1. Introduction
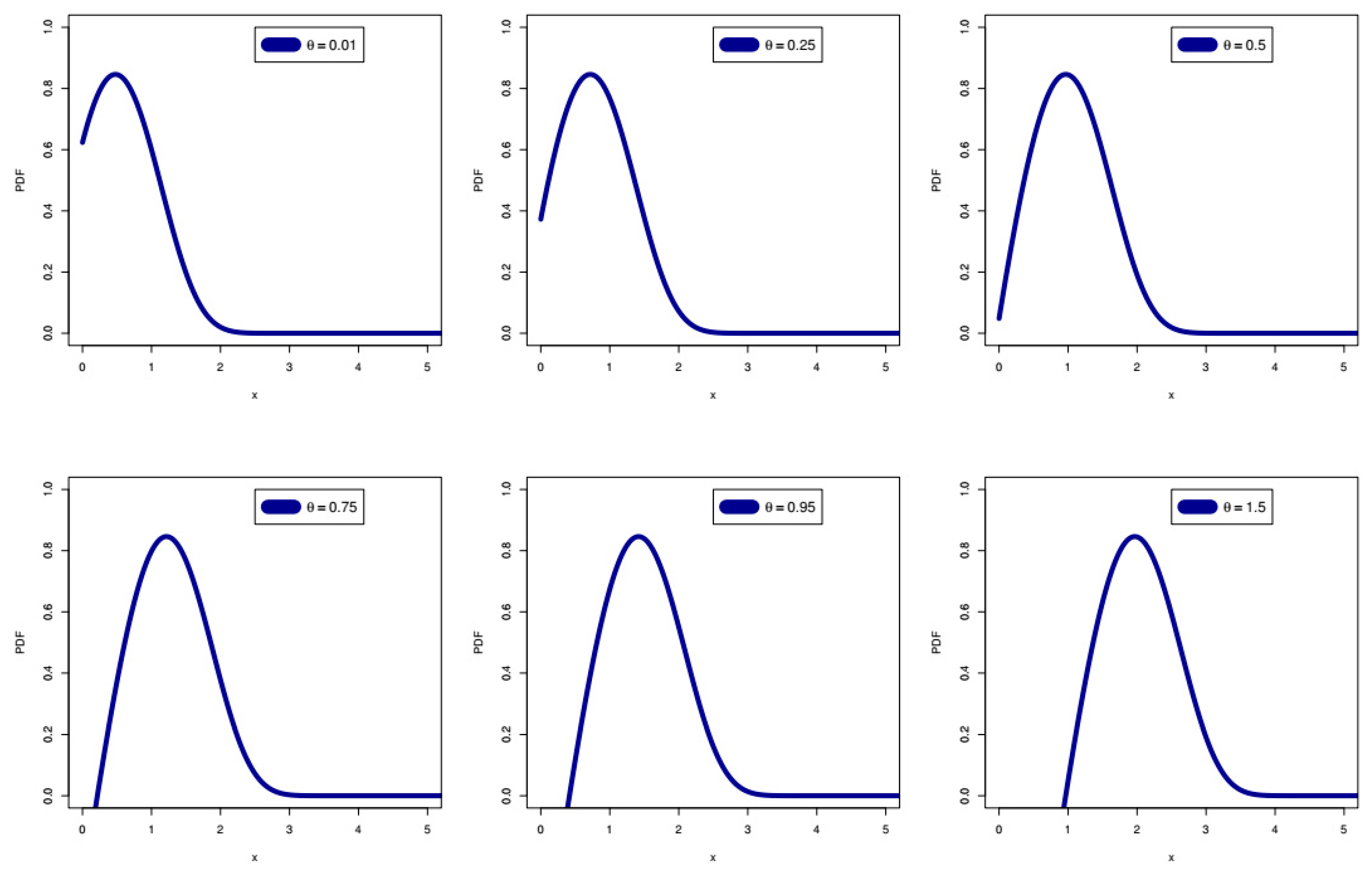
Skewed distributions are important in insurance and the actuarial sciences because they help insurers and actuaries to understand the frequency and severity of potential losses. In the insurance industry, loss data are often modeled using a skewed distribution such as the lognormal distribution, which is commonly used to model losses in areas such as natural disasters, medical malpractice, and product liability. By using a skewed distribution, insurers can better estimate the likelihood and potential magnitude of losses, which is important for pricing policies and when managing risk. For this main purpose, we present a new asymmetric distribution, called the right-skewed exponential (RSEx) distribution, which has high flexibility in terms of its probability density function (PDF) and its failure rate function (FRF). The RSEx distribution is recommended as an adequate alternative to the well-known exponential (Ex) distribution.
However, the traditional Ex distribution is a probability distribution that models the time between events in a Poisson process, where the events occur continuously and independently at a constant average rate. It is often used in actuarial risk analysis and insurance due to its simplicity and applicability to various scenarios. It has the crucial characteristic of being memoryless and it can be considered as the continuous version of the geometric distribution theory proposed by Kemp [
1]. One of the most important characteristics of exponential distribution is its memoryless property. This means that the distribution of time to the next event does not depend on how much time has already passed. This property makes it suitable for modeling scenarios where past history does not affect the future occurrence of events. The Ex distribution is employed in several different applications, in addition to the study of Poisson point processes. The Ex distribution is the only continuous probability distribution with a constant FRF.
The RSEx distribution is very similar to the exponential distribution in regard to some properties and it has only one parameter. However, the mathematical form of the RSEx distribution differs from the exponential distribution. Thus, statistical properties such as moments, function-generating moments, etc., will be different and may need more effort to derive them. In addition, the parameter range of the new distribution differs from the parameter range of the exponential distribution. The parameter of the new distribution is
, the range of which depends on and is related to the random variable (RV). In this paper, we do not pay much attention to the theoretical results or to the properties of mathematics and algebraic derivations. This is because the main objective of the paper is to explore and illustrate the importance of the new distribution in practice and its significance in the areas of statistical modeling, as well as in the field of application to actuarial risks. However, it may be easy to study any probability distribution theoretically, but it is not at all easy to prove the importance of the new distribution from the practical perspective and from the point of view of statistical modeling. By studying the statistical literature, we will find many distributions that are a generalization of the exponential distribution. Most of these extensions have a large number of parameters (often more than two). However, the RSEx distribution contains only one parameter; this is the first advantage of the new distribution, even before it has been studied. The survival function (SF) of the RSEx model can be expressed as:
where
is the base for the natural log. The corresponding PDF of the RSEx can be written as:
The cumulative distribution function (CDF) corresponding to (1) can be expressed as While the Ex distribution achieves the relationship Pr Pr , the memoryless capacity does not exist with the RSEx model, where Pr Pr .
