
Assessment of Porosity Defects in Ingot Using Machine Learning Methods during Electro Slag Remelting Process

 , ,
, ,
Abstract
:1. Introduction
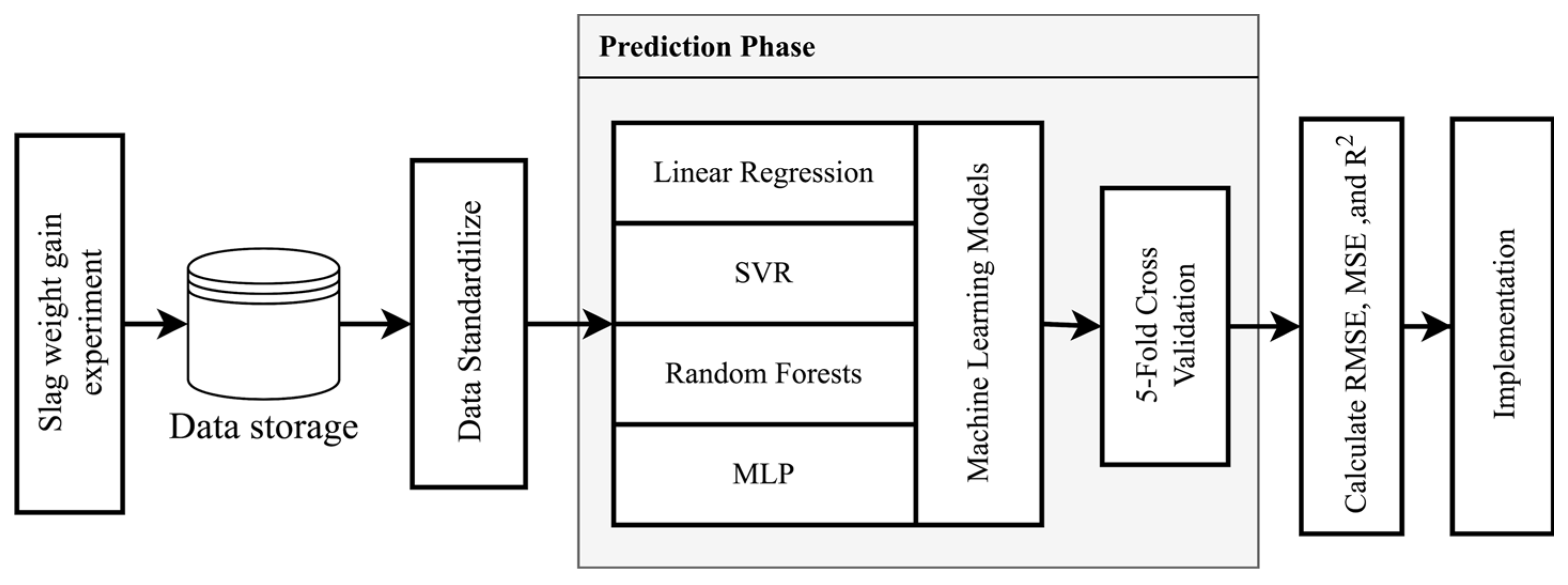
2. Experiments and Machine Learning Methods
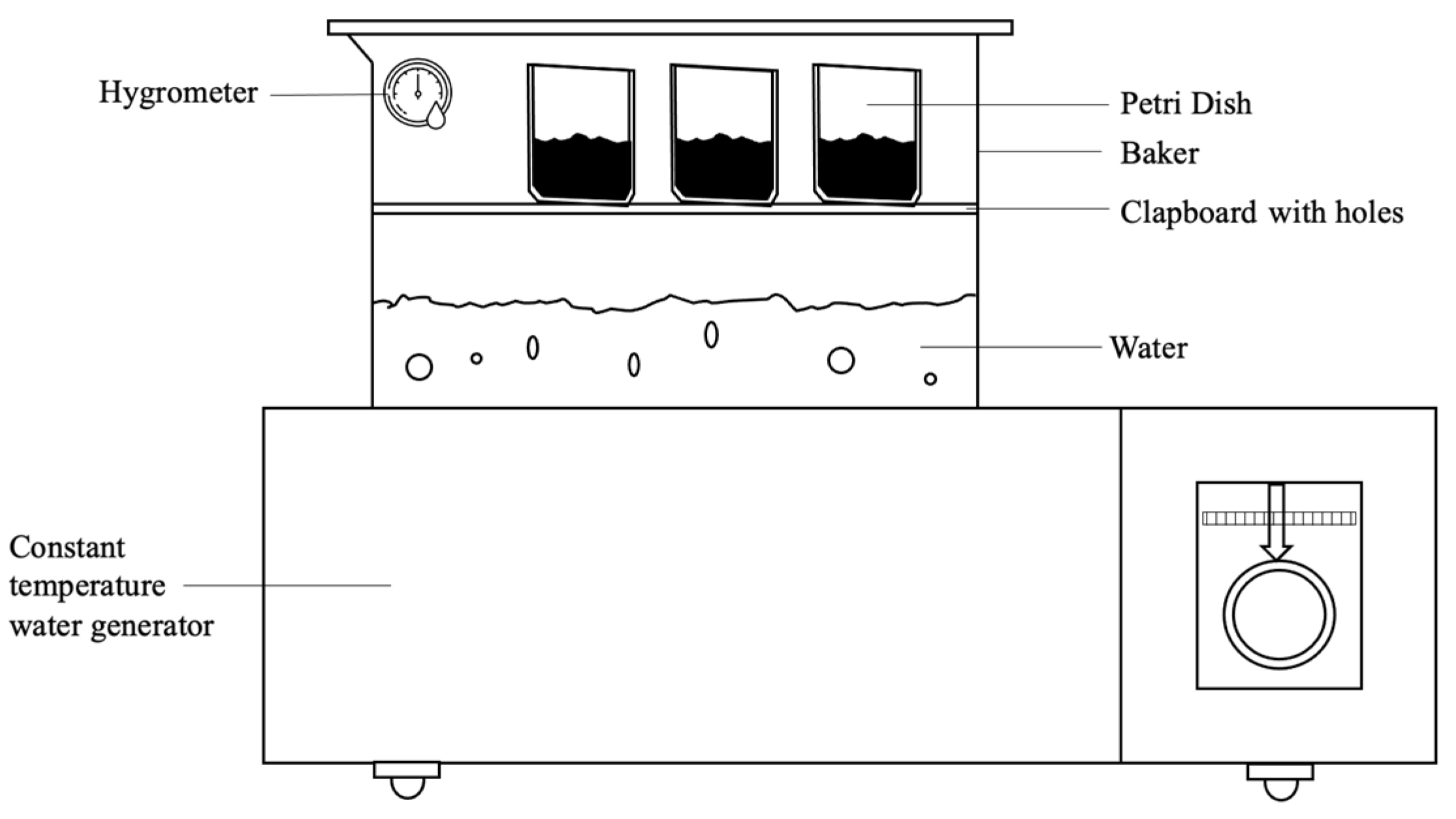
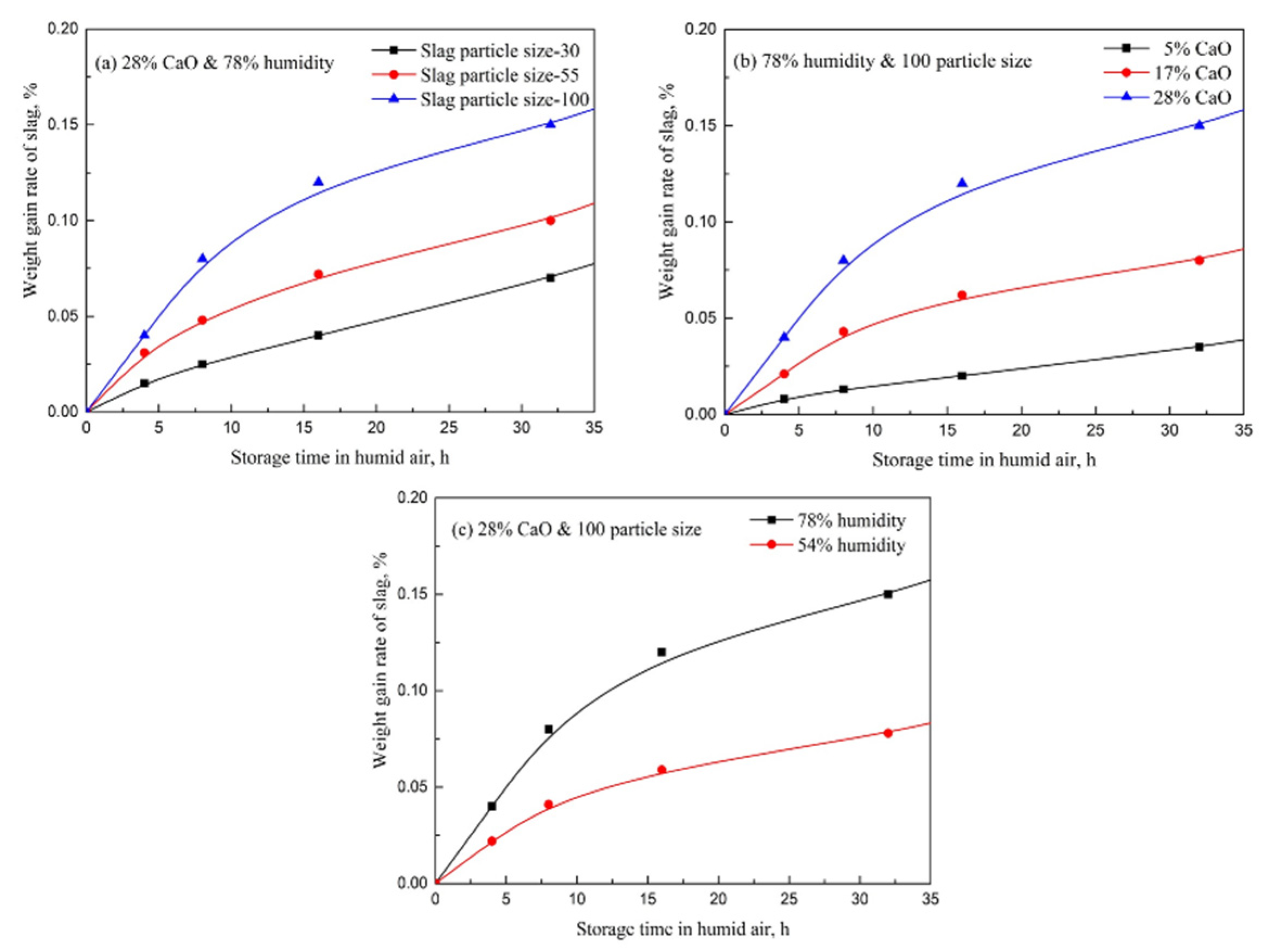
