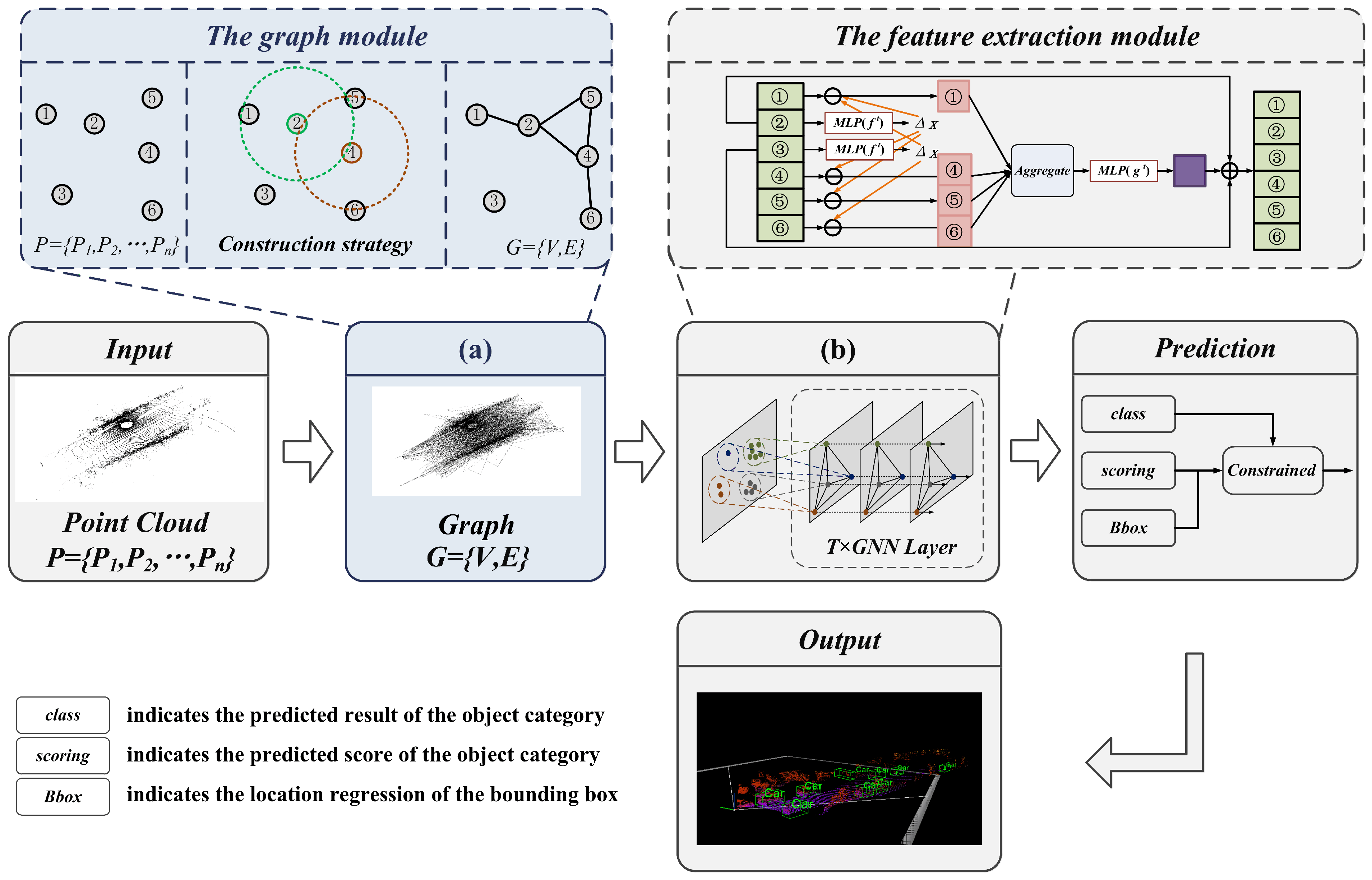
3.1. Framework Overview
The framework of the proposed method is shown in
Figure 1. This method adopts a LiDAR point cloud as input, and mainly consists of a graph representation module, feature extraction module, and prediction module.
The graph module utilizes the mapping function to determine the number of grids and points, which obtains the sparse point cloud with retaining enriched information. Then, the vertex and edge features of the graph representation are constructed by searching the neighbors with a fixed radius.
The feature extraction module achieves information transfer by sharing structural features between vertices and edges. In the iteration process, to update the vertices and reduce the offset error, the aggregated feature vectors are computed with the neighbor and edge features. In addition, to avoid repeated grouping and sampling, the edge features of each layer are reused for feature learning.
The prediction module calculates a weighted sum using the location and scale information, which is used to correct the scores of the classification. Then, the bounding box regression prediction is calculated by combining all overlapping bounding boxes of the prediction object.
