
Classification of Retinal Diseases in Optical Coherence Tomography Images Using Artificial Intelligence and Firefly Algorithm


Abstract
:1. Introduction
- The first is to present a system that gives high accuracy, such as DL methods, with a smaller amount of data and training time, such as ML methods, to those who do not have enough quality equipment for automatic classification problems.
- The second is to classify these retinal diseases on OCT images with the help of artificial intelligence to prevent the effects that these retinal diseases cause, as well as to make things easier for clinical experts or for health centers that do not have enough clinical experts.
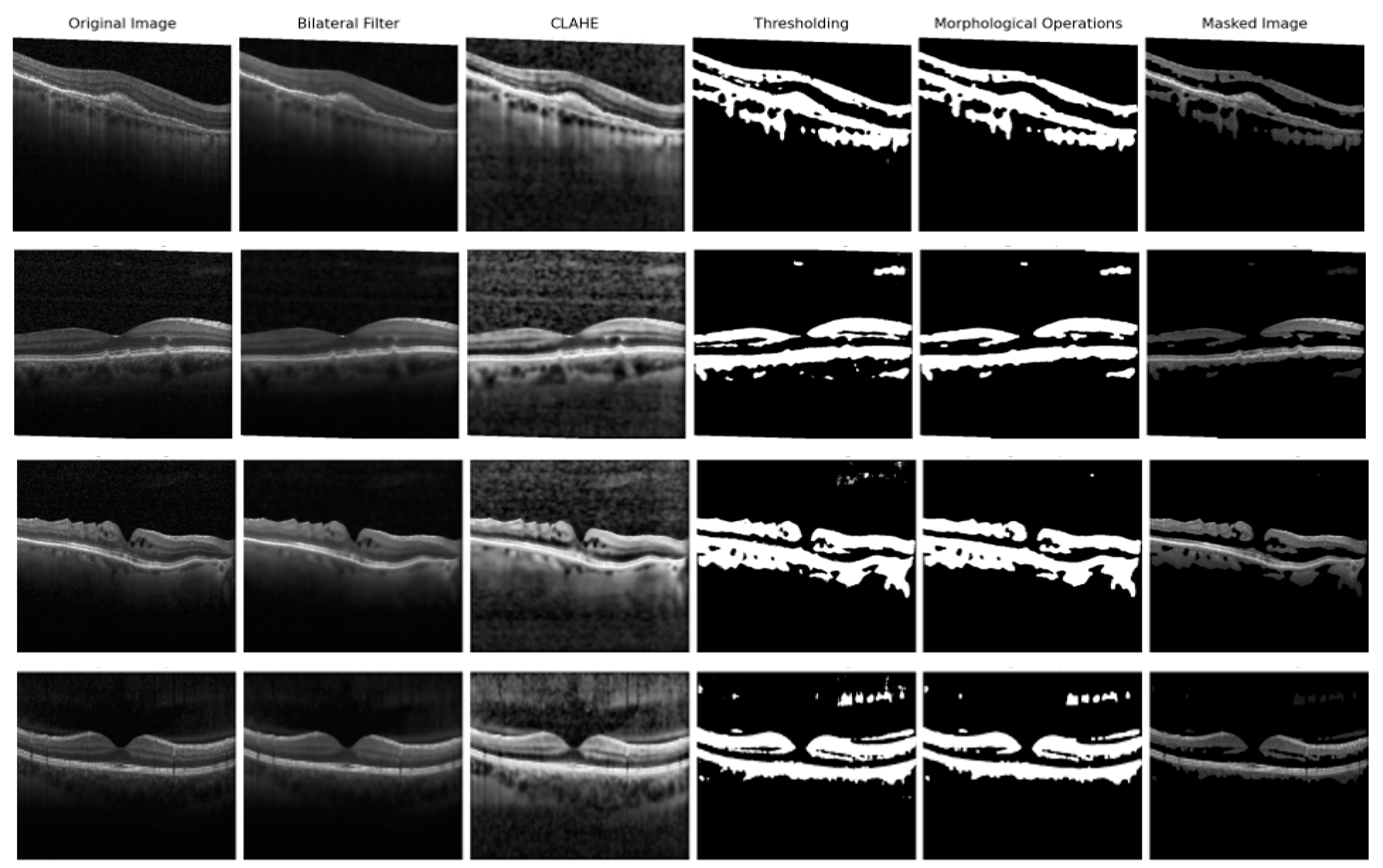
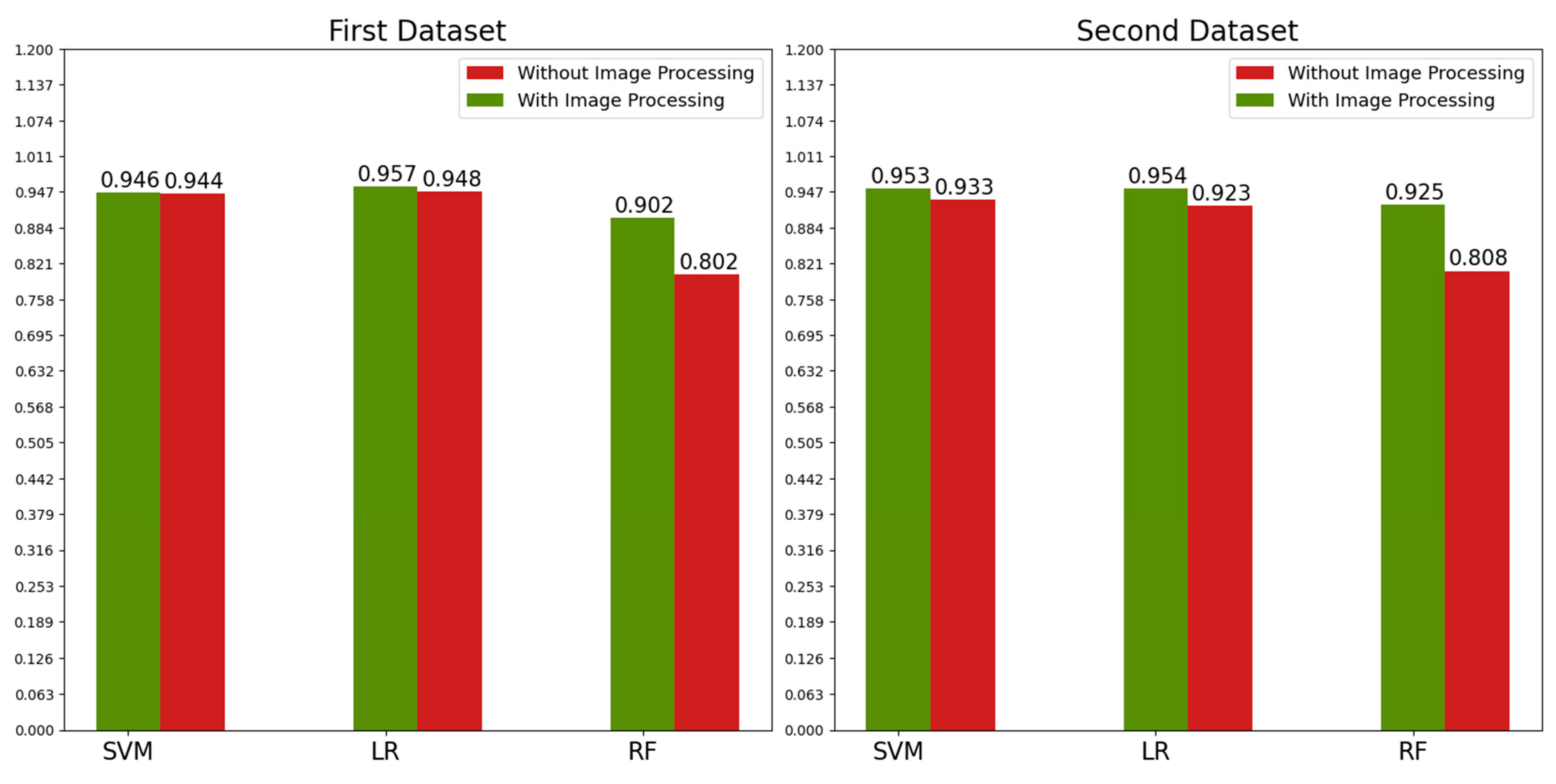
- First, image preprocessing techniques, such as the Bilateral filter, Contrast Limited Adaptive Histogram Equalization (CLAHE), thresholding, morphologic operations (opening and closing), and masking, were used to remove unnecessary features so the classifiers could only focus on the important ones. These techniques were applied to increase the effectiveness of the study. They are not in the system we present because they can be applied or changed for different real-world data problems.
