
Unsupervised Clustering Pipeline to Obtain Diversified Light Spectra for Subject Studies and Correlation Analyses



Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
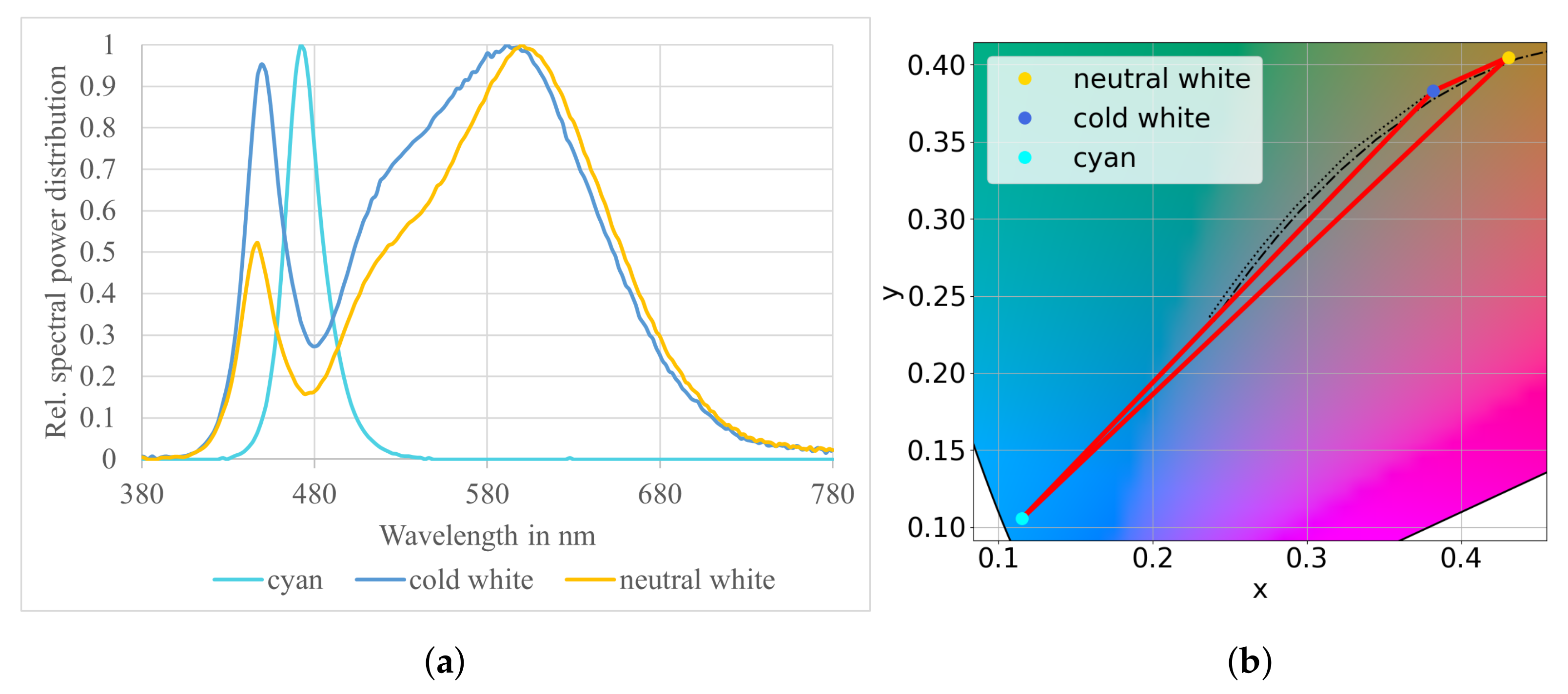
2.1. Test Setup and Input Data
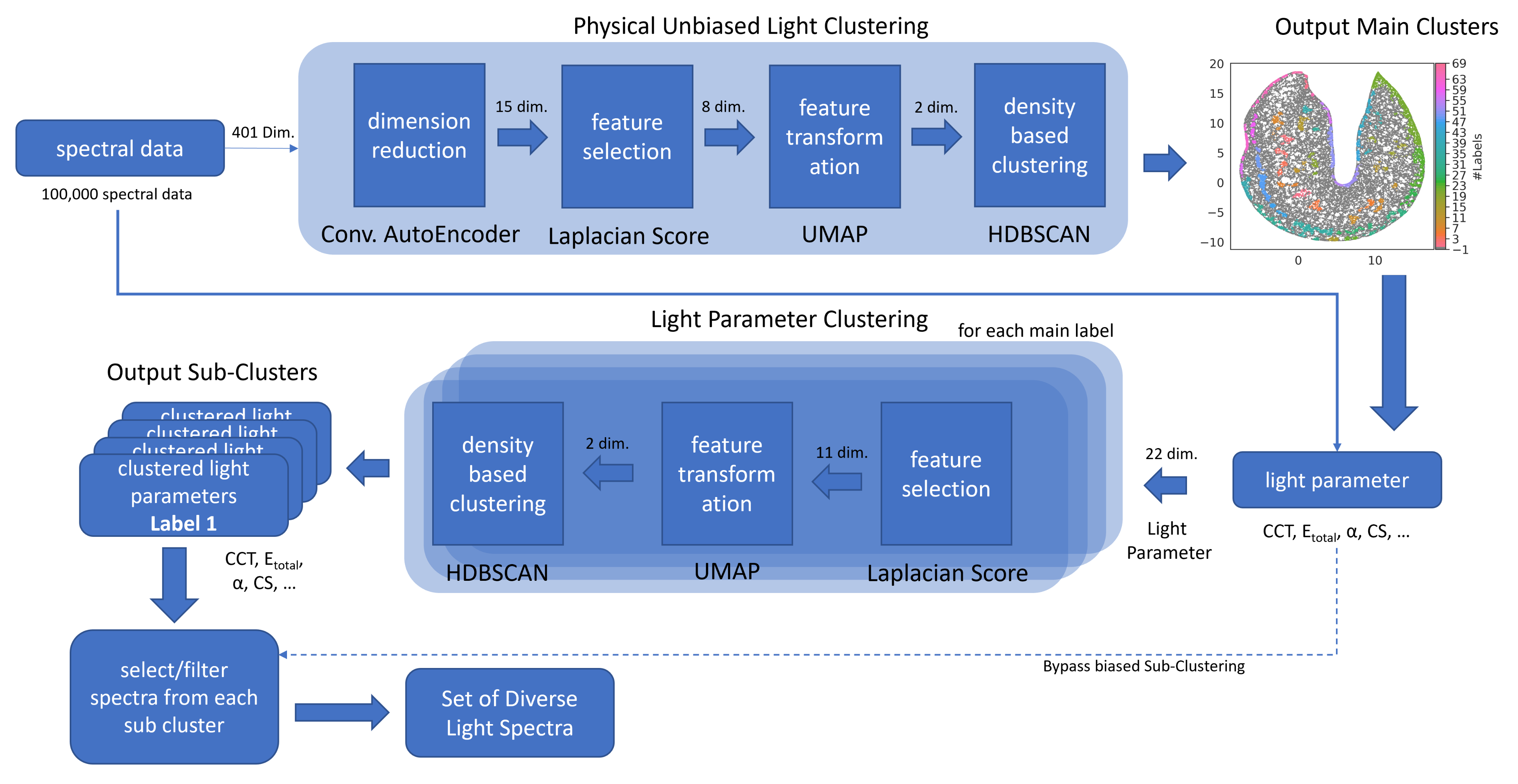
2.2. Feature Reduction and Main Clustering
2.2.1. Convolutional Autoencoder
2.2.2. Laplacian Score
2.2.3. UMAP
2.2.4. HDBSCAN
2.3. Sub-Clustering Based on Lighting Parameters
3. Results
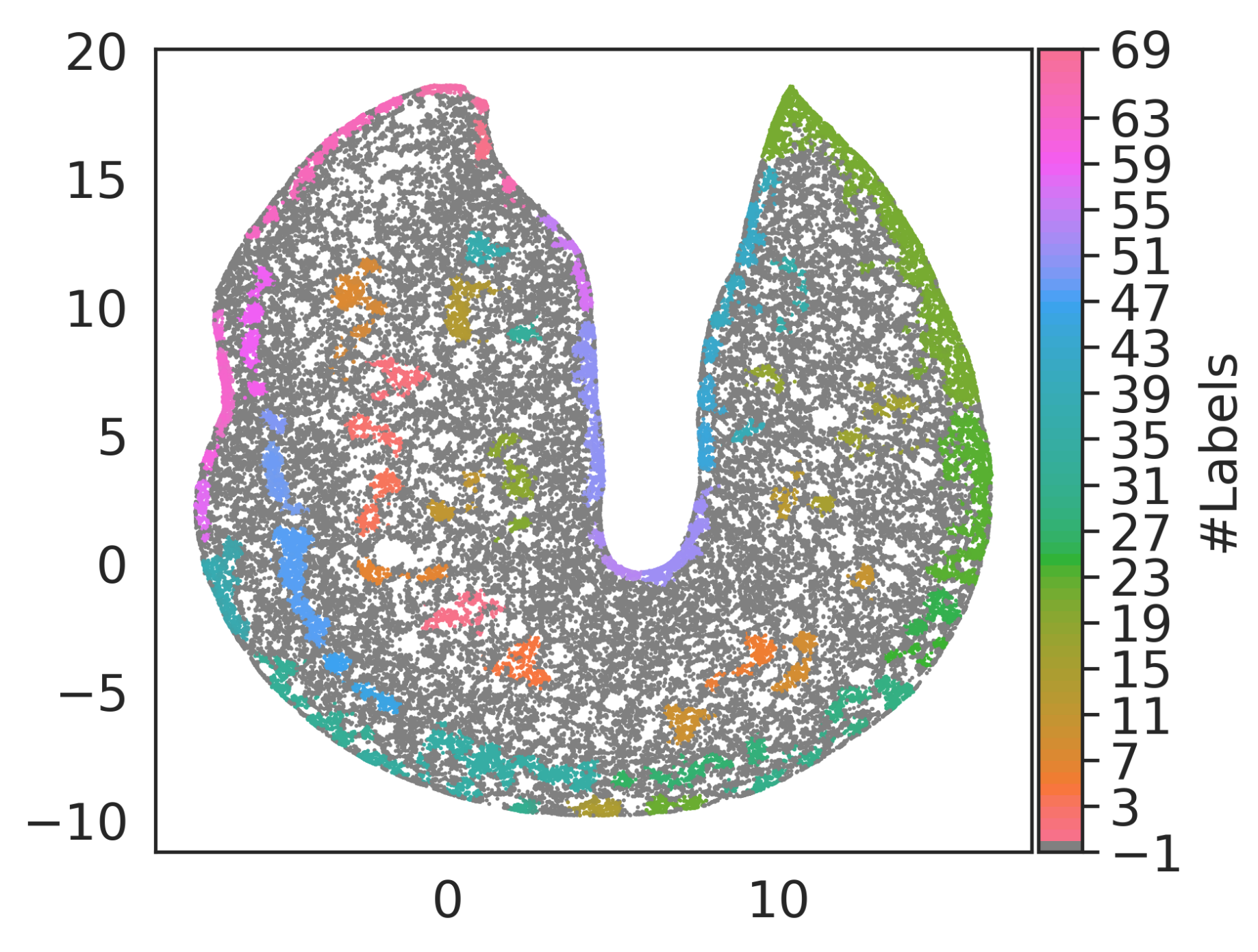
3.1. Autoencoding and Main Clustering of the Embedded Space Representation
3.2. Sub-Clustering and Data Filtering
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pust, P.; Schmidt, P.J.; Schnick, W. A revolution in lighting. Nat. Mater. 2015, 14, 454–458. [Google Scholar] [CrossRef] [PubMed]
- Khanh, T.Q.; Bodrogi, P.; Guo, X.; Vinh, Q.T.; Fischer, S. Colour Preference, Naturalness, Vividness and Colour Quality Metrics, Part 5: A Colour Preference Experiment at 2000 lx in a Real Room. Light. Res. Technol. 2019, 51, 262–279. [Google Scholar] [CrossRef]
- Bodrogi, P.; Guo, X.; Stojanovic, D.; Fischer, S.; Khanh, T.Q. Observer preference for perceived illumination chromaticity. Color Res. Appl. 2018, 43, 506–516. [Google Scholar] [CrossRef]
