1. Introduction
Uterine myomas, also known as uterine leiomyomas, fibroids, or leiomyomas, are the most commonly encountered benign uterine tumors [
1]. They have an incidence rate of 40–60% in women under 30 years old, and 70–80% in women over 50 years old [
2]. Uterine myomas are responsible for 2–3% of women’s infertility [
3] and are globally the most common indication for hysterectomy. In the United States, more than 479,000 hysterectomies are performed each year, with 46.6% due to myomas, and 47.7% occurring in women between the ages of 18 and 44 [
4]. Uterine myomas can be single or multiple, varying in size, and have great heterogeneity in pathophysiology, size, location, and clinical symptoms [
5]. The most common symptom is heavy menstrual bleeding (HMB), which often leads to anemia, fatigue, or dysmenorrhea [
5,
6,
7]. Other possible symptoms are back pain and pelvic compression or pain, which can affect the quality of life. When uterine myomas exceed a certain size, they can put pressure on the bladder or intestines, causing bladder dysfunction or constipation, among other symptoms. In addition, uterine myomas may affect the outcome of pregnancy, and become the cause of infertility and recurrent abortion. Almost one-third of women with uterine myomas seek treatment [
8].
The International Federation of Gynecology and Obstetrics (FIGO) classifies uterine myomas into eight types on the basis of their relationship to the uterine wall, uterine cavity, and mixed myomas [
9]. This classification plays a crucial role in helping doctors in developing surgical plans. However, patient satisfaction with the current treatment plans is often low, leading to women undergoing major surgery such as hysterectomy [
10]. Personalized treatments according to FIGO classification, main symptoms (HMB, infertility), and patients’ real intentions are necessary. Intelligent diagnosis is a significant current research highlight in the medical field [
11,
12,
13], but there is a relative gap in the area of the auxiliary diagnosis of uterine diseases. Therefore, it is urgent and necessary to perform auxiliary diagnostic research on the uterine region, which could significantly benefit patients with uterine myomas and gynecologists.
Several methods have been proposed for segmenting the uterus. Yao et al. [
14] used the cascade method of the fast-marching and Laplacian level sets to segment the uterus. Liao et al. [
15] proposed an adaptive local region and edge-based active contour model to segment uterine myomas in ultrasound images. Militello et al. [
16] discussed the study of magnetic resonance-guided focused ultrasound (MRgFUS) in the treatment of uterine myomas. Casarino et al. [
17] proposed a region-growth-based method that could segment myomas with different pixel intensity levels. Fallahi et al. [
18] proposed a fuzzy C-means-based method to segment uterine myomas in T1-weighted MR-enhanced images. The MR-guided high-intensity focused ultrasound was used by Antila et al. [
19] to segment the uterine myoma region. Militello et al. [
20] proposed a two-dimensional segmentation method for uterine myomas in MRgFUS treatment evaluation using fuzzy C-means and adaptive threshold segmentation methods. However, accurate segmentation results cannot be obtained without clear gray boundary differences, especially in scenes with complex and diverse shapes of tissues or organs. Deep-learning technology can automate the entire process of medical image segmentation and reduce dependence on expert intervention. Hodneland et al. [
21] used a 3D segmentation model to automatically segment endometrial cancer on MRI, and Kurata et al. first tried to use UNet to automatically segment the uterus on MRI [
22]. Zhang et al. [
23] proposed HIFUNet for the segmentation of the uterus, myomas, and the spine before HIFU surgery. Niu et al. [
24] used the Hessian matrix to extract image edges and completed the semantic segmentation of uterine MRI. Tang et al. [
25] proposed AR-UNet for the automatic segmentation of uterine myomas from T2-weighted MRI.
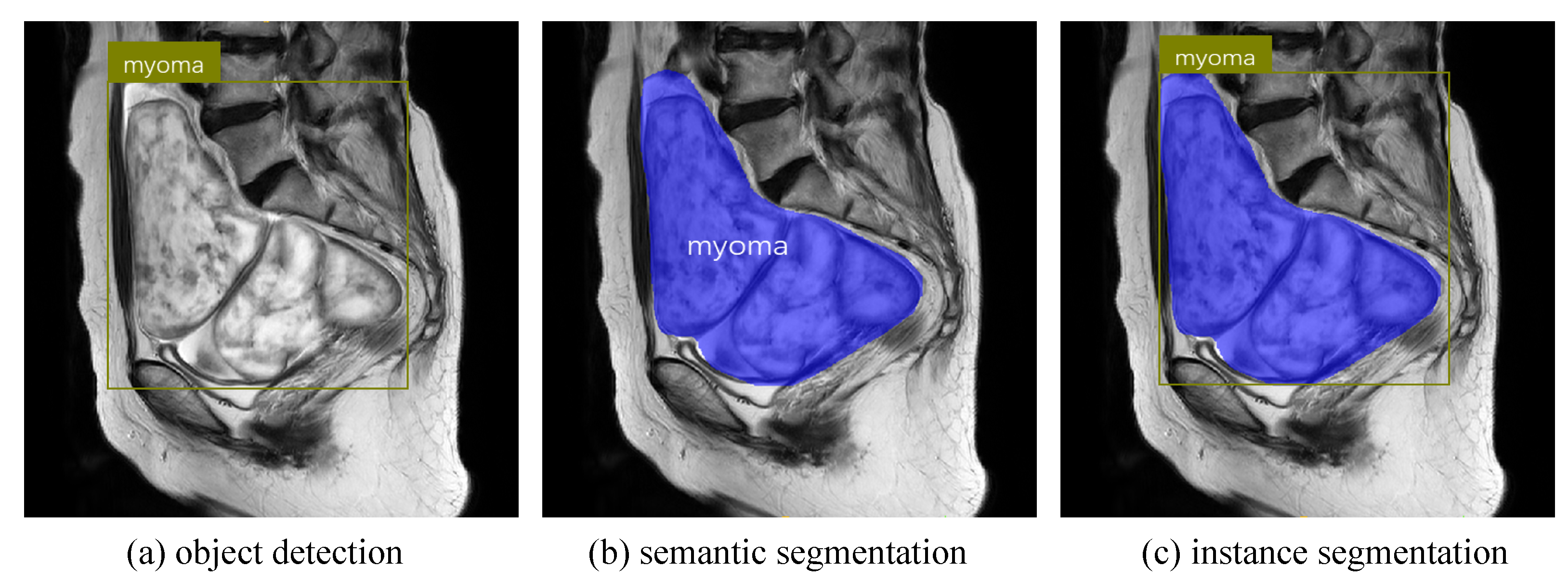
Most existing studies on the uterine region employ traditional or machine-learning methods, with some deep-learning studies being limited to semantic segmentation of uterine myomas or uterus. These studies only achieved pixel-level classification in images and could not distinguish between different instances of the same class. Instance segmentation combines the advantages of object detection and semantic segmentation by achieving pixel-level classification, and object positioning and classification (as shown in
Figure 1). It has the ability to accurately determine boundaries, size, and category of human organs or lesions while understanding multiangle and indepth semantic information. Instance segmentation can be divided into two- and one-stage methods. Two-stage models generally achieve higher segmentation AP, but have longer segmentation times. Representative methods include Mask-RCNN [
26], RefineMask [
27], and SSAP [
28]. One-stage models can achieve faster segmentation than two-stage models can, but their AP is generally lower. Typical models include YOLACT++ [
29] and SOLOv2 [
30]. The Mask-RCNN model is a two-stage instance segmentation model proposed by He et al. It mainly improves the ROIAlign operation on the basis of high-precision object detection model Faster-RCNN [
31], and added a mask branch to predict segmentation masks, achieving 37.1% AP in the COCO dataset [
32]. Since the introduction of Mask-RCNN, its excellent performance and model design ideas have become benchmarks for many subsequent instance segmentation models. Although many new models have good innovative ideas and new architectures, their metrics often cannot reach or exceed those of Mask-RCNN [
29,
33,
34,
35].
