1. Introduction
Skewed distributions can have important implications for statistical analysis. For example, if the data are positively skewed, the mean may not be a good measure of central tendency, as it will be influenced by the few extreme values on the right-hand side of the distribution. In this case, the median may be a better measure of central tendency. Similarly, if the data are negatively skewed, the mean may be lower than expected, and again, the median may be a better measure of central tendency. In a negatively skewed distribution, the mean is less than the median, and the tail of the distribution is longer on the left-hand side. This means that there are more data points on the right-hand side of the distribution than on the left-hand side. An example of a negatively skewed distribution is the distribution of reaction times, where most people react quickly, but a few people take a long time to react (see Aboraya et al. [
1], Acerbi and Tasche [
2]).
Following Adcock et al. [
3], Eling [
4] and Ali et al. [
5,
6], the concept of symmetry refers to the shape of a probability distribution. When the left and right sides of a probability distribution mirror the other side exactly, the distribution is said to be symmetric. Or, to put it another way, the left and right sides of the distribution would be identical if a vertical line were drawn down the center of it. The most well-known illustration of a symmetric distribution is probably the normal distribution. In the study of statistics, the normal distribution is commonly used to describe a wide range of real-world events. The mean and the median are both located in the center of the bell-shaped curve that symbolizes the normal distribution. Because of the distribution’s symmetry, the mean, median, and mode are the same in a normal distribution. As a result, symmetry plays a crucial role in the definition of a probability distribution’s shape in the field of probability theory. Anything from a circle to a bell curve might be this shape. Symmetric distributions are commonly used in the areas of statistical inference, decision-making, and probability computation. However, not all distributions are symmetric, and probability theory also heavily utilizes asymmetric distributions, also referred to as skewed distributions.
This study investigates a new model called the generalized exponential Lomax (GELX) for the negatively skewed insurance data. The new model is a new generalization of the well-known Lomax (LX) model. A random variable (RV)
has the LX distribution if it has cumulative distribution function (CDF) (for
) given by
where
and
refers to the shape parameter. The scale parameter is considered as 2 for reducing the number of the parameters. Then, the corresponding probability density function (PDF) of (1) is
Based on Alizadeh et al. [
7], the CDF and PDF of GELX model is given, respectively, by
where
,
and
where
are two additional shape parameters. Henceforth,
GELX(
) denotes an RV having density function (4). The reliability function (rf) and hazard rate function (HRF) of
are, respectively, given by
, where
In this paper, we employ the new model in (4) in two significant directions which are the risk analysis and distributional validity. The use of probability-based distributions to describe risk exposure is an important new statistical direction. Typically, a single number or a small set of numbers, known as key risk indicators (KRIs), are used to represent the level of risk exposure. The KRIs serve as a valuable tool for actuaries and risk managers by providing information about the extent to which a company is exposed to specific risks. Various KRIs, such as value-at-risk (VaRK), tail-value-at-risk (TVaRK), conditional-value-at-risk (CVaRK), tail variance (TV), and tail mean-variance (TMV), can be analyzed. For the risk validation, the Rao–Robson Nikulin (RRNIK) test statistic (see Nikulin [
8], Nikulin [
9], Nikulin [
10], and Rao and Robson [
11]) is used for uncensored validation. On the other hand, a new modified version of the RRNIK test statistic is used for the censored validation. Finally, the actuarial datasets are examined for validation under the RRNIK test statistic. These risk indicators help investors and risk managers make informed decisions by quantifying and assessing the potential downside risk of investments. They contribute to a more comprehensive understanding of risk and support the development of robust risk management strategies.
The following reasons are the primary drivers driving the introduction of this new distribution:
- I.
We created a new probability distribution with only three parameters for validation and risk analysis. For applied modeling, estimation, simulation trials, etc., the fewer the distribution parameters, the better.
- II.
A new probability distribution is presented with simple mathematical features that make it simple to compute and use. The quantile function is the only mathematical or statistical property of the present distribution that cannot be obtained in precise formulas, as will be demonstrated later. The latest statistical programs such as “R” and “Mathcad”, however, greatly aid in overcoming this issue with numerical approaches and fixes. In these circumstances, it is essential to comprehend numerical methods (and the numerical solutions they provide) in order to get around some of the more difficult formulations that researchers may run against.
- III.
We examined numerous traditional estimation techniques in light of the new distribution, either through simulative experiments or through real-world applications.
- IV.
The majority of practical statistical work must include the new distributions into the modeling procedures. In this work, we did this by employing an old, well-known goodness-of-fit test and a new, modified goodness-of-fit test, and we gave evidence and justifications in support of the validity of the new modified test as well as the significance of the new distribution.
