
Unified Human Intention Recognition and Heuristic-Based Trajectory Generation for Haptic Teleoperation of Non-Holonomic Vehicles


Abstract
:1. Introduction
- A bilateral shared teleoperation control scheme based on admittance is proposed to realize the HIR based on the HMM. Through solving the model and determining the model parameters, the identification results are finally used for trajectory generation;
- Based on the HIR, an online heuristic trajectory generation strategy is proposed to realize feasible and smooth online trajectory docking of vehicles in complex environments, and finally send the trajectory information to the vehicle motion controller;
- The bilateral shared teleoperation control scheme described in this paper realizes the balance between the autonomy of the system and the control right of the human. Under this framework, the human only needs to give high-level instructions, rather than low-level vehicle trajectory plan and control. In this process, the movement information of the vehicle is still transmitted to the human through the control handle in the form of haptic cues.
2. System Configuration
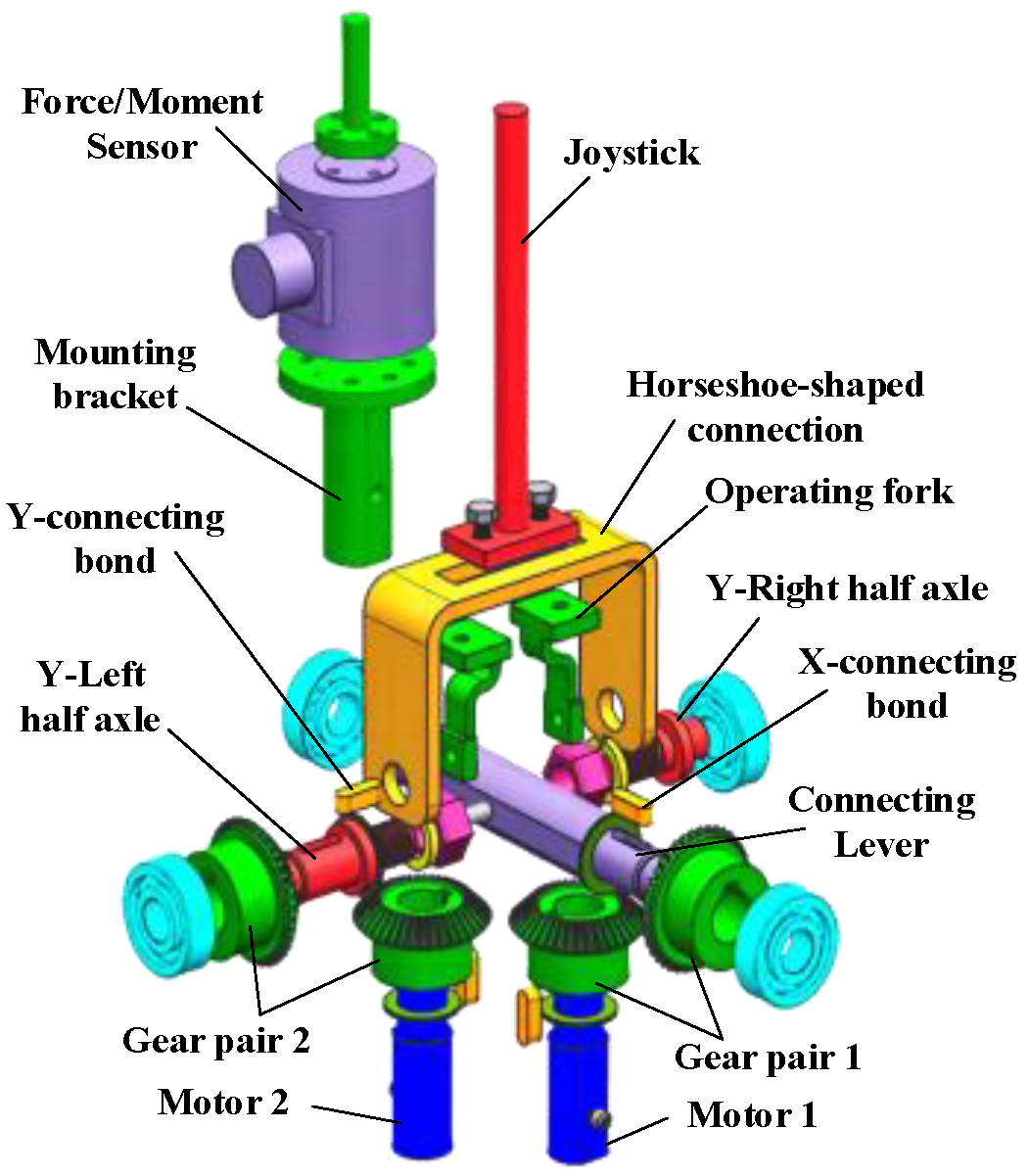
2.1. 2-DOFs Joystick Design
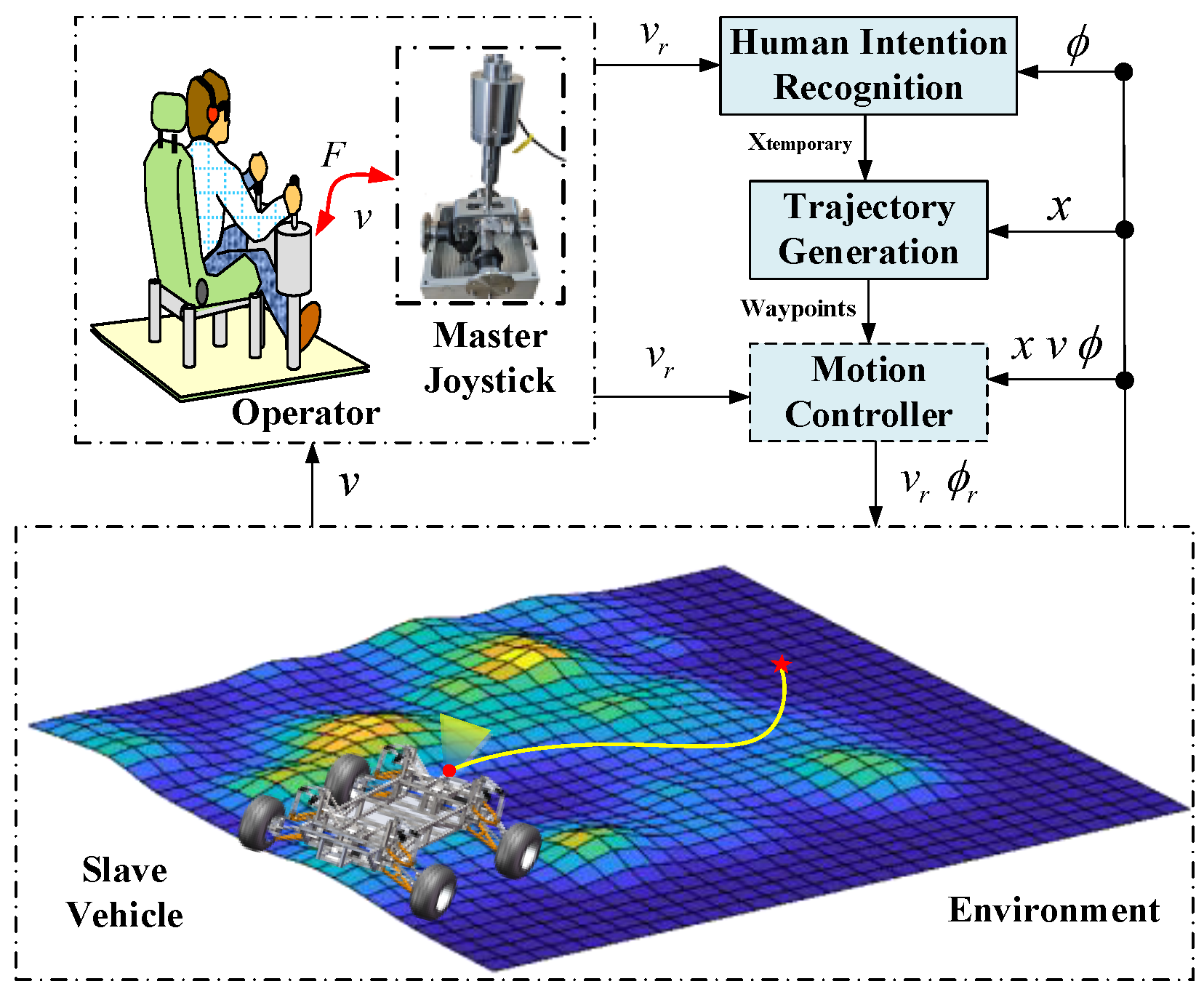
2.2. Bilateral Teleoperation Scheme with Haptic Cues
3. Human Intention Recognition
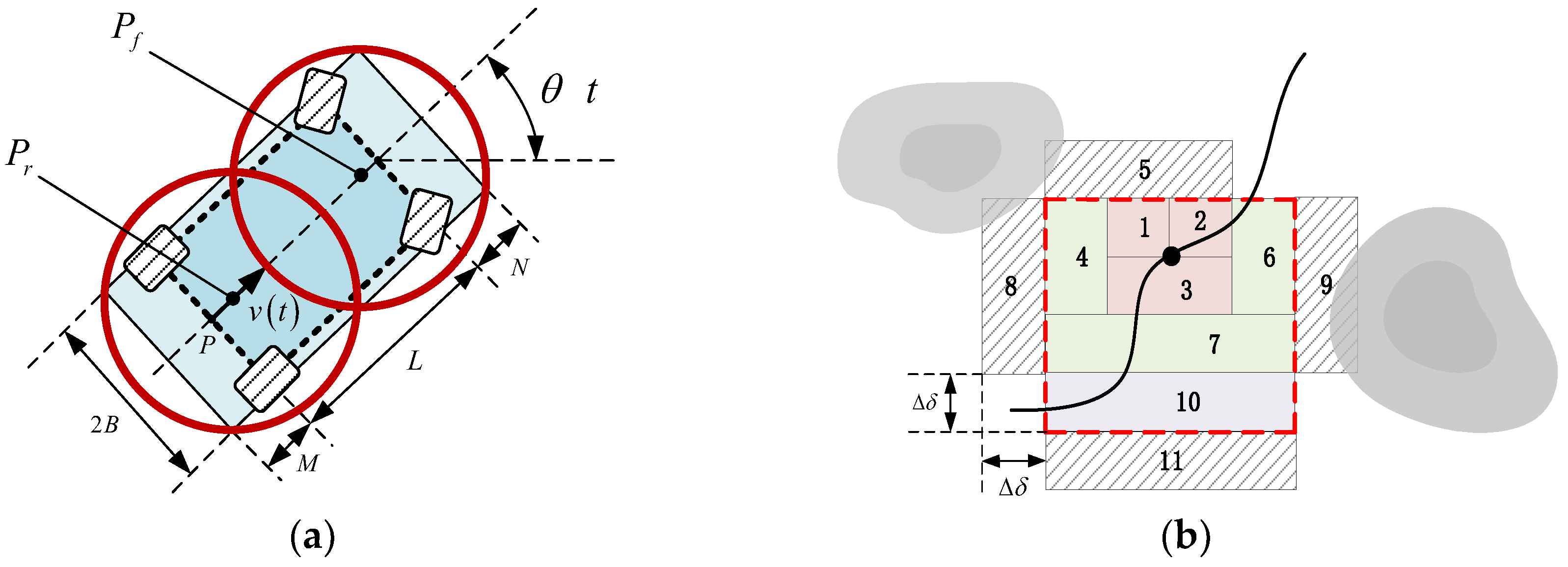
3.1. Human Intention Definition
3.2. Hidden Markov Model Principle
| Algorithm 1 Human intention estimation algorithm |
| \begin{minipage}{12cm} |
| \begin{algorithm}[H] |
| \begin{footnotesize} |
| \setcounter{algorithm}{0} |
| \caption{{\footnotesize Human intention estimation algorithm}} |
| \label{2} |
| \begin{algorithmic}[1] |
| \State Discretizing the human intention workspace into 8 parts equally |
| \State Initializing the hidden states probability matrix $\pi$ |
| \State Measuring a set of user force input $f_{h}(t)$ for model initialization |
| \State Compute $P(o_{1}|q_{1})$ using the Gaussian distribution law |
| \vspace{1ex} |
| \State $f(o_{i})=\frac{1}{\sqrt{(2\pi)^2|\sum|}}exp(\frac{1}{2}(o_{i}-\mu)^T\sum^{-1}(o_{i}-\mu))$ |
| \vspace{1ex} |
| \State Update the state-transition matrix $A$ |
