1. Introduction
Motors are widely utilized as the main power source in modern industries, and can be roughly classified into two types: direct current (DC) and alternating current (AC) motors. DC motors operate on the principle of basic magnetism, and the speed and torque are easy to control; however, DC motors have the disadvantages of high operation and maintenance costs. Furthermore, DC motors cannot operate under explosive and hazardous conditions because sparking occurs at the brush. Currently, AC motors are more widely utilized in industrial applications. AC motors can be classified into two parts: induction motors [
1] and synchronous motors [
2]. This study analyzes permanent magnet synchronous motors (PMSMs). Because of the advantages of high power density, high reliability, and low motor volume, PMSMs are used in computer numerical control (CNC) machines, electric vehicle drive systems, and robots. Field-oriented control (FOC) [
3] is a popular strategy for controlling AC motors. FOC decouples the torque and flux by transforming the stationary phase currents to a rotating d-q frame. By using the FOC method, the AC motor control challenge can be simplified to a DC motor control challenge.
The control accuracy of the motor directly affects the performance of the system. The literature [
4] indicates that the rotation speed and propulsive force are two important parameters in an air-borne bolting system. The breakage of the drill pipe and the inability of the drill bit to cut the coal adequately can be caused by the unreasonable rotation speed and propulsive force. In [
5], it was found that, to produce precision parts, precise rotational accuracy and a constant machine tool spindle speed are required. However, inevitable changes in the spindle speed caused by the cutting force will lead to low-quality surfaces. In addition, the rotation speed of the pin tool is an important controlled variable in friction stir welding machines [
6]. By controlling the rotating speed, a constant vertical force is obtained during the welding process.
Generally, the proportional derivative (PD), proportional-integral (PI), and proportional-integral-derivative (PID) are the most common controllers used to design the control system [
7,
8]. In addition, a few studies have proposed alternative algorithms for motor speed control. The literature [
9] proposes an on-line tuning fuzzy proportional derivative controller based on the equivalent errors to deal with the contouring control of robot manipulators. The results show that the controller can effectively deal with highly non-linear dynamic systems following an analytic/non-analytic path. A hybrid fuzzy-PI controller is proposed to address the challenges of chattering effects and large execution times [
10]. Nonlinear controllers such as feedback linear control [
11], sliding mode control [
12], and adaptive control [
13] are presented. In addition, model prediction control has been successfully used for the current and torque control of motors [
14,
15]. However, the aforementioned algorithms require precise knowledge of the nonlinear model of the motor, which is difficult to obtain.
This study adopts the particle swarm optimization (PSO) and deep deterministic policy gradient (DDGP) algorithms to address the motor speed tracking challenge. In 1995, the PSO algorithm was proposed by Kennedy and Eberhart [
16]. The PSO algorithm is inspired by the intelligent collective behavior of some animals, and is initialized with a group of random particles, where each individual particle represents a single solution. The particles move through the search space to obtain the optimized solution. The movement direction and velocity of the particles are updated according to the local and global best solutions. Numerous studies have indicated that the PSO algorithm is a powerful optimization method used in various applications. In [
17], a learning model is used to determine the distance between the mobile sensor node and the anchor node. A PSO-based artificial neural network is proposed to improve the estimation accuracy. In contrast to the conventional optimization method of feed-forward backpropagation, PSO is utilized to update the weights of the network. In [
18], a PSO-based PID controller is proposed to address the position control of the hydraulic system. The PSO algorithm is utilized to tune the parameters of the PID controller, and the results indicate that the rising time, settling time, and integral time absolute error can be reduced. The literature [
19] reveals that the PSO algorithm can also be implemented in the field of control. In [
19], a PSO-IAC algorithm, integrated by the adaptive inertia weight and constriction factor, is proposed to increase the convergence velocity. The results indicate that the challenge of reaching the avoidance problem can be addressed. A PSO, combined with a radial basis function neural network, is proposed to deal with the pitch control of a wind turbine [
20]. In addition, a graphical approach is utilized to visualize the 2D or 3D boundaries of the PID controller. Under the delay time effects, the stochastic inertia weight PSO can effectively handle pitch control.
Recently, machine learning has become a popular technique. Generally, unsupervised learning [
21], supervised learning [
22], and reinforcement learning [
23] are the three main types of machine learning strategies. First, unsupervised learning is typically utilized in the fields of data clustering and dimensionality reduction. It does not require a complete and clean labeled dataset, such as principle component analysis [
24], autoencoder [
25], and t-SNE [
26]. Supervised learning deals mainly with classification and regression problems. It requires well-labelled dataset, such as a convolutional neural network [
27], long short-term memory [
28], and random forest [
29]. In addition, in the literature [
30], a two-layer recursive neural network was used to approximate a motor model, and the network was considered to be a motor speed predictor.
