
Call Failure Prediction in IP Multimedia Subsystem (IMS) Networks


Abstract
:1. Introduction
2. Related Work and Paper Contributions
2.1. Related Work
2.2. Paper Contribution
- (i)
- Call failure use cases analysis: Based on a SIP traces (Call Data Records (CDRs)) dataset obtained from an Egyptian mobile network operator, we analyze three different call failure use cases (Section 3). In the aforementioned call failure use cases, we conclude that the failure in any protocol inside the IMS domain will lead to SIP protocol failure.
- (ii)
- SIP features: We analyze for SIP traces, which is conducted to identify the features inside the SIP that classify the success and failure calls (Section 4).
- (iii)
- Machine learning model: We propose an IMS call failure prediction model by building eight different ML prediction models to predict whether the ongoing call will succeed/fail based on the aforementioned SIP features (Section 6). We compare four different ML classifiers: decision tree, naive Bayes, K-Nearest Neighbor (KNN) and SVM with using two feature selection methods. The feature selection methods are; (i) the Filter Selection method using the ReliefF algorithm and (ii) the Wrapper Model using the Slime Mould Algorithm (SMA) and Whale Optimization Algorithm (WOA). Predicting the failure enables the operator to prevent the failure by redirecting the call to another radio access technique by initiating the Circuit Switching fallback (CS-fallback) through the 380 SIP error response sent to the handset [12].
- (iv)
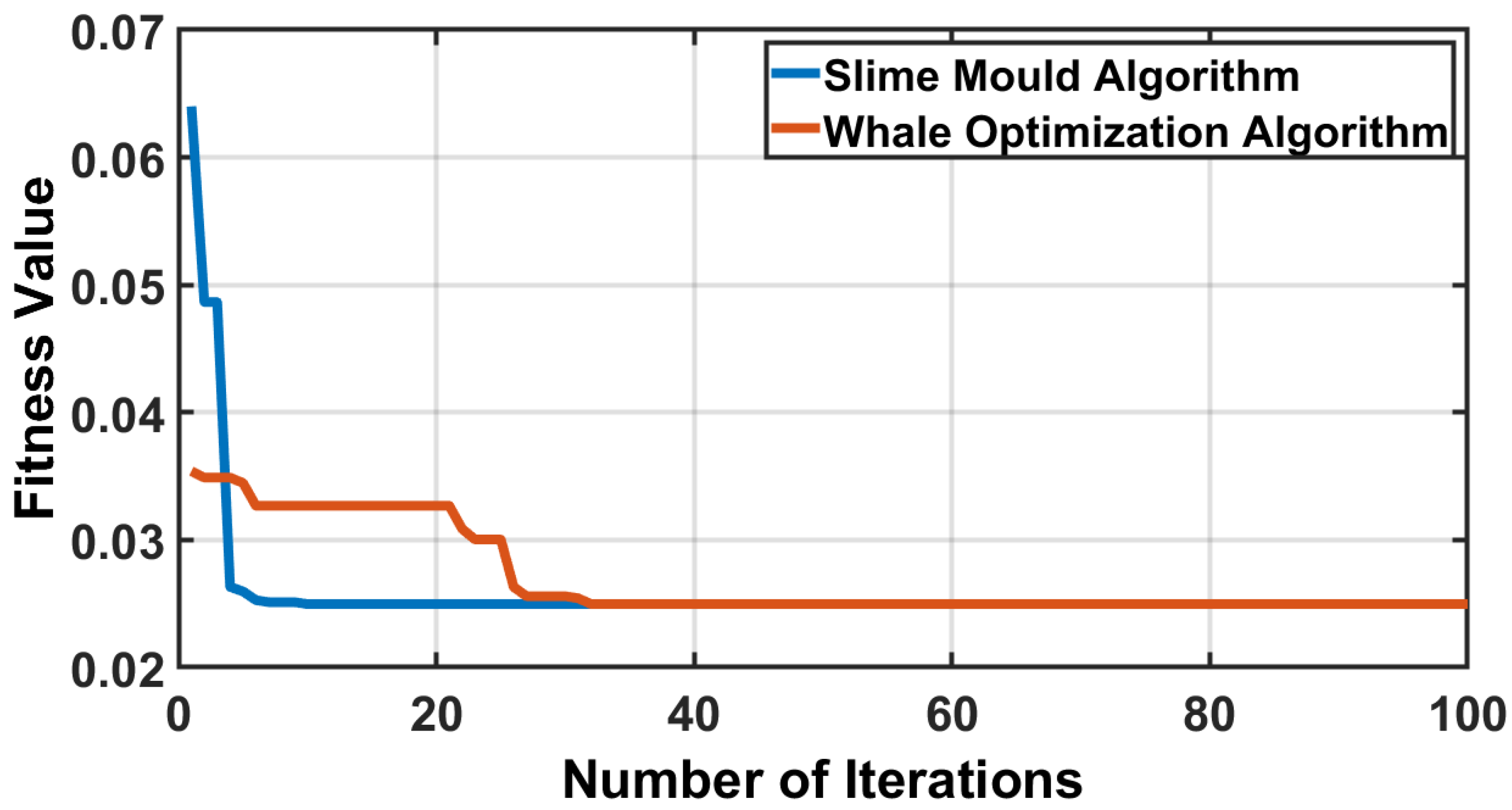
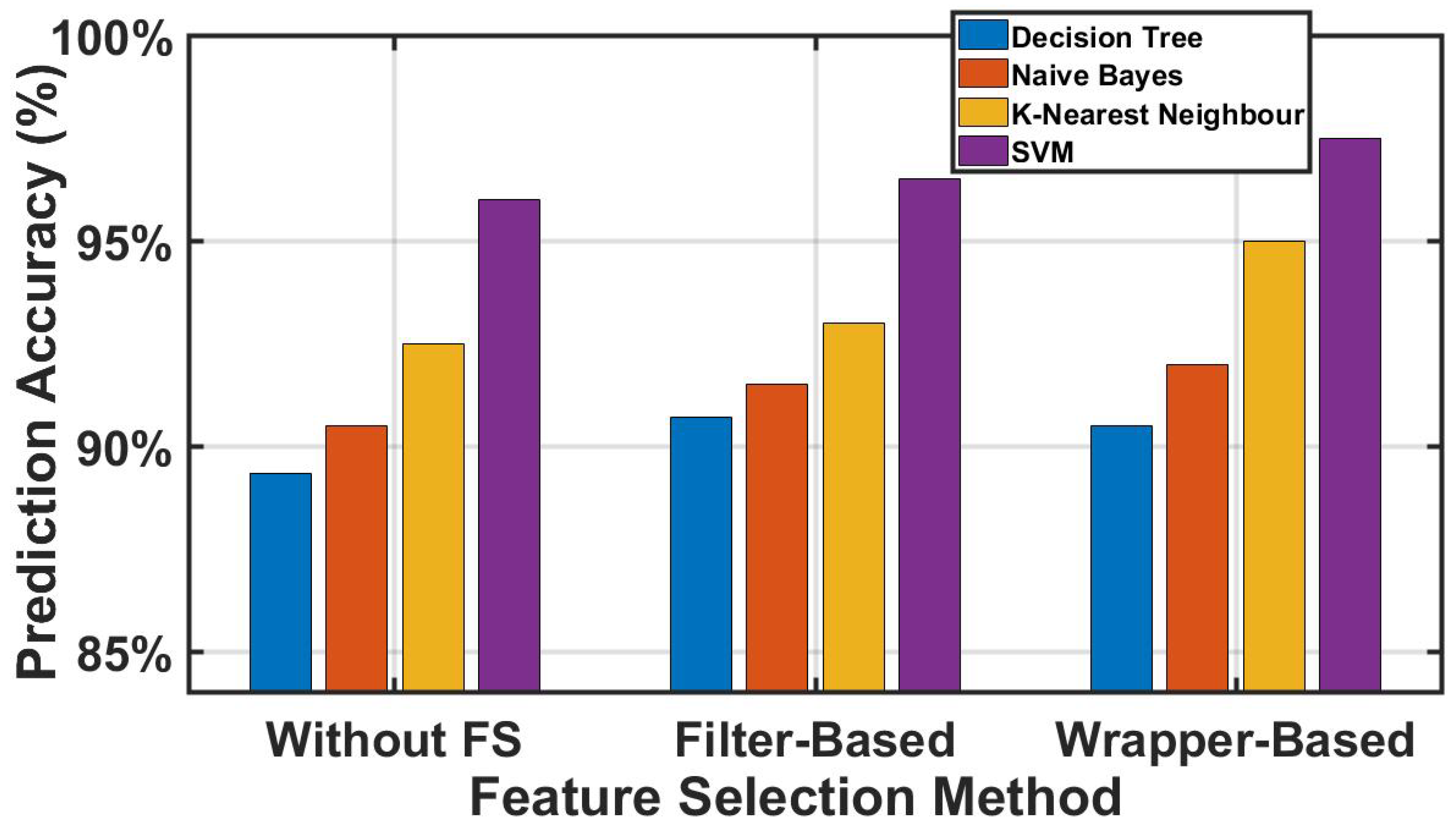
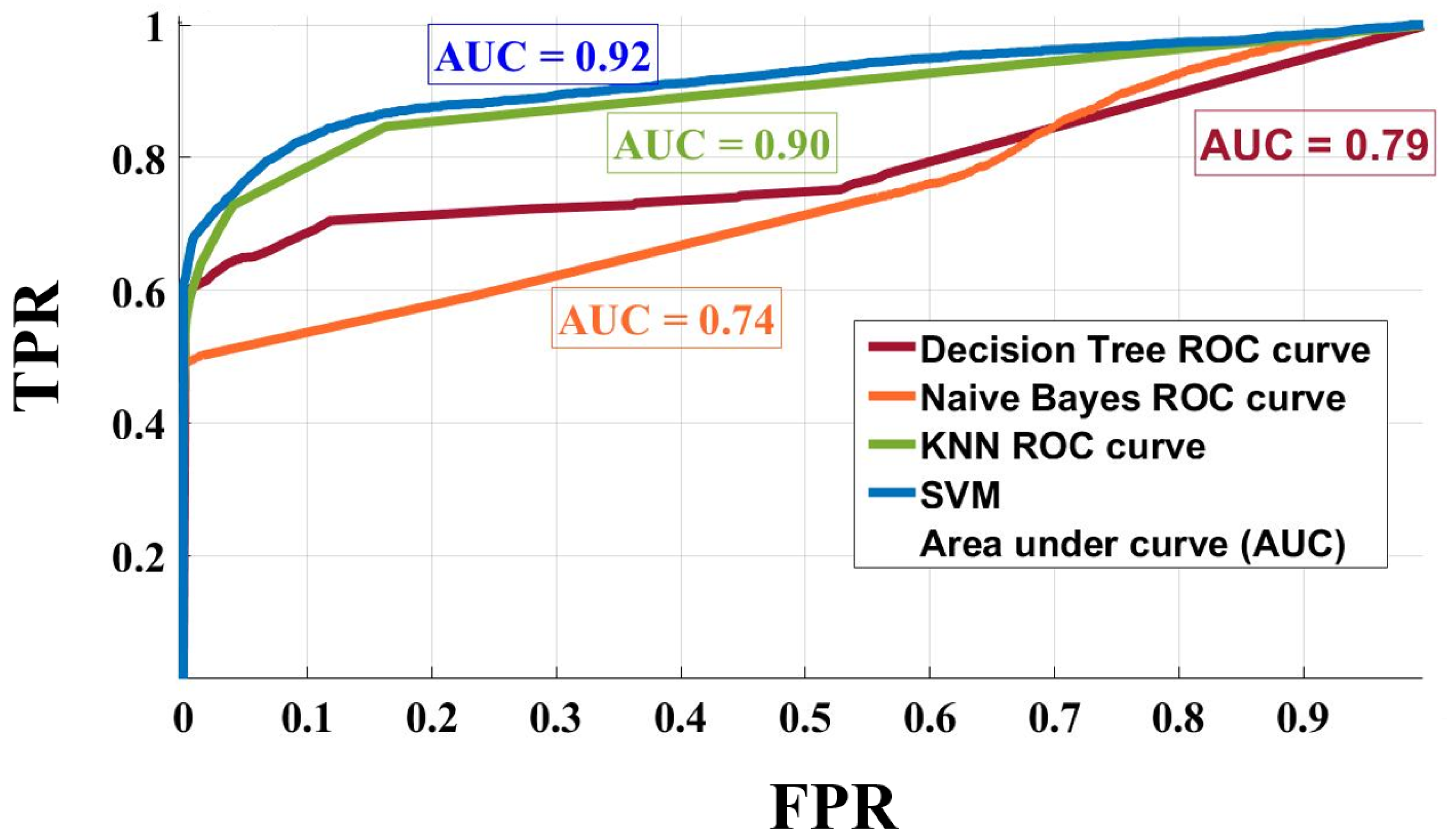
