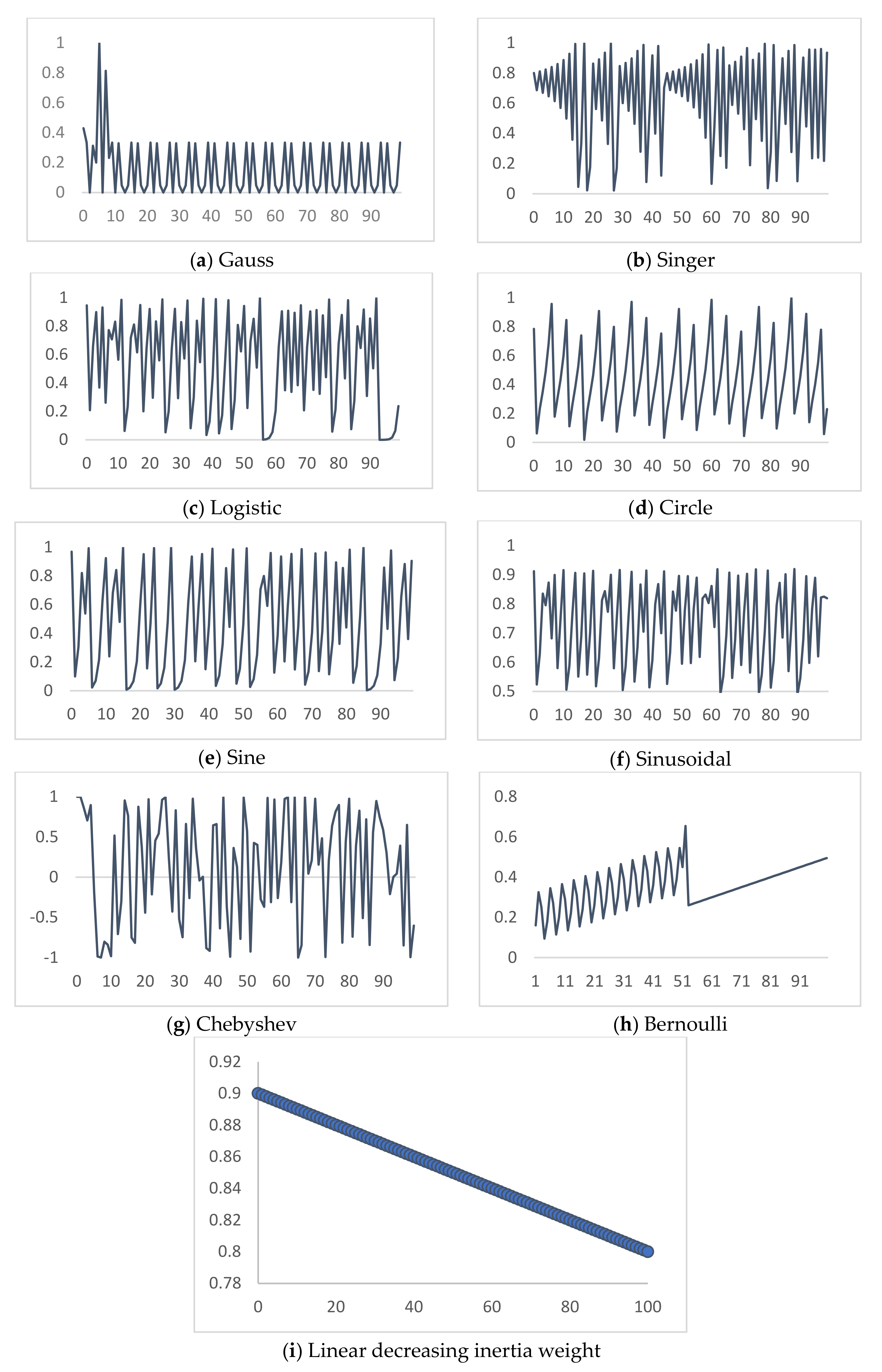
6.1. Preliminary Observations
To assess the behaviors in optimizing the three estimation methods, we follow the procedure of tuning the following two parameters of the MUCPSO algorithm: population
p and chaotic maps as described in [
63]. Here, for each estimation method, 80 experiments are performed using a combination of 10 values of
p = 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, and eight chaotic maps = Bernoulli, Chebyshev, Circle, Gauss, Logistic, Sine, Singer, and Sinusoidal, which can be defined as pairs of (10, Bernoulli), (10, Chebyshev), …, (100, Sinusoidal). To reduce the coincidence, 1000 runs were applied to each pair in experiment. The common parameter value of
p is finally selected as a fixed-optimum value for all the estimation methods.
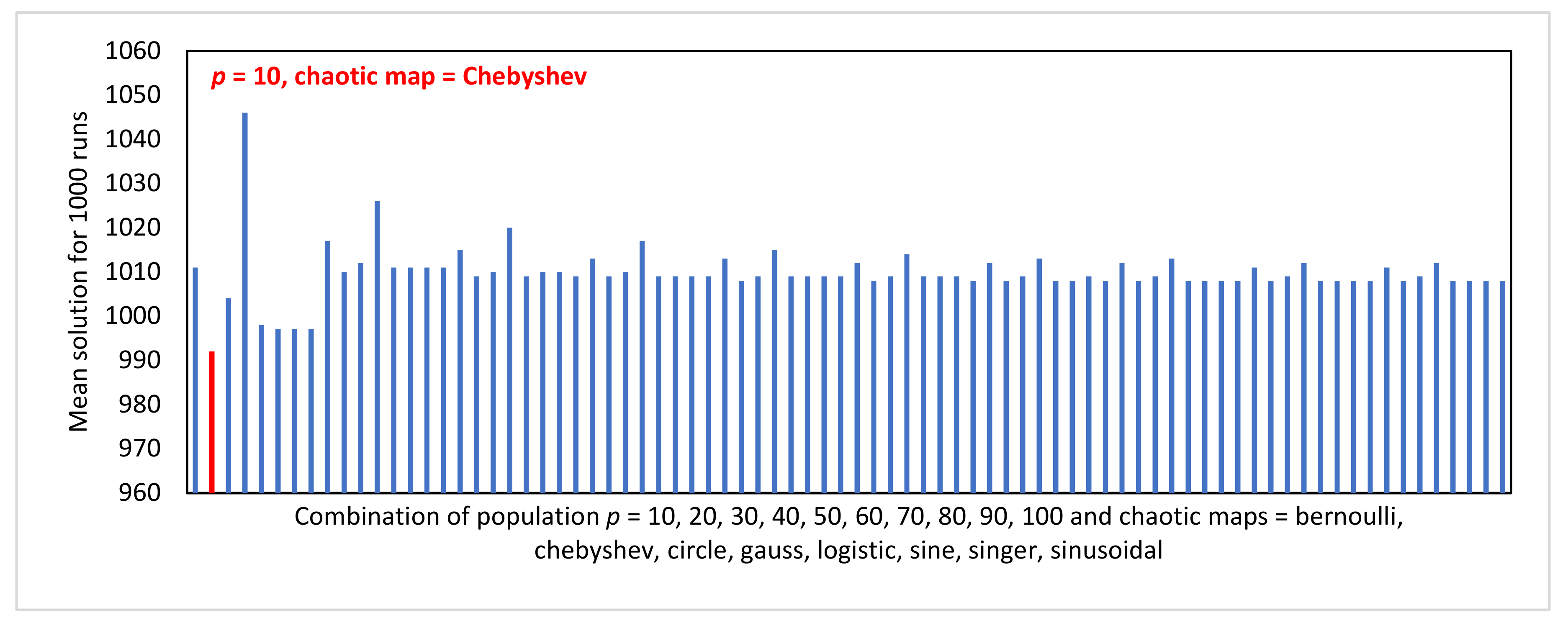
Figure 2 illustrates the experimental results for the problem of searching a minimum solution for the Use Case Points estimation method. The vertical axis shows all results from eighty experiments. It can be seen that a small population
p (10) means the MUCPSO produces a good solution. In contrast, the bigger the
p, the worse the solution. Hence, the combination of small
p and Chebyshev as the chaotic function is recommended. The optimum combination is reached using
p = 10 and chaotic = Chebyshev.
