
Geometallurgical Responses on Lithological Domains Modelled by a Hybrid Domaining Framework

Abstract
:1. Introduction
2. Methodology
2.1. PluriGaussian Simulation
2.2. Turning Bands Simulation
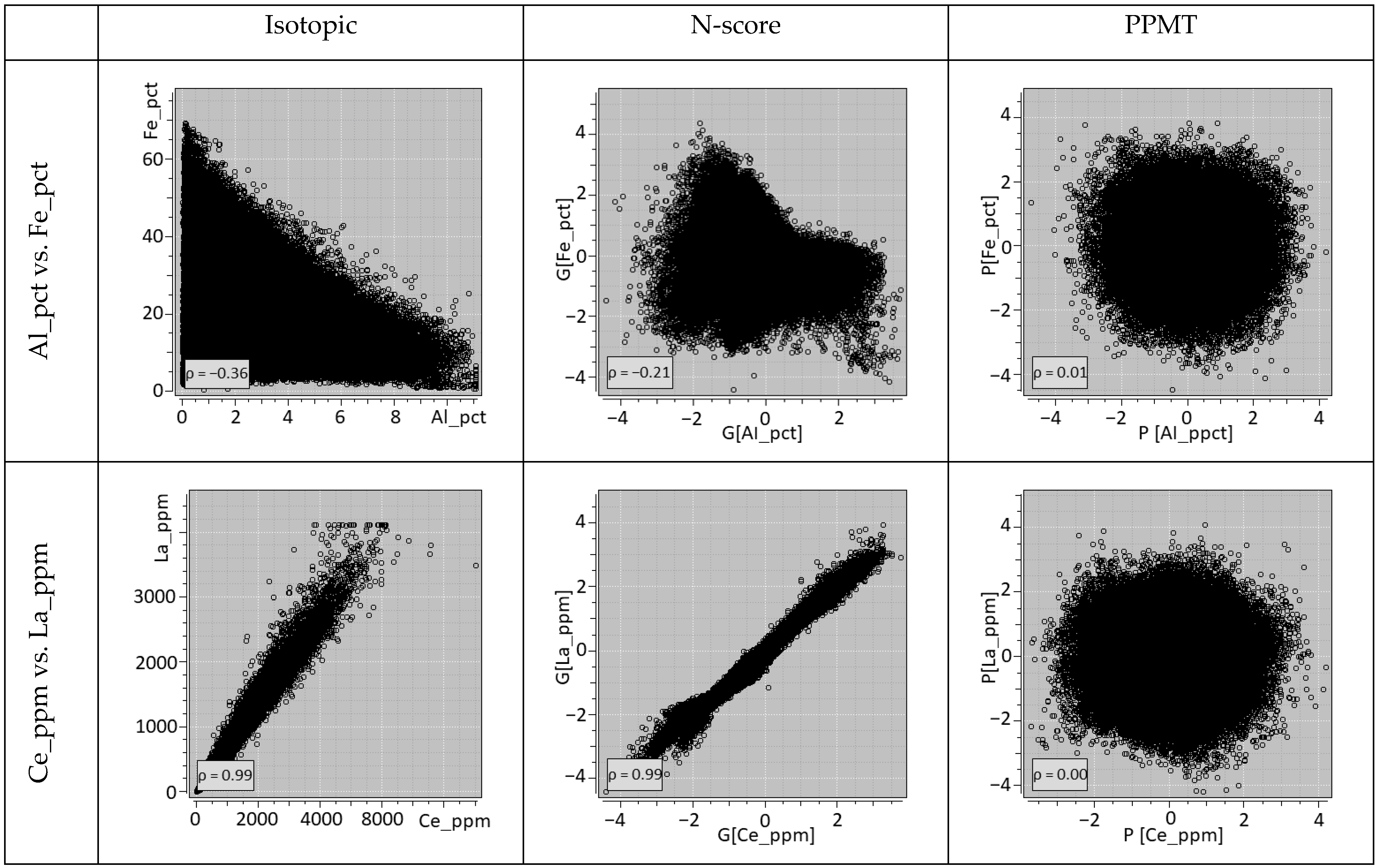
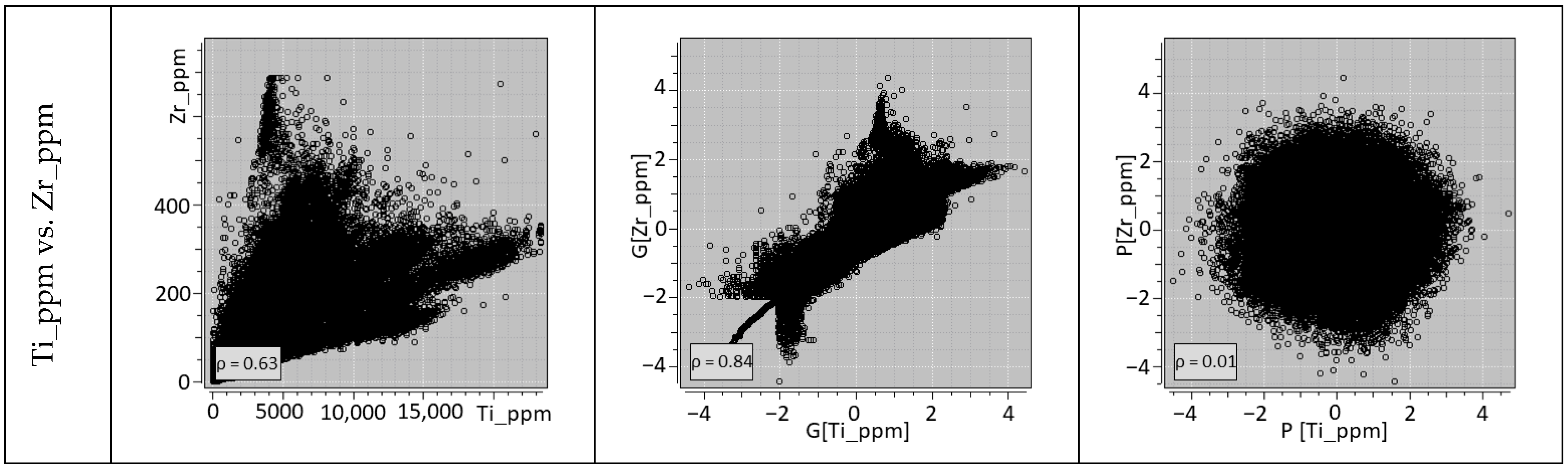
2.3. Projection Pursuit Multivariate Transform
2.4. Extreme Gradient Boosting
2.5. Preprocessing: HybridRepairFilter
2.6. Workflow of the Study
- PluriGaussian simulation—PGS;
- Hybrid domaining framework with imbalanced input for the classifier—HDF imbalanced;
- Hybrid domaining framework with balanced input for the classifier—HDF + SMOTE;
- Hybrid domaining framework with noise filtered and balanced input for the classifier—HDF + HRF + SMOTE.