- Call failures analysis: The advantage of the model is not limited to call failure prediction, but also to knowing the reason (root causes) behind the failure; more specifically, the multi-factorial reasons by using machine learning, which cannot be obtained using the traditional method (manual tracking of the traces). We perform an analysis for the prediction result (Section 7.3) for the KNN classifier using the Wrapper WOA feature selection algorithm, as it presents the highest prediction accuracy and best ROC performance. This enables us to obtain the call failures’ root causes.
3. VoLTE Call Failure Use Cases
- 1.
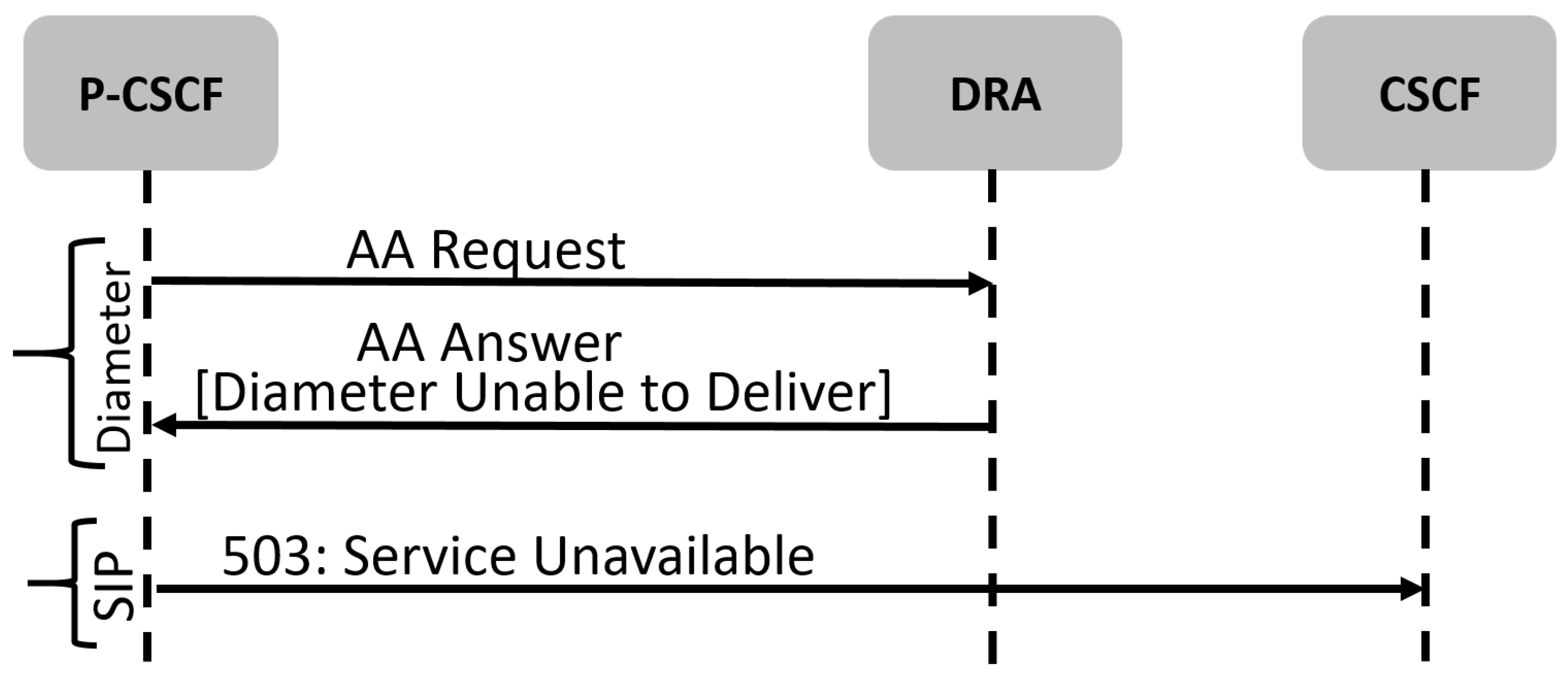
- Bearer Assignment Failure: This use case includes failure that occurs in the bearer assignment procedure leading to Diameter protocol failure, and then SIP protocol failure. As shown in Figure 1, the invite message was sent from the S-CSCF network node towards P-CSCF as a standard procedure to make a call. The P-CSCF sent an Authentication Authorization Request (AAR) towards PCRF through the Diameter Routing Agent (DRA) to assign the Quality of Service Class Identifier (QCI) bearer to perform the call on the VoLTE Domain. However, DRA responded with a DIAMETER UNABLE TO DELIVER error leading to a successive SIP 503 SERVICE UNAVAILABLE error originating from P-CSCF and sent towards S-CSCF. The root cause was identified as the originating number going out of coverage during performing a call. This leads to a termination request sent from the Packet Data Network Gateway (PDN-GW), deleting the subscriber binding information. As a result, the DRA could not find any binding information for the user and replied with an Diameter UNABLE-To-DELIVER error, as mentioned previously.