- Classic feature extractors were used along with the pretrained DL feature extractors in this study to obtain a higher accuracy value with fewer data and training time. These feature extractors consist of the Histogram of Gradients (HOG), Gray Level Co-occurrence Matrix (GLCM), pretrained VGG16, and DenseNet121 feature extractors. The reason we use classic feature extractors is that they do not require as much data or training time. However, they do not give a high accuracy value, and they did not in our study. For this problem, we added pretrained DL feature extractors. As pre-trained models already have weights, they only need one iteration, removing the burden of training the entire model for iterations. With this method, we aimed to save training time while also obtaining a higher accuracy value.
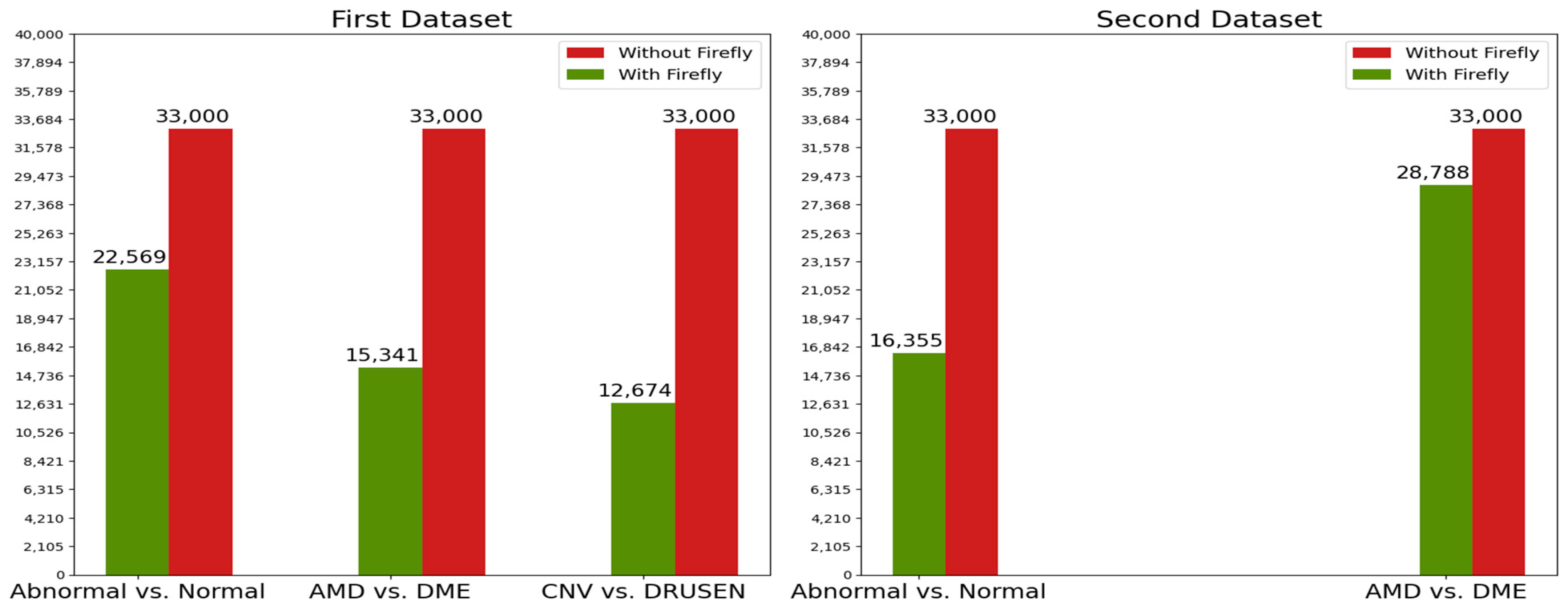
- Even if we saved time and obtained higher accuracy with the previous method, there were so many features because so many feature extractors were used. Some of these features may not affect accuracy in a good way. Therefore, to remove unnecessary features and obtain the same or higher accuracy value with fewer data and therefore less training time, we used the Firefly algorithm for feature selection. We achieved our goal by choosing the best features with the help of this method.
- Another method we used to improve accuracy was to use multiple binary classifications rather than multiclass classifications because binary classifications give the best accuracy values in ML classifiers. If there are four classes, three binary classifications are conducted instead of one four-class classification to increase the accuracy. This classification technique is called hierarchy classification. Classic ML classifiers, which are Support Vector Machine, Logistic Regression, and Random Forest were used in hierarchy classification.
2. Related Work
- Some of the studies do not have high accuracy values.
- The ones that have high accuracy values either have too many images, classify just two classes, or do not specify the training or testing image number they used.
- Using so many images for training takes a lot of time, a known fact in artificial intelligence studies.
- By classifying just two classes, high accuracy values can be achieved easily.
- If the number of training and testing images is not specified, no reliable comment can be made about the results in this situation.
- Almost all DL studies had a high level of accuracy. However, they had to use a lot of data.
- In addition to using a large amount of data, they had to create CNN models with a minimum of seven layers. When the number of neurons in the layers is considered, high-quality equipment is required to handle the computational load, which is why they all use GPUs.
- Training with so much data and computational load requires a lot of time for CPU users.
- Given the literature gap in both ML and DL studies, the goal of this study is to:
- Developing a hybrid system with the same high and close accuracy as DL studies
- Achieving this high accuracy value in a short time and with fewer data, such as in ML studies.
- Conducting this study using a CPU and providing a system with a low computational load for those who do not have enough computational load or data.