2.1. Slag Weight Gain in Humid Air Experiment Design
2.2. Dataset Description
2.3. Machine Learning Methods
2.3.1. Linear Regression (LR)
2.3.2. Support Vector Regression (SVR)
2.3.3. Random Forests Regression (RFR)
2.3.4. Multi-Layer Perceptron (MLP)
2.4. Cross Validation
2.5. Evaluation Metrics
3. Results and Discussion
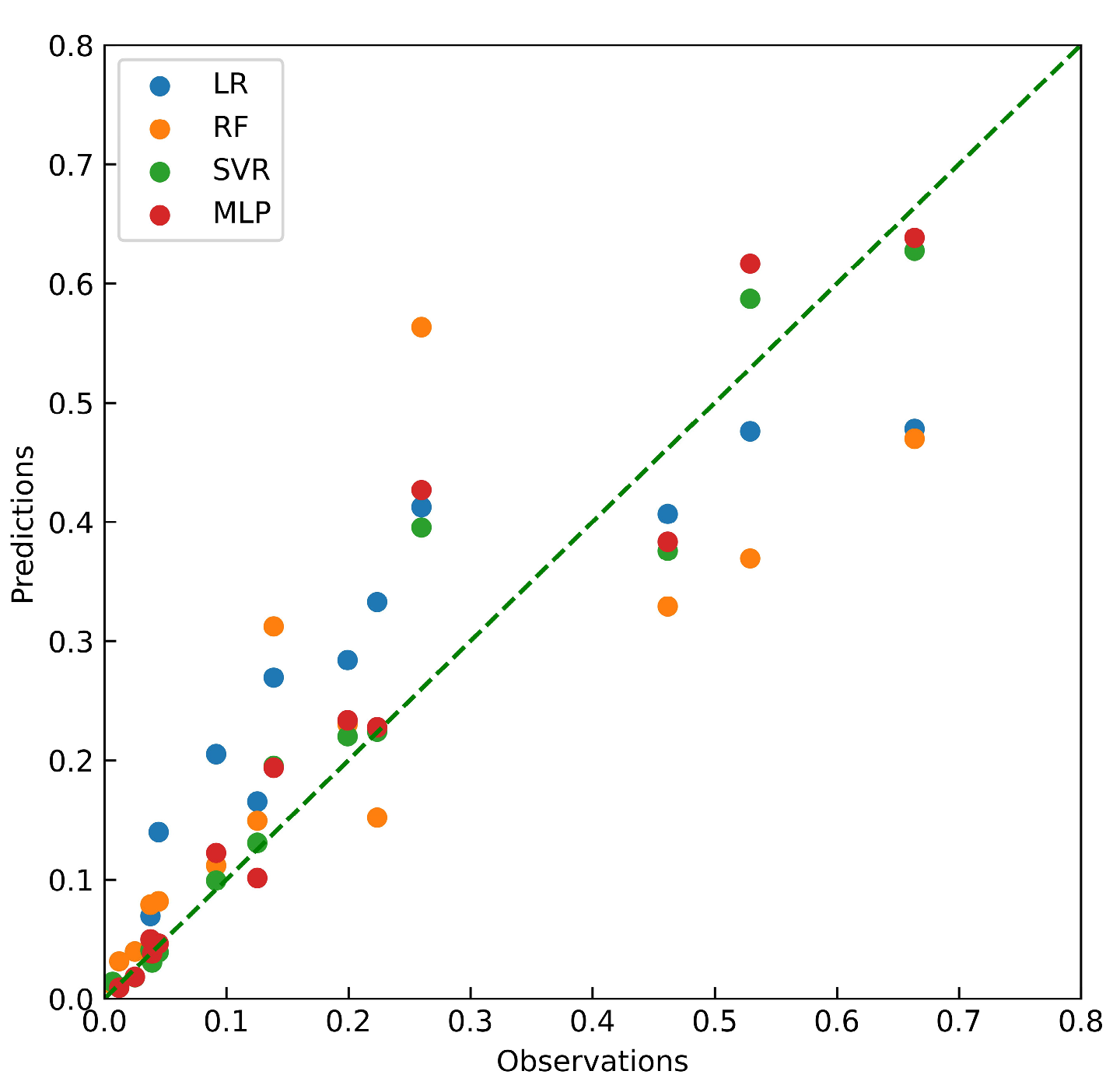
