
Spatial Fuzzy C-Means Clustering Analysis of U.S. Presidential Election and COVID-19 Related Factors in the Rustbelt States in 2020


Abstract
:1. Introduction
2. Methodology
2.1. Research Method
2.2. Data Description
2.3. C-Means Clustering
2.4. Fuzzy C-Means Clustering
2.5. Spatial Fuzzy C-Means Clustering
3. Results
3.1. Fuzzy C-Means and Generalized Fuzzy C-Means Clustering
3.2. Spatial C-Means and Generalized C-Means
3.3. Spatial Generalized Fuzzy C-Means (SGFCM)
3.4. Comparison of the Four Algorithms
4. Discussion
- (1)
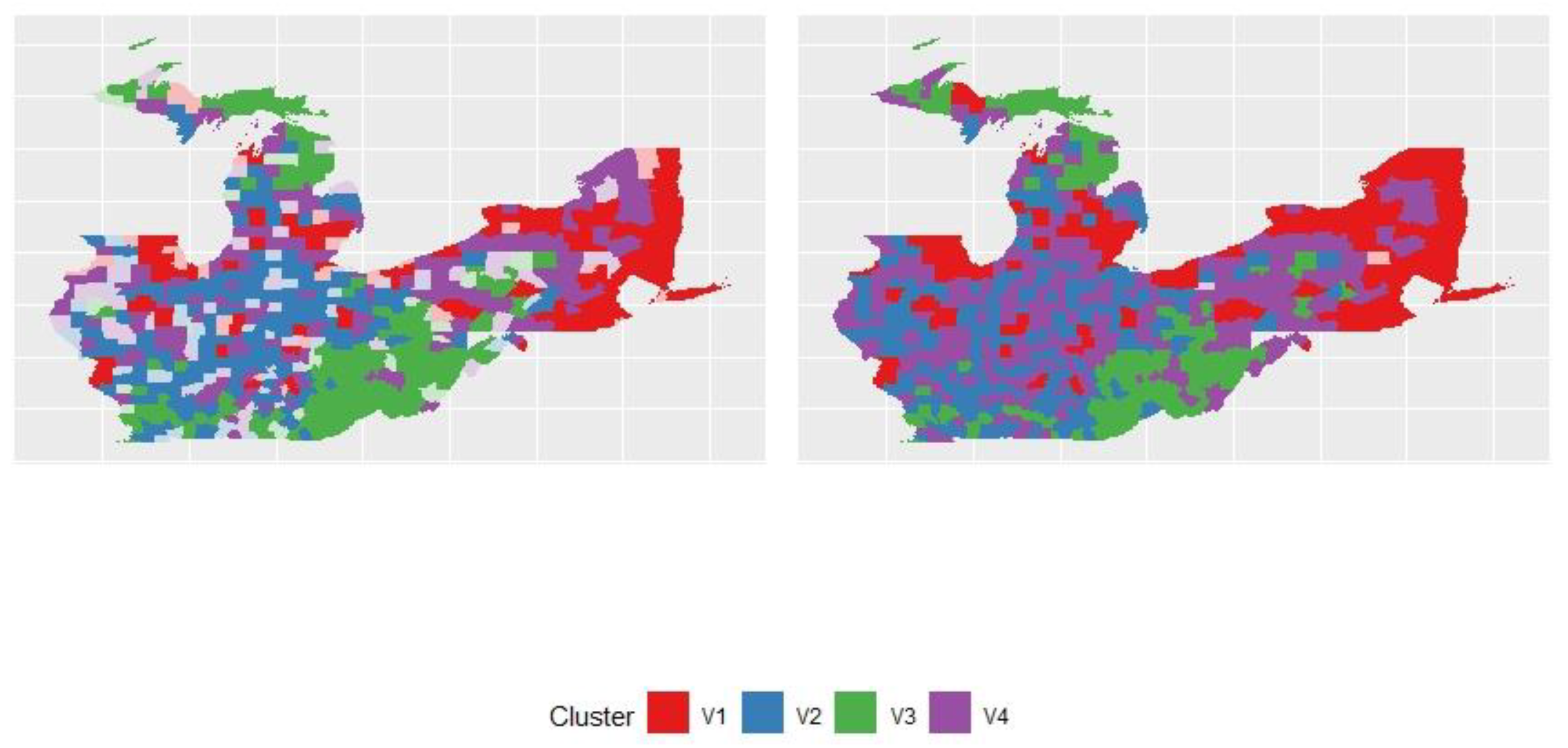
- First cluster: the cluster had lower X1 (mean < 0.5), higher X2, higher X4, lower X5, and higher X6 values. Other variables did not seem obvious. We can conclude that people in this region were not inclined to support the Republican candidate, often wore masks, had more high-school graduates or above, had a lower unemployment rate, and a higher income. The first cluster included a little part of southeastern Pennsylvania, New York state and other scatter parts of the rustbelt states.