- V.
We examined the new distribution from a number of perspectives in order to better understand it, including the mathematical side, the modeling side, the estimation and simulation processes in various ways, and the statistical hypothesis tests.
In fact, the specialized literature has a good number of extensions of the LX distribution, and these extensions were mostly used in mathematical and statistical modeling processes. The Lomax distribution is often used to model extreme events or rare occurrences that fall in the upper tail of a distribution. In actuarial sciences, extreme events are of particular interest since they often represent catastrophic or high-impact events such as insurance claims, natural disasters, or financial losses. The Lomax distribution provides a flexible framework for modeling the tail behavior of these events and estimating their probabilities. Actuaries play a crucial role in the insurance industry by assessing and managing risks. The Lomax distribution is often employed in insurance modeling, particularly in areas such as property and casualty insurance. It helps actuaries estimate the likelihood and severity of extreme events, which is essential for determining appropriate insurance premiums, policy limits, and reserves (see Aboraya et al. [
1]).
Actuarial risk analysis involves modeling the frequency and severity of losses or claims. The Lomax distribution can be used to model the severity component, representing the distribution of individual claim sizes or losses. By fitting the Lomax distribution to historical data, actuaries can gain insights into the statistical properties of losses and make informed decisions regarding risk management and pricing. Actuarial risk analysis involves estimating extreme quantiles, such as value-at-risk or Conditional Tail Expectation, which are used to assess the potential losses or liabilities associated with extreme events. The Lomax distribution can be fitted to historical data or used in combination with other models to estimate these tail quantiles accurately. Its tail heaviness allows for the extreme values and tail behavior of the data to be captured better (see Wirch [
12] and Tasche [
13]). The LX distribution serves as a useful tool for actuarial science researchers. It provides a flexible framework for studying extreme value theory, analyzing heavy-tailed distributions, and developing new statistical models for actuarial risk. Researchers can explore various aspects of risk analysis, such as dependence modeling, copulas, multivariate extensions, and time series modeling, using the Lomax distribution as a building block. For more details, regression models, applications, and real datasets, see Butt and Khalil [
14] for a novel skewed bimodal model for modeling the asymmetric heavy-tail bimodal datasets, Reyes et al. [
15] for a new bimodal exponential extension with some applications in risk theory, and Gómez et al. [
