1. Introduction
The fourth industrial revolution is strongly promoted by governments around the world. Although industrial robots have already been widely deployed in factories for repetitive tasks, such as loading/unloading and pick-and-place, there are many tasks in factories that still require human operators. The use of manipulators is highly likely to increase, and the intelligence of the manipulator will therefore become increasingly important. For example, the smart and automatic generation of efficient or fast motion trajectories for a manipulator is needed. Trajectory planning has been an important issue for several decades because it strongly determines the effectiveness and cost of factory operations. Although the issue is classic, solutions continue to evolve due to the development of new technologies, such as artificial intelligence (AI). In the following section, related works on the trajectory optimization of robot arms are listed, including the traditional and the machine-learning methods.
The trajectory optimization of manipulators has been reported using the classic method, especially for energetic optimization. Singh and Leu used dynamic programming to optimize the trajectory to improve the energy efficiency and speed of one and two degrees of freedom (DOF) manipulators [
1]. Field and Stepanenko adopted iterative dynamic programming for the trajectory energy optimization of a six-DOF industrial robot [
2]. Hirakawa and Kawamura optimized the trajectory energy of a three-DOF robot arm using the cost function method [
3]. Gregory et al. studied trajectory planning problems for a selective compliance articulated robot arm (SCARA) using an optimal control method [
4]. Hansen et al. optimized the trajectory for an industrial robot; they considered a dynamic model of the robot, friction losses, and losses related to the servo and inverter [
5]. Wigström et al. used a dynamic planning method to reduce the energy consumption of a robot arm by 10–20% [
6]. Along with some works aiming for joint torque optimization [
7,
8], speed and time optimization are other popular targets. Sahar and Hollerbach used a graph search to optimize the time-minimum path for a two-DOF robot [
9]. Gasparetto and Zanotto optimized a trajectory by considering the integral of jerk and execution time [
10]. Rubio et al. proposed a computationally efficient algorithm to generate a time optimal and collision-free trajectory by evolving the trajectories in a discretization space and considering the physical constraints of industrial robots in industrial environments [
11]. Ghasemi et al. translated the control problem into a nonlinear two-point boundary value problem to calculate the time-optimal trajectories of robot arms [
12]. Schulman et al. developed trajectory optimization based on the sequential convex optimization procedure and efficient formulation of constraints to apply to various collision-free robot tasks in simulation [
13]. On the other hand, some papers dealt with the control optimization for manipulators based on dynamic models. For instance, Krivošej and Šika actuated a three-DOF manipulator by the auxiliary cable mechanism and optimized the cable force distribution by using the simplex and genetic algorithm (GA) based on dynamic model analysis [
14].
The typical trajectory optimization problem can also be approached by AI. Choi et al. proposed a two-phase learning algorithm to achieve global and local trajectory optimization and obstacle avoidance for more energy-efficient aircraft navigation [
15]. Garg and Kumar used a GA and simulated annealing to find the optimal trajectory with minimum torque [
16]. Tian and Collins used a GA to plan the trajectory with obstacle avoidance [
17]. Števo et al. used the GA to optimize trajectory planning for an ABB robot arm [
18]. Abu-Dakka et al. planned time-optimal trajectories for an industrial robot using an evolutionary algorithm [
19]. Among research studies on AI, machine learning with deep neural network (DNN) models, aiding its versatility, has been utilized for the trajectory planning problem. Glasius et al. used the neural network method to generate trajectories with obstacle avoidance for a two-DOF robot arm [
20]. Martín and Millán also utilized DNN to calculate the inverse kinematics for a robot manipulator, which enabled the robot to avoid obstacles [
21]. Imajo et al. applied a recurrent neural network to generate obstacle-avoidance trajectories [
22]. Levine et al. used deep learning for a robot arm to perform hand–eye coordinated grasping tasks [
23]. Qiao et al. designed constraint equations for various physical limitations and self-collision avoidance for a mobile manipulator, defined the trajectory tracking as an optimization problem, and proposed the differential evolution algorithm to solve it [
24].
To tackle the implicit relationship between the goal and complex dynamics, reinforcement learning (RL) has recently become a popular method in robotics [
25] and task-oriented research. Stulp et al. used RL to generate motions for a robot manipulator for pick-and-place tasks [
26]. Cheng and Zhang used deep reinforcement learning to develop obstacle avoidance control strategies and applied them to an unmanned marine vessel [
27]. Cao et al. utilized Q-learning to construct a scalable and applicable method that can maximize the probability of arriving on time for vehicles in transportation systems [
28]. For trajectory optimization, Kollar and Roy used RL for dynamic programming and a support vector machine to optimize the trajectory efficiency of robot campus exploration [
29]. Akrour et al. developed a model-free trajectory optimization algorithm, which back-propagated a local Q-function, achieved a policy update in a closed form, and was deployed for two trajectory optimization tasks in simulations [
30]. Li et al. used RL based on the path integral of dynamic movement primitive in joint space, and trained a manipulator with visual feedback to grasp objects under external perturbations [
31]. Bucinskas et al. deployed online deep Q-learning to improve the positioning accuracy for an industrial manipulator with various operation times, speed, and load [
32].
While the energy consumption of trajectory planning algorithms largely depends on the dynamic model of robot arms, the reported works rarely investigated physical models and trajectory optimization simultaneously. However, many industrial tasks require the precise estimation of the energy consumption and joint torque of the manipulator. For example, if a factory must use a manipulator to move very heavy loads, it needs to estimate and minimize energy consumption through trajectory optimization to save on electricity costs. In addition, the manipulator utilized in this paper was designed to carry sensors to examine patients lying in a hospital bed. More specifically, the proposed application is a postoperative free-flap registration and tracking system [
33,
34]. The goal of the application is to monitor the condition of the free flap on the face, head, or neck after surgery. The robot arm is set up beside the bed, and attached is an infrared camera and an RGB camera. The image system periodically calculates the condition of the free flap. The cameras need to keep a specific distance and angle from the free flap to obtain valid images, but the patient might move slightly or roll over unconsciously. Therefore, the image system will calculate where the cameras should be placed, and then the robot arm will move the cameras to that position. Some monitors or instruments placed around the bed to measure the patient’s health condition constitute obstacles, so the robot arm must avoid collisions with these objects. In such scenarios, the torque values of the manipulator should be precisely determined to meet medical safety standards and mitigate severe injuries that could result from accidents.