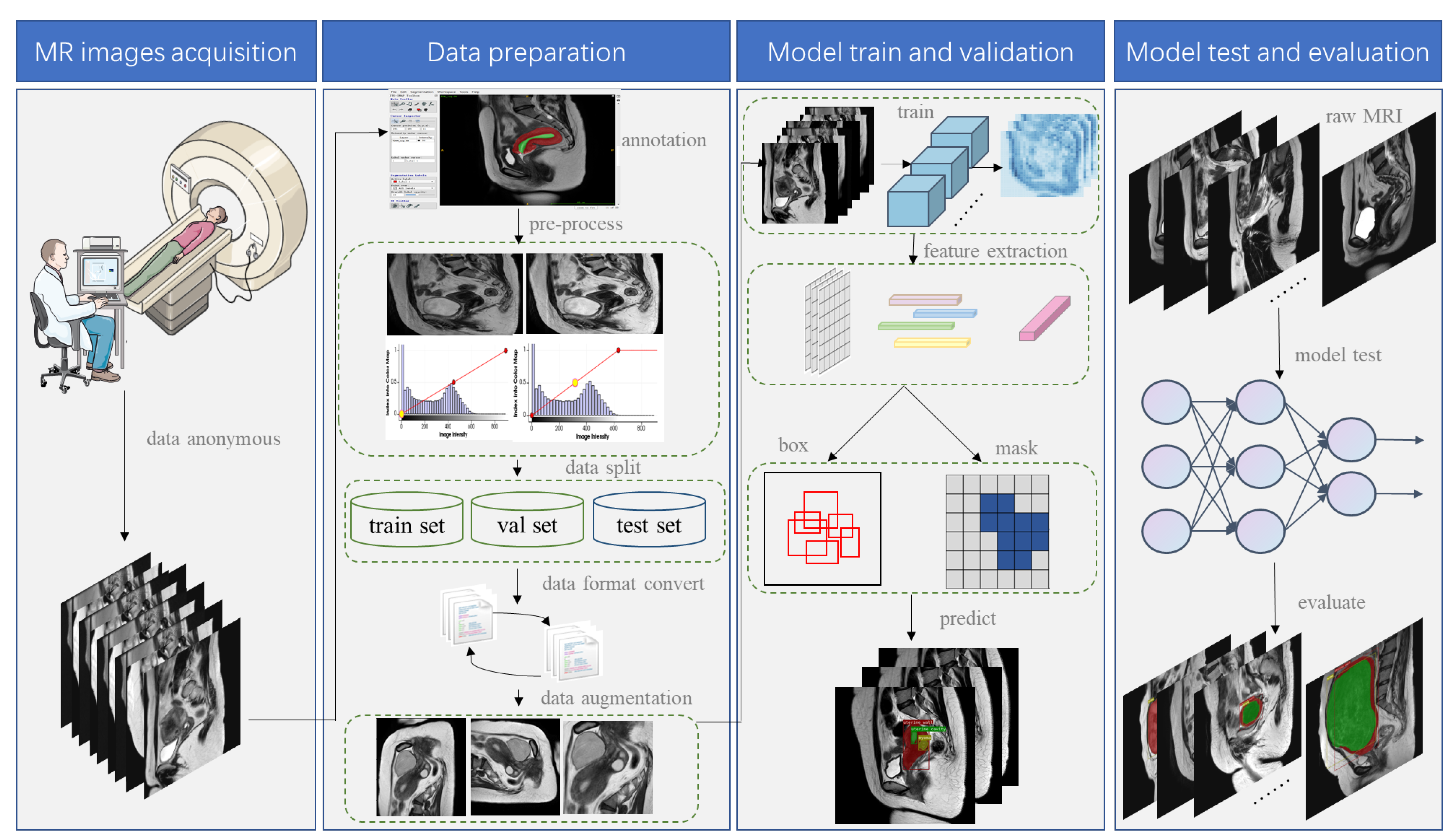
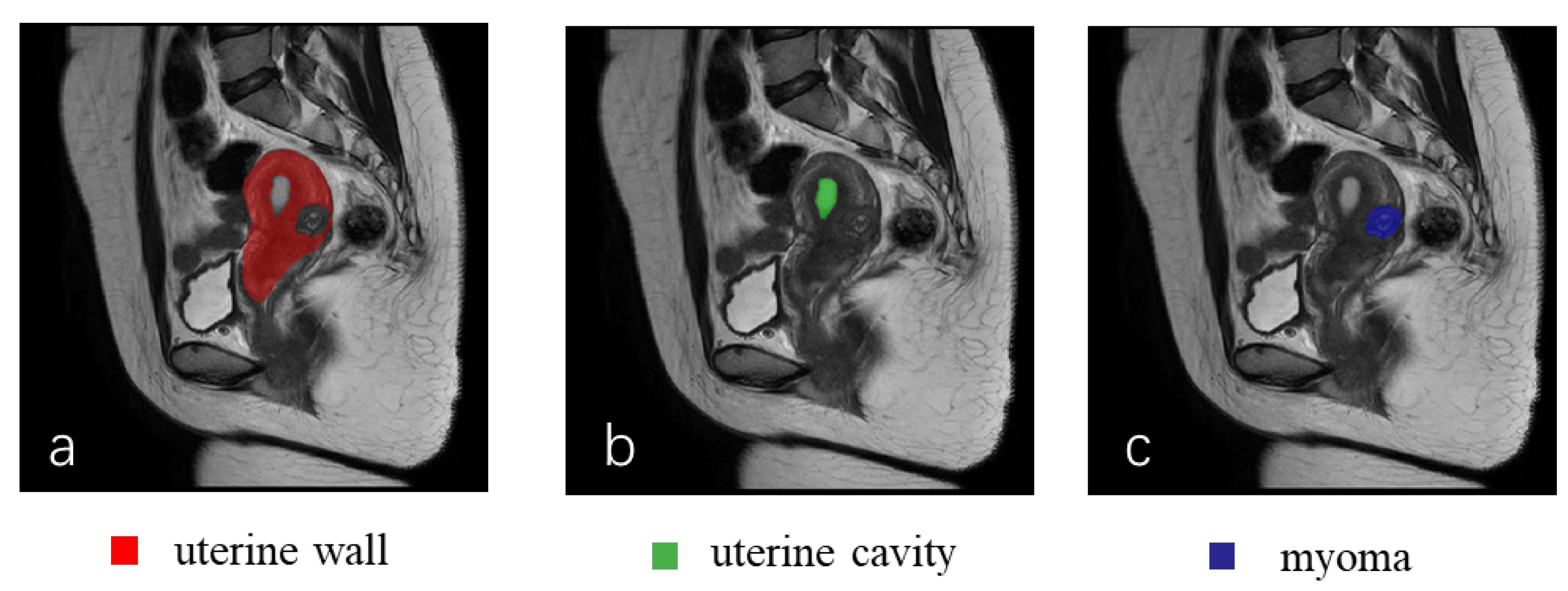
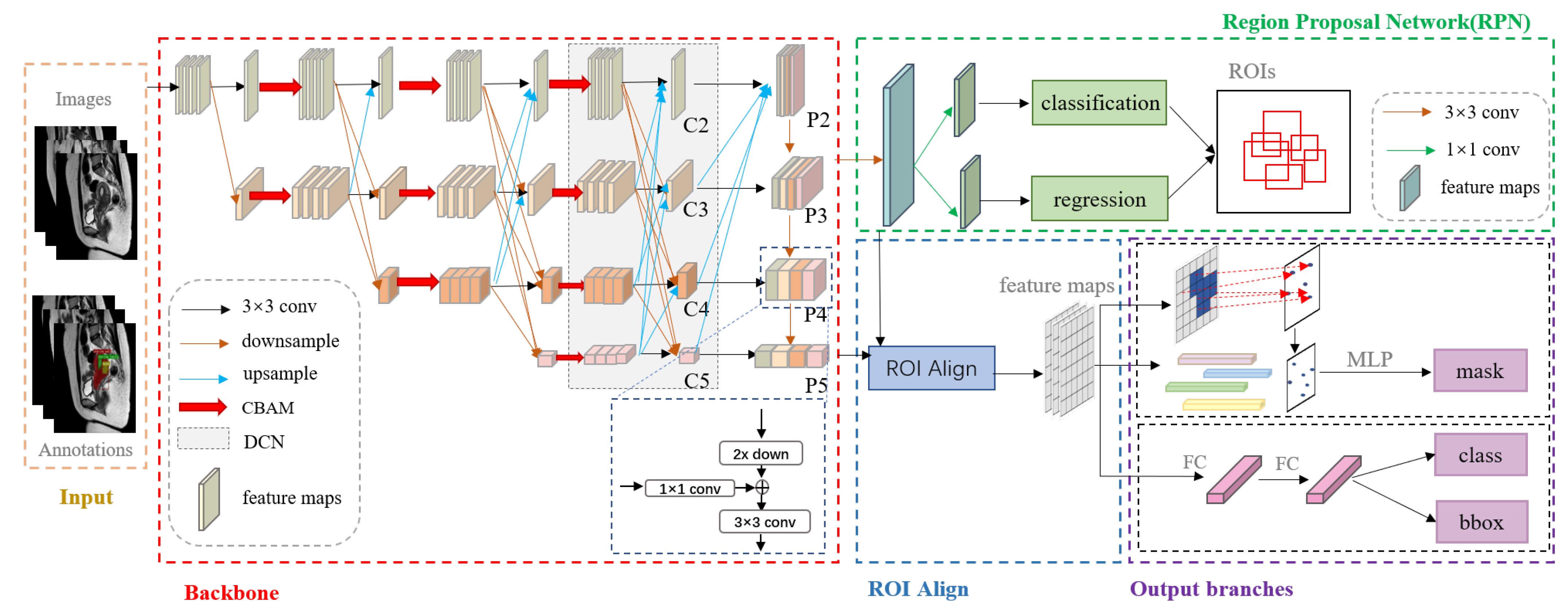
The instance segmentation of myomas, and the uterine wall and cavity in MR images is an essential precondition for achieving FIGO classification and preoperative evaluation. To the best of our knowledge, no relevant instance segmentation studies have been reported [
36]. The main challenges are as follows: (1) large variations in shape and size between categories; (2) the low contrast between adjacent organs and tissues, hindering distinguishing boundaries; (3) difficulty in identifying fine and narrow uterine-cavity and small-scale myomas. As precision is more important than real-time performance in the medical field, we optimized and improved the Mask-RCNN model, which could segment the uterine