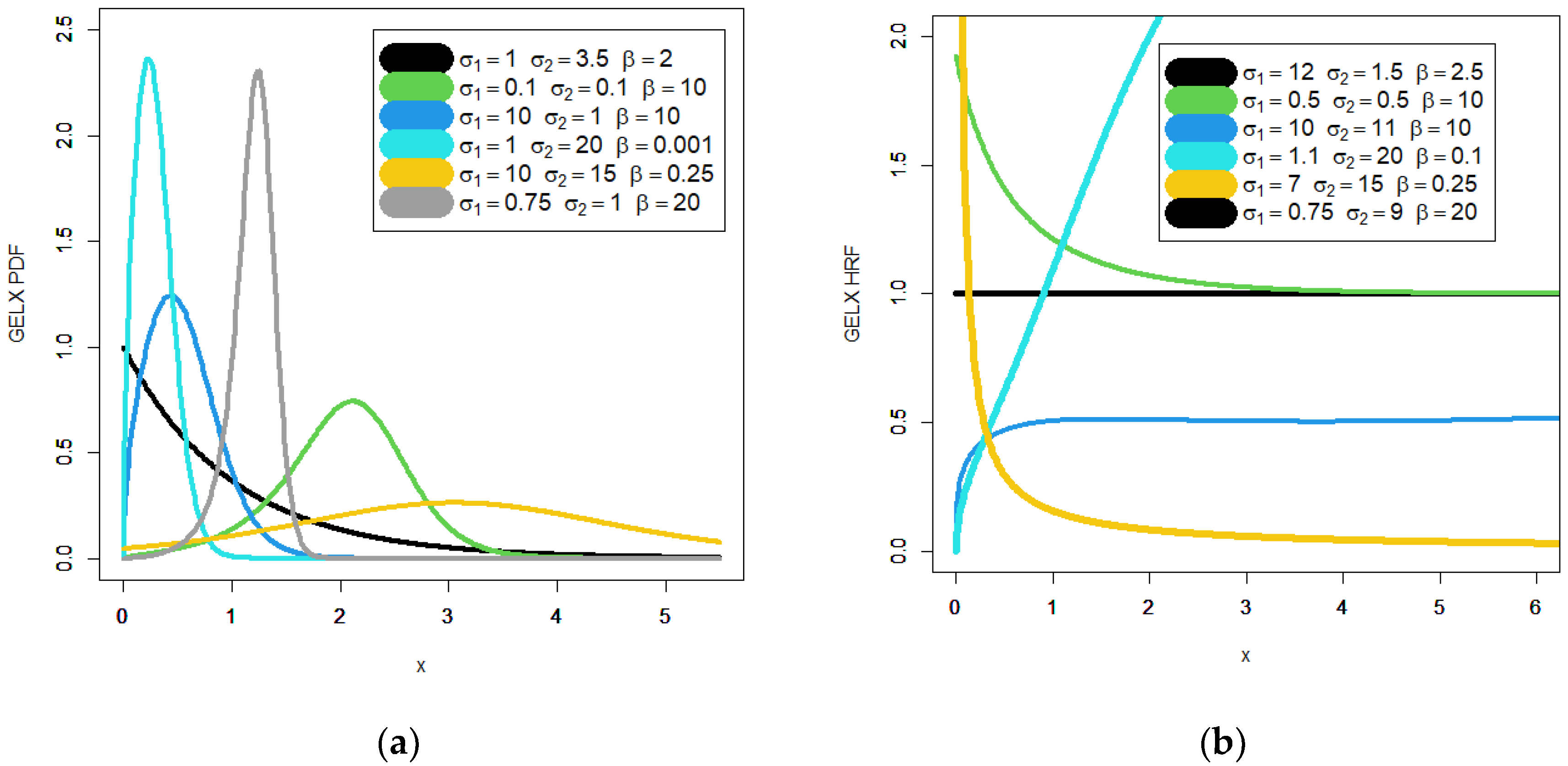
16] for asymmetric bimodal double-regression modeling. A few plots of the GELX PDF and HRF are shown in
Figure 1. We conclude from
Figure 1′s left panel that the PDF of the GELX distribution displays a variety of significant forms with varied kurtosis values. Based on
Figure 1a, it is seen that the new PDF can be symmetric with one peak, asymmetric with one peak and right skewed with no peak. Based on
Figure 1b, it is seen that the new HRF can be constant, decreasing, increasing, and increasing–constant.
Section 2 presents some mathematical properties of the new model.
Section 3 presents the KRIs. The risk assessment using different estimation methods is given in
Section 4. A case study is illustrated in
Section 5. The construction of the RRNIK statistic for the GELX model is given in
Section 6.
Section 7 and
Section 8 give the uncensored and censored distributional validations, respectively.
Section 9 offers some concluding remarks.
2. Mathematical Properties
First, we give a simple formula for (4). Using the following series expansion which holds for
and
real non-integer
to expand the quantity
we obtain
Then, the novel PDF in (4) can be derived as
Expanding the quantity
using the power series
we obtain
Then, the PDF in (4) can be formulated as
We apply the series expansion again to the quantity
. Then, we can obtain
where
represents the PDF of the exp-LX model with power parameter
and
The CDF of the GELX model can also be expressed as a mixture of exponentiated Lomax (ELX) CDFs. By integrating (4), we obtain the same mixture representation
where
is the CDF of the ELX model with power parameter
. The stochastic properties of probability distributions are important because they describe the behavior of random variables and stochastic processes. These properties are used to model and analyze a wide range of real-world phenomena, from stock prices to weather patterns to the behavior of subatomic particles.
Stochastic properties are used to model the uncertainty of and variability in financial assets and to analyze the risk associated with investments. The mean and variance of probability distributions are used to calculate the expected return and risk of a portfolio of assets.
3. The KRIs
The VaRK is a widely used risk indicator that estimates the maximum potential loss within a specified confidence level over a given time horizon. It provides a single number that represents the worst-case loss a portfolio or investment is expected to experience. VaRK helps investors assess and compare the riskiness of different assets or portfolios and set risk management limits. It is particularly useful in risk measurement, risk monitoring, and regulatory compliance; see Wirch [
12], Tasche [
13], and Acerbi and Tasche [
2] for more details and applications. We can simply obtain the quantity VaR
for the GELX distribution from the following probability:
where
.
