
An Efficient Stress–Strength Reliability Estimate of the Unit Gompertz Distribution Using Ranked Set Sampling
 , ,
, ,  ,
, 
Abstract
:1. Introduction
2. Maximum Likelihood Estimate of
2.1. MLE Based on the RSS
2.2. MLE Based on the SRS
3. LS and WLS Estimates of
4. Maximum Product Spacing Estimate of
5. Other Estimation Methods
5.1. Estimates of Based on the RSS
5.2. Estimates of Based on the SRS
6. Numerical Evaluation
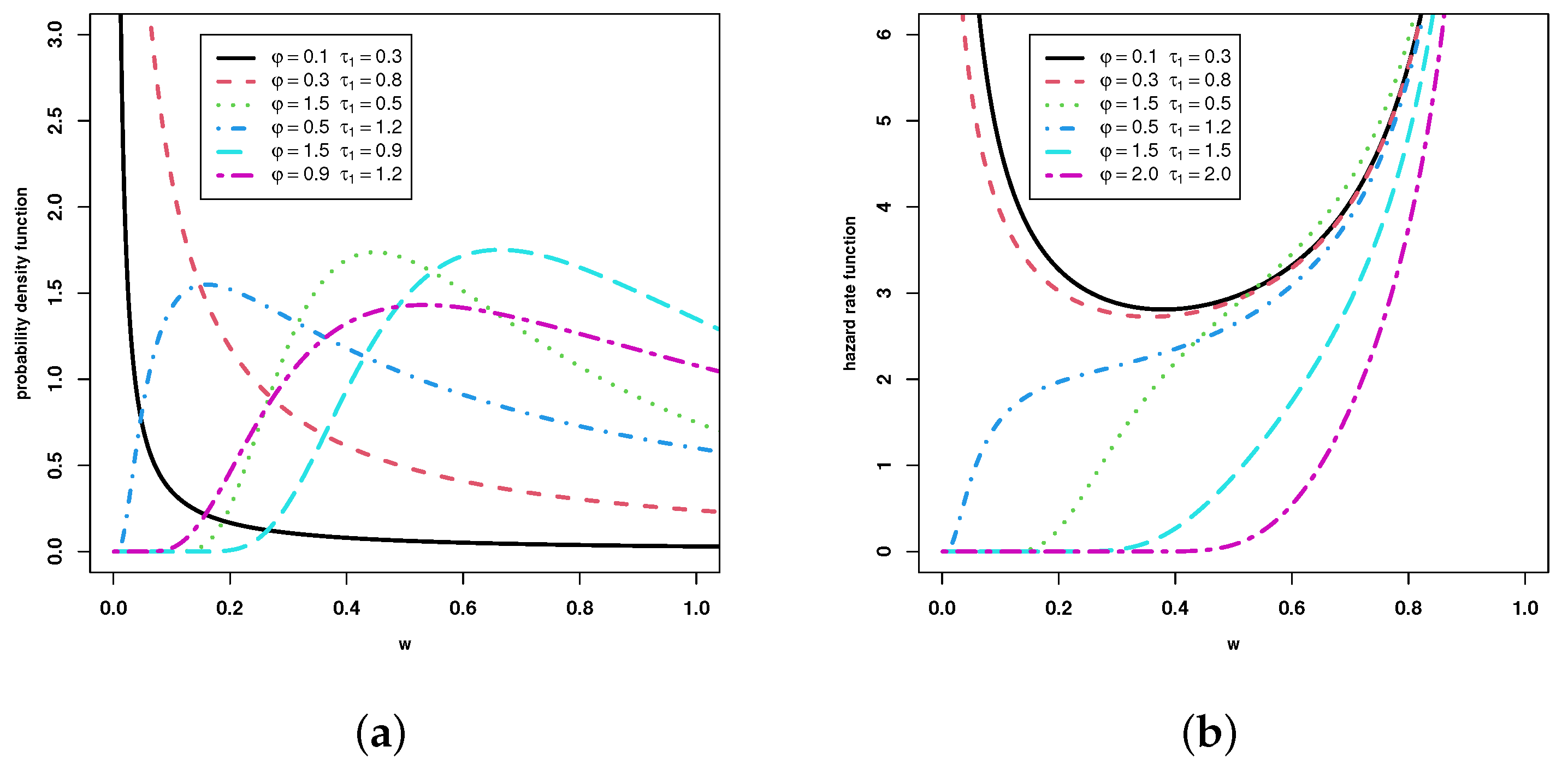
- The parameter values are chosen as , and the true value of is determined as 0.2857, 0.6000, 0.7143, and 0.9375, respectively.
