


Performance and Agreement When Annotating Chest X-ray Text Reports—A Preliminary Step in the Development of a Deep Learning-Based Prioritization and Detection System

 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Diagnostic Labeling Scheme for Text Annotations
2.2. Dataset
- (1)
- Truly randomly selected.
- (2)
- Randomly selected cases containing any abnormal findings.
- (3)
- Randomly selected cases, within the top 10% of all cases that had the greatest number of associated labels per case relative to the length of the report.
- (4)
- Randomly selected cases, within the bottom 10% of cases that had the least number of labels associated per case relative to the length of the report.
2.3. Participants and Annotation Process
2.4. Presentation of Data and Statistical Analysis
- (1)
- Match with the exact same label, or
- (2)
- Match with an ancestral or descendent node (e.g., for “vascular changes” it could be either “aneurism” or “widening of mediastinum” etc. (Figure 1))
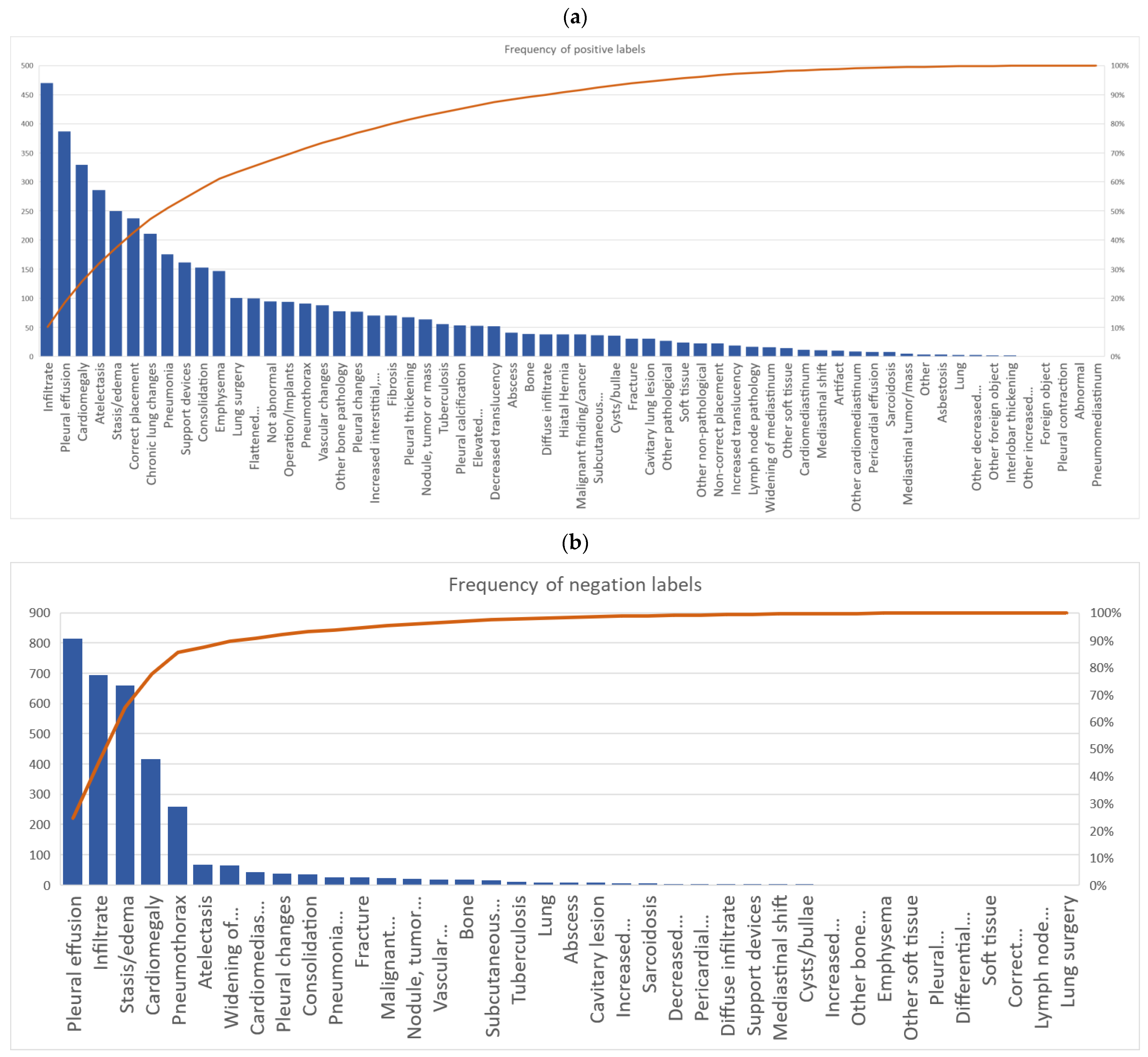
3. Results
3.1. Annotator Performance and Agreement
3.2. Label Specific Agreement

{kind=link}
{kind=link}
{kind=link}
| Gold Standard * | |||||||
|---|---|---|---|---|---|---|---|
| Annotators * | Cardiomediastinum | Cardiomegaly | Widening of Mediastinum | Lymph Node Pathology | Other Cardiomediastinum | Vascular Changes | |
| Cardiomediastinum | 1 | 16 | 8 | 1 | 1 | ||
| Cardiomegaly | 3 | 472 | |||||
| Widening of Mediastinum | 1 | 36 | 1 | ||||
| Lymph node pathology | 9 | ||||||
| Mediastinal tumor | 1 | ||||||
| Other cardiomediastinum | 4 | ||||||
| Vascular changes | 2 | 32 | |||||
 0 labels matched 100+ labels matched | |||||||
4. Discussion
4.1. Performance of Annotators
4.2. Majority Vote Labeling
4.3. The Labeling Scheme
4.4. Bias, Limitations and Future Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Annotators | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Radiologist, Inter- Mediate | Radiologist, Novice | Radiographer, Experienced | Radiographer, Novice | Physician, Non-Radiologist | Senior Medical Student | Senior Radiologist 3 | Senior Radiologist 2 | Senior Radiologist 1 | All | ||
| Labels | Abnormal | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Abscess | 6 | 5 | 5 | 3 | 5 | 5 | 5 | 6 | 1 | 41 | |
| Asbestosis | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 4 | |
| Atelectasis | 33 | 31 | 31 | 32 | 33 | 33 | 35 | 35 | 23 | 286 | |
| Bone | 0 | 6 | 0 | 16 | 5 | 3 | 8 | 1 | 0 | 39 | |
| Cardiomediastinum | 0 | 0 | 0 | 1 | 9 | 0 | 1 | 1 | 0 | 12 | |
| Cardiomegaly | 39 | 37 | 38 | 38 | 34 | 36 | 36 | 39 | 33 | 330 | |
| Cavitary lesion | 2 | 2 | 8 | 6 | 3 | 4 | 2 | 0 | 4 | 31 | |
| Chronic lung changes | 33 | 33 | 17 | 28 | 17 | 29 | 21 | 26 | 7 | 211 | |
| Consolidation | 25 | 29 | 33 | 5 | 12 | 25 | 12 | 7 | 5 | 153 | |
| Correct placement | 32 | 42 | 11 | 29 | 34 | 7 | 27 | 24 | 32 | 238 | |