3.1. Prediction of Weight Gain Rate by Machine Learning Methods
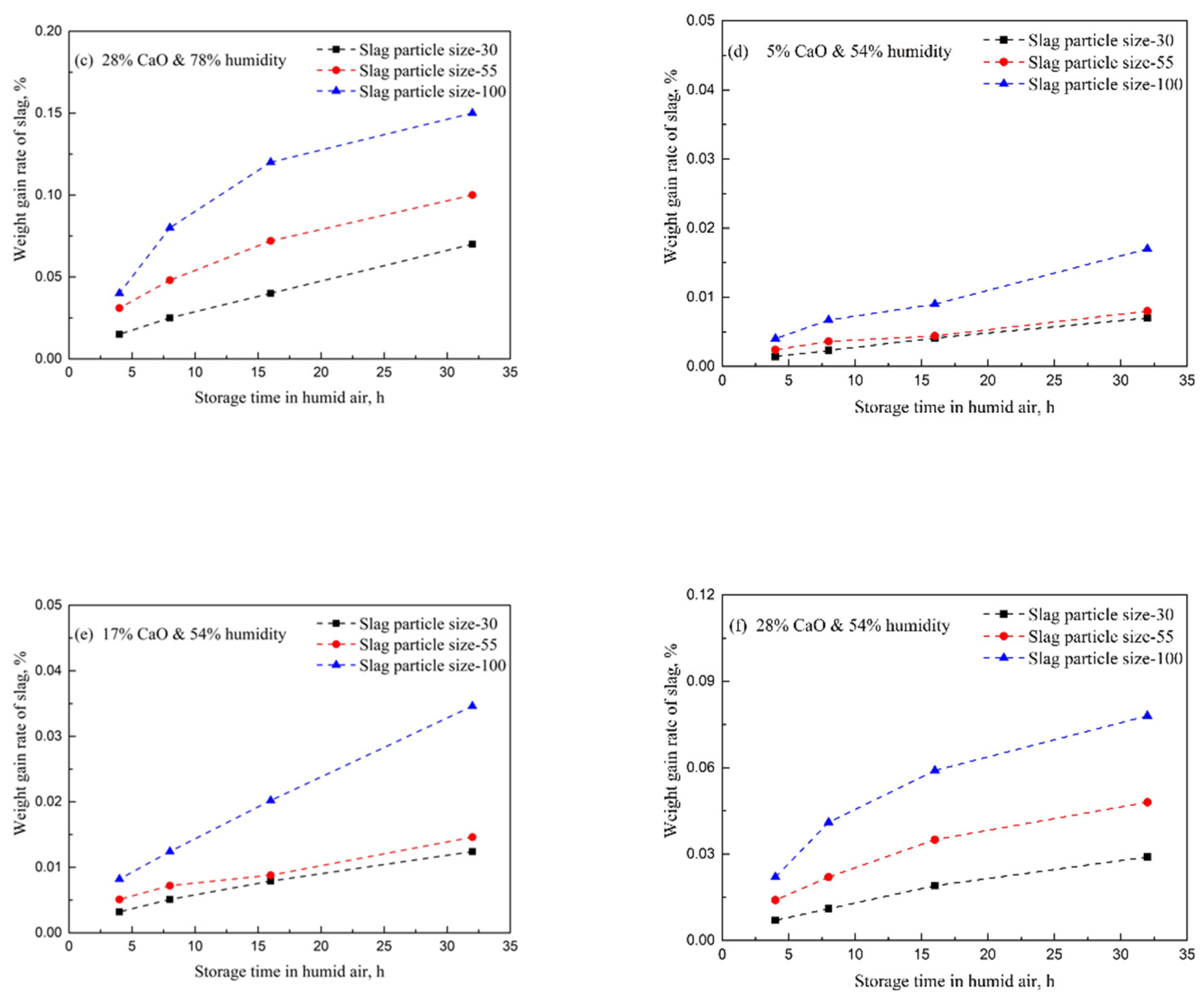
3.2. Analysis of Reasons for Slag Weight Gain
3.3. Application of Machine Learning Methods
4. Conclusions
- (1)
- The porosity defect in the ingot during the ESR process often appears when the moisture in the slag exceeds 0.02%. Considering saving electric energy, the complexity of on-site scheduling, and 4 h of scheduling time, the slag T3 (CaF2:CaO:Al2O3:MgO = 37:28:30:5) is selected to produce H13 steel ESR ingot in the winter, and slag T2 (CaF2:CaO:Al2O3:MgO = 48:17:30:5) is selected to produce H13 steel ESR ingot in the summer.