The TVaRK, which is also known as conditional value-at-risk (CVaR), is an extension of VaR by considering the expected loss beyond the VaRK threshold. Unlike VaR, which only measures the loss at a specific confidence level, TVaRK estimates the average loss in the tail of the distribution (see Hogg and Klugman [
17], Klugman et al. [
18], Lane [
19], McNeil et al. [
20], Vernic [
21], Artzner [
22], and Charpentier [
23]). This risk indicator provides additional information about extreme losses and tail risks. TVaRK is often used to evaluate downside risk and is popular in risk measurement, risk budgeting, and portfolio optimization. The
can also be derived due to the main result below as
which can be simplified to
Then, using (5), we reach
where
Thus, the quantity TVaRK
is an average of all VaRK values above the confidence level
, which provides more information about the tail of the GELX distribution. Further, it can also be expressed as
where
is the mean excess loss function evaluated at the
th quantile. So, TVaRK
is larger than its corresponding VaRK
by the amount of average excess of all losses that exceed the MELS
value of VaRK
(see Acerbi and Tasche [
2], Wirch [
12], and Tasche [
13] for more details and applications). Tail variance measures the variability in or dispersion of returns in the extreme tails of the distribution. It focuses on the higher moments of the distribution beyond the mean and standard deviation. The TV provides information about the thickness and shape of the tails, helping investors gauge the potential losses in extreme market conditions. It is particularly useful in assessing tail risk, designing risk management strategies, and constructing tail risk hedging instruments. Following Furman and Landsman [
24], the TV risk indicator can be derived due to the following formula:
then, using (6) we reach
and
Inserting (9) and (12) in (11), the TVq
can be expressed as
The TMVK analysis combines elements of mean-variance analysis with a focus on the tail of the distribution. It considers the trade-off between expected return and risk, specifically targeting the downside risk associated with extreme losses. By incorporating tail risk measures, such as TVaRK or tail variance, into the traditional mean-variance framework, investors can construct portfolios that optimize risk-adjusted returns, giving more weight to the tail behavior of the returns distribution. Following Landsman [
25], the TMVK risk can be expressed as
Then, for any LRV, TMVK
TVq
and, for
,
TVaRK
For more applications, see Punzo [
26] and Punzo et al. [
27,
28].
4. Risk Assessment Using Different Estimation Methods
In this section, we consider the following estimation methods—maximum likelihood estimation (MAXLE), ordinary least squares (OLS), L-Moment (L-MO), and Anderson Darling estimation (ADE)—for calculating the KRIs. These quantities are estimated using
with different sample sizes
and three confidence levels (CLs) (
). All results are calculated and checked using the Mathcad program and reported in
Table 1 (
),
Table 2 (
),
Table 3 (
), and
Table 4 (
), from which we conclude:
VaRK, TVaRK, TVq, and increase when increases for all selected methods. For example,
5. Risk Analysis under the Actuarial Negatively Skewed Claims Data: A Case Study
The applications of these risk indicators are varied, but some common applications include:
- I.
Investors and portfolio managers use these risk indicators to assess and manage the risk exposure of their portfolios. They aid in setting risk limits, designing optimal asset allocations, and monitoring portfolio performance (see Furman and Landsman [
24]).
- II.
Financial institutions, regulatory bodies, and risk management professionals use these indicators to quantify and report risks associated with different investment strategies. They provide insights into potential losses and help ensure compliance with regulatory requirements.
- III.
Risk indicators play a crucial role in stress testing and scenario analysis. By simulating extreme market conditions, these indicators help assess the resilience of portfolios and investment strategies in adverse scenarios.
- IV.
Risk indicators facilitate the effective communication of risk to stakeholders, including investors, clients, and regulators. They provide a standardized and concise measure of risk that can be easily understood and compared across different investments. Skewed distributions are used in risk management to model the potential losses from different types of risks, such as credit risk, market risk, and operational risk. For example, the skewed-t distribution is commonly used to model credit risk in banking. Skewed distributions are widely used in insurance to model the frequency and severity of losses (see Shrahili et al. [
20]). For example, the Lomax distribution is often used to model the distribution of losses in insurance claims.
We examine the actuarial claims payment triangle from a U.K. Motor Non-Comprehensive account in this section as a practical illustration of case studies. We choose the 2007–2013 origin period for practical reasons (Charpentier [
23]). The actuarial claims payment data frame displays the claims data similarly to how a database would normally keep it. The development year, incremental payments, and origin year are all listed in the first column and range from 2007 to 2013. You should be aware that these actuarial claims data are initially assessed using a probability-based distribution (for relevant applications, see Ali et al. [
5]).
Table 5 and
Table 6 present the results obtained from the analysis. The key risk indicators (KRIs) for the GELX model under the four different techniques are listed in four sections of
Table 5: MAXLE, ORLSE, L-MO, and AD.
Table 6 also has four sections, each of which lists the KRIs for the ELX model using the same procedures.