A special section is devoted to the characterization of the RSEx distribution: (i) based on two truncated moments and (ii) in terms of the FRF. For characterization (i), the CDF does not need to have a closed form. Characterizations (i) and (ii) will be presented in
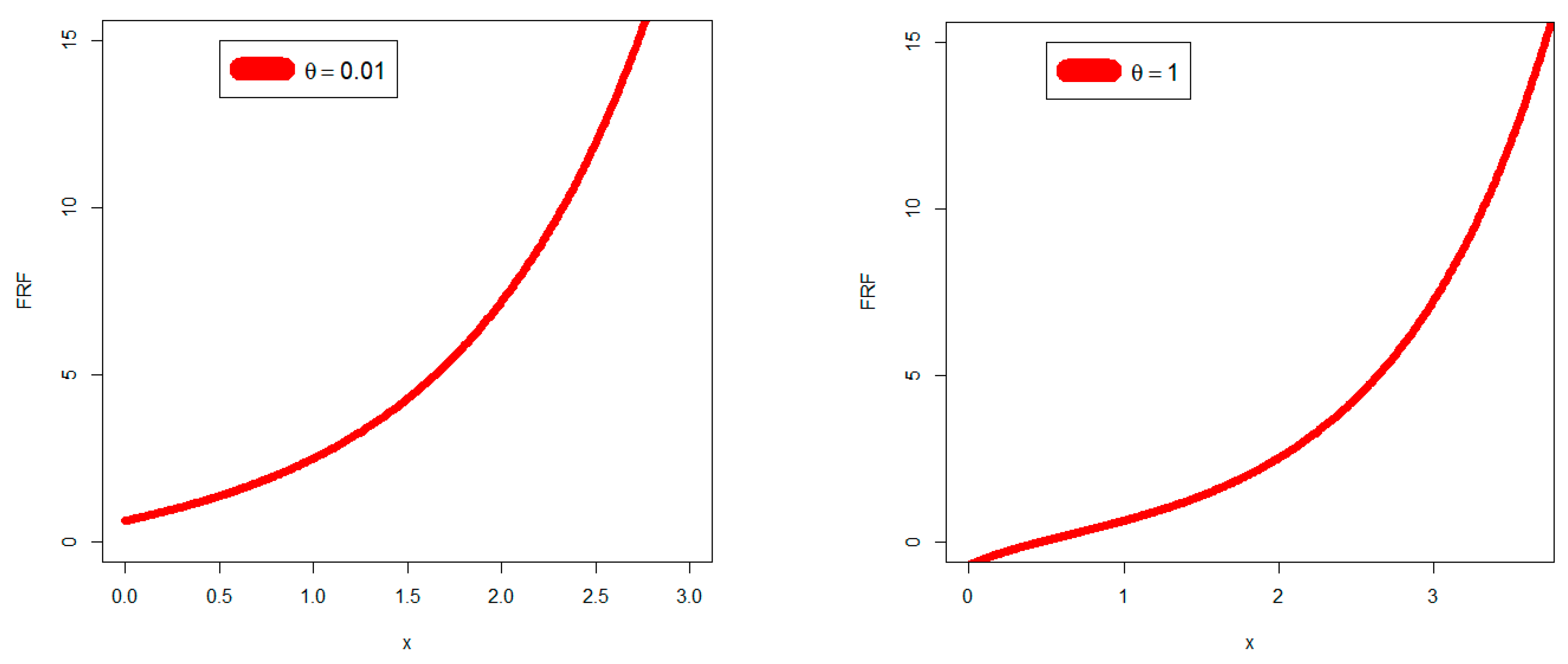
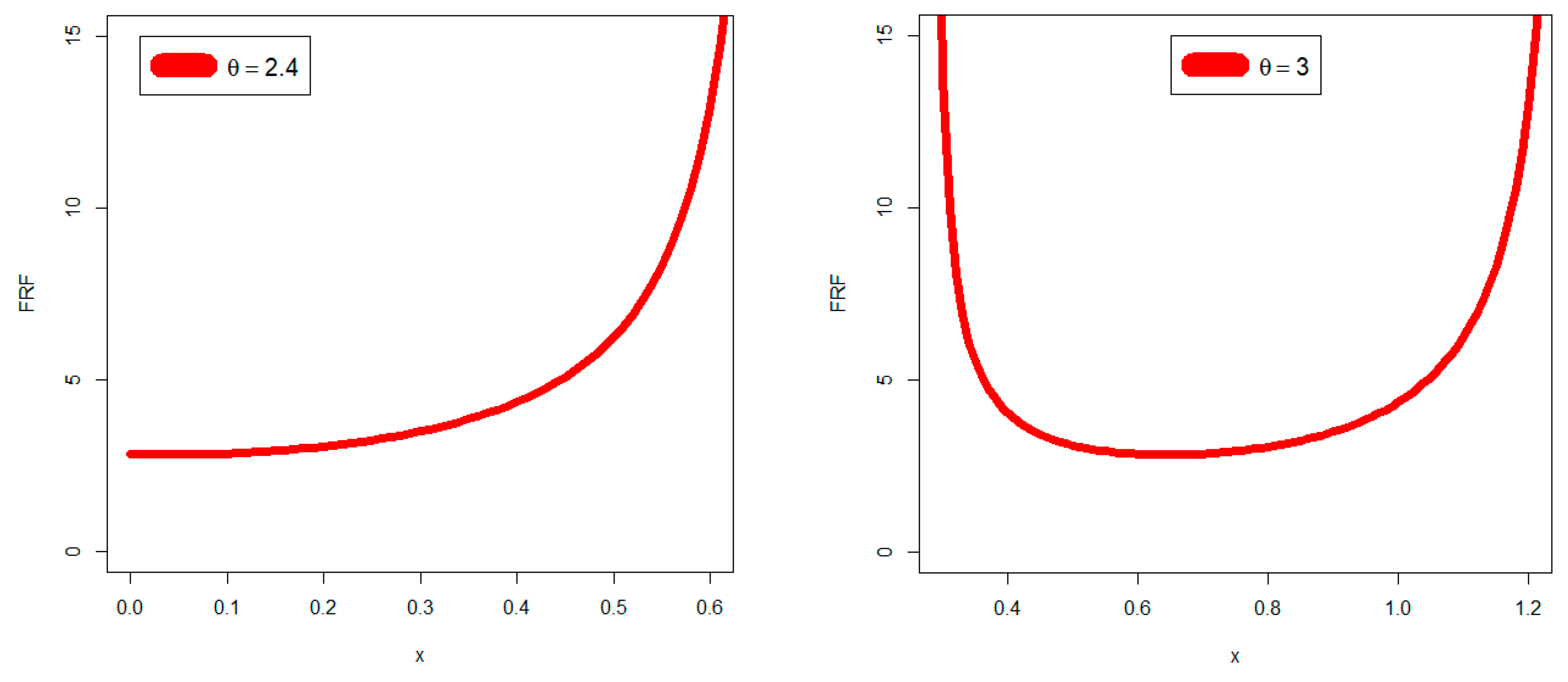
Section 2. The FRF, which is sometimes referred to as the danger rate, solely relates to broken objects. It is essential when creating secure software applications and the engineering, financial, insurance, and regulatory sectors frequently rely on it. The FRF represents the frequency with which an engineered system or component fails, expressed in terms of failures per unit of time, and is often used in reliability engineering. The failure rate of a system usually depends on time. The FRF of the RSEx can be expressed as:
Recently, actuaries have analyzed some actual insurance data using several new continuous distributions (see, for example, Hamed et al. [
2], Shrahili et al. [
3], and Mohamed et al. [
4,
5,
6]. The skewness of the insurance data sets can be left, right, or right with heavy tails. In this study, we describe how a skewed U.K. insurance claims data set may be described using the flexible continuous asymmetric heavy-tailed RSEx distribution. Despite its enormous potential, using U.K. skewed insurance claims data is tricky. Moreover, identifying its quality and calculating the number of incomplete or missing observations represent the biggest challenge (see Stein et al. [
7], Hogg and Klugman [
8], Lane [
9], and Ibragimov and Prokhorov [
10] for more details).