3.2. The Point Cloud Processing Module
The LiDAR point cloud with a large number of points usually consists of tens of thousands of points. Constructing a graph representation with all points as vertices introduces a huge computational cost, which may lead to an unsatisfactory processing speed in the model. Therefore, we propose to construct the graph with the point cloud after the down-sampling process. It is worth noting that the voxelization here is only used to reduce the density of the point cloud, and it is not used as a representation of the point cloud for feature extraction.
Therefore, point clouds are sparsely processed in several research works. A common method of point cloud down-sampling is structural voxelization. In this method, the point
is assigned to the corresponding voxel
according to its spatial coordinates. The down-sampling point cloud is achieved by sampling a fixed number of points in each voxel grid, as shown in Equations (
1) and (
2):
where
denotes the mapping of the voxel
where each point
is located, and
denotes the mapping of the set of points in the voxel
.
In the structure voxelization method, if the number of assigned points in the voxel grid exceeds the default value, the extra points are dropped. Otherwise, the remaining part will be filled to zero. However, the LiDAR point cloud is a non-Euclidean structure, and the distribution in the point cloud is random and disorderly. If the point cloud is processed using structural voxelization, the critical information might be discarded with high density, as well as adding ineffective space and computational cost with sparse density. Therefore, balancing the density of points and detection accuracy in LiDAR point cloud detection has significant investigative importance.
To address the mentioned limitations, we propose a dynamic sparsification method for point cloud processing, as shown in
Figure 2.
We define the point cloud as
. Instead of sampling points to a fixed voxel, we propose to preserve the entire mapping relationship between points and voxels, as shown in Equations (
3) and (
4):
We analyze the random sampling method for reducing the density of the point cloud, which will not ensure that the point cloud preserves the complete critical information.
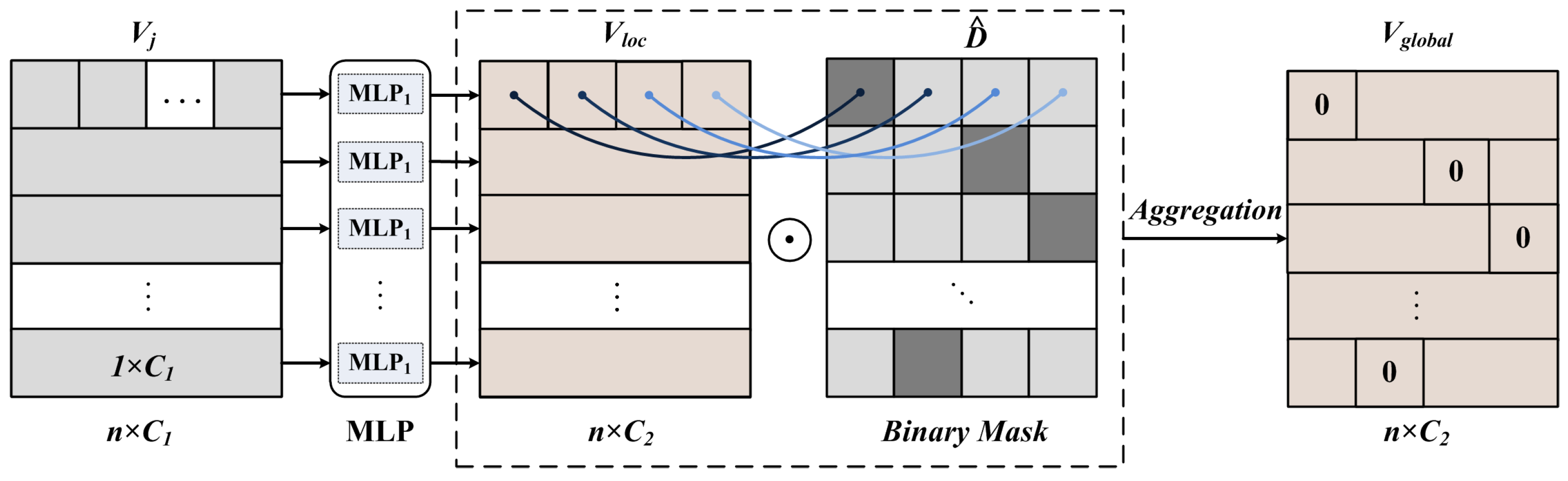
Firstly, the constructed voxel feature
is mapped to the local voxel feature
, which contains information about the number of dynamic voxel grids, as shown in Equation (
5):
Secondly, the local voxel feature
is aggregated with the binary mask
, and the global voxel feature
is obtained for dynamic sparse point cloud processing, as shown in Equation (
6):
where
Agg() denotes the function that aggregates the available feature information.
Finally, the global voxel feature
is embedded in
as shown in Equations (
7) and (
8):
This method eliminates the fixed memory requirements of downsampling operations, and it does not randomly discard points and grids. It can solve the problem of loss of critical information and null operations caused by sparsity and density imbalance in 3D point clouds. The dynamic sparsification method enables dynamic and efficient resource allocation to manage all points and voxels. The ability to generate a deterministic voxel embedding assures more stable detection results with dynamic sparsification.
