

Reinforcement Learning with Dual Safety Policies for Energy Savings in Building Energy Systems

Abstract
:1. Introduction
- (1)
- This paper proposes an RL algorithm with dual safety policies to ensure the safety of RL. Implicit safety policy is an optimization policy integrated into RL to make the agent learn optimal safety policy by long-term learning. In order to ensure the safety of real-time action, especially in the early phase of the explore process, explicit safety policy is proposed. Through the dual safety policies, it can not only ensure the safety of real-time action, but also enable the agent to learn long-term safety policy.
- (2)
- Rather than offline learning, explicit safety policy adopts an online learning method, which makes the learning process more difficult. In order to solve the above problem, we propose a method based on residual learning, based on the characteristics of the HVAC real-time data, which not only ensures the accuracy of the algorithm, but also improves the stability of the algorithm.
- (3)
- Most importantly, unlike most RL algorithms that are still in the experimental simulation stage, our algorithm has been deployed in practical scenario. The results showed that the implemented algorithm achieved impressive energy savings while maintaining indoor temperature requirements, compared to rule control and PID control.
2. Methods
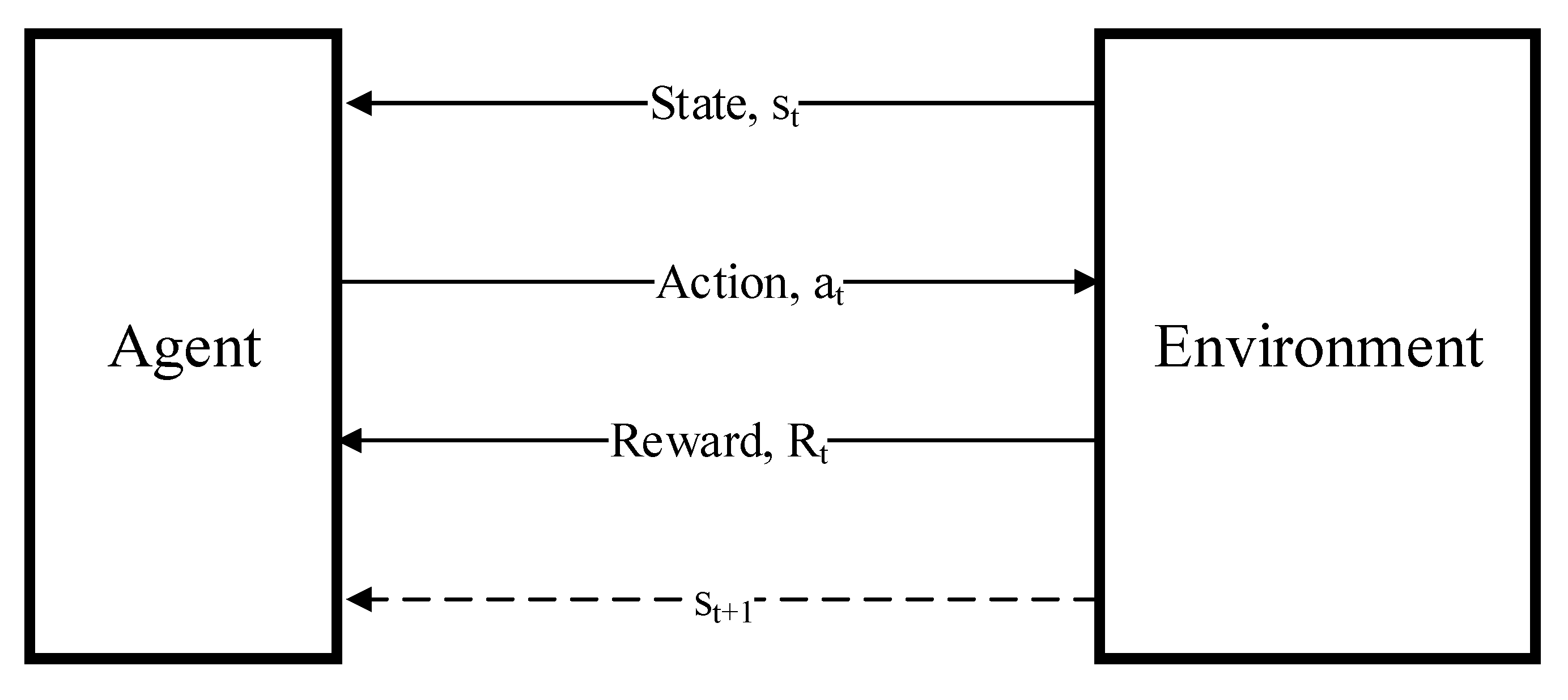
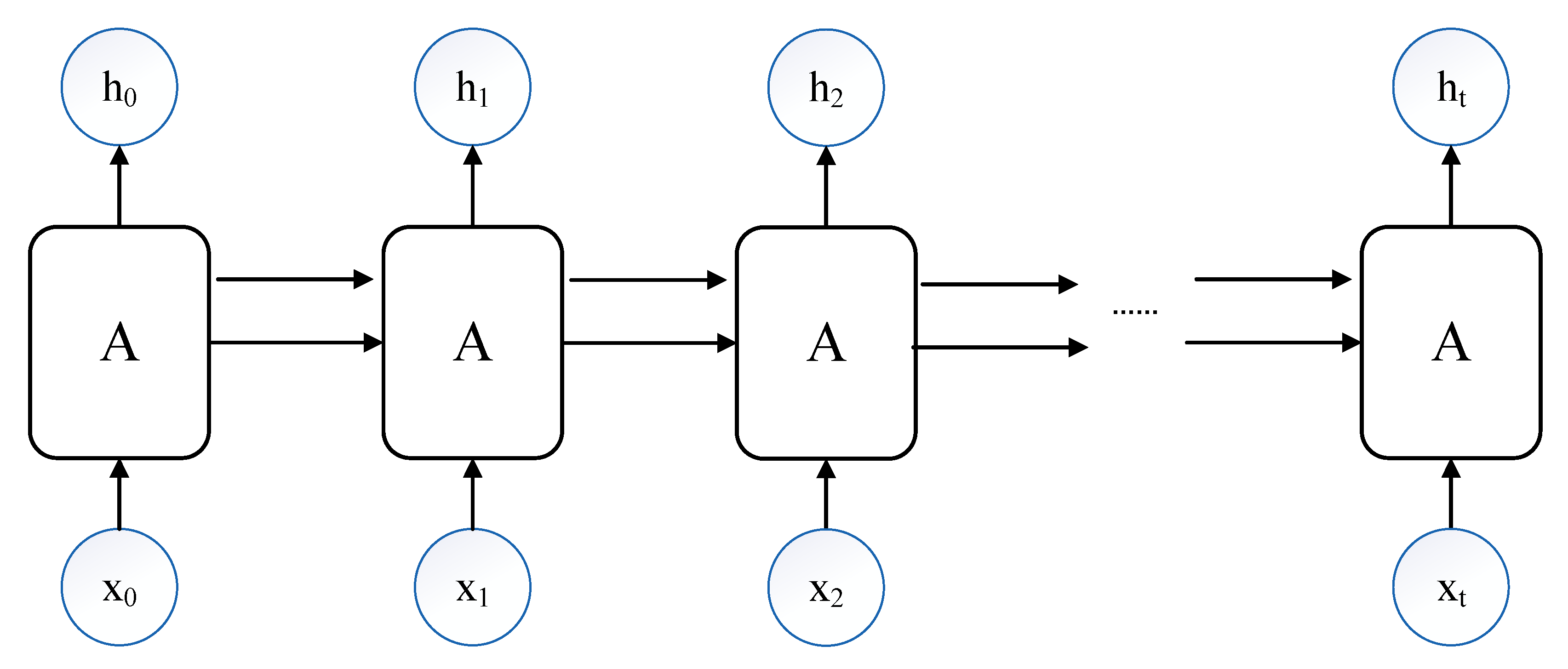
2.1. Reinforcement Learning
2.2. SAC
2.3. Online Learning
3. Framework of Proposed Algorithm
3.1. Problem Definition
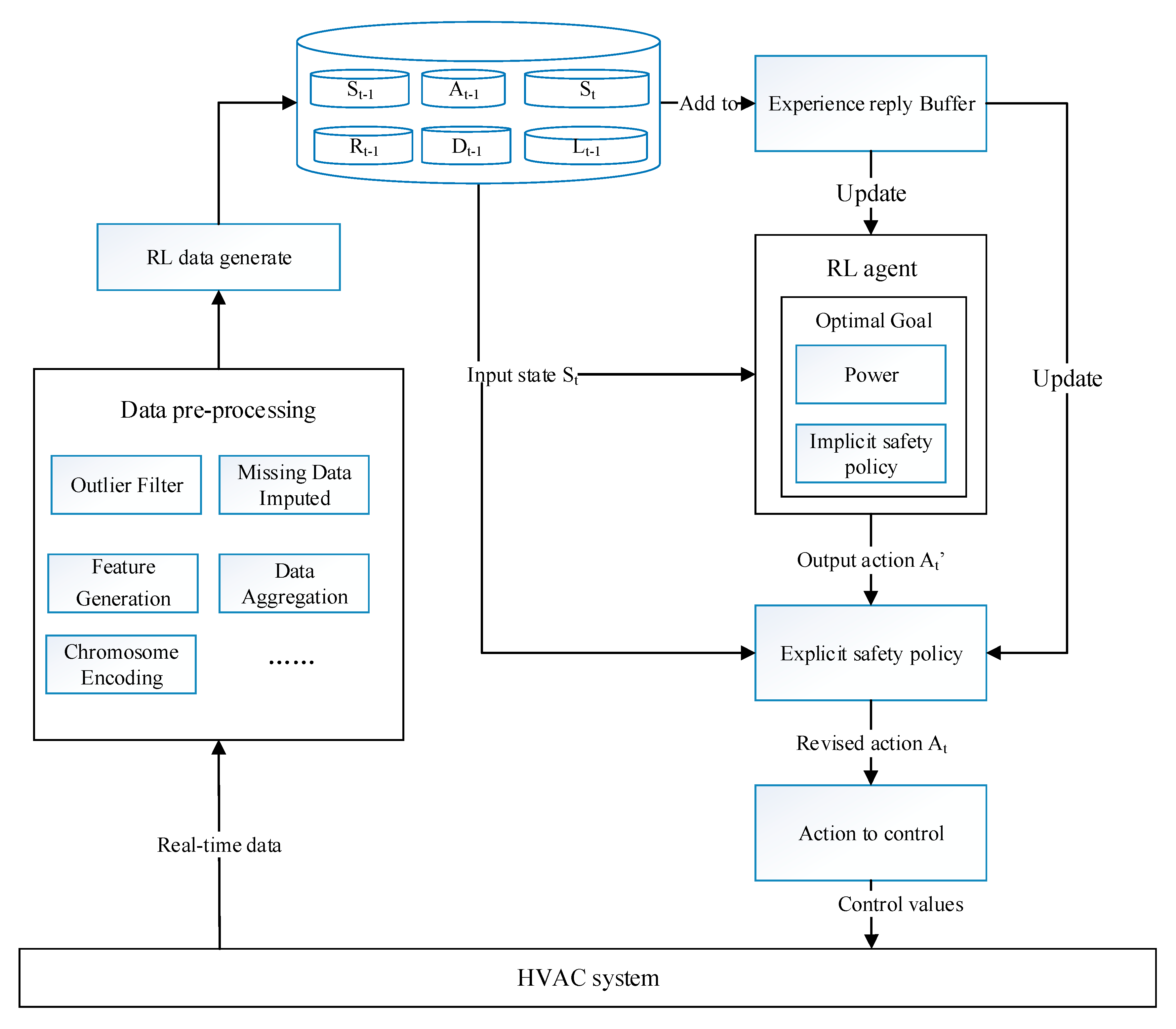
3.2. Framwork Overview
3.3. Data Pre-Processing
3.3.1. Data Pre-Processing Introduction
3.3.2. Settings of Reinforcement Learning
3.4. Implicit Safety Policy
3.5. Explicit Safety Policy
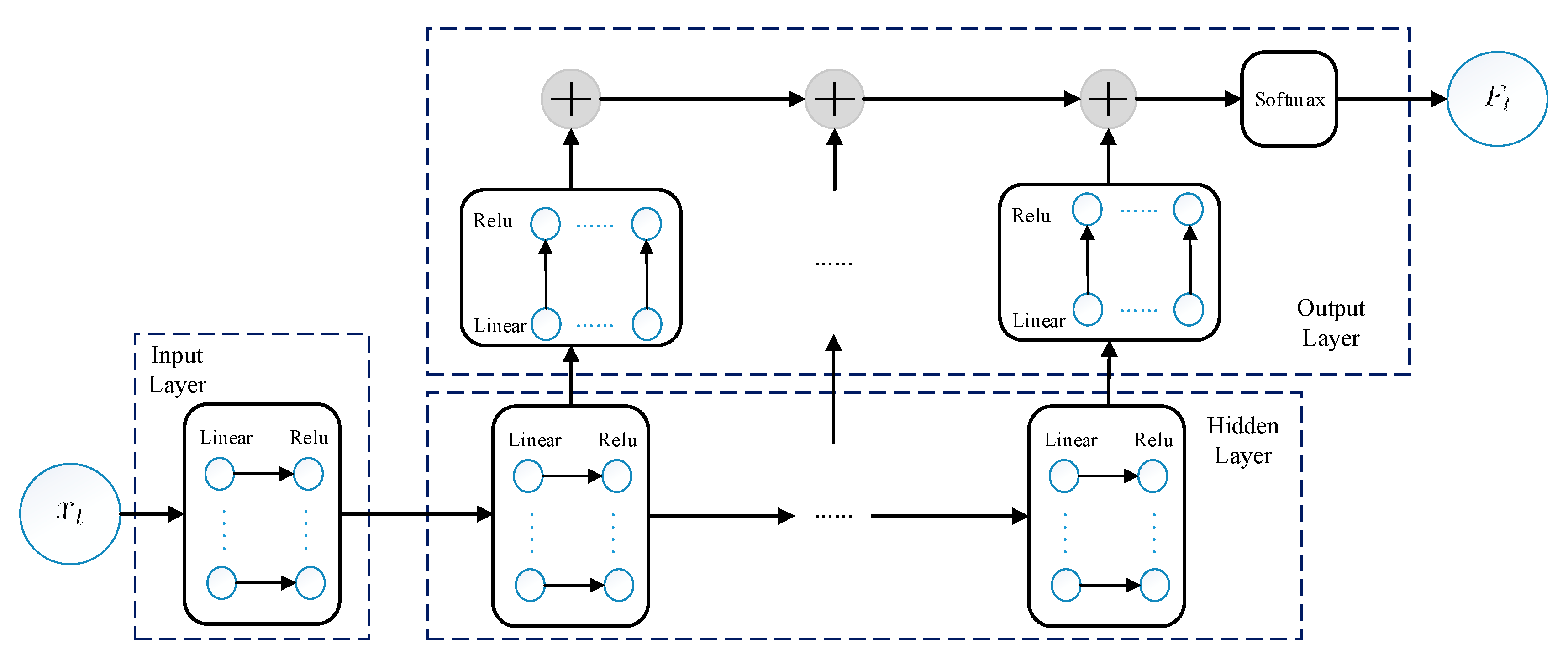
3.5.1. Online Safety Classifier
- If a network consists of hidden layers, each layer will correspond to an output layer, and each output layer’s learning objectives are not the same. For the layer , the learning objective is . In this way, different network structures can be implemented.