- Tähkämö, L.; Partonen, T.; Pesonen, A.K. Systematic review of light exposure impact on human circadian rhythm. Chronobiol. Int. 2019, 36, 151–170. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Babilon, S.; Lenz, J.; Beck, S.; Myland, P.; Klabes, J.; Klir, S.; Khanh, T.Q. Task-related Luminance Distributions for Office Lighting Scenarios. Light Eng. 2021, 29, 115–128. [Google Scholar] [CrossRef]
- Yan, L.; Chen, Y.; Chen, B. Integrated analog dimming controller for 0–10 V dimming system. In Proceedings of the 10th China International Forum on Solid State Lighting (ChinaSSL), Beijing, China, 10–12 November 2013; Institute of Electrical and Electronics Engineers (IEEE): Beijing, China, 2013; pp. 147–149. [Google Scholar] [CrossRef]
- Gagliardi, G.; Casavola, A.; Lupia, M.; Cario, G.; Tedesco, F.; Lo Scudo, F.; Cicchello Gaccio, F.; Augimeri, A. A smart city adaptive lighting system. In Proceedings of the Third International Conference on Fog and Mobile Edge Computing (FMEC), Barcelona, Spain, 23–26 April 2018; Institute of Electrical and Electronics Engineers (IEEE): Barcelona, Spain, 2018; pp. 258–263. [Google Scholar] [CrossRef]
