
Deep-Learning-Based COVID-19 Diagnosis and Implementation in Embedded Edge-Computing Device

Abstract
:1. Introduction
- We propose an improved VGGNet to increase the detection accuracy by adding a channel attention mechanism;
- We use a mixed loss function of center loss and cross-entropy loss to train the model to better distinguish different classes of pneumonia;
- We apply the algorithm to an NVIDIA Jetson (TX2, Nano) to validate the feasibility of the algorithm on the embedded edge-computing platform.
2. Related Works
2.1. X-ray Image-Based Methods
2.2. CT-Image-Based Methods
3. Materials and Methods
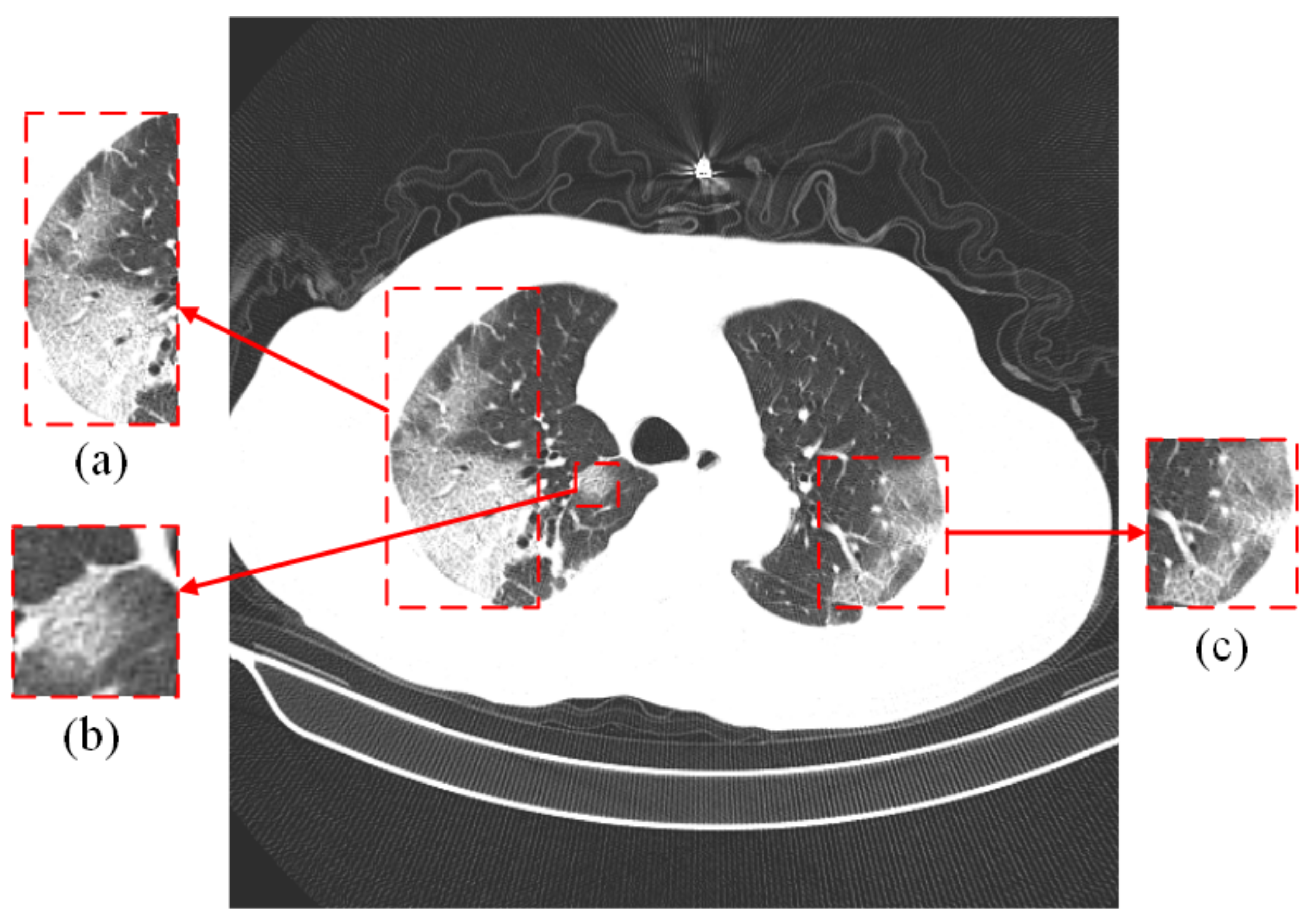
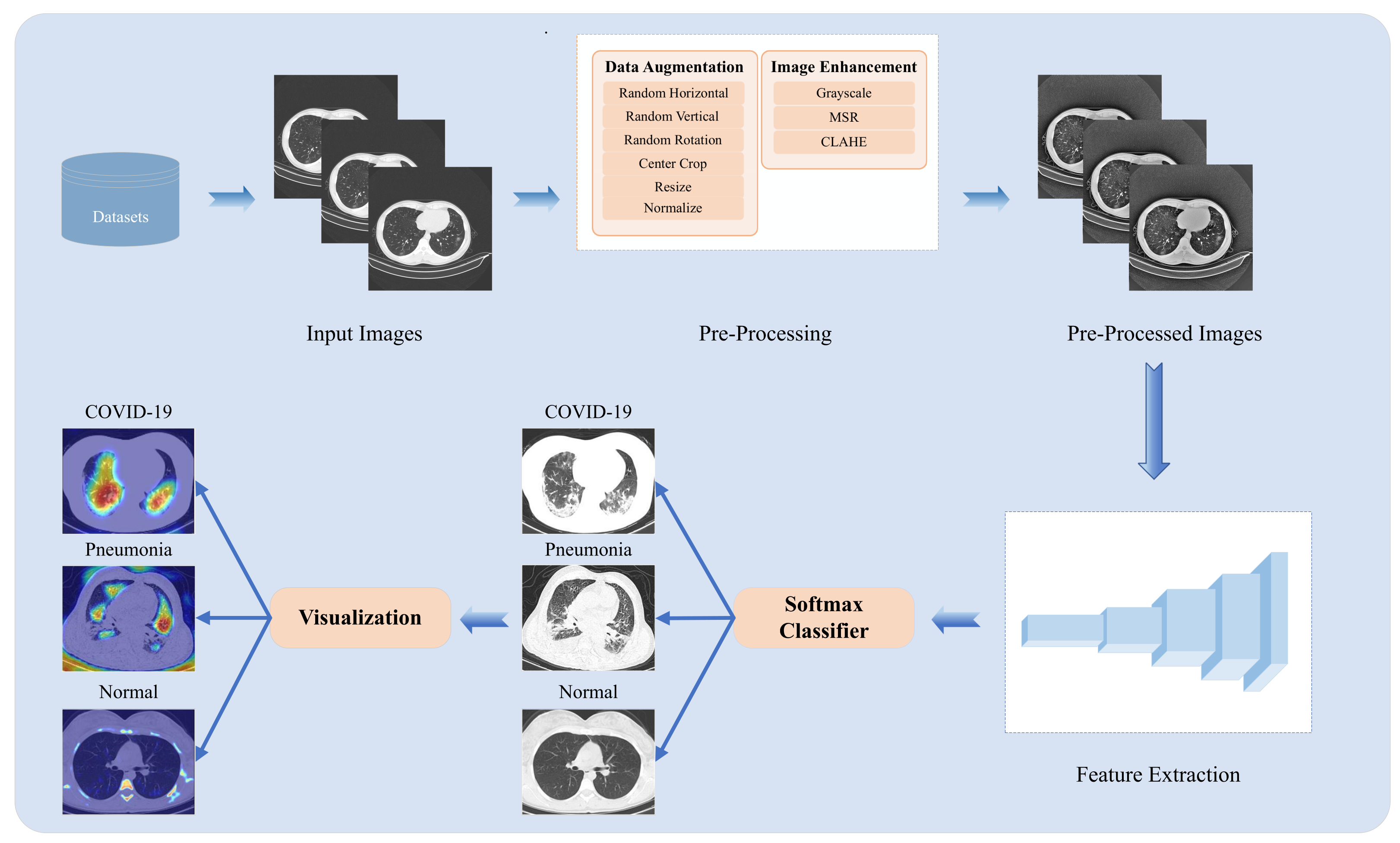
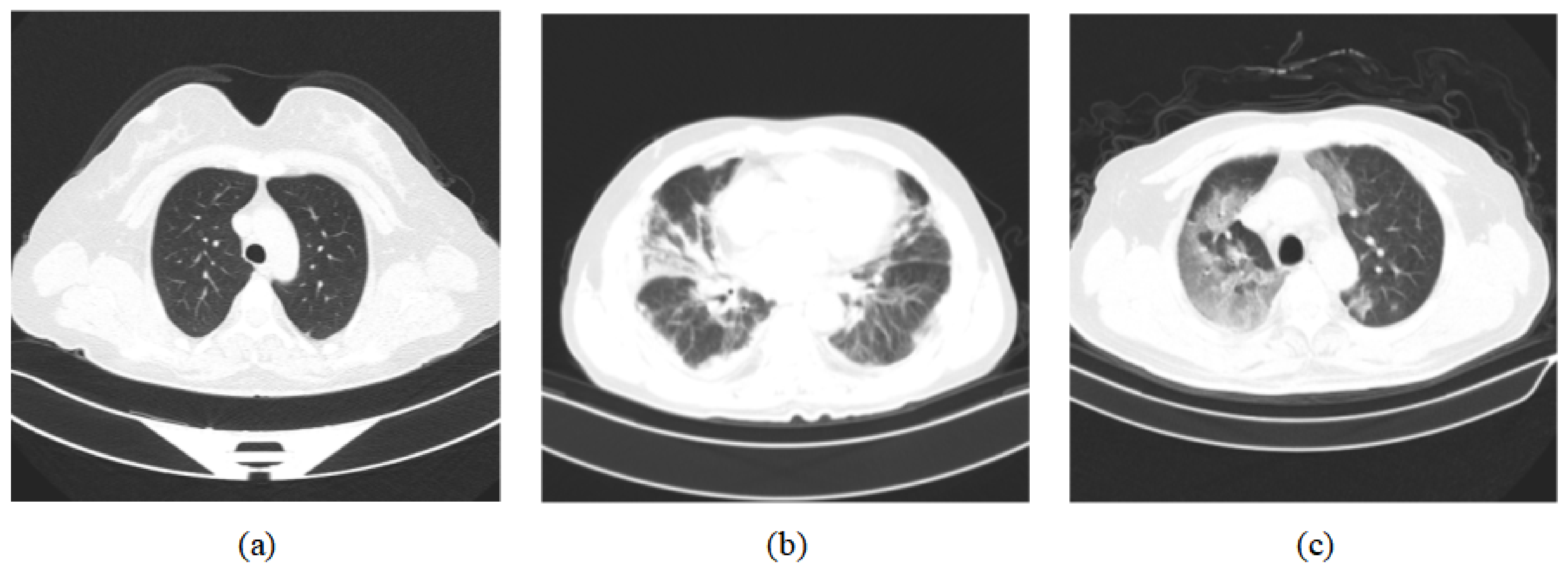
3.1. Dataset Preprocessing
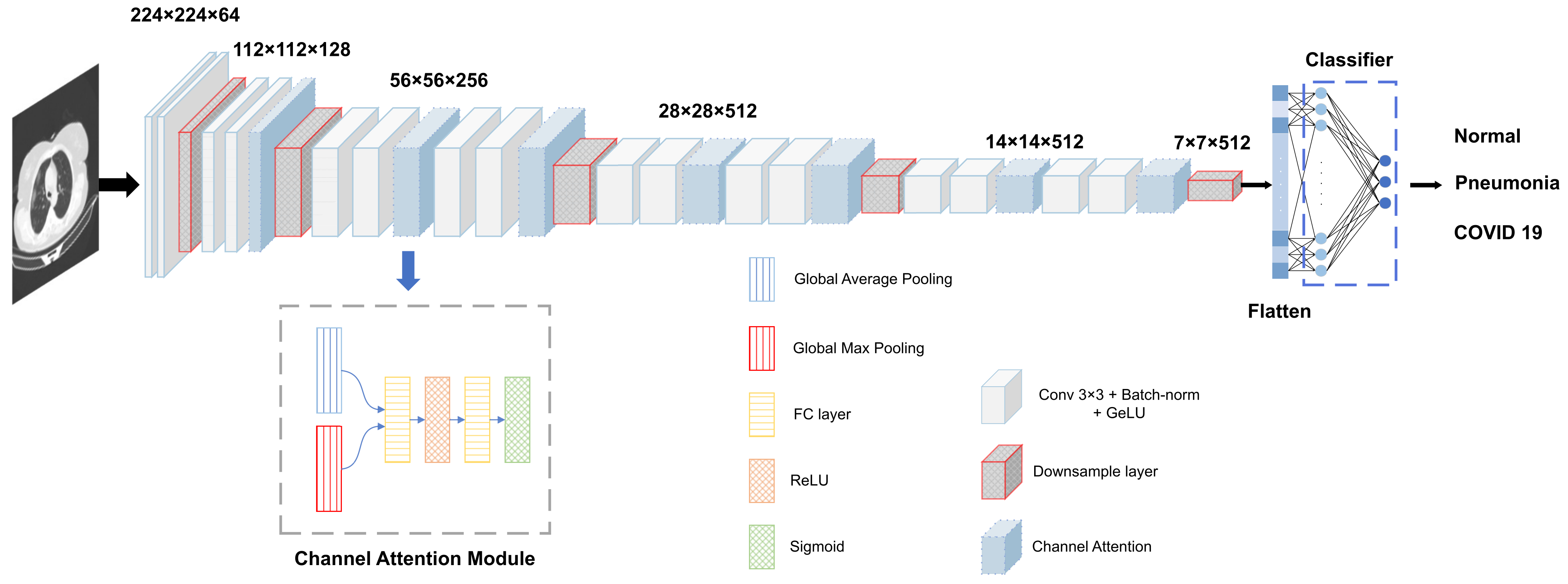
3.2. Methodology
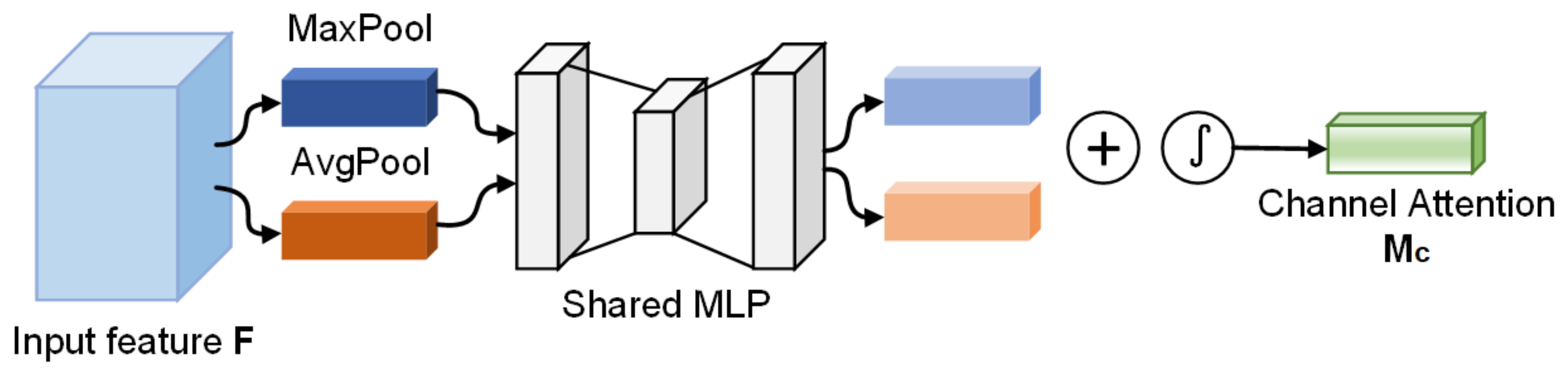
3.2.1. Channel Attention Module
3.2.2. Mixed Loss
4. Experiment and Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Results
4.3.1. Preprocessing Comparison
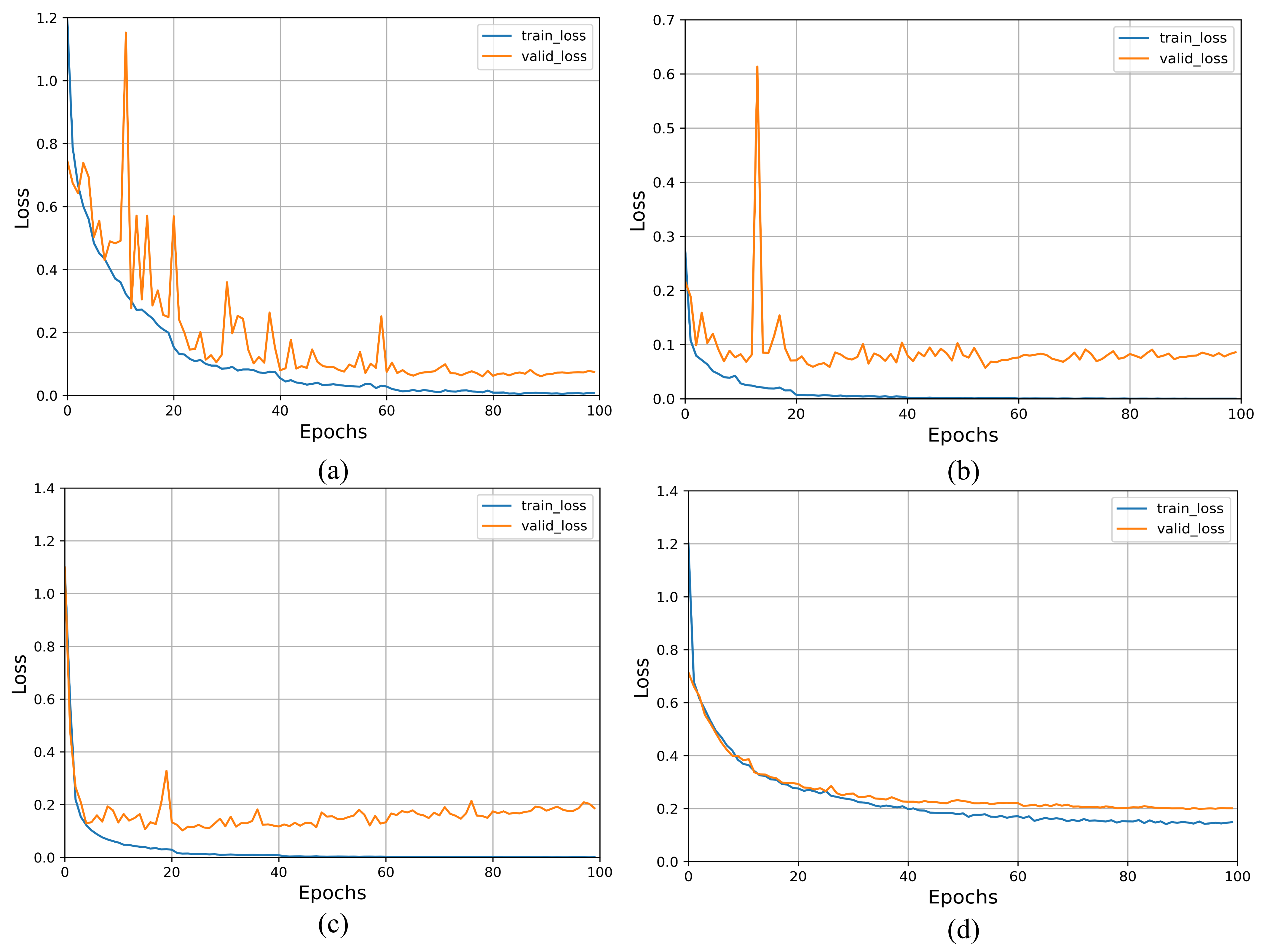
4.3.2. Loss Curve
4.3.3. Parameters and Complexity
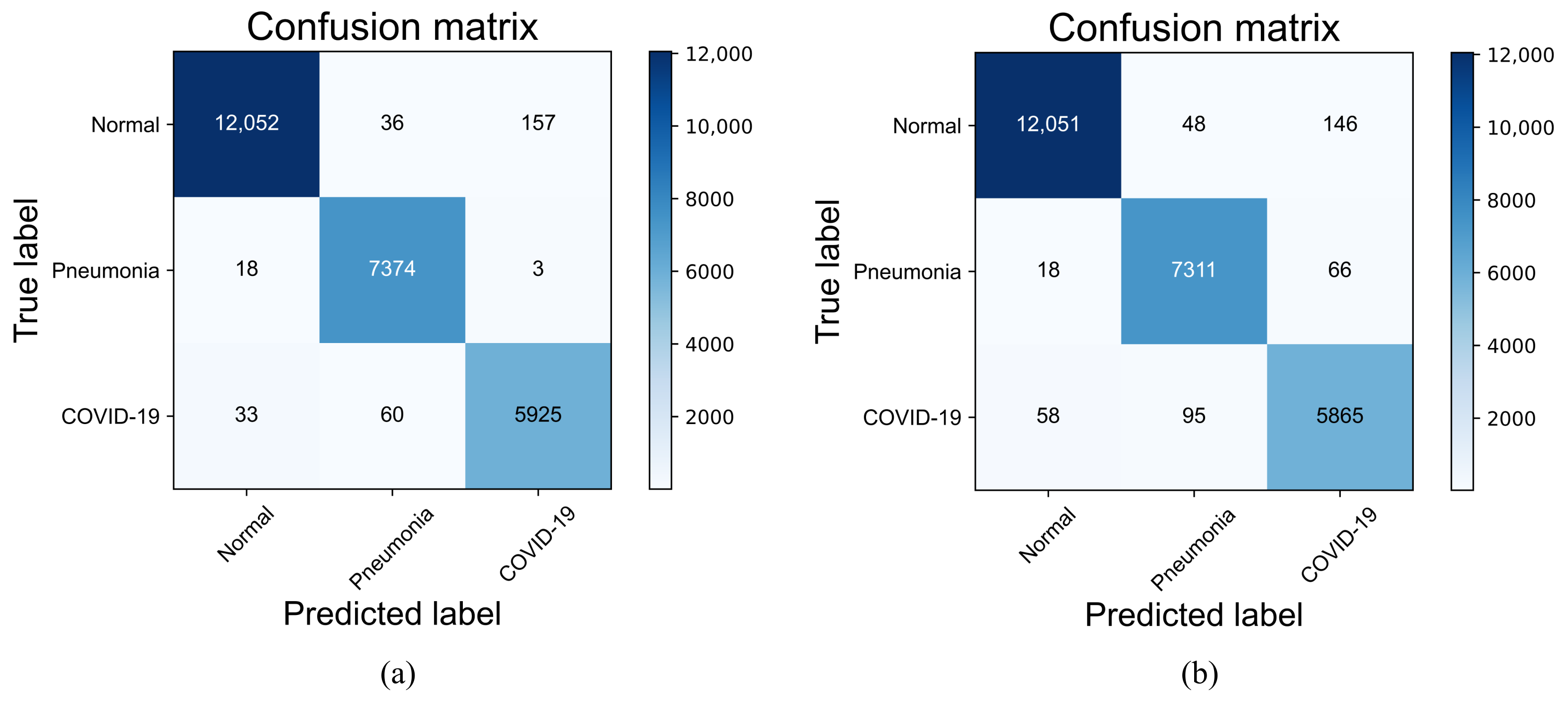
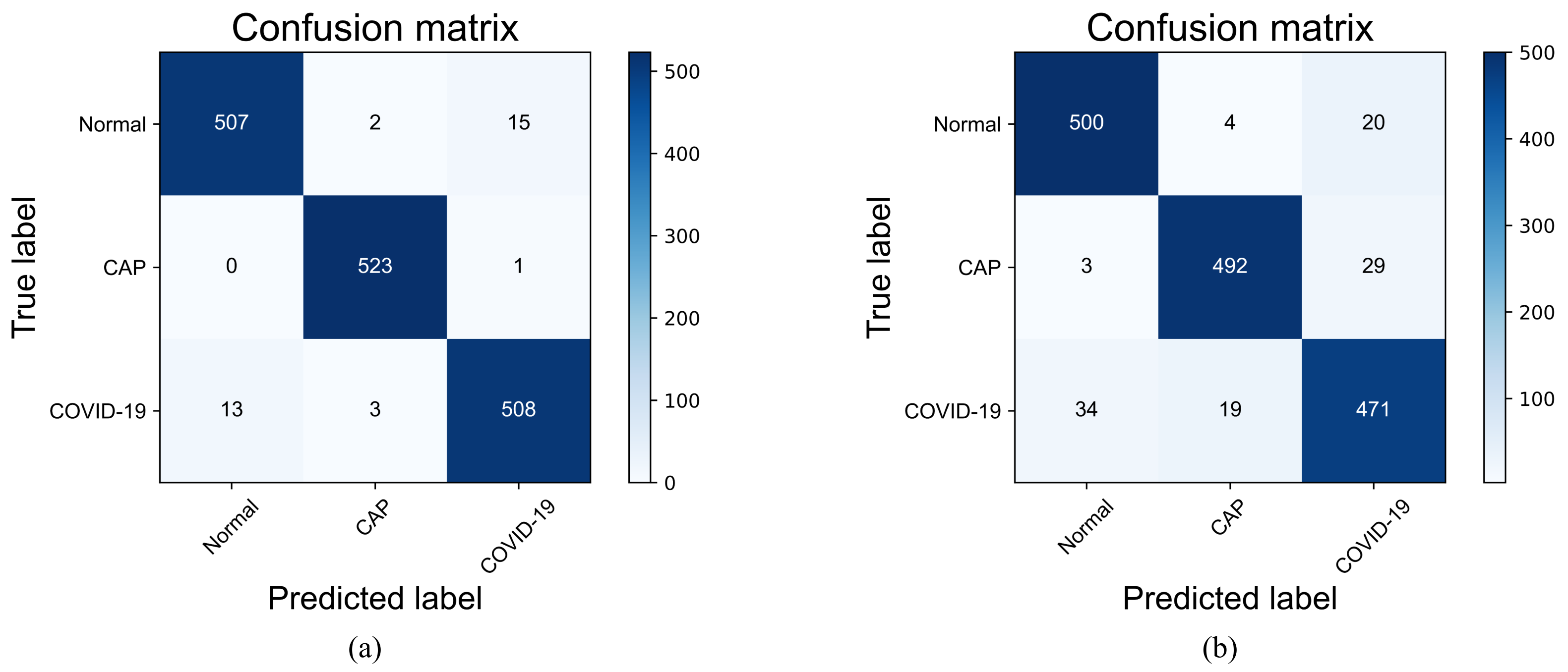
4.3.4. Confusion Matrix and Classification Performance
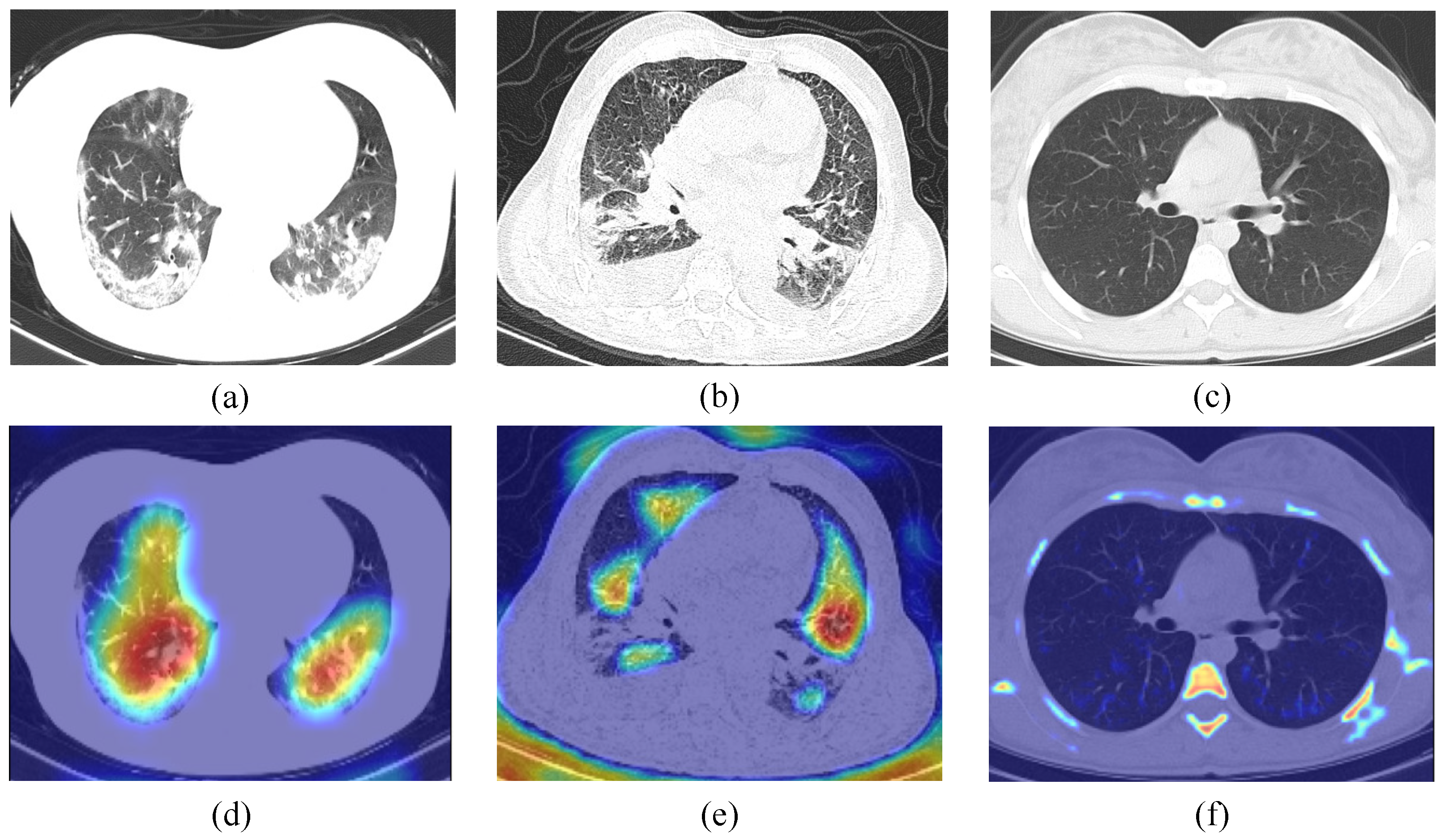
4.3.5. Lesion Visualization
4.3.6. Comparison with State-of-the-Art Methods
4.3.7. Implementation on NVIDIA Jetson Device
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, L.; Wang, Y.; Ye, D.; Liu, Q. Review of the 2019 novel coronavirus (SARS-CoV-2) based on current evidence. Int. J. Antimicrob. Agents 2020, 55, 105948. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Wang, Y.; Li, X.; Ren, L.; Zhao, J.; Hu, Y.; Zhang, L.; Fan, G.; Xu, J.; Gu, X.; et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- WHO. Coronavirus (COVID-19) Dashboard. Available online: https://covid19.who.int (accessed on 7 June 2022).