- The parameters of network are not updated simultaneously with backward propagation. The parameters of each hidden and output layer are updated layer by layer. When the parameter of a layer is updated, a new sample is required to update the shallow network. The updating formula is listed as follows in Equations (11) and (12).
3.5.2. Alternative Action Collection Generation and Optimal Action Selection
| Algorithm 1. Explicit safety policy |
| Input: Learning rate parameter Initialize: with hidden layers and 1. for do 2. Receive instance ; 3. Predict ; 4. If then 5. Obtain alternative action collection; 6. Obtain best action; 7. Obtain true label ; 8. If then 9. for do 10. Predict ; 11. Calculate Loss ; 12. Update ; 13. Update to with ; 14. end |
4. Results and Discussion
4.1. Case System
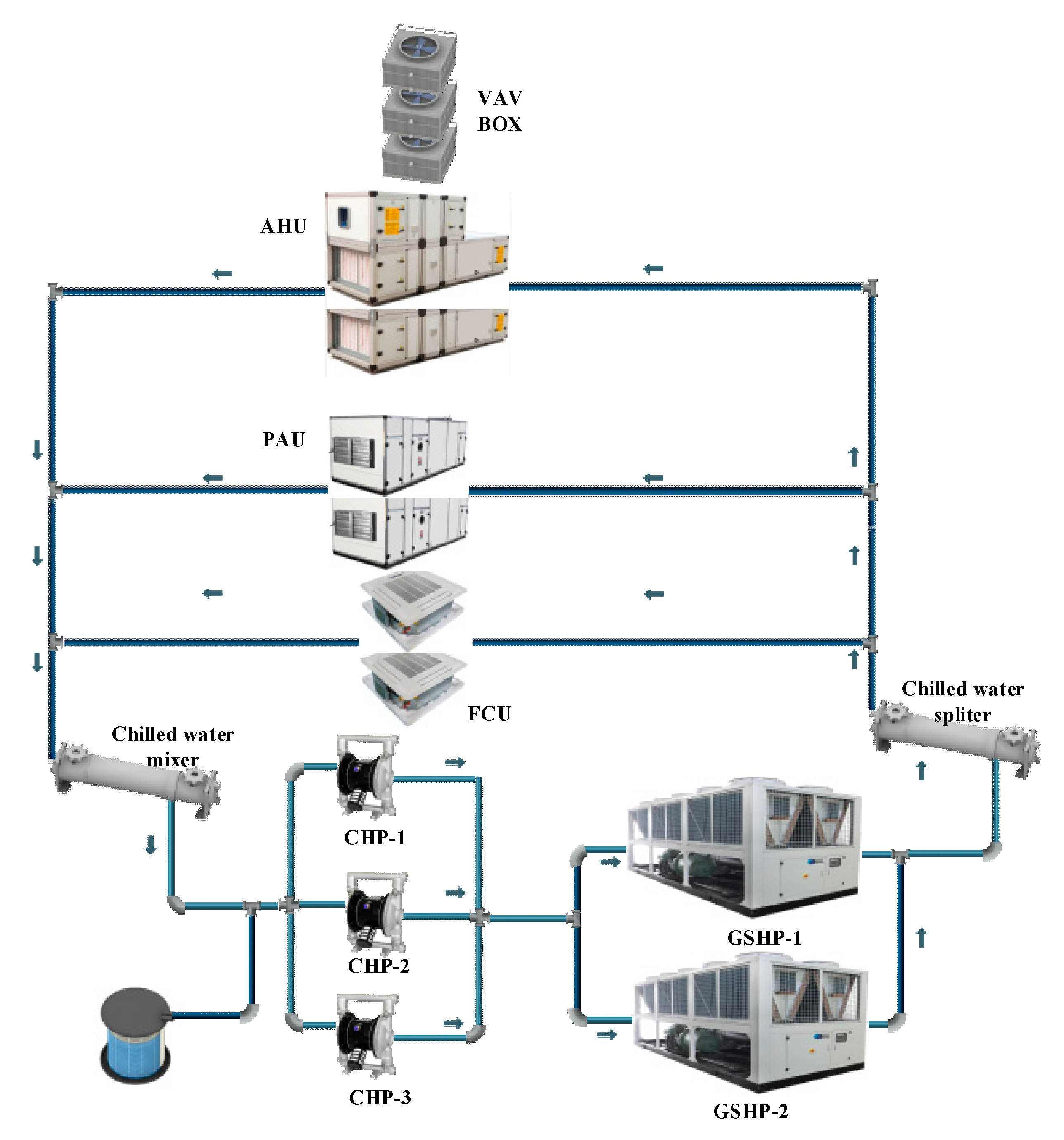
4.1.1. System Structure
4.1.2. System Characteristics
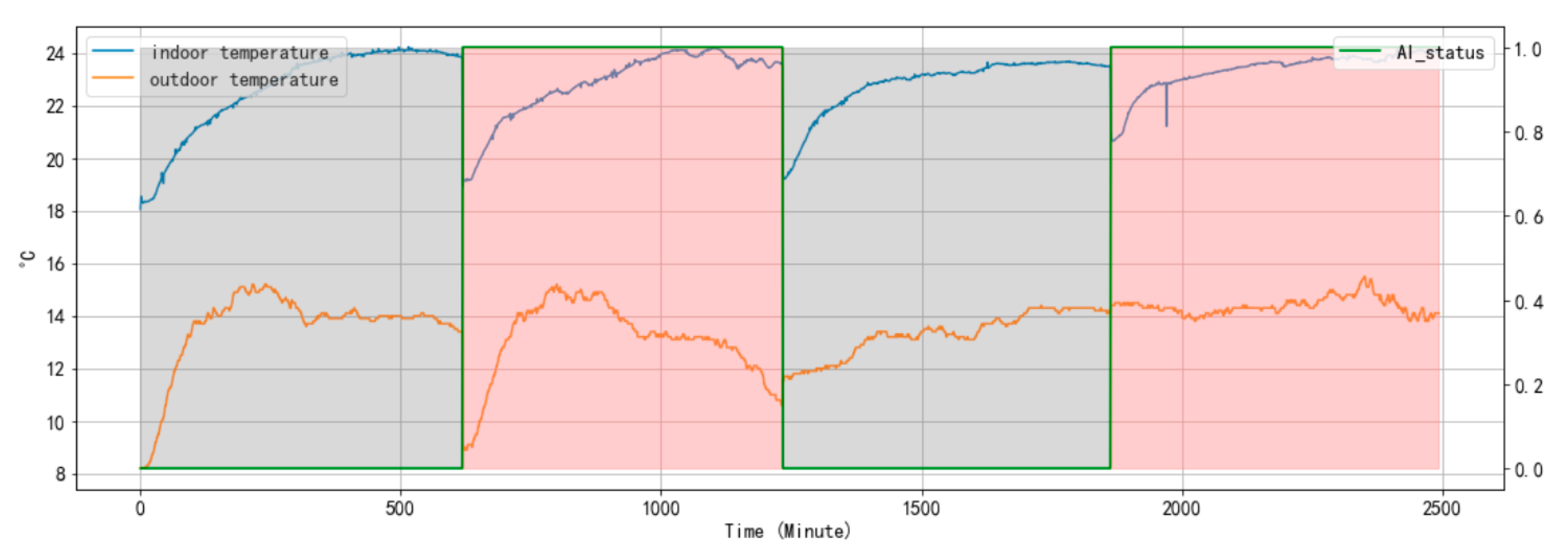
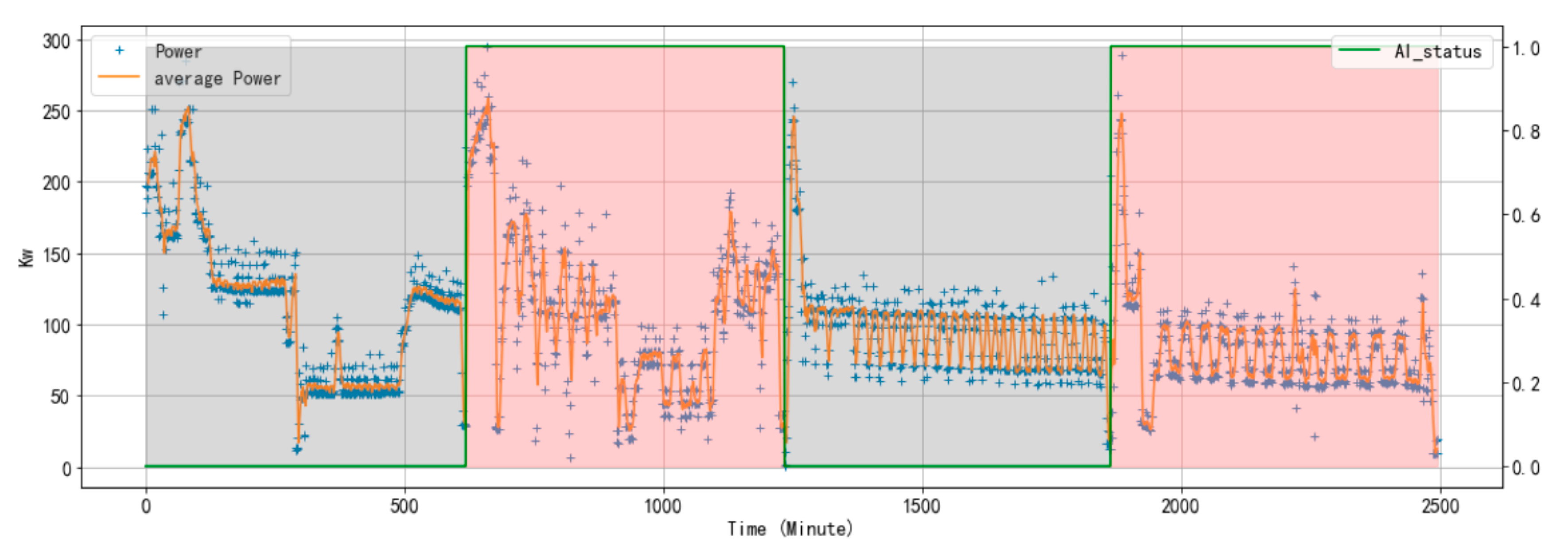
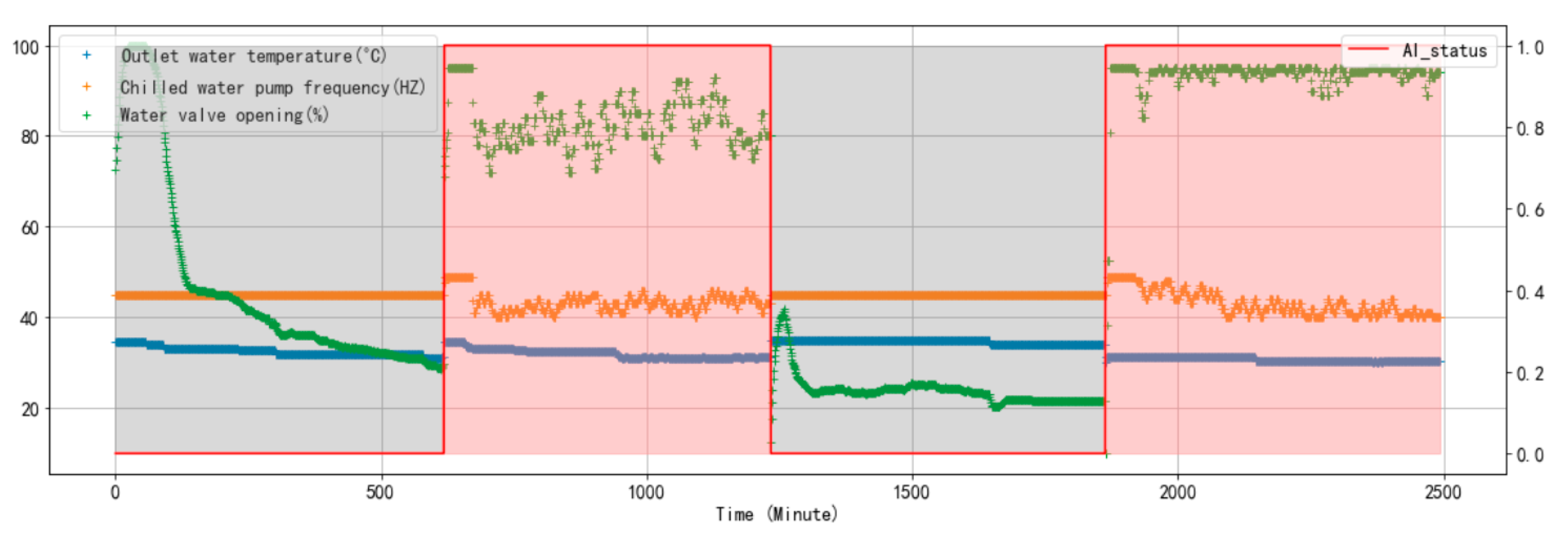
4.2. Effectiveness of Proposed Algorithm
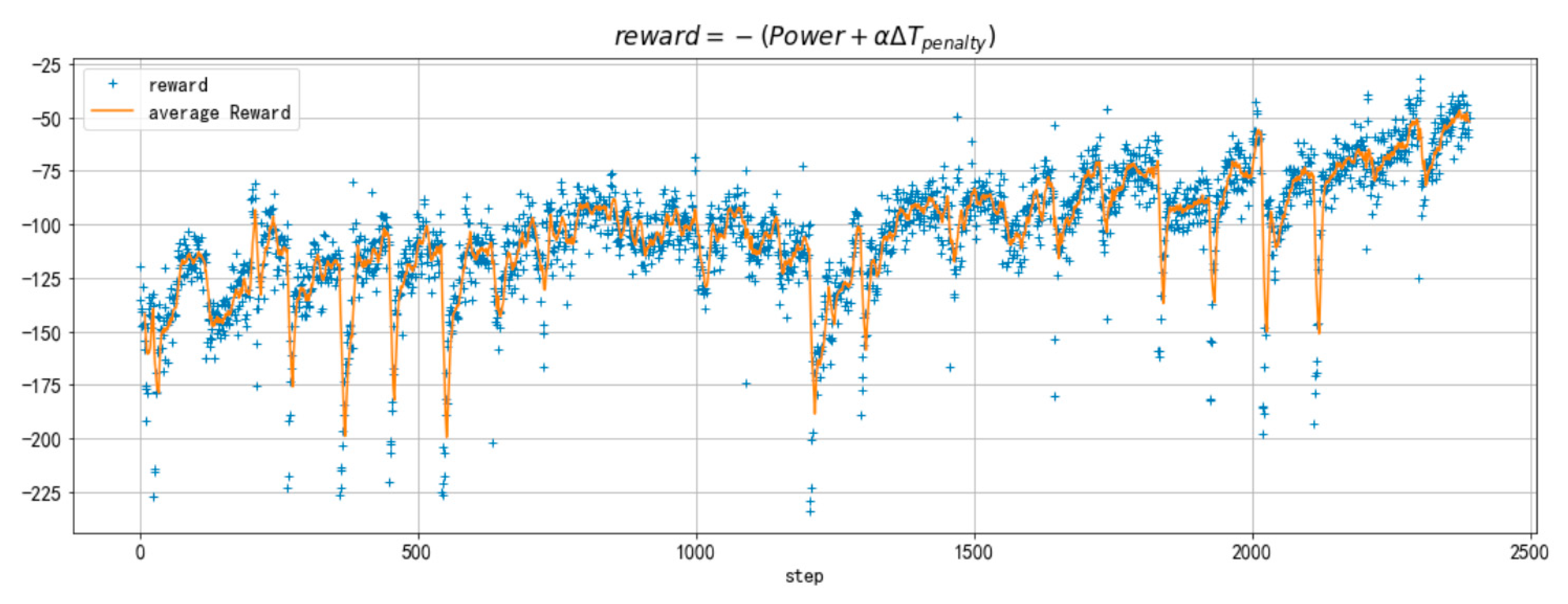
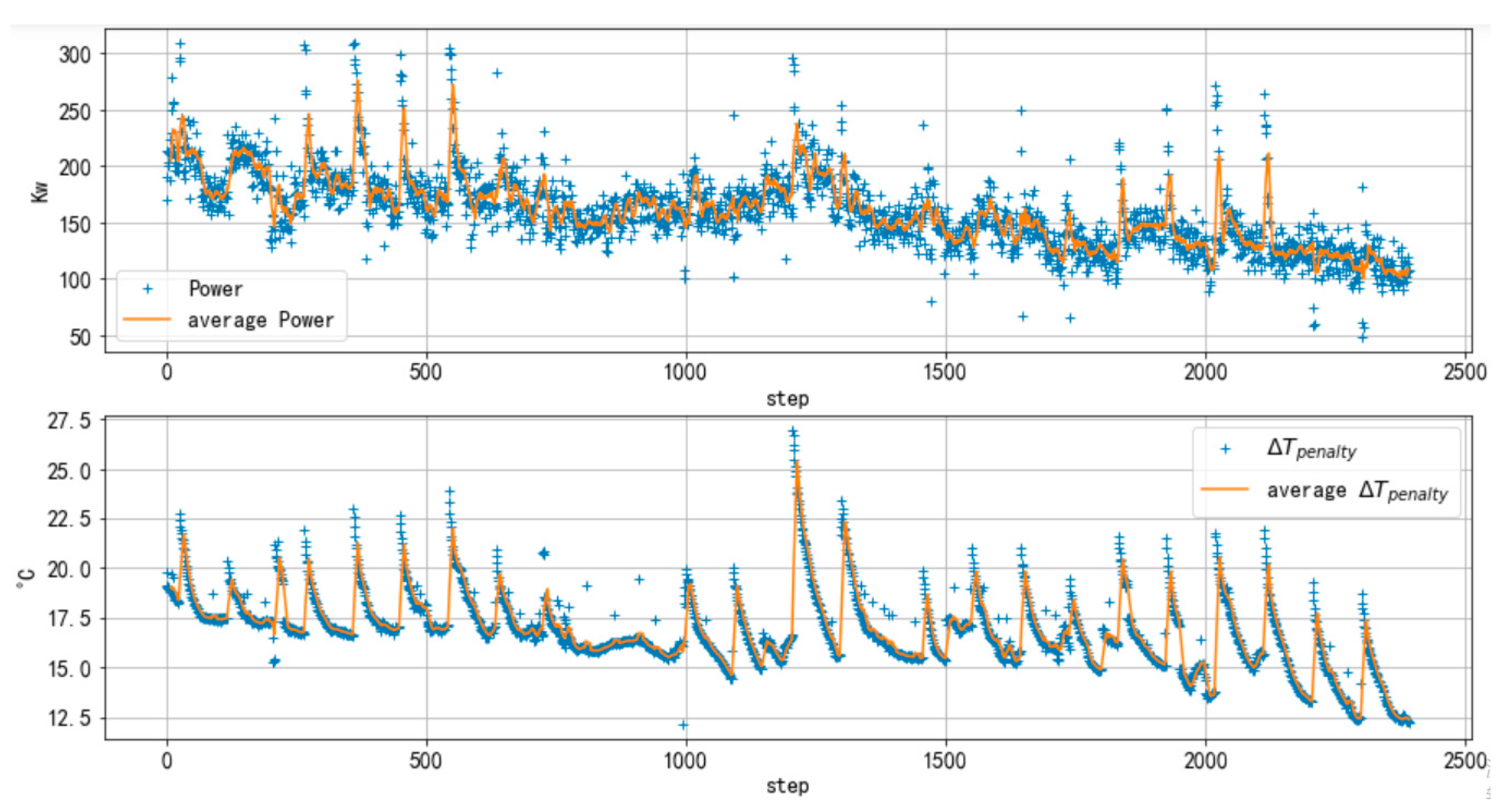
4.2.1. Overview
4.2.2. Performance of Online Safety Classifier
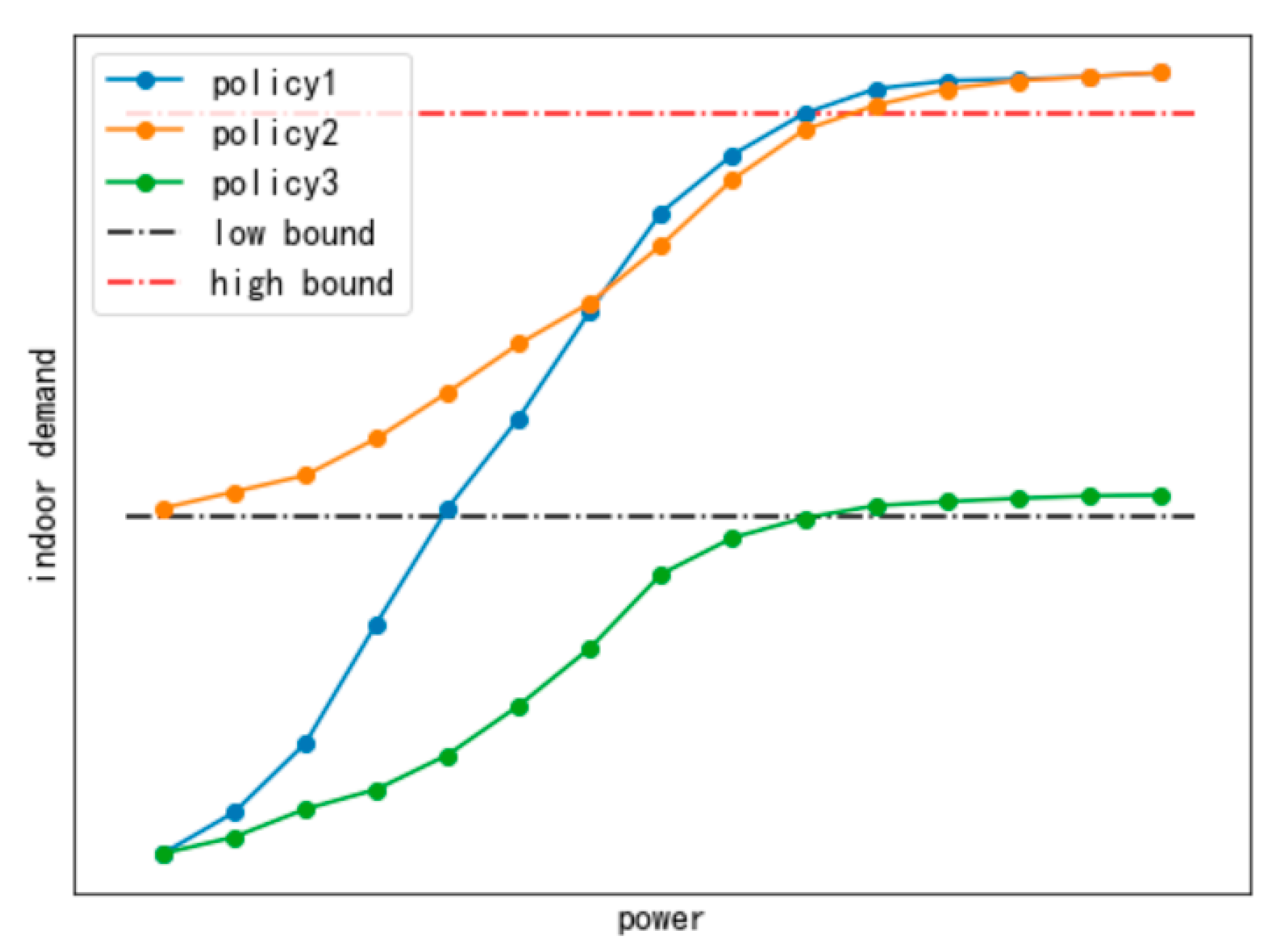
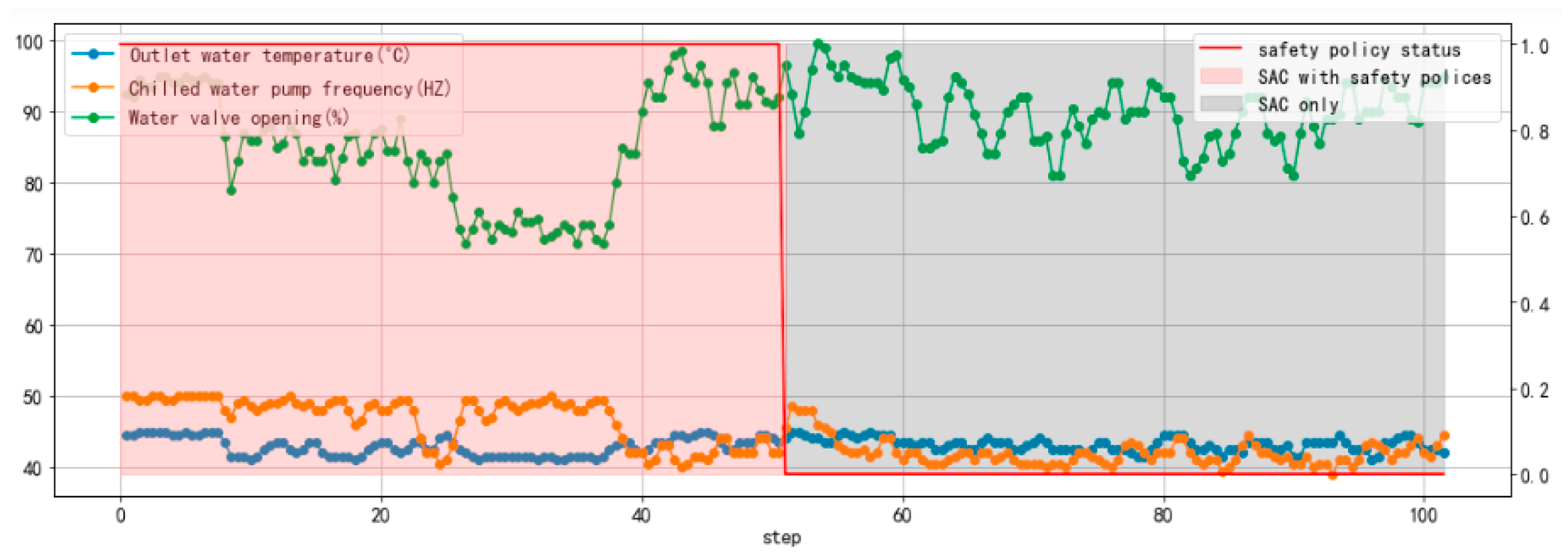
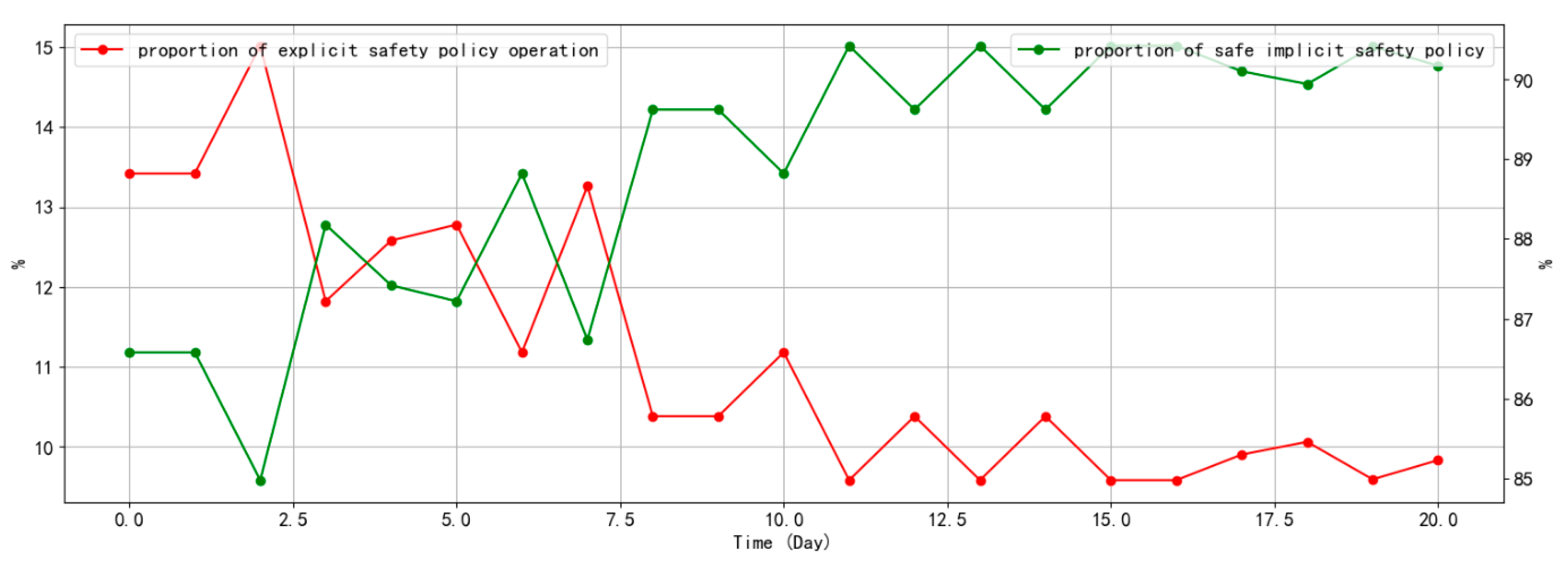
4.2.3. Performance of Safety Policies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Niu, Z.; Wu, J.; Liu, X.; Huang, L.; Nielsen, P.S. Understanding energy demand behaviors through spatio-temporal smart meter data analysis. Energy 2021, 226, 120493. [Google Scholar] [CrossRef]
- Biemann, M.; Scheller, F.; Liu, X.; Huang, L. Experimental evaluation of model-free reinforcement learning algorithms for continuous HVAC control. Appl. Energy 2021, 298, 117164. [Google Scholar] [CrossRef]
- Geng, G.; Geary, G.M. On performance and tuning of PID controllers in HVAC systems. In Proceedings of the IEEE International Conference on Control and Applications, Vancouver, BC, Canada, 13–16 September 1993; Volume 2, pp. 819–824. [Google Scholar] [CrossRef]