- 2.
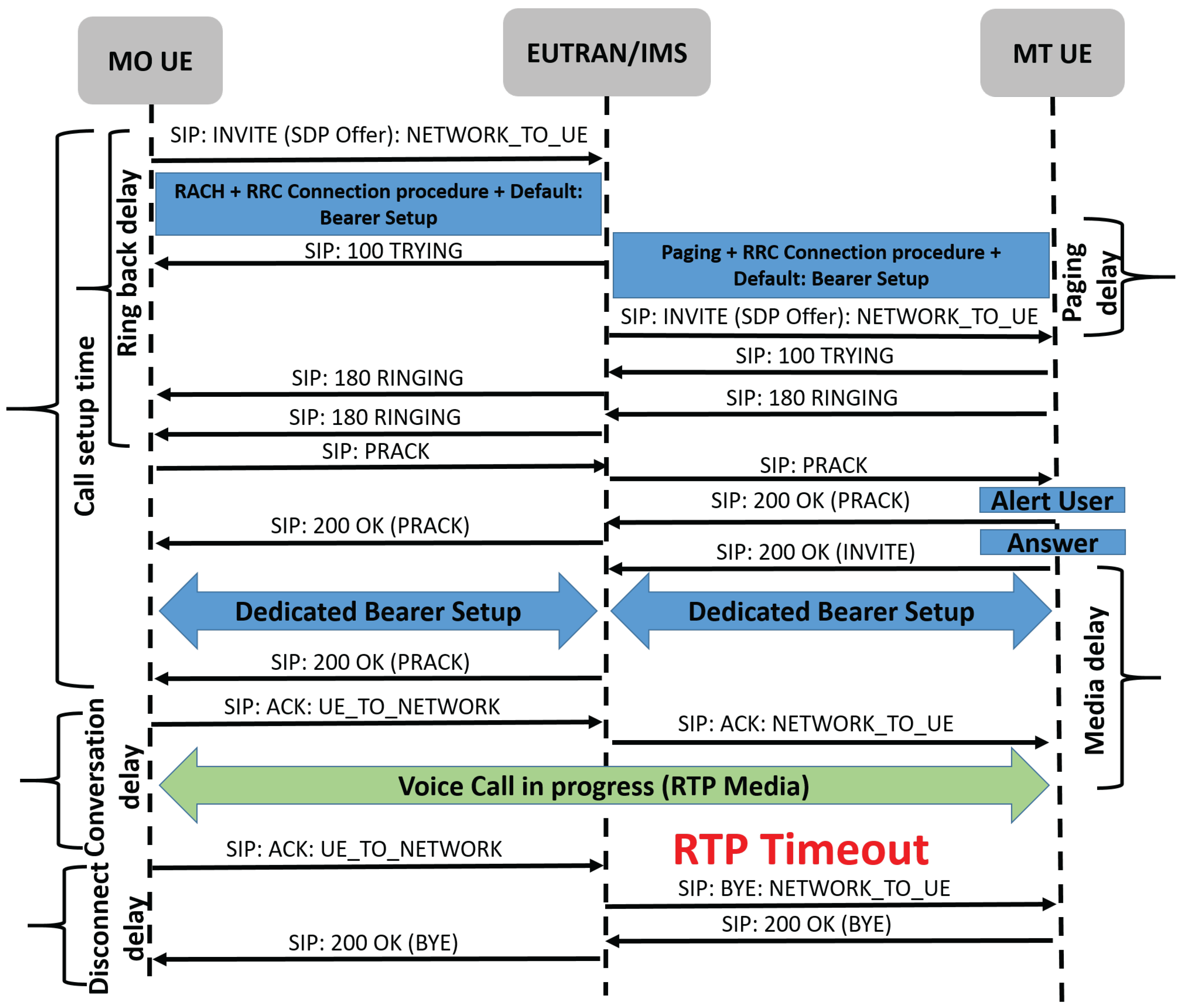
- Media Failure: This use case shows a failure that occurred in the opening media channel procedures for a VoLTE call leading to RTP protocol failure then, consecutively, a SIP protocol failure. As shown in Figure 2, the RTP Timeout error in the RTP protocol leads to a CANCEL SIP message containing RTP Timeout, which was sent from the handset side towards P-CSCF, leading to call failure. The RTP Timeout error shows that there was no response received from the IMS Media Gateway side, which led to this call failure.
- 3.
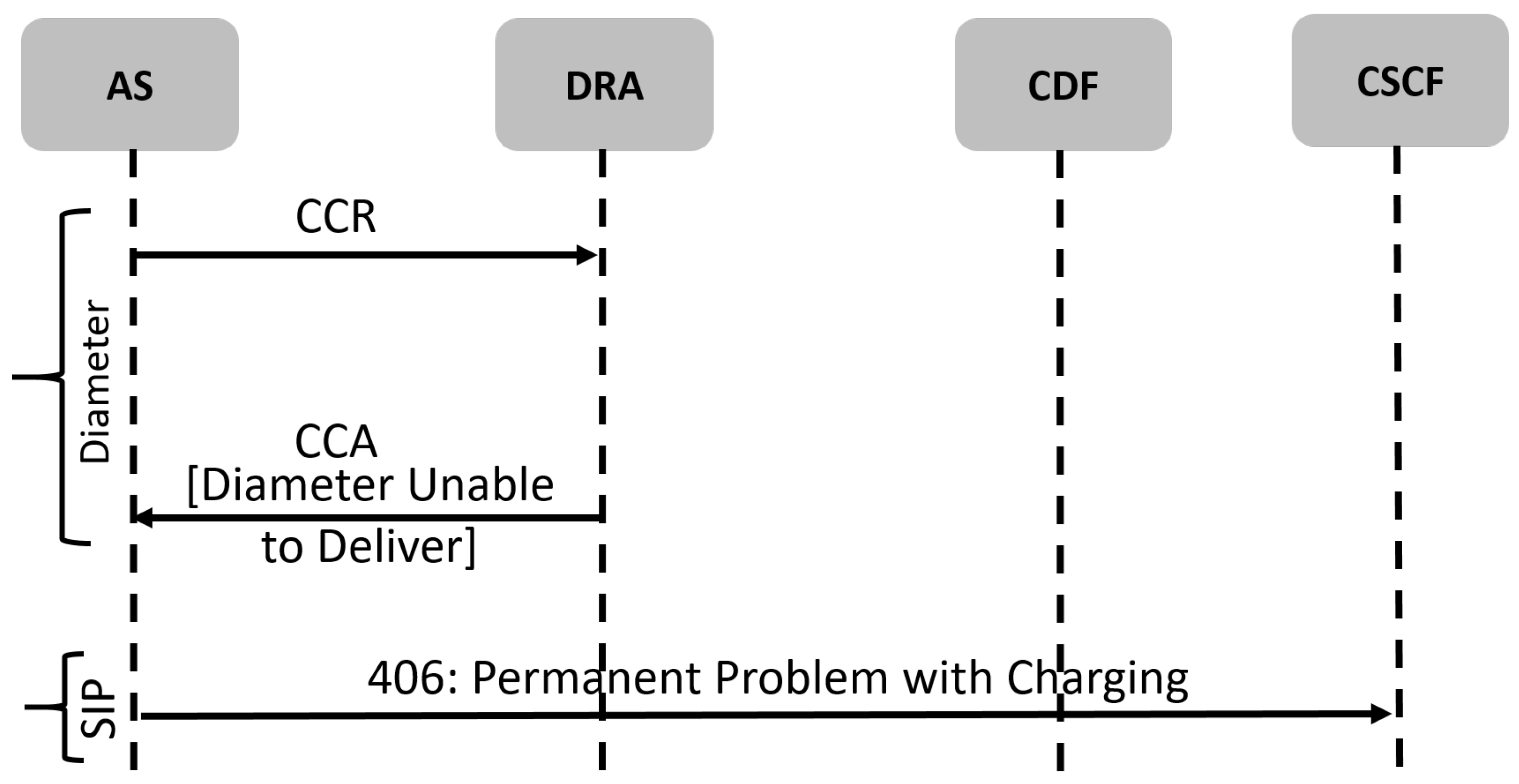
- Charging Failure: Figure 3 shows a call SIP/Diameter trace for a charging procedure where a failure occurs in the Diameter protocol, leading to the SIP protocol failure. Before the VoLTE call starts, the Application Server (AS) sends an accounting request to the Charging Data Function (CDF) to open a CDR for the call. This CDR will be used afterward in charging the customer. However, in this use case, the CDF responded with the DIAMETER UNABLE TO DELIVER error. This leads to a SIP 406 NOT ACCEPTABLE error (permanent problem with charging). After investigating the root cause of the failure, it is discovered that the diameter peers between the charging nodes and DRA were down.