| Cysts/bullae | 4 | 2 | 7 | 4 | 4 | 3 | 4 | 4 | 4 | 36 | |
| Decreased translucency | 3 | 0 | 0 | 29 | 10 | 3 | 4 | 3 | 0 | 52 | |
| Diffuse infiltrate | 3 | 5 | 0 | 0 | 22 | 3 | 0 | 5 | 0 | 38 | |
| Elevated (hemi)diaphragm | 7 | 7 | 7 | 6 | 6 | 6 | 6 | 6 | 2 | 53 | |
| Emphysema | 16 | 15 | 18 | 24 | 19 | 18 | 10 | 10 | 17 | 147 | |
| Enlarged mediastinum | 2 | 2 | 2 | 2 | 0 | 2 | 2 | 2 | 2 | 16 | |
| Fibrosis | 12 | 10 | 11 | 8 | 10 | 7 | 7 | 4 | 2 | 71 | |
| Flattened (hemi)diaphragm | 8 | 13 | 14 | 13 | 12 | 13 | 15 | 10 | 2 | 100 | |
| Foreign object | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | |
| Fracture | 7 | 1 | 4 | 0 | 1 | 4 | 3 | 4 | 7 | 31 | |
| Hiatal hernia | 5 | 5 | 4 | 3 | 3 | 5 | 4 | 5 | 4 | 38 | |
| Increased interstitial.... | 6 | 10 | 5 | 1 | 5 | 16 | 3 | 11 | 14 | 71 | |
| Increased translucency | 1 | 0 | 1 | 2 | 13 | 1 | 0 | 1 | 0 | 19 | |
| Infiltrate | 52 | 45 | 53 | 64 | 39 | 62 | 60 | 31 | 64 | 470 | |
| Interlobar septal thickening | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | |
| Lung | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 3 | |
| Lung surgery | 5 | 12 | 7 | 17 | 15 | 19 | 5 | 14 | 7 | 101 | |
| Lymph node pathology | 2 | 3 | 2 | 2 | 0 | 2 | 2 | 3 | 1 | 17 | |
| Malignant/cancer | 3 | 3 | 4 | 5 | 7 | 7 | 2 | 7 | 0 | 38 | |
| Mediastinal shift | 2 | 3 | 1 | 0 | 0 | 1 | 1 | 2 | 1 | 11 | |
| Mediastinal tumor | 0 | 1 | 2 | 0 | 0 | 1 | 0 | 0 | 1 | 5 | |
| Nodule, tumor or mass | 6 | 8 | 3 | 4 | 10 | 6 | 8 | 3 | 16 | 64 | |
| Not abnormal | 9 | 23 | 13 | 2 | 16 | 10 | 12 | 6 | 4 | 95 | |
| Non-correct placement | 2 | 2 | 3 | 4 | 1 | 1 | 3 | 6 | 1 | 23 | |
| Operation/implants | 23 | 10 | 8 | 1 | 6 | 3 | 17 | 10 | 16 | 94 | |
| Artifact | 0 | 7 | 2 | 0 | 0 | 0 | 0 | 1 | 0 | 10 | |
| Other bone pathology | 11 | 9 | 7 | 5 | 12 | 11 | 5 | 12 | 6 | 78 | |
| Other cardiomediastinum | 1 | 1 | 0 | 0 | 1 | 3 | 1 | 1 | 1 | 9 | |
| Other | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 4 | |
| Other foreign object | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 2 | |
| Other decreased translucency | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 3 | |
| Other increased translucency | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | |
| Other non-pathological | 1 | 18 | 2 | 0 | 0 | 0 | 0 | 2 | 0 | 23 | |
| Other pathological | 8 | 1 | 11 | 0 | 2 | 3 | 1 | 1 | 0 | 27 | |
| Other soft tissue | 0 | 0 | 1 | 1 | 3 | 5 | 1 | 1 | 3 | 15 | |
| Pericardial effusion | 1 | 0 | 0 | 1 | 1 | 1 | 3 | 1 | 0 | 8 | |
| Pleural calcification | 8 | 8 | 1 | 2 | 8 | 7 | 5 | 8 | 7 | 54 | |
| Pleural changes | 11 | 6 | 13 | 13 | 11 | 8 | 7 | 4 | 4 | 77 | |
| Pleural contraction | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| Pleural effusion | 41 | 43 | 42 | 38 | 41 | 47 | 49 | 44 | 42 | 387 | |
| Pleural thickening | 10 | 10 | 0 | 5 | 8 | 6 | 7 | 10 | 12 | 68 | |