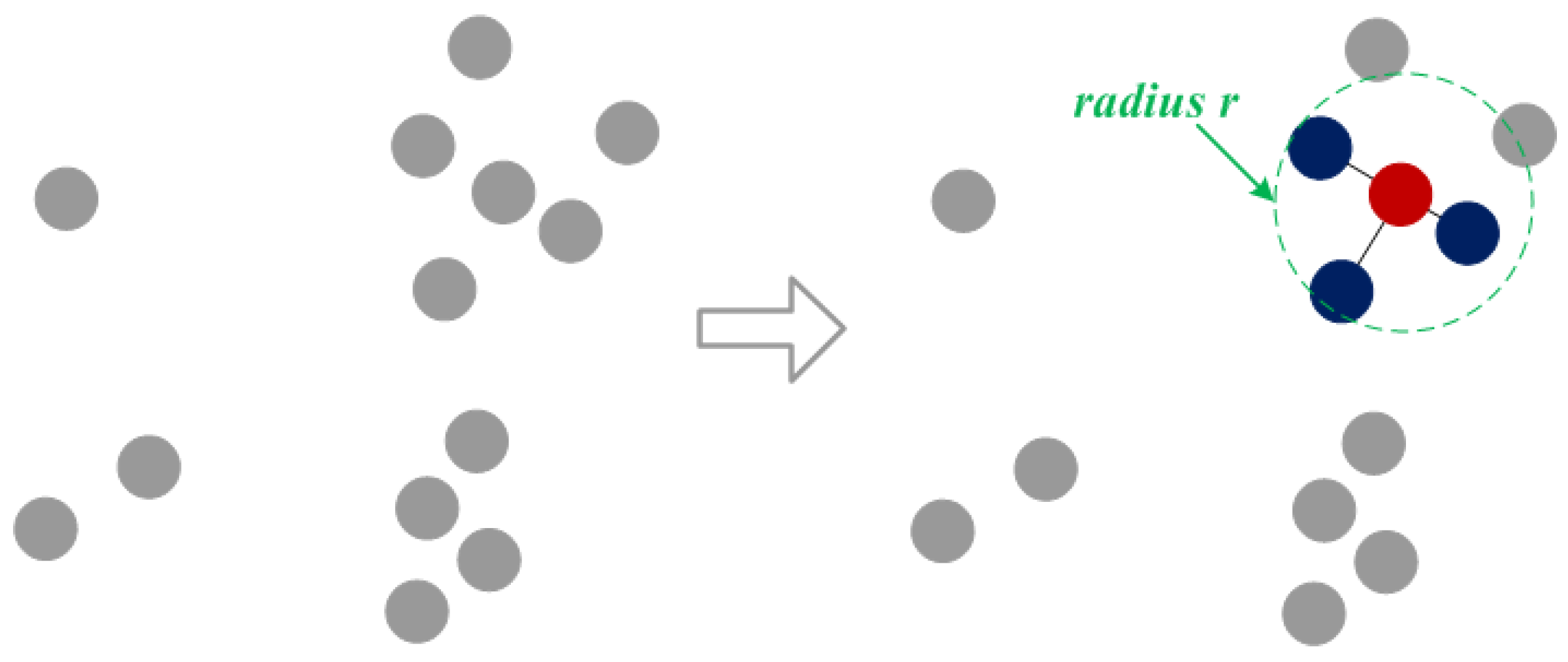
The point cloud structure only contains information about points, and there is no information about the edges inherently. Therefore, when constructing the graph representation, the definition of edge features needs to be added manually by using the vertex features in the point cloud.
As shown in
Figure 3, we are given a point cloud
, which is used to construct a graph representation
. We create an edge
E by taking
as a vertex
V and connecting the point to the neighbor within its fixed radius
r.
We convert the graph representation to a fixed radius nearest neighbor search problem. The runtime complexity
problem is efficiently solved by using a list of cells to find pairs of points within a fixed distance, which contains the maximum number of neighbors within the radius, as shown in Equation (
9):
3.3. The Feature Extraction Module
We introduce a graph neural network (GNN), which employs standard information transfer to extract features from graph representations. GNNs can maintain the symmetry of the graph information. The vertices are sorted in a different way, which can also guarantee that the prediction results do not change. In the t-th iteration, we set the vertex feature vector to be and the edge feature vector to be .
FNRG [
27] exploited the consistency of local neighborhood structures to deal with outliers, which is effective for the outlier removal problem. The main reason is that the correspondences preserve local neighborhood structures of feature points. The importance of the neighbor feature structure is demonstrated.
