1. Introduction
Dysarthric speaking is often associated with aging as well as with medical conditions, such as cerebral palsy (CP) and amyotrophic lateral sclerosis (ALS) [
1]. It is a motor speech disorder caused by muscle weakness or lack of control and often makes someone’s speech unclear; hence, patients cannot communicate well with people (or machines). Currently, augmentative and alternative communication (AAC) systems are used to improve patient communication capabilities, such as communication boards [
2], head tracking [
3], gesture controlling [
4], and eye-tracking [
5] technologies. Previous studies have shown that these systems provided benefits to help patients communicate with people; however, there is still room for improvement. For example, communication using these devices is often slow and unnatural for dysarthric patients [
6]; hence, it affects the communication performance of dysarthric patients directly. To overcome these issues, many studies [
7] have proposed speech command recognition (SCR) systems that can help patients control devices via their voice, such as automatic speech recognition (ASR) systems [
8] and acoustic pattern recognition technologies [
9].
For SCR systems used in dysarthric patients, one challenge is the phonetic variation of speech [
1,
10,
11,
12]. Phonetic variation in dysarthric patients is a common issue, caused by limitations from neurological injury to the motor component of the motor–speech system [
13]. To alleviate phonetic variation of a dysarthric patient’s speech, most related works on the recognition of dysarthric speech have been focused on acoustic modeling to obtain suitable acoustic cues for dysarthric speech. Hasegawa-Johnson et al. [
14] evaluate recognition performance for dysarthric speech compared with automatic speech recognition (ASR) systems based on Gaussian mixture model–hidden Markov models (GMM–HMMs) and support vector machines (SVMs) [
15]. The experimental results showed that the HMM-based model may provide robustness against large-scale word-length variances; meanwhile, the SVM-based model can alleviate the effect of deletion of or reduction in consonants. Rudzicz et al. [
16,
17] investigated acoustic models of GMM–HMM, conditional random field, SVM, and artificial neural networks (ANNs) [
17], and the results showed that the ANNs provided higher accuracy than other models.
Recently, deep learning technology has been widely used in many fields [
18,
19,
20] and has proven it can provide better performance than conventional classification models in SCR tasks. For example, Snyder et al. [
21] apply a deep neural network (DNN) with a data augmentation technique to perform ASR. They achieve better performance in the x-vector system; however, it is not helpful as an i-vector extractor. Fathima et al. [
22] applied a multilingual Time Delay Neural Network (TDNN) system that combined acoustic modeling and language specific information to increase ASR performance. The experimental results showed that the TDNN-based ASR system achieved suitable performance, as the word error rate was 16.07% in this study.
Although the ASR-based approach is a classical technology [
8] in the dysarthric SCR task, other studies indicate that ASR systems still need huge improvements for severely dysarthric patients (e.g., cerebral palsy or stroke) [
23,
24,
25]. This may be because ASR systems are trained without including dysarthric speech [
14,
23,
26,
27]. Therefore, studies have tried to modify the approach of the ASR system to achieve higher performance. For example, Hawley et al. [
28] suggested that a small-vocabulary speaker-dependent recognition system (i.e., the personalized SCR system in this study, which the dysarthric patients need to record their speech) can be more effective for severely dysarthric users in SCR tasks. Farooq et al. [
29] applied the wavelet technique [
30] to transform the acoustic data to achieve speech recognition. In the experiment, they found that the wavelet technique can achieve better performance than the traditional transform technique Mel-frequency cepstral coefficient (MFCC) in a voiced stops situation; however, MFCC showed better performance in other situations, such as with voiced fricatives. Shahamiri et al. [
8] used the best-performing set MFCC [
31,
32] with artificial neural networks to perform speaker-independent ASR. The experiment results showed an average 68.4% word recognition rate with the dysarthric speaker-independent ASR model and 95.0% word recognition rate in speaker-dependent ASR systems. Park et al. [
21] used the data augmentation approach called SpecAugment to improve the ASR performance, and the results showed that this approach could achieve 6.8% world error rate (WER). Yang et al. [
25] applied cycle-consistent adversarial training methods to improve dysarthric speech. They achieved a lower WER (33.4%) compared with automatic speech recognition of the generated utterance on a held-out test set. Recognition performance, such as with the above systems, allows users to individually train a system using their speech, thus making it possible to account for the variations in dysarthric speech [
28]. Although these approaches can provide suitable performance in this task, there are some issues to overcome, including privacy (i.e., the recorded data uploaded to the server in most ASR systems) and higher computing power needed to use the ASR system. Thus, edge computing-based SCR systems, such as those using acoustic pattern recognition technologies [
33,
34], are the other approaches selected in this application task.