| Pneumomediastinum | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| Pneumonia | 32 | 32 | 19 | 18 | 29 | 14 | 0 | 30 | 2 | 176 | |
| Pneumothorax | 10 | 10 | 10 | 10 | 13 | 10 | 10 | 10 | 8 | 91 | |
| Sarcoidosis | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 8 | |
| Soft tissue | 0 | 1 | 0 | 8 | 11 | 0 | 4 | 0 | 0 | 24 | |
| Stasis/edema | 30 | 31 | 23 | 23 | 32 | 26 | 29 | 29 | 27 | 250 | |
| Subcutaneous emphysema | 6 | 6 | 4 | 0 | 5 | 5 | 2 | 5 | 3 | 37 | |
| Support devices | 10 | 0 | 34 | 40 | 12 | 12 | 11 | 17 | 3 | 162 | |
| Tuberculosis | 8 | 8 | 3 | 6 | 8 | 8 | 6 | 6 | 8 | 56 | |
| Vascular changes | 15 | 0 | 15 | 11 | 0 | 0 | 16 | 11 | 0 | 88 | |
| Annotators | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Radiologist, Inter-Mediate | Radiologist, Novice | Radiographer, Experienced | Radiographer, Novice | Physician, Non-Radiologist | Senior Medical Student | Senior Radiologist 3 | Senior Radiologist 2 | Senior Radiologist 1 | All | ||
| Labels | Abscess | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 8 |
| Atelectasis | 9 | 8 | 8 | 10 | 6 | 8 | 5 | 8 | 7 | 69 | |
| Bone | 3 | 3 | 0 | 3 | 1 | 2 | 4 | 2 | 0 | 18 | |
| Cardiomediastinum | 0 | 7 | 1 | 0 | 21 | 5 | 5 | 5 | 0 | 44 | |
| Cardiomegaly | 52 | 43 | 50 | 53 | 31 | 48 | 43 | 42 | 55 | 417 | |
| Cavitary lesion | 0 | 0 | 3 | 2 | 0 | 1 | 1 | 0 | 1 | 8 | |
| Consolidation | 2 | 1 | 23 | 1 | 0 | 4 | 1 | 1 | 2 | 35 | |
| Correct placement | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| Cysts/bullae | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | |
| Differential diagnosis | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| Decreased translucency | 0 | 0 | 0 | 1 | 3 | 0 | 0 | 1 | 0 | 5 | |
| Diffuse infiltrate | 0 | 0 | 2 | 0 | 1 | 0 | 0 | 1 | 0 | 4 | |
| Emphysema | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 2 | |
| Enlarged mediastinum | 18 | 9 | 2 | 8 | 0 | 6 | 11 | 11 | 1 | 66 | |
| Fracture | 3 | 4 | 3 | 1 | 3 | 3 | 3 | 3 | 3 | 26 | |
| Increased interstitial | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 7 | |
| Increased translucency | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 2 | |
| Infiltrate | 86 | 73 | 60 | 84 | 65 | 88 | 81 | 77 | 82 | 696 | |
| Lung | 2 | 1 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 8 | |
| Lung surgery | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | |
| Lymph node pathology | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | |
| Malignant/cancer | 3 | 3 | 5 | 3 | 4 | 2 | 2 | 2 | 0 | 24 | |
| Mediastinal shift | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | |
| Nodule, tumor or mass | 1 | 9 | 1 | 1 | 2 | 2 | 1 | 1 | 4 | 22 | |
| Other bone pathology | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 2 | |
| Other soft tissue | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | |
| Pericardial effusion | 0 | 0 | 2 | 1 | 0 | 0 | 2 | 0 | 0 | 5 | |
| Pleural changes | 1 | 2 | 20 | 0 | 6 | 3 | 2 | 1 | 4 | 39 | |