wall, uterine cavity, and myomas in sagittal (SAG) T2W MR images. The main contributions of this paper are summarized as follows:
We propose an instance segmentation network that could achieve the full automatic instance identification of multiple classes within the uterine region.
We designed a new backbone network that reduces the loss of feature information caused by continuous convolutional operations, and can better adapt to complex and variable object shapes, and resist noise.
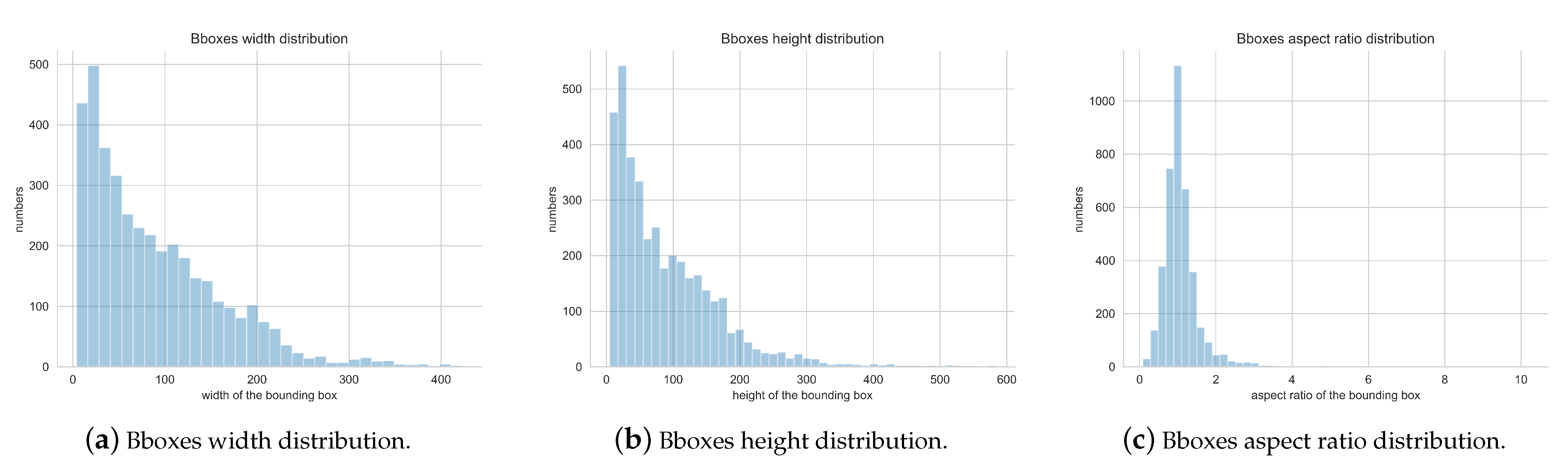
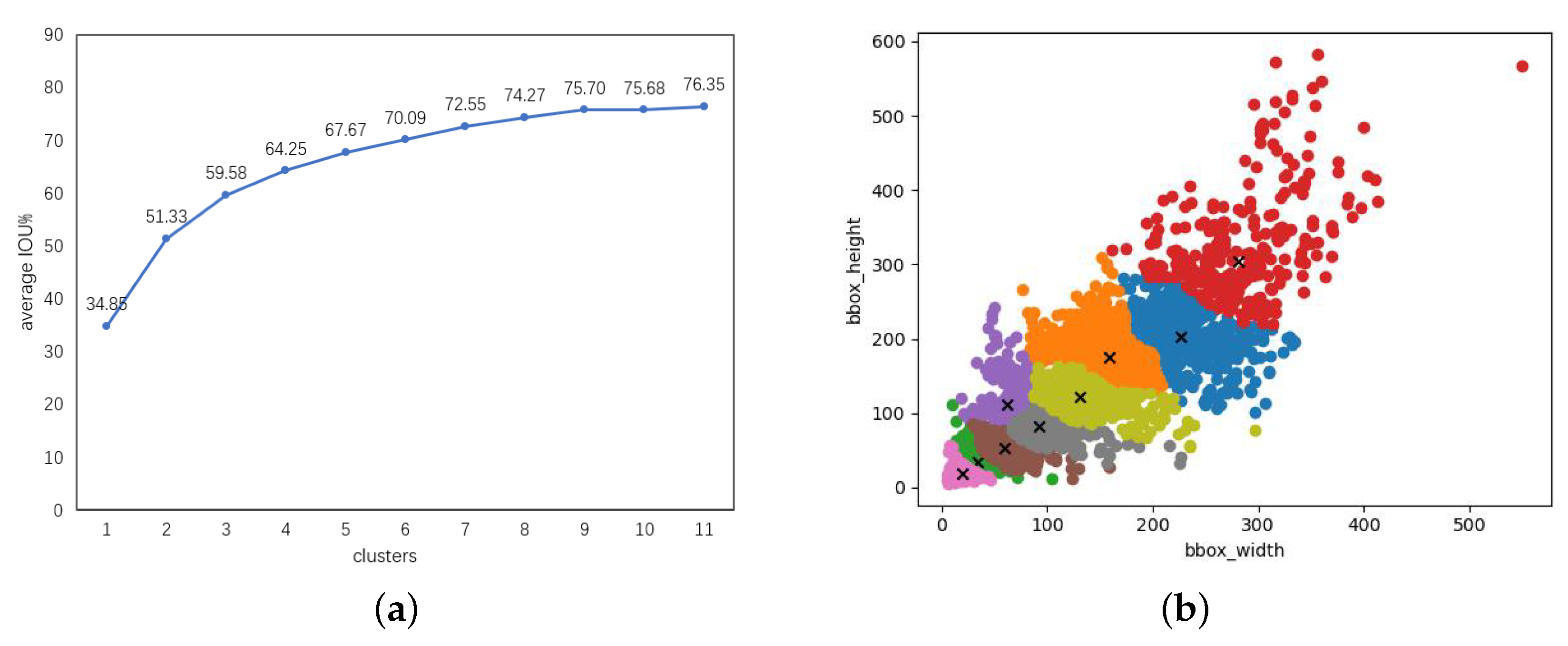
We optimized the generation method of anchor boxes. We used the k-means algorithm to adjust the size and scale of anchor boxes of each feature layer. This approach reduces the generation of redundant anchor boxes and accelerates bounding box regression.
