1. Introduction
With the rapid development of technology, the modern industrial system has become more and more integrated and sophisticated. The increasing complexity and uncertainty of the system has led to a higher need for accurate and efficient prognostics and maintenance. To deal with this problem, prognostics and health management (PHM) is proposed. PHM plays a crucial role in modern industry because it aims at reducing maintenance costs, improving reliability, and enhancing performance [
1]. A PHM system can effectively detect the early faults of components of machinery, monitor and predict the degradation process, and help in developing or automatically triggering maintenance schedules and management decisions [
2]. Remaining useful life (RUL) prediction is a vital approach for prognostics and a crucial part of the PHM system. The RUL of a system is defined as “ the time from the current time to the end of the useful life” [
3]. Accurate RUL prediction result is the basis for efficient and reliable health management and maintenance. For example, for aero engines, if its RUL can be predicted accurately, we can develop a maintenance schedule in advance and replace components with potential failure risks. Thus, the operating life is extended and maintenance costs are reduced. Additionally, possible casualties are avoided.
RUL prediction approaches can be roughly divided into model-based approaches, data-driven approaches, and hybrid approaches. Model-based approaches describe the degradation processes of machinery through building mathematical models on the basis of the failure mechanisms or the first principle of damage [
4]. For example, a Paris–Erdogan (PE) model-based RUL prediction method under the framework of Bayesian estimation is proposed in [
5], and the system state transition is described with the PE model. However, model-based approaches require a large amount of prior expertise, which is often hard to obtain, and it is increasingly difficult to build accurate physical models due to the increasing complexity of industrial systems. With the gradual improvement of signal processing and feature extraction technology, condition monitoring (CM) using dedicated sensors can provide a large amount of real-time health information for the system. These informative data provide the possibility to construct more effective RUL prediction methods. Data-driven approaches try to utilize machine learning techniques to learn the degradation patterns from monitoring data, so the RUL of systems can be accurately predicted.
A large number of data-driven approaches have been proposed, such as a support vector regression (SVR)-based method [
6,
7], a hidden Markov model (HMM)-based method [
8,
9], an artificial neural network (ANN)-based method [
10], etc. reference [
6], an SVR-based method was proposed for RUL prediction of lithium-ion batteries (LIBs), where the artificial bee colony (ABC) algorithm was utilized for optimization of kernel parameters. HMM-based methods are another important class of RUL prediction methods. For example, Liu et al. [
8] proposed a novel switching hidden semi-Markov model (SHSMM) to represent the degradation process of equipment, and it has a more generalized form and a more powerful ability to describe the degradation process with time-varying working mode compared to traditional HMM-based methods. The ANN-based methods have actually developed into the most popular methods currently in use, i.e., the deep learning method. Deep learning is a popular branch of machine learning technology. It can extract deep features and degradation information from original monitoring data without any manual operation, so it can effectively model the degradation process of the monitored system. Therefore, the RUL prediction methods based on deep learning have also been widely studied. In reference [
11], a method using a multi-scale deep convolutional neural network (CNN) with an attention mechanism is proposed to effectively fuse multi-sensor data and learn representations from different temporal scales.
Recurrent neural network (RNN) is a classic method that can model the temporal correlation, and long short-term memory (LSTM) [
12] is an upgraded version of RNN. Its purpose is to overcome the gradient vanishing and exploding problem. Due to its outstanding performance on temporal sequences modeling, it has been widely used in speech recognition [
13], natural language processing [
14], and other fields. In industrial big data analysis, the benefit is from its suitability for processing time-series vibration signals that widely exist and are collected in industrial systems. RUL prediction methods based on RNNs and LSTMs have also been widely studied [
15,
16,
17,
18,
19,
20,
21,
22]. Ren et al. [
16] proposed a novel architecture that combined deep CNN and LSTM, which is called Auto-CNN-LSTM. The method overcame the problem of insufficient data in RUL prediction due to the ability of mining deeper information from finite data. In [
22] researchers proposed a convolution-based long short-term memory (CLSTM) network by cleverly embedding CNN into LSTM, which not only preserves the advantages of LSTM but also incorporates time-frequency features. These data-driven methods can avoid the problem of building physical models, which is usually hard in real applications. Since acquiring a large amount of monitoring data and powerful computing resources required by the data-driven method has become a reality, and due to the characteristic of model-free and expertise-free, data-driven methods had attracted increased attention and have became the most promising direction in RUL prediction.