3. Application to a Case Study
3.1. Case Study Overview
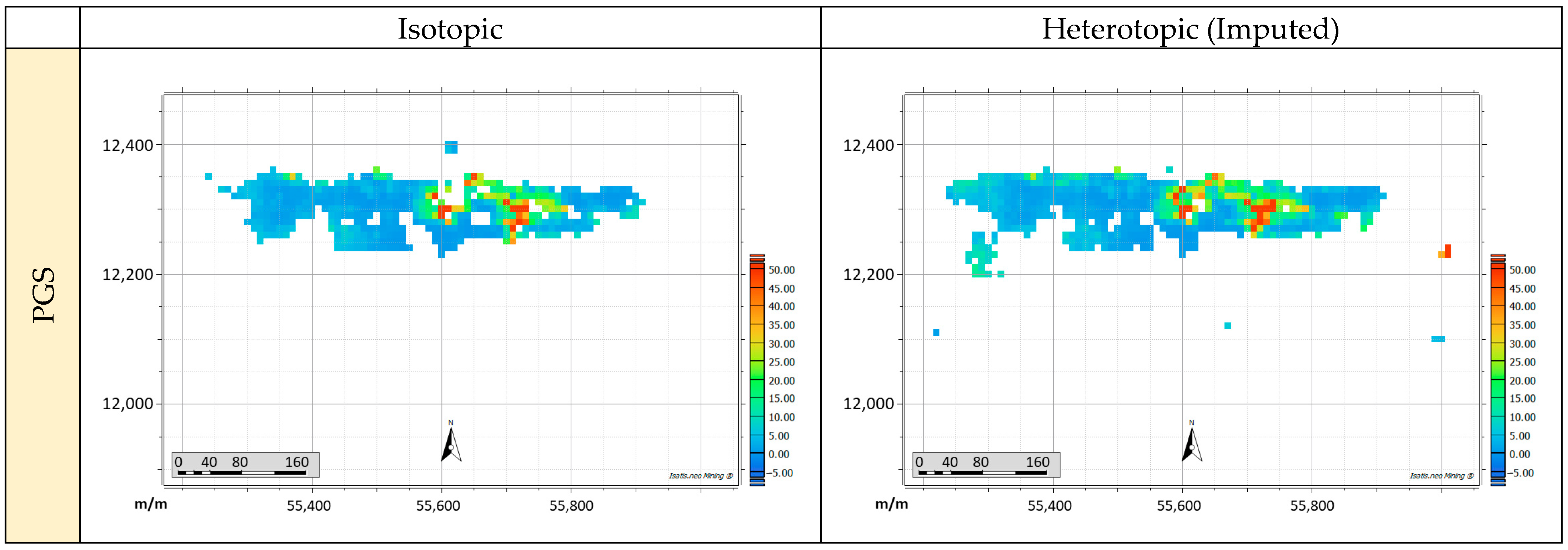
3.2. PluriGaussian Simulation
3.3. Hybrid Domaining Framework
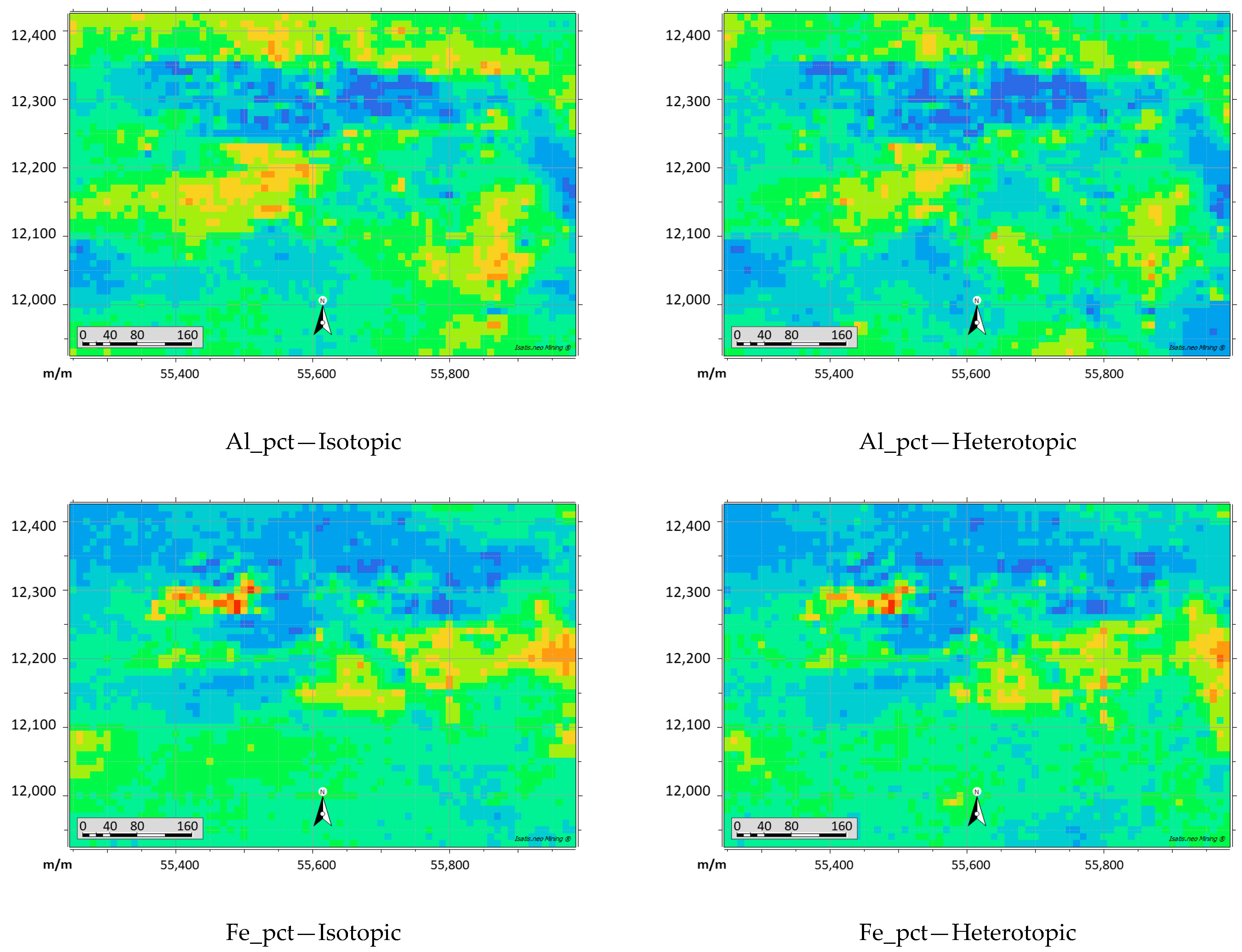
3.3.1. Modelling and Simulation of Continuous Grade Variables
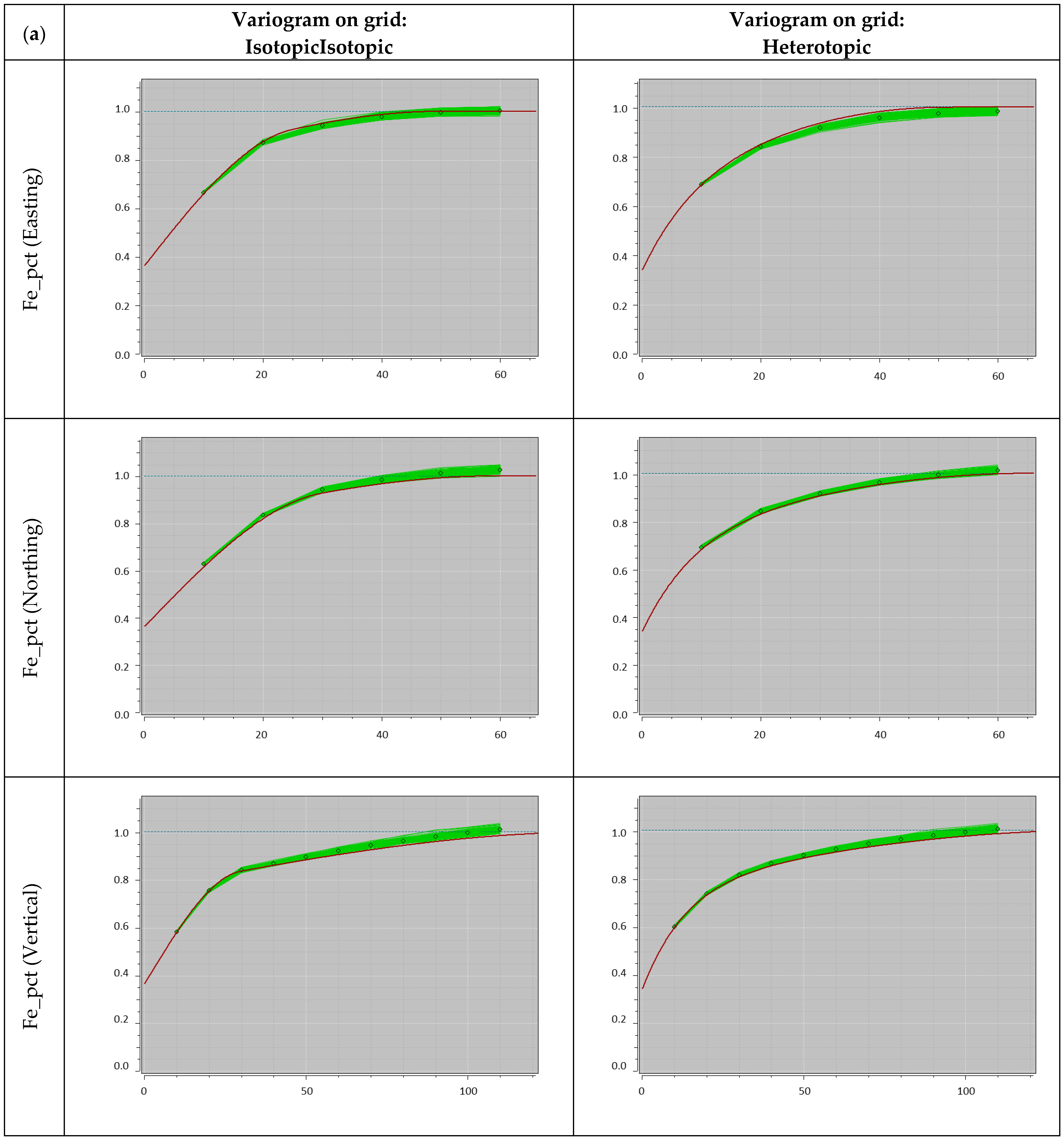
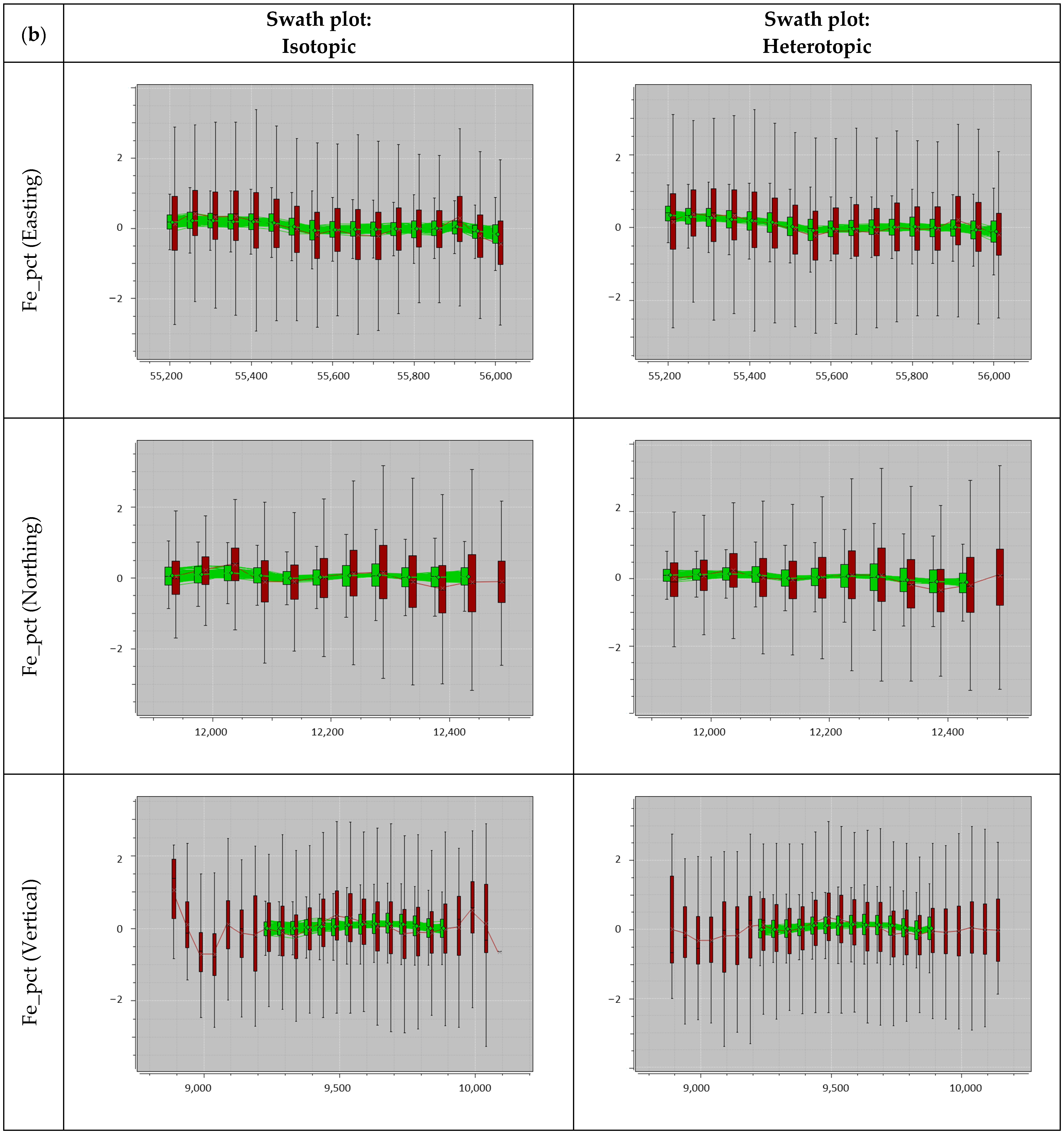
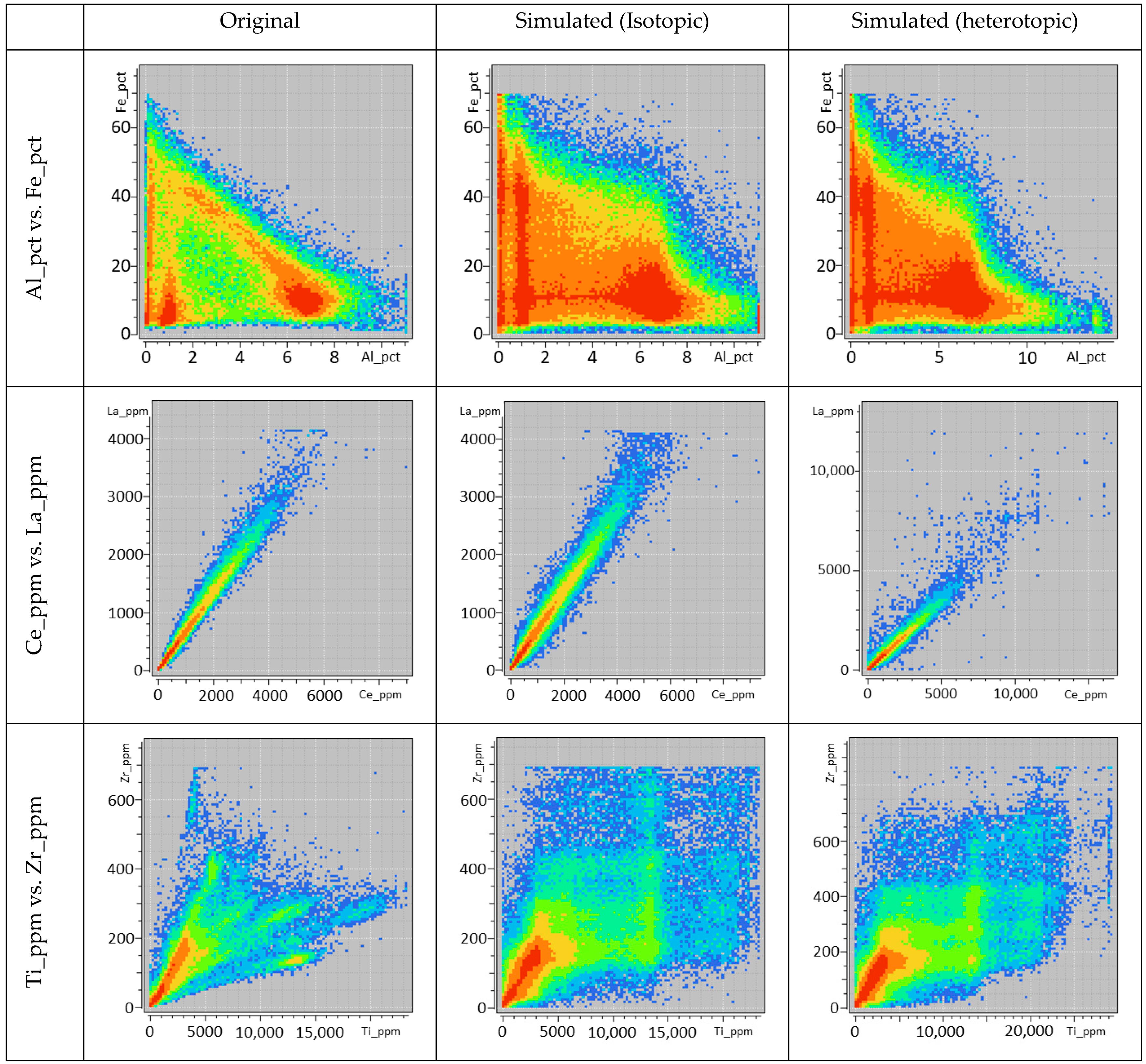
3.3.2. Validation of Simulation Results
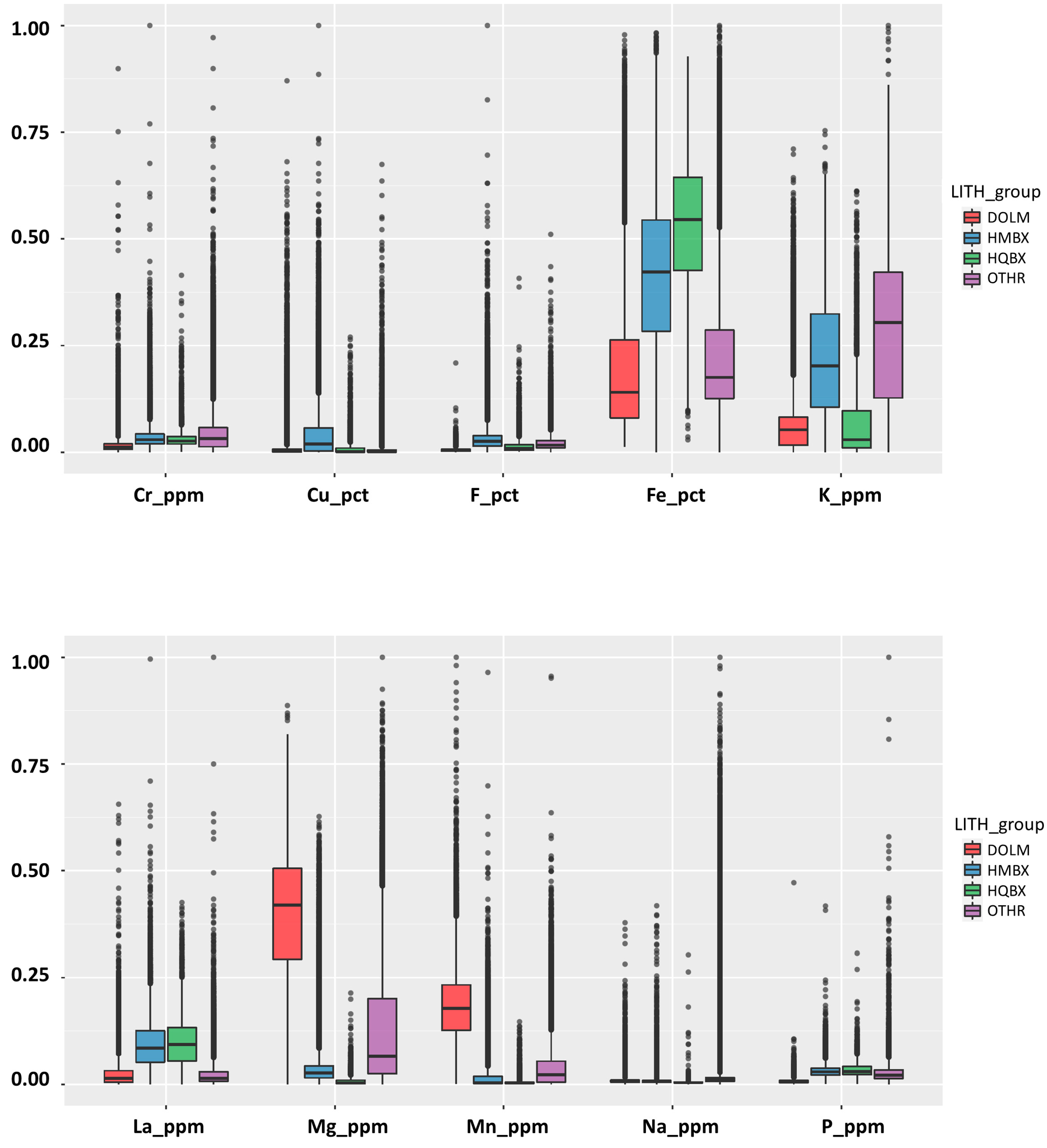
3.3.3. Preprocessing of Noisy and Misinterpreted Lithology Classes in Samples
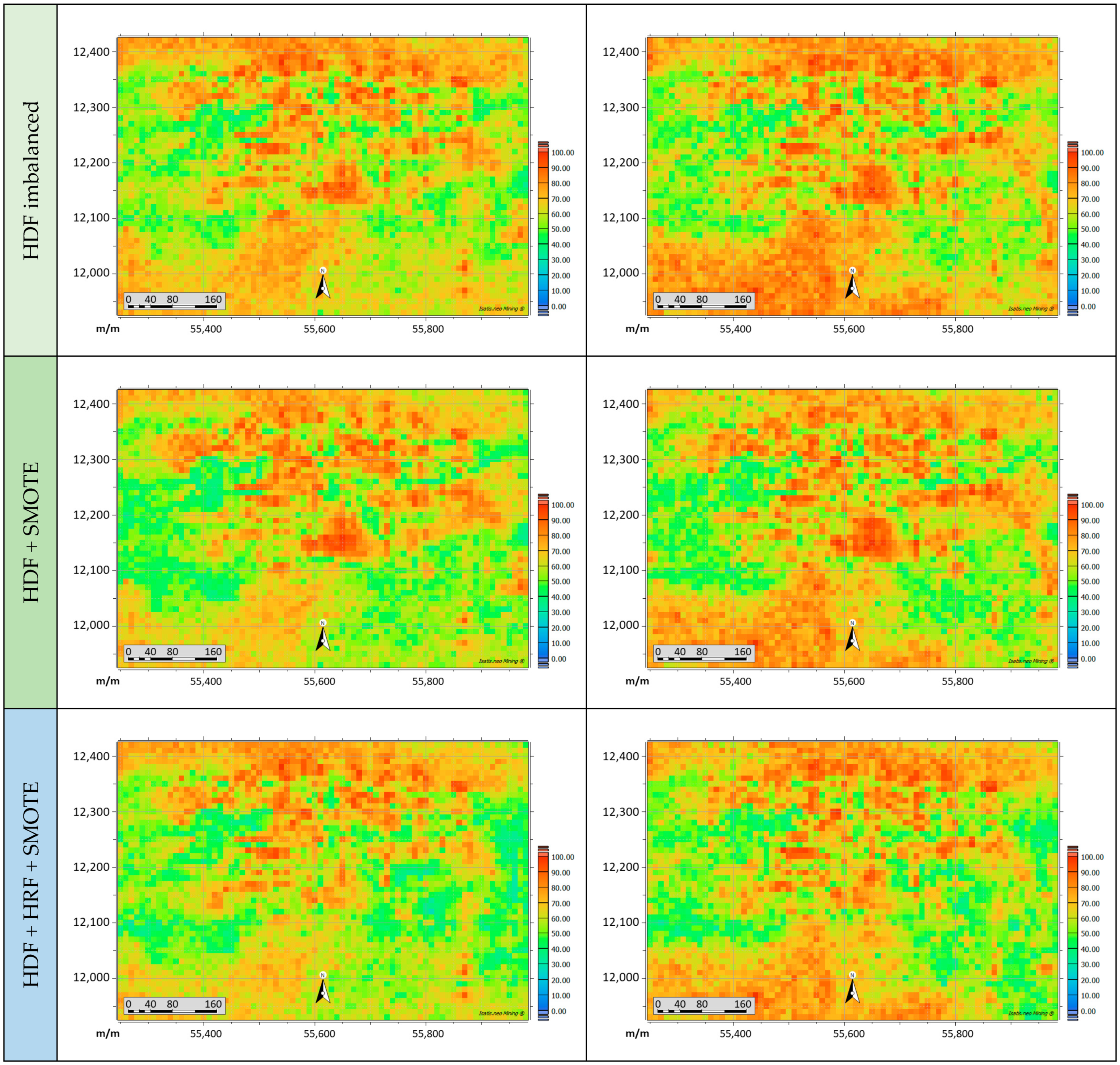
3.3.4. Domain (Lithology) Classification and Uncertainty Quantification
3.4. Post-Processing the Realisations: Geometallurgical Domains
3.4.1. Net Smelter Return
3.4.2. Grinding Time
4. Results and Discussion
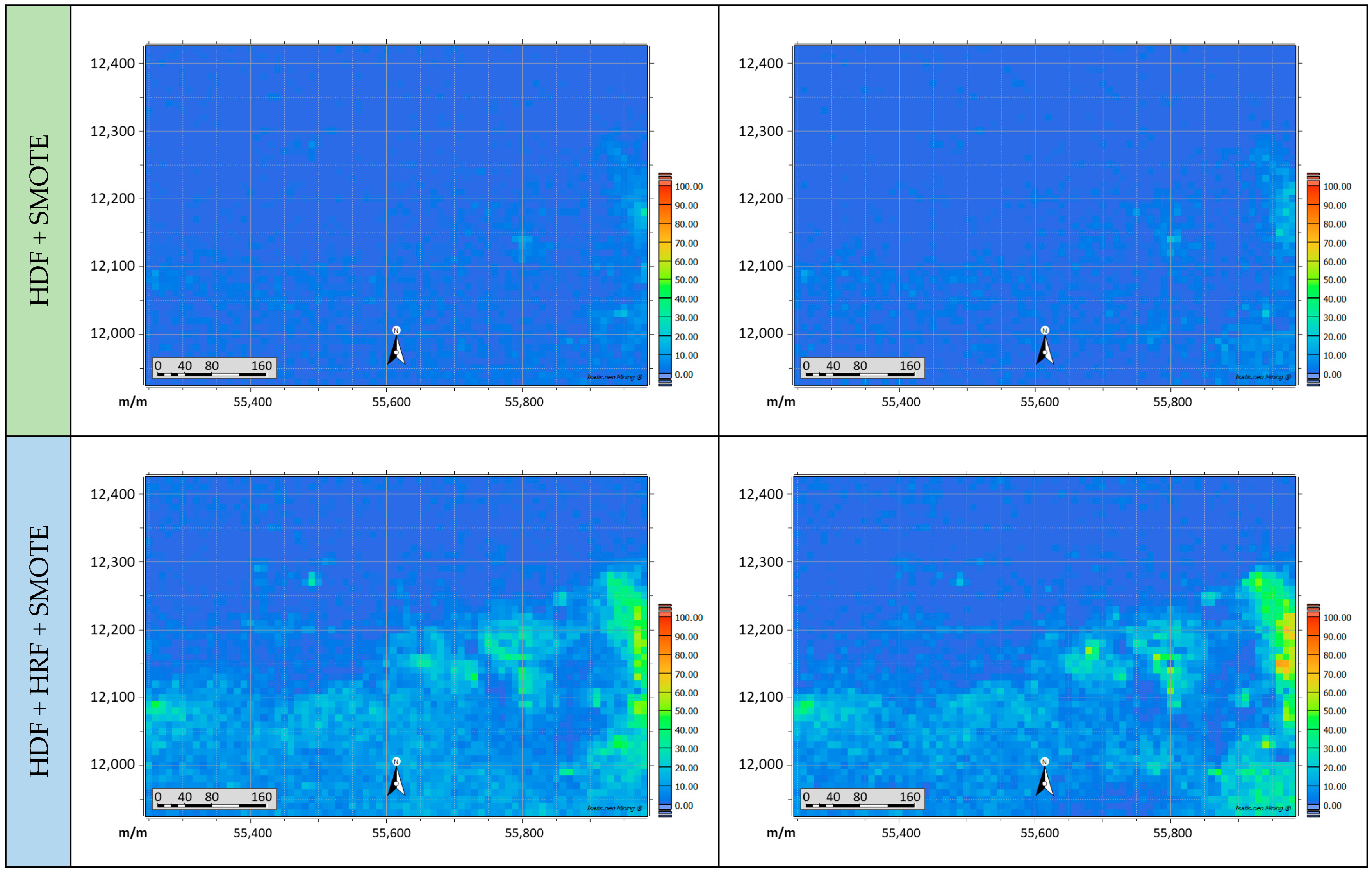
4.1. Geometallurgical Model: Net Smelter Return
4.2. Geometallurgical Model: Grinding Time—HQBX
4.3. General Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Coward, S.; Dowd, P. Geometallurgical models for the quantification of uncertainty in mining project value chains. In Proceedings of the International Symposium on the Application of Computers and Operations Research in the Mineral Industry (APCOM), Fairbanks, AK, USA, 23–27 May 2015; pp. 360–369. [Google Scholar]
- Macfarlane, A.; Williams, T. Optimizing value on a copper mine by adopting a geometallurgical solution. J. South. Afr. Inst. Min. Metall. 2014, 114, 929–935. [Google Scholar]
- Tercan, A.; Sohrabian, B. Multivariate geostatistical simulation of coal quality data by independent components. Int. J. Coal Geol. 2013, 112, 53–66. [Google Scholar] [CrossRef]
- Dowd, P.; Xu, C.; Coward, S. Strategic mine planning and design: Some challenges and strategies for addressing them. Min. Technol. 2016, 125, 22–34. [Google Scholar] [CrossRef]
- Lishchuk, V.; Koch, P.-H.; Ghorbani, Y.; Butcher, A.R. Towards integrated geometallurgical approach: Critical review of current practices and future trends. Miner. Eng. 2020, 145, 106072. [Google Scholar] [CrossRef]
- Deutsch, J.; Szymanski, J.; Etsell, T. Metallurgical variable re-expression for geostatistics. In Geostatistical and Geospatial Approaches for the Characterization of Natural Resources in the Environment: Challenges, Processes and Strategies; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 83–88. [Google Scholar]
- Abildin, Y.; Madani, N.; Topal, E. A hybrid approach for joint simulation of geometallurgical variables with inequality constraint. Minerals 2019, 9, 24. [Google Scholar] [CrossRef] [Green Version]
- Adeli, A.; Dowd, P.; Emery, X.; Xu, C. Using cokriging to predict metal recovery accounting for non-additivity and preferential sampling designs. Miner. Eng. 2021, 170, 106923. [Google Scholar] [CrossRef]
- Sepulveda, E.; Dowd, P.; Xu, C.; Addo, E. Multivariate modelling of geometallurgical variables by projection pursuit. Math. Geosci. 2017, 49, 121–143. [Google Scholar] [CrossRef]
- Cowan, E.; Beatson, R.; Ross, H.; Fright, W.; McLennan, T.; Evans, T.; Carr, J.; Lane, R.; Bright, D.; Gillman, A. Practical implicit geological modelling. In Proceedings of the 5th International Mining Geology Conference, Bendigo, VIC, Australia, 17–19 November 2003; pp. 89–99. [Google Scholar]
- Gonçalves, Í.G.; Kumaira, S.; Guadagnin, F. A machine learning approach to the potential-field method for implicit modeling of geological structures. Comput. Geosci. 2017, 103, 173–182. [Google Scholar] [CrossRef]