| \State Compute the initial probability $P(q_{1}|o_{1})$ |
| \vspace{1ex} |
| \State $P(q_{1}|o_{1}) $\propto$ P(o_{1}|q_{1})P(q_{1})$ |
| \vspace{1ex} |
| \State Update the emission probability matrix $B$ |
| \State Using Baum-Welch algorithm to get $\lambda$ including $A$,$B$ and $\pi$, such that |
| \Repeat |
| \State Measure user force input $f_{h}(t)$ in real time and compute $o_{t}$ |
| \State Update the observation sequence $O_{t}$ |
| \State Time update: |
| \vspace{1ex} |
| \State $P(i_{t+1}=q_{j}|O_{t+1})=P(i_{t+1}=q_{j}|i_{t}=q_{i})P(i_{t}=q_{i}|O_{t})$ and update $A$ |
| \vspace{1ex} |
| \State Obsevation: |
| \vspace{1ex} |
| \State $P(i_{t+1}=q_{j}|O_{t+1}) $\propto$ P(o_{t+1}|i_{t+1}=q_{j})P(i_{t+1}=q_{j}|O_{t})$ and update $B$ |
| \vspace{1ex} |
| \State Find the intention state $q_{j}$ using Viterbi algorithm, such that |
| \vspace{1ex} |
| \State $j=\mathop{argmax}\limits_{1\le j\le N}{P(i_{t+1}=q_{j}|i_{t}=q_{i})}P(i_{t}=q_{i})$, $i_{t+1} \in Q $ |
| \vspace{1ex} |
| \State Pass the reference velocity $v_{r}$ and the hidden state $q_{j}$ to the trajectory |
| \State generator |
| \Until termination |
| \end{algorithmic} |
| \end{footnotesize} |
| \end{algorithm} |
| \end{minipage} |
3.3. HMM Identification
3.3.1. Baum–Welch Algorithm
- (1)
- E Step:
- (2)
- M Step:
3.3.2. Training Data Acquisition
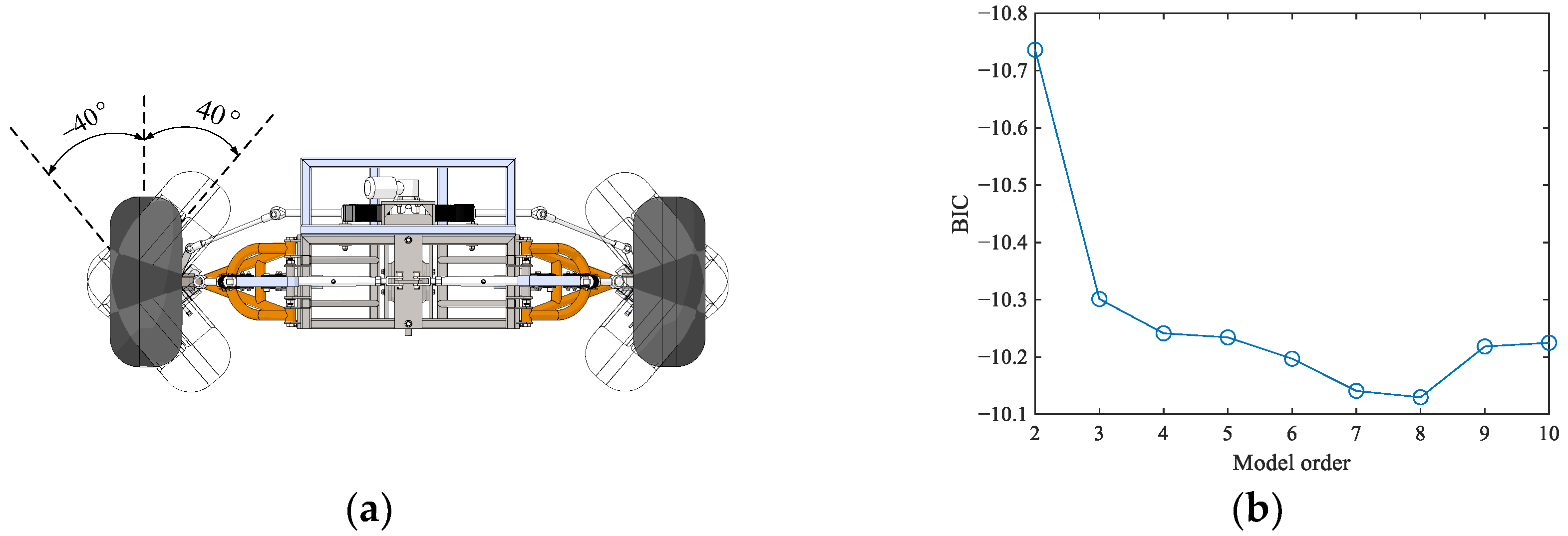
3.3.3. Hidden State Number Identification
3.3.4. HMM Training
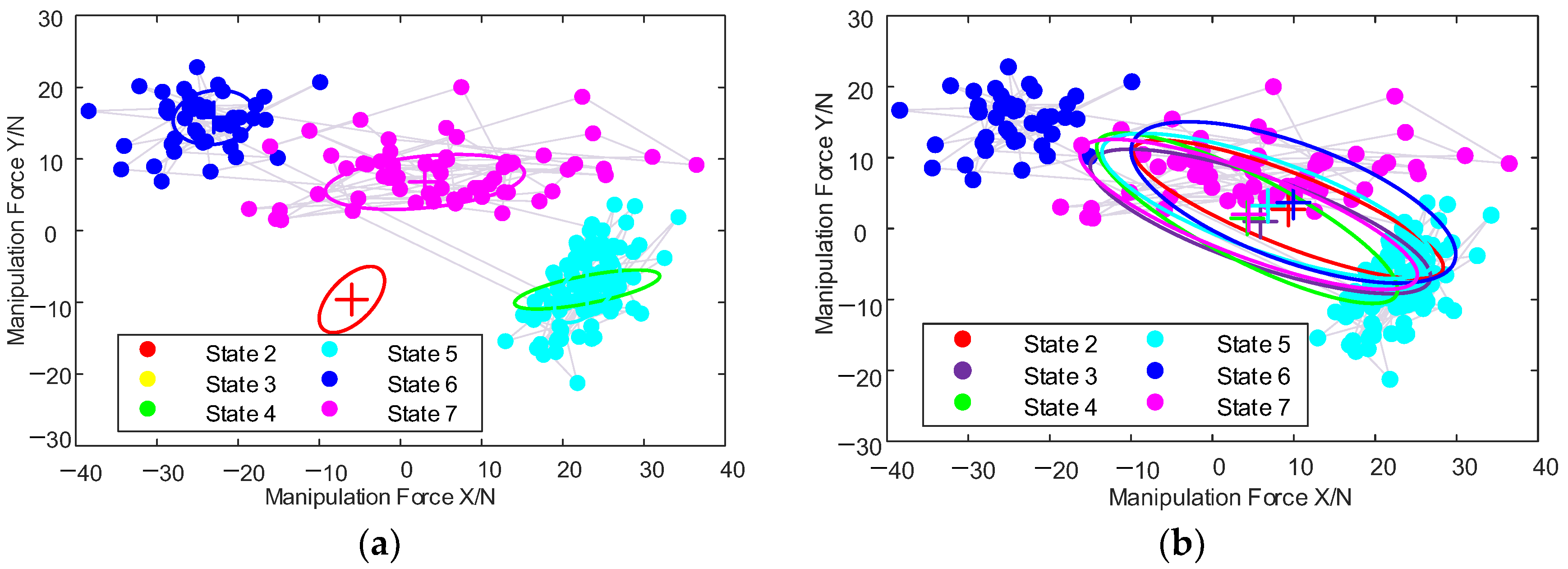
3.4. Human Intention Recognition
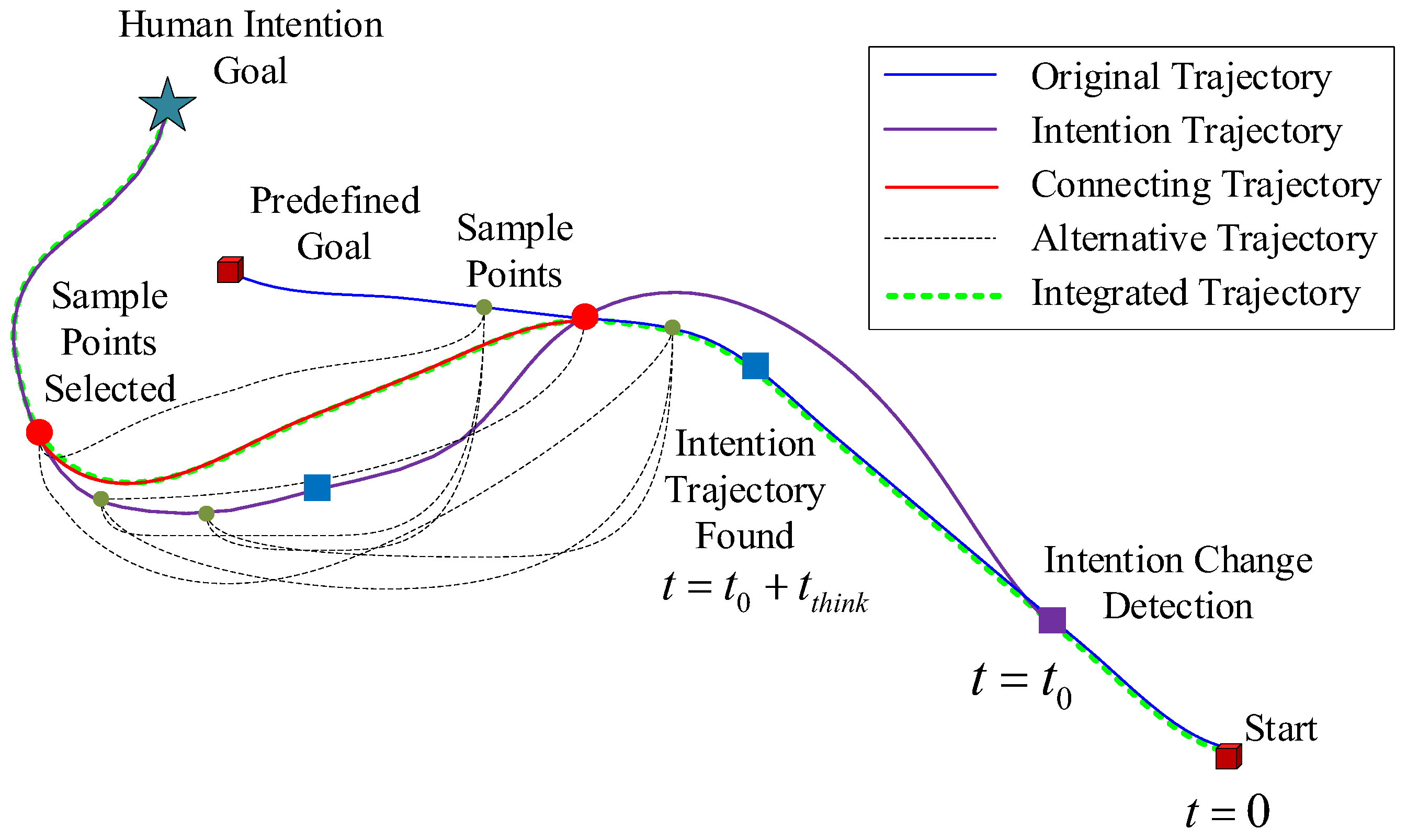
4. Online Heuristic Trajectory Generation Based on HIR
| Algorithm 2 Trajectory generation with human intention |
| \begin{minipage}{12cm} |
| \begin{algorithm}[H] |
| \begin{footnotesize} |
| \setcounter{algorithm}{1} |
| \caption{{\footnotesize Trajectory generation with human intention}} |
| \label{2} |
| \begin{algorithmic}[1] |
| \Require |
| A target position $X_{temporary}$ representing human intention, |
| intention change time $t_{0}$,obstacles $obs$,original trajectory $Traj_{original}$ |
| \Ensure |
| A collaborative trajectory $\varGamma(x,y,\theta,v,\phi,t_{f},a,\omega)$ |
| \State Identify $t_{0}$ and $X_{temporary}$ |