- Gagliardi, G.; Lupia, M.; Cario, G.; Tedesco, F.; Cicchello Gaccio, F.; Lo Scudo, F.; Casavola, A. Advanced adaptive street lighting systems for smart cities. Smart Cities 2020, 3, 1495–1512. [Google Scholar] [CrossRef]
- Sinha, A.; Sharma, S.; Goswami, P.; Verma, V.K.; Manas, M. Design of an energy efficient IoT enabled smart system based on DALI network over MQTT protocol. In Proceedings of the 3rd International Conference on Computational Intelligence & Communication Technology (CICT), Ghaziabad, India, 9–10 February 2017; Institute of Electrical and Electronics Engineers (IEEE): Ghaziabad, India, 2017. [Google Scholar] [CrossRef]
- Sikder, A.K.; Acar, A.; Aksu, H.; Uluagac, A.S.; Akkaya, K.; Conti, M. IoT-enabled smart lighting systems for smart cities. In Proceedings of the 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; Institute of Electrical and Electronics Engineers (IEEE): Las Vegas, NV, USA, 2018; pp. 639–645. [Google Scholar] [CrossRef]
- Adam, G.K. DALI LED driver control system for lighting operations based on Raspberry Pi and kernel modules. Electronics 2019, 8, 1021. [Google Scholar] [CrossRef] [Green Version]