In practice, there is a large number of disturbances in industrial sites such as vibrations, shock, electromagnetic interference, chemical corrosion, etc., which lead to unpredictable corrupted sensor data. Ordinary data-driven methods will fail with corruption in the input data because these models are often trained from complete data; therefore, what these models modeled is the distribution of the complete data. However, the corruption in the input data in real applications is not present in the training data, which means it deviates from the distribution of the training data, and the model cannot generalize well. Therefore, it is necessary to introduce corruption data in the training process. A naive way is to directly train the model with the corrupted data, but the learning ability of the model will be challenged, since the unpredictability of the corruption values leads it to be close to random noises, which is hard for machine learning to deal with. Another method is to complement the corrupted values and perform the RUL prediction with the complementary data, including a mean value imputation, matrix completion, deep learning-based methods, etc. However, these operations will introduce imputation errors and human interference, resulting in limited RUL prediction performance.
To cope with the problem mentioned above, a novel RUL prediction method which can perform well under corrupted sensor data is proposed in this work. The architecture of the proposed model is a multi-task framework combining deep LSTM, a missing values imputation task, and an RUL prediction task—the latter two are deployed in parallel following the deep LSTM. With the recovery of missing values, the deep LSTM can fuse the features containing integral degradation information. The hidden representation which greatly benefits RUL prediction in the missing values imputation module is simultaneously used for RUL prediction. Additionally, to further improve the performance of the proposed method, a novel loss term is designed to smooth the predicted RUL. The proposed method is evaluated on the C-MAPSS dataset [
23], which is a classical dataset created by NASA and extensively utilized in many RUL prediction studies [
21,
24,
25,
26,
27]. The high-quality full life degradation data of multiple engines in C-MAPSS greatly helps for comprehensively and objectively evaluating the performance of the proposed method. The main contributions of this work are as follows:
- 1.
A novel multi-task method is proposed for RUL prediction under corrupted sensor data. With the assistance of the missing values imputation module, the proposed method can perform well in RUL prediction under corrupted sensor data.
- 2.
A novel loss term is introduced for improving the RUL prediction performance, which can smooth the predicted RUL without any manual post-processing.
- 3.
Extensive comparative experiments and ablation studies verified the effectiveness of the proposed method.
The rest of this article is organized as follows:
Section 2 describes the details of the proposed method, the effectiveness of the proposed method is verified in
Section 3, and, finally,
Section 4 concludes this work.
2. Methodology
2.1. Problem Statement
In industrial systems, the collected data from the sensor network is usually time-series signals, such as vibration signals, acoustic signals, temperature, voltage, etc. In the RUL prediction task, vibration signals are the most commonly used. The proposed method utilizes a deep model to extract degradation information from the vibration signals for RUL prediction. The common multi-sensor RUL prediction task based on the vibration signals can be expressed as: construct a regression model
, given multi-sensor time-series signals
collected until time
T, where
s denote the number of sensors. Then the RUL at time
T can be predicted with
However, in real industrial applications, many disturbances can lead to unpredictable corruption in the collected sensor data. It can be assumed that the corrupted data is detected, and thus the value is set equal to zero, which represents a missing value. Thus, the collected signal
with missing values is:
Therefore, the existing methods based on complete data will fail when encountering missing values. To deal with this problem, a novel RUL prediction method that can process the above-mentioned data with severe random missing values is proposed in this work.