| \State Plan an Intention Trajectory by construct an optimal control problem |
| \State Initialize a set $\Upsilon = \emptyset $ for alternative trajectory |
| \For {each $i$ \in \lbrace1,...,$N_{original}\rbrace$} |
| \For {each $j$ \in \lbrace1,...,$N_{intention}\rbrace$} |
| \State Plan an alternative trajectory $Traj_{alternative}(t)$ from the pose |
| \State $Traj_{original}(t_{i}^{sample})$ to the pose $Traj_{intention}(t_{j}^{sample})$ |
| \State by solving an optimal problem |
| \If {the vehicle $footprints$ ($Traj_{alternative}(t)\notin $obs$ $)} |
| \State Put $Traj_{alternative}(t)$ into $\Upsilon$ |
| \EndIf |
| \EndFor |
| \EndFor |
| \State Initialize $Traj_{connecting} = +\infty$ |
| \For {each $Traj_{alternative}(t) \in \Upsilon$} |
| \State Construct an integrated trajectory $Traj_{integrated}$ and evaluate its cost |
| \State $J_{current}$ |
| \If {$J_{current-best}>J_{current}$} |
| \State Set $\varGamma$ \leftarrow $Traj_{integrated}$ |
| \State Set $J_{current-best}$ \leftarrow $J_{current}$ |
| \EndIf |
| \EndFor |
| \end{algorithmic} |
| \end{footnotesize} |
| \end{algorithm} |
| \end{minipage} |
5. Simulation Experiments
5.1. Experimental Configuration
5.2. Experimental Design
5.3. Experimental Results and Analysis
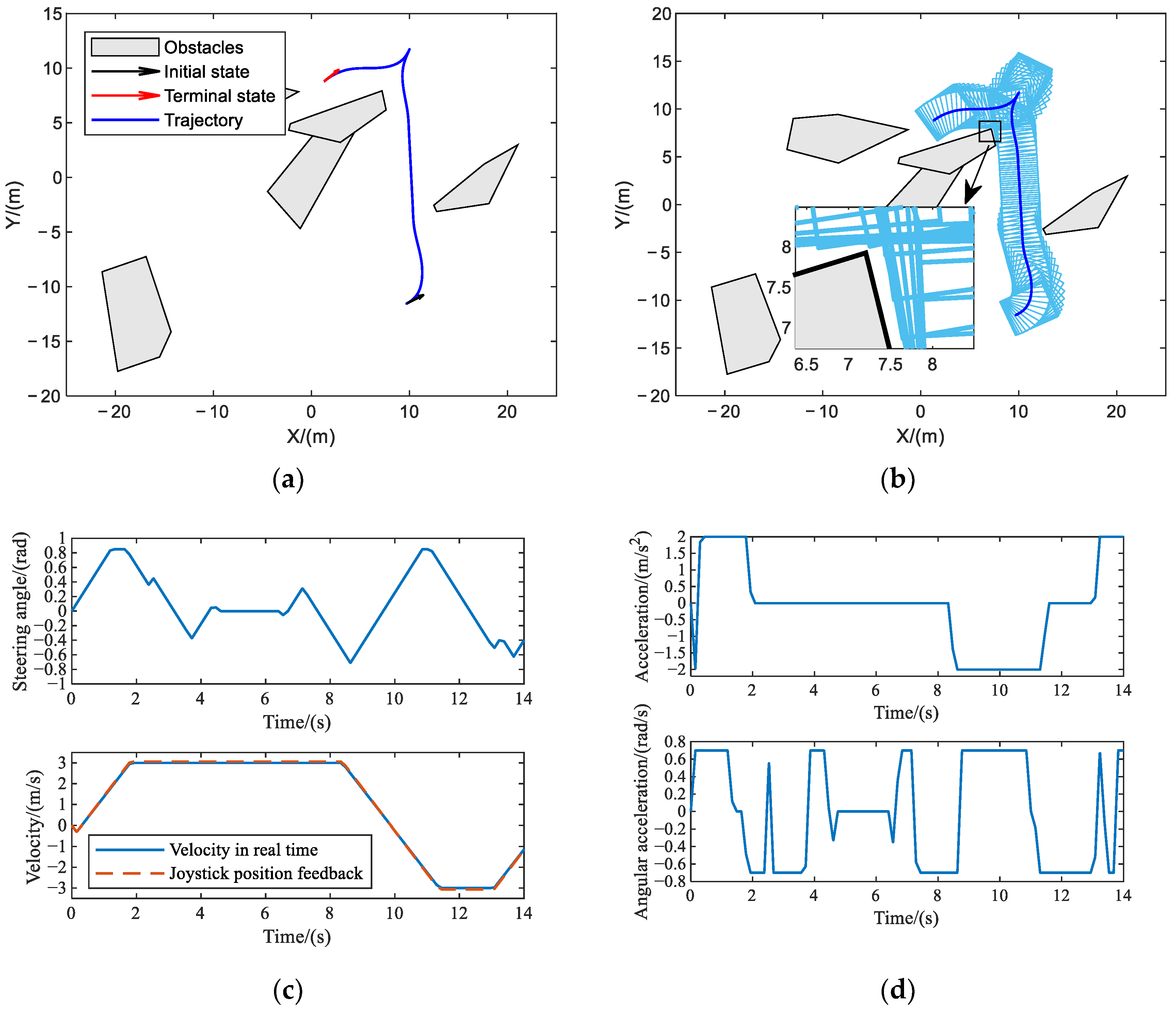
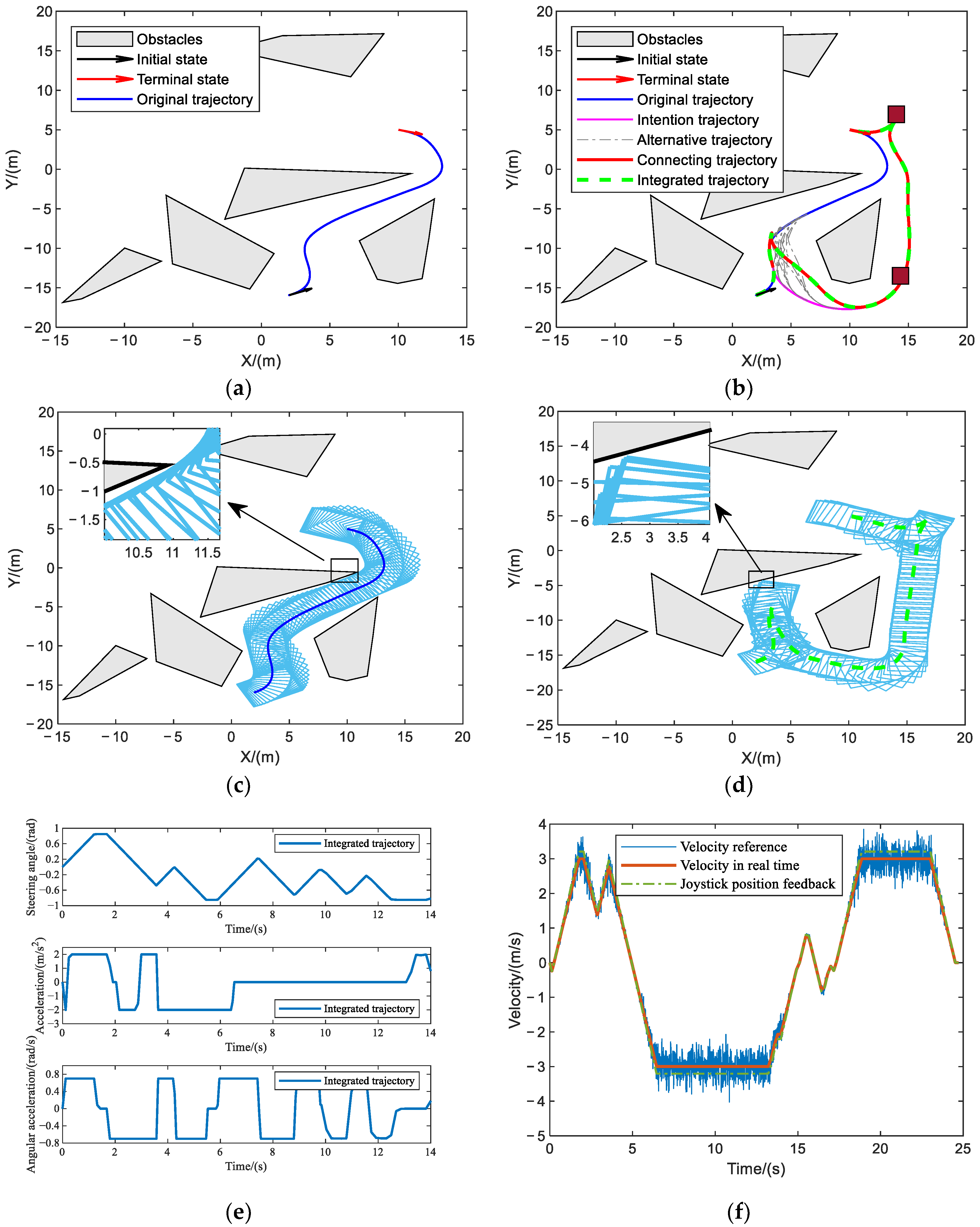
5.3.1. Obstacle Avoidance Verification
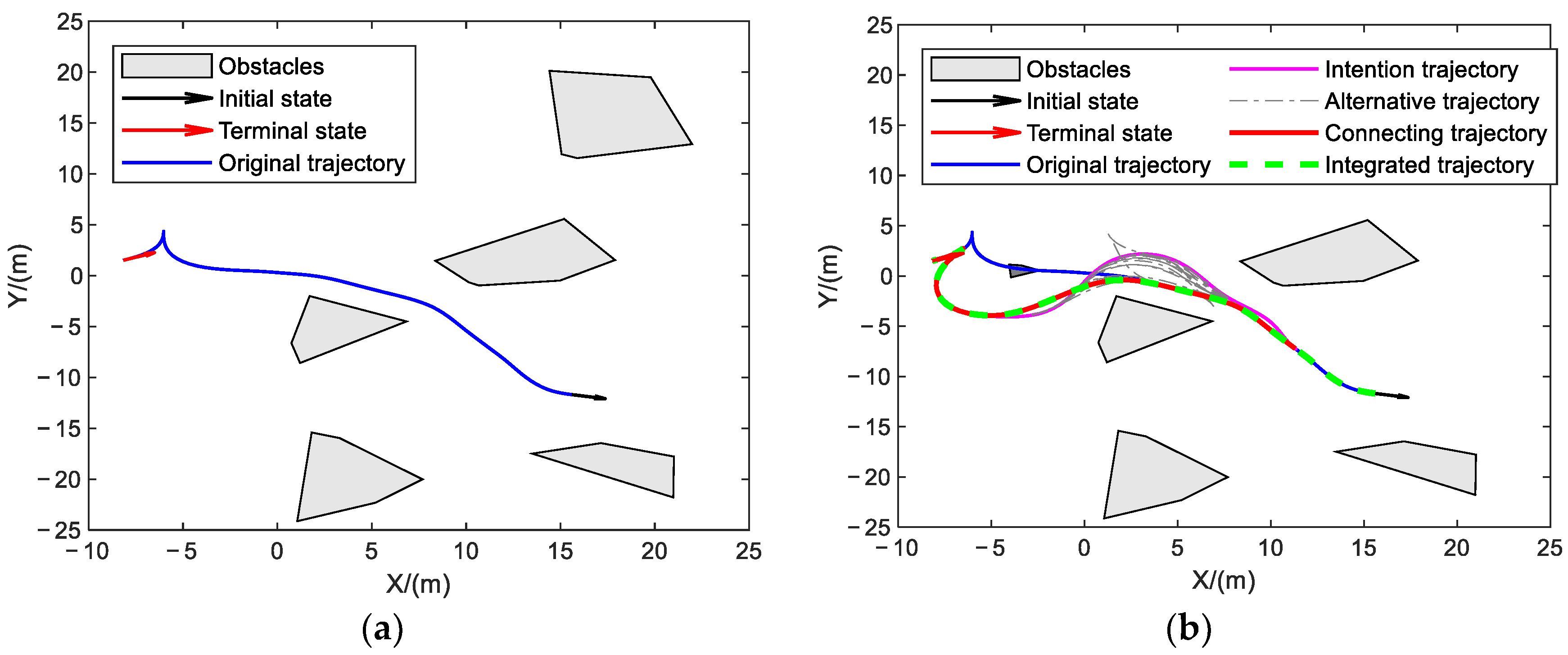
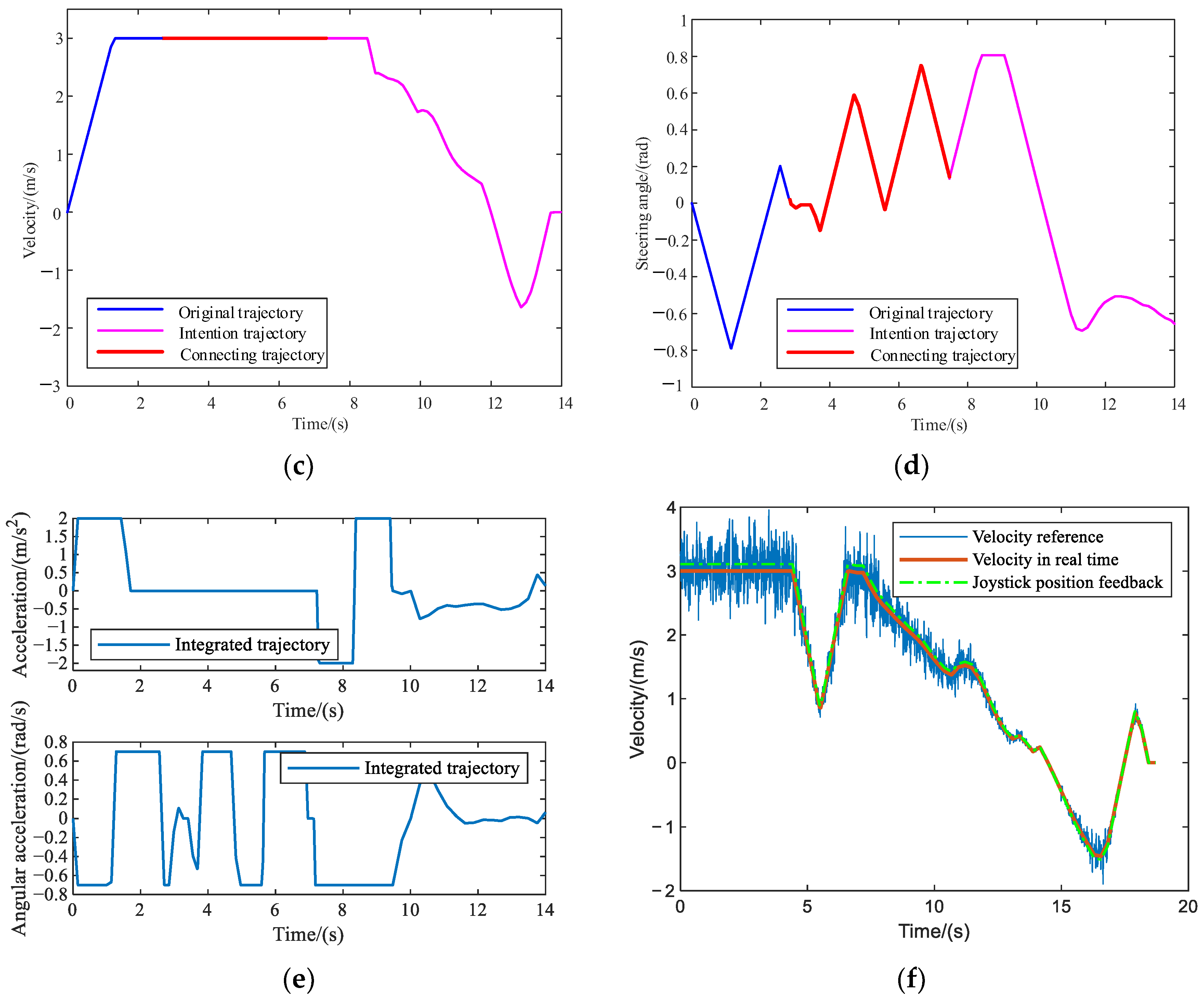
5.3.2. Unified HIR Obstacle Avoidance Verification
5.3.3. Unified HIR Specific Navigation Verification
5.4. Parameter Sensitivity Verification
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goertz, R.C. Mechanical master-slave manipulator. Nucleonics 1945, 12, 45–46. [Google Scholar]
- Clement, G.; Fournier, R.; Gravez, P.; Morillon, J. Computer aided teleoperation: From arm to vehicle control. In Proceedings of the IEEE International Conference on Robotics and Automation, Philadelphia, PA, USA, 24–29 April 1988. [Google Scholar]
- Luo, J.; Lin, Z.; Li, Y.; Yang, C. A Teleoperation Framework for Mobile Robots Based on Shared Control. IEEE Robot. Autom. Lett. 2020, 5, 377–384. [Google Scholar] [CrossRef]