- Kaleem, Z.; Ahmad, I.; Lee, C. Smart and energy efficient LED street light control system using ZigBee network. In Proceedings of the 12th International Conference on Frontiers of Information Technology, Islamabad, Pakistan, 17–19 December 2014; Institute of Electrical and Electronics Engineers (IEEE): Islamabad, Pakistan, 2014; pp. 361–365. [Google Scholar] [CrossRef]
- Varghese, S.G.; Kurian, C.P.; George, V.I.; John, A.; Nayak, V.; Upadhyay, A. Comparative study of ZigBee topologies for IoT-based lighting automation. IET Wirel. Sens. Syst. 2019, 9, 201–207. [Google Scholar] [CrossRef]
- Wei, W.; Min, W. The design of ZigBee routing algorithm in smart lighting system. Ferroelectrics 2019, 549, 254–265. [Google Scholar] [CrossRef]
- IEC International Electrotechnical Commission. IEC 60929:2011—AC and/or DC-Supplied Electronic Control Gear for Tubular Fluorescent Lamps: Performance Requirements. 2011. Available online: https://webstore.iec.ch/publication/3926 (accessed on 24 September 2021).
- IEC International Electrotechnical Commission. IEC 62386-207:2018—Digital Addressable Lighting Interface—Part 207: Particular Requirements for Control Gear—LED Modules (Device Type 6). 2018. Available online: https://webstore.iec.ch/publication/30618 (accessed on 24 September 2021).
