
Addressing Geological Challenges in Mineral Resource Estimation: A Comparative Study of Deep Learning and Traditional Techniques


Abstract
:1. Introduction
2. Materials and Methods
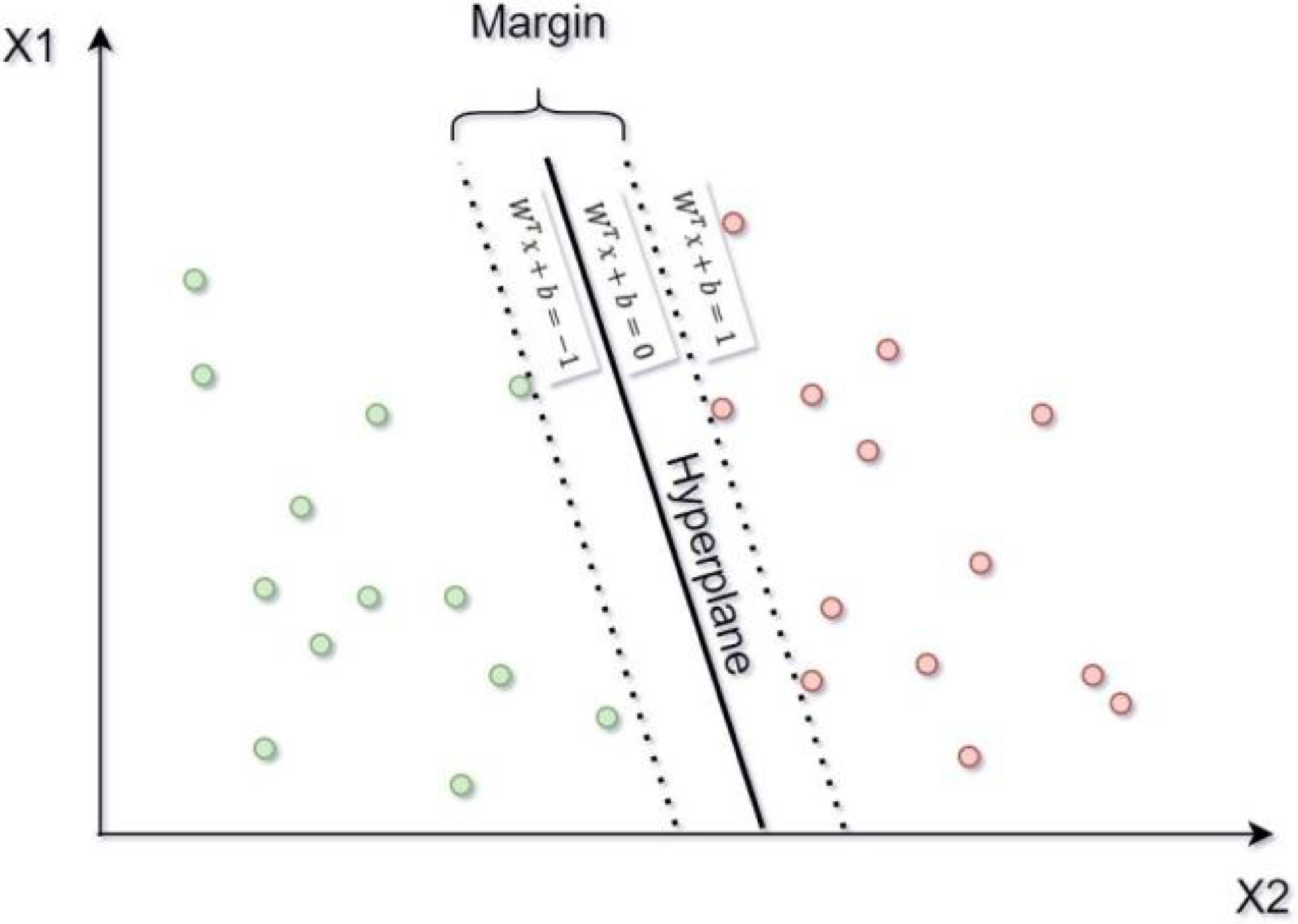
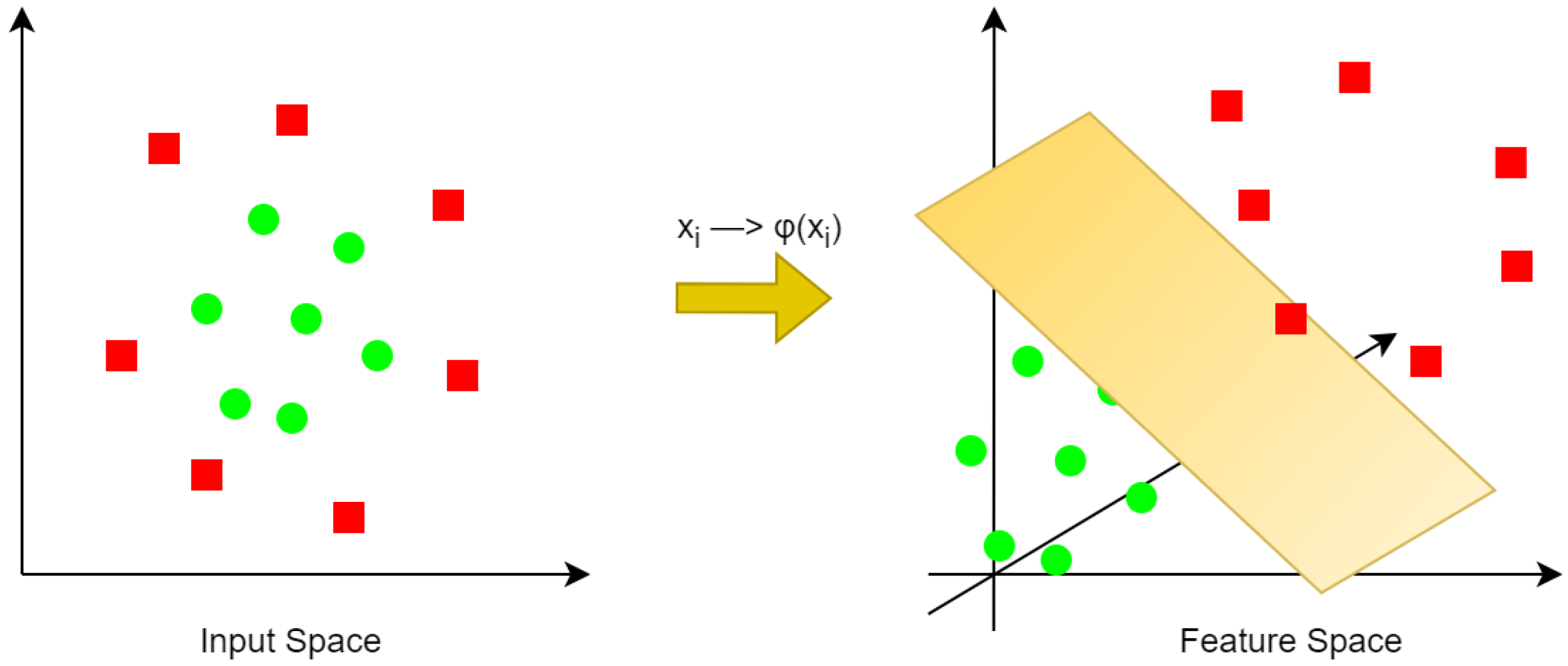
2.1. Support Vector Machine
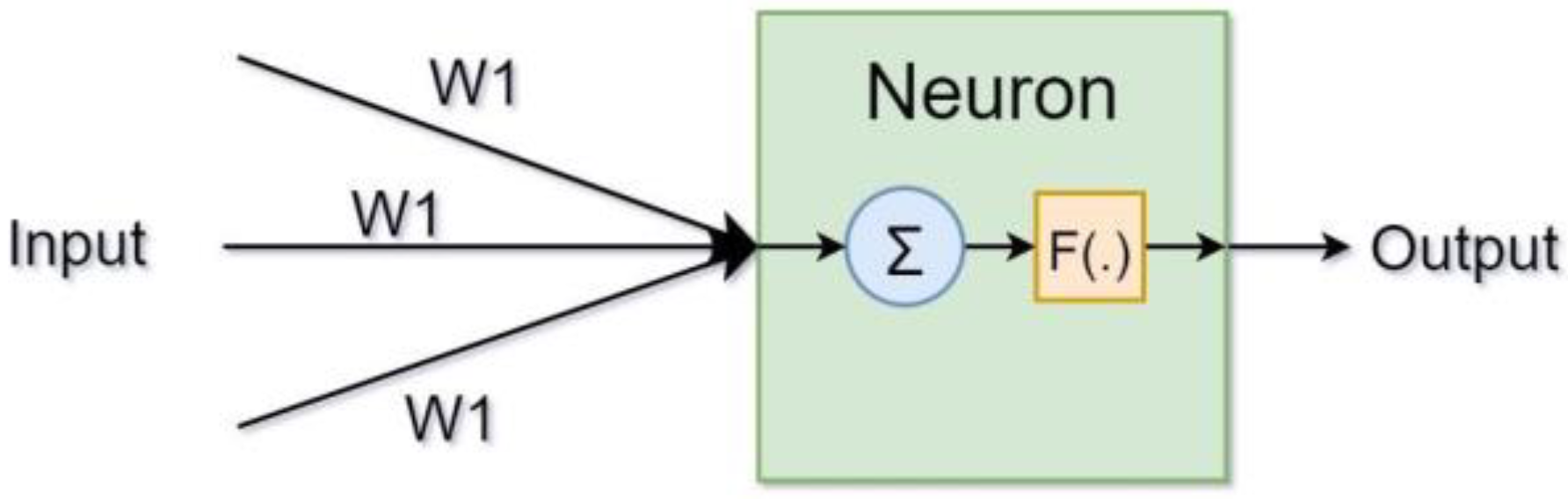
2.2. Multi-Layer Perceptron
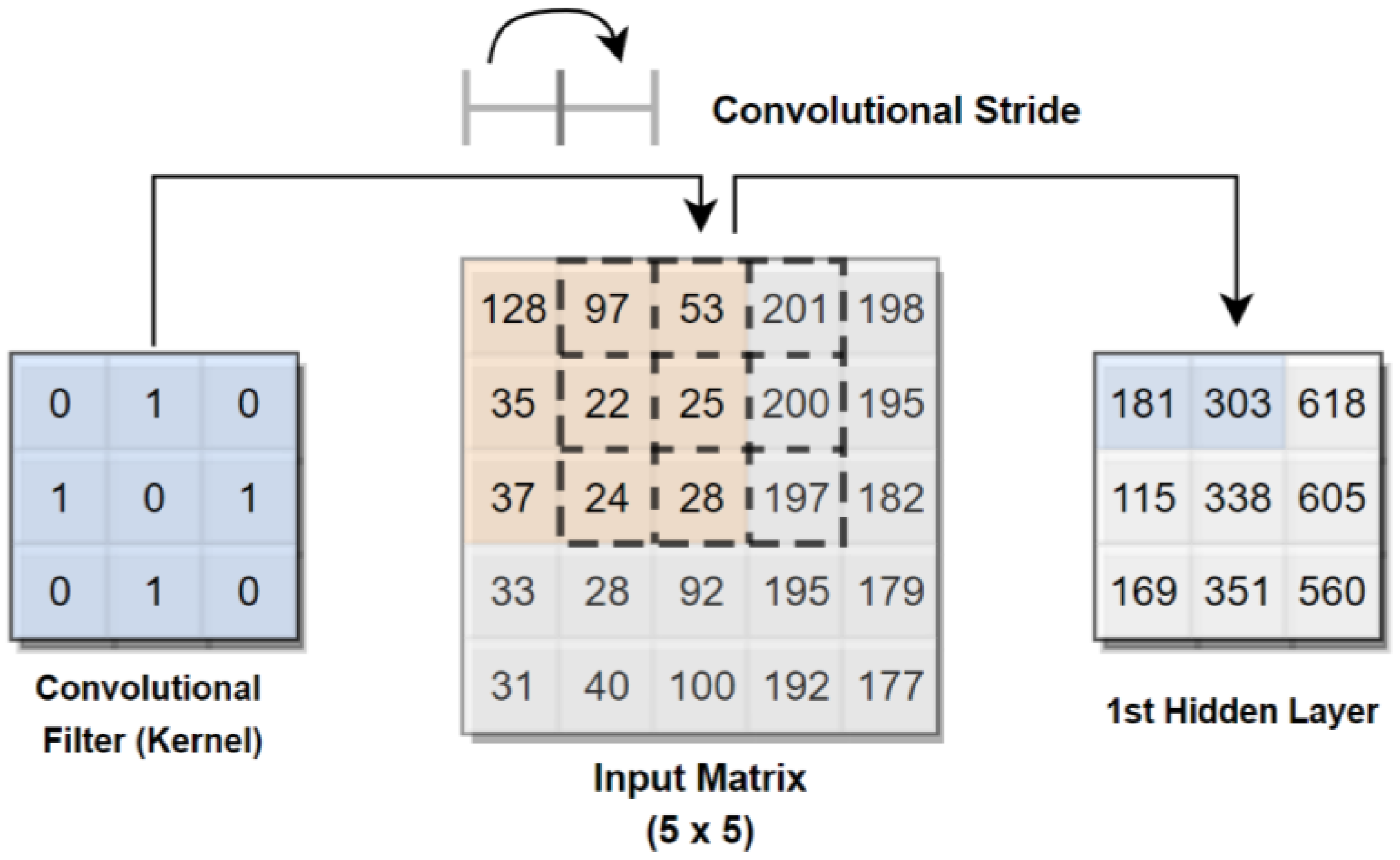
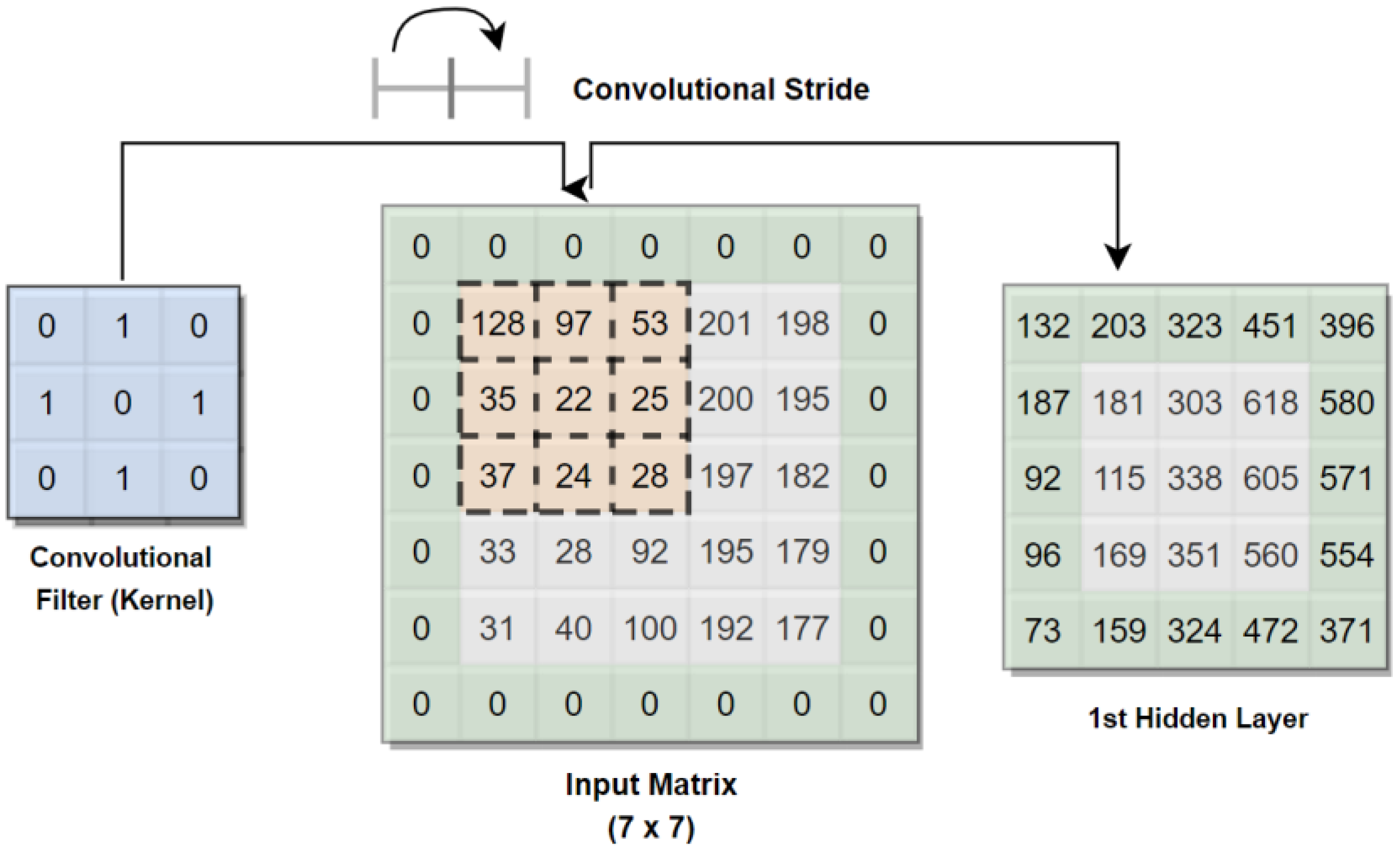
2.3. Convolutional Neural Network
2.3.1. Training Images
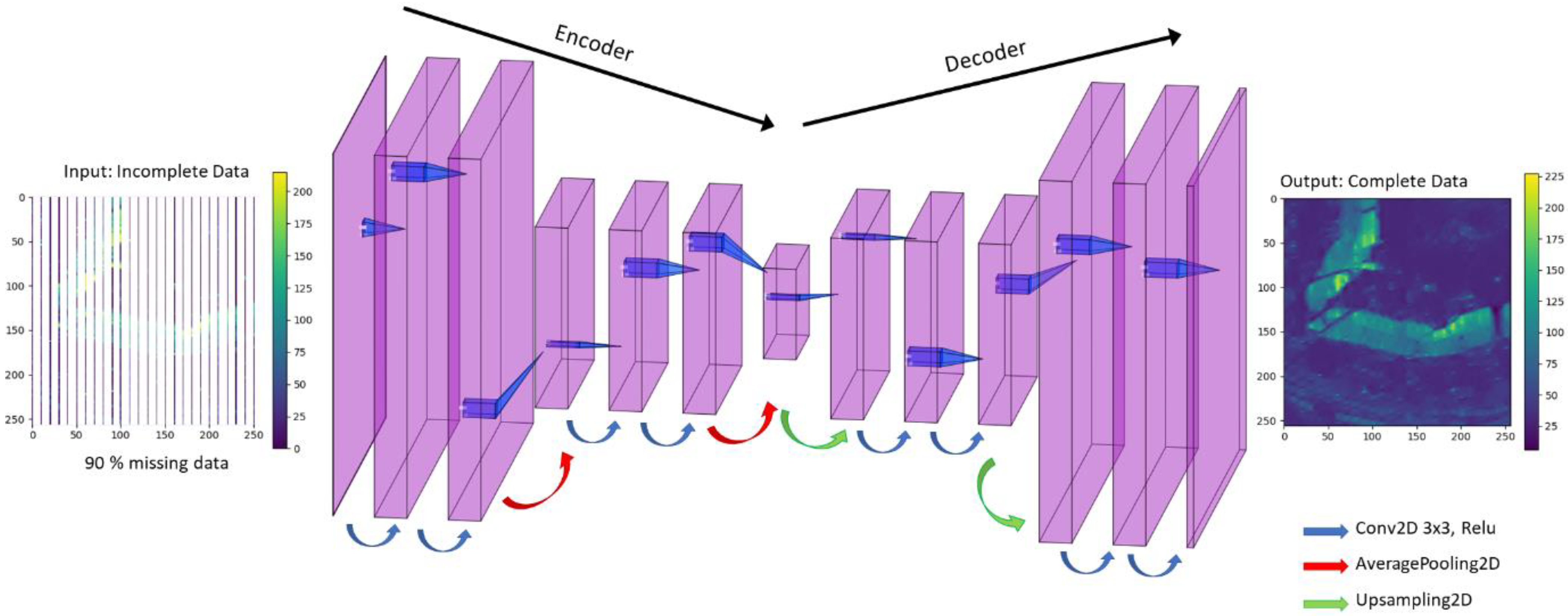
2.3.2. U-Net Architecture
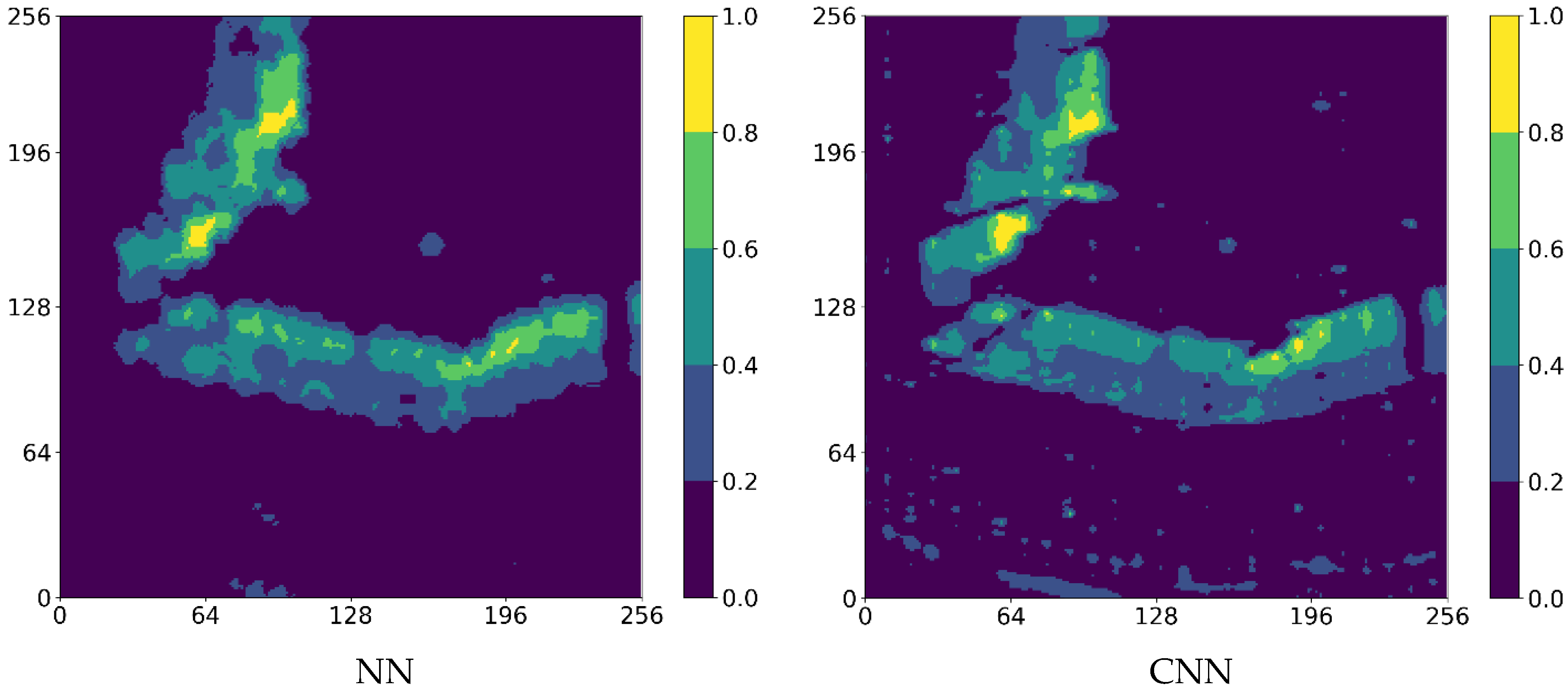
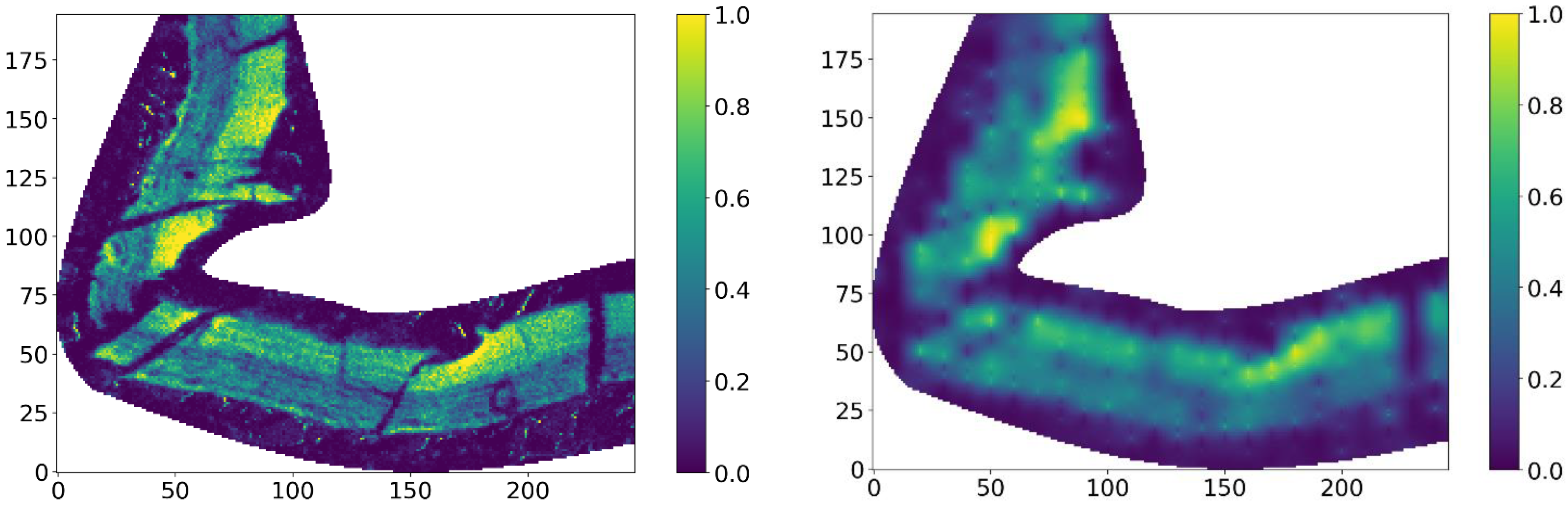
3. Results
4. Discussion
- -
- Investigation of the CNN layers and their combination to change the output results to follow the statistics of the input;
- -
- Optimization of the CNN structure and hyperparameters;
- -
- Use of more training images to be fed into the CNN model. As suggested by the literature review, more training images lead to better results. The training images can be expanded more by editing, flipping, and adjusting the level of saturation and brightness;
- -
- Post-processing steps of the result to make the distribution of predicted data follow the distribution of input data;
- -
- Application of other validation techniques such as statistical significance tests.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dimitrakopoulos, R. Stochastic mine planning—Methods, examples and value in an uncertain world. In Advances in Applied Strategic Mine Planning; Springer: Cham, Switzerland, 2018; pp. 101–115. [Google Scholar]
- Sterk, R.; de Jong, K.; Partington, G.; Kerkvliet, S.; van de Ven, M. Domaining in Mineral Resource Estimation: A Stock-Take of 2019 Common Practice. In Proceedings of the 11th International Mining Geology Conference, Perth, Australia, 5–26 November 2019. [Google Scholar]
- McManus, S.; Rahman, A.; Coombes, J.; Horta, A. Uncertainty assessment of spatial domain models in early stage mining projects—A review. Ore Geol. Rev. 2021, 133, 104098. [Google Scholar] [CrossRef]
- Rossi, M.E.; Deutsch, C.V. Mineral Resource Estimation; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Goovaerts, P. Geostatistics for Natural Resources Evaluation; Oxford University Press on Demand: Oxford, UK, 1997. [Google Scholar]