- Harahwa, T.; Yau, T.; Lim-Cooke, M.S.; Al-Haddi, S.; Zeinah, M.; Harky, A. The optimal diagnostic methods for COVID-19. Diagnosis 2020, 7, 349–356. [Google Scholar] [CrossRef] [PubMed]
- Corman, V.; Landt, O.; Kaiser, M.; Molenkamp, R.; Meijer, A.; Chu, D.; Bleicker, T.; Bruenink, S.; Schneider, J.; Schmidt, M.; et al. Detection of 2019 novel coronavirus (2019-nCoV) by real-time RT-PCR. Eurosurveillance 2020, 25, 2000045. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dhamad, A.; Abdal Rhida, M. COVID-19: Molecular and serological detection methods. PeerJ 2020, 8, e10180. [Google Scholar] [CrossRef]
- Giri, B.; Pandey, S.; Shrestha, R.; Pokharel, K.; Ligler, F.; Neupane, B. Review of analytical performance of COVID-19 detection methods. Anal. Bioanal. Chem. 2020, 413, 35–48. [Google Scholar] [CrossRef]
- Kubina, R.; Dziedzic, A. Molecular and Serological Tests for COVID-19 a Comparative Review of SARS-CoV-2 Coronavirus Laboratory and Point-of-Care Diagnostics. Diagnostics 2020, 10, 434. [Google Scholar] [CrossRef]
- Li, J.; Long, X.; Wang, X.; Fang, F.; Lv, X.; Zhang, D.; Sun, Y.; Hu, S.; Lin, Z.; Xiong, N. Radiology indispensable for tracking COVID-19. Diagn. Interv. Imaging 2021, 102, 69–75. [Google Scholar] [CrossRef]
- Fang, Y.; Zhang, H.; Xie, J.; Lin, M.; Ying, L.; Pang, P.; Ji, W. Sensitivity of Chest CT for COVID-19: Comparison to RT-PCR. Radiology 2020, 296, 200432. [Google Scholar] [CrossRef]
- Gunraj, H.; Sabri, A.; Koff, D.; Wong, A. COVID-Net CT-2: Enhanced Deep Neural Networks for Detection of COVID-19 From Chest CT Images Through Bigger, More Diverse Learning. Front. Med. 2022, 8, 3126. [Google Scholar] [CrossRef]