Next,
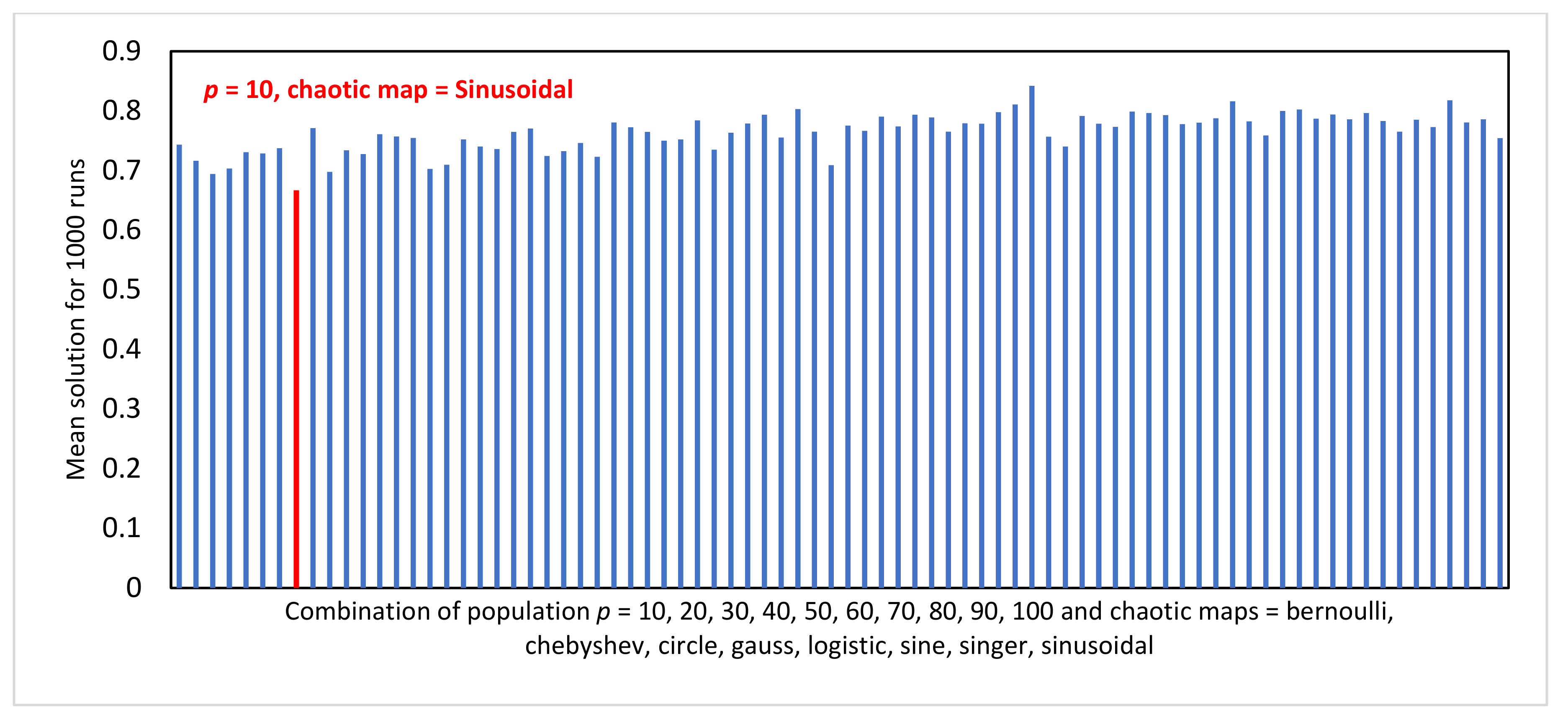
Figure 3 illustrates the experimental results for the problem of searching for a minimum solution in the Agile estimation method. The vertical axis shows all results from eighty experiments. It can be seen that a small population
p (10) means the MUCPSO produces a good solution. In contrast, the bigger the
p, the worse the solution. Hence, the combination of small
p and Sinusoidal as the chaotic function is recommended. The optimum combination is reached using
p = 10 and chaotic = Sinusoidal.