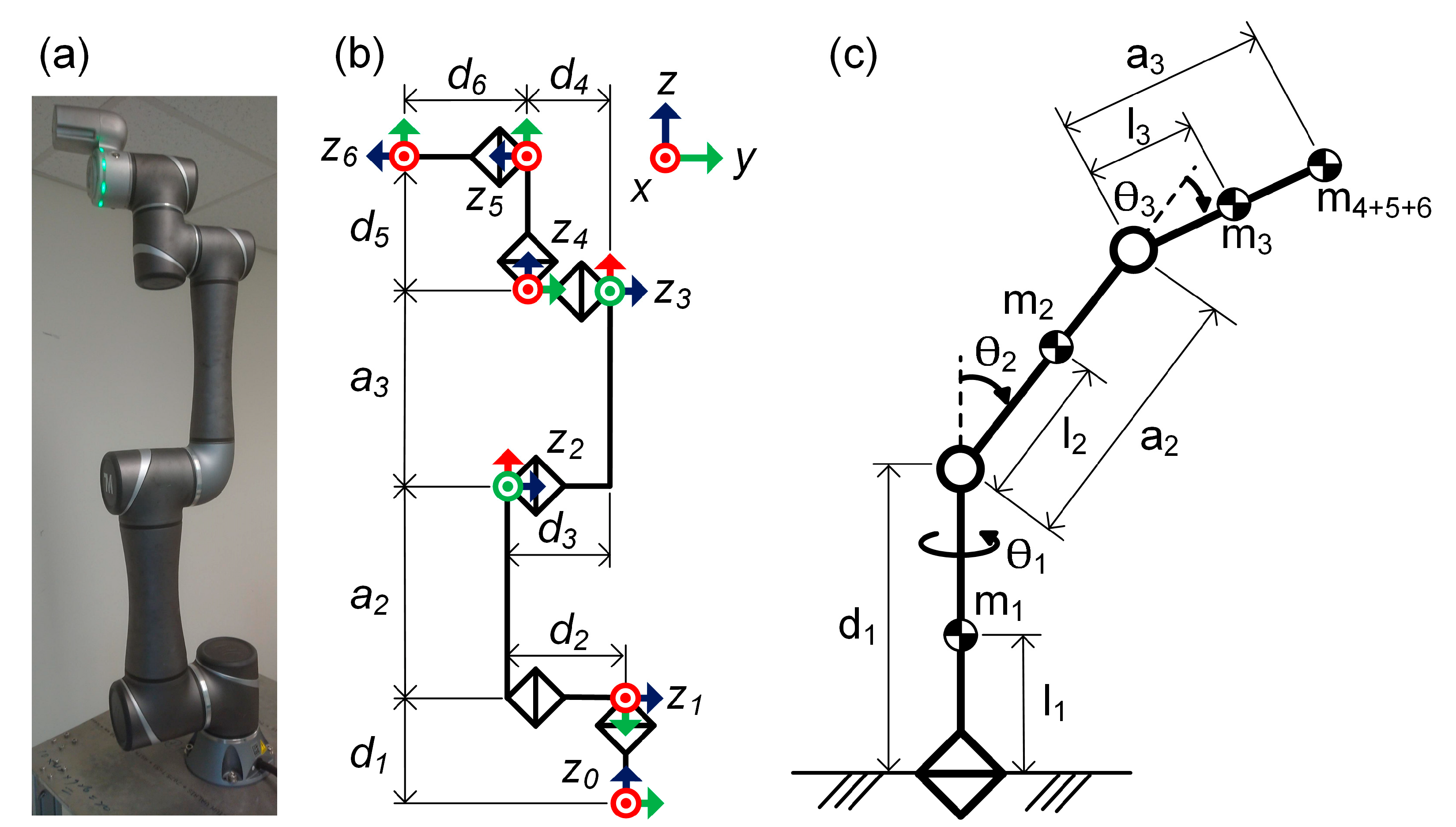
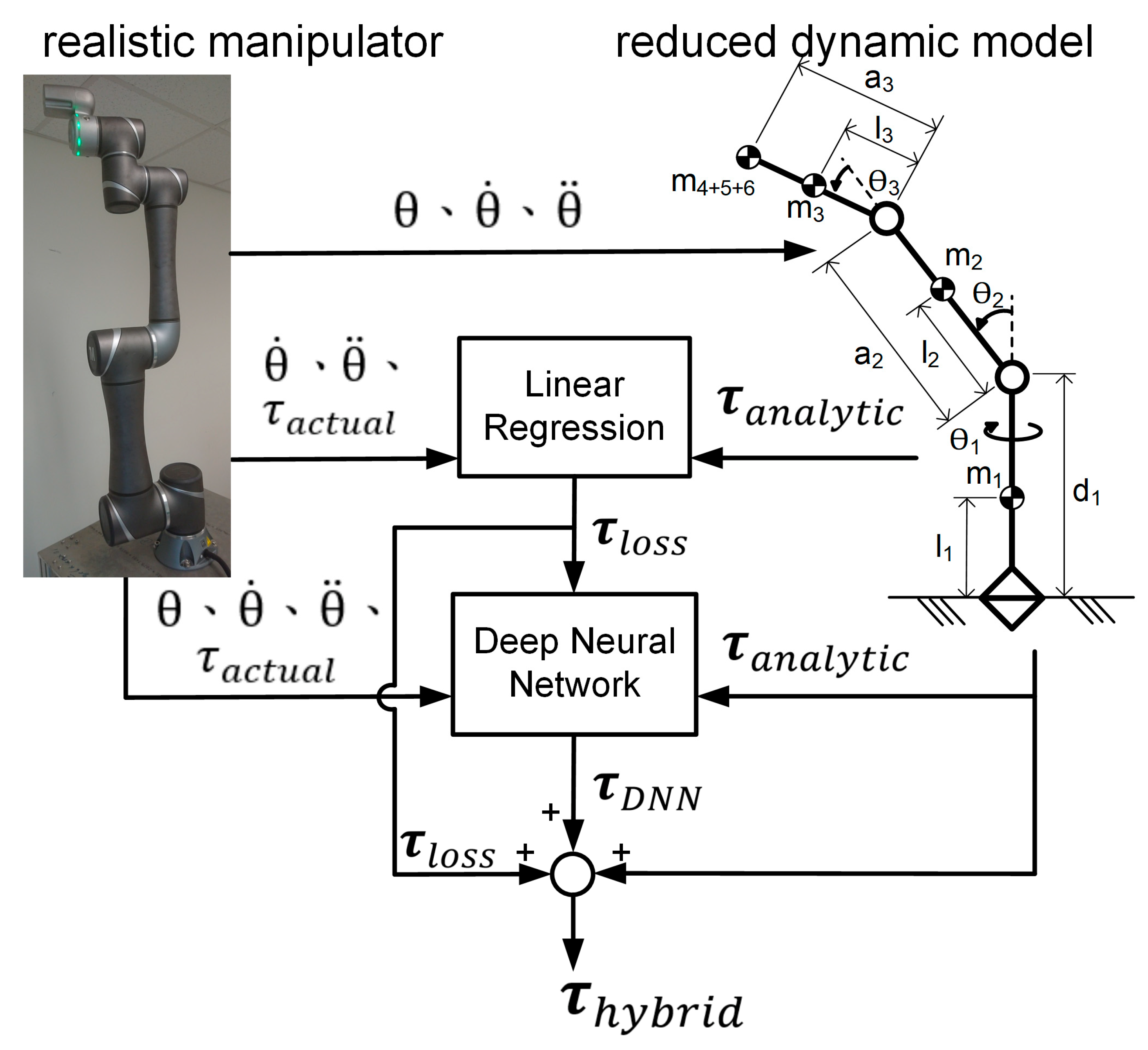
To precisely know the joint torques and calculate energy consumption, the precise dynamic model has to be figured out. Among research of robot arm dynamic model calibration, scarce reported work combined a physical-based model with a black-box (like DNN) model, while there exist many empirical factors in the dynamic model of manipulators other than analytic parts. For this paper, this approach was adopted, and the results are reported in two serial parts. The first is the development of a hybrid dynamic model, and the second is using the deep RL method to optimize the collision-free trajectory for energy and time consumption based on the developed dynamic model. The contributions are summarized as follows:
A hybrid dynamic model of the manipulator was constructed, which was composed of an analytic three-DOF reduced-order dynamic model, linear non-idealized terms for mechanical energy loss, and a DNN model to calibrate other non-measurable and high-order empirical factors. While the hybrid model can largely decrease the computation complexity of the analytic model and reduce the training load and dataset size for DNN, it maintained high similarity to the real robot arm.