2.2. Overview
The process of the proposed method is as follows: First, the corrupted data is simulated manually based on the complete data; this is a critical part of the proposed method. This is because the mapping from corrupted data to complete data needs to be modeled, which is the missing values imputation task mentioned later, so both complete data and corresponding corrupted data are necessary. The specific simulation process is described in
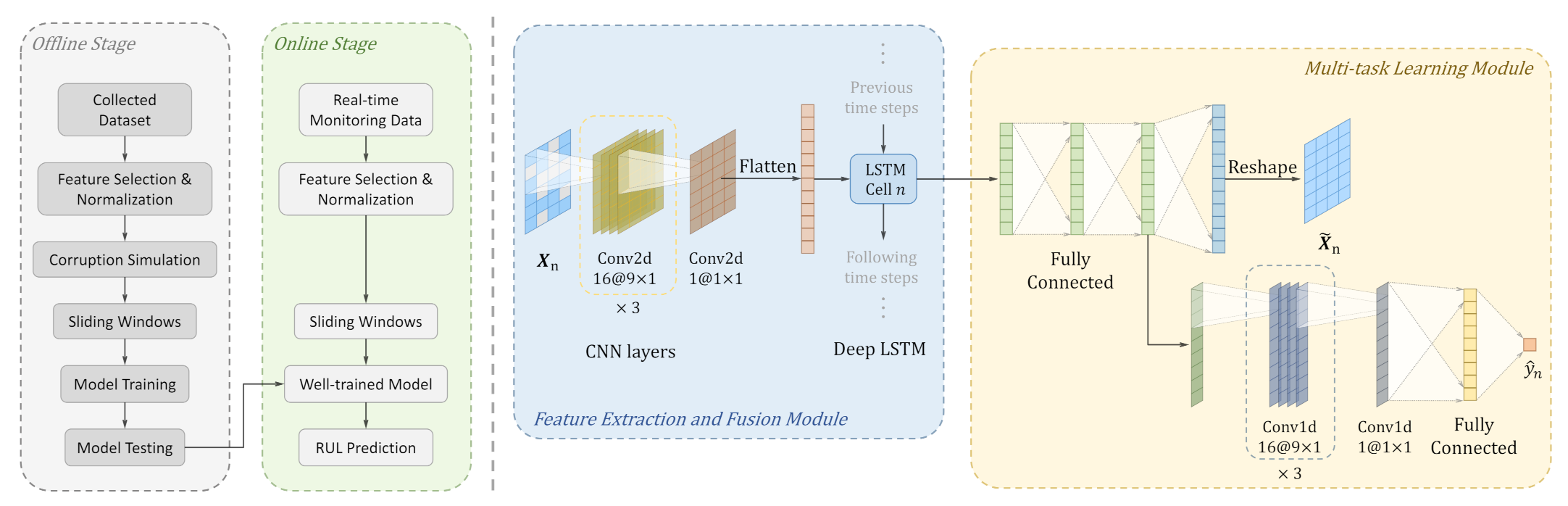
Section 3.3 considering it is a part of data processing. Second, the proposed multi-task deep LSTM (MTD-LSTM) will be trained using the simulated corrupted data and tested using testing samples with corrupted values under different missing rates. Note that the corresponding complete values are not required in the testing process, which is consistent with real applications. Third, the well-trained model will be deployed in real industrial applications. It should be noted that the basic assumption is that the corrupted values of the input data have been detected and replaced by 0 values, and the detection method is not considered in this work. The flowchart of the proposed method is shown in the left part of
Figure 1.
The core of the proposed MTD-LSTM is a multi-task learning framework with a deep LSTM. The architecture of MTD-LSTM is shown in the right part of
Figure 1. There are two main parts in MTD-LSTM, first, a degradation feature extraction and fusion module consisting of a CNN and a deep LSTM and second, a multi-task learning module consisting of missing value imputation module and RUL prediction module.
Firstly, the signals with missing values are fed into the degradation feature extraction and fusion module to extract and fuse the degradation information, where the CNN and deep LSTM are employed sequentially. CNN is commonly used for feature extraction and the deep LSTM can effectively fuse the extracted features along with time steps. The fused features are next fed into the multi-task learning module for missing value imputation and RUL prediction.