Finally,
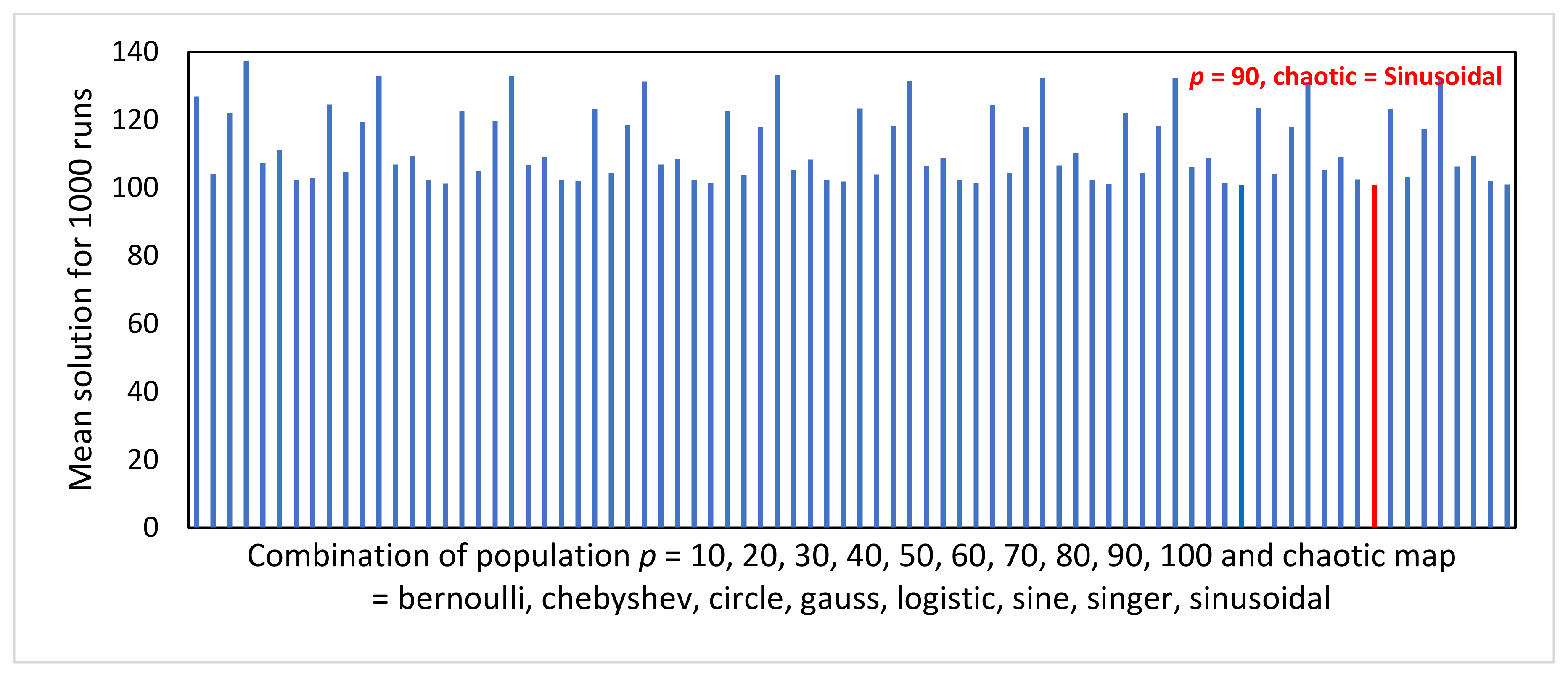
Figure 4 illustrates the experimental results for the problem of searching for a minimum solution using the COCOMO estimation method. The vertical axis shows all results from eighty experiments. It can be seen that a large population
p (90) means the MUCPSO produces a good solution. In contrast, the smaller the
p, the worse the solution. Hence, the combination of large
p and Sinusoidal as the chaotic function is recommended. The optimum combination is reached for
p = 90 and chaotic = Sinusoidal.
6.2. Parameter Settings
Based on previous research in [
23,
24,
47,
64], the best population size for each algorithm has been defined. However, due to the difference of function between software effort estimation methods, we conducted ten experiments with
p = 10, 20, …, 100 to find the optimum
p for each algorithm based on the Friedman Mean Rank (FMR).
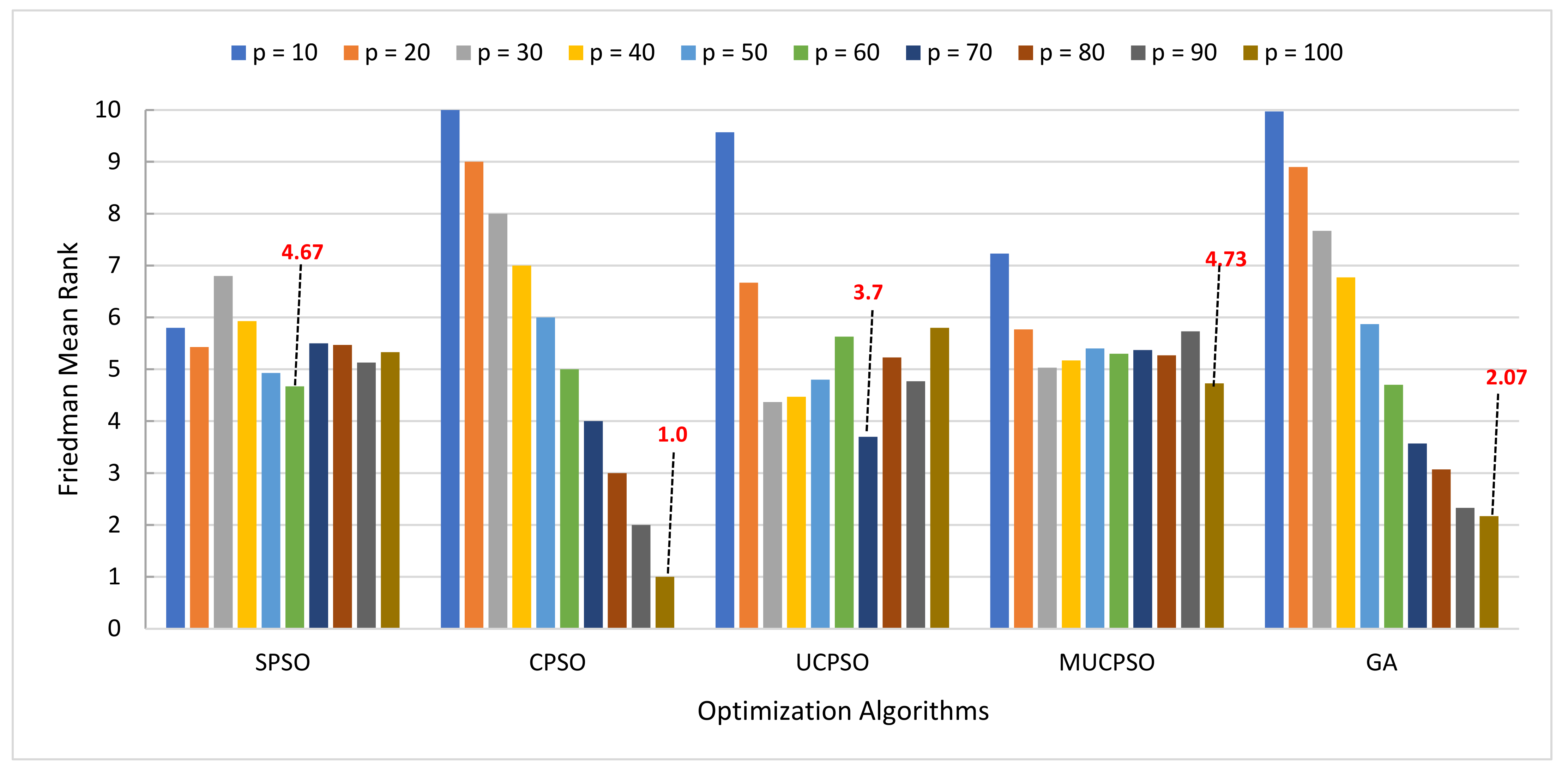
Figure 5 illustrates the experimental results for the COCOMO estimation method. The behavior of
p is quite similar for CPSO, MUCPSO, and GA. The larger the
p, the better the rank. The optimum value is reached using
p = 100 for the three algorithms. Meanwhile,
p gives a different effect for SPSO and UCPSO that achieves the optimum value through
p = 60 and 70, respectively.