- Royapoor, M.; Antony, A.; Roskilly, T. A review of building climate and plant controls, and a survey of industry perspectives. Energy Build. 2018, 158, 453–465. [Google Scholar] [CrossRef]
- Afram, A.; Janabi-Sharifi, F. Theory and applications of HVAC control systems–A review of model predictive control (MPC). Build. Environ. 2014, 72, 343–355. [Google Scholar] [CrossRef]
- Namatēvs, I. Deep Reinforcement Learning on HVAC Control. Inf. Technol. Manag. Sci. 2018, 21, 29–36. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Hong, T. Reinforcement learning for building controls: The opportunities and challenges. Appl. Energy 2020, 269, 115036. [Google Scholar] [CrossRef]
- Schreiber, T.; Eschweiler, S.; Baranski, M.; Dirk, M. Application of two promising Reinforcement Learning algorithms for load shifting in a cooling supply System—ScienceDirect. Energy Build. 2020, 229, 110490. [Google Scholar] [CrossRef]
- Afroz, Z.; Shafiullah, G.M.; Urmee, T.; Higgins, G. Modeling techniques used in building HVAC control systems: A review. Renew. Sustain. Energy Rev. 2018, 83, 64–84. [Google Scholar] [CrossRef]
- Kontes, G.D.; Giannakis, G.I.; Sánchez, V.; Agustin-Camacho, P.D.; Gruen, G. Simulation-based evaluation and optimization of control strategies in buildings. Energies 2018, 11, 3376. [Google Scholar] [CrossRef] [Green Version]
- Azuatalam, D.; Lee, W.L.; de Nijs, F.; Liebman, A. Reinforcement learning for whole-building HVAC control and demand response. Energy AI 2020, 2, 100020. [Google Scholar] [CrossRef]
- Raman, N.S.; Devraj, A.M.; Barooah, P.; Meyn, S.P. Reinforcement Learning for Control of Building HVAC Systems[C]//2020 American Control Conference (ACC); IEEE: New York, NY, USA, 2020; pp. 2326–2332. [Google Scholar]
- Mason, K.; Grijalva, S. A review of reinforcement learning for autonomous building energy management. Comput. Electr. Eng. 2019, 78, 300–312. [Google Scholar] [CrossRef] [Green Version]