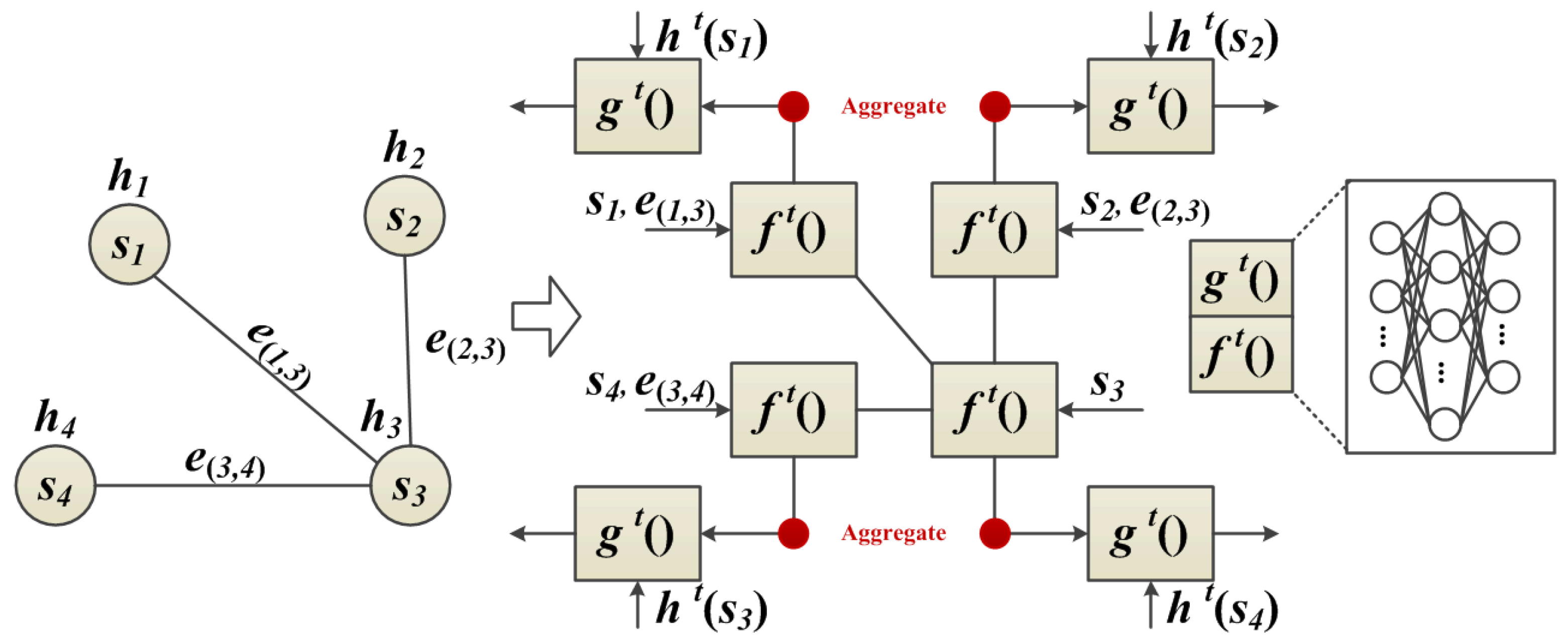
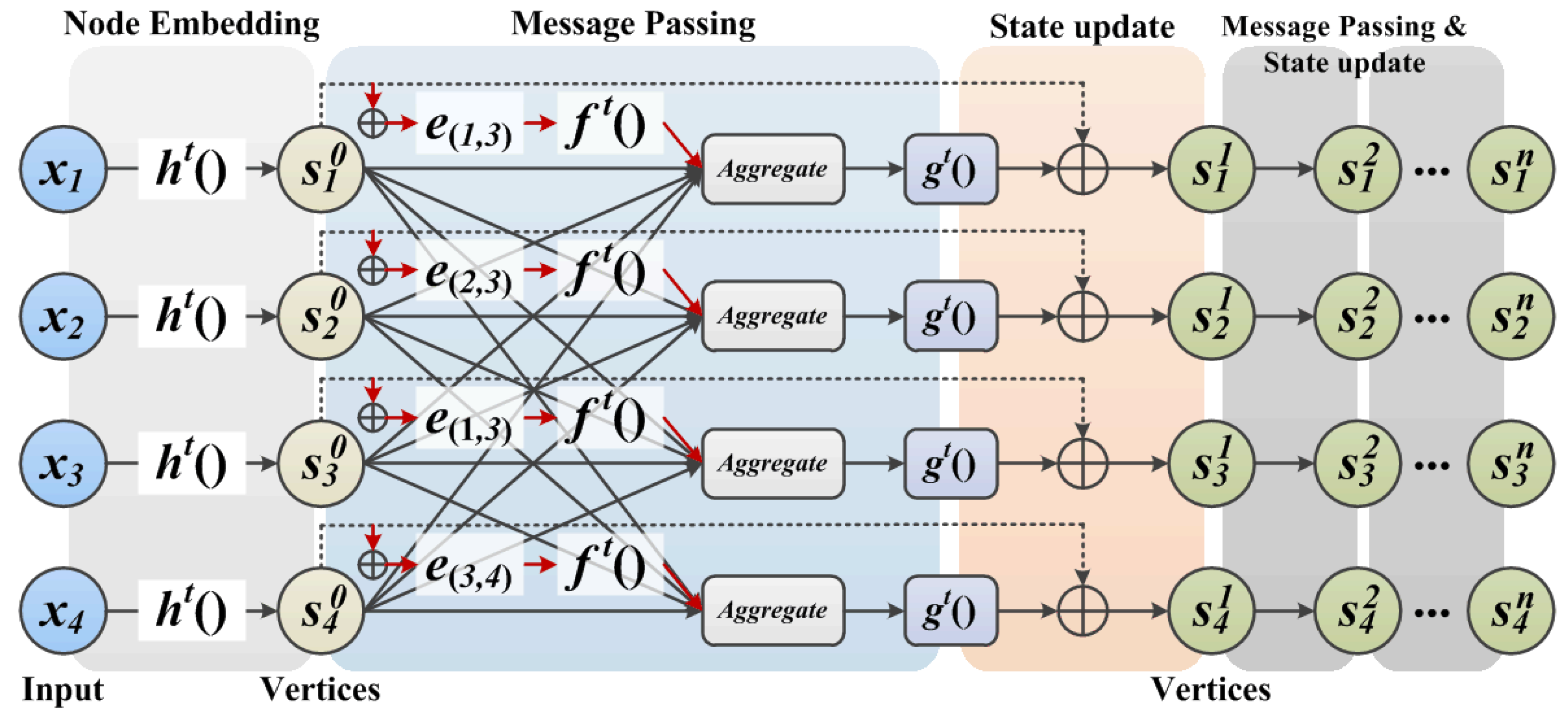
The proposed neighbor feature alignment mechanism is introduced by the example shown in
Figure 4. We assume a connection relationship between the centroid
and its neighbors (
,
and
) by denoting
s as a vertex and
e as an edge. In this case,
indicates that there is a connection between the centroid
and its neighbor
. In this example, we can observe the message passing and state updating process of the vertex.