| Pleural effusion | 102 | 102 | 44 | 94 | 81 | 102 | 99 | 97 | 94 | 815 | |
| Pleural thickening | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| Pneumonia | 8 | 7 | 3 | 0 | 1 | 1 | 0 | 7 | 0 | 27 | |
| Pneumothorax | 30 | 31 | 28 | 29 | 26 | 30 | 30 | 30 | 25 | 259 | |
| Sarcoidosis | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 6 | |
| Soft tissue | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | |
| Stasis/edema | 82 | 81 | 51 | 80 | 63 | 77 | 76 | 78 | 72 | 660 | |
| Subcutaneous emphysema | 2 | 2 | 2 | 0 | 2 | 2 | 1 | 2 | 2 | 15 | |
| Support devices | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 2 | 0 | 4 | |
| Tuberculosis | 2 | 2 | 0 | 0 | 1 | 1 | 0 | 2 | 2 | 10 | |
| Vascular changes | 3 | 0 | 0 | 2 | 0 | 10 | 4 | 0 | 0 | 19 | |
| Number of Unmatched Labels (by Annotator) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Radiologist, Intermediate | Radiologist, Novice | Radiogra-pher, Experienced | Radiogra-pher, Novice | Physician, Non-Radiologist | Senior Medical Student | Majority | Majority excl. Intermed. Radiologist | Gold Standard | ||
| Compared to annotator | Radiologist, intermediate | 101 | 144 | 128 | 121 | 114 | 30 | 75 | 32 | |
| Radiologist, novice | 118 | 169 | 150 | 130 | 135 | 45 | 70 | 58 | ||
| Radiographer, experienced | 288 | 296 | 271 | 277 | 277 | 180 | 205 | 209 | ||
| Radiographer, novice | 182 | 187 | 181 | 164 | 155 | 71 | 84 | 88 | ||
| Physician, non-radiologist | 214 | 206 | 226 | 203 | 205 | 110 | 139 | 133 | ||
| Senior medical student | 135 | 139 | 154 | 122 | 133 | 41 | 62 | 57 | ||
| Majority | 173 | 171 | 179 | 160 | 160 | 163 | 61 | 96 | ||
| Majority excl. Intermed. Radiologist | 157 | 135 | 143 | 112 | 128 | 123 | 0 | 75 | ||
| Gold Standard | 201 | 210 | 234 | 203 | 209 | 205 | 122 | 162 | ||
 Fewest unmatched (best) 50% fractile Most unmatched (worst) | ||||||||||
| Gold Standard * | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Annotators * | Bone | Correct Placement | Fracture | Non-Correct Placement | Operation and Implants | Other Bone Pathology | Stasis/Edema | Subcutaneous Emphysema | Support Devices | |
| Bone | 11 | 10 | 10 | |||||||
| Correct placement | 115 | 13 | ||||||||
| Differential diagnosis | 1 | |||||||||
| Foreign object | 1 | |||||||||
| Fracture | 2 | 29 | ||||||||
| Non-correct placement | 6 | 1 | ||||||||
| Operation and implants | 38 | |||||||||
| Other bone pathology | 3 | 38 | ||||||||
| Soft tissue | 1 | |||||||||
| Stasis/edema | 576 | |||||||||
| Subcutaneous emphysema | 28 | |||||||||
| Support devices | 48 | 24 | ||||||||
 0 labels matched 100+ labels matched | ||||||||||
References
- Performance Analysis Team. Diagnostic Imaging Dataset Statistical Release; NHS: London, UK, 2022/2023. Available online: https://www.england.nhs.uk/statistics/statistical-work-areas/diagnostic-imaging-dataset/diagnostic-imaging-dataset-2022-23-data/ (accessed on 7 February 2022).