- (2)
- Second cluster: The cluster had higher X1 (mean > 0.5), higher X2, lower X4, lower X5, and higher X6 values. Other variables did not seem obvious. We can conclude that people in this region were inclined to support the Republican candidate, often wore masks, had less high-school graduates, a lower unemployment rate, and higher income. The second cluster included the larger part of New York state, most part of Michigan and northern Illinois.
- (3)
- Third cluster: The cluster had higher X1 (mean > 0.5), lower X2, lower X4, higher X5, lower X6, and higher X7 values. This means that people in this region tended to support the Republican candidate, wore masks less frequently, had less high-school graduates or above, a higher unemployment rate, lower income, and higher COVID-19 death toll. The cluster included some parts of Kentucky, West Virginia and Ohio and other scatter parts of the rustbelt states.
- (4)
- Fourth cluster: The cluster had higher X1 (mean > 0.5), lower X2, lower X4, lower X5, higher X6, and higher X7 values. This means that people in this region tended to support the Republican candidate, wore masks less frequently, had less high-school graduates or above, a lower unemployment rate, higher income, and higher COVID-19 death toll. The cluster included the larger part of Indiana, Ohio and part of Illinois.
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | |
|---|---|---|---|---|---|---|---|
| Q5 | 0.222 | 0.514 | 28 | 9872.6 | 2.9 | 46,288.2 | 7 |
| Q10 | 0.27 | 0.549 | 67 | 16,480.8 | 3.2 | 49,515 | 19 |
| Q25 | 0.37 | 0.641 | 198 | 41,764 | 3.4 | 58,222 | 45 |
| Q50 | 0.446 | 0.742 | 379 | 132,127 | 3.8 | 66,270 | 81 |
| Q75 | 0.533 | 0.788 | 501 | 211,597 | 4.2 | 86,108 | 103 |
| Q90 | 0.614 | 0.82 | 596 | 347,971.4 | 4.9 | 94,521 | 153 |
| Q95 | 0.678 | 0.842 | 632 | 522,061 | 5.4 | 100,887 | 165 |
| Mean | 0.448 | 0.71 | 342.689 | 168,655.4 | 3.901 | 70,973.15 | 80.35 |
| Std | 0.134 | 0.107 | 187.555 | 199,205.9 | 0.793 | 17,662.76 | 48.11 |
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | |
|---|---|---|---|---|---|---|---|
| Q5 | 0.417 | 0.449 | 49.4 | 4579.6 | 3.1 | 43,118 | 9 |