Next,
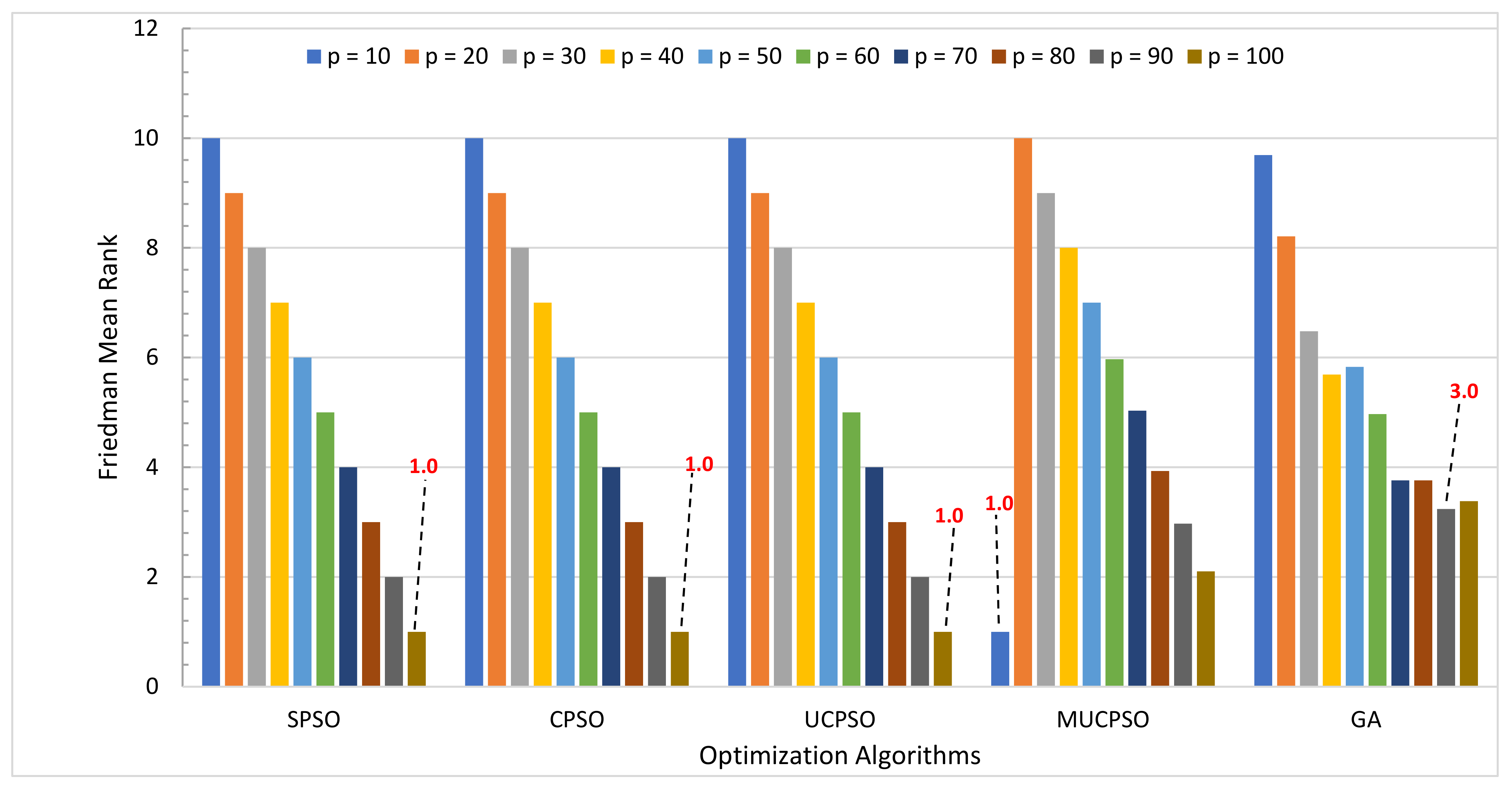
Figure 6 illustrates the experiment results for the UCP estimation method. The behavior of
p is similar for SPSO, CPSO, and UCPSO. The larger the
p, the better the rank. The optimum value is reached on
p = 100 for the three algorithms. Meanwhile, the behavior of
p provides a different effect for MUCPSO and GA that achieves the optimum value via
p = 10 and 90, respectively.
Finally,
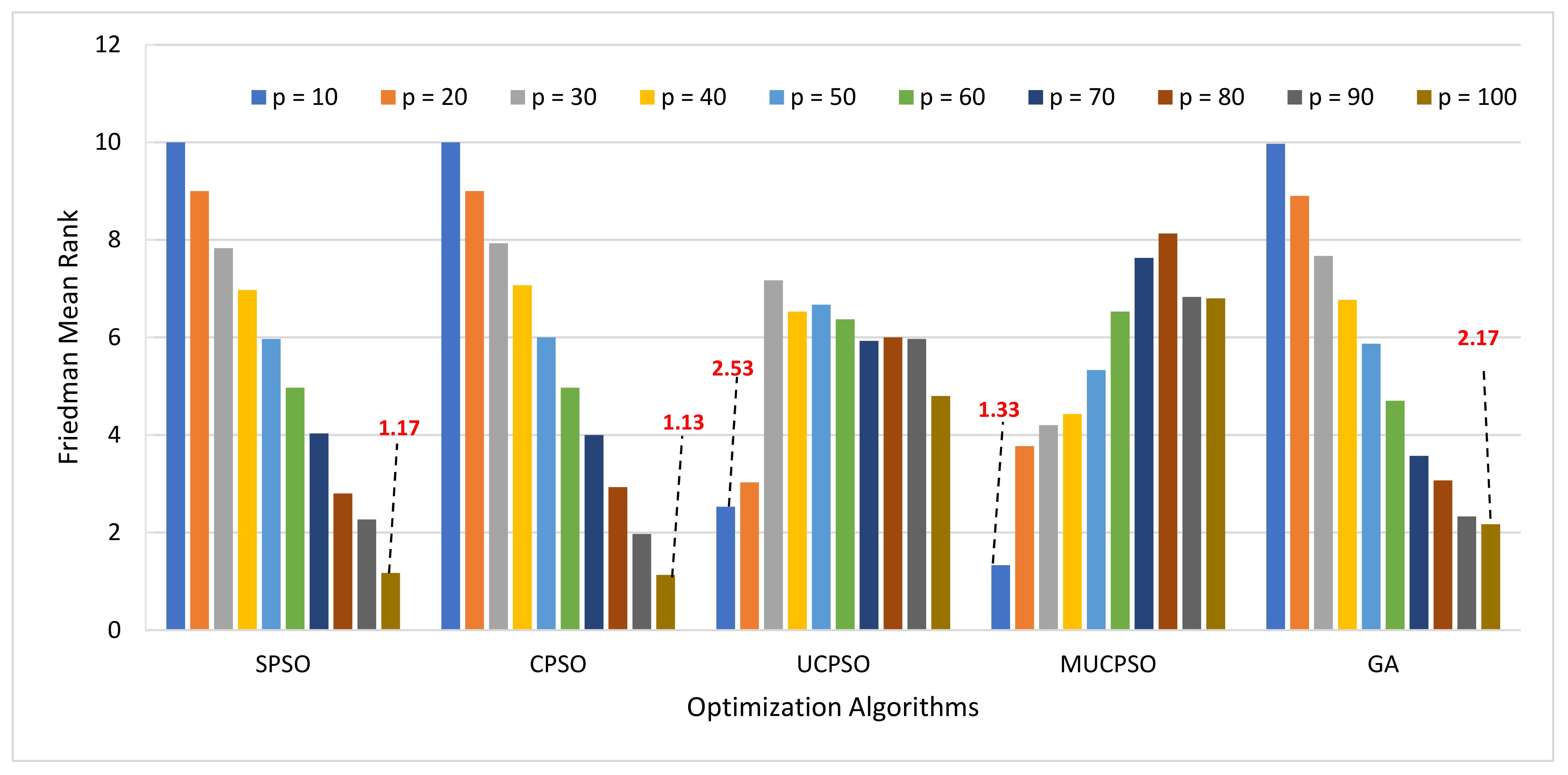
Figure 7 illustrates the experimental results for the Agile estimation method. The behavior of
p is similar for SPSO, CPSO, and GA. The larger the
p, the better the rank. The optimum value is reached using
p = 100 for the three algorithms. Meanwhile, the behavior of
p also provides similar effect for UCPSO and MUCPSO that achieves the optimum value through
p = 10.