4. SIP Protocol Analysis
4.1. SIP Interfaces
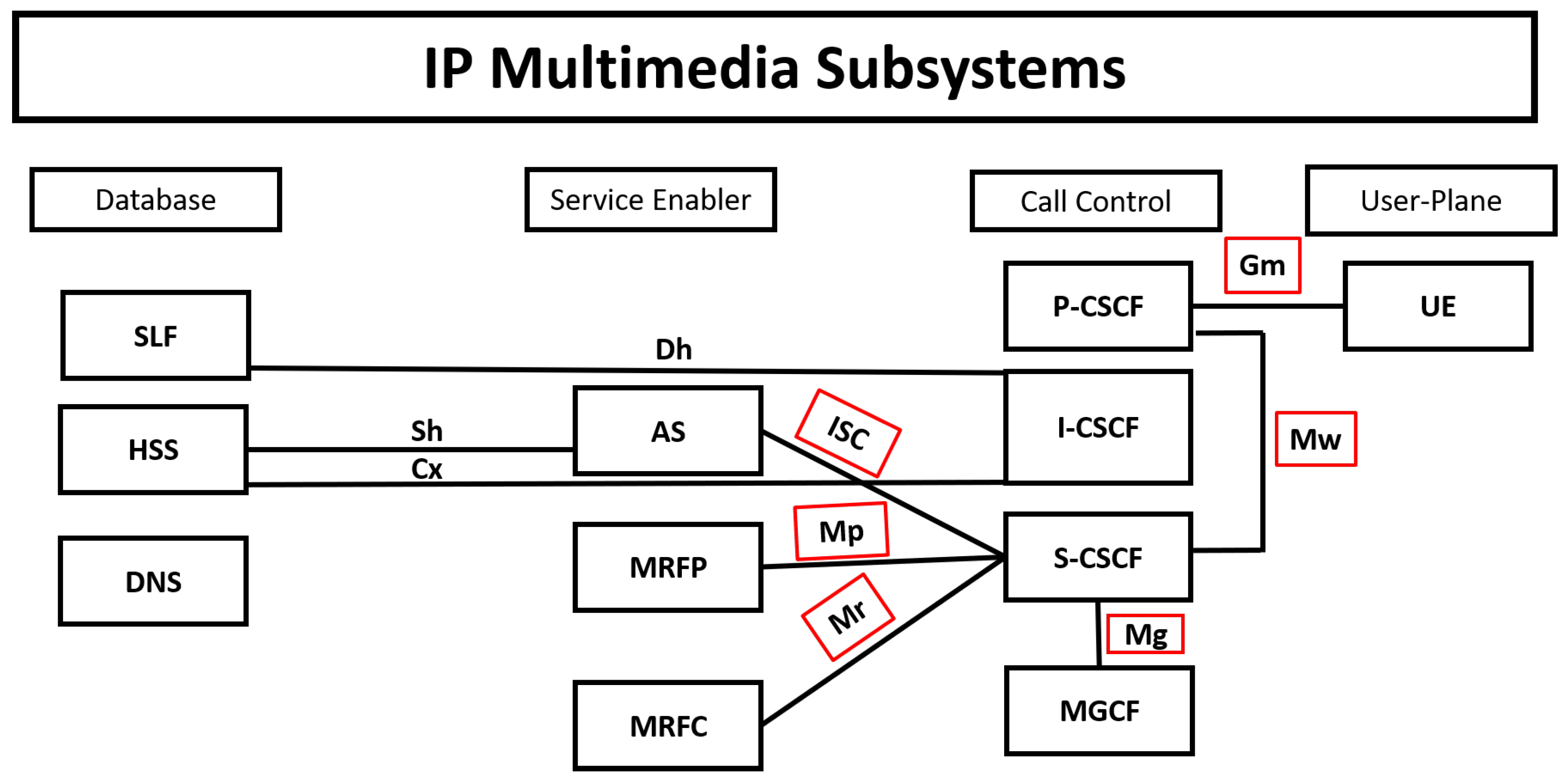
- Mw Interface: The interface between S-CSCF/I-CSCF (Interrogating Call Session Control Function) and P-CSCF;
- Gm Interface: The interface between Subscriber (Handset) and P-CSCF;
- Mg Interface: The interface between Mobile Switching Center (MSC) (circuit switching domain) and I-CSCF;
- ISC Interface: The interface between S-CSCF and the Application server;
- Mj Interface: The interface between the Breakout Gateway Control Function (BGCF) and Media Gateway Controller Function (MGCF);
- Mi Interface: The interface between BGCF and S-CSCF.

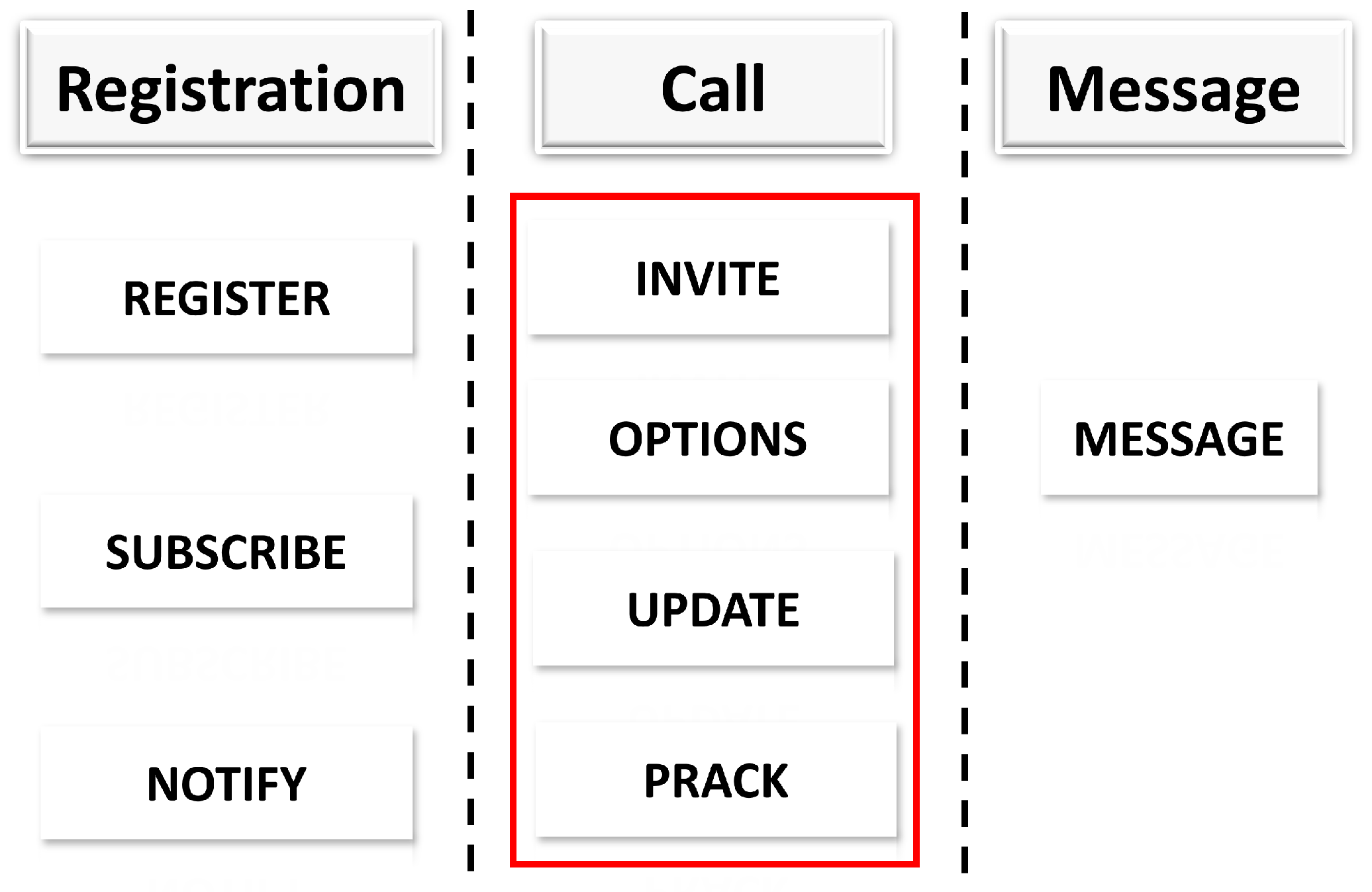
4.2. SIP Request
- REGISTER: Message used for subscriber registration.
- INVITE: Message used for initiating call session.
- OPTIONS: Request used to query Server capabilities
- MESSAGE: Transport instant messaging message.