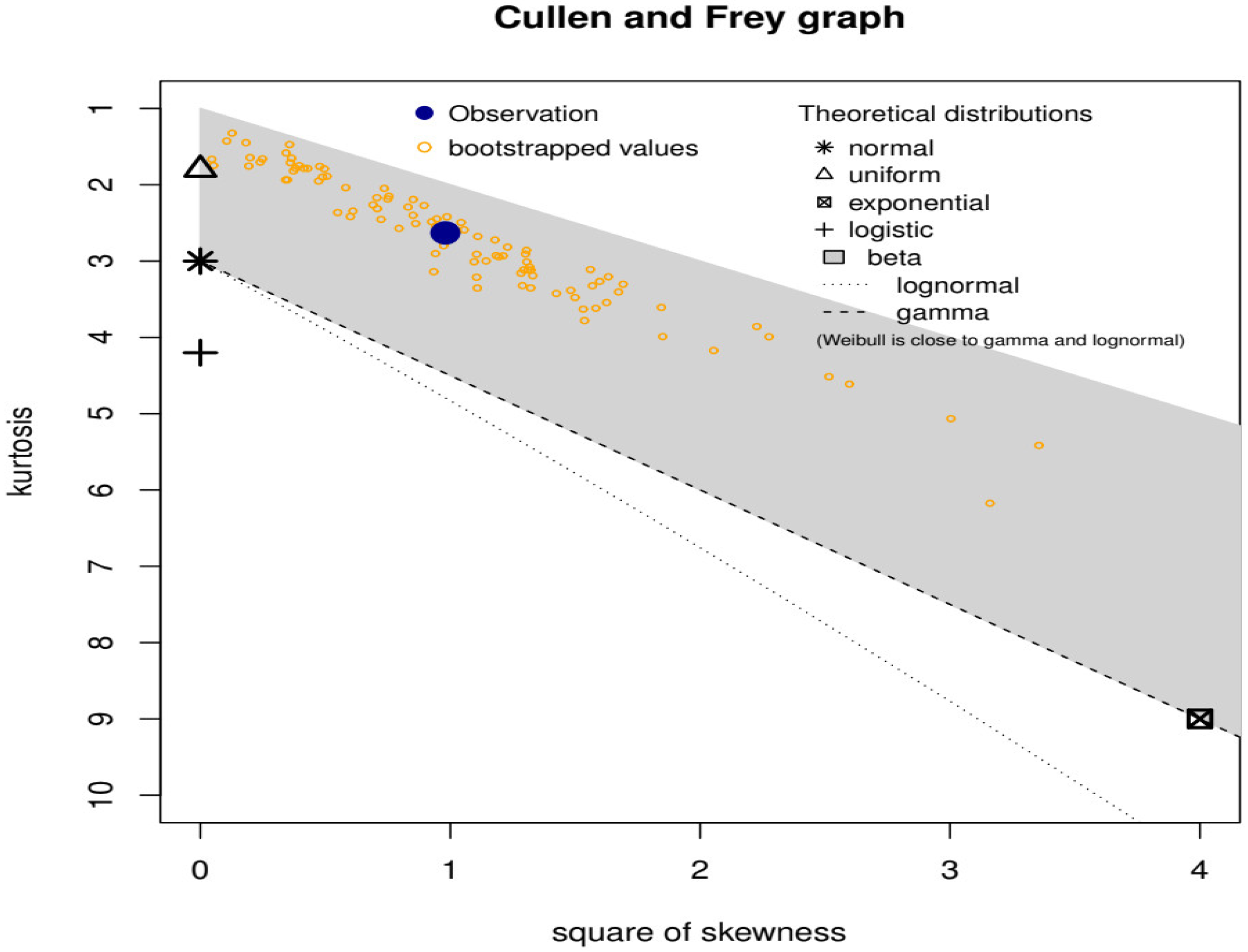
In addition to numerical research, graphical methods are employed to look at how theoretical distributions initially fit and how the densities of actuarial claims take shape. The Cullen and Frey plot helps identify whether a dataset deviates from a normal distribution. Understanding the distributional characteristics of data is crucial in many statistical analyses, as assumptions about normality often underlie many statistical tests. Skewness, which is represented on the
x-axis of the plot, measures the extent to which the data distribution is asymmetric. Positive skewness indicates a longer right tail, while negative skewness suggests a longer left tail. The plot helps visualize and quantify the skewness of the dataset. Kurtosis, shown on the
y-axis of the plot, measures the degree of peakedness or flatness of a distribution compared to a normal distribution. High positive kurtosis implies heavy tails, while negative kurtosis suggests lighter tails. Analyzing kurtosis helps us understand the presence of outliers or extreme values in the dataset.
Figure 2 gives the Cullen and Frey plot for actuarial claims data. The Cullen and Frey (skewness–kurtosis plot) in
Figure 2 reveals that the data are left-skewed with a kurtosis of less than 3. The big blue dot refers to our insurance data. It is clear that the data stay away from the main points which represent normal distribution and exponential distribution. Also, our insurance data are away from the lines which represent gamma distribution and lognormal distribution. By projecting vertically to those lines, we can see that the data have lower kurtosis than the lognormal and the gamma models of the same skewness.