- Li, D.; Pehrson, L.M.; Lauridsen, C.A.; Tottrup, L.; Fraccaro, M.; Elliott, D.; Zajac, H.D.; Darkner, S.; Carlsen, J.F.; Nielsen, M.B. The Added Effect of Artificial Intelligence on Physicians’ Performance in Detecting Thoracic Pathologies on CT and Chest X-ray: A Systematic Review. Diagnostics 2021, 11, 2206. [Google Scholar] [CrossRef]
- Kim, T.S.; Jang, G.; Lee, S.; Kooi, T. Did You Get What You Paid For? Rethinking Annotation Cost of Deep Learning Based Computer Aided Detection in Chest Radiographs. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 261–270. [Google Scholar]
- Willemink, M.J.; Koszek, W.A.; Hardell, C.; Wu, J.; Fleischmann, D.; Harvey, H.; Folio, L.R.; Summers, R.M.; Rubin, D.L.; Lungren, M.P. Preparing medical imaging data for machine learning. Radiology 2020, 295, 4–15. [Google Scholar] [CrossRef]
- Bustos, A.; Pertusa, A.; Salinas, J.-M.; de la Iglesia-Vayá, M. Padchest: A large chest x-ray image dataset with multi-label annotated reports. Med. Image Anal. 2020, 66, 101797. [Google Scholar] [CrossRef]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 590–597. [Google Scholar]
- Putha, P.; Tadepalli, M.; Reddy, B.; Raj, T.; Chiramal, J.A.; Govil, S.; Sinha, N.; KS, M.; Reddivari, S.; Jagirdar, A. Can artificial intelligence reliably report chest X-rays?: Radiologist validation of an algorithm trained on 2.3 million X-rays. arXiv 2018, arXiv:1807.07455. [Google Scholar]
- Li, D.; Pehrson, L.M.; Tottrup, L.; Fraccaro, M.; Bonnevie, R.; Thrane, J.; Sorensen, P.J.; Rykkje, A.; Andersen, T.T.; Steglich-Arnholm, H.; et al. Inter- and Intra-Observer Agreement When Using a Diagnostic Labeling Scheme for Annotating Findings on Chest X-rays-An Early Step in the Development of a Deep Learning-Based Decision Support System. Diagnostics 2022, 12, 3112. [Google Scholar] [CrossRef]
- Mehrotra, P.; Bosemani, V.; Cox, J. Do radiologists still need to report chest x rays? Postgrad. Med. J. 2009, 85, 339. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, X.; Lu, L.; Bagheri, M.; Summers, R.; Lu, Z. NegBio: A high-performance tool for negation and uncertainty detection in radiology reports. AMIA Summits Transl. Sci. Proc. 2018, 2018, 188. [Google Scholar]
- McDermott, M.B.; Hsu, T.M.H.; Weng, W.-H.; Ghassemi, M.; Szolovits, P. Chexpert++: Approximating the chexpert labeler for speed, differentiability, and probabilistic output. In Proceedings of the Machine Learning for Healthcare Conference, Durham, NC, USA, 7–8 August 2020; pp. 913–927. [Google Scholar]
- Wang, S.; Cai, J.; Lin, Q.; Guo, W. An Overview of Unsupervised Deep Feature Representation for Text Categorization. IEEE Trans. Comput. Soc. Syst. 2019, 6, 504–517. [Google Scholar] [CrossRef]
- Thangaraj, M.; Sivakami, M. Text classification techniques: A literature review. Interdiscip. J. Inf. Knowl. Manag. 2018, 13, 117. [Google Scholar] [CrossRef] [Green Version]
- Calderon-Ramirez, S.; Giri, R.; Yang, S.; Moemeni, A.; Umaña, M.; Elizondo, D.; Torrents-Barrena, J.; Molina-Cabello, M.A. Dealing with Scarce Labelled Data: Semi-supervised Deep Learning with Mix Match for Covid-19 Detection Using Chest X-ray Images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5294–5301. [Google Scholar]
- Munappy, A.; Bosch, J.; Olsson, H.H.; Arpteg, A.; Brinne, B. Data Management Challenges for Deep Learning. In Proceedings of the 2019 45th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Kallithea-Chalkidiki, Greece, 28–30 August 2019; pp. 140–147. [Google Scholar]
- Brady, A.P. Radiology reporting-from Hemingway to HAL? Insights Imaging 2018, 9, 237–246. [Google Scholar] [CrossRef] [Green Version]
- Ogawa, M.; Lee, C.H.; Friedman, B. Multicenter survey clarifying phrases in emergency radiology reports. Emerg. Radiol. 2022, 29, 855–862. [Google Scholar] [CrossRef]
- Klobuka, A.J.; Lee, J.; Buranosky, R.; Heller, M. When the Reading Room Meets the Team Room: Resident Perspectives From Radiology and Internal Medicine on the Effect of Personal Communication After Implementing a Resident-Led Radiology Rounds. Curr. Probl. Diagn. Radiol. 2019, 48, 312–322. [Google Scholar] [CrossRef]
- Hansell, D.M.; Bankier, A.A.; MacMahon, H.; McLoud, T.C.; Muller, N.L.; Remy, J. Fleischner Society: Glossary of terms for thoracic imaging. Radiology 2008, 246, 697–722. [Google Scholar] [CrossRef] [Green Version]
- Chicco, D.; Jurman, G. The Matthews correlation coefficient (MCC) should replace the ROC AUC as the standard metric for assessing binary classification. BioData Min. 2023, 16, 4. [Google Scholar] [CrossRef]
- McKinney, W. Data Structures for Statistical Computing in Python. 2010, pp. 56–61. Available online: https://conference.scipy.org/proceedings/scipy2010/pdfs/mckinney.pdf (accessed on 7 February 2022).