- (2)
- The weight gain rate of slag increases with the increase of air humidity and CaO content in slag. The smaller the slag particle size is, the greater the weight gain rate of slag is. Free CaO in slag makes the air humidity have a large influence on the slag weight gain rate.
- (3)
- The SVR model can be used to make accurate predictions about “slag weight gain in humid air”, and the calculated results of the SVR model agree well with the measured data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, C.B.; Li, J.; Cho, J.W.; Jiang, F.; Jung, I.H. Effect of SiO2 on the crystallization behaviors and in-mold performance of CaF2-CaO-Al2O3 slags for drawing-ingot-type electroslag remelting. Metall. Mater. Trans. B 2015, 46, 2110–2120. [Google Scholar] [CrossRef] [Green Version]
- Duan, S.C.; Shi, X.; Wang, F.; Zhang, M.C.; Sun, Y.; Guo, H.J.; Guo, J. A review of methodology development for controlling loss of alloying elements during the electroslag remelting process. Metall. Mater. Trans. B 2019, 50, 3055–3071. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Yang, S.F.; Qu, J.L.; Li, J.S.; Dong, A.P.; Gu, Y. Effects of different melting technologies on the purity of superal-loy GH4738. Materials 2018, 11, 1838. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fang, J.L.; Pang, Z.G.; Xing, X.D.; Xu, R.S. Thermodynamic properties, viscosity, and structure of CaO-SiO2-MgO-Al2O3-TiO2-based slag. Materials 2021, 14, 124. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.H.; Min, D.J. A novel electrochemical process for desulfurization in the CaO-SiO2-Al2O3 system. Materials 2020, 13, 2478. [Google Scholar] [CrossRef]
- Gao, Y.X.; Leng, M.; Chen, Y.F.; Chen, Z.C.; Li, J.L. Crystallization products and structural characterization of CaO-SiO2-based mold fluxes with varying Al2O3/SiO2 ratios. Materials 2019, 12, 206. [Google Scholar] [CrossRef] [Green Version]
- Leng, M.; Lai, F.F.; Li, J.L. Effect of cooling rate on phase and crystal morphology transitions of CaO-SiO2-based systems and CaO-Al2O3-based systems. Materials 2019, 12, 62. [Google Scholar] [CrossRef] [Green Version]
- Gu, S.P.; Wen, G.H.; Ding, Z.Q.; Tang, P.; Liu, Q. Effect of shear stress on isothermal crystallization behavior of CaO-Al2O3-SiO2 -Na2O-CaF2 Slags. Materials 2018, 11, 1085. [Google Scholar] [CrossRef] [Green Version]
- Bandyopadhyay, T.R.; Rao, P.K.; Prabhu, N. Behavior of alloying elements during electro-slag remelting of ultrahigh strength steel. Metall. Min. Ind. 2012, 4, 6–16. [Google Scholar]
- Jiang, Z.; Dong, Y.; Liang, L.; Li, Z. Hydrogen pick-up during electroslag remelting process. J. Iron Steel Res. Int. 2011, 18, 19–23. [Google Scholar] [CrossRef]
- Polonsky, A.T.; Echlin, M.P.; Lenthe, W.C.; Dehoff, R.R.; Kirka, M.M.; Pollock, T.M. Defects and 3D structural inhomogeneity in electron beam additively manufactured inconel 718. Mater. Charact. 2018, 143, 171–181. [Google Scholar] [CrossRef]
- Jiang, Z.H.; Hou, D.; Dong, Y.W.; Cao, Y.L.; Cao, H.B.; Gong, W. Effect of slag on titanium, silicon and aluminum content in superalloy during electroslag remelting. Metall. Mater. Trans. B 2016, 47, 1465–1474. [Google Scholar] [CrossRef]
- Hou, D.; Jiang, Z.H.; Dong, Y.W.; Cao, Y.L.; Cao, H.B.; Gong, W. Thermodynamic design of electroslag remelting slag for high titanium and low aluminium stainless steel based on IMCT. Ironmak. Steelmak. 2016, 43, 517–525. [Google Scholar] [CrossRef]
- Hou, D.; Jiang, Z.H.; Dong, Y.W.; Gong, W.; Cao, Y.L.; Cao, H.B. Effect of slag composition on the oxidation kinetics of al-loying elements during electroslag remelting of stainless steel: Part-2 control of titanium and aluminum content. ISIJ Int. 2017, 57, 1410–1419. [Google Scholar] [CrossRef] [Green Version]
- Hou, D.; Jiang, Z.H.; Dong, Y.W.; Gong, W.; Cao, Y.L.; Cao, H.B. Effect of slag composition on the oxidation kinetics of al-loying elements during electroslag remelting of stainless steel: Part-1 mass-transfer model. ISIJ Int. 2017, 57, 1400–1409. [Google Scholar] [CrossRef] [Green Version]