To achieve energy efficiency with obstacle avoidance, the trajectory optimization of the manipulator was treated as a bandit problem. A trajectory planner initialized by a bi-directional rapidly-exploring random tree (Bi-RRT) and optimized by deep RL was introduced to spare complex mathematical deduction and calculations of the compound-goaled problem.
Simulations and experiments were thoroughly conducted. In addition, performance comparisons to GA, human-taught trajectories, and the time compression method were executed as well. The results show that the proposed optimization method yields better performance.
The remainder of the paper is organized as follows.
Section 2 describes the hybrid model and bounding box model of the manipulator, and
Section 3 introduces the trajectory planning and optimization using RL.
Section 4 reports the results of the simulation and experiments, and
Section 5 concludes the work.
3. Trajectory Optimization by Reinforcement Learning
After the model was constructed and the collision avoidance strategy was set up, the next step was trajectory optimization for energy efficiency or motion speed, which improves the performance of the manipulator in an empirical factory utilization.
The general motion trajectory of the manipulator is composed of key positions, including a start point, via points, and an end point. While the start and end points are usually known a priori, the variation of the trajectory lies in the position and time stamp of the via points, which are the optimization variables. In between the start, via, and end points, a cubic spline trajectory was adopted [
41]. The speed limitation of the first three joints of the manipulator was also considered and set to
according to the manipulator’s operation manual [
42]. In this case, a smooth trajectory (i.e., position and velocity continuity) prevents the manipulator from wasting energy with abrupt motions that easily reach joint torque limits; thus, the generated trajectory can be optimized for the overall motion requirement, but it is not constrained by undesired abrupt movements.
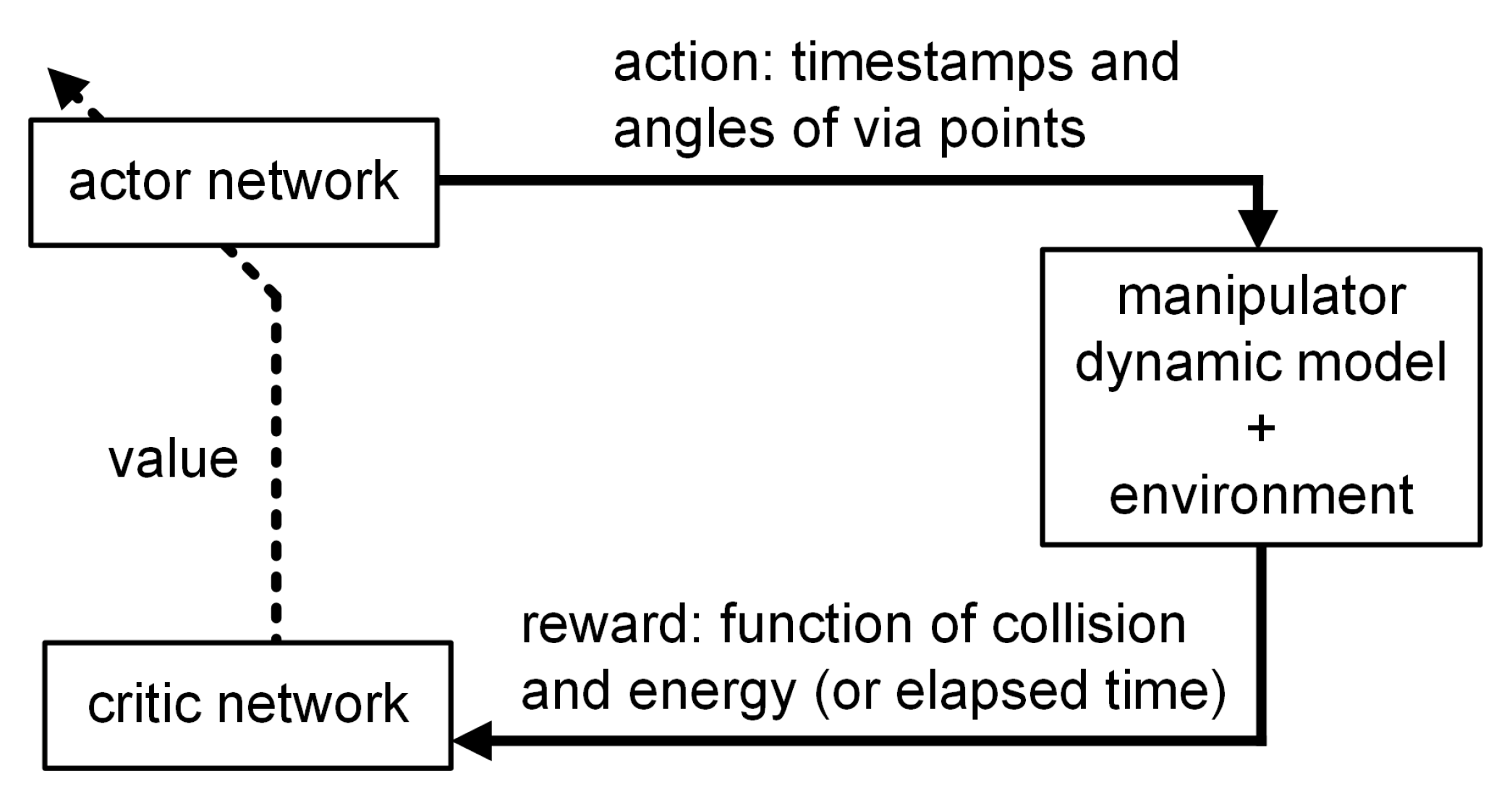
Deep reinforcement learning was utilized for trajectory optimization because it can spare complicated constraint setting and analytics while achieving comparably good results, which is user-friendly for industrial users. The algorithm used here was proximal policy optimization (PPO), proposed by OpenAI in 2017 [
43]. The PPO is based on the actor-critic structure. The actor, which is gradually optimized regarding its performance during the training process, takes actions by changing the positions or time stamps of via points in this case. This is followed by the critic, which gives the actor a score according to the action it takes and guides the actor to change its action to achieve a higher score. The reward here was set for energy or speed optimization, and the reward of the trajectory was higher if its energy consumption or elapsed time was lower. Different trajectories have different rewards, and the trajectory with the highest reward is the desired one. The actor-critic structure in PPO is illustrated in
Figure 5.
The optimization was treated as a bandit problem or a stateless problem since the arrangement of object position in industrial factories changes once in a long time; therefore, the state, containing the start point, end point, and obstacles, almost maintains constant. The classic RL problem generates action data corresponding to various state data. In contrast, each case of the trajectory planning was trained and optimized separately without any state data inputting to the DNN. During this process, it is not necessary to consider transition models as well. In the actor space, the algorithm adjusted the positions of the via points for energy optimization or adjusted the timestamps of the via points for speed optimization. Then, the value function was updated by collecting action and reward data. Finally, the data were used to update the parameters of the actor and the critic.