- Lajaunie, C.; Courrioux, G.; Manuel, L. Foliation fields and 3D cartography in geology: Principles of a method based on potential interpolation. Math. Geol. 1997, 29, 571–584. [Google Scholar] [CrossRef]
- Manchuk, J.G.; Deutsch, C.V. Boundary modeling with moving least squares. Comput. Geosci. 2019, 126, 96–106. [Google Scholar] [CrossRef]
- Armstrong, M.; Galli, A.; Beucher, H.; Loc’h, G.; Renard, D.; Doligez, B.; Eschard, R.; Geffroy, F. Plurigaussian Simulations in Geosciences; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Emery, X.; Séguret, S.A. Geostatistics for the Mining Industry: Applications to Porphyry Copper Deposits; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Journel, A.; Isaaks, E. Conditional indicator simulation: Application to a Saskatchewan uranium deposit. J. Int. Assoc. Math. Geol. 1984, 16, 685–718. [Google Scholar] [CrossRef]
- Journel, A.G. Nonparametric estimation of spatial distributions. J. Int. Assoc. Math. Geol. 1983, 15, 445–468. [Google Scholar] [CrossRef]
- Xu, C.; Dowd, P.A.; Mardia, K.V.; Fowell, R.J. A flexible true plurigaussian code for spatial facies simulations. Comput. Geosci. 2006, 32, 1629–1645. [Google Scholar] [CrossRef]
- Emery, X.; Ortiz, J.; Cáceres, A. Geostatistical modelling of rock type domains with spatially varying proportions: Application to a porphyry copper deposit. J. South. Afr. Inst. Min. Metall. 2008, 108, 284–292. [Google Scholar]
- Maleki, M.; Emery, X.; Cáceres, A.; Ribeiro, D.; Cunha, E. Quantifying the uncertainty in the spatial layout of rock type domains in an iron ore deposit. Comput. Geosci. 2016, 20, 1013–1028. [Google Scholar] [CrossRef]
- Silva, D. Enhanced Geologic Modeling of Multiple Categorical Variables. Ph.D. Thesis, University of Alberta, Edmonton, AB, Canada, 2018. [Google Scholar]
- Séguret, S.A. Analysis and estimation of multi-unit deposits: Application to a porphyry copper deposit. Math. Geosci. 2013, 45, 927–947. [Google Scholar] [CrossRef] [Green Version]
- Adeli, A.; Emery, X.; Dowd, P. Geological modelling and validation of geological interpretations via simulation and classification of quantitative covariates. Minerals 2017, 8, 7. [Google Scholar] [CrossRef] [Green Version]
- Fouedjio, F.; Hill, E.J.; Laukamp, C. Geostatistical clustering as an aid for ore body domaining: Case study at the Rocklea Dome channel iron ore deposit, Western Australia. Appl. Earth Sci. 2018, 127, 15–29. [Google Scholar] [CrossRef]
- Madani, N.; Maleki, M.; Emery, X. Nonparametric geostatistical simulation of subsurface facies: Tools for validating the reproduction of, and uncertainty in, facies geometry. Nat. Resour. Res. 2019, 28, 1163–1182. [Google Scholar] [CrossRef]
- Moreira, G.d.C.; Coimbra Leite Costa, J.F.; Marques, D.M. Defining geologic domains using cluster analysis and indicator correlograms: A phosphate-titanium case study. Appl. Earth Sci. 2020, 129, 176–190. [Google Scholar] [CrossRef]
- Sepúlveda, E.; Dowd, P.; Xu, C. Fuzzy clustering with spatial correction and its application to geometallurgical domaining. Math. Geosci. 2018, 50, 895–928. [Google Scholar] [CrossRef] [Green Version]
- Kasmaee, S.; Raspa, G.; de Fouquet, C.; Tinti, F.; Bonduà, S.; Bruno, R. Geostatistical estimation of multi-domain deposits with transitional boundaries: A sensitivity study for the Sechahun iron mine. Minerals 2019, 9, 115. [Google Scholar] [CrossRef] [Green Version]
- Amarante, F.A.N.; Rolo, R.M.; Coimbra Leite Costa, J.F. Boundary simulation–a hierarchical approach for multiple categories. Appl. Earth Sci. 2021, 130, 114–130. [Google Scholar] [CrossRef]