- Gunraj, H.; Wang, L.; Wong, A. COVIDNet-CT: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases From Chest CT Images. Front. Med. 2020, 7, 1025. [Google Scholar] [CrossRef] [PubMed]
- Arora, V.; Ng, E.Y.K.; Leekha, R.S.; Darshan, M.; Singh, A. Transfer learning-based approach for detecting COVID-19 ailment in lung CT scan. Comput. Biol. Med. 2021, 135, 104575. [Google Scholar] [CrossRef] [PubMed]
- Ahuja, S.; Panigrahi, B.K.; Dey, N.; Rajinikanth, V.; Gandhi, T.K. Deep Transfer Learning-Based Automated Detection of COVID-19 from Lung CT Scan Slices. Appl. Intell. 2021, 51, 571–585. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Zheng, B.; Zhu, Y.; Yu, F.; Zhang, R.; Chen, B. COVID-19 lesion discrimination and localization network based on multi-receptive field attention module on CT images. Optik 2021, 241, 167100. [Google Scholar] [CrossRef]
- Wang, S.H.; Fernandes, S.L.; Zhu, Z.; Zhang, Y.D. AVNC: Attention-Based VGG-Style Network for COVID-19 Diagnosis by CBAM. IEEE Sensors J. 2022, 22, 17431–17438. [Google Scholar] [CrossRef]
- Khan, E.; Rehman, M.Z.U.; Ahmed, F.; Alfouzan, F.A.; Alzahrani, N.M.; Ahmad, J. Chest X-ray Classification for the Detection of COVID-19 Using Deep Learning Techniques. Sensors 2022, 22, 1211. [Google Scholar] [CrossRef]
- Zhou, T.; Lu, H.; Yang, Z.; Qiu, S.; Huo, B.; Dong, Y. The ensemble deep learning model for novel COVID-19 on CT images. Appl. Soft Comput. 2021, 98, 106885. [Google Scholar] [CrossRef]
- Hasani, S.; Nasiri, H. COV-ADSX: An Automated Detection System using X-ray Images, Deep Learning, and XGBoost for COVID-19. Softw. Impacts 2022, 11, 100210. [Google Scholar] [CrossRef]