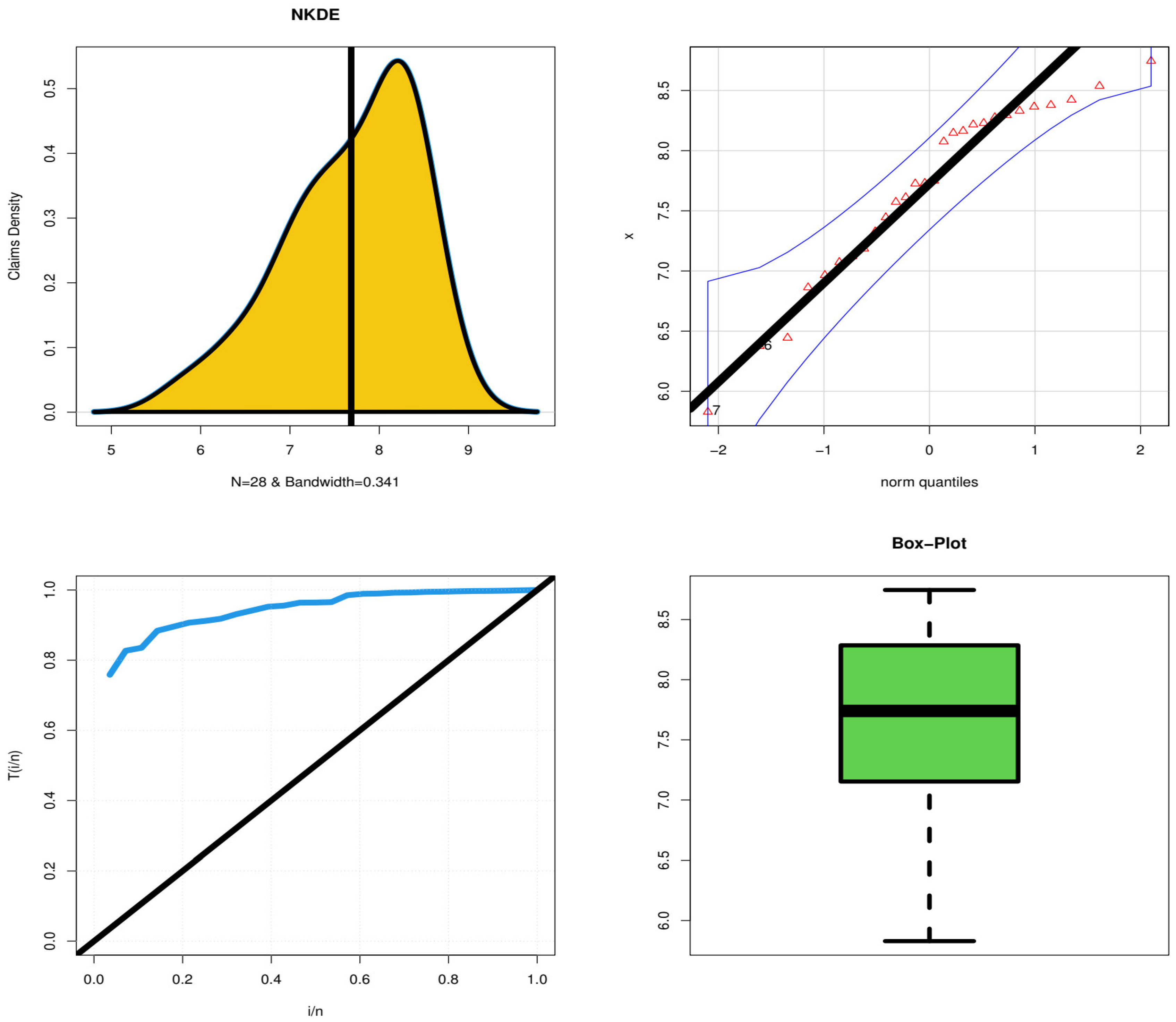
The nonparametric kernel density estimation (NKDE) method (top left), the quantile-quantile (Q-Q) plot (top right), the total time on test (TTT) plot (bottom left), and the “box plot” (bottom right) are only a few of the graphical techniques shown in
Figure 3 below.
Figure 3 (top left panel) shows that the initial density is an asymmetric function with a left tail and that there are no extreme observations.
Figure 3 (top right panel) shows that data do not contain any extreme values. According to the TTT plot (
Figure 3 (bottom right panel)), the hazard rate function for the models used to explain the current data should be consistently growing.