- Madani, N.; Maleki, M.; Soltani-Mohammadi, S. Geostatistical modeling of heterogeneous geo-clusters in a copper deposit integrated with multinomial logistic regression: An exercise on resource estimation. Ore Geol. Rev. 2022, 150, 105132. [Google Scholar] [CrossRef]
- Madenova, Y.; Madani, N. Application of Gaussian mixture model and geostatistical co-simulation for resource modeling of geometallurgical variables. Nat. Resour. Res. 2021, 30, 1199–1228. [Google Scholar] [CrossRef]
- Battalgazy, N.; Madani, N. Stochastic modeling of chemical compounds in a limestone deposit by unlocking the complexity in bivariate relationships. Minerals 2019, 9, 683. [Google Scholar] [CrossRef] [Green Version]
- Abildin, Y.; Madani, N.; Topal, E. A hybrid approach for joint simulation of geometallurgical variables with inequality constraint. Minerals 2019, 9, 24. [Google Scholar] [CrossRef] [Green Version]
- Emery, X.; Lantuéjoul, C. Tbsim: A computer program for conditional simulation of three-dimensional gaussian random fields via the turning bands method. Comput. Geosci. 2006, 32, 1615–1628. [Google Scholar] [CrossRef]
- Battalgazy, N.; Madani, N. Categorization of mineral resources based on different geostatistical simulation algorithms: A case study from an iron ore deposit. Nat. Resour. Res. 2019, 28, 1329–1351. [Google Scholar] [CrossRef]
- Armstrong, M.; Galli, A.; Beucher, H.; Loc’h, G.; Renard, D.; Doligez, B.; Eschard, R.; Geffroy, F. Plurigaussian Simulations in Geosciences; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar]
- Prior, T.; Giurco, D.; Mudd, G.; Mason, L.; Behrisch, J. Resource depletion, peak minerals and the implications for sustainable resource management. Glob. Environ. Chang. 2012, 22, 577–587. [Google Scholar] [CrossRef]
- Valenta, R.; Kemp, D.; Owen, J.; Corder, G.; Lèbre, É. Re-thinking complex orebodies: Consequences for the future world supply of copper. J. Clean. Prod. 2019, 220, 816–826. [Google Scholar] [CrossRef]
- Delgado, A.V. Mineral resource depletion assessment. In Eco-Efficient Construction and Building Materials; Elsevier: Amsterdam, The Netherlands, 2014; pp. 13–37. [Google Scholar]