- Abildin, Y.; Xu, C.; Dowd, P.; Adeli, A. A hybrid framework for modelling domains using quantitative covariates. Appl. Comput. Geosci. 2022, 16, 100107. [Google Scholar] [CrossRef]
- Adeli, A.; Emery, X. Geostatistical simulation of rock physical and geochemical properties with spatial filtering and its application to predictive geological mapping. J. Geochem. Explor. 2021, 220, 106661. [Google Scholar] [CrossRef]
- Rossi, M.E.; Deutsch, C.V. Mineral Resource Estimation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Matheron, G.; Beucher, H.; de Fouquet, C.; Galli, A.; Guérillot, D.; Ravenne, C. Conditional simulation of the geometry of fluvio-deltaic reservoirs. In Proceedings of the SPE Annual Technical Conference and Exhibition, Dallas, TX, USA, 27–30 September 1987. [Google Scholar]
- Sadeghi, M.; Madani, N.; Falahat, R.; Sabeti, H.; Amini, N. Hierarchical reservoir lithofacies and acoustic impedance simulation: Application to an oil field in SW of Iran. J. Pet. Sci. Eng. 2022, 208, 109552. [Google Scholar] [CrossRef]
- Dowd, P.; Pardo-Igúzquiza, E.; Xu, C. Plurigau: A computer program for simulating spatial facies using the truncated plurigaussian method. Comput. Geosci. 2003, 29, 123–141. [Google Scholar] [CrossRef]
- Madani, N.; Emery, X. Plurigaussian modeling of geological domains based on the truncation of non-stationary Gaussian random fields. Stoch. Environ. Res. Risk Assess. 2017, 31, 893–913. [Google Scholar] [CrossRef]
- Emery, X.; Lantuéjoul, C. Tbsim: A computer program for conditional simulation of three-dimensional gaussian random fields via the turning bands method. Comput. Geosci. 2006, 32, 1615–1628. [Google Scholar] [CrossRef]
- Le Loc’h, G.; Galli, A. Truncated plurigaussian method: Theoretical and practical points of view. Geostat. Wollongong 1997, 96, 211–222. [Google Scholar]
- Emery, X. Simulation of geological domains using the plurigaussian model: New developments and computer programs. Comput. Geosci. 2007, 33, 1189–1201. [Google Scholar] [CrossRef]
- Lantuéjoul, C. Geostatistical Simulation: Models and Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Arroyo, D.; Emery, X. Spectral simulation of vector random fields with stationary Gaussian increments in d-dimensional Euclidean spaces. Stoch. Environ. Res. Risk Assess. 2017, 31, 1583–1592. [Google Scholar] [CrossRef]
- Emery, X. A turning bands program for conditional co-simulation of cross-correlated Gaussian random fields. Comput. Geosci. 2008, 34, 1850–1862. [Google Scholar] [CrossRef]
- Friedman, J.H.; Tukey, J.W. A projection pursuit algorithm for exploratory data analysis. IEEE Trans. Comput. 1974, 100, 881–890. [Google Scholar] [CrossRef]
- Barnett, R.M.; Manchuk, J.G.; Deutsch, C.V. Projection pursuit multivariate transform. Math. Geosci. 2014, 46, 337–359. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Gu, Y.; Zhang, D.; Bao, Z. Lithological classification via an improved extreme gradient boosting: A demonstration of the Chang 4+ 5 member, Ordos Basin, Northern China. J. Asian Earth Sci. 2021, 215, 104798. [Google Scholar] [CrossRef]
- Morales, P.; Luengo, J.; Garcia, L.P.F.; Lorena, A.C.; de Carvalho, A.C.; Herrera, F. The NoiseFiltersR Package: Label Noise Preprocessing in R. R J. 2017, 9, 219. [Google Scholar] [CrossRef] [Green Version]