- Verma, A.; Amin, S.B.; Naeem, M.; Saha, M. Detecting COVID-19 from chest computed tomography scans using AI-driven android application. Comput. Biol. Med. 2022, 143, 105298. [Google Scholar] [CrossRef]
- Basantwani, N.; Kumar, A.; Gangwar, S.; Olkha, A.; Prijwal, P.; Mathur, G. COVID-19 detection android app based on chest X-rays & ct scans. INFOCOMP J. Comput. Sci. 2021, 20, 91–100. [Google Scholar]
- Krömer, P.; Nowaková, J. Medical Image Analysis with NVIDIA Jetson GPU Modules. In Proceedings of the 13th International Conference on Intelligent Networking and Collaborative Systems (INCoS-2021)—Advances in Intelligent Networking and Collaborative Systems, Taichung, Taiwan, 1–3 September 2021; pp. 233–242. [Google Scholar] [CrossRef]
- Rungsuptaweekoon, K.; Visoottiviseth, V.; Takano, R. Evaluating the power efficiency of deep learning inference on embedded GPU systems. In Proceedings of the 2017 2nd International Conference on Information Technology (INCIT), Nakhonpathom, Thailand, 2–3 November 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Mijwil, M. Implementation of Machine Learning Techniques for the Classification of Lung X-Ray Images Used to Detect COVID-19 in Humans. Iraqi J. Sci. 2021, 62, 2099–2109. [Google Scholar] [CrossRef]
- Ezzoddin, M.; Nasiri, H.; Dorrigiv, M. Diagnosis of COVID-19 Cases from Chest X-ray Images Using Deep Neural Network and LightGBM. In Proceedings of the 2022 International Conference on Machine Vision and Image Processing (MVIP), Ahvaz, Iran, 23–24 February 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Nasiri, H.; Kheyroddin, G.; Dorrigiv, M.; Esmaeili, M.; Nafchi, A.R.; Ghorbani, M.H.; Zarkesh-Ha, P. Classification of COVID-19 in Chest X-ray Images Using Fusion of Deep Features and LightGBM. In Proceedings of the 2022 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 6–9 June 2022; pp. 201–206. [Google Scholar] [CrossRef]