The parameter settings for MUCPSO and other benchmark algorithms are listed in
Table 4. Parameters
c1 and
c2 are set to integer two since it, on average, sets the weights for “social” and “cognition” to 1 [
14,
64]. The stochastic parameters
r1 and
r1 are two random functions in the range [0,1] [
64]. The parameters are introduced in SPSO, and UCPSO, while CPSO and MUCPSO use the chaotic map function as their stochastic parameters.
6.3. Investigation on Three Estimation Methods
The proposed MUCPSO algorithm is examined and compared with four other algorithms, as follows: SPSO, CPSO, GA, and UCPSO to search the optimum solutions to the UCP, COCOMO, and Agile estimation method as formulated in Equation (10) to Equation (25). For each estimation method, the maximum particles size is set to 2500, with 30 runs to reduce the coincidence. The random seeds of the 30 initial populations (for each estimation method) are the same to obtain fairness. The evolution is illustrated using the step sizes of 40 to obtain fairness. Thus, all the algorithms show the same generations from 20 to 980.
Table 5 illustrates the examination results based on the following four metrics: best solution, worst solution, mean solution, and standard deviation (STD) as explained further in the following passages.
The best solution for UCP estimation is yielded by MUCPSO, whereas the highest worst and mean solution metric is obtained using UCPSO, and MUCPSO, respectively. If we compare the two lower standard deviation values between MUCPSO (0.32) and UCPSO (0.18), we can observe that the deviation value is slightly different. Hence, we can conclude that UCPSO and MUCPSO has the smallest and smaller amount of variation, respectively. In other words, the mean for MUCPSO is less reliable than the mean for MUCPSO.
The lowest best and mean solution for COCOMO estimation is yielded by SPSO, MUCPSO, respectively, whereas the highest worst solution is yielded by MUCPSO. Although SPSO has the lowest best solution, however, due to the lowest mean and standard deviation is yielded by MUCPSO compared with four other algorithms, we can conclude that MUCPSO has the smallest amount of variation and most reliable for the mean value.