- The observed RSS from the strength and , , from the stress having the set sizes: (2,2), (2,3), (3,3), (3,4), (4,4), (4,5), (5,5), with the cycle numbers . The sample sizes are (20,20), (20,30), (30,40), (40.40),(40,50), (50,50).
- In view of the SRS, the observed SRS , , are drawn from strength and stress with sample sizes (20,20), (20,30), (30,40), (40.40), (40,50), (50,50).
- Using the inverse transformation method, 1000 random samples are created from the strength UGD, and stress UGD.
- Different estimation techniques, along with the selected sample scheme, were used to determine the MLE, MPSE, LSE, WLSE, CVE, ADE, and RTADE, namely, , , based on the RSS, and , , , , , , based on the SRS.
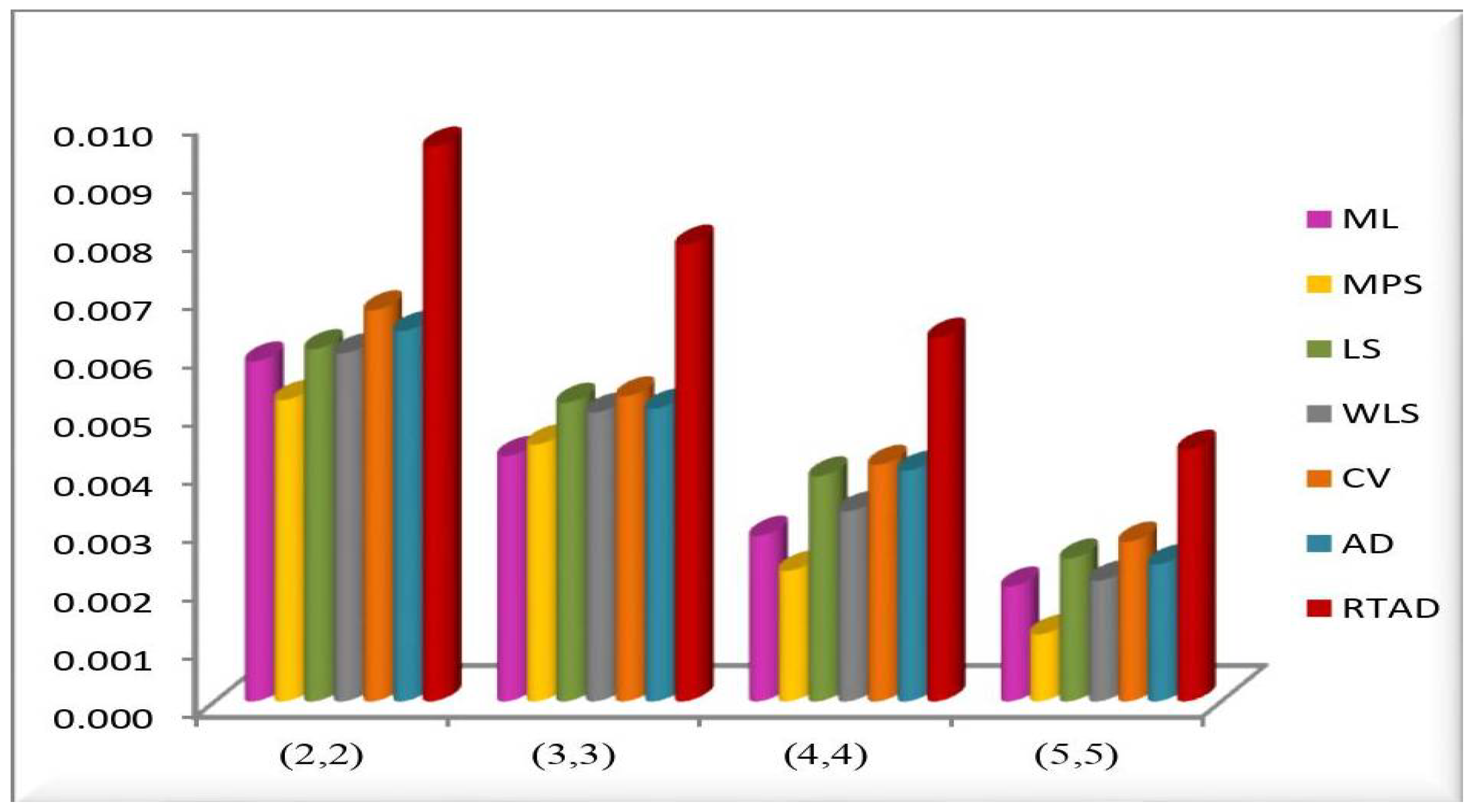
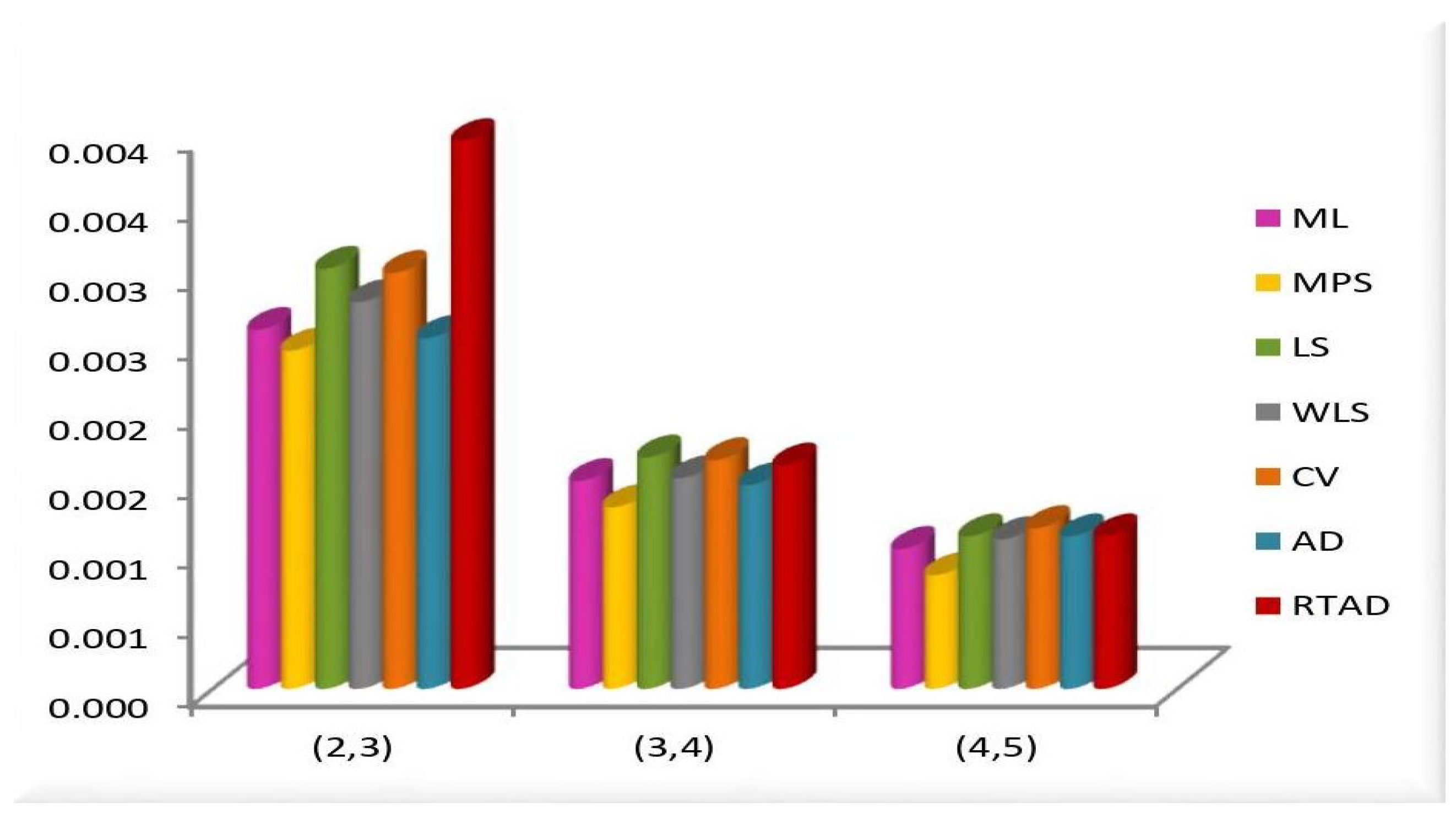
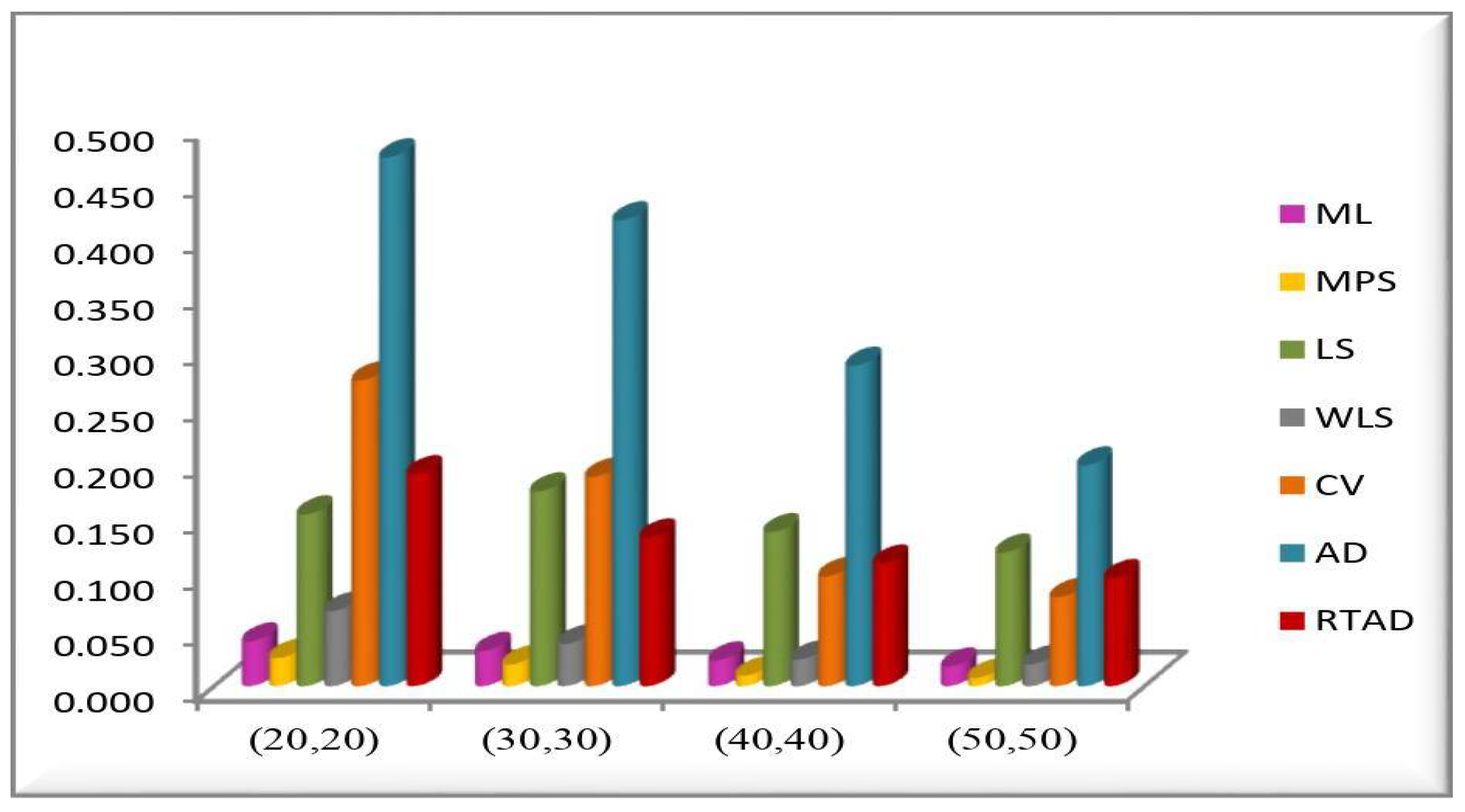
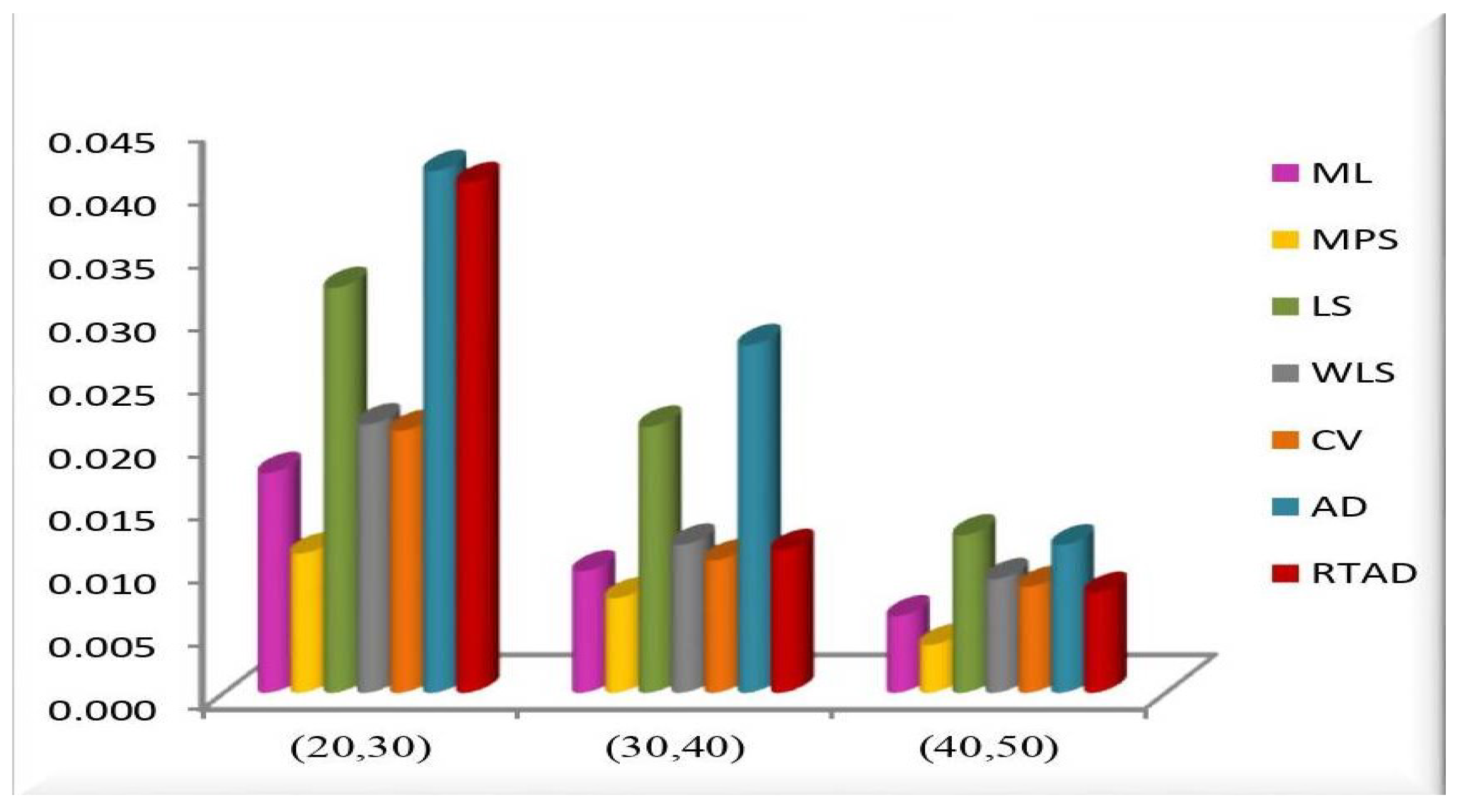
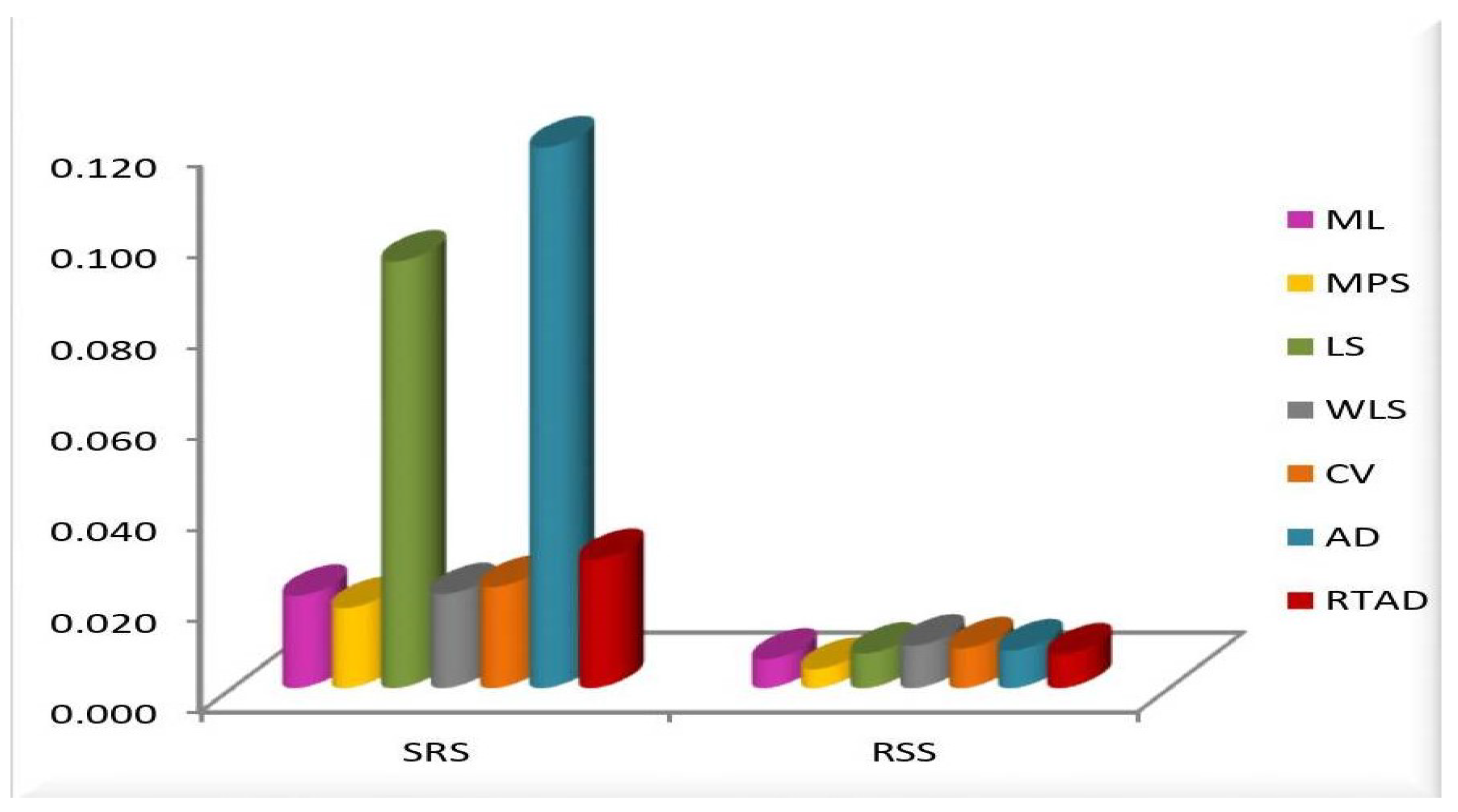
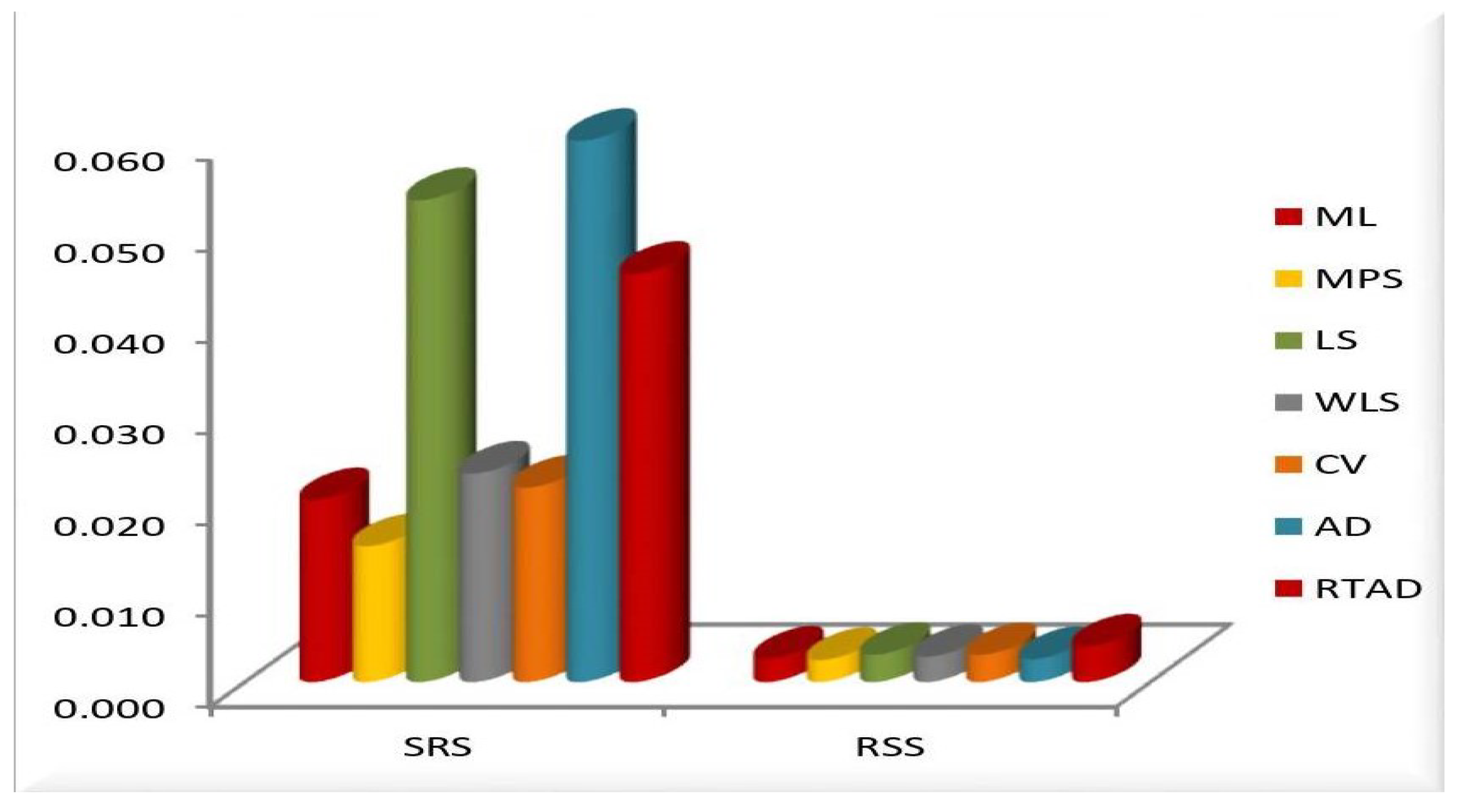
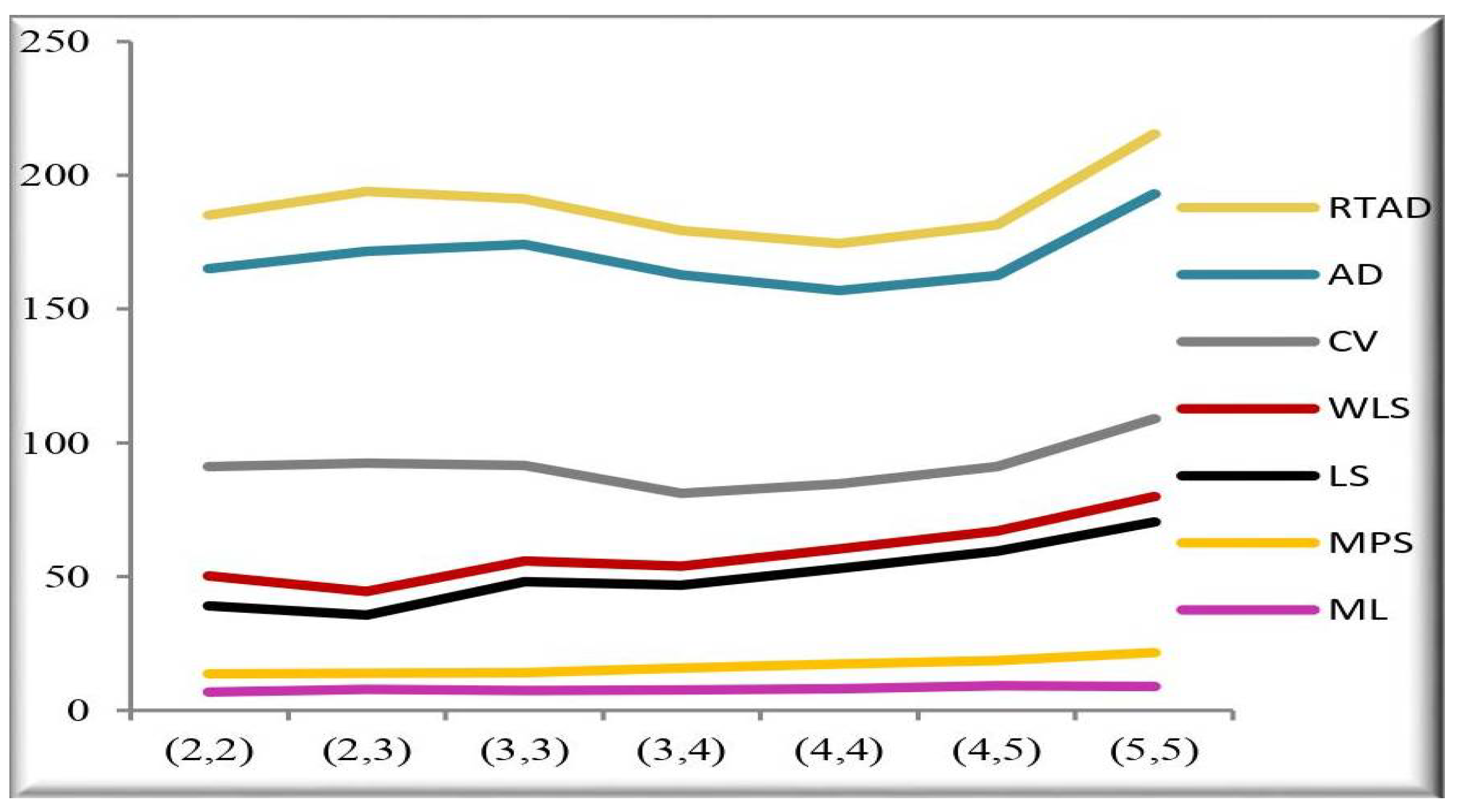
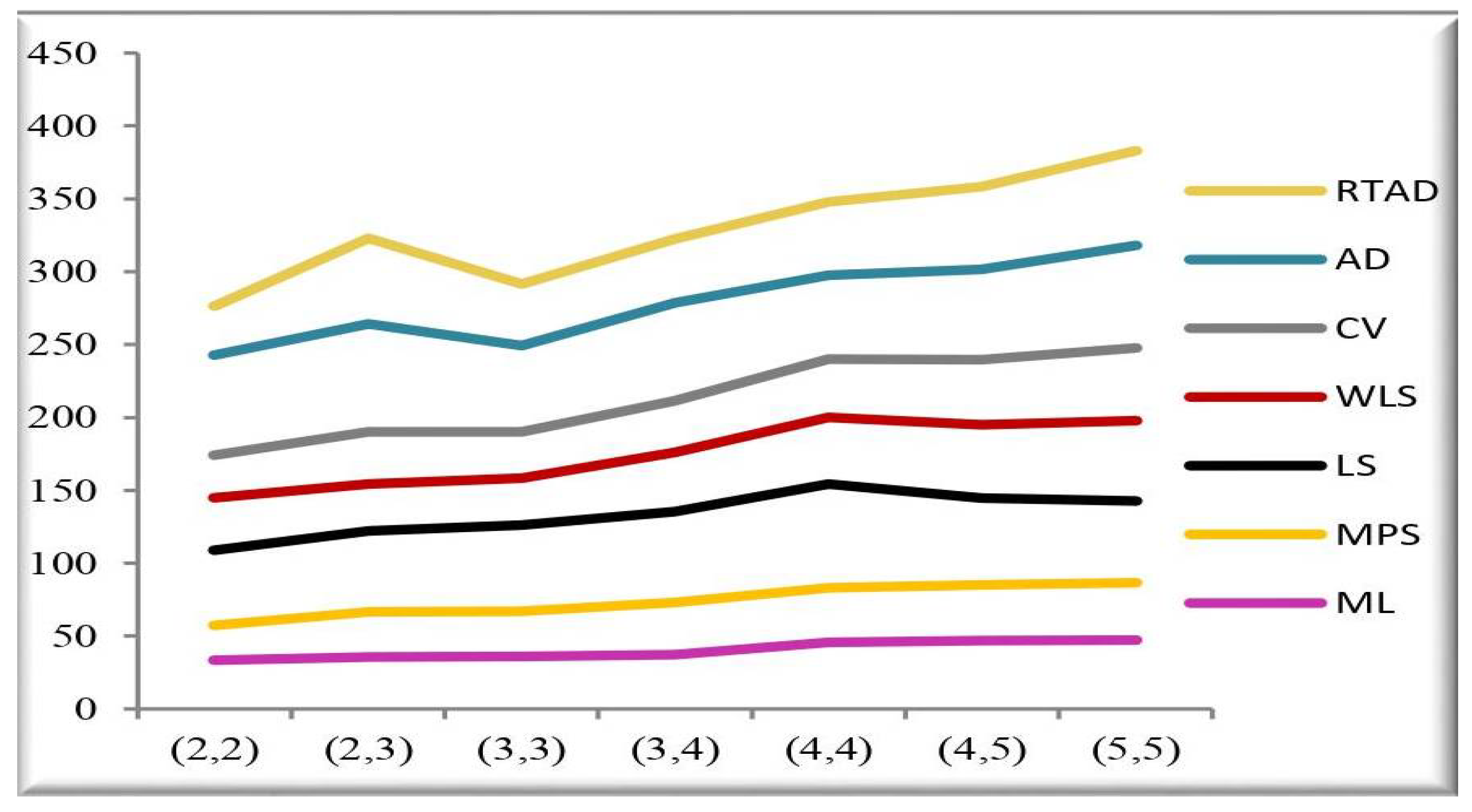
- In the majority of the cases, as seen in Figure 2, the MSEs of the estimates decrease as and increase.