- SUBSCRIBE: Subscribes to event notification
- REFER: Asks a recipient to issue a SIP request
- UPDATE: Modifies state of a session without changing the state of the dialog and notify the subscriber of a new event.
- CANCEL: Cancels any pending requests.
- PUBLISH: Publishes an event to the server.
- PRACK: Provisional acknowledgment.
- BYE: used in call termination.

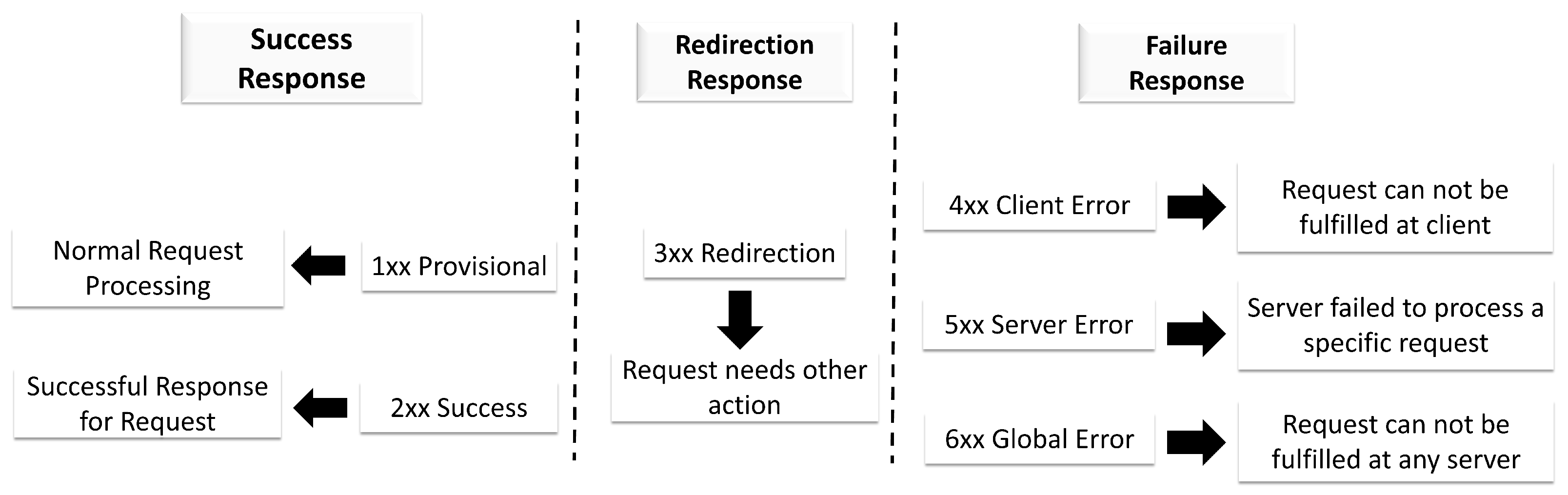
4.3. SIP Response
5. Dataset Description
- 1.
- Device model: The type of the user mobile handset.
- 2.
- Audio codec: Indicates the type of codec used for voice calls. Codec is the abbreviation for coder-decoder or compression-decompression. The two most used codec Narrow-Band Adaptive Multi-Rate (NB-AMR) and Wide-Band AMR (WB-AMR) [46]. The numbers 101 and 102 are defined for WB-AMR and AMR, respectively [46].
- 3.
- Video codec: Indicates the type of codec used for video calls. In the shown example there is no video calls, so all fields of the video codec equal zero. The types of video codecs and the way they are expressed in the CDRs are shown in [46].
- 4.
- Alerting time: The time for the user handset in milliseconds between receiving a 180 ringing SIP response and a 200 ok SIP response.
- 5.
- Answer time: The time of the call in milliseconds.
- 6.
- SRVCC flag: SRVCC is the abbreviation for Single Radio Voice Call Continuity. It is a binary value. It equals one if the user makes a Inter RAT handover from packet data to circuit switched data voice calls. Meanwhile, it equals zero otherwise.
6. Proposed System Model and Machine Learning Prediction Models
6.1. Dataset Pre-Processing
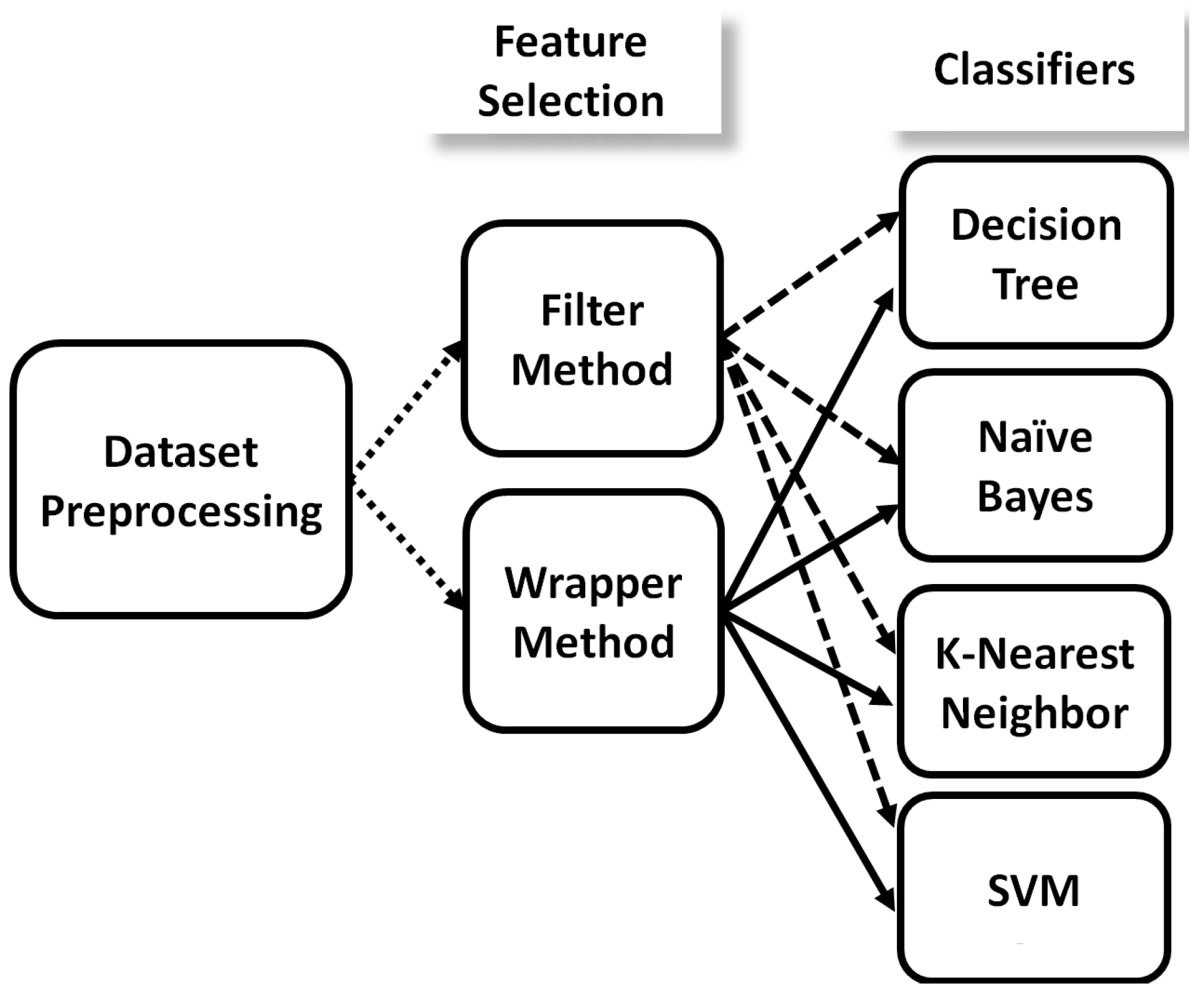
6.2. Feature Selection Methods
- (i)
- Filter method: In the Filter method, the relationship between each input feature and output feature is measured, and each feature is granted a scoring based on statistical tests. Then, the features with a high score are considered. Filter methods are preferred in terms of their easiness in implementation and very low computational time. Several algorithms are present in the Filter method feature selection technique. Algorithms are chosen based on dataset properties such as data dimensions, percentage of redundant, irrelevant features and interaction between features [48]. Since the features present in IMS calls are highly dependent on each other, we use the ReliefF algorithm [49].
- (ii)
- Wrapper method: In the wrapper method, evaluation of features is performed through training a model using ML algorithms, then selecting the best performing features in the model [50]. Moreover, Wrapper methods contain different algorithms. Swarm-based meta-heuristic algorithms have been widely used in several engineering fields due to the fact that they have an advantage over other classes of nature-inspired algorithms [51]. It offers an edge over evaluation-based algorithms by preserving the search space information after each subsequent iteration and fewer operators for successful execution [52]. We have used two of these Swarm Algorithms, WOA and SMA. We have chosen both algorithms for their high capability of solving complex optimization problems compared with other algorithms. In addition, we had a large number of features (256 features) inside our dataset, which led to complex optimization problems.