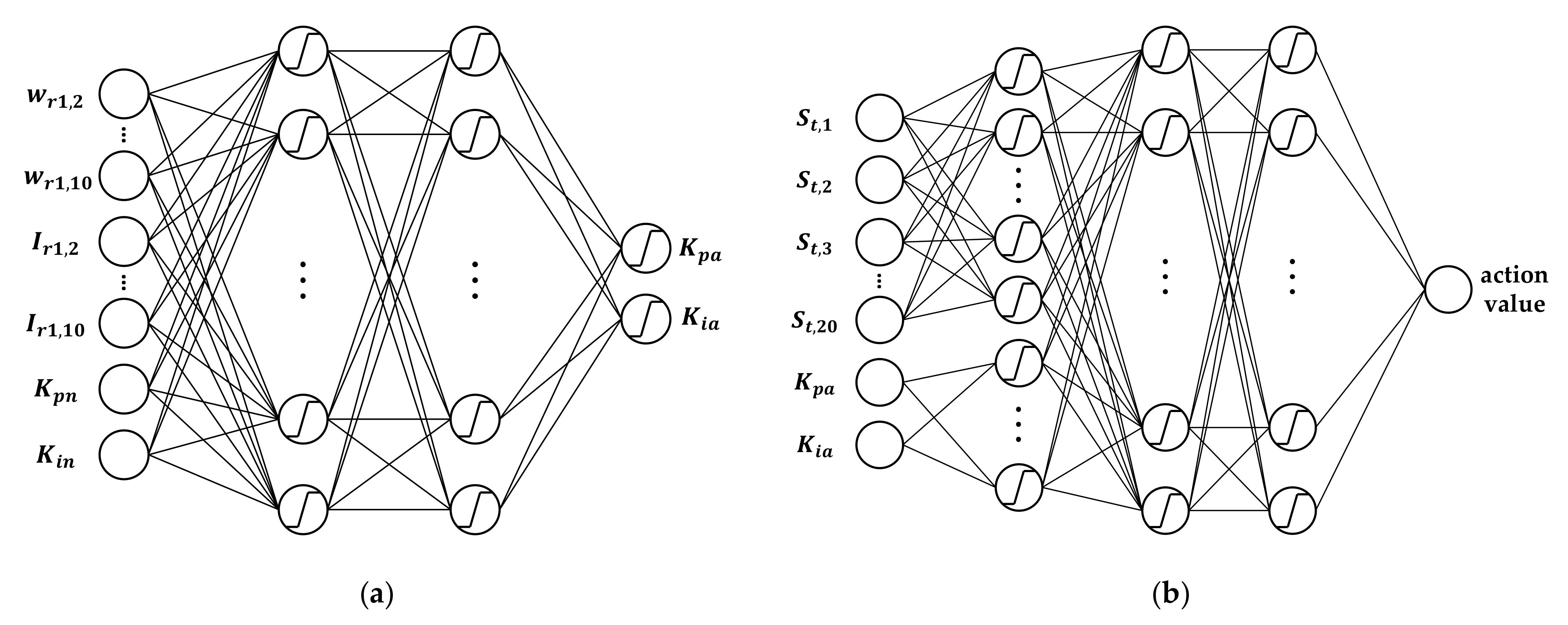
Reinforcement learning is a framework for learning the relationship between states and actions. Ultimately, the agent can maximize the expected reward and learn how to complete a mission. Q-learning [
31] and deep Q network (DQN) [
32] are common value-based reinforcement learning algorithms. The policy usually takes the largest action with the largest action value. For the DQN, the Q table is replaced by a deep neural network to estimate the action value. Experience replay is utilized to break the correlations between the samples, which prevents the agent from overfitting to the sequence of training. In [
33], unlike the conventional control method, the complex nonlinear model of the PMSM does not need to be known. A DQN-based controller is proposed to control the direct torque of the PMSM; however, DQN can only deal with discrete and low-dimension action spaces. In contrast to value-based learning, policy-based learning uses a stochastic policy that gives the probability of action in a specific state. The policy gradient [
34] is a basic policy-based learning algorithm. The advantage of policy-based learning is that it can effectively deal with high-dimensional and continuous action spaces; however, the learning methods tend to converge to the local optima. To improve the performance of reinforcement learning, DDPG [
35], TD3 [
36], and SAC [
37], combining Q-learning and policy gradient algorithms, are proposed. In [
38], DDPG is used to solve the road-keeping challenge. The agent can determine the steering angle of the vehicle by observing the distance between the vehicle and the road boundaries. In [
39], an optimal torque distribution control for multi-axle electric vehicles with in-wheel motors is proposed. The DDPG algorithm can optimize the drive torque for each motor to reduce the energy consumption of the vehicle.
The contributions of this paper are as follows:
This paper proposes an online-learning DDPG with the PSO method to control the motor speed under a load disturbance.
The PSO algorithm is used to find a sub-optimized solution of the PI controller using an approximate motor model. To safely train the model online and converge faster, the sub-optimized solutions are added into the policy function of the DDPG as a constraint.
The proposed network is a model-free method; hence, a precise mathematical model of the motor is not required for speed control.
The proposed model can deal with the delay problem as well.
The experimental results demonstrate that the proposed method can effectively reduce the settling time and overshoot of the speed response when a load disturbance occurs. Furthermore, the results indicate that the proposed method performs better than the conventional PSO and PI controllers.
The remainder of this paper is organized as follows.
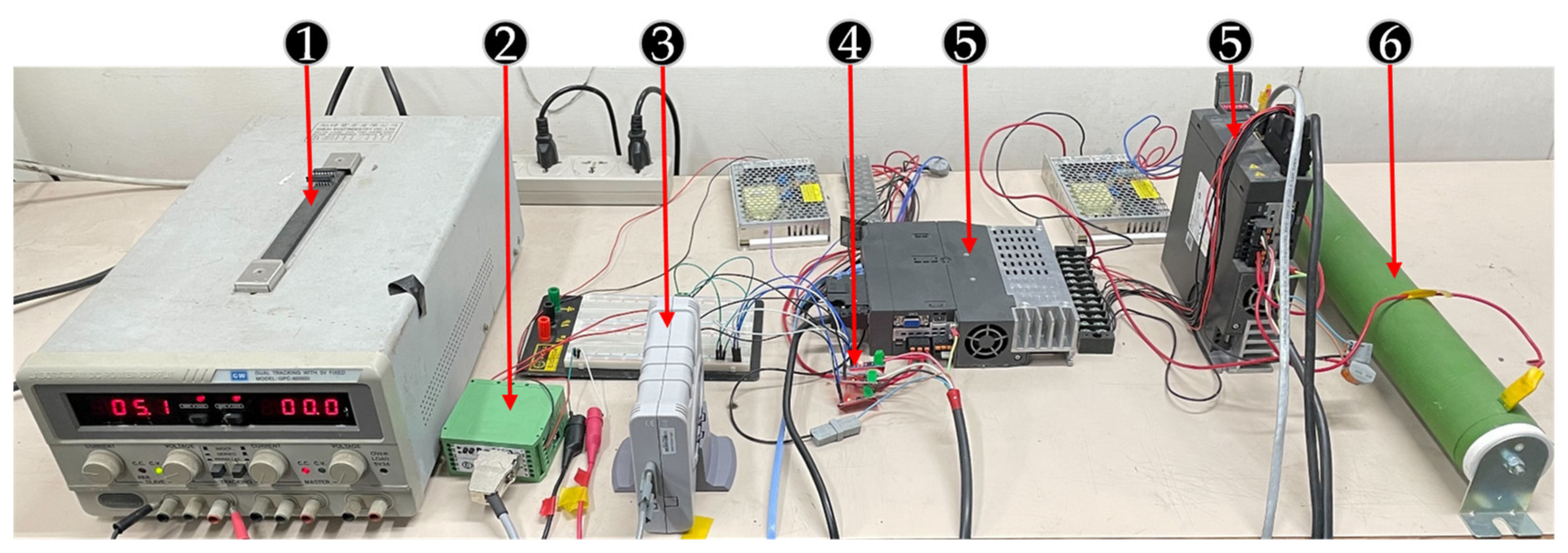
Section 2 presents the structure of the motor testing platform.