- For both sampling methods, the MSEs of the estimates for the MPS method have the lowest values. While the MSEs of the estimates for the AD method take the highest values in the SRS, the highest values are given to the MSEs of the estimates for the RTAD method in the RSS scheme.
- The MSE always decreases as and increase, indicating that the estimates are all consistent.
- The estimates become more accurate as and increase, indicating that they are asymptotically unbiased.
- The MSE always decreases as the true value of increases, indicating that the estimates are all consistent.
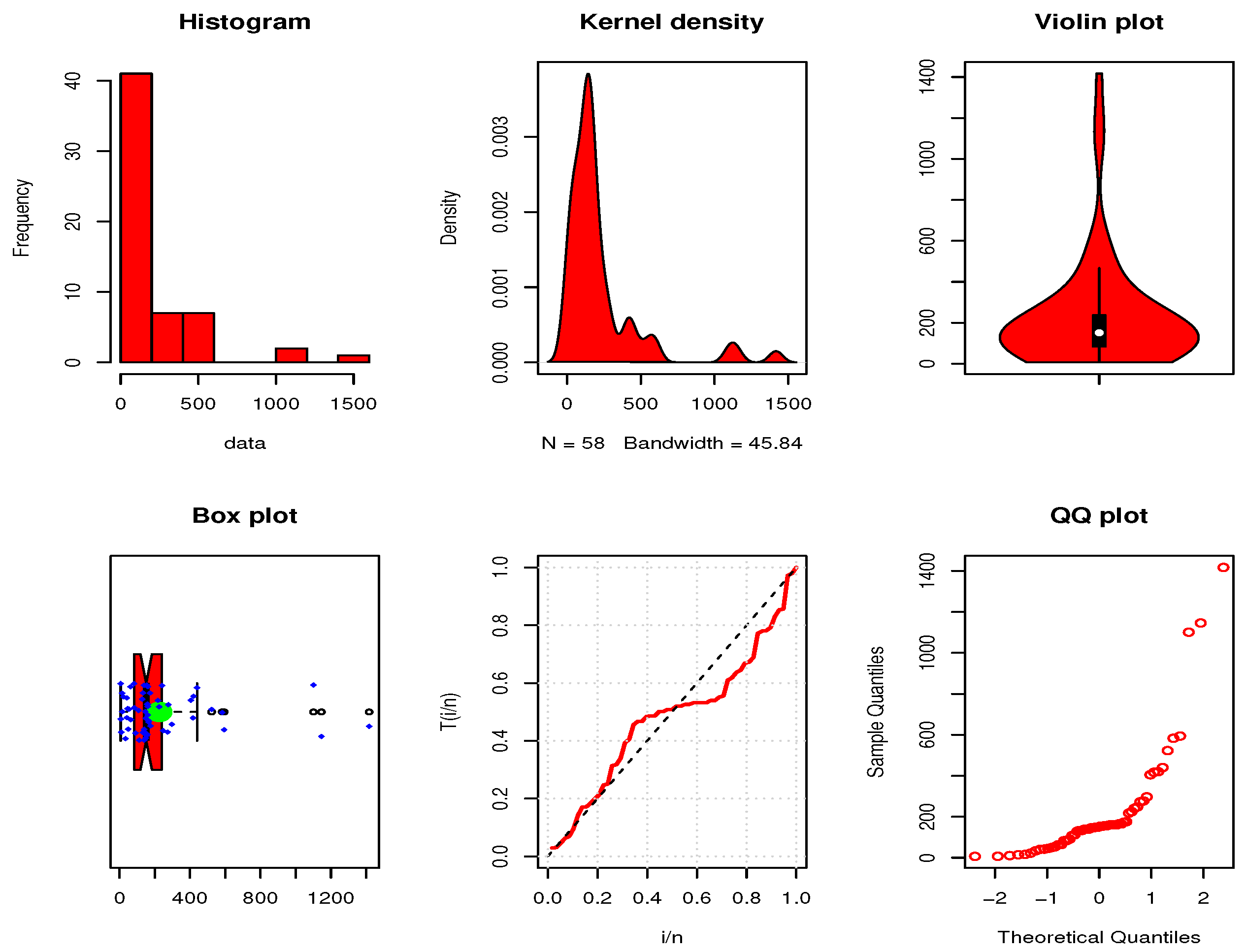
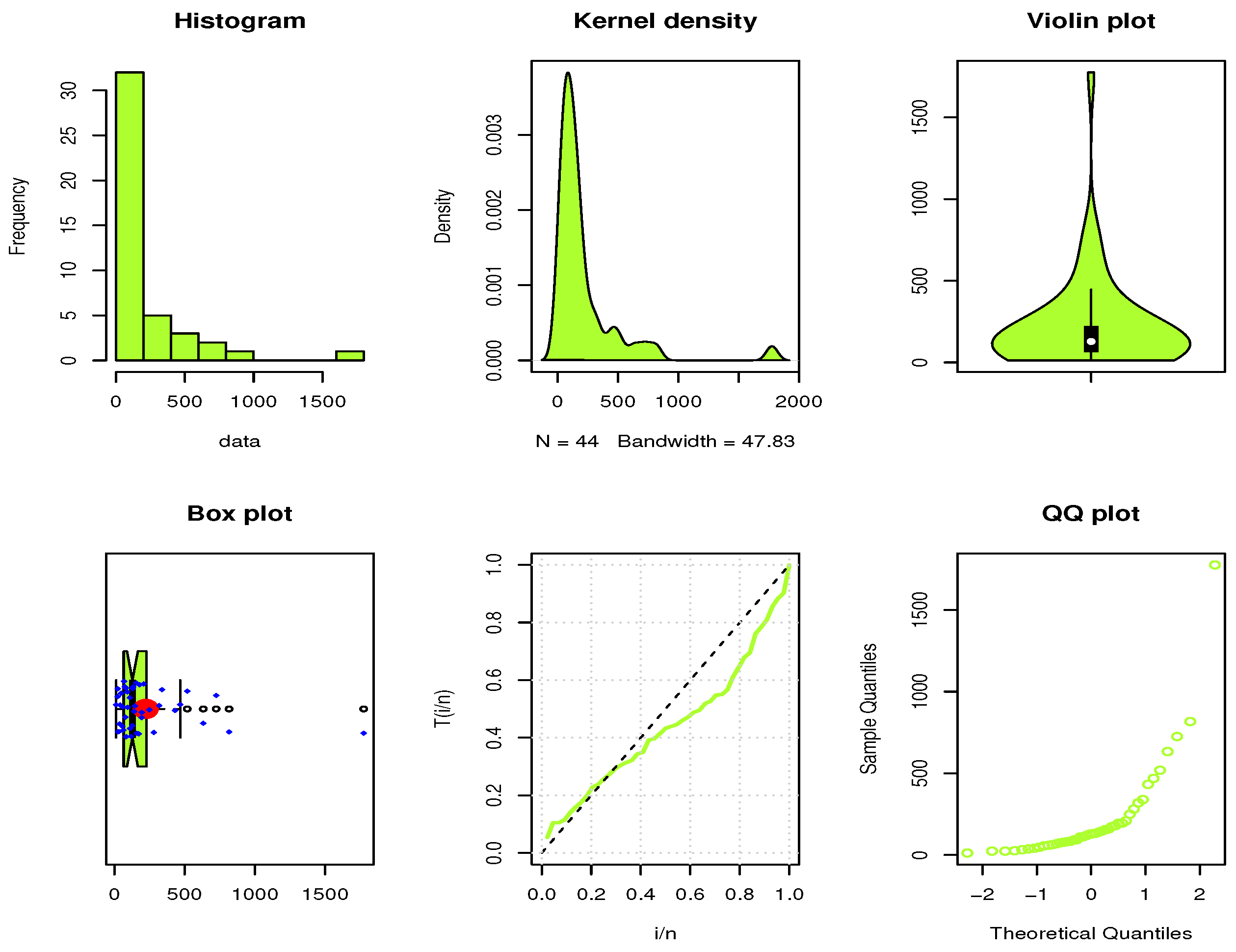
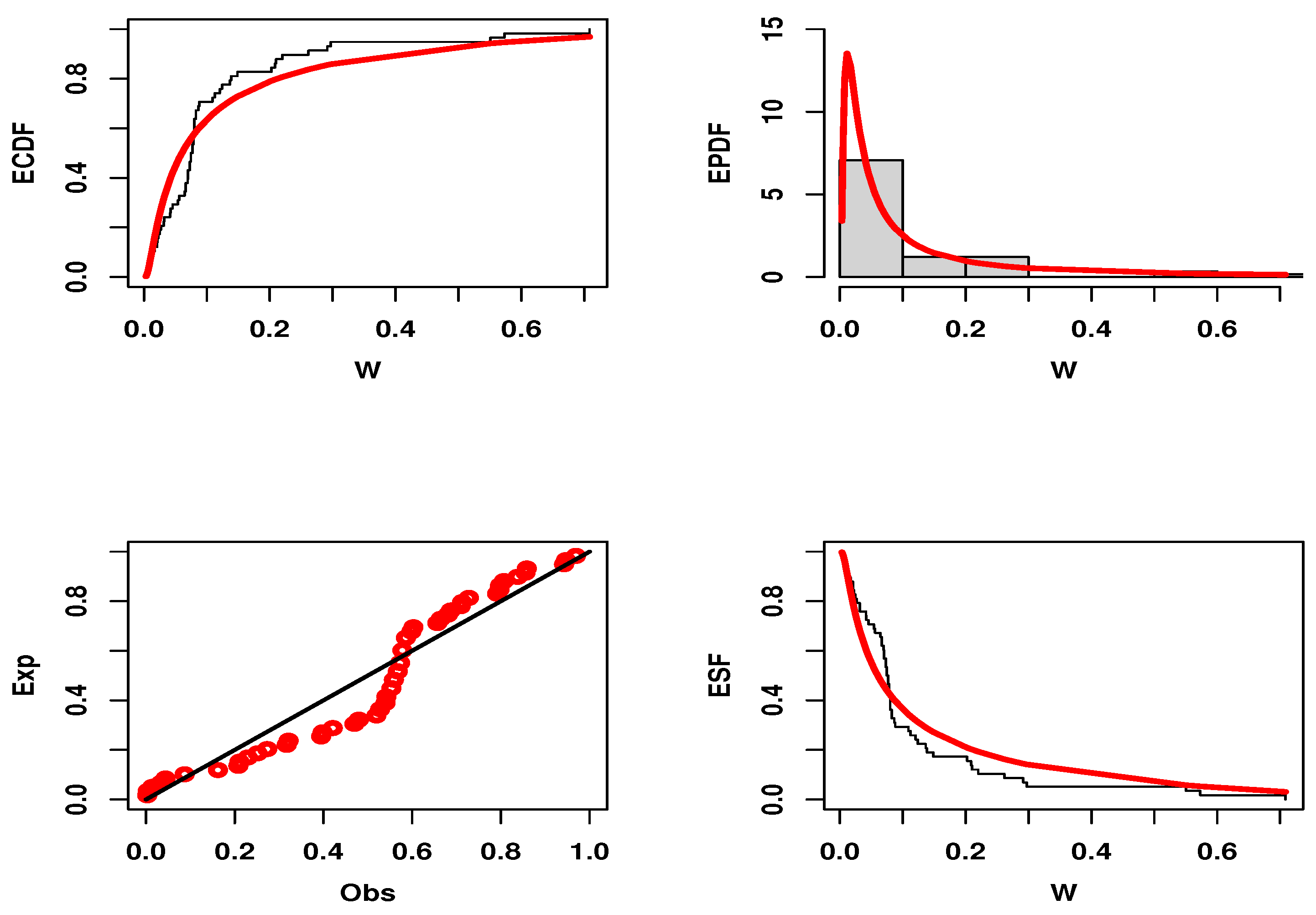
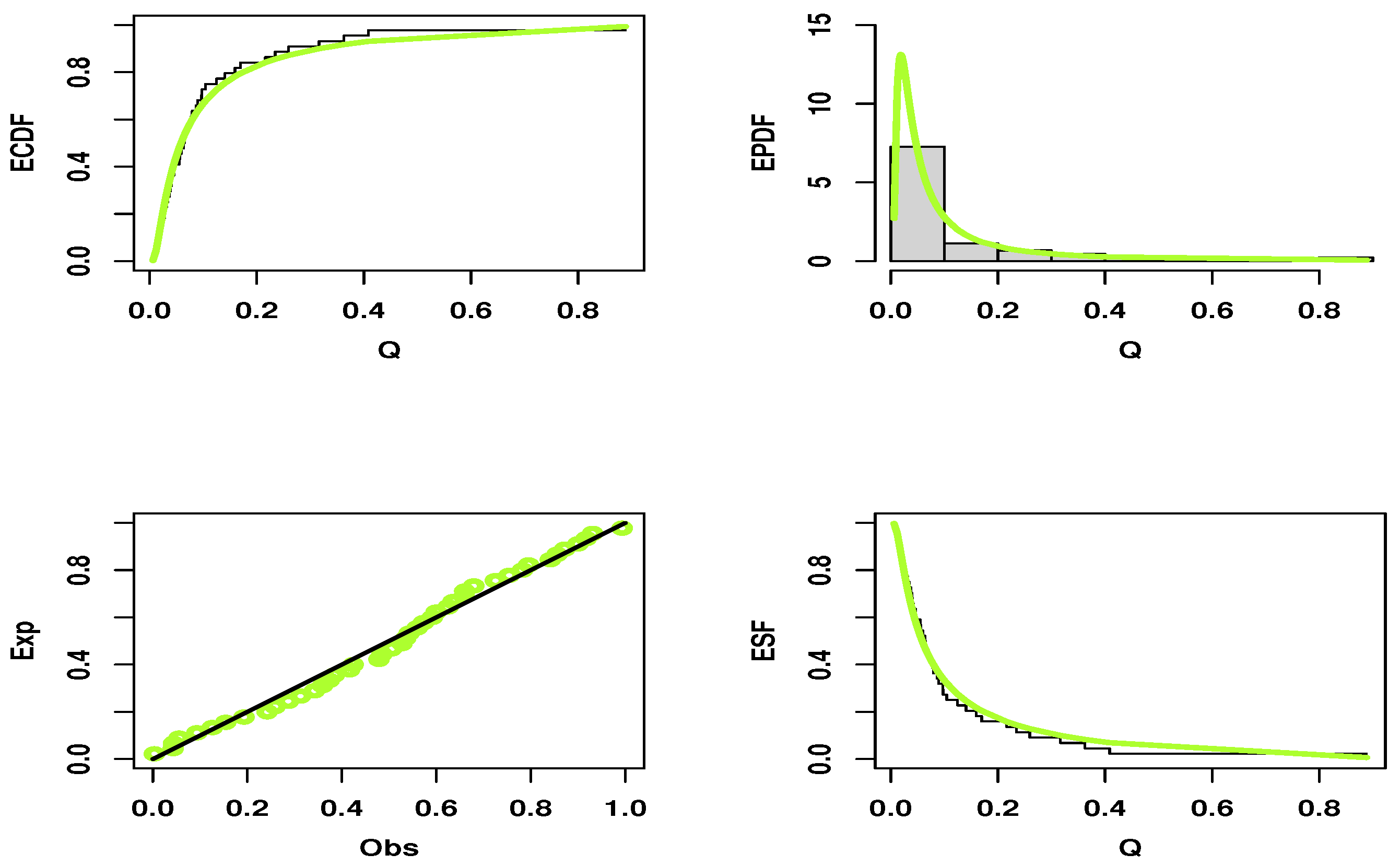
7. Real Data Applications
8. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. The unit-Birnbaum–Saunders distribution with applications. Chil. J. Stat. 2018, 9, 47–57. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Fernandes, L.B.; de Oliveira, R.P.; Ghitany, M.E. The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. J. Appl. Stat. 2020, 47, 954–974. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. Unit-Gompertz distribution with applications. Stat. J. Appl. Stat. 2019, 79, 25–43. [Google Scholar]
- Ghitany, M.E.; Mazucheli, J.; Menezes, A.F.B.; Alqallaf, F. The unit-inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval. Commun. Stat. Theory Methods 2019, 48, 3423–3438. [Google Scholar] [CrossRef]
- Korkmaz, M.C.; Chesneau, C. On the unit Burr-XII distribution with the quantile regression modeling and applications. Comput. Appl. Math. 2021, 40, 29. [Google Scholar] [CrossRef]
- Bantan, R.A.R.; Jamal, F.; Chesneau, C.; Elgarhy, M. Theory and applications of the unit Gamma/Gompertz distribution. Mathematics 2021, 9, 1850. [Google Scholar] [CrossRef]
- Bhatti, F.A.; Ali, A.; Hamedani, G.G.; Korkmaz, M.; Ahmad, M. The unit generalized log Burr XII distribution: Properties and application. AIMS Math. 2021, 6, 10222–10252. [Google Scholar] [CrossRef]
- Hassan, A.S.; Fayomi, A.; Algarni, A.; Almetwally, E.M. Bayesian and non-Bayesian inference for unit-exponentiated half-logistic distribution with data analysis. Appl. Sci. 2022, 12, 11253. [Google Scholar] [CrossRef]
- Khaoula, A.; Dey, S.; Kumar, D.; Seddik-Ameur, N. Different classical methods of estimation and chi-squared goodness-of-fit test for unit generalized inverse Weibull distribution. Austrian J. Stat. 2021, 50, 77–100. [Google Scholar] [CrossRef]
- Ribeiro, T.F.; Peña-Ramírez, F.A.; Guerra, R.R.; Cordeiro, G.M. Another unit Burr XII quantile regression model based on the different reparameterization applied to dropout in Brazilian undergraduate courses. PLoS ONE 2022, 17, e0276695. [Google Scholar] [CrossRef] [PubMed]
- Hashmi, S.; ul-Haq, M.A.; Zafar, J.; and Khaleel, M.A. Unit Xgamma Distribution: Its Properties, Estimation and Application. Proc. Pak. Acad. Sci. 2022, 59, 49–59. [Google Scholar] [CrossRef]
- Chesneau, C. A note on an extreme left skewed unit distribution: Theory, modelling and data fitting. Open Stat. 2021, 2, 1–23. [Google Scholar] [CrossRef]
- Fayomi, A.; Hassan, A.S.; Baaqeel, H.M.; Almetwally, E.M. Bayesian inference and data analysis of the unit-power Burr X distribution. Axioms 2023, 12, 297. [Google Scholar] [CrossRef]
- Hassan, A.S.; Alharbi, R.S. Different estimation methods for the unit inverse exponentiated Weibull distribution. Commun. Stat. Appl. Meth. 2023, 30, 191–213. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Korkmaz, Z.S. The unit log–log distribution: A new unit distribution with alternative quantile regression modeling and educational measurements applications. J. Appl. Stat. 2023, 50, 889–908. [Google Scholar] [CrossRef] [PubMed]
- Jha, M.K.; Dey, S.; Alotaibi, R.M.; Alomani, G.; Tripathi, Y.M. Reliability estimation of a multicomponent stress-strength model for unit Gompertz distribution under progressive Type II censoring. Qual. Reliab. Eng. Inter. 2020, 36, 965–987. [Google Scholar] [CrossRef]
- Jha, M.K.; Dey, S.; Tripathi, Y. Reliability estimation in a multicomponent stress-strength based on unit-Gompertz distribution. Inter. J. Qual. Reliab. Manag. 2019, 37, 428–450. [Google Scholar] [CrossRef]
- Kumar, D.; Dey, S.; Ormoz, E.; MirMostafaee, S.M.T.K. Inference for the unit-Gompertz model based on record values and inter-record times with an application. Rend. Circ. Mat. Palermo Ser. 2 2020, 69, 1295–1319. [Google Scholar] [CrossRef]
- Arshada, M.; Azhadc, Q.J.; Gupta, N.; Pathake, A.K. Bayesian inference of Unit Gompertz distribution based on dual generalized order statistics. Commun. Stat. Simul. Comput. 2021, 1–19. [Google Scholar] [CrossRef]
- McIntyre, G.A. A method for unbiased selective sampling, using ranked sets. Aust. J. Agric. Res. 1952, 3, 385–390. [Google Scholar] [CrossRef]
- Takahasi, K.W. On unbiased estimates of the population mean based on the sample stratified by means of ordering. Ann. Inst. Stat. Math. 1968, 21, 249–255. [Google Scholar] [CrossRef]
- Dell, D.R.; Clutter, J.L. Ranked set sampling theory with order statistics background. Biometrics 1972, 28, 545–555. [Google Scholar] [CrossRef]
- Wolfe, D.A. Ranked Set Sampling: Its Relevance and Impact on Statistical Inference. Int. Sch. Res. Not. Probab. Stat. 2012, 1–32. [Google Scholar] [CrossRef]
- Halls, L.K.; Dell, T.R. Trial of ranked-set sampling for forage yields. For. Sci. 1966, 12, 22–26. [Google Scholar]