- Nayak, S.R.; Nayak, D.R.; Sinha, U.; Arora, V.; Pachori, R.B. An Efficient Deep Learning Method for Detection of COVID-19 Infection Using Chest X-ray Images. Diagnostics 2023, 13, 131. [Google Scholar] [CrossRef] [PubMed]
- Rahman, T.; Khandakar, A.; Qiblawey, Y.; Tahir, A.; Kiranyaz, S.; Abul Kashem, S.B.; Islam, M.T.; Al Maadeed, S.; Zughaier, S.M.; Khan, M.S.; et al. Exploring the effect of image enhancement techniques on COVID-19 detection using chest X-ray images. Comput. Biol. Med. 2021, 132, 104319. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Chakraborty, S.; Murali, B.; Mitra, A.K. An Efficient Deep Learning Model to Detect COVID-19 Using Chest X-ray Images. Int. J. Environ. Res. Public Health 2022, 19, 2013. [Google Scholar] [CrossRef]
- Mahapatra, A.K.; Satyam Oza, R.; Shankar, S. Deploying Deep Transfer Learning Models to a Web-App for Sars-Cov-2 Detection Using Chest Radiography Images. In Proceedings of the 2021 5th International Conference on Electrical, Electronics, Communication, Computer Technologies and Optimization Techniques (ICEECCOT), Mysuru, India, 10–11 December 2021; pp. 137–144. [Google Scholar] [CrossRef]
- Fan, X.; Feng, X.; Dong, Y.; Hou, H. COVID-19 CT image recognition algorithm based on transformer and CNN. Displays 2022, 72, 102150. [Google Scholar] [CrossRef]
- Ter-Sarkisov, A. Detection and segmentation of lesion areas in chest CT scans for the prediction of COVID-19. medRxiv 2020. [Google Scholar] [CrossRef]