6.3. Machine Learning Classifiers
- (i)
- Decision Tree: The decision tree classifier is considered as a simple classifier and requires a few parameters. Moreover, the famous advantage of decision tree over other classifiers is its high ability to perform causality assessment (understanding the relation between feature and result). This is on the contrary to black-box modeling techniques, where their internal logic can be challenging to understand.
- (ii)
- Naive Bayes: The naive Bayes classifier is based on Bayes theorem, which measures the probability of an event occurring given another event.where x is the feature vector; c is the classification variable. It is easy and fast to predict the class of test data set. When the assumption of independence holds, a naive Bayes classifier performs better than other models, such as logistic regression, and it also needs less training data. It performs well in categorical input variables compared to a numerical variable(s), and the data present in CDRs are a categorical data type.
- (iii)
- K-Nearest Neighbor: We apply KNN classifier since the dataset is sufficiently large and the number of observations is very high compared to the number of features; thus, we went for a low bias and high variance algorithm. Moreover, KNN represents a good option in terms of computational time.
- (iv)
- SVM: We apply a SVM classifier since they are suitable for binary classification tasks, which is related to and contains elements of non-parametric applied statistics, neural networks and machine learning. It is more efficient in spaces which are high dimensional. It makes adequate use of memory.
6.4. Problem Complexity
7. Results and Analysis
7.1. Evaluation Settings
7.2. Numerical Results
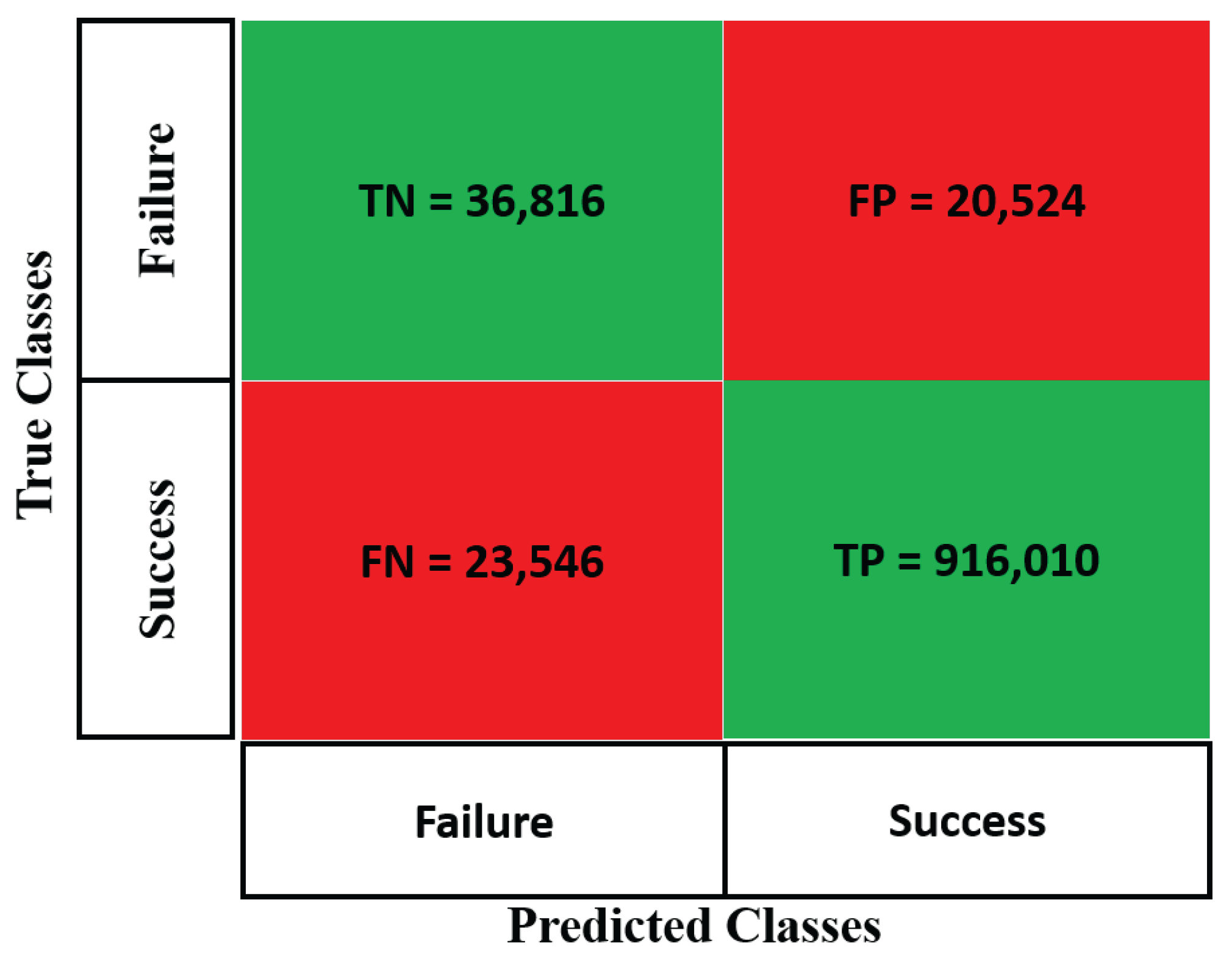
- True Positive (TP): Successful calls rightly predicted as a success (bottom right).
- True Negative (TN): Failed calls rightly predicted as failure (top left).
- False Negative (FN): Successful calls wrongly predicted as failure (bottom left).
- False Positive (FP): Failed calls wrongly predicted as successful calls (top right).
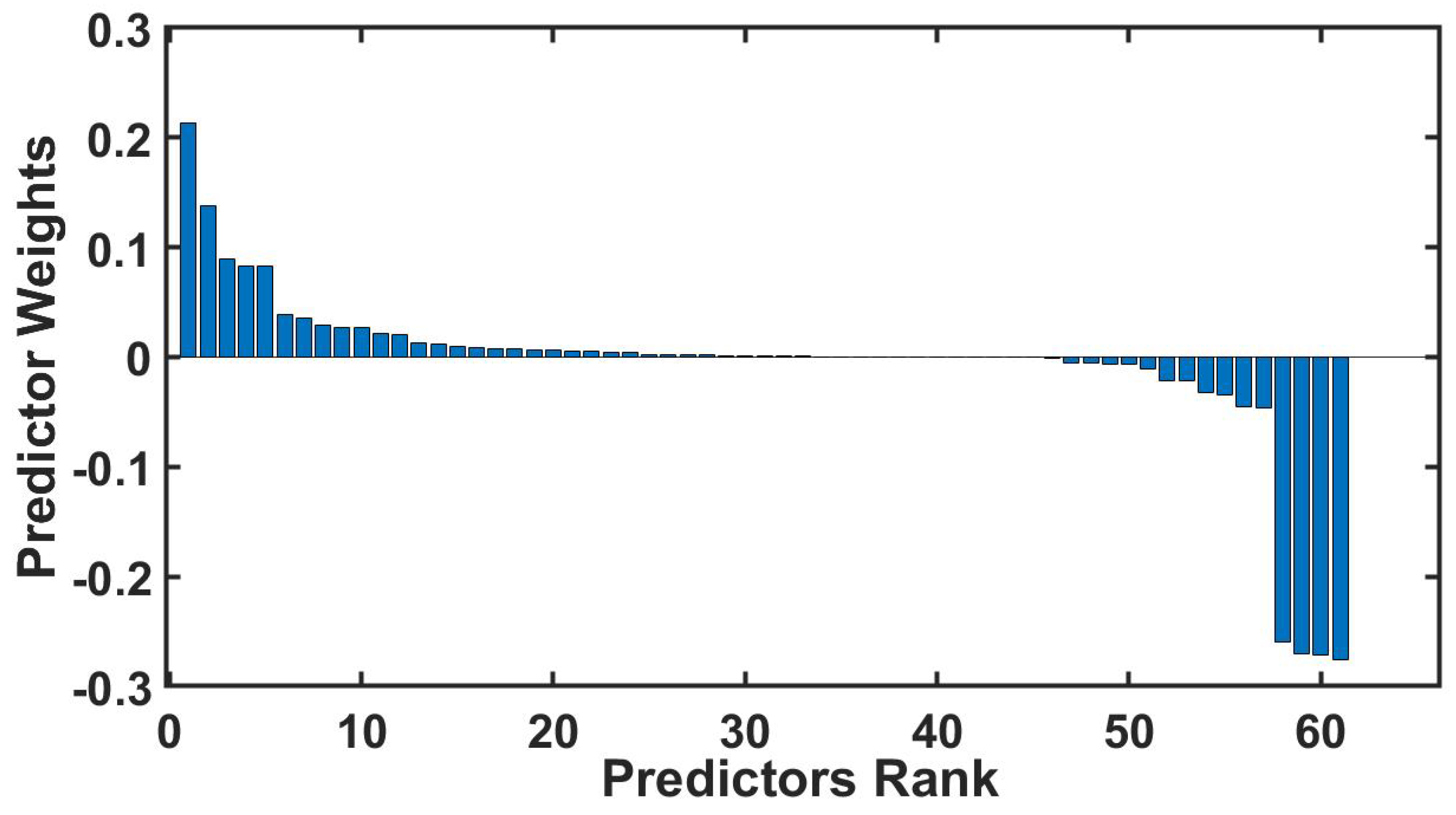
7.3. Call Failure Analysis
- Firstly, the root causes depend on the dataset (CDRs). Therefore, applying different datasets leads to different root causes.