- Lee, S.; Sukhatme, G.; Kim, G.J.; Park, C.M. Haptic Teleoperation of a Mobile Robot: A User Study. Presence 2005, 14, 345–365. [Google Scholar] [CrossRef]
- Hou, X.; Mahony, R.; Schi, F. Comparative Study of Haptic Interfaces for Bilateral Teleoperation of VTOL Aerial Robots. IEEE Trans. Syst. Man Cybern. Syst. 2016, 46, 1352–1363. [Google Scholar] [CrossRef]
- Yuan, W.; Li, Z. Brain Teleoperation Control of a Nonholonomic Mobile Robot Using Quadrupole Potential Function. IEEE Trans. Cogn. Dev. Syst. 2019, 11, 527–538. [Google Scholar] [CrossRef]
- Ju, C.; Son, H.I. Evaluation of Haptic Feedback in the Performance of a Teleoperated Unmanned Ground Vehicle in an Obstacle Avoidance Scenario. Int. J. Control Autom. Syst. 2019, 17, 168–180. [Google Scholar] [CrossRef]
- Li, W.; Ding, L.; Gao, H.; Tavakoli, M. Haptic Tele-Driving of Wheeled Mobile Robots Under Nonideal Wheel Rolling, Kinematic Control and Communication Time Delay. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 336–347. [Google Scholar] [CrossRef]
- Lam, T.M.; Boschloo, H.W.; Mulder, M.; Van Paassen, M.M. Artificial Force Field for Haptic Feedback in UAV Teleoperation. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2009, 39, 1316–1330. [Google Scholar] [CrossRef]
- Courtois, H.; Aouf, N. Haptic Feedback for Obstacle Avoidance Applied to Unmanned Aerial Vehicles. In Proceedings of the International Conference on Unmanned Aircraft Systems (ICUAS’17), Miami, FL, USA, 13–16 June 2017. [Google Scholar]
- Lin, Z.; Luo, J.; Yang, C. A Teleoperated Shared Control Approach with Haptic Feedback for Mobile Assistive Robot. In Proceedings of the 25th International Conference on Automation and Computing (ICAC), Lancaster, UK, 5–7 September 2019. [Google Scholar]
- Han, H.; Kim, C.; Lee, D.Y. Collision Avoidance for Haptic Master of Active-Steering Catheter Robot. In Proceedings of the 19th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 19–22 April 2019. [Google Scholar]
- Pruks, V.; Ryu, J.-H. Method for generating real-time interactive virtual fixture for shared teleoperation in unknown environments. Int. J. Robot. Res. 2022, 41, 925–951. [Google Scholar] [CrossRef]
