1. Introduction
Recent advances in technology have ushered in the fourth industrial revolution (4IR), a concept introduced by Klaus Schwab [
1] that includes three-dimensional (3D) printing, virtual reality, and artificial intelligence (AI), with AI being the most active [
1]. As presented in [
2], the branches of AI include expert systems, machine learning (ML), robotics, computer vision, planning, and natural language processing (NLP). ML is when an algorithm learns from data. ML comes in supervised learning, unsupervised learning, and reinforcement learning variants [
3].
In supervised learning, the training set contains both the inputs and desired outputs. The training set is used to teach the model to generate the desired output, and the goal of supervised learning is to learn a mapping between the input and the output spaces [
3]. Supervised learning was often used in image recognition, and self-supervised semi-supervised learning (S4L) was proposed to solve the image classification problem [
4]. In unsupervised learning, the training set contains unlabeled inputs that do not have any assigned desired output. The goal of unsupervised learning is typically to discover the properties of the data generating process, and its applications include clustering documents with similar topics [
3] or identifying the phases and phase transitions of systems [
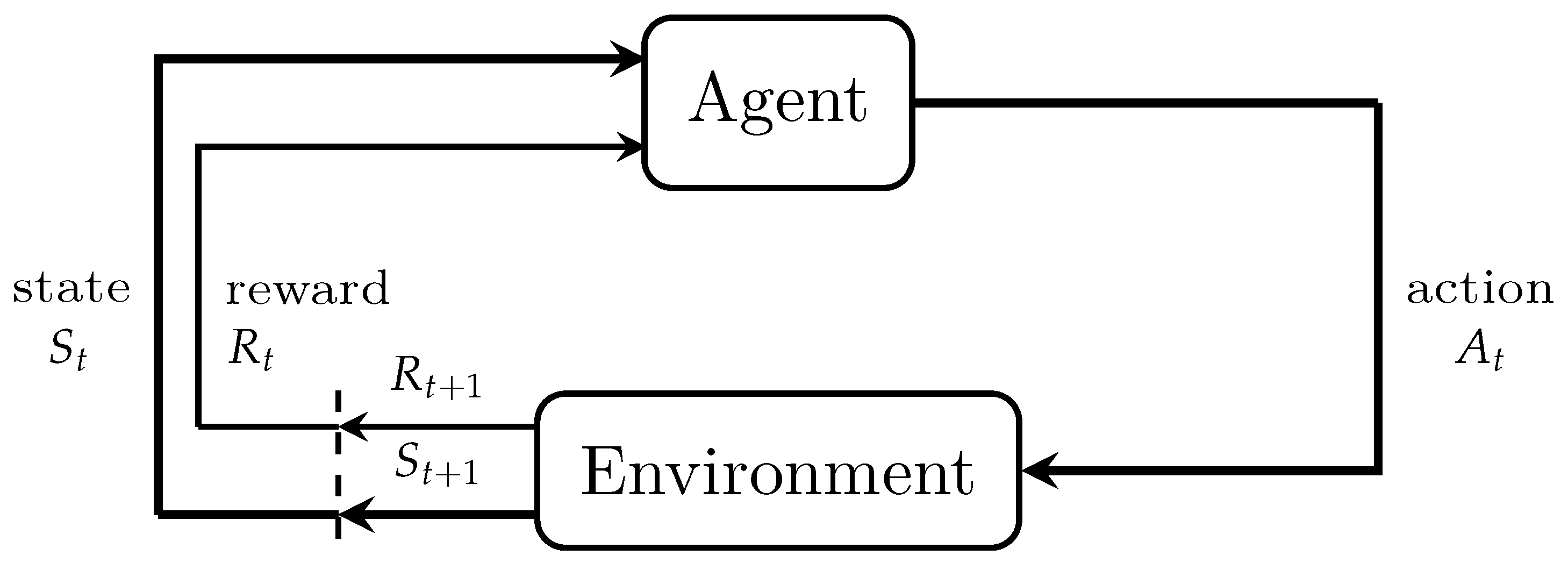
5]. Reinforcement learning is similar to supervised and unsupervised learning and has advantages of both. Some form of supervision exists, but reinforcement learning does not require a desired output to be specified for each input in the data; the reinforcement learning algorithm receives feedback from the environment only after selecting an output for a given input or observation [
3]. In other words, the building system model is unnecessary for reinforcement learning algorithms [
6].
In reinforcement learning, the most challenging problem is finding the best trade-off between exploration and exploitation; this trade-off dominates the performance of the agent. By combining Monte Carlo methods and dynamic programming (DP) ideas, temporal difference (TD) learning is a brilliant solution to the problems of reinforcement learning. Two TD control methods, Q-learning and Sarsa, were proposed on the basis of the TD learning method [
7]. Q-Learning [
8] is a form of model-free reinforcement learning. It can also be viewed as a method of asynchronous DP. It provides agents with the capability of learning to act optimally in Markovian domains by experiencing the consequences of actions without requiring maps of the domains to be built [
9,
10]. The Sarsa algorithm was first explored in 1994 by Rummery and Niranjan [
11] and was termed modified Q-learning. In 1996, the name Sarsa was introduced by Sutton [
7].
Conventionally, Sarsa and Q-learning have been applied to robotics problems [
11]. Recently, a fuzzy Sarsa learning (known as FSL) algorithm was proposed to control a biped walking robot [
12] and a PID-SARSA-RAL algorithm was proposed in the ClowdFlows platform to improve parallel data processing [
13]. Q-learning is often applied in combination with a proportional integral derivative (PID) controller. Specifically, an adaptive PID controller was proposed in [
14], a self-tuning PID controller for a soccer robot was proposed in [
15], and a Q-Learning approach was used to tune an adaptive PID controller in [
16]. Moreover, the Q-learning algorithm was applied to the tracking problem for discrete-time systems with an
approach [
17] and linear quadratic tracking control [
18,
19]. Recently, some relevant applications of model-free reinforcement learning for tracking problems can be found in [
20,
21]. In these results [
12,
13,
14,
15,
16,
17,
18], the PID controller has attracted substantial attention as an application of reinforcement learning algorithms [
13,
14,
15,
16]. However, the literature [
13,
15,
16,
17,
18] has provided optimal but static gains in control, and a complete search of the Q-table is required in [
14]. Moreover, most of the results [
12,
13,
14,
16,
17,
18,
19] were validated in a simulated environment.
For the time-varying PID control design, conventional approaches in the literature can be found as gain-scheduled PID control [
22,
23], fuzzy PID control [
24,
25,
26,
27], or fuzzy gain-scheduling PID control [
28,
29], in which the fuzzy logic were utilized to determine the controller parameters instead of directly producing the control signal. Nowadays, the application of fuzzy PID control can be found in the automatic voltage regulator (AVR) system [
30], hydraulic transplanting robot control system [
31], and the combination with fast terminal sliding mode control [
32].