The DNN models in the learning algorithm contain an actor network and a critic network. There is no input layer in the networks. Although they were tuned slightly using heuristics, the following network configurations referenced the model structure in the original PPO paper [
43]. The two networks both have two fully-connected hidden layers based on rectified linear unit (ReLU) neurons. Both networks have 512 neurons in the first layer and 256 neurons in the second layer. The critic network only has one neuron in the output layer, and the action data from the actor network contain angles of the first three manipulator joints for all via points. The output layer of the actor network parallel includes the mean layer
μ and the covariance layer
σ, both as the same dimensions as the number of action data, passing through a Gaussian probability function to increase exploration when training [
44]. In this study, RL was used to solve this optimization problem, and the goal was to find the best via points connected by cubic equations. That is, once the via points were determined, the trajectory was also determined. As shown in
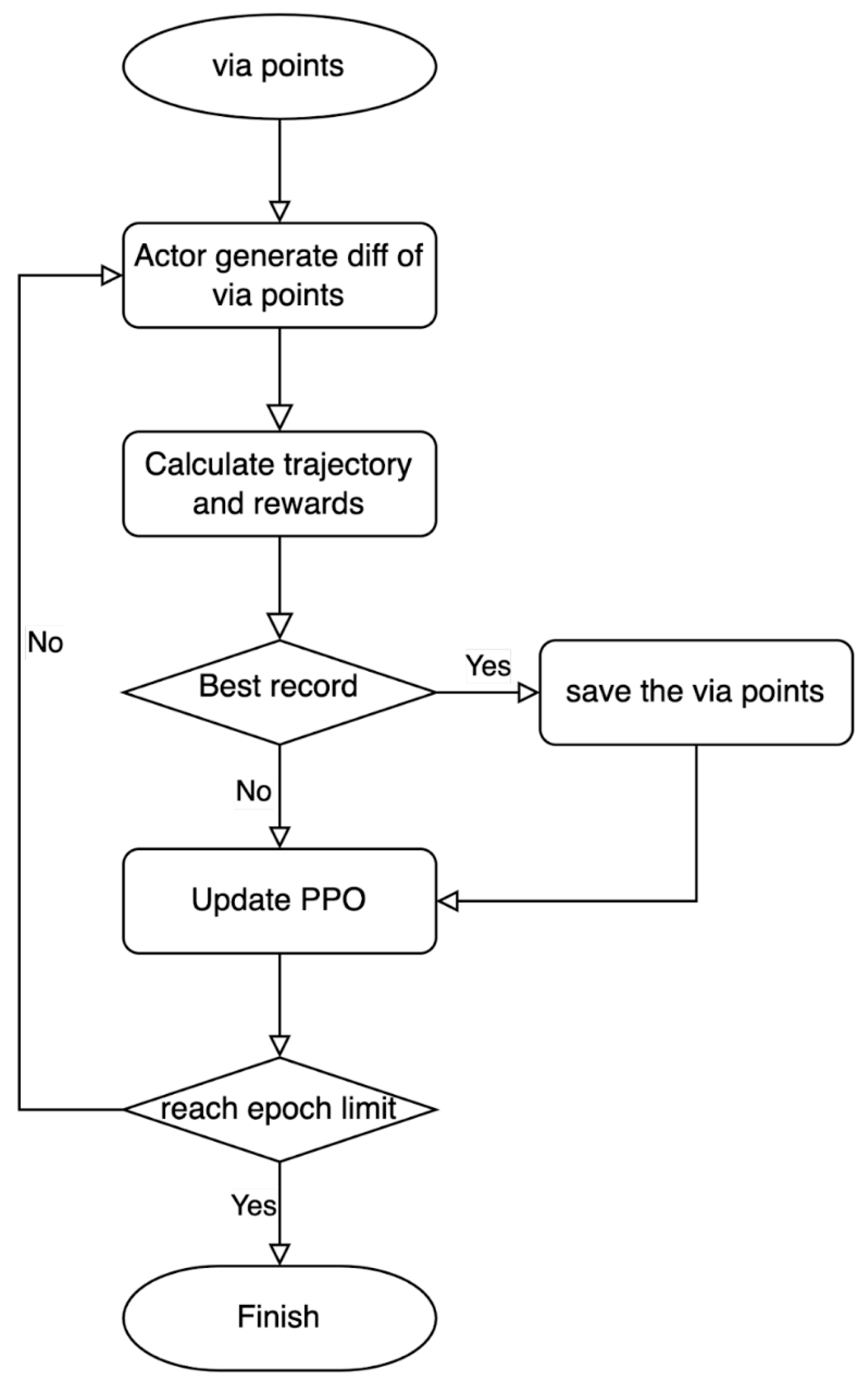
Figure 5, the action output from the actor network led to adjustments to the via points, and the reward given back by the dynamic model considered the collision and energy consumption. Here, the principle was that the more serious the collision was, the more negative the reward would be; if there was no collision, less total energy consumed by the entire trajectory could obtain a more positive reward. The total algorithm to optimize the via points based on PPO is depicted in
Figure 6.
3.1. Determination of The Initial Via Points
If there is no obstacle, the determination of the initial via points is not critical because the follow-up optimization will adjust the position and time stamp of the via points. In contrast, when obstacles do exist, the initially selected via points should be outside and away from the obstacles to speed the optimization convergence. The bi-directional rapidly-exploring random tree (Bi-RRT) [
45] was utilized to find the initial via points.
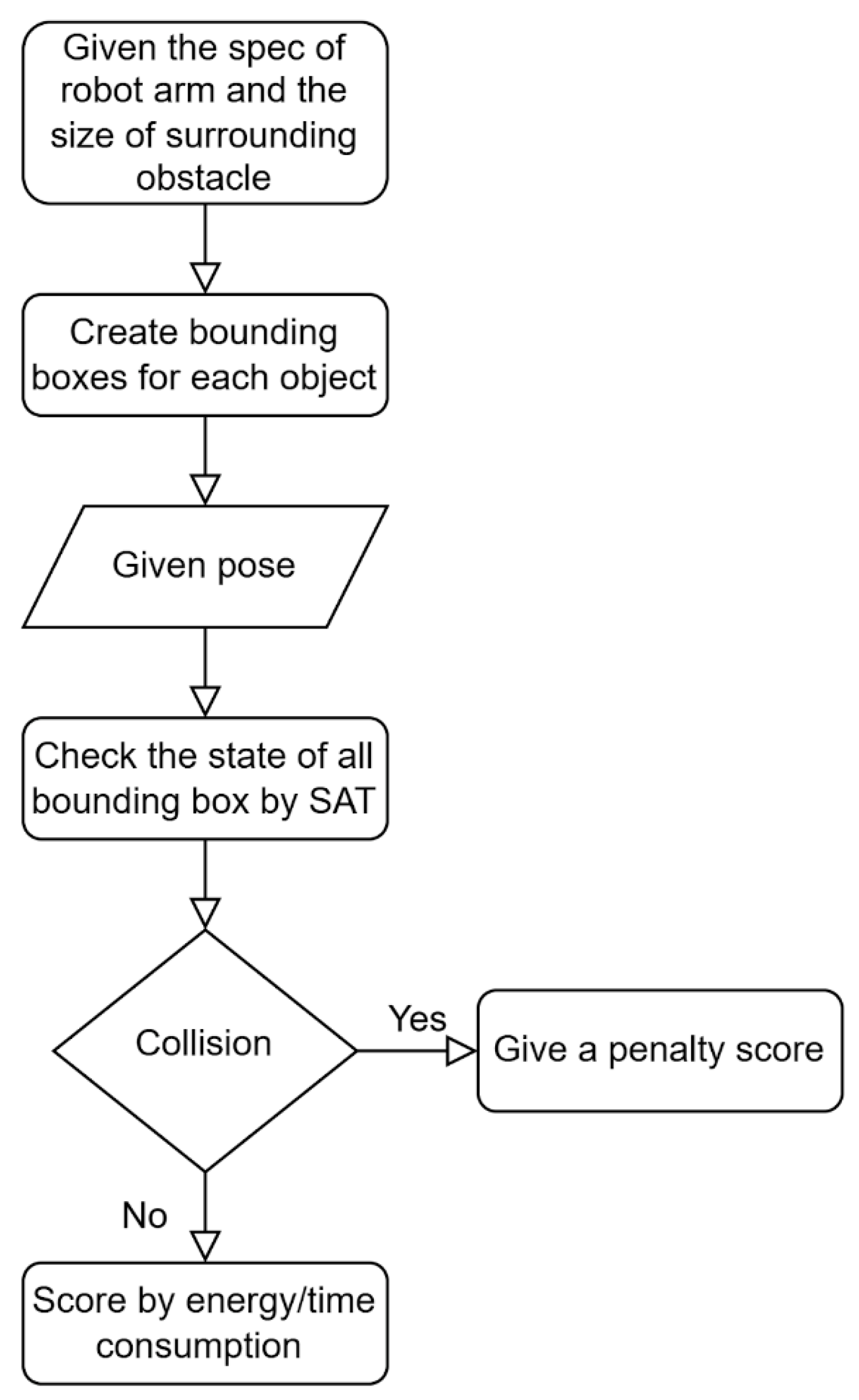
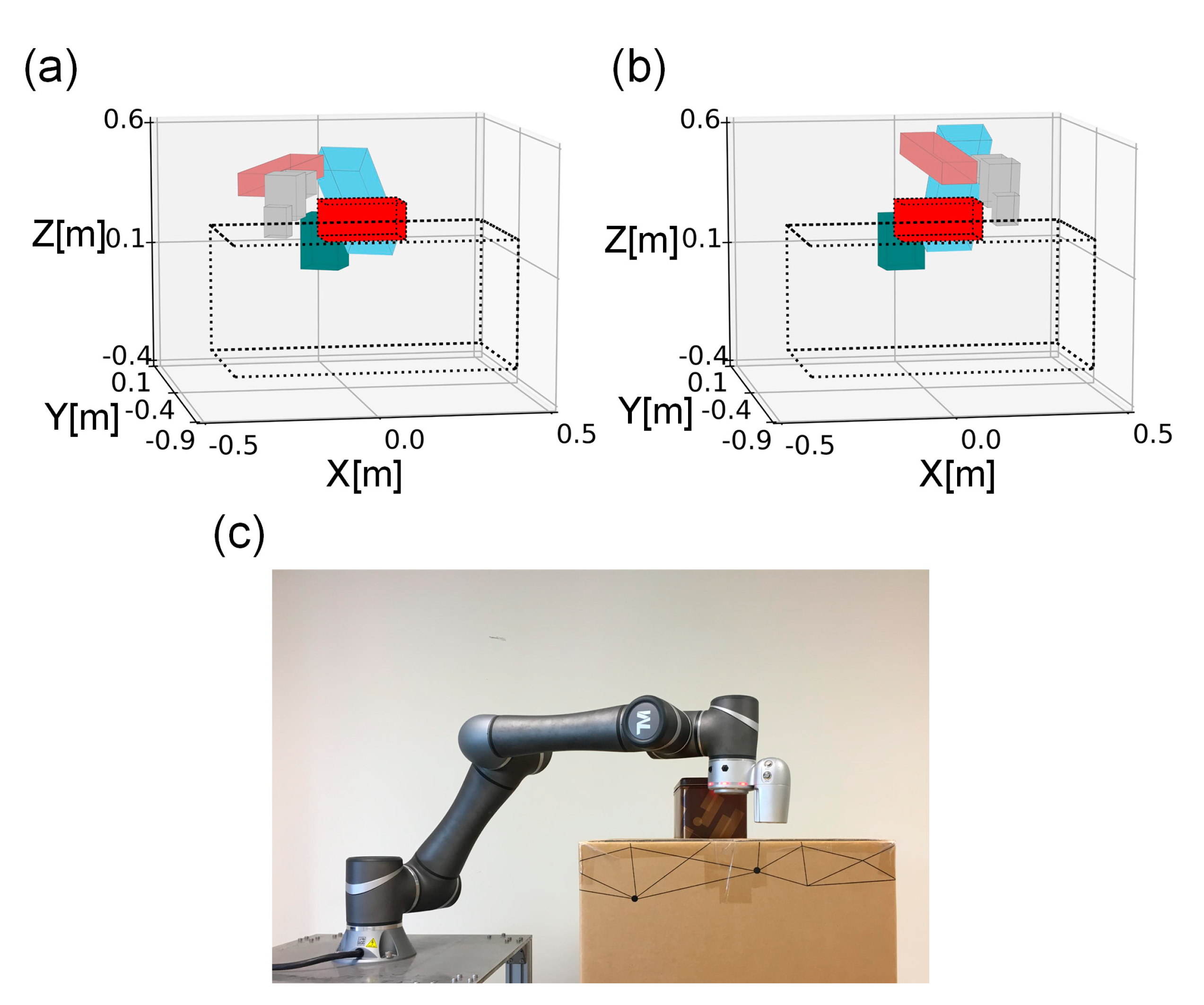
The details of the implementation of the Bi-RRT are described as follows. First, the physical spaces taken by the manipulator and the obstacles were modeled as bounding boxes, as described in
Section 2.2, which were to be avoided by the Bi-RRT. Second, points on the midplane were selected as goals for the Bi-RRT to search from the start and end points. The midplane was defined as the plane that was normal to and intersected with the midpoint of the line segment between the start and end points. Third, the convex hull formed by the projected vertices of the obstacles on the midplane was computed. Then, eight points with an equal angular distribution (i.e.,