- Luo, J.; Yang, C.; Wang, N.; Wang, M. Enhanced teleoperation performance using hybrid control and virtual fixture. Int. J. Syst. Sci. 2019, 50, 451–462. [Google Scholar] [CrossRef]
- Feng, H.; Yin, C.; Li, R.; Ma, W.; Yu, H.; Cao, D.; Zhou, J. Flexible virtual fixtures for human-excavator cooperative system. Autom. Constr. 2019, 106, 102897. [Google Scholar] [CrossRef]
- Yoon, H.U.; Wang, R.F.; Hutchinson, S.A.; Hur, P. Customizing haptic and visual feedback for assistive human–robot interface and the effects on performance improvement. Robot. Auton. Syst. 2017, 91, 258–269. [Google Scholar] [CrossRef]
- Kong, H.; Yang, C.; Li, G.; Dai, S.L. A sEMG-Based Shared Control System with No-Target Obstacle Avoidance for Omnidirectional Mobile Robots. IEEE Access 2020, 8, 26030–26040. [Google Scholar] [CrossRef]
- Chicaiza, F.A.; Slawiñski, E.; Salinas, L.R.; Mut, V.A. Evaluation of Path Planning with Force Feedback for Bilateral Teleoperation of Unmanned Rotorcraft Systems. J. Intell. Robot. Syst. 2022, 105, 34. [Google Scholar] [CrossRef]
- Hou, X. Haptic teleoperation of a multirotor aerial robot using path planning with human intention estimation. Intell. Serv. Robot. 2021, 14, 33–46. [Google Scholar] [CrossRef]
- Masone, C.; Mohammadi, M.; Giordano, P.R.; Franchi, A. Shared planning and control for mobile robots with integral haptic feedback. Int. J. Robot. Res. 2018, 37, 1395–1420. [Google Scholar] [CrossRef]
- Jiang, S.-Y.; Lin, C.-Y.; Huang, K.-T.; Song, K.-T. Shared Control Design of a Walking-Assistant Robot. IEEE Trans. Control Syst. Technol. 2017, 25, 2143–2150. [Google Scholar] [CrossRef]
- Zhang, H.-Y.; Lin, W.-M.; Chen, A.-X. Path Planning for the Mobile Robot: A Review. Symmetry 2018, 10, 450. [Google Scholar] [CrossRef]
- Martins, O.O.; Adekunle, A.A.; Adejuyigbe, S.B.; Adeyemi, O.H.; Arowolo, M.O. Wheeled Mobile Robot Path Planning and Path Tracking Controller Algorithms: A Review. J. Eng. Sci. Technol. Rev. 2020, 13, 152–164. [Google Scholar] [CrossRef]
- Li, B.; Acarman, T.; Zhang, Y.; Ouyang, Y.; Yaman, C.; Kong, Q.; Zhong, X.; Peng, X. Optimization-Based Trajectory Planning for Autonomous Parking with Irregularly Placed Obstacles: A Lightweight Iterative Framework. IEEE Trans. Intell. Transp. Syst. 2022, 23, 11970–11981. [Google Scholar] [CrossRef]