3. Materials and Methods
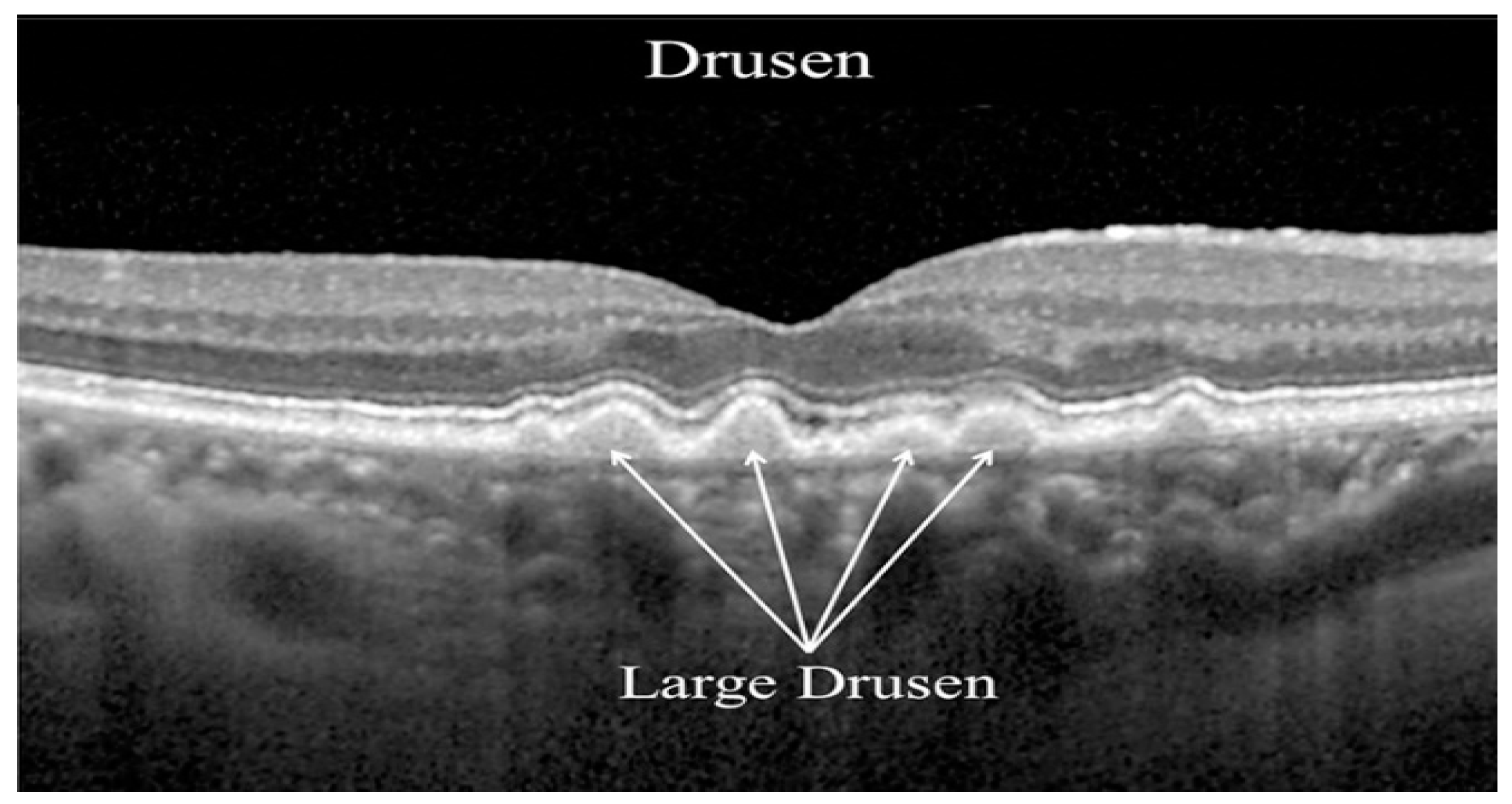
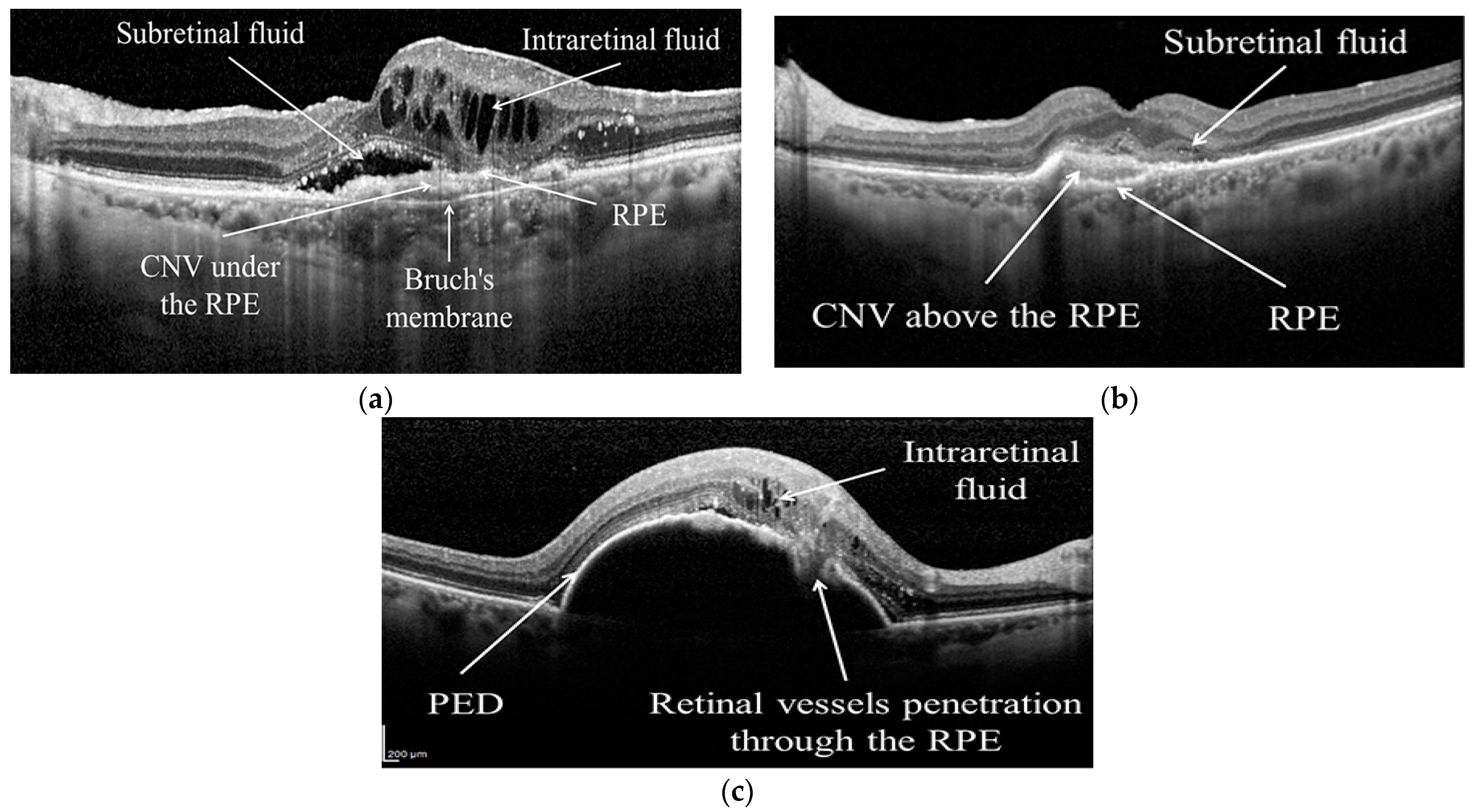
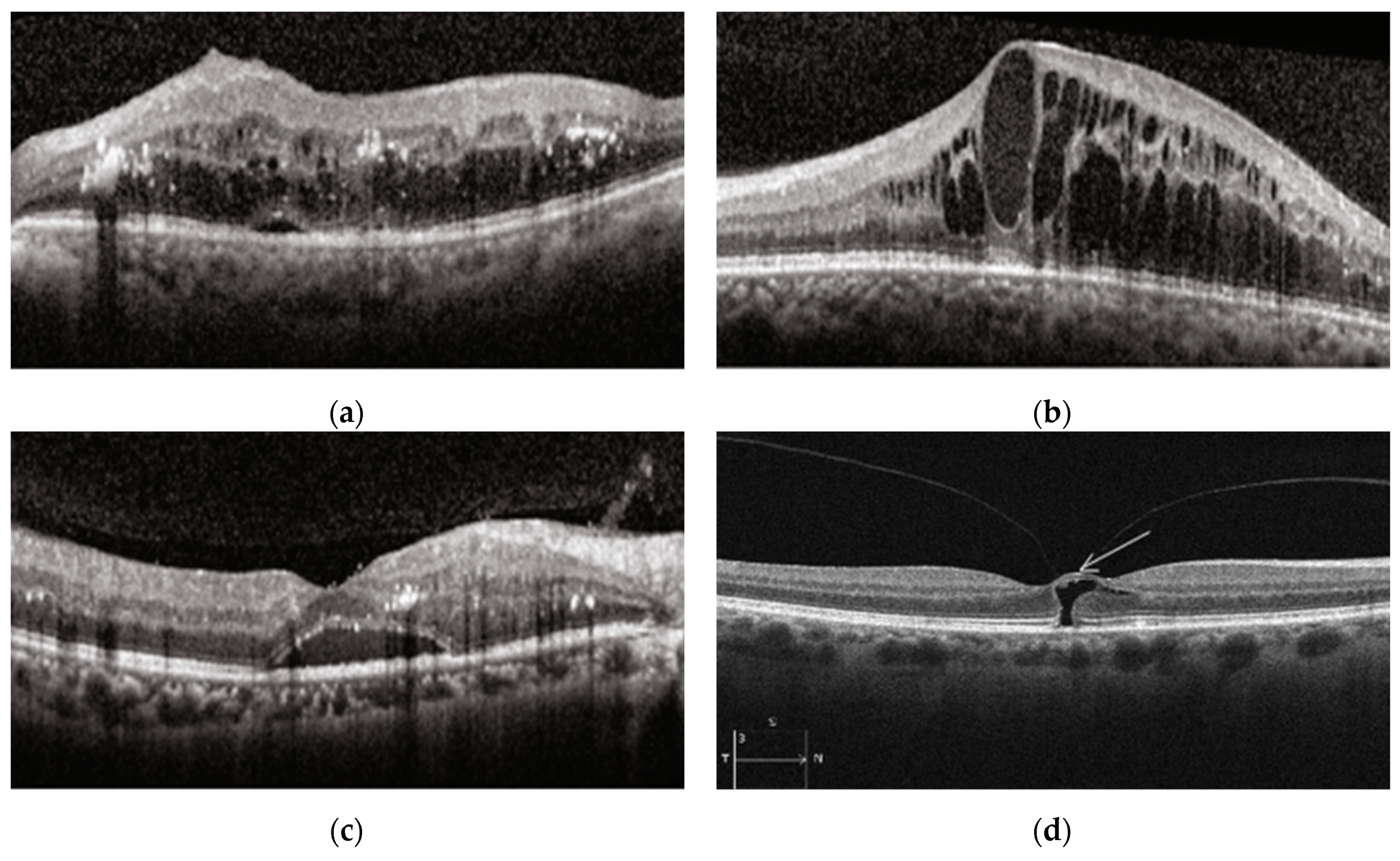
3.1. Database
3.2. Image Processing
- Bilateral filter to remove background noises.
- CLAHE operation to enhance the contrast.
- Thresholding operation to create a binary image.
- Morphological operations to remove noises in the binary image
- Masking operation, multiplying the binary image with the original image.
3.3. Feature Extraction
- Gray Level Co-occurrence Matrix (GLCM)
- Histogram of Gradients (HOG)
- VGG16 feature extractor
- DenseNet121 feature extractor
3.4. Feature Selection
Binary Firefly Algorithm
- Regardless of gender, all fireflies will be attracted to one another.
- Each firefly is attracted to the others by their brightness and the distance between them. Less-bright fireflies will move to the brighter fireflies. Attractiveness decreases when the distance increases between fireflies. If one firefly is the brightest, then this firefly will move randomly.
- Firefly brightness is determined by fitness function.
- We generated a firefly population that has 20 fireflies, which means 20 subsets of features and 33,000 values (There are 33,000 features in our dataset). These 33,000 values are made up of “0” and “1” values. “0” represents an unselected feature, and “1” represents a selected feature. There is an example of this firefly population in Table 5. In Table 5, f stands for fireflies (subset features), F stands for features in the dataset. For instance, as seen in Table 5, , , and features are not selected for firefly, which means these features are removed from the dataset when training or testing for only firefly.
- Every firefly (subset features) has a fitness function value that is given in Equation (1) [47].In Equation (1), w is a constant, and is the accuracy value of the ith firefly (ith subset features). The K-Nearest Neighbor classifier is used to obtain the accuracy values. For training, a validation set is used; then, with a testing set, the accuracy values are acquired for all fireflies. The term ‘’ is the total number of selected features of the ith firefly and the ‘’ term is the total number of features of the ith firefly, which is equal to the total number of features in the dataset (33,000).
- Now we have a fitness function value for all of the fireflies. That means we have brightness values for all of the fireflies. Now every firefly will move to a brighter firefly. A “i” firefly, which has a lower fitness function value (brightness value), moves toward a “j” firefly, which has a higher fitness function value with Equation (2).In Equation (2), X values are the position values, which have 33,000 values that consist of “0” and “1” values. R is a random number between zero and one, and is a randomization parameter that defines the random movement of the firefly, which is determined by the users. is an attractiveness value, and its formula is given in Equation (3).In Equation (3), r is the distance between two fireflies and is given in Equation (4) [46]. is determined by the users and defines the value when r is equal to zero. value is a light absorption coefficient, which is also determined by users.If “i” firefly is brighter than “j” firefly, then “i” firefly will move randomly. For this condition, new position values for the “i” firefly are calculated according to Equation (5).As seen in Table 5, the position values of the fireflies must consist of “0” and “1” values to determine which features will be selected. At the end of the third step of the algorithm, new position values can be decimal values or may be outside the 0–1 range. With these new position values, we cannot tell if a feature is selected or not for ith firefly. To address this problem, first the position values are drawn to the 0–1 range with Equation (6) [46], then Equation (7) is applied [46,47].
- After obtaining the final position values for ith firefly, the new fitness function value for ith firefly is calculated according to Equation (1); ith firefly and all other fireflies in the population go through the same processes. As we have 20 fireflies in the population, this means ith firefly’s position values and fitness function value will change 20 times.
- The algorithm continues from step one with a new firefly, which is . The same processes are conducted between the firefly and all of the other fireflies in the population.
- When all of the fireflies’ (, , …) position values and their fitness function values from these position values are calculated, a new iteration begins.
- When maximum iteration is reached, a firefly that has acquired the maximum fitness function value is selected to be used in classification. The pseudo code of Binary Firefly algorithm is given in Algorithm 1.
Algorithm 1 Binary Firefly Algorithm Input: Firefly population as in Table 5 (with their fitness function value calculated by Equation (1))
Output: Firefly (subset features) with maximum fitness function valuewhile iteration < maximum iteration for i = 1 to n (n = number of fireflies) for j = 1 to n (n = number of fireflies) if move ith firefly towards jth firefly with the Equation (2) apply Equation (6)–(7) else move ith firefly randomly with the Equation (5) apply Equation (6)–(7) end if calculate new fitness function value of new ith firefly with the Equation (1) end for end for rank the fireflies (subset features) according to their fitness function values end while Obtain the firefly (subset features) which has the maximum fitness function value
3.5. Classification
- Image processing techniques are used to extract retinal layers, so feature extractors can only focus on the necessary features.
- Hybrid feature extractors are used for better accuracy. Each one of them is not enough alone for better accuracy. As we were going to use the Firefly algorithm for feature selection, we decided to use them all.
- The reason we used so many feature extractors is to choose the best features among the ones they extracted. For this method, we were going to be able to take advantage of every feature extractor. As this study’s aim is to obtain the highest accuracy value with the least amount of data and training time, using the Firefly algorithm was inevitable for our study because this method can choose the best features for the best accuracy. By selecting the best features, we would reduce the amount of data for the classifiers and benefit from the best practices of all of the feature extractors.