- West, J. Decreasing Metal Ore Grades: Are They Really Being Driven by the Depletion of High-Grade Deposits? J. Ind. Ecol. 2011, 15, 165–168. [Google Scholar] [CrossRef]
- Caté, A.; Perozzi, L.; Gloaguen, E.; Blouin, M. Machine learning as a tool for geologists. Lead. Edge 2017, 36, 215–219. [Google Scholar] [CrossRef]
- Hill, E.J.; Oliver, N.H.; Fisher, L.; Cleverley, J.S.; Nugus, M.J. Using geochemical proxies to model nuggety gold deposits: An example from Sunrise Dam, Western Australia. J. Geochem. Explor. 2014, 145, 12–24. [Google Scholar] [CrossRef]
- Jalloh, A.B.; Kyuro, S.; Jalloh, Y.; Barrie, A.K. Integrating artificial neural networks and geostatistics for optimum 3D geological block modeling in mineral reserve estimation: A case study. Int. J. Min. Sci. Technol. 2016, 26, 581–585. [Google Scholar] [CrossRef]
- Dutta, S.; Bandopadhyay, S.; Ganguli, R.; Misra, D. Machine learning algorithms and their application to ore reserve estimation of sparse and imprecise data. J. Intell. Learn. Syst. Appl. 2010, 2, 86. [Google Scholar] [CrossRef] [Green Version]
- Tahmasebi, P.; Hezarkhani, A. A hybrid neural networks-fuzzy logic-genetic algorithm for grade estimation. Comput. Geosci. 2012, 42, 18–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chatterjee, S.; Bandopadhyay, S.; Machuca, D. Ore grade prediction using a genetic algorithm and clustering based ensemble neural network model. Math. Geosci. 2010, 42, 309–326. [Google Scholar] [CrossRef]
- Wu, X.; Zhou, Y. Reserve estimation using neural network techniques. Comput. Geosci. 1993, 19, 567–575. [Google Scholar] [CrossRef]
- Guo, W.W. A novel application of neural networks for instant iron-ore grade estimation. Expert Syst. 2010, 37, 8729–8735. [Google Scholar] [CrossRef]
- Nezamolhosseini, S.A.; Mojtahedzadeh, S.H.; Gholamnejad, J. The application of artificial neural networks to ore reserve estimation at choghart iron ore deposit. J. Anal. Numer. Methods Min. Eng. 2017, 6, 73–83. [Google Scholar]
- Afeni, T.B.; Lawal, A.I.; Adeyemi, R.A. Re-examination of Itakpe iron ore deposit for reserve estimation using geostatistics and artificial neural network techniques. Arab. J. Geosci. 2020, 13, 657. [Google Scholar] [CrossRef]