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Asch, V.V. Macro-and Micro-Averaged Evaluation Measures [BASIC DRAFT]. 2013. Available online: https://cupdf.com/document/macro-and-micro-averaged-evaluation-measures-basic-draft.html?page=1 (accessed on 7 February 2022).
- Hagberg, A.A.; Schult, D.A.; Swart, P.J. Exploring Network Structure, Dynamics, and Function Using NetworkX. In Proceedings of the 7th Python in Science Conference, Pasadena, CA, USA, 19–24 August 2008; pp. 11–15. [Google Scholar]
- Wigness, M.; Draper, B.A.; Ross Beveridge, J. Efficient label collection for unlabeled image datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 4594–4602. [Google Scholar]
- Lee, B.; Whitehead, M.T. Radiology Reports: What YOU Think You’re Saying and What THEY Think You’re Saying. Curr. Probl. Diagn. Radiol. 2017, 46, 186–195. [Google Scholar] [CrossRef]
- Lacson, R.; Odigie, E.; Wang, A.; Kapoor, N.; Shinagare, A.; Boland, G.; Khorasani, R. Multivariate Analysis of Radiologists’ Usage of Phrases that Convey Diagnostic Certainty. Acad. Radiol. 2019, 26, 1229–1234. [Google Scholar] [CrossRef]
- Shinagare, A.B.; Lacson, R.; Boland, G.W.; Wang, A.; Silverman, S.G.; Mayo-Smith, W.W.; Khorasani, R. Radiologist Preferences, Agreement, and Variability in Phrases Used to Convey Diagnostic Certainty in Radiology Reports. J. Am. Coll. Radiol. 2019, 16, 458–464. [Google Scholar] [CrossRef]
- Berlin, L. Medicolegal: Malpractice and ethical issues in radiology. Proofreading radiology reports. AJR Am. J. Roentgenol. 2013, 200, W691–W692. [Google Scholar] [CrossRef]
- Mylopoulos, M.; Woods, N.N. Having our cake and eating it too: Seeking the best of both worlds in expertise research. Med. Educ. 2009, 43, 406–413. [Google Scholar] [CrossRef]
- Winder, M.; Owczarek, A.J.; Chudek, J.; Pilch-Kowalczyk, J.; Baron, J. Are We Overdoing It? Changes in Diagnostic Imaging Workload during the Years 2010-2020 including the Impact of the SARS-CoV-2 Pandemic. Healthcare 2021, 9, 1557. [Google Scholar] [CrossRef]
- Sriram, V.; Bennett, S. Strengthening medical specialisation policy in low-income and middle-income countries. BMJ Glob. Health 2020, 5, e002053. [Google Scholar] [CrossRef] [Green Version]
- Mylopoulos, M.; Regehr, G.; Ginsburg, S. Exploring residents’ perceptions of expertise and expert development. Acad. Med. 2011, 86, S46–S49. [Google Scholar] [CrossRef]
- Farooq, F.; Mahboob, U.; Ashraf, R.; Arshad, S. Measuring Adaptive Expertise in Radiology Residents: A Multicenter Study. Health Prof. Educ. J. 2022, 5, 9–14. [Google Scholar] [CrossRef]
- Grant, S.; Guthrie, B. Efficiency and thoroughness trade-offs in high-volume organisational routines: An ethnographic study of prescribing safety in primary care. BMJ Qual. Saf. 2018, 27, 199–206. [Google Scholar] [CrossRef] [Green Version]
- Croskerry, P. Adaptive expertise in medical decision making. Med. Teach. 2018, 40, 803–808. [Google Scholar] [CrossRef]
- Lafortune, M.; Breton, G.; Baudouin, J.L. The radiological report: What is useful for the referring physician? Can. Assoc. Radiol. J. 1988, 39, 140–143. [Google Scholar]
- Branstetter, B.F.t.; Morgan, M.B.; Nesbit, C.E.; Phillips, J.A.; Lionetti, D.M.; Chang, P.J.; Towers, J.D. Preliminary reports in the emergency department: Is a subspecialist radiologist more accurate than a radiology resident? Acad. Radiol. 2007, 14, 201–206. [Google Scholar] [CrossRef]
- Clinger, N.J.; Hunter, T.B.; Hillman, B.J. Radiology reporting: Attitudes of referring physicians. Radiology 1988, 169, 825–826. [Google Scholar] [CrossRef]