- Yang, L.; Wang, S.H.; Zhang, Y.D. EDNC: Ensemble Deep Neural Network for COVID-19 Recognition. Tomography 2022, 8, 869–890. [Google Scholar] [CrossRef] [PubMed]
- Chetoui, M.; Akhloufi, M.A. Efficient Deep Neural Network for an Automated Detection of COVID-19 using CT images. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, VIC, Australia, 17–20 October 2021; pp. 1769–1774. [Google Scholar] [CrossRef]
- Nair, R.; Alhudhaif, A.; Koundal, D.; Doewes, R.I.; Sharma, P. Deep learning-based COVID-19 detection system using pulmonary CT scans. Turk. J. Electr. Eng. Comput. Sci. 2021, 29, 2716–2727. [Google Scholar] [CrossRef]
- Chaudhary, S.; Sadbhawna, S.; Jakhetiya, V.; Subudhi, B.N.; Baid, U.; Guntuku, S.C. Detecting COVID-19 and Community Acquired Pneumonia Using Chest CT Scan Images With Deep Learning. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 8583–8587. [Google Scholar] [CrossRef]
- Perumal, V.; Narayanan, V.; Rajasekar, S.J.S. Prediction of COVID-19 with Computed Tomography Images using Hybrid Learning Techniques. Dis. Markers 2021, 2021, 5522729. [Google Scholar] [CrossRef]
- Garg, P.; Ranjan, R.; Upadhyay, K.; Agrawal, M.; Deepak, D. Multi-Scale Residual Network for COVID-19 Diagnosis Using Ct-Scans. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 8558–8562. [Google Scholar] [CrossRef]
- Maftouni, M.; Law, A.C.C.; Shen, B.; Zhou, Y.; Ayoobi Yazdi, N.; Kong, Z. A Robust Ensemble-Deep Learning Model for COVID-19 Diagnosis based on an Integrated CT Scan Images Database. In Proceedings of the 2021 IISE Annual Conference, Online, 22–25 May 2021. [Google Scholar]
- Zhang, G.; Sun, D.; Yan, P.; Zhao, H.; Li, Z. A LDCT Image Contrast Enhancement Algorithm Based on Single-Scale Retinex Theory. In Proceedings of the 2008 International Conference on Computational Intelligence for Modelling Control & Automation, Vienna, Austria, 10–12 December 2008; pp. 1282–1287. [Google Scholar] [CrossRef]