The details of our proposed neighbor feature alignment mechanism are introduced as follows.
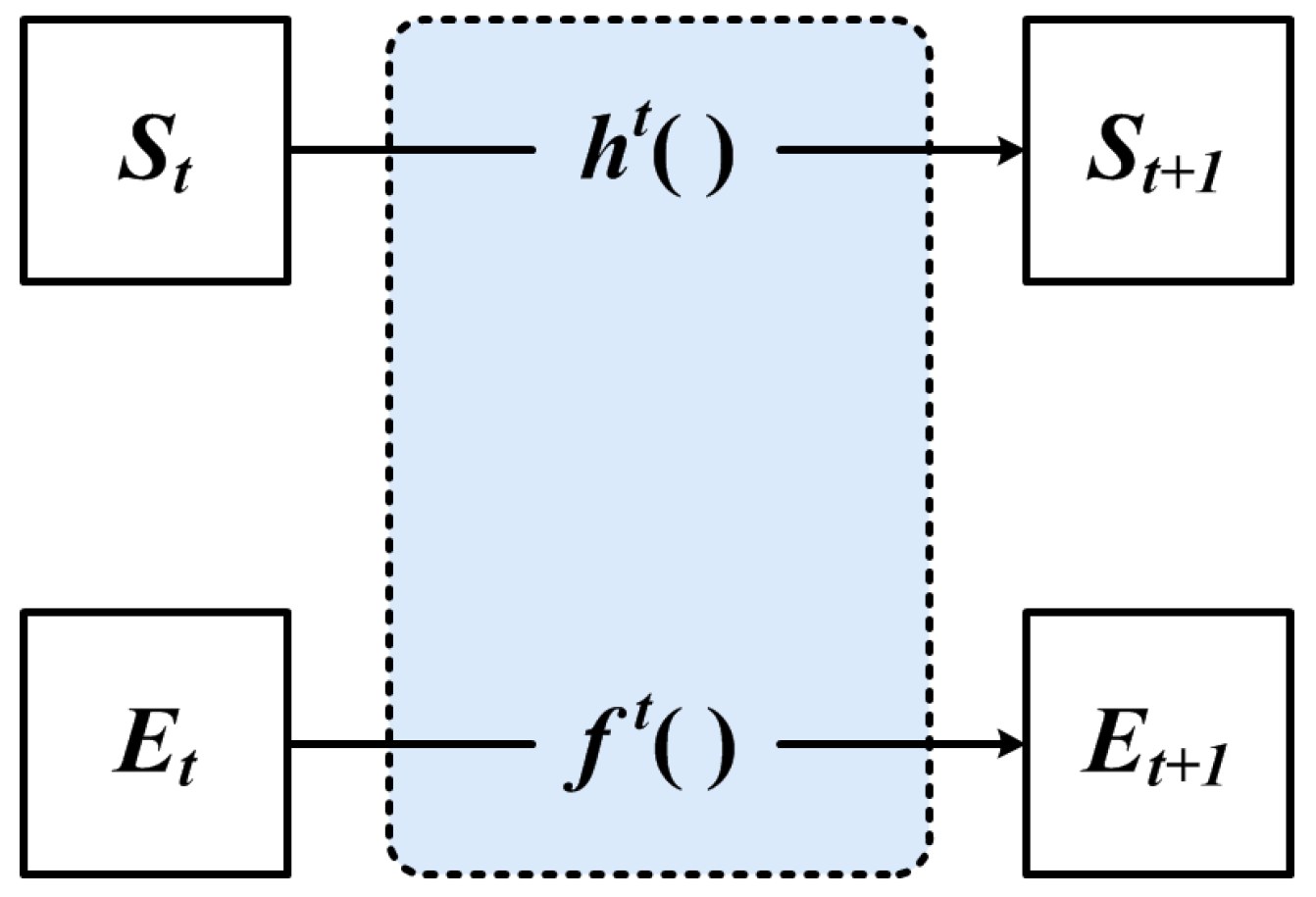
The classical GNN feature extraction process is shown in
Figure 5, where both functions
and
are Multi-Layer Perceptron (MLP) functions. All vertex features share a multilayer perceptron function, and all edge features share a multilayer perceptron function. In the
t+1-th iteration process, the feature vectors of both vertices and edges are updated, and the structure of the graph will not change.