- Kruger, P.; Lynskey, S.; Sutherland, A. Are orthopaedic surgeons reading radiology reports? A Trans-Tasman Survey. J. Med. Imaging Radiat. Oncol. 2019, 63, 324–328. [Google Scholar] [CrossRef]
- Lin, C.; Bethard, S.; Dligach, D.; Sadeque, F.; Savova, G.; Miller, T.A. Does BERT need domain adaptation for clinical negation detection? J. Am. Med. Inf. Assoc. 2020, 27, 584–591. [Google Scholar] [CrossRef]
- van Es, B.; Reteig, L.C.; Tan, S.C.; Schraagen, M.; Hemker, M.M.; Arends, S.R.S.; Rios, M.A.R.; Haitjema, S. Negation detection in Dutch clinical texts: An evaluation of rule-based and machine learning methods. BMC Bioinform. 2023, 24, 10. [Google Scholar] [CrossRef]
- Rokach, L.; Romano, R.; Maimon, O. Negation recognition in medical narrative reports. Inf. Retr. 2008, 11, 499–538. [Google Scholar] [CrossRef]
- Zhang, J. Knowledge Learning With Crowdsourcing: A Brief Review and Systematic Perspective. IEEE/CAA J. Autom. Sin. 2022, 9, 749–762. [Google Scholar] [CrossRef]
- Li, J.; Zhang, R.; Mensah, S.; Qin, W.; Hu, C. Classification-oriented dawid skene model for transferring intelligence from crowds to machines. Front. Comput. Sci. 2023, 17, 175332. [Google Scholar] [CrossRef]
- Whitehill, J.; Ruvolo, P.; Wu, T.; Bergsma, J.; Movellan, J. Whose vote should count more: Optimal integration of labels from labelers of unknown expertise. In Proceedings of the Advances in Neural Information Processing Systems 22-Proceedings of the 2009 Conference, Vancouver, BC, Canada, 7–9 December 2009; pp. 2035–2043. [Google Scholar]
- Sheng, V.S.; Zhang, J.; Gu, B.; Wu, X. Majority Voting and Pairing with Multiple Noisy Labeling. IEEE Trans. Knowl. Data Eng. 2019, 31, 1355–1368. [Google Scholar] [CrossRef]
- Schmidt, H.G.; Boshuizen, H.P.A. On acquiring expertise in medicine. Educ. Psychol. Rev. 1993, 5, 205–221. [Google Scholar] [CrossRef] [Green Version]
- Yavas, U.S.; Calisir, C.; Ozkan, I.R. The Interobserver Agreement between Residents and Experienced Radiologists for Detecting Pulmonary Embolism and DVT with Using CT Pulmonary Angiography and Indirect CT Venography. Korean J. Radiol. 2008, 9, 498–502. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R. ChestX-ray14: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Frénay, B.; Verleysen, M. Classification in the Presence of Label Noise: A Survey. Neural Netw. Learn. Syst. IEEE Trans. 2014, 25, 845–869. [Google Scholar] [CrossRef]
- Callen, A.L.; Dupont, S.M.; Price, A.; Laguna, B.; McCoy, D.; Do, B.; Talbott, J.; Kohli, M.; Narvid, J. Between Always and Never: Evaluating Uncertainty in Radiology Reports Using Natural Language Processing. J. Digit. Imaging 2020, 33, 1194–1201. [Google Scholar] [CrossRef]
- Wootton, D.; Feldman, C. The diagnosis of pneumonia requires a chest radiograph (X-ray)-yes, no or sometimes? Pneumonia 2014, 5, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Loeb, M.B.; Carusone, S.B.; Marrie, T.J.; Brazil, K.; Krueger, P.; Lohfeld, L.; Simor, A.E.; Walter, S.D. Interobserver reliability of radiologists’ interpretations of mobile chest radiographs for nursing home-acquired pneumonia. J. Am. Med. Dir. Assoc. 2006, 7, 416–419. [Google Scholar] [CrossRef]
- Byrt, T.; Bishop, J.; Carlin, J.B. Bias, prevalence and kappa. J. Clin. Epidemiol. 1993, 46, 423–429. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [Green Version]
- Hight, S.L.; Petersen, D.P. Dissent in a Majority Voting System. IEEE Trans. Comput. 1973, 100, 168–171. [Google Scholar] [CrossRef]



| Gold Standard | |||
|---|---|---|---|
| Annotator(s) | Labels used | Labels NOT used | |
| Labels used | TP | FP | |
| Labels NOT used | FN | TN | |