- Li, B.; Ouyang, Y.; Li, X.; Cao, D.; Zhang, T.; Wang, Y. Mixed-integer and Conditional Trajectory Planning for an Autonomous Mining Truck in Loading/Dumping Scenarios: A Global Optimization Approach. IEEE Trans. Intell. Veh. 2022, 8, 1512–1522. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, H. Design of Synchronization Tracking Adaptive Control for Bilateral Teleoperation System with Time-Varying Delays. Sensors 2022, 22, 7798. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Song, A.; Li, H.; Chen, D.; Fan, L. Adaptive Finite-Time Control Scheme for Teleoperation with Time-Varying Delay and Uncertainties. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 1552–1566. [Google Scholar] [CrossRef]
- Wang, H. Bilateral control of teleoperator systems with time-varying delay. Automatica 2021, 134, 109707. [Google Scholar] [CrossRef]
- Sheridan, T.B. Telerobotics. Automatica 1987, 25, 487–507. [Google Scholar] [CrossRef]
- Kleinsmith, A.; Bianchi-Berthouze, N. Affective Body Expression Perception and Recognition: A Survey. IEEE Trans. Affect. Comput. 2013, 4, 15–33. [Google Scholar] [CrossRef]
- Wang, Q.; Jiao, W.; Yu, R.; Johnson, M.T.; Zhang, Y. Virtual Reality Robot-Assisted Welding Based on Human Intention Recognition. IEEE Trans. Autom. Sci. Eng. 2020, 17, 799–808. [Google Scholar] [CrossRef]
- Huang, J.; Huo, W.; Xu, W.; Mohammed, S.; Amirat, Y. Control of Upper-Limb Power-Assist Exoskeleton Using a Human-Robot Interface Based on Motion Intention Recognition. IEEE Trans. Autom. Sci. Eng. 2015, 12, 1257–1270. [Google Scholar] [CrossRef]
- Morelli, L.; Guadagni, S.; Di Franco, G.; Palmeri, M.; Di Candio, G.; Mosca, F. Da Vinci single site© surgical platform in clinical practice: A systematic review. Int. J. Med. Robot. Comput. Assist. Surg. 2016, 12, 724–734. [Google Scholar] [CrossRef]
- Li, Y.; Ge, S.S. Human-robot collaboration based on motion intention estimation. IEEE/ASME Trans. Mechatron. 2014, 19, 1007–1014. [Google Scholar] [CrossRef]
- Kelley, R.; Tavakkoli, A.; King, C. Understanding Human Intentions via Hidden Markov Models in Autonomous Mobile Robots. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, Amsterdam, The Netherlands, 7–10 March 2008. [Google Scholar]