- Hou, D.; Jiang, Z.H.; Qu, T.P.; Wang, D.Y.; Liu, F.B. Aluminum, titanium and oxygen control during electroslag remelting of stainless steel based on thermodynamic analysis. J. Iron Steel Res. Int. 2019, 26, 20–31. [Google Scholar] [CrossRef]
- Hou, D.; Wang, D.Y.; Qu, T.P.; Tian, J.; Wang, H.H. Kinetic study on alloying element transfer during an electroslag re-melting process. Metall. Mater. Trans. B 2019, 50, 3088–3102. [Google Scholar] [CrossRef]
- Hou, D.; Wang, D.Y.; Jiang, Z.H.; Qu, T.P.; Wang, H.H.; Dong, J.W. Investigation on slag-metal-inclusion multiphase reac-tions during electroslag remelting of die steel. Metall. Mater. Trans. B 2021, 52, 478–493. [Google Scholar] [CrossRef]
- Hong, L.; Chen, W.P.; Hou, D. Kinetic analysis of spinel formation from powder compaction of magnesia and alumina. Ceram. Int. 2020, 46, 2853–2861. [Google Scholar] [CrossRef]
- Hou, D.; Jiang, Z.H.; Dong, Y.W.; Li, Y.; Gong, W.; Liu, F.B. Mass transfer model of desulfurization in the electroslag re-melting process. Metall. Mater. Trans. B 2017, 48, 1885–1897. [Google Scholar] [CrossRef]
- Liu, W.H.; Li, H.; Zhu, H.M.; Xu, P.J. Effects of steel-slag components on interfacial-reaction characteristics of permeable steel-slag-bitumen mixture. Materials 2020, 13, 3885. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Long, X.; Wang, L.Z.; Tong, S.H.; Wang, X.T.; Zhang, Y.; Li, Y.T. Inclusion characteristics in 95CrMo steels with different calcium and sulfur contents. Materials 2020, 13, 619. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, B.; Shi, X.; Guo, H.J.; Guo, J. Study on precipitation and growth of TiN in GCr15 bearing steel during solidification. Materials 2019, 12, 1463. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, J.H.; Bae, K.M.; Hong, S.K.; Park, H.; Kwak, J.-H.; Wang, H.S.; Joe, D.J.; Park, J.H.; Jung, Y.H.; Hur, S.; et al. Machine learning-based self-powered acoustic sensor for speaker recognition. Nano Energy 2018, 53, 658–665. [Google Scholar] [CrossRef]
- Tandel, N.H.; Prajapati, H.B.; Dabhi, V.K. Voice recognition and voice comparison using machine learning techniques: A survey. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Piscataway, NJ, USA, 1 March 2020; IEEE: New York, NY, USA, 2020; pp. 459–465. [Google Scholar]
- Kaur, R.; Jain, A.; Kumar, S. Optimization classification of sunflower recognition through machine learning. In Proceedings of the Materials Today-Proceedings, Bengaluru, India, 1–2 May 2021; Elsevier: Amsterdam, The Netherlands, 2022; Volume 51, pp. 207–211. [Google Scholar]
- Celli, F.; Bruni, E.; Lepri, B. Automatic personality and interaction style recognition from facebook profile pictures. In Proceedings of the Proceedings of the 2014 ACM Conference on Multimedia (mm’14), Orlando, FL, USA, 3–7 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1101–1104. [Google Scholar]
- Dada, E.G.; Bassi, J.S.; Chiroma, H.; Abdulhamid, S.M.; Adetunmbi, A.O.; Ajibuwa, O.E. Machine learning for email spam filtering: Review, approaches and open research problems. Heliyon 2019, 5, e01802. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Choi, J.-A.; Lim, K. Identifying machine learning techniques for classification of target advertising. ICT Express 2020, 6, 175–180. [Google Scholar] [CrossRef]
- Karaman, O.; Çakın, H.; Alhudhaif, A.; Polat, K. Robust automated parkinson disease detection based on voice signals with transfer learning. Expert Syst. Appl. 2021, 178, 115013. [Google Scholar] [CrossRef]
- Alhudhaif, A.; Polat, K.; Karaman, O. Determination of COVID-19 pneumonia based on generalized convolutional neural network model from chest X-ray images. Expert Syst. Appl. 2021, 180, 115141. [Google Scholar] [CrossRef]
- Polat, Ç.; Karaman, O.; Karaman, C.; Korkmaz, G.; Balcı, M.C.; Kelek, S.E. COVID-19 diagnosis from chest X-ray images using transfer learning: Enhanced performance by debiasing dataloader. J. Xray Sci. Technol. 2021, 29, 19–36. [Google Scholar] [CrossRef]