- Baxter, J.; Bartlett, P.L. Infinite-horizon policy-gradient estimation. J. Artif. Intell. Res. 2001, 15, 319–350. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-Policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Zhang, C.; Kuppannagari, S.R.; Kannan, R.; Prasanna, V.K. Building HVAC scheduling using reinforcement learning via neural network based model approximation. In Proceedings of the 6th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, New York, NY, USA, 13 November 2019; pp. 287–296. [Google Scholar]
- Liu, Y.; Halev, A.; Liu, X. Policy learning with constraints in model-free reinforcement learning: A survey. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 18 January 2021. [Google Scholar]
- Chow, Y.; Nachum, O.; Duenez-Guzman, E.; Ghavamzadeh, M. A lyapunov-based approach to safe reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Pham, T.H.; De Magistris, G.; Tachibana, R. Optlayer-practical constrained optimization for deep reinforcement learning in the real world. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6236–6243. [Google Scholar]
- Wei, T.; Wang, Y.; Zhu, Q. Deep reinforcement learning for building HVAC control. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar]
- Stavrakakis, G.M.; Katsaprakakis, D.A.; Damasiotis, M. Basic Principles, Most Common Computational Tools, and Capabilities for Building Energy and Urban Microclimate Simulations. Energies 2021, 14, 6707. [Google Scholar] [CrossRef]
- Fu, Y.; Zuo, W.; Wetter, M.; Vangilder, J.W.; Han, X.; Plamondon, D. Equation-Based Object-Oriented Modeling and Simulation for Data Center Cooling: A Case Study. Energy Build. 2019, 186, 108–125. [Google Scholar] [CrossRef]
- Yu, L.; Sun, Y.; Xu, Z.; Shen, C.; Yue, D.; Jiang, T.; Guan, X. Multi-agent deep reinforcement learning for HVAC control in commercial buildings. IEEE Trans. Smart Grid 2020, 12, 407–419. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Zinkevich, M. Online convex programming and generalized infinitesimal gradient ascent. In Proceedings of the 20th International Conference on Machine Learning (icml-03), Washington, DC, USA, 21–24 August 2003; pp. 928–936. [Google Scholar]