For the RUL prediction task, it is difficult to achieve an accurate prediction if there are missing values in the input data. The reason lies in that the missing values lead to the loss of degradation information. To deal with this, multi-task learning is utilized. Specifically, the missing values imputation module is implemented to recover the complete data. That being the case, the hidden representation in the missing values imputation module contains the integral degradation information. Based on the idea of multi-task learning, the hidden representation containing integral degradation information is used for RUL prediction simultaneously, thus a better RUL prediction performance can be achieved. Moreover, the proposed monotone and linearly decreasing loss (MoLD Loss) is imposed on the predicted RUL for smoother results.
2.3. Feature Extraction and Fusion Module
In the feature extraction and fusion module, the CNN and deep LSTM are utilized to extract and fuse the features from the input data with missing values. CNN was originally used in computer vision; however, some studies show it also performs well in processing time-series signals [
28]. Here, we utilized CNN for local feature extraction on the input data with missing values. The original multi-sensor signals are firstly processed into samples by the sliding window technique. The input sample
n can be expressed as
where
w and
s denote window size and the number of sensors. We implemented a 4-layer CNN model with tanh activation function to extract local features from the input samples. The details of the CNN model are shown in
Figure 1. Note that the output feature map is reshaped into a vector to adapt the input dimension of deep LSTM. Only using the CNN model to extract the local feature is not enough for RUL prediction under corrupted sensor data because the severe missing values may occur in sample
, which will lead to severe degradation information loss. Therefore, the historical information in the previous samples must be considered and temporal correlations must be modeled to fully explore the available information under corrupted sensor data.
Here, the deep LSTM is employed following CNN to model the temporal correlations, and features extracted from past time steps are fused. An LSTM consists of a series of units; the structure of the unit is shown in
Figure 2. The input at time
t includes current data
, the hidden state
, and the memory cell state
from time
. After calculation,
and
passed the long-term memory and short-term memory along with new information from
on to next unit. This mechanism is achieved by controlling the data flow through control gates, namely, the input gate, forget gate, and output gate, which are shown in
Figure 2. In deep LSTM, the hidden state of the previous layer is used as the input data for the next layer.
In LSTM, since the memory cell state and hidden state contain long-term and short-term memory, respectively, they contain abundant historical degradation information in different stages. This provides the possibility of recovering the complete data in the following missing values imputation task, even if is highly incomplete. By iteratively inputting the samples before sample n into the model, the deep LSTM can model the temporal correlations of the time series signals, and the output hidden representation of sample n integrated the historical degradation information. Moreover, the deep LSTM can fully explore the correlation between different sensors to make full use of the available information in for recovering the missing values. So, the extracted fully integrated the available information and leads to effective missing values imputation followed by a better RUL prediction performance, even if the input data is highly incomplete.
2.4. Multi-Task Learning
After extracting and fusing the degradation features from the input data with missing values, the hidden representation will be fed into the multi-task learning module for missing value imputation and RUL prediction tasks.
In the missing values imputation module,
output by the deep LSTM at time step
n is used for recovering the complete data
corresponding to the incomplete input
. To map
from hidden representation space to high-dimensional observation space, a 3-layer fully connected network (FCN) is implemented in this module. The output vector of this module is reshaped to a matrix
to adapt the samples’ dimension. Due to the strong fitting ability of FCN, it can fit the detailed information in the complete data
to recover the missing values from
. In this module, the rectified linear unit (ReLU) activation function is used for nonlinear transformation. The target of the missing values imputation task is to let the output of the module be as similar as possible to the complete data. Mean squared error (MSE) is used as the loss function to measure the error between the output and the complete data. Assuming that
and
denote the output and the complete data of sample
n, the imputation loss is
where
N,
w, and
s denote the number of total samples, window size, and the number of sensors, respectively.
Missing values imputation is not the final goal, but an auxiliary means for RUL prediction under corrupted sensor data. For prediction, an RUL prediction module is employed that shares the first two layers of FCN with the missing values imputation module. Following the shared layers, a 4-layer 1D CNN is utilized to extract the degradation features from the hidden representation. Note that the hidden representation is shared for the missing values imputation task, which means the shared representation contains the integral degradation information, and this greatly benefits RUL prediction. The details of the 1D CNN model are shown in
Figure 1. Following the 1D CNN, a 2-layer FCN with 512 neurons in the hidden layer is employed to fit the target RUL from the extracted features. The commonly used MSE loss in regression tasks is utilized to calculate the prediction error. Assuming that
and
denote the predicted value and the target RUL of sample
n, the prediction loss is
where
N denotes the number of total samples. In order to let the missing values imputation task assist RUL prediction, the overall loss function is
where
denotes the weight of
.