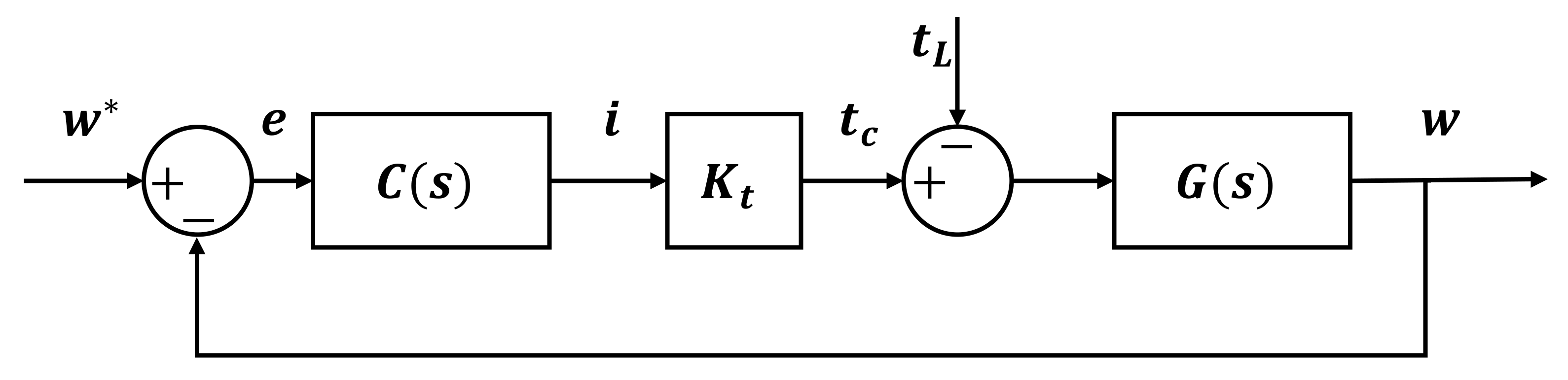
Section 3 describes the methodology, in which the formulation and implementation of the system and reinforcement learning solution are discussed in detail. In
Section 4, the experimental results obtained from a real platform are presented. The experimental results indicate that the proposed method can effectively handle speed tracking control.
Section 5 concludes this study.
4. Experimental Results
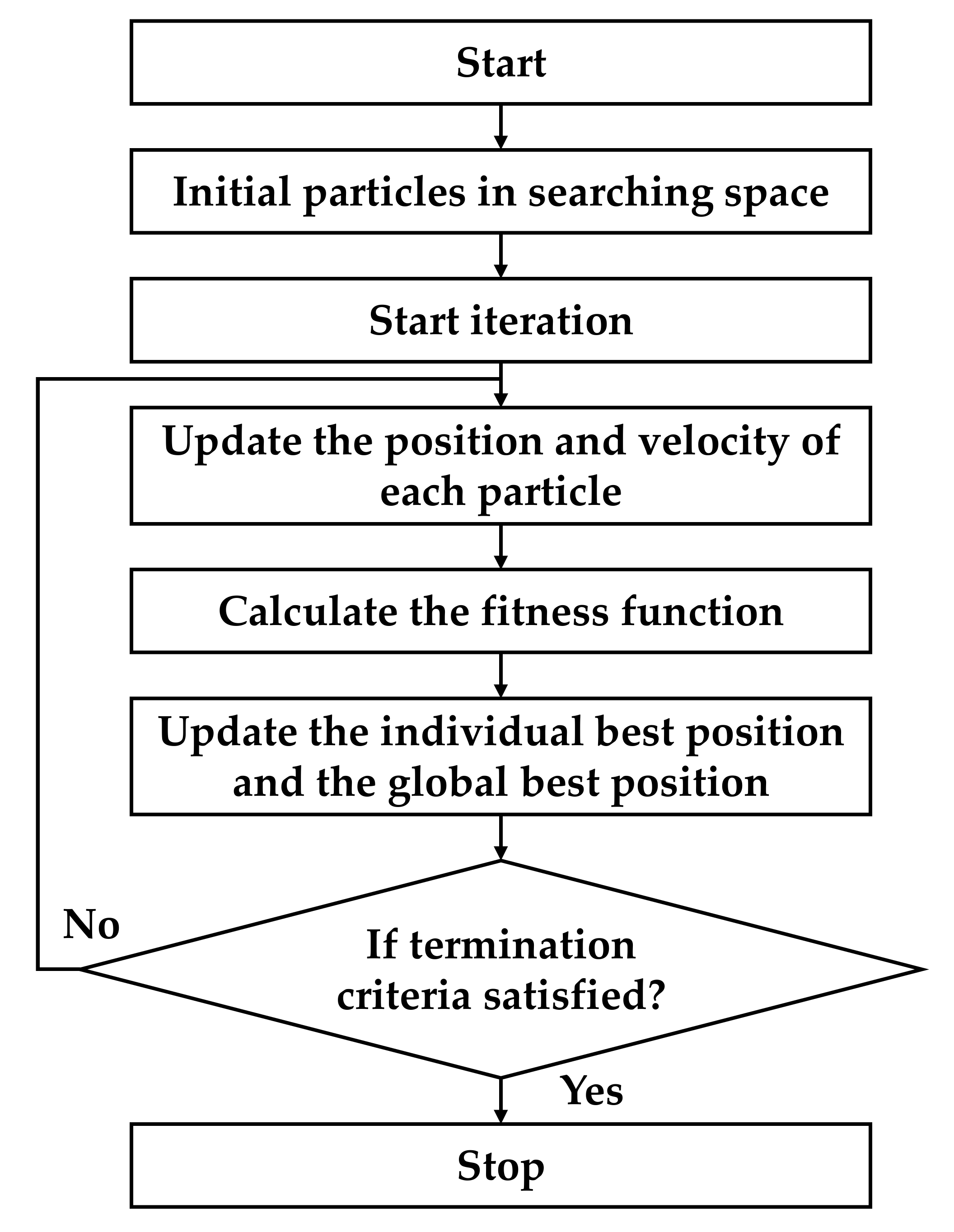
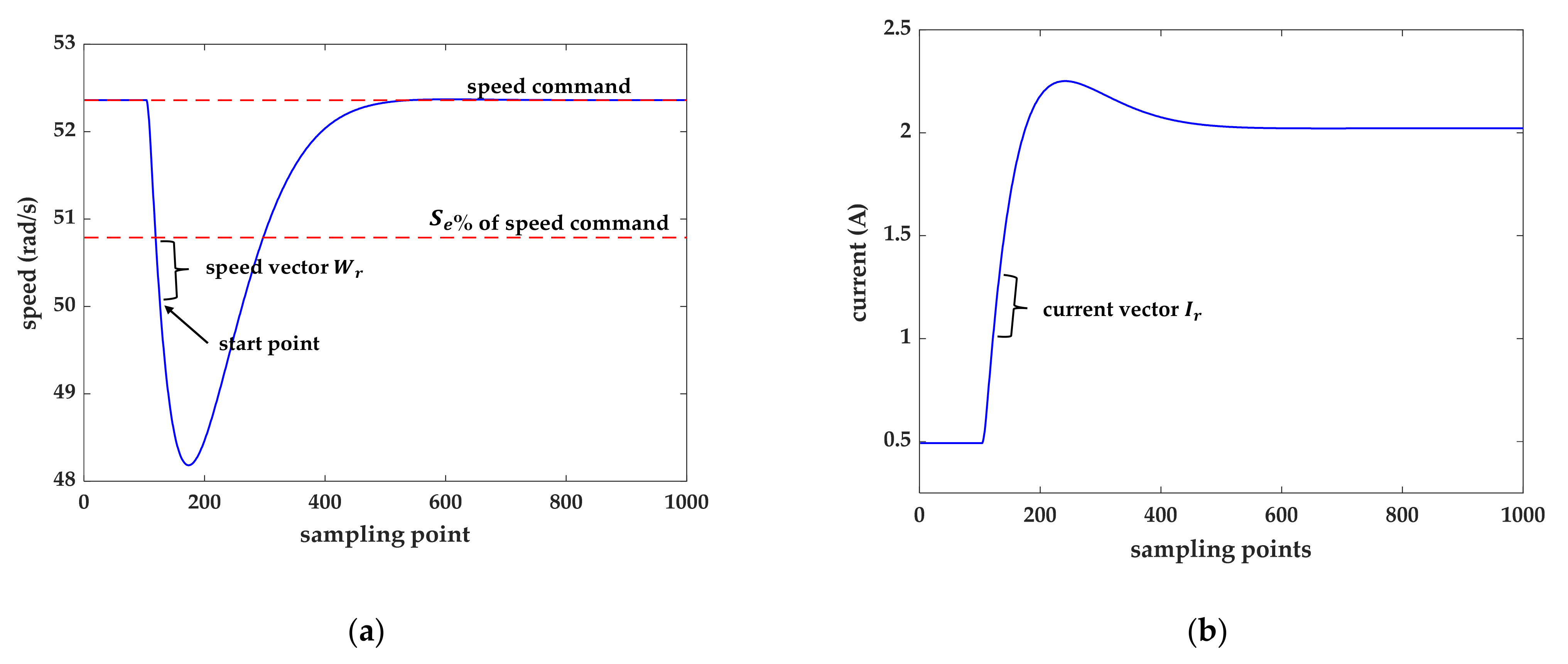
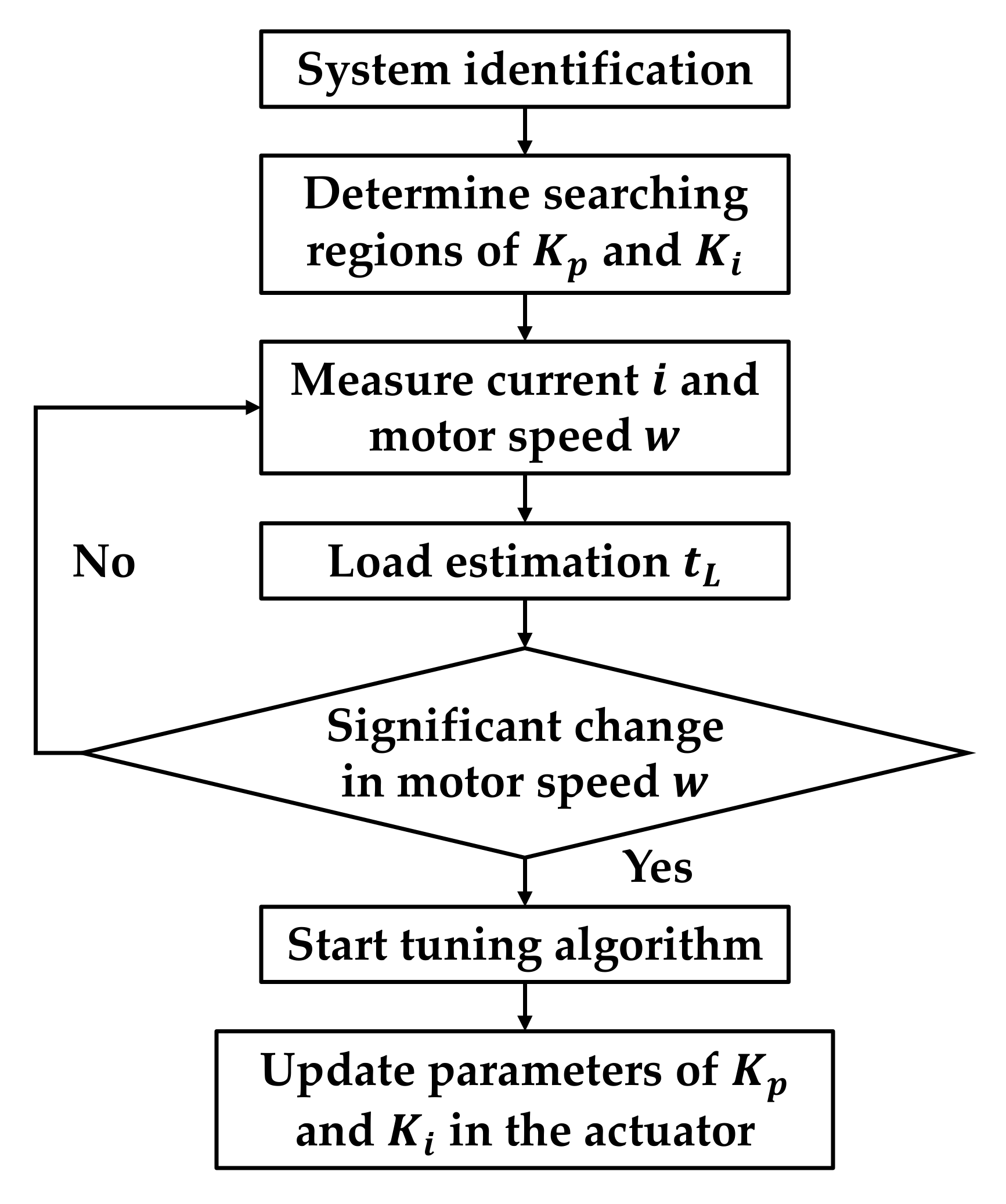
In this section, the results of the experiment are discussed. The flowchart of the proposed online tuning method is shown in
Figure 8. First, the approximate model of the motor was obtained by the system identification. To verify the stability of the system, the Routh–Hurwitz [
49] stability criterion was used. Afterward, the searching regions of
and
could be determined. By using the Hall sensor and speed sensor, the current signal and the motor speed could be acquired. When a significant change happened in the motor speed, the tuning algorithm started. In this study, three tuning methods, including the fixed method, PSO algorithm, and DDPG, were compared. Finally, the desired parameters of
and
could be obtained and updated in the actuator.