- Li, X.-L.; Li, L.-H.; Zhang, B.-L.; Guo, Q.-J. Hybrid self-adaptive learning based particle swarm optimization and support vector regression model for grade estimation. Neurocomputing 2013, 118, 179–190. [Google Scholar] [CrossRef]
- Mostafaei, K.; Jodeiri, B. A new gold grade estimation approach by using support vector machine (SVM) and back propagation neural network (BPNN)-A Case study: Dalli deposit, Iran. arXiv 2022, arXiv:2008568. [Google Scholar]
- Abbaszadeh, M. Grade Estimation in Esfordi Phosphate Deposit Using Support Vector Regression Method. J. Miner. Resour. Eng. 2019, 4, 1–16. [Google Scholar]
- Chatterjee, S.; Bandopadhyay, S. Goodnews Bay Platinum resource estimation using least squares support vector regression with selection of input space dimension and hyperparameters. Nat. Resour. Res. 2011, 20, 117–129. [Google Scholar] [CrossRef]
- Zaki, M.; Chen, S.; Zhang, J.; Feng, F.; Khoreshok, A.A.; Mahdy, M.A.; Salim, K.M. A Novel Approach for Resource Estimation of Highly Skewed Gold Using Machine Learning Algorithms. Minerals 2022, 12, 900. [Google Scholar] [CrossRef]
- Barker, R.D.; Barker, S.L.; Wilson, S.A.; Stock, E.D. Quantitative Mineral Mapping of Drill Core Surfaces I: A Method for µ XRF Mineral Calculation and Mapping of Hydrothermally Altered, Fine-Grained Sedimentary Rocks from a Carlin-Type Gold Deposit. Econ. Geol. 2021, 116, 803–819. [Google Scholar] [CrossRef]
- Gholami, R.; Fakhari, N. Support vector machine: Principles, parameters, and applications. In Handbook of Neural Computation; Elsevier: Amsterdam, The Netherlands, 2017; pp. 515–535. [Google Scholar]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Huang, S.; Cai, N.; Pacheco, P.P.; Narrandes, S.; Wang, Y.; Xu, W. Applications of support vector machine (SVM) learning in cancer genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar]
- Mercer, J. Xvi. functions of positive and negative type, and their connection the theory of integral equations. Philos. Trans. R. Soc. Lond. Ser. A Contain. Pap. A Math. Phys. Character 1909, 209, 415–446. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hasan, T.T.; Jasim, M.H.; Hashim, I.A. Heart disease diagnosis system based on multi-layer perceptron neural network and support vector machine. Int. J. Curr. Eng. Technol. 2017, 77, 2277–4106. [Google Scholar]