To model insurance payment data, and more specifically, to model huge insurance claim payment data, many research studies have used the Pareto and lognormal distributions. Several academics have employed a modified Pareto distribution (see Beirlant et al. [
11]).
Usually, only one number is used to describe the level of risk exposure. These risk exposure levels, sometimes known as key risk indicators (KRIs), are unmistakably the actuarial functions of a certain model that are used in insurance, actuarial science, and financial risk analysis for portfolios and securities. Actuaries and risk managers can learn from such KRIs to identify how exposed a company is to various dangers. Value-at-risk (VAR), conditional-value-at-risk (CVAR), tail variance (TV), tail-value-at-risk (TVAR), and tail mean-variance (TMV) are just a few of the KRIs that can be taken into account. In particular, the VAR is a quantile of the distribution of total losses. Actuaries and risk managers typically focus on using the VAR indicator to show the probability of a poor result at a specific probability/confidence level (see Artzner [
12] and Figueiredo et al. [
13] for more details).
The process of assessing the actuarial risks or other risks, of course, requires validation testing from another aspect of the analysis. This validation testing can be performed through the well-known goodness-of-fit tests or by presenting a new or at least modified goodness-of-fit test. In this work, the Barzilai–Borwein (BB) algorithm is used for this purpose. The construction of the Rao–Robson–Nikulin (RRNU) statistic for the RSEx model under uncensored case conditions is presented in detail; a simulation study for assessing the RRNU statistics under uncensored case conditions is performed. Four real-world data application scenarios are presented under uncensored case conditions: the first uncensored data set comprises reliability data on carbon fibers, the second uncensored data set is of the heat exchanger tube crack data, the third uncensored data set concerns the various strengths of glass fibers, and the fourth uncensored data set comprises gene-based breast cancer data. Moreover, the construction of the RRNU statistic for the RSEx model under censored case conditions is presented in detail, and a simulation study for assessing the RRNU statistics under censored case conditions is presented. Four censored real-world data applications are analyzed under censored case conditions: the first one comprises data on cancer of the lung, the second data set concerns capacitor reliability data, the third data set is on aluminum cells under reduction conditions, and the fourth data set comprises head and neck cancer data. In this paper, the RSEx distribution is examined from a different angle. Using four different applications and a broad collection of simulation experiences, we dealt with the numerous theoretical and applied aspects. We have not overlooked the theory of statistical hypothesis testing and distributional verification in this context; to prove it, we provided eight examples through study and analysis, four of which used complete data sets and four of which used censored data sets. Moreover, two different ways to characterize the RSEx distribution are discussed herein, such as characterization using two truncated moments and characterization using the FRF. The innovations of this study can be highlighted as follows:
We present a new right-skewed one-parameter distribution, which can be considered as an alternative to the Chen distribution, Pareto type II (PaII) distribution, and generalized gamma (GG) distribution.
We analyze an actuarial data set with the new model as well as with some competing models, such as the Chen distribution, PaII distribution, and GG distribution due to certain risk indicators.
We present a new type test for uncensored data sets, with four applications for uncensored distributional validation.
We present a new, modified type test for censored data sets, with examples of censored distributional validation.
The new model is characterized by a probability density function that is more flexible than the probability density functions of its competing distributions; the research indicated that it can be nominated as an alternative distribution.
The new failure rate function includes many forms suitable for modeling real-world data in various engineering, medical, and other fields, and nine examples have been presented to support this finding.
5. Maximum Likelihood Risk Assessment
In this section, we consider the maximum likelihood estimation (MLE) for calculating the KRIs. The quantities of the KRIs are estimated using
with different sample sizes
and their corresponding confidence levels (CLs) (
). All results of the risk analysis are reported in
Table 1 (
),
Table 2 (
),
Table 3 (
), and
Table 4 (
).
Table 1 gives the five KRIs under the influence of artificial data for
.
Table 2 lists the five KRIs under the influence of artificial data for
.
Table 3 lists the five KRIs under the influence of artificial data for
.
Table 3 lists the five KRIs under the influence of artificial data for
. Based on
Table 1,
Table 2,
Table 3 and
Table 4, the following results can be highlighted:
VARq, TVARq and TMVq increase when increases, for all sample sizes and initial parameter values.
TVq and ELq decrease when increases, for all sample sizes and initial parameter values.
For VARq () . For TVARq. For TMVq() . However, TVq() started with 0.06527 and ended with 0.01708, while ELq() started with 0.32382 and ended with 0.14764. For VARq() .
For TVARq() . For TMVq() . However, TVq() started with 0.06527 and ended with 0.01708, while ELq() started with 0.32382 and ended with 0.14764.
For VARq() . For TVARq() . For TMVq() . However, TVq() started with 0.06527 and ended with 0.0196, while ELq() started with 0.32382 and ended with 0.14748. For VARq() .