- Secondly, we had to make sure that the dataset was extracted in a normal day time without any anomaly behavior. For example, when a dataset is extracted during an outage inside the network, the model prediction accuracy turns out to be very high. Since specific features will lead to call failures (e.g., faulty nodes), they could be determined easily in our model, as they will have a very high weight relative to other features. Therefore, the prediction accuracy, in this case, is not reliable.
- Thirdly, we are tackling problems that occur due to multi-factorial reasons and are hardly detected using the traditional way (single trace analysis). In contrast, they can be detected using ML Algorithms.
- Failures that occur for VoLTE calls that suffered from the Single Radio Voice Call Continuity (SRVCC) are more significant than the normal VoLTE calls without SRVCC.
- When SRVCC occurs through specific P-CSCF IPs, subscriber suffers from call failures with a percentage reaching 99%. This is a case where the failure is due to multifactorial reasons (P-CSCF IP and SRVCC).
- Specific 5 Tracking Area Identities (TAIs) in the network contribute to a higher percentage of call failures rather than other TAIs.
- The calls where the originating user is using VoLTE and the terminating user is using circuit switching (e.g., 3G)—or vice versa—fail more than the calls where the originating and terminating users are using VoLTE.
- As the invite response time increase, the probability of a call failure increases.
- Twenty percent of used shortcodes have a failure rate of 100%, which shows that these shortcodes are not working inside the IMS domain.
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- GSMA. Understanding 5G: Perspectives on Future Technological Advancements in Mobile; Technical Report; Groupe Speciale Mobile Association: London, UK, 2014. [Google Scholar]
- Shehata, M.; Elbanna, A.; Musumeci, F.; Tornatore, M. Multiplexing Gain and Processing Savings of 5G Radio-Access-Network Functional Splits. IEEE Trans. Green Commun. Netw. 2018, 2, 982–991. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Huang, Y.; Chen, Z.; Liu, L.; Wang, Q.; Li, N. 5G Deployment: Standalone vs. Non-Standalone from the Operator Perspective. IEEE Commun. Mag. 2020, 58, 83–89. [Google Scholar] [CrossRef]
- Teral, S. 5G Best Choice Architecture; White Paper; IHS Markit Technology: London, UK, 2019. [Google Scholar]
- Brown, G. Service-Based Architecture for 5G Core Networks; Technical Report; Huawei Technologies Co. Ltd.: Shenzhen, China, 2017. [Google Scholar]
- Park, S.; Cho, H.; Park, Y.; Choi, B.; Kim, D.; Yim, K. Security problems of 5G voice communication. In Proceedings of the 21st International Conference on Information Security Applications (WISA), Jeju Island, Korea, 26–28 August 2020; pp. 403–415. [Google Scholar]
- 3GPP. IP Multimedia Subsystem (IMS), Version 16.6.0 ed; Technical Specification (TS) 23.228, 3rd Generation Partnership Project (3GPP); 3GPP: Sophia Antipolis, France, 2021. [Google Scholar]
- Huawei Technologies Co. Ltd. Vo5G Technical White Paper; Technical Report; Huawei Technologies Co. Ltd.: Shenzhen, China, 2018. [Google Scholar]
- Asghar, A.; Farooq, H.; Imran, A. Self-Healing in Emerging Cellular Networks: Review, Challenges, and Research Directions. IEEE Commun. Surv. Tutorials 2018, 20, 1682–1709. [Google Scholar] [CrossRef]
- GSMA. 5G Implementation Guidelines: NSA Option 3, Version 14.2.2 ed; Technical Report; Groupe Speciale Mobile Association: London, UK, 2017. [Google Scholar]
- GSMA. VoLTE Description and Implementation Guideline, Version 2.0 ed; Technical Report; Groupe Speciale Mobile Association: London, UK, 2014. [Google Scholar]
- 3GPP. IP Multimedia Call Control Protocol Based on Session Initiation Protocol (SIP) and Session Description Protocol (SDP), Version 12.9.0 ed; Technical Specification (TS) 24.229, 3rd Generation Partnership Project (3GPP); 3GPP: Sophia Antipolis, France, 2015. [Google Scholar]
- Garcia-Martin, M.; Belinchon, M.; Pallares-Lopez, M.; Canales-Valenzuela, C.; Tammi, K. Technical Report: RFC 4740-Diameter Session Initiation Protocol (SIP) Application; IETF: Wilmington, DE, USA, 2006. [Google Scholar]
- 3GPP. IP Multimedia Subsystem (IMS) Charging, Version 17.1.0 ed; Technical Specification (TS) 32.260, 3rd Generation Partnership Project (3GPP); 3GPP: Sophia Antipolis, France, 2021. [Google Scholar]
- 3GPP. IP Multimedia Subsystem (IMS); Multimedia Telephony; Media Handling and Interaction; Technical Specification (TS) 26.114, 3rd Generation Partnership Project (3GPP), Version 16.8.2; 3GPP: Sophia Antipolis, France, 2021. [Google Scholar]
- 3GPP. Cx and Dx Interfaces Based on the Diameter Protocol; Protocol Details, Version 11.0.0 ed; Technical Specification (TS) 29.229, 3rd Generation Partnership Project (3GPP); 3GPP: Sophia Antipolis, France, 2011. [Google Scholar]
- Kibria, M.G.; Nguyen, K.; Villardi, G.P.; Zhao, O.; Ishizu, K.; Kojima, F. Big data analytics, Machine Learning, and Artificial Intelligence in Next-Generation Wireless Networks. IEEE Access 2018, 6, 32328–32338. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Ren, Y.; Han, Z.; Chen, K.C.; Hanzo, L. Machine Learning Paradigms for Next-Generation Wireless Networks. IEEE Wirel. Commun. 2016, 24, 98–105. [Google Scholar] [CrossRef] [Green Version]
- Musumeci, F.; Rottondi, C.; Corani, G.; Shahkarami, S.; Cugini, F.; Tornatore, M. A Tutorial on Machine Learning for Failure Management in Optical Networks. J. Light. Technol. 2019, 37, 4125–4139. [Google Scholar] [CrossRef] [Green Version]
- Tóthfalusi, T.; Varga, P. Assembling SIP-Based VoLTE Call Data Records Based on Network Monitoring. Telecommun. Syst. 2018, 68, 393–407. [Google Scholar] [CrossRef]
- Ali, A.; Alshamrani, M.; Kuwadekar, A.; Al-Begain, K. Evaluating SIP Signaling Performance for VoIP over LTE Based Mission-Critical Communication Systems. In Proceedings of the 9th International Conference on Next Generation Mobile Applications, Services and Technologies (NGMAST), Cambridge, UK, 9–11 September 2015; pp. 199–205. [Google Scholar]
- Bensalah, F.; El Hamzaoui, M.; Bahnasse, A.; El kamoun, N. Behavior Study of SIP on IP Multimedia Subsystem Architecture MPLS as Transport Layer. Int. J. Inf. Technol. 2018, 10, 113–121. [Google Scholar] [CrossRef]
- Khiat, A.; El Khaili, M.; Bakkoury, J.; Bahnasse, A. Study and evaluation of voice over IP signaling protocols performances on MIPv6 protocol in mobile 802.11 network: SIP and H. 323. In Proceedings of the International Symposium on Networks, Computers and Communications (ISNCC), Marrakech, Morocco, 16–18 May 2017; pp. 1–8. [Google Scholar]
- Hyun, J.; Li, J.; Im, C.; Yoo, J.H.; Hong, J.W.K. A VoLTE Traffic Classification Method in LTE Network. In Proceedings of the 16th Asia-Pacific Network Operations and Management Symposium (APNOMS), Hsinchu, Taiwan, 17–19 September 2014; pp. 1–6. [Google Scholar]
- Hsieh, W.B.; Leu, J.S. Implementing a secure VoIP communication over SIP-based networks. Wirel. Netw. 2018, 24, 2915–2926. [Google Scholar] [CrossRef]
- Abualhaj, M.M.; Al-Tahrawi, M.M.; Al-Khatib, S.N. Performance evaluation of VoIP systems in cloud computing. J. Eng. Sci. Technol. 2019, 14, 1398–1405. [Google Scholar]