- Miranda, A.L.; Garcia, L.P.F.; Carvalho, A.C.; Lorena, A.C. Use of classification algorithms in noise detection and elimination. In Proceedings of the Hybrid Artificial Intelligence Systems: 4th International Conference, HAIS 2009, Salamanca, Spain, 10–12 June 2009; pp. 417–424. [Google Scholar]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Williams, P.J.; Barton, M.D.; Johnson, D.A.; Fontboté, L.; De Haller, A.; Mark, G.; Oliver, N.H.; Marschik, R. Iron oxide copper-gold deposits: Geology, space-time distribution, and possible modes of origin. Econ. Geol. 2005, 100, 371–405. [Google Scholar] [CrossRef]
- Belperio, A.; Flint, R.; Freeman, H. Prominent Hill: A hematite-dominated, iron oxide copper-gold system. Econ. Geol. 2007, 102, 1499–1510. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Bühlmann, P. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Emery, X. Testing the correctness of the sequential algorithm for simulating Gaussian random fields. Stoch. Environ. Res. Risk Assess. 2004, 18, 401–413. [Google Scholar] [CrossRef]
- Leuangthong, O.; McLennan, J.A.; Deutsch, C.V. Minimum acceptance criteria for geostatistical realizations. Nat. Resour. Res. 2004, 13, 131–141. [Google Scholar] [CrossRef]
- Code, J. Australasian code for reporting of exploration results, mineral resources and ore reserves. AusIMM Melb. 2012, 44, 320. [Google Scholar]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Category | Name | Heterotopic Data | Isotopic Data | ||
|---|---|---|---|---|---|---|
| Number of Samples | Proportion (%) | Number of Samples | Proportion (%) | |||
| 1 | HMBX | Hematite Breccia | 37,755 | 28.74 | 25,966 | 28.01 |
| 2 | HQBX | Hematite Quartz Breccia | 3510 | 2.67 | 1182 | 1.27 |
| 3 | DOLM | Dolomite | 31,506 | 23.99 | 25,809 | 27.84 |
| 4 | OTHR | All other classes | 58,574 | 44.60 | 39,749 | 42.88 |
| No. | Abbreviation | Description | Number of Samples | Min. | Max. | Mean | Variance |
|---|---|---|---|---|---|---|---|
| 1 | Al_pct | Aluminium | 125,779 | 0.0 | 14.8 | 3.74 | 7.34 |
| 2 | Au_ppm | Gold | 131,343 | 0.0 | 137.6 | 0.34 | 1.58 |
| 3 | Ba_pct | Barium | 131,261 | 0.0 | 13.1 | 0.31 | 0.38 |
| 4 | Ca_pct | Calcium | 128,036 | 0.0 | 27.2 | 4.12 | 30.6 |
| 5 | Ce_ppm | Cerium | 131,310 | 2.0 | 1.7 × 104 | 817.80 | 8.2 × 105 |
| 6 | Cr_ppm | Chromium | 131,261 | 1.0 | 1.6 × 103 | 62.79 | 6.4 × 103 |
| 7 | Cu_pct | Copper | 131,345 | 0.0 | 20.6 | 0.4 | 0.89 |
| 8 | F_pct | Fluorine | 102,786 | 0.0 | 13.2 | 0.27 | 0.15 |
| 9 | Fe_pct | Iron | 131,311 | 0.4 | 69.5 | 19.87 | 165.4 |
| 10 | K_ppm | Potassium | 131,064 | 25 | 8.6 × 104 | 1.8 × 104 | 2.0 × 108 |
| 11 | La_ppm | Lanthanum | 131,258 | 2.0 | 1.2 × 104 | 5.5 × 102 | 3.9 × 105 |
| 12 | Mg_ppm | Magnesium | 131,261 | 25 | 1.7 × 105 | 2.8 × 104 | 9.5 × 108 |
| 13 | Mn_ppm | Manganese | 128,245 | 10 | 3.3 × 104 | 2.3 × 103 | 8.8 × 106 |
| 14 | Na_ppm | Sodium | 131,261 | 20 | 6.0 × 104 | 1.5 × 103 | 1.8 × 107 |
| 15 | P_ppm | Phosphorus | 131,261 | 2.5 | 5.5 × 104 | 1.3 × 103 | 1.2 × 106 |
| 16 | S_pct | Sulphur | 127,799 | 0.0 | 15.3 | 0.37 | 0.30 |
| 17 | Si_pct | Silicon | 125,653 | 0.1 | 44.9 | 18.56 | 64.4 |
| 18 | Ti_ppm | Titanium | 131,261 | 5.0 | 2.9 × 104 | 3.7 × 103 | 1.4 × 107 |
| 19 | Zn_ppm | Zinc | 131,345 | 1.0 | 1.0 × 104 | 35.4 | 4.7 × 103 |
| 20 | Zr_ppm | Zirconium | 93,100 | 2.5 | 862.5 | 125.3 | 1.0 × 104 |
| No. | Gaussian Random Field | Nugget | Structure 1 | Structure 2 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| c | a (EW), m | a (NS), m | a (vert), m | c | a (EW), m | a (NS), m | a (vert), m | |||
| a | 0 | 0.30 Sph | 30 | 90 | 30 | 0.70 Sph | 250 | 90 | 300 | |
| c | 0 | 0.40 Sph | 30 | 90 | 60 | 0.60 Sph | 330 | 150 | 300 | |
| b | 0 | 0.30 Gauss | 50 | 50 | 70 | 0.70 Cub | 400 | 130 | 450 | |
| d | 0 | 0.40 Exp | 50 | 50 | 50 | 0.60 Exp | 330 | 170 | 300 | |