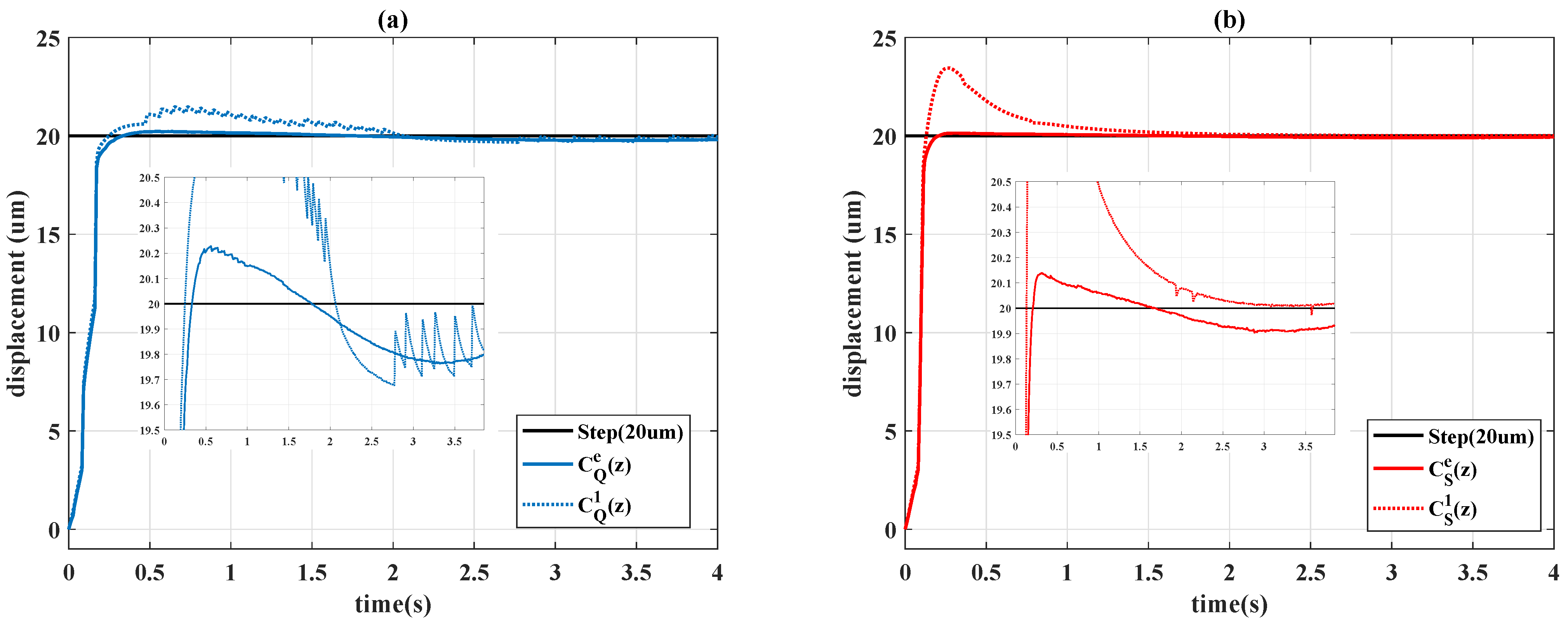
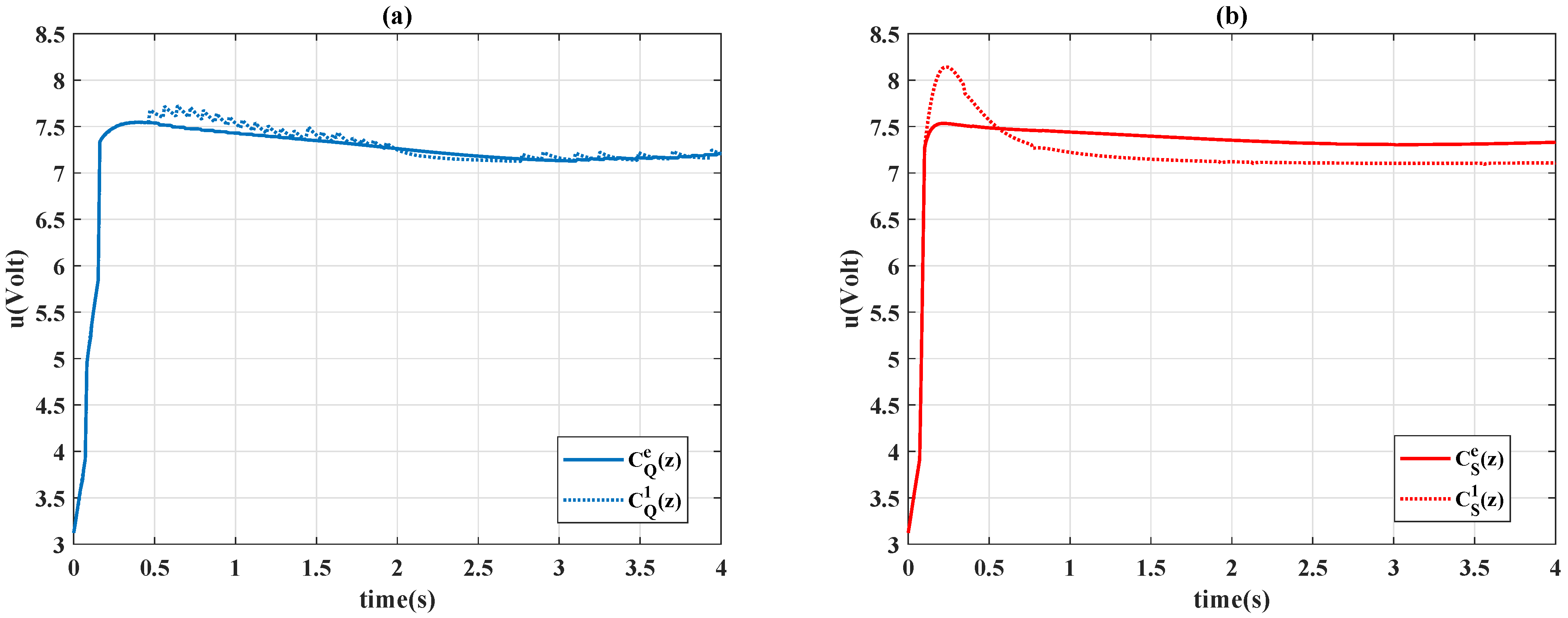
In this paper, a time-varying PID controller following the structure in [
28], which features the use of a model-free reinforcement learning algorithm, was proposed to achieve reference tracking in the absence of any knowledge of system dynamics. Based on the concept underlying the
n-armed bandit problem [
33,
34], this study’s method allows for the control coefficients to be assigned online without a complete searching process for the Q-table. The time-varying