- Zandi, B.; Eissfeldt, A.; Herzog, A.; Khanh, T.Q. Melanopic limits of metamer spectral optimisation in multi-channel smart lighting systems. Energies 2021, 14, 527. [Google Scholar] [CrossRef]
- Schweitzer, S.; Schinagl, C.; Djuras, G.; Frühwirth, M.; Hoschopf, H.; Wagner, F.; Schulz, B.; Nemitz, W.; Grote, V.; Reidl, S.; et al. Investigation of gender- and age-related preferences of men and women regarding lighting conditions for activation and relaxation. In Proceedings of the Fifteenth International Conference on Solid State Lighting and LED-based Illumination Systems, San Diego, CA, USA, 28 August–1 September 2016; Volume 9954, p. 99540. [Google Scholar] [CrossRef]
- Despenic, M.; Chraibi, S.; Lashina, T.; Rosemann, A. Lighting preference profiles of users in an open office environment. Build. Environ. 2017, 116, 89–107. [Google Scholar] [CrossRef]
- Chraibi, S.; Lashina, T.; Shrubsole, P.; Aries, M.; van Loenen, E.; Rosemann, A. Satisfying light conditions: A field study on perception of consensus light in Dutch open office environments. Build. Environ. 2016, 105, 116–127. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Yang, M.; Yao, Y.; Xiong, X.; Li, X.; Zhou, G.; Ma, N. Effects of Illuminance and Correlated Color Temperature on Daytime Cognitive Performance, Subjective Mood, and Alertness in Healthy Adults. Environ. Behav. 2019, 51, 199–230. [Google Scholar] [CrossRef]
- Finlayson, G.; Mackiewicz, M.; Hurlbert, A.; Pearce, B.; Crichton, S. On calculating metamer sets for spectrally tunable LED illuminators. J. Opt. Soc. Am. A 2014, 31, 1577. [Google Scholar] [CrossRef] [Green Version]
- Allen, A.E.; Hazelhoff, E.M.; Martial, F.P.; Cajochen, C.; Lucas, R.J. Exploiting metamerism to regulate the impact of a visual display on alertness and melatonin suppression independent of visual appearance. Sleep 2018, 41. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Huang, H.C.; Chuang, Y.Y.; Chen, C.S. Affinity aggregation for spectral clustering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 773–780. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.; Gupta, A.; Efros, A.A. Unsupervised discovery of mid-level discriminative patches. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7573 LNCS, pp. 73–86. [Google Scholar] [CrossRef] [Green Version]
- Hariharan, B.; Malik, J.; Ramanan, D. Discriminative decorrelation for clustering and classification. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7575 LNCS, pp. 459–472. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- IES-TM-30-15. Method for Evaluating Light Source Color Rendition; Illuminating Engineering Society of North America: New York, NY, USA, 2015. [Google Scholar]
- Lucas, R.J.; Peirson, S.N.; Berson, D.M.; Brown, T.M.; Cooper, H.M.; Czeisler, C.A.; Figueiro, M.G.; Gamlin, P.D.; Lockley, S.W.; O’Hagan, J.B.; et al. Measuring and using light in the melanopsin age. Trends Neurosci. 2014, 37, 1–9. [Google Scholar] [CrossRef]
- Celebi, M.E.; Aydin, K. Unsupervised Learning Algorithms; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Kramer, M.A. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal Component Analysis. Chemometr. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- McConville, R.; Santos-Rodríguez, R.; Piechocki, R.J.; Craddock, I. N2D: (Not too) deep clustering via clustering the local manifold of an autoencoded embedding. arXiv 2019, arXiv:1908.05968. [Google Scholar]
- Amarbayasgalan, T.; Jargalsaikhan, B.; Ryu, K.H. Unsupervised novelty detection using deep autoencoders with density based clustering. Appl. Sci. 2018, 8, 1468. [Google Scholar] [CrossRef] [Green Version]
- Zaidi, F.H.; Hull, J.T.; Peirson, S.N.; Wulff, K.; Aeschbach, D.; Gooley, J.J.; Brainard, G.C.; Gregory-Evans, K.; Rizzo, J.F.; Czeisler, C.A.; et al. Short-Wavelength Light Sensitivity of Circadian, Pupillary, and Visual Awareness in Humans Lacking an Outer Retina. Curr. Biol. 2007, 17, 2122–2128. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- IEC International Electrotechnical Commission. IEC 62386-102:2009—Digital Addressable Lighting Interface—Part 102: General Requirements—Control Gear. 2009. Available online: https://webstore.iec.ch/publication/20477 (accessed on 24 September 2021).