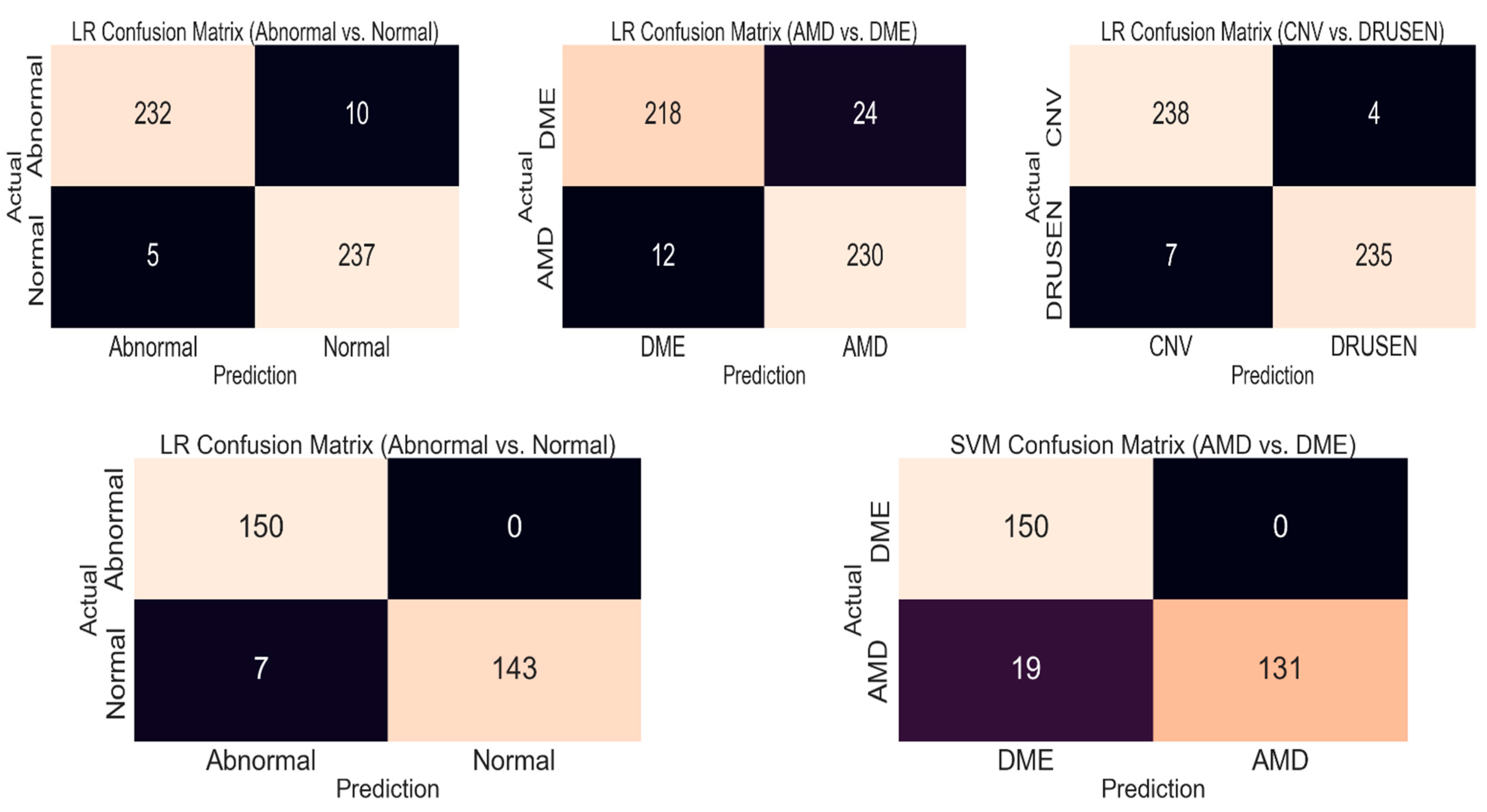
- Although we used some techniques to improve the accuracy, for training time, we had to use ML classifiers. In addition, these classifiers do not give a high accuracy value for multiclass classification. Therefore, we decided to use the hierarchy classification technique as some of the classes include other classes, such as the ABNORMAL class, which includes the AMD and DME classes, or the AMD class, which includes the CNV and DRUSEN classes. In this way, we turned our classification system into a multiple-binary classification system, which has a higher accuracy value. This system is different from “one vs. one” or “one vs. other” classification systems because unnecessary classifications are conducted in those systems, such as DME vs. NORMAL. Instead of classifying the DME and NORMAL classes, we classify the ABNORMAL and NORMAL classes as ABNORMAL includes DME. A process flow diagram about the methods used in the study is given in Figure 5.
4. Results
5. Discussion
- The studies that used filtering techniques used BM3D and medium filtering. BM3D filtering is very good but not very fast. The filtering technique we used, bilateral filter, is enough to keep the important areas of the retinal layers, while removing noise better than a medium filter, and it is faster than BM3D filtering.
- Lots of ML studies used cropping for retinal layer extraction, but it may cause important features to be overlooked in some images, which affects the accuracy in a bad way. Our image processing techniques do not have this problem, as we successfully extracted the retinal layers by using every part of the image.
- DL studies train their own models, which is time-consuming. Our hybrid feature extractors do not require as much time.
- Using only basic feature extractors does not give the high accuracy values that are used in ML studies. By combining basic feature extractors with transfer learning, our hybrid feature extractors can provide high accuracy with limited data and a short amount of time.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Mathematical Expressions of Image Processing Techniques
Appendix B. Mathematical Expressions of Feature Extraction Techniques
References
- Eladawi, N.; Elmogy, M.; Ghazal, M.; Helmy, O.; Aboelfetouh, A.; Riad, A.; Schaal, S.; El-Baz, A. Classification of retinal diseases based on OCT Images. Front. Biosci. -Landmark 2018, 23, 247–264. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, M.R.; Fathalla, K.M.; Youssef, S.M. HyCAD-OCT: A Hybrid Computer-Aided Diagnosis of Retinopathy by Optical Coherence Tomography Integrating Machine Learning and Feature Maps Localization. Appl. Sci. 2020, 10, 4716. [Google Scholar] [CrossRef]
- Wang, D.; Wang, L. On OCT Image Classification via Deep Learning. IEEE Photonics J. 2019, 11, 1–14. [Google Scholar] [CrossRef]
- Rasti, R.; Rabbani, H.; Mehridehnavi, A.; Hajizadeh, F. Macular OCT Classification Using a Multi-Scale Convolutional Neural Network Ensemble. IEEE Trans. Med. Imaging 2018, 37, 1024–1034. [Google Scholar] [CrossRef]
- Mathenge, W. Age-related macular degeneration. Community Eye Health 2014, 27, 49–50. [Google Scholar] [PubMed]
- Flores, R.; Carneiro, A.; Vieira, M.; Tenreiro, S.; Seabra, M.C. Age-Related Macular Degeneration: Pathophysiology, Management, and Future Perspectives. Ophthalmologica 2021, 244, 495–511. [Google Scholar] [CrossRef]
- Hadziahmetovic, M.; Malek, G. Age-Related Macular Degeneration Revisited: From Pathology and Cellular Stress to Potential Therapies. Front. Cell Dev. Biol. 2021, 8, e612812. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Wang, L.; Cheng, S.; Li, Y. MHANet: A hybrid attention mechanism for retinal diseases classification. PLoS ONE 2021, 16, e0261285. [Google Scholar] [CrossRef]
- Arabi, P.M.; Krishna, N.; Ashwini, V.; Prathibha, H.M. Identification of Age-Related Macular Degeneration Using OCT Images. In Proceedings of the IOP Conf. Series: Materials Science and Engineering, Bengaluru, India, 17–19 August 2017. [Google Scholar] [CrossRef]
- Elsharkawy, M.; Elrazzaz, M.; Ghazal, M.; Alhalabi, M.; Soliman, A.; Mahmoud, A.; El-Daydamony, E.; Atwan, A.; Thanos, A.; Sandhu, H.S.; et al. Role of Optical Coherence Tomography Imaging in Predicting Progression of Age-Related Macular Disease: A Survey. Diagnostics 2021, 11, 2313. [Google Scholar] [CrossRef]
- Sulzbacher, F.; Pollreisz, A.; Kaider, A.; Kickinger, S.; Sacu, S.; Schmidt-Erfurth, U. Identification and clinical role of choroidal neovascularization characteristics based on optical coherence tomography angiography. Acta Ophthalmol. 2017, 95, 414–420. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, A.; Handa, S.; Marchese, A.; Parrulli, S.; Invernizzi, A.; Erckens, R.J.; Berendschot, T.T.J.M.; Webers, C.A.B.; Bansal, R.; Gupta, V. Optical Coherence Tomography Findings of Underlying Choroidal Neovascularization in Punctate Inner Choroidopathy. Front. Med. 2021, 8, e758370. [Google Scholar] [CrossRef] [PubMed]
- OCT Club Istanbul Retina Institute. Available online: https://en.octclub.org/yasa-bagli-makula-dejenerasyonu/ (accessed on 30 July 2022).