apart) and on the boundary of the convex hull were chosen as the initial via points. In addition, the midpoint of the line segment between the start and end points was chosen. Finally, the Bi-RRT was utilized to find collision-free paths that connected the start and end points to the eight goal points, i.e., at most nine Bi-RRT paths if all searches were successful.
Because the nodes generated by the Bi-RRT were determined by the length of each search step, not all the nodes should be the initial via points, and the node was removed if the path without it was shorter and still collision-free. The nodes from the start point were sequentially and individually checked and iterated until no node could be removed. The remaining nodes were set as the initial via points.
3.2. Energy Optimization
For energy optimization, the reward was set as:
The symbol
indicates the minimum distance between the two nearest bounding boxes in the whole trajectory. The symbol
is the total energy consumption of the model, which is defined as:
where
are the start and final time stamps of the trajectory, and
are the j
th joint torque and joint angle, respectively. The main idea of the reward setting shown in Equation (7) is that if the collision occurs, then the reward is negative, and the reward is lower if the collision is more severe. In contrast, if there is no collision, the reward is positive, and the score is higher when the energy consumption is lower. Equation (7) can be utilized regardless of the number of obstacles.
3.3. Speed Optimization
The speed optimization process is similar to the energy optimization process, but the goal is to reduce the elapsed time from the start point to the end point while avoiding an overloaded operation. The reward was set as:
where
is the difference of time consumption before and after optimization. The main idea of the reward setting shown in Equation (9) is that if the computed torque exceeds the limit, the reward is negative, and the more the torque exceeds, the lower the reward. In contrast, the reward is positive and higher if the time reduction is more significant.
Note that the energy-optimized trajectory was utilized as the initial trajectory for speed optimization because it is collision-free, and the motion profile is relatively smooth. In this case, the optimization aims at maintaining the same profile while increasing the magnitudes of the motion states and torques until the manipulator achieves its torque limit [
46,
47]. In this work, the energy and speed optimizations were executed separately because the optimization of these two goals is generally oriented toward different optimized sets. Therefore, rather than using a reward composed of both energy consumption and speed objectives, energy and speed were optimized separately with different reward functions.