The lowest solution value for Agile estimation is yielded by MUCPSO in terms of the best and mean solution. For the highest worst solution is also yielded by MUCPSO. This result is supported by its lowest standard deviation value (0.007), indicating that MUCPSO has the smallest amount of variation which means that the data points are most concentrated around the reliable mean solution. Furthermore, based on the Friedman mean rank (FMR), we can observe that MUCPSO yielded the first rank, followed by SPSO, CPSO, UCPSO, and GA.
The Wilcoxon rank-sum test illustrated in
Table 6 confirms that MUCPSO is significantly better than all the competitor algorithms for the three estimation benchmark methods. All the
p-values are lower than the significance level of 0.05, except the UCP estimation where MUCPSO is worse than UCPSO with a
p-value of greater than 0.05. However, since the proposed method has 11 better results (91.67%) out of 12 significant results, we can conclude that the proposed method is better than most of the benchmark algorithms in almost all the estimation methods.
Furthermore, we discussed the detailed investigations of the convergence analysis of MUCPSO and its competitors. For each estimation method benchmark, the maximum number of particles is set to 2500 with 30 runs.
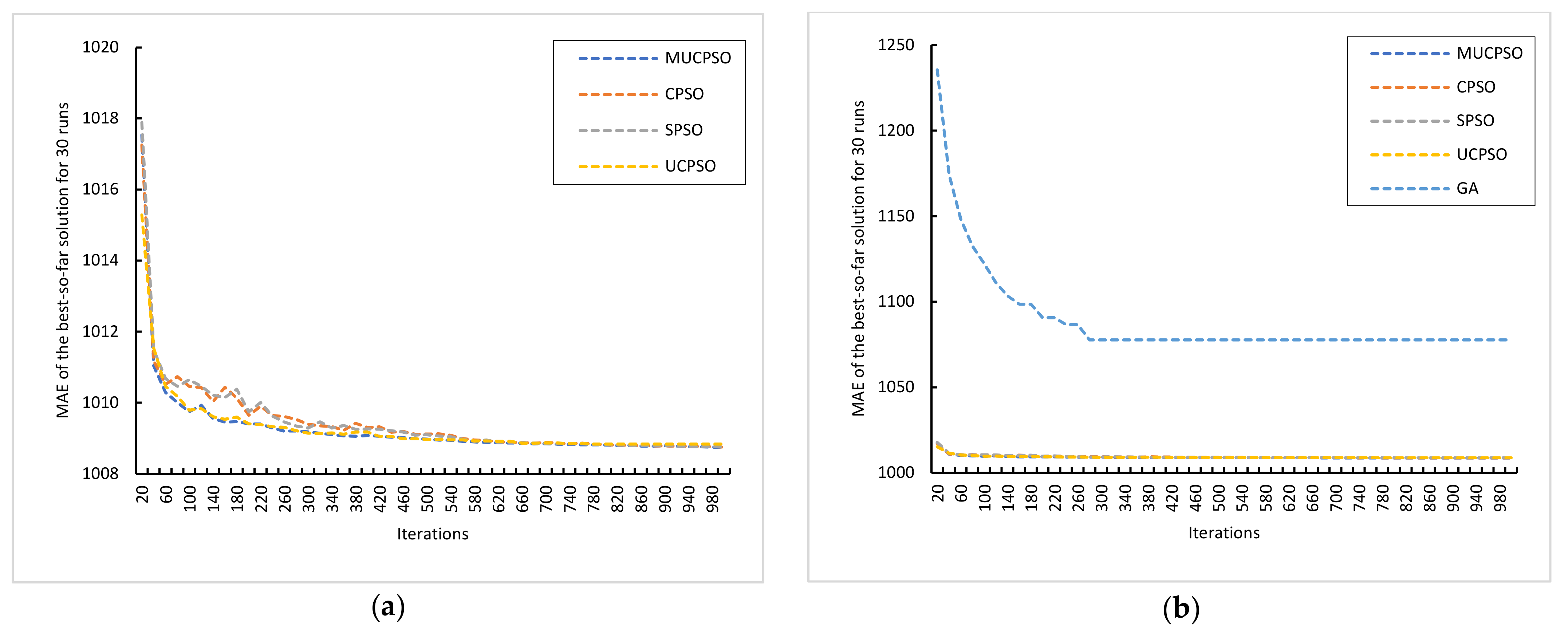
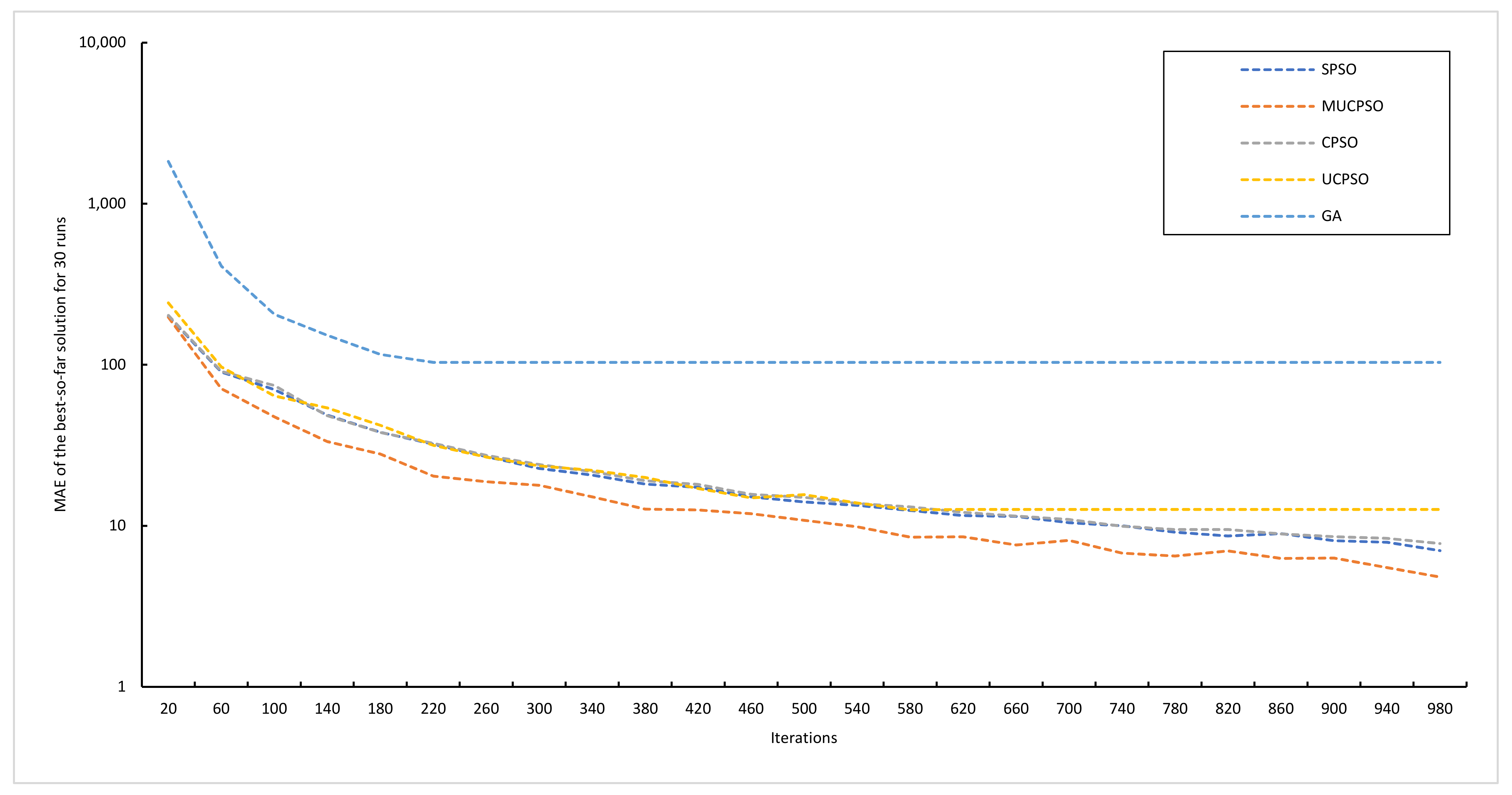
Figure 8a illustrates the evolutionary processes of four algorithms (SPSO, CPSO, UCPSO, and MUCPSO) until they converge with the optimum solution for the UCP estimation method.
Figure 8b illustrates the evolutionary process of all of the algorithms until convergence with the optimum solution. In this benchmark, MUCPSO converges to a much better solution than the other algorithms. Impressively, MUCPSO evolves at the greatest speed in the initial generations and finally provides the best mean solution of 1009.81.
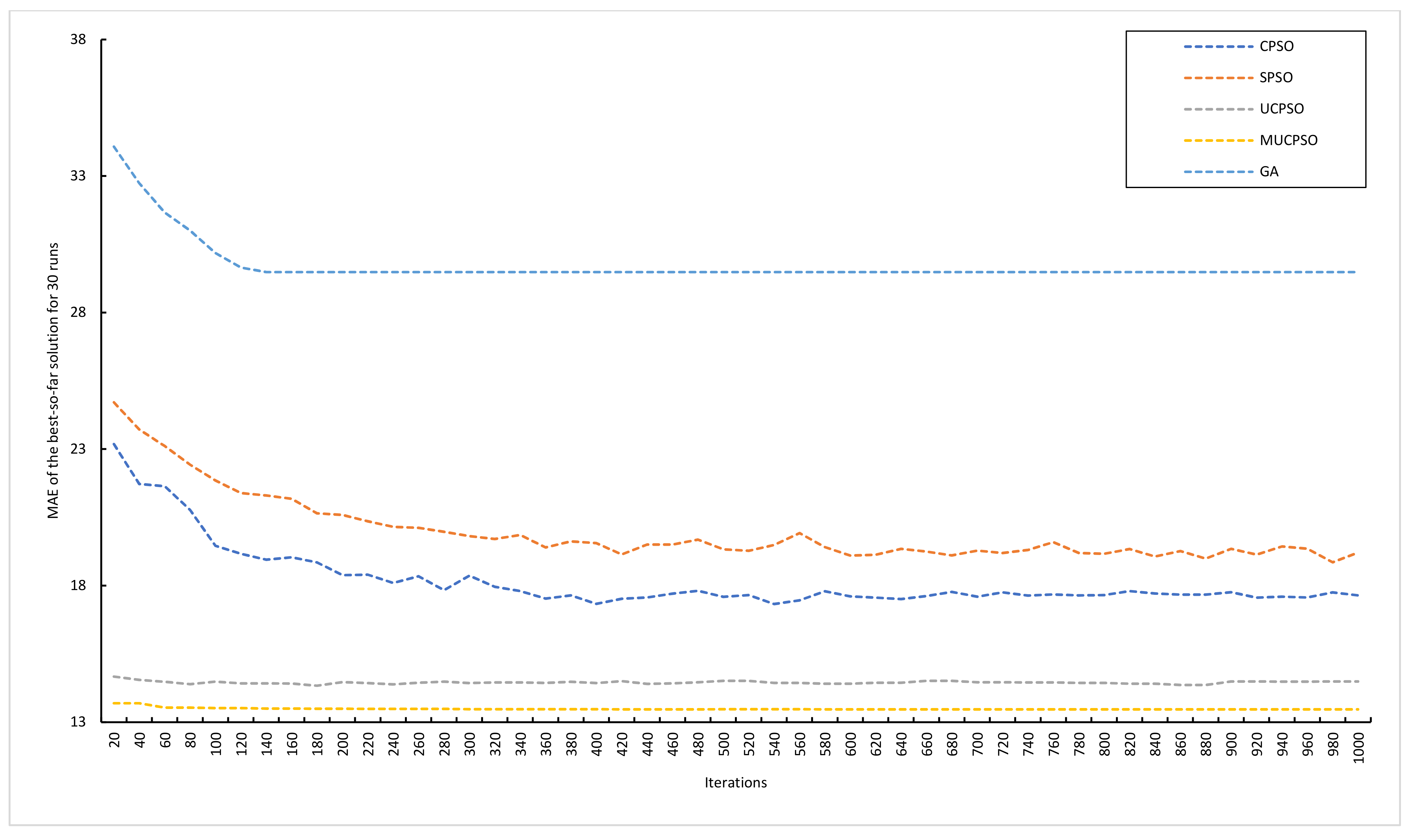
Next, the convergence analysis is provided for the COCOMO estimation method benchmark.