- Tan, C.S.; Chew, M.C.; Lim, L.W.; Sadda, S.R. Advances in retinal imaging for diabetic retinopathy and diabetic macular edema. Indian J. Ophthalmol. 2016, 64, 76–83. [Google Scholar] [CrossRef] [PubMed]
- Cole, E.D.; Novais, E.A.; Louzada, R.N.; Waheed, N.K. Contemporary retinal imaging techniques in diabetic retinopathy: A review. Clin. Exp. Ophthalmol. 2016, 44, 289–299. [Google Scholar] [CrossRef] [Green Version]
- Pachiyappan, A.; Das, U.N.; Murthy, T.V.; Tatavarti, R. Automated diagnosis of diabetic retinopathy and glaucoma using fundus and OCT images. Lipids Health Dis. 2012, 11, 73. [Google Scholar] [CrossRef] [Green Version]
- Pece, A.; Isola, V.; Holz, F.; Milani, P.; Brancato, R. Autofluorescence Imaging of Cystoid Macular Edema in Diabetic Retinopathy. Ophthalmologica 2010, 224, 230–235. [Google Scholar] [CrossRef] [PubMed]
- BuAbbud, J.C.; Al-latayfeh, M.M.; Sun, J.K. Optical Coherence Tomography Imaging for Diabetic Retinopathy and Macular Edema. Curr. Diabetes Rep. 2010, 10, 264–269. [Google Scholar] [CrossRef]
- Chung, Y.; Kim, Y.H.; Ha, S.J.; Byeon, H.; Cho, C.; Kim, J.H.; Lee, K. Role of Inflammation in Classification of Diabetic Macular Edema by Optical Coherence Tomography. J. Diabetes Res. 2019, 2019, e8164250. [Google Scholar] [CrossRef] [PubMed]
- Trichonas, G.; Kaiser, P.K. Optical coherence tomography imaging of macular oedema. Br. J. Ophthalmol. 2014, 98, 24–29. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, M.; Ishikawa, H.; Wollstein, G.; Schuman, S.J.; Rehg, J.M. Automated macular pathology diagnosis in retinal OCT images using multi-scale spatial pyramid and local binary patterns in texture and shape encoding. Med. Image Anal. 2011, 15, 748–759. [Google Scholar] [CrossRef] [Green Version]
- Anantrasirichai, N.; Achim, A.; Morgan, J.E.; Erchova, I.; Nicholson, L. SVM-based texture classification in Optical Coherence Tomography. In Proceedings of the 2013 IEEE 10th International Symposium on Biomedical Imaging, San Francisco, CA, USA, 7–11 April 2013. [Google Scholar] [CrossRef] [Green Version]
- Alqudah, A.; Alqudah, A.M.; AlTantawi, M. Artificial Intelligence Hybrid System for Enhancing Retinal Diseases Classification Using Automated Deep Features Extracted from OCT Images. Int. J. Intell. Syst. Appl. Eng. 2021, 9, 91–100. [Google Scholar] [CrossRef]
- Srinivasan, P.P.; Kim, L.A.; Mettu, P.S.; Cousins, S.W.; Comer, G.M.; Izatt, J.A.; Farsiu, S. Fully automated detection of diabetic macular edema and dry age-related macular degeneration from optical coherence tomography images. Biomed. Opt. Express 2014, 5, 3568–3577. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Zhang, Y.; Yao, Z.; Zhao, R.; Zhou, F. Machine learning based detection of age-related macular degeneration (AMD) and diabetic macular edema (DME) from optical coherence tomography (OCT) images. Biomed. Opt. Express 2016, 7, 4928–4940. [Google Scholar] [CrossRef] [Green Version]
- Albarrak, A.; Coenen, F.; Zheng, Y. Age-related Macular Degeneration Identification in Volumetric Optical Coherence Tomography Using Decomposition and Local Feature Extraction. In Proceedings of the 2013 International Conference on Medical Image, Understanding and Analysis, Birmingham, UK, 17–19 July 2013. [Google Scholar]
- Alsaih, K.; Lemaitre, G.; Rastgoo, M.; Massich, J.; Sidibe, D.; Meriaudeau, F. Machine learning techniques for diabetic macular edema (DME) classification on SD-OCT images. Biomed. Eng. Online 2017, 16, e68. [Google Scholar] [CrossRef] [Green Version]
- Santos, A.M.; Paiva, A.C.; Santos, A.P.M.; Mpinda, S.A.T.; Gomes, D.L., Jr.; Silva, A.C.; Braz, G., Jr.; Almeida, J.D.S.; Gattass, M. Semivariogram and Semimadogram functions as descriptors for AMD diagnosis on SD-OCT topographic maps using Support Vector Machine. Biomed. Eng. Online 2018, 17, e160. [Google Scholar] [CrossRef] [Green Version]
- Sunija, A.P.; Kar, S.; Gayathri, S.; Gopi, V.P.; Palanisamy, P. OctNET: A Lightweight CNN for Retinal Disease Classification from Optical Coherence Tomography Images. Comput. Methods Programs Biomed. 2021, 200, e105877. [Google Scholar] [CrossRef]
- Fang, L.; Jin, Y.; Huang, L.; Guo, S.; Zhao, G.; Chen, X. Iterative fusion convolutional neural networks for classification of optical coherence tomography images. J. Vis. Commun. Image Represent. 2019, 59, 327–333. [Google Scholar] [CrossRef]
- Das, V.; Dandapat, S.; Bora, P.K. Automated Classification of Retinal OCT Images Using a Deep Multi-Scale Fusion CNN. IEEE Sens. J. 2021, 21, 23256–23265. [Google Scholar] [CrossRef]
- Huang, L.; He, X.; Fang, L.; Chen, X. Automatic Classification of Retinal Optical Coherence Tomography Images with Layer Guided Convolutional Neural Network. IEEE Signal Process. Lett. 2019, 26, 1026–1030. [Google Scholar] [CrossRef]
- Das, V.; Prabhakararao, E.; Dandapat, S. B-Scan Attentive CNN for the Classification of Retinal Optical Coherence Tomography Volumes. IEEE Signal Process. Lett. 2020, 27, 1025–1029. [Google Scholar] [CrossRef]
- Ai, Z.; Huang, X.; Feng, J.; Wang, H.; Tao, Y.; Zeng, F.; Lu, Y. FN-OCT: Disease Detection Algorithm for Retinal Optical Coherence Tomography Based on a Fusion Network. Front. Neuroinformatics 2022, 16, e876927. [Google Scholar] [CrossRef]
- Kim, J.; Tran, L. Retinal Disease Classification from OCT Images Using Deep Learning Algorithms. In Proceedings of the 2021 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Melbourne, Australia, 13–15 October 2021. [Google Scholar] [CrossRef]
- Li, F.; Chen, H.; Liu, Z.; Zhang, X.; Wu, Z. Fully automated detection of retinal disorders by image-based deep learning. Graefe’s Arch. Clin. Exp. Ophthalmol. 2019, 257, 495–505. [Google Scholar] [CrossRef] [PubMed]
- Asif, S.; Amjad, K.; Qurrat-ul-Ain. Deep Residual Network for Diagnosis of Retinal Diseases Using Optical Coherence Tomography Images. Interdiscip. Sci. Comput. Life Sci. 2022, 14, 906–916. [Google Scholar] [CrossRef]
- Rong, Y.; Xiang, D.; Zhu, W.; Yu, K.; Shi, F.; Fan, Z.; Chen, X. Surrogate-Assisted Retinal OCT Image Classification Based on Convolutional Neural Network. IEEE J. Biomed. Health Inform. 2019, 23, 253–263. [Google Scholar] [CrossRef] [PubMed]
- Tayal, A.; Gupta, J.; Solanki, A.; Bisht, K.; Nayyar, A.; Masud, M. DL-CNN-based approach with image processing techniques for diagnosis of retinal diseases. Multimed. Syst. 2022, 28, 1417–1438. [Google Scholar] [CrossRef]
- Kaggle. Available online: https://www.kaggle.com/datasets/naredlaajayreddy/oct-retina-images (accessed on 30 July 2021).