- Cesa-Bianchi, N.; Lugosi, G. Prediction, Learning, and Games; Cambridge University Press: Cambridge, CA, USA, 2006. [Google Scholar]
- Lobo, J.L.; Del Ser, J.; Bifet, A.; Kasabov, N. Spiking neural networks and online learning: An overview and perspectives. Neural Netw. 2020, 121, 88–100. [Google Scholar] [CrossRef]
- Gama, J.; Sebastiao, R.; Rodrigues, P.P. On evaluating stream learning algorithms. Mach. Learn. 2013, 90, 317–346. [Google Scholar] [CrossRef] [Green Version]
- Pérez-Sánchez, B.; Fontenla-Romero, O.; Guijarro-Berdiñas, B. A review of adaptive online learning for artificial neural networks. Artif. Intell. Rev. 2018, 49, 281–299. [Google Scholar] [CrossRef]
- Alippi, C.; Boracchi, G.; Roveri, M. A just-in-time adaptive classification system based on the intersection of confidence intervals rule. Neural Netw. 2011, 24, 791–800. [Google Scholar] [CrossRef] [PubMed]
- Kuncheva, L.I.; Žliobaitė, I. On the window size for classification in changing environments. Intell. Data Anal. 2009, 13, 861–872. [Google Scholar] [CrossRef] [Green Version]
- Ghazikhani, A.; Monsefi, R.; Yazdi, H.S. Online neural network model for non-stationary and imbalanced data stream classification. Int. J. Mach. Learn. Cybern. 2014, 5, 51–62. [Google Scholar] [CrossRef]
- Pavlidis, N.G.; Tasoulis, D.K.; Adams, N.M.; Hand, D.J. λ-Perceptron: An adaptive classifier for data streams. Pattern Recognit. 2011, 44, 78–96. [Google Scholar] [CrossRef] [Green Version]
- Ditzler, G.; Rosen, G.; Polikar, R. Domain adaptation bounds for multiple expert systems under concept drift. In 2014 International Joint Conference on Neural Networks (IJCNN); IEEE: Piscataway, NJ, USA, 2014; pp. 595–601. [Google Scholar]
- Qiao, J.; Li, F.; Han, H.; Li, W. Constructive algorithm for fully connected cascade feedforward neural networks. Neurocomputing 2016, 182, 154–164. [Google Scholar] [CrossRef]