- Jobson, D.; Rahman, Z.; Woodell, G. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pizer, S.; Johnston, R.; Ericksen, J.; Yankaskas, B.; Muller, K. Contrast-limited adaptive histogram equalization: Speed and effectiveness. In Proceedings of the First Conference on Visualization in Biomedical Computing, Atlanta, GA, USA, 22–25 May 1990; pp. 337–345. [Google Scholar] [CrossRef]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2014, arXiv:1412.6806. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 499–515. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef] [Green Version]
- Hasija, S.; Akash, P.; Bhargav Hemanth, M.; Kumar, A.; Sharma, S. A novel approach for detection of COVID-19 and Pneumonia using only binary classification from chest CT-scans. Neurosci. Informat. 2022, 2, 100069. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Class | Training | Validation | Test |
|---|---|---|---|---|
| Integrated CT scan | Normal | 1570 | 524 | 524 |
| CAP | 1570 | 524 | 524 | |
| COVID-19 | 1570 | 524 | 524 | |
| Total | 4710 | 1572 | 1572 | |
| COVIDx CT-2A | Normal | 25,496 | 6244 | 12,245 |
| Pneumonia | 25,496 | 6244 | 7395 | |
| COVID-19 | 25,496 | 6244 | 6018 | |
| Total | 76,488 | 18,732 | 25,658 |
| Dataset | CLAHE | MSR | Precision (%) | Recall (%) | F-Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Integrated CT scan | ✗ | ✗ | 97.13 | 97.14 | 97.13 | 97.14 |
| ✓ | ✗ | 97.66 | 97.65 | 97.65 | 97.65 | |
| ✓ | ✓ | 97.83 | 97.84 | 97.83 | 97.84 | |
| COVIDx CT-2A | ✗ | ✗ | 98.39 | 98.76 | 98.57 | 98.66 |
| ✓ | ✗ | 98.59 | 98.83 | 98.71 | 98.82 | |