control gains were capable of achieving the various performance requirements and have the potential to handle nonlinear effects. Both the Q-learning and Sarsa algorithms were applied in the proposed control design, and the performance was compared with experimental results on a piezo-actuated stage.
3. Controller Design
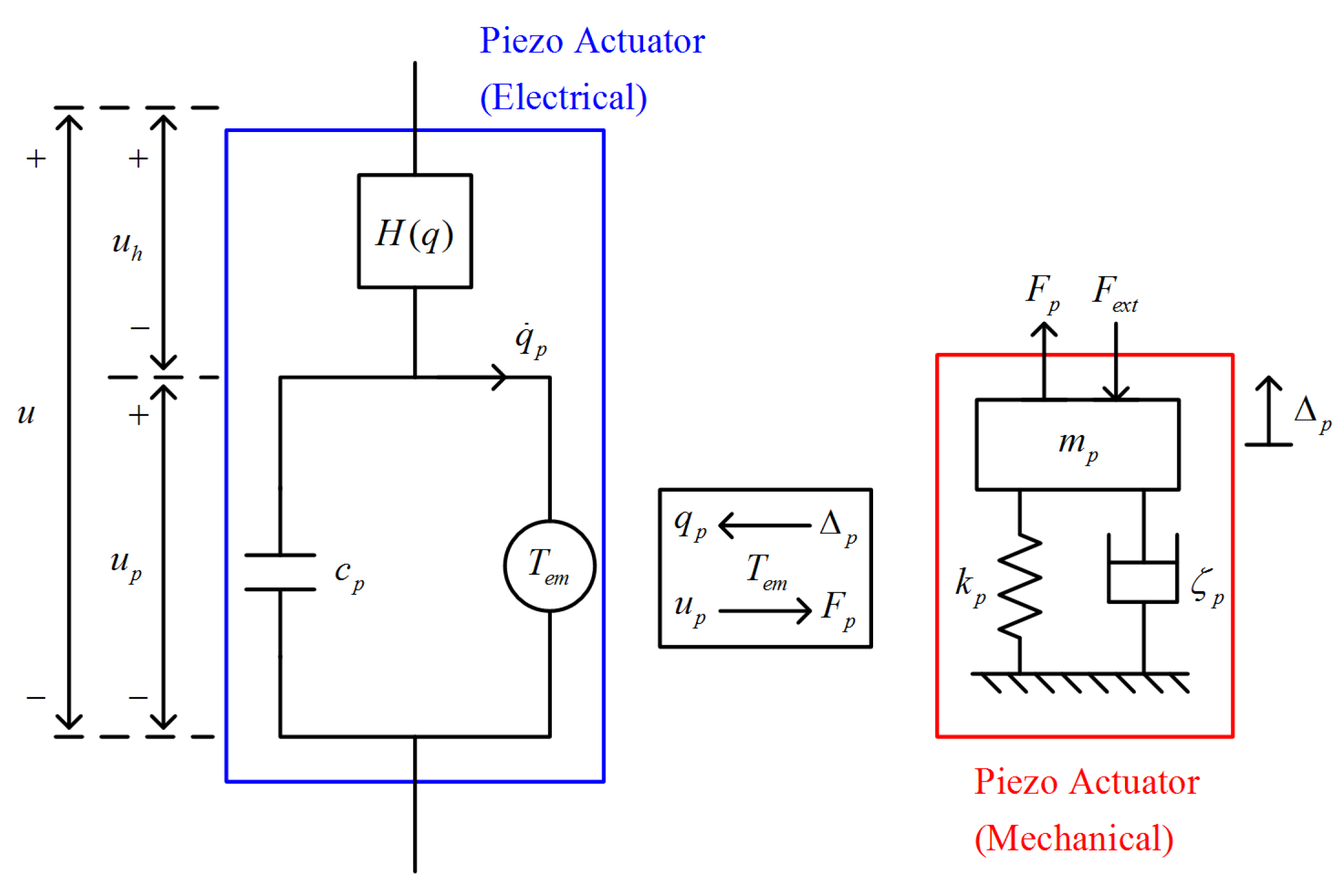
In this section, we describe our fundamental scheme of the time-varying PID controller. According to [
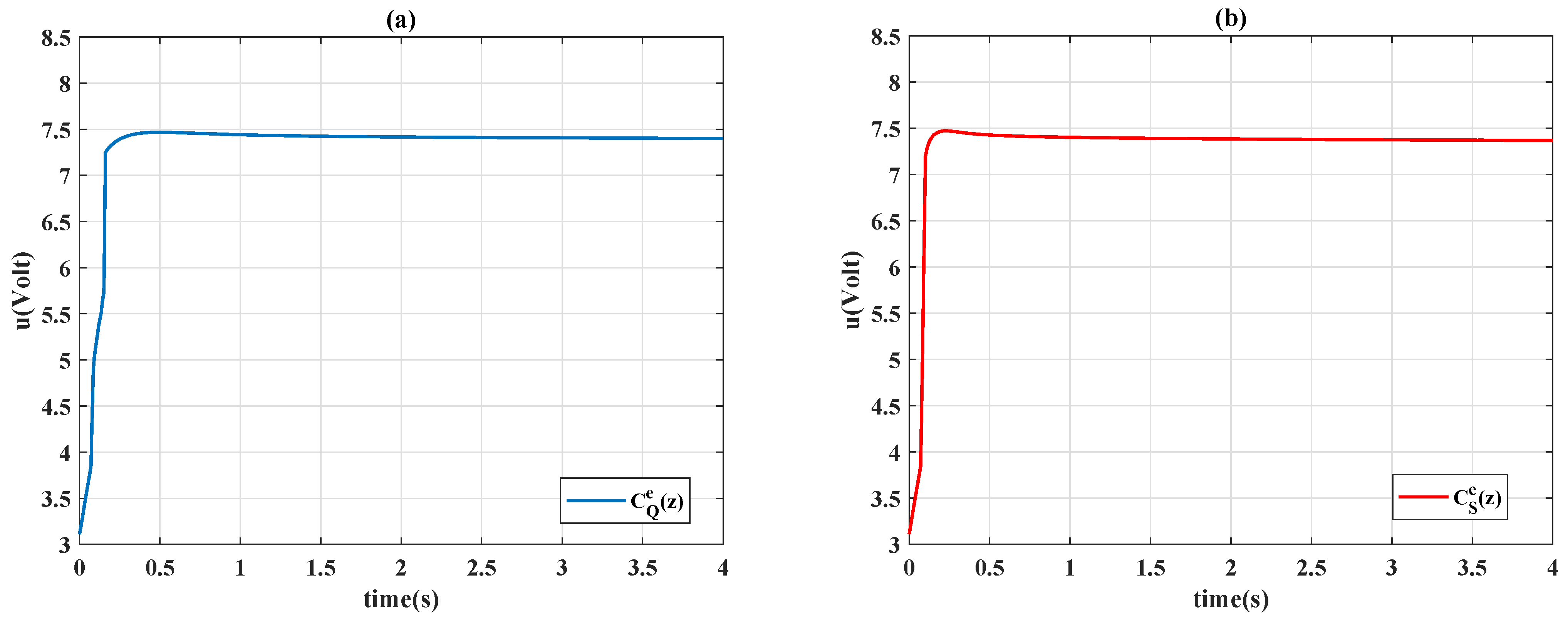
37], the control input