4.1. System Description and Stability
The motor system was considered to be a two-order transfer function, which is shown in Equation (1). By measuring the three-phase current and the output speed, and using the MATLAB system identification toolbox, the coefficients of
,
,
, and
were found to be 4.4720
, 1.0181, 3.9129, and 886.21519, respectively. To confirm the performance of the system identification process, motor under settings of
and
were tested.
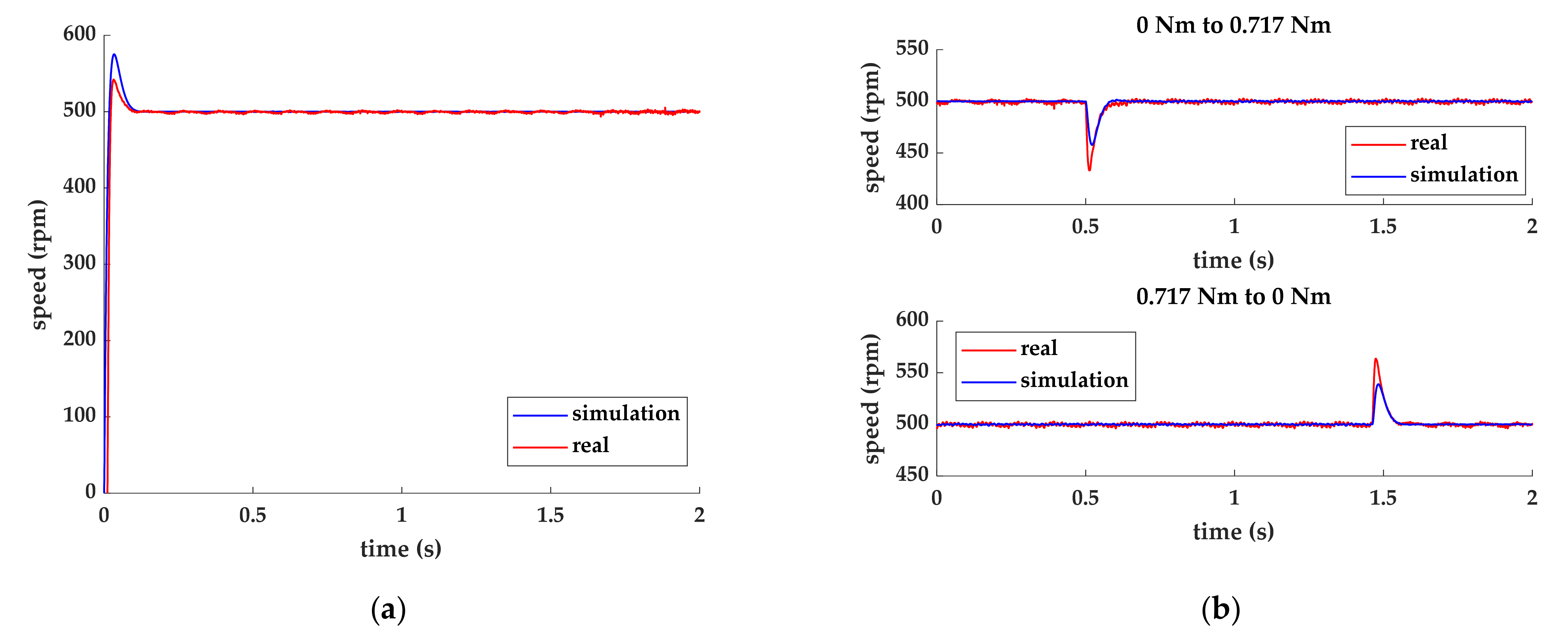
Figure 9a illustrates the transient and steady state response under the command speed of 500 rpm. In addition,
Figure 9b shows the speed response to load disturbance. The results show that the settling times of the approximate model and the real motor were similar. However, different amounts of overshoot and undershoot were found to exist. In
Figure 9a, it can be seen that the overshoots of the simulation and real motor were 15.0% and 8.4%, respectively. In
Figure 9b, when adding a load to the motor, the undershoot of the simulation and real motor were found to be 8.4% and 13.4%, respectively. However, when releasing the load, the overshoot of the simulation and real motor were observed to be 7.7% and 12.7%, respectively.