For TVARq() . For TMVq() . However, TVq() started with 0.06527 and ended with 0.01708, while ELq() started with 0.32382 and ended with 0.14764.
For VARq() . For TVARq() . For TMVq() . However, TVq() started with 0.06527 and ended with 0.0196, while ELq() started with 0.32382 and ended with 0.14748.
For VARq() . For TVARq() . For TMVq() . However, TVq() started with 0.06527 and ended with 0.01708, while ELq() started with 0.32382 and ended with 0.14764.
For VARq() . For TVARq() . For TMVq() . However, TVq() started with 0.06527 and ended with 0.0196, while ELq() started with 0.32382 and ended with 0.14748.
For VARq() . For For TVARq() . For TMVq() . However, TVq() started with 0.06527 and ended with 0.01708, while ELq() started with 0.32382 and ended with 0.14764.
It is clear that the results of some actuarial risk assessments have stabilized with an increase in the sample size. For example:
- (1)
TVq() started with 0.06527 and ended with 0.01708 for all sample sizes and .
- (2)
ELq() started with 0.32382 and ended with 0.14764 for all sample sizes and .
Table 1.
KRIs under artificial data for n = 50.
Table 1.
KRIs under artificial data for n = 50.
| KRIs→ | | | | | |
|---|
| q↓θ→ | 6 |
| 70% | 6.92807 | 7.25189 | 0.06527 | 7.28452 | 0.32382 |
| 75% | 7.00591 | 7.30899 | 0.05866 | 7.33832 | 0.30308 |
| 80% | 7.09275 | 7.37413 | 0.05195 | 7.40011 | 0.28138 |
| 85% | 7.19364 | 7.45161 | 0.04497 | 7.47409 | 0.25796 |
| 90% | 7.31929 | 7.55058 | 0.03742 | 7.56929 | 0.23129 |
| 95% | 7.50127 | 7.69838 | 0.02843 | 7.7126 | 0.19711 |
| 99% | 7.82418 | 7.97182 | 0.01708 | 7.98036 | 0.14764 |
| q↓θ→ | 0.9 |
| 70% | 1.82807 | 2.15189 | 0.06527 | 2.18452 | 0.32382 |
| 75% | 1.90591 | 2.20899 | 0.05866 | 2.23832 | 0.30308 |
| 80% | 1.99275 | 2.27413 | 0.05195 | 2.30011 | 0.28138 |
| 85% | 2.09364 | 2.35161 | 0.04497 | 2.37409 | 0.25796 |
| 90% | 2.21929 | 2.45058 | 0.03742 | 2.46929 | 0.23129 |
| 95% | 2.40127 | 2.59838 | 0.02843 | 2.6126 | 0.19711 |
| 99% | 2.72418 | 2.87182 | 0.01708 | 2.88036 | 0.19711 |
| q↓θ→ | 2.5 |
| 70% | 3.42807 | 3.75189 | 0.06527 | 3.78452 | 0.32382 |
| 75% | 3.50591 | 3.80899 | 0.05866 | 3.83832 | 0.30308 |
| 80% | 3.59275 | 3.87413 | 0.05195 | 3.90011 | 0.28138 |
| 85% | 3.69364 | 3.95161 | 0.04497 | 3.97409 | 0.25796 |
| 90% | 3.81929 | 4.05058 | 0.03742 | 4.06929 | 0.23129 |
| 95% | 4.00127 | 4.19838 | 0.02843 | 4.2126 | 0.19711 |
| 99% | 4.32418 | 4.47182 | 0.01708 | 4.48036 | 0.14764 |
| q↓θ→ | 100 |
| 70% | 100.92807 | 101.25189 | 0.06527 | 101.28452 | 0.32382 |
| 75% | 101.00591 | 101.30899 | 0.05866 | 101.33832 | 0.30308 |
| 80% | 101.09275 | 101.37413 | 0.01717 | 101.38272 | 0.28138 |
| 85% | 101.19364 | 101.45161 | 0.04497 | 101.47409 | 0.25796 |
| 90% | 101.31929 | 101.55058 | 0.03742 | 101.56929 | 0.23129 |
| 95% | 101.50127 | 101.69838 | 0.02842 | 101.71259 | 0.19711 |
| 99% | 101.82418 | 101.97182 | 0.01708 | 101.98036 | 0.14764 |
Table 2.
KRIs under artificial data for n = 150.
Table 2.
KRIs under artificial data for n = 150.
| KRIs→ | | | | | |
|---|
| q↓θ→ | 6 |
| 70% | 6.90866 | 7.23249 | 0.06527 | 7.26512 | 0.32382 |
| 75% | 6.98651 | 7.28959 | 0.05866 | 7.31892 | 0.30308 |
| 80% | 7.07335 | 7.35473 | 0.05195 | 7.3807 | 0.28138 |
| 85% | 7.17424 | 7.4322 | 0.04497 | 7.45469 | 0.25796 |
| 90% | 7.29989 | 7.53118 | 0.03742 | 7.54989 | 0.23129 |
| 95% | 7.48187 | 7.67898 | 0.02843 | 7.6932 | 0.19711 |
| 99% | 7.80478 | 7.95226 | 0.0196 | 7.96206 | 0.14748 |
| q↓θ→ | 0.9 |
| 70% | 1.8082 | 2.13202 | 0.06527 | 2.16466 | 0.32382 |
| 75% | 1.88604 | 2.18912 | 0.05866 | 2.21845 | 0.30308 |
| 80% | 1.97288 | 2.25427 | 0.05195 | 2.28024 | 0.28138 |
| 85% | 2.07378 | 2.33174 | 0.04497 | 2.35423 | 0.25796 |
| 90% | 2.19942 | 2.43071 | 0.03742 | 2.44942 | 0.23129 |
| 95% | 2.3814 | 2.57852 | 0.02843 | 2.59273 | 0.19711 |
| 99% | 2.70432 | 2.85196 | 0.01708 | 2.8605 | 0.14764 |
| q↓θ→ | 2.5 |
| 70% | 3.40877 | 3.73259 | 0.06527 | 3.76523 | 0.32382 |
| 75% | 3.48662 | 3.7897 | 0.05866 | 3.81903 | 0.30308 |
| 80% | 3.57346 | 3.85484 | 0.05195 | 3.88081 | 0.28138 |
| 85% | 3.67435 | 3.93231 | 0.04497 | 3.9548 | 0.25796 |
| 90% | 3.79999 | 4.03129 | 0.03742 | 4.04999 | 0.23129 |
| 95% | 3.98198 | 4.17909 | 0.02843 | 4.19331 | 0.19711 |
| 99% | 4.30489 | 4.45253 | 0.01708 | 4.46107 | 0.14764 |
| q↓θ→ | 100 |
| 70% | 100.90846 | 101.23228 | 0.06527 | 101.26491 | 0.32382 |
| 75% | 100.9863 | 101.28938 | 0.05866 | 101.31871 | 0.30308 |
| 80% | 101.07314 | 101.35452 | 0.01717 | 101.36311 | 0.28138 |
| 85% | 101.17404 | 101.43200 | 0.04497 | 101.45448 | 0.25796 |
| 90% | 101.29968 | 101.53097 | 0.03742 | 101.54968 | 0.23129 |
| 95% | 101.48166 | 101.67877 | 0.02842 | 101.69299 | 0.19711 |
| 99% | 101.80457 | 101.95221 | 0.01708 | 101.96075 | 0.14764 |
Table 3.