- Stokes, S.L.; Sager, T.W. Characterization of a ranked-set sample with application to estimating distribution functions. J. Am. Stat. Assoc. 1988, 83, 374–381. [Google Scholar] [CrossRef]
- Johnson, G.D.; Paul, G.P.; Sinha, A.K. Ranked set sampling for vegetation research. Abstr. Bot. 1993, 17, 87–102. [Google Scholar]
- Gore, S.D.; Patil, G.P.; Sinha, A.K. Environmental Chemistry, Statistical Modeling, and Observational Economy. In Environmental Statistics, Assessment, and Forecasting; Cothern, C.R., Ross, N.P., Eds.; Lewis Publishing/CRC Press: Boca Raton, FL, USA, 1994; pp. 57–97. [Google Scholar]
- Al-Saleh, M.F.; Al-Shrafat, K. Estimation of milk yield using ranked set sampling. Envirometrics 2001, 12, 395–399. [Google Scholar] [CrossRef]
- Al-Saleh, M.F.; Al-Omari, A.I. Multistage ranked set sampling. J. Stat. Plann. Inference 2002, 102, 273–286. [Google Scholar] [CrossRef]
- Husby, C.E.; Stansy, E.A.; Wolfe, D.A. An application of ranked set sampling for mean and median estimation using USDA crop production data. J. Agric. Biolog. Environ. Stat. 2005, 10, 354–373. [Google Scholar] [CrossRef]
- Kowalczyk, B. Alternative sampling designs some applications of qualitative data in survey sampling. Stat. Trans. 2005, 7, 427–443. [Google Scholar]
- Ganeslingam, S.; Ganesh, S. Ranked set sampling versus simple random sampling in the estimation of the mean and the ratio. J. Stat. Manag. Syst. 2006, 2, 459–472. [Google Scholar] [CrossRef]
- Wang, Y.G.; Ye, Y.; Milton, D.A. Efficient designs for sampling and subsampling in fisheries research based on ranked sets. J. Marine Sci. 2009, 66, 928–934. [Google Scholar] [CrossRef]
- Kotz, S.; Lumelskii, Y.; Pensky, M. The Stress-Strength Model and Its Generalizations: Theory and Applications; World Scientific: Singapore, 2003. [Google Scholar]
- Birnbaum, Z.W. On a use if Mann-Whitney statistics. Proc. Third Berkeley Symp. Math. Stat. Probab. 1956, 1, 1317. [Google Scholar]
- Kundu, D.; Gupta, R.D. Estimation of P(Y < X) for Weibull distribution. IEEE Trans. Reliab. 2006, 55, 270–280. [Google Scholar]
- Raqab, M.Z.; Madi, M.D.; Kundu, D. Estimation of P(Y < X) for the 3-parameter generalized exponential distribution. Commun. Stat. Theory Meth. 2008, 37, 2854–2864. [Google Scholar]
- Asgharzadeh, A.; Valiollahi, R.; Raqab, M.Z. Estimation of Pr(Y < X) for the two-parameter generalized exponential records. Commun. Stat. Simul. Comput. 2017, 46, 371–394. [Google Scholar]
- Nadeb, H.; Torabi, H.; Zhao, Y. Stress-strength reliability of exponentiated Fréchet distributions based on Type-II censored data. J. Stat. Comput. Simul. 2019, 89, 1863–1876. [Google Scholar] [CrossRef]
- Muttlak, H.A.; Abu-Dayyeh, W.A.; Saleh, M.F.; Al-Sawi, E. Estimating P(Y < X) using ranked set sampling in case of the exponential distribution. Commun. Stat. Theory Methods 2010, 39, 1855–1868. [Google Scholar]
- Akgül, F.G.; Şenoğlu, B. Estimation of P (X < Y) using ranked set sampling for the Weibull distribution. Qual. Technol. Quant. Manag. 2017, 14, 296–309. [Google Scholar]
- Akgül, F.G.; Acıtaş, Ş.; Şenoğlu, B. Inferences on stress-strength reliability based on ranked set sampling data in case of Lindley distribution. J. Stat. Comput. Simul. 2018, 88, 3018–3032. [Google Scholar] [CrossRef]
- Akgül, F.G.; Acıtaş, Ş.; Şenoğlu, B. Inferences for stress-strength reliability of Burr Type X distributions based on ranked set sampling. Commun. Stat. Simul. Comput. 2022, 51, 3324–3340. [Google Scholar] [CrossRef]
- Esemen, M.; Gurler, S.; Sevinc, B. Estimation of stress-strength reliability based on ranked set sampling for generalized exponential distribution. Int. J. Reliab. Qual. Saf. Eng. 2021, 28, 2150011. [Google Scholar] [CrossRef]
- Hassan, A.S.; Al-Omari, A.I.; Nagy, H.F. Stress-Strength reliability for the generalized inverted exponential distribution using MRSS. Iran. J. Sci. Technol. Trans. A Sci. 2021, 45, 641–659. [Google Scholar] [CrossRef]
- Al-Omari, A.I.; Hassan, A.S.; Alotaibi, N.; Shrahili, M.; Nagy, H.F. Reliability estimation of inverse Lomax distribution using extreme ranked set sampling. Adv. Math. Phys. 2021, 2021, 4599872. [Google Scholar] [CrossRef]
- Yousef, M.M.; Hassan, A.S.; Al-Nefaie, A.H.; Almetwally, E.M.; Almongy, H.M. Bayesian estimation using MCMC method of system reliability for inverted Topp-Leone distribution based on ranked set sampling. Mathematics 2022, 10, 3122. [Google Scholar] [CrossRef]
- Hassan, A.S.; Elshaarawy, R.S.; Onyango, R.; Nagy, H.F. Estimating system reliability using neoteric and median RSS data for generalized exponential distribution. Int. J. Math. Math. Sci. 2022, 2022, 2608656. [Google Scholar] [CrossRef]
- Yahya, M.; Shaaban, M. Estimation of stress-strength reliability from exponentiated inverse Rayleigh Rayleigh distribution based on neoteric ranked set sampling approach. Pak. J. Stat. 2022, 38, 491–511. [Google Scholar]
- Hassan, A.S.; Almanjahie, I.M.; Al-Omari, A.I.; Alzoubi, L.; Nagy, H.F. Stress- strength modeling using median-ranked set sampling: Estimation, simulation, and application. Mathematics 2023, 11, 318. [Google Scholar] [CrossRef]
- Hassan, A.S.; Alsadat, N.; Elgarhy, M.; Chesneau, C.; Nagy, H.F. Analysis of R = P[Y < X < Z] using ranked set sampling for a generalized inverse exponential model. Axioms 2023, 12, 302. [Google Scholar]