3.4. Genetic Algorithm
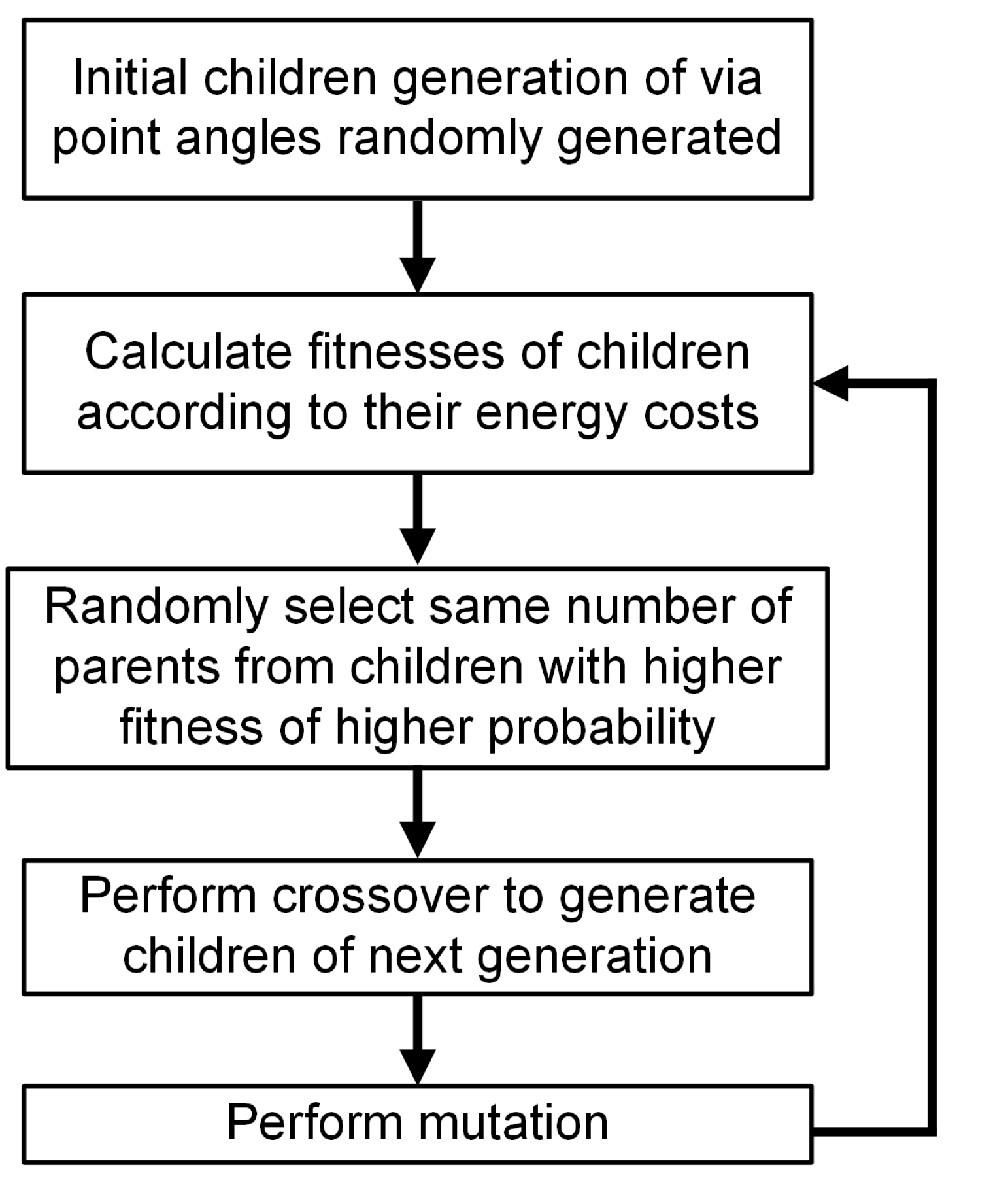
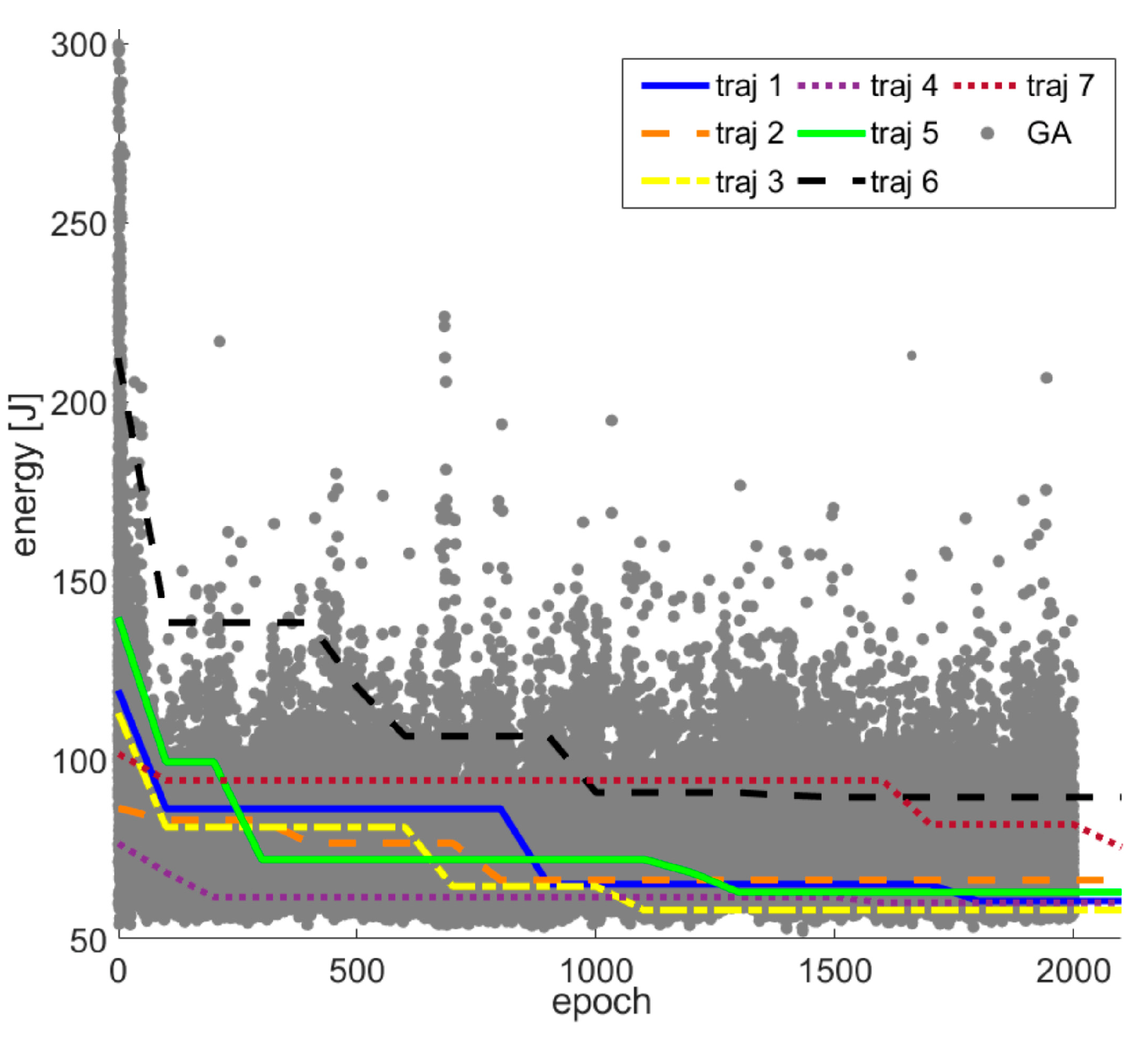
Furthermore, to compare the performance of the proposed method with classic artificial intelligence methods, GA was adopted for evaluation as well. GA mimics natural genetic exchange rules and follows the idea of the “survival of the fittest” to generate increasingly better offspring over several generations. In each generation loop, a set of children, of which each consists of six lines of binary values as genes, would first be converted to decimal values as six via angles, and the energy cost based on Equation (8) would be calculated corresponding to each child. Then, the same number of children would be randomly selected as parents of the next generation in the children set, following the rule that the child with a lower energy cost was assigned a higher probability to be chosen.