- Petković, T.; Puljiz, D.; Marković, I.; Björn, H. Human intention estimation based on Hidden Markov Model Motion validation for safe flexible robotized warehouses. Robotics 2019, 57, 182–196. [Google Scholar] [CrossRef]
- Liu, T.; Lyu, E.; Wang, J.; Meng, M.Q.-H. Unified Intention Inference and Learning for Human–Robot Cooperative Assembly. IEEE Trans. Autom. Sci. Eng. 2022, 19, 2256–2266. [Google Scholar] [CrossRef]
- Aarno, D.; Kragic, D. Layered HMM for motion intention recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006. [Google Scholar]
- Koert, D.; Trick, S.; Ewerton, M.; Lutter, M.; Peters, J. Incremental learning of an open-ended collaborative skill library. Int. J. Hum. Robot. 2020, 17, 2050001. [Google Scholar] [CrossRef]
- Kelley, R.; Tavakkoli, A.; King, C.; Ambardekar, A.; Nicolescu, M.; Nicolescu, M. Context-Based Bayesian Intent Recognition. IEEE Trans. Auton. Ment. Dev. 2012, 4, 215–225. [Google Scholar] [CrossRef]
- Bachman, P.; Milecki, A. Investigation of electrohydraulic drive control system with the haptic joystick. Acta Mech. Autom. 2018, 12, 5–10. [Google Scholar] [CrossRef]
- Hogan, N. Impedance control: An approach to manipulation: Part I–Theory. J. Dyn. Syst. Meas. Control 1985, 107, 1–7. [Google Scholar] [CrossRef]
- Na, U.J. A new impedance force control of a haptic teleoperation system for improved transparency. J. Mech. Sci. Technol. 2017, 31, 6005–6017. [Google Scholar] [CrossRef]
- Michel, Y.; Rahal, R.; Pacchierotti, C.; Giordano, P.R.; Lee, D. Bilateral Teleoperation with Adaptive Impedance Control for Contact Tasks. IEEE Robot. Autom. Lett. 2021, 6, 5429–5436. [Google Scholar] [CrossRef]
- Estrada, E.; Yu, W.; Li, X. Stability and transparency of delayed bilateral teleoperation with haptic feedback. Int. J. Appl. Math. Comput. Sci. 2019, 29, 681–692. [Google Scholar] [CrossRef]
- Yang, C.; Peng, G.; Cheng, L.; Na, J.; Li, Z. Force Sensorless Admittance Control for Teleoperation of Uncertain Robot Manipulator Using Neural Networks. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 3282–3292. [Google Scholar] [CrossRef]