- Bega, D.; Gramaglia, M.; Banchs, A.; Sciancalepore, V.; Costa-Pérez, X. A Machine Learning Approach to 5G Infrastructure Market Optimization. IEEE Trans. Mob. Comput. 2019, 19, 498–512. [Google Scholar] [CrossRef]
- Fourati, H.; Maaloul, R.; Chaari, L. A Survey of 5G Network Systems: Challenges and Machine Learning Approaches. Int. J. Mach. Learn. Cybern. 2021, 12, 385–431. [Google Scholar] [CrossRef]
- Ma, B.; Guo, W.; Zhang, J. A Survey of Online Data-Driven Proactive 5G Network Optimisation Using Machine Learning. IEEE Access 2020, 8, 35606–35637. [Google Scholar] [CrossRef]
- Chernogorov, F.; Chernov, S.; Brigatti, K.; Ristaniemi, T. Sequence-Based Detection of Sleeping Cell Failures in Mobile Networks. Wirel. Networks 2015, 22, 2029–2048. [Google Scholar] [CrossRef] [Green Version]
- Manzanilla-Salazar, O.; Malandra, F.; Sansò, B. eNodeB Failure Detection from Aggregated Performance KPIs in Smart-City LTE Infrastructures. In Proceedings of the 15th International Conference on the Design of Reliable Communication Networks (DRCN), Coimbra, Portugal, 19–21 March 2019; pp. 51–58. [Google Scholar]
- Mulvey, D.; Foh, C.H.; Imran, M.A.; Tafazolli, R. Cell Coverage Degradation Detection using Deep Learning Techniques. In Proceedings of the 9th International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 17–19 October 2018; pp. 441–447. [Google Scholar]
- Takeshita, K.; Yokota, M.; Nishimatsu, K. Early Network Failure Detection System by Analyzing Twitter Data. In Proceedings of the IFIP/IEEE International Symposium on Integrated Network Management (IM), Bordeaux, France, 18–20 May 2015; pp. 279–286. [Google Scholar]
- Riihijarvi, J.; Mahonen, P. Machine Learning for Performance Prediction in Mobile Cellular Networks. IEEE Comput. Intell. Mag. 2018, 13, 51–60. [Google Scholar] [CrossRef]
- Sultan, K.; Ali, H.; Zhang, Z. Call Detail Records Driven Anomaly Detection and Traffic Prediction in Mobile Cellular Networks. IEEE Access 2018, 6, 41728–41737. [Google Scholar] [CrossRef]
- Hussain, B.; Du, Q.; Ren, P. Semi-Supervised Learning Based Big Data-Driven Anomaly Detection in Mobile Wireless Networks. China Commun. 2018, 15, 41–57. [Google Scholar] [CrossRef]
- Krevatin, I.; Presečki, Ž.; Gudelj, M. Improvements in failure detection for emergency service centers in IMS network. In Proceedings of the 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Jeju Island, Korea, 26–28 August 2015; pp. 496–500. [Google Scholar]
- Chen, W.E.; Tseng, L.Y.; Chu, C.L. An Effective Failure Recovery Mechanism for SIP/IMS Services. Mob. Networks Appl. 2017, 22, 51–60. [Google Scholar] [CrossRef]
- Przybysz, H.; Forsman, T.; Lövsén, L.; Blanco, G.B.; Rydnell, G.; Johansson, K. Failure Recovery in an IP Multimedia Subsytem Network. Telefonaktiebolaget L M Ericsson (publ) Patent EP2195995B1, 6 April 2011. [Google Scholar]
- Przybysz, H.; Vergara, M.C.B.; Forsman, T.; Schumacher, A. Failure Recovery in an IP Multimedia Subsytem Network. Telefonaktiebolaget L M Ericsson (publ) Patent WO2009039890A1, 2 April 2009. [Google Scholar]
- Raza, M.T.; Lu, S. Uninterruptible IMS: Maintaining Users Access During Faults in Virtualized IP Multimedia Subsystem. IEEE J. Sel. Areas Commun. 2020, 38, 1464–1477. [Google Scholar] [CrossRef]
- Chen, X.; Zhou, J.; Liu, K. VoLTE problem location method based on big data. Proc. J. Phys. Conf. Ser. 2021, 1828, 012085. [Google Scholar] [CrossRef]
- Schooler, E.; Rosenberg, J.; Schulzrinne, H.; Johnston, A.; Camarillo, G.; Peterson, J.; Sparks, R.; Handley, M.J. Technical Report: RFC 3261 SIP: Session Initiation Protocol; IEFT: Wilmington, DE, USA, 2002. [Google Scholar] [CrossRef] [Green Version]
- Resnick, P. Technical Report: RFC 2822 Internet Message Format; IEFT: Wilmington, DE, USA, 2001. [Google Scholar] [CrossRef] [Green Version]
- Johnston, A.; Levin, O. Technical Report: RFC 4579 Session Initiation Protocol (SIP) Call Control-Conferencing for User Agents; IEFT: Wilmington, DE, USA, August 2006. [Google Scholar] [CrossRef] [Green Version]
- 3GPP. Universal Mobile Telecommunications System (UMTS); LTE; IP Multimedia Subsystem (IMS); Multimedia Telephony; Media Handling and Interaction; Technical Specification (TS) 26.114, 3rd Generation Partnership Project (3GPP), Version 13.3.0; 3GPP: Sophia Antipolis, France, 2016. [Google Scholar]
- Mafarja, M.; Mirjalili, S. Whale optimization approaches for wrapper feature selection. Appl. Soft Comput. 2018, 62, 441–453. [Google Scholar] [CrossRef]
- Bommert, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal. 2020, 143, 106839. [Google Scholar] [CrossRef]
- Urbanowicz, R.J.; Meeker, M.; La Cava, W.; Olson, R.S.; Moore, J.H. Relief-based feature selection: Introduction and review. J. Biomed. Informatics 2018, 85, 189–203. [Google Scholar] [CrossRef] [PubMed]
- Corrales, D.C.; Lasso, E.; Ledezma, A.; Corrales, J.C. Feature selection for classification tasks: Expert knowledge or traditional methods? J. Intell. Fuzzy Syst. 2018, 34, 2825–2835. [Google Scholar] [CrossRef]
- Hussain, K.; Salleh, M.N.M.; Cheng, S.; Shi, Y. On the exploration and exploitation in popular swarm-based metaheuristic algorithms. Neural Comput. Appl. 2019, 31, 7665–7683. [Google Scholar] [CrossRef]
- Kumar, A.; Bawa, S. Generalized ant colony optimizer: Swarm-based meta-heuristic algorithm for cloud services execution. Computing 2019, 101, 1609–1632. [Google Scholar] [CrossRef]
- Sani, H.M.; Lei, C.; Neagu, D. Computational complexity analysis of decision tree algorithms. In Proceedings of the International Conference on Innovative Techniques and Applications of Artificial Intelligence, Cambridge, UK, 11–13 December 2018; Springer: Cambridge, UK, 2018; pp. 191–197. [Google Scholar]
- Zheng, Z. Naive Bayesian classifier committees. In Proceedings Proceedings of the European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 196–207. [Google Scholar]
- Cunningham, P.; Delany, S.J. k-Nearest neighbour classifiers-A Tutorial. ACM Comput. Surv. (CSUR) 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Abdiansah, A.; Wardoyo, R. Time complexity analysis of support vector machines (SVM) in LibSVM. Int. J. Comput. Appl. 2015, 128, 28–34. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device Model | Audio Codec | Video Codec | Invite Response Time | Answer Time | SRVCC Flag |
|---|---|---|---|---|---|
| iphone | 101 | 0 | 6569 | 21,656 | 0 |
| iphone | 101 | 0 | 3190 | 13,241 | 0 |
| Samsung | 102 | 0 | 3506 | 28,264 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bahaa, A.; Shehata, M.; Gasser, S.M.; El-Mahallawy, M.S. Call Failure Prediction in IP Multimedia Subsystem (IMS) Networks. Appl. Sci. 2022, 12, 8378. https://doi.org/10.3390/app12168378
Bahaa A, Shehata M, Gasser SM, El-Mahallawy MS. Call Failure Prediction in IP Multimedia Subsystem (IMS) Networks. Applied Sciences. 2022; 12(16):8378. https://doi.org/10.3390/app12168378
Chicago/Turabian StyleBahaa, Amr, Mohamed Shehata, Safa M. Gasser, and Mohamed S. El-Mahallawy. 2022. "Call Failure Prediction in IP Multimedia Subsystem (IMS) Networks" Applied Sciences 12, no. 16: 8378. https://doi.org/10.3390/app12168378