- Thomas, P.; Suhner, M.C. A new multilayer perceptron pruning algorithm for classification and regression applications. Neural Process. Lett. 2015, 42, 437–458. [Google Scholar] [CrossRef]
- Silva, A.M.; Caminhas, W.; Lemos, A.; Gomide, F. A fast learning algorithm for evolving neo-fuzzy neuron. Appl. Soft Comput. 2014, 14, 194–209. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, J.; Infield, D.; Liu, Y.; Lien, F.-S. Short-term forecasting and uncertainty analysis of wind turbine power based on long short-term memory network and Gaussian mixture model. Appl. Energy 2019, 241, 229–244. [Google Scholar] [CrossRef] [Green Version]
- Qiu, D.; Dong, Z.; Zhang, X.; Wang, Y.; Strbac, G. Safe reinforcement learning for real-time automatic control in a smart energy-hub. Appl. Energy 2022, 309, 118403. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Katsaprakakis, D.; Kagiamis, V.; Zidianakis, G.; Ambrosini, L. Operation Algorithms and Computational Simulation of Physical Cooling and Heat Recovery for Indoor Space Conditioning. A Case Study for a Hydro Power Plant in Lugano, Switzerland. Sustainability 2019, 11, 4574. [Google Scholar] [CrossRef] [Green Version]
- Katsaprakakis, D.A. Computational Simulation and Dimensioning of Solar-Combi Systems for Large-Size Sports Facilities: A Case Study for the Pancretan Stadium, Crete, Greece. Energies 2020, 13, 2285. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Space | Structure | Material Type or Schedule |
|---|---|---|
| Envelop | Exterior wall | Hollow bricks wall |
| Window | Dual-glazed windows | |
| Floor | Concrete | |
| Schedule | Occupancy schedule | 7:30 am to 5 pm on weekdays Closed on weekends |
| HVAC schedule | 7 am to 5 pm on weekdays Closed on weekends |
| Space | Parameters |
|---|---|
| States | Outdoor air temperature |
| Outdoor relative humidity | |
| Status of heat pumps, AHU, PAU, FCU and VAV box | |
| Frequencies of AHU, PAU and FUC | |
| Actions | Setting temperature of heat pump outlet water |