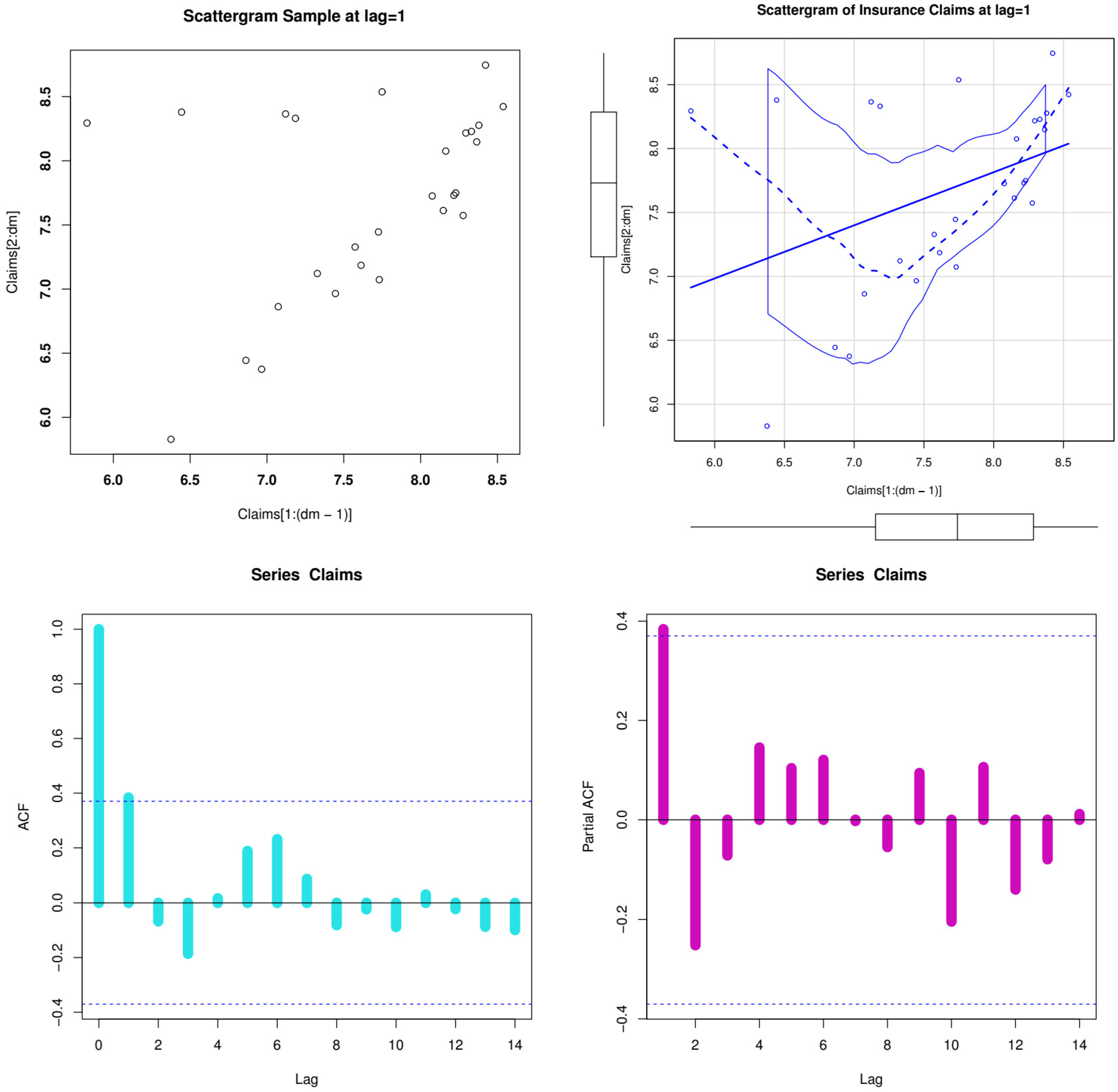
Figure 3 (bottom right panel) shows that the data do not contain any extreme values. The scattergrams for the data on actuarial claim size are shown in
Figure 4 (first row panels), where
Figure 4 (top left) refers to the initial scattergram and
Figure 4 (top right) refers to the fitted scattergram. For the actuarial claim size data, the autocorrelation function (ACF) and partial autocorrelation function (partial-ACF) are shown in
Figure 4’s second row. We offer the ACF, which can be used to demonstrate how the correlation between any two signal values alters when the distance between them alters the ACF.