- Swain, J.; Venkatraman, S.; Wilson, J. Least squares estimation of distribution function in Johnson’s translation system. J. Stat. Comput. Simul. 1988, 29, 271–297. [Google Scholar] [CrossRef]
- Cheng, R.C.H.; Amin, N.A.K. Estimating parameters in continuous univariate distributions with a shifted origin. J. R. Stat. Soc. 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Ranneby, B. The maximum spacing method: An estimation method related to the maximum likelihood method. Scand. J. Stat. 1984, 11, 93–112. [Google Scholar]
- Efron, B. Logistic regression, survival analysis, and the Kaplan-Meier curve. J. Am. Stat. Assoc. 1988, 83, 414–425. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RSS | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Measures | ML | MPS | LS | WLS | CV | AD | RTAD | |||
| 0.28570 | (2,2) | (20,20) | AB | 0.00984 | 0.00526 | 0.00824 | 0.00645 | 0.00735 | 0.00842 | 0.00743 |
| MSE | 0.00584 | 0.00518 | 0.00605 | 0.00598 | 0.00672 | 0.00636 | 0.00954 | |||
| (2,3) | (20,30) | AB | 0.00865 | 0.00515 | 0.00764 | 0.00532 | 0.00634 | 0.00804 | 0.00694 | |
| MSE | 0.00484 | 0.00496 | 0.00573 | 0.00554 | 0.00582 | 0.00563 | 0.00832 | |||
| (3,3) | (30,30) | AB | 0.00724 | 0.00456 | 0.00698 | 0.00486 | 0.00597 | 0.00784 | 0.00617 | |
| MSE | 0.00421 | 0.00441 | 0.00513 | 0.00496 | 0.00524 | 0.00503 | 0.00785 | |||
| (3,4) | (30,40) | AB | 0.00736 | 0.00414 | 0.00615 | 0.00443 | 0.00524 | 0.00705 | 0.00585 | |
| MSE | 0.00384 | 0.00327 | 0.00475 | 0.00425 | 0.00495 | 0.00486 | 0.00715 | |||
| (4,4) | (40,40) | AB | 0.00635 | 0.00385 | 0.00595 | 0.00419 | 0.00492 | 0.00674 | 0.00516 | |
| MSE | 0.00284 | 0.00224 | 0.00386 | 0.00326 | 0.00406 | 0.00396 | 0.00625 | |||
| (4,5) | (40,50) | AB | 0.00574 | 0.00313 | 0.00553 | 0.00394 | 0.00421 | 0.00618 | 0.00497 | |
| MSE | 0.00214 | 0.00196 | 0.00314 | 0.00273 | 0.00374 | 0.00304 | 0.00535 | |||
| (5,5) | (50,50) | AB | 0.00527 | 0.00265 | 0.00428 | 0.00316 | 0.00407 | 0.00544 | 0.00421 | |
| MSE | 0.00197 | 0.00115 | 0.00245 | 0.00207 | 0.00274 | 0.00235 | 0.00432 | |||
| 0.60000 | (2,2) | (20,20) | AB | 0.00743 | 0.00498 | 0.00072 | 0.00039 | 0.00434 | 0.00084 | 0.00583 |
| MSE | 0.00477 | 0.0039 | 0.0054 | 0.00498 | 0.00611 | 0.00468 | 0.00783 | |||
| (2,3) | (20,30) | AB | 0.00718 | 0.00402 | 0.00034 | 0.00032 | 0.00343 | 0.00027 | 0.00924 | |
| MSE | 0.00347 | 0.00303 | 0.00386 | 0.00374 | 0.00423 | 0.00345 | 0.00531 | |||
| (3,3) | (30,30) | AB | 0.00722 | 0.00186 | 0.00035 | 0.00021 | 0.0011 | 0.0003 | 0.00356 | |
| MSE | 0.00235 | 0.00219 | 0.00262 | 0.0024 | 0.00281 | 0.00235 | 0.00345 | |||
| (3,4) | (30,40) | AB | 0.00662 | 0.0038 | 0.00026 | 0.00085 | 0.00314 | 0.00025 | 0.0044 | |
| MSE | 0.00186 | 0.00174 | 0.00211 | 0.00197 | 0.00225 | 0.00189 | 0.00287 | |||
| (4,4) | (40,40) | AB | 0.00149 | 0.00437 | 0.00014 | 0.00022 | 0.001 | 0.00012 | 0.00215 | |
| MSE | 0.00118 | 0.00125 | 0.00146 | 0.00136 | 0.00158 | 0.00129 | 0.00167 | |||
| (4,5) | (40,50) | AB | 0.00099 | 0.00972 | 0.0028 | 0.00236 | 0.00011 | 0.0032 | 0.00189 | |
| MSE | 0.00094 | 0.00086 | 0.00128 | 0.0012 | 0.00095 | 0.00119 | 0.0011 | |||
| (5,5) | (50,50) | AB | 0.00119 | 0.00355 | 0.00011 | 0.00011 | 0.00098 | 0.0001 | 0.00316 | |
| MSE | 0.00075 | 0.00071 | 0.0011 | 0.001 | 0.00107 | 0.00099 | 0.00097 | |||
| 0.71430 | (2,2) | (20,20) | AB | 0.00865 | 0.00122 | 0.00029 | 0.00206 | 0.00887 | 0.00012 | 0.00815 |
| MSE | 0.00385 | 0.00354 | 0.00422 | 0.00396 | 0.00465 | 0.0038 | 0.00578 | |||
| (2,3) | (20,30) | AB | 0.00656 | 0.00137 | 0.00118 | 0.00204 | 0.00823 | 0.00012 | 0.00952 | |
| MSE | 0.00259 | 0.00244 | 0.00303 | 0.00279 | 0.003 | 0.00253 | 0.00395 | |||
| (3,3) | (30,30) | AB | 0.00216 | 0.00143 | 0.00158 | 0.00001 | 0.00448 | 0.00257 | 0.0043 | |
| MSE | 0.00185 | 0.00163 | 0.0019 | 0.00178 | 0.00205 | 0.00165 | 0.0022 | |||
| (3,4) | (30,40) | AB | 0.00227 | 0.01319 | 0.0021 | 0.00114 | 0.00288 | 0.00248 | 0.00254 | |
| MSE | 0.0015 | 0.00131 | 0.00167 | 0.00152 | 0.00165 | 0.00147 | 0.00161 | |||
| (4,4) | (40,40) | AB | 0.00862 | 0.00487 | 0.00222 | 0.00338 | 0.00658 | 0.0011 | 0.00659 | |
| MSE | 0.0012 | 0.00114 | 0.00122 | 0.00124 | 0.00143 | 0.00123 | 0.0014 | |||
| (4,5) | (40,50) | AB | 0.0025 | 0.00112 | 0.00064 | 0.00111 | 0.00471 | 0.00039 | 0.00569 | |
| MSE | 0.00101 | 0.00082 | 0.0011 | 0.00108 | 0.00116 | 0.0011 | 0.0011 | |||
| (5,5) | (50,50) | AB | 0.00213 | 0.01059 | 0.0012 | 0.00221 | 0.00479 | 0.00012 | 0.00539 | |
| MSE | 0.00082 | 0.00063 | 0.00099 | 0.00084 | 0.00097 | 0.00084 | 0.00086 | |||
| 0.93750 | (2,2) | (20,20) | AB | 0.00274 | 0.00148 | 0.00646 | 0.00468 | 0.00128 | 0.00441 | 0.00191 |
| MSE | 0.00077 | 0.00052 | 0.00093 | 0.00084 | 0.00083 | 0.00077 | 0.00127 | |||
| (2,3) | (20,30) | AB | 0.00149 | 0.00129 | 0.00605 | 0.00453 | 0.00047 | 0.00411 | 0.00203 | |
| MSE | 0.00049 | 0.00036 | 0.00058 | 0.00066 | 0.00058 | 0.00056 | 0.00069 | |||
| (3,3) | (30,30) | AB | 0.0015 | 0.00113 | 0.0048 | 0.00307 | 0.00046 | 0.00335 | 0.00168 | |
| MSE | 0.00034 | 0.0003 | 0.00048 | 0.00041 | 0.00038 | 0.00052 | 0.00046 | |||
| (3,4) | (30,40) | AB | 0.00019 | 0.0011 | 0.00488 | 0.00368 | 0.00069 | 0.00338 | 0.00204 | |
| MSE | 0.00026 | 0.00021 | 0.00034 | 0.00029 | 0.0003 | 0.00041 | 0.00026 | |||
| (4,4) | (40,40) | AB | 0.00094 | 0.00946 | 0.00365 | 0.0023 | 0.00034 | 0.00256 | 0.00083 | |
| MSE | 0.00015 | 0.00012 | 0.00027 | 0.00022 | 0.00025 | 0.00034 | 0.00017 | |||