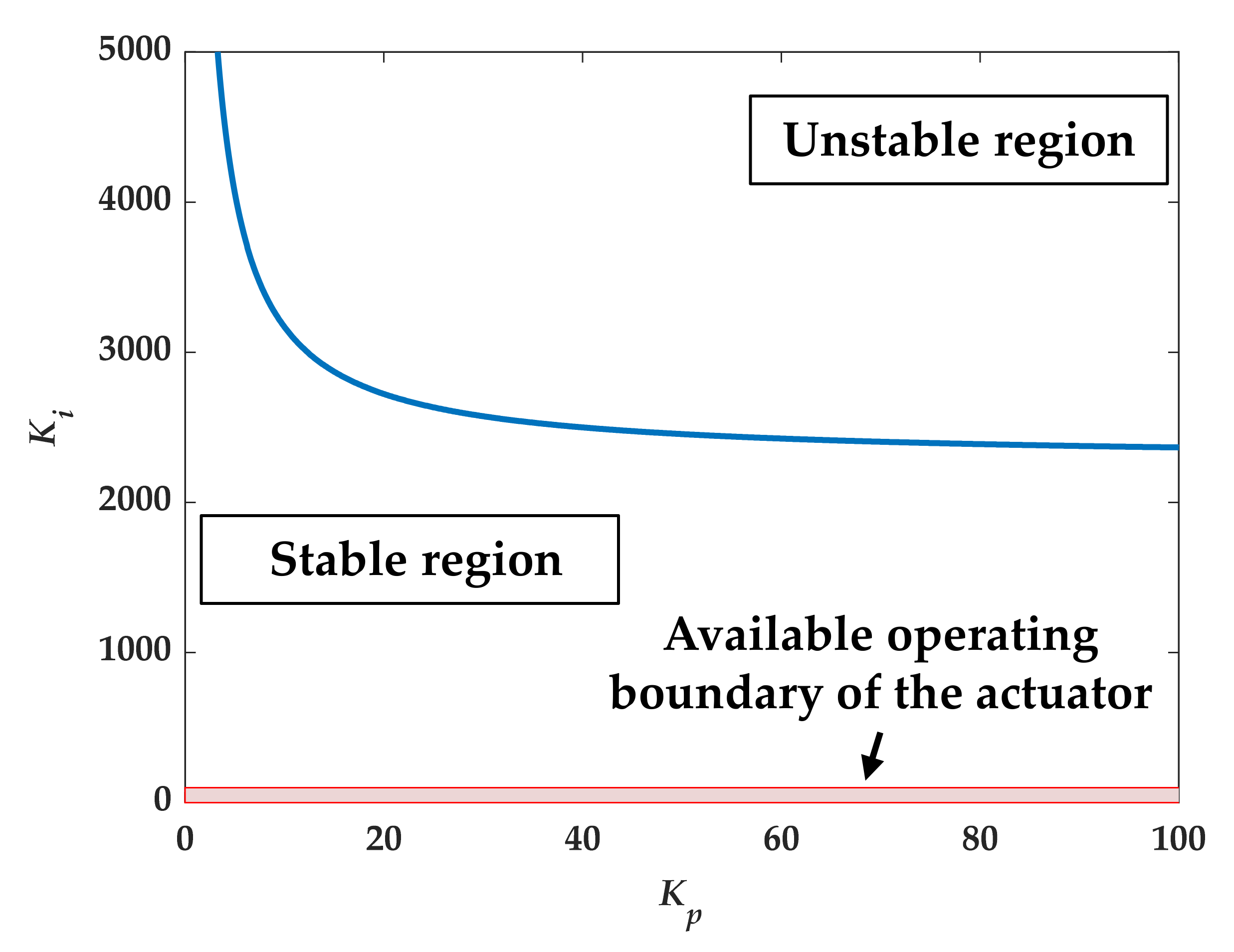
In order to implement the online learning method, the stability of the system needed to be considered. Inappropriate tuning parameters would cause the system to be unstable. According to the Routh–Hurwitz criterion, the stable boundaries of
and
that cause the system to be stable were calculated and are shown in
Figure 10. The positive area below the blue curve is the stable region. As mentioned in
Section 3.4.2, the available setting ranges of
and
of the actuator were [0, 500] and [0, 100], respectively. The available operating area, the red boundary, is shown in
Figure 10. All the operating area was in the stable region. Hence, the settings of the actuator were all allowed.
4.2. Online-Tuning Results
The experiment was divided into four stages representing the load conditions of 0
0.717 Nm, 0.717
0 Nm, 0
0.717 Nm, and 0.717
0 Nm, respectively.
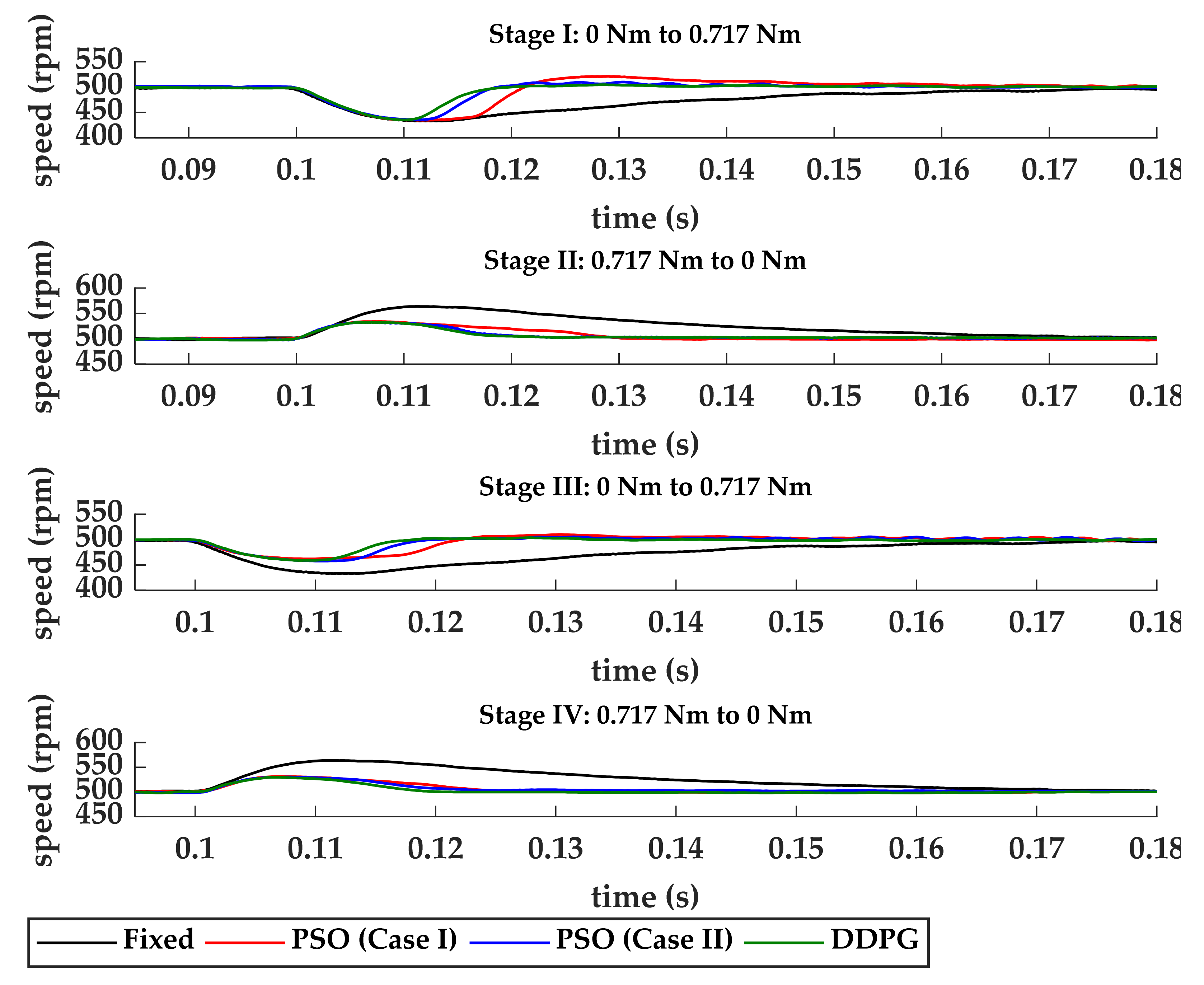
Figure 11 shows the comparison of the four methods. As shown in
Figure 11, using fixed values of
and
, the settling time, undershoot and overshoot were about 100 ms, 13.4%, and 12.7%, respectively. To improve the performance of the time response, PSO tuning method is first discussed. Two parameter settings of PSO algorithm are shown in
Table 5.