KRIs under artificial data for n = 300.
Table 3.
KRIs under artificial data for n = 300.
| KRIs→ | | | | | |
|---|
| q↓θ→ | 6 |
| 70% | 6.9033 | 7.22712 | 0.06527 | 7.25975 | 0.32382 |
| 75% | 6.98114 | 7.28422 | 0.05866 | 7.31355 | 0.30308 |
| 80% | 7.06798 | 7.34936 | 0.05195 | 7.37534 | 0.28138 |
| 85% | 7.16888 | 7.42684 | 0.04497 | 7.44932 | 0.25796 |
| 90% | 7.29452 | 7.52581 | 0.03742 | 7.54452 | 0.23129 |
| 95% | 7.4765 | 7.67361 | 0.02843 | 7.68783 | 0.19711 |
| 99% | 7.79941 | 7.9469 | 0.0196 | 7.95669 | 0.14748 |
| q↓θ→ | 0.9 |
| 70% | 1.80356 | 2.12738 | 0.06527 | 2.16002 | 0.32382 |
| 75% | 1.8814 | 2.18448 | 0.05866 | 2.21381 | 0.30308 |
| 80% | 1.96825 | 2.24963 | 0.05195 | 2.2756 | 0.28138 |
| 85% | 2.06914 | 2.3271 | 0.04497 | 2.34959 | 0.25796 |
| 90% | 2.19478 | 2.42608 | 0.03742 | 2.44478 | 0.23129 |
| 95% | 2.37677 | 2.57388 | 0.02843 | 2.58809 | 0.19711 |
| 99% | 2.69968 | 2.84732 | 0.01708 | 2.85586 | 0.14764 |
| q↓θ→ | 2.5 |
| 70% | 3.40334 | 3.72716 | 0.06527 | 3.75979 | 0.32382 |
| 75% | 3.48118 | 3.78426 | 0.05866 | 3.81359 | 0.30308 |
| 80% | 3.56802 | 3.8494 | 0.05195 | 3.87538 | 0.28138 |
| 85% | 3.66891 | 3.92687 | 0.04497 | 3.94936 | 0.25796 |
| 90% | 3.79456 | 4.02585 | 0.03742 | 4.04456 | 0.23129 |
| 95% | 3.97654 | 4.17365 | 0.02843 | 4.18787 | 0.19711 |
| 99% | 4.29945 | 4.44709 | 0.01708 | 4.45563 | 0.14764 |
| q↓θ→ | 100 |
| 70% | 100.90343 | 101.22725 | 0.06527 | 101.25988 | 0.32382 |
| 75% | 100.98127 | 101.28435 | 0.05866 | 101.31368 | 0.30308 |
| 80% | 101.06811 | 101.34949 | 0.01717 | 101.35808 | 0.28138 |
| 85% | 101.16901 | 101.42697 | 0.04497 | 101.44945 | 0.25796 |
| 90% | 101.29465 | 101.52594 | 0.03742 | 101.54465 | 0.23129 |
| 95% | 101.47663 | 101.67374 | 0.02842 | 101.68796 | 0.19711 |
| 99% | 101.79954 | 101.94718 | 0.01708 | 101.95572 | 0.14764 |
Table 4.
KRIs under artificial data for n = 500.
Table 4.
KRIs under artificial data for n = 500.
| KRIs→ | | | | | |
|---|
| q↓θ→ | 6 |
| 70% | 6.9013 | 7.22513 | 0.06527 | 7.25776 | 0.32382 |
| 75% | 6.97915 | 7.28223 | 0.05866 | 7.31156 | 0.30308 |
| 80% | 7.06599 | 7.34737 | 0.05195 | 7.37335 | 0.28138 |
| 85% | 7.16688 | 7.42484 | 0.04497 | 7.44733 | 0.25796 |
| 90% | 7.29253 | 7.52382 | 0.03742 | 7.54253 | 0.23129 |
| 95% | 7.47451 | 7.67162 | 0.02843 | 7.68584 | 0.19711 |
| 99% | 7.79742 | 7.9449 | 0.0196 | 7.9547 | 0.14748 |
| q↓θ→ | 0.9 |
| 70% | 1.80138 | 2.12521 | 0.06527 | 2.15784 | 0.32382 |
| 75% | 1.87923 | 2.18231 | 0.05866 | 2.21164 | 0.30308 |
| 80% | 1.96607 | 2.24745 | 0.05195 | 2.27342 | 0.28138 |
| 85% | 2.06696 | 2.32492 | 0.04497 | 2.34741 | 0.25796 |
| 90% | 2.19261 | 2.4239 | 0.03742 | 2.44261 | 0.23129 |
| 95% | 2.37459 | 2.5717 | 0.02843 | 2.58592 | 0.19711 |
| 99% | 2.6975 | 2.84514 | 0.01708 | 2.85368 | 0.14764 |
| q↓θ→ | 2.5 |
| 70% | 3.40131 | 3.72513 | 0.06527 | 3.75777 | 0.32382 |
| 75% | 3.47915 | 3.78223 | 0.05866 | 3.81156 | 0.30308 |
| 80% | 3.56599 | 3.84738 | 0.05195 | 3.87335 | 0.28138 |
| 85% | 3.66689 | 3.92485 | 0.04497 | 3.94734 | 0.25796 |
| 90% | 3.79253 | 4.02382 | 0.03742 | 4.04253 | 0.23129 |
| 95% | 3.97451 | 4.17163 | 0.02843 | 4.18584 | 0.19711 |
| 99% | 4.29742 | 4.44506 | 0.01708 | 4.45361 | 0.14764 |
| q↓θ→ | 100 |
| 70% | 100.90134 | 101.22516 | 0.06527 | 101.2578 | 0.32382 |
| 75% | 100.97918 | 101.28226 | 0.05866 | 101.31159 | 0.30308 |
| 80% | 101.06602 | 101.34741 | 0.01717 | 101.35599 | 0.28138 |
| 85% | 101.16692 | 101.42488 | 0.04497 | 101.44737 | 0.25796 |
| 90% | 101.29256 | 101.52385 | 0.03742 | 101.54256 | 0.23129 |
| 95% | 101.47454 | 101.67166 | 0.02842 | 101.68587 | 0.19711 |
| 99% | 101.79745 | 101.94509 | 0.01708 | 101.95364 | 0.14764 |
6. Risk Analysis Using U.K. Insurance Claims Data
Skewed distributions are also important in data modeling, where they are used to model data that are not normally distributed. For example, in finance, the distribution of stock returns is often positively skewed, with a longer tail on the right-hand side. By using a skewed distribution, financial analysts can better estimate the risks and potential returns of investments. The RSEx distribution can be used to model the severity and frequency of insurance losses. Actuarial risk analysis involves assessing and managing the risks associated with insurance products. The RSEx distribution could aid in quantifying these risks by providing a mathematical framework to model the occurrence and timing of events. It will allow actuaries to calculate probabilities, develop risk mitigation strategies, and make informed decisions. In this section, we explore the structure of claims for insurance payment from a U.K. motor non-comprehensive account in this paper, as a practical illustration. We chose the 2007–2013 origin period for practical reasons. The U.K. insurance claims payment data frame presents the claims data in the manner in which a database would normally keep it. The origin year, which ranges from 2007 to 2013, the development year, and the incremental payments are all listed in the first column. It is worth mentioning that these U.K. insurance claims data sets are first analyzed under a probability-based distribution (see Hamed et al. [