Recent studies have found that deep learning-based acoustic pattern recognition approaches [
33,
34], such as the DNN [
35,
36] and convolution neural network (CNN) [
37,
38] models, with MFCC features provide suitable performance in the dysarthric SCR task. More specifically, one-dimensional waveform signals were preprocessed by the MFCC feature extraction unit to obtain the two-dimensional spectrographic images used to train the CNN model. Following this, the trained CNN model was used to predict results from these two-dimensional spectrographic images in the application phase. Currently, this approach, called CNN–MFCC in this study, is widely used in speech or acoustic event detection tasks. For example, Chen et al. [
39] used the CNN–MFCC structure to predict the tones of Mandarin from input speech, and the results showed that this approach provided higher accuracy than classical approaches. Rubin et al. [
40] applied the CNN–MFCC structure for the automatic classification of heart sounds, and the results suggested that this structure can also provide suitable performance in this application task. Che et al. [
41] used a similar concept to CNN–MFCC in a partial discharge recognition task, and the results showed that the MFCC and CNN may be a promising event recognition method for this application too. The structure of CNN–MFCC be used to help dysarthric patients. Nakashika et al. [
42] proposed a robust feature extraction method using a CNN model, which extracted the disordered speech features from a segment MFCC map. The experiment results of this study showed that the CNN-based feature extraction from the MFCC map provided better word-recognition results than other conventional feature extraction methods. More recently, Yakoub et al. [
43] proposed an empirical model decomposition and Hurst-based model selection (EMDH)-CNN system to improve the recognition of dysarthric speech. The results showed that the proposed system provided higher accuracy than the hidden Markov with Gaussian Mixture model and the CNN model by 20.72% and 9.95%, respectively. From the above studies, we infer that a robust speech feature can benefit the acoustic pattern recognition system in the application of a dysarthric patient SCR task.
Recently, a novel speech feature, the phonetic posteriorgram (PPG), was proposed; this is a time-versus-class vector that expresses the posterior probabilities of phonetic classes for a specific timeframe (for a detailed description, refer to 2.2). Many studies’ results show that the PPG feature can benefit many speech signal-processing tasks. For example, Zhao et al. [
44] used PPG to process accent conversion, and the results showed a 20% improvement in speech quality. Zhou et al. [
45] applied PPG to achieve cross-lingual voice conversion; the results showed effectiveness in intralingual and cross-lingual voice conversion between English and Mandarin speakers. More recently, in our previous study, the PPG was used to assist the gated CNN-based voice conversion model to convert dysarthric to normal speech [
46], and the results showed that the PPG speech feature can benefit the voice conversion system for the dysarthric patient speech conversion task. Following the success of PPG features in previous dysarthric patient speech signal processing tasks, the first purpose of this study is to propose a hybrid system, called CNN–PPG, which is a CNN model with PPG features which could be used to improve the SCR accuracy for severe dysarthric patients. It should be noted that the goal of the proposed CNN–PPG in this study is to achieve high accuracy and stable recognition performance. Therefore, the concept of the personalized SCR system is also adopted in this study. The second purpose of this study is to compare the proposed CNN–PPG system with two classical systems (CNN model with MFCC features and ASR-based system) to ensure the benefits of this proposed system in this task. The third purpose of this study is to study the relation between the number of parameters and accuracy in these three systems, which can help us to reduce the cost of implementation in the future.
The rest of the article is organized as follows.
Section 2 and
Section 3 presents the method and experimental results. Finally,
Section 4 summarizes our findings.