| No. | Grade Variable | Nugget | Structure 1 | Structure 2 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| c | a (EW), m | a (NS), m | a (vert), m | c | a (EW), m | a (NS), m | a (vert), m | |||
| 1 | 0.40 | 0.45 | 25 | 17 | 24 | 0.15 | 500 | 324 | 500 | |
| 2 | 0.45 | 0.48 | 34 | 33 | 41 | 0.07 | 274 | 500 | 176 | |
| 3 | 0.41 | 0.32 | 21 | 37 | 39 | 0.27 | 130 | 67 | 130 | |
| 4 | 0.32 | 0.38 | 22 | 31 | 43 | 0.30 | 500 | 207 | 222 | |
| 5 | 0.34 | 0.40 | 20 | 17 | 26 | 0.26 | 203 | 92 | 188 | |
| 6 | 0.40 | 0.44 | 20 | 18 | 26 | 0.16 | 289 | 120 | 380 | |
| 7 | 0.28 | 0.49 | 32 | 42 | 51 | 0.23 | 140 | 50 | 90 | |
| 8 | 0.24 | 0.42 | 19 | 19 | 23 | 0.34 | 180 | 112 | 184 | |
| 9 | 0.36 | 0.40 | 25 | 30 | 30 | 0.24 | 50 | 59 | 140 | |
| 10 | 0.25 | 0.51 | 18 | 14 | 18 | 0.24 | 107 | 56 | 184 | |
| 11 | 0.43 | 0.39 | 20 | 21 | 28 | 0.18 | 351 | 303 | 500 | |
| 12 | 0.35 | 0.36 | 23 | 28 | 33 | 0.29 | 426 | 284 | 226 | |
| 13 | 0.21 | 0.41 | 18 | 20 | 28 | 0.38 | 165 | 99 | 153 | |
| 14 | 0.28 | 0.37 | 10 | 20 | 19 | 0.35 | 117 | 81 | 111 | |
| 15 | 0.35 | 0.41 | 27 | 19 | 24 | 0.24 | 222 | 87 | 500 | |
| 16 | 0.27 | 0.23 | 19 | 36 | 29 | 0.50 | 234 | 126 | 249 | |
| 17 | 0.30 | 0.39 | 15 | 11 | 18 | 0.31 | 100 | 73 | 120 | |
| 18 | 0.25 | 0.47 | 18 | 15 | 19 | 0.28 | 53 | 48 | 94 | |
| 19 | 0.26 | 0.43 | 17 | 12 | 17 | 0.31 | 105 | 61 | 128 | |
| 20 | 0.30 | 0.43 | 18 | 14 | 17 | 0.27 | 87 | 66 | 102 | |
| No. | Grade Variable | Nugget | Structure 1 | Structure 2 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| c | a (EW), m | a (NS), m | a (vert), m | c | a (EW), m | a (NS), m | a (vert), m | |||
| 1 | 0.35 | 0.46 | 20 | 16 | 23 | 0.19 | 344 | 196 | 500 | |
| 2 | 0.41 | 0.45 | 32 | 36 | 43 | 0.14 | 500 | 500 | 303 | |
| 3 | 0.38 | 0.32 | 22 | 35 | 35 | 0.30 | 163 | 87 | 151 | |
| 4 | 0.33 | 0.34 | 21 | 26 | 32 | 0.33 | 500 | 199 | 310 | |
| 5 | 0.33 | 0.41 | 24 | 16 | 27 | 0.26 | 224 | 101 | 217 | |
| 6 | 0.34 | 0.46 | 19 | 18 | 26 | 0.20 | 358 | 167 | 417 | |
| 7 | 0.28 | 0.58 | 44 | 43 | 72 | 0.14 | 500 | 324 | 167 | |
| 8 | 0.24 | 0.43 | 18 | 15 | 19 | 0.33 | 180 | 111 | 210 | |
| 9 | 0.34 | 0.45 | 30 | 28 | 40 | 0.21 | 50 | 65 | 141 | |
| 10 | 0.25 | 0.50 | 19 | 14 | 19 | 0.25 | 163 | 130 | 283 | |
| 11 | 0.39 | 0.41 | 19 | 19 | 27 | 0.20 | 333 | 245 | 500 | |
| 12 | 0.31 | 0.35 | 22 | 28 | 31 | 0.34 | 480 | 285 | 311 | |
| 13 | 0.21 | 0.40 | 19 | 20 | 29 | 0.39 | 188 | 120 | 203 | |
| 14 | 0.26 | 0.43 | 10 | 18 | 22 | 0.31 | 117 | 87 | 116 | |
| 15 | 0.33 | 0.43 | 26 | 17 | 24 | 0.24 | 375 | 238 | 500 | |
| 16 | 0.27 | 0.23 | 20 | 30 | 27 | 0.5 | 220 | 120 | 241 | |
| 17 | 0.28 | 0.40 | 15 | 10 | 18 | 0.32 | 141 | 73 | 146 | |
| 18 | 0.29 | 0.47 | 19 | 19 | 25 | 0.24 | 112 | 67 | 150 | |
| 19 | 0.27 | 0.40 | 18 | 16 | 18 | 0.33 | 170 | 80 | 213 | |
| 20 | 0.33 | 0.67 | 31 | 18 | 31 | |||||
| Mean | Variance | |||||||
|---|---|---|---|---|---|---|---|---|
| Grade Assays | Isotopic | Mean of 100 Realisations | Heterotopic | Mean of 100 Realisations | Isotopic | Mean of 100 Realisations | Heterotopic | Mean of 100 Realisations |
| Al_pct | 3.55 | 3.72 | 3.74 | 3.76 | 7.05 | 5.41 | 7.34 | 5.50 |
| Au_ppm | 0.33 | 0.39 | 0.34 | 0.40 | 0.98 | 1.61 | 6.30 | 11.90 |
| Ba_pct | 0.27 | 0.54 | 0.31 | 0.48 | 0.31 | 1.01 | 0.38 | 0.72 |
| Ca_pct | 4.82 | 3.26 | 4.12 | 2.86 | 34.39 | 16.88 | 30.63 | 13.74 |
| Ce_ppm | 788.10 | 798.69 | 817.76 | 741.80 | 7.8 × 105 | 6.9 × 105 | 8.2 × 105 | 7.0 × 105 |
| Cr_ppm | 59.03 | 81.72 | 62.79 | 66.59 | 5.3 × 103 | 1.1 × 104 | 6.4 × 103 | 6.9 × 103 |