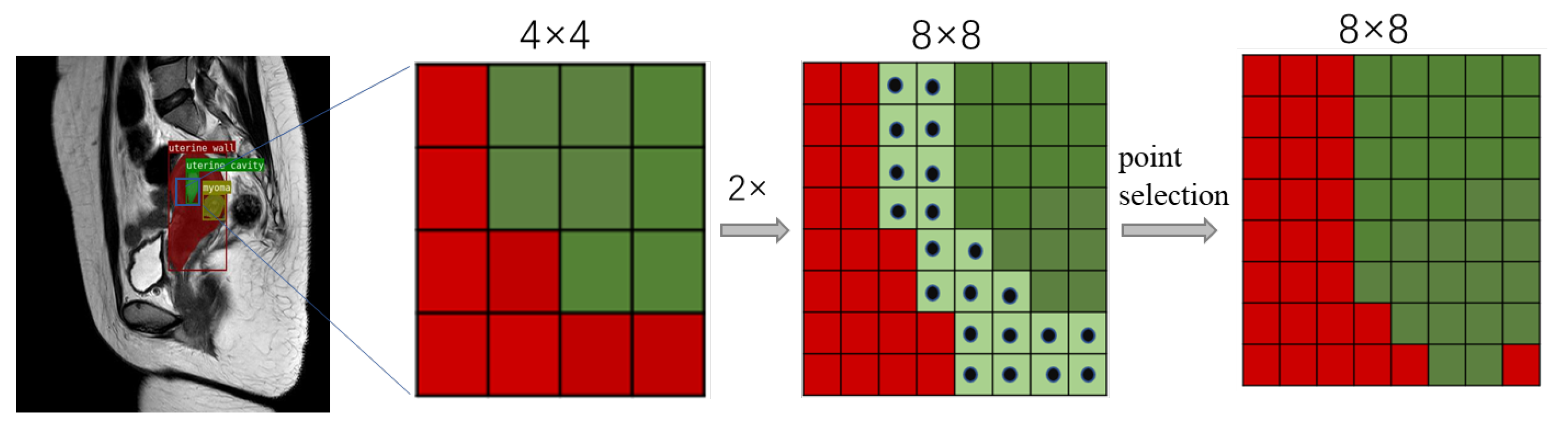
We introduce a fine segmentation mask head. In the mask branch, we used an iterative subdivision strategy to gradually refine rough masks and correct any misclassified pixels.
We validated our approach with some excellent models and visualized its segmentation performance.
The structure of this paper is as follows:
Section 2 describes the dataset and the proposed network architecture.
Section 3 covers the experimental configuration and results, and evaluation metrics. In