However, it can be noticed that there is a problem in the GNN model illustrated in
Figure 5, that is, the structural information of the graph is not used in the feature extraction. Although GNN transforms the feature vectors of vertices and edges, there is no information sharing between vertices and edges.
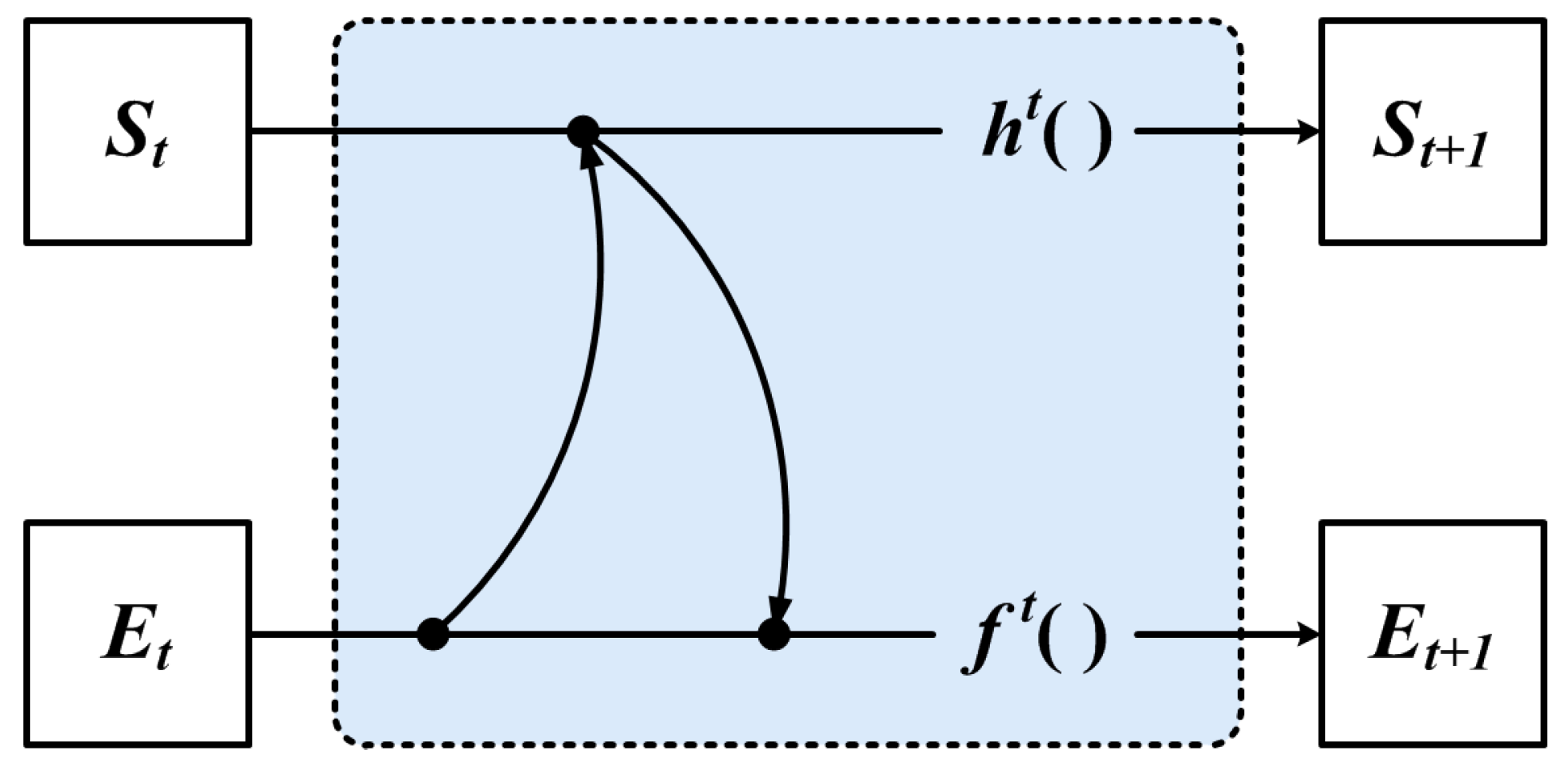
Firstly, we propose to share feature information between vertex and edge features by encoding neighbors, as shown in
Figure 6.