- Chen, J.; de Hoogh, K.; Gulliver, J.; Hoffmann, B.; Hertel, O.; Ketzel, M.; Bauwelinck, M.; van Donkelaar, A.; Hvidtfeldt, U.A.; Katsouyanni, K.; et al. A comparison of linear regression, regularization, and machine learning algorithms to develop europe-wide spatial models of fine particles and nitrogen dioxide. Environ. Int. 2019, 130, 104934. [Google Scholar] [CrossRef]
- Gholamnia, K.; Nachappa, T.G.; Ghorbanzadeh, O.; Blaschke, T. Comparisons of diverse machine learning approaches for wildfire susceptibility mapping. Symmetry 2020, 12, 604. [Google Scholar] [CrossRef] [Green Version]
- Ivo, R.F.; de A. Rodrigues, D.; Bezerra, G.M.; Freitas, F.N.C.; de Abreu, H.F.G.; Rebouc, P.P. Non-grain oriented electrical steel photomicrograph classification using transfer learning. J. Mater. Res. Technol. JMRT 2020, 9, 8580–8591. [Google Scholar] [CrossRef]
- Colla, V.; Pietrosanti, C.; Malfa, E.; Peters, K. Environment 4.0: How digitalization and machine learning can improve the environmental footprint of the steel production processes. Mater. Tech. 2020, 108, 507. [Google Scholar] [CrossRef]
- Amin, D.; Akhter, S. Deep learning-based defect detection system in steel sheet surfaces. In Proceedings of the 2020 IEEE Region 10 Symposium (tensymp)—Technology for Impactful Sustainable Development, Dhaka, Bangladesh, 5–7 June 2020; IEEE: New York, NY, USA, 2020; pp. 444–448. [Google Scholar]
- Wauters, M.; Vanhoucke, M. Support vector machine regression for project control forecasting. Autom. Constr. 2014, 47, 92–106. [Google Scholar] [CrossRef] [Green Version]
- Nauman, F.; Nattila, J. Exploring helical dynamos with machine learning: Regularized linear regression outperforms ensemble methods. Astron. Astrophys. 2019, 629, A89. [Google Scholar] [CrossRef]
- Candelieri, A. Clustering and support vector regression for water demand forecasting and anomaly detection. Water 2017, 9, 224. [Google Scholar] [CrossRef]
- Weizhen, H.; Zhengqiang, L.; Yuhuan, Z.; Hua, X.; Ying, Z.; Kaitao, L.; Donghui, L.; Peng, W.; Yan, M. Using support vector regression to predict PM10 and PM2.5. In Proceedings of the 35th International Symposium on Remote Sensing of Environment (ISRSE35), Beijing, China, 22–26 April 2013; Guo, H., Ed.; IOP Publishing Ltd.: Bristol, UK, 2014; Volume 17, p. 012268. [Google Scholar]
- Jokhakar, V.N.; Patel, S.V. A random forest based machine learning approach for mild steel defect diagnosis. In Proceedings of the 2016 IEEE International Conference on Computational Intelligence and Computing Research, Chennai, India, 15–17 December 2016; Krishnan, N., Karthikeyan, M., Eds.; IEEE: New York, NY, USA, 2016; pp. 144–151. [Google Scholar]
- Zhang, W.; Wu, C.; Li, Y.; Wang, L.; Samui, P. Assessment of pile drivability using random forest regression and multivariate adaptive regression splines. Georisk 2021, 15, 27–40. [Google Scholar] [CrossRef]
- Askari, M.; Keynia, F. Mid-term electricity load forecasting by a new composite method based on optimal learning MLP algorithm. IET Gener. Transm. Distrib. 2020, 14, 845–852. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Cohen, I., Huang, Y., Chen, J., Benesty, J., Eds.; Springer Topics in Signal Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. ISBN 978-3-642-00296-0. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Amoako, R.; Jha, A.; Zhong, S. Rock fragmentation prediction using an artificial neural network and support vector regression hybrid approach. Mining 2022, 2, 233–247. [Google Scholar] [CrossRef]
- Astudillo, G.; Carrasco, R.; Fernandez-Campusano, C.; Chacon, M. Copper price prediction using support vector regression technique. Appl. Sci. 2020, 10, 6648. [Google Scholar] [CrossRef]
- Malchiodi, D.; da Costa Pereira, C.; Tettamanzi, A.G.B. Predicting the possibilistic score of OWL axioms through support vector regression. In Proceedings of the 12th International Conference on Scalable Uncertainty Management (SUM 2018); Milan, Italy, 3–5 October 2018, Ciucci, D., Pasi, G., Vantaggi, B., Eds.; Springer International Publishing AG: Cham, Switzerland, 2018; Volume 11142, pp. 380–386. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Lee, M.G.; Park, Y.K.; Jung, K.K.; Hwang, S.I.; Lee, D.K. Forecasting and analysis for smart vending machine using neural networks. In Proceedings of the 19th World Multi-Conference on Systemics, Cybernetics and Informatics, WMSCI 2015, Orlando, FL, USA, 12–15 July 2015; International Institute of Informatics and Systemics, IIIS: Orlando, FL, USA, 2015; Volume 1, pp. 263–266. [Google Scholar]