- Kornprobst, P.; Tumblin, J.; Durand, F. Bilateral Filtering: Theory and Applications. Found. Trends Comput. Graph. Vis. 2009, 4, 1–74. [Google Scholar] [CrossRef]
- Mohanaiah, P.; Sathyanarayana, P.; Gurukumar, L. Image Texture Feature Extraction Using GLCM Approach. Int. J. Sci. Res. Publ. 2013, 3, e2250-3153. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Huo, G. Face recognition using locality sensitive histograms of oriented gradients. Optik 2016, 127, 3489–3494. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, X.; Gong, D. A return-cost-based binary firefly algorithm for feature selection. Inf. Sci. 2017, 418–419, 561–574. [Google Scholar] [CrossRef]
- Maza, S.; Zouache, D. Binary Firefly Algorithm for Feature Selection in Classification. In Proceedings of the 2019 International Conference on Theoretical and Applicative Aspects of Computer Science (ICTAACS), Skikda, Algeria, 15–16 December 2019. [Google Scholar] [CrossRef]
- Emary, E.; Zawbaa, H.M.; Ghany, K.K.A.; Hassanien, A.E.; Parv, B. Firefly Optimization Algorithm for Feature Selection. In Proceedings of the 7th Balkan Conference on Informatics Conference (BCI’15), Craiova, Romania, 2–4 September 2015. [Google Scholar] [CrossRef]
- Garg, P.; Jain, T. A Comparative Study on Histogram Equalization and Cumulative Histogram Equalization. Int. J. New Technol. Res. (IJNTR) 2017, 3, 41–43. [Google Scholar]
- PS, S.K.; Vs, D. Extraction of Texture Features using GLCM and Shape Features using Connected Regions. Int. J. Eng. Technol. 2016, 8, 2926–2930. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Studies | Dataset | Number of Classes | Algorithms | Results | ||||
|---|---|---|---|---|---|---|---|---|
| Training | Testing | Total | FE | FS | CLS | |||
| Liu et al. [21] | - | - | 326 | 4 (one vs. rest) | LBP MSSP | PCA | SVM | 0.93 AUC |
| Anantrasirichai et al. [22] | - | 24 | - | Unspecified | ILB CWT, etc. | PCA | SVM | 0.8515 ACC |
| Alqudah et al. [23] | 136,000 | 1250 | 137,250 | 5 | AOCTNet | - | KNN | 0.9944 ACC |
| Wang et al. [25] | - | - | 2367 | 3 | LCP + MSSP | - | SMO | 0.9913 ACC |
| Albarrak et al. [26] | - | - | 140 | 2 | LBP HOG | PCA | Bayesian | 0.914 ACC |
| Alsaih et al. [27] | - | - | 4096 | 2 | LBP HOG | PCA BoW | SVM | 0.875 specificity |
| Studies | Dataset | Number of Classes | Algorithms | Number of Layers | PU | Results (ACC) | |
|---|---|---|---|---|---|---|---|
| Training | Testing | ||||||
| A P et al. [29] | 83,484 | 968 | 4 | OCTNet | 29 | GPU | 0.9969 |
| Fang et al. [30] | 84,484 | - | 4 | CNN | >15 | GPU | 0.8515 |
| Das et al. [31] | 84,484 | - | 4 | DMF-CNN | >7 | GPU | 0.9603 |
| Kim and Tran [35] | 34,464 | 1000 | 4 (one vs. one) | UNet + FCN VGG16 VGG19 InceptionV3 | - | CPU + GPU | 0.983 |
| Li et al. [36] | 109,312 | 1000 | 4 | VGG16 | 16 | CPU + GPU | 0.986 |
| Asif et al. [37] | 83,484 | 968 | 4 | ResNet50 | 50 | GPU | 0.994 |
| Tayal et al. [39] | 75,269 | 1535 | 4 | CNN | 7 | GPU | 0.965 |
| Classification | ABNORMAL vs. NORMAL (CNV + DRUSEN + DME vs. NORMAL) | AMD vs. DME (CNV + DRUSEN vs. DME) | CNV vs. DRUSEN | |||
|---|---|---|---|---|---|---|
| Class | ABNORMAL | NORMAL | AMD | DME | CNV | DRUSEN |
| Training | 1200 + 1200 + 1200 = 3600 | 3600 | 2000 + 2000 = 4000 | 4000 | 3000 | 3000 |
| Testing | 81 + 81 + 80 = 242 | 242 | 121 + 121 = 242 | 242 | 242 | 242 |
| Validation | 200 + 200 + 200 = 600 | 600 | 400 + 400 = 800 | 800 | 600 | 600 |
| Classification | ABNORMAL vs. NORMAL (CNV + DRUSEN + DME vs. NORMAL) | AMD vs. DME (CNV + DRUSEN vs. DME) | ||
|---|---|---|---|---|
| Class | ABNORMAL | NORMAL | AMD | DME |
| Training | 473 + 851 = 1324 | 1157 | 473 | 473 |
| Testing | 75 + 75 = 150 | 150 | 150 | 150 |
| Validation | 50 + 50 = 100 | 100 | 100 | 100 |
| F1 | F2 | F3 | F4 | … | F33,000 | |
|---|---|---|---|---|---|---|
| f1 | 0 | 1 | 0 | 0 | 1 | 1 |
| f2 | 1 | 1 | 0 | 1 | 0 | 0 |
| f3 | 0 | 1 | 0 | 1 | 1 | 1 |
| … | 1 | 1 | 1 | 1 | 1 | 0 |
| f20 | 1 | 1 | 0 | 1 | 0 | 0 |
| Dataset | Classifications | Metrics | Classes | SVM | LR | RF |
|---|---|---|---|---|---|---|
| First Dataset | Abnormal vs. Normal | Accuracy | 0.967 | 0.969 | 0.923 | |
| Precision | Abnormal | 0.975 | 0.978 | 0.918 | ||
| Normal | 0.959 | 0.959 | 0.928 | |||
| Recall | Abnormal | 0.958 | 0.958 | 0.929 | ||
| Normal | 0.975 | 0.979 | 0.917 | |||
| F1-Score | Abnormal | 0.966 | 0.968 | 0.924 | ||
| Normal | 0.967 | 0.969 | 0.923 | |||
| AMD vs. DME | Accuracy | 0.909 | 0.925 | 0.851 | ||
| Precision | DME | 0.93 | 0.947 | 0.912 | ||
| AMD | 0.889 | 0.905 | 0.805 | |||
| Recall | DME | 0.884 | 0.9 | 0.776 | ||
| AMD | 0.933 | 0.95 | 0.925 | |||
| F1-Score | DME | 0.906 | 0.923 | 0.839 | ||
| AMD | 0.911 | 0.927 | 0.861 | |||
| CNV vs. DRUSEN | Accuracy | 0.964 | 0.977 | 0.933 | ||