of the controller in discrete-time is defined as
where
t is the discrete time index;
is the time interval of sampling;
,
, and
are the proportional, integral, and derivative gains, respectively; and the error signal
is defined in terms of the system output
and desired reference
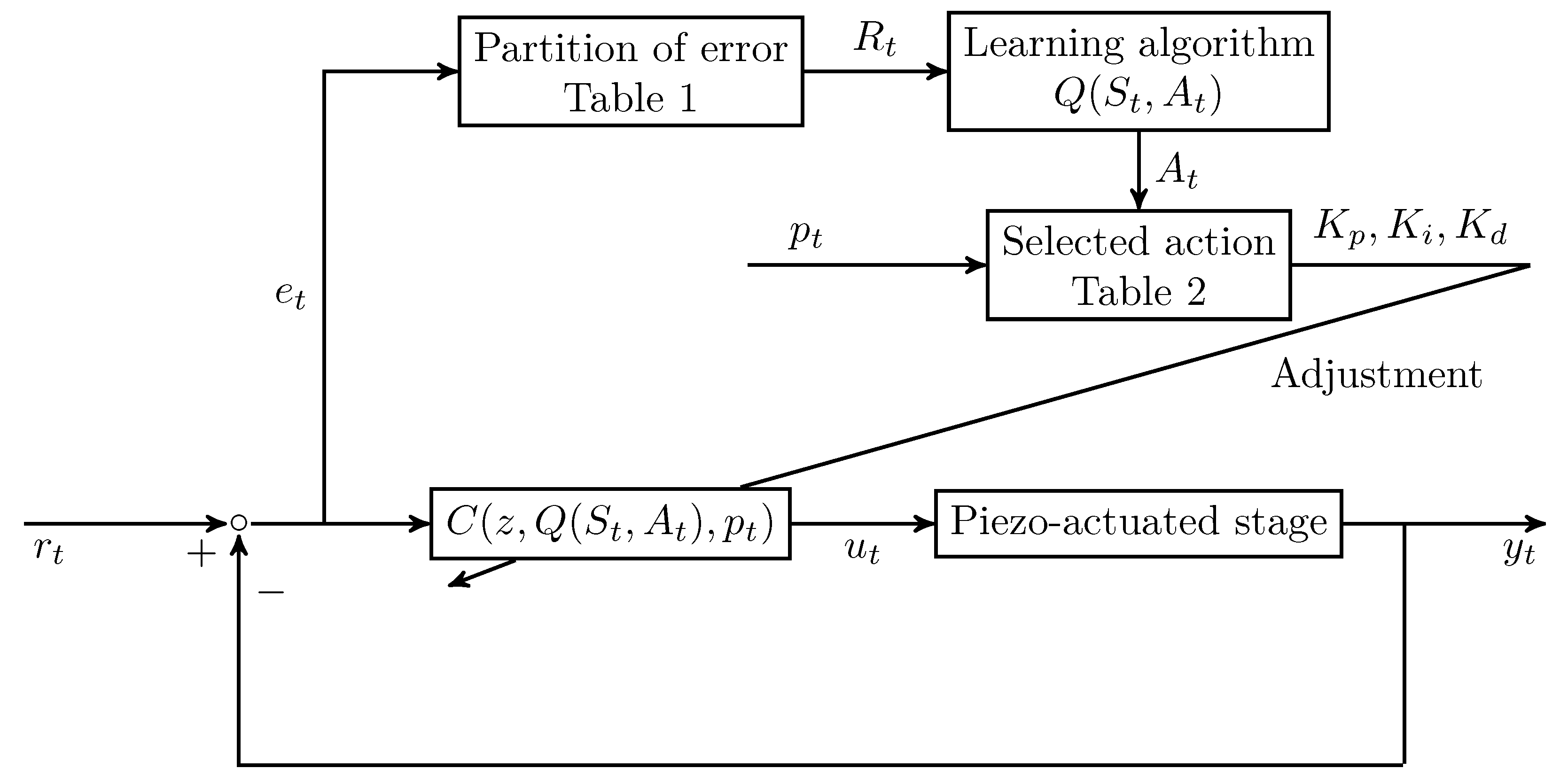
. Control design typically requires a compromise between various performance requirements; therefore, time-varying PID gains were used to simultaneously achieve multiple requirements. In each time step
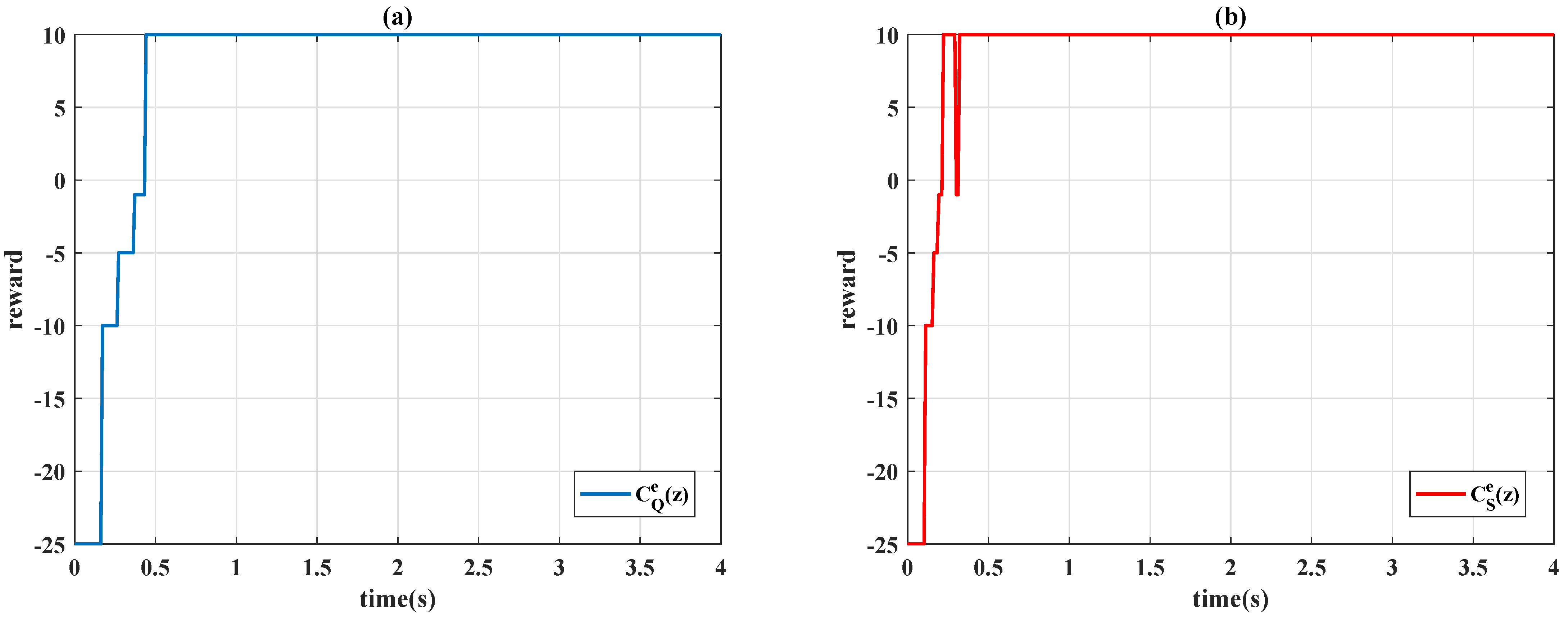