| ✓ | ✓ | 98.55 | 98.86 | 98.70 | 98.80 |
| Model | Params. (M) | Flops (G) |
|---|---|---|
| The original VGG19 | 139.58 | 19.88 |
| The improved VGG19 | 21.89 | 22.30 |
| Methods | Precision (%) | Recall (%) | F-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| The original VGG19 | 97.99 | 98.25 | 98.12 | 98.32 |
| Fan et al. [35] | 97.45 | 97.76 | 96.36 | 96.73 |
| Ter-Sarkisov [36] | 91.66 | - | - | 95.64 |
| Yang et al. [37] | 95.65 | 100.0 | 97.78 | 97.83 |
| Hasija et al. [51] | 98.11 | 98.06 | 98.09 | 98.38 |
| Chetoui et al. [38] | - | 97.00 | - | 96.37 |
| The proposed VGG19 | 98.55 | 98.86 | 98.70 | 98.80 |
| Methods | Precision (%) | Recall (%) | F-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| The original VGG19 | 93.07 | 93.07 | 93.07 | 93.07 |
| NAIR et al. [39] | - | 90.00 | - | - |
| Chaudhary et al. [40] | 88.19 | 87.56 | 87.87 | 89.30 |
| Perumal et al. [41] | - | 96.00 | - | 96.69 |
| Garg et al. [42] | - | - | - | 95.76 |
| Maftouni et al. [43] | 97.93 | 90.80 | 94.23 | 95.31 |
| The proposed VGG19 | 97.83 | 97.84 | 97.83 | 97.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lou, L.; Liang, H.; Wang, Z. Deep-Learning-Based COVID-19 Diagnosis and Implementation in Embedded Edge-Computing Device. Diagnostics 2023, 13, 1329. https://doi.org/10.3390/diagnostics13071329
Lou L, Liang H, Wang Z. Deep-Learning-Based COVID-19 Diagnosis and Implementation in Embedded Edge-Computing Device. Diagnostics. 2023; 13(7):1329. https://doi.org/10.3390/diagnostics13071329
Chicago/Turabian StyleLou, Lu, Hong Liang, and Zhengxia Wang. 2023. "Deep-Learning-Based COVID-19 Diagnosis and Implementation in Embedded Edge-Computing Device" Diagnostics 13, no. 7: 1329. https://doi.org/10.3390/diagnostics13071329