In the
t+1-th iteration, the updated form of each vertex is as shown in Equation (
10):
GNN uses the feature of the vertex to compute the feature of the neighbor, which is used to represent the iterative update process of edge features, as shown in Equation (
11):
However, we use the GNN of
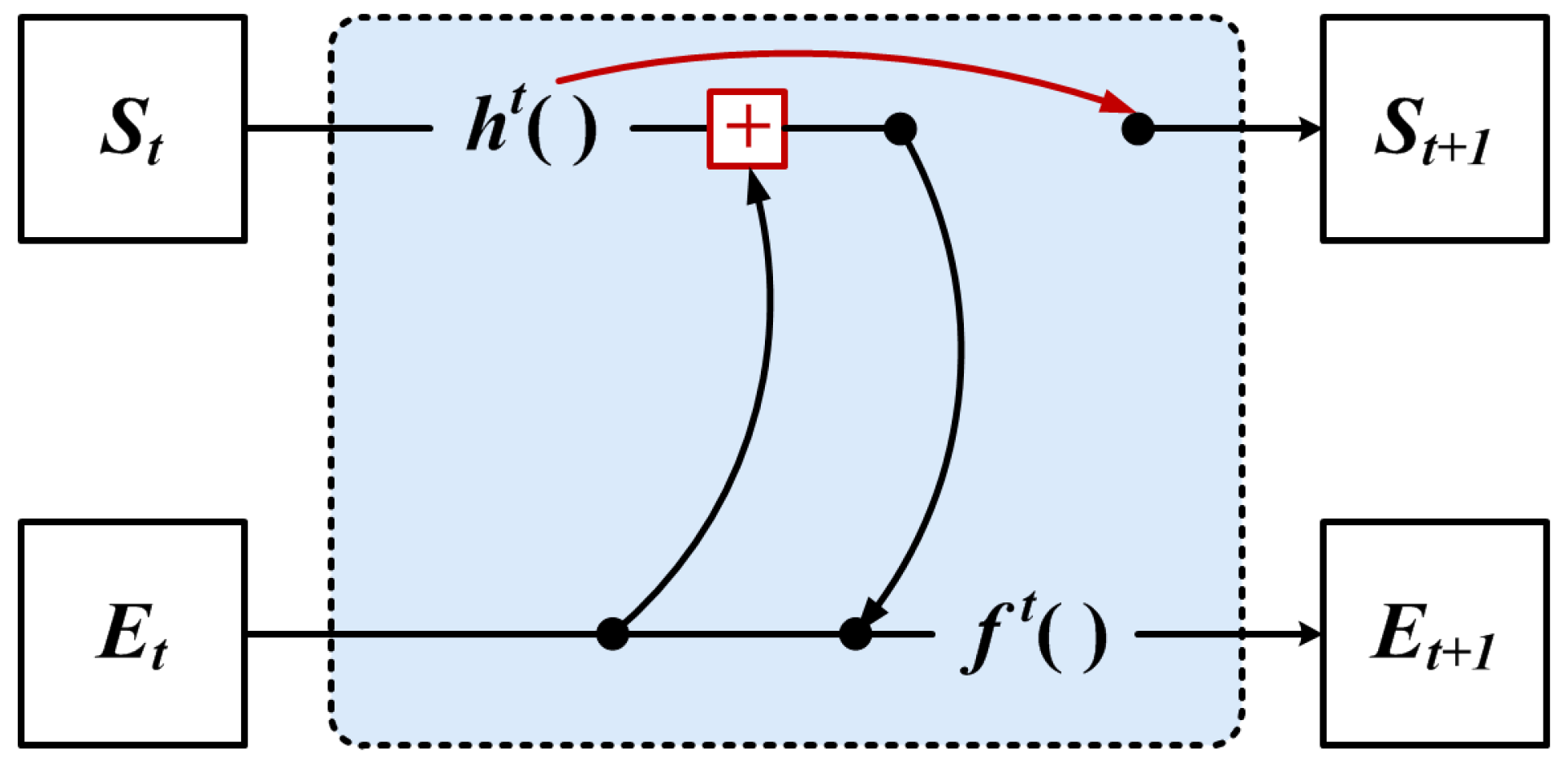
Figure 6 for iteration, which can only achieve the encoding of the local neighbor feature, and the original global structure might be lost. Therefore, we propose to use the global structural features aggregated with the local neighbor features in the iteration update process, as shown in
Figure 7.
However, encoding by aggregating local and global information can ensure the information sharing between vertex and edge features, allowing the structural features of the graph to be maximally used. However, the input variables of the function increase when the vertices are shifted, which causes the relative coordinates of the local information to change.