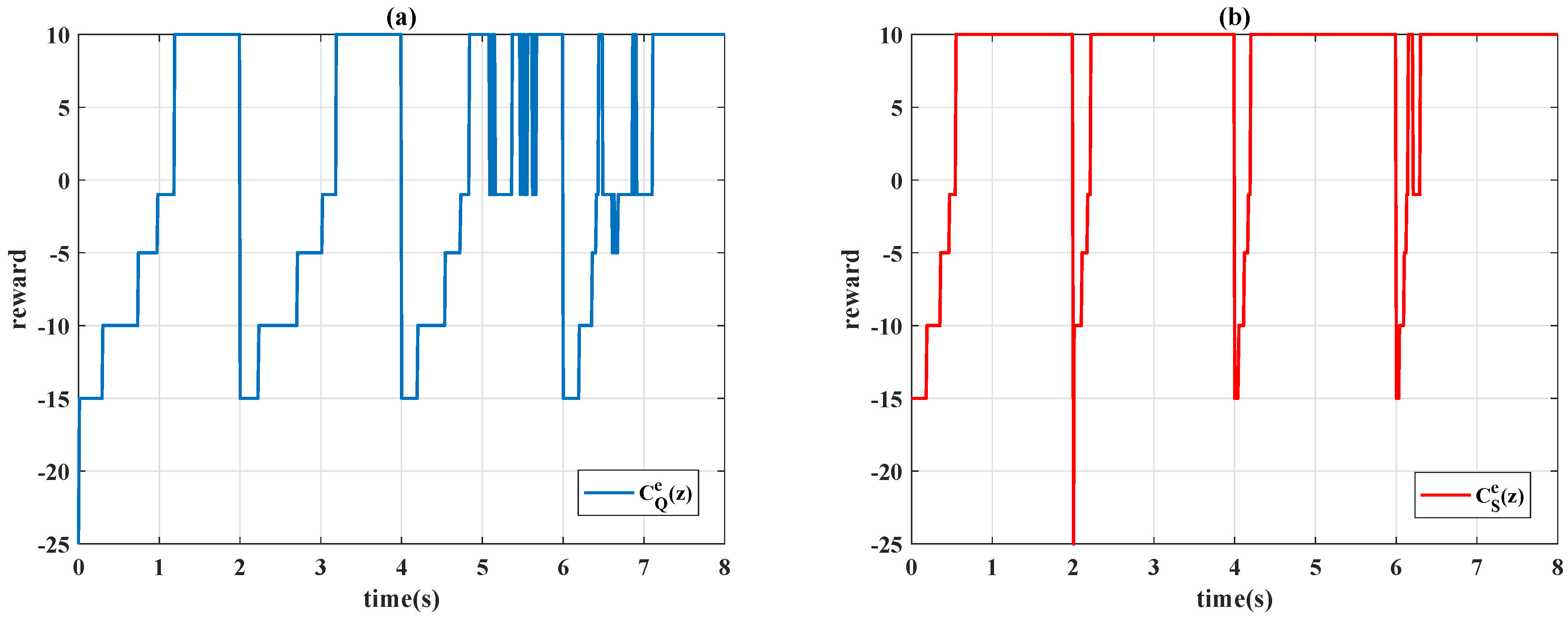
t, a numerical reward
is received by the agent according to the partitions in
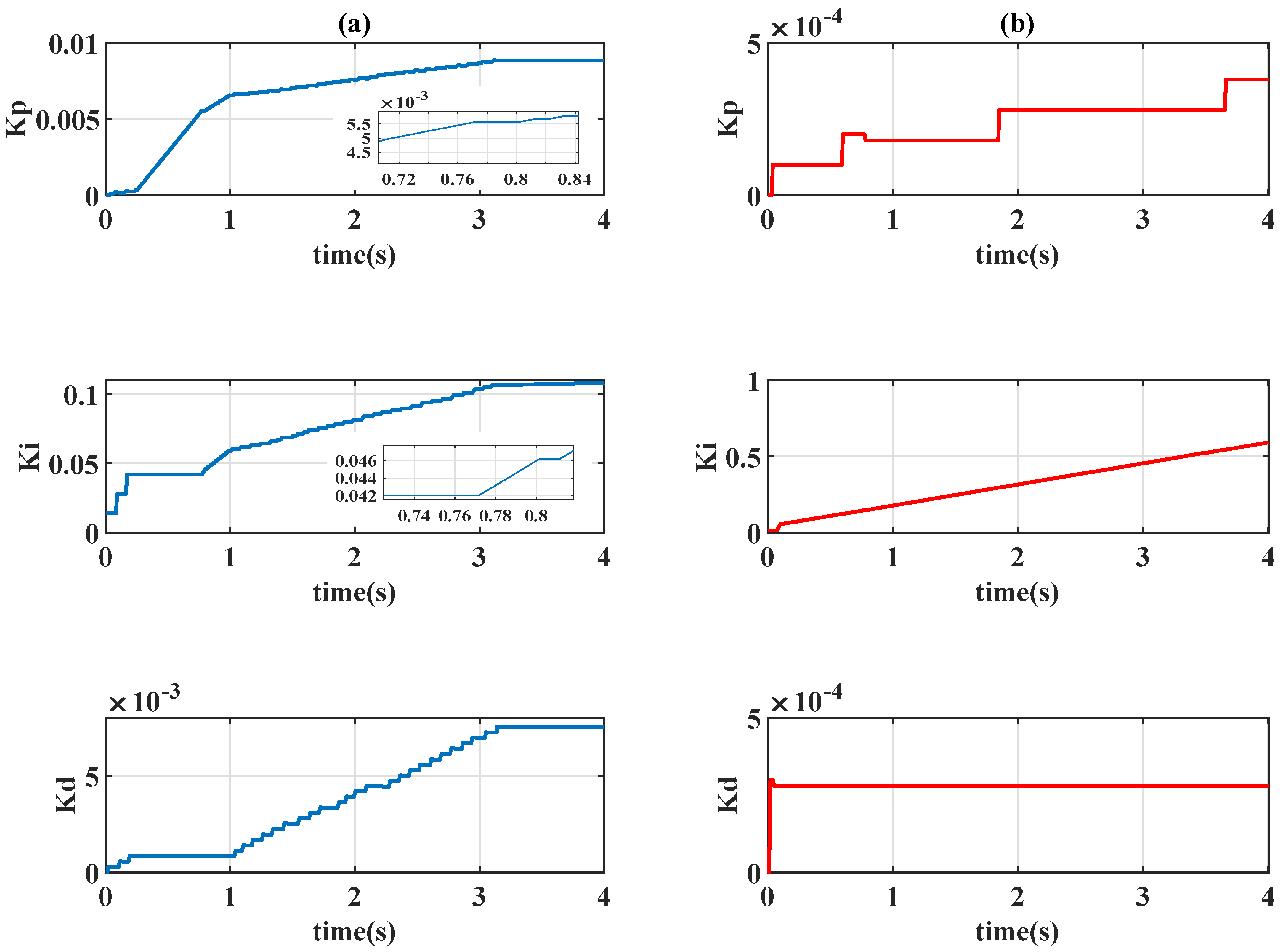
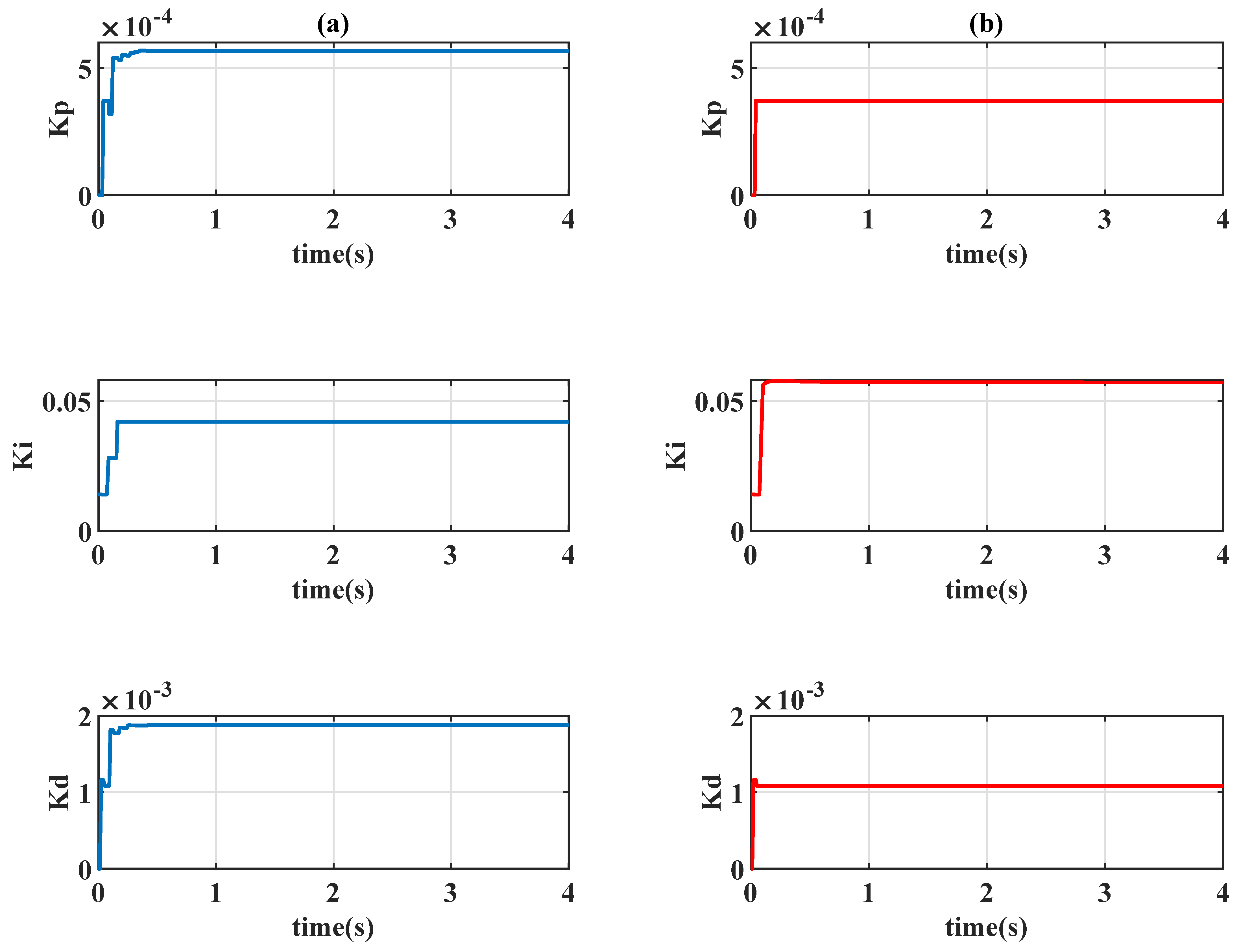
Table 1, and the control gains
,
, and
are adjusted by the chosen actions according to a learning algorithm. This design concept coincides with the original form of the
n-armed bandit problem [
33,
34], and the parameter specification is thus straightforward.
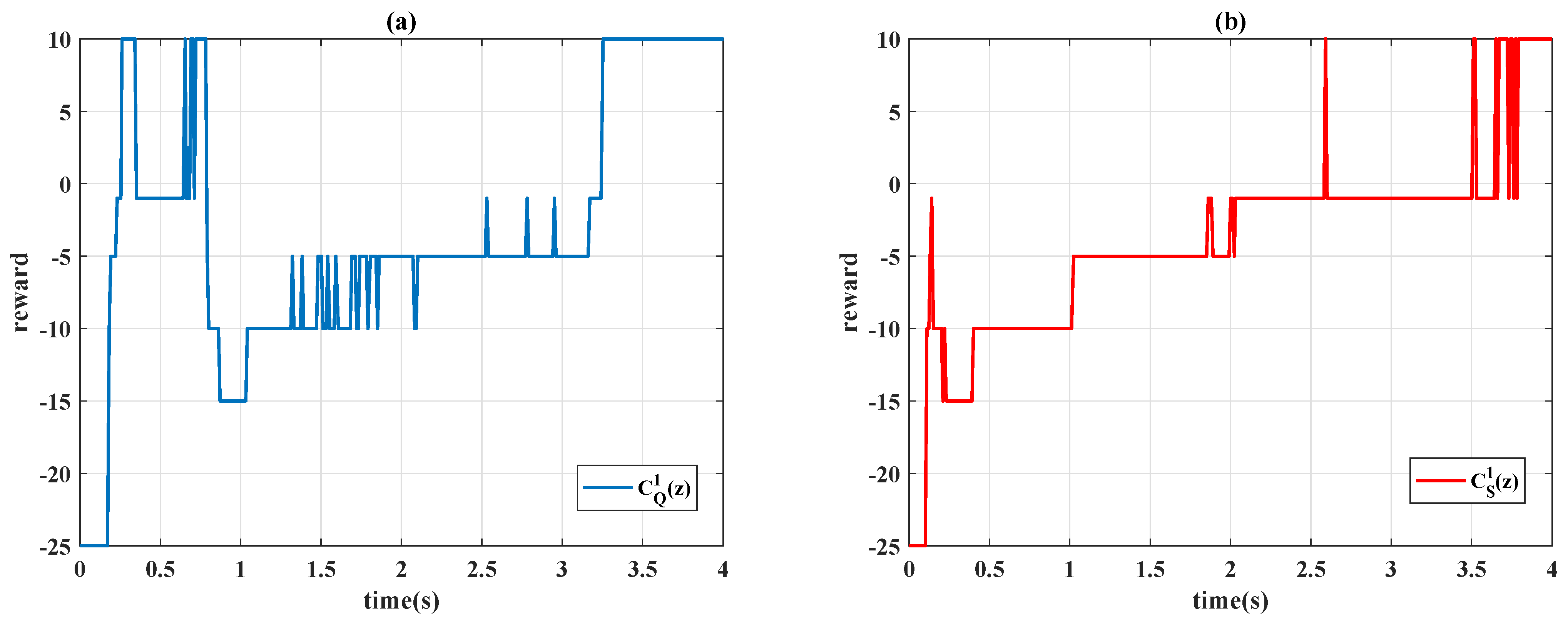
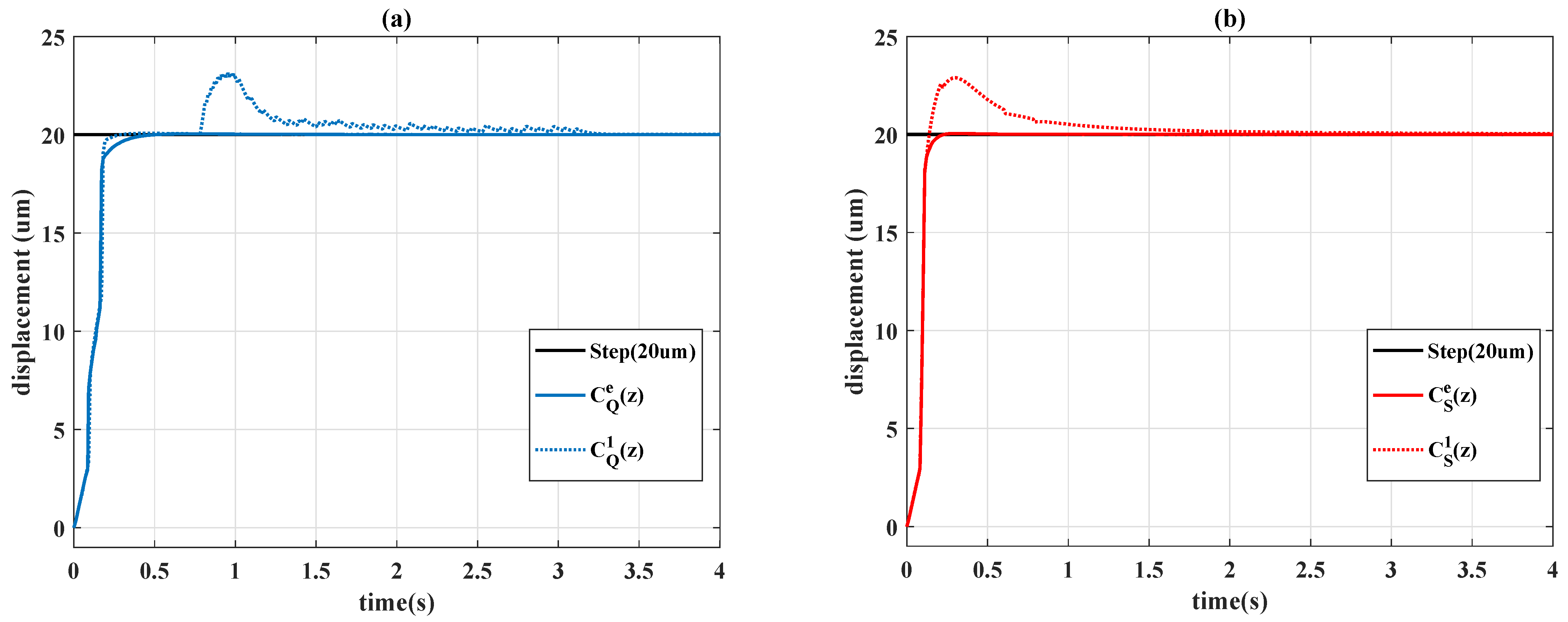