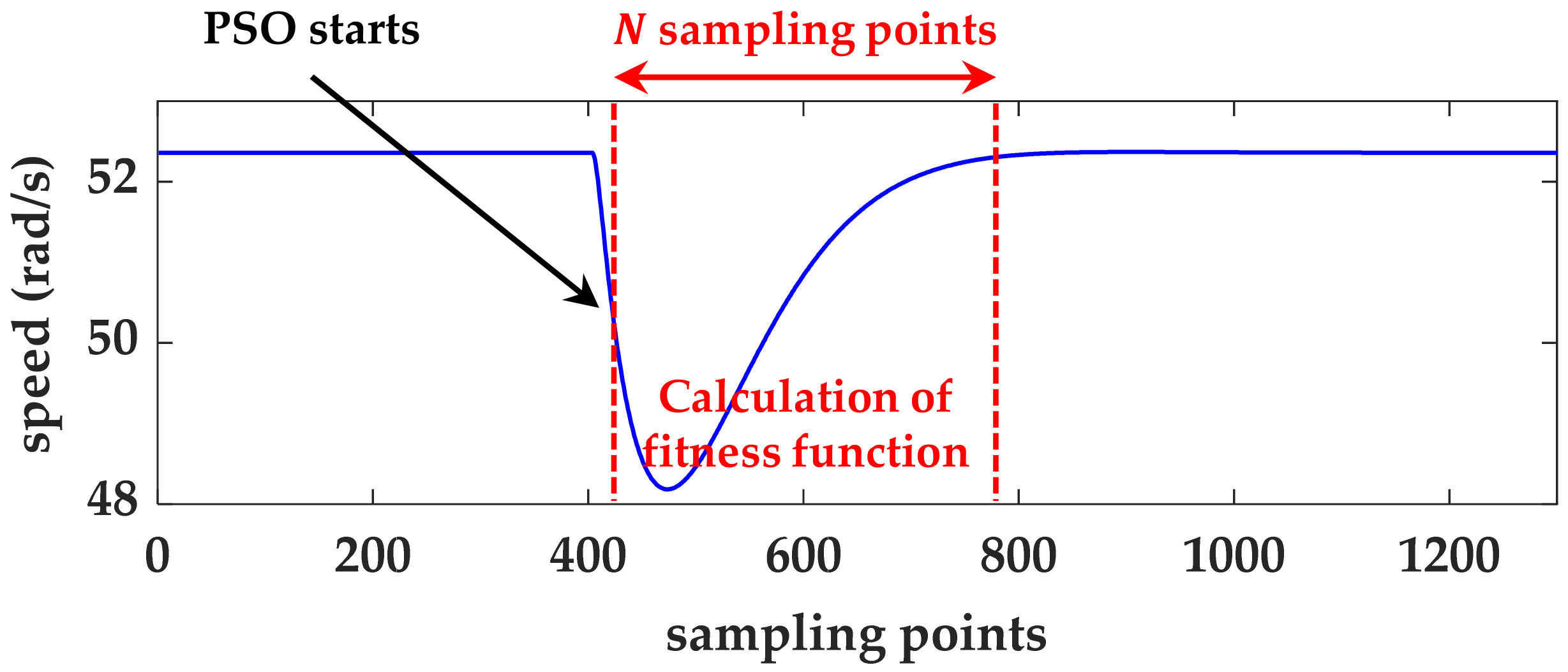
In Case I, when twenty continuous sampling points of the rotating speed was lower than 97% of the command speed, the PSO tuning method started. To calculate the fitness equation as shown in Equation (15), 300 sampling points of the speed response after the starting point were predicted by Equations (5) and (10). Subsequently, the sub-optimized solutions could be obtained and sent into the actuator.
First, for comparison with the fixed method, the values of and were initialized to 226 and 36. In stage I, the settling time could be improved from 100 ms to 58 ms. However, the undershoot did not undergo significant change, and was about 13%. In stage II, the settling time was decreased to 39 ms, which was 61 ms better than that of the fixed method. Moreover, the overshoot was decreased to 6.8%. To confirm the performance of the motor encountering the same load conditions, stages III and IV were conducted. In stage III, the settling time and undershoot were 34 ms and 7.6%, respectively. Because the values of and had been tuned, a better ability to compensate the current is shown. In stage IV, the settling time was 34 ms, and the overshoot was 6.26% which was 0.54% better than that in stage II. The results suggest that the performance of the time response was improved. However, the tuning results were affected by the computational consumption and delay time. In stage I, the real tuning point was operated after the lowest point, which was far from the start point. The delay time caused the solutions determined by the PSO algorithm to be sub-optimized solutions. In Case I, the PSO algorithm took about 2 ms to yield the solutions. In addition, the delay time of communicating with the actuator was about 10 ms. The results show that the time consumption is an important issue.
In order to minimize the influence of computational time and delay time, some parameter settings were changed. In Case II, the threshold , error number , and the iteration number were modified to 98.5% and 5. By changing the settings, the calculation time of the PSO algorithm was reduced to 1 ms. A lower value of led the tuning method to be more sensitive to the speed error; however, it made the start point move forward by about 2.5 ms.