| Q10 | 0.463 | 0.487 | 89 | 5836.6 | 3.3 | 46,262 | 15 |
| Q25 | 0.539 | 0.54 | 198 | 11,116 | 3.8 | 49,767 | 37 |
| Q50 | 0.605 | 0.612 | 368 | 20,204 | 4.4 | 53,901 | 77 |
| Q75 | 0.674 | 0.723 | 510 | 41,229 | 4.9 | 60,121 | 115 |
| Q90 | 0.729 | 0.79 | 608 | 68,550 | 5.5 | 66,521 | 155 |
| Q95 | 0.762 | 0.827 | 633.6 | 109,462 | 5.7 | 73,006.8 | 174.2 |
| Mean | 0.599 | 0.627 | 356.193 | 35,019.47 | 4.415 | 55,596.35 | 79.845 |
| Std | 0.105 | 0.119 | 186.098 | 62,713.13 | 0.899 | 9592.194 | 52.128 |
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | |
|---|---|---|---|---|---|---|---|
| Q5 | 0.576 | 0.341 | 29.4 | 2415 | 3.84 | 30,950 | 7 |
| Q10 | 0.624 | 0.368 | 56 | 3297 | 4.2 | 33,218 | 13 |
| Q25 | 0.693 | 0.409 | 155 | 5072 | 4.9 | 38,171 | 43 |
| Q50 | 0.747 | 0.475 | 341 | 8354 | 5.6 | 43,457 | 81 |
| Q75 | 0.787 | 0.54 | 518 | 13,670 | 6.4 | 48,182 | 129 |
| Q90 | 0.83 | 0.611 | 604 | 25,221 | 7.4 | 51,812.2 | 169 |
| Q95 | 0.856 | 0.641 | 631.6 | 34,390.8 | 8.3 | 55,443.8 | 195 |
| Mean | 0.734 | 0.481 | 334.757 | 14,615.75 | 5.743 | 43,457.84 | 88.095 |
| Std | 0.088 | 0.097 | 199.112 | 47,465.07 | 1.377 | 8146.738 | 57.705 |
| X1 | X2 | X3 | X4 | X5 | X6 | X7 | |
|---|---|---|---|---|---|---|---|
| Q5 | 0.555 | 0.285 | 35 | 3184.2 | 2.7 | 41,799.2 | 9 |
| Q10 | 0.602 | 0.33 | 60 | 4188.8 | 2.98 | 44,913 | 21 |
| Q25 | 0.673 | 0.392 | 146 | 6912 | 3.3 | 48,342 | 49 |
| Q50 | 0.728 | 0.462 | 289 | 11,761 | 4 | 52,798 | 97 |
| Q75 | 0.76 | 0.529 | 473 | 18,689 | 4.5 | 57,705 | 145 |
| Q90 | 0.789 | 0.584 | 585 | 33,791.4 | 5.1 | 63,827.4 | 175.4 |
| Q95 | 0.809 | 0.627 | 629.6 | 45,496 | 5.46 | 67,758 | 193 |
| Mean | 0.707 | 0.459 | 308.856 | 18,494.64 | 4.009 | 53,761.27 | 98.385 |
| Std | 0.084 | 0.106 | 190.401 | 46,181.82 | 0.91 | 8948.192 | 58.712 |
References
- Greenberg, J.; Pyszczynski, T.; Solomon, S.; Rosenblatt, A.; Veeder, M.; Kirkland, S.; Lyon, D. Evidence for terror management theory II: The effects of mortality salience on reactions to those who threaten or bolster the cultural worldview. J. Pers. Soc. Psychol. 1990, 58, 308. [Google Scholar] [CrossRef]