| Precision | CNV | 0.959 | 0.971 | 0.91 | ||
| DRUSEN | 0.97 | 0.983 | 0.96 | |||
| Recall | CNV | 0.971 | 0.983 | 0.962 | ||
| DRUSEN | 0.958 | 0.971 | 0.904 | |||
| F1-Score | CNV | 0.965 | 0.977 | 0.935 | ||
| DRUSEN | 0.964 | 0.977 | 0.931 | |||
| Mean Accuracy | 0.946 | 0.957 | 0.902 | |||
| Second Dataset | Abnormal vs. Normal | Accuracy | 0.97 | 0.976 | 0.94 | |
| Precision | Abnormal | 0.966 | 0.955 | 0.902 | ||
| Normal | 0.973 | 1 | 0.985 | |||
| Recall | Abnormal | 0.973 | 1 | 0.986 | ||
| Normal | 0.966 | 0.953 | 0.893 | |||
| F1-Score | Abnormal | 0.9701 | 0.977 | 0.942 | ||
| Normal | 0.969 | 0.976 | 0.937 | |||
| AMD vs. DME | Accuracy | 0.936 | 0.933 | 0.91 | ||
| Precision | DME | 0.887 | 0.882 | 0.855 | ||
| AMD | 1 | 1 | 0.984 | |||
| Recall | DME | 1 | 1 | 0.986 | ||
| AMD | 0.873 | 0.866 | 0.833 | |||
| F1-Score | DME | 0.94 | 0.937 | 0.916 | ||
| AMD | 0.932 | 0.928 | 0.902 | |||
| Mean Accuracy | 0.953 | 0.954 | 0.925 | |||
| Dataset | Classifications | Metrics | Firefly Algorithm | SVM | LR | RF |
|---|---|---|---|---|---|---|
| First Dataset | Abnormal vs. Normal | Accuracy | Yes | 0.967 | 0.969 | 0.923 |
| No | 0.969 | 0.967 | 0.886 | |||
| Training time (s) | Yes | 315.31 | 63.84 | 55.46 | ||
| No | 452.92 | 81.4 | 68.38 | |||
| AMD vs. DME | Accuracy | Yes | 0.909 | 0.926 | 0.851 | |
| No | 0.929 | 0.934 | 0.828 | |||
| Training time (s) | Yes | 141.94 | 47.15 | 36.34 | ||
| No | 307.82 | 86.83 | 52.67 | |||
| CNV vs. DRUSEN | Accuracy | Yes | 0.965 | 0.977 | 0.934 | |
| No | 0.965 | 0.971 | 0.934 | |||
| Training time (s) | Yes | 117.24 | 24.93 | 35.29 | ||
| No | 308 | 64.17 | 61.06 | |||
| Second Dataset | Abnormal vs. Normal | Accuracy | Yes | 0.97 | 0.976 | 0.94 |
| No | 0.973 | 0.976 | 0.953 | |||
| Training time (s) | Yes | 11.71 | 7.17 | 9.33 | ||
| No | 23.52 | 11.17 | 13.61 | |||
| AMD vs. DME | Accuracy | Yes | 0.933 | 0.933 | 0.91 | |
| No | 0.936 | 0.927 | 0.916 | |||
| Training time (s) | Yes | 9.36 | 5.2 | 4.23 | ||
| No | 10.86 | 5.99 | 4.54 |
| Dataset | Classification | Image Preprocessing | SVM | LR | RF |
|---|---|---|---|---|---|
| First Dataset | Abnormal vs. Normal | Yes | 0.967 | 0.969 | 0.923 |
| No | 0.956 | 0.95 | 0.77 | ||
| AMD vs. DME | Yes | 0.909 | 0.926 | 0.851 | |
| No | 0.923 | 0.931 | 0.762 | ||
| CNV vs. DRUSEN | Yes | 0.964 | 0.977 | 0.933 | |
| No | 0.954 | 0.963 | 0.874 | ||
| Second Dataset | Abnormal vs. Normal | Yes | 0.97 | 0.976 | 0.94 |
| No | 0.986 | 0.983 | 0.896 | ||
| AMD vs. DME | Yes | 0.936 | 0.933 | 0.91 | |
| No | 0.88 | 0.863 | 0.72 |
| Studies | Dataset | Number of Classes | Algorithms | PU | Results | |||
|---|---|---|---|---|---|---|---|---|
| Training | Testing | FE | FS | CLS | ||||
| A P et al. [29] | 83,484 | 968 | 4 | OCTNet | - | OCTNet | GPU | 0.9969 ACC |
| Alqudah et al. [23] | 136,000 | 1250 | 5 | AOCTNet | - | KNN | CPU | 0.9944 ACC |
| Asif et al. [37] | 83,484 | 968 | 4 | ResNet50 | - | ResNet50 | GPU | 0.994 ACC |
| Wang et al. [25] | 2367 total | 3 | LCP + MSSP | CFS | SMO | - | 0.9913 ACC | |
| Li et al. [37] | 109,312 | 1000 | 4 | VGG16 | - | VGG16 | CPU+ GPU | 0.986 ACC |
| Kim and Tran [35] | 34,464 | 1000 | 4 (one vs. one) | UNet + FCN VGG16 VGG19 InceptionV3 | - | VGG16 VGG19 InceptionV3 | CPU+ GPU | 0.983 ACC |
| Tayal et al. [40] | 75,269 | 1535 | 4 | CNN | - | CNN | GPU | 0.965 ACC |
| Das et al. [31] | 84,484 | - | 4 | DMF-CNN | - | DMF-CNN | GPU | 0.9603 ACC |
| Ours | 13,600 | 968 | 4 (hierarchy) | GLCM HOG VGG16 DenseNet | Firefly Algorithm | LR | CPU | 0.957 ACC |
| Liu et al. [21] | 326 total | 4 (one vs. rest) | LBP MSSP | PCA | SVM | CPU | 0.93 AUC | |
| Albarrak et al. [26] | 140 total | 2 | LBP HOG | PCA | Bayesian | CPU | 0.914 ACC | |
| Alsaih et al. [27] | 4096 total | 2 | LBP HOG | PCA BoW | SVM | CPU | 0.875 SPC | |
| Fang et al. [30] | 84,484 | - | 4 | CNN | - | CNN | GPU | 0.8515 ACC |
| Anantrasirichai et al. [22] | - | 24 | - | ILB CWT, etc. | PCA | SVM | CPU | 0.8515 ACC |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Özdaş, M.B.; Uysal, F.; Hardalaç, F. Classification of Retinal Diseases in Optical Coherence Tomography Images Using Artificial Intelligence and Firefly Algorithm. Diagnostics 2023, 13, 433. https://doi.org/10.3390/diagnostics13030433
Özdaş MB, Uysal F, Hardalaç F. Classification of Retinal Diseases in Optical Coherence Tomography Images Using Artificial Intelligence and Firefly Algorithm. Diagnostics. 2023; 13(3):433. https://doi.org/10.3390/diagnostics13030433
Chicago/Turabian StyleÖzdaş, Mehmet Batuhan, Fatih Uysal, and Fırat Hardalaç. 2023. "Classification of Retinal Diseases in Optical Coherence Tomography Images Using Artificial Intelligence and Firefly Algorithm" Diagnostics 13, no. 3: 433. https://doi.org/10.3390/diagnostics13030433