- Wan, S.; Liang, Y.; Zhang, Y.; Guizani, M. Deep multi-layer perceptron classifier for behavior analysis to estimate Parkinson’s disease severity using smartphones. IEEE Access 2018, 6, 36825–36833. [Google Scholar] [CrossRef]
- Yan, C.; Yi, W.; Xiong, J.; Ma, J. Preparation and visible light photocatalytic activity of Bi2O3/Bi2WO6 heterojunction photocatalysts. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Beijing, China, 28–31 December 2017; p. 012086. [Google Scholar]
- Sharma, P.; Singh, D.; Bandil, M.K.; Mishra, N. Decision support system for malaria and dengue disease diagnosis (DSSMD). Int. J. Inf. Comput. Technol. 2013, 3, 633–640. [Google Scholar]
- Weissbart, L. Performance analysis of multilayer perceptron in profiling side-channel analysis. In Proceedings of the International Conference on Applied Cryptography and Network Security, Rome, Italy, 19–22 October 2020; pp. 198–216. [Google Scholar]
- Heaton, J. Artificial Intelligence for Humans, Volume 3: Deep Learning and Neural Networks; Heaton Research, Inc.: St. Louis, MO, USA, 2015. [Google Scholar]
- Suzuki, K. Overview of deep learning in medical imaging. Radiol. Phys. Technol. 2017, 10, 257–273. [Google Scholar] [CrossRef]
- Alban, M.; Gilligan, T. Automated Detection of Diabetic Retinopathy Using Fluorescein Angiography Photographs, in Report of Standford Education. 2016. Available online: http://cs231n.stanford.edu/reports/2016/pdfs/309_Report.pdf (accessed on 22 June 2023).
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Pratt, H.; Coenen, F.; Broadbent, D.M.; Harding, S.P.; Zheng, Y. Convolutional neural networks for diabetic retinopathy. Procedia Comput. Sci. 2016, 90, 200–205. [Google Scholar] [CrossRef] [Green Version]
- San, G.L.Y.; Lee, M.L.; Hsu, W. Constrained-MSER detection of retinal pathology. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 2059–2062. [Google Scholar]
- Bayramoglu, N.; Heikkilä, J. Transfer learning for cell nuclei classification in histopathology images. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; pp. 532–539. [Google Scholar]