- Pham, B.T.; Nguyen, M.D.; Bui, K.-T.T.; Prakash, I.; Chapi, K.; Bui, D.T. A novel artificial intelligence approach based on multi-layer perceptron neural network and biogeography-based optimization for predicting coefficient of consolidation of soil. CATENA 2019, 173, 302–311. [Google Scholar] [CrossRef]
- Menapace, A.; Zanfei, A.; Righetti, M. Tuning ANN hyperparameters for forecasting drinking water demand. Appl. Sci. 2021, 11, 4290. [Google Scholar] [CrossRef]
- Roozbeh, M.; Arashi, M.; Hamzah, N.A. Generalized cross-validation for simultaneous optimization of tuning parameters in ridge regression. Iran J. Sci. Technol. Trans. Sci. 2020, 44, 473–485. [Google Scholar] [CrossRef]
- Roelofs, R.; Shankar, V.; Recht, B.; Fridovich-Keil, S.; Hardt, M.; Miller, J.; Schmidt, L. A meta-analysis of overfitting in machine learning. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 13–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Zhang, G.; Hu, Y.; Yang, D.; Ma, L.; Zhang, M.; Liu, X. Short-term bathwater demand forecasting for shared shower rooms in smart campuses using machine learning methods. Water 2022, 14, 1291. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Slag. | CaO (%) | CaF2 (%) | Al2O3 (%) | MgO (%) |
|---|---|---|---|---|
| T1 | 5 | 60 | 30 | 5 |
| T2 | 17 | 48 | 30 | 5 |
| T3 | 28 | 37 | 30 | 5 |
| Types of Variables | Attribute Name | Description | PCC |
|---|---|---|---|
| Independent variables | X1 | Slag particle size | 0.371 |
| X2 | CaO % | 0.563 | |
| X3 | Humidity | 0.353 | |
| X4 | Placement time | 0.406 | |
| Dependent variable | Y | Weight gain rate | - |
| X1 | X2 | X3 | X4 | Y | |
|---|---|---|---|---|---|
| Mean | 61.67 | 16.67 | 66.00 | 15.00 | 0.027 |
| Std. | 29.16 | 9.46 | 12.08 | 10.80 | 0.029 |
| Min | 30.00 | 5.00 | 54.00 | 4.00 | 0.001 |
| Max | 100.00 | 28.00 | 78.00 | 32.00 | 0.150 |
| Model | RMSE | MSE | R2 |
|---|---|---|---|
| LR | 0.1009 | 0.0112 | 0.2717 |
| RF | 0.0753 | 0.0062 | 0.7229 |
| SVR | 0.0270 | 0.0008 | 0.9545 |
| MLP | 0.0371 | 0.0023 | 0.9326 |
| Slag. | Steel | Moisture Absorption Time (h) | Season in Coastal Areas | Atmospheric Humidity | Porosity in Ingot | Power Consumption per Ton Steel kW·h |
|---|---|---|---|---|---|---|
| T1 | H13 | 38 | Winter | 43% | Yes | 1490 |
| T1 | H13 | 33 | Winter | 43% | No | 1500 |
| T1 | H13 | 16 | Summer | 78% | Yes | 1470 |
| T2 | H13 | 15 | Winter | 43% | No | 1240 |
| T2 | H13 | 5 | Summer | 78% | Yes | 1220 |
| T3 | H13 | 5 | Winter | 43% | Yes | 950 |
| Slag. | Steel | Moisture Absorption Time (h) | Season in Coastal Areas | Atmospheric Humidity | Porosity in Ingot |
|---|---|---|---|---|---|
| T1 | H13 | >36 | Winter | 43% | Yes |
| T1 | H13 | >16 | Summer | 78% | Yes |
| T2 | H13 | >18 | Winter | 43% | Yes |
| T2 | H13 | >4 | Summer | 78% | Yes |
| T3 | H13 | >5 | Winter | 43% | Yes |
| T3 | H13 | >1.5 | Summer | 78% | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Hu, Y.; Hou, D.; Yang, D.; Zhang, Q.; Hu, Y.; Liu, X. Assessment of Porosity Defects in Ingot Using Machine Learning Methods during Electro Slag Remelting Process. Metals 2022, 12, 958. https://doi.org/10.3390/met12060958
Zhang G, Hu Y, Hou D, Yang D, Zhang Q, Hu Y, Liu X. Assessment of Porosity Defects in Ingot Using Machine Learning Methods during Electro Slag Remelting Process. Metals. 2022; 12(6):958. https://doi.org/10.3390/met12060958
Chicago/Turabian StyleZhang, Ganggang, Yingbin Hu, Dong Hou, Dongxuan Yang, Qingchuan Zhang, Yapeng Hu, and Xinliang Liu. 2022. "Assessment of Porosity Defects in Ingot Using Machine Learning Methods during Electro Slag Remelting Process" Metals 12, no. 6: 958. https://doi.org/10.3390/met12060958