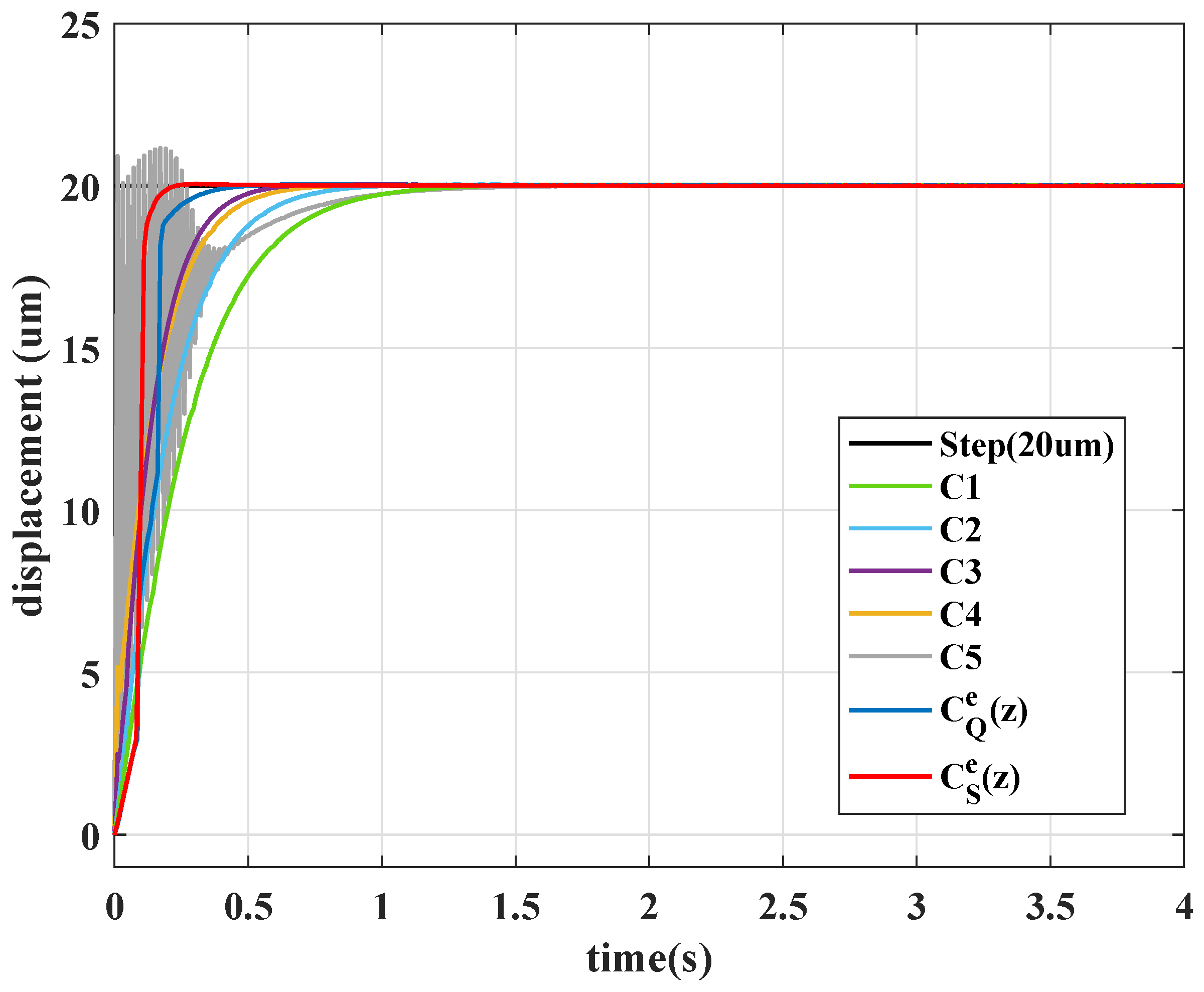
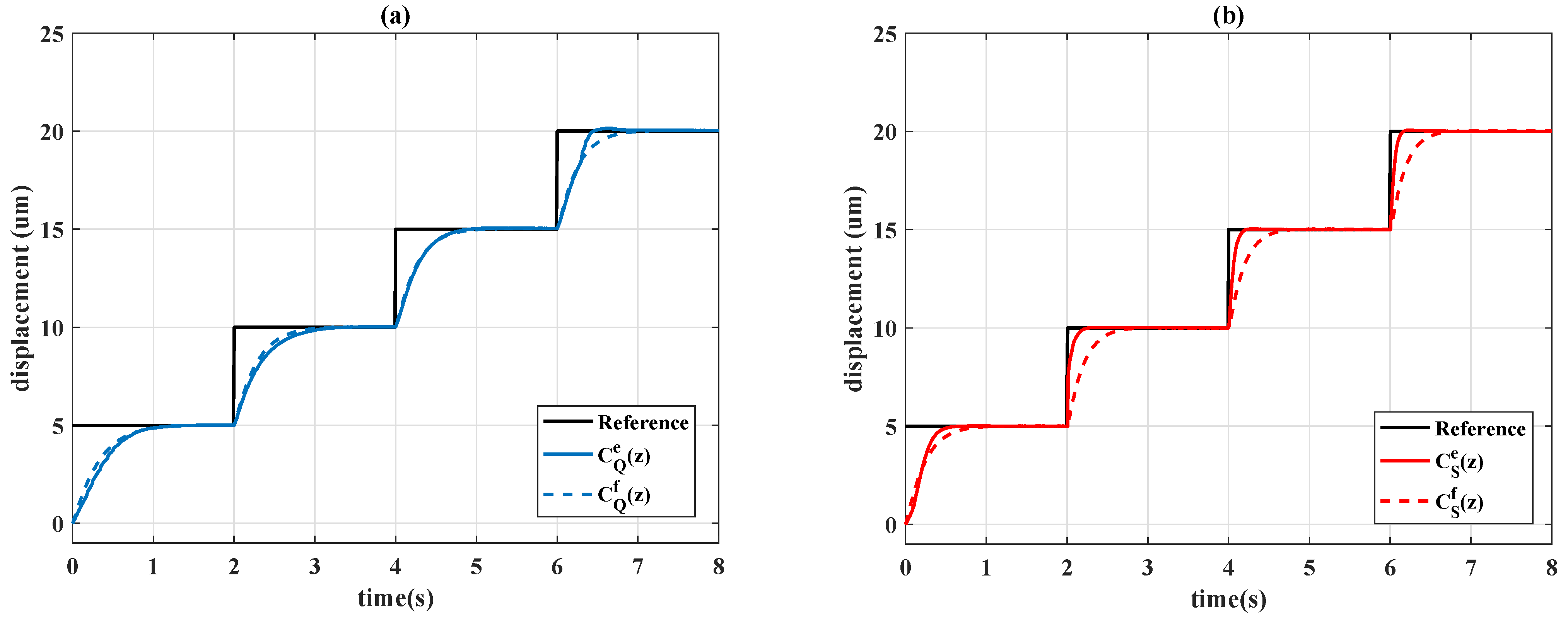
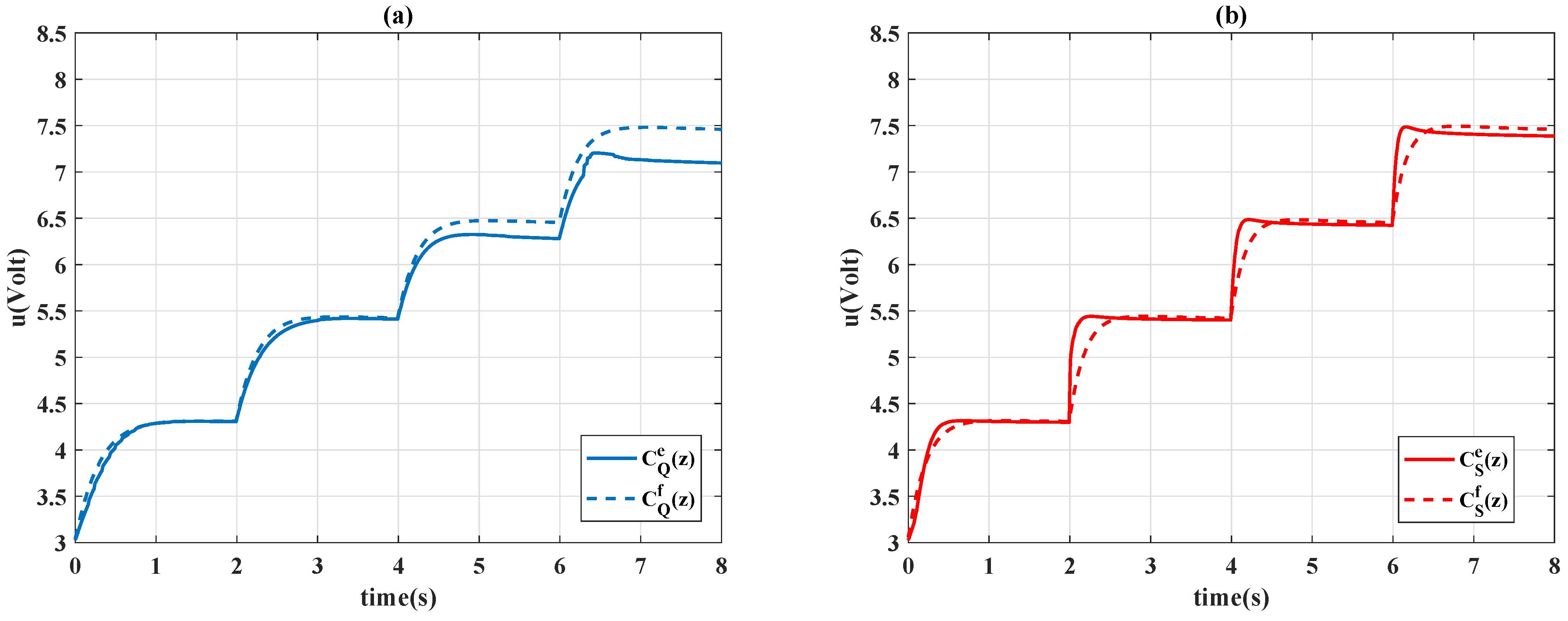
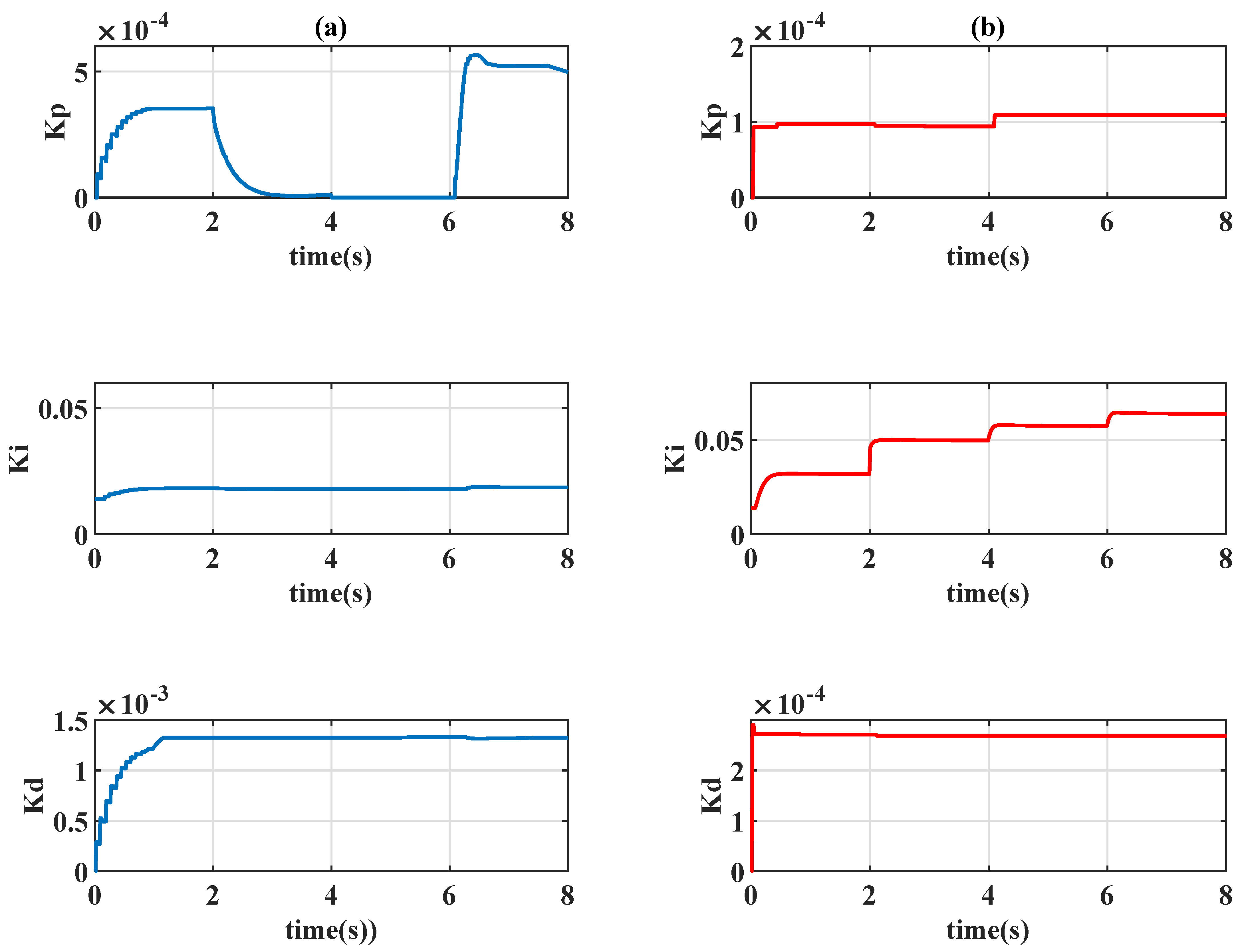
Remark 2. In the conventional application of the reinforcement learning (see example 6.6 of [7]), the numerical value of reward is separately assigned for the gridworld example. The same concept is used in this paper to provide more degree-of-freedoms of adjustment; a partition error is consequently used instead of a continuous domain value as . In this paper, eight cases of action for the agent are examined, and the movement of the actions are detailed in