| Setting frequency of Primary chilled water pump | |
| Setting opening of AHU water valve |
| Factors | Heat Pump Power | Primary Chilled Water Pump Power | AHU Power | System Power | Indoor Temperature |
|---|---|---|---|---|---|
| Heat pump outlet water temperature | 0.52 | 0.24 | 0.20 | 0.44 | 0.14 |
| Primary chilled water pump frequency | −0.16 | 0.75 | 0.05469 | −0.0 | 0.08 |
| AHU water valve position | 0.17 | 0.24 | −0.20 | 0.17 | 0.46 |
| Outdoor temperature | 0.25 | −0.07 | 0.29 | 0.30 | 0.52 |
| Outdoor humidity | 0.18 | 0.11 | 0.13 | 0.25 | 0.32 |
| Phase | Date | Average Indoor Temperature | Average Outdoor Temperature | Control Method | Energy Saving Rate |
|---|---|---|---|---|---|
| test1 | 3 February 2021 | 21.71 °C | 13.54 °C | BA | 6.51% |
| 4 February 2021 | 22.33 °C | 13.11 °C | AI | ||
| test2 | 12 March 2021 | 22.21 °C | 13.30 °C | BA | 15.02% |
| 16 March 2021 | 22.62 °C | 14.39 °C | AI |
| Metric | Mid-Phase | Late-Phase | Entire Phase |
|---|---|---|---|
| precision | 0.91 | 0.945 | 0.937 |
| recall | 0.75 | 0.78 | 0.774 |
| Model | Date | Average Outdoor Temperature | Average Indoor Temperature | Room TemperatureDissatisfaction Rate | Power Consumption |
|---|---|---|---|---|---|
| SAC with safety policy | 17 March 2021 | 11.58 °C | 21.06 °C | 9.58% | 1671.4 kWh |
| SAC only | 18 March 2021 | 11.73 °C | 21.37 °C | 34.64% | 1533.7 kWh |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, X.; Yuan, D.; Li, X. Reinforcement Learning with Dual Safety Policies for Energy Savings in Building Energy Systems. Buildings 2023, 13, 580. https://doi.org/10.3390/buildings13030580
Lin X, Yuan D, Li X. Reinforcement Learning with Dual Safety Policies for Energy Savings in Building Energy Systems. Buildings. 2023; 13(3):580. https://doi.org/10.3390/buildings13030580
Chicago/Turabian StyleLin, Xingbin, Deyu Yuan, and Xifei Li. 2023. "Reinforcement Learning with Dual Safety Policies for Energy Savings in Building Energy Systems" Buildings 13, no. 3: 580. https://doi.org/10.3390/buildings13030580