Figure 9 illustrates the evolutionary processes of all algorithms until convergence with the optimum solution. In this benchmark, MUCPSO converges to a much better solution than the SPSO, CPSO, GA, and UCPSO algorithm. MUCPSO demonstrates and impressive convergence from the beginning to the end of generation.
Finally,
Figure 10 illustrates the evolutionary processes of all algorithms until convergence with the optimum solution for the Agile estimation method. In this benchmark, MUCPSO converges stably to the better solution than the other algorithm. From the beginning of generation, MUCPSO is able to compete with four other algorithms and finally provides the best mean solution of 13.475.
Beside the convergence analysis, we further explore the diversity analysis of the best solution for the benchmark algorithm using three effort estimation methods.
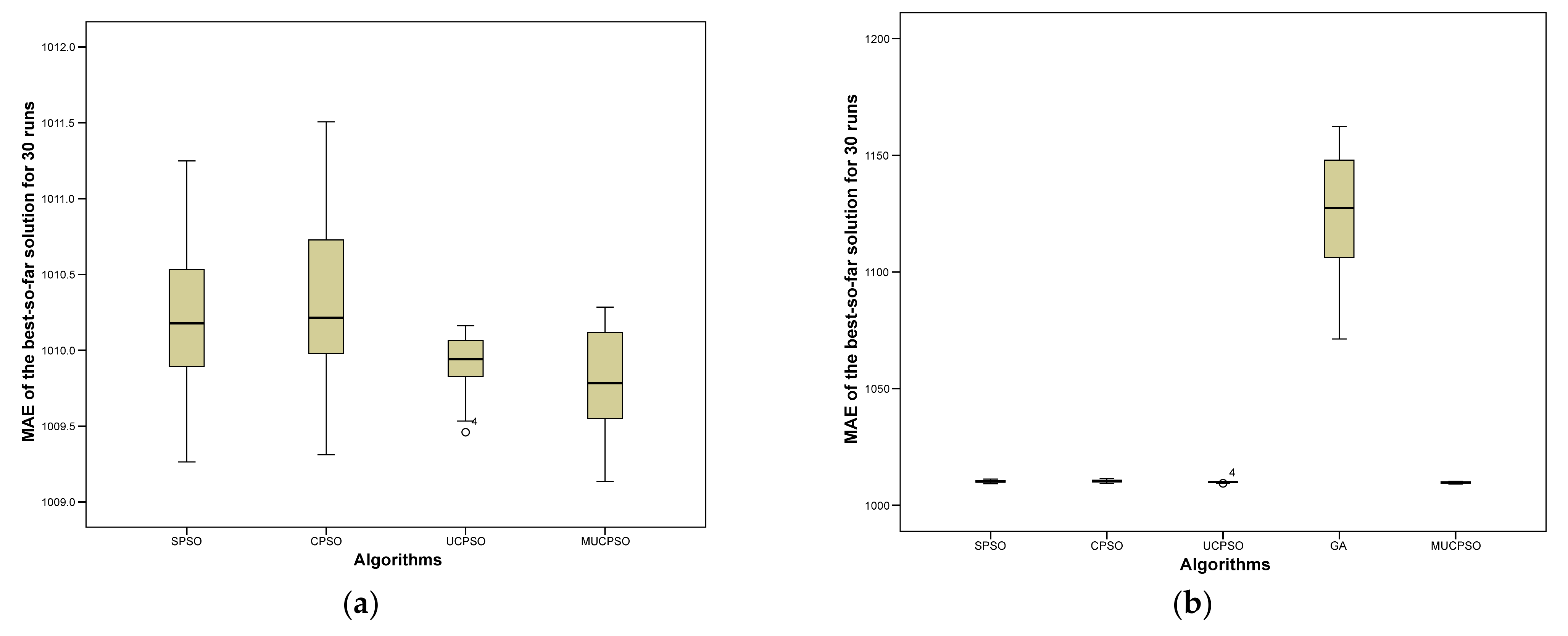
Figure 11 depicts the diversity analysis for UCP estimation.
Figure 11a depicts the diversity analysis between four algorithms (SPSO, CPSO, UCPSO, and MUCPSO), excluding GA, to demonstrate a clearer center and the spreads of each result. Based on
Figure 11a, we can observe that the median for MUCPSO is smaller compared with SPSO, CPSO and UCPSO. However, the spread of MUCPSO is quite large compared with UCPSO. In
Figure 11b, we compare all benchmark algorithms, including GA. We are able to observe that the difference between GA and the aforementioned algorithms is quite large.