After that, each parent would have a high probability to exchange some of their binary elements with one of the children (selected randomly) at random element places, generating offspring as the next generation. Through the process, parents with a lower energy cost would generate more offspring, and finally the optimal set of via angles would appear in the last generation. The illustration depicting the GA procedure is shown in
Figure 7.
5. Conclusions
This article has reported the construction of the hybrid dynamic model as the digital twin and strategy to optimize the energy and speed of a manipulator by using RL, based on the dynamic model.
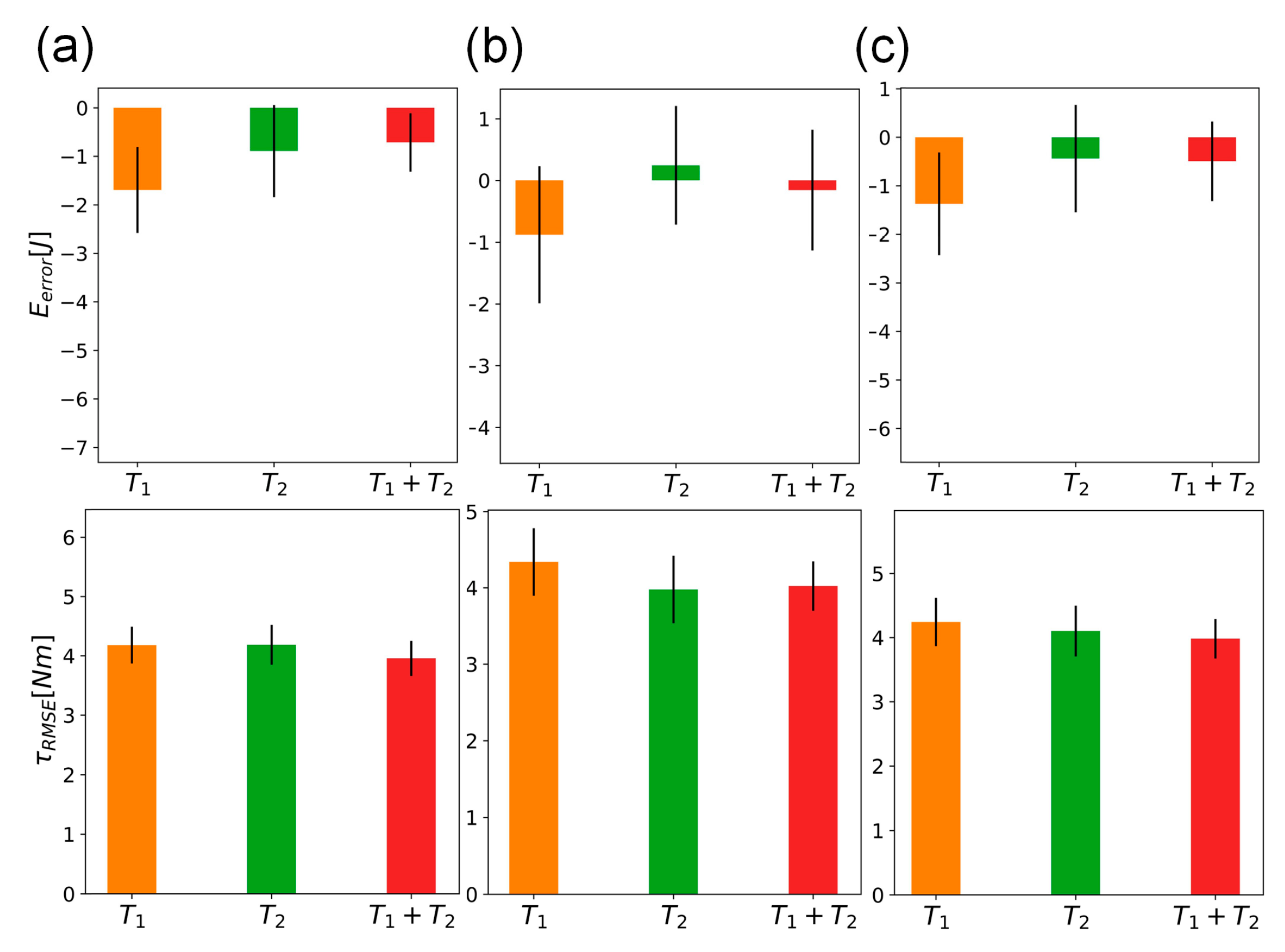
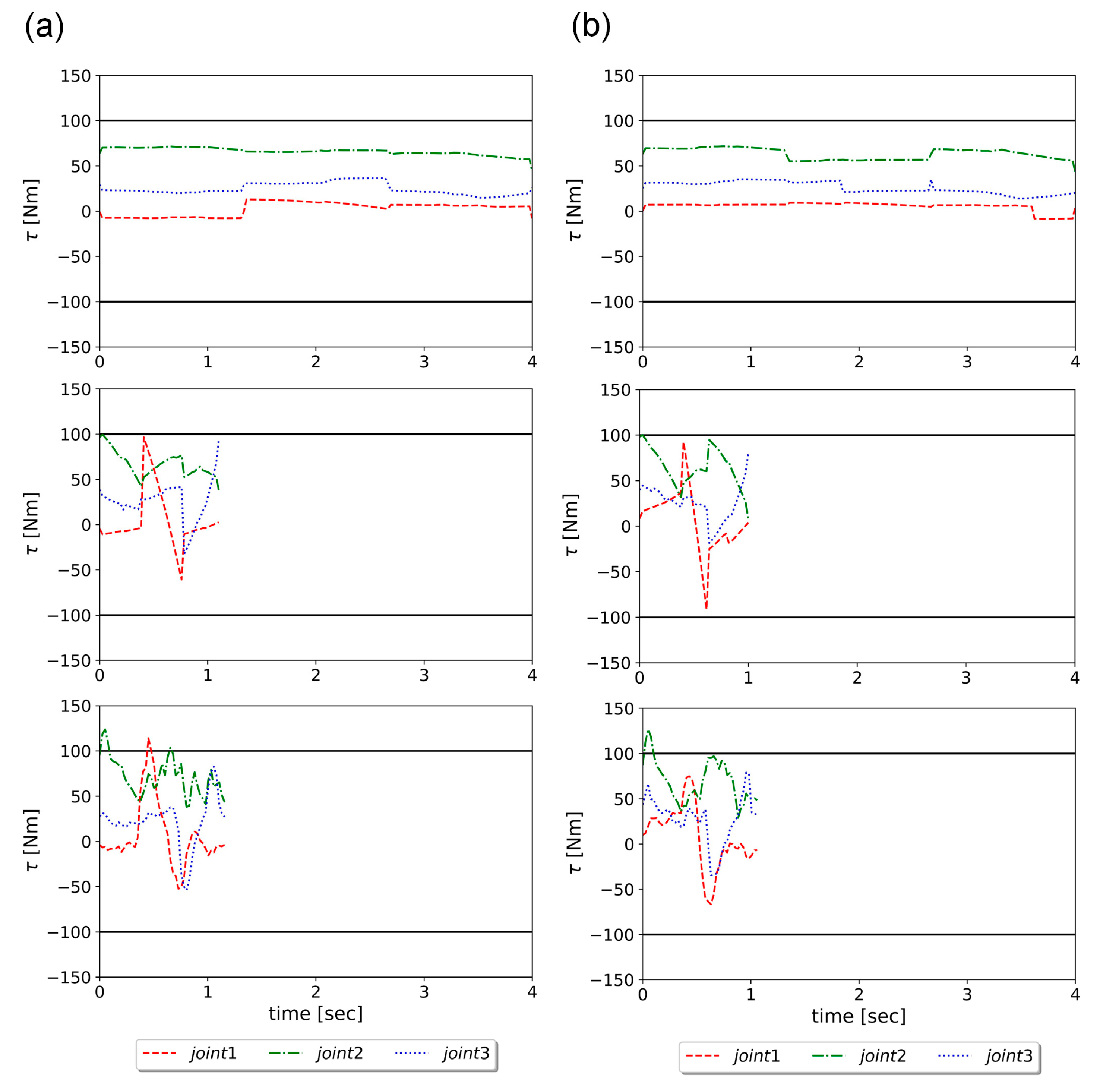
The hybrid model is composed of a reduced-order analytic model, a linear empirical compensation, and a DNN model. To spare computing complexity, the analytic dynamic model was reduced to a three-DOF manipulator, with the other links fixed as a mass point, and constructed given mechanical parameters from specification. The empirical part, compensating for inertia, damping, and friction, and the DNN model, ameliorating for the rest of the un-modeled dynamics, were both trained by actual torque data. The experimental results showed that averaged energy errors between the manipulator results and the analytic model (), the analytic model with energy loss terms (), and the hybrid model (), are −22.1, −2.1, and −0.2 J, respectively, which confirms that the hybrid composition of the model can significantly augment energy estimation accuracy. In cases where the manipulator was subjected to different payloads, the results exhibited a similar trend in amelioration.