Section 4, we analyze and discuss the experimental results. Lastly,
Section 5 provides conclusions and perspectives.
4. Discussion
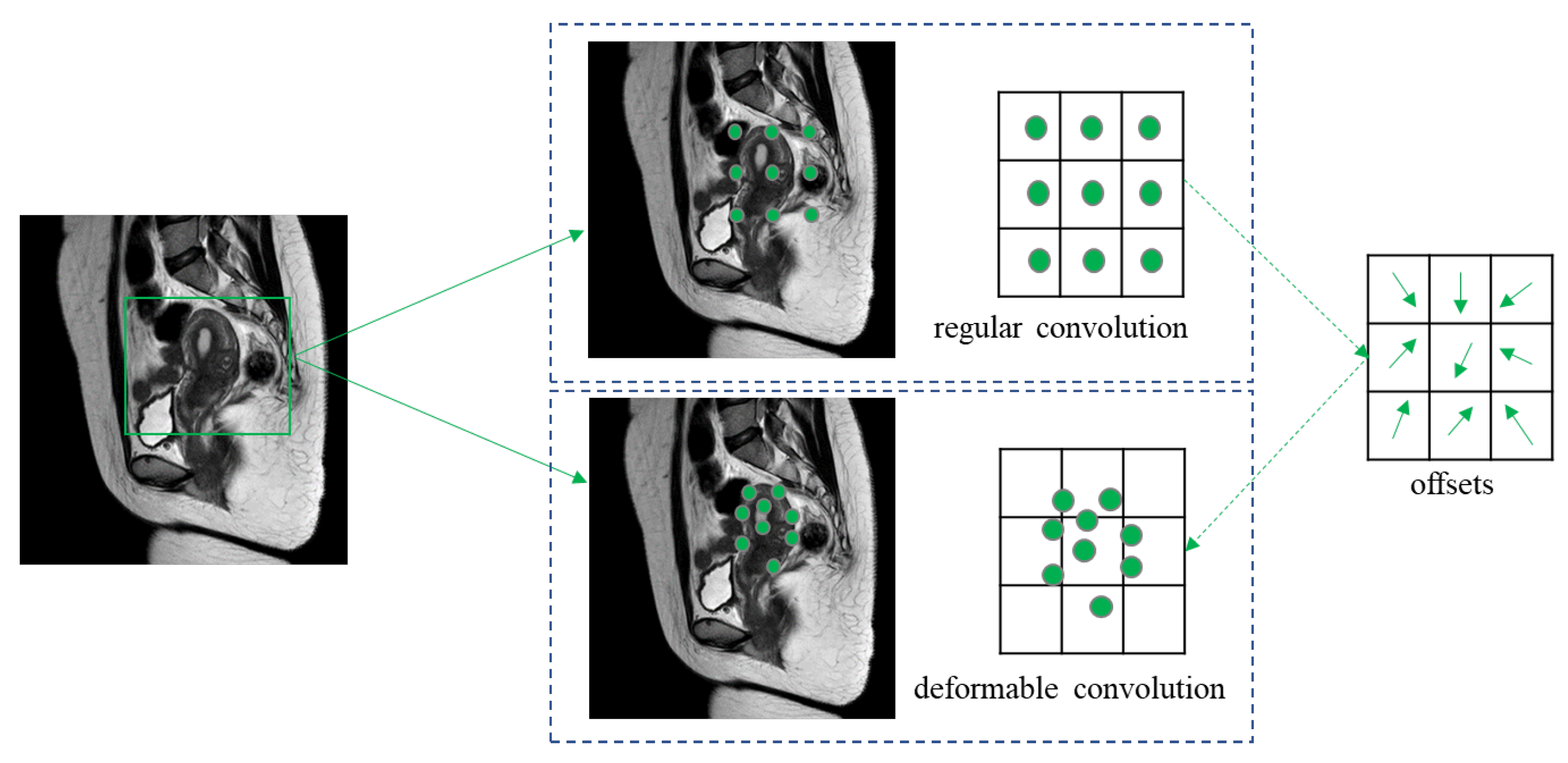
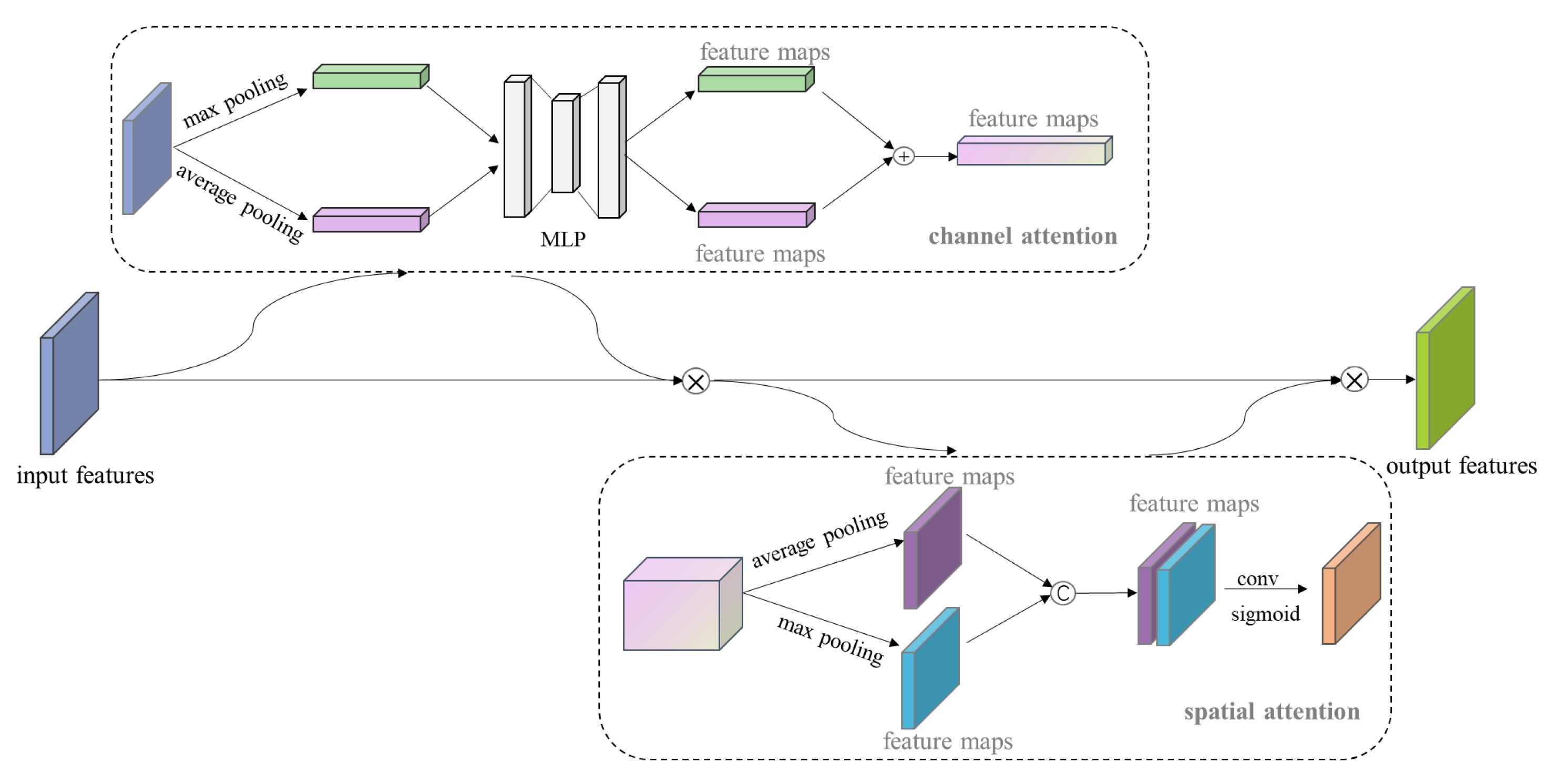
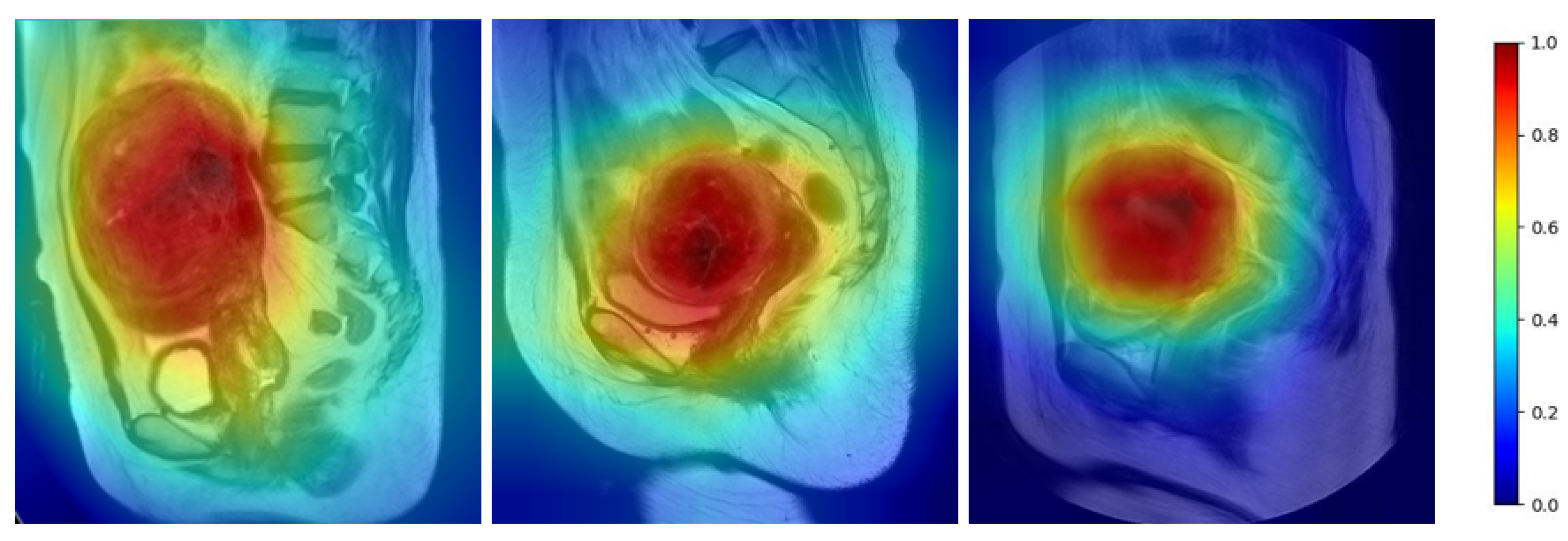
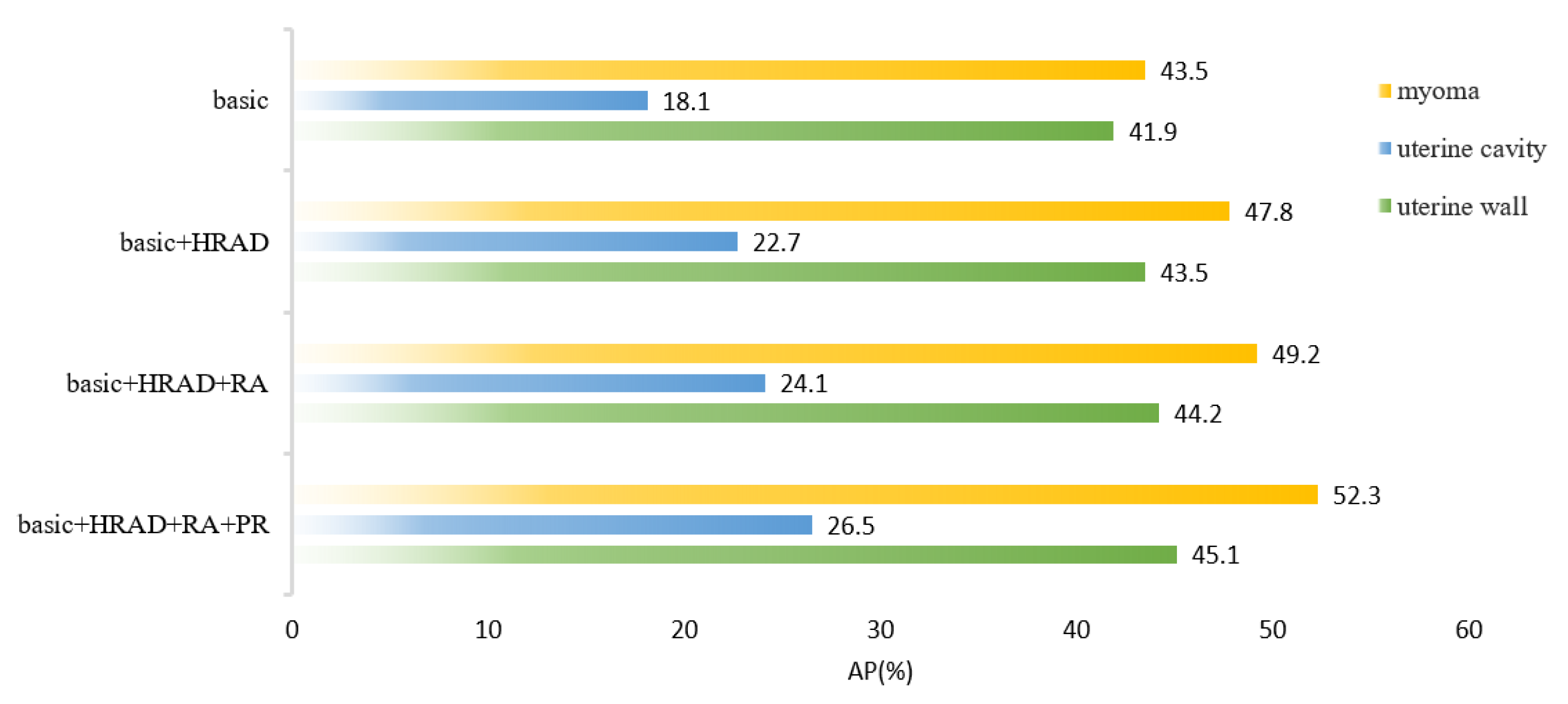
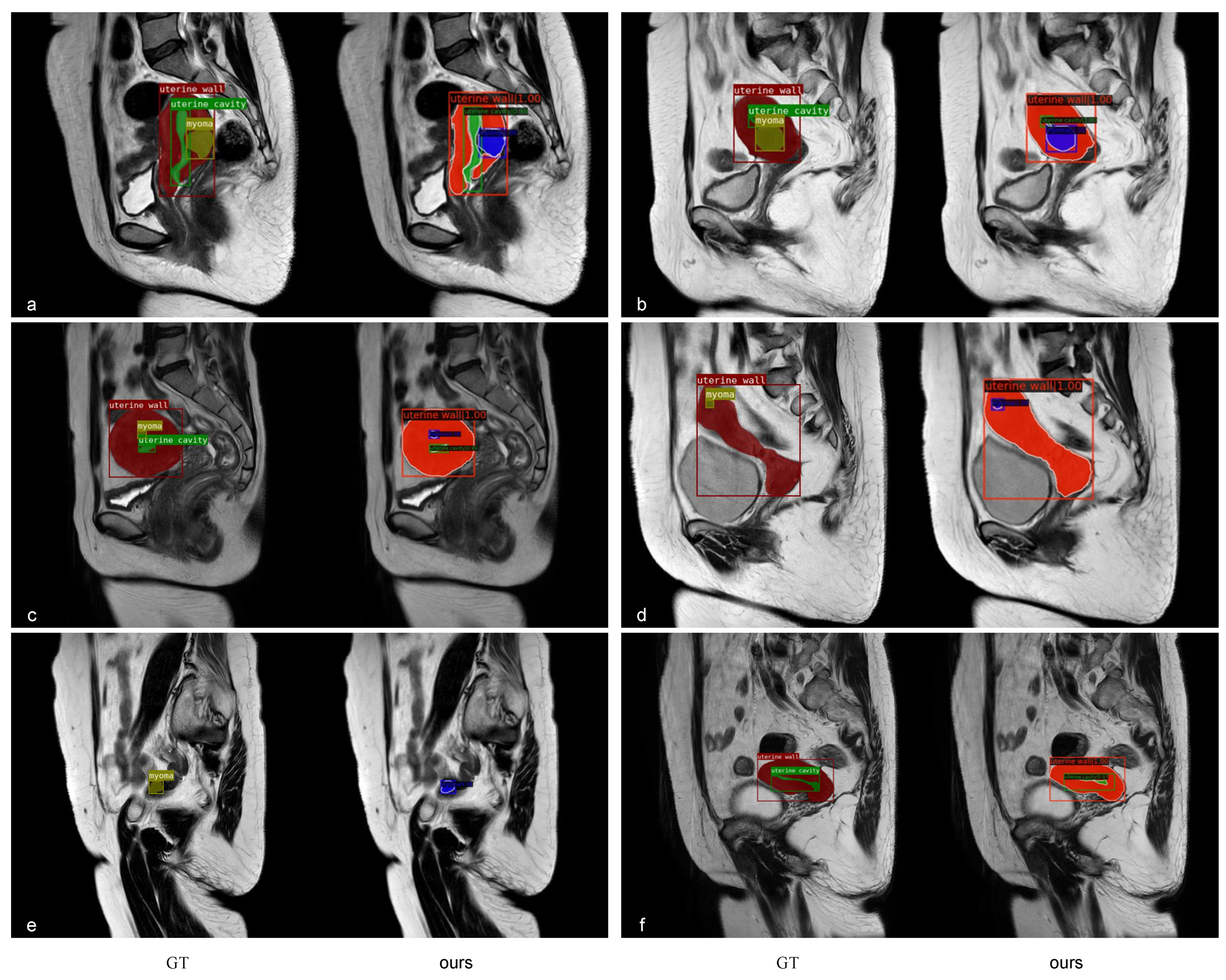
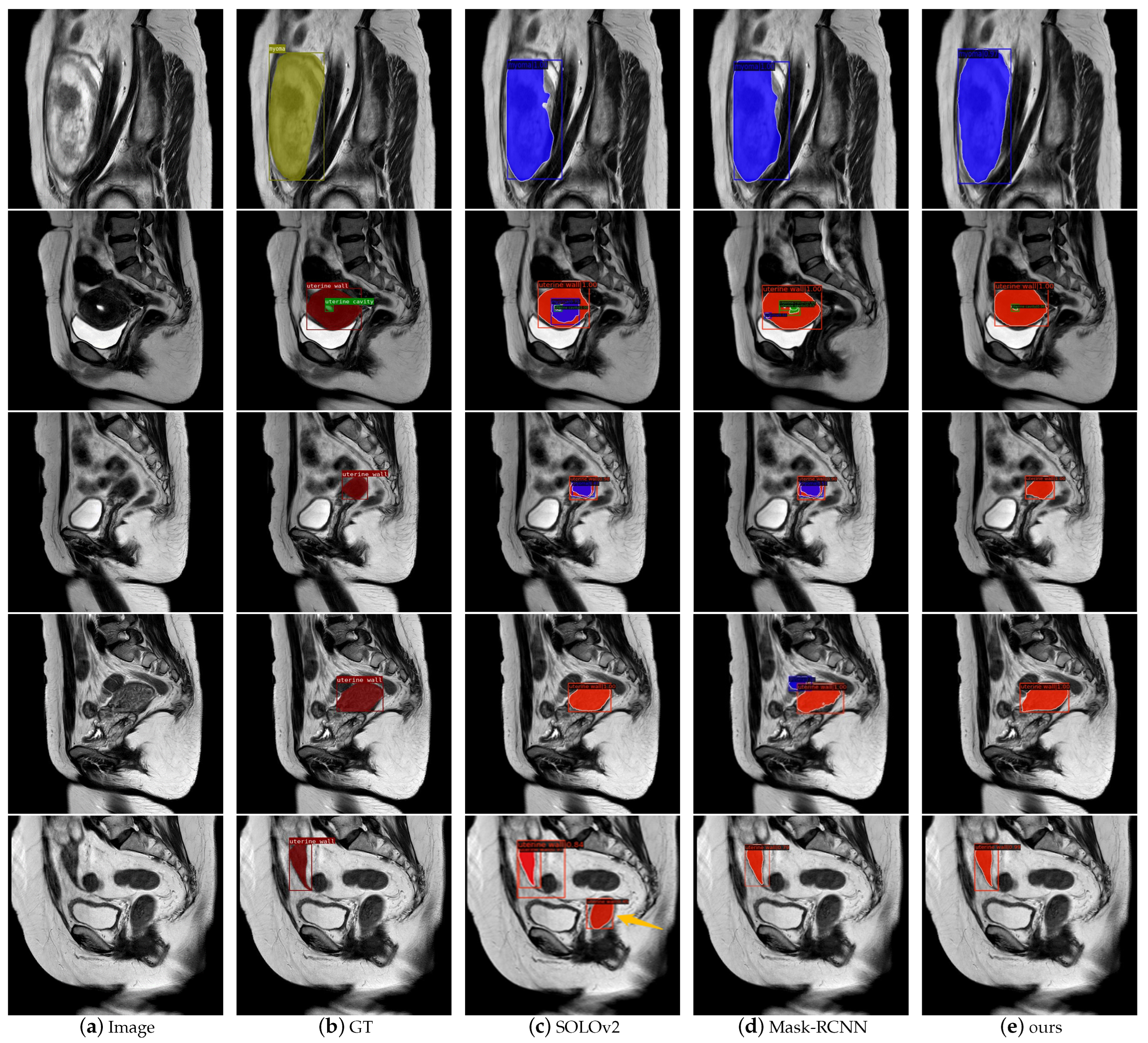
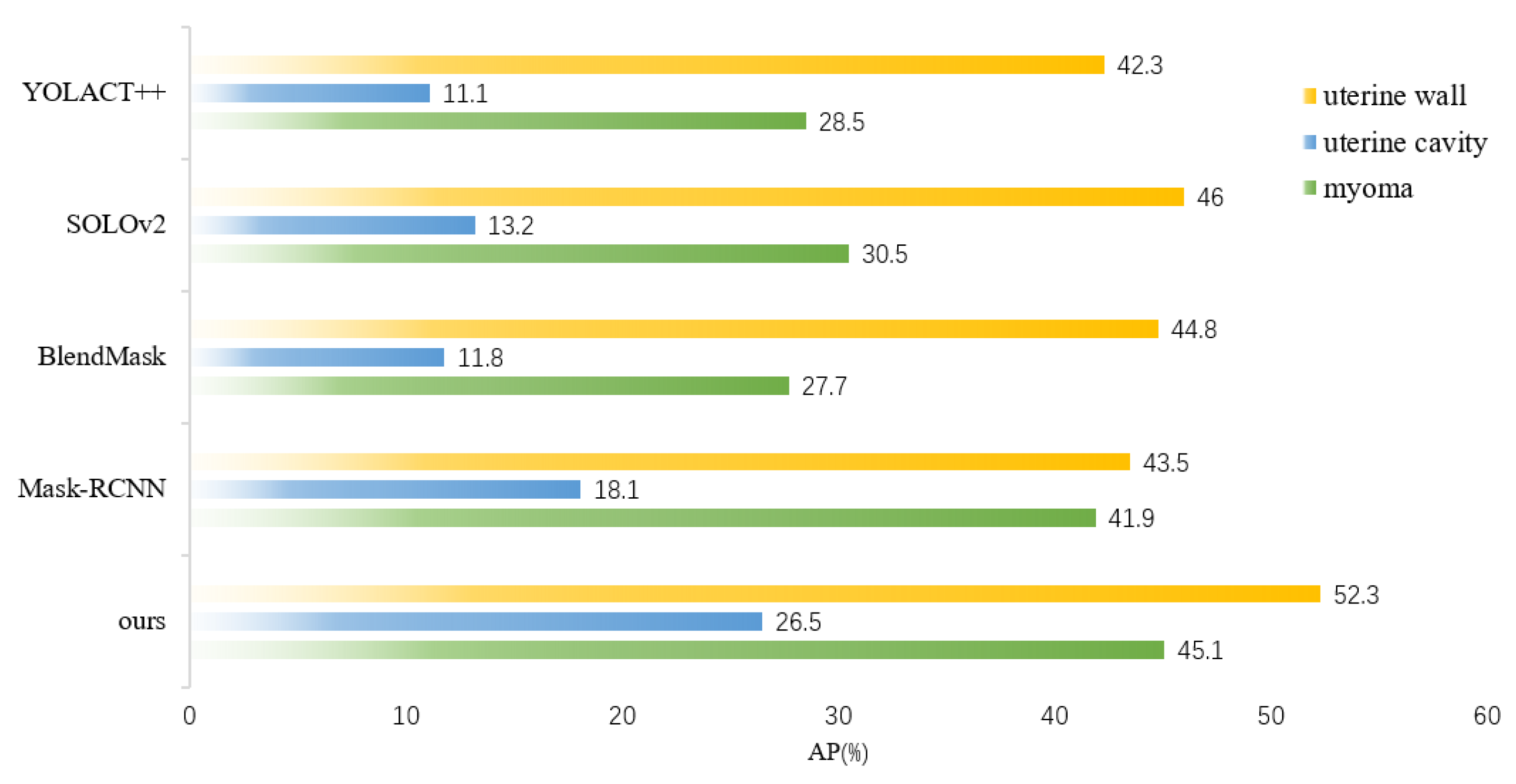
In this paper, we proposed an instance segmentation model based on deep learning for the auxiliary diagnosis of uterine myomas in MRI. Our method achieved better AP results than those of state-of-the-art instance segmentation models on the same dataset. The visualization results demonstrate that the mask output of our method fit better with the real object. Specifically, in the uterine MRI with complex backgrounds, our model had better resistance to background noise and did not detect nonuterine objects as our targets. This is mainly because our backbone structure maintained high-resolution features containing detailed information, and the attention mechanism enhanced the focus on features related to the uterine region while filtering out irrelevant noise. Additionally, our improved anchor box generation strategy rendered our model more suitable for the size of multiple categories in the uterine region and could perform better at the small, medium-sized, and large scales. The DCN could learn the shape features of objects more flexibly, while the PointRend module further ensured the fineness of the mask for complex objects with various shapes.