- Razzak, M.I.; Alhaqbani, B. Automatic detection of malarial parasite using microscopic blood images. J. Med. Imaging Health Inform. 2015, 5, 591–598. [Google Scholar] [CrossRef]
- Jia, X.; Meng, M.Q.-H. A deep convolutional neural network for bleeding detection in wireless capsule endoscopy images. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 639–642. [Google Scholar]
- Wolterink, J.M.; Leiner, T.; Viergever, M.A.; Išgum, I. Automatic coronary calcium scoring in cardiac CT angiography using convolutional neural networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 589–596. [Google Scholar]
- Kooi, T.; van Ginneken, B.; Karssemeijer, N.; den Heeten, A. Discriminating solitary cysts from soft tissue lesions in mammography using a pretrained deep convolutional neural network. Med. Phys. 2017, 44, 1017–1027. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Yu, G.; Kang, Y.; Zhao, Y.; Qu, Q. Breast tumor detection in digital mammography based on extreme learning machine. Neurocomputing 2014, 128, 175–184. [Google Scholar] [CrossRef]
- Huynh, B.; Drukker, K.; Giger, M. MO-DE-207B-06: Computer-aided diagnosis of breast ultrasound images using transfer learning from deep convolutional neural networks. Med. Phys. 2016, 43, 3705. [Google Scholar] [CrossRef]
- Sarraf, S.; Tofighi, G.; Anderson, J. Deepad: Alzheimer’s disease classification via deep convolutional neural networks using mri and fmri. bioRxiv 2016. bioRxiv: 070441. [Google Scholar]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Zuo, R.; Xiong, Y.; Wang, J.; Carranza, E.J.M. Deep learning and its application in geochemical mapping. Earth Sci. Rev. 2019, 192, 1–14. [Google Scholar] [CrossRef]
- Avalos, S.; Ortiz, J.M. Geological modeling using a recursive convolutional neural networks approach. arXiv 2019, arXiv:1904.12190. [Google Scholar]
- Avalos, S.; Ortiz, J.M. Recursive convolutional neural networks in a multiple-point statistics framework. Comput. Geosci. 2020, 141, 104522. [Google Scholar] [CrossRef]
- Bai, T.; Tahmasebi, P. Hybrid geological modeling: Combining machine learning and multiple-point statistics. Comput. Geosci. 2020, 142, 104519. [Google Scholar] [CrossRef]