- He, X.; Cai, D.; Niyogi, P. Laplacian Score for feature selection. Adv. Neural Inf. Process. Syst. 2005, 18, 507–514. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- McInnes, L.; Healy, J. Accelerated Hierarchical Density Based Clustering. In Proceedings of the IEEE International Conference on Data Mining Workshops, ICDMW, New Orleans, LA, USA, 18–21 November 2017; pp. 33–42. [Google Scholar] [CrossRef] [Green Version]
- Mousavi, S.M.; Zhu, W.; Ellsworth, W.; Beroza, G. Unsupervised Clustering of Seismic Signals Using Deep Convolutional Autoencoders. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1693–1697. [Google Scholar] [CrossRef]
- Lee, K.; Carlberg, K.T. Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders. J. Comput. Phys. 2020, 404, 108973. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Chen, H.; Wu, L.; Wang, J. A novel smart meter data compression method via stacked convolutional sparse auto-encoder. Int. J. Electr. Power Energy Syst. 2020, 118, 105761. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, H.; Zhao, S. Auto-encoder based dimensionality reduction. Neurocomputing 2016, 184, 232–242. [Google Scholar] [CrossRef]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked convolutional auto-encoders for hierarchical feature extraction. In Artificial Neural Networks and Machine Learning—ICANN 2011; Honkela, T., Duch, W., Girolami, M., Kaski, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 52–59. [Google Scholar] [CrossRef] [Green Version]
- Gholamalinezhad, H.; Khosravi, H. Pooling Methods in Deep Neural Networks, a Review. arXiv 2020, arXiv:2009.07485. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. (CSUR) 2018, 50, 94. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Niyogi, P. Locality preserving projections. Adv. Neural Inf. Process. Syst. 2004, 6, 153–160. [Google Scholar]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. Adv. Neural Inf. Process. Syst. 2002, 14, 585–591. [Google Scholar] [CrossRef] [Green Version]
- van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2625. [Google Scholar]
- van der Maaten, L. Accelerating t-SNE using Tree-Based Algorithms. J. Mach. Learn. Res. 2014, 15, 3221–3245. [Google Scholar]
- Tang, J.; Liu, J.; Zhang, M.; Mei, Q. Visualizing large-scale and high-dimensional data. In Proceedings of the 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2016; pp. 287–297. [Google Scholar] [CrossRef] [Green Version]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Davis, W. Color quality scale. Opt. Eng. 2010, 49, 033602. [Google Scholar] [CrossRef] [Green Version]
- Rea, M.S.; Figueiro, M.G. Light as a circadian stimulus for architectural lighting. Light. Res. Technol. 2018, 50, 497–510. [Google Scholar] [CrossRef]
- Houser, K.W.; Tiller, D.K.; Bernecker, C.A.; Mistrick, R.G. The subjective response to linear fluorescent direct/indirect lighting systems. Light. Res. Technol. 2002, 34, 243–260. [Google Scholar] [CrossRef]
- Hashimoto, K.; Yano, T.; Shimizu, M.; Nayatani, Y. New method for specifying color-rendering properties of light sources based on feeling of contrast. Color Res. Appl. 2007, 32, 361–371. [Google Scholar] [CrossRef]
- Smet, K.A.; Ryckaert, W.R.; Pointer, M.R.; Deconinck, G.; Hanselaer, P. A memory colour quality metric for white light sources. Energy Build. 2012, 49, 216–225. [Google Scholar] [CrossRef]
- Thornton, W.A. A validation of the color-preference index. J. Illum. Eng. Soc. 1974, 4, 48–52. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lighting Parameter | Description |
|---|---|
| CCT | correlated color temperature |
| total illuminance | |
| distance from the planckian locus for a given CCT in CIE 1960 uniform chromaticity space | |
| illuminance of the indirect part of the luminaire | |
| [56] | general color quality scale (NIST CQS 9.0) |
| average CIELAB chroma difference to reference illuminant calculated for the 15 NIST CQS 9.0 color samples | |
| CS [57] | circadian stimulus |
| CL [57] | circadian light |
| [58] | / |
| [31] | integrated L-, M-, S-cone, rod, and ipRGC values |
| irradiance | |
| [31] | color fidelity index |
| [31] | color gamut Index |
| [31] | general metameric uncertainty index |
| FCI [59] | feeling of contrast index |
| MCRI [60] | memory color rendition index |
| CPI [61] | color preference index |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Klir, S.; Fathia, R.; Babilon, S.; Benkner, S.; Khanh, T.Q. Unsupervised Clustering Pipeline to Obtain Diversified Light Spectra for Subject Studies and Correlation Analyses. Appl. Sci. 2021, 11, 9062. https://doi.org/10.3390/app11199062
Klir S, Fathia R, Babilon S, Benkner S, Khanh TQ. Unsupervised Clustering Pipeline to Obtain Diversified Light Spectra for Subject Studies and Correlation Analyses. Applied Sciences. 2021; 11(19):9062. https://doi.org/10.3390/app11199062
Chicago/Turabian StyleKlir, Stefan, Reda Fathia, Sebastian Babilon, Simon Benkner, and Tran Quoc Khanh. 2021. "Unsupervised Clustering Pipeline to Obtain Diversified Light Spectra for Subject Studies and Correlation Analyses" Applied Sciences 11, no. 19: 9062. https://doi.org/10.3390/app11199062