2], Shrahili et al. [
3], and Mohamed et al. [
4,
5,
6] for the relevant applications).
Table 5 (first part) gives the KRIs for the U.K. insurance claims data and MLE method for the RSEx model, where
,
and
Table 5 (second part) gives the KRIs for the U.K. insurance-claims data and MLE method for the Ex model, where
,
and
Table 5 also presents the risk analysis under other common distributions, such as the Chen distribution, PaII distribution, and GG distribution. Based on
Table 5 (first part), for the RSEx model:
and:
The VARq is monotonically increasing, starting with 340.898174 and ending with 341.794290; the TVARq in monotonically increasing, starting with 341.221996 and ending with 341.941930; the TVq, the TMVq, and the MEL are monotonically increasing from 341.254631 to 341.950471. However, the TVq is monotonically decreasing, starting with 0.06527 and ending with 0.017083, while the TVq is monotonically decreasing, starting with 0.323822 and ending with 0.14764.
Table 5.
KRIs for the U.K. insurance claims data for the RSEx and Ex models.
Table 5.
KRIs for the U.K. insurance claims data for the RSEx and Ex models.
| KRIs→ | | | | | |
|---|
| → | 340 |
| 70% | 340.898174 | 341.221996 | 0.065270 | 341.254631 | 0.323822 |
| 75% | 340.976019 | 341.279098 | 0.058659 | 341.308428 | 0.30308 |
| 80% | 341.062859 | 341.344241 | 0.051949 | 341.370215 | 0.281381 |
| 85% | 341.163752 | 341.421714 | 0.044975 | 341.444201 | 0.257962 |
| 90% | 341.289399 | 341.520689 | 0.037420 | 341.539399 | 0.231290 |
| 95% | 341.471379 | 341.668491 | 0.028435 | 341.682709 | 0.197112 |
| 99% | 341.794290 | 341.941930 | 0.017083 | 341.950471 | 0.147640 |
| → | | | 0.00037 | | |
| 70% | 3253.822502 | 5956.39411 | 7303890.179716 | 3657901.483968 | 2702.571608 |
| 75% | 3746.559532 | 6449.131141 | 7303889.986944 | 3658394.124613 | 2702.571609 |
| 80% | 4349.620918 | 7052.192529 | 7303889.747701 | 3658997.066379 | 2702.571611 |
| 85% | 5127.102268 | 7829.67388 | 7303889.433890 | 3659774.390825 | 2702.571612 |
| 90% | 6222.900684 | 8925.472299 | 7310217.716185 | 3664034.330392 | 2702.571615 |
| 95% | 8096.180450 | 10798.75207 | 7303888.179811 | 3662742.841975 | 2702.571620 |
| 99% | 12445.80137 | 15148.372999 | 7303886.183256 | 3667091.464627 | 2702.571631 |
| → | | | 0.25197, 0.00049 | | |
| 70% | 3018.15114 | 4228.50442 | 895,307.4237 | 451,882.21629 | 1210.35329 |
| 75% | 3476.19141 | 4557.14429 | 755,914.93665 | 382,514.61261 | 1080.95288 |
| 80% | 4018.19508 | 4967.15111 | 617,382.04437 | 313,658.17330 | 948.956031 |
| 85% | 4771.39214 | 5568.55644 | 448,149.30644 | 229,643.20960 | 797.164333 |
| 90% | 5388.71252 | 6083.13747 | 369,667.95180 | 190,917.11340 | 694.424993 |
| 95% | 6523.60475 | 7069.40074 | 243,602.67980 | 128,870.74060 | 545.795920 |
| 99% | 7749.24104 | 8177.12548 | 157,453.69710 | 86,903.974017 | 427.884441 |
| → | | | 941.397,1.00008 | | |
| 70% | 3111.073814 | 5021.84633 | 3603201.421 | 1806622.557 | 1910.7725 |
| 75% | 3463.603492 | 5369.795921 | 3595282.615 | 1803011.103 | 1906.1924 |
| 80% | 3892.708942 | 5794.719753 | 3586988.902 | 1799289.166 | 1902.0108 |
| 85% | 4443.266082 | 6341.237823 | 3579959.560 | 1796321.017 | 1897.9718 |
| 90% | 5215.885110 | 7110.030851 | 3571410.804 | 1792815.429 | 1894.1457 |
| 95% | 6531.315081 | 8421.415024 | 3562554.546 | 1789698.686 | 1890.0999 |
| 99% | 9573.577212 | 11459.39600 | 3552197.802 | 1787558.297 | 1885.8187 |
| → | | | 0.00015, 0.28234 | | |
| 70% | 3496.50393 | 4558.57623 | 699524.8015 | 354320.977 | 1062.0723 |
| 75% | 3753.40310 | 4745.68200 | 628280.2448 | 318885.801 | 992.27861 |
| 80% | 4038.69390 | 4958.81501 | 556528.2668 | 283222.948 | 920.12123 |
| 85% | 4368.96622 | 5212.06731 | 482468.7281 | 246446.432 | 843.10141 |
| 90% | 4779.27921 | 5535.60102 | 402705.2214 | 206888.212 | 756.32163 |
| 95% | 5373.20032 | 6019.48194 | 308229.5957 | 160134.278 | 646.28152 |
Generally, we report the following main results:
.