- Chan, S.; Elsheikh, A.H. Parametrization of stochastic inputs using generative adversarial networks with application in geology. Front. Water 2020, 2, 5. [Google Scholar] [CrossRef]
- Eilertsen, G.; Kronander, J.; Denes, G.; Mantiuk, R.K.; Unger, J. HDR image reconstruction from a single exposure using deep CNNs. ACM Trans. Graph. (TOG) 2017, 36, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chai, X.; Gu, H.; Li, F.; Duan, H.; Hu, X.; Lin, K. Deep learning for irregularly and regularly missing data reconstruction. Sci. Rep. 2020, 10, 3302. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Remy, N.; Boucher, A.; Wu, J. Applied Geostatistics with SGeMS: A User’s Guide; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Asghari, O.; Safikhani, M.; Talesh Hosseini, S. Determining the optimum search range for 2D and 3D mapping based on kriging through quantitative analysis. Boll. Geofis. Teor. Appl. 2020, 61, 177–198. [Google Scholar]
- Yamamoto, J.K. Correcting the smoothing effect of ordinary kriging estimates. Math. Geol. 2005, 37, 69–94. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Zhang, J.; Li, C.; Yin, Y.; Zhang, J.; Grzegorzek, M. Applications of artificial neural networks in microorganism image analysis: A comprehensive review from conventional multilayer perceptron to popular convolutional neural network and potential visual transformer. Artif. Intell. Rev. 2023, 56, 1013–1070. [Google Scholar] [CrossRef]
- Liu, R.; Li, Y.; Tao, L.; Liang, D.; Zheng, H.-T. Are we ready for a new paradigm shift? a survey on visual deep mlp. Patterns 2022, 3, 100520. [Google Scholar] [CrossRef]
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Ground Truth | Sample Data | Train Subset (80%) | Test Subset (20%) |
|---|---|---|---|---|
| Number of samples | 65,536 | 6656 | 5324 | 1332 |
| Mean | 33.50 | 32.57 | 32.82 | 31.55 |
| Standard Deviation | 53.75 | 53.02 | 53.41 | 51.42 |
| Min | 0.00 | 0.00 | 0.00 | 0.00 |
| Max | 255.00 | 255.00 | 255.00 | 255.00 |
| Hidden layer size | 200, 75, 50 |
| Maximum number of iterations | 40,000 |
| Activation function | RELU |
| Solver function | LBFGS |
| Alpha | 0.005 |
| Learning rate | Constant |