| (4,5) | (40,50) | AB | 0.00108 | 0.00855 | 0.00303 | 0.00183 | 0.00018 | 0.00184 | 0.00069 | |
| MSE | 0.00013 | 0.0001 | 0.00021 | 0.00018 | 0.00019 | 0.00019 | 0.00014 | |||
| (5,5) | (50,50) | AB | 0.00163 | 0.00702 | 0.00247 | 0.00108 | 0.0007 | 0.00119 | 0.00015 | |
| MSE | 0.00009 | 0.00007 | 0.00018 | 0.00016 | 0.00016 | 0.00015 | 0.00011 | |||
| SRS | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Measures | ML | MPS | LS | WLS | CV | AD | RTAD | ||
| 0.28570 | (20,20) | AB | 0.17519 | 0.16174 | 0.70317 | 0.03157 | 0.26093 | 0.68545 | 0.27421 |
| MSE | 0.04012 | 0.03529 | 0.1537 | 0.06734 | 0.2734 | 0.47193 | 0.18969 | ||
| (20,30) | AB | 0.0155 | 0.08533 | 0.00692 | 0.15086 | 0.06247 | 0.68119 | 0.03833 | |
| MSE | 0.03795 | 0.02963 | 0.1251 | 0.04891 | 0.27865 | 0.44683 | 0.1861 | ||
| (30,30) | AB | 0.01155 | 0.01964 | 0.00495 | 0.1309 | 0.04692 | 0.5967 | 0.02273 | |
| MSE | 0.03158 | 0.02953 | 0.17423 | 0.03795 | 0.18737 | 0.4159 | 0.13309 | ||
| (30,40) | AB | 0.00786 | 0.00738 | 0.00375 | 0.12996 | 0.01081 | 0.30458 | 0.01076 | |
| MSE | 0.02984 | 0.02638 | 0.14688 | 0.03057 | 0.13454 | 0.3966 | 0.11841 | ||
| (40,40) | AB | 0.00516 | 0.00628 | 0.00175 | 0.11865 | 0.01036 | 0.31973 | 0.01107 | |
| MSE | 0.02315 | 0.02057 | 0.13789 | 0.02395 | 0.09834 | 0.28643 | 0.10976 | ||
| (40,50) | AB | 0.00428 | 0.00416 | 0.00462 | 0.11579 | 0.00972 | 0.28663 | 0.01087 | |
| MSE | 0.01976 | 0.01863 | 0.12788 | 0.02064 | 0.09012 | 0.21727 | 0.10107 | ||
| (50,50) | AB | 0.00397 | 0.00267 | 0.00246 | 0.10546 | 0.00171 | 0.21865 | 0.01025 | |
| MSE | 0.01765 | 0.01456 | 0.11956 | 0.01965 | 0.07966 | 0.19753 | 0.09674 | ||
| 0.60000 | (20,20) | AB | 0.16002 | 0.13942 | 0.38944 | 0.13881 | 0.12924 | 0.37839 | 0.2296 |
| MSE | 0.03454 | 0.02722 | 0.15278 | 0.04306 | 0.05375 | 0.14373 | 0.07758 | ||
| (20,30) | AB | 0.15797 | 0.13129 | 0.38094 | 0.1309 | 0.12695 | 0.37826 | 0.21932 | |
| MSE | 0.03334 | 0.02279 | 0.11157 | 0.04075 | 0.04296 | 0.14344 | 0.06812 | ||
| (30,30) | AB | 0.15625 | 0.13065 | 0.35707 | 0.13 | 0.12106 | 0.37306 | 0.18365 | |
| MSE | 0.02932 | 0.02111 | 0.13672 | 0.03384 | 0.03406 | 0.13996 | 0.05182 | ||
| (30,40) | AB | 0.14254 | 0.12985 | 0.35202 | 0.12101 | 0.09539 | 0.37205 | 0.15646 | |
| MSE | 0.02769 | 0.02039 | 0.13388 | 0.027 | 0.02869 | 0.13431 | 0.04696 | ||
| (40,40) | AB | 0.1479 | 0.11533 | 0.39135 | 0.15334 | 0.10949 | 0.38588 | 0.13785 | |
| MSE | 0.0204 | 0.01768 | 0.12339 | 0.02076 | 0.02234 | 0.11897 | 0.02834 | ||
| (40,50) | AB | 0.13747 | 0.11036 | 0.38623 | 0.14828 | 0.10107 | 0.37535 | 0.12876 | |
| MSE | 0.01887 | 0.01526 | 0.11963 | 0.01946 | 0.01974 | 0.11223 | 0.01936 | ||
| (50,50) | AB | 0.11556 | 0.10785 | 0.31877 | 0.12854 | 0.10096 | 0.32765 | 0.11876 | |
| MSE | 0.01505 | 0.01288 | 0.11546 | 0.01624 | 0.01583 | 0.11056 | 0.01758 | ||
| 0.71430 | (20,20) | AB | 0.14297 | 0.12973 | 0.27983 | 0.17008 | 0.15636 | 0.2394 | 0.23269 |
| MSE | 0.02638 | 0.01974 | 0.07833 | 0.03225 | 0.02796 | 0.06102 | 0.05619 | ||
| (20,30) | AB | 0.1322 | 0.11779 | 0.27176 | 0.12216 | 0.10126 | 0.24578 | 0.20279 | |
| MSE | 0.02006 | 0.01498 | 0.05396 | 0.02298 | 0.02145 | 0.05146 | 0.04489 | ||
| (30,30) | AB | 0.11959 | 0.12683 | 0.27559 | 0.12866 | 0.11089 | 0.2472 | 0.12942 | |
| MSE | 0.01765 | 0.01282 | 0.04602 | 0.01516 | 0.01954 | 0.04177 | 0.02913 | ||
| (30,40) | AB | 0.11096 | 0.11965 | 0.22987 | 0.12098 | 0.10944 | 0.22875 | 0.11987 | |
| MSE | 0.01588 | 0.01095 | 0.03987 | 0.01304 | 0.01698 | 0.03864 | 0.02226 | ||
| (40,40) | AB | 0.10875 | 0.11258 | 0.21877 | 0.11877 | 0.07861 | 0.21545 | 0.11543 | |
| MSE | 0.01499 | 0.00995 | 0.02397 | 0.01087 | 0.01515 | 0.03265 | 0.01995 | ||
| (40,50) | AB | 0.10087 | 0.10998 | 0.18763 | 0.10258 | 0.05789 | 0.20966 | 0.10976 | |
| MSE | 0.01268 | 0.00734 | 0.02065 | 0.00955 | 0.01341 | 0.02968 | 0.01592 | ||
| (50,50) | AB | 0.08446 | 0.05676 | 0.16868 | 0.08634 | 0.03668 | 0.18443 | 0.10025 | |
| MSE | 0.01086 | 0.00575 | 0.01065 | 0.00785 | 0.01135 | 0.02267 | 0.01299 | ||
| 0.93750 | (20,20) | AB | 0.07436 | 0.09124 | 0.93698 | 0.11872 | 0.2761 | 0.87643 | 0.58189 |
| MSE | 0.02577 | 0.01244 | 0.04794 | 0.03022 | 0.02426 | 0.05289 | 0.04265 | ||
| (20,30) | AB | 0.20656 | 0.22591 | 0.93733 | 0.24662 | 0.71968 | 0.9375 | 0.24549 | |
| MSE | 0.0175 | 0.0111 | 0.03217 | 0.02135 | 0.02084 | 0.04142 | 0.04047 | ||
| (30,30) | AB | 0.14405 | 0.20795 | 0.93725 | 0.43749 | 0.41608 | 0.98324 | 0.1437 | |
| MSE | 0.01226 | 0.00928 | 0.02844 | 0.01315 | 0.01211 | 0.03079 | 0.01935 | ||
| (30,40) | AB | 0.23887 | 0.32184 | 0.99743 | 0.61278 | 0.51933 | 0.98764 | 0.05003 | |
| MSE | 0.00968 | 0.00754 | 0.02117 | 0.01181 | 0.01056 | 0.02763 | 0.01138 | ||
| (40,40) | AB | 0.13043 | 0.23449 | 0.93731 | 0.2402 | 0.49519 | 0.9375 | 0.04162 | |
| MSE | 0.00684 | 0.0045 | 0.01922 | 0.01006 | 0.00999 | 0.01953 | 0.00854 | ||
| (40,50) | AB | 0.20397 | 0.27371 | 0.76449 | 0.22049 | 0.70024 | 0.84536 | 0.17623 | |
| MSE | 0.0061 | 0.00381 | 0.01254 | 0.00906 | 0.00845 | 0.01176 | 0.00796 | ||
| (50,50) | AB | 0.15677 | 0.21486 | 0.79876 | 0.28434 | 0.61279 | 0.87534 | 0.11587 | |
| MSE | 0.00425 | 0.00275 | 0.01008 | 0.00885 | 0.00795 | 0.01056 | 0.00715 | ||
| RE | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| ML | MPS | LS | WLS | CV | AD | RTAD | |||
| 0.28570 | (2,2) | (20,20) | 6.86986 | 6.81801 | 25.40496 | 11.26087 | 40.68452 | 74.16785 | 19.88365 |