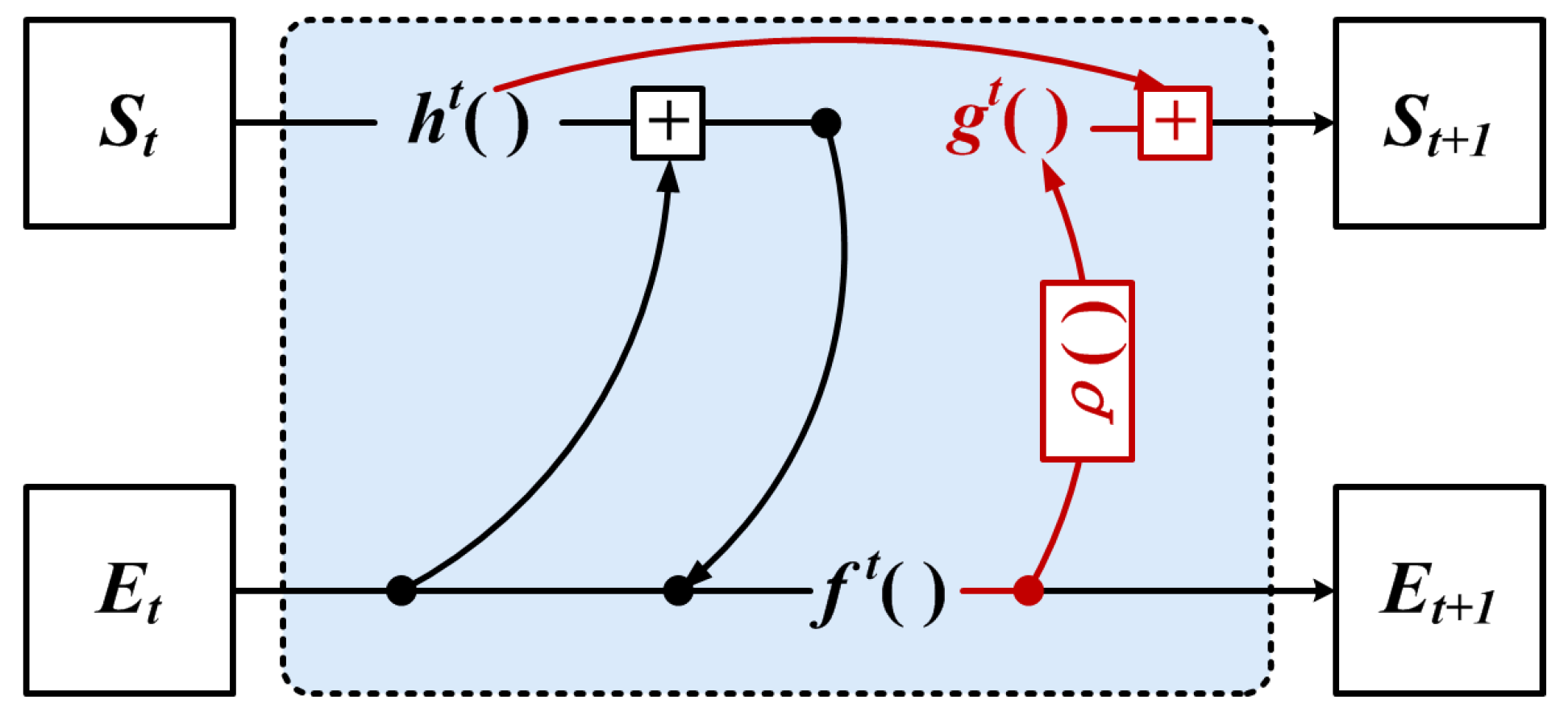
Motivated by the above, we propose a neighbor feature alignment mechanism, as shown in
Figure 8.
The GNN based on the neighbor feature alignment mechanism used the structural information from the previous layer of iteration for aligning the relative coordinates, which reduces the sensitivity of local information to the vertex feature offset.
Firstly, we define the coordinate offset representation of the vertex feature as shown in Equation (
12):
In the
t+1-th iteration process, the edge features are updated by combining with the coordinate offsets of the vertex features, the weighted sum of the local neighbor information, and the global structure information, as shown in Equation (
13):
The state of the vertex features is updated by aggregating the edge features and the global structure information, as shown in Equation (
14):
where
and
denote the neighbor features,
denotes the coordinate offset of the vertex, and
denotes the state value of the vertex features from the
t-th iteration. The function
is used to compute the edge features between vertices,
is used to aggregate the edge features of each vertex,
updates the state values of the vertices by the aggregated edge features, and
computes the offset using the center vertex state values from the previous iteration. It is noted that the offset can be disabled in GNN here by setting
to zero. Practically, the functions
,
and
are implemented using the MLP, and
is chosen to be the mean value.
In summary, the message passing and state updating process of our proposed GNN based on the neighbor feature alignment mechanism is shown in
Figure 9.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}