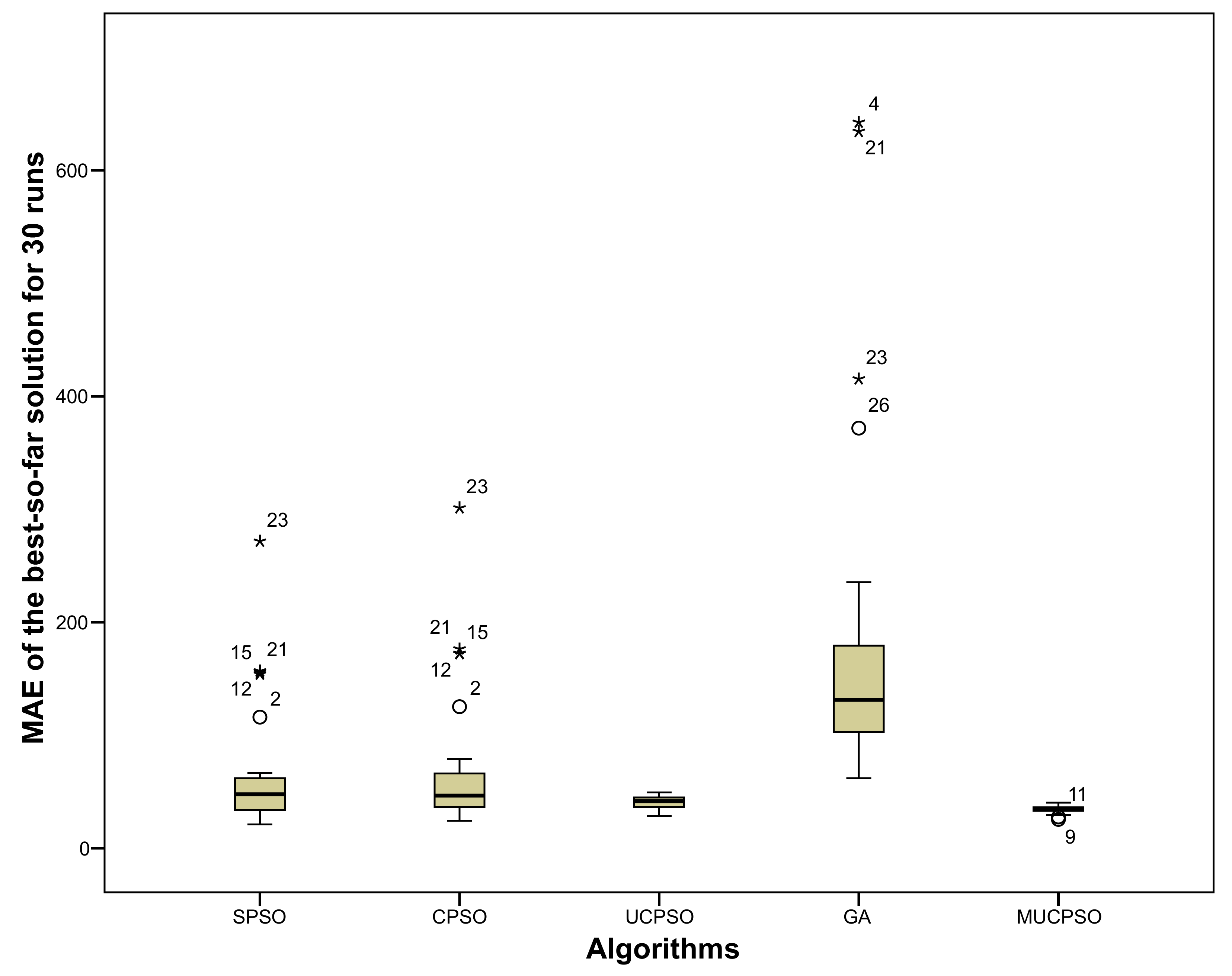
Next, we analyze the diversity of COCOMO estimation.
Figure 12 shows that the median of SPSO, CPSO, UCPSO, and MUCPSO is quite similar. However, based on the interquartile box, we can observe that MUCPSO has the smallest shape compared with other algorithms. This shape indicates that MUCPSO has the lowest spread.
Finally,
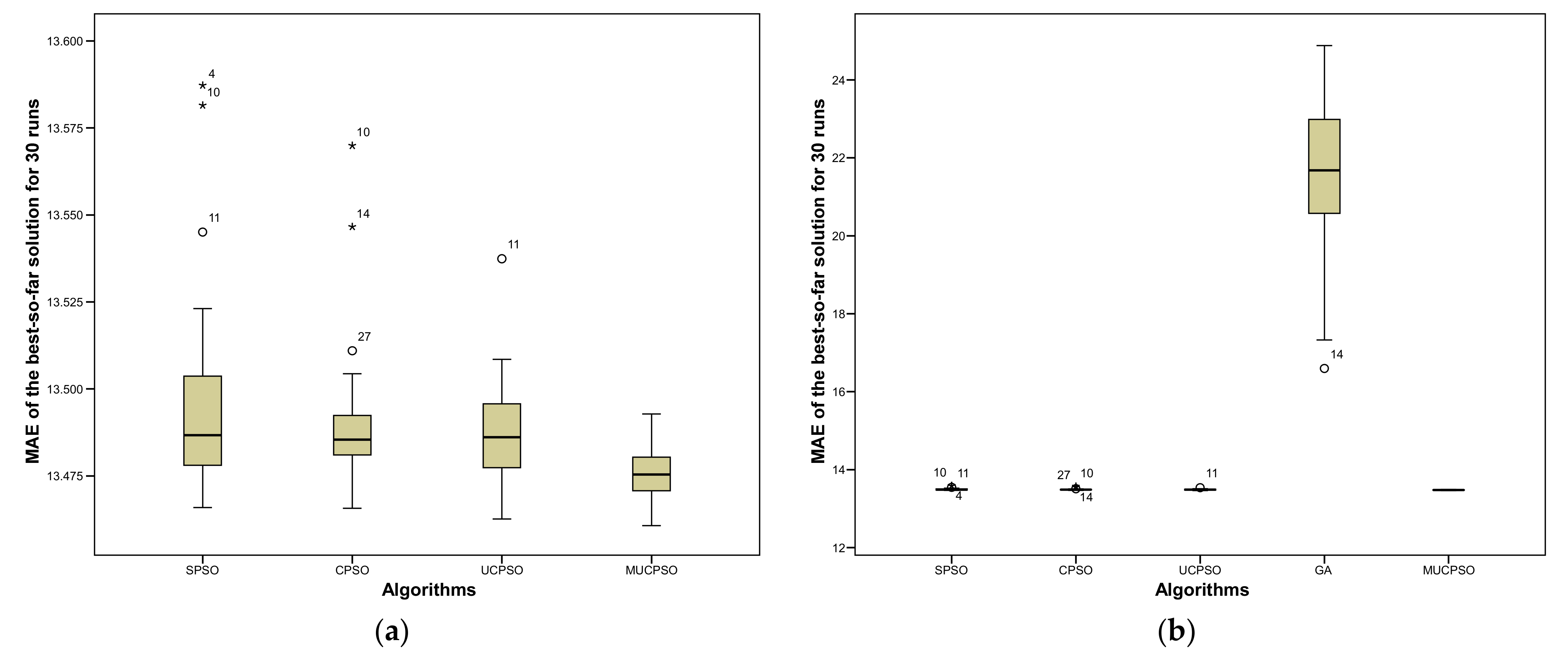
Figure 13 describe the diversity analysis of Agile estimation. Similar to
Figure 11, we split the results into two parts, presented as
Figure 13a,b. Due to the large difference observed when including GA in the group of boxplots, we provide clearer results by excluding GA in
Figure 13a. Based on the boxplots in
Figure 13a we observe that MUCPSO has the lowest median, whereas the rest (SPSO, CPSO, and UCPSO) are quite similar. Furthermore, the interquartile of MUCPSO shows the smallest shape, indicating that the proposed method has the lowest spread. Almost identical with
Figure 11b, when GA is included, the difference of results is found to be very large, and a comparison of the rest of the algorithms proves quite difficult.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}