| Cu_pct | 0.39 | 0.33 | 0.40 | 0.29 | 0.84 | 0.59 | 0.89 | 0.51 |
| F_pct | 0.26 | 0.30 | 0.27 | 0.27 | 0.13 | 0.24 | 0.15 | 0.16 |
| Fe_pct | 19.39 | 21.30 | 19.87 | 21.09 | 167.60 | 149.00 | 165.40 | 131.30 |
| K_ppm | 1.7 × 104 | 1.7 × 104 | 1.8 × 104 | 1.7 × 104 | 1.9 × 108 | 1.4 × 108 | 2.0 × 108 | 1.4 × 108 |
| La_ppm | 5.3 × 102 | 5.3 × 102 | 5.5 × 102 | 5.1 × 102 | 3.5 × 105 | 2.9 × 105 | 3.9 × 105 | 3.8 × 105 |
| Mg_ppm | 3.2 × 104 | 2.1 × 104 | 2.8 × 104 | 1.9 × 104 | 1.0 × 109 | 4.8 × 108 | 9.5 × 108 | 4.4 × 108 |
| Mn_ppm | 2.7 × 103 | 1.9 × 103 | 2.3 × 103 | 1.7 × 103 | 9.8 × 106 | 5.3 × 106 | 8.8 × 106 | 4.8 × 106 |
| Na_ppm | 1.5 × 103 | 1.9 × 103 | 1.5 × 103 | 2.2 × 103 | 1.5 × 107 | 2.4 × 107 | 1.8 × 107 | 3.2 × 107 |
| P_ppm | 1.2 × 103 | 1.5 × 103 | 1.3 × 103 | 1.6 × 103 | 9.9 × 105 | 2.4 × 106 | 1.2 × 106 | 3.5 × 106 |
| S_pct | 0.36 | 0.42 | 0.37 | 0.38 | 0.27 | 0.35 | 0.30 | 0.40 |
| Si_pct | 17.79 | 20.01 | 18.56 | 20.41 | 66.40 | 47.19 | 64.28 | 42.17 |
| Ti_ppm | 3.5 × 103 | 4.3 × 103 | 3.7 × 103 | 4.5 × 103 | 1.4 × 107 | 1.6 × 107 | 1.4 × 107 | 1.6 × 107 |
| Zn_ppm | 35.30 | 38.94 | 35.42 | 40.91 | 2.6 × 103 | 5.0 × 103 | 4.7 × 103 | 4.6 × 103 |
| Zr_ppm | 125.07 | 151.61 | 125.34 | 155.23 | 1.0 × 104 | 1.2 × 104 | 1.0 × 104 | 1.0 × 104 |
| HQBX | HMBX | DOLM | OTHR | |||||
|---|---|---|---|---|---|---|---|---|
| Removed | Re-Labelled | Removed | Re-Labelled | Removed | Re-Labelled | Removed | Re-Labelled | |
| HQBX | - | - | 2029 | 1953 | 701 | 300 | 1585 | 865 |
| HMBX | 128 | 0 | - | - | 839 | 447 | 2308 | 2035 |
| DOLM | 30 | 0 | 903 | 328 | - | - | 3011 | 1833 |
| OTHR | 56 | 3 | 1637 | 705 | 1343 | 1775 | - | - |
| Total | 214 | 3 | 4569 | 2986 | 2883 | 2522 | 6904 | 4733 |
| Original | HybridRepairFilter | |||
|---|---|---|---|---|
| Number of Samples | Proportion (%) | Number of Samples | Proportion (%) | |
| HQBX | 1182 | 1.27 | 4083 | 5.19 |
| HMBX | 25,966 | 28.01 | 20,893 | 26.56 |
| DOLM | 25,809 | 27.84 | 22,565 | 28.68 |
| OTHR | 39,749 | 42.88 | 31,137 | 39.58 |
| Original Imbalanced | Original Balanced | Noise Filtered Balanced | |
|---|---|---|---|
| Class | Balanced Accuracy | Balanced Accuracy | Balanced Accuracy |
| HQBX | 0.707 | 0.752 | 0.866 |
| HMBX | 0.863 | 0.881 | 0.901 |
| DOLM | 0.931 | 0.937 | 0.946 |
| OTHR | 0.895 | 0.896 | 0.913 |
| Average | 0.849 | 0.867 | 0.907 |
| HMBX | HQBX | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Methods | Most Probable | Prob. >50 | Prob. >60 | Prob. >70 | Most Probable | Prob. >50 | Prob. >60 | Prob. >70 | |
| Isotopic | PGS | 58,569 | 48,090 | 37,575 | 29,420 | 1337 | 966 | 673 | 441 |
| HDF imbalanced | 48,798 | 32,743 | 17,511 | 7871 | 0 | 0 | 0 | 0 | |
| HDF + SMOTE | 68,881 | 43,586 | 23,961 | 11,667 | 3 | 0 | 0 | 0 | |
| HDF + HRF + SMOTE | 39,974 | 17,982 | 8176 | 2753 | 4945 | 737 | 168 | 20 | |
| Heterotopic | PGS | 44,272 | 41,819 | 35,324 | 28,943 | 2261 | 2111 | 1421 | 929 |
| HDF imbalanced | 51,187 | 40,484 | 23,317 | 11,362 | 0 | 0 | 0 | 0 | |
| HDF + SMOTE | 66,173 | 50,211 | 30,477 | 15,702 | 2 | 0 | 0 | 0 | |
| HDF + HRF + SMOTE | 43,263 | 24,320 | 12,306 | 5118 | 6286 | 1615 | 550 | 145 | |
| Isotopic | Heterotopic (Imputed) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| OTHR | HQBX | HMBX | DOLM | OTHR | HQBX | HMBX | DOLM | ||
| PGS | Number of blocks | 183,092 | 1337 | 58,569 | 17,002 | 194,283 | 2261 | 44,272 | 19,184 |
| Proportion (%) | 70.42 | 0.51 | 22.53 | 6.54 | 74.72 | 0.87 | 17.03 | 7.38 | |
| HDF imbalanced | Number of blocks | 196,240 | 0 | 48,798 | 14,962 | 195,644 | 0 | 51,187 | 13,169 |