The theoretical ACF is a time domain measure of the stochastic process memory and offers no insight into the frequency content of the process. Also included is the theoretical partial ACF with Lag = k = 1; see
Figure 4 (bottom right panel). The initial lag value is statistically significant, while none of the other partial autocorrelations for any other delays are, according to
Figure 4’s bottom right corner. This proposes an autoregressive (AR(1)) model as a potential fit to these data. Due to our data, skewness = −0.74828 (left-skewed data), kurtosis
3, and dispersion index (DIx)
(under dispersed data). Based on these
Table 5 and
Table 6, the following results can be highlighted:
- 2.
For all risk assessment methods:
- 3.
For all risk assessment methods:
- 4.
For all risk assessment methods:
- 5.
For all risk assessment methods:
- 6.
Under the MAXLE method and the GELX model: The VaRK is consistently growing, starting with 3104.32244 and ending with 12,791.47826; the TVaRK is consistently growing, starting with 5606.27701 and ending with 17,177.67141.
- 7.
Under the ORLSE method and the GELX model: The VaRK is consistently growing, starting with 3559.79706 and ending with 18,274.02938; the TVaRK is consistently growing, starting with 7134.33969 and ending with 26,462.60076.
- 8.
Under the L-MO method and the GELX model: The VaRK is consistently growing, starting with 2684.87356 and ending with 7251.04539; the TVaRK is consistently growing, starting with 3955.54267 and ending with 8938.81397.
- 9.
Under the ADE method and the GELX model: The VaRK is consistently growing, starting with 3428.17317 and ending with 14,714.50356; the TVaRK is consistently growing, starting with 6329.36348 and ending with 19,871.73902. Similarly, the TVq, the and the MEL are consistently growing. Under the ADE method and the ELX model: The VaRK is consistently growing, starting with 3440.462517 and ending with 11,119.778633; the TVaRK is consistently growing, starting with 5686.884025 and ending with 13,422.696625. However, the TVq, the TMVK, and the MEL are monotonically decreasing.
- 10.
For the GELX model: For nearly for all values, the ORLSE method is recommended since it provides the most acceptable risk exposure analysis; then, the MAXLE method is recommended as a second one, then the ADE method, and then the L-MO method. However, the other two methods perform well. For the ELX model: For nearly for all values, the ORLSE method is recommended since it provides the most acceptable risk exposure analysis; then, the MAXLE method is recommended as a second one. However, the other two methods also perform well.
6. Construction of RRNIK Statistic for the GELX Model
Many statistical tests assume that the data are normally distributed. If the data are skewed, these tests may not be appropriate and can lead to incorrect conclusions. By using a skewed distribution to model the data, more robust statistical tests can be used to test hypotheses and make inferences. Skewed distributions can be used to make better decisions in various fields, such as finance, insurance, and engineering. By accurately modeling the data and estimating the likelihood of extreme events, decisions can be made that are more informed and better account for risk.
The RRNIK statistic is a well-known substitute for the traditional chi-squared tests where there are complete data (for additional information, see Nikulin [
8], Nikulin [
9], Nikulin [
10], and Rao and Robson [
11]). The most popular test to check whether a mathematical model is suitable for the data from observations is the Pearson chi-square statistic. But in cases where the model’s parameters are unknown or the data are censored, these tests are useless. For the entire set of data, Nikulin [
8], Nikulin [
9], Nikulin [
10], and Rao and Robson [
11] all indicated natural variations in the Pearson statistic, which is referred to as RRNIK. The chi-square distribution, a logical extension of the Pearson statistic, is used in this statistical test.
When the filtering is applied on top of the unknown parameter, the standard test is not strong enough to establish the null hypothesis. Nikulin [
8], Nikulin [
9], Nikulin [
10], and Rao and Robson [
11] suggest that the RRNIK statistic be modified to take into consideration random right censoring. In the current study, we provide a modified chi-square test for the GELX model (see also Bagdonavičius et al. [
29], Bagdonavičius and Nikulin [
30], Bagdonavičius and Nikulin [
31] for more details). To test the theory, Nikulin [
8], Nikulin [
9], Nikulin [
10], and Rao and Robson [
11] established the RRNIK statistic
). Let
Then, according to Nikulin [
8], Nikulin [
9], Nikulin [
10] and Rao and Robson [
11], we have
where
and
is the information matrix for the grouped data
with
and then
where
refers to the estimated Fisher INFMX. Then, the
statistic has
degrees of freedom (DOF), and it follows the Chi square model. Consider a set of observations that are divided into
, where
and
In this research, we create a modified goodness-of-fit test known as the RRNIK statistic to examine if the used data follow the distribution of the GELX model when a parameter is unknown. Our new statistic relies on the estimated Fisher INFMX, which we employ after computing the highest likelihood estimator of the unknown GELX distribution parameter on the dataset.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}