- Kosloff, S.; Greenberg, J.; Weise, D.; Solomon, S. The effects of mortality salience on political preferences: The roles of charisma and political orientation. J. Exp. Soc. Psychol. 2010, 46, 139–145. [Google Scholar] [CrossRef]
- Altiparmakis, A.; Bojar, A.; Brouard, S.; Foucault, M.; Kriesi, H.; Nadeau, R. Pandemic politics: Policy evaluations of government responses to COVID-19. West Eur. Polit. 2021, 44, 1159–1179. [Google Scholar] [CrossRef]
- Bol, D.; Giani, M.; Blais, A.; Loewen, P. The effect of COVID-19 lockdowns on political support: Some good news for democracy? Eur. J. Polit. Res. 2020, 60, 497–505. [Google Scholar] [CrossRef]
- Gasper, J.T.; Reeves, A. Make it rain? Retrospection and the attentive electorate in the context of natural disasters. Am. J. Pol. Sci. 2011, 55, 340–355. [Google Scholar] [CrossRef]
- Hart, J. Did the COVID-19 pandemic help or hurt Donald Trump’s political fortunes? PLoS ONE 2021, 16, e0247664. [Google Scholar] [CrossRef] [PubMed]
- Baccini, L.; Brodeur, A.; Weymouth, S. The COVID-19 pandemic and the 2020 US presidential election. J. Popul. Econ. 2021, 34, 739–767. [Google Scholar] [CrossRef] [PubMed]
- Panos, A. Reading about geography and race in the rural rustbelt: Mobilizing dis/affiliation as a practice of whiteness. Linguist. Educ. 2021, 65, 100955. [Google Scholar] [CrossRef]
- Gugushvili, A.; Koltai, J.; Stuckler, D.; Mckee, M. Populism, and pandemics. Int. J. Public Health 2020, 65, 721–722. [Google Scholar] [CrossRef] [PubMed]
- Gimpel, J.G. The 2020 election campaign was over quickly. Polit. Geogr. 2021, 102430. [Google Scholar] [CrossRef]
- Yoon, S.; McClean, S.T.; Chawla, N.; Kim, J.K.; Koopman, J.; Rosen, C.C.; Trougakos, J.P.; McCarthy, J.M. Working through an “infodemic”: The impact of COVID-19 news consumption on employee uncertainty and work behaviors. J. Appl. Psychol. 2021, 106, 501–517. [Google Scholar] [CrossRef] [PubMed]
- Di Nardo, M.; van Leeuwen, G.; Loreti, A.; Barbieri, M.A.; Guner, Y.; Locatelli, F.; Ranieri, V.M. A literature review of 2019 novel coronavirus (SARS-CoV2) infection in neonates and children. Pediatr. Res. 2021, 89, 1101–1108. [Google Scholar] [CrossRef] [PubMed]