In stage I, the settling time was about 28 ms, which was 22 ms better than that of Case I. However, the change of the settings did not make great improvement on the undershoot. In stage II, the settling time was decreased to 20 ms. Furthermore, the overshoot was decreased to 6.4%. In stage III, the settling time and undershoot were 19 ms and 8.3%, respectively. In stage IV, the settling time was 22 ms, and overshoot was 6.26%. The results show that, by reducing the processing time, some parts of the performance could be improved.
To deal with the delay time problem and imprecise mathematical model, DDPG model-free reinforcement learning was used to train online. By observing the experimental results of Cases I and II, the values of
and
were set to 98.5% and 10 in the Cases of DDPG. In addition, the TensorFlow Lite technique was utilized to accelerate the prediction process without losing accuracy. The prediction time could be reduced to 0.03 ms, which was about 300 times smaller than that of Case II. As illustrated in
Figure 11, when a load was added to the motor, the DDPG method could provide the best current compensation. The settling times in stages I and II were 18 and 16 ms, which were the smallest values in each Case. When releasing the load, in stages II and IV, the settling times were 20 ms and 18 ms, respectively.
Table 6 list the values of settling time, undershoot, and overshoot of each method. The fixed value settings obtained from the Delta actuator performed the worst. For the undershoot and overshoot, the other three methods had similar performance. However, for the settling time, the proposed method had the smallest values.
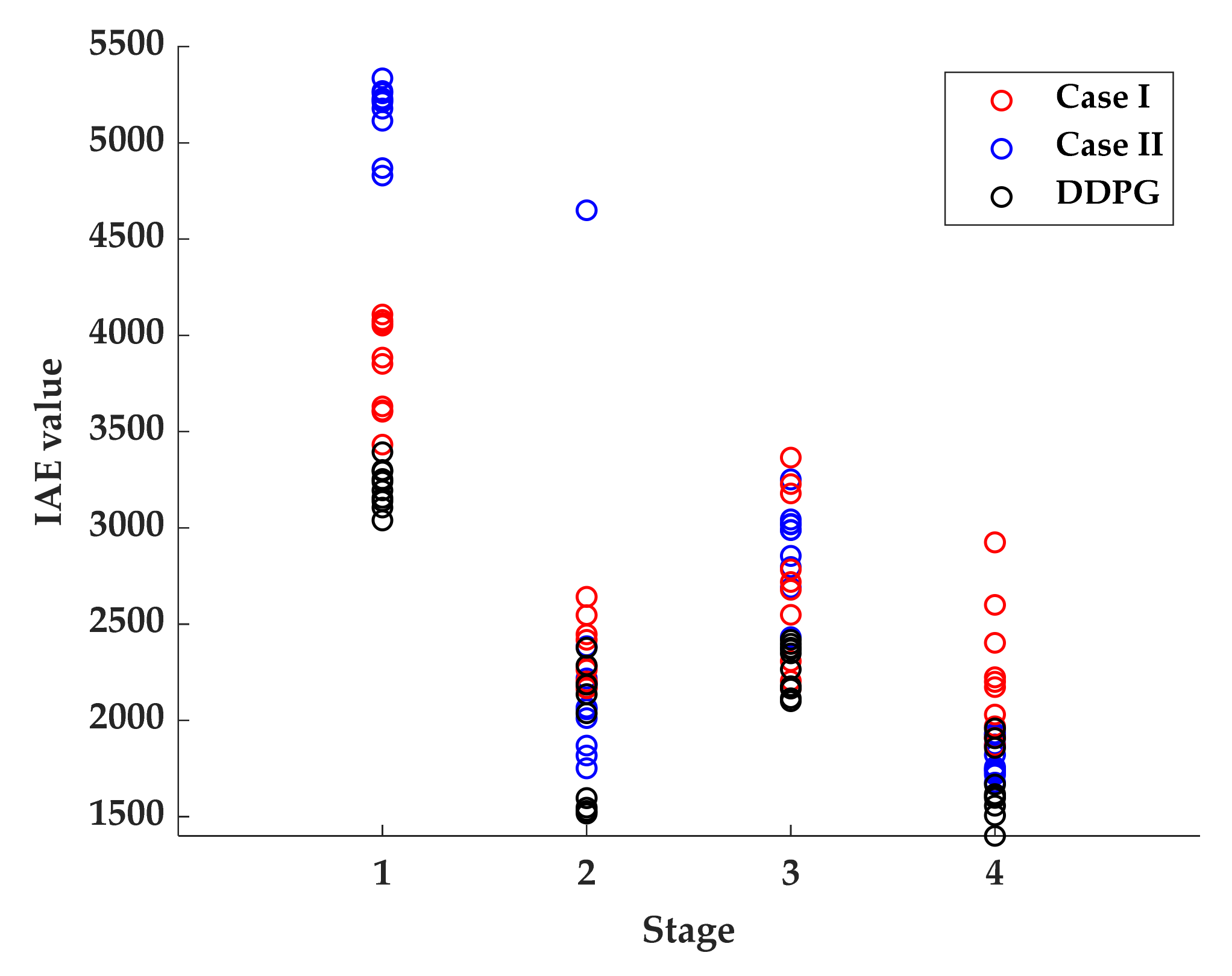
Figure 12 shows ten experimental results of the IAE calculation in different stages for each method. In Case I, the average IAE values of each stage were 5151.84, 2305.85, 2908.35, and 1792.76, respectively. In Case II, the average IAE values of each stage were 3831.83, 2333.24, 2718.14, and 2230.39, respectively. Generally, in stage I, the tuning results of Case II were better than those of Case I. Because the starting point was moved forward and the calculation time was decreased, the solutions of
and
could operate at a more suitable point. In stages II and III, the average IAE values were similar. In stage IV, the tuning results of Case I were better than those of Case II. Furthermore, in Case I, the standard deviations of each stage were 169.69, 205.41, 277.11, and 89.92, respectively. In Case II, the standard deviations of each stage were 246.02, 169.64, 429.51, and 322.51, respectively. The solutions of Case II were more separated, which was caused by the smaller number of iterations. However, some solutions determined by Case II were better than Case I.
The average IAE values of the proposed DDPG showed the best performance. Furthermore, according to the standard deviation of the IAE value, the solutions determined by the proposed DDPG were more converged, which is shown in
Figure 12.
Table 7 lists the average and standard deviation of the IAE value of the four methods. The experimental results show that the DDPG method combines the advantages of Cases I and II. The proposed method can learn the unknown model of the motor system and determine better tuning solutions for the load disturbance.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}