.
.
.
.
The results of the RSEx model are better than the corresponding results for the Chen model for all risk indicators | q = (70%,75%,80%,85%,90%,99%) and 99%.
The results of the RSEx model are better than the corresponding results for the PaII model for all risk indicators | q = (70%,75%,80%,85%,90%,99%) and 99%.
The results of the RSEx model are better than the corresponding results for the GG model for all risk indicators | q = (70%,75%,80%,85%,90%,99%) and 99%.
9. Censored Distributional Validation
When our data sets have been censored and the parameters of the model are unknown, we can use the statistic type test, based on a variation of the RRNU statistic proposed by Bagdonavičius and Nikulin [
23], as well as by Bagdonavičius et al. [
24] to confirm the adequacy of the RSEx model. Here, we adjust this test for an RSEx model since the failure rate, x i, follows an RSEx distribution. Consider the following coupled notions:
The cumulative FRF of the RSEx distribution can be expressed as:
With this selection of intervals, we have a constant value of
for every
. The intervals can be computed repeatedly since the inverse FRF of the RSEx distribution lacks a defined shape. Let us split the finite time interval
into
as shorter intervals. Here, is the study’s maximum runtime and
:
According to Bagdonavičius and Nikulin [
23], as well as Bagdonavičius et al. [
24], the estimated value of
can be derived as:
where:
where
. Then, the statistic proposed by Bagdonavičius and Nikulin [
23] and Bagdonavičius et al. [
24] can be expressed as:
where:
and
reflects the total number of failures that have been observed over these times, which can be used to test for hypothesis
. The test statistic can be written as follows:
where the components of the test are given by Nikulin [
19,
20,
21] and by Rao and Robson [
22]. The major element of the
statistic test of the RSEx model is the matrix
, which is given by Yadav et al. [
25,
26] and Yousof et al. [
27] in further detail.
9.1. Censored Simulation Study with the RRNU Statistics
Conducting a censored simulation study using the NRR statistics involves generating data from a known distribution and then introducing censoring to simulate the types of censoring that may occur in real-world data. The censored data are then tested against a hypothesized distribution, using one or more of the RRNU statistics. The performance of the statistics is evaluated based on their ability to correctly identify the underlying distribution, as well as their sensitivity to sample size, parameter values, and other factors. In order to test
H0, we considered
at
and that DOF = 5 grouping intervals will be utilized to determine whether the sample fits the RSEx model’s null hypothesis,
. We calculated the average value of the null hypothesis’ non-rejection numbers for different theoretical levels
, where
.
Table 7, which compares the theoretical and empirical levels, shows how closely the value of the calculated empirical level equals the value of the corresponding theoretical level. As a result, we infer that the custom test is perfectly matched to the RSEx model.
The results presented herein support the notion that the theoretical level of the chi-square distribution regarding degrees of freedom corresponds to the empirical significance level of the new statistics at which it is statistically significant. The censored data derived from the RSEx distribution can, thus, be satisfactorily fitted using the proposed test, according to this evidence.
9.2. Censored Applications Using the RRNU Statistics
9.2.1. Example 1: The Cancer Data
According to Loprinzi et al. [
32], the survival of patients with advanced lung cancer can be expressed as
where the censored items
. Then,
and, as in the work of Bagdonavičius and Nikulin [
23] and Bagdonavičius et al. [
24], the test statistic
elements are displayed as follows.
| 92.099 | 171.602 | 216.127 | 283.176 | 355.435 | 456.487 | 685.199 | 1022.3174 |
| 29 | 30 | 35 | 31 | 32 | 25 | 28 | 18 |
| 5.0473 | 5.0473 | 5.0473 | 5.0473 | 5.0473 | 5.0473 | 5.0473 | 5.0473 |
The estimated matrix
and the estimated fisher matrix are as given as follows.
| 0.5039 | −0.4556 | 0.8437 | 0.7772 | 0.4315 | −0.2804 | 0.5140 | 0.2631 |
Conversely, the critical value is . Then, using the previous results, we find that the calculated statistic of the proposed test is . Since , then we can say that our hypothesis H0 is accepted. This leads us to conclude that the data regarding cancer of the lung can follow the RSEx distribution with a risk of error.
9.2.2. Example 2: The Reliability Data Set
Following the example of Meeker and Escobar [
29],
and censored items
. Assuming that the data are distributed using the RSEx distribution, the maximum likelihood estimator for the parameter vector is
. The statistical test
has the following components, below.
| 346.1493 | 469.359 | 587.708 | 679.112 | 1078.876 | 1089.365 | 1102.169 | 1106.444 |
| 11 | 15 | 6 | 10 | 6 | 5 | 6 | 5 |
| 4.85103 | 4.85103 | 4.85103 | 4.85103 | 4.85103 | 4.85103 | 4.85103 | 4.85103 |
The estimated matrix
and the estimated fisher matrix are given as follows.
| −0.3236 | 0.78247 | −0.40357 | 0.26059 | 0.29613 | 0.84759 | 0.600021 | 0.263458 |
Then, and . Then, since , then we can say that our hypothesis H0 can be accepted. This leads us to conclude that the reliability data can follow the RSEx distribution, with a risk of error.
9.2.3. Example 3: Aluminum Cells under Reduction Data
According to the data reported by Whitmore [
33], who considered the times of failures for
aluminum cells under reduction, the numbers of failures in
days, in terms of units are: 0.725, 0.838, 0.468, 0.853, 1.139, 0.965, 1.142, 1.317, 1.304, 1.427, 2.244*, 1.658, 1.554, 1.764, 1.990, 2.010, 2.224, 1.776, 2.279*, and 2.286*, where those values with “*” are the censored items. Assuming that these data are distributed in accordance with the RSEx distribution, the maximum likelihood estimator of the parameter vector is
. The element of the statistic test
is given as follows.
| 0.9607 | 1.19075 | 1.7002 | 2.2945 |
| 4 | 3 | 5 | 8 |
| 2.5381 | 2.5381 | 2.5381 | 2.5381 |
The estimated matrix
and the estimated fisher matrix are given as follows:
| −0.73894 | 0.26137 | 0.44579 | 0.10068 |
Then, we have and . Since , then, we observe that our hypothesis H0 is accepted. This leads us to conclude that the aluminum cells under reduction data can follow the RSEx distribution with a risk of error.