- Martin, J.C.; Bustamante-Sánchez, N.S.; Indelicato, A. Analyzing the Main Determinants for Being an Immigrant in Cuenca (Ecuador) Based on a Fuzzy Clustering Approach. Axioms 2022, 11, 74. [Google Scholar] [CrossRef]
- Cai, W.; Chen, S.; Zhang, D. Fast and robust fuzzy c-means clustering algorithms incorporating local information for image segmentation. Pattern Recognit. 2007, 40, 825–838. [Google Scholar] [CrossRef]
- Zhao, F.; Jiao, L.; Liu, H. Kernel generalized fuzzy c-means clustering with spatial information for image segmentation. Digit. Signal Process. A Rev. J. 2013, 23, 184–199. [Google Scholar] [CrossRef]
- Zhao, F.; Liu, H.; Fan, J. A multiobjective spatial fuzzy clustering algorithm for image segmentation. Appl. Soft Comput. J. 2015, 30, 48–57. [Google Scholar] [CrossRef]
- Ferraro, M.B.; Giordani, P.; Serafini, A. Fclust: An R Package for Fuzzy Clustering. R J. 2019, 11, 1–18. [Google Scholar] [CrossRef]
- Gelb, J.; Apparicio, P. Apport de la classification floue c-means spatiale en géographie: Essai de taxinomie socio-résidentielle et environnementale à Lyon. Cybergeo 2021, 1–26. [Google Scholar] [CrossRef]
- Warshaw, C.; Vavreck, L.; Baxter-King, R. Fatalities from COVID-19 are reducing Americans’ support for Republicans at every level of federal office. Sci. Adv. 2020, 6, eabd8564. [Google Scholar] [CrossRef] [PubMed]











| Variable | Meaning |
|---|---|
| X1 | Republican’s share of votes in U.S. presidential election |
| X2 | The share of respondents who thought they wore face masks often |
| X3 | The number of housing units |
| X4 | The number of residents who were high-school graduates or above |
| X5 | Unemployment rate |
| X6 | Household income |
| X7 | Death toll of COVID-19 cases |
| Statistic | N | Mean | St.Dev | Min. | Max. |
|---|---|---|---|---|---|
| X1 | 669 | 0.662 | 0.127 | 0.120 | 0.900 |
| X2 | 669 | 0.536 | 0.139 | 0.190 | 0.880 |
| X3 | 669 | 52,630.64 | 135,268.2 | 1107 | 2,204,019 |
| X4 | 669 | 34,032.23 | 84,810.53 | 616 | 1,314,995 |
| X5 | 669 | 4.591 | 1.273 | 2.400 | 13.00 |
| X6 | 669 | 52,867.07 | 12,235.31 | 26,278 | 115,301 |
| X7 | 669 | 71.175 | 306.17 | 0 | 5517 |
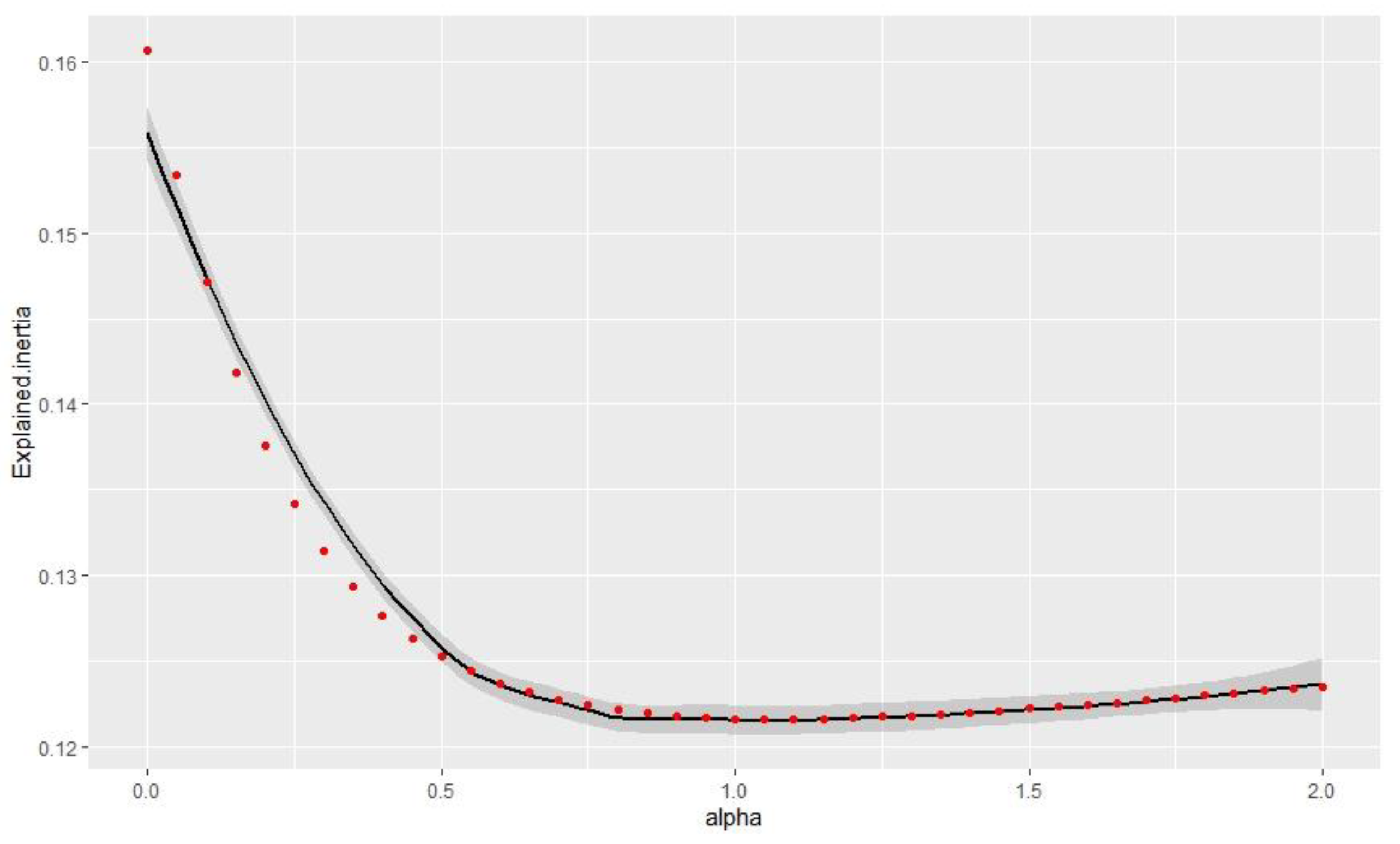
| Beta | Silhouette Index | Xie and Beni Index | Explained Inertia |