| Radiologist, Intermediate | Radiologist, Novice | Radiographer, Experienced | Radiographer, Novice | Physician, Non-Radiologist | Senior Medical Student | |
|---|---|---|---|---|---|---|
| MCC | 0.77 | 0.71 | 0.57 | 0.65 | 0.64 | 0.71 |
| (a) | ||||||
| Radiologist, Intermediate | Radiologist, Novice | Radiographer, Experienced | Radiographer, Novice | Physician, Non-Radiologist | Senior Medical Student | |
| MCC | 0.92 | 0.88 | 0.64 | 0.88 | 0.77 | 0.88 |
| (b) | ||||||
| Radiologist, Intermediate | Radiologist, Novice | Radiographer, Experienced | Radiographer, Novice | Physician, Non-Radiologist | Senior Medical Student | Majority | Majority excl. Intermed. Radiologist | Gold Standard | |
| Radiologist, intermediate | 849 | 679 | 785 | 753 | 832 | 794 | 810 | 766 | |
| Radiologist, novice | 849 | 654 | 763 | 744 | 811 | 779 | 815 | 740 | |
| Radiographer, experienced | 679 | 654 | 642 | 597 | 669 | 664 | 680 | 589 | |
| Radiographer, novice | 785 | 763 | 642 | 710 | 791 | 753 | 801 | 710 | |
| Physician, non-radiologist | 753 | 744 | 597 | 710 | 741 | 714 | 746 | 665 | |
| Senior medical student | 832 | 811 | 669 | 791 | 741 | 783 | 823 | 741 | |
| Majority | 794 | 779 | 664 | 753 | 714 | 783 | 824 | 702 | |
| Majority excl. Intermed. Radiologist | 810 | 815 | 680 | 801 | 746 | 823 | 824 | 723 | |
| Gold Standard | 766 | 740 | 589 | 710 | 665 | 741 | 702 | 723 | |
 Fewest matched (worst) 50% fractile Most matched (best) | |||||||||
| Gold Standard * | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Annotators * | Atelectasis | Consolidation | Cysts/Bullae | Increased Interstitial | Infiltrate | Decreased Translucency | Nodule, Tumor or Mass | Pleural Calcification | Pleural Changes | Pleural Effusion | Pleural Thickening | |
| Atelectasis | 219 | |||||||||||
| Cavitary lesion | 8 | |||||||||||
| Consolidation | 22 | 53 | 3 | |||||||||
| Cysts/bullae | 21 | |||||||||||
| Diffuse infiltrate | 30 | |||||||||||
| Increased interstitial… | 20 | |||||||||||
| Infiltrate | 4 | 687 | 1 | 10 | ||||||||
| Lung | 1 | 1 | 1 | 2 | ||||||||
| Decreased translucency | 1 | 3 | 1 | 5 | 5 | 2 | 2 | 1 | 9 | 1 | ||
| Nodule, tumor or mass | 8 | 28 | ||||||||||
| Pleural calcification | 32 | |||||||||||
| Pleural changes | 10 | 10 | 13 | |||||||||
| Pleural effusion | 743 | |||||||||||
| Pleural thickening | 30 | |||||||||||
 0 labels matched 100+ labels matched | ||||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Pehrson, L.M.; Bonnevie, R.; Fraccaro, M.; Thrane, J.; Tøttrup, L.; Lauridsen, C.A.; Butt Balaganeshan, S.; Jankovic, J.; Andersen, T.T.; et al. Performance and Agreement When Annotating Chest X-ray Text Reports—A Preliminary Step in the Development of a Deep Learning-Based Prioritization and Detection System. Diagnostics 2023, 13, 1070. https://doi.org/10.3390/diagnostics13061070
Li D, Pehrson LM, Bonnevie R, Fraccaro M, Thrane J, Tøttrup L, Lauridsen CA, Butt Balaganeshan S, Jankovic J, Andersen TT, et al. Performance and Agreement When Annotating Chest X-ray Text Reports—A Preliminary Step in the Development of a Deep Learning-Based Prioritization and Detection System. Diagnostics. 2023; 13(6):1070. https://doi.org/10.3390/diagnostics13061070
Chicago/Turabian StyleLi, Dana, Lea Marie Pehrson, Rasmus Bonnevie, Marco Fraccaro, Jakob Thrane, Lea Tøttrup, Carsten Ammitzbøl Lauridsen, Sedrah Butt Balaganeshan, Jelena Jankovic, Tobias Thostrup Andersen, and et al. 2023. "Performance and Agreement When Annotating Chest X-ray Text Reports—A Preliminary Step in the Development of a Deep Learning-Based Prioritization and Detection System" Diagnostics 13, no. 6: 1070. https://doi.org/10.3390/diagnostics13061070