4. Conclusions and Future Works
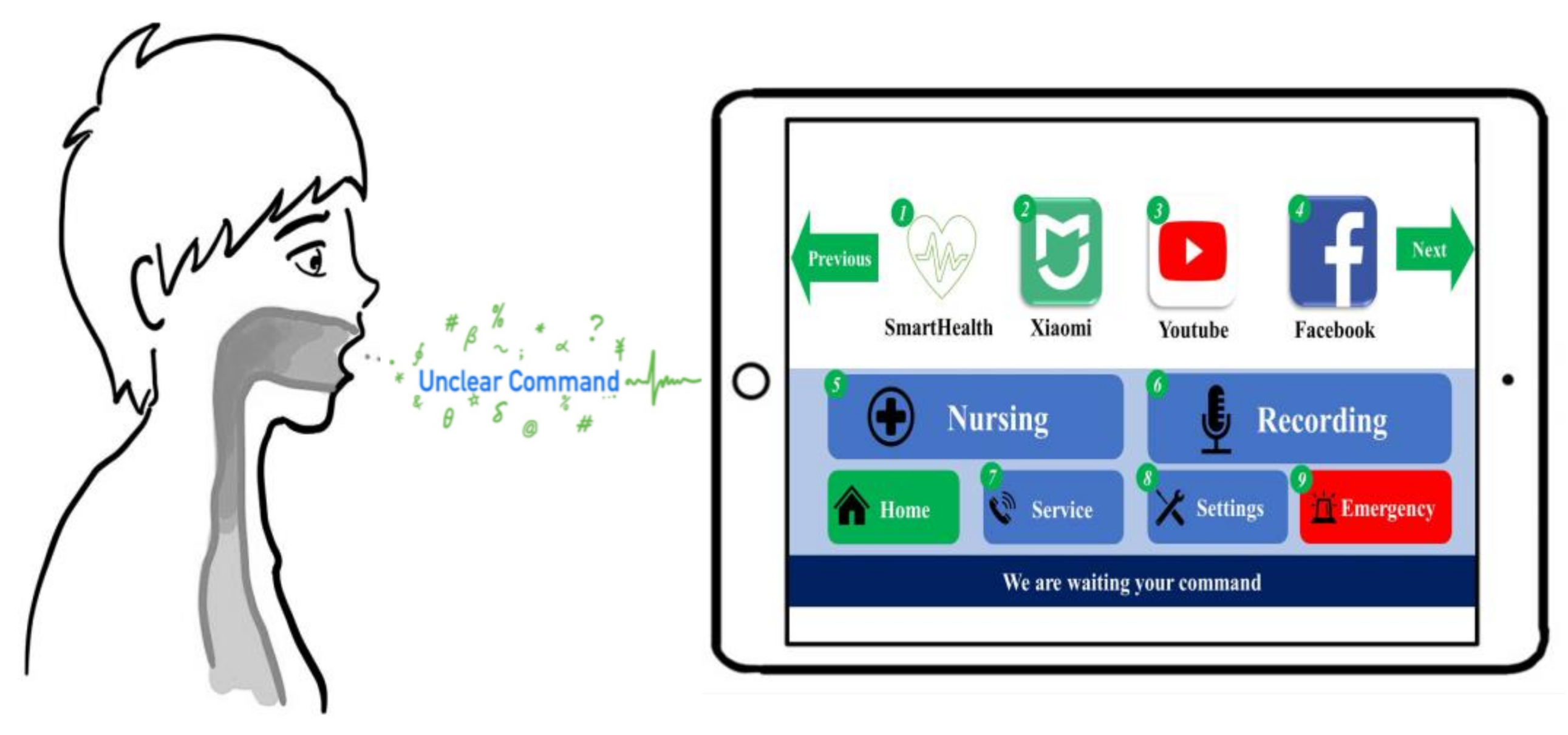
This study aimed to use a deep learning-based SCR system to help dysarthric patients control mobile devices via speech. Our results showed that: (1) the speech feature of PPG can achieve better recognition performance than MFCC and (2) the proposed CNN–PPG SCR system can provide higher recognition accuracy than two classical SCR systems in this study; meanwhile, only a small model size is needed to compare the CNN–MFCC and ASR-based SCR systems. More specifically, the average accuracy of CNN–PPG achieved an acceptable performance (i.e., 93.49% recognition rate) in this study; therefore, the CNN–PPG can be applied in the SCR system to help dysarthric patients control a communication device using their speech commands, as shown in
Figure 5. Specifically, the dysarthric patients can use combinations of 19 commands to select application software functions (e.g., YouTube, Facebook, and messaging). In addition, we plan to use natural language processing technology to provide automated options from the interlocutor’s speech; meanwhile, these candidates’ response sentences will be selected through the patient’s 19 commands, thereby accelerating the patient’s response rate. Finally, we plan to implement this proposed CNN–PPG in a mobile device to help dysarthric patients improve their communication quality in future studies.
The proposed CNN–PPG system provided higher performance than two baseline SCR systems in a personalized application condition; however, the performance of the proposed system could be limited in general application (i.e., without asking the user to record the speech commands), because of the challenging the issues of individual variability and phonetic variation in the speech [
10,
11,
12] of dysarthric patients. To overcome this challenge and further improve system benefits, two possible research directions appear. First, we will provide this system for free use to dysarthric patients and many patients’ voice commands, with the users’ consent. Next, the data obtained can, therefore, be used to retrain the CNN–PPG system to improve performance in a generalization application condition. Second, advanced deep learning technologies [
50,
76,
77,
78,
79], such as few-shots audio classification, 1D/2D CNN audio temporal integration, semi-supervised speaker diarization deep neural embeddings, convolutional 2D audio stream management, and data augmentation, can be used to further improve the performance of the proposed CNN–PPG SCR system in future studies.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