| (2,3) | (20,30) | 7.84091 | 5.97379 | 21.83246 | 8.82852 | 47.87801 | 79.3659 | 22.36779 | |
| (3,3) | (30,30) | 7.50119 | 6.69615 | 33.96296 | 7.65121 | 35.75763 | 82.6839 | 16.95414 | |
| (3,4) | (30,40) | 7.77083 | 8.06728 | 30.92211 | 7.19294 | 27.1798 | 81.60494 | 16.56084 | |
| (4,4) | (40,40) | 8.15141 | 9.18304 | 35.7228 | 7.3454 | 24.22167 | 72.33081 | 17.5616 | |
| (4,5) | (40,50) | 9.23364 | 9.5051 | 40.72611 | 7.56044 | 24.09626 | 71.46967 | 18.89234 | |
| (5,5) | (50,50) | 8.95939 | 12.66087 | 48.80122 | 9.49275 | 29.07409 | 84.05532 | 22.39398 | |
| 0.60000 | (2,2) | (20,20) | 7.24109 | 6.97949 | 28.29259 | 8.64659 | 8.79705 | 30.71154 | 9.90805 |
| (2,3) | (20,30) | 9.60807 | 7.52145 | 28.90415 | 10.89572 | 10.15603 | 41.57681 | 12.82863 | |
| (3,3) | (30,30) | 12.4766 | 9.63927 | 52.18321 | 14.11176 | 12.121 | 59.55745 | 15.02029 | |
| (3,4) | (30,40) | 14.8871 | 11.71839 | 63.45024 | 13.70558 | 12.75111 | 71.06349 | 16.36237 | |
| (4,4) | (40,40) | 17.28814 | 14.144 | 84.5137 | 15.26471 | 14.13924 | 92.22481 | 16.92951 | |
| (4,5) | (40,50) | 20.07447 | 17.84795 | 93.46406 | 16.21833 | 20.78211 | 94.31429 | 17.60364 | |
| (5,5) | (50,50) | 20.12032 | 18.23654 | 104.96364 | 16.243 | 14.79215 | 111.67677 | 18.12062 | |
| 0.71430 | (2,2) | (20,20) | 6.85195 | 5.57627 | 18.56161 | 8.14394 | 6.0129 | 16.05789 | 9.72145 |
| (2,3) | (20,30) | 7.74517 | 6.13811 | 17.80858 | 8.23656 | 7.15 | 20.33992 | 11.36456 | |
| (3,3) | (30,30) | 9.54054 | 7.86503 | 24.22105 | 8.51685 | 9.53171 | 25.31515 | 13.24091 | |
| (3,4) | (30,40) | 10.58667 | 8.36031 | 23.87545 | 8.58092 | 10.28848 | 26.28571 | 13.81141 | |
| (4,4) | (40,40) | 12.4875 | 8.72807 | 19.64754 | 8.7621 | 10.5972 | 26.54472 | 14.24065 | |
| (4,5) | (40,50) | 12.55149 | 8.95537 | 18.77582 | 8.83796 | 11.56379 | 26.98 | 14.47545 | |
| (5,5) | (50,50) | 13.24756 | 9.13365 | 10.76061 | 9.34881 | 11.70103 | 26.99214 | 15.1 | |
| 0.93750 | (2,2) | (20,20) | 33.46753 | 23.92308 | 51.54839 | 35.97024 | 29.23012 | 68.68831 | 33.57953 |
| (2,3) | (20,30) | 35.71429 | 30.84444 | 55.4569 | 32.35152 | 35.93264 | 73.96964 | 58.64638 | |
| (3,3) | (30,30) | 36.05882 | 30.92333 | 59.25 | 32.07561 | 31.85526 | 59.20981 | 42.06522 | |
| (3,4) | (30,40) | 37.24615 | 35.90524 | 62.25 | 40.7069 | 35.20667 | 67.39268 | 43.78077 | |
| (4,4) | (40,40) | 45.59333 | 37.51833 | 71.19778 | 45.74091 | 39.96 | 57.45294 | 50.23529 | |
| (4,5) | (40,50) | 46.92308 | 38.14 | 59.72857 | 50.33333 | 44.47368 | 61.89474 | 56.88571 | |
| (5,5) | (50,50) | 47.26667 | 39.34286 | 56 | 55.3125 | 49.70938 | 70.37333 | 64.96364 | |
| Sampling | Parameter | ML | LS | WLS | CV | AD | RTAD |
|---|---|---|---|---|---|---|---|
| RSS | 0.0985 | 0.0364 | 0.02502 | 0.01995 | 0.08008 | 0.01273 | |
| 0.0658 | 0.0215 | 0.01479 | 0.01095 | 0.0517 | 0.00782 | ||
| 0.8061 | 1.1919 | 1.3158 | 1.42399 | 0.88302 | 1.57378 | ||
| 0.59954 | 0.62828 | 0.62844 | 0.64563 | 0.60768 | 0.61925 | ||
| SRS | 0.0999 | 0.05228 | 0.04501 | 0.01016 | 0.1442 | 0.006 | |
| 0.06654 | 0.02944 | 0.02361 | 0.00536 | 0.09 | 0.00367 | ||
| 0.8119 | 1.05798 | 1.10582 | 1.6 | 0.69261 | 1.83009 | ||
| 0.60021 | 0.63978 | 0.65594 | 0.65453 | 0.61571 | 0.62078 |
| Data | Method | Design | CVT | ADT | K-ST | p-Value |
|---|---|---|---|---|---|---|
| Data I (W) | ML | RSS | 0.31307 | 1.77129 | 0.80208 | 0.19792 |
| SRS | 0.35676 | 1.97197 | 0.83753 | 0.16247 | ||
| LS | RSS | 0.58241 | 3.02593 | 0.59506 | 0.40494 | |
| SRS | 0.81977 | 4.03263 | 0.6442 | 0.3558 | ||
| WLS | RSS | 0.68988 | 3.51439 | 0.64709 | 0.35291 | |
| SRS | 0.85842 | 4.21798 | 0.66789 | 0.33211 | ||
| CV | RSS | 0.80507 | 4.03447 | 0.46013 | 0.5399 | |
| SRS | 1.19579 | 5.85561 | 0.8254 | 0.1746 | ||
| AD | RSS | 0.31975 | 1.80642 | 0.80061 | 0.19939 | |
| SRS | 0.46097 | 2.52828 | 0.80468 | 0.19532 | ||
| RTAD | RSS | 0.92209 | 4.56446 | 0.54294 | 0.45706 | |
| SRS | 1.33812 | 6.5031 | 0.6411 | 0.3589 | ||
| Data II (Q) | ML | RSS | 0.09068 | 0.52067 | 0.85594 | 0.14406 |
| SRS | 0.11648 | 0.69209 | 0.92817 | 0.07183 | ||
| LS | RSS | 0.17787 | 24.00754 | 0.44851 | 0.55149 | |
| SRS | 1.20519 | 25.88331 | 0.89192 | 0.10808 | ||
| WLS | RSS | 0.24755 | 24.41183 | 0.52657 | 0.47343 | |
| SRS | 1.22362 | 26.32725 | 0.90168 | 0.09832 | ||
| CV | RSS | 0.32337 | 24.82667 | 0.56885 | 0.43115 | |
| SRS | 0.57053 | 25.14119 | 0.94204 | 0.05796 | ||
| AD | RSS | 0.07759 | 23.39339 | 0.16622 | 0.83378 | |
| SRS | 0.15845 | 23.91292 | 0.89778 | 0.10222 | ||
| RTAD | RSS | 0.46001 | 2.58214 | 0.71077 | 0.28923 | |
| SRS | 0.78925 | 4.15739 | 0.94517 | 0.05483 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsadat, N.; Hassan, A.S.; Elgarhy, M.; Chesneau, C.; Mohamed, R.E. An Efficient Stress–Strength Reliability Estimate of the Unit Gompertz Distribution Using Ranked Set Sampling. Symmetry 2023, 15, 1121. https://doi.org/10.3390/sym15051121
Alsadat N, Hassan AS, Elgarhy M, Chesneau C, Mohamed RE. An Efficient Stress–Strength Reliability Estimate of the Unit Gompertz Distribution Using Ranked Set Sampling. Symmetry. 2023; 15(5):1121. https://doi.org/10.3390/sym15051121
Chicago/Turabian StyleAlsadat, Najwan, Amal S. Hassan, Mohammed Elgarhy, Christophe Chesneau, and Rokaya Elmorsy Mohamed. 2023. "An Efficient Stress–Strength Reliability Estimate of the Unit Gompertz Distribution Using Ranked Set Sampling" Symmetry 15, no. 5: 1121. https://doi.org/10.3390/sym15051121