Table 2, where
is the scheduling variable [
38] to be determined. According to the current value of the scheduling signal, the scheduling variable provides an additional chance for the agent to adapt to environmental changes. On the basis of these actions, the discrete time transfer function expression of the control law (
4) is given as
with the controller design
where the control gains
,
,
are adjusted through the selected reinforcement learning algorithm
and the scheduling variable
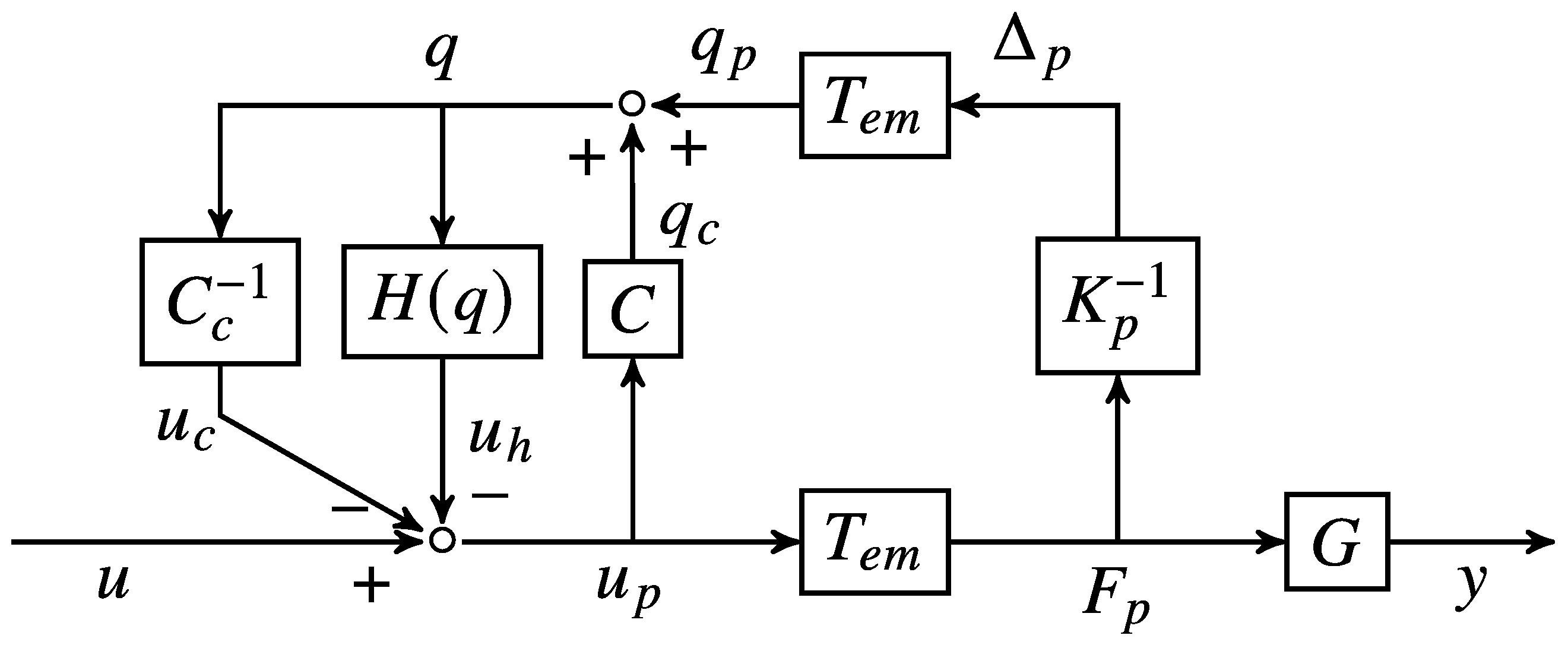
. The closed-loop control system structure is shown in
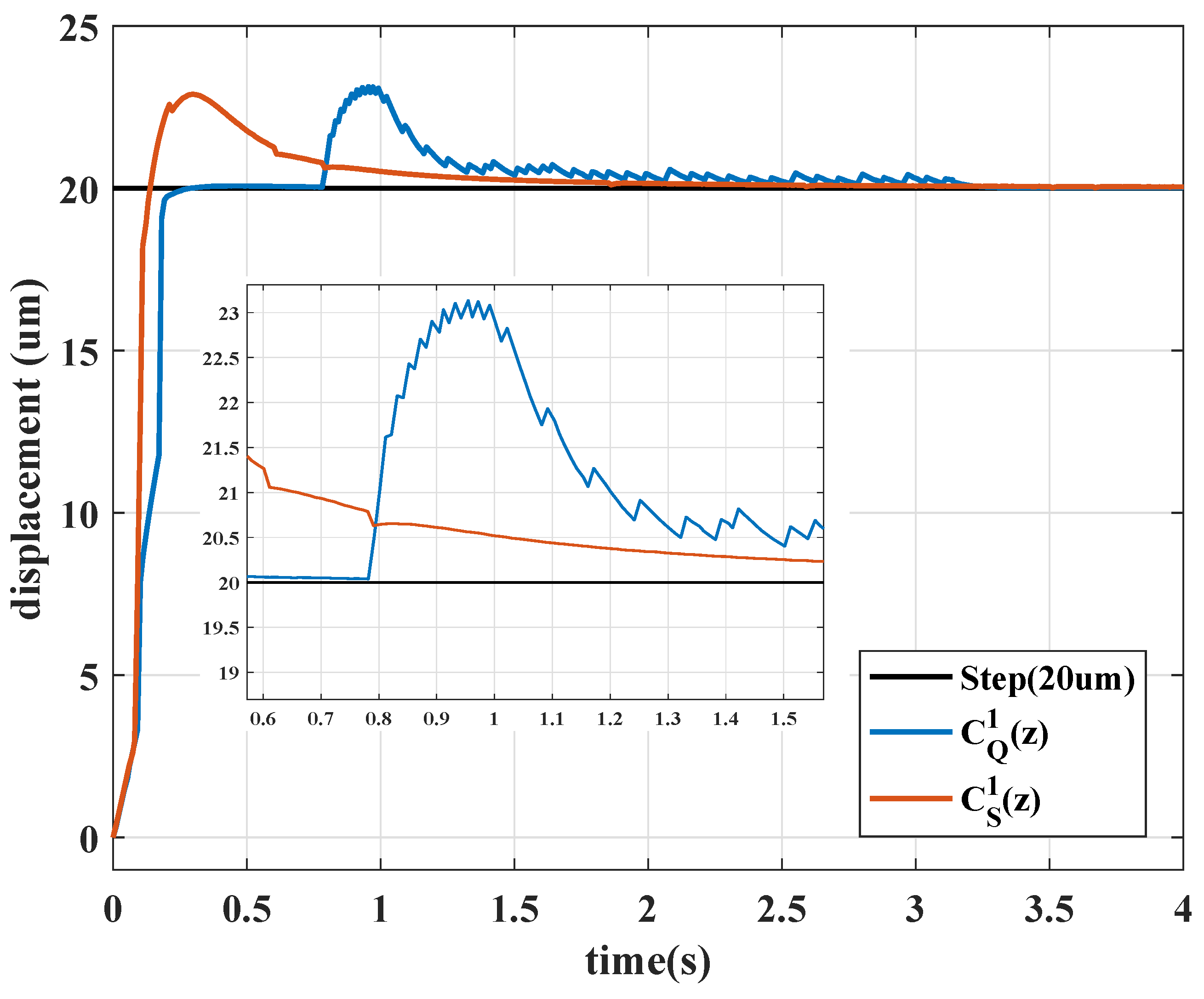
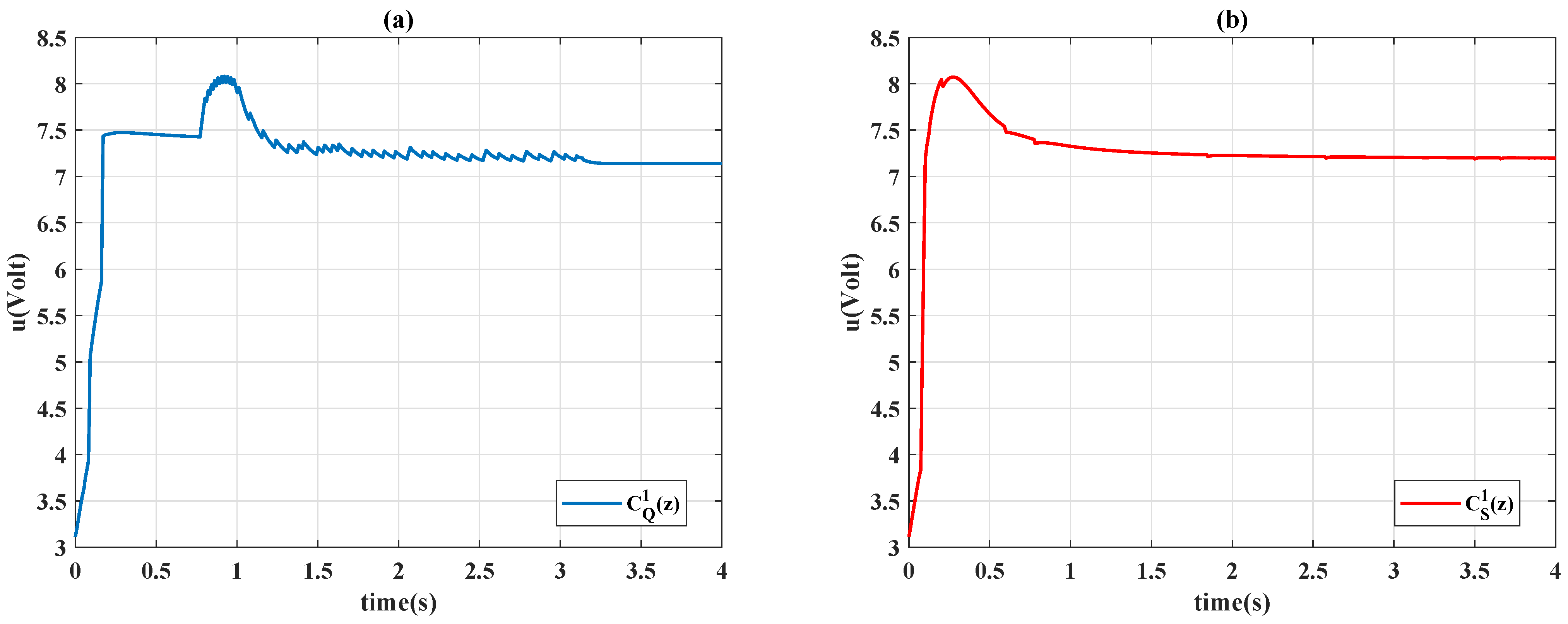
Figure 4.
Remark 3. In this paper, the only state S of Algorithms 1 and 2 is the error signal ; therefore, the condition "S is terminal" for the algorithms is naturally satisfied for each step, and only one decision is made for each episode since the concept of n-armed bandit is employed.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}