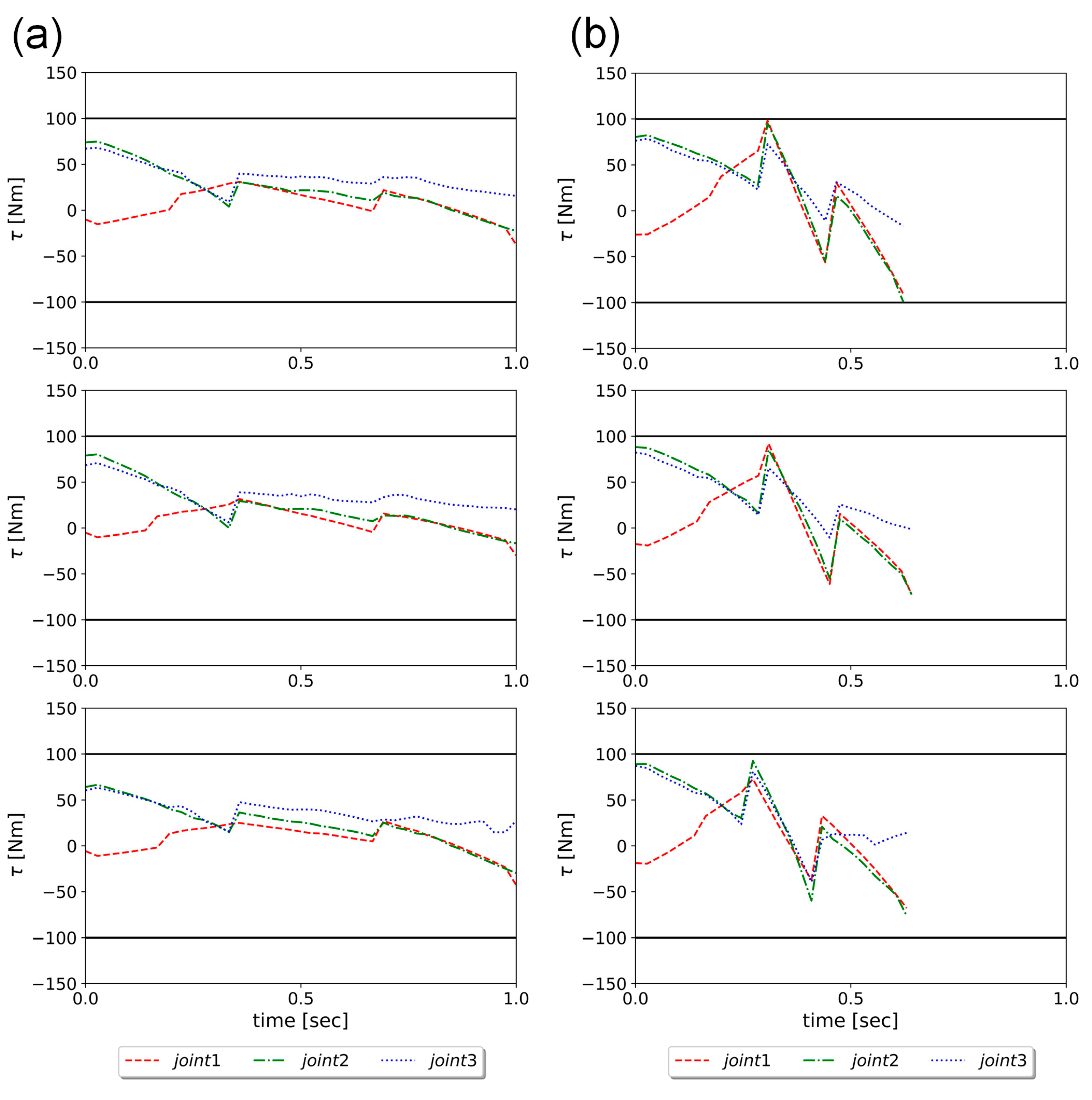
Afterwards, the hybrid model was used in the manipulator trajectory optimization for energy efficiency and speed. The optimization was treated as a bandit problem and solved by RL. The Bi-RRT was utilized to find the initial via points of the trajectories, and then the PPO algorithm was used for trajectory optimization with an obstacle-avoidance capability. In addition, the trajectory optimization using GA was implemented for a performance comparison as well. The simulation results showed that RL can reach almost the same optimization effect as GA, but using only one tenth of the computation time of GA. In the energy optimization experiment, the human-taught method was compared to RL, and the results showed that the energy consumption of the 15 trajectories designed by the testers ranged between 33.9 and 90.9 J, while that of the five trajectories derived by RL had a mean and STD 33.1 ± 0.7 J, attesting to the effectiveness of energy optimization using RL. For the speed optimization experiments, the performance of the RL method was better than that of the time compression method by approximately 27%. In short, RL can effectively reduce energy and time consumption in the manipulator obstacle-avoiding tasks with much less computation time compared to other optimization algorithms.
We are currently working on using different artificial intelligence techniques for the same energy and speed optimization problem as well as deploying the developed technique for other types of manipulators. Moreover, more efficient algorithms are also being investigated. The PPO algorithm can be deployed in the same way as the distributed PPO (DPPO) to augment the solution searching space and speed up optimization convergence. The hyperparameters of the NN structure can be further optimized by using Bayesian optimization.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