9.2.4. Example 4: The Head and Neck Cancer Data
Consider the data reported by Efron [
34] which represents the survival times in days for those patients where the data are: 7, 225, 42, 34,63, 64, 440, 160, 74*, 84, 91, 83, 108, 112, 133, 129, 133, 139, 140, 146, 140, 149, 154, 185*, 157, 160, 165, 1101, 173, 176, 1226*, 218, 241, 248, 273, 277, 279*, 297, 1146, 319*, 405, 417, 1417, 420, 523*, 523, 583, 594, 1116*, 1349*, and 1412*, where the values with “*” are the censored items. Here,
, and the elements of the test statistic
can be presented as follows:
| 2.768 | 5.102 | 9.784 | 21.008 | 37.10087 | 44.464 | 46.903 |
| 7 | 7 | 20 | 10 | 2 | 3 | 2 |
| 1.9764 | 1.9764 | 1.9764 | 1.9764 | 1.9764 | 1.9764 | 1.9764 |
The estimated matrix
and the estimated fisher matrix are given as follows:
| 0.3425 | 0.4183 | 0.3647 | −0.1648 | 0.3465 | −0.4137 | 0.0499 |
Since and , first, ; then, we note that our hypothesis H0 can be accepted. This leads us to conclude that aluminum cells under the influence of reduction data can follow the RSEx distribution with a risk of error.
10. Concluding Remarks
Asymmetric probability-based distributions might be able to explain risk exposure effectively. Usually, one main value, or, at the very least, a limited number of values are used to describe the level of risk exposure. This work is focused on the present task of analyzing an asymmetric probability-based distribution for the purposes of risk analysis and distributional validation. The new distribution can be considered an alternative distribution, with merit to some of the more well-known distributions used in the actuarial literature, such as the Chen distribution, exponential distribution, Pareto type II distribution, and the generalized gamma distribution.
The value-at-risk (VAR), tail-value-at-risk (TVAR), conditional-value-at-risk (CVAR), tail variance (TV), and tail mean-variance (TMV) are just a few of the KRIs that can be utilized as the most popular key risk indicators. For this purpose (and for other purposes including distributional verification), in this paper, we introduce a new distribution called the quasi-exponential model. Some mathematical characterizations of the new distribution are derived with simplicity, in order to focus on the applied aspects of the model. Two different ways to characterize the RSEx distribution are discussed, such as characterization using two truncated moments and characterization using the FRF. The parameter of the new distribution is estimated using the maximum likelihood method. For the estimating and evaluating processes using uncensored samples and the uncensored maximum likelihood method, the BB algorithm is utilized. A simulation study is conducted to evaluate the Rao–Robson–Nikulin (RRNU) statistics used in the uncensored case. The building of the RRNU statistic for the RSEx model in light of the uncensored case is discussed in detail. The first uncensored data represent the breaking stress of fibers, the second is the heat exchanger tube crack data, the third is the strengthening of fibers, and the fourth is the gene-based breast cancer data. Four real-world data applications are provided in response to an uncensored situation. Additionally, a simulation study for evaluating RRNU statistics according to the censored case is presented, along with the construction of the RRNU statistic for the RSEx model in the censored case. Four censored real-world data applications are also analyzed in terms of the censored case, including data on lung cancer, capacitors, aluminum cells under reduction, and head and neck cancer.
We expect that the RSEx distribution will have a major role in many potential studies, including presenting a new discrete distribution based on the RSEx distribution, offering a new and discrete G family of distribution based on the RSEx distribution, presenting some continuous G families based on this, and presenting new generalizations by adding new features to the RSEx baseline model.
Regarding the results of the analysis and the assessment of actuarial risks using the RSEx distribution, we highlight the following main findings:
VARq, TVARq and TMVq increase when increases for all sample sizes and initial parameter values.
TVq and ELq decrease when increases for all sample sizes and initial parameter values.
It is clear that the results of some actuarial risk assessments have stabilized with the increase in the sample size. For example, TVq() started with 0.06527 and ended with 0.01708, while ELq() started with 0.32382 and ended with 0.14764.
Regarding the risk assessment under the influence of the insurance data:
- (1)
- (2)
- (3)
- (4)
The VARq is monotonically increasing, starting with 340.898174 and ending with 341.794290; the TVARq is monotonically increasing, starting with 341.221996 and ending with 341.941930; the TVq, the TMVq, and the MEL are monotonically increasing from 341.254631 to 341.950471. However, the TVq is monotonically decreasing, starting with 0.06527 and ending with 0.017083, while the TVq is monotonically decreasing, starting with 0.323822 and ending with 0.14764.
With regard to the results of the distributional validation using the RSEx distribution, we highlight the following main findings:
- (1)
For the uncensored reliability data of the carbon fibers: . This means that the RSEx model can model the reliability data of the carbon fibers, or the reliability data of the carbon fibers can be represented and modeled using the RSEx distribution.
- (2)
For the uncensored reliability heat data: . This means that the RSEx model can model a heat exchanger tube crack or the heat exchanger tube crack data can be represented and modeled using this distribution.
- (3)
For the uncensored reliability strengths data: . This means that the RSEx model is able to model data on the strength of glass fibers, or the data on the strength of glass fibers can be represented and modeled using this distribution.
- (4)
For the uncensored gene-based breast cancer data: . This means that the RSEx model can model the gene-based breast cancer data or the gene-based breast cancer data can be represented and modeled using this distribution.
- (5)
For the uncensored lung cancer data: ; then, hypothesis H0 is accepted, which leads us to conclude that the data on lung cancer can follow an RSEx distribution with a risk of error.
- (6)
For the uncensored lung cancer data: , then, H0 is accepted, which means that the reliability data can follow an RSEx distribution with a risk of error.
- (7)
For the uncensored lung cancer data: ; then, we accept H0, which leads us to conclude that the aluminum cells under reduction data can follow an RSEx distribution with a risk of error.
- (8)
For the uncensored lung cancer data: ; then, hypothesis H0 is accepted, which leads us to conclude that the aluminum cells under the influence of reduction data can follow an RSEx distribution with a risk of error.


 ,
, 


{kind=link}
{kind=link}
{kind=link}