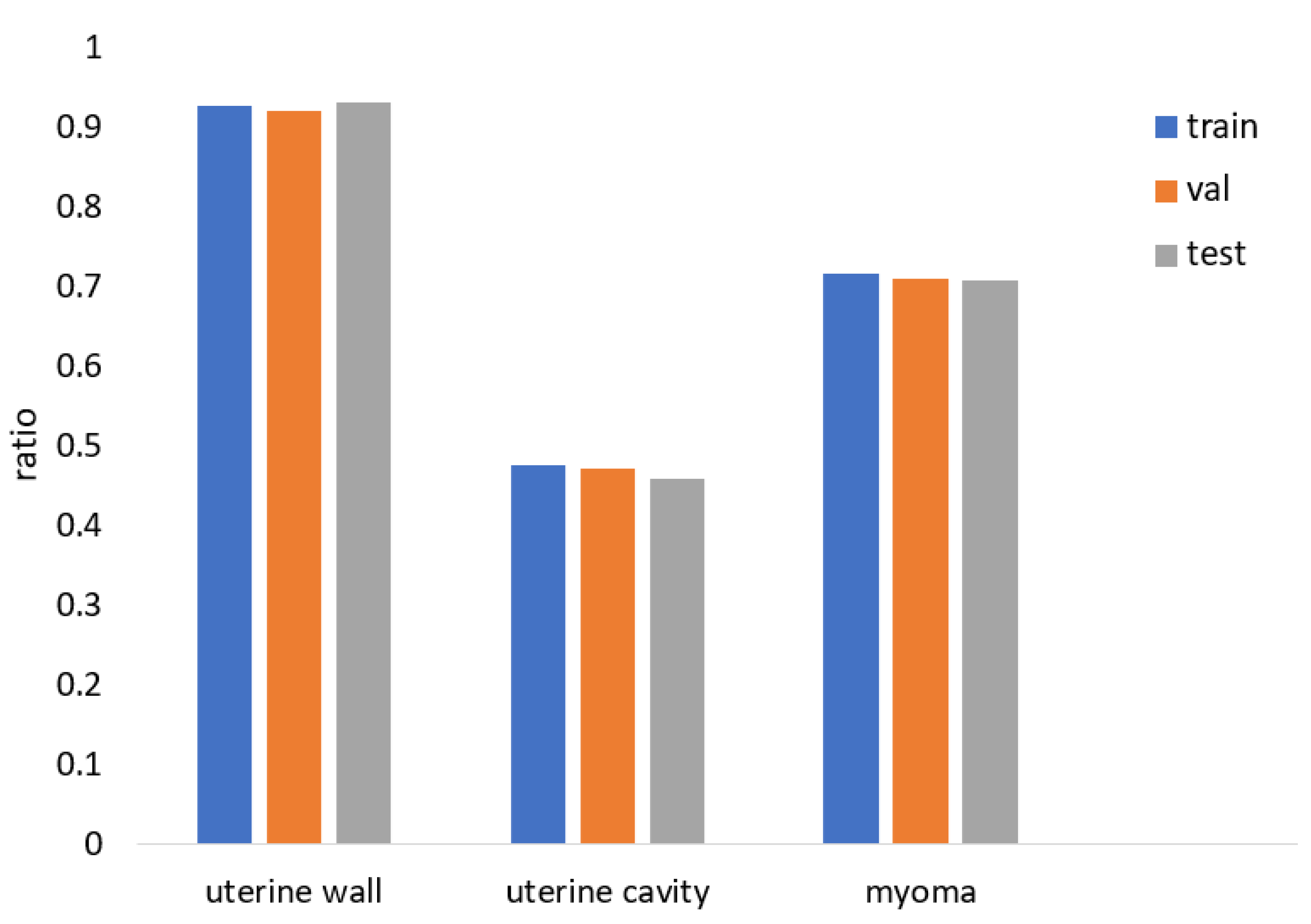
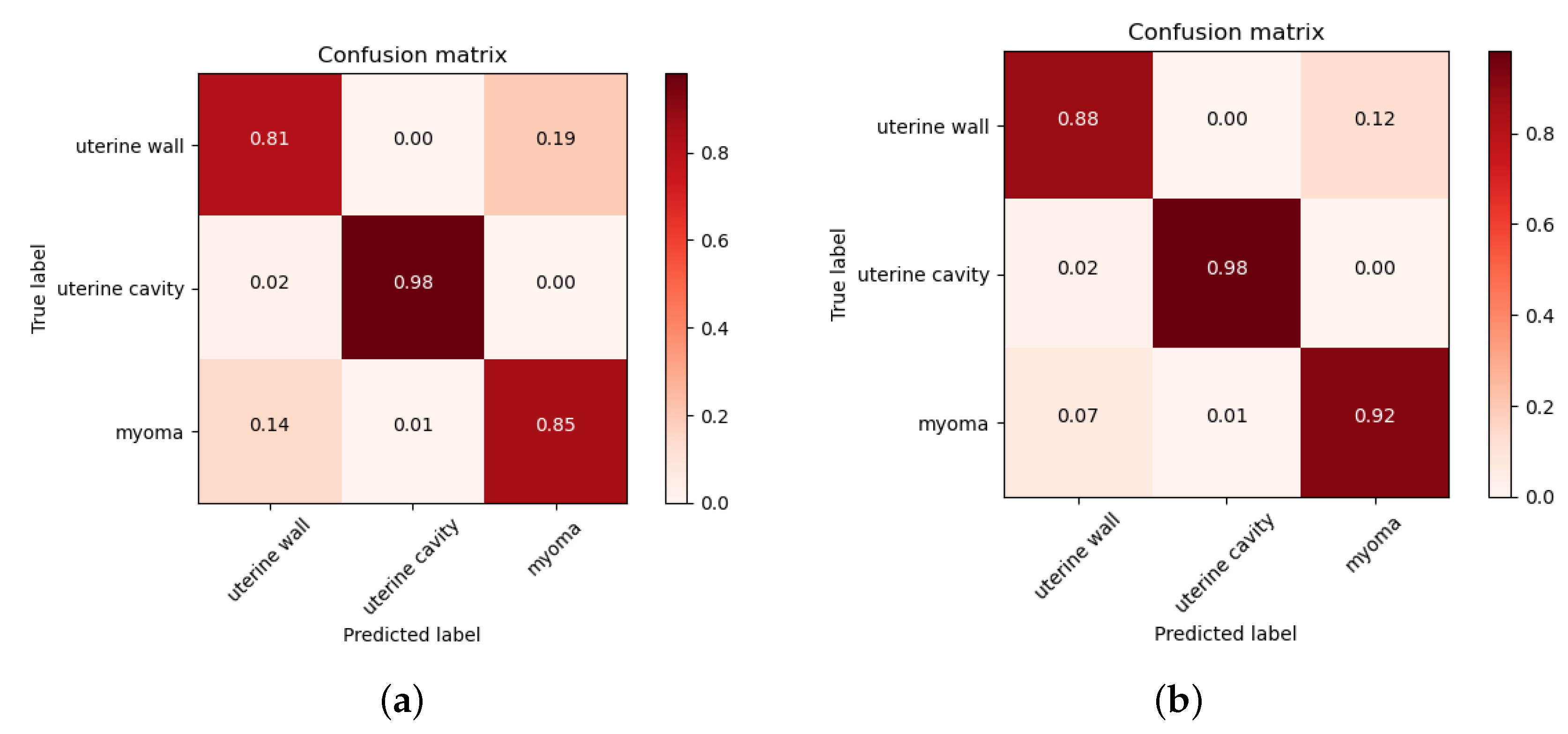
However, the AP of the uterine cavity and the APs of all categories were relatively low, as shown in these metrics, mainly because uterine walls or myomas compress the uterine cavity, rendering it very thin and narrow, and there were some small-scale myomas in early onset or in different MRI slices. These objects had only a few pixels, hindering the model from learning useful features. In the future, we plan to conduct further research to address these issues and improve the results of these objects. Furthermore, the 3D image features of the uterus are essential in clinical and deep-learning technique research, as it can provide more contextual information and spatial features. Due to the limitation of GPU resources, we only conducted experiments on 2D images. Our next step is to extend computing resources, and explore the potential of instance segmentation on 3D uterine MR images.
5. Conclusions
In this paper, we proposed a deep-learning-based instance-segmentation model that could automatically output the class, location, and masks of the uterine wall, uterine cavity, and uterine myomas. Experimental verification and visualization results demonstrate that our approach had excellent instance segmentation ability in the uterine region. Our approach could reduce the burden of the manual segmentation of lesions for doctors, alleviate the pressure of manual film reading, accelerate the diagnostic process for uterine myomas, and improve patient satisfaction. It can also be used for the auxiliary diagnosis of uterine myomas, providing gynecologists with a quick and objective reference to develop individualized treatment plans, such as hysteroscopic and laparoscopic surgeries, and drug therapy. Relatively few studies use deep-learning technology to achieve instance segmentation in the uterine region, and this study provides a promising solution, and has potential applications in the diagnosis of uterine diseases. In the future, we will build larger and richer datasets, and strive to improve the segmentation precision of our model on the uterine cavity and small-scale objects to further enhance the application of instance segmentation techniques in medical-image-assisted diagnosis.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}