| Layer (Type) | Output Shape | Parameters |
|---|---|---|
| input_1 (InputLayer) | [(None, 256, 256, 1)] | 0 |
| conv2d (Conv2D) | (None, 256, 256, 32) | 320 |
| conv2d_1 (Conv2D) | (None, 256, 256, 32) | 9248 |
| average_pooling2d (AveragePooling) | (None, 128, 128, 32) | 0 |
| conv2d_2 (Conv2D) | (None, 128, 128, 32) | 9248 |
| conv2d_3 (Conv2D) | (None, 128, 128, 32) | 9248 |
| average_pooling2d_1 (AveragePooling) | (None, 64, 64, 32) | 0 |
| up_sampling2d (UpSampling2D) | (None, 128, 128, 32) | 0 |
| conv2d_4 (Conv2D) | (None, 128, 128, 32) | 9248 |
| conv2d_5 (Conv2D) | (None, 128, 128, 32) | 9248 |
| up_sampling2d_1 (UpSampling2) | (None, 256, 256, 32) | 0 |
| conv2d_6 (Conv2D) | (None, 256, 256, 32) | 9248 |
| conv2d_7 (Conv2D) | (None, 256, 256, 32) | 9248 |
| conv2d_8 (Conv2D) | (None, 256, 256, 1) | 289 |
| Total number of parameters | 65,345 | |
| Number of trainable parameters | 63,345 | |
| Methods | MSE | R2 Score |
|---|---|---|
| SVR | 0.01600 | 0.63990 |
| MLP | 0.01518 | 0.65835 |
| NN | 0.01396 | 0.68570 |
| CNN | 0.01240 | 0.72084 |
| SK | 0.01118 | 0.74837 |
| Methods | MSE | R2 Score |
|---|---|---|
| SVR | 0.02531 | 0.66323 |
| MLP | 0.02735 | 0.63620 |
| NN | 0.02564 | 0.65886 |
| CNN | 0.01944 | 0.74141 |
| SK | 0.01901 | 0.74705 |
| SVM | MLP | NN | CNN | KRIG |
|---|---|---|---|---|
| 2218.6 | 2253.0 | 2272.4 | 1884.4 | 1906 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Battalgazy, N.; Valenta, R.; Gow, P.; Spier, C.; Forbes, G. Addressing Geological Challenges in Mineral Resource Estimation: A Comparative Study of Deep Learning and Traditional Techniques. Minerals 2023, 13, 982. https://doi.org/10.3390/min13070982
Battalgazy N, Valenta R, Gow P, Spier C, Forbes G. Addressing Geological Challenges in Mineral Resource Estimation: A Comparative Study of Deep Learning and Traditional Techniques. Minerals. 2023; 13(7):982. https://doi.org/10.3390/min13070982
Chicago/Turabian StyleBattalgazy, Nurassyl, Rick Valenta, Paul Gow, Carlos Spier, and Gordon Forbes. 2023. "Addressing Geological Challenges in Mineral Resource Estimation: A Comparative Study of Deep Learning and Traditional Techniques" Minerals 13, no. 7: 982. https://doi.org/10.3390/min13070982