Fusion LSTM (Liu et al., 2016) | 85.2 | 84.6 |
| 300D Matching-LSTM (Wang et al., 2015) | 92.0 | 86.1 |
| 200D Decomposable Attention Models (Parikh et al., 2016) | 90.5 | 86.8 |
| 300D Re-read LSTM (Sha et al. 2016) | 90.7 | 87.5 |
| 600D ESIM (Chen et al. 2017) | 92.6 | 88.0 |
| AF-DMN (Duan et.al., 2017) | 94.5 | 88.6 |
| Model in this paper | 95.8 | 89.0 |
| Model | Matching Set (%) | Unmatched Set (%) |
|---|---|---|
| CBOW (Williams et al., 2018) | 64.8 | 64.5 |
| BiLSTM (Williams et al., 2018) | 66.9 | 66.9 |
| ESIM (Chen et al., 2017) | 76.8 | 75.8 |
| AF-DMN (Duan et al., 2018) | 76.9 | 76.3 |
| Model in this paper | 77.1 | 75.3 |
| Interactive Integration Mode | Accuracy Rate (%) | Best Iteration | Training Time (h) | Hyper-Parameters |
|---|---|---|---|---|
| Heuristic matching + BiLSTM | 88.7 | 9 | 26.87 | 47,071,203 |
| Heuristic matching | 89.0 | 8 | 22.87 | 43,285,803 |
| Model Composition | Accuracy Rate (%) | Training Time (H) | Hyper-Parameters |
|---|---|---|---|
| SCF-DMN | 89.0 | 22.87 | 43,285,803 |
| SCF-DMN (without dependent convolution layer) | 88.3 | 14.15 | 23,535,603 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, W.; Zhou, Y.; Liu, S.; Tian, J.; Yang, B.; Yin, L. A Deep Fusion Matching Network Semantic Reasoning Model. Appl. Sci. 2022, 12, 3416. https://doi.org/10.3390/app12073416
Zheng W, Zhou Y, Liu S, Tian J, Yang B, Yin L. A Deep Fusion Matching Network Semantic Reasoning Model. Applied Sciences. 2022; 12(7):3416. https://doi.org/10.3390/app12073416
Chicago/Turabian StyleZheng, Wenfeng, Yu Zhou, Shan Liu, Jiawei Tian, Bo Yang, and Lirong Yin. 2022. "A Deep Fusion Matching Network Semantic Reasoning Model" Applied Sciences 12, no. 7: 3416. https://doi.org/10.3390/app12073416