|---|---|---|---|
| 0 | 0.287 | 2.476 | 0.161 |
| 0.05 | 0.29 | 2.282 | 0.171 |
| 0.1 | 0.294 | 2.113 | 0.181 |
| 0.15 | 0.298 | 1.964 | 0.191 |
| 0.2 | 0.3 | 1.83 | 0.201 |
| 0.25 | 0.303 | 1.706 | 0.212 |
| 0.3 | 0.307 | 1.584 | 0.223 |
| 0.35 | 0.313 | 1.47 | 0.235 |
| 0.4 | 0.315 | 1.374 | 0.247 |
| 0.45 | 0.315 | 1.292 | 0.26 |
| 0.5 | 0.292 | 1.478 | 0.265 |
| 0.55 | 0.289 | 1.41 | 0.277 |
| 0.6 | 0.286 | 1.349 | 0.289 |
| 0.65 | 0.283 | 1.295 | 0.301 |
| 0.7 | 0.281 | 1.249 | 0.313 |
| 0.75 | 0.277 | 1.211 | 0.325 |
| 0.8 | 0.273 | 1.182 | 0.337 |
| 0.85 | 0.268 | 1.163 | 0.349 |
| 0.9 | 0.259 | 1.157 | 0.361 |
| 0.95 | 0.249 | 1.172 | 0.371 |
| 1 | 0.235 | 1.296 | 0.374 |
| GFCM | FCM | |
|---|---|---|
| Silhouette index | 0.273 | 0.287 |
| Partition entropy | 0.323 | 0.951 |
| Partition coeff | 0.837 | 0.486 |
| XieBeni index | 1.182 | 2.476 |
| Fukuyama Sugeno index | 1096.84 | 1706.23 |
| Explained inertia | 0.337 | 0.161 |
| SFCM | SGFCM | |
|---|---|---|
| Silhouette index | 0.219 | 0.319 |
| Partition entropy | 1.043 | 0.682 |
| Partition coeff | 0.431 | 0.633 |
| XieBeni index | 5.008 | 1.394 |
| Fukuyama Sugeno index | 1824.58 | 1290.69 |
| Explained inertia | 0.134 | 0.248 |
| sp consistency | 0.276 | 0.262 |
| FCM | GFCM | SFCM | SGFCM | |
|---|---|---|---|---|
| Cluster 1 | 0.642 | 0.602 | 0.769 | 0.696 |
| Cluster 2 | 0.349 | 0.187 | 0.501 | 0.66 |
| Cluster 3 | 0.691 | 0.595 | 0.809 | 0.823 |
| Cluster 4 | 0.205 | 0.14 | 0.674 | 0.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S. Spatial Fuzzy C-Means Clustering Analysis of U.S. Presidential Election and COVID-19 Related Factors in the Rustbelt States in 2020. Axioms 2022, 11, 401. https://doi.org/10.3390/axioms11080401
Wu S. Spatial Fuzzy C-Means Clustering Analysis of U.S. Presidential Election and COVID-19 Related Factors in the Rustbelt States in 2020. Axioms. 2022; 11(8):401. https://doi.org/10.3390/axioms11080401
Chicago/Turabian StyleWu, Shianghau. 2022. "Spatial Fuzzy C-Means Clustering Analysis of U.S. Presidential Election and COVID-19 Related Factors in the Rustbelt States in 2020" Axioms 11, no. 8: 401. https://doi.org/10.3390/axioms11080401