- Kimura, S.; Nozaki, T.; Murakami, T. Admittance Control-based Bilateral Control System Considering Position Error. In Proceedings of the IEEE International Conference on Mechatronics, Kashiwa, Japan, 7–9 March 2021. [Google Scholar]
- Grewal, J.K.; Krzywinski, M.; Altman, N. Markov models—Hidden Markov models. Nat. Methods 2019, 16, 795–796. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Yin, Z.; Ouyang, Y.; Zhang, Y.; Zhong, X.; Tang, S. Online Trajectory Replanning for Sudden Environmental Changes during Automated Parking: A Parallel Stitching Method. IEEE Trans. Intell. Veh. 2022, 7, 748–757. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Description | Values | Parameters | Description | Values |
|---|---|---|---|---|---|
| Front overhang of the vehicle | 0.9600 m | Maximum velocity | 3.00 m/s | ||
| Rear overhang of the vehicle | 0.9290 m | Maximum acceleration | 2.00 m/s2 | ||
| Length of the vehicle | 2.8000 m | Maximum steering angle | 0.85 rad | ||
| Width of the vehicle | 1.9420 m | Maximum angular acceleration | 0.70 rad/s |
| Case Index | Middle Goal Position | |||
|---|---|---|---|---|
| 1 | ― | ― | ||
| 2 | ― | |||
| 3 |
| The Number of Sampling Points | Cost Function Value | The Number of Sampling Points | Cost Function Value |
|---|---|---|---|
| 13.4343 s | 12.4590 s | ||
| 16.3493 s | 13.0369 s | ||
| 14.3939 s | 12.8421 s | ||
| 15.8179 s | 13.2860 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; Ni, T.; Zhao, Z.; Ren, C. Unified Human Intention Recognition and Heuristic-Based Trajectory Generation for Haptic Teleoperation of Non-Holonomic Vehicles. Machines 2023, 11, 528. https://doi.org/10.3390/machines11050528
Zhang P, Ni T, Zhao Z, Ren C. Unified Human Intention Recognition and Heuristic-Based Trajectory Generation for Haptic Teleoperation of Non-Holonomic Vehicles. Machines. 2023; 11(5):528. https://doi.org/10.3390/machines11050528
Chicago/Turabian StyleZhang, Panhong, Tao Ni, Zeren Zhao, and Changan Ren. 2023. "Unified Human Intention Recognition and Heuristic-Based Trajectory Generation for Haptic Teleoperation of Non-Holonomic Vehicles" Machines 11, no. 5: 528. https://doi.org/10.3390/machines11050528