| Proportion (%) | 75.48 | 0.00 | 18.77 | 5.75 | 75.25 | 0.00 | 19.69 | 5.07 | |
| HDF + SMOTE | Number of blocks | 172,416 | 3 | 68,881 | 18,700 | 177,596 | 2 | 66,173 | 16,229 |
| Proportion (%) | 66.31 | 0.00 | 26.49 | 7.19 | 68.31 | 0.00 | 25.45 | 6.24 | |
| HDF + HRF + SMOTE | Number of blocks | 199,768 | 4945 | 39,974 | 15,313 | 197,144 | 6286 | 43,263 | 13,307 |
| Proportion (%) | 76.83 | 1.91 | 15.37 | 5.89 | 75.82 | 2.42 | 16.64 | 5.12 | |
| Methods | Threshold | Number of Blocks | Mean | Std Dev. | Q5 | Q25 | Q50 | Q75 | Q95 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Isotopic | PGS | MP | 17,002 | 7.17 | 11.40 | 0.40 | 1.48 | 3.92 | 8.53 | 23.47 |
| P-50 | 16,813 | 7.03 | 11.22 | 0.40 | 1.44 | 3.88 | 8.34 | 22.79 | ||
| P-70 | 10,691 | 6.36 | 11.78 | 0.36 | 1.11 | 2.69 | 6.53 | 24.05 | ||
| HDF imbalanced | MP | 14,962 | 7.00 | 12.80 | 0.35 | 1.16 | 2.92 | 7.13 | 26.91 | |
| P-50 | 12,295 | 6.54 | 12.52 | 0.32 | 1.01 | 2.49 | 6.09 | 26.65 | ||
| P-70 | 4610 | 6.66 | 12.61 | 0.30 | 0.83 | 1.97 | 6.25 | 30.32 | ||
| HDF + SMOTE | MP | 18,700 | 7.02 | 12.26 | 0.38 | 1.32 | 3.42 | 7.66 | 24.14 | |
| P-50 | 14,531 | 6.55 | 12.15 | 0.34 | 1.07 | 2.68 | 6.58 | 25.12 | ||
| P-70 | 5966 | 6.42 | 12.38 | 0.29 | 0.85 | 2.00 | 5.68 | 29.75 | ||
| HDF + HRF + SMOTE | MP | 15,313 | 7.21 | 13.06 | 0.34 | 1.18 | 3.03 | 7.35 | 27.42 | |
| P-50 | 12,374 | 6.51 | 12.45 | 0.32 | 1.01 | 2.48 | 6.15 | 26.31 | ||
| P-70 | 4594 | 6.56 | 12.34 | 0.29 | 0.83 | 1.98 | 5.87 | 30.13 | ||
| Heterotopic | PGS | MP | 19,184 | 7.76 | 12.79 | 0.40 | 1.45 | 3.81 | 8.78 | 27.54 |
| P-50 | 18,045 | 7.63 | 12.91 | 0.39 | 1.40 | 3.62 | 8.32 | 27.69 | ||
| P-70 | 14,039 | 7.21 | 13.16 | 0.37 | 1.22 | 3.04 | 7.22 | 28.05 | ||
| HDF imbalanced | MP | 13,169 | 6.94 | 13.23 | 0.34 | 1.08 | 2.73 | 6.56 | 27.77 | |
| P-50 | 11,042 | 6.45 | 12.42 | 0.31 | 0.95 | 2.36 | 5.94 | 27.19 | ||
| P-70 | 4027 | 6.64 | 12.15 | 0.28 | 0.81 | 2.06 | 6.64 | 29.91 | ||
| HDF + SMOTE | MP | 16,229 | 6.94 | 12.70 | 0.36 | 1.19 | 3.07 | 7.12 | 25.96 | |
| P-50 | 13,089 | 6.43 | 12.27 | 0.33 | 1.02 | 2.55 | 6.04 | 26.46 | ||
| P-70 | 5315 | 6.49 | 12.25 | 0.29 | 0.84 | 2.03 | 5.93 | 28.75 | ||
| HDF + HRF + SMOTE | MP | 13,307 | 6.97 | 13.19 | 0.34 | 1.10 | 2.73 | 6.59 | 27.75 | |
| P-50 | 11,160 | 6.44 | 12.50 | 0.31 | 0.97 | 2.38 | 5.98 | 27.59 | ||
| P-70 | 4022 | 6.76 | 12.42 | 0.29 | 0.82 | 2.09 | 6.46 | 28.85 |
| Isotopic | Heterotopic | |||||||
|---|---|---|---|---|---|---|---|---|
| Methods | Most Probable | Prob. >50 | Prob. >60 | Prob. >70 | Most Probable | Prob. >50 | Prob. >60 | Prob. >70 |
| PGS | 1337 | 966 | 673 | 441 | 2261 | 2111 | 1421 | 929 |
| HDF imbalanced | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| HDF + SMOTE | 3 | 0 | 0 | 0 | 2 | 0 | 0 | 0 |
| HDF + HRF + SMOTE | 4945 | 737 | 168 | 20 | 6286 | 1615 | 550 | 145 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abildin, Y.; Xu, C.; Dowd, P.; Adeli, A. Geometallurgical Responses on Lithological Domains Modelled by a Hybrid Domaining Framework. Minerals 2023, 13, 918. https://doi.org/10.3390/min13070918
Abildin Y, Xu C, Dowd P, Adeli A. Geometallurgical Responses on Lithological Domains Modelled by a Hybrid Domaining Framework. Minerals. 2023; 13(7):918. https://doi.org/10.3390/min13070918
Chicago/Turabian StyleAbildin, Yerniyaz, Chaoshui Xu, Peter Dowd, and Amir Adeli. 2023. "Geometallurgical Responses on Lithological Domains Modelled by a Hybrid Domaining Framework" Minerals 13, no. 7: 918. https://doi.org/10.3390/min13070918