2.5. Monotone and Linearly Decreasing Loss
For the purpose of improving the smoothness of RUL prediction, a monotone and linearly decreasing (MoLD) loss term is applied to the prediction results. This term is inspired by the nature of RUL: monotone and linear decline. Specifically, we assume that
and
denote the predicted RUL of sample
n and the sample
time steps earlier than
n, respectively, and
denotes the difference between
and
. Ideally,
should be equal to
according to the nature of RUL mentioned above. However, in practice, due to the effect of the limited performance of the model, the noise in the collected signal, and the missing value in the data,
is usually not equal to
, which means the fluctuation of prediction results. A common approach is to apply smoothing post-processing to the prediction results, but it is cumbersome and human interference is introduced to the output of the model. To let the model output the smoothed RUL directly, we propose to add the MoLD loss term
to Equation (
6) to constrain the RUL prediction result, which leads the model to directly output a smooth RUL prediction:
where
denotes the weight of
and
where
is a hyper-parameter to control the intensity of smoothness. Intuitively, if
, there is no penalty on the result. However, whether the predicted value is greater or less than the ideal value, a penalty will be imposed on the result. In other words, the RUL prediction result will be locally smoothed without any manual post-processing.
4. Conclusions
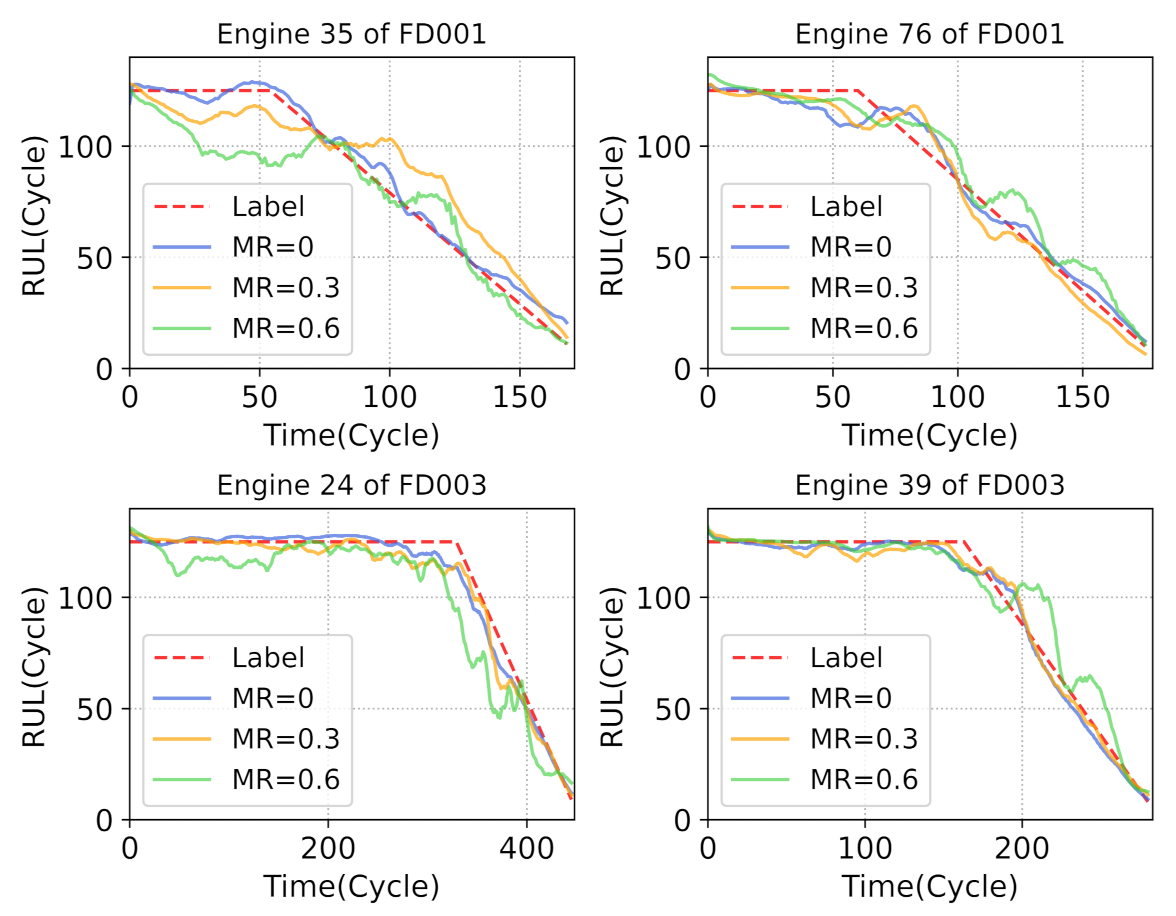
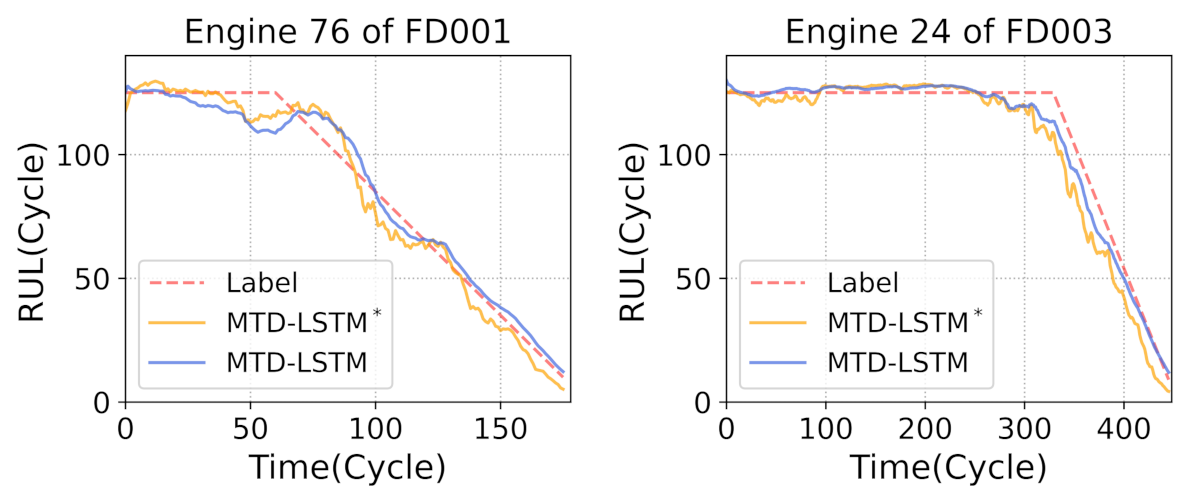
In this work, we proposed an LSTM-based multi-task model (i.e., MTD-LSTM) for RUL prediction under corrupted sensor data. The corrupted data is first fed into the feature extraction and fusion module, and the extracted features are next simultaneously sent to the missing values imputation and RUL prediction module. The purpose of the missing values imputation task is to extract integral degradation information from the incomplete data; therefore, the RUL module can perform better under corrupted sensor data. In addition, to automatically smooth the predicted RUL, the proposed MoLD loss is applied to the output value. Experiments conducted on the simulated dataset verified the effectiveness of the proposed method.
There are still some drawbacks in the proposed method. For example, in this method the missing values must be simulated using complete data, and the distribution of this artificial simulation missing values is usually different from real scenarios. In addition, in real applications there are often a variety of problems including missing values in the data, such as sensor drifting; precision reduction; and so on. The proposed method does not deal with these problems well.
In future work, we will further explore robust and generalized RUL prediction methods under sensor faults to adapt to various harsh industrial conditions, since data corruptions may occur in the data under sensor faults. Multiple types of abnormal values should be handled, such as outliers, data drifting, and so on. To this end, more powerful methods may be utilized, such as transformer [
36] and others.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}